Text Environments
Text environments provide a learning ground for language agents. It allows a language model to use tools to accomplish a task such as using a Python interpreter to answer math questions or using a search index for trivia questions. Having access to tools allows language models to solve tasks that would be very hard for the models itself but can be trivial for the appropriate tools. A good example is arithmetics of large numbers that become a simple copy-paste task once you have access to a calculator.
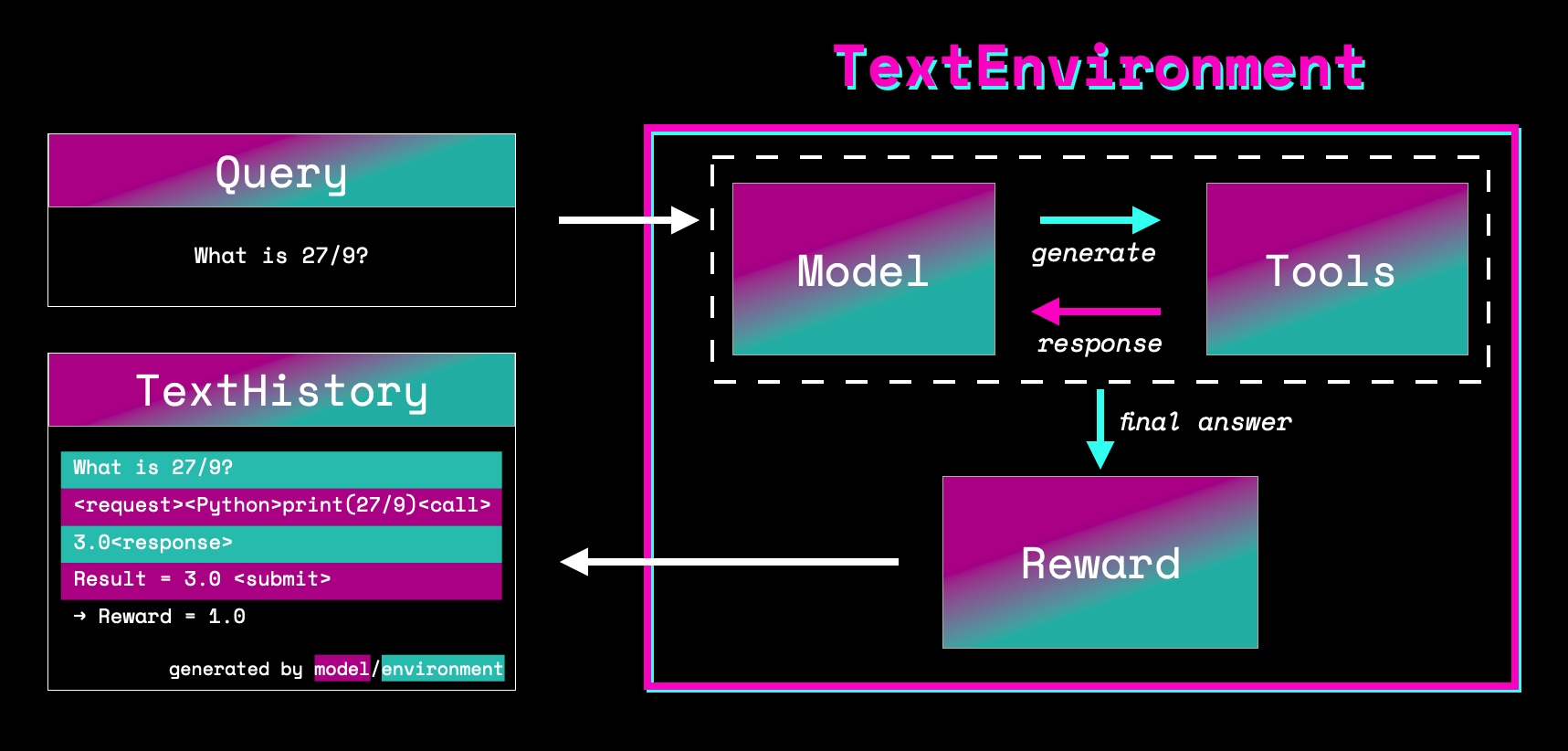
Let’s dive into how text environments work and start with tools!
