Datasets:

The full dataset viewer is not available (click to read why). Only showing a preview of the rows.
Error code: DatasetGenerationCastError
Exception: DatasetGenerationCastError
Message: An error occurred while generating the dataset
All the data files must have the same columns, but at some point there are 5 new columns ({'average_running_time', 'average_memory', 'num', 'source_code', 'source_lang'}) and 4 missing columns ({'incorrect_solutions', 'solutions', 'type', 'code_language'}).
This happened while the json dataset builder was generating data using
hf://datasets/m-a-p/CodeEditorBench/code_polishment_plus.jsonl (at revision 9bd3f75915e7583feae1d0e98c09176c20a6bd1d)
Please either edit the data files to have matching columns, or separate them into different configurations (see docs at https://hf.co/docs/hub/datasets-manual-configuration#multiple-configurations)
Traceback: Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 2011, in _prepare_split_single
writer.write_table(table)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 585, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2302, in table_cast
return cast_table_to_schema(table, schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2256, in cast_table_to_schema
raise CastError(
datasets.table.CastError: Couldn't cast
idx: int64
num: int64
title: string
difficulty: string
source_code: string
source_lang: string
average_running_time: int64
average_memory: int64
public_tests_input: string
public_tests_output: string
private_tests_input: list<item: string>
child 0, item: string
private_tests_output: list<item: string>
child 0, item: string
to
{'idx': Value(dtype='int64', id=None), 'title': Value(dtype='string', id=None), 'code_language': Value(dtype='string', id=None), 'incorrect_solutions': Value(dtype='string', id=None), 'solutions': Value(dtype='string', id=None), 'type': Value(dtype='string', id=None), 'difficulty': Value(dtype='string', id=None), 'public_tests_input': Value(dtype='string', id=None), 'public_tests_output': Value(dtype='string', id=None), 'private_tests_input': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'private_tests_output': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}
because column names don't match
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1321, in compute_config_parquet_and_info_response
parquet_operations = convert_to_parquet(builder)
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 935, in convert_to_parquet
builder.download_and_prepare(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1027, in download_and_prepare
self._download_and_prepare(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1122, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1882, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 2013, in _prepare_split_single
