Transformers documentation
إنشاء بنية مخصصة
إنشاء بنية مخصصة
تحدد فئة AutoClass تلقائيًا بنية النموذج وتقوم بتنزيل تكوين وأوزان مسبقين للنموذج. بشكل عام، نوصي باستخدام AutoClass لإنتاج كود غير مرتبط بنسخة معينة. ولكن يمكن للمستخدمين الذين يريدون مزيدًا من التحكم في معلمات النموذج المحددة إنشاء نموذج مخصص من 🤗 Transformers من مجرد بضع فئات أساسية. قد يكون هذا مفيدًا بشكل خاص لأي شخص مهتم بدراسة نموذج 🤗 Transformers أو تدريبه أو إجراء تجارب عليه. في هذا الدليل، سنغوص بشكل أعمق في إنشاء نموذج مخصص بدون AutoClass. تعرف على كيفية:
- تحميل تكوين النموذج وتخصيصه.
- إنشاء بنية نموذج.
- إنشاء مجزء لغوى سريع وبطيء للنص.
- إنشاء معالج صور لمهام الرؤية.
- إنشاء مستخرج ميزات لمهام الصوت.
- إنشاء معالج للمهام متعددة الوسائط.
التكوين
يشير مصطلح التكوين إلى الخصائص المحددة للنموذج. لكل تكوين نموذج خصائصه الخاصة؛ على سبيل المثال، تشترك جميع نماذج NLP في الخصائص hidden_size وnum_attention_heads وnum_hidden_layers وvocab_size المشتركة. تحدد هذه الخصائص عدد رؤوس الانتباه أو الطبقات المخفية لبناء نموذج بها.
اطلع على DistilBERT من خلال DistilBertConfig لمعاينة خصائصه:
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}يعرض DistilBertConfig جميع الخصائص الافتراضية المستخدمة لبناء نموذج DistilBertModel أساسي. جميع الخصائص قابلة للتعديل، مما ييتيح مجالاً للتجريب. على سبيل المثال، يمكنك تعديل نموذج افتراضي لـ:
- تجربة دالة تنشيط مختلفة باستخدام معامل
activation. - استخدام معدل إسقاط أعلى الاحتمالات الانتباه مع معامل
attention_dropout.
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
يمكن تعديل خصائص النموذج المدرب مسبقًا في دالة from_pretrained() :
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)بمجرد أن تصبح راضيًا عن تكوين نموذجك، يمكنك حفظه باستخدام save_pretrained(). يتم تخزين ملف التكوين الخاص بك على أنه ملف JSON في دليل الحفظ المحدد:
>>> my_config.save_pretrained(save_directory="./your_model_save_path")لإعادة استخدام ملف التكوين، قم بتحميله باستخدام from_pretrained():
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")النموذج
الخطوة التالية هي إنشاء نموذج. النموذج - ويُشار إليه أحيانًا باسم البنية - يُحدد وظيفة كل طبقة والعمليات الحسابية المُنفذة. تُستخدم خصائص مثل num_hidden_layers من التكوين لتحديد هذه البنية. تشترك جميع النماذج في فئة أساسية واحدة هي PreTrainedModel وبعض الوظائف المُشتركة مثل غيير حجم مُدخلات الكلمات وتقليص رؤوس آلية الانتباه الذاتي. بالإضافة إلى ذلك، فإن جميع النماذج هي فئات فرعية إما من torch.nn.Module، tf.keras.Model أو flax.linen.Module . هذا يعني النماذج متوافقة مع كل استخدام لإطار العمل الخاص بها.
قم بتحميل خصائص التكوين المخصصة الخاصة بك في النموذج:
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)هذا ينشئ نموذجًا بقيم عشوائية بدلاً من الأوزان المُدربة مسبقًا. لن يكون هذا النموذج مفيدًا حتى يتم تدريبه. تُعد عملية التدريب مكلفة وتستغرق وقتًا طويلاً. من الأفضل بشكل عام استخدام نموذج مُدرب مسبقًا للحصول على نتائج أفضل بشكل أسرع، مع استخدام جزء بسيط فقط من الموارد المطلوبة للتدريب.
