PoolFormer
Overview
The PoolFormer model was proposed in MetaFormer is Actually What You Need for Vision by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model’s performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of “MetaFormer”, a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.
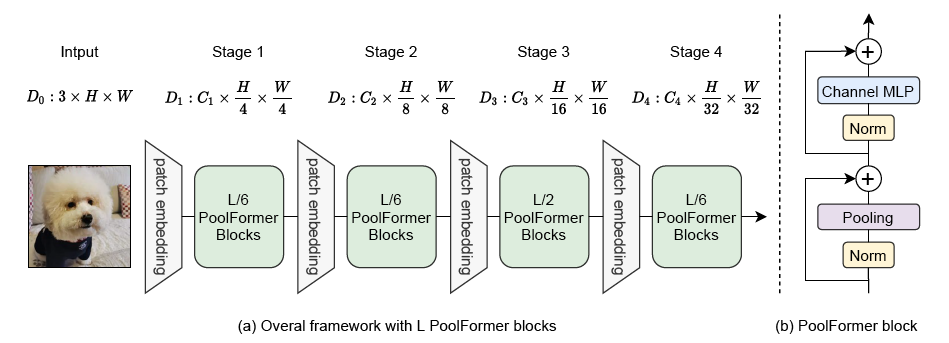
The figure below illustrates the architecture of PoolFormer. Taken from the original paper.
Tips:
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the hub.
- One can use PoolFormerFeatureExtractor to prepare images for the model.
- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
| Model variant | Depths | Hidden sizes | Params (M) | ImageNet-1k Top 1 |
|---|---|---|---|---|
| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
This model was contributed by heytanay. The original code can be found here.
PoolFormerConfig
class transformers.PoolFormerConfig
< source >( num_channels = 3 patch_size = 16 stride = 16 pool_size = 3 mlp_ratio = 4.0 depths = [2, 2, 6, 2] hidden_sizes = [64, 128, 320, 512] patch_sizes = [7, 3, 3, 3] strides = [4, 2, 2, 2] padding = [2, 1, 1, 1] num_encoder_blocks = 4 drop_path_rate = 0.0 hidden_act = 'gelu' use_layer_scale = True layer_scale_init_value = 1e-05 initializer_range = 0.02 **kwargs )
Parameters
-
num_channels (
int, optional, defaults to 3) — The number of channels in the input image. -
patch_size (
int, optional, defaults to 16) — The size of the input patch. -
stride (
int, optional, defaults to 16) — The stride of the input patch. -
pool_size (
int, optional, defaults to 3) — The size of the pooling window. -
mlp_ratio (
float, optional, defaults to 4.0) — The ratio of the number of channels in the output of the MLP to the number of channels in the input. -
depths (
list, optional, defaults to[2, 2, 6, 2]) — The depth of each encoder block. -
hidden_sizes (
list, optional, defaults to[64, 128, 320, 512]) — The hidden sizes of each encoder block. -
patch_sizes (
list, optional, defaults to[7, 3, 3, 3]) — The size of the input patch for each encoder block. -
strides (
list, optional, defaults to[4, 2, 2, 2]) — The stride of the input patch for each encoder block. -
padding (
list, optional, defaults to[2, 1, 1, 1]) — The padding of the input patch for each encoder block. -
num_encoder_blocks (
int, optional, defaults to 4) — The number of encoder blocks. -
drop_path_rate (
float, optional, defaults to 0.0) — The dropout rate for the dropout layers. -
hidden_act (
str, optional, defaults to"gelu") — The activation function for the hidden layers. -
use_layer_scale (
bool, optional, defaults toTrue) — Whether to use layer scale. -
layer_scale_init_value (
float, optional, defaults to 1e-5) — The initial value for the layer scale. -
initializer_range (
float, optional, defaults to 0.02) — The initializer range for the weights.