raise DatasetGenerationCastError.from_cast_error(
datasets.exceptions.DatasetGenerationCastError: An error occurred while generating the dataset
All the data files must have the same columns, but at some point there are 5 new columns ({'average_running_time', 'average_memory', 'num', 'source_code', 'source_lang'}) and 4 missing columns ({'incorrect_solutions', 'solutions', 'type', 'code_language'}).
This happened while the json dataset builder was generating data using
hf://datasets/m-a-p/CodeEditorBench/code_polishment_plus.jsonl (at revision 9bd3f75915e7583feae1d0e98c09176c20a6bd1d)
Please either edit the data files to have matching columns, or separate them into different configurations (see docs at https://hf.co/docs/hub/datasets-manual-configuration#multiple-configurations)Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
idx
int64 | title
string | code_language
string | incorrect_solutions
string | solutions
string | type
string | difficulty
string | public_tests_input
string | public_tests_output
string | private_tests_input
sequence | private_tests_output
sequence |
|---|---|---|---|---|---|---|---|---|---|---|
1,325 |
java
| "\nclass Solution {\n public List<List<Integer>> combinationSum(int[] candidates, int target) {\n(...TRUNCATED) | "class Solution {\n public List<List<Integer>> combinationSum(int[] candidates, int target) {\n (...TRUNCATED) |
syntax error:misused == or =
|
medium
|
candidates = \[2,3,6,7\], target = 7
|
\[\[2,2,3\],\[7\]\]
| ["[1,2,3,4,5,6,7,8,9]\n12","[1, 2, 3, 4]\n5","[1,2,3,4,5,6,7,8,9]\n28","[1,2,3,4,5,6,7,8,9]\n30","[1(...TRUNCATED) | ["[[1]]\n","[[1, 2], [1, 1, 1]]\n","[[8, 9, 9], [6, 6, 7, 7], [6, 6, 6, 8], [5, 7, 7, 7], [5, 6, 7, (...TRUNCATED) |
|
1,329 |
java
| "\nclass Solution {\n public void moveZeroes(int[] nums) {\n int m=-1;\n for(int i=(...TRUNCATED) | "class Solution {\n public void moveZeroes(int[] nums) {\n int m=-1;\n for(int i=0;(...TRUNCATED) |
syntax error:misused == or =
|
easy
|
nums = \[0,1,0,3,12\]
|
\[1,3,12,0,0\]
| ["[0, 0, 0, 1, 1]","[0,0,0,0,0]","[1, 1, 1, 0, 1]","[1, 1, 0, 1, 0]","[0, 1, 0, 0, 1]","[0, 1, 1, 0,(...TRUNCATED) | ["null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n",(...TRUNCATED) |
|
1,330 |
java
| "\nclass Solution {\n public void nextPermutation(int[] n) {\n //breakpoint\n if( n(...TRUNCATED) | "class Solution {\n public void nextPermutation(int[] n) {\n //breakpoint\n if( n==(...TRUNCATED) |
logic error:condition error
|
medium
|
nums = \[1,2,3\]
|
\[1,3,2\]
| ["[8, 7, 6, 5, 4, 3, 2, 1]","[1,2,3,4]","[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]","[1, 1, 1, 1(...TRUNCATED) | ["null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n",(...TRUNCATED) |
|
1,332 |
java
