Learning Tools (Experimental 🧪)
Using Large Language Models (LLMs) with tools has been a popular topic recently with awesome works such as ToolFormer and ToolBench. In TRL, we provide a simple example of how to teach LLM to use tools with reinforcement learning.
Here’s an overview of the scripts in the trl repository:
| File | Description |
|---|---|
calculator.py | Script to train LLM to use a calculator with reinforcement learning. |
triviaqa.py | Script to train LLM to use a wiki tool to answer questions. |
python_interpreter.py | Script to train LLM to use python interpreter to solve math puzzles. |
Note that the scripts above rely heavily on the TextEnvironment API which is still under active development. The API may change in the future. Please see TextEnvironment for the related docs.
Learning to Use a Calculator
The rough idea is as follows:
Load a tool such as ybelkada/simple-calculator that parse a text calculation like
"14 + 34"and return the calulated number:from transformers import AutoTokenizer, load_tool tool = load_tool("ybelkada/simple-calculator") tool_fn = lambda text: str(round(float(tool(text)), 2)) # rounding to 2 decimal placesDefine a reward function that returns a positive reward if the tool returns the correct answer. In the script we create a dummy reward function like
reward_fn = lambda x: 1, but we override the rewards directly later.Create a prompt on how to use the tools
# system prompt prompt = """\ What is 13.1-3? <request><SimpleCalculatorTool>13.1-3<call>10.1<response> Result=10.1<submit> What is 4*3? <request><SimpleCalculatorTool>4*3<call>12<response> Result=12<submit> What is 12.1+1? <request><SimpleCalculatorTool>12.1+1<call>13.1<response> Result=13.1<submit> What is 12.1-20? <request><SimpleCalculatorTool>12.1-20<call>-7.9<response> Result=-7.9<submit>"""Create a
trl.TextEnvironmentwith the modelenv = TextEnvironment( model, tokenizer, {"SimpleCalculatorTool": tool_fn}, reward_fn, prompt, generation_kwargs=generation_kwargs, )Then generate some data such as
tasks = ["\n\nWhat is 13.1-3?", "\n\nWhat is 4*3?"]and run the environment withqueries, responses, masks, rewards, histories = env.run(tasks). The environment will look for the<call>token in the prompt and append the tool output to the response; it will also return the mask associated with the response. You can further use thehistoriesto visualize the interaction between the model and the tool;histories[0].show_text()will show the text with color-coded tool output andhistories[0].show_tokens(tokenizer)will show visualize the tokens.
Finally, we can train the model with
train_stats = ppo_trainer.step(queries, responses, rewards, masks). The trainer will use the mask to ignore the tool output when computing the loss, make sure to pass that argument tostep.
Experiment results
We trained a model with the above script for 10 random seeds. You can reproduce the run with the following command. Feel free to remove the --slurm-* arguments if you don’t have access to a slurm cluster.
