Transformers documentation
SegFormer
SegFormer
Overview
The SegFormer model was proposed in SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on image segmentation benchmarks such as ADE20K and Cityscapes.
The abstract from the paper is the following:
We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding, thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from different layers, and thus combining both local attention and global attention to render powerful representations. We show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters, being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.
The figure below illustrates the architecture of SegFormer. Taken from the original paper.
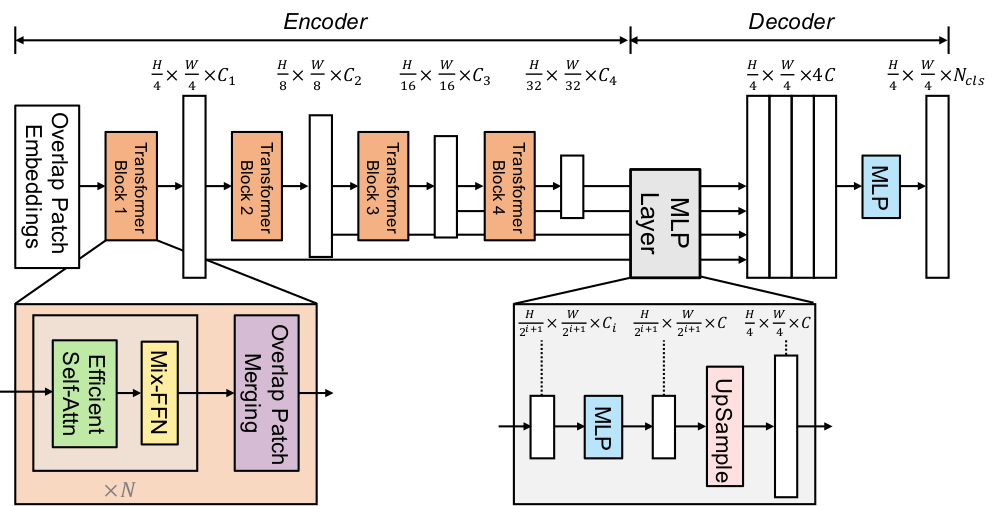
This model was contributed by nielsr. The TensorFlow version of the model was contributed by sayakpaul. The original code can be found here.
Tips:
- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head. SegformerModel is the hierarchical Transformer encoder (which in the paper is also referred to as Mix Transformer or MiT). SegformerForSemanticSegmentation adds the all-MLP decoder head on top to perform semantic segmentation of images. In addition, there’s SegformerForImageClassification which can be used to - you guessed it - classify images. The authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be found on the hub.
- The quickest way to get started with SegFormer is by checking the example notebooks (which showcase both inference and fine-tuning on custom data). One can also check out the blog post introducing SegFormer and illustrating how it can be fine-tuned on custom data.
- TensorFlow users should refer to this repository that shows off-the-shelf inference and fine-tuning.
- One can also check out this interactive demo on Hugging Face Spaces to try out a SegFormer model on custom images.
- SegFormer works on any input size, as it pads the input to be divisible by
config.patch_sizes. - One can use SegformerFeatureExtractor to prepare images and corresponding segmentation maps for the model. Note that this feature extractor is fairly basic and does not include all data augmentations used in the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found here. The most important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size, such as 512x512 or 640x640, after which they are normalized.
- One additional thing to keep in mind is that one can initialize SegformerFeatureExtractor with
reduce_labelsset toTrueorFalse. In some datasets (like ADE20k), the 0 index is used in the annotated segmentation maps for background. However, ADE20k doesn’t include the “background” class in its 150 labels. Therefore,reduce_labelsis used to reduce all labels by 1, and to make sure no loss is computed for the background class (i.e. it replaces 0 in the annotated maps by 255, which is the ignore_index of the loss function used by SegformerForSemanticSegmentation). However, other datasets use the 0 index as background class and include this class as part of all labels. In that case,reduce_labelsshould be set toFalse, as loss should also be computed for the background class. - As most models, SegFormer comes in different sizes, the details of which can be found in the table below (taken from Table 7 of the original paper).
| Model variant | Depths | Hidden sizes | Decoder hidden size | Params (M) | ImageNet-1k Top 1 |
|---|---|---|---|---|---|
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For SegFormer’s results on the segmentation datasets like ADE20k, refer to the paper.
