Efficient Inference on a Single GPU
このガイドに加えて、1つのGPUでのトレーニングガイドとCPUでの推論ガイドに関連する情報があります。
Flash Attention 2
この機能は実験的であり、将来のバージョンで大幅に変更される可能性があります。たとえば、Flash Attention 2 APIは近い将来BetterTransformer APIに移行するかもしれません。
Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって公式のFlash Attentionリポジトリで導入されました。Flash Attentionに関する科学論文はこちらで見ることができます。
Flash Attention 2を正しくインストールするには、上記のリポジトリに記載されているインストールガイドに従ってください。
以下のモデルに対してFlash Attention 2をネイティブサポートしています:
- Llama
- Falcon
さらに多くのモデルにFlash Attention 2のサポートを追加することをGitHubで提案することもでき、変更を統合するためにプルリクエストを開くこともできます。サポートされているモデルは、パディングトークンを使用してトレーニングを含む、推論とトレーニングに使用できます(現在のBetterTransformer APIではサポートされていない)。
Flash Attention 2は、モデルのdtypeがfp16またはbf16の場合にのみ使用でき、NVIDIA-GPUデバイスでのみ実行されます。この機能を使用する前に、モデルを適切なdtypeにキャストし、サポートされているデバイスにロードしてください。
Quick usage
モデルでFlash Attention 2を有効にするには、from_pretrainedの引数にattn_implementation="flash_attention_2"を追加します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)こちらは、生成または微調整のために使用するテキストです。
Expected speedups
特に長いシーケンスに対して、微調整と推論の際には、かなりの高速化が期待できます。ただし、Flash Attentionはパディングトークンを使用してアテンションスコアを計算しないため、シーケンスにパディングトークンが含まれる場合、バッチ推論においてアテンションスコアを手動でパッド/アンパッドする必要があり、パディングトークンを含むバッチ生成の大幅な遅延が発生します。
これを克服するために、トレーニング中にシーケンスにパディングトークンを使用せずにFlash Attentionを使用する必要があります(たとえば、データセットをパックすることにより、シーケンスを最大シーケンス長に達するまで連結することなど)。ここに例が提供されています。
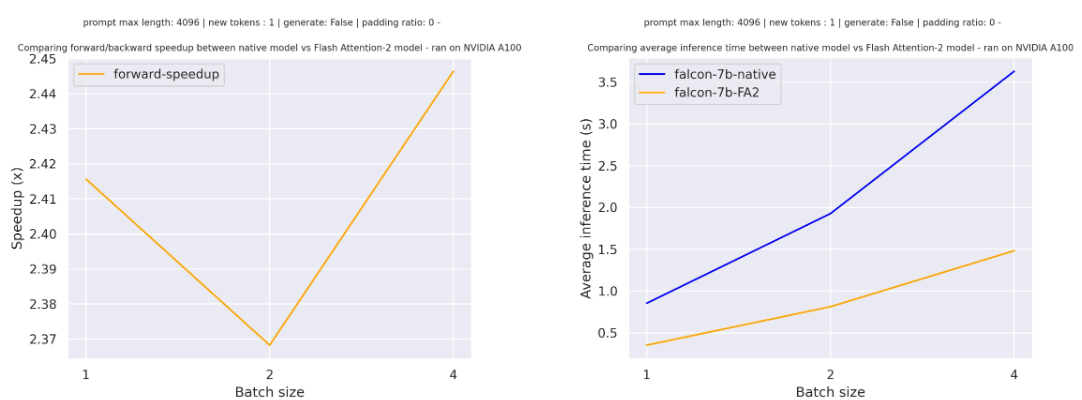
以下は、パディングトークンのない場合に、シーケンス長が4096のtiiuae/falcon-7bに対する単純なフォワードパスの予想される高速化です。さまざまなバッチサイズが示されています:
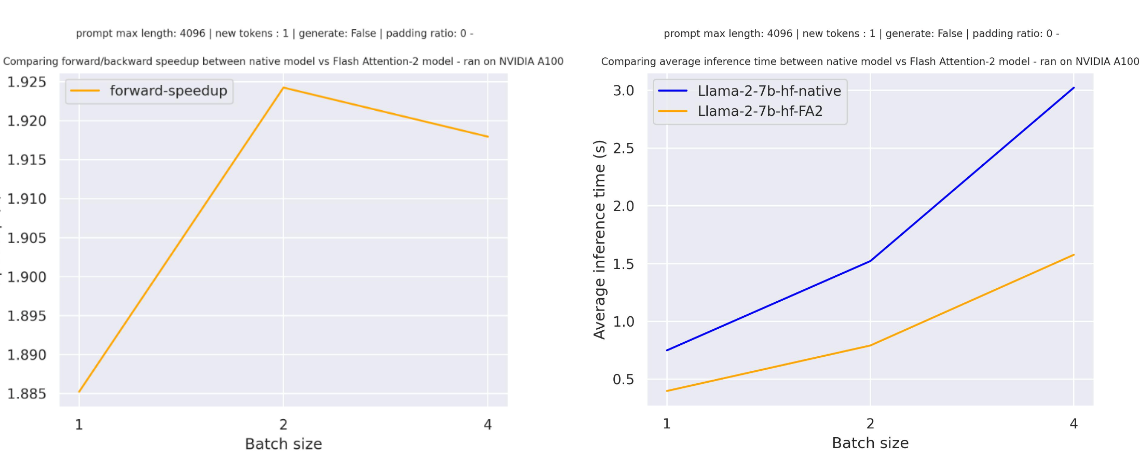
以下は、パディングトークンのない場合に、シーケンス長が4096のmeta-llama/Llama-7b-hfに対する単純なフォワードパスの予想される高速化です。さまざまなバッチサイズが示されています:
パディングトークンを含むシーケンス(パディングトークンを使用してトレーニングまたは生成する)の場合、アテンションスコアを正しく計算するために入力シーケンスをアンパッド/パッドする必要があります。比較的小さいシーケンス長の場合、純粋なフォワードパスではパディングトークンが30%未満しか埋められていないため、これはわずかな高速化をもたらします。
