
modelId
stringlengths 4
122
| author
stringlengths 2
42
| last_modified
unknown | downloads
int64 0
392M
| likes
int64 0
6.56k
| library_name
stringclasses 368
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 51
values | createdAt
unknown | card
stringlengths 1
1M
|
|---|---|---|---|---|---|---|---|---|---|
TechxGenus/starcoder2-15b-instruct-v0.1-GPTQ | TechxGenus | "2024-04-30T17:38:54Z" | 798,363 | 0 | transformers | [
"transformers",
"safetensors",
"starcoder2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] | text-generation | "2024-04-30T17:06:03Z" | Entry not found |
ai-forever/sbert_large_nlu_ru | ai-forever | "2024-10-07T11:09:02Z" | 790,447 | 60 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"PyTorch",
"Transformers",
"ru",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language:
- ru
tags:
- PyTorch
- Transformers
---
# BERT large model (uncased) for Sentence Embeddings in Russian language.
The model is described [in this article](https://habr.com/ru/company/sberdevices/blog/527576/)
For better quality, use mean token embeddings.
## Usage (HuggingFace Models Repository)
You can use the model directly from the model repository to compute sentence embeddings:
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
#Sentences we want sentence embeddings for
sentences = ['Привет! Как твои дела?',
'А правда, что 42 твое любимое число?']
#Load AutoModel from huggingface model repository
tokenizer = AutoTokenizer.from_pretrained("ai-forever/sbert_large_nlu_ru")
model = AutoModel.from_pretrained("ai-forever/sbert_large_nlu_ru")
#Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=24, return_tensors='pt')
#Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
#Perform pooling. In this case, mean pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
```
# Authors
+ [SberDevices](https://sberdevices.ru/) Team.
+ Aleksandr Abramov: [HF profile](https://huggingface.co/Andrilko), [Github](https://github.com/Ab1992ao), [Kaggle Competitions Master](https://www.kaggle.com/andrilko);
+ Denis Antykhov: [Github](https://github.com/gaphex);
+ Ibragim Badertdinov: [Github](https://github.com/ibragim-bad) |
kredor/punctuate-all | kredor | "2024-04-26T05:37:58Z" | 790,083 | 17 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"dataset:wmt/europarl",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-04-09T12:05:11Z" | ---
license: mit
datasets:
- wmt/europarl
metrics:
- f1
- recall
- precision
---
This is based on [Oliver Guhr's work](https://huggingface.co/oliverguhr/fullstop-punctuation-multilang-large). The difference is that it is a finetuned xlm-roberta-base instead of an xlm-roberta-large and on twelve languages instead of four. The languages are: English, German, French, Spanish, Bulgarian, Italian, Polish, Dutch, Czech, Portugese, Slovak, Slovenian.
----- report -----
precision recall f1-score support
0 0.99 0.99 0.99 73317475
. 0.94 0.95 0.95 4484845
, 0.86 0.86 0.86 6100650
? 0.88 0.85 0.86 136479
- 0.60 0.29 0.39 233630
: 0.71 0.49 0.58 152424
accuracy 0.98 84425503
macro avg 0.83 0.74 0.77 84425503
weighted avg 0.98 0.98 0.98 84425503
----- confusion matrix -----
t/p 0 . , ? - :
0 1.0 0.0 0.0 0.0 0.0 0.0
. 0.0 1.0 0.0 0.0 0.0 0.0
, 0.1 0.0 0.9 0.0 0.0 0.0
? 0.0 0.1 0.0 0.8 0.0 0.0
- 0.1 0.1 0.5 0.0 0.3 0.0
: 0.0 0.3 0.1 0.0 0.0 0.5 |
TheBloke/Claire-7B-0.1-GPTQ | TheBloke | "2023-11-14T13:33:43Z" | 788,463 | 1 | transformers | [
"transformers",
"safetensors",
"falcon",
"text-generation",
"pretrained",
"conversational",
"custom_code",
"fr",
"base_model:OpenLLM-France/Claire-7B-0.1",
"base_model:quantized:OpenLLM-France/Claire-7B-0.1",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] | text-generation | "2023-11-14T11:54:52Z" | ---
base_model: OpenLLM-France/Claire-7B-0.1
inference: false
language:
- fr
license: cc-by-nc-sa-4.0
model_creator: OpenLLM France
model_name: Claire 7B 0.1
model_type: falcon
pipeline_tag: text-generation
prompt_template: '- Bonjour BotName, {prompt}
- Bonjour UserName,
'
quantized_by: TheBloke
tags:
- pretrained
- conversational
widget:
- example_title: Request for a recipe
group: Dash
text: '- Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui ?
- Bonjour Camille,'
- example_title: Request for a recipe
group: Intervenant
text: '[Intervenant 1:] Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui
?
[Intervenant 2:] Bonjour Camille,'
- example_title: Request for a recipe
group: FirstName
text: '[Camille:] Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui ?
[Dominique:] Bonjour Camille,'
- example_title: Request for a recipe
group: Named
text: '[Camille Durand:] Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui
?
[Dominique Petit:] Bonjour Camille,'
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Claire 7B 0.1 - GPTQ
- Model creator: [OpenLLM France](https://huggingface.co/OpenLLM-France)
- Original model: [Claire 7B 0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1)
<!-- description start -->
# Description
This repo contains GPTQ model files for [OpenLLM France's Claire 7B 0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Claire-7B-0.1-GGUF)
* [OpenLLM France's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/OpenLLM-France/Claire-7B-0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: OpenLLM-France
```
- Bonjour BotName, {prompt}
- Bonjour UserName,
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KoboldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [french](https://huggingface.co/datasets/Kant1/French_Wikipedia_articles/viewer/) | 2048 | 4.04 GB | No | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [french](https://huggingface.co/datasets/Kant1/French_Wikipedia_articles/viewer/) | 2048 | 4.43 GB | No | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [french](https://huggingface.co/datasets/Kant1/French_Wikipedia_articles/viewer/) | 2048 | 4.99 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [french](https://huggingface.co/datasets/Kant1/French_Wikipedia_articles/viewer/) | 2048 | 4.96 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [french](https://huggingface.co/datasets/Kant1/French_Wikipedia_articles/viewer/) | 2048 | 4.94 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [french](https://huggingface.co/datasets/Kant1/French_Wikipedia_articles/viewer/) | 2048 | 4.17 GB | No | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Claire-7B-0.1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Claire-7B-0.1-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Claire-7B-0.1-GPTQ`:
```shell
mkdir Claire-7B-0.1-GPTQ
huggingface-cli download TheBloke/Claire-7B-0.1-GPTQ --local-dir Claire-7B-0.1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Claire-7B-0.1-GPTQ
huggingface-cli download TheBloke/Claire-7B-0.1-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Claire-7B-0.1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Claire-7B-0.1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Claire-7B-0.1-GPTQ --local-dir Claire-7B-0.1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Claire-7B-0.1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Claire-7B-0.1-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Claire-7B-0.1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Claire-7B-0.1-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''- Bonjour BotName, {prompt}
- Bonjour UserName,
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## Python code example: inference from this GPTQ model
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install --upgrade transformers optimum
# If using PyTorch 2.1 + CUDA 12.x:
pip3 install --upgrade auto-gptq
# or, if using PyTorch 2.1 + CUDA 11.x:
pip3 install --upgrade auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
```
If you are using PyTorch 2.0, you will need to install AutoGPTQ from source. Likewise if you have problems with the pre-built wheels, you should try building from source:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.5.1
pip3 install .
```
### Example Python code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Claire-7B-0.1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''- Bonjour BotName, {prompt}
- Bonjour UserName,
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: OpenLLM France's Claire 7B 0.1
# Claire-7B-0.1
**Claire-7B-0.1 is a 7B parameter causal decoder-only model built by [LINAGORA](https://labs.linagora.com/) and [OpenLLM-France](https://github.com/OpenLLM-France)**
**adapted from [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b) on French conversational data.**
Claire-7B-0.1 is a pretrained language model designed to be attuned to the dynamics of linguistic interactions in dialogue. Without further training, its expected use is to generate continuations of dialogues. Its main purpose is to serve as a base model for fine-tuning on dialogue generation (e.g., chat) and dialogue understanding (e.g., meeting summarization) tasks. Please note that due to its training, the model is prone to generate dialogues with disfluencies and other constructions common to spoken language.
## Typical usage
```python
import transformers
import torch
model_name = "OpenLLM-France/Claire-7B-0.1"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
model = transformers.AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
load_in_4bit=True # For efficient inference, if supported by the GPU card
)
pipeline = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_kwargs = dict(
num_return_sequences=1, # Number of variants to generate.
return_full_text= False, # Do not include the prompt in the generated text.
max_new_tokens=200, # Maximum length for the output text.
do_sample=True, top_k=10, temperature=1.0, # Sampling parameters.
pad_token_id=tokenizer.eos_token_id, # Just to avoid a harmless warning.
)
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
completions = pipeline(prompt, **generation_kwargs)
for completion in completions:
print(prompt + " […]" + completion['generated_text'])
```
This will print something like:
```
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille, […] je vous prépare un plat de saison, une daube provençale.
- Ah je ne connais pas cette recette.
- C'est très facile à préparer, vous n'avez qu'à mettre de l'eau dans une marmite, y mettre de l'oignon émincé, des carottes coupées en petits morceaux, et vous allez mettre votre viande de bœuf coupé en petits morceaux également.
- Je n'ai jamais cuisiné de viande de bœuf, mais c'est vrai que ça a l'air bien facile.
- Vous n'avez plus qu'à laisser mijoter, et ensuite il sera temps de servir les clients.
- Très bien.
```
You will need at least 6GB of VRAM to run inference using 4bit quantization (16GB of VRAM without 4bit quantization).
If you have trouble running this code, make sure you have recent versions of `torch`, `transformers` and `accelerate` (see [requirements.txt](requirements.txt)).
### Typical prompts
Claire-7B-0.1 was trained on diarized French conversations. During training, the dialogues were normalized in several formats. The possible formats for expected prompts are as follows:
A monologue can be specified as a single line prompt (though keep in mind that Claire might still return a dialogue because of its training):
```python
prompt = "Mesdames et messieurs les députés, chers collègues, bonsoir. Vous l'aurez peut-être remarqué, je cite rarement"
```
A dialogue between two speakers can be specified with one line per speech turn starting with a dash:
```python
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
```
A dialogue or multilogue (with two or more speakers) can be specified with lines that start with `[Intervenant X:]` where `X` is a number:
```python
prompt = """\
[Intervenant 1:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Intervenant 2:] Bonjour Camille,\
"""
```
A dialogue or multilogue with named speakers can be specified with lines that start with `[SpeakerName:]`
where `SpeakerName` can be a first name, a first and a last name, a nickname, a title…
```python
prompt = """\
[Mme Camille Durand:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Mr. Dominique Petit:] Bonjour Camille,\
"""
```
## Training Details
### Training Data
Claire-7B-0.1 was tuned from Falcon-7b on the following data distribution:
| **Data type** | **Words** | **Training Sampling Weight** | **Sources** |
|-------------------------------|------------|------------------------------|-----------------------------------------------------|
| Parliamentary Proceedings | 135M | 35% | assemblee-nationale.fr |
| Theatre | 16M | 18% | theatre-classique.fr, theatregratuit.com |
| Interviews | 6.4M | 29% | TCOF, CFPP, CFPB, ACSYNT, PFC, Valibel (ORFEO), ESLO |
| Free Conversations | 2.2M | 10% | CRFP, OFROM, CID, Rhapsodie, ParisStories, PFC, CLAPI, C-ORAL-ROM (ORFEO), LinTO, ESLO |
| Meetings | 1.2M | 5% | SUMM-RE, LinTO, Réunions de travail (ORFEO) |
| Debates | 402k | <2% | FreD, ESLO |
| Assistance | 159k | <1% | Fleuron (ORFEO), Accueil UBS, OTG, ESLO |
| Presentation, Formal Address | 86k | <0.5% | Valibel (ORFEO), LinTO, ESLO |
Training data was augmented with the following techniques:
* varying the format used to indicate speech turns (dashes or [XXX:])
* substituting [Intervenant X:] for [SpeakerName:] or vice versa, where [SpeakerName:] might be a real name or a randomly generated name
* removing punctuation marks and/or casing (to prepare the model for transcripts produced by some Automatic Speech Recognition systems)
Long conversations were truncated at a maximum of 2048 tokens. Where possible, they were split between speaker turns.
While the model has been trained and evaluated only on French dialogues, it may be able to generate conversations in other languages from the original Falcon-7b training data.
### Training Procedure
Claire-7B-0.1 is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
See [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b) for more details.
Claire-7B-0.1 was trained on 1 A100 80GB GPU for about 50 GPU hours.
Hyperparameters were the following:
| **Hyperparameter** | **Value** |
|--------------------|------------|
| Precision | `bfloat16` |
| Optimizer | AdamW |
| Learning rate | 1e-4 |
| Weight decay | 1e-2 |
| Batch size | 132 |
| LoRA rank | 16 |
| LoRA alpha | 32 |
| Dropout | 0.05 |
| gradient clipping | 1 |
## Evaluation
To evaluate Claire-7B-0.1’s ability to generate natural sounding, French conversations, we compared its responses to a variety of prompts with those of three other models:
* [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b),
* [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* [Claire-Mistral-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-Mistral-7B-0.1) (a version of Mistral-7B-v0.1 adapted in the same fashion as Claire-7B-0.1)
We tested an even mixture of monologue and dialogue-style prompts.
Each of the four generated responses was evaluated along three dimensions:
Interaction, Fluency and Relevance.
Evaluators were also asked to rank the four responses by preference.
Our results confirm that continual pre-training of Falcon-7b and Mistral-7B-v0.1 leads to improvement (relative to the base models) along all three evaluation dimensions and that Claire-7B-0.1 outperforms the adapted Mistral counterpart in the Fluency and Relevance categories
(and in the Interaction category if we focus on dialogue-style prompts).
Ranking results also reveal a clear subjective preference for Claire-7B-0.1,
as shown in the following table:
<!--| | **Claire-Falcon** | **Claire-Mistral** | **Falcon** | **Mistral** | -->
| | <span style="font-weight: normal">... over</span><br /> **Claire-Falcon** | <span style="font-weight: normal">... over</span><br /> **Claire-Mistral** | <span style="font-weight: normal">... over</span><br /> **Falcon** | <span style="font-weight: normal">... over</span><br /> **Mistral** |
|--------------------------------------|----------------------|-----------------------|---------------|---------------------|
| prefer<br /> **Claire-Falcon** ... | | **62.2%** | **63.9%** | **83.8%** |
| prefer<br /> **Claire-Mistral** ... | _34.8%_ | | **56.2%** | **75.3%** |
| prefer<br /> **Falcon** ... | _36.1%_ | _43.8%_ | | **81.4%** |
| prefer<br /> **Mistral** ... | _16.2%_ | _24.7%_ | _18.6%_ | |
(In this table,
"Claire-Falcon" stands for Claire-7B-0.1,
"Falcon", for [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b),
"Mistral", for [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
and "Claire-Mistral", for [Claire-Mistral-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-Mistral-7B-0.1).)
Please note that the model can generate disfluencies and humorous responses as a result of its training on spoken and theatrical text.
More evaluation details will be provided in a separate publication.
## License
Given that some of the corpora used for training are only available under CC-BY-NC-SA licenses,
Claire-7B-0.1 is made available under the [CC-BY-NC-SA 4.0 license](https://creativecommons.org/licenses/by-nc-sa/4.0/).
You can find a variant of this model published under the Apache 2.0 license at [OpenLLM-France/Claire-7B-Apache-0.1](https://huggingface.co/OpenLLM-France/Claire-7B-Apache-0.1).
## Acknowledgements
This work was performed using HPC resources from GENCI–IDRIS (Grant 2023-AD011014561).
Claire-7B-0.1 was created by members of [LINAGORA](https://labs.linagora.com/) (in alphabetical order): Ismaïl Harrando, Julie Hunter, Jean-Pierre Lorré, Jérôme Louradour, Michel-Marie Maudet, Virgile Rennard, Guokan Shang.
Special thanks to partners from the OpenLLM-France community, especially Christophe Cerisara (LORIA), Pierre-Carl Langlais and Anastasia Stasenko (OpSci), and Pierre Colombo, for valuable advice.
## Contact
contact@openllm-france.fr
|
naver/splade-cocondenser-selfdistil | naver | "2022-05-11T08:02:55Z" | 788,206 | 10 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"en",
"dataset:ms_marco",
"arxiv:2205.04733",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-05-09T12:48:34Z" | ---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
datasets:
- ms_marco
---
## SPLADE CoCondenser SelfDistil
SPLADE model for passage retrieval. For additional details, please visit:
* paper: https://arxiv.org/abs/2205.04733
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) |
| --- | --- | --- |
| `splade-cocondenser-selfdistil` | 37.6 | 98.4 |
## Citation
If you use our checkpoint, please cite our work:
```
@misc{https://doi.org/10.48550/arxiv.2205.04733,
doi = {10.48550/ARXIV.2205.04733},
url = {https://arxiv.org/abs/2205.04733},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
``` |
sentence-transformers/distilbert-base-nli-stsb-mean-tokens | sentence-transformers | "2024-11-05T16:43:41Z" | 788,201 | 11 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/distilbert-base-nli-stsb-mean-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/distilbert-base-nli-stsb-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/distilbert-base-nli-stsb-mean-tokens')
model = AutoModel.from_pretrained('sentence-transformers/distilbert-base-nli-stsb-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/distilbert-base-nli-stsb-mean-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
nvidia/dragon-multiturn-context-encoder | nvidia | "2024-05-24T17:38:53Z" | 784,950 | 24 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2401.10225",
"arxiv:2302.07452",
"license:other",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-04-30T21:21:45Z" | ---
language:
- en
tag:
- dragon
- retriever
- conversation
- multi-turn
- conversational query
license:
- other
---
## Model Description
We introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combine dialogue history with the current query. It is built on top of the [Dragon](https://huggingface.co/facebook/dragon-plus-query-encoder) retriever. The details of Dragon-multiturn can be found in [here](https://arxiv.org/pdf/2401.10225). **Please note that Dragon-multiturn is a dual encoder consisting of a query encoder and a context encoder. This repository is only for the context encoder of Dragon-multiturn for getting the context embeddings, and you also need the query encoder to get query embeddings, which can be found [here](https://huggingface.co/nvidia/dragon-multiturn-query-encoder). Both query encoder and context encoder share the same tokenizer.**
## Other Resources
[Llama3-ChatQA-1.5-8B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)   [Llama3-ChatQA-1.5-70B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-70B)   [Evaluation Data](https://huggingface.co/datasets/nvidia/ChatRAG-Bench)   [Training Data](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data)   [Website](https://chatqa-project.github.io/)   [Paper](https://arxiv.org/pdf/2401.10225)
## Benchmark Results
<style type="text/css">
.tg {border:none;border-collapse:collapse;border-spacing:0;}
.tg td{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;overflow:hidden;
padding:10px 5px;word-break:normal;}
.tg th{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;font-weight:normal;
overflow:hidden;padding:10px 5px;word-break:normal;}
.tg .tg-c3ow{border-color:inherit;text-align:center;vertical-align:center}
.tg .tg-0pky{border-color:inherit;text-align:left;vertical-align:center}
</style>
<table class="tg">
<thead>
<tr>
<th class="tg-0pky" rowspan="2"></th>
<th class="tg-c3ow" colspan="2">Average</th>
<th class="tg-c3ow" colspan="2">Doc2Dial</th>
<th class="tg-c3ow" colspan="2">QuAC</th>
<th class="tg-c3ow" colspan="2">QReCC</th>
<th class="tg-c3ow" colspan="2">TopiOCQA</th>
<th class="tg-c3ow" colspan="2">INSCIT</th>
</tr>
<tr>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-0pky">Dragon</td>
<td class="tg-c3ow">46.3</td>
<td class="tg-c3ow">73.1</td>
<td class="tg-c3ow">43.3</td>
<td class="tg-c3ow">75.6</td>
<td class="tg-c3ow">56.8</td>
<td class="tg-c3ow">82.9</td>
<td class="tg-c3ow">46.2</td>
<td class="tg-c3ow">82.0</td>
<td class="tg-c3ow">57.7</td>
<td class="tg-c3ow">78.8</td>
<td class="tg-c3ow">27.5</td>
<td class="tg-c3ow">46.2</td>
</tr>
<tr>
<td class="tg-0pky">Dragon-multiturn</td>
<td class="tg-c3ow">53.0</td>
<td class="tg-c3ow">81.2</td>
<td class="tg-c3ow">48.6</td>
<td class="tg-c3ow">83.5</td>
<td class="tg-c3ow">54.8</td>
<td class="tg-c3ow">83.2</td>
<td class="tg-c3ow">49.6</td>
<td class="tg-c3ow">86.7</td>
<td class="tg-c3ow">64.5</td>
<td class="tg-c3ow">85.2</td>
<td class="tg-c3ow">47.4</td>
<td class="tg-c3ow">67.1</td>
</tr>
</tbody>
</table>
Retrieval results across five multi-turn QA datasets (Doc2Dial, QuAC, QReCC, TopiOCQA, INSCIT) with the average top-1 and top-5 recall scores. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets.
## How to use
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('nvidia/dragon-multiturn-query-encoder')
query_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-query-encoder')
context_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-context-encoder')
query = [
{"role": "user", "content": "I need help planning my Social Security benefits for my survivors."},
{"role": "agent", "content": "Are you currently planning for your future?"},
{"role": "user", "content": "Yes, I am."}
]
contexts = [
"Benefits Planner: Survivors | Planning For Your Survivors \nAs you plan for the future , you'll want to think about what your family would need if you should die now. Social Security can help your family if you have earned enough Social Security credits through your work. You can earn up to four credits each year. In 2019 , for example , you earn one credit for each $1,360 of wages or self - employment income. When you have earned $5,440 , you have earned your four credits for the year. The number of credits needed to provide benefits for your survivors depends on your age when you die. No one needs more than 40 credits 10 years of work to be eligible for any Social Security benefit. But , the younger a person is , the fewer credits they must have for family members to receive survivors benefits. Benefits can be paid to your children and your spouse who is caring for the children even if you don't have the required number of credits. They can get benefits if you have credit for one and one - half years of work 6 credits in the three years just before your death. For Your Widow Or Widower \nThere are about five million widows and widowers receiving monthly Social Security benefits based on their deceased spouse's earnings record.",
"Benefits Planner: Retirement \nOther Things to Consider \nWhat Is The Best Age To Start Your Benefits? The answer is that there is no one \" best age \" for everyone and, ultimately, it is your choice. You should make an informed decision about when to apply for benefits based on your individual and family circumstances. Your monthly benefit amount can differ substantially based on the age when you start receiving benefits. If you decide to start benefits : before your full retirement age , your benefit will be smaller but you will receive it for a longer period of time. at your full retirement age or later , you will receive a larger monthly benefit for a shorter period of time. The amount you receive when you first get benefits sets the base for the amount you will receive for the rest of your life. You may want to consider the following when you make that decision : If you plan to continue working , there are limits on how much you can earn each year between age 62 and full retirement age and still get all your benefits. Depending on the amount of your benefit and your earnings for the year , you may have to give up some of your benefits."
]
## convert query into a format as follows:
## user: {user}\nagent: {agent}\nuser: {user}
formatted_query = '\n'.join([turn['role'] + ": " + turn['content'] for turn in query]).strip()
## get query and context embeddings
query_input = tokenizer(formatted_query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, max_length=512, return_tensors='pt')
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :] # (1, emb_dim)
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :] # (num_ctx, emb_dim)
## Compute similarity scores using dot product
similarities = query_emb.matmul(ctx_emb.transpose(0, 1)) # (1, num_ctx)
## rank the similarity (from highest to lowest)
ranked_results = torch.argsort(similarities, dim=-1, descending=True) # (1, num_ctx)
```
## Evaluations on Multi-Turn QA Retrieval Benchmark
**(UPDATE!!)** We evaluate multi-turn QA retrieval on five datasets: Doc2Dial, QuAC, QReCC, TopiOCQA, and INSCIT, which can be found in the [ChatRAG Bench](https://huggingface.co/datasets/nvidia/ChatRAG-Bench). The evaluation scripts can be found [here](https://huggingface.co/nvidia/dragon-multiturn-query-encoder/tree/main/evaluation).
## License
Dragon-multiturn is built on top of [Dragon](https://arxiv.org/abs/2302.07452). We refer users to the original license of the Dragon model. Dragon-multiturn is also subject to the [Terms of Use](https://openai.com/policies/terms-of-use).
## Correspondence to
Zihan Liu (zihanl@nvidia.com), Wei Ping (wping@nvidia.com)
## Citation
<pre>
@article{liu2024chatqa,
title={ChatQA: Surpassing GPT-4 on Conversational QA and RAG},
author={Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2401.10225},
year={2024}}
</pre>
|
nvidia/dragon-multiturn-query-encoder | nvidia | "2024-05-24T17:37:31Z" | 783,439 | 57 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2401.10225",
"arxiv:2302.07452",
"license:other",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-04-30T18:44:35Z" | ---
language:
- en
tag:
- dragon
- retriever
- conversation
- multi-turn
- conversational query
license:
- other
---
## Model Description
We introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combine dialogue history with the current query. It is built on top of the [Dragon](https://huggingface.co/facebook/dragon-plus-query-encoder) retriever. The details of Dragon-multiturn can be found in [here](https://arxiv.org/pdf/2401.10225). **Please note that Dragon-multiturn is a dual encoder consisting of a query encoder and a context encoder. This repository is only for the query encoder of Dragon-multiturn for getting the query embeddings, and you also need the context encoder to get context embeddings, which can be found [here](https://huggingface.co/nvidia/dragon-multiturn-context-encoder). Both query encoder and context encoder share the same tokenizer.**
## Other Resources
[Llama3-ChatQA-1.5-8B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)   [Llama3-ChatQA-1.5-70B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-70B)   [Evaluation Data](https://huggingface.co/datasets/nvidia/ChatRAG-Bench)   [Training Data](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data)   [Website](https://chatqa-project.github.io/)   [Paper](https://arxiv.org/pdf/2401.10225)
## Benchmark Results
<style type="text/css">
.tg {border:none;border-collapse:collapse;border-spacing:0;}
.tg td{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;overflow:hidden;
padding:10px 5px;word-break:normal;}
.tg th{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;font-weight:normal;
overflow:hidden;padding:10px 5px;word-break:normal;}
.tg .tg-c3ow{border-color:inherit;text-align:center;vertical-align:center}
.tg .tg-0pky{border-color:inherit;text-align:left;vertical-align:center}
</style>
<table class="tg">
<thead>
<tr>
<th class="tg-0pky" rowspan="2"></th>
<th class="tg-c3ow" colspan="2">Average</th>
<th class="tg-c3ow" colspan="2">Doc2Dial</th>
<th class="tg-c3ow" colspan="2">QuAC</th>
<th class="tg-c3ow" colspan="2">QReCC</th>
<th class="tg-c3ow" colspan="2">TopiOCQA</th>
<th class="tg-c3ow" colspan="2">INSCIT</th>
</tr>
<tr>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-0pky">Dragon</td>
<td class="tg-c3ow">46.3</td>
<td class="tg-c3ow">73.1</td>
<td class="tg-c3ow">43.3</td>
<td class="tg-c3ow">75.6</td>
<td class="tg-c3ow">56.8</td>
<td class="tg-c3ow">82.9</td>
<td class="tg-c3ow">46.2</td>
<td class="tg-c3ow">82.0</td>
<td class="tg-c3ow">57.7</td>
<td class="tg-c3ow">78.8</td>
<td class="tg-c3ow">27.5</td>
<td class="tg-c3ow">46.2</td>
</tr>
<tr>
<td class="tg-0pky">Dragon-multiturn</td>
<td class="tg-c3ow">53.0</td>
<td class="tg-c3ow">81.2</td>
<td class="tg-c3ow">48.6</td>
<td class="tg-c3ow">83.5</td>
<td class="tg-c3ow">54.8</td>
<td class="tg-c3ow">83.2</td>
<td class="tg-c3ow">49.6</td>
<td class="tg-c3ow">86.7</td>
<td class="tg-c3ow">64.5</td>
<td class="tg-c3ow">85.2</td>
<td class="tg-c3ow">47.4</td>
<td class="tg-c3ow">67.1</td>
</tr>
</tbody>
</table>
Retrieval results across five multi-turn QA datasets (Doc2Dial, QuAC, QReCC, TopiOCQA, INSCIT) with the average top-1 and top-5 recall scores. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets.
## How to use
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('nvidia/dragon-multiturn-query-encoder')
query_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-query-encoder')
context_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-context-encoder')
query = [
{"role": "user", "content": "I need help planning my Social Security benefits for my survivors."},
{"role": "agent", "content": "Are you currently planning for your future?"},
{"role": "user", "content": "Yes, I am."}
]
contexts = [
"Benefits Planner: Survivors | Planning For Your Survivors \nAs you plan for the future , you'll want to think about what your family would need if you should die now. Social Security can help your family if you have earned enough Social Security credits through your work. You can earn up to four credits each year. In 2019 , for example , you earn one credit for each $1,360 of wages or self - employment income. When you have earned $5,440 , you have earned your four credits for the year. The number of credits needed to provide benefits for your survivors depends on your age when you die. No one needs more than 40 credits 10 years of work to be eligible for any Social Security benefit. But , the younger a person is , the fewer credits they must have for family members to receive survivors benefits. Benefits can be paid to your children and your spouse who is caring for the children even if you don't have the required number of credits. They can get benefits if you have credit for one and one - half years of work 6 credits in the three years just before your death. For Your Widow Or Widower \nThere are about five million widows and widowers receiving monthly Social Security benefits based on their deceased spouse's earnings record.",
"Benefits Planner: Retirement \nOther Things to Consider \nWhat Is The Best Age To Start Your Benefits? The answer is that there is no one \" best age \" for everyone and, ultimately, it is your choice. You should make an informed decision about when to apply for benefits based on your individual and family circumstances. Your monthly benefit amount can differ substantially based on the age when you start receiving benefits. If you decide to start benefits : before your full retirement age , your benefit will be smaller but you will receive it for a longer period of time. at your full retirement age or later , you will receive a larger monthly benefit for a shorter period of time. The amount you receive when you first get benefits sets the base for the amount you will receive for the rest of your life. You may want to consider the following when you make that decision : If you plan to continue working , there are limits on how much you can earn each year between age 62 and full retirement age and still get all your benefits. Depending on the amount of your benefit and your earnings for the year , you may have to give up some of your benefits."
]
## convert query into a format as follows:
## user: {user}\nagent: {agent}\nuser: {user}
formatted_query = '\n'.join([turn['role'] + ": " + turn['content'] for turn in query]).strip()
## get query and context embeddings
query_input = tokenizer(formatted_query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, max_length=512, return_tensors='pt')
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :]
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :]
## Compute similarity scores using dot product
similarities = query_emb.matmul(ctx_emb.transpose(0, 1)) # (1, num_ctx)
## rank the similarity (from highest to lowest)
ranked_results = torch.argsort(similarities, dim=-1, descending=True) # (1, num_ctx)
```
## Evaluations on Multi-Turn QA Retrieval Benchmark
**(UPDATE!!)** We evaluate multi-turn QA retrieval on five datasets: Doc2Dial, QuAC, QReCC, TopiOCQA, and INSCIT, which can be found in the [ChatRAG Bench](https://huggingface.co/datasets/nvidia/ChatRAG-Bench). The evaluation scripts can be found [here](https://huggingface.co/nvidia/dragon-multiturn-query-encoder/tree/main/evaluation).
## License
Dragon-multiturn is built on top of [Dragon](https://arxiv.org/abs/2302.07452). We refer users to the original license of the Dragon model. Dragon-multiturn is also subject to the [Terms of Use](https://openai.com/policies/terms-of-use).
## Correspondence to
Zihan Liu (zihanl@nvidia.com), Wei Ping (wping@nvidia.com)
## Citation
<pre>
@article{liu2024chatqa,
title={ChatQA: Surpassing GPT-4 on Conversational QA and RAG},
author={Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2401.10225},
year={2024}}
</pre>
|
microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract | microsoft | "2023-11-06T18:04:15Z" | 773,169 | 66 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"exbert",
"en",
"arxiv:2007.15779",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | ---
language: en
tags:
- exbert
license: mit
widget:
- text: "[MASK] is a tyrosine kinase inhibitor."
---
## MSR BiomedBERT (abstracts only)
<div style="border: 2px solid orange; border-radius:10px; padding:0px 10px; width: fit-content;">
* This model was previously named **"PubMedBERT (abstracts)"**.
* You can either adopt the new model name "microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract" or update your `transformers` library to version 4.22+ if you need to refer to the old name.
</div>
Pretraining large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. However, most pretraining efforts focus on general domain corpora, such as newswire and Web. A prevailing assumption is that even domain-specific pretraining can benefit by starting from general-domain language models. [Recent work](https://arxiv.org/abs/2007.15779) shows that for domains with abundant unlabeled text, such as biomedicine, pretraining language models from scratch results in substantial gains over continual pretraining of general-domain language models.
This BiomedBERT is pretrained from scratch using _abstracts_ from [PubMed](https://pubmed.ncbi.nlm.nih.gov/). This model achieves state-of-the-art performance on several biomedical NLP tasks, as shown on the [Biomedical Language Understanding and Reasoning Benchmark](https://aka.ms/BLURB).
## Citation
If you find BiomedBERT useful in your research, please cite the following paper:
```latex
@misc{pubmedbert,
author = {Yu Gu and Robert Tinn and Hao Cheng and Michael Lucas and Naoto Usuyama and Xiaodong Liu and Tristan Naumann and Jianfeng Gao and Hoifung Poon},
title = {Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing},
year = {2020},
eprint = {arXiv:2007.15779},
}
```
<a href="https://huggingface.co/exbert/?model=microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract&modelKind=bidirectional&sentence=Gefitinib%20is%20an%20EGFR%20tyrosine%20kinase%20inhibitor,%20which%20is%20often%20used%20for%20breast%20cancer%20and%20NSCLC%20treatment.&layer=10&heads=..0,1,2,3,4,5,6,7,8,9,10,11&threshold=0.7&tokenInd=17&tokenSide=right&maskInds=..&hideClsSep=true">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
pparasurama/raceBERT-ethnicity | pparasurama | "2021-11-09T20:42:29Z" | 764,399 | 2 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | Entry not found |
timm/tf_mobilenetv3_large_minimal_100.in1k | timm | "2023-04-27T22:49:48Z" | 762,395 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | "2022-12-16T05:39:06Z" | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_mobilenetv3_large_minimal_100.in1k
A MobileNet-v3 image classification model. Trained on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 3.9
- GMACs: 0.2
- Activations (M): 4.4
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_mobilenetv3_large_minimal_100.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_large_minimal_100.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 24, 56, 56])
# torch.Size([1, 40, 28, 28])
# torch.Size([1, 112, 14, 14])
# torch.Size([1, 960, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_large_minimal_100.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 960, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
liuhaotian/llava-v1.5-7b | liuhaotian | "2024-05-08T22:15:49Z" | 761,390 | 366 | transformers | [
"transformers",
"pytorch",
"llava",
"text-generation",
"image-text-to-text",
"autotrain_compatible",
"region:us"
] | image-text-to-text | "2023-10-05T18:25:51Z" | ---
inference: false
pipeline_tag: image-text-to-text
---
<br>
<br>
# LLaVA Model Card
## Model details
**Model type:**
LLaVA is an open-source chatbot trained by fine-tuning LLaMA/Vicuna on GPT-generated multimodal instruction-following data.
It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
LLaVA-v1.5-7B was trained in September 2023.
**Paper or resources for more information:**
https://llava-vl.github.io/
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
**Where to send questions or comments about the model:**
https://github.com/haotian-liu/LLaVA/issues
## Intended use
**Primary intended uses:**
The primary use of LLaVA is research on large multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
- 558K filtered image-text pairs from LAION/CC/SBU, captioned by BLIP.
- 158K GPT-generated multimodal instruction-following data.
- 450K academic-task-oriented VQA data mixture.
- 40K ShareGPT data.
