BridgeTower
Overview
BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning で提案されました。ドゥアン。このモデルの目標は、 各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
この論文は AAAI’23 会議に採択されました。
論文の要約は次のとおりです。
TWO-TOWER アーキテクチャを備えたビジョン言語 (VL) モデルは、近年の視覚言語表現学習の主流となっています。 現在の VL モデルは、軽量のユニモーダル エンコーダーを使用して、ディープ クロスモーダル エンコーダーで両方のモダリティを同時に抽出、位置合わせ、融合することを学習するか、事前にトレーニングされたディープ ユニモーダル エンコーダーから最終層のユニモーダル表現を上部のクロスモーダルエンコーダー。 どちらのアプローチも、視覚言語表現の学習を制限し、モデルのパフォーマンスを制限する可能性があります。この論文では、ユニモーダル エンコーダの最上位層とクロスモーダル エンコーダの各層の間の接続を構築する複数のブリッジ層を導入する BRIDGETOWER を提案します。 これにより、効果的なボトムアップのクロスモーダル調整と、クロスモーダル エンコーダー内の事前トレーニング済みユニモーダル エンコーダーのさまざまなセマンティック レベルの視覚表現とテキスト表現の間の融合が可能になります。 BRIDGETOWER は 4M 画像のみで事前トレーニングされており、さまざまな下流の視覚言語タスクで最先端のパフォーマンスを実現します。 特に、VQAv2 テスト標準セットでは、BRIDGETOWER は 78.73% の精度を達成し、同じ事前トレーニング データとほぼ無視できる追加パラメータと計算コストで以前の最先端モデル METER を 1.09% 上回りました。 特に、モデルをさらにスケーリングすると、BRIDGETOWER は 81.15% の精度を達成し、桁違いに大きなデータセットで事前トレーニングされたモデルを上回りました。
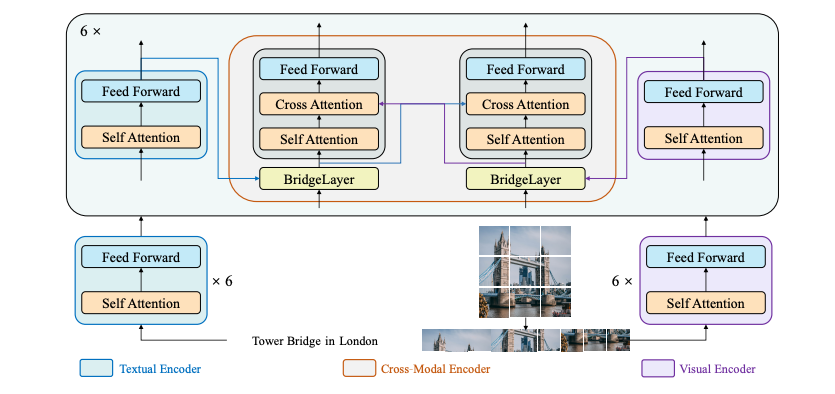 ブリッジタワー アーキテクチャ。 元の論文から抜粋。
ブリッジタワー アーキテクチャ。 元の論文から抜粋。 このモデルは、Anahita Bhiwandiwalla、Tiep Le、[Shaoyen Tseng](https://huggingface.co/shaoyent)。元のコードは ここ にあります。
Usage tips and examples
BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。 このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。 原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
BridgeTowerProcessor は、RobertaTokenizer と BridgeTowerImageProcessor を単一のインスタンスにラップし、両方の機能を実現します。
テキストをエンコードし、画像をそれぞれ用意します。
次の例は、BridgeTowerProcessor と BridgeTowerForContrastiveLearning を使用して対照学習を実行する方法を示しています。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs次の例は、BridgeTowerProcessor と BridgeTowerForImageAndTextRetrieval を使用して画像テキストの取得を実行する方法を示しています。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()次の例は、BridgeTowerProcessor と BridgeTowerForMaskedLM を使用してマスクされた言語モデリングを実行する方法を示しています。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.チップ:
- BridgeTower のこの実装では、
RobertaTokenizerを使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。 - 事前トレーニングされた bridgeTower-base および bridgetower マスクされた言語モデリングと画像テキスト マッチング のチェックポイント がリリースされました。
- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、表 5 を参照してください。
- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
BridgeTowerConfig
class transformers.BridgeTowerConfig
< source >( share_cross_modal_transformer_layers = True hidden_act = 'gelu' hidden_size = 768 initializer_factor = 1 layer_norm_eps = 1e-05 share_link_tower_layers = False link_tower_type = 'add' num_attention_heads = 12 num_hidden_layers = 6 tie_word_embeddings = False init_layernorm_from_vision_encoder = False text_config = None vision_config = None **kwargs )
Parameters
- share_cross_modal_transformer_layers (
bool, optional, defaults toTrue) — Whether cross modal transformer layers are shared. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - initializer_factor (
float, optional, defaults to 1) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing). - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - share_link_tower_layers (
bool, optional, defaults toFalse) — Whether the bride/link tower layers are shared. - link_tower_type (
str, optional, defaults to"add") — Type of the bridge/link layer. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 6) — Number of hidden layers in the Transformer encoder. - tie_word_embeddings (
bool, optional, defaults toFalse) — Whether to tie input and output embeddings. - init_layernorm_from_vision_encoder (
bool, optional, defaults toFalse) — Whether to init LayerNorm from the vision encoder. - text_config (
dict, optional) — Dictionary of configuration options used to initialize BridgeTowerTextConfig. - vision_config (
dict, optional) — Dictionary of configuration options used to initialize BridgeTowerVisionConfig.
