Transformers documentation
Text to speech
Text to speech
Text-to-speech (TTS) is the task of creating natural-sounding speech from text, where the speech can be generated in multiple languages and for multiple speakers. The only text-to-speech model currently available in 🤗 Transformers is SpeechT5, though more will be added in the future. SpeechT5 is pre-trained on a combination of speech-to-text and text-to-speech data, allowing it to learn a unified space of hidden representations shared by both text and speech. This means that the same pre-trained model can be fine-tuned for different tasks. Furthermore, SpeechT5 supports multiple speakers through x-vector speaker embeddings.
This guide illustrates how to:
- Fine-tune SpeechT5 that was originally trained on English speech on the Dutch (
nl) language subset of the VoxPopuli dataset. - Use your fine-tuned model for inference.
Before you begin, make sure you have all the necessary libraries installed:
pip install datasets soundfile speechbrain accelerate
Install 🤗Transformers from source as not all the SpeechT5 features have been merged into an official release yet:
pip install git+https://github.com/huggingface/transformers.git
To follow this guide you will need a GPU. If you’re working in a notebook, run the following line to check if a GPU is available:
!nvidia-smi
We encourage you to log in to your Hugging Face account to upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()Load the dataset
VoxPopuli is a large-scale multilingual speech corpus consisting of data sourced from 2009-2020 European Parliament event recordings. It contains labelled audio-transcription data for 15 European languages. In this guide, we are using the Dutch language subset, feel free to pick another subset.
Note that VoxPopuli or any other automated speech recognition (ASR) dataset may not be the most suitable option for training TTS models. The features that make it beneficial for ASR, such as excessive background noise, are typically undesirable in TTS. However, finding top-quality, multilingual, and multi-speaker TTS datasets can be quite challenging.
Let’s load the data:
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
>>> len(dataset)
2096820968 examples should be sufficient for fine-tuning. SpeechT5 expects audio data to have a sampling rate of 16 kHz, so make sure the examples in the dataset meet this requirement:
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))Preprocess the data
Let’s begin by defining the model checkpoint to use and loading the appropriate processor:
>>> from transformers import SpeechT5Processor
>>> checkpoint = "microsoft/speecht5_tts"
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)Text cleanup for SpeechT5 tokenization
Start by cleaning up the text data. You’ll need the tokenizer part of the processor to process the text:
>>> tokenizer = processor.tokenizerThe dataset examples contain raw_text and normalized_text features. When deciding which feature to use as the text input,
consider that the SpeechT5 tokenizer doesn’t have any tokens for numbers. In normalized_text the numbers are written
out as text. Thus, it is a better fit, and we recommend using normalized_text as input text.
Because SpeechT5 was trained on the English language, it may not recognize certain characters in the Dutch dataset. If
left as is, these characters will be converted to <unk> tokens. However, in Dutch, certain characters like à are
used to stress syllables. In order to preserve the meaning of the text, we can replace this character with a regular a.
To identify unsupported tokens, extract all unique characters in the dataset using the SpeechT5Tokenizer which
works with characters as tokens. To do this, write the extract_all_chars mapping function that concatenates
the transcriptions from all examples into one string and converts it to a set of characters.
Make sure to set batched=True and batch_size=-1 in dataset.map() so that all transcriptions are available at once for
the mapping function.
>>> def extract_all_chars(batch):
... all_text = " ".join(batch["normalized_text"])
... vocab = list(set(all_text))
... return {"vocab": [vocab], "all_text": [all_text]}
>>> vocabs = dataset.map(
... extract_all_chars,
... batched=True,
... batch_size=-1,
... keep_in_memory=True,
... remove_columns=dataset.column_names,
... )
>>> dataset_vocab = set(vocabs["vocab"][0])
>>> tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}Now you have two sets of characters: one with the vocabulary from the dataset and one with the vocabulary from the tokenizer. To identify any unsupported characters in the dataset, you can take the difference between these two sets. The resulting set will contain the characters that are in the dataset but not in the tokenizer.