## Evaluation dataset
A collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs. |
Alibaba-NLP/gte-multilingual-base | Alibaba-NLP | "2024-09-17T16:15:55Z" | 758,939 | 125 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"new",
"feature-extraction",
"mteb",
"transformers",
"multilingual",
"sentence-similarity",
"custom_code",
"af",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"gl",
"gu",
"he",
"hi",
"hr",
"ht",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ky",
"lo",
"lt",
"lv",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"pa",
"pl",
"pt",
"qu",
"ro",
"ru",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"uk",
"ur",
"vi",
"yo",
"zh",
"arxiv:2407.19669",
"arxiv:2210.09984",
"arxiv:2402.03216",
"arxiv:2007.15207",
"arxiv:2104.08663",
"arxiv:2402.07440",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-07-20T08:37:28Z" | ---
tags:
- mteb
- sentence-transformers
- transformers
- multilingual
- sentence-similarity
license: apache-2.0
language:
- af
- ar
- az
- be
- bg
- bn
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- es
- et
- eu
- fa
- fi
- fr
- gl
- gu
- he
- hi
- hr
- ht
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ky
- lo
- lt
- lv
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- pa
- pl
- pt
- qu
- ro
- ru
- si
- sk
- sl
- so
- sq
- sr
- sv
- sw
- ta
- te
- th
- tl
- tr
- uk
- ur
- vi
- yo
- zh
model-index:
- name: gte-multilingual-base (dense)
results:
- task:
type: Clustering
dataset:
type: PL-MTEB/8tags-clustering
name: MTEB 8TagsClustering
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 33.66681726329994
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: b44c3b011063adb25877c13823db83bb193913c4
metrics:
- type: cos_sim_spearman
value: 43.54760696384009
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: 0f319b1142f28d00e055a6770f3f726ae9b7d865
metrics:
- type: cos_sim_spearman
value: 48.91186363417501
- task:
type: Classification
dataset:
type: PL-MTEB/allegro-reviews
name: MTEB AllegroReviews
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 41.689860834990064
- task:
type: Clustering
dataset:
type: lyon-nlp/alloprof
name: MTEB AlloProfClusteringP2P
config: default
split: test
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
metrics:
- type: v_measure
value: 54.20241337977897
- task:
type: Clustering
dataset:
type: lyon-nlp/alloprof
name: MTEB AlloProfClusteringS2S
config: default
split: test
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
metrics:
- type: v_measure
value: 44.34083695608643
- task:
type: Reranking
dataset:
type: lyon-nlp/mteb-fr-reranking-alloprof-s2p
name: MTEB AlloprofReranking
config: default
split: test
revision: 666fdacebe0291776e86f29345663dfaf80a0db9
metrics:
- type: map
value: 64.91495250072002
- task:
type: Retrieval
dataset:
type: lyon-nlp/alloprof
name: MTEB AlloprofRetrieval
config: default
split: test
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
metrics:
- type: ndcg_at_10
value: 53.638
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.95522388059702
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 80.717625
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 43.64199999999999
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (de)
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.108
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (es)
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.169999999999995
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (fr)
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.56799999999999
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (ja)
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 35.75000000000001
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 33.342000000000006
- task:
type: Retrieval
dataset:
type: mteb/arguana
name: MTEB ArguAna
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: ndcg_at_10
value: 58.231
- task:
type: Retrieval
dataset:
type: clarin-knext/arguana-pl
name: MTEB ArguAna-PL
config: default
split: test
revision: 63fc86750af76253e8c760fc9e534bbf24d260a2
metrics:
- type: ndcg_at_10
value: 53.166000000000004
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 46.01900557959478
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 41.06626465345723
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.87514497610431
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_spearman
value: 81.21450112991194
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: e3dda5e115e487b39ec7e618c0c6a29137052a55
metrics:
- type: cos_sim_spearman
value: 51.71589543397271
- task:
type: Retrieval
dataset:
type: maastrichtlawtech/bsard
name: MTEB BSARDRetrieval
config: default
split: test
revision: 5effa1b9b5fa3b0f9e12523e6e43e5f86a6e6d59
metrics:
- type: ndcg_at_10
value: 26.115
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (de-en)
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: f1
value: 98.6169102296451
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (fr-en)
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: f1
value: 97.89603052314916
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (ru-en)
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: f1
value: 97.12388869645537
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (zh-en)
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: f1
value: 98.15692469720906
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.36038961038962
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 37.5903826674123
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 34.21474277151329
- task:
type: Classification
dataset:
type: PL-MTEB/cbd
name: MTEB CBD
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 62.519999999999996
- task:
type: PairClassification
dataset:
type: PL-MTEB/cdsce-pairclassification
name: MTEB CDSC-E
config: default
split: test
revision: None
metrics:
- type: cos_sim_ap
value: 74.90132799162956
- task:
type: STS
dataset:
type: PL-MTEB/cdscr-sts
name: MTEB CDSC-R
config: default
split: test
revision: None
metrics:
- type: cos_sim_spearman
value: 90.30727955142524
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: 4b6227591c6c1a73bc76b1055f3b7f3588e72476
metrics:
- type: v_measure
value: 37.94850105022274
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: e458b3f5414b62b7f9f83499ac1f5497ae2e869f
metrics:
- type: v_measure
value: 38.11958675421534
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: 8d7f1e942507dac42dc58017c1a001c3717da7df
metrics:
- type: map
value: 86.10950950485399
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: 23d186750531a14a0357ca22cd92d712fd512ea0
metrics:
- type: map
value: 87.28038294231966
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-android
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: f46a197baaae43b4f621051089b82a364682dfeb
metrics:
- type: ndcg_at_10
value: 47.099000000000004
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-english
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
metrics:
- type: ndcg_at_10
value: 45.973000000000006
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-gaming
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: ndcg_at_10
value: 55.606
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-gis
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: 5003b3064772da1887988e05400cf3806fe491f2
metrics:
- type: ndcg_at_10
value: 36.638
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-mathematica
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
metrics:
- type: ndcg_at_10
value: 30.711
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-physics
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
metrics:
- type: ndcg_at_10
value: 44.523
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-programmers
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
metrics:
- type: ndcg_at_10
value: 37.940000000000005
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: ndcg_at_10
value: 38.12183333333333
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-stats
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
metrics:
- type: ndcg_at_10
value: 32.684000000000005
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-tex
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: ndcg_at_10
value: 26.735
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-unix
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: ndcg_at_10
value: 36.933
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-webmasters
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
metrics:
- type: ndcg_at_10
value: 33.747
- task:
type: Retrieval
dataset:
type: mteb/cqadupstack-wordpress
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: ndcg_at_10
value: 28.872999999999998
- task:
type: Retrieval
dataset:
type: mteb/climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: ndcg_at_10
value: 34.833
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: cd540c506dae1cf9e9a59c3e06f42030d54e7301
metrics:
- type: ndcg_at_10
value: 43.78
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: 41bc36f332156f7adc9e38f53777c959b2ae9766
metrics:
- type: cos_sim_ap
value: 84.00640599186677
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: 1271c7809071a13532e05f25fb53511ffce77117
metrics:
- type: ndcg_at_10
value: 80.60000000000001
- task:
type: Retrieval
dataset:
type: mteb/dbpedia
name: MTEB DBPedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: ndcg_at_10
value: 40.116
- task:
type: Retrieval
dataset:
type: clarin-knext/dbpedia-pl
name: MTEB DBPedia-PL
config: default
split: test
revision: 76afe41d9af165cc40999fcaa92312b8b012064a
metrics:
- type: ndcg_at_10
value: 32.498
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: a1a333e290fe30b10f3f56498e3a0d911a693ced
metrics:
- type: ndcg_at_10
value: 87.547
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: 687de13dc7294d6fd9be10c6945f9e8fec8166b9
metrics:
- type: ndcg_at_10
value: 64.85
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.949999999999996
- task:
type: Retrieval
dataset:
type: mteb/fever
name: MTEB FEVER
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: ndcg_at_10
value: 92.111
- task:
type: Retrieval
dataset:
type: clarin-knext/fiqa-pl
name: MTEB FiQA-PL
config: default
split: test
revision: 2e535829717f8bf9dc829b7f911cc5bbd4e6608e
metrics:
- type: ndcg_at_10
value: 28.962
- task:
type: Retrieval
dataset:
type: mteb/fiqa
name: MTEB FiQA2018
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: ndcg_at_10
value: 45.005
- task:
type: Clustering
dataset:
type: lyon-nlp/clustering-hal-s2s
name: MTEB HALClusteringS2S
config: default
split: test
revision: e06ebbbb123f8144bef1a5d18796f3dec9ae2915
metrics:
- type: v_measure
value: 25.133776435657595
- task:
type: Retrieval
dataset:
type: mteb/hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: ndcg_at_10
value: 63.036
- task:
type: Retrieval
dataset:
type: clarin-knext/hotpotqa-pl
name: MTEB HotpotQA-PL
config: default
split: test
revision: a0bd479ac97b4ccb5bd6ce320c415d0bb4beb907
metrics:
- type: ndcg_at_10
value: 56.904999999999994
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: 421605374b29664c5fc098418fe20ada9bd55f8a
metrics:
- type: accuracy
value: 44.59407464409388
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 74.912
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: b7c64bd89eb87f8ded463478346f76731f07bf8b
metrics:
- type: accuracy
value: 79.26829268292683
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: 17f9b096f80380fce5ed12a9be8be7784b337daf
metrics:
- type: cos_sim_spearman
value: 74.8601229809791
- task:
type: Clustering
dataset:
type: mlsum
name: MTEB MLSUMClusteringP2P
config: default
split: test
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
metrics:
- type: v_measure
value: 42.331902754246556
- task:
type: Clustering
dataset:
type: mlsum
name: MTEB MLSUMClusteringS2S
config: default
split: test
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
metrics:
- type: v_measure
value: 40.92029335502153
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: 8e0c766dbe9e16e1d221116a3f36795fbade07f6
metrics:
- type: map
value: 32.19266316591337
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: 539bbde593d947e2a124ba72651aafc09eb33fc2
metrics:
- type: ndcg_at_10
value: 79.346
- task:
type: Retrieval
dataset:
type: mteb/msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: ndcg_at_10
value: 39.922999999999995
- task:
type: Retrieval
dataset:
type: clarin-knext/msmarco-pl
name: MTEB MSMARCO-PL
config: default
split: test
revision: 8634c07806d5cce3a6138e260e59b81760a0a640
metrics:
- type: ndcg_at_10
value: 55.620999999999995
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.53989968080255
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (de)
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 88.26993519301212
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (es)
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.87725150100067
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (fr)
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.48512370811149
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (hi)
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.45141627823591
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (th)
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 83.45750452079565
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 72.57637938896488
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (de)
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 63.50803043110736
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (es)
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.6577718478986
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (fr)
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 64.05887879736925
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (hi)
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 65.27070634636071
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (th)
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 63.04520795660037
- task:
type: Classification
dataset:
type: masakhane/masakhanews
name: MTEB MasakhaNEWSClassification (fra)
config: fra
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: accuracy
value: 80.66350710900474
- task:
type: Clustering
dataset:
type: masakhane/masakhanews
name: MTEB MasakhaNEWSClusteringP2P (fra)
config: fra
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: v_measure
value: 44.016506455899425
- task:
type: Clustering
dataset:
type: masakhane/masakhanews
name: MTEB MasakhaNEWSClusteringS2S (fra)
config: fra
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: v_measure
value: 40.67730129573544
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (af)
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.94552790854068
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (am)
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 49.273705447209146
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ar)
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.490921318090116
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (az)
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.97511768661733
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (bn)
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.5689307330195
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (cy)
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.34902488231337
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (da)
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.6684599865501
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (de)
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.54539340954942
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (el)
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.08675184936112
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.12508406186953
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (es)
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.41425689307331
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fa)
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.59515803631474
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fi)
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.90517821116342
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fr)
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.91526563550774
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (he)
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.198386012104905
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hi)
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.04371217215869
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hu)
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.31203765971756
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hy)
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.521183591123055
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (id)
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.06254203093476
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (is)
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.01546738399461
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (it)
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.27975790181574
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ja)
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.79556153328849
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (jv)
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.18493611297915
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ka)
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 47.888365837256224
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (km)
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.79690652320108
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (kn)
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.225958305312716
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ko)
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.58641560188299
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (lv)
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.08204438466711
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ml)
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.54606590450572
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (mn)
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.443174176193665
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ms)
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.65097511768661
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (my)
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.45662407531944
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nb)
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.739071956960316
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nl)
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.36180228648286
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pl)
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.3920645595158
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pt)
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.06993947545395
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ro)
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.123739071956955
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ru)
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.46133154001346
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sl)
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.54472091459314
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sq)
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.204438466711494
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sv)
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.69603227975792
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sw)
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.684599865501
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ta)
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.523873570948226
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (te)
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.53396099529253
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (th)
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.88298587760591
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tl)
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.65097511768662
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tr)
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.8453261600538
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ur)
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.6247478143914
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (vi)
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.16274377942166
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.61667787491594
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-TW)
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.17283120376598
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (af)
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.89912575655683
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (am)
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.27975790181573
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ar)
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.269670477471415
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (az)
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.10423671822461
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (bn)
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.40753194351043
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (cy)
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 55.369872225958304
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (da)
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.60726294552792
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (de)
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.30262273032952
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (el)
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.52925353059851
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.28446536650976
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (es)
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.45460659045058
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fa)
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.26563550773368
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fi)
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.20578345662408
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fr)
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.64963012777405
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (he)
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.698049764626774
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hi)
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.14458641560188
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hu)
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.51445864156018
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hy)
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.13786146603901
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (id)
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.61533288500337
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (is)
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.526563550773375
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (it)
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.99731002017484
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ja)
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.59381304640216
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (jv)
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.010759919300604
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ka)
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 53.26160053799597
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (km)
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.800941492938804
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (kn)
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.387357094821795
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ko)
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.5359784801614
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (lv)
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.36919973100203
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ml)
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.81506388702084
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (mn)
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.35104236718225
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ms)
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.67787491593813
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (my)
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.4250168123739
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nb)
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.49630127774043
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nl)
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.95696032279758
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pl)
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.11768661735036
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pt)
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.86953597848016
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ro)
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.51042367182247
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ru)
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.65097511768661
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sl)
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.81573638197713
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sq)
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.26227303295225
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sv)
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.51513113651646
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sw)
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.29858776059179
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ta)
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.72696704774714
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (te)
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.57700067249496
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (th)
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.22797579018157
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tl)
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.97041022192333
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tr)
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.72629455279085
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ur)
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.16072629455278
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (vi)
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.92199058507062
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.40484196368527
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-TW)
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.61398789509079
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: 2039188fb5800a9803ba5048df7b76e6fb151fc6
metrics:
- type: ndcg_at_10
value: 61.934999999999995
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.052031054565205
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.969909524076794
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.7530992892652
- task:
type: Retrieval
dataset:
type: jinaai/mintakaqa
name: MTEB MintakaRetrieval (fr)
config: fr
split: test
revision: efa78cc2f74bbcd21eff2261f9e13aebe40b814e
metrics:
- type: ndcg_at_10
value: 34.705999999999996
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (ar)
config: ar
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 55.166000000000004
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (de)
config: de
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 55.155
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (en)
config: en
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 50.993
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (es)
config: es
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 81.228
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (fr)
config: fr
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 76.19
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (hi)
config: hi
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 45.206
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (it)
config: it
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 66.741
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (ja)
config: ja
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 52.111
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (ko)
config: ko
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 46.733000000000004
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (pt)
config: pt
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 79.105
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (ru)
config: ru
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 64.21
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (th)
config: th
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 35.467
- task:
type: Retrieval
dataset:
type: Shitao/MLDR
name: MTEB MultiLongDocRetrieval (zh)
config: zh
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 27.419
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: 46958b007a63fdbf239b7672c25d0bea67b5ea1a
metrics:
- type: accuracy
value: 61.02000000000001
- task:
type: Retrieval
dataset:
type: mteb/nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: ndcg_at_10
value: 36.65
- task:
type: Retrieval
dataset:
type: clarin-knext/nfcorpus-pl
name: MTEB NFCorpus-PL
config: default
split: test
revision: 9a6f9567fda928260afed2de480d79c98bf0bec0
metrics:
- type: ndcg_at_10
value: 26.831
- task:
type: Retrieval
dataset:
type: mteb/nq
name: MTEB NQ
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: ndcg_at_10
value: 58.111000000000004
- task:
type: Retrieval
dataset:
type: clarin-knext/nq-pl
name: MTEB NQ-PL
config: default
split: test
revision: f171245712cf85dd4700b06bef18001578d0ca8d
metrics:
- type: ndcg_at_10
value: 43.126999999999995
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: 66e76a618a34d6d565d5538088562851e6daa7ec
metrics:
- type: cos_sim_ap
value: 72.67630697316041
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: e610f2ebd179a8fda30ae534c3878750a96db120
metrics:
- type: accuracy
value: 84.85000000000001
- task:
type: PairClassification
dataset:
type: GEM/opusparcus
name: MTEB OpusparcusPC (fr)
config: fr
split: test
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
metrics:
- type: cos_sim_ap
value: 100
- task:
type: Classification
dataset:
type: laugustyniak/abusive-clauses-pl
name: MTEB PAC
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 65.99189110918043
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: 9c6a90e430ac22b5779fb019a23e820b11a8b5e1
metrics:
- type: cos_sim_spearman
value: 16.124364530596228
- task:
type: PairClassification
dataset:
type: PL-MTEB/ppc-pairclassification
name: MTEB PPC
config: default
split: test
revision: None
metrics:
- type: cos_sim_ap
value: 92.43431057460192
- task:
type: PairClassification
dataset:
type: PL-MTEB/psc-pairclassification
name: MTEB PSC
config: default
split: test
revision: None
metrics:
- type: cos_sim_ap
value: 99.06090138049724
- task:
type: PairClassification
dataset:
type: paws-x
name: MTEB PawsX (fr)
config: fr
split: test
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
metrics:
- type: cos_sim_ap
value: 58.9314954874314
- task:
type: Classification
dataset:
type: PL-MTEB/polemo2_in
name: MTEB PolEmo2.0-IN
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 69.59833795013851
- task:
type: Classification
dataset:
type: PL-MTEB/polemo2_out
name: MTEB PolEmo2.0-OUT
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 44.73684210526315
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: 790b0510dc52b1553e8c49f3d2afb48c0e5c48b7
metrics:
- type: cos_sim_spearman
value: 39.36450754137984
- task:
type: Retrieval
dataset:
type: clarin-knext/quora-pl
name: MTEB Quora-PL
config: default
split: test
revision: 0be27e93455051e531182b85e85e425aba12e9d4
metrics:
- type: ndcg_at_10
value: 80.76299999999999
- task:
type: Retrieval
dataset:
type: mteb/quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 88.022
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.719165988934385
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.25390069273025
- task:
type: Retrieval
dataset:
type: mteb/scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 18.243000000000002
- task:
type: Retrieval
dataset:
type: clarin-knext/scidocs-pl
name: MTEB SCIDOCS-PL
config: default
split: test
revision: 45452b03f05560207ef19149545f168e596c9337
metrics:
- type: ndcg_at_10
value: 14.219000000000001
- task:
type: PairClassification
dataset:
type: PL-MTEB/sicke-pl-pairclassification
name: MTEB SICK-E-PL
config: default
split: test
revision: None
metrics:
- type: cos_sim_ap
value: 75.4022630307816
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_spearman
value: 79.34269390198548
- task:
type: STS
dataset:
type: PL-MTEB/sickr-pl-sts
name: MTEB SICK-R-PL
config: default
split: test
revision: None
metrics:
- type: cos_sim_spearman
value: 74.0651660446132
- task:
type: STS
dataset:
type: Lajavaness/SICK-fr
name: MTEB SICKFr
config: default
split: test
revision: e077ab4cf4774a1e36d86d593b150422fafd8e8a
metrics:
- type: cos_sim_spearman
value: 78.62693119733123
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_spearman
value: 77.50660544631359
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_spearman
value: 85.55415077723738
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_spearman
value: 81.67550814479077
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_spearman
value: 88.94601412322764
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_spearman
value: 84.33844259337481
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ko-ko)
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 81.58650681159105
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ar-ar)
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 78.82472265884256
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-ar)
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 76.43637938260397
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-de)
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 84.71008299464059
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 88.88074713413747
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-tr)
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 76.36405640457285
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-en)
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 83.84737910084762
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-es)
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 87.03931621433031
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (fr-en)
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 84.43335591752246
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (it-en)
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 83.85268648747021
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (nl-en)
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 82.45786516224341
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 67.20227303970304
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de)
config: de
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 60.892838305537126
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es)
config: es
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 72.01876318464508
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl)
config: pl
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 42.3879320510127
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (tr)
config: tr
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 65.54048784845729
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ar)
config: ar
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 58.55244068334867
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ru)
config: ru
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 66.48710288440624
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 66.585754901838
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr)
config: fr
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 81.03001290557805
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-en)
config: de-en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 62.28001859884359
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-en)
config: es-en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 79.64106342105019
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (it)
config: it
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 78.27915339361124
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl-en)
config: pl-en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 78.28574268257462
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh-en)
config: zh-en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 72.92658860751482
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-it)
config: es-it
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 74.83418886368217
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-fr)
config: de-fr
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 56.01064022625769
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-pl)
config: de-pl
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 53.64332829635126
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr-pl)
config: fr-pl
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_spearman
value: 73.24670207647144
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: 0cde68302b3541bb8b3c340dc0644b0b745b3dc0
metrics:
- type: cos_sim_spearman
value: 80.7157790971544
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_spearman
value: 86.45763616928973
- task:
type: STS
dataset:
type: stsb_multi_mt
name: MTEB STSBenchmarkMultilingualSTS (fr)
config: fr
split: test
revision: 93d57ef91790589e3ce9c365164337a8a78b7632
metrics:
- type: cos_sim_spearman
value: 84.4335500335282
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 84.15276484499303
- task:
type: Retrieval
dataset:
type: mteb/scifact
name: MTEB SciFact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: ndcg_at_10
value: 73.433
- task:
type: Retrieval
dataset:
type: clarin-knext/scifact-pl
name: MTEB SciFact-PL
config: default
split: test
revision: 47932a35f045ef8ed01ba82bf9ff67f6e109207e
metrics:
- type: ndcg_at_10
value: 58.919999999999995
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_ap
value: 95.40564890916419
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 63.41856697730145
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 31.709285904909112
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.09341030060322
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_spearman
value: 30.58262517835034
- task:
type: Summarization
dataset:
type: lyon-nlp/summarization-summeval-fr-p2p
name: MTEB SummEvalFr
config: default
split: test
revision: b385812de6a9577b6f4d0f88c6a6e35395a94054
metrics:
- type: cos_sim_spearman
value: 29.744542072951358
- task:
type: Reranking
dataset:
type: lyon-nlp/mteb-fr-reranking-syntec-s2p
name: MTEB SyntecReranking
config: default
split: test
revision: b205c5084a0934ce8af14338bf03feb19499c84d
metrics:
- type: map
value: 88.03333333333333
- task:
type: Retrieval
dataset:
type: lyon-nlp/mteb-fr-retrieval-syntec-s2p
name: MTEB SyntecRetrieval
config: default
split: test
revision: 77f7e271bf4a92b24fce5119f3486b583ca016ff
metrics:
- type: ndcg_at_10
value: 83.043
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: 76631901a18387f85eaa53e5450019b87ad58ef9
metrics:
- type: map
value: 67.08577894804324
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: 8731a845f1bf500a4f111cf1070785c793d10e64
metrics:
- type: ndcg_at_10
value: 84.718
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: 317f262bf1e6126357bbe89e875451e4b0938fe4
metrics:
- type: accuracy
value: 48.726
- task:
type: Retrieval
dataset:
type: mteb/trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: ndcg_at_10
value: 57.56
- task:
type: Retrieval
dataset:
type: clarin-knext/trec-covid-pl
name: MTEB TRECCOVID-PL
config: default
split: test
revision: 81bcb408f33366c2a20ac54adafad1ae7e877fdd
metrics:
- type: ndcg_at_10
value: 59.355999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (sqi-eng)
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 82.765
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fry-eng)
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 73.69942196531792
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kur-eng)
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 32.86585365853657
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tur-eng)
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 95.81666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (deu-eng)
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 97.75
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nld-eng)
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 93.78333333333335
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ron-eng)
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 90.72333333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ang-eng)
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 42.45202558635395
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ido-eng)
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 77.59238095238095
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jav-eng)
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 35.69686411149825
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (isl-eng)
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 82.59333333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slv-eng)
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 84.1456922987907
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cym-eng)
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 52.47462133594857
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kaz-eng)
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 67.62965440356746
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (est-eng)
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 79.48412698412699
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (heb-eng)
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 75.85
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gla-eng)
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 27.32600866497127
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mar-eng)
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 84.38
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lat-eng)
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 42.98888712165028
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bel-eng)
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 85.55690476190476
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pms-eng)
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 46.68466031323174
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gle-eng)
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 32.73071428571428
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pes-eng)
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 88.26333333333334
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nob-eng)
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 96.61666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bul-eng)
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.30666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cbk-eng)
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 70.03714285714285
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hun-eng)
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 89.09
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uig-eng)
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 59.570476190476185
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (rus-eng)
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 92.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (spa-eng)
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 97.68333333333334
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hye-eng)
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 80.40880503144653
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tel-eng)
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 89.7008547008547
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (afr-eng)
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 81.84833333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mon-eng)
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 71.69696969696969
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arz-eng)
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 55.76985790822269
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hrv-eng)
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.66666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nov-eng)
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 68.36668519547896
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gsw-eng)
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 36.73992673992674
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nds-eng)
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 63.420952380952365
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ukr-eng)
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.28999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uzb-eng)
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 40.95392490046146
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lit-eng)
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 77.58936507936508
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ina-eng)
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.28999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lfn-eng)
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 63.563650793650794
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (zsm-eng)
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 94.35
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ita-eng)
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.43
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cmn-eng)
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 95.73333333333332
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lvs-eng)
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 79.38666666666667
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (glg-eng)
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 89.64
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ceb-eng)
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 21.257184628237262
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bre-eng)
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 13.592316017316017
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ben-eng)
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 73.22666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swg-eng)
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 51.711309523809526
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arq-eng)
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 24.98790634904795
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kab-eng)
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 17.19218192918193
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fra-eng)
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 93.26666666666667
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (por-eng)
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 94.57333333333334
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tat-eng)
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 42.35127206127206
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (oci-eng)
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 51.12318903318903
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pol-eng)
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 94.89999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (war-eng)
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 23.856320290390055
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (aze-eng)
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 79.52833333333334
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (vie-eng)
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 95.93333333333334
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nno-eng)
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 90.75333333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cha-eng)
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 30.802919708029197
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mhr-eng)
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 15.984076294076294
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dan-eng)
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.82666666666667
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ell-eng)
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (amh-eng)
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 76.36054421768706
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pam-eng)
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 9.232711399711398
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hsb-eng)
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 45.640803181175855
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (srp-eng)
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 86.29
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (epo-eng)
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 88.90833333333332
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kzj-eng)
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 11.11880248978075
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (awa-eng)
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 48.45839345839346
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fao-eng)
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 65.68157033805888
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mal-eng)
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 94.63852498786997
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ile-eng)
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 81.67904761904761
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bos-eng)
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 89.35969868173258
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cor-eng)
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 5.957229437229437
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cat-eng)
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 91.50333333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (eus-eng)
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 63.75498778998778
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yue-eng)
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 82.99190476190476
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swe-eng)
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 92.95
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dtp-eng)
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 9.054042624042623
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kat-eng)
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 72.77064981488574
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jpn-eng)
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 93.14
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (csb-eng)
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 29.976786498525627
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (xho-eng)
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 67.6525821596244
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (orv-eng)
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 33.12964812964813
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ind-eng)
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 92.30666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tuk-eng)
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 34.36077879427633
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (max-eng)
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 52.571845212690285
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swh-eng)
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 58.13107263107262
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hin-eng)
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 93.33333333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dsb-eng)
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 42.87370133925458
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ber-eng)
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 20.394327616827614
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tam-eng)
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 84.29967426710098
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slk-eng)
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 88.80666666666667
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tgl-eng)
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 67.23062271062273
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ast-eng)
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 78.08398950131233
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mkd-eng)
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 77.85166666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (khm-eng)
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 67.63004001231148
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ces-eng)
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 89.77000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tzl-eng)
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 40.2654503616042
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (urd-eng)
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 83.90333333333334
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ara-eng)
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 77.80666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kor-eng)
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 84.08
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yid-eng)
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 60.43098607367475
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fin-eng)
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 88.19333333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tha-eng)
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 90.55352798053529
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (wuu-eng)
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: f1
value: 88.44999999999999
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: 5798586b105c0434e4f0fe5e767abe619442cf93
metrics:
- type: v_measure
value: 57.25416429643288
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: 8a8b2caeda43f39e13c4bc5bea0f8a667896e10d
metrics:
- type: v_measure
value: 56.616646560243524
- task:
type: Retrieval
dataset:
type: mteb/touche2020
name: MTEB Touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: ndcg_at_10
value: 22.819
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.02579999999999
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 57.60045274476514
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 50.346666699466205
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_ap
value: 71.88199004440489
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_ap
value: 85.41587779677383
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: 58c2597a5943a2ba48f4668c3b90d796283c5639
metrics:
- type: ndcg_at_10
value: 72.792
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: 339287def212450dcaa9df8c22bf93e9980c7023
metrics:
- type: accuracy
value: 82.58000000000001
- task:
type: Retrieval
dataset:
type: jinaai/xpqa
name: MTEB XPQARetrieval (fr)
config: fr
split: test
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
metrics:
- type: ndcg_at_10
value: 67.327
---
## gte-multilingual-base
The **gte-multilingual-base** model is the latest in the [GTE](https://huggingface.co/collections/Alibaba-NLP/gte-models-6680f0b13f885cb431e6d469) (General Text Embedding) family of models, featuring several key attributes:
- **High Performance**: Achieves state-of-the-art (SOTA) results in multilingual retrieval tasks and multi-task representation model evaluations when compared to models of similar size.
- **Training Architecture**: Trained using an encoder-only transformers architecture, resulting in a smaller model size. Unlike previous models based on decode-only LLM architecture (e.g., gte-qwen2-1.5b-instruct), this model has lower hardware requirements for inference, offering a 10x increase in inference speed.
- **Long Context**: Supports text lengths up to **8192** tokens.
- **Multilingual Capability**: Supports over **70** languages.
- **Elastic Dense Embedding**: Support elastic output dense representation while maintaining the effectiveness of downstream tasks, which significantly reduces storage costs and improves execution efficiency.
- **Sparse Vectors**: In addition to dense representations, it can also generate sparse vectors.
**Paper**: [mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval](https://arxiv.org/pdf/2407.19669)
## Model Information
- Model Size: 305M
- Embedding Dimension: 768
- Max Input Tokens: 8192
## Usage
- **It is recommended to install xformers and enable unpadding for acceleration,
refer to [enable-unpadding-and-xformers](https://huggingface.co/Alibaba-NLP/new-impl#recommendation-enable-unpadding-and-acceleration-with-xformers).**
- **How to use it offline: [new-impl/discussions/2](https://huggingface.co/Alibaba-NLP/new-impl/discussions/2#662b08d04d8c3d0a09c88fa3)**
- **How to use with [TEI](https://github.com/huggingface/text-embeddings-inference): [refs/pr/7](https://huggingface.co/Alibaba-NLP/gte-multilingual-base/discussions/7#66bfb82ea03b764ca92a2221)**
### Get Dense Embeddings with Transformers
```python
# Requires transformers>=4.36.0
import torch.nn.functional as F
from transformers import AutoModel, AutoTokenizer
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
model_name_or_path = 'Alibaba-NLP/gte-multilingual-base'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True)
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=8192, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
dimension=768 # The output dimension of the output embedding, should be in [128, 768]
embeddings = outputs.last_hidden_state[:, 0][:dimension]
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
# [[0.3016996383666992, 0.7503870129585266, 0.3203084468841553]]
```
### Use with sentence-transformers
```python
# Requires sentences-transformers>=3.0.0
from sentence_transformers import SentenceTransformer
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
model_name_or_path="Alibaba-NLP/gte-multilingual-base"
model = SentenceTransformer(model_name_or_path, trust_remote_code=True)
embeddings = model.encode(input_texts, normalize_embeddings=True) # embeddings.shape (4, 768)
# sim scores
scores = model.similarity(embeddings[:1], embeddings[1:])
print(scores.tolist())
# [[0.301699697971344, 0.7503870129585266, 0.32030850648880005]]
```
### Use with custom code to get dense embeddigns and sparse token weights
```python
# You can find the script gte_embedding.py in https://huggingface.co/Alibaba-NLP/gte-multilingual-base/blob/main/scripts/gte_embedding.py
from gte_embedding import GTEEmbeddidng
model_name_or_path = 'Alibaba-NLP/gte-multilingual-base'
model = GTEEmbeddidng(model_name_or_path)
query = "中国的首都在哪儿"
docs = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
embs = model.encode(docs, return_dense=True,return_sparse=True)
print('dense_embeddings vecs', embs['dense_embeddings'])
print('token_weights', embs['token_weights'])
pairs = [(query, doc) for doc in docs]
dense_scores = model.compute_scores(pairs, dense_weight=1.0, sparse_weight=0.0)
sparse_scores = model.compute_scores(pairs, dense_weight=0.0, sparse_weight=1.0)
hybrid_scores = model.compute_scores(pairs, dense_weight=1.0, sparse_weight=0.3)
print('dense_scores', dense_scores)
print('sparse_scores', sparse_scores)
print('hybrid_scores', hybrid_scores)
# dense_scores [0.85302734375, 0.257568359375, 0.76953125, 0.325439453125]
# sparse_scores [0.0, 0.0, 4.600879669189453, 1.570279598236084]
# hybrid_scores [0.85302734375, 0.257568359375, 2.1497951507568356, 0.7965233325958252]
```
## Evaluation
We validated the performance of the **gte-multilingual-base** model on multiple downstream tasks, including multilingual retrieval, cross-lingual retrieval, long text retrieval, and general text representation evaluation on the [MTEB Leaderboard](https://huggingface.co/spaces/mteb/leaderboard), among others.
### Retrieval Task
Retrieval results on [MIRACL](https://arxiv.org/abs/2210.09984) and [MLDR](https://arxiv.org/abs/2402.03216) (multilingual), [MKQA](https://arxiv.org/abs/2007.15207) (crosslingual), [BEIR](https://arxiv.org/abs/2104.08663) and [LoCo](https://arxiv.org/abs/2402.07440) (English).

- Detail results on [MLDR](https://arxiv.org/abs/2402.03216)

- Detail results on [LoCo](https://arxiv.org/abs/2402.07440)
### MTEB
Results on MTEB English, Chinese, French, Polish

**More detailed experimental results can be found in the [paper](https://arxiv.org/pdf/2407.19669)**.
## Cloud API Services
In addition to the open-source [GTE](https://huggingface.co/collections/Alibaba-NLP/gte-models-6680f0b13f885cb431e6d469) series models, GTE series models are also available as commercial API services on Alibaba Cloud.
- [Embedding Models](https://help.aliyun.com/zh/model-studio/developer-reference/general-text-embedding/): Rhree versions of the text embedding models are available: text-embedding-v1/v2/v3, with v3 being the latest API service.
- [ReRank Models](https://help.aliyun.com/zh/model-studio/developer-reference/general-text-sorting-model/): The gte-rerank model service is available.
Note that the models behind the commercial APIs are not entirely identical to the open-source models.
## Citation
If you find our paper or models helpful, please consider cite:
```
@misc{zhang2024mgte,
title={mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval},
author={Xin Zhang and Yanzhao Zhang and Dingkun Long and Wen Xie and Ziqi Dai and Jialong Tang and Huan Lin and Baosong Yang and Pengjun Xie and Fei Huang and Meishan Zhang and Wenjie Li and Min Zhang},
year={2024},
eprint={2407.19669},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.19669},
}
``` |
botp/stable-diffusion-v1-5 | botp | "2023-05-05T06:22:02Z" | 756,396 | 24 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2023-05-05T06:22:02Z" | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: true
extra_gated_prompt: >-
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. CompVis claims no rights on the outputs you generate, you are free to use
them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here:
https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
duplicated_from: runwayml/stable-diffusion-v1-5
---
# Stable Diffusion v1-5 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-5** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and the [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion).
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
### Original GitHub Repository
1. Download the weights
- [v1-5-pruned-emaonly.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt) - 4.27GB, ema-only weight. uses less VRAM - suitable for inference
- [v1-5-pruned.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt) - 7.7GB, ema+non-ema weights. uses more VRAM - suitable for fine-tuning
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion).