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a BridgeTower model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the bridgetower-base BridgeTower/bridgetower-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import BridgeTowerModel, BridgeTowerConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration
>>> configuration = BridgeTowerConfig()
>>> # Initializing a model from the BridgeTower/bridgetower-base style configuration
>>> model = BridgeTowerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configfrom_text_vision_configs
< source >( text_config: BridgeTowerTextConfig vision_config: BridgeTowerVisionConfig **kwargs )
Instantiate a BridgeTowerConfig (or a derived class) from BridgeTower text model configuration. Returns: BridgeTowerConfig: An instance of a configuration object
BridgeTowerTextConfig
class transformers.BridgeTowerTextConfig
< source >( vocab_size = 50265 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 initializer_factor = 1 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 514 type_vocab_size = 1 layer_norm_eps = 1e-05 pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 position_embedding_type = 'absolute' use_cache = True **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 50265) — Vocabulary size of the text part of the model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling BridgeTowerModel. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (often named feed-forward) layer in the Transformer encoder. - hidden_act (
strorCallable, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. - hidden_dropout_prob (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. - max_position_embeddings (
int, optional, defaults to 514) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - type_vocab_size (
int, optional, defaults to 2) — The vocabulary size of thetoken_type_ids. - initializer_factor (
float, optional, defaults to 1) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing). - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - position_embedding_type (
str, optional, defaults to"absolute") — Type of position embedding. Choose one of"absolute","relative_key","relative_key_query". For positional embeddings use"absolute". For more information on"relative_key", please refer to Self-Attention with Relative Position Representations (Shaw et al.). For more information on"relative_key_query", please refer to Method 4 in Improve Transformer Models with Better Relative Position Embeddings (Huang et al.). - is_decoder (
bool, optional, defaults toFalse) — Whether the model is used as a decoder or not. IfFalse, the model is used as an encoder. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=True.
This is the configuration class to store the text configuration of a BridgeTowerModel. The default values here are copied from RoBERTa. Instantiating a configuration with the defaults will yield a similar configuration to that of the bridgetower-base BridegTower/bridgetower-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
BridgeTowerVisionConfig
class transformers.BridgeTowerVisionConfig
< source >( hidden_size = 768 num_hidden_layers = 12 num_channels = 3 patch_size = 16 image_size = 288 initializer_factor = 1 layer_norm_eps = 1e-05 stop_gradient = False share_layernorm = True remove_last_layer = False **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in visual encoder model. - patch_size (
int, optional, defaults to 16) — The size (resolution) of each patch. - image_size (
int, optional, defaults to 288) — The size (resolution) of each image. - initializer_factor (
float, optional, defaults to 1) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing). - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - stop_gradient (
bool, optional, defaults toFalse) — Whether to stop gradient for training. - share_layernorm (
bool, optional, defaults toTrue) — Whether LayerNorm layers are shared. - remove_last_layer (
bool, optional, defaults toFalse) — Whether to remove the last layer from the vision encoder.