>>> dataset_vocab - tokenizer_vocab
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}To handle the unsupported characters identified in the previous step, define a function that maps these characters to
valid tokens. Note that spaces are already replaced by ▁ in the tokenizer and don’t need to be handled separately.
>>> replacements = [
... ("à", "a"),
... ("ç", "c"),
... ("è", "e"),
... ("ë", "e"),
... ("í", "i"),
... ("ï", "i"),
... ("ö", "o"),
... ("ü", "u"),
... ]
>>> def cleanup_text(inputs):
... for src, dst in replacements:
... inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
... return inputs
>>> dataset = dataset.map(cleanup_text)Now that you have dealt with special characters in the text, it’s time to shift focus to the audio data.
Speakers
The VoxPopuli dataset includes speech from multiple speakers, but how many speakers are represented in the dataset? To determine this, we can count the number of unique speakers and the number of examples each speaker contributes to the dataset. With a total of 20,968 examples in the dataset, this information will give us a better understanding of the distribution of speakers and examples in the data.
>>> from collections import defaultdict
>>> speaker_counts = defaultdict(int)
>>> for speaker_id in dataset["speaker_id"]:
... speaker_counts[speaker_id] += 1By plotting a histogram you can get a sense of how much data there is for each speaker.
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.hist(speaker_counts.values(), bins=20)
>>> plt.ylabel("Speakers")
>>> plt.xlabel("Examples")
>>> plt.show()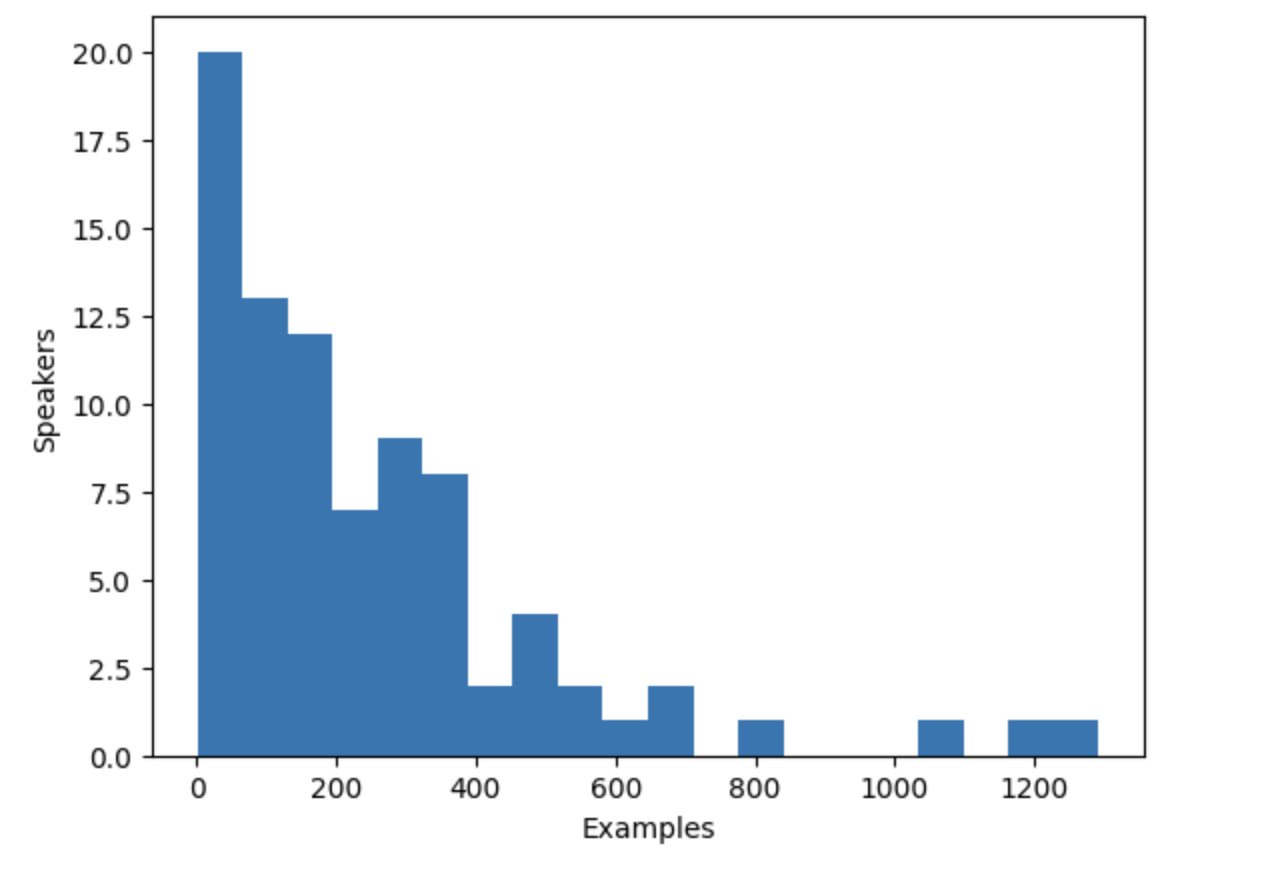
The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit the data to speakers with between 100 and 400 examples.
