Transformers documentation
FastSpeech2Conformer
This model was released on 2020-10-26 and added to Hugging Face Transformers on 2024-01-03.
FastSpeech2Conformer
Overview
The FastSpeech2Conformer model was proposed with the paper Recent Developments On Espnet Toolkit Boosted By Conformer by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
The abstract from the original FastSpeech2 paper is the following:
Non-autoregressive text to speech (TTS) models such as FastSpeech (Ren et al., 2019) can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated and time-consuming, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs in training and use predicted values in inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of fully end-to-end inference. Experimental results show that 1) FastSpeech 2 achieves a 3x training speed-up over FastSpeech, and FastSpeech 2s enjoys even faster inference speed; 2) FastSpeech 2 and 2s outperform FastSpeech in voice quality, and FastSpeech 2 can even surpass autoregressive models. Audio samples are available at https://speechresearch.github.io/fastspeech2/.
This model was contributed by Connor Henderson. The original code can be found here.
🤗 Model Architecture
FastSpeech2’s general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library.
FastSpeech2 Model Architecture

Conformer Blocks

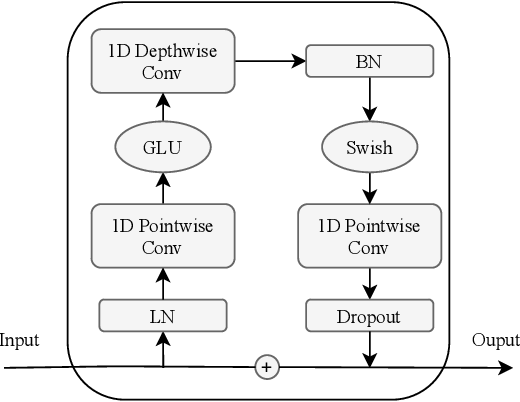
Convolution Module
🤗 Transformers Usage
You can run FastSpeech2Conformer locally with the 🤗 Transformers library.
- First install the 🤗 Transformers library, g2p-en:
pip install --upgrade pip pip install --upgrade transformers g2p-en
- Run inference via the Transformers modelling code with the model and hifigan separately
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerModel, FastSpeech2ConformerHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
output_dict = model(input_ids, return_dict=True)
spectrogram = output_dict["spectrogram"]
hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
waveform = hifigan(spectrogram)
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- Run inference via the Transformers modelling code with the model and hifigan combined
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
output_dict = model(input_ids, return_dict=True)
waveform = output_dict["waveform"]
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- Run inference with a pipeline and specify which vocoder to use
from transformers import pipeline, FastSpeech2ConformerHifiGan
import soundfile as sf
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
speech = synthesiser("Hello, my dog is cooler than you!")
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])FastSpeech2ConformerConfig
class transformers.FastSpeech2ConformerConfig
< source >( hidden_size = 384 vocab_size = 78 num_mel_bins = 80 encoder_num_attention_heads = 2 encoder_layers = 4 encoder_linear_units = 1536 decoder_layers = 4 decoder_num_attention_heads = 2 decoder_linear_units = 1536 speech_decoder_postnet_layers = 5 speech_decoder_postnet_units = 256 speech_decoder_postnet_kernel = 5 positionwise_conv_kernel_size = 3 encoder_normalize_before = False decoder_normalize_before = False encoder_concat_after = False decoder_concat_after = False reduction_factor = 1 speaking_speed = 1.0 use_macaron_style_in_conformer = True use_cnn_in_conformer = True encoder_kernel_size = 7 decoder_kernel_size = 31 duration_predictor_layers = 2 duration_predictor_channels = 256 duration_predictor_kernel_size = 3 energy_predictor_layers = 2 energy_predictor_channels = 256 energy_predictor_kernel_size = 3 energy_predictor_dropout = 0.5 energy_embed_kernel_size = 1 energy_embed_dropout = 0.0 stop_gradient_from_energy_predictor = False pitch_predictor_layers = 5 pitch_predictor_channels = 256 pitch_predictor_kernel_size = 5 pitch_predictor_dropout = 0.5 pitch_embed_kernel_size = 1 pitch_embed_dropout = 0.0 stop_gradient_from_pitch_predictor = True encoder_dropout_rate = 0.2 encoder_positional_dropout_rate = 0.2 encoder_attention_dropout_rate = 0.2 decoder_dropout_rate = 0.2 decoder_positional_dropout_rate = 0.2 decoder_attention_dropout_rate = 0.2 duration_predictor_dropout_rate = 0.2 speech_decoder_postnet_dropout = 0.5 max_source_positions = 5000 use_masking = True use_weighted_masking = False num_speakers = None num_languages = None speaker_embed_dim = None is_encoder_decoder = True convolution_bias = True **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 384) — The dimensionality of the hidden layers. - vocab_size (