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-5 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
Currently six Stable Diffusion checkpoints are provided, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2` - 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2` - 225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) Resumed from `stable-diffusion-v1-2` - 595,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-inpainting`](https://huggingface.co/runwayml/stable-diffusion-inpainting) Resumed from `stable-diffusion-v1-5` - then 440,000 steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PNDM/PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
jinaai/jina-embeddings-v3 | jinaai | "2024-11-11T09:46:21Z" | 748,328 | 479 | transformers | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"feature-extraction",
"sentence-similarity",
"mteb",
"sentence-transformers",
"custom_code",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2409.10173",
"license:cc-by-nc-4.0",
"model-index",
"region:eu"
] | feature-extraction | "2024-09-05T11:56:46Z" | ---
license: cc-by-nc-4.0
tags:
- feature-extraction
- sentence-similarity
- mteb
- sentence-transformers
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
inference: false
library_name: transformers
model-index:
- name: jina-embeddings-v3
results:
- dataset:
config: default
name: MTEB AFQMC (default)
revision: b44c3b011063adb25877c13823db83bb193913c4
split: validation
type: C-MTEB/AFQMC
metrics:
- type: cosine_pearson
value: 41.74237700998808
- type: cosine_spearman
value: 43.4726782647566
- type: euclidean_pearson
value: 42.244585459479964
- type: euclidean_spearman
value: 43.525070045169606
- type: main_score
value: 43.4726782647566
- type: manhattan_pearson
value: 42.04616728224863
- type: manhattan_spearman
value: 43.308828270754645
- type: pearson
value: 41.74237700998808
- type: spearman
value: 43.4726782647566
task:
type: STS
- dataset:
config: default
name: MTEB ArguAna-PL (default)
revision: 63fc86750af76253e8c760fc9e534bbf24d260a2
split: test
type: clarin-knext/arguana-pl
metrics:
- type: main_score
value: 50.117999999999995
- type: map_at_1
value: 24.253
- type: map_at_10
value: 40.725
- type: map_at_100
value: 41.699999999999996
- type: map_at_1000
value: 41.707
- type: map_at_20
value: 41.467999999999996
- type: map_at_3
value: 35.467
- type: map_at_5
value: 38.291
- type: mrr_at_1
value: 24.751066856330013
- type: mrr_at_10
value: 40.91063808169072
- type: mrr_at_100
value: 41.885497923928675
- type: mrr_at_1000
value: 41.89301098419842
- type: mrr_at_20
value: 41.653552355442514
- type: mrr_at_3
value: 35.656709340919775
- type: mrr_at_5
value: 38.466097676623946
- type: nauc_map_at_1000_diff1
value: 7.503000359807567
- type: nauc_map_at_1000_max
value: -11.030405164830546
- type: nauc_map_at_1000_std
value: -8.902792782585117
- type: nauc_map_at_100_diff1
value: 7.509899249593199
- type: nauc_map_at_100_max
value: -11.023581259404406
- type: nauc_map_at_100_std
value: -8.892241185067272
- type: nauc_map_at_10_diff1
value: 7.24369711881512
- type: nauc_map_at_10_max
value: -10.810000200433278
- type: nauc_map_at_10_std
value: -8.987230542165776
- type: nauc_map_at_1_diff1
value: 11.37175831832417
- type: nauc_map_at_1_max
value: -13.315221903223055
- type: nauc_map_at_1_std
value: -9.398199605510275
- type: nauc_map_at_20_diff1
value: 7.477364530860648
- type: nauc_map_at_20_max
value: -10.901251218105566
- type: nauc_map_at_20_std
value: -8.868148116405925
- type: nauc_map_at_3_diff1
value: 6.555548802174882
- type: nauc_map_at_3_max
value: -12.247274800542934
- type: nauc_map_at_3_std
value: -9.879475250984811
- type: nauc_map_at_5_diff1
value: 7.426588563355882
- type: nauc_map_at_5_max
value: -11.347695686001805
- type: nauc_map_at_5_std
value: -9.34441892203972
- type: nauc_mrr_at_1000_diff1
value: 5.99737552143614
- type: nauc_mrr_at_1000_max
value: -11.327205136505727
- type: nauc_mrr_at_1000_std
value: -8.791079115519503
- type: nauc_mrr_at_100_diff1
value: 6.004622525255784
- type: nauc_mrr_at_100_max
value: -11.320336759899723
- type: nauc_mrr_at_100_std
value: -8.780602249831777
- type: nauc_mrr_at_10_diff1
value: 5.783623516930227
- type: nauc_mrr_at_10_max
value: -11.095971693467078
- type: nauc_mrr_at_10_std
value: -8.877242032013582
- type: nauc_mrr_at_1_diff1
value: 9.694937537703797
- type: nauc_mrr_at_1_max
value: -12.531905083727912
- type: nauc_mrr_at_1_std
value: -8.903992940100146
- type: nauc_mrr_at_20_diff1
value: 5.984841206233873
- type: nauc_mrr_at_20_max
value: -11.195236951048969
- type: nauc_mrr_at_20_std
value: -8.757266039186018
- type: nauc_mrr_at_3_diff1
value: 5.114333824261379
- type: nauc_mrr_at_3_max
value: -12.64809799843464
- type: nauc_mrr_at_3_std
value: -9.791146138025184
- type: nauc_mrr_at_5_diff1
value: 5.88941606224512
- type: nauc_mrr_at_5_max
value: -11.763903418071918
- type: nauc_mrr_at_5_std
value: -9.279175712709446
- type: nauc_ndcg_at_1000_diff1
value: 7.076950652226086
- type: nauc_ndcg_at_1000_max
value: -10.386482092087371
- type: nauc_ndcg_at_1000_std
value: -8.309190917074046
- type: nauc_ndcg_at_100_diff1
value: 7.2329220284865245
- type: nauc_ndcg_at_100_max
value: -10.208048403220337
- type: nauc_ndcg_at_100_std
value: -7.997975874274613
- type: nauc_ndcg_at_10_diff1
value: 6.065391100006953
- type: nauc_ndcg_at_10_max
value: -9.046164377601153
- type: nauc_ndcg_at_10_std
value: -8.34724889697153
- type: nauc_ndcg_at_1_diff1
value: 11.37175831832417
- type: nauc_ndcg_at_1_max
value: -13.315221903223055
- type: nauc_ndcg_at_1_std
value: -9.398199605510275
- type: nauc_ndcg_at_20_diff1
value: 6.949389989202601
- type: nauc_ndcg_at_20_max
value: -9.35740451760307
- type: nauc_ndcg_at_20_std
value: -7.761295171828212
- type: nauc_ndcg_at_3_diff1
value: 5.051471796151364
- type: nauc_ndcg_at_3_max
value: -12.158763333711653
- type: nauc_ndcg_at_3_std
value: -10.078902544421926
- type: nauc_ndcg_at_5_diff1
value: 6.527454512611454
- type: nauc_ndcg_at_5_max
value: -10.525118233848586
- type: nauc_ndcg_at_5_std
value: -9.120055125584031
- type: nauc_precision_at_1000_diff1
value: -10.6495668199151
- type: nauc_precision_at_1000_max
value: 12.070656425217841
- type: nauc_precision_at_1000_std
value: 55.844551709649004
- type: nauc_precision_at_100_diff1
value: 19.206967129266285
- type: nauc_precision_at_100_max
value: 16.296851020813456
- type: nauc_precision_at_100_std
value: 45.60378984257811
- type: nauc_precision_at_10_diff1
value: 0.6490335354304879
- type: nauc_precision_at_10_max
value: 0.5757198255366447
- type: nauc_precision_at_10_std
value: -4.875847131691451
- type: nauc_precision_at_1_diff1
value: 11.37175831832417
- type: nauc_precision_at_1_max
value: -13.315221903223055
- type: nauc_precision_at_1_std
value: -9.398199605510275
- type: nauc_precision_at_20_diff1
value: 4.899369866929203
- type: nauc_precision_at_20_max
value: 5.988537297189552
- type: nauc_precision_at_20_std
value: 4.830900387582837
- type: nauc_precision_at_3_diff1
value: 0.8791156910997744
- type: nauc_precision_at_3_max
value: -11.983373635905993
- type: nauc_precision_at_3_std
value: -10.646185111581257
- type: nauc_precision_at_5_diff1
value: 3.9314486166548432
- type: nauc_precision_at_5_max
value: -7.798591396895839
- type: nauc_precision_at_5_std
value: -8.293043407234125
- type: nauc_recall_at_1000_diff1
value: -10.649566819918673
- type: nauc_recall_at_1000_max
value: 12.070656425214647
- type: nauc_recall_at_1000_std
value: 55.84455170965023
- type: nauc_recall_at_100_diff1
value: 19.206967129265127
- type: nauc_recall_at_100_max
value: 16.296851020813722
- type: nauc_recall_at_100_std
value: 45.60378984257728
- type: nauc_recall_at_10_diff1
value: 0.6490335354304176
- type: nauc_recall_at_10_max
value: 0.5757198255366095
- type: nauc_recall_at_10_std
value: -4.875847131691468
- type: nauc_recall_at_1_diff1
value: 11.37175831832417
- type: nauc_recall_at_1_max
value: -13.315221903223055
- type: nauc_recall_at_1_std
value: -9.398199605510275
- type: nauc_recall_at_20_diff1
value: 4.899369866929402
- type: nauc_recall_at_20_max
value: 5.98853729718968
- type: nauc_recall_at_20_std
value: 4.830900387582967
- type: nauc_recall_at_3_diff1
value: 0.8791156910997652
- type: nauc_recall_at_3_max
value: -11.983373635905997
- type: nauc_recall_at_3_std
value: -10.64618511158124
- type: nauc_recall_at_5_diff1
value: 3.9314486166548472
- type: nauc_recall_at_5_max
value: -7.7985913968958585
- type: nauc_recall_at_5_std
value: -8.293043407234132
- type: ndcg_at_1
value: 24.253
- type: ndcg_at_10
value: 50.117999999999995
- type: ndcg_at_100
value: 54.291999999999994
- type: ndcg_at_1000
value: 54.44799999999999
- type: ndcg_at_20
value: 52.771
- type: ndcg_at_3
value: 39.296
- type: ndcg_at_5
value: 44.373000000000005
- type: precision_at_1
value: 24.253
- type: precision_at_10
value: 8.016
- type: precision_at_100
value: 0.984
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.527
- type: precision_at_3
value: 16.808999999999997
- type: precision_at_5
value: 12.546
- type: recall_at_1
value: 24.253
- type: recall_at_10
value: 80.156
- type: recall_at_100
value: 98.43499999999999
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_20
value: 90.54100000000001
- type: recall_at_3
value: 50.427
- type: recall_at_5
value: 62.731
task:
type: Retrieval
- dataset:
config: default
name: MTEB DBPedia-PL (default)
revision: 76afe41d9af165cc40999fcaa92312b8b012064a
split: test
type: clarin-knext/dbpedia-pl
metrics:
- type: main_score
value: 34.827000000000005
- type: map_at_1
value: 7.049999999999999
- type: map_at_10
value: 14.982999999999999
- type: map_at_100
value: 20.816000000000003
- type: map_at_1000
value: 22.33
- type: map_at_20
value: 17.272000000000002
- type: map_at_3
value: 10.661
- type: map_at_5
value: 12.498
- type: mrr_at_1
value: 57.25
- type: mrr_at_10
value: 65.81934523809524
- type: mrr_at_100
value: 66.2564203928212
- type: mrr_at_1000
value: 66.27993662923856
- type: mrr_at_20
value: 66.0732139130649
- type: mrr_at_3
value: 64.08333333333333
- type: mrr_at_5
value: 65.27083333333333
- type: nauc_map_at_1000_diff1
value: 16.41780871174038
- type: nauc_map_at_1000_max
value: 30.193946325654654
- type: nauc_map_at_1000_std
value: 31.46095497039037
- type: nauc_map_at_100_diff1
value: 18.57903165498531
- type: nauc_map_at_100_max
value: 29.541476938623262
- type: nauc_map_at_100_std
value: 28.228604103301052
- type: nauc_map_at_10_diff1
value: 24.109434489748946
- type: nauc_map_at_10_max
value: 21.475954208048968
- type: nauc_map_at_10_std
value: 9.964464537806988
- type: nauc_map_at_1_diff1
value: 38.67437644802124
- type: nauc_map_at_1_max
value: 14.52136658726491
- type: nauc_map_at_1_std
value: -2.8981666782088755
- type: nauc_map_at_20_diff1
value: 21.42547228801935
- type: nauc_map_at_20_max
value: 25.04510402960458
- type: nauc_map_at_20_std
value: 16.533079346431155
- type: nauc_map_at_3_diff1
value: 26.63648858245477
- type: nauc_map_at_3_max
value: 13.632235789780415
- type: nauc_map_at_3_std
value: -0.40129174577700716
- type: nauc_map_at_5_diff1
value: 24.513861031197933
- type: nauc_map_at_5_max
value: 16.599888813946688
- type: nauc_map_at_5_std
value: 3.4448514739556346
- type: nauc_mrr_at_1000_diff1
value: 36.57353464537154
- type: nauc_mrr_at_1000_max
value: 55.34763483979515
- type: nauc_mrr_at_1000_std
value: 40.3722796438533
- type: nauc_mrr_at_100_diff1
value: 36.555989566513134
- type: nauc_mrr_at_100_max
value: 55.347805216808396
- type: nauc_mrr_at_100_std
value: 40.38465945075711
- type: nauc_mrr_at_10_diff1
value: 36.771572999261984
- type: nauc_mrr_at_10_max
value: 55.41239897909165
- type: nauc_mrr_at_10_std
value: 40.52058934624793
- type: nauc_mrr_at_1_diff1
value: 38.2472828531032
- type: nauc_mrr_at_1_max
value: 51.528473828685705
- type: nauc_mrr_at_1_std
value: 33.03676467942882
- type: nauc_mrr_at_20_diff1
value: 36.642602571889036
- type: nauc_mrr_at_20_max
value: 55.3763342076553
- type: nauc_mrr_at_20_std
value: 40.41520090500838
- type: nauc_mrr_at_3_diff1
value: 36.79451847426628
- type: nauc_mrr_at_3_max
value: 54.59778581826193
- type: nauc_mrr_at_3_std
value: 39.48392075873095
- type: nauc_mrr_at_5_diff1
value: 36.92150807529304
- type: nauc_mrr_at_5_max
value: 55.03553978718272
- type: nauc_mrr_at_5_std
value: 40.20147745489917
- type: nauc_ndcg_at_1000_diff1
value: 21.843092744321268
- type: nauc_ndcg_at_1000_max
value: 44.93275990394279
- type: nauc_ndcg_at_1000_std
value: 47.09186225236347
- type: nauc_ndcg_at_100_diff1
value: 25.180282568979095
- type: nauc_ndcg_at_100_max
value: 41.737709709508394
- type: nauc_ndcg_at_100_std
value: 38.80950644139446
- type: nauc_ndcg_at_10_diff1
value: 24.108368037214046
- type: nauc_ndcg_at_10_max
value: 41.29298370689967
- type: nauc_ndcg_at_10_std
value: 35.06450769738732
- type: nauc_ndcg_at_1_diff1
value: 35.51010679525079
- type: nauc_ndcg_at_1_max
value: 42.40790024212412
- type: nauc_ndcg_at_1_std
value: 26.696412036243157
- type: nauc_ndcg_at_20_diff1
value: 23.909989673256195
- type: nauc_ndcg_at_20_max
value: 39.78444647091927
- type: nauc_ndcg_at_20_std
value: 33.39544470364529
- type: nauc_ndcg_at_3_diff1
value: 22.50484297956035
- type: nauc_ndcg_at_3_max
value: 39.14551926034168
- type: nauc_ndcg_at_3_std
value: 30.330135925392014
- type: nauc_ndcg_at_5_diff1
value: 21.7798872028265
- type: nauc_ndcg_at_5_max
value: 40.23856975248015
- type: nauc_ndcg_at_5_std
value: 32.438381067440396
- type: nauc_precision_at_1000_diff1
value: -21.62692442272279
- type: nauc_precision_at_1000_max
value: 0.9689046974430882
- type: nauc_precision_at_1000_std
value: 18.54001058230465
- type: nauc_precision_at_100_diff1
value: -10.132258779856192
- type: nauc_precision_at_100_max
value: 23.74516110444681
- type: nauc_precision_at_100_std
value: 47.03416663319965
- type: nauc_precision_at_10_diff1
value: 1.543656509571949
- type: nauc_precision_at_10_max
value: 36.98864812757555
- type: nauc_precision_at_10_std
value: 46.56427199077426
- type: nauc_precision_at_1_diff1
value: 38.2472828531032
- type: nauc_precision_at_1_max
value: 51.528473828685705
- type: nauc_precision_at_1_std
value: 33.03676467942882
- type: nauc_precision_at_20_diff1
value: -4.612864872734335
- type: nauc_precision_at_20_max
value: 34.03565449182125
- type: nauc_precision_at_20_std
value: 48.880727648349534
- type: nauc_precision_at_3_diff1
value: 6.360850444467829
- type: nauc_precision_at_3_max
value: 36.25816942368427
- type: nauc_precision_at_3_std
value: 34.48882647419187
- type: nauc_precision_at_5_diff1
value: 2.6445596936740037
- type: nauc_precision_at_5_max
value: 37.174463388899056
- type: nauc_precision_at_5_std
value: 40.25254370626113
- type: nauc_recall_at_1000_diff1
value: 13.041227176748077
- type: nauc_recall_at_1000_max
value: 39.722336427072094
- type: nauc_recall_at_1000_std
value: 52.04032890059214
- type: nauc_recall_at_100_diff1
value: 18.286096899139153
- type: nauc_recall_at_100_max
value: 34.072389201930314
- type: nauc_recall_at_100_std
value: 37.73637623416653
- type: nauc_recall_at_10_diff1
value: 22.35560419280504
- type: nauc_recall_at_10_max
value: 19.727247199595197
- type: nauc_recall_at_10_std
value: 8.58498575109203
- type: nauc_recall_at_1_diff1
value: 38.67437644802124
- type: nauc_recall_at_1_max
value: 14.52136658726491
- type: nauc_recall_at_1_std
value: -2.8981666782088755
- type: nauc_recall_at_20_diff1
value: 19.026320886902916
- type: nauc_recall_at_20_max
value: 22.753562309469867
- type: nauc_recall_at_20_std
value: 14.89994263882445
- type: nauc_recall_at_3_diff1
value: 23.428129702129684
- type: nauc_recall_at_3_max
value: 10.549153954790542
- type: nauc_recall_at_3_std
value: -1.7590608997055206
- type: nauc_recall_at_5_diff1
value: 21.27448645803921
- type: nauc_recall_at_5_max
value: 13.620279707461677
- type: nauc_recall_at_5_std
value: 2.0577962208292675
- type: ndcg_at_1
value: 46.75
- type: ndcg_at_10
value: 34.827000000000005
- type: ndcg_at_100
value: 38.157999999999994
- type: ndcg_at_1000
value: 44.816
- type: ndcg_at_20
value: 34.152
- type: ndcg_at_3
value: 39.009
- type: ndcg_at_5
value: 36.826
- type: precision_at_1
value: 57.25
- type: precision_at_10
value: 27.575
- type: precision_at_100
value: 8.84
- type: precision_at_1000
value: 1.949
- type: precision_at_20
value: 20.724999999999998
- type: precision_at_3
value: 41.167
- type: precision_at_5
value: 35.199999999999996
- type: recall_at_1
value: 7.049999999999999
- type: recall_at_10
value: 19.817999999999998
- type: recall_at_100
value: 42.559999999999995
- type: recall_at_1000
value: 63.744
- type: recall_at_20
value: 25.968000000000004
- type: recall_at_3
value: 11.959
- type: recall_at_5
value: 14.939
task:
type: Retrieval
- dataset:
config: default
name: MTEB FiQA-PL (default)
revision: 2e535829717f8bf9dc829b7f911cc5bbd4e6608e
split: test
type: clarin-knext/fiqa-pl
metrics:
- type: main_score
value: 38.828
- type: map_at_1
value: 19.126
- type: map_at_10
value: 31.002000000000002
- type: map_at_100
value: 32.736
- type: map_at_1000
value: 32.933
- type: map_at_20
value: 31.894
- type: map_at_3
value: 26.583000000000002
- type: map_at_5
value: 28.904000000000003
- type: mrr_at_1
value: 37.808641975308646
- type: mrr_at_10
value: 46.36745541838134
- type: mrr_at_100
value: 47.14140915794908
- type: mrr_at_1000
value: 47.190701435388846
- type: mrr_at_20
value: 46.81387776440309
- type: mrr_at_3
value: 43.750000000000014
- type: mrr_at_5
value: 45.23919753086418
- type: nauc_map_at_1000_diff1
value: 38.5532285881503
- type: nauc_map_at_1000_max
value: 34.44383884813453
- type: nauc_map_at_1000_std
value: -1.3963497949476722
- type: nauc_map_at_100_diff1
value: 38.49292464176943
- type: nauc_map_at_100_max
value: 34.33752755618645
- type: nauc_map_at_100_std
value: -1.4794032905848582
- type: nauc_map_at_10_diff1
value: 38.26061536370962
- type: nauc_map_at_10_max
value: 33.16977912721411
- type: nauc_map_at_10_std
value: -2.3853370604730393
- type: nauc_map_at_1_diff1
value: 46.288767289528344
- type: nauc_map_at_1_max
value: 25.67706785013364
- type: nauc_map_at_1_std
value: -6.989769609924645
- type: nauc_map_at_20_diff1
value: 38.507270129330685
- type: nauc_map_at_20_max
value: 33.70963328055982
- type: nauc_map_at_20_std
value: -1.9835510011554272
- type: nauc_map_at_3_diff1
value: 39.81061518646884
- type: nauc_map_at_3_max
value: 30.101186374147748
- type: nauc_map_at_3_std
value: -4.027120247237715
- type: nauc_map_at_5_diff1
value: 38.55602589746512
- type: nauc_map_at_5_max
value: 31.515174267015983
- type: nauc_map_at_5_std
value: -3.4064239358570303
- type: nauc_mrr_at_1000_diff1
value: 45.030514454725726
- type: nauc_mrr_at_1000_max
value: 43.878919881666164
- type: nauc_mrr_at_1000_std
value: 2.517594250297626
- type: nauc_mrr_at_100_diff1
value: 45.00868212878687
- type: nauc_mrr_at_100_max
value: 43.87437011120001
- type: nauc_mrr_at_100_std
value: 2.5257874265014966
- type: nauc_mrr_at_10_diff1
value: 44.855044606754056
- type: nauc_mrr_at_10_max
value: 43.946617058785186
- type: nauc_mrr_at_10_std
value: 2.5173751662794044
- type: nauc_mrr_at_1_diff1
value: 49.441510997817346
- type: nauc_mrr_at_1_max
value: 43.08547383044357
- type: nauc_mrr_at_1_std
value: -1.8747770703324347
- type: nauc_mrr_at_20_diff1
value: 45.019880416584215
- type: nauc_mrr_at_20_max
value: 43.85691473662242
- type: nauc_mrr_at_20_std
value: 2.4625487605091303
- type: nauc_mrr_at_3_diff1
value: 45.322041658604036
- type: nauc_mrr_at_3_max
value: 43.95079293074395
- type: nauc_mrr_at_3_std
value: 2.4644274393435737
- type: nauc_mrr_at_5_diff1
value: 44.99461837803437
- type: nauc_mrr_at_5_max
value: 43.97934275090601
- type: nauc_mrr_at_5_std
value: 2.5353091695125096
- type: nauc_ndcg_at_1000_diff1
value: 39.38449023275524
- type: nauc_ndcg_at_1000_max
value: 39.48382767312788
- type: nauc_ndcg_at_1000_std
value: 3.414789408343409
- type: nauc_ndcg_at_100_diff1
value: 38.29675861135578
- type: nauc_ndcg_at_100_max
value: 38.2674786507297
- type: nauc_ndcg_at_100_std
value: 2.7094055381218207
- type: nauc_ndcg_at_10_diff1
value: 38.09514955708717
- type: nauc_ndcg_at_10_max
value: 36.664923238906525
- type: nauc_ndcg_at_10_std
value: 0.6901410544967921
- type: nauc_ndcg_at_1_diff1
value: 49.441510997817346
- type: nauc_ndcg_at_1_max
value: 43.08547383044357
- type: nauc_ndcg_at_1_std
value: -1.8747770703324347
- type: nauc_ndcg_at_20_diff1
value: 38.44967736231759
- type: nauc_ndcg_at_20_max
value: 36.871179313622584
- type: nauc_ndcg_at_20_std
value: 1.157560360065234
- type: nauc_ndcg_at_3_diff1
value: 39.02419271805571
- type: nauc_ndcg_at_3_max
value: 37.447669442586324
- type: nauc_ndcg_at_3_std
value: 0.41502589779297794
- type: nauc_ndcg_at_5_diff1
value: 38.10233452742001
- type: nauc_ndcg_at_5_max
value: 35.816381905465676
- type: nauc_ndcg_at_5_std
value: -0.3704499913387088
- type: nauc_precision_at_1000_diff1
value: 2.451267097838658
- type: nauc_precision_at_1000_max
value: 29.116394969085306
- type: nauc_precision_at_1000_std
value: 14.85900786538363
- type: nauc_precision_at_100_diff1
value: 8.10919082251277
- type: nauc_precision_at_100_max
value: 36.28388256191417
- type: nauc_precision_at_100_std
value: 14.830039904317657
- type: nauc_precision_at_10_diff1
value: 15.02446609920477
- type: nauc_precision_at_10_max
value: 41.008463775454054
- type: nauc_precision_at_10_std
value: 10.431403152334486
- type: nauc_precision_at_1_diff1
value: 49.441510997817346
- type: nauc_precision_at_1_max
value: 43.08547383044357
- type: nauc_precision_at_1_std
value: -1.8747770703324347
- type: nauc_precision_at_20_diff1
value: 14.222022201169926
- type: nauc_precision_at_20_max
value: 40.10189643835305
- type: nauc_precision_at_20_std
value: 12.204443815975527
- type: nauc_precision_at_3_diff1
value: 25.41905395341234
- type: nauc_precision_at_3_max
value: 41.56133905339819
- type: nauc_precision_at_3_std
value: 5.575516915590082
- type: nauc_precision_at_5_diff1
value: 20.20081221089351
- type: nauc_precision_at_5_max
value: 40.95218555916681
- type: nauc_precision_at_5_std
value: 7.2040745500708745
- type: nauc_recall_at_1000_diff1
value: 28.021198234033395
- type: nauc_recall_at_1000_max
value: 36.165148684597504
- type: nauc_recall_at_1000_std
value: 28.28852356008973
- type: nauc_recall_at_100_diff1
value: 21.882447802741897
- type: nauc_recall_at_100_max
value: 26.979684607567222
- type: nauc_recall_at_100_std
value: 9.783658817010082
- type: nauc_recall_at_10_diff1
value: 28.493097951178818
- type: nauc_recall_at_10_max
value: 29.40937476550134
- type: nauc_recall_at_10_std
value: 2.7593763576979353
- type: nauc_recall_at_1_diff1
value: 46.288767289528344
- type: nauc_recall_at_1_max
value: 25.67706785013364
- type: nauc_recall_at_1_std
value: -6.989769609924645
- type: nauc_recall_at_20_diff1
value: 27.638381299425234
- type: nauc_recall_at_20_max
value: 27.942035836106328
- type: nauc_recall_at_20_std
value: 3.489835161380808
- type: nauc_recall_at_3_diff1
value: 33.90054781392646
- type: nauc_recall_at_3_max
value: 27.778812533030322
- type: nauc_recall_at_3_std
value: -0.03054068020022706
- type: nauc_recall_at_5_diff1
value: 30.279060732221346
- type: nauc_recall_at_5_max
value: 27.49854749597931
- type: nauc_recall_at_5_std
value: 0.5434664581939099
- type: ndcg_at_1
value: 37.809
- type: ndcg_at_10
value: 38.828
- type: ndcg_at_100
value: 45.218
- type: ndcg_at_1000
value: 48.510999999999996
- type: ndcg_at_20
value: 41.11
- type: ndcg_at_3
value: 34.466
- type: ndcg_at_5
value: 35.843
- type: precision_at_1
value: 37.809
- type: precision_at_10
value: 11.157
- type: precision_at_100
value: 1.762
- type: precision_at_1000
value: 0.233
- type: precision_at_20
value: 6.497
- type: precision_at_3
value: 23.044999999999998
- type: precision_at_5
value: 17.284
- type: recall_at_1
value: 19.126
- type: recall_at_10
value: 46.062
- type: recall_at_100
value: 70.22800000000001
- type: recall_at_1000
value: 89.803
- type: recall_at_20
value: 53.217999999999996
- type: recall_at_3
value: 30.847
- type: recall_at_5
value: 37.11
task:
type: Retrieval
- dataset:
config: default
name: MTEB HotpotQA-PL (default)
revision: a0bd479ac97b4ccb5bd6ce320c415d0bb4beb907
split: test
type: clarin-knext/hotpotqa-pl
metrics:
- type: main_score
value: 60.27
- type: map_at_1
value: 35.199000000000005
- type: map_at_10
value: 51.369
- type: map_at_100
value: 52.212
- type: map_at_1000
value: 52.28
- type: map_at_20
value: 51.864
- type: map_at_3
value: 48.446
- type: map_at_5
value: 50.302
- type: mrr_at_1
value: 70.39837947332883
- type: mrr_at_10
value: 76.8346141067273
- type: mrr_at_100
value: 77.10724392048137
- type: mrr_at_1000
value: 77.12037412892865
- type: mrr_at_20
value: 77.01061532947222
- type: mrr_at_3
value: 75.5908170155299
- type: mrr_at_5
value: 76.39095205941899
- type: nauc_map_at_1000_diff1
value: 24.701387884989117
- type: nauc_map_at_1000_max
value: 23.25553235642178
- type: nauc_map_at_1000_std
value: 7.1803506915661774
- type: nauc_map_at_100_diff1
value: 24.674498622483103
- type: nauc_map_at_100_max
value: 23.234948525052175
- type: nauc_map_at_100_std
value: 7.168677997105447
- type: nauc_map_at_10_diff1
value: 24.676025039755626
- type: nauc_map_at_10_max
value: 23.171971872726964
- type: nauc_map_at_10_std
value: 6.485610909852058
- type: nauc_map_at_1_diff1
value: 68.90178464319715
- type: nauc_map_at_1_max
value: 46.05537868917558
- type: nauc_map_at_1_std
value: 1.7658552480698708
- type: nauc_map_at_20_diff1
value: 24.69297151842494
- type: nauc_map_at_20_max
value: 23.213064691673637
- type: nauc_map_at_20_std
value: 6.9357946556849
- type: nauc_map_at_3_diff1
value: 26.279128947950507
- type: nauc_map_at_3_max
value: 23.929537354117922
- type: nauc_map_at_3_std
value: 4.625061565714759
- type: nauc_map_at_5_diff1
value: 25.04448959482816
- type: nauc_map_at_5_max
value: 23.432012857899338
- type: nauc_map_at_5_std
value: 5.845744681998008
- type: nauc_mrr_at_1000_diff1
value: 66.7503918108276
- type: nauc_mrr_at_1000_max
value: 48.42897342336844
- type: nauc_mrr_at_1000_std
value: 5.3097517971144415
- type: nauc_mrr_at_100_diff1
value: 66.74645215862695
- type: nauc_mrr_at_100_max
value: 48.4368663009989
- type: nauc_mrr_at_100_std
value: 5.322297898555188
- type: nauc_mrr_at_10_diff1
value: 66.69310166180729
- type: nauc_mrr_at_10_max
value: 48.475437698330225
- type: nauc_mrr_at_10_std
value: 5.258183461631702
- type: nauc_mrr_at_1_diff1
value: 68.90178464319715
- type: nauc_mrr_at_1_max
value: 46.05537868917558
- type: nauc_mrr_at_1_std
value: 1.7658552480698708
- type: nauc_mrr_at_20_diff1
value: 66.72000262431975
- type: nauc_mrr_at_20_max
value: 48.45593642981319
- type: nauc_mrr_at_20_std
value: 5.353665929072101
- type: nauc_mrr_at_3_diff1
value: 66.84936676396276
- type: nauc_mrr_at_3_max
value: 48.466611276778295
- type: nauc_mrr_at_3_std
value: 4.485810398557475
- type: nauc_mrr_at_5_diff1
value: 66.62362565394174
- type: nauc_mrr_at_5_max
value: 48.456431835482014
- type: nauc_mrr_at_5_std
value: 5.08482458391903
- type: nauc_ndcg_at_1000_diff1
value: 29.984825173719443
- type: nauc_ndcg_at_1000_max
value: 27.289179238639893
- type: nauc_ndcg_at_1000_std
value: 10.661480455527526
- type: nauc_ndcg_at_100_diff1
value: 29.322074257047877
- type: nauc_ndcg_at_100_max
value: 26.850650276220605
- type: nauc_ndcg_at_100_std
value: 10.599247982501902
- type: nauc_ndcg_at_10_diff1
value: 29.659909113886094
- type: nauc_ndcg_at_10_max
value: 26.836139599331005
- type: nauc_ndcg_at_10_std
value: 8.12844399452719
- type: nauc_ndcg_at_1_diff1
value: 68.90178464319715
- type: nauc_ndcg_at_1_max
value: 46.05537868917558
- type: nauc_ndcg_at_1_std
value: 1.7658552480698708
- type: nauc_ndcg_at_20_diff1
value: 29.510802214854294
- type: nauc_ndcg_at_20_max
value: 26.775562637730722
- type: nauc_ndcg_at_20_std
value: 9.341342661702363
- type: nauc_ndcg_at_3_diff1
value: 32.741885846292966
- type: nauc_ndcg_at_3_max
value: 28.44225108761343
- type: nauc_ndcg_at_3_std
value: 5.204440768465042
- type: nauc_ndcg_at_5_diff1
value: 30.57856348635919
- type: nauc_ndcg_at_5_max
value: 27.475007474301698
- type: nauc_ndcg_at_5_std
value: 6.961546044312487
- type: nauc_precision_at_1000_diff1
value: 0.002113156309413332
- type: nauc_precision_at_1000_max
value: 11.198242419541286
- type: nauc_precision_at_1000_std
value: 28.69676419166541
- type: nauc_precision_at_100_diff1
value: 3.6049575557782627
- type: nauc_precision_at_100_max
value: 12.499173524574791
- type: nauc_precision_at_100_std
value: 23.3755281004721
- type: nauc_precision_at_10_diff1
value: 10.922574784853193
- type: nauc_precision_at_10_max
value: 16.23221529562036
- type: nauc_precision_at_10_std
value: 12.45014808813857
- type: nauc_precision_at_1_diff1
value: 68.90178464319715
- type: nauc_precision_at_1_max
value: 46.05537868917558
- type: nauc_precision_at_1_std
value: 1.7658552480698708
- type: nauc_precision_at_20_diff1
value: 8.840710781302827
- type: nauc_precision_at_20_max
value: 14.804644554205524
- type: nauc_precision_at_20_std
value: 16.245009770815237
- type: nauc_precision_at_3_diff1
value: 19.447291487137573
- type: nauc_precision_at_3_max
value: 21.47123471597057
- type: nauc_precision_at_3_std
value: 6.441862800128802
- type: nauc_precision_at_5_diff1
value: 14.078545719721108
- type: nauc_precision_at_5_max
value: 18.468288046016387
- type: nauc_precision_at_5_std
value: 9.58650641691393
- type: nauc_recall_at_1000_diff1
value: 0.0021131563095336584
- type: nauc_recall_at_1000_max
value: 11.198242419541558
- type: nauc_recall_at_1000_std
value: 28.6967641916655
- type: nauc_recall_at_100_diff1
value: 3.6049575557781393
- type: nauc_recall_at_100_max
value: 12.499173524574765
- type: nauc_recall_at_100_std
value: 23.375528100472074
- type: nauc_recall_at_10_diff1
value: 10.922574784853168
- type: nauc_recall_at_10_max
value: 16.2322152956203
- type: nauc_recall_at_10_std
value: 12.450148088138535
- type: nauc_recall_at_1_diff1
value: 68.90178464319715
- type: nauc_recall_at_1_max
value: 46.05537868917558
- type: nauc_recall_at_1_std
value: 1.7658552480698708
- type: nauc_recall_at_20_diff1
value: 8.840710781302905
- type: nauc_recall_at_20_max
value: 14.804644554205515
- type: nauc_recall_at_20_std
value: 16.245009770815273
- type: nauc_recall_at_3_diff1
value: 19.447291487137498
- type: nauc_recall_at_3_max
value: 21.47123471597054
- type: nauc_recall_at_3_std
value: 6.441862800128763
- type: nauc_recall_at_5_diff1
value: 14.07854571972115
- type: nauc_recall_at_5_max
value: 18.468288046016337
- type: nauc_recall_at_5_std
value: 9.586506416913904
- type: ndcg_at_1
value: 70.39800000000001
- type: ndcg_at_10