WANDB_TAGS="calculator_final" python benchmark/benchmark.py \
--command "python examples/research_projects/tools/calculator.py" \
--num-seeds 10 \
--start-seed 1 \
--workers 10 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 8 \
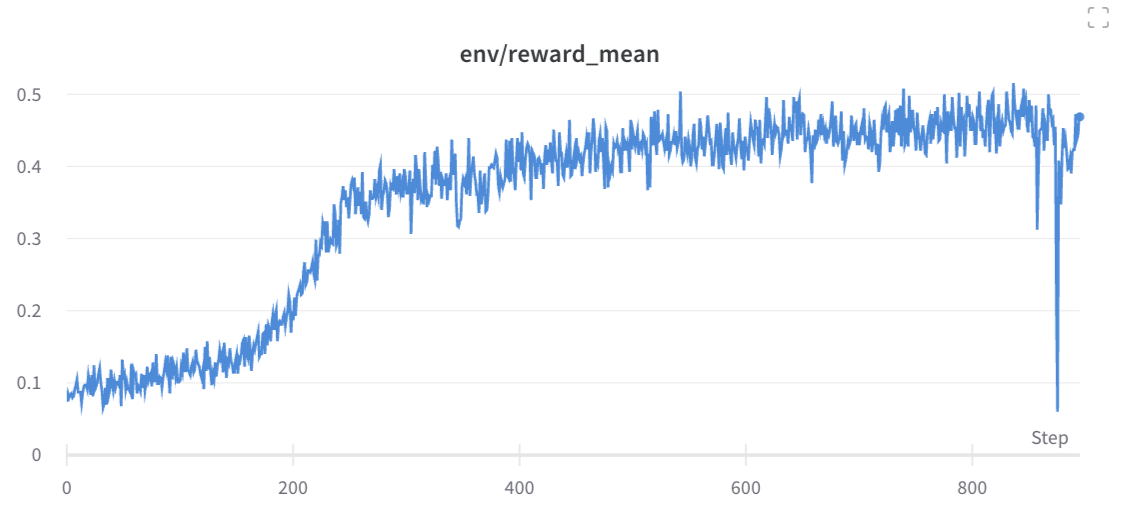
--slurm-template-path benchmark/trl.slurm_templateWe can then use openrlbenchmark which generates the following plot.
python -m openrlbenchmark.rlops_multi_metrics \
--filters '?we=openrlbenchmark&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.tracker_project_name&cen=trl_ppo_trainer_config.value.log_with&metrics=env/reward_mean&metrics=objective/kl' \
'wandb?tag=calculator_final&cl=calculator_mask' \
--env-ids trl \
--check-empty-runs \
--pc.ncols 2 \
--pc.ncols-legend 1 \
--output-filename static/0compare \
--scan-history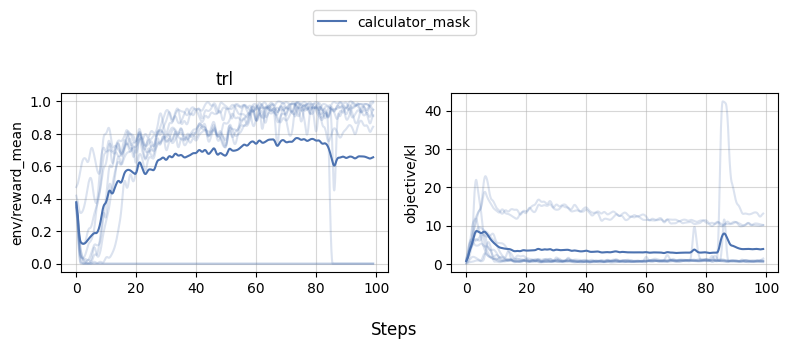
As we can see, while 1-2 experiments crashed for some reason, most of the runs obtained near perfect proficiency in the calculator task.
(Early Experiments 🧪): learning to use a wiki tool for question answering
In the ToolFormer paper, it shows an interesting use case that utilizes a Wikipedia Search tool to help answer questions. In this section, we attempt to perform similar experiments but uses RL instead to teach the model to use a wiki tool on the TriviaQA dataset.
Note that many settings are different so the results are not directly comparable.
Building a search index
Since ToolFormer did not open source, we needed to first replicate the search index. It is mentioned in their paper that the authors built the search index using a BM25 retriever that indexes the Wikipedia dump from KILT
Fortunately, pyserini already implements the BM25 retriever and provides a prebuilt index for the KILT Wikipedia dump. We can use the following code to search the index.