Tools
One of the core building blocks of text environments are tools that the model can use to solve tasks. In general tools can be any Python function that takes a string as input and returns string. The TextEnvironment offers two options for tools: either go with predefined tools from transformers.Tool or define your own function or class with __call__ method. Let’s have a look at both!
transformers.Tool
Text environments fully support tools of the class transformers.Tool. The advantage of building tools in that framework is that they can easily be shared
from transformers import load_tool
# simple calculator tool that runs +-/* operations
calc_tool = load_tool("ybelkada/simple-calculator")
# python interpreter that executes program and returns outputs
py_tool = load_tool("lvwerra/python-interpreter")
# wikipedia search index that returns best search match
wiki_tool = load_tool("vwxyzjn/pyserini-wikipedia-kilt-doc")These tools are either loaded from the hub or from a local folder. Using the tool is as simple as calling them with a text query:
calc_tool("1/2")
>>> "0.5"Note that both input and return values are strings to enable easy usage with a language model.
Custom Tools
The following is an example of a tool that adds two integers:
def add(text):
int_1, int_2 = text.split("+")
result = int(int_1) + int(int_2)
return str(result)
print(add("1+1"))
>>> "2"We looked at basic examples such as a calculator but the principle holds for more complex tools as well such as a web search tool where you input the query and get the search results in return. Now let’s look at how the model can use the tools with the call syntax.
Call syntax
In order to have a unified way for the model to call a tool we created a simple syntax that looks as follows:
"<request><TOOL_NAME>QUERY<call>TOOL_RESPONSE<response>"There are a few special tokens involved so let’s decompose it: First the model can signal that it wants to use a tool by emitting the <request> token. After that we want to know the name of the tool to call which is done by enclosing the tool name with <> brackets. Once we know which tool to call the tool query follows which is in free text form. The <call> tokens signifies the end of the query and stops the model generation. At this point the model output is parsed and the query sent to the tool. The environment appends the tool response to the string followed by the <response> token to show the end the tool output.
Let’s look at the concrete example of the calculator and assume its name is Calculator (more on how the name of a tool is inferred later):
"<request><Calculator>1/2<call>0.5<response>"Finally, the episode is ended and generation stops when the model generates <submit> which marks the interaction as completed.
Now let’s have a look how we can create a new text environment!
Create a TextEnvironment
prompt = """\
What is 13-3?
<request><SimpleCalculatorTool>13-3<call>10.0<response>
Result=10<submit>
"""
def reward_fn(result, answer):
"""Simplified reward function returning 1 if result matches answer and 0 otherwise."""
result_parsed = result.split("=")[1].split("<")[0]
return int(result_parsed==answer)
text_env = TextEnvironemnt(
model=model,
tokenizer=tokenizer,
tools= {"SimpleCalculatorTool": load_tool("ybelkada/simple-calculator")},
reward_fn=exact_match_reward,
prompt=prompt,
max_turns=1
max_tool_response=100
generation_kwargs={"do_sample": "true"}
)Let’s decompose the settings:
| Argument | Description |
|---|---|
model | Language model to interact with the environment and generate requests. |
tokenizer | Tokenizer of language model handling tokenization of strings. |
tools | list of dict of tools. If former the name of the tool is inferred from class name and otherwise it’s the keys of the dictionary. |
reward_fn | A function that takes a string as input and returns. Can have extra arguments that are passed to .run() such as ground truth. |
prompt | Prompt to prepend to every task. Usually a few examples to demonstrate to the model how to use the tools in a few-shot fashion. |
max_turns | Maximum number of interactions between model and tools before episode ends. |
max_tool_response | The tool response is truncated to this number to avoid running out of model context. |
max_length | The maximum number of tokens to allow in an episode. |
generation_kwargs | Generation settings used by the language model. |
You can customize the environment to your needs and add custom tools and settings. Let’s see how you can use the environment to have the model interact with the available tools!
