
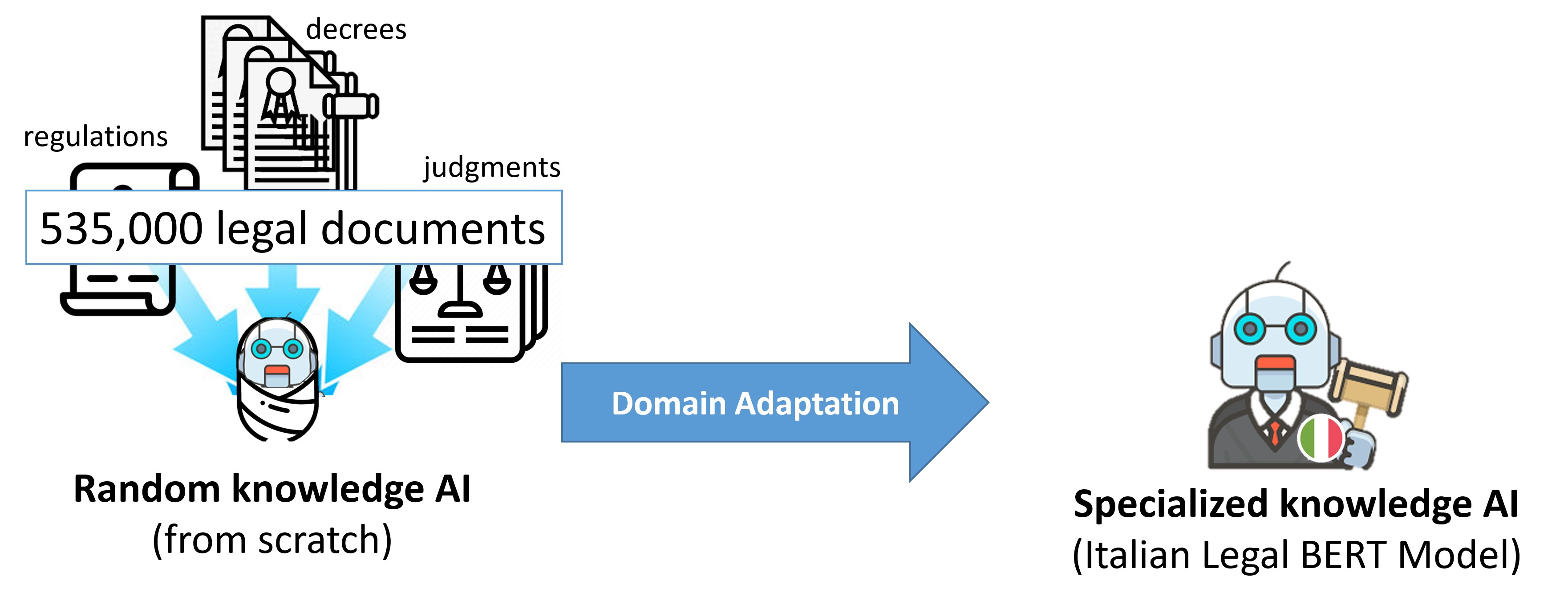
ITALIAN-LEGAL-BERT-SC
It is the ITALIAN-LEGAL-BERT variant pre-trained from scratch on Italian legal documents (ITA-LEGAL-BERT-SC) based on the CamemBERT architecture
Training procedure
It was trained from scratch using a larger training dataset, 6.6GB of civil and criminal cases. We used CamemBERT architecture with a language modeling head on top, AdamW Optimizer, initial learning rate 2e-5 (with linear learning rate decay), sequence length 512, batch size 18, 1 million training steps, device 8*NVIDIA A100 40GB using distributed data parallel (each step performs 8 batches). It uses SentencePiece tokenization trained from scratch on a subset of training set (5 milions sentences) and vocabulary size of 32000
Usage
ITALIAN-LEGAL-BERT model can be loaded like:
from transformers import AutoModel, AutoTokenizer
model_name = "dlicari/Italian-Legal-BERT-SC"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
You can use the Transformers library fill-mask pipeline to do inference with ITALIAN-LEGAL-BERT.
# %pip install sentencepiece
# %pip install transformers
from transformers import pipeline
model_name = "dlicari/Italian-Legal-BERT-SC"
fill_mask = pipeline("fill-mask", model_name)
fill_mask("Il <mask> ha chiesto revocarsi l'obbligo di pagamento")
# [{'score': 0.6529251933097839,'token_str': 'ricorrente',
# {'score': 0.0380014143884182, 'token_str': 'convenuto',
# {'score': 0.0360226035118103, 'token_str': 'richiedente',
# {'score': 0.023908283561468124,'token_str': 'Condominio',
# {'score': 0.020863816142082214, 'token_str': 'lavoratore'}]
- Downloads last month
- 359