from pyserini.search.lucene import LuceneSearcher
import json
searcher = LuceneSearcher.from_prebuilt_index('wikipedia-kilt-doc')
def search(query):
hits = searcher.search(query, k=1)
hit = hits[0]
contents = json.loads(hit.raw)['contents']
return contents
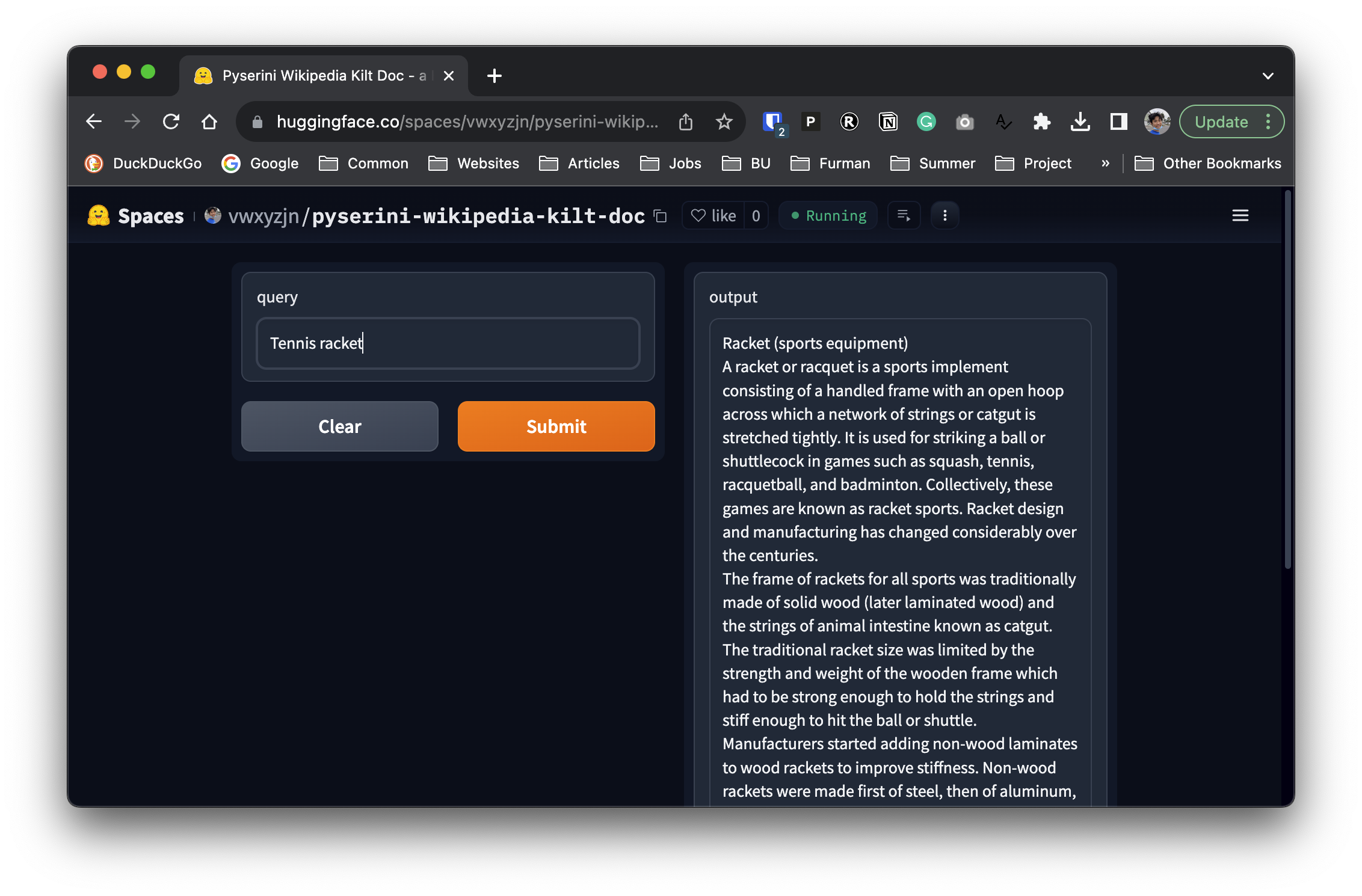
print(search("tennis racket"))Racket (sports equipment)
A racket or racquet is a sports implement consisting of a handled frame with an open hoop across which a network of strings or catgut is stretched tightly. It is used for striking a ball or shuttlecock in games such as squash, tennis, racquetball, and badminton. Collectively, these games are known as racket sports. Racket design and manufacturing has changed considerably over the centuries.