SegformerConfig
class transformers.SegformerConfig
< source >( num_channels = 3 num_encoder_blocks = 4 depths = [2, 2, 2, 2] sr_ratios = [8, 4, 2, 1] hidden_sizes = [32, 64, 160, 256] patch_sizes = [7, 3, 3, 3] strides = [4, 2, 2, 2] num_attention_heads = [1, 2, 5, 8] mlp_ratios = [4, 4, 4, 4] hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 classifier_dropout_prob = 0.1 initializer_range = 0.02 drop_path_rate = 0.1 layer_norm_eps = 1e-06 decoder_hidden_size = 256 is_encoder_decoder = False semantic_loss_ignore_index = 255 **kwargs )
Parameters
-
num_channels (
int, optional, defaults to 3) — The number of input channels. -
num_encoder_blocks (
int, optional, defaults to 4) — The number of encoder blocks (i.e. stages in the Mix Transformer encoder). -
depths (
List[int], optional, defaults to [2, 2, 2, 2]) — The number of layers in each encoder block. -
sr_ratios (
List[int], optional, defaults to [8, 4, 2, 1]) — Sequence reduction ratios in each encoder block. -
hidden_sizes (
List[int], optional, defaults to [32, 64, 160, 256]) — Dimension of each of the encoder blocks. -
patch_sizes (
List[int], optional, defaults to [7, 3, 3, 3]) — Patch size before each encoder block. -
strides (
List[int], optional, defaults to [4, 2, 2, 2]) — Stride before each encoder block. -
num_attention_heads (
List[int], optional, defaults to [1, 2, 5, 8]) — Number of attention heads for each attention layer in each block of the Transformer encoder. -
mlp_ratios (
List[int], optional, defaults to [4, 4, 4, 4]) — Ratio of the size of the hidden layer compared to the size of the input layer of the Mix FFNs in the encoder blocks. -
hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. -
hidden_dropout_prob (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. -
attention_probs_dropout_prob (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. -
classifier_dropout_prob (
float, optional, defaults to 0.1) — The dropout probability before the classification head. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. -
drop_path_rate (
float, optional, defaults to 0.1) — The dropout probability for stochastic depth, used in the blocks of the Transformer encoder. -
layer_norm_eps (
float, optional, defaults to 1e-6) — The epsilon used by the layer normalization layers. -
decoder_hidden_size (
int, optional, defaults to 256) — The dimension of the all-MLP decode head. -
semantic_loss_ignore_index (
int, optional, defaults to 255) — The index that is ignored by the loss function of the semantic segmentation model.
This is the configuration class to store the configuration of a SegformerModel. It is used to instantiate an SegFormer model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the SegFormer nvidia/segformer-b0-finetuned-ade-512-512 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import SegformerModel, SegformerConfig
>>> # Initializing a SegFormer nvidia/segformer-b0-finetuned-ade-512-512 style configuration
>>> configuration = SegformerConfig()
>>> # Initializing a model from the nvidia/segformer-b0-finetuned-ade-512-512 style configuration
>>> model = SegformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSegformerFeatureExtractor
class transformers.SegformerFeatureExtractor
< source >( do_resize = True size = 512 resample = <Resampling.BILINEAR: 2> do_normalize = True image_mean = None image_std = None reduce_labels = False **kwargs )
Parameters
-
do_resize (
bool, optional, defaults toTrue) — Whether to resize the input based on a certainsize. -
size (
intorTuple(int), optional, defaults to 512) — Resize the input to the given size. If a tuple is provided, it should be (width, height). If only an integer is provided, then the input will be resized to (size, size). Only has an effect ifdo_resizeis set toTrue. -
resample (
int, optional, defaults toPIL.Image.BILINEAR) — An optional resampling filter. This can be one ofPIL.Image.NEAREST,PIL.Image.BOX,PIL.Image.BILINEAR,PIL.Image.HAMMING,PIL.Image.BICUBICorPIL.Image.LANCZOS. Only has an effect ifdo_resizeis set toTrue. -
do_normalize (
bool, optional, defaults toTrue) — Whether or not to normalize the input with mean and standard deviation. -
image_mean (
int, optional, defaults to[0.485, 0.456, 0.406]) — The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean. -
image_std (
int, optional, defaults to[0.229, 0.224, 0.225]) — The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the ImageNet std. -
reduce_labels (
bool, optional, defaults toFalse) — Whether or not to reduce all label values of segmentation maps by 1. Usually used for datasets where 0 is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k). The background label will be replaced by 255.