value: 60.27
- type: ndcg_at_100
value: 63.400999999999996
- type: ndcg_at_1000
value: 64.847
- type: ndcg_at_20
value: 61.571
- type: ndcg_at_3
value: 55.875
- type: ndcg_at_5
value: 58.36599999999999
- type: precision_at_1
value: 70.39800000000001
- type: precision_at_10
value: 12.46
- type: precision_at_100
value: 1.493
- type: precision_at_1000
value: 0.169
- type: precision_at_20
value: 6.65
- type: precision_at_3
value: 35.062
- type: precision_at_5
value: 23.009
- type: recall_at_1
value: 35.199000000000005
- type: recall_at_10
value: 62.302
- type: recall_at_100
value: 74.666
- type: recall_at_1000
value: 84.355
- type: recall_at_20
value: 66.496
- type: recall_at_3
value: 52.593
- type: recall_at_5
value: 57.522
task:
type: Retrieval
- dataset:
config: default
name: MTEB MSMARCO-PL (default)
revision: 8634c07806d5cce3a6138e260e59b81760a0a640
split: test
type: clarin-knext/msmarco-pl
metrics:
- type: main_score
value: 64.886
- type: map_at_1
value: 1.644
- type: map_at_10
value: 12.24
- type: map_at_100
value: 28.248
- type: map_at_1000
value: 33.506
- type: map_at_20
value: 17.497
- type: map_at_3
value: 4.9399999999999995
- type: map_at_5
value: 8.272
- type: mrr_at_1
value: 83.72093023255815
- type: mrr_at_10
value: 91.08527131782945
- type: mrr_at_100
value: 91.08527131782945
- type: mrr_at_1000
value: 91.08527131782945
- type: mrr_at_20
value: 91.08527131782945
- type: mrr_at_3
value: 91.08527131782945
- type: mrr_at_5
value: 91.08527131782945
- type: nauc_map_at_1000_diff1
value: -36.428271627303424
- type: nauc_map_at_1000_max
value: 44.87615127218638
- type: nauc_map_at_1000_std
value: 67.92696808824724
- type: nauc_map_at_100_diff1
value: -28.11674206786188
- type: nauc_map_at_100_max
value: 36.422779766334955
- type: nauc_map_at_100_std
value: 49.99876313755116
- type: nauc_map_at_10_diff1
value: -5.838593619806058
- type: nauc_map_at_10_max
value: 11.026519190509742
- type: nauc_map_at_10_std
value: 2.5268752263522045
- type: nauc_map_at_1_diff1
value: 17.897907271073016
- type: nauc_map_at_1_max
value: 12.229062762540844
- type: nauc_map_at_1_std
value: -4.088830895573149
- type: nauc_map_at_20_diff1
value: -13.871097716255626
- type: nauc_map_at_20_max
value: 19.291271635609533
- type: nauc_map_at_20_std
value: 16.745335606507826
- type: nauc_map_at_3_diff1
value: 4.425238457033843
- type: nauc_map_at_3_max
value: 4.611864744680824
- type: nauc_map_at_3_std
value: -8.986916608582863
- type: nauc_map_at_5_diff1
value: -6.254849256920095
- type: nauc_map_at_5_max
value: 2.729437079919823
- type: nauc_map_at_5_std
value: -7.235906279913092
- type: nauc_mrr_at_1000_diff1
value: 52.18669104947672
- type: nauc_mrr_at_1000_max
value: 68.26259125411818
- type: nauc_mrr_at_1000_std
value: 56.345086428353575
- type: nauc_mrr_at_100_diff1
value: 52.18669104947672
- type: nauc_mrr_at_100_max
value: 68.26259125411818
- type: nauc_mrr_at_100_std
value: 56.345086428353575
- type: nauc_mrr_at_10_diff1
value: 52.18669104947672
- type: nauc_mrr_at_10_max
value: 68.26259125411818
- type: nauc_mrr_at_10_std
value: 56.345086428353575
- type: nauc_mrr_at_1_diff1
value: 56.55126663944154
- type: nauc_mrr_at_1_max
value: 66.37014285522565
- type: nauc_mrr_at_1_std
value: 53.2508271389779
- type: nauc_mrr_at_20_diff1
value: 52.18669104947672
- type: nauc_mrr_at_20_max
value: 68.26259125411818
- type: nauc_mrr_at_20_std
value: 56.345086428353575
- type: nauc_mrr_at_3_diff1
value: 52.18669104947672
- type: nauc_mrr_at_3_max
value: 68.26259125411818
- type: nauc_mrr_at_3_std
value: 56.345086428353575
- type: nauc_mrr_at_5_diff1
value: 52.18669104947672
- type: nauc_mrr_at_5_max
value: 68.26259125411818
- type: nauc_mrr_at_5_std
value: 56.345086428353575
- type: nauc_ndcg_at_1000_diff1
value: -19.06422926483731
- type: nauc_ndcg_at_1000_max
value: 56.30853514590265
- type: nauc_ndcg_at_1000_std
value: 70.30810947505557
- type: nauc_ndcg_at_100_diff1
value: -25.72587586459692
- type: nauc_ndcg_at_100_max
value: 51.433781241604194
- type: nauc_ndcg_at_100_std
value: 68.37678512652792
- type: nauc_ndcg_at_10_diff1
value: -23.21198108212602
- type: nauc_ndcg_at_10_max
value: 43.5450720846516
- type: nauc_ndcg_at_10_std
value: 48.78307907005605
- type: nauc_ndcg_at_1_diff1
value: 44.00179301267447
- type: nauc_ndcg_at_1_max
value: 48.202370455680395
- type: nauc_ndcg_at_1_std
value: 25.69655992704088
- type: nauc_ndcg_at_20_diff1
value: -33.88168753446507
- type: nauc_ndcg_at_20_max
value: 45.16199742613164
- type: nauc_ndcg_at_20_std
value: 61.87098383164902
- type: nauc_ndcg_at_3_diff1
value: 11.19174449544048
- type: nauc_ndcg_at_3_max
value: 44.34069860560555
- type: nauc_ndcg_at_3_std
value: 27.451258369798115
- type: nauc_ndcg_at_5_diff1
value: -7.186520929432436
- type: nauc_ndcg_at_5_max
value: 43.41869981139378
- type: nauc_ndcg_at_5_std
value: 34.89898115995178
- type: nauc_precision_at_1000_diff1
value: -34.43998154563451
- type: nauc_precision_at_1000_max
value: 29.172655907480372
- type: nauc_precision_at_1000_std
value: 65.15824469614837
- type: nauc_precision_at_100_diff1
value: -37.82409643259692
- type: nauc_precision_at_100_max
value: 38.24986991317909
- type: nauc_precision_at_100_std
value: 72.74768183105327
- type: nauc_precision_at_10_diff1
value: -32.21556182780535
- type: nauc_precision_at_10_max
value: 34.27170432382651
- type: nauc_precision_at_10_std
value: 58.358255004394664
- type: nauc_precision_at_1_diff1
value: 56.55126663944154
- type: nauc_precision_at_1_max
value: 66.37014285522565
- type: nauc_precision_at_1_std
value: 53.2508271389779
- type: nauc_precision_at_20_diff1
value: -40.18751579026395
- type: nauc_precision_at_20_max
value: 33.960783153758896
- type: nauc_precision_at_20_std
value: 65.42918390184195
- type: nauc_precision_at_3_diff1
value: -7.073870209006578
- type: nauc_precision_at_3_max
value: 50.81535269862325
- type: nauc_precision_at_3_std
value: 59.248681565955685
- type: nauc_precision_at_5_diff1
value: -31.136580596983876
- type: nauc_precision_at_5_max
value: 45.88147792380426
- type: nauc_precision_at_5_std
value: 67.46814230928243
- type: nauc_recall_at_1000_diff1
value: -23.15699999594577
- type: nauc_recall_at_1000_max
value: 39.77277799761876
- type: nauc_recall_at_1000_std
value: 60.326168012901114
- type: nauc_recall_at_100_diff1
value: -21.636664823598498
- type: nauc_recall_at_100_max
value: 31.104969346131583
- type: nauc_recall_at_100_std
value: 38.811686891592096
- type: nauc_recall_at_10_diff1
value: -10.542765625053569
- type: nauc_recall_at_10_max
value: 2.043876058107446
- type: nauc_recall_at_10_std
value: -5.578449908984766
- type: nauc_recall_at_1_diff1
value: 17.897907271073016
- type: nauc_recall_at_1_max
value: 12.229062762540844
- type: nauc_recall_at_1_std
value: -4.088830895573149
- type: nauc_recall_at_20_diff1
value: -15.132909355710103
- type: nauc_recall_at_20_max
value: 12.659765287241065
- type: nauc_recall_at_20_std
value: 8.277887800815819
- type: nauc_recall_at_3_diff1
value: -3.1975017812715016
- type: nauc_recall_at_3_max
value: -3.5539857085038538
- type: nauc_recall_at_3_std
value: -14.712102851318118
- type: nauc_recall_at_5_diff1
value: -14.040507717380743
- type: nauc_recall_at_5_max
value: -6.126912150131701
- type: nauc_recall_at_5_std
value: -13.821624015640355
- type: ndcg_at_1
value: 71.318
- type: ndcg_at_10
value: 64.886
- type: ndcg_at_100
value: 53.187
- type: ndcg_at_1000
value: 59.897999999999996
- type: ndcg_at_20
value: 58.96
- type: ndcg_at_3
value: 69.736
- type: ndcg_at_5
value: 70.14099999999999
- type: precision_at_1
value: 83.721
- type: precision_at_10
value: 71.163
- type: precision_at_100
value: 29.465000000000003
- type: precision_at_1000
value: 5.665
- type: precision_at_20
value: 57.791000000000004
- type: precision_at_3
value: 82.171
- type: precision_at_5
value: 81.86
- type: recall_at_1
value: 1.644
- type: recall_at_10
value: 14.238000000000001
- type: recall_at_100
value: 39.831
- type: recall_at_1000
value: 64.057
- type: recall_at_20
value: 21.021
- type: recall_at_3
value: 5.53
- type: recall_at_5
value: 9.623
task:
type: Retrieval
- dataset:
config: default
name: MTEB NFCorpus-PL (default)
revision: 9a6f9567fda928260afed2de480d79c98bf0bec0
split: test
type: clarin-knext/nfcorpus-pl
metrics:
- type: main_score
value: 31.391000000000002
- type: map_at_1
value: 4.163
- type: map_at_10
value: 10.744
- type: map_at_100
value: 14.038999999999998
- type: map_at_1000
value: 15.434999999999999
- type: map_at_20
value: 12.16
- type: map_at_3
value: 7.614999999999999
- type: map_at_5
value: 9.027000000000001
- type: mrr_at_1
value: 39.0092879256966
- type: mrr_at_10
value: 48.69809327239668
- type: mrr_at_100
value: 49.20788148442068
- type: mrr_at_1000
value: 49.25509336494706
- type: mrr_at_20
value: 48.99606551850896
- type: mrr_at_3
value: 46.284829721362236
- type: mrr_at_5
value: 47.77089783281735
- type: nauc_map_at_1000_diff1
value: 22.75421477116417
- type: nauc_map_at_1000_max
value: 49.242283787799046
- type: nauc_map_at_1000_std
value: 29.056888272331832
- type: nauc_map_at_100_diff1
value: 23.585977398585594
- type: nauc_map_at_100_max
value: 48.25845199409498
- type: nauc_map_at_100_std
value: 24.944264511223693
- type: nauc_map_at_10_diff1
value: 27.386613094780255
- type: nauc_map_at_10_max
value: 41.52415346691586
- type: nauc_map_at_10_std
value: 12.93872448563755
- type: nauc_map_at_1_diff1
value: 46.78688143865053
- type: nauc_map_at_1_max
value: 37.20408843995871
- type: nauc_map_at_1_std
value: 4.383444959401098
- type: nauc_map_at_20_diff1
value: 25.590969047740288
- type: nauc_map_at_20_max
value: 44.57109307999418
- type: nauc_map_at_20_std
value: 16.45855141821407
- type: nauc_map_at_3_diff1
value: 36.30017108362863
- type: nauc_map_at_3_max
value: 34.66149613991648
- type: nauc_map_at_3_std
value: 5.67985905078467
- type: nauc_map_at_5_diff1
value: 31.157644795417223
- type: nauc_map_at_5_max
value: 37.274738661636825
- type: nauc_map_at_5_std
value: 8.70088872394168
- type: nauc_mrr_at_1000_diff1
value: 25.638564218157384
- type: nauc_mrr_at_1000_max
value: 57.77788270285353
- type: nauc_mrr_at_1000_std
value: 43.507586592911274
- type: nauc_mrr_at_100_diff1
value: 25.662002580561584
- type: nauc_mrr_at_100_max
value: 57.80578394278584
- type: nauc_mrr_at_100_std
value: 43.543905743986635
- type: nauc_mrr_at_10_diff1
value: 25.426034796339835
- type: nauc_mrr_at_10_max
value: 57.68443186258669
- type: nauc_mrr_at_10_std
value: 43.438009108331215
- type: nauc_mrr_at_1_diff1
value: 26.073028156311075
- type: nauc_mrr_at_1_max
value: 52.11817916720053
- type: nauc_mrr_at_1_std
value: 37.41073893153695
- type: nauc_mrr_at_20_diff1
value: 25.548645553336147
- type: nauc_mrr_at_20_max
value: 57.78552760401915
- type: nauc_mrr_at_20_std
value: 43.521687428822325
- type: nauc_mrr_at_3_diff1
value: 25.72662577397805
- type: nauc_mrr_at_3_max
value: 56.891263536265605
- type: nauc_mrr_at_3_std
value: 41.384872305390104
- type: nauc_mrr_at_5_diff1
value: 25.552211551655386
- type: nauc_mrr_at_5_max
value: 57.976813828353926
- type: nauc_mrr_at_5_std
value: 43.504564461855544
- type: nauc_ndcg_at_1000_diff1
value: 23.456158044182757
- type: nauc_ndcg_at_1000_max
value: 60.05411773552709
- type: nauc_ndcg_at_1000_std
value: 47.857510017262584
- type: nauc_ndcg_at_100_diff1
value: 19.711635700390772
- type: nauc_ndcg_at_100_max
value: 56.178746740470665
- type: nauc_ndcg_at_100_std
value: 42.36829180286942
- type: nauc_ndcg_at_10_diff1
value: 18.364428967788413
- type: nauc_ndcg_at_10_max
value: 54.38372506578223
- type: nauc_ndcg_at_10_std
value: 41.75765411340369
- type: nauc_ndcg_at_1_diff1
value: 26.571093272640773
- type: nauc_ndcg_at_1_max
value: 51.061788341958284
- type: nauc_ndcg_at_1_std
value: 36.514987974075986
- type: nauc_ndcg_at_20_diff1
value: 18.345487193027697
- type: nauc_ndcg_at_20_max
value: 54.62621882656994
- type: nauc_ndcg_at_20_std
value: 41.42835554714241
- type: nauc_ndcg_at_3_diff1
value: 23.260105658139025
- type: nauc_ndcg_at_3_max
value: 52.07747385334546
- type: nauc_ndcg_at_3_std
value: 36.91985577837284
- type: nauc_ndcg_at_5_diff1
value: 20.40428109665566
- type: nauc_ndcg_at_5_max
value: 53.52015347884604
- type: nauc_ndcg_at_5_std
value: 39.46008849580017
- type: nauc_precision_at_1000_diff1
value: -7.3487344916380035
- type: nauc_precision_at_1000_max
value: 16.58045221394852
- type: nauc_precision_at_1000_std
value: 38.94030932397075
- type: nauc_precision_at_100_diff1
value: -5.257743986683922
- type: nauc_precision_at_100_max
value: 34.43071687475306
- type: nauc_precision_at_100_std
value: 53.499519170670474
- type: nauc_precision_at_10_diff1
value: 2.385136433119139
- type: nauc_precision_at_10_max
value: 47.210743878631064
- type: nauc_precision_at_10_std
value: 47.22767704186548
- type: nauc_precision_at_1_diff1
value: 26.073028156311075
- type: nauc_precision_at_1_max
value: 52.11817916720053
- type: nauc_precision_at_1_std
value: 37.41073893153695
- type: nauc_precision_at_20_diff1
value: -0.3531531127238474
- type: nauc_precision_at_20_max
value: 44.78044604856974
- type: nauc_precision_at_20_std
value: 49.532804150743615
- type: nauc_precision_at_3_diff1
value: 15.350050569991447
- type: nauc_precision_at_3_max
value: 51.01572315596549
- type: nauc_precision_at_3_std
value: 38.801125728413155
- type: nauc_precision_at_5_diff1
value: 9.109003666144694
- type: nauc_precision_at_5_max
value: 50.935269774898494
- type: nauc_precision_at_5_std
value: 43.323548180559676
- type: nauc_recall_at_1000_diff1
value: 16.64743647648886
- type: nauc_recall_at_1000_max
value: 38.46012283772285
- type: nauc_recall_at_1000_std
value: 36.02016164796441
- type: nauc_recall_at_100_diff1
value: 14.005834785186744
- type: nauc_recall_at_100_max
value: 37.70026105513647
- type: nauc_recall_at_100_std
value: 27.085222642129697
- type: nauc_recall_at_10_diff1
value: 21.204106627422632
- type: nauc_recall_at_10_max
value: 36.737624881893424
- type: nauc_recall_at_10_std
value: 13.755054514272702
- type: nauc_recall_at_1_diff1
value: 46.78688143865053
- type: nauc_recall_at_1_max
value: 37.20408843995871
- type: nauc_recall_at_1_std
value: 4.383444959401098
- type: nauc_recall_at_20_diff1
value: 19.740977611421933
- type: nauc_recall_at_20_max
value: 39.21908969539783
- type: nauc_recall_at_20_std
value: 16.560269670318494
- type: nauc_recall_at_3_diff1
value: 32.189359545367815
- type: nauc_recall_at_3_max
value: 31.693634445562758
- type: nauc_recall_at_3_std
value: 6.246326281543587
- type: nauc_recall_at_5_diff1
value: 25.51586860499901
- type: nauc_recall_at_5_max
value: 33.15934725342885
- type: nauc_recall_at_5_std
value: 9.677778511696705
- type: ndcg_at_1
value: 37.307
- type: ndcg_at_10
value: 31.391000000000002
- type: ndcg_at_100
value: 28.877999999999997
- type: ndcg_at_1000
value: 37.16
- type: ndcg_at_20
value: 29.314
- type: ndcg_at_3
value: 35.405
- type: ndcg_at_5
value: 33.922999999999995
- type: precision_at_1
value: 39.009
- type: precision_at_10
value: 24.52
- type: precision_at_100
value: 7.703
- type: precision_at_1000
value: 2.04
- type: precision_at_20
value: 18.08
- type: precision_at_3
value: 34.469
- type: precision_at_5
value: 30.712
- type: recall_at_1
value: 4.163
- type: recall_at_10
value: 15.015999999999998
- type: recall_at_100
value: 30.606
- type: recall_at_1000
value: 59.606
- type: recall_at_20
value: 19.09
- type: recall_at_3
value: 9.139
- type: recall_at_5
value: 11.477
task:
type: Retrieval
- dataset:
config: default
name: MTEB NQ-PL (default)
revision: f171245712cf85dd4700b06bef18001578d0ca8d
split: test
type: clarin-knext/nq-pl
metrics:
- type: main_score
value: 54.017
- type: map_at_1
value: 34.193
- type: map_at_10
value: 47.497
- type: map_at_100
value: 48.441
- type: map_at_1000
value: 48.481
- type: map_at_20
value: 48.093
- type: map_at_3
value: 44.017
- type: map_at_5
value: 46.111000000000004
- type: mrr_at_1
value: 37.949015063731174
- type: mrr_at_10
value: 49.915772315105954
- type: mrr_at_100
value: 50.62841255829997
- type: mrr_at_1000
value: 50.656773027666745
- type: mrr_at_20
value: 50.37785276657083
- type: mrr_at_3
value: 46.98725376593267
- type: mrr_at_5
value: 48.763035921205066
- type: nauc_map_at_1000_diff1
value: 39.5632191792873
- type: nauc_map_at_1000_max
value: 37.4728247053629
- type: nauc_map_at_1000_std
value: 5.742498414663762
- type: nauc_map_at_100_diff1
value: 39.555570352061906
- type: nauc_map_at_100_max
value: 37.497880976847334
- type: nauc_map_at_100_std
value: 5.7798021019465375
- type: nauc_map_at_10_diff1
value: 39.5423723444454
- type: nauc_map_at_10_max
value: 37.41661971723365
- type: nauc_map_at_10_std
value: 5.2378002164144695
- type: nauc_map_at_1_diff1
value: 41.52697034146981
- type: nauc_map_at_1_max
value: 28.558995576942863
- type: nauc_map_at_1_std
value: 0.13094542859192052
- type: nauc_map_at_20_diff1
value: 39.55484628943701
- type: nauc_map_at_20_max
value: 37.5247794933719
- type: nauc_map_at_20_std
value: 5.702881342279231
- type: nauc_map_at_3_diff1
value: 39.949323925425325
- type: nauc_map_at_3_max
value: 35.770298168901924
- type: nauc_map_at_3_std
value: 2.9127112432479874
- type: nauc_map_at_5_diff1
value: 39.768310617004545
- type: nauc_map_at_5_max
value: 37.1549191664796
- type: nauc_map_at_5_std
value: 4.4681285748269515
- type: nauc_mrr_at_1000_diff1
value: 39.14001746706457
- type: nauc_mrr_at_1000_max
value: 37.477376518267775
- type: nauc_mrr_at_1000_std
value: 6.8088891531621565
- type: nauc_mrr_at_100_diff1
value: 39.13054707413684
- type: nauc_mrr_at_100_max
value: 37.498126443766274
- type: nauc_mrr_at_100_std
value: 6.839411380129971
- type: nauc_mrr_at_10_diff1
value: 39.09764730048156
- type: nauc_mrr_at_10_max
value: 37.58593798217306
- type: nauc_mrr_at_10_std
value: 6.713795164982413
- type: nauc_mrr_at_1_diff1
value: 41.581599918664075
- type: nauc_mrr_at_1_max
value: 31.500589231378722
- type: nauc_mrr_at_1_std
value: 2.059116370339438
- type: nauc_mrr_at_20_diff1
value: 39.09011023988447
- type: nauc_mrr_at_20_max
value: 37.55856008791344
- type: nauc_mrr_at_20_std
value: 6.847165397615844
- type: nauc_mrr_at_3_diff1
value: 39.382542043738
- type: nauc_mrr_at_3_max
value: 36.49265363659468
- type: nauc_mrr_at_3_std
value: 4.759157976438336
- type: nauc_mrr_at_5_diff1
value: 39.304826333759976
- type: nauc_mrr_at_5_max
value: 37.46326016736024
- type: nauc_mrr_at_5_std
value: 6.122608305766621
- type: nauc_ndcg_at_1000_diff1
value: 38.568500038453266
- type: nauc_ndcg_at_1000_max
value: 39.799710882413166
- type: nauc_ndcg_at_1000_std
value: 9.357010223096639
- type: nauc_ndcg_at_100_diff1
value: 38.38026091343228
- type: nauc_ndcg_at_100_max
value: 40.48398173542486
- type: nauc_ndcg_at_100_std
value: 10.373054013302214
- type: nauc_ndcg_at_10_diff1
value: 38.27340980909964
- type: nauc_ndcg_at_10_max
value: 40.35241649744093
- type: nauc_ndcg_at_10_std
value: 8.579139930345168
- type: nauc_ndcg_at_1_diff1
value: 41.581599918664075
- type: nauc_ndcg_at_1_max
value: 31.500589231378722
- type: nauc_ndcg_at_1_std
value: 2.059116370339438
- type: nauc_ndcg_at_20_diff1
value: 38.26453028884807
- type: nauc_ndcg_at_20_max
value: 40.70517858426641
- type: nauc_ndcg_at_20_std
value: 9.987693876137905
- type: nauc_ndcg_at_3_diff1
value: 39.2078971733273
- type: nauc_ndcg_at_3_max
value: 37.48672195565316
- type: nauc_ndcg_at_3_std
value: 4.051464994659221
- type: nauc_ndcg_at_5_diff1
value: 38.883693595665285
- type: nauc_ndcg_at_5_max
value: 39.763115634437135
- type: nauc_ndcg_at_5_std
value: 6.738980451582073
- type: nauc_precision_at_1000_diff1
value: -7.223215910619012
- type: nauc_precision_at_1000_max
value: 13.075844604892161
- type: nauc_precision_at_1000_std
value: 19.864336920890107
- type: nauc_precision_at_100_diff1
value: 1.3305994810812418
- type: nauc_precision_at_100_max
value: 25.9219108557104
- type: nauc_precision_at_100_std
value: 27.5076605928207
- type: nauc_precision_at_10_diff1
value: 18.441551484970326
- type: nauc_precision_at_10_max
value: 39.85995330437054
- type: nauc_precision_at_10_std
value: 20.561269077428914
- type: nauc_precision_at_1_diff1
value: 41.581599918664075
- type: nauc_precision_at_1_max
value: 31.500589231378722
- type: nauc_precision_at_1_std
value: 2.059116370339438
- type: nauc_precision_at_20_diff1
value: 12.579593891480531
- type: nauc_precision_at_20_max
value: 36.620221830588775
- type: nauc_precision_at_20_std
value: 26.40364876775059
- type: nauc_precision_at_3_diff1
value: 30.158859294487073
- type: nauc_precision_at_3_max
value: 41.168215766389174
- type: nauc_precision_at_3_std
value: 9.44345004450809
- type: nauc_precision_at_5_diff1
value: 25.438624678672785
- type: nauc_precision_at_5_max
value: 42.72802023518524
- type: nauc_precision_at_5_std
value: 15.357657388511099
- type: nauc_recall_at_1000_diff1
value: 24.987564782718003
- type: nauc_recall_at_1000_max
value: 70.508416373353
- type: nauc_recall_at_1000_std
value: 69.75092280398808
- type: nauc_recall_at_100_diff1
value: 29.504202856421397
- type: nauc_recall_at_100_max
value: 63.41356585545318
- type: nauc_recall_at_100_std
value: 50.09250954437847
- type: nauc_recall_at_10_diff1
value: 32.355776022971774
- type: nauc_recall_at_10_max
value: 49.47121901667283
- type: nauc_recall_at_10_std
value: 19.418439406631244
- type: nauc_recall_at_1_diff1
value: 41.52697034146981
- type: nauc_recall_at_1_max
value: 28.558995576942863
- type: nauc_recall_at_1_std
value: 0.13094542859192052
- type: nauc_recall_at_20_diff1
value: 31.57334731023589
- type: nauc_recall_at_20_max
value: 54.06567225197383
- type: nauc_recall_at_20_std
value: 29.222029720570468
- type: nauc_recall_at_3_diff1
value: 36.45033533275773
- type: nauc_recall_at_3_max
value: 40.39529713780803
- type: nauc_recall_at_3_std
value: 5.21893897772794
- type: nauc_recall_at_5_diff1
value: 35.18471678478859
- type: nauc_recall_at_5_max
value: 46.20100816867823
- type: nauc_recall_at_5_std
value: 11.94481894633221
- type: ndcg_at_1
value: 37.949
- type: ndcg_at_10
value: 54.017
- type: ndcg_at_100
value: 58.126
- type: ndcg_at_1000
value: 59.073
- type: ndcg_at_20
value: 55.928
- type: ndcg_at_3
value: 47.494
- type: ndcg_at_5
value: 50.975
- type: precision_at_1
value: 37.949
- type: precision_at_10
value: 8.450000000000001
- type: precision_at_100
value: 1.083
- type: precision_at_1000
value: 0.117
- type: precision_at_20
value: 4.689
- type: precision_at_3
value: 21.051000000000002
- type: precision_at_5
value: 14.664
- type: recall_at_1
value: 34.193
- type: recall_at_10
value: 71.357
- type: recall_at_100
value: 89.434
- type: recall_at_1000
value: 96.536
- type: recall_at_20
value: 78.363
- type: recall_at_3
value: 54.551
- type: recall_at_5
value: 62.543000000000006
task:
type: Retrieval
- dataset:
config: default
name: MTEB Quora-PL (default)
revision: 0be27e93455051e531182b85e85e425aba12e9d4
split: test
type: clarin-knext/quora-pl
metrics:
- type: main_score
value: 84.114
- type: map_at_1
value: 65.848
- type: map_at_10
value: 79.85900000000001
- type: map_at_100
value: 80.582
- type: map_at_1000
value: 80.60300000000001
- type: map_at_20
value: 80.321
- type: map_at_3
value: 76.741
- type: map_at_5
value: 78.72200000000001
- type: mrr_at_1
value: 75.97
- type: mrr_at_10
value: 83.04630158730119
- type: mrr_at_100
value: 83.22785731032968
- type: mrr_at_1000
value: 83.23123717623899
- type: mrr_at_20
value: 83.17412021320565
- type: mrr_at_3
value: 81.83333333333287
- type: mrr_at_5
value: 82.61933333333275
- type: nauc_map_at_1000_diff1
value: 73.26316553371083
- type: nauc_map_at_1000_max
value: 27.92567859085245
- type: nauc_map_at_1000_std
value: -47.477909533360446
- type: nauc_map_at_100_diff1
value: 73.2690602807223
- type: nauc_map_at_100_max
value: 27.915868327849996
- type: nauc_map_at_100_std
value: -47.525777766107595
- type: nauc_map_at_10_diff1
value: 73.45464428464894
- type: nauc_map_at_10_max
value: 27.451611487246296
- type: nauc_map_at_10_std
value: -49.35818715843809
- type: nauc_map_at_1_diff1
value: 77.29690208952982
- type: nauc_map_at_1_max
value: 19.839875762282293
- type: nauc_map_at_1_std
value: -45.355684654708284
- type: nauc_map_at_20_diff1
value: 73.35102731979796
- type: nauc_map_at_20_max
value: 27.741506490134583
- type: nauc_map_at_20_std
value: -48.22006207310331
- type: nauc_map_at_3_diff1
value: 73.94878241064137
- type: nauc_map_at_3_max
value: 24.761321386766728
- type: nauc_map_at_3_std
value: -51.20638883618126
- type: nauc_map_at_5_diff1
value: 73.66143558047698
- type: nauc_map_at_5_max
value: 26.53483405013543
- type: nauc_map_at_5_std
value: -50.697541279640056
- type: nauc_mrr_at_1000_diff1
value: 73.84632320009759
- type: nauc_mrr_at_1000_max
value: 30.50182733610048
- type: nauc_mrr_at_1000_std
value: -44.3021647995251
- type: nauc_mrr_at_100_diff1
value: 73.84480792662302
- type: nauc_mrr_at_100_max
value: 30.50749424571614
- type: nauc_mrr_at_100_std
value: -44.29615086388113
- type: nauc_mrr_at_10_diff1
value: 73.79442772949346
- type: nauc_mrr_at_10_max
value: 30.55724252219984
- type: nauc_mrr_at_10_std
value: -44.50997069462057
- type: nauc_mrr_at_1_diff1
value: 75.23369827945945
- type: nauc_mrr_at_1_max
value: 29.20073967447664
- type: nauc_mrr_at_1_std
value: -43.1920147658285
- type: nauc_mrr_at_20_diff1
value: 73.82731678072307
- type: nauc_mrr_at_20_max
value: 30.566328605497667
- type: nauc_mrr_at_20_std
value: -44.24683607643705
- type: nauc_mrr_at_3_diff1
value: 73.61997576749954
- type: nauc_mrr_at_3_max
value: 30.150393853381917
- type: nauc_mrr_at_3_std
value: -44.96847297506626
- type: nauc_mrr_at_5_diff1
value: 73.69084310616132
- type: nauc_mrr_at_5_max
value: 30.578033703441125
- type: nauc_mrr_at_5_std
value: -44.74920746066566
- type: nauc_ndcg_at_1000_diff1
value: 72.89349862557452
- type: nauc_ndcg_at_1000_max
value: 29.824725190462086
- type: nauc_ndcg_at_1000_std
value: -44.96284395063211
- type: nauc_ndcg_at_100_diff1
value: 72.85212753715273
- type: nauc_ndcg_at_100_max
value: 29.933114207845605
- type: nauc_ndcg_at_100_std
value: -44.944225570663754
- type: nauc_ndcg_at_10_diff1
value: 72.80576740454528
- type: nauc_ndcg_at_10_max
value: 29.16829118320828
- type: nauc_ndcg_at_10_std
value: -48.149473740079614
- type: nauc_ndcg_at_1_diff1
value: 75.00032534968587
- type: nauc_ndcg_at_1_max
value: 29.61849062038547
- type: nauc_ndcg_at_1_std
value: -42.560207043864054
- type: nauc_ndcg_at_20_diff1
value: 72.88440406302502
- type: nauc_ndcg_at_20_max
value: 29.65496676092656
- type: nauc_ndcg_at_20_std
value: -46.21238462167732
- type: nauc_ndcg_at_3_diff1
value: 72.37916962766987
- type: nauc_ndcg_at_3_max
value: 27.125094834547586
- type: nauc_ndcg_at_3_std
value: -48.62942991399391
- type: nauc_ndcg_at_5_diff1
value: 72.57017330527658
- type: nauc_ndcg_at_5_max
value: 28.470485561757254
- type: nauc_ndcg_at_5_std
value: -49.07593345591059
- type: nauc_precision_at_1000_diff1
value: -41.67915575853946
- type: nauc_precision_at_1000_max
value: 1.2012264478568844
- type: nauc_precision_at_1000_std
value: 44.723834559400466
- type: nauc_precision_at_100_diff1
value: -40.45196679236971
- type: nauc_precision_at_100_max
value: 2.3525450401714894
- type: nauc_precision_at_100_std
value: 43.7092529413952
- type: nauc_precision_at_10_diff1
value: -30.256026923068767
- type: nauc_precision_at_10_max
value: 8.313422052132559
- type: nauc_precision_at_10_std
value: 25.929372356449694
- type: nauc_precision_at_1_diff1
value: 75.00032534968587
- type: nauc_precision_at_1_max
value: 29.61849062038547
- type: nauc_precision_at_1_std
value: -42.560207043864054
- type: nauc_precision_at_20_diff1
value: -35.61971069986584
- type: nauc_precision_at_20_max
value: 5.4664303079116765
- type: nauc_precision_at_20_std
value: 34.992352471692826
- type: nauc_precision_at_3_diff1
value: -5.691231842471157
- type: nauc_precision_at_3_max
value: 14.797949087742444
- type: nauc_precision_at_3_std
value: -0.1930317395644928
- type: nauc_precision_at_5_diff1
value: -20.03913781462645
- type: nauc_precision_at_5_max
value: 11.956771408712749
- type: nauc_precision_at_5_std
value: 13.179251389859731
- type: nauc_recall_at_1000_diff1
value: 64.03509042729674
- type: nauc_recall_at_1000_max
value: 40.91691485428493
- type: nauc_recall_at_1000_std
value: 16.12968625875372
- type: nauc_recall_at_100_diff1
value: 63.83116179628575
- type: nauc_recall_at_100_max
value: 43.72908117676382
- type: nauc_recall_at_100_std
value: -20.50966716852155
- type: nauc_recall_at_10_diff1
value: 66.42071960186394
- type: nauc_recall_at_10_max
value: 28.983207818687205
- type: nauc_recall_at_10_std
value: -56.61417798753744
- type: nauc_recall_at_1_diff1
value: 77.29690208952982
- type: nauc_recall_at_1_max
value: 19.839875762282293
- type: nauc_recall_at_1_std
value: -45.355684654708284
- type: nauc_recall_at_20_diff1
value: 66.32360705219874
- type: nauc_recall_at_20_max
value: 33.30698111822631
- type: nauc_recall_at_20_std
value: -43.89233781737452
- type: nauc_recall_at_3_diff1
value: 69.67029394927077
- type: nauc_recall_at_3_max
value: 22.67803039327696
- type: nauc_recall_at_3_std
value: -56.43327209861502
- type: nauc_recall_at_5_diff1
value: 68.05622143936131
- type: nauc_recall_at_5_max
value: 26.67795559040675
- type: nauc_recall_at_5_std
value: -58.158231198510954
- type: ndcg_at_1
value: 76.08
- type: ndcg_at_10
value: 84.114
- type: ndcg_at_100
value: 85.784
- type: ndcg_at_1000
value: 85.992
- type: ndcg_at_20
value: 84.976
- type: ndcg_at_3
value: 80.74799999999999
- type: ndcg_at_5
value: 82.626
- type: precision_at_1
value: 76.08
- type: precision_at_10
value: 12.926000000000002
- type: precision_at_100
value: 1.509
- type: precision_at_1000
value: 0.156
- type: precision_at_20
value: 6.912999999999999
- type: precision_at_3
value: 35.5
- type: precision_at_5
value: 23.541999999999998
- type: recall_at_1
value: 65.848
- type: recall_at_10
value: 92.611
- type: recall_at_100
value: 98.69
- type: recall_at_1000
value: 99.83999999999999
- type: recall_at_20
value: 95.47200000000001
- type: recall_at_3
value: 83.122
- type: recall_at_5
value: 88.23
task:
type: Retrieval
- dataset:
config: default
name: MTEB SCIDOCS-PL (default)
revision: 45452b03f05560207ef19149545f168e596c9337
split: test
type: clarin-knext/scidocs-pl
metrics:
- type: main_score
value: 15.379999999999999
- type: map_at_1
value: 3.6029999999999998
- type: map_at_10
value: 8.843
- type: map_at_100
value: 10.433
- type: map_at_1000
value: 10.689
- type: map_at_20
value: 9.597
- type: map_at_3
value: 6.363
- type: map_at_5
value: 7.603
- type: mrr_at_1
value: 17.7
- type: mrr_at_10
value: 26.58900793650793
- type: mrr_at_100