| "\nclass Solution {\n public int maxNumberOfBalloons(String text) {\n final int[][] cache (...TRUNCATED) | "class Solution {\n public int maxNumberOfBalloons(String text) {\n final int[][] cache = (...TRUNCATED) |
syntax error:missing colons
|
easy
|
text = "nlaebolko "
|
1
| ["\"aobnaloonl\"","balon ","\"bballoonalo\"","\"lbnaoolon\"","\"lnbaoolona\"","\"bnanooloa\"","loonb(...TRUNCATED) | ["1\n","2\n","1\n","1\n","0\n","1\n","1\n","1\n","1\n","1\n","1\n","1\n","1\n","1\n","1\n","0\n","1\(...TRUNCATED) |
|
1,338 |
java
| "\nclass Solution {\n public boolean isAnagram(String s, String t) {\n if(s.length()!=t.le(...TRUNCATED) | "class Solution {\n public boolean isAnagram(String s, String t) {\n if(s.length()!=t.leng(...TRUNCATED) |
reference error:undefined objects
|
easy
|
s = "anagram", t = "nagaram"
|
true
| ["a\nb","rat\ncar","a\nd","hello\noellh","triangle\nintegral","world\ndrolw","rat\ncar","abcde\nebcd(...TRUNCATED) | ["true\n","true\n","true\n","true\n","true\n","false\n","true\n","true\n","true\n","true\n","true\n"(...TRUNCATED) |
|
1,339 |
java
| "\nclass Solution {\n public void nextPermutation(int[] n) {\n //breakpoint\n if( n(...TRUNCATED) | "class Solution {\n public void nextPermutation(int[] n) {\n //breakpoint\n if( n==(...TRUNCATED) |
syntax error:unclosed parentheses
|
medium
|
nums = \[1,2,3\]
|
\[1,3,2\]
| ["[8, 7, 6, 5, 4, 3, 2, 1]","[1,2,3,4]","[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]","[1, 1, 1, 1(...TRUNCATED) | ["null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n","null\n",(...TRUNCATED) |
|
1,341 |
java
| "\nclass Solution {\n public int removeDuplicates(int[] nums) {\n int index = 1;\n int(...TRUNCATED) | "class Solution {\n public int removeDuplicates(int[] nums) {\n int index = 1;\n int (...TRUNCATED) |
reference error:faulty indexing
|
medium
|
: nums = \[1,1,1,2,2,3\]
|
: 5, nums = \[1,1,2,2,3,\_\]
| ["[0, 0, 1, 1, 1, 1, 2, 2, 3, 3]","[1,1,1,1,2,2,2,3,3,4,4,5,5]","[0, 0, 1, 1, 1, 1, 2, 2, 2, 2]","[0(...TRUNCATED) | ["7\n","8\n","6\n","8\n","7\n","9\n","6\n","6\n","6\n","6\n","7\n","8\n","8\n","7\n","6\n","7\n","8\(...TRUNCATED) |
|
1,343 |
java
| "\nclass Solution {\n public int longestValidParentheses(String s) {\n Stack<Integer> st =(...TRUNCATED) | "class Solution {\n public int longestValidParentheses(String s) {\n Stack<Integer> st = n(...TRUNCATED) |
logic error:operation error
|
hard
|
s = "(() "
|
2
|
[
"))()",
")()()",
"(()))()",
"()()()()()",
"(())",
"()",
"()(()",
"()(()(",
"(()",
")((())"
] |
[
"2\n",
"4\n",
"2\n",
"2\n",
"2\n",
"4\n",
"4\n",
"10\n",
"4\n",
"2\n"
] |
|
1,346 |
java
| "\nclass Solution {\n String convert(String s)\n {\n char prevCh = s.charAt(0);\n (...TRUNCATED) | "class Solution {\n String convert(String s)\n {\n char prevCh = s.charAt(0);\n (...TRUNCATED) |