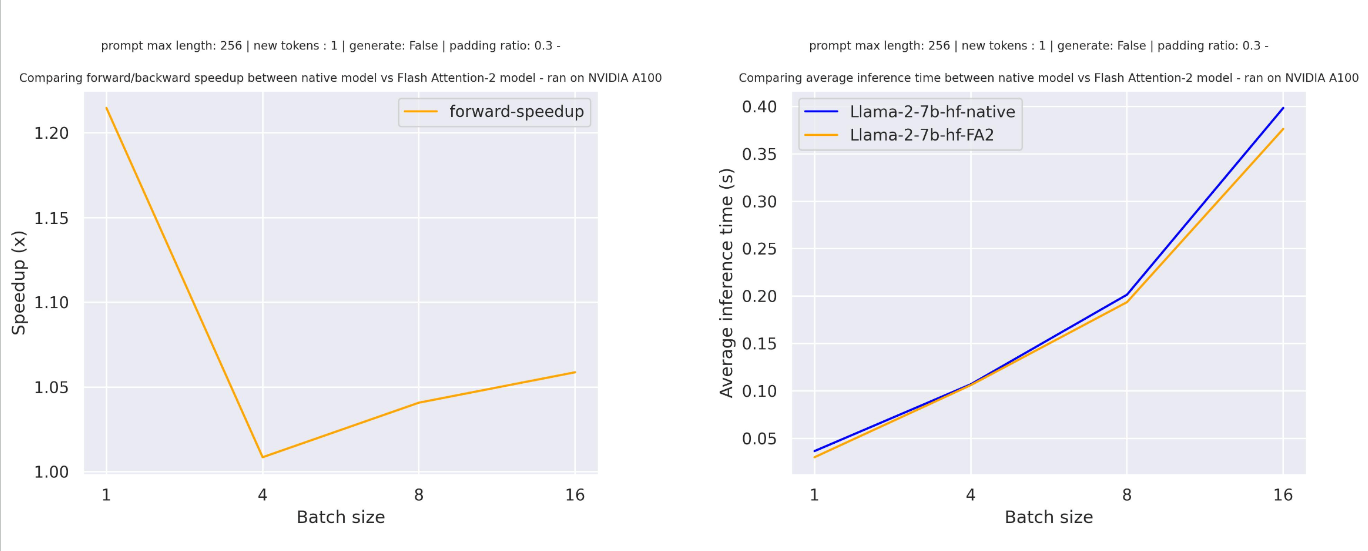
しかし、大きなシーケンス長の場合、純粋な推論(トレーニングも含む)には興味深い高速化が得られます。
Flash Attentionは、アテンション計算をよりメモリ効率の良いものにし、大きなシーケンス長でのCUDA OOMの問題を回避できるようにします。大きなシーケンス長に対して最大20のメモリ削減をもたらすことがあります。詳細については、公式のFlash Attentionリポジトリをご覧ください。

Advanced usage
この機能をモデルの最適化に多くの既存の機能と組み合わせることができます。以下にいくつかの例を示します:
Combining Flash Attention 2 and 8-bit models
この機能を8ビットの量子化と組み合わせることができます:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)Combining Flash Attention 2 and 4-bit models
この機能を 4 ビットの量子化と組み合わせることができます:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)Combining Flash Attention 2 and PEFT
この機能を使用して、Flash Attention 2をベースにアダプターをトレーニングする際にPEFTを組み合わせることができます。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
from peft import LoraConfig
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
lora_config = LoraConfig(
r=8,
task_type="CAUSAL_LM"
)
model.add_adapter(lora_config)
... # train your modelBetterTransformer
BetterTransformerは、🤗 TransformersモデルをPyTorchネイティブの高速パス実行に変換します。これにより、Flash Attentionなどの最適化されたカーネルが内部で呼び出されます。
BetterTransformerは、テキスト、画像、およびオーディオモデルの単一およびマルチGPUでの高速な推論をサポートしています。
Flash Attentionは、fp16またはbf16のdtypeを使用するモデルにのみ使用できます。BetterTransformerを使用する前に、モデルを適切なdtypeにキャストしてください。
Encoder models
PyTorchネイティブのnn.MultiHeadAttentionアテンション高速パス、BetterTransformerと呼ばれるものは、🤗 Optimumライブラリの統合を通じてTransformersと一緒に使用できます。
PyTorchのアテンション高速パスを使用すると、カーネルフュージョンとネストされたテンソルの使用により、推論を高速化できます。詳細なベンチマーク情報はこのブログ記事にあります。
optimumパッケージをインストールした後、推論中にBetter Transformerを使用するには、関連する内部モジュールを呼び出すことで置き換える必要がありますto_bettertransformer():
model = model.to_bettertransformer()
メソッド reverse_bettertransformer() は、モデルを保存する前に使用すべきで、標準のトランスフォーマーモデリングを使用するためのものです:
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")BetterTransformer APIを使ったエンコーダーモデルの可能性について詳しく知るには、このブログポストをご覧ください。