قم بإنشاء نموذج مُدرب مسبقًا باستخدام from_pretrained():
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")عند بتحميل الأوزان المُدربة مسبقًا، يتم تحميل تكوين النموذج الافتراضي تلقائيًا إذا كان النموذج من مكتبة 🤗 Transformers. ومع ذلك، يمكنك أيضًا استبدال - بعض أو كل - سإعدادات النموذج الافتراضية بإعداداتك الخاصة:
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased"، config=my_config)قم بتحميل خصائص التكوين المُخصصة الخاصة بك في النموذج:
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)هذا ينشئ نموذجًا بقيم عشوائية بدلاً من الأوزان المُدربة مسبقًا. لن يكون هذا النموذج مفيدًا حتى يتم تدريبه. تُعد عملية التدريب مكلفة وتستغرق وقتًا طويلاً. من الأفضل بشكل عام استخدام نموذج مُدرب مسبقًا للحصول على نتائج أفضل بشكل أسرع، مع استخدام جزء بسيط فقط من الموارد المطلوبة للتدريب.
قم بإنشاء نموذج مُدرب مسبقًا باستخدام from_pretrained():
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")عندما تقوم بتحميل الأوزان المُدربة مسبقًا،يتم تحميل إعدادات النموذج الافتراضي تلقائيًا إذا كان النموذج من مكتبة 🤗 Transformers. ومع ذلك، يمكنك أيضًا استبدال - بعض أو كل - إعدادات النموذج الافتراضية بإعداداتك الخاصة:
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased"، config=my_config)رؤوس النموذج
في هذه المرحلة، لديك نموذج DistilBERT الأساسي الذي يخرج حالات الكامنة. تُمرَّر هذه الحالات الكامنة كمدخلات لرأس النموذج لإنتاج المخرجات النهائية. توفر مكتبة 🤗 Transformers رأس نموذج مختلف لكل مهمة طالما أن النموذج يدعم المهمة (أي لا يمكنك استخدام DistilBERT لمهمة تسلسل إلى تسلسل مثل الترجمة).
على سبيل المثال، DistilBertForSequenceClassification هو نموذج DistilBERT الأساس مزودًا برأس تصنيف تسلسلي. يُشكّل رأس التصنيف التسلسلي طبقة خطية فوق المخرجات المجمعة.
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")أعد استخدام هذا نقطة التحقق هذه لمهمة أخرى بسهولة، وذلك بتغيير رأس النموذج.ففي مهمة الإجابة على الأسئلة، ستستخدم رأس النموذج DistilBertForQuestionAnswering. رأس الإجابة على الأسئلة مشابه لرأس التصنيف التسلسلي باستثناء أنه طبقة خطية فوق مخرجات الحالات الكامنة.
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")على سبيل المثال، TFDistilBertForSequenceClassification هو نموذج DistilBERT الأساسي برأس تصنيف تسلسل. رأس التصنيف التسلسلي هو طبقة خطية أعلى المخرجات المجمعة.
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")أعد استخدام هذا نقطة التحقق لمهمة أخرى عن طريق التبديل إلى رأس نموذج مختلف. لمهمة الإجابة على الأسئلة، ستستخدم رأس النموذج TFDistilBertForQuestionAnswering. رأس الإجابة على الأسئلة مشابه لرأس التصنيف التسلسلي باستثناء أنه طبقة خطية أعلى حالات الإخراج المخفية.
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")مجزئ النصوص
الفئة الأساسية الأخيرة التي تحتاجها قبل استخدام نموذج للبيانات النصية هي مجزئ النصوص لتحويل النص الخام إلى تنسورات (tensors). هناك نوعان من المحولات الرموز التي يمكنك استخدامها مع 🤗 Transformers:
PreTrainedTokenizer: تنفيذ Python لمجزئ النصوص.PreTrainedTokenizerFast: مجزئ النصوص من مكتبة 🤗 Tokenizer المُبنية على لغة Rust. هذا النوع من المجزئات أسرع بكثير، خاصةً عند معالجة دفعات النصوص، وذلك بفضل تصميمه بلغة Rust. كما يوفر مجزئ النصوص السريع طرقًا إضافية مثل مخطط الإزاحة الذي يُطابق الرموز بكلماتها أو أحرفها الأصلية.
يدعم كلا النوعين من المجزئات طرقًا شائعة مثل الترميز وفك الترميز، وإضافة رموز جديدة، وإدارة الرموز الخاصة.
لا يدعم كل نموذج مجزئ النصوص سريع. الق نظرة على هذا جدول للتحقق مما إذا كان النموذج يحتوي على دعم مجزئ النصوص سريع.