int, optional, defaults to 78) — The size of the vocabulary. - num_mel_bins (
int, optional, defaults to 80) — The number of mel filters used in the filter bank. - encoder_num_attention_heads (
int, optional, defaults to 2) — The number of attention heads in the encoder. - encoder_layers (
int, optional, defaults to 4) — The number of layers in the encoder. - encoder_linear_units (
int, optional, defaults to 1536) — The number of units in the linear layer of the encoder. - decoder_layers (
int, optional, defaults to 4) — The number of layers in the decoder. - decoder_num_attention_heads (
int, optional, defaults to 2) — The number of attention heads in the decoder. - decoder_linear_units (
int, optional, defaults to 1536) — The number of units in the linear layer of the decoder. - speech_decoder_postnet_layers (
int, optional, defaults to 5) — The number of layers in the post-net of the speech decoder. - speech_decoder_postnet_units (
int, optional, defaults to 256) — The number of units in the post-net layers of the speech decoder. - speech_decoder_postnet_kernel (
int, optional, defaults to 5) — The kernel size in the post-net of the speech decoder. - positionwise_conv_kernel_size (
int, optional, defaults to 3) — The size of the convolution kernel used in the position-wise layer. - encoder_normalize_before (
bool, optional, defaults toFalse) — Specifies whether to normalize before encoder layers. - decoder_normalize_before (
bool, optional, defaults toFalse) — Specifies whether to normalize before decoder layers. - encoder_concat_after (
bool, optional, defaults toFalse) — Specifies whether to concatenate after encoder layers. - decoder_concat_after (
bool, optional, defaults toFalse) — Specifies whether to concatenate after decoder layers. - reduction_factor (
int, optional, defaults to 1) — The factor by which the speech frame rate is reduced. - speaking_speed (
float, optional, defaults to 1.0) — The speed of the speech produced. - use_macaron_style_in_conformer (
bool, optional, defaults toTrue) — Specifies whether to use macaron style in the conformer. - use_cnn_in_conformer (
bool, optional, defaults toTrue) — Specifies whether to use convolutional neural networks in the conformer. - encoder_kernel_size (
int, optional, defaults to 7) — The kernel size used in the encoder. - decoder_kernel_size (
int, optional, defaults to 31) — The kernel size used in the decoder. - duration_predictor_layers (
int, optional, defaults to 2) — The number of layers in the duration predictor. - duration_predictor_channels (
int, optional, defaults to 256) — The number of channels in the duration predictor. - duration_predictor_kernel_size (
int, optional, defaults to 3) — The kernel size used in the duration predictor. - energy_predictor_layers (
int, optional, defaults to 2) — The number of layers in the energy predictor. - energy_predictor_channels (
int, optional, defaults to 256) — The number of channels in the energy predictor. - energy_predictor_kernel_size (
int, optional, defaults to 3) — The kernel size used in the energy predictor. - energy_predictor_dropout (
float, optional, defaults to 0.5) — The dropout rate in the energy predictor. - energy_embed_kernel_size (
int, optional, defaults to 1) — The kernel size used in the energy embed layer. - energy_embed_dropout (
float, optional, defaults to 0.0) — The dropout rate in the energy embed layer. - stop_gradient_from_energy_predictor (
bool, optional, defaults toFalse) — Specifies whether to stop gradients from the energy predictor. - pitch_predictor_layers (
int, optional, defaults to 5) — The number of layers in the pitch predictor. - pitch_predictor_channels (
int, optional, defaults to 256) — The number of channels in the pitch predictor. - pitch_predictor_kernel_size (
int, optional, defaults to 5) — The kernel size used in the pitch predictor. - pitch_predictor_dropout (
float, optional, defaults to 0.5) — The dropout rate in the pitch predictor. - pitch_embed_kernel_size (
int, optional, defaults to 1) — The kernel size used in the pitch embed layer. - pitch_embed_dropout (
float, optional, defaults to 0.0) — The dropout rate in the pitch embed layer. - stop_gradient_from_pitch_predictor (
bool, optional, defaults toTrue) — Specifies whether to stop gradients from the pitch predictor. - encoder_dropout_rate (
float, optional, defaults to 0.2) — The dropout rate in the encoder. - encoder_positional_dropout_rate (
float, optional, defaults to 0.2) — The positional dropout rate in the encoder. - encoder_attention_dropout_rate (