syntax error:unclosed string
|
medium
|
n = 1
|
"1 "
| ["16","4","32","37","42","34","2","20","2","17","3","8","27","3","15","31","1","9","18","5","11","35(...TRUNCATED) | ["11131221133112132113212221\n","11\n","311311222113111231133211121312211231131112311211133112111312(...TRUNCATED) |
|
1,351 |
java
| "\nclass Solution{\n public String addStrings(String num1, String num2) {\n long nattu = L(...TRUNCATED) | "class Solution:\n def addStrings(self, num1: str, num2: str) -> str:\n sys.set_int_max_st(...TRUNCATED) |
syntax error:unclosed parentheses
|
easy
|
num1 = "11 ", num2 = "123 "
|
"134 "
| ["123456789\n987654321","9\n99","0001\n0009","000009\n999999","00001\n00009","0\n0","1234567890123\n(...TRUNCATED) | ["333333\n","0\n","010\n","11111111101110\n","500000000000000000000000005\n","1111111110111111110\n"(...TRUNCATED) |
CodeEditorBench
🌐 Homepage | 🤗 Dataset | 📖 arXiv | GitHub
Introduction
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.

Results
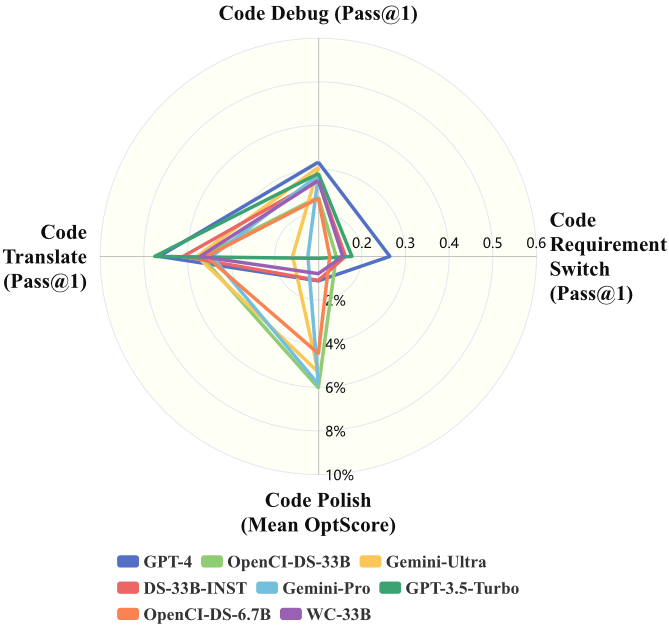
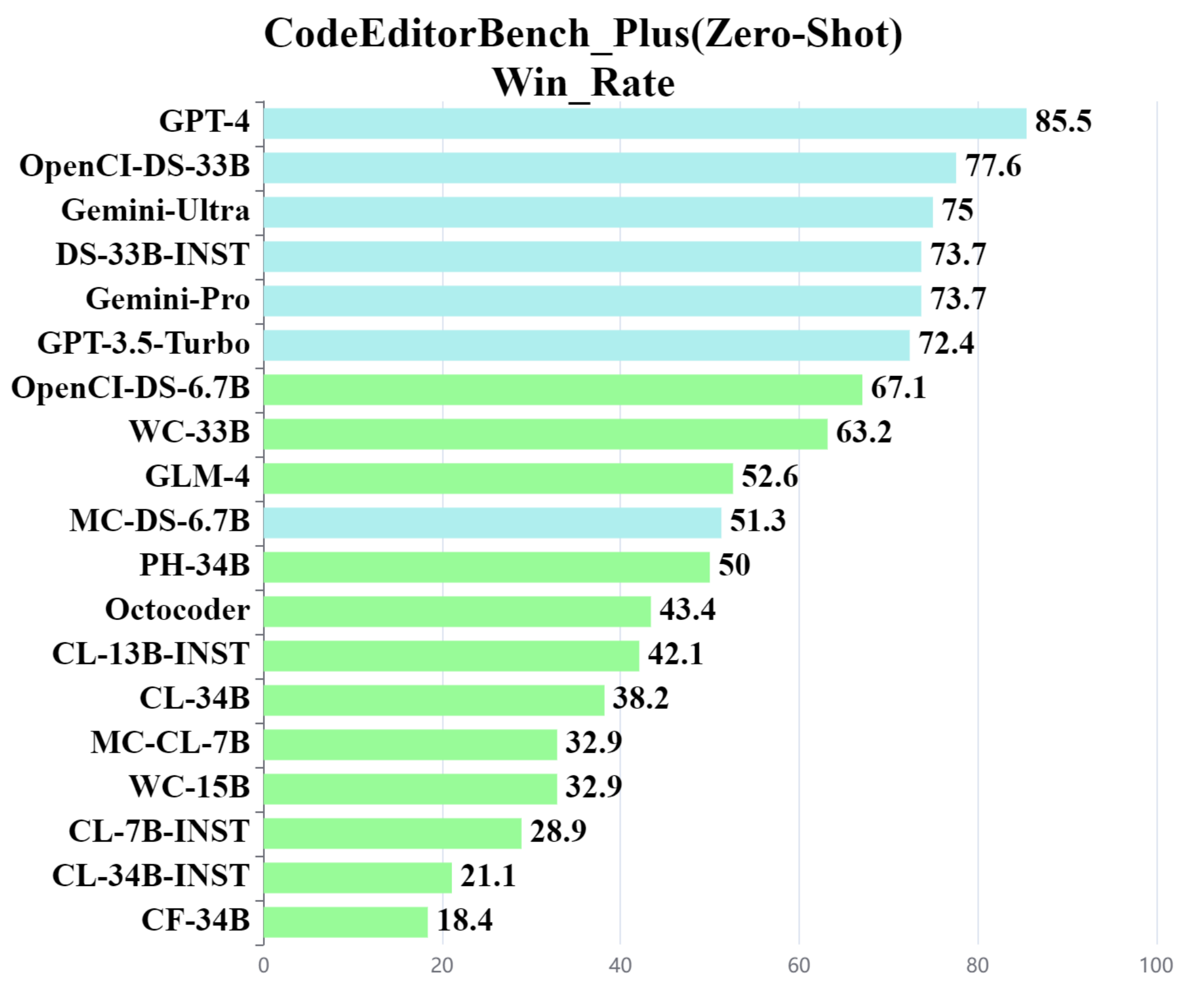
We propose evaluating LLMs across four scenarios capturing various code editing capabilities, namely code debug, code translate, code polish, and code requirement switch.The figure in left depicts various model performances across the four scenarios available in CodeEditorBench_Plus in a radial plot – highlighting how relative differences across models change across the scenarios. We also give the Performance of open-source and closed-source models on CodeEditorBench_Plus in zero-shot evaluated through win_rate in the right figure.
🎯All results of models are generated by greedy decoding.
✨Code Debug, Code Translate and Code Requirement Switch are evaluated with pass@1, while Code Polish is evaluated with Mean OptScore.
Disclaimers
The guidelines for the annotators emphasized strict compliance with copyright and licensing rules from the initial data source, specifically avoiding materials from websites that forbid copying and redistribution. Should you encounter any data samples potentially breaching the copyright or licensing regulations of any site, we encourage you to contact us. Upon verification, such samples will be promptly removed.
Contact
- Ge Zhang: zhangge@01.ai
- Wenhu Chen: wenhuchen@uwaterloo.ca
- Jie Fu: jiefu@ust.hk
Citation
BibTeX:
@misc{guo2024codeeditorbench,
title={CodeEditorBench: Evaluating Code Editing Capability of Large Language Models},
author={Jiawei Guo and Ziming Li and Xueling Liu and Kaijing Ma and Tianyu Zheng and Zhouliang Yu and Ding Pan and Yizhi LI and Ruibo Liu and Yue Wang and Shuyue Guo and Xingwei Qu and Xiang Yue and Ge Zhang and Wenhu Chen and Jie Fu},
year={2024},
eprint={2404.03543},
archivePrefix={arXiv},
primaryClass={cs.SE}
}
- Downloads last month
- 254