Decoder models
テキストモデル、特にデコーダーベースのモデル(GPT、T5、Llamaなど)にとって、BetterTransformer APIはすべての注意操作をtorch.nn.functional.scaled_dot_product_attentionオペレーター(SDPA)を使用するように変換します。このオペレーターはPyTorch 2.0以降でのみ利用可能です。
モデルをBetterTransformerに変換するには、以下の手順を実行してください:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
# convert the model to BetterTransformer
model.to_bettertransformer()
# Use it for training or inferenceSDPAは、ハードウェアや問題のサイズに応じてFlash Attentionカーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、torch.backends.cuda.sdp_kernelをコンテキストマネージャとして使用します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
# convert the model to BetterTransformer
model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))もしトレースバックにバグが表示された場合
RuntimeError: No available kernel. Aborting execution.
Flash Attention の広範なカバレッジを持つかもしれない PyTorch のナイトリーバージョンを試してみることをお勧めします。
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
Or make sure your model is correctly casted in float16 or bfloat16
モデルが正しくfloat16またはbfloat16にキャストされていることを確認してください。
Have a look at this detailed blogpost to read more about what is possible to do with BetterTransformer + SDPA API.
BetterTransformer + SDPA APIを使用して何が可能かについて詳しく読むには、この詳細なブログポストをご覧ください。
bitsandbytes integration for FP4 mixed-precision inference
FP4混合精度推論のためのbitsandbytes統合
You can install bitsandbytes and benefit from easy model compression on GPUs. Using FP4 quantization you can expect to reduce up to 8x the model size compared to its native full precision version. Check out below how to get started.
bitsandbytesをインストールし、GPUで簡単なモデルの圧縮を利用できます。FP4量子化を使用すると、ネイティブのフルプレシジョンバージョンと比較してモデルサイズを最大8倍削減できることが期待できます。以下を確認して、どのように始めるかをご覧ください。
Note that this feature can also be used in a multi GPU setup.