float, optional, defaults to 0.2) — The attention dropout rate in the encoder. - decoder_dropout_rate (
float, optional, defaults to 0.2) — The dropout rate in the decoder. - decoder_positional_dropout_rate (
float, optional, defaults to 0.2) — The positional dropout rate in the decoder. - decoder_attention_dropout_rate (
float, optional, defaults to 0.2) — The attention dropout rate in the decoder. - duration_predictor_dropout_rate (
float, optional, defaults to 0.2) — The dropout rate in the duration predictor. - speech_decoder_postnet_dropout (
float, optional, defaults to 0.5) — The dropout rate in the speech decoder postnet. - max_source_positions (
int, optional, defaults to 5000) — if"relative"position embeddings are used, defines the maximum source input positions. - use_masking (
bool, optional, defaults toTrue) — Specifies whether to use masking in the model. - use_weighted_masking (
bool, optional, defaults toFalse) — Specifies whether to use weighted masking in the model. - num_speakers (
int, optional) — Number of speakers. If set to > 1, assume that the speaker ids will be provided as the input and use speaker id embedding layer. - num_languages (
int, optional) — Number of languages. If set to > 1, assume that the language ids will be provided as the input and use the language id embedding layer. - speaker_embed_dim (
int, optional) — Speaker embedding dimension. If set to > 0, assume that speaker_embedding will be provided as the input. - is_encoder_decoder (
bool, optional, defaults toTrue) — Specifies whether the model is an encoder-decoder. - convolution_bias (
bool, optional, defaults toTrue) — Specifies whether to use bias in convolutions of the conformer’s convolution module.
This is the configuration class to store the configuration of a FastSpeech2ConformerModel. It is used to instantiate a FastSpeech2Conformer model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the FastSpeech2Conformer espnet/fastspeech2_conformer architecture.
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
Example:
>>> from transformers import FastSpeech2ConformerModel, FastSpeech2ConformerConfig
>>> # Initializing a FastSpeech2Conformer style configuration
>>> configuration = FastSpeech2ConformerConfig()
>>> # Initializing a model from the FastSpeech2Conformer style configuration
>>> model = FastSpeech2ConformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerHifiGanConfig
class transformers.FastSpeech2ConformerHifiGanConfig
< source >( model_in_dim = 80 upsample_initial_channel = 512 upsample_rates = [8, 8, 2, 2] upsample_kernel_sizes = [16, 16, 4, 4] resblock_kernel_sizes = [3, 7, 11] resblock_dilation_sizes = [[1, 3, 5], [1, 3, 5], [1, 3, 5]] initializer_range = 0.01 leaky_relu_slope = 0.1 normalize_before = True **kwargs )
Parameters
- model_in_dim (
int, optional, defaults to 80) — The number of frequency bins in the input log-mel spectrogram. - upsample_initial_channel (
int, optional, defaults to 512) — The number of input channels into the upsampling network. - upsample_rates (
tuple[int]orlist[int], optional, defaults to[8, 8, 2, 2]) — A tuple of integers defining the stride of each 1D convolutional layer in the upsampling network. The length of upsample_rates defines the number of convolutional layers and has to match the length of upsample_kernel_sizes. - upsample_kernel_sizes (
tuple[int]orlist[int], optional, defaults to[16, 16, 4, 4]) — A tuple of integers defining the kernel size of each 1D convolutional layer in the upsampling network. The length of upsample_kernel_sizes defines the number of convolutional layers and has to match the length of upsample_rates. - resblock_kernel_sizes (
tuple[int]orlist[int], optional, defaults to[3, 7, 11]) — A tuple of integers defining the kernel sizes of the 1D convolutional layers in the multi-receptive field fusion (MRF) module. - resblock_dilation_sizes (
tuple[tuple[int]]orlist[list[int]], optional, defaults to[[1, 3, 5], [1, 3, 5], [1, 3, 5]]) — A nested tuple of integers defining the dilation rates of the dilated 1D convolutional layers in the multi-receptive field fusion (MRF) module. - initializer_range (
float, optional, defaults to 0.01) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - leaky_relu_slope (
float, optional, defaults to 0.1) — The angle of the negative slope used by the leaky ReLU activation. - normalize_before (
bool, optional, defaults toTrue) — Whether or not to normalize the spectrogram before vocoding using the vocoder’s learned mean and variance.