This is the configuration class to store the vision configuration of a BridgeTowerModel. Instantiating a configuration with the defaults will yield a similar configuration to that of the bridgetower-base BridgeTower/bridgetower-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
BridgeTowerImageProcessor
class transformers.BridgeTowerImageProcessor
< source >( do_resize: bool = True size: Dict = 288 size_divisor: int = 32 resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_center_crop: bool = True do_pad: bool = True **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden by thedo_resizeparameter in thepreprocessmethod. - size (
Dict[str, int]optional, defaults to 288) — Resize the shorter side of the input tosize["shortest_edge"]. The longer side will be limited to underint((1333 / 800) * size["shortest_edge"])while preserving the aspect ratio. Only has an effect ifdo_resizeis set toTrue. Can be overridden by thesizeparameter in thepreprocessmethod. - size_divisor (
int, optional, defaults to 32) — The size by which to make sure both the height and width can be divided. Only has an effect ifdo_resizeis set toTrue. Can be overridden by thesize_divisorparameter in thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toResampling.BICUBIC) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. Can be overridden by theresampleparameter in thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Only has an effect ifdo_rescaleis set toTrue. Can be overridden by therescale_factorparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod. Can be overridden by theimage_stdparameter in thepreprocessmethod. - do_center_crop (
bool, optional, defaults toTrue) — Whether to center crop the image. Can be overridden by thedo_center_cropparameter in thepreprocessmethod. - do_pad (
bool, optional, defaults toTrue) — Whether to pad the image to the(max_height, max_width)of the images in the batch. Can be overridden by thedo_padparameter in thepreprocessmethod.
Constructs a BridgeTower image processor.
preprocess
< source >( images: Union do_resize: Optional = None size: Optional = None size_divisor: Optional = None resample: Resampling = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None do_pad: Optional = None do_center_crop: Optional = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Controls the size of the image afterresize. The shortest edge of the image is resized tosize["shortest_edge"]whilst preserving the aspect ratio. If the longest edge of this resized image is >int(size["shortest_edge"] * (1333 / 800)), then the image is resized again to make the longest edge equal toint(size["shortest_edge"] * (1333 / 800)). - size_divisor (
int, optional, defaults toself.size_divisor) — The image is resized to a size that is a multiple of this value. - resample (
PILImageResampling, optional, defaults toself.resample) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean to normalize the image by ifdo_normalizeis set toTrue. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation to normalize the image by ifdo_normalizeis set toTrue. - do_pad (
bool, optional, defaults toself.do_pad) — Whether to pad the image to the (max_height, max_width) in the batch. IfTrue, a pixel mask is also created and returned. - do_center_crop (
bool, optional, defaults toself.do_center_crop) — Whether to center crop the image. If the input size is smaller thancrop_sizealong any edge, the image is padded with 0’s and then center cropped. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
BridgeTowerProcessor
class transformers.BridgeTowerProcessor
< source >( image_processor tokenizer )
Parameters
- image_processor (
BridgeTowerImageProcessor) — An instance of BridgeTowerImageProcessor. The image processor is a required input. - tokenizer (
RobertaTokenizerFast) — An instance of [‘RobertaTokenizerFast`]. The tokenizer is a required input.
Constructs a BridgeTower processor which wraps a Roberta tokenizer and BridgeTower image processor into a single processor.
BridgeTowerProcessor offers all the functionalities of BridgeTowerImageProcessor and
RobertaTokenizerFast. See the docstring of call() and
decode() for more information.