value: 27.699652322890987
- type: mrr_at_1000
value: 27.78065313118353
- type: mrr_at_20
value: 27.215020950411816
- type: mrr_at_3
value: 23.36666666666668
- type: mrr_at_5
value: 25.211666666666666
- type: nauc_map_at_1000_diff1
value: 21.92235143827129
- type: nauc_map_at_1000_max
value: 37.50300940750989
- type: nauc_map_at_1000_std
value: 20.872586122198552
- type: nauc_map_at_100_diff1
value: 21.917408170465833
- type: nauc_map_at_100_max
value: 37.4654466815513
- type: nauc_map_at_100_std
value: 20.621643878648534
- type: nauc_map_at_10_diff1
value: 22.914388723621183
- type: nauc_map_at_10_max
value: 36.468131213468794
- type: nauc_map_at_10_std
value: 16.760980140791492
- type: nauc_map_at_1_diff1
value: 29.00799502838457
- type: nauc_map_at_1_max
value: 26.64926291797503
- type: nauc_map_at_1_std
value: 8.167291261637361
- type: nauc_map_at_20_diff1
value: 22.46580947804047
- type: nauc_map_at_20_max
value: 36.656294842562275
- type: nauc_map_at_20_std
value: 18.099232417722078
- type: nauc_map_at_3_diff1
value: 23.436009032045934
- type: nauc_map_at_3_max
value: 31.325807212280914
- type: nauc_map_at_3_std
value: 9.780905232048852
- type: nauc_map_at_5_diff1
value: 22.891704394665528
- type: nauc_map_at_5_max
value: 35.40584466642894
- type: nauc_map_at_5_std
value: 13.476986099394656
- type: nauc_mrr_at_1000_diff1
value: 25.052937655397866
- type: nauc_mrr_at_1000_max
value: 29.64431912670108
- type: nauc_mrr_at_1000_std
value: 14.549744963988044
- type: nauc_mrr_at_100_diff1
value: 25.070871266969224
- type: nauc_mrr_at_100_max
value: 29.68743604652336
- type: nauc_mrr_at_100_std
value: 14.582010154574432
- type: nauc_mrr_at_10_diff1
value: 24.88881466938897
- type: nauc_mrr_at_10_max
value: 29.488430770768144
- type: nauc_mrr_at_10_std
value: 14.269241073852266
- type: nauc_mrr_at_1_diff1
value: 29.220540327267503
- type: nauc_mrr_at_1_max
value: 26.81908580507911
- type: nauc_mrr_at_1_std
value: 8.00840295809718
- type: nauc_mrr_at_20_diff1
value: 25.067912695721944
- type: nauc_mrr_at_20_max
value: 29.759227563849628
- type: nauc_mrr_at_20_std
value: 14.685076859257357
- type: nauc_mrr_at_3_diff1
value: 24.645848739182696
- type: nauc_mrr_at_3_max
value: 27.73368549660351
- type: nauc_mrr_at_3_std
value: 11.475742805586943
- type: nauc_mrr_at_5_diff1
value: 24.895295760909946
- type: nauc_mrr_at_5_max
value: 29.130755033240423
- type: nauc_mrr_at_5_std
value: 12.955802929145404
- type: nauc_ndcg_at_1000_diff1
value: 20.68434434777729
- type: nauc_ndcg_at_1000_max
value: 37.67055146424174
- type: nauc_ndcg_at_1000_std
value: 29.57493715069776
- type: nauc_ndcg_at_100_diff1
value: 20.396834816492383
- type: nauc_ndcg_at_100_max
value: 37.460575228670514
- type: nauc_ndcg_at_100_std
value: 27.826534756761944
- type: nauc_ndcg_at_10_diff1
value: 22.640844106236027
- type: nauc_ndcg_at_10_max
value: 35.21291764462327
- type: nauc_ndcg_at_10_std
value: 19.53289455984506
- type: nauc_ndcg_at_1_diff1
value: 29.220540327267503
- type: nauc_ndcg_at_1_max
value: 26.81908580507911
- type: nauc_ndcg_at_1_std
value: 8.00840295809718
- type: nauc_ndcg_at_20_diff1
value: 22.117126657768623
- type: nauc_ndcg_at_20_max
value: 35.79395781940806
- type: nauc_ndcg_at_20_std
value: 22.242748346260786
- type: nauc_ndcg_at_3_diff1
value: 23.00596063212187
- type: nauc_ndcg_at_3_max
value: 30.149013627580523
- type: nauc_ndcg_at_3_std
value: 11.07904064662722
- type: nauc_ndcg_at_5_diff1
value: 22.81875419630523
- type: nauc_ndcg_at_5_max
value: 34.24267468356626
- type: nauc_ndcg_at_5_std
value: 15.307780280752088
- type: nauc_precision_at_1000_diff1
value: 9.606677689029972
- type: nauc_precision_at_1000_max
value: 32.74855550489271
- type: nauc_precision_at_1000_std
value: 42.65372585937895
- type: nauc_precision_at_100_diff1
value: 11.528981313529545
- type: nauc_precision_at_100_max
value: 35.642529490132404
- type: nauc_precision_at_100_std
value: 38.146151426052306
- type: nauc_precision_at_10_diff1
value: 18.783957183811836
- type: nauc_precision_at_10_max
value: 36.1982008334257
- type: nauc_precision_at_10_std
value: 25.09349473195891
- type: nauc_precision_at_1_diff1
value: 29.220540327267503
- type: nauc_precision_at_1_max
value: 26.81908580507911
- type: nauc_precision_at_1_std
value: 8.00840295809718
- type: nauc_precision_at_20_diff1
value: 17.458766320828214
- type: nauc_precision_at_20_max
value: 36.000404903025235
- type: nauc_precision_at_20_std
value: 29.1608044138323
- type: nauc_precision_at_3_diff1
value: 20.213669462067166
- type: nauc_precision_at_3_max
value: 31.120650847205912
- type: nauc_precision_at_3_std
value: 12.390972418818118
- type: nauc_precision_at_5_diff1
value: 20.114245715785678
- type: nauc_precision_at_5_max
value: 37.30360111495823
- type: nauc_precision_at_5_std
value: 19.053109037822853
- type: nauc_recall_at_1000_diff1
value: 9.85800049032612
- type: nauc_recall_at_1000_max
value: 32.48319160802687
- type: nauc_recall_at_1000_std
value: 43.79941601741161
- type: nauc_recall_at_100_diff1
value: 11.375255270968337
- type: nauc_recall_at_100_max
value: 35.1868784124497
- type: nauc_recall_at_100_std
value: 38.422680583482666
- type: nauc_recall_at_10_diff1
value: 18.445783123521938
- type: nauc_recall_at_10_max
value: 35.633267936276766
- type: nauc_recall_at_10_std
value: 24.94469506254716
- type: nauc_recall_at_1_diff1
value: 29.00799502838457
- type: nauc_recall_at_1_max
value: 26.64926291797503
- type: nauc_recall_at_1_std
value: 8.167291261637361
- type: nauc_recall_at_20_diff1
value: 17.314906604151936
- type: nauc_recall_at_20_max
value: 35.66067699203996
- type: nauc_recall_at_20_std
value: 29.400137012506082
- type: nauc_recall_at_3_diff1
value: 19.873710875648698
- type: nauc_recall_at_3_max
value: 30.92404718742849
- type: nauc_recall_at_3_std
value: 12.400871018075199
- type: nauc_recall_at_5_diff1
value: 19.869948324233192
- type: nauc_recall_at_5_max
value: 37.06832511687574
- type: nauc_recall_at_5_std
value: 19.0798814966156
- type: ndcg_at_1
value: 17.7
- type: ndcg_at_10
value: 15.379999999999999
- type: ndcg_at_100
value: 22.09
- type: ndcg_at_1000
value: 27.151999999999997
- type: ndcg_at_20
value: 17.576
- type: ndcg_at_3
value: 14.219999999999999
- type: ndcg_at_5
value: 12.579
- type: precision_at_1
value: 17.7
- type: precision_at_10
value: 8.08
- type: precision_at_100
value: 1.7840000000000003
- type: precision_at_1000
value: 0.3
- type: precision_at_20
value: 5.305
- type: precision_at_3
value: 13.167000000000002
- type: precision_at_5
value: 11.06
- type: recall_at_1
value: 3.6029999999999998
- type: recall_at_10
value: 16.413
- type: recall_at_100
value: 36.263
- type: recall_at_1000
value: 61.016999999999996
- type: recall_at_20
value: 21.587999999999997
- type: recall_at_3
value: 8.013
- type: recall_at_5
value: 11.198
task:
type: Retrieval
- dataset:
config: default
name: MTEB SciFact-PL (default)
revision: 47932a35f045ef8ed01ba82bf9ff67f6e109207e
split: test
type: clarin-knext/scifact-pl
metrics:
- type: main_score
value: 64.764
- type: map_at_1
value: 49.778
- type: map_at_10
value: 59.88
- type: map_at_100
value: 60.707
- type: map_at_1000
value: 60.729
- type: map_at_20
value: 60.419999999999995
- type: map_at_3
value: 57.45400000000001
- type: map_at_5
value: 58.729
- type: mrr_at_1
value: 52.33333333333333
- type: mrr_at_10
value: 61.29193121693122
- type: mrr_at_100
value: 61.95817765126313
- type: mrr_at_1000
value: 61.97583284368782
- type: mrr_at_20
value: 61.72469949641003
- type: mrr_at_3
value: 59.44444444444444
- type: mrr_at_5
value: 60.494444444444454
- type: nauc_map_at_1000_diff1
value: 62.21235294015774
- type: nauc_map_at_1000_max
value: 48.83996609100249
- type: nauc_map_at_1000_std
value: 5.23892781043174
- type: nauc_map_at_100_diff1
value: 62.20170226789429
- type: nauc_map_at_100_max
value: 48.8391766453537
- type: nauc_map_at_100_std
value: 5.2664077457917715
- type: nauc_map_at_10_diff1
value: 61.961975488329024
- type: nauc_map_at_10_max
value: 48.397109987625186
- type: nauc_map_at_10_std
value: 4.314859710827481
- type: nauc_map_at_1_diff1
value: 65.0865197011516
- type: nauc_map_at_1_max
value: 41.38862781954889
- type: nauc_map_at_1_std
value: -0.9182122632530586
- type: nauc_map_at_20_diff1
value: 61.99173935851292
- type: nauc_map_at_20_max
value: 48.79961814179307
- type: nauc_map_at_20_std
value: 5.262181845825118
- type: nauc_map_at_3_diff1
value: 62.37910539880477
- type: nauc_map_at_3_max
value: 47.13627890977091
- type: nauc_map_at_3_std
value: 2.327897198087264
- type: nauc_map_at_5_diff1
value: 61.60080757149592
- type: nauc_map_at_5_max
value: 47.60052458345962
- type: nauc_map_at_5_std
value: 3.1770196981231047
- type: nauc_mrr_at_1000_diff1
value: 62.86810952814966
- type: nauc_mrr_at_1000_max
value: 52.13248094447774
- type: nauc_mrr_at_1000_std
value: 10.100485746570733
- type: nauc_mrr_at_100_diff1
value: 62.85364829491874
- type: nauc_mrr_at_100_max
value: 52.134528010631854
- type: nauc_mrr_at_100_std
value: 10.120945685447369
- type: nauc_mrr_at_10_diff1
value: 62.65679301829915
- type: nauc_mrr_at_10_max
value: 52.09270719182349
- type: nauc_mrr_at_10_std
value: 9.913834434725441
- type: nauc_mrr_at_1_diff1
value: 66.84108271415636
- type: nauc_mrr_at_1_max
value: 46.67646429855176
- type: nauc_mrr_at_1_std
value: 5.5505252956352304
- type: nauc_mrr_at_20_diff1
value: 62.72473227039611
- type: nauc_mrr_at_20_max
value: 52.13479097802757
- type: nauc_mrr_at_20_std
value: 10.188278833464084
- type: nauc_mrr_at_3_diff1
value: 63.797429185518496
- type: nauc_mrr_at_3_max
value: 52.16486999573481
- type: nauc_mrr_at_3_std
value: 9.094360767062762
- type: nauc_mrr_at_5_diff1
value: 62.592917975475494
- type: nauc_mrr_at_5_max
value: 52.330741486107414
- type: nauc_mrr_at_5_std
value: 9.742175534421389
- type: nauc_ndcg_at_1000_diff1
value: 61.38859337672476
- type: nauc_ndcg_at_1000_max
value: 51.48380058339184
- type: nauc_ndcg_at_1000_std
value: 9.670547660897673
- type: nauc_ndcg_at_100_diff1
value: 61.02438489641434
- type: nauc_ndcg_at_100_max
value: 51.781246646780865
- type: nauc_ndcg_at_100_std
value: 10.592961553245187
- type: nauc_ndcg_at_10_diff1
value: 60.03678353308358
- type: nauc_ndcg_at_10_max
value: 50.70725688848762
- type: nauc_ndcg_at_10_std
value: 7.9472446491016315
- type: nauc_ndcg_at_1_diff1
value: 66.84108271415636
- type: nauc_ndcg_at_1_max
value: 46.67646429855176
- type: nauc_ndcg_at_1_std
value: 5.5505252956352304
- type: nauc_ndcg_at_20_diff1
value: 59.828482718480224
- type: nauc_ndcg_at_20_max
value: 51.45831789601284
- type: nauc_ndcg_at_20_std
value: 10.722673683272049
- type: nauc_ndcg_at_3_diff1
value: 61.68982937524109
- type: nauc_ndcg_at_3_max
value: 49.745326748604775
- type: nauc_ndcg_at_3_std
value: 4.948298621202247
- type: nauc_ndcg_at_5_diff1
value: 59.67396171973207
- type: nauc_ndcg_at_5_max
value: 49.87855139298281
- type: nauc_ndcg_at_5_std
value: 6.08990428055584
- type: nauc_precision_at_1000_diff1
value: -1.594227972036865
- type: nauc_precision_at_1000_max
value: 32.48431723086185
- type: nauc_precision_at_1000_std
value: 53.84748466965268
- type: nauc_precision_at_100_diff1
value: 8.06411455192293
- type: nauc_precision_at_100_max
value: 39.91003601878948
- type: nauc_precision_at_100_std
value: 55.52979711075091
- type: nauc_precision_at_10_diff1
value: 26.610514456014066
- type: nauc_precision_at_10_max
value: 47.09062494321172
- type: nauc_precision_at_10_std
value: 33.91984226498748
- type: nauc_precision_at_1_diff1
value: 66.84108271415636
- type: nauc_precision_at_1_max
value: 46.67646429855176
- type: nauc_precision_at_1_std
value: 5.5505252956352304
- type: nauc_precision_at_20_diff1
value: 16.947688843085583
- type: nauc_precision_at_20_max
value: 45.40488186572008
- type: nauc_precision_at_20_std
value: 48.354421924500905
- type: nauc_precision_at_3_diff1
value: 49.11263981720622
- type: nauc_precision_at_3_max
value: 52.7084625111683
- type: nauc_precision_at_3_std
value: 16.734612173556453
- type: nauc_precision_at_5_diff1
value: 39.06503705015792
- type: nauc_precision_at_5_max
value: 52.21710506893391
- type: nauc_precision_at_5_std
value: 23.350948149460233
- type: nauc_recall_at_1000_diff1
value: 43.1559290382817
- type: nauc_recall_at_1000_max
value: 83.66013071895456
- type: nauc_recall_at_1000_std
value: 86.27450980392177
- type: nauc_recall_at_100_diff1
value: 46.016860850620375
- type: nauc_recall_at_100_max
value: 69.3944888744547
- type: nauc_recall_at_100_std
value: 55.286945696152735
- type: nauc_recall_at_10_diff1
value: 49.65877895350921
- type: nauc_recall_at_10_max
value: 53.02636695700889
- type: nauc_recall_at_10_std
value: 13.967608945823828
- type: nauc_recall_at_1_diff1
value: 65.0865197011516
- type: nauc_recall_at_1_max
value: 41.38862781954889
- type: nauc_recall_at_1_std
value: -0.9182122632530586
- type: nauc_recall_at_20_diff1
value: 43.355308229973524
- type: nauc_recall_at_20_max
value: 57.04187909533764
- type: nauc_recall_at_20_std
value: 33.578720846660524
- type: nauc_recall_at_3_diff1
value: 56.922996057428165
- type: nauc_recall_at_3_max
value: 50.74417041895424
- type: nauc_recall_at_3_std
value: 5.623890124328387
- type: nauc_recall_at_5_diff1
value: 50.55620076865238
- type: nauc_recall_at_5_max
value: 51.3316854622085
- type: nauc_recall_at_5_std
value: 8.995457887269255
- type: ndcg_at_1
value: 52.333
- type: ndcg_at_10
value: 64.764
- type: ndcg_at_100
value: 68.167
- type: ndcg_at_1000
value: 68.816
- type: ndcg_at_20
value: 66.457
- type: ndcg_at_3
value: 60.346
- type: ndcg_at_5
value: 62.365
- type: precision_at_1
value: 52.333
- type: precision_at_10
value: 8.799999999999999
- type: precision_at_100
value: 1.057
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_20
value: 4.8
- type: precision_at_3
value: 23.889
- type: precision_at_5
value: 15.6
- type: recall_at_1
value: 49.778
- type: recall_at_10
value: 78.206
- type: recall_at_100
value: 93.10000000000001
- type: recall_at_1000
value: 98.333
- type: recall_at_20
value: 84.467
- type: recall_at_3
value: 66.367
- type: recall_at_5
value: 71.35000000000001
task:
type: Retrieval
- dataset:
config: default
name: MTEB TRECCOVID-PL (default)
revision: 81bcb408f33366c2a20ac54adafad1ae7e877fdd
split: test
type: clarin-knext/trec-covid-pl
metrics:
- type: main_score
value: 72.18900000000001
- type: map_at_1
value: 0.214
- type: map_at_10
value: 1.755
- type: map_at_100
value: 9.944
- type: map_at_1000
value: 24.205
- type: map_at_20
value: 3.1510000000000002
- type: map_at_3
value: 0.6
- type: map_at_5
value: 0.9560000000000001
- type: mrr_at_1
value: 82.0
- type: mrr_at_10
value: 89.06666666666666
- type: mrr_at_100
value: 89.06666666666666
- type: mrr_at_1000
value: 89.06666666666666
- type: mrr_at_20
value: 89.06666666666666
- type: mrr_at_3
value: 87.66666666666666
- type: mrr_at_5
value: 89.06666666666666
- type: nauc_map_at_1000_diff1
value: -9.342037623635543
- type: nauc_map_at_1000_max
value: 45.71499810252398
- type: nauc_map_at_1000_std
value: 76.86482845196852
- type: nauc_map_at_100_diff1
value: -6.932395299866198
- type: nauc_map_at_100_max
value: 36.097801891181604
- type: nauc_map_at_100_std
value: 65.6085215411685
- type: nauc_map_at_10_diff1
value: -6.3654843824342775
- type: nauc_map_at_10_max
value: 9.564437521432714
- type: nauc_map_at_10_std
value: 21.8377319336476
- type: nauc_map_at_1_diff1
value: 8.269590874255034
- type: nauc_map_at_1_max
value: 3.482498491294516
- type: nauc_map_at_1_std
value: 8.985226819412189
- type: nauc_map_at_20_diff1
value: -4.971435767877232
- type: nauc_map_at_20_max
value: 22.88801858567121
- type: nauc_map_at_20_std
value: 32.38492618534027
- type: nauc_map_at_3_diff1
value: 1.1615973694623123
- type: nauc_map_at_3_max
value: 1.935417800315643
- type: nauc_map_at_3_std
value: 10.289328305818698
- type: nauc_map_at_5_diff1
value: -2.4675967231444105
- type: nauc_map_at_5_max
value: 2.4611483736622373
- type: nauc_map_at_5_std
value: 15.082324305750811
- type: nauc_mrr_at_1000_diff1
value: 13.098526703499063
- type: nauc_mrr_at_1000_max
value: 56.37362177417431
- type: nauc_mrr_at_1000_std
value: 73.2456769749587
- type: nauc_mrr_at_100_diff1
value: 13.098526703499063
- type: nauc_mrr_at_100_max
value: 56.37362177417431
- type: nauc_mrr_at_100_std
value: 73.2456769749587
- type: nauc_mrr_at_10_diff1
value: 13.098526703499063
- type: nauc_mrr_at_10_max
value: 56.37362177417431
- type: nauc_mrr_at_10_std
value: 73.2456769749587
- type: nauc_mrr_at_1_diff1
value: 12.099350148694809
- type: nauc_mrr_at_1_max
value: 53.75041304108387
- type: nauc_mrr_at_1_std
value: 68.84018063663402
- type: nauc_mrr_at_20_diff1
value: 13.098526703499063
- type: nauc_mrr_at_20_max
value: 56.37362177417431
- type: nauc_mrr_at_20_std
value: 73.2456769749587
- type: nauc_mrr_at_3_diff1
value: 12.173557857011161
- type: nauc_mrr_at_3_max
value: 57.540780562363395
- type: nauc_mrr_at_3_std
value: 75.42098189580211
- type: nauc_mrr_at_5_diff1
value: 13.098526703499063
- type: nauc_mrr_at_5_max
value: 56.37362177417431
- type: nauc_mrr_at_5_std
value: 73.2456769749587
- type: nauc_ndcg_at_1000_diff1
value: -8.951471847310401
- type: nauc_ndcg_at_1000_max
value: 43.86942237288822
- type: nauc_ndcg_at_1000_std
value: 74.61077735148591
- type: nauc_ndcg_at_100_diff1
value: -17.754559361083817
- type: nauc_ndcg_at_100_max
value: 53.97187119773482
- type: nauc_ndcg_at_100_std
value: 80.7944136146514
- type: nauc_ndcg_at_10_diff1
value: -26.637734697836414
- type: nauc_ndcg_at_10_max
value: 47.70102699133149
- type: nauc_ndcg_at_10_std
value: 70.26909560828646
- type: nauc_ndcg_at_1_diff1
value: -1.2250530785563207
- type: nauc_ndcg_at_1_max
value: 46.60509554140131
- type: nauc_ndcg_at_1_std
value: 62.63906581740976
- type: nauc_ndcg_at_20_diff1
value: -22.44286466550908
- type: nauc_ndcg_at_20_max
value: 55.40492058090103
- type: nauc_ndcg_at_20_std
value: 72.11813912145738
- type: nauc_ndcg_at_3_diff1
value: -14.8152721896563
- type: nauc_ndcg_at_3_max
value: 38.952259383027595
- type: nauc_ndcg_at_3_std
value: 59.819750166537766
- type: nauc_ndcg_at_5_diff1
value: -19.150105688904375
- type: nauc_ndcg_at_5_max
value: 42.311180547775315
- type: nauc_ndcg_at_5_std
value: 66.6632229321094
- type: nauc_precision_at_1000_diff1
value: -11.555591477978941
- type: nauc_precision_at_1000_max
value: 43.7311644834851
- type: nauc_precision_at_1000_std
value: 52.10644767999648
- type: nauc_precision_at_100_diff1
value: -16.94803099801117
- type: nauc_precision_at_100_max
value: 54.08281631067633
- type: nauc_precision_at_100_std
value: 82.77237347891331
- type: nauc_precision_at_10_diff1
value: -27.351332814863355
- type: nauc_precision_at_10_max
value: 48.08237549065846
- type: nauc_precision_at_10_std
value: 69.37250843534329
- type: nauc_precision_at_1_diff1
value: 12.099350148694809
- type: nauc_precision_at_1_max
value: 53.75041304108387
- type: nauc_precision_at_1_std
value: 68.84018063663402
- type: nauc_precision_at_20_diff1
value: -18.2422222283388
- type: nauc_precision_at_20_max
value: 59.517328129343696
- type: nauc_precision_at_20_std
value: 72.05149307342747
- type: nauc_precision_at_3_diff1
value: -10.226547543075897
- type: nauc_precision_at_3_max
value: 43.14684818832875
- type: nauc_precision_at_3_std
value: 57.31936467418288
- type: nauc_precision_at_5_diff1
value: -14.28521589468673
- type: nauc_precision_at_5_max
value: 41.633426753962596
- type: nauc_precision_at_5_std
value: 64.94400576804541
- type: nauc_recall_at_1000_diff1
value: -0.9648831207497152
- type: nauc_recall_at_1000_max
value: 31.70832946085005
- type: nauc_recall_at_1000_std
value: 63.21471613968869
- type: nauc_recall_at_100_diff1
value: -1.360254380933586
- type: nauc_recall_at_100_max
value: 25.960597782099605
- type: nauc_recall_at_100_std
value: 51.52757589609674
- type: nauc_recall_at_10_diff1
value: -0.3899439424189566
- type: nauc_recall_at_10_max
value: 5.094341897886072
- type: nauc_recall_at_10_std
value: 11.266045616925698
- type: nauc_recall_at_1_diff1
value: 8.269590874255034
- type: nauc_recall_at_1_max
value: 3.482498491294516
- type: nauc_recall_at_1_std
value: 8.985226819412189
- type: nauc_recall_at_20_diff1
value: 6.4797098359254175
- type: nauc_recall_at_20_max
value: 15.663700985336124
- type: nauc_recall_at_20_std
value: 17.154099587904913
- type: nauc_recall_at_3_diff1
value: 3.7245972450393507
- type: nauc_recall_at_3_max
value: 0.4063857187240345
- type: nauc_recall_at_3_std
value: 6.641948062821941
- type: nauc_recall_at_5_diff1
value: 4.013879477591466
- type: nauc_recall_at_5_max
value: -1.4266586618013566
- type: nauc_recall_at_5_std
value: 7.311601874411205
- type: ndcg_at_1
value: 75.0
- type: ndcg_at_10
value: 72.18900000000001
- type: ndcg_at_100
value: 54.022999999999996
- type: ndcg_at_1000
value: 49.492000000000004
- type: ndcg_at_20
value: 68.51
- type: ndcg_at_3
value: 73.184
- type: ndcg_at_5
value: 72.811
- type: precision_at_1
value: 82.0
- type: precision_at_10
value: 77.4
- type: precision_at_100
value: 55.24
- type: precision_at_1000
value: 21.822
- type: precision_at_20
value: 73.0
- type: precision_at_3
value: 79.333
- type: precision_at_5
value: 79.2
- type: recall_at_1
value: 0.214
- type: recall_at_10
value: 1.9980000000000002
- type: recall_at_100
value: 13.328999999999999
- type: recall_at_1000
value: 47.204
- type: recall_at_20
value: 3.7310000000000003
- type: recall_at_3
value: 0.628
- type: recall_at_5
value: 1.049
task:
type: Retrieval
- dataset:
config: default
name: MTEB CEDRClassification (default)
revision: c0ba03d058e3e1b2f3fd20518875a4563dd12db4
split: test
type: ai-forever/cedr-classification
metrics:
- type: accuracy
value: 47.30605738575983
- type: f1
value: 41.26091043925065
- type: lrap
value: 72.89452709883206
- type: main_score
value: 47.30605738575983
task:
type: MultilabelClassification
- dataset:
config: ru
name: MTEB MIRACLReranking (ru)
revision: 6d1962c527217f8927fca80f890f14f36b2802af
split: dev
type: miracl/mmteb-miracl-reranking
metrics:
- type: MAP@1(MIRACL)
value: 20.721999999999998
- type: MAP@10(MIRACL)
value: 33.900999999999996
- type: MAP@100(MIRACL)
value: 36.813
- type: MAP@1000(MIRACL)
value: 36.813
- type: MAP@20(MIRACL)
value: 35.684
- type: MAP@3(MIRACL)
value: 28.141
- type: MAP@5(MIRACL)
value: 31.075000000000003
- type: NDCG@1(MIRACL)
value: 32.799
- type: NDCG@10(MIRACL)
value: 42.065000000000005
- type: NDCG@100(MIRACL)
value: 49.730999999999995
- type: NDCG@1000(MIRACL)
value: 49.730999999999995
- type: NDCG@20(MIRACL)
value: 46.0
- type: NDCG@3(MIRACL)
value: 34.481
- type: NDCG@5(MIRACL)
value: 37.452999999999996
- type: P@1(MIRACL)
value: 32.799
- type: P@10(MIRACL)
value: 11.668000000000001
- type: P@100(MIRACL)
value: 1.9529999999999998
- type: P@1000(MIRACL)
value: 0.19499999999999998
- type: P@20(MIRACL)
value: 7.51
- type: P@3(MIRACL)
value: 20.823
- type: P@5(MIRACL)
value: 16.728
- type: Recall@1(MIRACL)
value: 20.721999999999998
- type: Recall@10(MIRACL)
value: 54.762
- type: Recall@100(MIRACL)
value: 79.952
- type: Recall@1000(MIRACL)
value: 79.952
- type: Recall@20(MIRACL)
value: 66.26100000000001
- type: Recall@3(MIRACL)
value: 34.410000000000004
- type: Recall@5(MIRACL)
value: 42.659000000000006
- type: main_score
value: 42.065000000000005
- type: nAUC_MAP@1000_diff1(MIRACL)
value: 14.33534992502818
- type: nAUC_MAP@1000_max(MIRACL)
value: 12.367998764646115
- type: nAUC_MAP@1000_std(MIRACL)
value: 4.569686002935006
- type: nAUC_MAP@100_diff1(MIRACL)
value: 14.33534992502818
- type: nAUC_MAP@100_max(MIRACL)
value: 12.367998764646115
- type: nAUC_MAP@100_std(MIRACL)
value: 4.569686002935006
- type: nAUC_MAP@10_diff1(MIRACL)
value: 16.920323975680027
- type: nAUC_MAP@10_max(MIRACL)
value: 9.327171297204082
- type: nAUC_MAP@10_std(MIRACL)
value: 3.2039133783079015
- type: nAUC_MAP@1_diff1(MIRACL)
value: 28.698973487482206
- type: nAUC_MAP@1_max(MIRACL)
value: 2.9217687660885034
- type: nAUC_MAP@1_std(MIRACL)
value: -1.1247408800976524
- type: nAUC_MAP@20_diff1(MIRACL)
value: 15.359083081640476
- type: nAUC_MAP@20_max(MIRACL)
value: 11.310494233946345
- type: nAUC_MAP@20_std(MIRACL)
value: 4.4171898386022885
- type: nAUC_MAP@3_diff1(MIRACL)
value: 22.27430591851617
- type: nAUC_MAP@3_max(MIRACL)
value: 6.407438291284658
- type: nAUC_MAP@3_std(MIRACL)
value: 0.9799184530397409
- type: nAUC_MAP@5_diff1(MIRACL)
value: 19.20571689941054
- type: nAUC_MAP@5_max(MIRACL)
value: 7.987468654026893
- type: nAUC_MAP@5_std(MIRACL)
value: 1.8324246565938962
- type: nAUC_NDCG@1000_diff1(MIRACL)
value: 3.7537669018914768
- type: nAUC_NDCG@1000_max(MIRACL)
value: 20.7944707840533
- type: nAUC_NDCG@1000_std(MIRACL)
value: 8.444837055303063
- type: nAUC_NDCG@100_diff1(MIRACL)
value: 3.7537669018914768
- type: nAUC_NDCG@100_max(MIRACL)
value: 20.7944707840533
- type: nAUC_NDCG@100_std(MIRACL)
value: 8.444837055303063
- type: nAUC_NDCG@10_diff1(MIRACL)
value: 10.829575656103888
- type: nAUC_NDCG@10_max(MIRACL)
value: 13.0445496498929
- type: nAUC_NDCG@10_std(MIRACL)
value: 6.050412212625362
- type: nAUC_NDCG@1_diff1(MIRACL)
value: 19.1388712233292
- type: nAUC_NDCG@1_max(MIRACL)
value: 10.871900994781642
- type: nAUC_NDCG@1_std(MIRACL)
value: 3.218568248751811
- type: nAUC_NDCG@20_diff1(MIRACL)
value: 7.093172181746442
- type: nAUC_NDCG@20_max(MIRACL)
value: 16.955238078958836
- type: nAUC_NDCG@20_std(MIRACL)
value: 8.325656379573035
- type: nAUC_NDCG@3_diff1(MIRACL)
value: 17.134437303330802
- type: nAUC_NDCG@3_max(MIRACL)
value: 10.235328822955793
- type: nAUC_NDCG@3_std(MIRACL)
value: 3.2341358691084814
- type: nAUC_NDCG@5_diff1(MIRACL)
value: 14.733664618337636
- type: nAUC_NDCG@5_max(MIRACL)
value: 11.181897412035282
- type: nAUC_NDCG@5_std(MIRACL)
value: 3.642277088791985
- type: nAUC_P@1000_diff1(MIRACL)
value: -26.330038284867573
- type: nAUC_P@1000_max(MIRACL)
value: 28.450694137240458
- type: nAUC_P@1000_std(MIRACL)
value: 9.892993775474912
- type: nAUC_P@100_diff1(MIRACL)
value: -26.330038284867552
- type: nAUC_P@100_max(MIRACL)
value: 28.45069413724051
- type: nAUC_P@100_std(MIRACL)
value: 9.892993775474928
- type: nAUC_P@10_diff1(MIRACL)
value: -17.436937353231112
- type: nAUC_P@10_max(MIRACL)
value: 24.327018012947857
- type: nAUC_P@10_std(MIRACL)
value: 11.78803527706634
- type: nAUC_P@1_diff1(MIRACL)
value: 19.1388712233292
- type: nAUC_P@1_max(MIRACL)
value: 10.871900994781642
- type: nAUC_P@1_std(MIRACL)
value: 3.218568248751811
- type: nAUC_P@20_diff1(MIRACL)
value: -22.947528755272426
- type: nAUC_P@20_max(MIRACL)
value: 27.773093471902538
- type: nAUC_P@20_std(MIRACL)
value: 14.898619107087221
- type: nAUC_P@3_diff1(MIRACL)
value: 1.4100426412400944
- type: nAUC_P@3_max(MIRACL)
value: 17.397472872058845
- type: nAUC_P@3_std(MIRACL)
value: 8.240008229861875
- type: nAUC_P@5_diff1(MIRACL)
value: -7.971349332207021
- type: nAUC_P@5_max(MIRACL)
value: 22.198441167940963
- type: nAUC_P@5_std(MIRACL)
value: 9.00265164460082
- type: nAUC_Recall@1000_diff1(MIRACL)
value: -38.69835271863148
- type: nAUC_Recall@1000_max(MIRACL)
value: 50.9545152809108
- type: nAUC_Recall@1000_std(MIRACL)
value: 20.44270887092116
- type: nAUC_Recall@100_diff1(MIRACL)
value: -38.69835271863148
- type: nAUC_Recall@100_max(MIRACL)
value: 50.9545152809108
- type: nAUC_Recall@100_std(MIRACL)
value: 20.44270887092116
- type: nAUC_Recall@10_diff1(MIRACL)
value: -0.08109036309433801
- type: nAUC_Recall@10_max(MIRACL)
value: 12.696619907773568
- type: nAUC_Recall@10_std(MIRACL)
value: 8.791982704261589
- type: nAUC_Recall@1_diff1(MIRACL)
value: 28.698973487482206
- type: nAUC_Recall@1_max(MIRACL)
value: 2.9217687660885034
- type: nAUC_Recall@1_std(MIRACL)
value: -1.1247408800976524
- type: nAUC_Recall@20_diff1(MIRACL)
value: -13.312171017942623
- type: nAUC_Recall@20_max(MIRACL)
value: 24.19847346821666
- type: nAUC_Recall@20_std(MIRACL)
value: 15.8157702609797
- type: nAUC_Recall@3_diff1(MIRACL)
value: 16.909128321353343
- type: nAUC_Recall@3_max(MIRACL)
value: 6.552122731902991
- type: nAUC_Recall@3_std(MIRACL)
value: 1.9963898223457228
- type: nAUC_Recall@5_diff1(MIRACL)
value: 9.990292655247721
- type: nAUC_Recall@5_max(MIRACL)
value: 9.361722273507574
- type: nAUC_Recall@5_std(MIRACL)
value: 3.270918827854495
task:
type: Reranking
- dataset:
config: default
name: MTEB SensitiveTopicsClassification (default)
revision: 416b34a802308eac30e4192afc0ff99bb8dcc7f2
split: test
type: ai-forever/sensitive-topics-classification
metrics:
- type: accuracy
value: 30.634765625
- type: f1
value: 32.647559808678665
- type: lrap
value: 45.94319661458259
- type: main_score
value: 30.634765625
task:
type: MultilabelClassification
- dataset:
config: default
name: MTEB ATEC (default)
revision: 0f319b1142f28d00e055a6770f3f726ae9b7d865
split: test
type: C-MTEB/ATEC
metrics:
- type: cosine_pearson
value: 47.541497334563296
- type: cosine_spearman
value: 49.06268944206629
- type: euclidean_pearson
value: 51.838926748581635
- type: euclidean_spearman
value: 48.930697157135356
- type: main_score
value: 49.06268944206629
- type: manhattan_pearson
value: 51.835306769406365
- type: manhattan_spearman
value: 48.86135493444834
- type: pearson
value: 47.541497334563296
- type: spearman
value: 49.06268944206629
task:
type: STS
- dataset:
config: default
name: MTEB AllegroReviews (default)
revision: b89853e6de927b0e3bfa8ecc0e56fe4e02ceafc6
split: test
type: PL-MTEB/allegro-reviews
metrics:
- type: accuracy
value: 49.51292246520874
- type: f1
value: 44.14350234332397
- type: f1_weighted
value: 51.65508998354552
- type: main_score
value: 49.51292246520874
task:
type: Classification
- dataset:
config: default
name: MTEB AlloProfClusteringP2P (default)
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
split: test
type: lyon-nlp/alloprof
metrics:
- type: main_score
value: 63.883383458621665
- type: v_measure
value: 63.883383458621665
- type: v_measure_std
value: 2.693666879958465
task:
type: Clustering
- dataset:
config: default
name: MTEB 8TagsClustering
revision: None
split: test
type: PL-MTEB/8tags-clustering
metrics:
- type: v_measure
value: 43.657212124525546
task:
type: Clustering
- dataset:
config: default
name: MTEB AlloProfClusteringS2S (default)
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
split: test
type: lyon-nlp/alloprof
metrics:
- type: main_score
value: 46.85924588755251
- type: v_measure
value: 46.85924588755251
- type: v_measure_std
value: 2.1918258880872377
task:
type: Clustering
- dataset:
config: default
name: MTEB AlloprofReranking (default)
revision: e40c8a63ce02da43200eccb5b0846fcaa888f562
split: test
type: lyon-nlp/mteb-fr-reranking-alloprof-s2p
metrics:
- type: map
value: 66.39013753839347
- type: mrr
value: 67.68045617786551
- type: main_score
value: 66.39013753839347