This is the configuration class to store the configuration of a FastSpeech2ConformerHifiGanModel. It is used to
instantiate a FastSpeech2Conformer HiFi-GAN vocoder model according to the specified arguments, defining the model
architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the
FastSpeech2Conformer
espnet/fastspeech2_conformer_hifigan architecture.
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
Example:
>>> from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerHifiGanConfig
>>> # Initializing a FastSpeech2ConformerHifiGan configuration
>>> configuration = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = FastSpeech2ConformerHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerWithHifiGanConfig
class transformers.FastSpeech2ConformerWithHifiGanConfig
< source >( model_config: typing.Optional[dict] = None vocoder_config: typing.Optional[dict] = None **kwargs )
This is the configuration class to store the configuration of a FastSpeech2ConformerWithHifiGan. It is used to
instantiate a FastSpeech2ConformerWithHifiGanModel model according to the specified sub-models configurations,
defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the FastSpeech2ConformerModel espnet/fastspeech2_conformer and FastSpeech2ConformerHifiGan espnet/fastspeech2_conformer_hifigan architectures.
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
model_config (FastSpeech2ConformerConfig, optional):
Configuration of the text-to-speech model.
vocoder_config (FastSpeech2ConformerHiFiGanConfig, optional):
Configuration of the vocoder model.
Example:
>>> from transformers import (
... FastSpeech2ConformerConfig,
... FastSpeech2ConformerHifiGanConfig,
... FastSpeech2ConformerWithHifiGanConfig,
... FastSpeech2ConformerWithHifiGan,
... )
>>> # Initializing FastSpeech2ConformerWithHifiGan sub-modules configurations.
>>> model_config = FastSpeech2ConformerConfig()
>>> vocoder_config = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a FastSpeech2ConformerWithHifiGan module style configuration
>>> configuration = FastSpeech2ConformerWithHifiGanConfig(model_config.to_dict(), vocoder_config.to_dict())
>>> # Initializing a model (with random weights)
>>> model = FastSpeech2ConformerWithHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerTokenizer
class transformers.FastSpeech2ConformerTokenizer
< source >( vocab_file bos_token = '<sos/eos>' eos_token = '<sos/eos>' pad_token = '<blank>' unk_token = '<unk>' should_strip_spaces = False **kwargs )
Parameters
- vocab_file (
str) — Path to the vocabulary file. - bos_token (
str, optional, defaults to"<sos/eos>") — The begin of sequence token. Note that for FastSpeech2, it is the same as theeos_token. - eos_token (
str, optional, defaults to"<sos/eos>") — The end of sequence token. Note that for FastSpeech2, it is the same as thebos_token. - pad_token (
str, optional, defaults to"<blank>") — The token used for padding, for example when batching sequences of different lengths. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - should_strip_spaces (
bool, optional, defaults toFalse) — Whether or not to strip the spaces from the list of tokens.
Construct a FastSpeech2Conformer tokenizer.