Constructs a SegFormer feature extractor.
This feature extractor inherits from FeatureExtractionMixin which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
__call__
< source >( images: typing.Union[PIL.Image.Image, numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[PIL.Image.Image], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] segmentation_maps: typing.Union[PIL.Image.Image, numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[PIL.Image.Image], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs ) → BatchFeature
Parameters
-
images (
PIL.Image.Image,np.ndarray,torch.Tensor,List[PIL.Image.Image],List[np.ndarray],List[torch.Tensor]) — The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is the number of channels, H and W are image height and width. -
segmentation_maps (
PIL.Image.Image,np.ndarray,torch.Tensor,List[PIL.Image.Image],List[np.ndarray],List[torch.Tensor], optional) — Optionally, the corresponding semantic segmentation maps with the pixel-wise annotations. -
return_tensors (
stror TensorType, optional, defaults to'np') — If set, will return tensors of a particular framework. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return NumPynp.ndarrayobjects.'jax': Return JAXjnp.ndarrayobjects.
Returns
A BatchFeature with the following fields:
- pixel_values — Pixel values to be fed to a model, of shape (batch_size, num_channels, height, width).
- labels — Optional labels to be fed to a model (when
segmentation_mapsare provided)
Main method to prepare for the model one or several image(s) and optional corresponding segmentation maps.
NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass PIL images.
post_process_semantic_segmentation
< source >( outputs target_sizes: typing.List[typing.Tuple] = None ) → semantic_segmentation
Parameters
- outputs (SegformerForSemanticSegmentation) — Raw outputs of the model.
-
target_sizes (
List[Tuple]of lengthbatch_size, optional) — List of tuples corresponding to the requested final size (height, width) of each prediction. If left to None, predictions will not be resized.
Returns
semantic_segmentation
List[torch.Tensor] of length batch_size, where each item is a semantic
segmentation map of shape (height, width) corresponding to the target_sizes entry (if target_sizes is
specified). Each entry of each torch.Tensor correspond to a semantic class id.
Converts the output of SegformerForSemanticSegmentation into semantic segmentation maps. Only supports PyTorch.
SegformerModel
class transformers.SegformerModel
< source >( config )
Parameters
- config (SegformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare SegFormer encoder (Mix-Transformer) outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: FloatTensor
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using SegformerFeatureExtractor. See SegformerFeatureExtractor.call() for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (SegformerConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The SegformerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import SegformerFeatureExtractor, SegformerModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b0")
>>> model = SegformerModel.from_pretrained("nvidia/mit-b0")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 256, 16, 16]SegformerDecodeHead
SegformerForImageClassification
class transformers.SegformerForImageClassification
< source >( config )
Parameters
- config (SegformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
SegFormer Model transformer with an image classification head on top (a linear layer on top of the final hidden states) e.g. for ImageNet.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: typing.Optional[torch.FloatTensor] = None
labels: typing.Optional[torch.LongTensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.models.segformer.modeling_segformer.SegFormerImageClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using SegformerFeatureExtractor. See SegformerFeatureExtractor.call() for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.models.segformer.modeling_segformer.SegFormerImageClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.segformer.modeling_segformer.SegFormerImageClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (SegformerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, num_channels, height, width). Hidden-states (also called feature maps) of the model at the output of each stage. -
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The SegformerForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import SegformerFeatureExtractor, SegformerForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b0")
>>> model = SegformerForImageClassification.from_pretrained("nvidia/mit-b0")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catSegformerForSemanticSegmentation
class transformers.SegformerForSemanticSegmentation
< source >( config )
Parameters
- config (SegformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
SegFormer Model transformer with an all-MLP decode head on top e.g. for ADE20k, CityScapes. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: FloatTensor
labels: typing.Optional[torch.LongTensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.SemanticSegmenterOutput or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using SegformerFeatureExtractor. See SegformerFeatureExtractor.call() for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size, height, width), optional) — Ground truth semantic segmentation maps for computing the loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels > 1, a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SemanticSegmenterOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SemanticSegmenterOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (SegformerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels, logits_height, logits_width)) — Classification scores for each pixel.The logits returned do not necessarily have the same size as the
pixel_valuespassed as inputs. This is to avoid doing two interpolations and lose some quality when a user needs to resize the logits to the original image size as post-processing. You should always check your logits shape and resize as needed. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, patch_size, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The SegformerForSemanticSegmentation forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = feature_extractor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
>>> list(logits.shape)
[1, 150, 128, 128]TFSegformerDecodeHead
TFSegformerModel
class transformers.TFSegformerModel
< source >( *args **kwargs )
Parameters
- config (SegformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare SegFormer encoder (Mix-Transformer) outputting raw hidden-states without any specific head on top. This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
call
< source >(
pixel_values: Tensor
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
training: bool = False
)
→
transformers.modeling_tf_outputs.TFBaseModelOutput or tuple(tf.Tensor)
Parameters
-
pixel_values (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. -
training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation).