task:
type: Reranking
- dataset:
config: default
name: MTEB AlloprofRetrieval (default)
revision: fcf295ea64c750f41fadbaa37b9b861558e1bfbd
split: test
type: lyon-nlp/alloprof
metrics:
- type: main_score
value: 54.284
- type: map_at_1
value: 37.047000000000004
- type: map_at_10
value: 48.53
- type: map_at_100
value: 49.357
- type: map_at_1000
value: 49.39
- type: map_at_20
value: 49.064
- type: map_at_3
value: 45.675
- type: map_at_5
value: 47.441
- type: mrr_at_1
value: 37.04663212435233
- type: mrr_at_10
value: 48.5300326232969
- type: mrr_at_100
value: 49.35708199037581
- type: mrr_at_1000
value: 49.39005824603193
- type: mrr_at_20
value: 49.06417416464799
- type: mrr_at_3
value: 45.67501439263105
- type: mrr_at_5
value: 47.44099021301103
- type: nauc_map_at_1000_diff1
value: 43.32474221868009
- type: nauc_map_at_1000_max
value: 39.407334029058575
- type: nauc_map_at_1000_std
value: -2.3728154448932606
- type: nauc_map_at_100_diff1
value: 43.32336300929909
- type: nauc_map_at_100_max
value: 39.432174777554835
- type: nauc_map_at_100_std
value: -2.356396922384349
- type: nauc_map_at_10_diff1
value: 43.1606520154482
- type: nauc_map_at_10_max
value: 39.33734650558226
- type: nauc_map_at_10_std
value: -2.5156222475075256
- type: nauc_map_at_1_diff1
value: 46.2178975214499
- type: nauc_map_at_1_max
value: 36.26173199049361
- type: nauc_map_at_1_std
value: -3.0897555582816443
- type: nauc_map_at_20_diff1
value: 43.272980702916456
- type: nauc_map_at_20_max
value: 39.4896977052276
- type: nauc_map_at_20_std
value: -2.3305501742917043
- type: nauc_map_at_3_diff1
value: 43.49525042967079
- type: nauc_map_at_3_max
value: 38.66352501824728
- type: nauc_map_at_3_std
value: -3.202794391620473
- type: nauc_map_at_5_diff1
value: 43.2266692546611
- type: nauc_map_at_5_max
value: 38.77368661115743
- type: nauc_map_at_5_std
value: -3.0897532130127954
- type: nauc_mrr_at_1000_diff1
value: 43.32474221868009
- type: nauc_mrr_at_1000_max
value: 39.407334029058575
- type: nauc_mrr_at_1000_std
value: -2.3728154448932606
- type: nauc_mrr_at_100_diff1
value: 43.32336300929909
- type: nauc_mrr_at_100_max
value: 39.432174777554835
- type: nauc_mrr_at_100_std
value: -2.356396922384349
- type: nauc_mrr_at_10_diff1
value: 43.1606520154482
- type: nauc_mrr_at_10_max
value: 39.33734650558226
- type: nauc_mrr_at_10_std
value: -2.5156222475075256
- type: nauc_mrr_at_1_diff1
value: 46.2178975214499
- type: nauc_mrr_at_1_max
value: 36.26173199049361
- type: nauc_mrr_at_1_std
value: -3.0897555582816443
- type: nauc_mrr_at_20_diff1
value: 43.272980702916456
- type: nauc_mrr_at_20_max
value: 39.4896977052276
- type: nauc_mrr_at_20_std
value: -2.3305501742917043
- type: nauc_mrr_at_3_diff1
value: 43.49525042967079
- type: nauc_mrr_at_3_max
value: 38.66352501824728
- type: nauc_mrr_at_3_std
value: -3.202794391620473
- type: nauc_mrr_at_5_diff1
value: 43.2266692546611
- type: nauc_mrr_at_5_max
value: 38.77368661115743
- type: nauc_mrr_at_5_std
value: -3.0897532130127954
- type: nauc_ndcg_at_1000_diff1
value: 43.01903168202974
- type: nauc_ndcg_at_1000_max
value: 40.75496622942232
- type: nauc_ndcg_at_1000_std
value: -1.3150412981845496
- type: nauc_ndcg_at_100_diff1
value: 42.98016493758145
- type: nauc_ndcg_at_100_max
value: 41.55869635162325
- type: nauc_ndcg_at_100_std
value: -0.5355252976886055
- type: nauc_ndcg_at_10_diff1
value: 42.218755211347506
- type: nauc_ndcg_at_10_max
value: 41.305042275175765
- type: nauc_ndcg_at_10_std
value: -1.4034484444573714
- type: nauc_ndcg_at_1_diff1
value: 46.2178975214499
- type: nauc_ndcg_at_1_max
value: 36.26173199049361
- type: nauc_ndcg_at_1_std
value: -3.0897555582816443
- type: nauc_ndcg_at_20_diff1
value: 42.66574440095576
- type: nauc_ndcg_at_20_max
value: 42.014620115124515
- type: nauc_ndcg_at_20_std
value: -0.5176162553751498
- type: nauc_ndcg_at_3_diff1
value: 42.837450505106055
- type: nauc_ndcg_at_3_max
value: 39.525369733082414
- type: nauc_ndcg_at_3_std
value: -3.1605948245795155
- type: nauc_ndcg_at_5_diff1
value: 42.37951815451173
- type: nauc_ndcg_at_5_max
value: 39.78840132935179
- type: nauc_ndcg_at_5_std
value: -2.936898430768135
- type: nauc_precision_at_1000_diff1
value: 49.69224988612385
- type: nauc_precision_at_1000_max
value: 79.57897547128005
- type: nauc_precision_at_1000_std
value: 45.040371354764645
- type: nauc_precision_at_100_diff1
value: 42.70597486048422
- type: nauc_precision_at_100_max
value: 65.74628759606188
- type: nauc_precision_at_100_std
value: 25.49157745244855
- type: nauc_precision_at_10_diff1
value: 38.565609931689345
- type: nauc_precision_at_10_max
value: 50.0239696180852
- type: nauc_precision_at_10_std
value: 3.976354829503967
- type: nauc_precision_at_1_diff1
value: 46.2178975214499
- type: nauc_precision_at_1_max
value: 36.26173199049361
- type: nauc_precision_at_1_std
value: -3.0897555582816443
- type: nauc_precision_at_20_diff1
value: 40.4134718566864
- type: nauc_precision_at_20_max
value: 57.121778108665374
- type: nauc_precision_at_20_std
value: 11.46021975428544
- type: nauc_precision_at_3_diff1
value: 40.90538379461529
- type: nauc_precision_at_3_max
value: 42.18393248057992
- type: nauc_precision_at_3_std
value: -3.005249943837297
- type: nauc_precision_at_5_diff1
value: 39.60162965860782
- type: nauc_precision_at_5_max
value: 43.28317158174058
- type: nauc_precision_at_5_std
value: -2.3469094487738054
- type: nauc_recall_at_1000_diff1
value: 49.69224988612252
- type: nauc_recall_at_1000_max
value: 79.57897547127862
- type: nauc_recall_at_1000_std
value: 45.04037135476256
- type: nauc_recall_at_100_diff1
value: 42.70597486048432
- type: nauc_recall_at_100_max
value: 65.74628759606213
- type: nauc_recall_at_100_std
value: 25.491577452448727
- type: nauc_recall_at_10_diff1
value: 38.56560993168935
- type: nauc_recall_at_10_max
value: 50.02396961808522
- type: nauc_recall_at_10_std
value: 3.9763548295040314
- type: nauc_recall_at_1_diff1
value: 46.2178975214499
- type: nauc_recall_at_1_max
value: 36.26173199049361
- type: nauc_recall_at_1_std
value: -3.0897555582816443
- type: nauc_recall_at_20_diff1
value: 40.41347185668637
- type: nauc_recall_at_20_max
value: 57.12177810866533
- type: nauc_recall_at_20_std
value: 11.460219754285431
- type: nauc_recall_at_3_diff1
value: 40.90538379461527
- type: nauc_recall_at_3_max
value: 42.18393248057989
- type: nauc_recall_at_3_std
value: -3.005249943837297
- type: nauc_recall_at_5_diff1
value: 39.601629658607784
- type: nauc_recall_at_5_max
value: 43.28317158174053
- type: nauc_recall_at_5_std
value: -2.3469094487738054
- type: ndcg_at_1
value: 37.047000000000004
- type: ndcg_at_10
value: 54.284
- type: ndcg_at_100
value: 58.34
- type: ndcg_at_1000
value: 59.303
- type: ndcg_at_20
value: 56.235
- type: ndcg_at_3
value: 48.503
- type: ndcg_at_5
value: 51.686
- type: precision_at_1
value: 37.047000000000004
- type: precision_at_10
value: 7.237
- type: precision_at_100
value: 0.914
- type: precision_at_1000
value: 0.099
- type: precision_at_20
value: 4.005
- type: precision_at_3
value: 18.898
- type: precision_at_5
value: 12.884
- type: recall_at_1
value: 37.047000000000004
- type: recall_at_10
value: 72.366
- type: recall_at_100
value: 91.408
- type: recall_at_1000
value: 99.136
- type: recall_at_20
value: 80.095
- type: recall_at_3
value: 56.693000000000005
- type: recall_at_5
value: 64.42099999999999
task:
type: Retrieval
- dataset:
config: en
name: MTEB AmazonCounterfactualClassification (en)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 89.49253731343283
- type: ap
value: 61.88098616359918
- type: ap_weighted
value: 61.88098616359918
- type: f1
value: 84.76516623679144
- type: f1_weighted
value: 89.92745276292968
- type: main_score
value: 89.49253731343283
task:
type: Classification
- dataset:
config: de
name: MTEB AmazonCounterfactualClassification (de)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 89.61456102783727
- type: ap
value: 93.11816566733742
- type: ap_weighted
value: 93.11816566733742
- type: f1
value: 88.27635757733722
- type: f1_weighted
value: 89.82581568285453
- type: main_score
value: 89.61456102783727
task:
type: Classification
- dataset:
config: default
name: MTEB AmazonPolarityClassification (default)
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
split: test
type: mteb/amazon_polarity
metrics:
- type: accuracy
value: 95.3825
- type: ap
value: 93.393033869502
- type: ap_weighted
value: 93.393033869502
- type: f1
value: 95.38109007966307
- type: f1_weighted
value: 95.38109007966305
- type: main_score
value: 95.3825
task:
type: Classification
- dataset:
config: en
name: MTEB AmazonReviewsClassification (en)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 49.768
- type: f1
value: 48.95084821944411
- type: f1_weighted
value: 48.9508482194441
- type: main_score
value: 49.768
task:
type: Classification
- dataset:
config: de
name: MTEB AmazonReviewsClassification (de)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 48.071999999999996
- type: f1
value: 47.24171107487612
- type: f1_weighted
value: 47.24171107487612
- type: main_score
value: 48.071999999999996
task:
type: Classification
- dataset:
config: es
name: MTEB AmazonReviewsClassification (es)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 48.102000000000004
- type: f1
value: 47.27193805278696
- type: f1_weighted
value: 47.27193805278696
- type: main_score
value: 48.102000000000004
task:
type: Classification
- dataset:
config: fr
name: MTEB AmazonReviewsClassification (fr)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 47.30800000000001
- type: f1
value: 46.41683358017851
- type: f1_weighted
value: 46.41683358017851
- type: main_score
value: 47.30800000000001
task:
type: Classification
- dataset:
config: zh
name: MTEB AmazonReviewsClassification (zh)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 44.944
- type: f1
value: 44.223824487744395
- type: f1_weighted
value: 44.22382448774439
- type: main_score
value: 44.944
task:
type: Classification
- dataset:
config: default
name: MTEB ArguAna (default)
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
split: test
type: mteb/arguana
metrics:
- type: map_at_1
value: 29.232000000000003
- type: map_at_10
value: 45.117000000000004
- type: map_at_100
value: 45.977000000000004
- type: map_at_1000
value: 45.98
- type: map_at_20
value: 45.815
- type: map_at_3
value: 39.912
- type: map_at_5
value: 42.693
- type: mrr_at_1
value: 29.659000000000002
- type: mrr_at_10
value: 45.253
- type: mrr_at_100
value: 46.125
- type: mrr_at_1000
value: 46.129
- type: mrr_at_20
value: 45.964
- type: mrr_at_3
value: 40.043
- type: mrr_at_5
value: 42.870000000000005
- type: ndcg_at_1
value: 29.232000000000003
- type: ndcg_at_10
value: 54.327999999999996
- type: ndcg_at_100
value: 57.86
- type: ndcg_at_1000
value: 57.935
- type: ndcg_at_20
value: 56.794
- type: ndcg_at_3
value: 43.516
- type: ndcg_at_5
value: 48.512
- type: precision_at_1
value: 29.232000000000003
- type: precision_at_10
value: 8.393
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.676
- type: precision_at_3
value: 17.994
- type: precision_at_5
value: 13.215
- type: recall_at_1
value: 29.232000000000003
- type: recall_at_10
value: 83.926
- type: recall_at_100
value: 99.075
- type: recall_at_1000
value: 99.644
- type: recall_at_20
value: 93.528
- type: recall_at_3
value: 53.983000000000004
- type: recall_at_5
value: 66.074
- type: main_score
value: 54.327999999999996
task:
type: Retrieval
- dataset:
config: default
name: MTEB ArxivClusteringP2P (default)
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
split: test
type: mteb/arxiv-clustering-p2p
metrics:
- type: main_score
value: 46.6636824632419
- type: v_measure
value: 46.6636824632419
- type: v_measure_std
value: 13.817129140714963
task:
type: Clustering
- dataset:
config: default
name: MTEB ArxivClusteringS2S (default)
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
split: test
type: mteb/arxiv-clustering-s2s
metrics:
- type: main_score
value: 39.271141892800024
- type: v_measure
value: 39.271141892800024
- type: v_measure_std
value: 14.276782483454827
task:
type: Clustering
- dataset:
config: default
name: MTEB AskUbuntuDupQuestions (default)
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
split: test
type: mteb/askubuntudupquestions-reranking
metrics:
- type: map
value: 65.04363277324629
- type: mrr
value: 78.2372598162072
- type: main_score
value: 65.04363277324629
task:
type: Reranking
- dataset:
config: default
name: MTEB MindSmallReranking (default)
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
split: test
type: mteb/mind_small
metrics:
- type: map
value: 30.83
- type: main_score
value: 30.83
task:
type: Reranking
- dataset:
config: default
name: MTEB BIOSSES (default)
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
split: test
type: mteb/biosses-sts
metrics:
- type: cosine_pearson
value: 88.80382082011027
- type: cosine_spearman
value: 88.68876782169106
- type: euclidean_pearson
value: 87.00802890147176
- type: euclidean_spearman
value: 87.43211268192712
- type: main_score
value: 88.68876782169106
- type: manhattan_pearson
value: 87.14062537179474
- type: manhattan_spearman
value: 87.59115245033443
- type: pearson
value: 88.80382082011027
- type: spearman
value: 88.68876782169106
task:
type: STS
- dataset:
config: default
name: MTEB BQ (default)
revision: e3dda5e115e487b39ec7e618c0c6a29137052a55
split: test
type: C-MTEB/BQ
metrics:
- type: cosine_pearson
value: 61.588006604878196
- type: cosine_spearman
value: 63.20615427154465
- type: euclidean_pearson
value: 61.818547092516496
- type: euclidean_spearman
value: 63.21558009151778
- type: main_score
value: 63.20615427154465
- type: manhattan_pearson
value: 61.665588158487616
- type: manhattan_spearman
value: 63.051544488238584
- type: pearson
value: 61.588006604878196
- type: spearman
value: 63.20615427154465
task:
type: STS
- dataset:
config: default
name: MTEB BSARDRetrieval (default)
revision: 5effa1b9b5fa3b0f9e12523e6e43e5f86a6e6d59
split: test
type: maastrichtlawtech/bsard
metrics:
- type: main_score
value: 64.414
- type: map_at_1
value: 14.865
- type: map_at_10
value: 21.605
- type: map_at_100
value: 22.762
- type: map_at_1000
value: 22.854
- type: map_at_20
value: 22.259999999999998
- type: map_at_3
value: 20.119999999999997
- type: map_at_5
value: 20.931
- type: mrr_at_1
value: 14.864864864864865
- type: mrr_at_10
value: 21.605176605176606
- type: mrr_at_100
value: 22.7622306460065
- type: mrr_at_1000
value: 22.85383406410312
- type: mrr_at_20
value: 22.259528463088845
- type: mrr_at_3
value: 20.12012012012012
- type: mrr_at_5
value: 20.930930930930934
- type: nauc_map_at_1000_diff1
value: 17.486265968689338
- type: nauc_map_at_1000_max
value: 22.736799291688836
- type: nauc_map_at_1000_std
value: 9.831687441977147
- type: nauc_map_at_100_diff1
value: 17.50754492049086
- type: nauc_map_at_100_max
value: 22.77693662806787
- type: nauc_map_at_100_std
value: 9.853899509675395
- type: nauc_map_at_10_diff1
value: 17.42133968580952
- type: nauc_map_at_10_max
value: 22.45861793882279
- type: nauc_map_at_10_std
value: 8.964888472915938
- type: nauc_map_at_1_diff1
value: 19.433947086968093
- type: nauc_map_at_1_max
value: 24.75657047550517
- type: nauc_map_at_1_std
value: 15.122329157218505
- type: nauc_map_at_20_diff1
value: 17.429856756008785
- type: nauc_map_at_20_max
value: 22.438850987431017
- type: nauc_map_at_20_std
value: 9.172746012213558
- type: nauc_map_at_3_diff1
value: 18.218182689678475
- type: nauc_map_at_3_max
value: 23.57169444088667
- type: nauc_map_at_3_std
value: 10.464473559366356
- type: nauc_map_at_5_diff1
value: 18.6075342519133
- type: nauc_map_at_5_max
value: 23.308845973576673
- type: nauc_map_at_5_std
value: 9.364009996445652
- type: nauc_mrr_at_1000_diff1
value: 17.486265968689338
- type: nauc_mrr_at_1000_max
value: 22.736799291688836
- type: nauc_mrr_at_1000_std
value: 9.831687441977147
- type: nauc_mrr_at_100_diff1
value: 17.50754492049086
- type: nauc_mrr_at_100_max
value: 22.77693662806787
- type: nauc_mrr_at_100_std
value: 9.853899509675395
- type: nauc_mrr_at_10_diff1
value: 17.42133968580952
- type: nauc_mrr_at_10_max
value: 22.45861793882279
- type: nauc_mrr_at_10_std
value: 8.964888472915938
- type: nauc_mrr_at_1_diff1
value: 19.433947086968093
- type: nauc_mrr_at_1_max
value: 24.75657047550517
- type: nauc_mrr_at_1_std
value: 15.122329157218505
- type: nauc_mrr_at_20_diff1
value: 17.429856756008785
- type: nauc_mrr_at_20_max
value: 22.438850987431017
- type: nauc_mrr_at_20_std
value: 9.172746012213558
- type: nauc_mrr_at_3_diff1
value: 18.218182689678475
- type: nauc_mrr_at_3_max
value: 23.57169444088667
- type: nauc_mrr_at_3_std
value: 10.464473559366356
- type: nauc_mrr_at_5_diff1
value: 18.6075342519133
- type: nauc_mrr_at_5_max
value: 23.308845973576673
- type: nauc_mrr_at_5_std
value: 9.364009996445652
- type: nauc_ndcg_at_1000_diff1
value: 16.327871824135745
- type: nauc_ndcg_at_1000_max
value: 23.308241052911495
- type: nauc_ndcg_at_1000_std
value: 11.50905911184097
- type: nauc_ndcg_at_100_diff1
value: 16.676226744692773
- type: nauc_ndcg_at_100_max
value: 24.323253721240974
- type: nauc_ndcg_at_100_std
value: 11.952612443651557
- type: nauc_ndcg_at_10_diff1
value: 16.030325121764594
- type: nauc_ndcg_at_10_max
value: 21.306799242079542
- type: nauc_ndcg_at_10_std
value: 6.63359364302513
- type: nauc_ndcg_at_1_diff1
value: 19.433947086968093
- type: nauc_ndcg_at_1_max
value: 24.75657047550517
- type: nauc_ndcg_at_1_std
value: 15.122329157218505
- type: nauc_ndcg_at_20_diff1
value: 16.013173605999857
- type: nauc_ndcg_at_20_max
value: 21.607217260736576
- type: nauc_ndcg_at_20_std
value: 7.319482417138996
- type: nauc_ndcg_at_3_diff1
value: 17.97958548328493
- type: nauc_ndcg_at_3_max
value: 23.58346522810145
- type: nauc_ndcg_at_3_std
value: 9.392582854708314
- type: nauc_ndcg_at_5_diff1
value: 18.734733324685287
- type: nauc_ndcg_at_5_max
value: 23.273244317623742
- type: nauc_ndcg_at_5_std
value: 7.638611545253834
- type: nauc_precision_at_1000_diff1
value: 7.919843339380295
- type: nauc_precision_at_1000_max
value: 31.575386234270486
- type: nauc_precision_at_1000_std
value: 39.332224386769404
- type: nauc_precision_at_100_diff1
value: 15.018050960000052
- type: nauc_precision_at_100_max
value: 34.98209513759861
- type: nauc_precision_at_100_std
value: 26.970034484359022
- type: nauc_precision_at_10_diff1
value: 12.102191084210922
- type: nauc_precision_at_10_max
value: 18.112541150340675
- type: nauc_precision_at_10_std
value: 0.7358784689406018
- type: nauc_precision_at_1_diff1
value: 19.433947086968093
- type: nauc_precision_at_1_max
value: 24.75657047550517
- type: nauc_precision_at_1_std
value: 15.122329157218505
- type: nauc_precision_at_20_diff1
value: 12.018814361204328
- type: nauc_precision_at_20_max
value: 19.75123746049928
- type: nauc_precision_at_20_std
value: 3.012204650582264
- type: nauc_precision_at_3_diff1
value: 17.41375604940955
- type: nauc_precision_at_3_max
value: 23.699834627021037
- type: nauc_precision_at_3_std
value: 6.793486779050103
- type: nauc_precision_at_5_diff1
value: 19.194631963780257
- type: nauc_precision_at_5_max
value: 23.31708702442155
- type: nauc_precision_at_5_std
value: 3.4591358279667332
- type: nauc_recall_at_1000_diff1
value: 7.919843339380378
- type: nauc_recall_at_1000_max
value: 31.57538623427063
- type: nauc_recall_at_1000_std
value: 39.332224386769546
- type: nauc_recall_at_100_diff1
value: 15.018050960000085
- type: nauc_recall_at_100_max
value: 34.9820951375986
- type: nauc_recall_at_100_std
value: 26.97003448435901
- type: nauc_recall_at_10_diff1
value: 12.102191084210837
- type: nauc_recall_at_10_max
value: 18.112541150340594
- type: nauc_recall_at_10_std
value: 0.7358784689405188
- type: nauc_recall_at_1_diff1
value: 19.433947086968093
- type: nauc_recall_at_1_max
value: 24.75657047550517
- type: nauc_recall_at_1_std
value: 15.122329157218505
- type: nauc_recall_at_20_diff1
value: 12.01881436120429
- type: nauc_recall_at_20_max
value: 19.751237460499222
- type: nauc_recall_at_20_std
value: 3.0122046505822135
- type: nauc_recall_at_3_diff1
value: 17.413756049409503
- type: nauc_recall_at_3_max
value: 23.699834627020998
- type: nauc_recall_at_3_std
value: 6.793486779050083
- type: nauc_recall_at_5_diff1
value: 19.194631963780203
- type: nauc_recall_at_5_max
value: 23.3170870244215
- type: nauc_recall_at_5_std
value: 3.459135827966664
- type: ndcg_at_1
value: 14.865
- type: ndcg_at_10
value: 24.764
- type: ndcg_at_100
value: 30.861
- type: ndcg_at_1000
value: 33.628
- type: ndcg_at_20
value: 27.078000000000003
- type: ndcg_at_3
value: 21.675
- type: ndcg_at_5
value: 23.148
- type: precision_at_1
value: 14.865
- type: precision_at_10
value: 3.4680000000000004
- type: precision_at_100
value: 0.644
- type: precision_at_1000
value: 0.087
- type: precision_at_20
value: 2.185
- type: precision_at_3
value: 8.709
- type: precision_at_5
value: 5.946
- type: recall_at_1
value: 14.865
- type: recall_at_10
value: 34.685
- type: recall_at_100
value: 64.414
- type: recall_at_1000
value: 86.937
- type: recall_at_20
value: 43.694
- type: recall_at_3
value: 26.125999999999998
- type: recall_at_5
value: 29.73
task:
type: Retrieval
- dataset:
config: default
name: MTEB Banking77Classification (default)
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
split: test
type: mteb/banking77
metrics:
- type: accuracy
value: 84.08116883116882
- type: f1
value: 84.05587055990273
- type: f1_weighted
value: 84.05587055990274
- type: main_score
value: 84.08116883116882
task:
type: Classification
- dataset:
config: default
name: MTEB BiorxivClusteringP2P (default)
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
split: test
type: mteb/biorxiv-clustering-p2p
metrics:
- type: main_score
value: 38.1941007822277
- type: v_measure
value: 38.1941007822277
- type: v_measure_std
value: 0.7502113547288178
task:
type: Clustering
- dataset:
config: default
name: MTEB BiorxivClusteringS2S (default)
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
split: test
type: mteb/biorxiv-clustering-s2s
metrics:
- type: main_score
value: 34.42075599178318
- type: v_measure
value: 34.42075599178318
- type: v_measure_std
value: 0.600256720497283
task:
type: Clustering
- dataset:
config: default
name: MTEB BlurbsClusteringP2P (default)
revision: a2dd5b02a77de3466a3eaa98ae586b5610314496
split: test
type: slvnwhrl/blurbs-clustering-p2p
metrics:
- type: main_score
value: 41.634627363047265
- type: v_measure
value: 41.634627363047265
- type: v_measure_std
value: 9.726923191225307
task:
type: Clustering
- dataset:
config: default
name: MTEB BlurbsClusteringS2S (default)
revision: 22793b6a6465bf00120ad525e38c51210858132c
split: test
type: slvnwhrl/blurbs-clustering-s2s
metrics:
- type: main_score
value: 20.996468295584197
- type: v_measure
value: 20.996468295584197
- type: v_measure_std
value: 9.225766688272197
task:
type: Clustering
- dataset:
config: default
name: MTEB CBD (default)
revision: 36ddb419bcffe6a5374c3891957912892916f28d
split: test
type: PL-MTEB/cbd
metrics:
- type: accuracy
value: 69.99
- type: ap
value: 22.57826353116948
- type: ap_weighted
value: 22.57826353116948
- type: f1
value: 59.04574955548393
- type: f1_weighted
value: 74.36235022309789
- type: main_score
value: 69.99
task:
type: Classification
- dataset:
config: default
name: MTEB CDSC-E (default)
revision: 0a3d4aa409b22f80eb22cbf59b492637637b536d
split: test
type: PL-MTEB/cdsce-pairclassification
metrics:
- type: cosine_accuracy
value: 88.7
- type: cosine_accuracy_threshold
value: 97.37848043441772
- type: cosine_ap
value: 73.0405088928302
- type: cosine_f1
value: 63.52201257861635
- type: cosine_f1_threshold
value: 96.98888063430786
- type: cosine_precision
value: 78.90625
- type: cosine_recall
value: 53.1578947368421
- type: dot_accuracy
value: 84.89999999999999
- type: dot_accuracy_threshold
value: 43603.09753417969
- type: dot_ap
value: 56.98157569085279
- type: dot_f1
value: 57.606490872210955
- type: dot_f1_threshold
value: 40406.23779296875
- type: dot_precision
value: 46.864686468646866
- type: dot_recall
value: 74.73684210526315
- type: euclidean_accuracy
value: 88.5
- type: euclidean_accuracy_threshold
value: 498.0483055114746
- type: euclidean_ap
value: 72.97328234816734
- type: euclidean_f1
value: 63.722397476340696
- type: euclidean_f1_threshold
value: 508.6186408996582
- type: euclidean_precision
value: 79.52755905511812
- type: euclidean_recall
value: 53.1578947368421
- type: main_score
value: 73.0405088928302
- type: manhattan_accuracy
value: 88.6
- type: manhattan_accuracy_threshold
value: 12233.079528808594
- type: manhattan_ap
value: 72.92148503992615
- type: manhattan_f1
value: 63.69426751592356
- type: manhattan_f1_threshold
value: 12392.754364013672
- type: manhattan_precision
value: 80.64516129032258
- type: manhattan_recall
value: 52.63157894736842
- type: max_accuracy
value: 88.7
- type: max_ap
value: 73.0405088928302
- type: max_f1
value: 63.722397476340696
- type: max_precision
value: 80.64516129032258
- type: max_recall
value: 74.73684210526315
- type: similarity_accuracy
value: 88.7
- type: similarity_accuracy_threshold
value: 97.37848043441772
- type: similarity_ap
value: 73.0405088928302
- type: similarity_f1
value: 63.52201257861635
- type: similarity_f1_threshold
value: 96.98888063430786
- type: similarity_precision
value: 78.90625
- type: similarity_recall
value: 53.1578947368421
task:
type: PairClassification
- dataset:
config: default
name: MTEB CDSC-R (default)
revision: 1cd6abbb00df7d14be3dbd76a7dcc64b3a79a7cd
split: test
type: PL-MTEB/cdscr-sts
metrics:
- type: cosine_pearson
value: 92.97492495289738
- type: cosine_spearman
value: 92.63248098608472
- type: euclidean_pearson
value: 92.04712487782031
- type: euclidean_spearman
value: 92.19679486755008
- type: main_score
value: 92.63248098608472
- type: manhattan_pearson
value: 92.0101187740438
- type: manhattan_spearman
value: 92.20926859332754
- type: pearson
value: 92.97492495289738
- type: spearman
value: 92.63248098608472
task:
type: STS
- dataset:
config: default
name: MTEB CLSClusteringP2P (default)
revision: 4b6227591c6c1a73bc76b1055f3b7f3588e72476
split: test
type: C-MTEB/CLSClusteringP2P
metrics:
- type: main_score
value: 39.96377851800628
- type: v_measure
value: 39.96377851800628
- type: v_measure_std
value: 0.9793033243093288
task:
type: Clustering
- dataset:
config: default
name: MTEB CLSClusteringS2S (default)
revision: e458b3f5414b62b7f9f83499ac1f5497ae2e869f
split: test
type: C-MTEB/CLSClusteringS2S
metrics:
- type: main_score
value: 38.788850224595784
- type: v_measure
value: 38.788850224595784
- type: v_measure_std
value: 1.0712604145916924
task:
type: Clustering
- dataset:
config: default
name: MTEB CMedQAv1
revision: 8d7f1e942507dac42dc58017c1a001c3717da7df
split: test
type: C-MTEB/CMedQAv1-reranking
metrics:
- type: map
value: 77.95952507806115
- type: mrr
value: 80.8643253968254
- type: main_score
value: 77.95952507806115
task:
type: Reranking
- dataset:
config: default
name: MTEB CMedQAv2
revision: 23d186750531a14a0357ca22cd92d712fd512ea0
split: test
type: C-MTEB/CMedQAv2-reranking
metrics:
- type: map
value: 78.21522500165045
- type: mrr
value: 81.28194444444443
- type: main_score
value: 78.21522500165045
task:
type: Reranking
- dataset:
config: default
name: MTEB CQADupstackAndroidRetrieval (default)
revision: f46a197baaae43b4f621051089b82a364682dfeb
split: test
type: mteb/cqadupstack-android
metrics:
- type: map_at_1
value: 33.377
- type: map_at_10
value: 46.371
- type: map_at_100
value: 47.829
- type: map_at_1000
value: 47.94
- type: map_at_20
value: 47.205000000000005
- type: map_at_3
value: 42.782
- type: map_at_5
value: 44.86
- type: mrr_at_1
value: 41.345
- type: mrr_at_10
value: 52.187
- type: mrr_at_100
value: 52.893
- type: mrr_at_1000
value: 52.929
- type: mrr_at_20
value: 52.637
- type: mrr_at_3
value: 49.714000000000006
- type: mrr_at_5
value: 51.373000000000005
- type: ndcg_at_1
value: 41.345
- type: ndcg_at_10
value: 52.946000000000005
- type: ndcg_at_100
value: 57.92699999999999
- type: ndcg_at_1000
value: 59.609
- type: ndcg_at_20
value: 54.900999999999996
- type: ndcg_at_3
value: 48.357
- type: ndcg_at_5
value: 50.739000000000004
- type: precision_at_1
value: 41.345
- type: precision_at_10
value: 10.186
- type: precision_at_100
value: 1.554
- type: precision_at_1000
value: 0.2
- type: precision_at_20
value: 5.959
- type: precision_at_3
value: 23.796
- type: precision_at_5
value: 17.024
- type: recall_at_1
value: 33.377
- type: recall_at_10
value: 65.067
- type: recall_at_100
value: 86.04899999999999
- type: recall_at_1000
value: 96.54899999999999
- type: recall_at_20
value: 72.071
- type: recall_at_3
value: 51.349999999999994
- type: recall_at_5
value: 58.41
- type: main_score
value: 52.946000000000005
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackEnglishRetrieval (default)
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
split: test
type: mteb/cqadupstack-english
metrics:
- type: map_at_1
value: 31.097
- type: map_at_10
value: 42.183
- type: map_at_100
value: 43.580999999999996
- type: map_at_1000
value: 43.718
- type: map_at_20
value: 42.921
- type: map_at_3
value: 38.963
- type: map_at_5
value: 40.815
- type: mrr_at_1
value: 39.745000000000005
- type: mrr_at_10
value: 48.736000000000004
- type: mrr_at_100
value: 49.405
- type: mrr_at_1000
value: 49.452
- type: mrr_at_20
value: 49.118
- type: mrr_at_3
value: 46.497
- type: mrr_at_5
value: 47.827999999999996
- type: ndcg_at_1
value: 39.745000000000005
- type: ndcg_at_10
value: 48.248000000000005
- type: ndcg_at_100
value: 52.956
- type: ndcg_at_1000
value: 54.99699999999999
- type: ndcg_at_20
value: 50.01
- type: ndcg_at_3
value: 43.946000000000005
- type: ndcg_at_5
value: 46.038000000000004
- type: precision_at_1
value: 39.745000000000005
- type: precision_at_10
value: 9.229
- type: precision_at_100
value: 1.5070000000000001
- type: precision_at_1000
value: 0.199
- type: precision_at_20
value: 5.489999999999999
- type: precision_at_3
value: 21.38
- type: precision_at_5
value: 15.274
- type: recall_at_1
value: 31.097
- type: recall_at_10
value: 58.617
- type: recall_at_100
value: 78.55199999999999
- type: recall_at_1000
value: 91.13900000000001
- type: recall_at_20
value: 64.92
- type: recall_at_3
value: 45.672000000000004
- type: recall_at_5
value: 51.669
- type: main_score
value: 48.248000000000005
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackGamingRetrieval (default)
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
split: test
type: mteb/cqadupstack-gaming
metrics:
- type: map_at_1
value: 39.745000000000005
- type: map_at_10
value: 52.063
- type: map_at_100
value: 53.077
- type: map_at_1000