__call__
< source >( text: Union[TextInput, PreTokenizedInput, list[TextInput], list[PreTokenizedInput], None] = None text_pair: Optional[Union[TextInput, PreTokenizedInput, list[TextInput], list[PreTokenizedInput]]] = None text_target: Union[TextInput, PreTokenizedInput, list[TextInput], list[PreTokenizedInput], None] = None text_pair_target: Optional[Union[TextInput, PreTokenizedInput, list[TextInput], list[PreTokenizedInput]]] = None add_special_tokens: bool = True padding: Union[bool, str, PaddingStrategy] = False truncation: Union[bool, str, TruncationStrategy, None] = None max_length: Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional[int] = None padding_side: Optional[str] = None return_tensors: Optional[Union[str, TensorType]] = None return_token_type_ids: Optional[bool] = None return_attention_mask: Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → BatchEncoding
Parameters
- text (
str,list[str],list[list[str]], optional) — The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_pair (
str,list[str],list[list[str]], optional) — The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_target (
str,list[str],list[list[str]], optional) — The sequence or batch of sequences to be encoded as target texts. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_pair_target (
str,list[str],list[list[str]], optional) — The sequence or batch of sequences to be encoded as target texts. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - add_special_tokens (
bool, optional, defaults toTrue) — Whether or not to add special tokens when encoding the sequences. This will use the underlyingPretrainedTokenizerBase.build_inputs_with_special_tokensfunction, which defines which tokens are automatically added to the input ids. This is useful if you want to addbosoreostokens automatically. - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence is provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.If left unset or set to
None, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. - stride (
int, optional, defaults to 0) — If set to a number along withmax_length, the overflowing tokens returned whenreturn_overflowing_tokens=Truewill contain some tokens from the end of the truncated sequence returned to provide some overlap between truncated and overflowing sequences. The value of this argument defines the number of overlapping tokens. - is_split_into_words (
bool, optional, defaults toFalse) — Whether or not the input is already pre-tokenized (e.g., split into words). If set toTrue, the tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace) which it will tokenize. This is useful for NER or token classification. - pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value. Requirespaddingto be activated. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability>= 7.5(Volta). - padding_side (
str, optional) — The side on which the model should have padding applied. Should be selected between [‘right’, ‘left’]. Default value is picked from the class attribute of the same name. - return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
- return_token_type_ids (
bool, optional) — Whether to return token type IDs. If left to the default, will return the token type IDs according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_overflowing_tokens (
bool, optional, defaults toFalse) — Whether or not to return overflowing token sequences. If a pair of sequences of input ids (or a batch of pairs) is provided withtruncation_strategy = longest_firstorTrue, an error is raised instead of returning overflowing tokens. - return_special_tokens_mask (
bool, optional, defaults toFalse) — Whether or not to return special tokens mask information. - return_offsets_mapping (
bool, optional, defaults toFalse) — Whether or not to return(char_start, char_end)for each token.This is only available on fast tokenizers inheriting from PreTrainedTokenizerFast, if using Python’s tokenizer, this method will raise
NotImplementedError. - return_length (
bool, optional, defaults toFalse) — Whether or not to return the lengths of the encoded inputs. - verbose (
bool, optional, defaults toTrue) — Whether or not to print more information and warnings. - **kwargs — passed to the
self.tokenize()method
Returns
A BatchEncoding with the following fields:
-
input_ids — List of token ids to be fed to a model.
-
token_type_ids — List of token type ids to be fed to a model (when
return_token_type_ids=Trueor if “token_type_ids” is inself.model_input_names). -
attention_mask — List of indices specifying which tokens should be attended to by the model (when
return_attention_mask=Trueor if “attention_mask” is inself.model_input_names). -
overflowing_tokens — List of overflowing tokens sequences (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
num_truncated_tokens — Number of tokens truncated (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
special_tokens_mask — List of 0s and 1s, with 1 specifying added special tokens and 0 specifying regular sequence tokens (when
add_special_tokens=Trueandreturn_special_tokens_mask=True). -
length — The length of the inputs (when
return_length=True)
Main method to tokenize and prepare for the model one or several sequence(s) or one or several pair(s) of sequences.
save_vocabulary
< source >( save_directory: str filename_prefix: typing.Optional[str] = None ) → Tuple(str)
Save the vocabulary and special tokens file to a directory.