إذا دربت مجزئ النصوص خاص بك، فيمكنك إنشاء واحد من قاموسك:```
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt"، do_lower_case=False، padding_side="left")من المهم أن تتذكر أن قاموس مجزئ النصوص المُخصص سيكون مختلفًا عن قاموس مجزئ النصوص نموذج مُدرّب مسبقًا. يجب عليك استخدام قاموس نموذج مُدرّب مسبقًا إذا كنت تستخدم نموذجًا مُدرّبًا مسبقًا، وإلا فلن تكون المدخلات ذات معنى. قم بإنشاء مجزئ النصوص باستخدام قاموس نموذج مُدرّب مسبقًا باستخدام فئة DistilBertTokenizer:
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")قم بإنشاء مجزئ نصوص سريع باستخدام فئة DistilBertTokenizerFast:
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")معالج الصور
يعالج معالج الصور بيانات الرؤية. وهو يرث من الفئة الأساسية ImageProcessingMixin.
لبناء معالج صور خاص بالنموذج المستخدم، أنشئ مثلاً مُعالج ViTImageProcessor افتراضيًا إذا كنت تستخدم ViT لتصنيف الصور:
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}إذا كنت لا تبحث عن أي تخصيص، فما عليك سوى استخدام طريقة from_pretrained لتحميل معلمات معالج الصور الافتراضية للنموذج.
عدل أيًا من معلمات ViTImageProcessor لإنشاء معالج الصور المخصص الخاص بك:
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}العمود الفقري
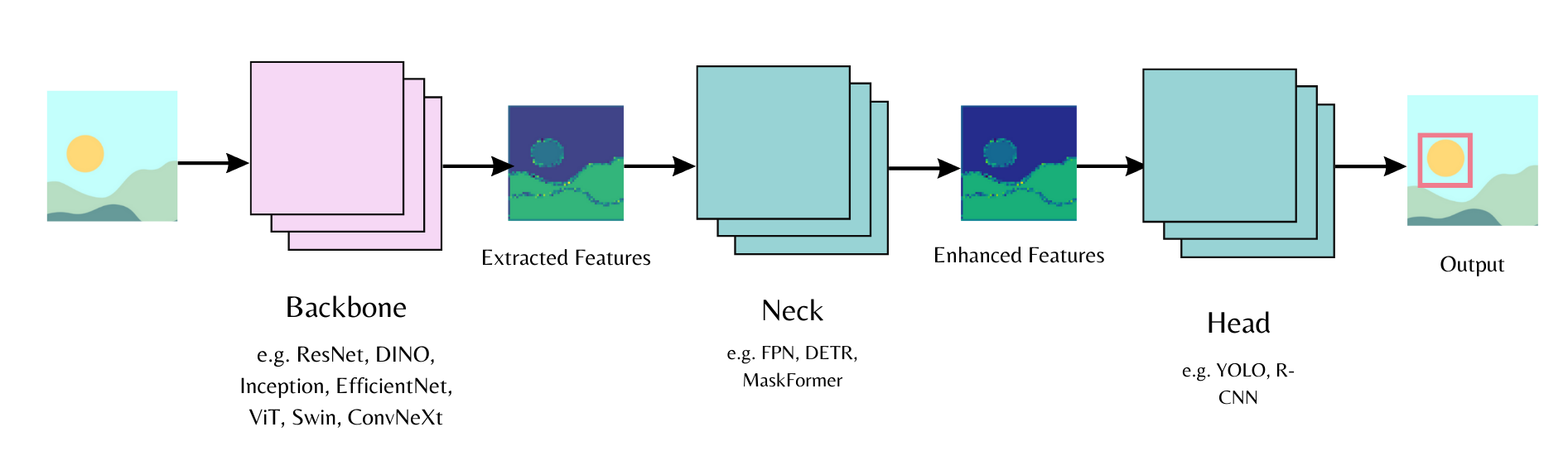
تتكون نماذج رؤية الحاسب من جزء أساسي، وجزء وسيط، وجزء معالجة نهائي. يستخرج الجزء الأساسي الميزات من صورة الإدخال، ويجمع الجزء الوسيط هذه الميزات المستخرجة ويعززها، ويُستخدم الجزء النهائي للمهمة الرئيسية (مثل اكتشاف الأجسام). ابدأ عبتهيئة الجزء الأساسي في تكوين النموذج وحدد ما إذا كنت تريد تحميل أوزان مدربة مسبقًا أو أوزانًا عشوائية. بعد ذلك، يمكنك تمرير تكوين النموذج إلى جزء المعالجة النهائي.