The frame of rackets for all sports was traditionally made of solid wood (later laminated wood) and the strings of animal intestine known as catgut. The traditional racket size was limited by the strength and weight of the wooden frame which had to be strong enough to hold the strings and stiff enough to hit the ball or shuttle. Manufacturers started adding non-wood laminates to wood rackets to improve stiffness. Non-wood rackets were made first of steel, then of aluminum, and then carbon fiber composites. Wood is still used for real tennis, rackets, and xare. Most rackets are now made of composite materials including carbon fiber or fiberglass, metals such as titanium alloys, or ceramics.
...We then basically deployed this snippet as a Hugging Face space here, so that we can use the space as a transformers.Tool later.
Experiment settings
We use the following settings:
- use the
bigcode/starcoderbasemodel as the base model - use the
pyserini-wikipedia-kilt-docspace as the wiki tool and only uses the first paragrahs of the search result, allowing theTextEnvironmentto obtain at mostmax_tool_reponse=400response tokens from the tool. - test if the response contain the answer string, if so, give a reward of 1, otherwise, give a reward of 0.
- notice this is a simplified evaluation criteria. In ToolFormer, the authors checks if the first 20 words of the response contain the correct answer.
- used the following prompt that demonstrates the usage of the wiki tool.
prompt = """\
Answer the following question:
Q: In which branch of the arts is Patricia Neary famous?
A: Ballets
A2: <request><Wiki>Patricia Neary<call>Patricia Neary (born October 27, 1942) is an American ballerina, choreographer and ballet director, who has been particularly active in Switzerland. She has also been a highly successful ambassador for the Balanchine Trust, bringing George Balanchine's ballets to 60 cities around the globe.<response>
Result=Ballets<submit>
Q: Who won Super Bowl XX?
A: Chicago Bears
A2: <request><Wiki>Super Bowl XX<call>Super Bowl XX was an American football game between the National Football Conference (NFC) champion Chicago Bears and the American Football Conference (AFC) champion New England Patriots to decide the National Football League (NFL) champion for the 1985 season. The Bears defeated the Patriots by the score of 46–10, capturing their first NFL championship (and Chicago's first overall sports victory) since 1963, three years prior to the birth of the Super Bowl. Super Bowl XX was played on January 26, 1986 at the Louisiana Superdome in New Orleans.<response>
Result=Chicago Bears<submit>
Q: """Result and Discussion
Our experiments show that the agent can learn to use the wiki tool to answer questions. The learning curves would go up mostly, but one of the experiment did crash.