batch_decode
< source >( sequences: Union[list[int], list[list[int]], np.ndarray, torch.Tensor] skip_special_tokens: bool = False clean_up_tokenization_spaces: Optional[bool] = None **kwargs ) → list[str]
Parameters
- sequences (
Union[list[int], list[list[int]], np.ndarray, torch.Tensor]) — List of tokenized input ids. Can be obtained using the__call__method. - skip_special_tokens (
bool, optional, defaults toFalse) — Whether or not to remove special tokens in the decoding. - clean_up_tokenization_spaces (
bool, optional) — Whether or not to clean up the tokenization spaces. IfNone, will default toself.clean_up_tokenization_spaces. - kwargs (additional keyword arguments, optional) — Will be passed to the underlying model specific decode method.
Returns
list[str]
The list of decoded sentences.
Convert a list of lists of token ids into a list of strings by calling decode.
FastSpeech2ConformerModel
class transformers.FastSpeech2ConformerModel
< source >( config: FastSpeech2ConformerConfig )
Parameters
- config (FastSpeech2ConformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
FastSpeech2Conformer Model.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor attention_mask: typing.Optional[torch.LongTensor] = None spectrogram_labels: typing.Optional[torch.FloatTensor] = None duration_labels: typing.Optional[torch.LongTensor] = None pitch_labels: typing.Optional[torch.FloatTensor] = None energy_labels: typing.Optional[torch.FloatTensor] = None speaker_ids: typing.Optional[torch.LongTensor] = None lang_ids: typing.Optional[torch.LongTensor] = None speaker_embedding: typing.Optional[torch.FloatTensor] = None return_dict: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Input sequence of text vectors. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- spectrogram_labels (
torch.FloatTensorof shape(batch_size, max_spectrogram_length, num_mel_bins), optional, defaults toNone) — Batch of padded target features. - duration_labels (
torch.LongTensorof shape(batch_size, sequence_length + 1), optional, defaults toNone) — Batch of padded durations. - pitch_labels (
torch.FloatTensorof shape(batch_size, sequence_length + 1, 1), optional, defaults toNone) — Batch of padded token-averaged pitch. - energy_labels (
torch.FloatTensorof shape(batch_size, sequence_length + 1, 1), optional, defaults toNone) — Batch of padded token-averaged energy. - speaker_ids (
torch.LongTensorof shape(batch_size, 1), optional, defaults toNone) — Speaker ids used to condition features of speech output by the model. - lang_ids (
torch.LongTensorof shape(batch_size, 1), optional, defaults toNone) — Language ids used to condition features of speech output by the model. - speaker_embedding (
torch.FloatTensorof shape(batch_size, embedding_dim), optional, defaults toNone) — Embedding containing conditioning signals for the features of the speech. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
Returns
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput or tuple(torch.FloatTensor)
A transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (FastSpeech2ConformerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Spectrogram generation loss. -
spectrogram (
torch.FloatTensorof shape(batch_size, sequence_length, num_bins), optional, defaults toNone) — The predicted spectrogram. -
encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional, defaults toNone) — Sequence of hidden-states at the output of the last layer of the encoder of the model. -
encoder_hidden_states (
tuple[torch.FloatTensor], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
-
encoder_attentions (
tuple[torch.FloatTensor], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
decoder_hidden_states (
tuple[torch.FloatTensor], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
-
decoder_attentions (
tuple[torch.FloatTensor], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
duration_outputs (
torch.LongTensorof shape(batch_size, max_text_length + 1), optional) — Outputs of the duration predictor. -
pitch_outputs (
torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — Outputs of the pitch predictor. -
energy_outputs (
torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — Outputs of the energy predictor.