__call__
< source >( images text: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 pad_to_multiple_of: Optional = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: Union = None **kwargs )
This method uses BridgeTowerImageProcessor.call() method to prepare image(s) for the model, and RobertaTokenizerFast.call() to prepare text for the model.
Please refer to the docstring of the above two methods for more information.
BridgeTowerModel
class transformers.BridgeTowerModel
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare BridgeTower Model transformer outputting BridgeTowerModelOutput object without any specific head on top.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None image_token_type_idx: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - output_hidden_states (
bool, optional) — If set toTrue, hidden states are returned as a list containing the hidden states of text, image, and cross-modal components respectively. i.e.(hidden_states_text, hidden_states_image, hidden_states_cross_modal)where each element is a list of the hidden states of the corresponding modality.hidden_states_txt/imgare a list of tensors corresponding to unimodal hidden states andhidden_states_cross_modalis a list of tuples containingcross_modal_text_hidden_statesandcross_modal_image_hidden_statesof each brdige layer. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels are currently not supported.
Returns
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput or tuple(torch.FloatTensor)
A transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
-
text_features (
torch.FloatTensorof shape(batch_size, text_sequence_length, hidden_size)) — Sequence of hidden-states at the text output of the last layer of the model. -
image_features (
torch.FloatTensorof shape(batch_size, image_sequence_length, hidden_size)) — Sequence of hidden-states at the image output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size x 2)) — Concatenation of last layer hidden-state of the first token of the text and image sequence (classification token), respectively, after further processing through layers used for auxiliary pretraining tasks. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. -
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The BridgeTowerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerModel
>>> from PIL import Image
>>> import requests
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "hello world"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
>>> model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> outputs.keys()
odict_keys(['text_features', 'image_features', 'pooler_output'])BridgeTowerForContrastiveLearning
class transformers.BridgeTowerForContrastiveLearning
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
BridgeTower Model with a image-text contrastive head on top computing image-text contrastive loss.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = True return_dict: Optional = None return_loss: Optional = None ) → transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - return_loss (
bool, optional) — Whether or not to return the contrastive loss.
Returns
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput or tuple(torch.FloatTensor)
A transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenreturn_lossisTrue— Image-text contrastive loss. - logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). - text_embeds (
torch.FloatTensor), optional, returned when model is initialized withwith_projection=True) — The text embeddings obtained by applying the projection layer to the pooler_output. - image_embeds (
torch.FloatTensor), optional, returned when model is initialized withwith_projection=True) — The image embeddings obtained by applying the projection layer to the pooler_output. - cross_embeds (
torch.FloatTensor), optional, returned when model is initialized withwith_projection=True) — The text-image cross-modal embeddings obtained by applying the projection layer to the pooler_output. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).
The BridgeTowerForContrastiveLearning forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> import torch
>>> image_urls = [
... "https://farm4.staticflickr.com/3395/3428278415_81c3e27f15_z.jpg",
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... ]
>>> texts = ["two dogs in a car", "two cats sleeping on a couch"]
>>> images = [Image.open(requests.get(url, stream=True).raw) for url in image_urls]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> inputs = processor(images, texts, padding=True, return_tensors="pt")
>>> loss = model(**inputs, return_loss=True).loss
>>> inputs = processor(images, texts[::-1], padding=True, return_tensors="pt")
>>> loss_swapped = model(**inputs, return_loss=True).loss
>>> print("Loss", round(loss.item(), 4))
Loss 0.0019
>>> print("Loss with swapped images", round(loss_swapped.item(), 4))
Loss with swapped images 2.126BridgeTowerForMaskedLM
class transformers.BridgeTowerForMaskedLM
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
BridgeTower Model with a language modeling head on top as done during pretraining.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_idsdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The BridgeTowerForMaskedLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.BridgeTowerForImageAndTextRetrieval
class transformers.BridgeTowerForImageAndTextRetrieval
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
BridgeTower Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the [CLS] token) for image-to-text matching.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, 1), optional) — Labels for computing the image-text matching loss. 0 means the pairs don’t match and 1 means they match. The pairs with 0 will be skipped for calculation.
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The BridgeTowerForImageAndTextRetrieval forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()