This is the configuration class to store the configuration of PoolFormerModel. It is used to instantiate a PoolFormer model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the PoolFormer sail/poolformer_s12 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import PoolFormerModel, PoolFormerConfig
>>> # Initializing a PoolFormer sail/poolformer_s12 style configuration
>>> configuration = PoolFormerConfig()
>>> # Initializing a model from the sail/poolformer_s12 style configuration
>>> model = PoolFormerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPoolFormerFeatureExtractor
class transformers.PoolFormerFeatureExtractor
< source >( do_resize_and_center_crop = True size = 224 resample = <Resampling.BICUBIC: 3> crop_pct = 0.9 do_normalize = True image_mean = None image_std = None **kwargs )
Parameters
-
do_resize_and_center_crop (
bool, optional, defaults toTrue) — Whether to resize the shortest edge of the image and center crop the input to a certainsize. -
size (
intorTuple(int), optional, defaults to 224) — Center crop the input to the given size. If a tuple is provided, it should be (width, height). If only an integer is provided, then the input will be center cropped to (size, size). Only has an effect ifdo_resize_and_center_cropis set toTrue. -
resample (
int, optional, defaults toPIL.Image.BICUBIC) — An optional resampling filter. This can be one ofPIL.Image.NEAREST,PIL.Image.BOX,PIL.Image.BILINEAR,PIL.Image.HAMMING,PIL.Image.BICUBICorPIL.Image.LANCZOS. Only has an effect ifdo_resize_and_center_cropis set toTrue. -
crop_pct (
float, optional, defaults to0.9) — The percentage of the image to crop from the center. Only has an effect ifdo_resize_and_center_cropis set toTrue. -
do_normalize (
bool, optional, defaults toTrue) — Whether or not to normalize the input withimage_meanandimage_std. -
image_mean (
List[int], defaults to[0.485, 0.456, 0.406]) — The sequence of means for each channel, to be used when normalizing images. -
image_std (
List[int], defaults to[0.229, 0.224, 0.225]) — The sequence of standard deviations for each channel, to be used when normalizing images.
Constructs a PoolFormer feature extractor.
This feature extractor inherits from FeatureExtractionMixin which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
__call__
< source >( images: typing.Union[PIL.Image.Image, numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[PIL.Image.Image], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs ) → BatchFeature
Parameters
-
images (
PIL.Image.Image,np.ndarray,torch.Tensor,List[PIL.Image.Image],List[np.ndarray],List[torch.Tensor]) — The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a number of channels, H and W are image height and width. -
return_tensors (
stror TensorType, optional, defaults to'np') — If set, will return tensors of a particular framework. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return NumPynp.ndarrayobjects.'jax': Return JAXjnp.ndarrayobjects.
Returns
A BatchFeature with the following fields:
- pixel_values — Pixel values to be fed to a model, of shape (batch_size, num_channels, height, width).
Main method to prepare for the model one or several image(s).
NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass PIL images.
PoolFormerModel
class transformers.PoolFormerModel
< source >( config )
Parameters
- config (PoolFormerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare PoolFormer Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: typing.Optional[torch.FloatTensor] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.BaseModelOutputWithNoAttention or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using PoolFormerFeatureExtractor. See PoolFormerFeatureExtractor.call() for details.
Returns
transformers.modeling_outputs.BaseModelOutputWithNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PoolFormerConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, num_channels, height, width).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
The PoolFormerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import PoolFormerFeatureExtractor, PoolFormerModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = PoolFormerFeatureExtractor.from_pretrained("sail/poolformer_s12")
>>> model = PoolFormerModel.from_pretrained("sail/poolformer_s12")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 512, 7, 7]PoolFormerForImageClassification
class transformers.PoolFormerForImageClassification
< source >( config )
Parameters
- config (PoolFormerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
PoolFormer Model transformer with an image classification head on top
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: typing.Optional[torch.FloatTensor] = None
labels: typing.Optional[torch.LongTensor] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using PoolFormerFeatureExtractor. See PoolFormerFeatureExtractor.call() for details. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PoolFormerConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, num_channels, height, width). Hidden-states (also called feature maps) of the model at the output of each stage.
The PoolFormerForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import PoolFormerFeatureExtractor, PoolFormerForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = PoolFormerFeatureExtractor.from_pretrained("sail/poolformer_s12")
>>> model = PoolFormerForImageClassification.from_pretrained("sail/poolformer_s12")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby cat