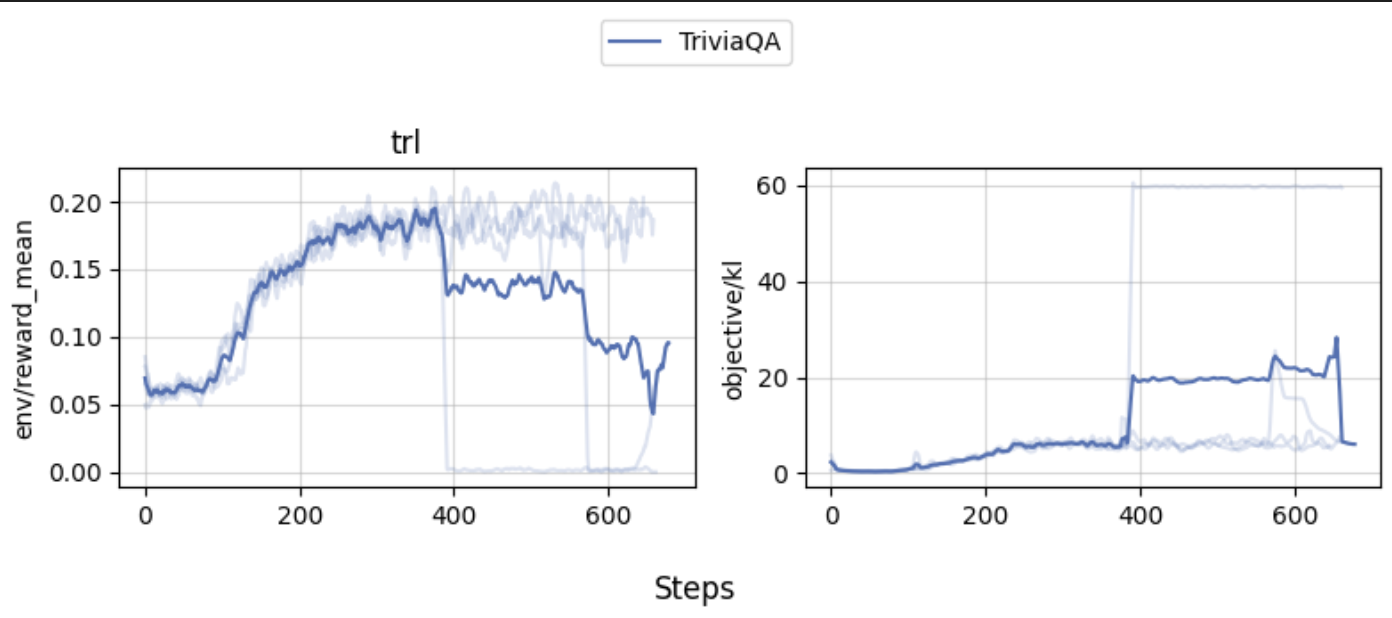
Wandb report is here for further inspection.
Note that the correct rate of the trained model is on the low end, which could be due to the following reasons:
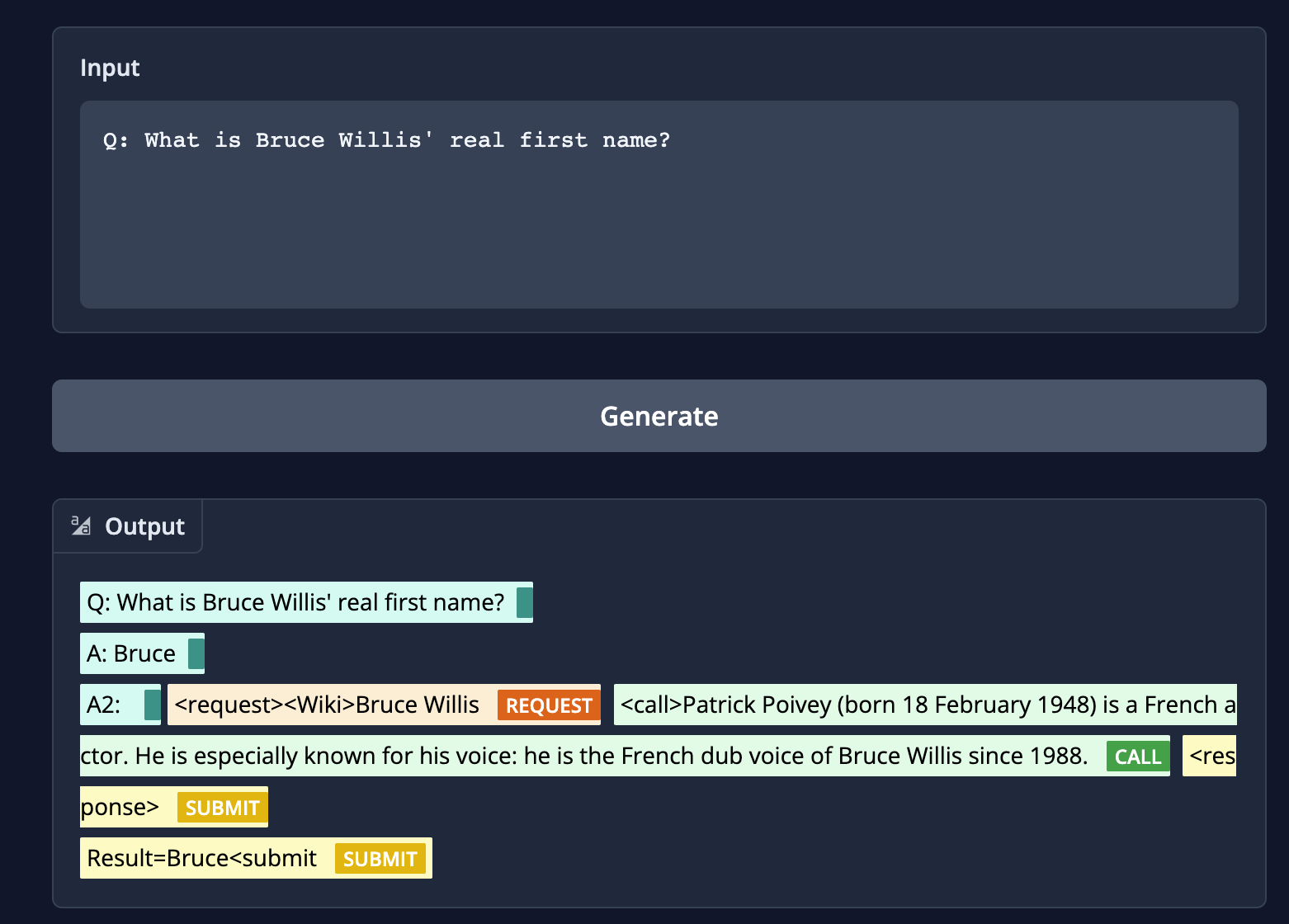
- incorrect searches: When given the question
"What is Bruce Willis' real first name?"if the model searches forBruce Willis, our wiki tool returns “Patrick Poivey (born 18 February 1948) is a French actor. He is especially known for his voice: he is the French dub voice of Bruce Willis since 1988.But a correct search should beWalter Bruce Willis (born March 19, 1955) is an American former actor. He achieved fame with a leading role on the comedy-drama series Moonlighting (1985–1989) and appeared in over a hundred films, gaining recognition as an action hero after his portrayal of John McClane in the Die Hard franchise (1988–2013) and other roles.[1][2]”
unnecessarily long response: The wiki tool by default sometimes output very long sequences. E.g., when the wiki tool searches for “Brown Act”
Our wiki tool returns “The Ralph M. Brown Act, located at California Government Code 54950 “et seq.”, is an act of the California State Legislature, authored by Assemblymember Ralph M. Brown and passed in 1953, that guarantees the public’s right to attend and participate in meetings of local legislative bodies.”
ToolFormer’s wiki tool returns “The Ralph M. Brown Act is an act of the California State Legislature that guarantees the public’s right to attend and participate in meetings of local legislative bodies.” which is more succinct.

(Early Experiments 🧪): solving math puzzles with python interpreter
In this section, we attempt to teach the model to use a python interpreter to solve math puzzles. The rough idea is to give the agent a prompt like the following:
prompt = """\
Example of using a Python API to solve math questions.
Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
<request><PythonInterpreter>
def solution():
money_initial = 23
bagels = 5
bagel_cost = 3
money_spent = bagels * bagel_cost
money_left = money_initial - money_spent
result = money_left
return result
print(solution())
<call>72<response>
Result = 72 <submit>
Q: """Training experiment can be found at https://wandb.ai/lvwerra/trl-gsm8k/runs/a5odv01y