PEFT documentation
Orthogonal Finetuning (OFT and BOFT)
Orthogonal Finetuning (OFT and BOFT)
This conceptual guide gives a brief overview of OFT, OFTv2 and BOFT, a parameter-efficient fine-tuning technique that utilizes orthogonal matrix to multiplicatively transform the pretrained weight matrices.
To achieve efficient fine-tuning, OFT represents the weight updates with an orthogonal transformation. The orthogonal transformation is parameterized by an orthogonal matrix multiplied to the pretrained weight matrix. These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are multiplied togethor.
Orthogonal Butterfly (BOFT) generalizes OFT with Butterfly factorization and further improves its parameter efficiency and finetuning flexibility. In short, OFT can be viewed as a special case of BOFT. Different from LoRA that uses additive low-rank weight updates, BOFT uses multiplicative orthogonal weight updates. The comparison is shown below.
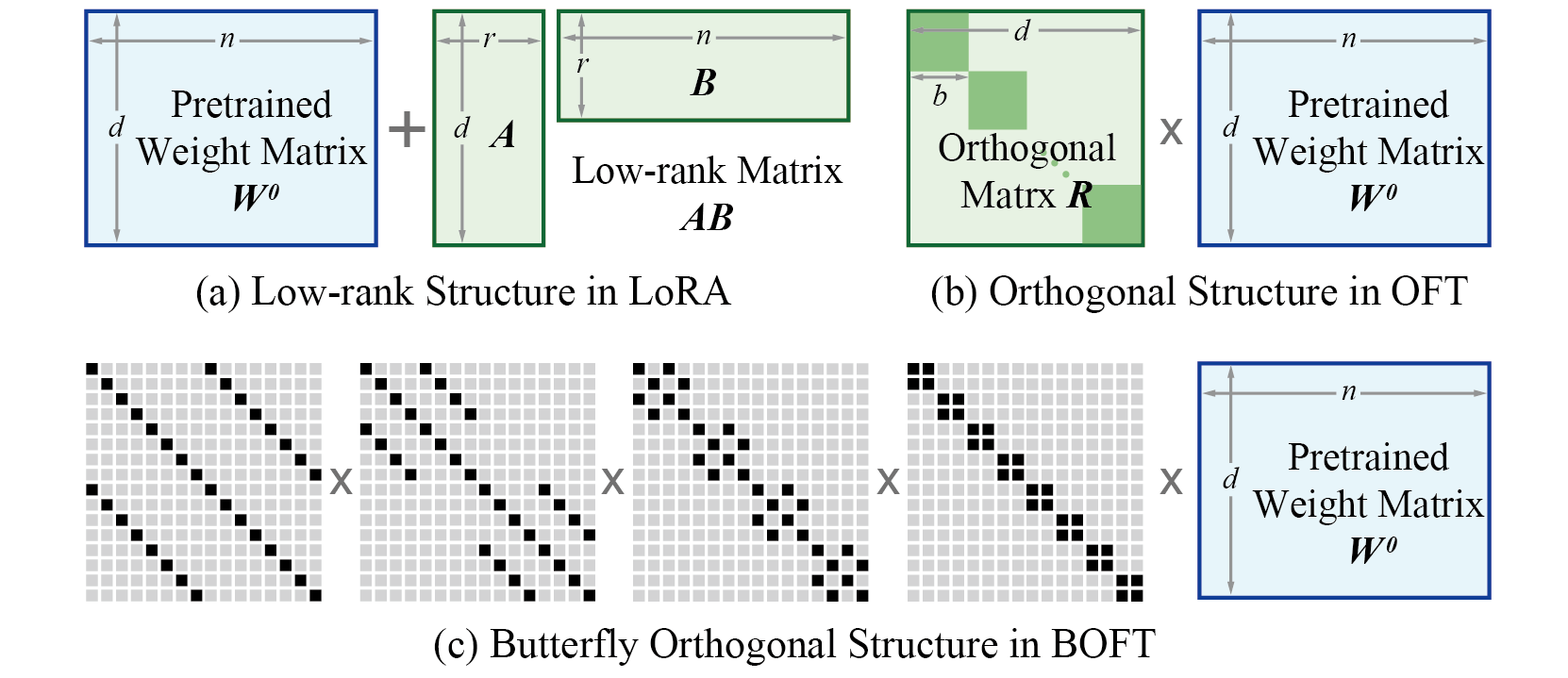
BOFT has some advantages compared to LoRA:
- BOFT proposes a simple yet generic way to finetune pretrained models to downstream tasks, yielding a better preservation of pretraining knowledge and a better parameter efficiency.
- Through the orthogonality, BOFT introduces a structural constraint, i.e., keeping the hyperspherical energy unchanged during finetuning. This can effectively reduce the forgetting of pretraining knowledge.
- BOFT uses the butterfly factorization to efficiently parameterize the orthogonal matrix, which yields a compact yet expressive learning space (i.e., hypothesis class).
- The sparse matrix decomposition in BOFT brings in additional inductive biases that are beneficial to generalization.
In principle, BOFT can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. Given the target layers for injecting BOFT parameters, the number of trainable parameters can be determined based on the size of the weight matrices.
Merge OFT/BOFT weights into the base model
Similar to LoRA, the weights learned by OFT/BOFT can be integrated into the pretrained weight matrices using the merge_and_unload() function. This function merges the adapter weights with the base model which allows you to effectively use the newly merged model as a standalone model.