The FastSpeech2ConformerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerModel,
... FastSpeech2ConformerHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
>>> output_dict = model(input_ids, return_dict=True)
>>> spectrogram = output_dict["spectrogram"]
>>> vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
>>> waveform = vocoder(spectrogram)
>>> print(waveform.shape)
torch.Size([1, 49664])FastSpeech2ConformerHifiGan
class transformers.FastSpeech2ConformerHifiGan
< source >( config: FastSpeech2ConformerHifiGanConfig )
Parameters
- config (FastSpeech2ConformerHifiGanConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
HiFi-GAN vocoder.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( spectrogram: FloatTensor ) → torch.FloatTensor
Parameters
- spectrogram (
torch.FloatTensor) — Tensor containing the log-mel spectrograms. Can be batched and of shape(batch_size, sequence_length, config.model_in_dim), or un-batched and of shape(sequence_length, config.model_in_dim).
Returns
torch.FloatTensor
Tensor containing the speech waveform. If the input spectrogram is batched, will be of
shape (batch_size, num_frames,). If un-batched, will be of shape (num_frames,).
Converts a log-mel spectrogram into a speech waveform. Passing a batch of log-mel spectrograms returns a batch of speech waveforms. Passing a single, un-batched log-mel spectrogram returns a single, un-batched speech waveform.
FastSpeech2ConformerWithHifiGan
class transformers.FastSpeech2ConformerWithHifiGan
< source >( config: FastSpeech2ConformerWithHifiGanConfig )
Parameters
- config (FastSpeech2ConformerWithHifiGanConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The FastSpeech2ConformerModel with a FastSpeech2ConformerHifiGan vocoder head that performs text-to-speech (waveform).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor attention_mask: typing.Optional[torch.LongTensor] = None spectrogram_labels: typing.Optional[torch.FloatTensor] = None duration_labels: typing.Optional[torch.LongTensor] = None pitch_labels: typing.Optional[torch.FloatTensor] = None energy_labels: typing.Optional[torch.FloatTensor] = None speaker_ids: typing.Optional[torch.LongTensor] = None lang_ids: typing.Optional[torch.LongTensor] = None speaker_embedding: typing.Optional[torch.FloatTensor] = None return_dict: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Input sequence of text vectors. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- spectrogram_labels (
torch.FloatTensorof shape(batch_size, max_spectrogram_length, num_mel_bins), optional, defaults toNone) — Batch of padded target features. - duration_labels (
torch.LongTensorof shape(batch_size, sequence_length + 1), optional, defaults toNone) — Batch of padded durations. - pitch_labels (
torch.FloatTensorof shape(batch_size, sequence_length + 1, 1), optional, defaults toNone) — Batch of padded token-averaged pitch. - energy_labels (
torch.FloatTensorof shape(batch_size, sequence_length + 1, 1), optional, defaults toNone) — Batch of padded token-averaged energy. - speaker_ids (
torch.LongTensorof shape(batch_size, 1), optional, defaults toNone) — Speaker ids used to condition features of speech output by the model. - lang_ids (
torch.LongTensorof shape(batch_size, 1), optional, defaults toNone) — Language ids used to condition features of speech output by the model. - speaker_embedding (
torch.FloatTensorof shape(batch_size, embedding_dim), optional, defaults toNone) — Embedding containing conditioning signals for the features of the speech. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
Returns
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput or tuple(torch.FloatTensor)
A transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (FastSpeech2ConformerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Spectrogram generation loss. -
spectrogram (
torch.FloatTensorof shape(batch_size, sequence_length, num_bins), optional, defaults toNone) — The predicted spectrogram. -
encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional, defaults toNone) — Sequence of hidden-states at the output of the last layer of the encoder of the model. -
encoder_hidden_states (
tuple[torch.FloatTensor], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
-
encoder_attentions (
tuple[torch.FloatTensor], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
decoder_hidden_states (
tuple[torch.FloatTensor], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
-
decoder_attentions (
tuple[torch.FloatTensor], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
duration_outputs (
torch.LongTensorof shape(batch_size, max_text_length + 1), optional) — Outputs of the duration predictor. -
pitch_outputs (
torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — Outputs of the pitch predictor. -
energy_outputs (
torch.FloatTensorof shape(batch_size, max_text_length + 1, 1), optional) — Outputs of the energy predictor.
The FastSpeech2ConformerWithHifiGan forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerWithHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
>>> output_dict = model(input_ids, return_dict=True)
>>> waveform = output_dict["waveform"]
>>> print(waveform.shape)
torch.Size([1, 49664])