
The dataset viewer is not available because its heuristics could not detect any supported data files. You can try uploading some data files, or configuring the data files location manually.
Dataset Summary
The HIT dataset is a structured dataset of paired observations of body's inner tissues and the body surface. More concretely, it is a dataset of paired full-body volumetric segmented (bones, lean, and adipose tissue) MRI scans and SMPL meshes capturing the body surface shape for male (N=157) and female (N=241) subjects respectively. This is relevant for medicine, sports science, biomechanics, and computer graphics as it can ease the creation of personalized anatomic digital twins that model our bones, lean, and adipose tissue. Dataset acquistion: We work with scans acquired with a 1.5 T scanner (Magnetom Sonata, Siemens Healthcare) following a standardized protocol for whole body adipose tissue topography mapping. All subjects gave prior informed written consent and the study was approved by the local ethics board. Each scan has around 110 slices, slightly varying depending on the height of the subject. The slice resolution is 256 × 192, with an approximate voxel size of 2 × 2 × 10 mm. These slices are segmented into bones, lean, and adipose tissue by leveraging initial automatic segmentations and manual annotations to train and refine nnUnets with the help of human supervision. For each subject, we then fit the SMPL body mesh to the surface of the segmented MRI in a manner that captures the flattened shape of subjects in their lying positions on belly in the scanner (refer to Sec 3.2 in main paper for further details). Therefore for each subject, we provide the MRI segmented array and the SMPL mesh faces and vertices (in addition to the SMPL parameters).
Supported Tasks and Leaderboards
HIT fosters a new direction and therefore there aren't any exisiting Benchmarks. We encourage the use of the dataset to open up new tasks and research directions.
Languages
[N/A]
Usage
Quick use
pip install datasets
from datasets import load_dataset
# name in ['male', 'female']
# split in ['train', 'validation', 'test']
male_train = load_dataset("varora/hit", name='male', split='train')
print(male_train.__len__())
print(next(iter(male_train)))
Visualize data
Download vis_hit_sample.py from the repo or git clone https://huggingface.co/datasets/varora/HIT
pip install datasets, open3d, pyvista
Visualize mesh and pointcloud
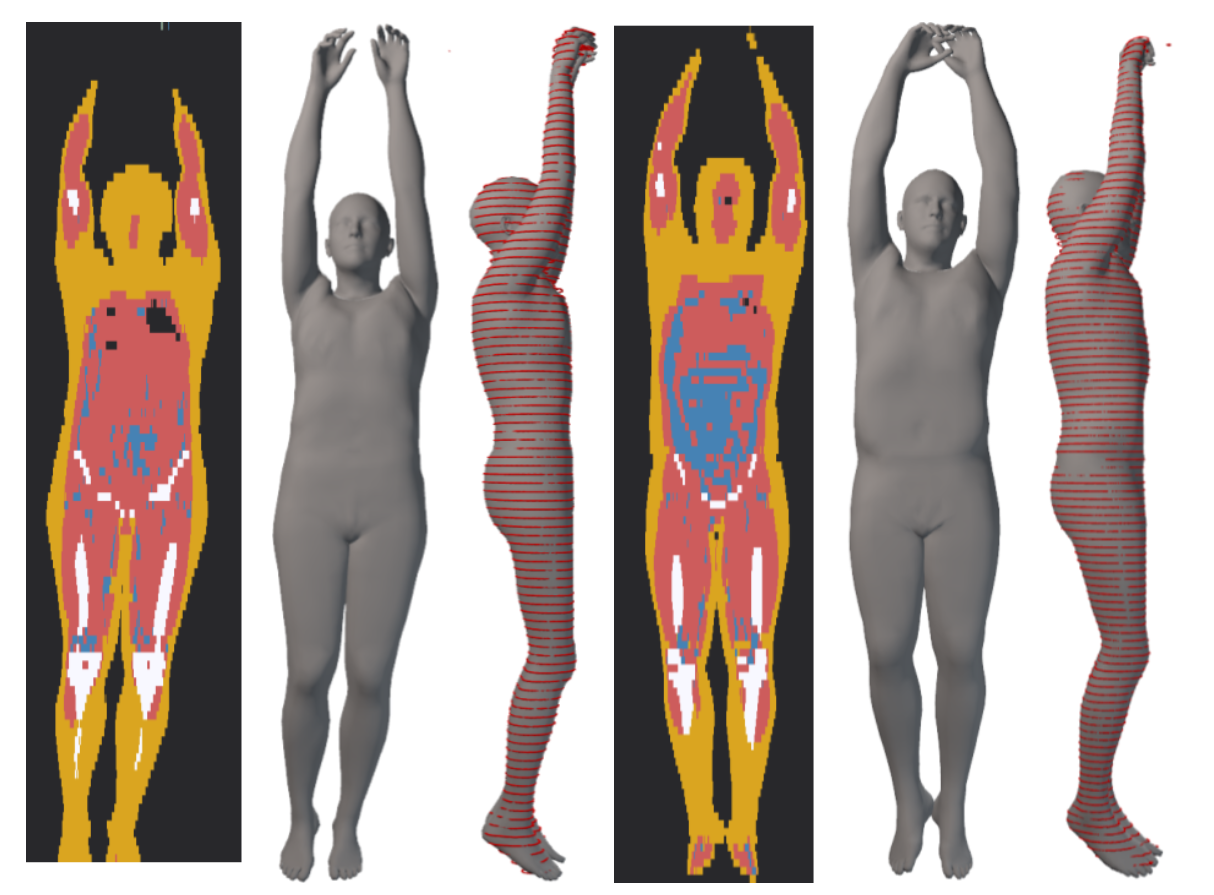
python vis_hit_sample.py --gender male --split test --idx 5 --show_skin
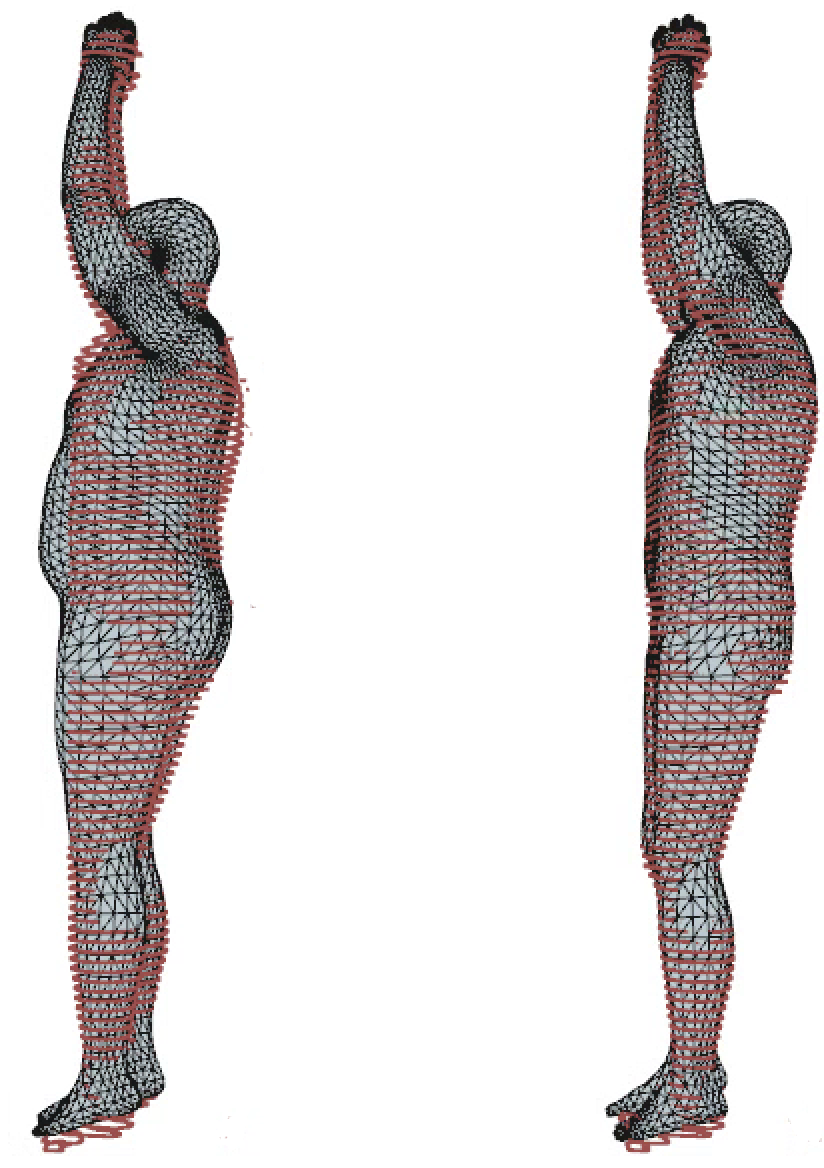
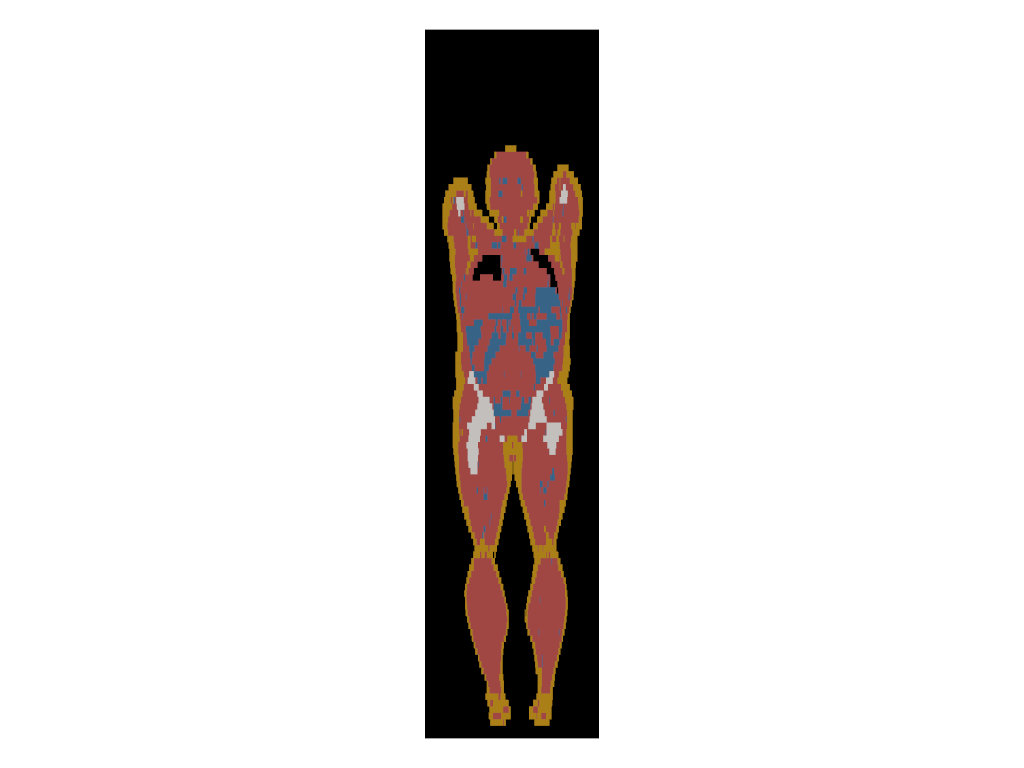
Visualize tissue slice
python vis_hit_sample.py --gender male --split test --idx 5 --show_tissue
Dataset Structure
The dataset is structured as follows:
|- male
|- train
|- 001.gz
|- 002.gz
|- …
|- 00X.gz
|- val
|-
|- …
|- 00X.gz
|- test
