Transformers documentation
Audio Spectrogram Transformer
Audio Spectrogram Transformer
Overview
The Audio Spectrogram Transformer model was proposed in AST: Audio Spectrogram Transformer by Yuan Gong, Yu-An Chung, James Glass. The Audio Spectrogram Transformer applies a Vision Transformer to audio, by turning audio into an image (spectrogram). The model obtains state-of-the-art results for audio classification.
The abstract from the paper is the following:
In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for end-to-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.
Tips:
- When fine-tuning the Audio Spectrogram Transformer (AST) on your own dataset, it’s recommended to take care of the input normalization (to make
sure the input has mean of 0 and std of 0.5). ASTFeatureExtractor takes care of this. Note that it uses the AudioSet
mean and std by default. You can check
ast/src/get_norm_stats.pyto see how the authors compute the stats for a downstream dataset. - Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the PSLA paper) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
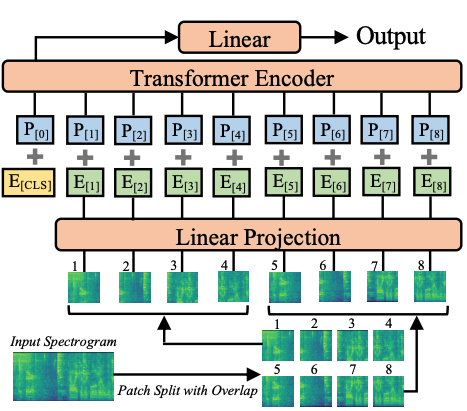 Audio pectrogram Transformer architecture. Taken from the original paper.
Audio pectrogram Transformer architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with the Audio Spectrogram Transformer.
- A notebook illustrating inference with AST for audio classification can be found here.
- ASTForAudioClassification is supported by this example script and notebook.
- See also: Audio classification.
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
ASTConfig
class transformers.ASTConfig
< source >( hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-12 patch_size = 16 qkv_bias = True frequency_stride = 10 time_stride = 10 max_length = 1024 num_mel_bins = 128 **kwargs )
Parameters
-
hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. -
num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. -
num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. -
intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. -
hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. -
hidden_dropout_prob (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. -
attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. -
layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. -
patch_size (
int, optional, defaults to16) — The size (resolution) of each patch. -
qkv_bias (
bool, optional, defaults toTrue) — Whether to add a bias to the queries, keys and values. -
frequency_stride (
int, optional, defaults to 10) — Frequency stride to use when patchifying the spectrograms. -
time_stride (
int, optional, defaults to 10) — Temporal stride to use when patchifying the spectrograms. -
max_length (
int, optional, defaults to 1024) — Temporal dimension of the spectrograms. -
num_mel_bins (
int, optional, defaults to 128) — Frequency dimension of the spectrograms (number of Mel-frequency bins).
This is the configuration class to store the configuration of a ASTModel. It is used to instantiate an AST model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the AST MIT/ast-finetuned-audioset-10-10-0.4593 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import ASTConfig, ASTModel
>>> # Initializing a AST MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
>>> configuration = ASTConfig()
>>> # Initializing a model (with random weights) from the MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
>>> model = ASTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configASTFeatureExtractor
class transformers.ASTFeatureExtractor
< source >( feature_size = 1 sampling_rate = 16000 num_mel_bins = 128 max_length = 1024 padding_value = 0.0 do_normalize = True mean = -4.2677393 std = 4.5689974 return_attention_mask = False **kwargs )
Parameters
-
feature_size (
int, optional, defaults to 1) — The feature dimension of the extracted features. -
sampling_rate (
int, optional, defaults to 16000) — The sampling rate at which the audio files should be digitalized expressed in hertz (Hz). -
num_mel_bins (
int, optional, defaults to 128) — Number of Mel-frequency bins. -
max_length (
int, optional, defaults to 1024) — Maximum length to which to pad/truncate the extracted features. -
do_normalize (
bool, optional, defaults toTrue) — Whether or not to normalize the log-Mel features usingmeanandstd. -
mean (
float, optional, defaults to -4.2677393) — The mean value used to normalize the log-Mel features. Uses the AudioSet mean by default. -
std (
float, optional, defaults to 4.5689974) — The standard deviation value used to normalize the log-Mel features. Uses the AudioSet standard deviation by default. -
return_attention_mask (
bool, optional, defaults toFalse) — Whether or not call() should returnattention_mask.
Constructs a Audio Spectrogram Transformer (AST) feature extractor.
This feature extractor inherits from SequenceFeatureExtractor which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
This class extracts mel-filter bank features from raw speech using TorchAudio, pads/truncates them to a fixed length and normalizes them using a mean and standard deviation.
__call__
< source >( raw_speech: typing.Union[numpy.ndarray, typing.List[float], typing.List[numpy.ndarray], typing.List[typing.List[float]]] sampling_rate: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs )
Parameters
-
raw_speech (
np.ndarray,List[float],List[np.ndarray],List[List[float]]) — The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float values, a list of numpy arrays or a list of list of float values. -
sampling_rate (
int, optional) — The sampling rate at which theraw_speechinput was sampled. It is strongly recommended to passsampling_rateat the forward call to prevent silent errors. -
return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
Main method to featurize and prepare for the model one or several sequence(s).
ASTModel
class transformers.ASTModel
< source >( config: ASTConfig )
Parameters
- config (ASTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare AST Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_values: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
-
input_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. See ASTFeatureExtractor.call() for details. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ASTConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ASTModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, ASTModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> model = ASTModel.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 1214, 768]ASTForAudioClassification
class transformers.ASTForAudioClassification
< source >( config: ASTConfig )
Parameters
- config (ASTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Audio Spectrogram Transformer model with an audio classification head on top (a linear layer on top of the pooled output) e.g. for datasets like AudioSet, Speech Commands v2.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_values: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
labels: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
input_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. See ASTFeatureExtractor.call() for details. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the audio classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ASTConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ASTForAudioClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoFeatureExtractor, ASTForAudioClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'Speech'
>>> # compute loss - target_label is e.g. "down"
>>> target_label = model.config.id2label[0]
>>> inputs["labels"] = torch.tensor([model.config.label2id[target_label]])
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
0.17