この機能は、マルチGPUセットアップでも使用できることに注意してください。
Requirements
Latest
bitsandbyteslibrarypip install bitsandbytes>=0.39.0Install latest
acceleratefrom sourcepip install git+https://github.com/huggingface/accelerate.gitInstall latest
transformersfrom sourcepip install git+https://github.com/huggingface/transformers.git
Running FP4 models - single GPU setup - Quickstart
以下のコードを実行することで、簡単に単一のGPUでFP4モデルを実行できます:
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)注意: device_mapはオプションですが、推論時に device_map = 'auto' を設定することが推奨されています。これにより、利用可能なリソースに効率的にモデルがディスパッチされます。
Running FP4 models - multi GPU setup
混合4ビットモデルを複数のGPUにロードする方法は、単一GPUセットアップと同じです(単一GPUセットアップと同じコマンドです):
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)しかし、accelerateを使用して、各GPUに割り当てるGPU RAMを制御することができます。以下のように、max_memory引数を使用します:
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)この例では、最初のGPUは600MBのメモリを使用し、2番目のGPUは1GBを使用します。
Advanced usage
このメソッドのさらなる高度な使用法については、量子化のドキュメンテーションページをご覧ください。
bitsandbytes integration for Int8 mixed-precision matrix decomposition
この機能は、マルチGPU環境でも使用できます。
論文LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(float16およびbfloat16)の重みの場合にnn.Linearサイズを2倍、単精度(float32)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。

Int8混合精度行列分解は、行列乗算を2つのストリームに分割することによって動作します:(1) システマティックな特徴外れ値ストリームがfp16で行列乗算(0.01%)、(2) int8行列乗算の通常のストリーム(99.9%)。この方法を使用すると、非常に大きなモデルに対して予測の劣化なしにint8推論が可能です。 このメソッドの詳細については、論文またはこの統合に関するブログ記事をご確認ください。

なお、この機能を使用するにはGPUが必要であり、カーネルはGPU専用にコンパイルされている必要があります。この機能を使用する前に、モデルの1/4(またはハーフ精度の重みの場合は1/2)を保存するのに十分なGPUメモリがあることを確認してください。 このモジュールを使用する際のヘルプに関する詳細は、以下のノートをご覧いただくか、Google Colabのデモをご覧ください。
Requirements
bitsandbytes<0.37.0を使用する場合、NVIDIA GPUを使用していることを確認し、8ビットテンソルコアをサポートしていることを確認してください(Turing、Ampere、またはそれ以降のアーキテクチャー、例:T4、RTX20s RTX30s、A40-A100など)。bitsandbytes>=0.37.0の場合、すべてのGPUがサポートされるはずです。- 正しいバージョンの
bitsandbytesをインストールするには、次のコマンドを実行してください:pip install bitsandbytes>=0.31.5 accelerateをインストールします:pip install accelerate>=0.12.0
Running mixed-Int8 models - single GPU setup
必要なライブラリをインストールした後、ミックス 8 ビットモデルを読み込む方法は次の通りです:
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)以下はシンプルな例です:
pipeline()関数の代わりに、モデルのgenerate()メソッドを使用することをお勧めします。pipeline()関数を使用して推論することは可能ですが、混合8ビットモデルに最適化されておらず、generate()メソッドを使用するよりも遅くなります。また、一部のサンプリング戦略(例:ヌクレウスサンプリング)は、pipeline()関数では混合8ビットモデルではサポートされていません。- すべての入力をモデルと同じデバイスに配置してください。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)Running mixed-int8 models - multi GPU setup
複数のGPUに混合8ビットモデルをロードする方法は、次の通りです(シングルGPUセットアップと同じコマンドです):
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)accelerateを使用して各GPUに割り当てるGPU RAMを制御する際には、以下のようにmax_memory引数を使用します:
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)In this example, the first GPU will use 1GB of memory and the second 2GB.
Colab demos
この方法を使用すると、以前のGoogle Colabでは推論できなかったモデルに対して推論を行うことができます。以下は、Google Colabで8ビット量子化を使用してT5-11b(fp32で42GB)を実行するデモのリンクです:
![]()
また、BLOOM-3Bのデモもご覧いただけます:
![]()
Advanced usage: mixing FP4 (or Int8) and BetterTransformer
異なる方法を組み合わせて、モデルの最適なパフォーマンスを得ることができます。例えば、BetterTransformerを使用してFP4ミックスプレシジョン推論とフラッシュアテンションを組み合わせることができます。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))