|-
|- …
|- 00X.gz
|- female
|- train
|- 001.gz
|- 002.gz
|- …
|- 00X.gz
|- val
|-
|- …
|- 00X.gz
|- test
|-
|- …
|- 00X.gz
Data Instances
Each data instance (male/train/001.gz for example) contains the following:
{
'gender': str ['male', 'female'],
'subject_ID': str
'mri_seg': numpy.ndarray (None, 192, 256),
'mri_labels': dict {'NO': 0, 'LT': 1, 'AT': 2, 'VAT': 3, 'BONE': 4},
'body_mask': numpy.ndarray (None, 192, 256),
'bondy_cont_pc': numpy.ndarray (None, 3),
'resolution': numpy.ndarray (N, 3),
'center': numpy.ndarray (N, 3),
'smpl_dict': dict dict_keys(['gender', 'verts_free', 'verts', 'faces', 'pose', 'betas', 'trans'])
}
Data Fields
Each data instance (male/train/001.gz for example) contains the following fields:
- 'gender': "gender of the subject",
- 'subject_ID': "anonymized name of the subject which is also the filename"
- 'mri_seg': "annotated array with the labels 0,1,2,3",
- 'mri_labels': "dictionary of mapping between label integer and name",
- 'body_mask': "binary array for body mask",
- 'body_cont_pc' "extracted point cloud from mri contours"
- 'resolution': "per slice resolution in meters",
- 'center': "per slice center, in pixels",
- 'smpl_dict': dictionary containing all the relevant SMPL parameters of the subject alongwith mesh faces and vertices ('verts': original fit, 'verts_free': compressed fit
Data Splits
The HIT dataset has 3 splits for each subject type (male, female): train, val, and test.