على سبيل المثال، لتحميل ResNet backbone في نموذج MaskFormer مع رأس تجزئة مثيل:
<hfoptions id="backbone"> <hfoption id="pretrained weights">قم بتعيين use_pretrained_backbone=True لتحميل الأوزان المسبقة التدريب لـ ResNet للعمود الفقري.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=True) # تكوين الجزء الأساسي والجزء الوسيط
model = MaskFormerForInstanceSegmentation(config) # جزء المعالجة النهائيقم بتعيين use_pretrained_backbone=False لتهيئة جزء ResNet الأساسي بشكل عشوائي.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=False) # تكوين الجزء الأساسي والجزء الوسيط
model = MaskFormerForInstanceSegmentation(config) # جزء المعالجة النهائييمكنك أيضًا تحميل تكوين الجزء الأساسي بشكل منفصل، ثم تمريره إلى تكوين النموذج.```
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig
backbone_config = ResNetConfig()
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)يتم تحميل نماذج timm داخل نموذج باستخدام use_timm_backbone=True أو باستخدام TimmBackbone و TimmBackboneConfig.
استخدم use_timm_backbone=True و use_pretrained_backbone=True لتحميل أوزان timm المُدرّبة مسبقًا للجزء الأساسي.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=True, use_timm_backbone=True) # تكوين الجزء الأساسي والجزء الوسيط
model = MaskFormerForInstanceSegmentation(config) # جزء المعالجة النهائيقم بتعيين use_timm_backbone=True و use_pretrained_backbone=False لتحميل عمود فقري timm مبدئي عشوائي.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=False, use_timm_backbone=True) # تكوين الجزء الأساسي والجزء الوسيط
model = MaskFormerForInstanceSegmentation(config) # جزء المعالجة النهائييمكنك أيضًا تحميل تكوين الجزء الأساسي واستخدامه لإنشاء TimmBackbone أو تمريره إلى تكوين النموذج. سيتم تحميلأوزان الجزء الأساسي لـ Timm المُدرّبة مسبقًا افتراضيًا. عيّن use_pretrained_backbone=False لتحميل الأوزان المبدئية العشوائية.
from transformers import TimmBackboneConfig, TimmBackbone
backbone_config = TimmBackboneConfig("resnet50", use_pretrained_backbone=False)
# قم بإنشاء مثيل من العمود الفقري
backbone = TimmBackbone(config=backbone_config)
# قم بإنشاء نموذج باستخدام عمود فقري timm
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)مستخرج الميزات
يقوم مُستخرج الميزات بمعالجة المدخلات الصوتية. يرث من فئة الأساس FeatureExtractionMixin، وقد يرث أيضًا من فئة SequenceFeatureExtractor لمعالجة المدخلات الصوتية.
للاستخدام، قم بإنشاء مستخرج ميزات مرتبط بالنموذج الذي تستخدمه. على سبيل المثال، قم بإنشاء مستخرج ميزات Wav2Vec2 الافتراضي إذا كنت تستخدم Wav2Vec2 لتصنيف الصوت:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}قم بتعديل أي من معلمات Wav2Vec2FeatureExtractor لإنشاء مستخرج ميزات مخصص:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000، do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor"،
"feature_size": 1،
"padding_side": "right"،
"padding_value": 0.0،
"return_attention_mask": false،
"sampling_rate": 8000
}المعالج
بالنسبة للنماذج التي تدعم مهام الوسائط المتعددة، توفر مكتبة 🤗 Transformers فئة معالج تجمع بفاعلية فئات المعالجة مثل مستخرج الميزات ومقسّم الرموز في كائن واحد. على سبيل المثال، دعنا نستخدم Wav2Vec2Processor لمهمة التعرف الآلي على الكلام (ASR). تقوم مهمة ASR بتحويل الصوت إلى نص، لذلك ستحتاج إلى مستخرج ميزات ومقسّم رموز.
قم بإنشاء مستخرج ميزات لمعالجة المدخلات الصوتية:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)قم بإنشاء مقسّم رموز لمعالجة المدخلات النصية:
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")قم بدمج مستخرج الميزات ومقسّم الرموز في Wav2Vec2Processor:
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)باستخدام فئتين أساسيتين - التكوين والنموذج - بالإضافة إلى فئة معالجة مسبق (مقسّم رموز أو معالج صورة أو مستخرج ميزات أو معالج)، يمكنك إنشاء أي من النماذج التي تدعمها مكتبة 🤗 Transformers. يمكن تكوين كل من هذه الفئات الأساسية، مما يسمح لك باستخدام السمات المطلوبة. يمكنك بسهولة تهيئة نموذج للتدريب أو تعديل نموذج مدرب مسبقاً لإجراء ضبط دقيق.
< > Update on GitHub