>>> def select_speaker(speaker_id):
... return 100 <= speaker_counts[speaker_id] <= 400
>>> dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])Let’s check how many speakers remain:
>>> len(set(dataset["speaker_id"]))
42Let’s see how many examples are left:
>>> len(dataset)
9973You are left with just under 10,000 examples from approximately 40 unique speakers, which should be sufficient.
Note that some speakers with few examples may actually have more audio available if the examples are long. However, determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a time-consuming process that involves loading and decoding each audio file. As such, we have chosen to skip this step here.
Speaker embeddings
To enable the TTS model to differentiate between multiple speakers, you’ll need to create a speaker embedding for each example. The speaker embedding is an additional input into the model that captures a particular speaker’s voice characteristics. To generate these speaker embeddings, use the pre-trained spkrec-xvect-voxceleb model from SpeechBrain.
Create a function create_speaker_embedding() that takes an input audio waveform and outputs a 512-element vector
containing the corresponding speaker embedding.
>>> import os
>>> import torch
>>> from speechbrain.pretrained import EncoderClassifier
>>> spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> speaker_model = EncoderClassifier.from_hparams(
... source=spk_model_name,
... run_opts={"device": device},
... savedir=os.path.join("/tmp", spk_model_name),
... )
>>> def create_speaker_embedding(waveform):
... with torch.no_grad():
... speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
... speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
... speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
... return speaker_embeddingsIt’s important to note that the speechbrain/spkrec-xvect-voxceleb model was trained on English speech from the VoxCeleb
dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
reasonable speaker embeddings for our Dutch dataset, this assumption may not hold true in all cases.
For optimal results, we recommend training an X-vector model on the target speech first. This will ensure that the model is better able to capture the unique voice characteristics present in the Dutch language.
Processing the dataset
Finally, let’s process the data into the format the model expects. Create a prepare_dataset function that takes in a
single example and uses the SpeechT5Processor object to tokenize the input text and load the target audio into a log-mel spectrogram.
It should also add the speaker embeddings as an additional input.
>>> def prepare_dataset(example):
... audio = example["audio"]
... example = processor(
... text=example["normalized_text"],
... audio_target=audio["array"],
... sampling_rate=audio["sampling_rate"],
... return_attention_mask=False,
... )
... # strip off the batch dimension
... example["labels"] = example["labels"][0]
... # use SpeechBrain to obtain x-vector
... example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
... return exampleVerify the processing is correct by looking at a single example:
>>> processed_example = prepare_dataset(dataset[0])
>>> list(processed_example.keys())
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']Speaker embeddings should be a 512-element vector:
>>> processed_example["speaker_embeddings"].shape
(512,)The labels should be a log-mel spectrogram with 80 mel bins.