| train | validation | test | |
|---|---|---|---|
| male | 126 | 16 | 15 |
| female | 191 | 25 | 25 |
Dataset Creation
Curation Rationale
The dataset was created to foster research in biomechanics, computer graphics and Human Digital Twins.
Source Data
Initial Data Collection and Normalization
We work with scans acquired with a 1.5 T scanner (Magnetom Sonata, Siemens Healthcare) following a standardized protocol for whole body adipose tissue topography mapping. All subjects gave prior informed written consent and the study was approved by the local ethics board. Each scan has around 110 slices, slightly varying depending on the height of the subject. The slice resolution is 256 × 192, with an approximate voxel size of 2 × 2 × 10 mm. These slices are segmented into bones, lean, and adipose tissue by leveraging initial automatic segmentations and manual annotations to train and refine nnUnets with the help of human supervision. For each subject, we then fit the SMPL body mesh to the surface of the segmented MRI in a manner that captures the flattened shape of subjects in their lying positions on belly in the scanner (refer to Sec 3.2 in main paper for further details). Therefore for each subject, we provide the MRI segmented array and the SMPL mesh faces and vertices (in addition to the SMPL parameters).
Who are the source language producers?
[N/A]
Annotations
Annotation process
Refer to Sec 3 of the paper.
Who are the annotators?
Refer to Sec 3 of the paper.
Personal and Sensitive Information
The dataset uses identity category of gender: male and female. As the dataset intends to foster research in estimating tissues from outer shape which vary subsequently between the genders, the dataset is categorized as such.
Considerations for Using the Data
Social Impact of Dataset
Today, many methods can estimate accurate SMPL bodies from images, and this dataset can be used to train models that can infer their internal tissues. As a good estimate of the body composition relates to health risks, HIT dataset could allow the estimation of health risks from a single image of a person. This is valuable as an early diagnostic tool when used with the persons knowledge, but could turn into a risk if it is used without consent.
Discussion of Biases
[N/A]
Other Known Limitations
Refer to Sec 3.3 of the paper
Additional Information
Dataset Curators
The HIT dataset was curated by Vaibhav Arora, Abdelmouttaleb Dakri, Jürgen Machann, Sergi Pujades
Licensing Information
Software Copyright License for non-commercial scientific research purposes
Please read carefully the following terms and conditions and any accompanying documentation before you download and/or use the HIT data and software, (the "Data & Software"), including trained models, 3D meshes, images, videos, textures, software, scripts, and animations. By downloading and/or using the Data & Software (including downloading, cloning, installing, and any other use of the corresponding github repository), you acknowledge that you have read these terms and conditions, understand them, and agree to be bound by them. If you do not agree with these terms and conditions, you must not download and/or use the Data & Software. Any infringement of the terms of this agreement will automatically terminate your rights under this License.
Ownership/Licensees
The Software and the associated materials has been developed at the Max Planck Institute for Intelligent Systems (hereinafter "MPI"), University of Tübingen, and INRIA. The original skeleton mesh is released with permission of Anatoscope (www.anatoscope.com). Any copyright or patent right is owned by and proprietary material of the Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. (hereinafter “MPG”; MPI and MPG hereinafter collectively “Max-Planck”), hereinafter the “Licensor”.