Run an Episode
To run a set of queries through the text environment one can simply use the run method.
queries = ["What is 1/2?"]
answers = ["0.5"]
queries, responses, masks, rewards, histories = text_env.run(queries, answers=answers)This will execute the model/tool feedback loop for each query until either no tool is called anymore, the maximum number of turns is reached or to maximum number of tokens in an episode is exceeded. The extra kwargs (e.g. answers=answers above) passed to run will be passed on to the reward function.
There are five objects that are returned by run:
queries: a list of the tokenized queriesresponses: all tokens that have been generated withing the environment including model and tool tokensmasks: mask that indicates which tokens have been generated by the model and which tokens are generated by the toolrewards: a list of reward for each query/responsehistories: list ofTextHistoryobjects, which are useful objects containing all the above and also the text equivalents
The masks are crucial for training as we don’t want to optimize tokens that the model has not generated which are tokens produced by the tools.
Next, we’ll train a PPO step with the generated responses!
Train
Training on episodes from the TextEnvironment is straight forward and simply requires forwarding all the returned variables except the TextHistory objects to the step method:
train_stats = ppo_trainer.step(queries, responses, rewards, masks)
TextHistory
The TextHistory object stores the interactions between the model and the text environment. It stores tokens and text generated in each turn and their source in each turn (model or system) as well as rewards. Let’s go through the class attributes and methods.
Attributes
The following table summarises the available attributes of the TextEnvironment class:
| Attribute | Description |
|---|---|
text | The full string of the text generated in the text environment with both model and system generated text. |
text_spans | A list of tuples with the spans for each model or system generated text segment. |
system_spans | A list of boolean values indicating if the segment is model or system generated. |
tokens | All tokens generated in text environment with both model and system generated tokens. |
token_spans | Similar to text_spans the token_spans indicate the boundaries of model andsystem generated tokens. |
token_masks | The token masks can be used to ignore system generated tokens by masking them. |
completed | Indicates if the interaction with the environment has completed. |
truncated | Indicates if the interaction with the environment has completed because max length was reached. |
With these attributes you can reconstruct every interaction of the model with the TextEnvironment. The TextHistory also lets you visualize the text history. Let’s have a look!
Visualization
When the model interacts inside the TextEnvironment it can be useful to visualize and separate which parts of the text outputs were generated by the model and which parts come from the system and tools. For that purpose there are the two methods TextHistory.show_text() and TextHistory.show_tokens(). They print the text and tokens respectively and highlight the various segments using the rich libray (make sure to install it before using these methods).
You can see that the prompt is highlighted in gray, whereas system segments such as query and tool responses are highlighted in green. All segments generated by the model are highlighted in blue and in addition to the pure text output the reward is displayed as additional text in plum. Here an example of show_text:

Sometimes there can be tricky tokenization related issues that are hidden when showing the decoded text. Thus TextHistory also offers an option to display the same highlighting on the tokens directly with show_tokens:

Note that you can turn on the colour legend by passing show_legend=True.
API Documentation
class trl.TextEnvironment
< source >( model = None tokenizer = None tools = None reward_fn = None prompt = None max_turns = 4 max_tool_reponse = 100 max_length = None generation_kwargs = None )
The TextEnvironment enables interaction of a LLM with an environment using tools.
Compute the reward for a list of histories.
Generate responses for a list of histories.
Parse request string. Expected format: <request><tool_name>query<call>
run
< source >( queries **rewards_kwargs )
Run the environment on a list of queries.
Step the environment forward one turn.
Check if the current generation sequence has finished.
Check if the current generation sequences have finished.
The TextHistory class keeps track of the history of an interaction between the language model and the environment.
Append a new segment to the history.
args:
text (str): The text of the new segment.
tokens (torch.LongTensor): The tokens of the new segment.
system (bool, optional): Whether the new segment is a system or user segment.
Mark the history as completed.
Print the colour legend.
Print the text history.
Print the history tokens.
Split the tokens into query and response tokens.