value: 53.13
- type: map_at_20
value: 52.66
- type: map_at_3
value: 48.662
- type: map_at_5
value: 50.507000000000005
- type: mrr_at_1
value: 45.391999999999996
- type: mrr_at_10
value: 55.528
- type: mrr_at_100
value: 56.16100000000001
- type: mrr_at_1000
value: 56.192
- type: mrr_at_20
value: 55.923
- type: mrr_at_3
value: 52.93600000000001
- type: mrr_at_5
value: 54.435
- type: ndcg_at_1
value: 45.391999999999996
- type: ndcg_at_10
value: 58.019
- type: ndcg_at_100
value: 61.936
- type: ndcg_at_1000
value: 63.015
- type: ndcg_at_20
value: 59.691
- type: ndcg_at_3
value: 52.294
- type: ndcg_at_5
value: 55.017
- type: precision_at_1
value: 45.391999999999996
- type: precision_at_10
value: 9.386
- type: precision_at_100
value: 1.232
- type: precision_at_1000
value: 0.136
- type: precision_at_20
value: 5.223
- type: precision_at_3
value: 23.177
- type: precision_at_5
value: 15.9
- type: recall_at_1
value: 39.745000000000005
- type: recall_at_10
value: 72.08099999999999
- type: recall_at_100
value: 88.85300000000001
- type: recall_at_1000
value: 96.569
- type: recall_at_20
value: 78.203
- type: recall_at_3
value: 56.957
- type: recall_at_5
value: 63.63100000000001
- type: main_score
value: 58.019
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackGisRetrieval (default)
revision: 5003b3064772da1887988e05400cf3806fe491f2
split: test
type: mteb/cqadupstack-gis
metrics:
- type: map_at_1
value: 26.651999999999997
- type: map_at_10
value: 35.799
- type: map_at_100
value: 36.846000000000004
- type: map_at_1000
value: 36.931000000000004
- type: map_at_20
value: 36.341
- type: map_at_3
value: 32.999
- type: map_at_5
value: 34.597
- type: mrr_at_1
value: 28.814
- type: mrr_at_10
value: 37.869
- type: mrr_at_100
value: 38.728
- type: mrr_at_1000
value: 38.795
- type: mrr_at_20
value: 38.317
- type: mrr_at_3
value: 35.235
- type: mrr_at_5
value: 36.738
- type: ndcg_at_1
value: 28.814
- type: ndcg_at_10
value: 41.028
- type: ndcg_at_100
value: 46.162
- type: ndcg_at_1000
value: 48.15
- type: ndcg_at_20
value: 42.824
- type: ndcg_at_3
value: 35.621
- type: ndcg_at_5
value: 38.277
- type: precision_at_1
value: 28.814
- type: precision_at_10
value: 6.361999999999999
- type: precision_at_100
value: 0.9450000000000001
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_20
value: 3.6159999999999997
- type: precision_at_3
value: 15.140999999999998
- type: precision_at_5
value: 10.712000000000002
- type: recall_at_1
value: 26.651999999999997
- type: recall_at_10
value: 55.038
- type: recall_at_100
value: 78.806
- type: recall_at_1000
value: 93.485
- type: recall_at_20
value: 61.742
- type: recall_at_3
value: 40.682
- type: recall_at_5
value: 46.855000000000004
- type: main_score
value: 41.028
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackMathematicaRetrieval (default)
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
split: test
type: mteb/cqadupstack-mathematica
metrics:
- type: map_at_1
value: 17.627000000000002
- type: map_at_10
value: 26.436999999999998
- type: map_at_100
value: 27.85
- type: map_at_1000
value: 27.955999999999996
- type: map_at_20
value: 27.233
- type: map_at_3
value: 23.777
- type: map_at_5
value: 25.122
- type: mrr_at_1
value: 22.387999999999998
- type: mrr_at_10
value: 31.589
- type: mrr_at_100
value: 32.641999999999996
- type: mrr_at_1000
value: 32.696999999999996
- type: mrr_at_20
value: 32.201
- type: mrr_at_3
value: 28.98
- type: mrr_at_5
value: 30.342000000000002
- type: ndcg_at_1
value: 22.387999999999998
- type: ndcg_at_10
value: 32.129999999999995
- type: ndcg_at_100
value: 38.562999999999995
- type: ndcg_at_1000
value: 40.903
- type: ndcg_at_20
value: 34.652
- type: ndcg_at_3
value: 27.26
- type: ndcg_at_5
value: 29.235
- type: precision_at_1
value: 22.387999999999998
- type: precision_at_10
value: 5.970000000000001
- type: precision_at_100
value: 1.068
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_20
value: 3.6999999999999997
- type: precision_at_3
value: 13.267000000000001
- type: precision_at_5
value: 9.403
- type: recall_at_1
value: 17.627000000000002
- type: recall_at_10
value: 44.71
- type: recall_at_100
value: 72.426
- type: recall_at_1000
value: 88.64699999999999
- type: recall_at_20
value: 53.65
- type: recall_at_3
value: 30.989
- type: recall_at_5
value: 36.237
- type: main_score
value: 32.129999999999995
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackPhysicsRetrieval (default)
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
split: test
type: mteb/cqadupstack-physics
metrics:
- type: map_at_1
value: 30.891000000000002
- type: map_at_10
value: 41.519
- type: map_at_100
value: 42.896
- type: map_at_1000
value: 42.992999999999995
- type: map_at_20
value: 42.287
- type: map_at_3
value: 37.822
- type: map_at_5
value: 39.976
- type: mrr_at_1
value: 37.921
- type: mrr_at_10
value: 47.260999999999996
- type: mrr_at_100
value: 48.044
- type: mrr_at_1000
value: 48.08
- type: mrr_at_20
value: 47.699999999999996
- type: mrr_at_3
value: 44.513999999999996
- type: mrr_at_5
value: 46.064
- type: ndcg_at_1
value: 37.921
- type: ndcg_at_10
value: 47.806
- type: ndcg_at_100
value: 53.274
- type: ndcg_at_1000
value: 55.021
- type: ndcg_at_20
value: 49.973
- type: ndcg_at_3
value: 42.046
- type: ndcg_at_5
value: 44.835
- type: precision_at_1
value: 37.921
- type: precision_at_10
value: 8.767999999999999
- type: precision_at_100
value: 1.353
- type: precision_at_1000
value: 0.168
- type: precision_at_20
value: 5.135
- type: precision_at_3
value: 20.051
- type: precision_at_5
value: 14.398
- type: recall_at_1
value: 30.891000000000002
- type: recall_at_10
value: 60.897999999999996
- type: recall_at_100
value: 83.541
- type: recall_at_1000
value: 94.825
- type: recall_at_20
value: 68.356
- type: recall_at_3
value: 44.65
- type: recall_at_5
value: 51.919000000000004
- type: main_score
value: 47.806
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackProgrammersRetrieval (default)
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
split: test
type: mteb/cqadupstack-programmers
metrics:
- type: map_at_1
value: 27.654
- type: map_at_10
value: 38.025999999999996
- type: map_at_100
value: 39.425
- type: map_at_1000
value: 39.528
- type: map_at_20
value: 38.838
- type: map_at_3
value: 34.745
- type: map_at_5
value: 36.537
- type: mrr_at_1
value: 34.018
- type: mrr_at_10
value: 43.314
- type: mrr_at_100
value: 44.283
- type: mrr_at_1000
value: 44.327
- type: mrr_at_20
value: 43.929
- type: mrr_at_3
value: 40.868
- type: mrr_at_5
value: 42.317
- type: ndcg_at_1
value: 34.018
- type: ndcg_at_10
value: 43.887
- type: ndcg_at_100
value: 49.791000000000004
- type: ndcg_at_1000
value: 51.834
- type: ndcg_at_20
value: 46.376
- type: ndcg_at_3
value: 38.769999999999996
- type: ndcg_at_5
value: 41.144
- type: precision_at_1
value: 34.018
- type: precision_at_10
value: 8.001999999999999
- type: precision_at_100
value: 1.2630000000000001
- type: precision_at_1000
value: 0.16
- type: precision_at_20
value: 4.737
- type: precision_at_3
value: 18.417
- type: precision_at_5
value: 13.150999999999998
- type: recall_at_1
value: 27.654
- type: recall_at_10
value: 56.111
- type: recall_at_100
value: 81.136
- type: recall_at_1000
value: 94.788
- type: recall_at_20
value: 65.068
- type: recall_at_3
value: 41.713
- type: recall_at_5
value: 48.106
- type: main_score
value: 43.887
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackRetrieval (default)
revision: CQADupstackRetrieval_is_a_combined_dataset
split: test
type: CQADupstackRetrieval_is_a_combined_dataset
metrics:
- type: main_score
value: 42.58858333333333
- type: ndcg_at_10
value: 42.58858333333333
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackStatsRetrieval (default)
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
split: test
type: mteb/cqadupstack-stats
metrics:
- type: map_at_1
value: 24.501
- type: map_at_10
value: 32.814
- type: map_at_100
value: 33.754
- type: map_at_1000
value: 33.859
- type: map_at_20
value: 33.324
- type: map_at_3
value: 30.758000000000003
- type: map_at_5
value: 31.936999999999998
- type: mrr_at_1
value: 27.761000000000003
- type: mrr_at_10
value: 35.662
- type: mrr_at_100
value: 36.443999999999996
- type: mrr_at_1000
value: 36.516999999999996
- type: mrr_at_20
value: 36.085
- type: mrr_at_3
value: 33.742
- type: mrr_at_5
value: 34.931
- type: ndcg_at_1
value: 27.761000000000003
- type: ndcg_at_10
value: 37.208000000000006
- type: ndcg_at_100
value: 41.839
- type: ndcg_at_1000
value: 44.421
- type: ndcg_at_20
value: 38.917
- type: ndcg_at_3
value: 33.544000000000004
- type: ndcg_at_5
value: 35.374
- type: precision_at_1
value: 27.761000000000003
- type: precision_at_10
value: 5.92
- type: precision_at_100
value: 0.899
- type: precision_at_1000
value: 0.12
- type: precision_at_20
value: 3.4130000000000003
- type: precision_at_3
value: 15.031
- type: precision_at_5
value: 10.306999999999999
- type: recall_at_1
value: 24.501
- type: recall_at_10
value: 47.579
- type: recall_at_100
value: 69.045
- type: recall_at_1000
value: 88.032
- type: recall_at_20
value: 54.125
- type: recall_at_3
value: 37.202
- type: recall_at_5
value: 41.927
- type: main_score
value: 37.208000000000006
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackTexRetrieval (default)
revision: 46989137a86843e03a6195de44b09deda022eec7
split: test
type: mteb/cqadupstack-tex
metrics:
- type: map_at_1
value: 18.29
- type: map_at_10
value: 26.183
- type: map_at_100
value: 27.351999999999997
- type: map_at_1000
value: 27.483999999999998
- type: map_at_20
value: 26.798
- type: map_at_3
value: 23.629
- type: map_at_5
value: 24.937
- type: mrr_at_1
value: 22.299
- type: mrr_at_10
value: 30.189
- type: mrr_at_100
value: 31.098
- type: mrr_at_1000
value: 31.177
- type: mrr_at_20
value: 30.697000000000003
- type: mrr_at_3
value: 27.862
- type: mrr_at_5
value: 29.066
- type: ndcg_at_1
value: 22.299
- type: ndcg_at_10
value: 31.202
- type: ndcg_at_100
value: 36.617
- type: ndcg_at_1000
value: 39.544000000000004
- type: ndcg_at_20
value: 33.177
- type: ndcg_at_3
value: 26.639000000000003
- type: ndcg_at_5
value: 28.526
- type: precision_at_1
value: 22.299
- type: precision_at_10
value: 5.8020000000000005
- type: precision_at_100
value: 1.0070000000000001
- type: precision_at_1000
value: 0.14400000000000002
- type: precision_at_20
value: 3.505
- type: precision_at_3
value: 12.698
- type: precision_at_5
value: 9.174
- type: recall_at_1
value: 18.29
- type: recall_at_10
value: 42.254999999999995
- type: recall_at_100
value: 66.60000000000001
- type: recall_at_1000
value: 87.31400000000001
- type: recall_at_20
value: 49.572
- type: recall_at_3
value: 29.342000000000002
- type: recall_at_5
value: 34.221000000000004
- type: main_score
value: 31.202
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackUnixRetrieval (default)
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
split: test
type: mteb/cqadupstack-unix
metrics:
- type: map_at_1
value: 27.722
- type: map_at_10
value: 37.698
- type: map_at_100
value: 38.899
- type: map_at_1000
value: 38.998
- type: map_at_20
value: 38.381
- type: map_at_3
value: 34.244
- type: map_at_5
value: 36.295
- type: mrr_at_1
value: 32.183
- type: mrr_at_10
value: 41.429
- type: mrr_at_100
value: 42.308
- type: mrr_at_1000
value: 42.358000000000004
- type: mrr_at_20
value: 41.957
- type: mrr_at_3
value: 38.401999999999994
- type: mrr_at_5
value: 40.294999999999995
- type: ndcg_at_1
value: 32.183
- type: ndcg_at_10
value: 43.519000000000005
- type: ndcg_at_100
value: 48.786
- type: ndcg_at_1000
value: 50.861999999999995
- type: ndcg_at_20
value: 45.654
- type: ndcg_at_3
value: 37.521
- type: ndcg_at_5
value: 40.615
- type: precision_at_1
value: 32.183
- type: precision_at_10
value: 7.603
- type: precision_at_100
value: 1.135
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_20
value: 4.408
- type: precision_at_3
value: 17.071
- type: precision_at_5
value: 12.668
- type: recall_at_1
value: 27.722
- type: recall_at_10
value: 57.230000000000004
- type: recall_at_100
value: 79.97999999999999
- type: recall_at_1000
value: 94.217
- type: recall_at_20
value: 64.864
- type: recall_at_3
value: 41.215
- type: recall_at_5
value: 48.774
- type: main_score
value: 43.519000000000005
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackWebmastersRetrieval (default)
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
split: test
type: mteb/cqadupstack-webmasters
metrics:
- type: map_at_1
value: 25.852999999999998
- type: map_at_10
value: 35.394999999999996
- type: map_at_100
value: 37.291999999999994
- type: map_at_1000
value: 37.495
- type: map_at_20
value: 36.372
- type: map_at_3
value: 32.336
- type: map_at_5
value: 34.159
- type: mrr_at_1
value: 31.818
- type: mrr_at_10
value: 40.677
- type: mrr_at_100
value: 41.728
- type: mrr_at_1000
value: 41.778
- type: mrr_at_20
value: 41.301
- type: mrr_at_3
value: 38.208
- type: mrr_at_5
value: 39.592
- type: ndcg_at_1
value: 31.818
- type: ndcg_at_10
value: 41.559000000000005
- type: ndcg_at_100
value: 48.012
- type: ndcg_at_1000
value: 50.234
- type: ndcg_at_20
value: 44.15
- type: ndcg_at_3
value: 36.918
- type: ndcg_at_5
value: 39.227000000000004
- type: precision_at_1
value: 31.818
- type: precision_at_10
value: 8.043
- type: precision_at_100
value: 1.625
- type: precision_at_1000
value: 0.245
- type: precision_at_20
value: 5.2170000000000005
- type: precision_at_3
value: 17.655
- type: precision_at_5
value: 12.845999999999998
- type: recall_at_1
value: 25.852999999999998
- type: recall_at_10
value: 53.093
- type: recall_at_100
value: 81.05799999999999
- type: recall_at_1000
value: 94.657
- type: recall_at_20
value: 62.748000000000005
- type: recall_at_3
value: 39.300000000000004
- type: recall_at_5
value: 45.754
- type: main_score
value: 41.559000000000005
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackWordpressRetrieval (default)
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
split: test
type: mteb/cqadupstack-wordpress
metrics:
- type: map_at_1
value: 19.23
- type: map_at_10
value: 28.128999999999998
- type: map_at_100
value: 29.195
- type: map_at_1000
value: 29.310000000000002
- type: map_at_20
value: 28.713
- type: map_at_3
value: 25.191000000000003
- type: map_at_5
value: 26.69
- type: mrr_at_1
value: 21.257
- type: mrr_at_10
value: 30.253999999999998
- type: mrr_at_100
value: 31.195
- type: mrr_at_1000
value: 31.270999999999997
- type: mrr_at_20
value: 30.747999999999998
- type: mrr_at_3
value: 27.633999999999997
- type: mrr_at_5
value: 28.937
- type: ndcg_at_1
value: 21.257
- type: ndcg_at_10
value: 33.511
- type: ndcg_at_100
value: 38.733000000000004
- type: ndcg_at_1000
value: 41.489
- type: ndcg_at_20
value: 35.476
- type: ndcg_at_3
value: 27.845
- type: ndcg_at_5
value: 30.264999999999997
- type: precision_at_1
value: 21.257
- type: precision_at_10
value: 5.619
- type: precision_at_100
value: 0.893
- type: precision_at_1000
value: 0.124
- type: precision_at_20
value: 3.29
- type: precision_at_3
value: 12.508
- type: precision_at_5
value: 8.946
- type: recall_at_1
value: 19.23
- type: recall_at_10
value: 48.185
- type: recall_at_100
value: 71.932
- type: recall_at_1000
value: 92.587
- type: recall_at_20
value: 55.533
- type: recall_at_3
value: 32.865
- type: recall_at_5
value: 38.577
- type: main_score
value: 33.511
task:
type: Retrieval
- dataset:
config: default
name: MTEB ClimateFEVER (default)
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
split: test
type: mteb/climate-fever
metrics:
- type: map_at_1
value: 19.594
- type: map_at_10
value: 32.519
- type: map_at_100
value: 34.1
- type: map_at_1000
value: 34.263
- type: map_at_20
value: 33.353
- type: map_at_3
value: 27.898
- type: map_at_5
value: 30.524
- type: mrr_at_1
value: 46.515
- type: mrr_at_10
value: 56.958
- type: mrr_at_100
value: 57.54899999999999
- type: mrr_at_1000
value: 57.574999999999996
- type: mrr_at_20
value: 57.315000000000005
- type: mrr_at_3
value: 54.852999999999994
- type: mrr_at_5
value: 56.153
- type: ndcg_at_1
value: 46.515
- type: ndcg_at_10
value: 42.363
- type: ndcg_at_100
value: 48.233
- type: ndcg_at_1000
value: 50.993
- type: ndcg_at_20
value: 44.533
- type: ndcg_at_3
value: 37.297000000000004
- type: ndcg_at_5
value: 38.911
- type: precision_at_1
value: 46.515
- type: precision_at_10
value: 12.520999999999999
- type: precision_at_100
value: 1.8980000000000001
- type: precision_at_1000
value: 0.242
- type: precision_at_20
value: 7.212000000000001
- type: precision_at_3
value: 27.752
- type: precision_at_5
value: 20.391000000000002
- type: recall_at_1
value: 19.594
- type: recall_at_10
value: 46.539
- type: recall_at_100
value: 66.782
- type: recall_at_1000
value: 82.049
- type: recall_at_20
value: 52.611
- type: recall_at_3
value: 32.528
- type: recall_at_5
value: 38.933
- type: main_score
value: 42.363
task:
type: Retrieval
- dataset:
config: default
name: MTEB CmedqaRetrieval (default)
revision: cd540c506dae1cf9e9a59c3e06f42030d54e7301
split: dev
type: C-MTEB/CmedqaRetrieval
metrics:
- type: main_score
value: 35.927
- type: map_at_1
value: 20.144000000000002
- type: map_at_10
value: 29.94
- type: map_at_100
value: 31.630000000000003
- type: map_at_1000
value: 31.778000000000002
- type: map_at_20
value: 30.798
- type: map_at_3
value: 26.534999999999997
- type: map_at_5
value: 28.33
- type: mrr_at_1
value: 31.23280820205051
- type: mrr_at_10
value: 38.66781179421835
- type: mrr_at_100
value: 39.656936166081785
- type: mrr_at_1000
value: 39.724602893117414
- type: mrr_at_20
value: 39.21272461558451
- type: mrr_at_3
value: 36.30907726931729
- type: mrr_at_5
value: 37.59814953738436
- type: nauc_map_at_1000_diff1
value: 44.5755334437146
- type: nauc_map_at_1000_max
value: 40.726916781400746
- type: nauc_map_at_1000_std
value: -19.591835061497367
- type: nauc_map_at_100_diff1
value: 44.54542899921038
- type: nauc_map_at_100_max
value: 40.68305902532837
- type: nauc_map_at_100_std
value: -19.658902089283487
- type: nauc_map_at_10_diff1
value: 44.56110529630953
- type: nauc_map_at_10_max
value: 39.89826167846008
- type: nauc_map_at_10_std
value: -20.62910633667902
- type: nauc_map_at_1_diff1
value: 50.82120107004449
- type: nauc_map_at_1_max
value: 33.208851367861584
- type: nauc_map_at_1_std
value: -20.29409730258174
- type: nauc_map_at_20_diff1
value: 44.51171242433788
- type: nauc_map_at_20_max
value: 40.30431132782945
- type: nauc_map_at_20_std
value: -20.290524142792417
- type: nauc_map_at_3_diff1
value: 45.80394138665133
- type: nauc_map_at_3_max
value: 37.766191281426956
- type: nauc_map_at_3_std
value: -21.223601997333876
- type: nauc_map_at_5_diff1
value: 45.00457218474283
- type: nauc_map_at_5_max
value: 38.901044576388365
- type: nauc_map_at_5_std
value: -20.893069613941634
- type: nauc_mrr_at_1000_diff1
value: 50.09855359231429
- type: nauc_mrr_at_1000_max
value: 46.481000170008826
- type: nauc_mrr_at_1000_std
value: -16.053461377096102
- type: nauc_mrr_at_100_diff1
value: 50.08205026347746
- type: nauc_mrr_at_100_max
value: 46.47262126963331
- type: nauc_mrr_at_100_std
value: -16.049112778748693
- type: nauc_mrr_at_10_diff1
value: 50.02363239081706
- type: nauc_mrr_at_10_max
value: 46.39287859062042
- type: nauc_mrr_at_10_std
value: -16.280866744769657
- type: nauc_mrr_at_1_diff1
value: 55.692503735317445
- type: nauc_mrr_at_1_max
value: 47.334834529801014
- type: nauc_mrr_at_1_std
value: -16.985483585693512
- type: nauc_mrr_at_20_diff1
value: 50.07725225722074
- type: nauc_mrr_at_20_max
value: 46.47279295070193
- type: nauc_mrr_at_20_std
value: -16.15168364678318
- type: nauc_mrr_at_3_diff1
value: 51.18685337274134
- type: nauc_mrr_at_3_max
value: 46.7286365021621
- type: nauc_mrr_at_3_std
value: -16.708451287313718
- type: nauc_mrr_at_5_diff1
value: 50.46777237893576
- type: nauc_mrr_at_5_max
value: 46.5352076502249
- type: nauc_mrr_at_5_std
value: -16.557413659905034
- type: nauc_ndcg_at_1000_diff1
value: 43.974299434438066
- type: nauc_ndcg_at_1000_max
value: 43.44628675071857
- type: nauc_ndcg_at_1000_std
value: -15.3495102005021
- type: nauc_ndcg_at_100_diff1
value: 43.336365081508504
- type: nauc_ndcg_at_100_max
value: 43.11345604460776
- type: nauc_ndcg_at_100_std
value: -15.571128070860615
- type: nauc_ndcg_at_10_diff1
value: 43.41266214720136
- type: nauc_ndcg_at_10_max
value: 41.519676787851914
- type: nauc_ndcg_at_10_std
value: -19.217175017223568
- type: nauc_ndcg_at_1_diff1
value: 55.692503735317445
- type: nauc_ndcg_at_1_max
value: 47.334834529801014
- type: nauc_ndcg_at_1_std
value: -16.985483585693512
- type: nauc_ndcg_at_20_diff1
value: 43.351653862834496
- type: nauc_ndcg_at_20_max
value: 42.11608469750499
- type: nauc_ndcg_at_20_std
value: -18.485363540641664
- type: nauc_ndcg_at_3_diff1
value: 45.64193888236677
- type: nauc_ndcg_at_3_max
value: 42.497135099009995
- type: nauc_ndcg_at_3_std
value: -18.764012041130094
- type: nauc_ndcg_at_5_diff1
value: 44.523392133895186
- type: nauc_ndcg_at_5_max
value: 41.564242030096345
- type: nauc_ndcg_at_5_std
value: -19.31080790984941
- type: nauc_precision_at_1000_diff1
value: 6.383464615714393
- type: nauc_precision_at_1000_max
value: 27.439930931284657
- type: nauc_precision_at_1000_std
value: 19.070716188143034
- type: nauc_precision_at_100_diff1
value: 12.599136754501284
- type: nauc_precision_at_100_max
value: 35.886310962337795
- type: nauc_precision_at_100_std
value: 14.06587592659196
- type: nauc_precision_at_10_diff1
value: 25.388891173150206
- type: nauc_precision_at_10_max
value: 46.10269270777384
- type: nauc_precision_at_10_std
value: -5.993803607158499
- type: nauc_precision_at_1_diff1
value: 55.692503735317445
- type: nauc_precision_at_1_max
value: 47.334834529801014
- type: nauc_precision_at_1_std
value: -16.985483585693512
- type: nauc_precision_at_20_diff1
value: 20.984013463099707
- type: nauc_precision_at_20_max
value: 42.9471854616888
- type: nauc_precision_at_20_std
value: -0.8045549929346024
- type: nauc_precision_at_3_diff1
value: 36.191850547148356
- type: nauc_precision_at_3_max
value: 48.09923832376049
- type: nauc_precision_at_3_std
value: -13.159407051271321
- type: nauc_precision_at_5_diff1
value: 31.04967966700407
- type: nauc_precision_at_5_max
value: 47.62867673349624
- type: nauc_precision_at_5_std
value: -10.345790325137353
- type: nauc_recall_at_1000_diff1
value: 11.03436839065707
- type: nauc_recall_at_1000_max
value: 42.32265076651575
- type: nauc_recall_at_1000_std
value: 30.478521053399206
- type: nauc_recall_at_100_diff1
value: 24.788349084510806
- type: nauc_recall_at_100_max
value: 36.72097184821956
- type: nauc_recall_at_100_std
value: -0.2241144179522076
- type: nauc_recall_at_10_diff1
value: 31.613053567704885
- type: nauc_recall_at_10_max
value: 34.4597322828833
- type: nauc_recall_at_10_std
value: -18.00022912690819
- type: nauc_recall_at_1_diff1
value: 50.82120107004449
- type: nauc_recall_at_1_max
value: 33.208851367861584
- type: nauc_recall_at_1_std
value: -20.29409730258174
- type: nauc_recall_at_20_diff1
value: 30.277002670708384
- type: nauc_recall_at_20_max
value: 35.212475675060375
- type: nauc_recall_at_20_std
value: -15.822788854733687
- type: nauc_recall_at_3_diff1
value: 38.87844958322257
- type: nauc_recall_at_3_max
value: 34.66914910044104
- type: nauc_recall_at_3_std
value: -20.234707300209127
- type: nauc_recall_at_5_diff1
value: 35.551139991687776
- type: nauc_recall_at_5_max
value: 34.61009958820695
- type: nauc_recall_at_5_std
value: -19.519180149293444
- type: ndcg_at_1
value: 31.233
- type: ndcg_at_10
value: 35.927
- type: ndcg_at_100
value: 43.037
- type: ndcg_at_1000
value: 45.900999999999996
- type: ndcg_at_20
value: 38.39
- type: ndcg_at_3
value: 31.366
- type: ndcg_at_5
value: 33.108
- type: precision_at_1
value: 31.233
- type: precision_at_10
value: 8.15
- type: precision_at_100
value: 1.402
- type: precision_at_1000
value: 0.17700000000000002
- type: precision_at_20
value: 4.91
- type: precision_at_3
value: 17.871000000000002
- type: precision_at_5
value: 12.948
- type: recall_at_1
value: 20.144000000000002
- type: recall_at_10
value: 44.985
- type: recall_at_100
value: 74.866
- type: recall_at_1000
value: 94.477
- type: recall_at_20
value: 53.37
- type: recall_at_3
value: 31.141000000000002
- type: recall_at_5
value: 36.721
task:
type: Retrieval
- dataset:
config: default
name: MTEB Cmnli (default)
revision: None
split: validation
type: C-MTEB/CMNLI
metrics:
- type: cos_sim_accuracy
value: 71.25676488274203
- type: cos_sim_accuracy_threshold
value: 78.11152935028076
- type: cos_sim_ap
value: 79.10444825556077
- type: cos_sim_f1
value: 74.10750923266312
- type: cos_sim_f1_threshold
value: 75.2312421798706
- type: cos_sim_precision
value: 66.02083714129044
- type: cos_sim_recall
value: 84.45171849427169
- type: dot_accuracy
value: 68.11785929043896
- type: dot_accuracy_threshold
value: 34783.23974609375
- type: dot_ap
value: 75.80201827987712
- type: dot_f1
value: 72.31670990679349
- type: dot_f1_threshold
value: 31978.036499023438
- type: dot_precision
value: 61.386623164763456
- type: dot_recall
value: 87.98223053542202
- type: euclidean_accuracy
value: 71.41310883944678
- type: euclidean_accuracy_threshold
value: 1374.9353408813477
- type: euclidean_ap
value: 79.23359768836457
- type: euclidean_f1
value: 74.38512297540491
- type: euclidean_f1_threshold
value: 1512.6035690307617
- type: euclidean_precision
value: 64.97816593886463
- type: euclidean_recall
value: 86.97685293429974
- type: manhattan_accuracy
value: 71.32892363199038
- type: manhattan_accuracy_threshold
value: 33340.49072265625
- type: manhattan_ap
value: 79.11973684118587
- type: manhattan_f1
value: 74.29401993355481
- type: manhattan_f1_threshold
value: 36012.52746582031
- type: manhattan_precision
value: 66.81605975723622
- type: manhattan_recall
value: 83.65676876315175
- type: max_accuracy
value: 71.41310883944678
- type: max_ap
value: 79.23359768836457
- type: max_f1
value: 74.38512297540491
task:
type: PairClassification
- dataset:
config: default
name: MTEB CovidRetrieval (default)
revision: 1271c7809071a13532e05f25fb53511ffce77117
split: dev
type: C-MTEB/CovidRetrieval
metrics:
- type: main_score
value: 78.917
- type: map_at_1
value: 67.281
- type: map_at_10
value: 75.262
- type: map_at_100
value: 75.60900000000001
- type: map_at_1000
value: 75.618
- type: map_at_20
value: 75.50200000000001
- type: map_at_3
value: 73.455
- type: map_at_5
value: 74.657
- type: mrr_at_1
value: 67.43940990516333
- type: mrr_at_10
value: 75.27367989696756
- type: mrr_at_100
value: 75.62029353306437
- type: mrr_at_1000
value: 75.62934741874726
- type: mrr_at_20
value: 75.51356607409173
- type: mrr_at_3
value: 73.5159817351598
- type: mrr_at_5
value: 74.73832103969093
- type: nauc_map_at_1000_diff1
value: 77.26666391867634
- type: nauc_map_at_1000_max
value: 49.928541012203496
- type: nauc_map_at_1000_std
value: -40.494469470474456
- type: nauc_map_at_100_diff1
value: 77.26087423162396
- type: nauc_map_at_100_max
value: 49.944275615664424
- type: nauc_map_at_100_std
value: -40.48299992715398
- type: nauc_map_at_10_diff1
value: 76.97400113500906
- type: nauc_map_at_10_max
value: 49.84177029115674
- type: nauc_map_at_10_std
value: -40.829250876511445
- type: nauc_map_at_1_diff1
value: 81.44050620630395
- type: nauc_map_at_1_max
value: 48.97711944070578
- type: nauc_map_at_1_std
value: -38.963689457570254
- type: nauc_map_at_20_diff1
value: 77.21791353089375
- type: nauc_map_at_20_max
value: 49.958206759079424
- type: nauc_map_at_20_std
value: -40.53067571658996
- type: nauc_map_at_3_diff1
value: 77.3555925208868
- type: nauc_map_at_3_max
value: 49.32158146451256
- type: nauc_map_at_3_std
value: -41.93552426981978
- type: nauc_map_at_5_diff1
value: 77.07099950431504
- type: nauc_map_at_5_max
value: 49.54190504495002
- type: nauc_map_at_5_std
value: -41.814968130918096
- type: nauc_mrr_at_1000_diff1
value: 77.31388774540477
- type: nauc_mrr_at_1000_max
value: 49.96779699175759
- type: nauc_mrr_at_1000_std
value: -40.43739645160277
- type: nauc_mrr_at_100_diff1
value: 77.30817786449413
- type: nauc_mrr_at_100_max
value: 49.982514428937655
- type: nauc_mrr_at_100_std
value: -40.42876582797744
- type: nauc_mrr_at_10_diff1
value: 77.02048060465756
- type: nauc_mrr_at_10_max
value: 49.87937207270602
- type: nauc_mrr_at_10_std
value: -40.77596560333177
- type: nauc_mrr_at_1_diff1
value: 81.27219599516599
- type: nauc_mrr_at_1_max
value: 49.3083394026327
- type: nauc_mrr_at_1_std
value: -38.31023037552026
- type: nauc_mrr_at_20_diff1
value: 77.26497089316055
- type: nauc_mrr_at_20_max
value: 49.996257597621415
- type: nauc_mrr_at_20_std
value: -40.476723608868014
- type: nauc_mrr_at_3_diff1
value: 77.38971294099257
- type: nauc_mrr_at_3_max
value: 49.38110328987404
- type: nauc_mrr_at_3_std
value: -41.7118646715979
- type: nauc_mrr_at_5_diff1
value: 77.08286142519952
- type: nauc_mrr_at_5_max
value: 49.655249374588685
- type: nauc_mrr_at_5_std
value: -41.48173039989406
- type: nauc_ndcg_at_1000_diff1
value: 76.47399204021758
- type: nauc_ndcg_at_1000_max
value: 50.55770139961048
- type: nauc_ndcg_at_1000_std
value: -39.55650430279072
- type: nauc_ndcg_at_100_diff1
value: 76.29355616618253
- type: nauc_ndcg_at_100_max
value: 51.003608112592936
- type: nauc_ndcg_at_100_std
value: -39.24769744605206
- type: nauc_ndcg_at_10_diff1
value: 74.88697528447634
- type: nauc_ndcg_at_10_max
value: 50.398416372815234
- type: nauc_ndcg_at_10_std
value: -40.76526585772833
- type: nauc_ndcg_at_1_diff1
value: 81.27219599516599
- type: nauc_ndcg_at_1_max
value: 49.3083394026327
- type: nauc_ndcg_at_1_std
value: -38.31023037552026
- type: nauc_ndcg_at_20_diff1
value: 75.85463512091866
- type: nauc_ndcg_at_20_max
value: 50.97338683654334
- type: nauc_ndcg_at_20_std
value: -39.353128774903404
- type: nauc_ndcg_at_3_diff1
value: 75.94015726123543
- type: nauc_ndcg_at_3_max
value: 49.22194251063148
- type: nauc_ndcg_at_3_std
value: -43.040457030630435
- type: nauc_ndcg_at_5_diff1
value: 75.19166189770303
- type: nauc_ndcg_at_5_max
value: 49.65696229797189
- type: nauc_ndcg_at_5_std
value: -42.81534909184424
- type: nauc_precision_at_1000_diff1
value: -14.830901395815788
- type: nauc_precision_at_1000_max
value: 19.686297136854623
- type: nauc_precision_at_1000_std
value: 61.19310360166978
- type: nauc_precision_at_100_diff1
value: 20.55469986751769
- type: nauc_precision_at_100_max
value: 50.78431835075583
- type: nauc_precision_at_100_std
value: 31.54986568374813
- type: nauc_precision_at_10_diff1
value: 45.991938532558656
- type: nauc_precision_at_10_max
value: 46.386318595630385
- type: nauc_precision_at_10_std
value: -23.463011435224608
- type: nauc_precision_at_1_diff1
value: 81.27219599516599
- type: nauc_precision_at_1_max
value: 49.3083394026327