License Grant
Licensor grants you (Licensee) personally a single-user, non-exclusive, non-transferable, free of charge right: - To install the Data & Software on computers owned, leased or otherwise controlled by you and/or your organization; - To use the Data & Software for the sole purpose of performing non-commercial scientific research, non-commercial education, or non-commercial artistic projects;
Any other use, in particular any use for commercial, pornographic, military, or surveillance, purposes is prohibited. This includes, without limitation, incorporation in a commercial product, use in a commercial service, or production of other artefacts for commercial purposes. The Data & Software may not be used to create fake, libelous, misleading, or defamatory content of any kind excluding analyses in peer-reviewed scientific research. The Software may not be reproduced, modified and/or made available in any form to any third party without Max-Planck’s prior written permission.
The Data & Software may not be used for pornographic purposes or to generate pornographic material whether commercial or not. This license also prohibits the use of the Software to train methods/algorithms/neural networks/etc. for commercial, pornographic, military, surveillance, or defamatory use of any kind. By downloading the Data & Software, you agree not to reverse engineer it.
No Distribution
The Data & Software and the license herein granted shall not be copied, shared, distributed, re-sold, offered for re-sale, transferred or sub-licensed in whole or in part except that you may make one copy for archive purposes only.
Disclaimer of Representations and Warranties
You expressly acknowledge and agree that the Data & Software results from basic research, is provided “AS IS”, may contain errors, and that any use of the Data & Software is at your sole risk. LICENSOR MAKES NO REPRESENTATIONS OR WARRANTIES OF ANY KIND CONCERNING THE DATA & SOFTWARE, NEITHER EXPRESS NOR IMPLIED, AND THE ABSENCE OF ANY LEGAL OR ACTUAL DEFECTS, WHETHER DISCOVERABLE OR NOT. Specifically, and not to limit the foregoing, licensor makes no representations or warranties (i) regarding the merchantability or fitness for a particular purpose of the Data & Software, (ii) that the use of the Data & Software will not infringe any patents, copyrights or other intellectual property rights of a third party, and (iii) that the use of the Data & Software will not cause any damage of any kind to you or a third party.
Limitation of Liability
Because this Data & Software License Agreement qualifies as a donation, according to Section 521 of the German Civil Code (Bürgerliches Gesetzbuch – BGB) Licensor as a donor is liable for intent and gross negligence only. If the Licensor fraudulently conceals a legal or material defect, they are obliged to compensate the Licensee for the resulting damage. Licensor shall be liable for loss of data only up to the amount of typical recovery costs which would have arisen had proper and regular data backup measures been taken. For the avoidance of doubt Licensor shall be liable in accordance with the German Product Liability Act in the event of product liability. The foregoing applies also to Licensor’s legal representatives or assistants in performance. Any further liability shall be excluded. Patent claims generated through the usage of the Data & Software cannot be directed towards the copyright holders. The Data & Software is provided in the state of development the licensor defines. If modified or extended by Licensee, the Licensor makes no claims about the fitness of the Data & Software and is not responsible for any problems such modifications cause.
No Maintenance Services
You understand and agree that Licensor is under no obligation to provide either maintenance services, update services, notices of latent defects, or corrections of defects with regard to the Data & Software. Licensor nevertheless reserves the right to update, modify, or discontinue the Data & Software at any time.
Defects of the Data & Software must be notified in writing to the Licensor with a comprehensible description of the error symptoms. The notification of the defect should enable the reproduction of the error. The Licensee is encouraged to communicate any use, results, modification or publication.
Publications using the Data & Software
You acknowledge that the Data & Software is a valuable scientific resource and agree to appropriately reference the following paper in any publication making use of the Data & Software.
Commercial licensing opportunities
For commercial uses of the Data & Software, please send email to ps-license@tue.mpg.de
This Agreement shall be governed by the laws of the Federal Republic of Germany except for the UN Sales Convention.
Citation Information
@inproceedings{Keller:CVPR:2024,
title = {{HIT}: Estimating Internal Human Implicit Tissues from the Body Surface},
author = {Keller, Marilyn and Arora, Vaibhav and Dakri, Abdelmouttaleb and Chandhok, Shivam and
Machann, Jürgen and Fritsche, Andreas and Black, Michael J. and Pujades, Sergi},
booktitle = {Proceedings IEEE/CVF Conf.~on Computer Vision and Pattern Recognition (CVPR)},
month = jun,
year = {2024},
month_numeric = {6}}
Contributions
[N/A]
- Downloads last month
- 357