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.imshow(processed_example["labels"].T)
>>> plt.show()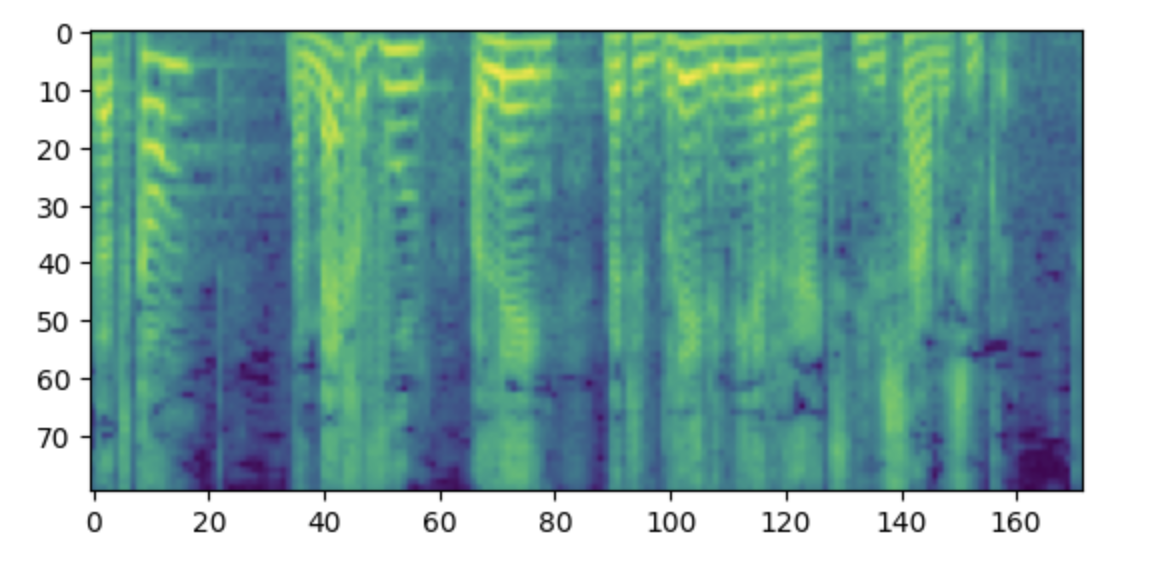
Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library, the y-axis is flipped and the spectrograms appear upside down.
Now apply the processing function to the entire dataset. This will take between 5 and 10 minutes.
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)You’ll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens). Remove those examples from the dataset. Here we go even further and to allow for larger batch sizes we remove anything over 200 tokens.
>>> def is_not_too_long(input_ids):
... input_length = len(input_ids)
... return input_length < 200
>>> dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
>>> len(dataset)
8259Next, create a basic train/test split:
>>> dataset = dataset.train_test_split(test_size=0.1)Data collator
In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with the special value -100. This special value
instructs the model to ignore that part of the spectrogram when calculating the spectrogram loss.
>>> from dataclasses import dataclass
>>> from typing import Any, Dict, List, Union
>>> @dataclass
... class TTSDataCollatorWithPadding:
... processor: Any
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
... label_features = [{"input_values": feature["labels"]} for feature in features]
... speaker_features = [feature["speaker_embeddings"] for feature in features]
... # collate the inputs and targets into a batch
... batch = processor.pad(input_ids=input_ids, labels=label_features, return_tensors="pt")
... # replace padding with -100 to ignore loss correctly
... batch["labels"] = batch["labels"].masked_fill(batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100)
... # not used during fine-tuning
... del batch["decoder_attention_mask"]
... # round down target lengths to multiple of reduction factor
... if model.config.reduction_factor > 1:
... target_lengths = torch.tensor([len(feature["input_values"]) for feature in label_features])
... target_lengths = target_lengths.new(
... [length - length % model.config.reduction_factor for length in target_lengths]
... )
... max_length = max(target_lengths)
... batch["labels"] = batch["labels"][:, :max_length]
... # also add in the speaker embeddings
... batch["speaker_embeddings"] = torch.tensor(speaker_features)
... return batchIn SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a multiple of 2.
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)Train the model
Load the pre-trained model from the same checkpoint as you used for loading the processor:
>>> from transformers import SpeechT5ForTextToSpeech
>>> model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)The use_cache=True option is incompatible with gradient checkpointing. Disable it for training.