This works because during training, the orthogonal weight matrix (R in the diagram above) and the pretrained weight matrices are separate. But once training is complete, these weights can actually be merged (multiplied) into a new weight matrix that is equivalent.
Utils for OFT / BOFT
Common OFT / BOFT parameters in PEFT
As with other methods supported by PEFT, to fine-tune a model using OFT or BOFT, you need to:
- Instantiate a base model.
- Create a configuration (
OFTConfigorBOFTConfig) where you define OFT/BOFT-specific parameters. - Wrap the base model with
get_peft_model()to get a trainablePeftModel. - Train the
PeftModelas you normally would train the base model.
OFT-specific parameters
OFTConfig allows you to control how OFT is applied to the base model through the following parameters:
r: OFT rank, number of OFT blocks per injected layer. Biggerrresults in more sparse update matrices with fewer trainable paramters. Note: You can only specify eitherroroft_block_size, but not both simultaneously, becauser×oft_block_size= layer dimension. For simplicity, we let the user speficy eitherroroft_block_sizeand infer the other one. Default set tor = 0, the user is advised to set theoft_block_sizeinstead for better clarity.oft_block_size: OFT block size across different layers. Biggeroft_block_sizeresults in more dense update matrices with more trainable parameters. Note: Please chooseoft_block_sizeto be divisible by layer’s input dimension (in_features), e.g., 4, 8, 16. You can only specify eitherroroft_block_size, but not both simultaneously, becauser×oft_block_size= layer dimension. For simplicity, we let the user speficy eitherroroft_block_sizeand infer the other one. Default set tooft_block_size = 32.use_cayley_neumann: Specifies whether to use the Cayley-Neumann parameterization (efficient but approximate) or the vanilla Cayley parameterization (exact but computationally expensive because of matrix inverse). We recommend to set it toTruefor better efficiency, but performance may be slightly worse because of the approximation error. Please test both settings (TrueandFalse) depending on your needs. Default isFalse.module_dropout: The multiplicative dropout probability, by setting OFT blocks to identity during training, similar to the dropout layer in LoRA.bias: specify if thebiasparameters should be trained. Can be"none","all"or"oft_only".target_modules: The modules (for example, attention blocks) to inject the OFT matrices.modules_to_save: List of modules apart from OFT matrices to be set as trainable and saved in the final checkpoint. These typically include model’s custom head that is randomly initialized for the fine-tuning task.
BOFT-specific parameters
BOFTConfig allows you to control how BOFT is applied to the base model through the following parameters:
boft_block_size: the BOFT matrix block size across different layers, expressed inint. Biggerboft_block_sizeresults in more dense update matrices with more trainable parameters. Note, please chooseboft_block_sizeto be divisible by most layer’s input dimension (in_features), e.g., 4, 8, 16. Also, please only specify eitherboft_block_sizeorboft_block_num, but not both simultaneously or leaving both to 0, becauseboft_block_sizexboft_block_nummust equal the layer’s input dimension.boft_block_num: the number of BOFT matrix blocks across different layers, expressed inint. Biggerboft_block_numresult in sparser update matrices with fewer trainable parameters. Note, please chooseboft_block_numto be divisible by most layer’s input dimension (in_features), e.g., 4, 8, 16. Also, please only specify eitherboft_block_sizeorboft_block_num, but not both simultaneously or leaving both to 0, becauseboft_block_sizexboft_block_nummust equal the layer’s input dimension.boft_n_butterfly_factor: the number of butterfly factors. Note, forboft_n_butterfly_factor=1, BOFT is the same as vanilla OFT, forboft_n_butterfly_factor=2, the effective block size of OFT becomes twice as big and the number of blocks become half.bias: specify if thebiasparameters should be trained. Can be"none","all"or"boft_only".boft_dropout: specify the probability of multiplicative dropout.target_modules: The modules (for example, attention blocks) to inject the OFT/BOFT matrices.modules_to_save: List of modules apart from OFT/BOFT matrices to be set as trainable and saved in the final checkpoint. These typically include model’s custom head that is randomly initialized for the fine-tuning task.
OFT Example Usage
For using OFT for quantized finetuning with TRL for SFT, PPO, or DPO fine-tuning, follow the following outline:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTTrainer
from peft import OFTConfig
if use_quantization:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_storage=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
"model_name",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained("model_name")
# Configure OFT
peft_config = OFTConfig(
oft_block_size=32,
use_cayley_neumann=True,
target_modules="all-linear",
bias="none",
task_type="CAUSAL_LM"
)
trainer = SFTTrainer(
model=model,
train_dataset=ds['train'],
peft_config=peft_config,
processing_class=tokenizer,
args=training_arguments,
data_collator=collator,
)
trainer.train()BOFT Example Usage
For an example of the BOFT method application to various downstream tasks, please refer to the following guides:
Take a look at the following step-by-step guides on how to finetune a model with BOFT:
For the task of image classification, one can initialize the BOFT config for a DinoV2 model as follows:
import transformers
from transformers import AutoModelForSeq2SeqLM, BOFTConfig
from peft import BOFTConfig, get_peft_model
config = BOFTConfig(
boft_block_size=4,
boft_n_butterfly_factor=2,
target_modules=["query", "value", "key", "output.dense", "mlp.fc1", "mlp.fc2"],
boft_dropout=0.1,
bias="boft_only",
modules_to_save=["classifier"],
)
model = transformers.Dinov2ForImageClassification.from_pretrained(
"facebook/dinov2-large",
num_labels=100,
)
boft_model = get_peft_model(model, config)