Returns
transformers.modeling_tf_outputs.TFBaseModelOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFBaseModelOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (SegformerConfig) and inputs.
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(tf.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFSegformerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import SegformerFeatureExtractor, TFSegformerModel
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b0")
>>> model = TFSegformerModel.from_pretrained("nvidia/mit-b0")
>>> inputs = feature_extractor(image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 256, 16, 16]TFSegformerForImageClassification
class transformers.TFSegformerForImageClassification
< source >( *args **kwargs )
Parameters
- config (SegformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
SegFormer Model transformer with an image classification head on top (a linear layer on top of the final hidden states) e.g. for ImageNet.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
call
< source >(
pixel_values: typing.Optional[tensorflow.python.framework.ops.Tensor] = None
labels: typing.Optional[tensorflow.python.framework.ops.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)
Parameters
-
pixel_values (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. -
training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation).
Returns
transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFSequenceClassifierOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (SegformerConfig) and inputs.
-
loss (
tf.Tensorof shape(batch_size, ), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
tf.Tensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFSegformerForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import SegformerFeatureExtractor, TFSegformerForImageClassification
>>> import tensorflow as tf
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b0")
>>> model = TFSegformerForImageClassification.from_pretrained("nvidia/mit-b0")
>>> inputs = feature_extractor(image, return_tensors="tf")
>>> logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = int(tf.math.argmax(logits, axis=-1))
>>> print(model.config.id2label[predicted_label])
tabby, tabby catTFSegformerForSemanticSegmentation
class transformers.TFSegformerForSemanticSegmentation
< source >( *args **kwargs )
Parameters
- config (SegformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
SegFormer Model transformer with an all-MLP decode head on top e.g. for ADE20k, CityScapes. This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
call
< source >(
pixel_values: Tensor
labels: typing.Optional[tensorflow.python.framework.ops.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_tf_outputs.TFSemanticSegmenterOutput or tuple(tf.Tensor)
Parameters
-
pixel_values (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoFeatureExtractor. SeeAutoFeatureExtractor.__call__()for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. -
training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation). -
labels (
tf.Tensorof shape(batch_size, height, width), optional) — Ground truth semantic segmentation maps for computing the loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels > 1, a (per-pixel) classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_tf_outputs.TFSemanticSegmenterOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFSemanticSegmenterOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (SegformerConfig) and inputs.
-
loss (
tf.Tensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
tf.Tensorof shape(batch_size, config.num_labels, logits_height, logits_width)) — Classification scores for each pixel.The logits returned do not necessarily have the same size as the
pixel_valuespassed as inputs. This is to avoid doing two interpolations and lose some quality when a user needs to resize the logits to the original image size as post-processing. You should always check your logits shape and resize as needed. -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, patch_size, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFSegformerForSemanticSegmentation forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import SegformerFeatureExtractor, TFSegformerForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> model = TFSegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> inputs = feature_extractor(images=image, return_tensors="tf")
>>> outputs = model(**inputs, training=False)
>>> # logits are of shape (batch_size, num_labels, height/4, width/4)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 150, 128, 128]