>>> model.config.use_cache = FalseDefine the training arguments. Here we are not computing any evaluation metrics during the training process. Instead, we’ll only look at the loss:
>>> from transformers import Seq2SeqTrainingArguments
>>> training_args = Seq2SeqTrainingArguments(
... output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
... per_device_train_batch_size=4,
... gradient_accumulation_steps=8,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=4000,
... gradient_checkpointing=True,
... fp16=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=2,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... report_to=["tensorboard"],
... load_best_model_at_end=True,
... greater_is_better=False,
... label_names=["labels"],
... push_to_hub=True,
... )Instantiate the Trainer object and pass the model, dataset, and data collator to it.
>>> from transformers import Seq2SeqTrainer
>>> trainer = Seq2SeqTrainer(
... args=training_args,
... model=model,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
... tokenizer=processor.tokenizer,
... )And with that, you’re ready to start training! Training will take several hours. Depending on your GPU,
it is possible that you will encounter a CUDA “out-of-memory” error when you start training. In this case, you can reduce
the per_device_train_batch_size incrementally by factors of 2 and increase gradient_accumulation_steps by 2x to compensate.
>>> trainer.train()Push the final model to the 🤗 Hub:
>>> trainer.push_to_hub()Inference
Great, now that you’ve fine-tuned a model, you can use it for inference! Load the model from the 🤗 Hub (make sure to use your account name in the following code snippet):
>>> model = SpeechT5ForTextToSpeech.from_pretrained("YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl")Pick an example, here we’ll take one from the test dataset. Obtain a speaker embedding.
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)Define some input text and tokenize it.
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"Preprocess the input text:
>>> inputs = processor(text=text, return_tensors="pt")Create a spectrogram with your model:
>>> spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)Visualize the spectrogram, if you’d like to:
>>> plt.figure()
>>> plt.imshow(spectrogram.T)
>>> plt.show()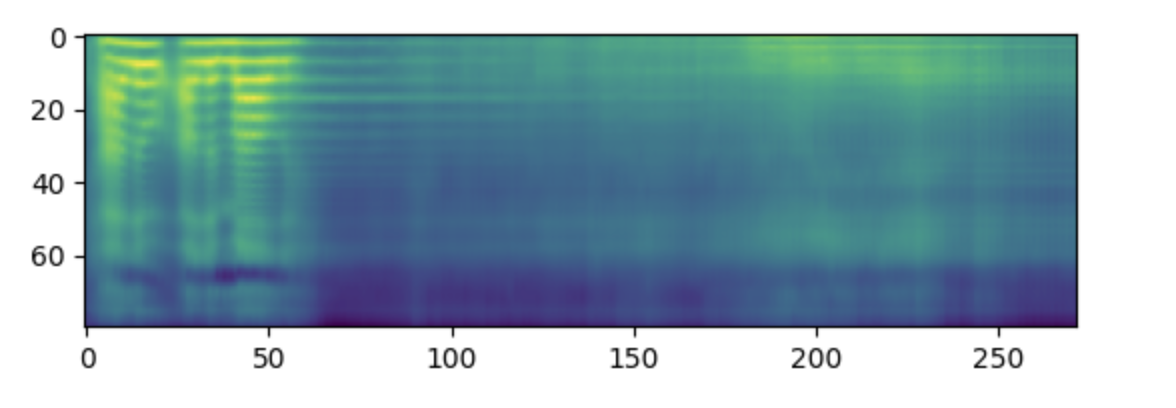
Finally, use the vocoder to turn the spectrogram into sound.
>>> with torch.no_grad():
... speech = vocoder(spectrogram)
>>> from IPython.display import Audio
>>> Audio(speech.numpy(), rate=16000)In our experience, obtaining satisfactory results from this model can be challenging. The quality of the speaker embeddings appears to be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best when using English speaker embeddings. If the synthesized speech sounds poor, try using a different speaker embedding.
Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
capture the voice characteristics of the speaker (compare to the original audio in the example).
Another thing to experiment with is the model’s configuration. For example, try using config.reduction_factor = 1 to
see if this improves the results.
Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it may also be used for malicious purposes, such as impersonating someone’s voice without their knowledge or consent. Please use TTS judiciously and responsibly.