- type: nauc_precision_at_1_std
value: -38.31023037552026
- type: nauc_precision_at_20_diff1
value: 41.53180472410822
- type: nauc_precision_at_20_max
value: 49.89800247204318
- type: nauc_precision_at_20_std
value: -2.4192847331537095
- type: nauc_precision_at_3_diff1
value: 67.37504651209993
- type: nauc_precision_at_3_max
value: 47.893537208629496
- type: nauc_precision_at_3_std
value: -43.2362212382819
- type: nauc_precision_at_5_diff1
value: 60.03438883791718
- type: nauc_precision_at_5_max
value: 48.29770502354206
- type: nauc_precision_at_5_std
value: -40.39588448271546
- type: nauc_recall_at_1000_diff1
value: 71.04741174480844
- type: nauc_recall_at_1000_max
value: 93.19056506596002
- type: nauc_recall_at_1000_std
value: 62.96994797650912
- type: nauc_recall_at_100_diff1
value: 65.00418176852641
- type: nauc_recall_at_100_max
value: 85.27352708427193
- type: nauc_recall_at_100_std
value: 2.8812005546518886
- type: nauc_recall_at_10_diff1
value: 61.263254794998865
- type: nauc_recall_at_10_max
value: 54.17618329507141
- type: nauc_recall_at_10_std
value: -39.80603966142593
- type: nauc_recall_at_1_diff1
value: 81.44050620630395
- type: nauc_recall_at_1_max
value: 48.97711944070578
- type: nauc_recall_at_1_std
value: -38.963689457570254
- type: nauc_recall_at_20_diff1
value: 64.42106091745396
- type: nauc_recall_at_20_max
value: 63.10796640821887
- type: nauc_recall_at_20_std
value: -22.60117424572222
- type: nauc_recall_at_3_diff1
value: 70.66311436592945
- type: nauc_recall_at_3_max
value: 48.69498944323469
- type: nauc_recall_at_3_std
value: -47.37847524874532
- type: nauc_recall_at_5_diff1
value: 66.12701111728848
- type: nauc_recall_at_5_max
value: 49.91763957934711
- type: nauc_recall_at_5_std
value: -48.173252920584126
- type: ndcg_at_1
value: 67.43900000000001
- type: ndcg_at_10
value: 78.917
- type: ndcg_at_100
value: 80.53399999999999
- type: ndcg_at_1000
value: 80.768
- type: ndcg_at_20
value: 79.813
- type: ndcg_at_3
value: 75.37
- type: ndcg_at_5
value: 77.551
- type: precision_at_1
value: 67.43900000000001
- type: precision_at_10
value: 9.115
- type: precision_at_100
value: 0.985
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.737
- type: precision_at_3
value: 27.081
- type: precision_at_5
value: 17.345
- type: recall_at_1
value: 67.281
- type: recall_at_10
value: 90.2
- type: recall_at_100
value: 97.576
- type: recall_at_1000
value: 99.368
- type: recall_at_20
value: 93.783
- type: recall_at_3
value: 80.822
- type: recall_at_5
value: 86.091
task:
type: Retrieval
- dataset:
config: default
name: MTEB DBPedia (default)
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
split: test
type: mteb/dbpedia
metrics:
- type: map_at_1
value: 9.041
- type: map_at_10
value: 18.662
- type: map_at_100
value: 26.054
- type: map_at_1000
value: 27.769
- type: map_at_20
value: 21.499
- type: map_at_3
value: 13.628000000000002
- type: map_at_5
value: 15.617
- type: mrr_at_1
value: 67.25
- type: mrr_at_10
value: 74.673
- type: mrr_at_100
value: 75.022
- type: mrr_at_1000
value: 75.031
- type: mrr_at_20
value: 74.895
- type: mrr_at_3
value: 73.042
- type: mrr_at_5
value: 74.179
- type: ndcg_at_1
value: 55.75
- type: ndcg_at_10
value: 41.004000000000005
- type: ndcg_at_100
value: 44.912
- type: ndcg_at_1000
value: 51.946000000000005
- type: ndcg_at_20
value: 40.195
- type: ndcg_at_3
value: 45.803
- type: ndcg_at_5
value: 42.976
- type: precision_at_1
value: 67.25
- type: precision_at_10
value: 31.874999999999996
- type: precision_at_100
value: 10.37
- type: precision_at_1000
value: 2.1430000000000002
- type: precision_at_20
value: 24.275
- type: precision_at_3
value: 48.417
- type: precision_at_5
value: 40.2
- type: recall_at_1
value: 9.041
- type: recall_at_10
value: 23.592
- type: recall_at_100
value: 49.476
- type: recall_at_1000
value: 71.677
- type: recall_at_20
value: 30.153000000000002
- type: recall_at_3
value: 14.777000000000001
- type: recall_at_5
value: 17.829
- type: main_score
value: 41.004000000000005
task:
type: Retrieval
- dataset:
config: default
name: MTEB DuRetrieval (default)
revision: a1a333e290fe30b10f3f56498e3a0d911a693ced
split: dev
type: C-MTEB/DuRetrieval
metrics:
- type: main_score
value: 83.134
- type: map_at_1
value: 23.907999999999998
- type: map_at_10
value: 74.566
- type: map_at_100
value: 77.706
- type: map_at_1000
value: 77.762
- type: map_at_20
value: 76.943
- type: map_at_3
value: 50.971999999999994
- type: map_at_5
value: 64.429
- type: mrr_at_1
value: 84.8
- type: mrr_at_10
value: 89.73218253968246
- type: mrr_at_100
value: 89.82853630655774
- type: mrr_at_1000
value: 89.83170411703153
- type: mrr_at_20
value: 89.79582030091501
- type: mrr_at_3
value: 89.32499999999992
- type: mrr_at_5
value: 89.58749999999992
- type: nauc_map_at_1000_diff1
value: -2.2736020650163717
- type: nauc_map_at_1000_max
value: 45.3937519555142
- type: nauc_map_at_1000_std
value: 10.824778228268581
- type: nauc_map_at_100_diff1
value: -2.2662939752750066
- type: nauc_map_at_100_max
value: 45.423960626031366
- type: nauc_map_at_100_std
value: 10.804239351738717
- type: nauc_map_at_10_diff1
value: 0.9395752585654343
- type: nauc_map_at_10_max
value: 42.53814836940551
- type: nauc_map_at_10_std
value: 0.7199313235265218
- type: nauc_map_at_1_diff1
value: 45.19415865267676
- type: nauc_map_at_1_max
value: -1.7261947382471912
- type: nauc_map_at_1_std
value: -32.16144291613605
- type: nauc_map_at_20_diff1
value: -1.884514152147472
- type: nauc_map_at_20_max
value: 44.830401115927174
- type: nauc_map_at_20_std
value: 8.118530414377219
- type: nauc_map_at_3_diff1
value: 25.678881127059967
- type: nauc_map_at_3_max
value: 12.191400431839758
- type: nauc_map_at_3_std
value: -27.201740587642327
- type: nauc_map_at_5_diff1
value: 13.227128780829572
- type: nauc_map_at_5_max
value: 26.978282739708977
- type: nauc_map_at_5_std
value: -17.555610348070584
- type: nauc_mrr_at_1000_diff1
value: 21.073512437502178
- type: nauc_mrr_at_1000_max
value: 64.9680257861005
- type: nauc_mrr_at_1000_std
value: 19.626288754404293
- type: nauc_mrr_at_100_diff1
value: 21.074637426957732
- type: nauc_mrr_at_100_max
value: 64.97612675661915
- type: nauc_mrr_at_100_std
value: 19.649504127800878
- type: nauc_mrr_at_10_diff1
value: 21.12003267626651
- type: nauc_mrr_at_10_max
value: 65.24362289059766
- type: nauc_mrr_at_10_std
value: 19.92351276180984
- type: nauc_mrr_at_1_diff1
value: 22.711430629147635
- type: nauc_mrr_at_1_max
value: 58.4059429497403
- type: nauc_mrr_at_1_std
value: 11.967886722567973
- type: nauc_mrr_at_20_diff1
value: 20.98220830510272
- type: nauc_mrr_at_20_max
value: 65.05737535197835
- type: nauc_mrr_at_20_std
value: 19.66672900782771
- type: nauc_mrr_at_3_diff1
value: 20.924796220048528
- type: nauc_mrr_at_3_max
value: 65.71388669932584
- type: nauc_mrr_at_3_std
value: 20.05912197134477
- type: nauc_mrr_at_5_diff1
value: 20.61978649468208
- type: nauc_mrr_at_5_max
value: 65.50709154526211
- type: nauc_mrr_at_5_std
value: 20.241434276181838
- type: nauc_ndcg_at_1000_diff1
value: 0.25363171946133656
- type: nauc_ndcg_at_1000_max
value: 54.12840465309885
- type: nauc_ndcg_at_1000_std
value: 20.749184325412546
- type: nauc_ndcg_at_100_diff1
value: 0.15649430250272792
- type: nauc_ndcg_at_100_max
value: 54.47995322413234
- type: nauc_ndcg_at_100_std
value: 21.266786634233267
- type: nauc_ndcg_at_10_diff1
value: 0.14579250840386346
- type: nauc_ndcg_at_10_max
value: 49.8643037948353
- type: nauc_ndcg_at_10_std
value: 12.960701643914216
- type: nauc_ndcg_at_1_diff1
value: 22.711430629147635
- type: nauc_ndcg_at_1_max
value: 58.4059429497403
- type: nauc_ndcg_at_1_std
value: 11.967886722567973
- type: nauc_ndcg_at_20_diff1
value: -0.6701559981776763
- type: nauc_ndcg_at_20_max
value: 52.95443437012488
- type: nauc_ndcg_at_20_std
value: 16.708883972005758
- type: nauc_ndcg_at_3_diff1
value: -0.19084922341962388
- type: nauc_ndcg_at_3_max
value: 46.2110230886874
- type: nauc_ndcg_at_3_std
value: 13.363250229683038
- type: nauc_ndcg_at_5_diff1
value: 0.9840019268192548
- type: nauc_ndcg_at_5_max
value: 43.56594891798146
- type: nauc_ndcg_at_5_std
value: 8.577017104088146
- type: nauc_precision_at_1000_diff1
value: -30.779179091501145
- type: nauc_precision_at_1000_max
value: 16.056094258615673
- type: nauc_precision_at_1000_std
value: 49.96303902363283
- type: nauc_precision_at_100_diff1
value: -31.583236638899585
- type: nauc_precision_at_100_max
value: 19.16571713603373
- type: nauc_precision_at_100_std
value: 51.870647903980036
- type: nauc_precision_at_10_diff1
value: -35.62134572732597
- type: nauc_precision_at_10_max
value: 31.6935186494612
- type: nauc_precision_at_10_std
value: 46.68659723766723
- type: nauc_precision_at_1_diff1
value: 22.711430629147635
- type: nauc_precision_at_1_max
value: 58.4059429497403
- type: nauc_precision_at_1_std
value: 11.967886722567973
- type: nauc_precision_at_20_diff1
value: -33.875460046920495
- type: nauc_precision_at_20_max
value: 24.188420133566442
- type: nauc_precision_at_20_std
value: 50.02387762958483
- type: nauc_precision_at_3_diff1
value: -28.875998450906827
- type: nauc_precision_at_3_max
value: 44.77058831167941
- type: nauc_precision_at_3_std
value: 31.77993710437207
- type: nauc_precision_at_5_diff1
value: -34.92525440306491
- type: nauc_precision_at_5_max
value: 39.855219917077086
- type: nauc_precision_at_5_std
value: 37.95432046169299
- type: nauc_recall_at_1000_diff1
value: -14.293309371874733
- type: nauc_recall_at_1000_max
value: 59.06948692482579
- type: nauc_recall_at_1000_std
value: 62.586254868312686
- type: nauc_recall_at_100_diff1
value: -4.344100947212704
- type: nauc_recall_at_100_max
value: 58.42120421043602
- type: nauc_recall_at_100_std
value: 46.48562009316997
- type: nauc_recall_at_10_diff1
value: 0.04948662912161709
- type: nauc_recall_at_10_max
value: 42.42809687119093
- type: nauc_recall_at_10_std
value: 0.6892504250411409
- type: nauc_recall_at_1_diff1
value: 45.19415865267676
- type: nauc_recall_at_1_max
value: -1.7261947382471912
- type: nauc_recall_at_1_std
value: -32.16144291613605
- type: nauc_recall_at_20_diff1
value: -7.634587864605111
- type: nauc_recall_at_20_max
value: 49.21327187174134
- type: nauc_recall_at_20_std
value: 16.408481068336346
- type: nauc_recall_at_3_diff1
value: 24.72546591038644
- type: nauc_recall_at_3_max
value: 6.620763400972902
- type: nauc_recall_at_3_std
value: -29.994703323331684
- type: nauc_recall_at_5_diff1
value: 12.65527364845842
- type: nauc_recall_at_5_max
value: 20.400121385794694
- type: nauc_recall_at_5_std
value: -22.34284568447213
- type: ndcg_at_1
value: 84.8
- type: ndcg_at_10
value: 83.134
- type: ndcg_at_100
value: 86.628
- type: ndcg_at_1000
value: 87.151
- type: ndcg_at_20
value: 85.092
- type: ndcg_at_3
value: 81.228
- type: ndcg_at_5
value: 80.2
- type: precision_at_1
value: 84.8
- type: precision_at_10
value: 40.394999999999996
- type: precision_at_100
value: 4.745
- type: precision_at_1000
value: 0.488
- type: precision_at_20
value: 22.245
- type: precision_at_3
value: 73.25
- type: precision_at_5
value: 61.86000000000001
- type: recall_at_1
value: 23.907999999999998
- type: recall_at_10
value: 85.346
- type: recall_at_100
value: 96.515
- type: recall_at_1000
value: 99.156
- type: recall_at_20
value: 91.377
- type: recall_at_3
value: 54.135
- type: recall_at_5
value: 70.488
task:
type: Retrieval
- dataset:
config: default
name: MTEB EcomRetrieval (default)
revision: 687de13dc7294d6fd9be10c6945f9e8fec8166b9
split: dev
type: C-MTEB/EcomRetrieval
metrics:
- type: main_score
value: 60.887
- type: map_at_1
value: 46.6
- type: map_at_10
value: 56.035000000000004
- type: map_at_100
value: 56.741
- type: map_at_1000
value: 56.764
- type: map_at_20
value: 56.513999999999996
- type: map_at_3
value: 53.733
- type: map_at_5
value: 54.913000000000004
- type: mrr_at_1
value: 46.6
- type: mrr_at_10
value: 56.034523809523776
- type: mrr_at_100
value: 56.74056360434383
- type: mrr_at_1000
value: 56.76373487222486
- type: mrr_at_20
value: 56.51374873879128
- type: mrr_at_3
value: 53.73333333333328
- type: mrr_at_5
value: 54.91333333333327
- type: nauc_map_at_1000_diff1
value: 65.13546939953387
- type: nauc_map_at_1000_max
value: 43.358890946774494
- type: nauc_map_at_1000_std
value: -9.973282105235036
- type: nauc_map_at_100_diff1
value: 65.12449309472493
- type: nauc_map_at_100_max
value: 43.377100882923145
- type: nauc_map_at_100_std
value: -9.971781228240555
- type: nauc_map_at_10_diff1
value: 64.83020018537475
- type: nauc_map_at_10_max
value: 43.25969482323034
- type: nauc_map_at_10_std
value: -10.120272176001547
- type: nauc_map_at_1_diff1
value: 69.58727592100516
- type: nauc_map_at_1_max
value: 38.236494689522026
- type: nauc_map_at_1_std
value: -14.833390831689597
- type: nauc_map_at_20_diff1
value: 65.01159809914586
- type: nauc_map_at_20_max
value: 43.33440319829618
- type: nauc_map_at_20_std
value: -10.039958228659726
- type: nauc_map_at_3_diff1
value: 65.2396323885909
- type: nauc_map_at_3_max
value: 42.26904017378952
- type: nauc_map_at_3_std
value: -11.793017036934044
- type: nauc_map_at_5_diff1
value: 64.96397227898036
- type: nauc_map_at_5_max
value: 43.231333789145424
- type: nauc_map_at_5_std
value: -10.349933732151372
- type: nauc_mrr_at_1000_diff1
value: 65.13546939953387
- type: nauc_mrr_at_1000_max
value: 43.358890946774494
- type: nauc_mrr_at_1000_std
value: -9.973282105235036
- type: nauc_mrr_at_100_diff1
value: 65.12449309472493
- type: nauc_mrr_at_100_max
value: 43.377100882923145
- type: nauc_mrr_at_100_std
value: -9.971781228240555
- type: nauc_mrr_at_10_diff1
value: 64.83020018537475
- type: nauc_mrr_at_10_max
value: 43.25969482323034
- type: nauc_mrr_at_10_std
value: -10.120272176001547
- type: nauc_mrr_at_1_diff1
value: 69.58727592100516
- type: nauc_mrr_at_1_max
value: 38.236494689522026
- type: nauc_mrr_at_1_std
value: -14.833390831689597
- type: nauc_mrr_at_20_diff1
value: 65.01159809914586
- type: nauc_mrr_at_20_max
value: 43.33440319829618
- type: nauc_mrr_at_20_std
value: -10.039958228659726
- type: nauc_mrr_at_3_diff1
value: 65.2396323885909
- type: nauc_mrr_at_3_max
value: 42.26904017378952
- type: nauc_mrr_at_3_std
value: -11.793017036934044
- type: nauc_mrr_at_5_diff1
value: 64.96397227898036
- type: nauc_mrr_at_5_max
value: 43.231333789145424
- type: nauc_mrr_at_5_std
value: -10.349933732151372
- type: nauc_ndcg_at_1000_diff1
value: 64.26802655199876
- type: nauc_ndcg_at_1000_max
value: 45.854310744745185
- type: nauc_ndcg_at_1000_std
value: -6.184417305204082
- type: nauc_ndcg_at_100_diff1
value: 63.99268329609827
- type: nauc_ndcg_at_100_max
value: 46.31270128748375
- type: nauc_ndcg_at_100_std
value: -6.1393433180558965
- type: nauc_ndcg_at_10_diff1
value: 62.6735104141137
- type: nauc_ndcg_at_10_max
value: 45.54954799462398
- type: nauc_ndcg_at_10_std
value: -7.348851199024871
- type: nauc_ndcg_at_1_diff1
value: 69.58727592100516
- type: nauc_ndcg_at_1_max
value: 38.236494689522026
- type: nauc_ndcg_at_1_std
value: -14.833390831689597
- type: nauc_ndcg_at_20_diff1
value: 63.25899651677274
- type: nauc_ndcg_at_20_max
value: 45.952196968886014
- type: nauc_ndcg_at_20_std
value: -6.807607465125713
- type: nauc_ndcg_at_3_diff1
value: 63.65618337476822
- type: nauc_ndcg_at_3_max
value: 43.507890965228945
- type: nauc_ndcg_at_3_std
value: -10.73845622217601
- type: nauc_ndcg_at_5_diff1
value: 63.079162432921855
- type: nauc_ndcg_at_5_max
value: 45.38303443868148
- type: nauc_ndcg_at_5_std
value: -8.063657824835534
- type: nauc_precision_at_1000_diff1
value: 63.01459977930557
- type: nauc_precision_at_1000_max
value: 92.4253034547151
- type: nauc_precision_at_1000_std
value: 84.4845513963158
- type: nauc_precision_at_100_diff1
value: 57.17217119405878
- type: nauc_precision_at_100_max
value: 80.70049725316484
- type: nauc_precision_at_100_std
value: 41.78392287147403
- type: nauc_precision_at_10_diff1
value: 53.115665404390725
- type: nauc_precision_at_10_max
value: 55.73825657341263
- type: nauc_precision_at_10_std
value: 5.406226305013257
- type: nauc_precision_at_1_diff1
value: 69.58727592100516
- type: nauc_precision_at_1_max
value: 38.236494689522026
- type: nauc_precision_at_1_std
value: -14.833390831689597
- type: nauc_precision_at_20_diff1
value: 53.77730697622828
- type: nauc_precision_at_20_max
value: 61.88170819253054
- type: nauc_precision_at_20_std
value: 13.678730470003856
- type: nauc_precision_at_3_diff1
value: 58.580196992291455
- type: nauc_precision_at_3_max
value: 47.404834585376626
- type: nauc_precision_at_3_std
value: -7.374978769024051
- type: nauc_precision_at_5_diff1
value: 56.44564652606437
- type: nauc_precision_at_5_max
value: 53.08973975162324
- type: nauc_precision_at_5_std
value: 0.22762700141423803
- type: nauc_recall_at_1000_diff1
value: 63.01459977930565
- type: nauc_recall_at_1000_max
value: 92.42530345471532
- type: nauc_recall_at_1000_std
value: 84.48455139631602
- type: nauc_recall_at_100_diff1
value: 57.17217119405904
- type: nauc_recall_at_100_max
value: 80.70049725316468
- type: nauc_recall_at_100_std
value: 41.783922871474275
- type: nauc_recall_at_10_diff1
value: 53.11566540439087
- type: nauc_recall_at_10_max
value: 55.738256573412656
- type: nauc_recall_at_10_std
value: 5.406226305013377
- type: nauc_recall_at_1_diff1
value: 69.58727592100516
- type: nauc_recall_at_1_max
value: 38.236494689522026
- type: nauc_recall_at_1_std
value: -14.833390831689597
- type: nauc_recall_at_20_diff1
value: 53.77730697622846
- type: nauc_recall_at_20_max
value: 61.881708192530525
- type: nauc_recall_at_20_std
value: 13.678730470003947
- type: nauc_recall_at_3_diff1
value: 58.5801969922914
- type: nauc_recall_at_3_max
value: 47.40483458537654
- type: nauc_recall_at_3_std
value: -7.37497876902413
- type: nauc_recall_at_5_diff1
value: 56.445646526064394
- type: nauc_recall_at_5_max
value: 53.08973975162332
- type: nauc_recall_at_5_std
value: 0.22762700141428024
- type: ndcg_at_1
value: 46.6
- type: ndcg_at_10
value: 60.887
- type: ndcg_at_100
value: 64.18199999999999
- type: ndcg_at_1000
value: 64.726
- type: ndcg_at_20
value: 62.614999999999995
- type: ndcg_at_3
value: 56.038
- type: ndcg_at_5
value: 58.150999999999996
- type: precision_at_1
value: 46.6
- type: precision_at_10
value: 7.630000000000001
- type: precision_at_100
value: 0.914
- type: precision_at_1000
value: 0.096
- type: precision_at_20
value: 4.154999999999999
- type: precision_at_3
value: 20.9
- type: precision_at_5
value: 13.56
- type: recall_at_1
value: 46.6
- type: recall_at_10
value: 76.3
- type: recall_at_100
value: 91.4
- type: recall_at_1000
value: 95.6
- type: recall_at_20
value: 83.1
- type: recall_at_3
value: 62.7
- type: recall_at_5
value: 67.80000000000001
task:
type: Retrieval
- dataset:
config: default
name: MTEB EmotionClassification (default)
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
split: test
type: mteb/emotion
metrics:
- type: accuracy
value: 73.29999999999998
- type: f1
value: 67.71473706580302
- type: f1_weighted
value: 74.83537255312045
- type: main_score
value: 73.29999999999998
task:
type: Classification
- dataset:
config: default
name: MTEB FEVER (default)
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
split: test
type: mteb/fever
metrics:
- type: map_at_1
value: 78.371
- type: map_at_10
value: 85.762
- type: map_at_100
value: 85.954
- type: map_at_1000
value: 85.966
- type: map_at_20
value: 85.887
- type: map_at_3
value: 84.854
- type: map_at_5
value: 85.408
- type: mrr_at_1
value: 84.443
- type: mrr_at_10
value: 90.432
- type: mrr_at_100
value: 90.483
- type: mrr_at_1000
value: 90.484
- type: mrr_at_20
value: 90.473
- type: mrr_at_3
value: 89.89399999999999
- type: mrr_at_5
value: 90.244
- type: ndcg_at_1
value: 84.443
- type: ndcg_at_10
value: 89.05499999999999
- type: ndcg_at_100
value: 89.68
- type: ndcg_at_1000
value: 89.87899999999999
- type: ndcg_at_20
value: 89.381
- type: ndcg_at_3
value: 87.73100000000001
- type: ndcg_at_5
value: 88.425
- type: precision_at_1
value: 84.443
- type: precision_at_10
value: 10.520999999999999
- type: precision_at_100
value: 1.103
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_20
value: 5.362
- type: precision_at_3
value: 33.198
- type: precision_at_5
value: 20.441000000000003
- type: recall_at_1
value: 78.371
- type: recall_at_10
value: 94.594
- type: recall_at_100
value: 96.97099999999999
- type: recall_at_1000
value: 98.18
- type: recall_at_20
value: 95.707
- type: recall_at_3
value: 90.853
- type: recall_at_5
value: 92.74799999999999
- type: main_score
value: 89.05499999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB FiQA2018 (default)
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
split: test
type: mteb/fiqa
metrics:
- type: map_at_1
value: 23.810000000000002
- type: map_at_10
value: 39.051
- type: map_at_100
value: 41.231
- type: map_at_1000
value: 41.376000000000005
- type: map_at_20
value: 40.227000000000004
- type: map_at_3
value: 33.915
- type: map_at_5
value: 36.459
- type: mrr_at_1
value: 48.148
- type: mrr_at_10
value: 55.765
- type: mrr_at_100
value: 56.495
- type: mrr_at_1000
value: 56.525999999999996
- type: mrr_at_20
value: 56.213
- type: mrr_at_3
value: 53.086
- type: mrr_at_5
value: 54.513999999999996
- type: ndcg_at_1
value: 48.148
- type: ndcg_at_10
value: 47.349999999999994
- type: ndcg_at_100
value: 54.61899999999999
- type: ndcg_at_1000
value: 56.830000000000005
- type: ndcg_at_20
value: 50.143
- type: ndcg_at_3
value: 43.108000000000004
- type: ndcg_at_5
value: 44.023
- type: precision_at_1
value: 48.148
- type: precision_at_10
value: 13.441
- type: precision_at_100
value: 2.085
- type: precision_at_1000
value: 0.248
- type: precision_at_20
value: 7.870000000000001
- type: precision_at_3
value: 28.909000000000002
- type: precision_at_5
value: 20.957
- type: recall_at_1
value: 23.810000000000002
- type: recall_at_10
value: 54.303000000000004
- type: recall_at_100
value: 81.363
- type: recall_at_1000
value: 94.391
- type: recall_at_20
value: 63.056999999999995
- type: recall_at_3
value: 38.098
- type: recall_at_5
value: 44.414
- type: main_score
value: 47.349999999999994
task:
type: Retrieval
- dataset:
config: default
name: MTEB GeoreviewClassification (default)
revision: 3765c0d1de6b7d264bc459433c45e5a75513839c
split: test
type: ai-forever/georeview-classification
metrics:
- type: accuracy
value: 48.0126953125
- type: f1
value: 47.65764016160488
- type: f1_weighted
value: 47.65701659482088
- type: main_score
value: 48.0126953125
task:
type: Classification
- dataset:
config: default
name: MTEB GeoreviewClusteringP2P (default)
revision: 97a313c8fc85b47f13f33e7e9a95c1ad888c7fec
split: test
type: ai-forever/georeview-clustering-p2p
metrics:
- type: main_score
value: 73.62357853672266
- type: v_measure
value: 73.62357853672266
- type: v_measure_std
value: 0.5942247545535766
task:
type: Clustering
- dataset:
config: default
name: MTEB GerDaLIR (default)
revision: 0bb47f1d73827e96964edb84dfe552f62f4fd5eb
split: test
type: jinaai/ger_da_lir
metrics:
- type: main_score
value: 16.227
- type: map_at_1
value: 8.082
- type: map_at_10
value: 12.959999999999999
- type: map_at_100
value: 13.923
- type: map_at_1000
value: 14.030999999999999
- type: map_at_20
value: 13.453000000000001
- type: map_at_3
value: 11.018
- type: map_at_5
value: 12.056000000000001
- type: mrr_at_1
value: 8.993332249146203
- type: mrr_at_10
value: 13.994013092850247
- type: mrr_at_100
value: 14.913737673149308
- type: mrr_at_1000
value: 15.00843809934407
- type: mrr_at_20
value: 14.470268462334007
- type: mrr_at_3
value: 12.000596302921846
- type: mrr_at_5
value: 13.070689000921561
- type: nauc_map_at_1000_diff1
value: 28.559639584013286
- type: nauc_map_at_1000_max
value: 25.533800126086714
- type: nauc_map_at_1000_std
value: 9.826551026628666
- type: nauc_map_at_100_diff1
value: 28.544724499331696
- type: nauc_map_at_100_max
value: 25.46734324526386
- type: nauc_map_at_100_std
value: 9.739314481785591
- type: nauc_map_at_10_diff1
value: 28.77447517718118
- type: nauc_map_at_10_max
value: 24.7431615237795
- type: nauc_map_at_10_std
value: 8.349878188033646
- type: nauc_map_at_1_diff1
value: 37.405452629895514
- type: nauc_map_at_1_max
value: 24.444208978394023
- type: nauc_map_at_1_std
value: 4.043820373810528
- type: nauc_map_at_20_diff1
value: 28.69764217789062
- type: nauc_map_at_20_max
value: 25.111848355996496
- type: nauc_map_at_20_std
value: 9.034829905305918
- type: nauc_map_at_3_diff1
value: 30.89053285076882
- type: nauc_map_at_3_max
value: 24.862886115911152
- type: nauc_map_at_3_std
value: 6.654260832396586
- type: nauc_map_at_5_diff1
value: 29.230629676604263
- type: nauc_map_at_5_max
value: 24.374302288018583
- type: nauc_map_at_5_std
value: 7.341846952319046
- type: nauc_mrr_at_1000_diff1
value: 28.086147932781426
- type: nauc_mrr_at_1000_max
value: 25.98698528264653
- type: nauc_mrr_at_1000_std
value: 9.917554348624545
- type: nauc_mrr_at_100_diff1
value: 28.069163279791336
- type: nauc_mrr_at_100_max
value: 25.949440010886804
- type: nauc_mrr_at_100_std
value: 9.874340979732578
- type: nauc_mrr_at_10_diff1
value: 28.239920869530046
- type: nauc_mrr_at_10_max
value: 25.351271409498576
- type: nauc_mrr_at_10_std
value: 8.669862759875162
- type: nauc_mrr_at_1_diff1
value: 35.96543040207856
- type: nauc_mrr_at_1_max
value: 25.488936487231967
- type: nauc_mrr_at_1_std
value: 4.76439131038345
- type: nauc_mrr_at_20_diff1
value: 28.18865871284607
- type: nauc_mrr_at_20_max
value: 25.67121763344746
- type: nauc_mrr_at_20_std
value: 9.297910707519472
- type: nauc_mrr_at_3_diff1
value: 30.166714199740717
- type: nauc_mrr_at_3_max
value: 25.541792491964877
- type: nauc_mrr_at_3_std
value: 7.083090296398472
- type: nauc_mrr_at_5_diff1
value: 28.68475284656478
- type: nauc_mrr_at_5_max
value: 24.994071363482835
- type: nauc_mrr_at_5_std
value: 7.687507254902365
- type: nauc_ndcg_at_1000_diff1
value: 25.292792613586467
- type: nauc_ndcg_at_1000_max
value: 29.211905289377178
- type: nauc_ndcg_at_1000_std
value: 18.088867467320355
- type: nauc_ndcg_at_100_diff1
value: 25.026905011089152
- type: nauc_ndcg_at_100_max
value: 27.98822281254431
- type: nauc_ndcg_at_100_std
value: 16.69456904301902
- type: nauc_ndcg_at_10_diff1
value: 25.972279051109503
- type: nauc_ndcg_at_10_max
value: 24.86486482734957
- type: nauc_ndcg_at_10_std
value: 10.398605822106353
- type: nauc_ndcg_at_1_diff1
value: 36.134710485184826
- type: nauc_ndcg_at_1_max
value: 25.384572790326025
- type: nauc_ndcg_at_1_std
value: 4.591863033771824
- type: nauc_ndcg_at_20_diff1
value: 25.850033660205536
- type: nauc_ndcg_at_20_max
value: 25.944243193140515
- type: nauc_ndcg_at_20_std
value: 12.392409721204892
- type: nauc_ndcg_at_3_diff1
value: 29.1966056380018
- type: nauc_ndcg_at_3_max
value: 24.978843156259913
- type: nauc_ndcg_at_3_std
value: 7.353914459205087
- type: nauc_ndcg_at_5_diff1
value: 26.795315295756282
- type: nauc_ndcg_at_5_max
value: 24.1196789150412
- type: nauc_ndcg_at_5_std
value: 8.311970988265172
- type: nauc_precision_at_1000_diff1
value: 9.128270550217984
- type: nauc_precision_at_1000_max
value: 35.79286915973607
- type: nauc_precision_at_1000_std
value: 39.15669472887154
- type: nauc_precision_at_100_diff1
value: 14.770289799034384
- type: nauc_precision_at_100_max
value: 34.58262232264337
- type: nauc_precision_at_100_std
value: 34.101148102981384
- type: nauc_precision_at_10_diff1
value: 19.899104673118178
- type: nauc_precision_at_10_max
value: 26.636940338985625
- type: nauc_precision_at_10_std
value: 15.73871357255849
- type: nauc_precision_at_1_diff1
value: 36.134710485184826
- type: nauc_precision_at_1_max
value: 25.384572790326025
- type: nauc_precision_at_1_std
value: 4.591863033771824
- type: nauc_precision_at_20_diff1
value: 19.423457975148942
- type: nauc_precision_at_20_max
value: 29.58123490878582
- type: nauc_precision_at_20_std
value: 20.847850110821618
- type: nauc_precision_at_3_diff1
value: 24.986416623492918
- type: nauc_precision_at_3_max
value: 25.973548400472975
- type: nauc_precision_at_3_std
value: 9.486410455972823
- type: nauc_precision_at_5_diff1
value: 21.237741424923332
- type: nauc_precision_at_5_max
value: 24.647141028200164
- type: nauc_precision_at_5_std
value: 11.102785032334147
- type: nauc_recall_at_1000_diff1
value: 15.999714888817829
- type: nauc_recall_at_1000_max
value: 44.34701908906545
- type: nauc_recall_at_1000_std
value: 51.13471291594717
- type: nauc_recall_at_100_diff1
value: 17.401714890483706
- type: nauc_recall_at_100_max
value: 33.39042631654808
- type: nauc_recall_at_100_std
value: 33.944446168451584
- type: nauc_recall_at_10_diff1
value: 20.30036232399894
- type: nauc_recall_at_10_max
value: 24.006718284396786
- type: nauc_recall_at_10_std
value: 14.049375108518669
- type: nauc_recall_at_1_diff1
value: 37.405452629895514
- type: nauc_recall_at_1_max
value: 24.444208978394023
- type: nauc_recall_at_1_std
value: 4.043820373810528
- type: nauc_recall_at_20_diff1
value: 20.23582802609045
- type: nauc_recall_at_20_max
value: 26.408063410785243
- type: nauc_recall_at_20_std
value: 18.617479515468112
- type: nauc_recall_at_3_diff1
value: 25.53221830103098
- type: nauc_recall_at_3_max
value: 24.283712329152678
- type: nauc_recall_at_3_std
value: 8.428947805841867
- type: nauc_recall_at_5_diff1
value: 21.741499601020823
- type: nauc_recall_at_5_max
value: 22.754924586295296
- type: nauc_recall_at_5_std
value: 9.966736688169814
- type: ndcg_at_1
value: 8.977
- type: ndcg_at_10
value: 16.227
- type: ndcg_at_100
value: 21.417
- type: ndcg_at_1000
value: 24.451
- type: ndcg_at_20
value: 17.982
- type: ndcg_at_3
value: 12.206999999999999
- type: ndcg_at_5
value: 14.059
- type: precision_at_1
value: 8.977
- type: precision_at_10
value: 2.933
- type: precision_at_100
value: 0.59
- type: precision_at_1000
value: 0.087
- type: precision_at_20
value: 1.8599999999999999
- type: precision_at_3
value: 5.550999999999999
- type: precision_at_5
value: 4.340999999999999
- type: recall_at_1
value: 8.082
- type: recall_at_10
value: 25.52
- type: recall_at_100
value: 50.32
- type: recall_at_1000
value: 74.021
- type: recall_at_20
value: 32.229
- type: recall_at_3
value: 14.66
- type: recall_at_5
value: 19.062
task:
type: Retrieval
- dataset:
config: default
name: MTEB GermanDPR (default)
revision: 5129d02422a66be600ac89cd3e8531b4f97d347d
split: test
type: deepset/germandpr
metrics:
- type: main_score
value: 82.422
- type: map_at_1
value: 64.39
- type: map_at_10
value: 77.273
- type: map_at_100
value: 77.375
- type: map_at_1000
value: 77.376
- type: map_at_20
value: 77.351
- type: map_at_3
value: 75.46300000000001
- type: map_at_5
value: 76.878
- type: mrr_at_1
value: 64.19512195121952
- type: mrr_at_10
value: 77.15842044134736
- type: mrr_at_100
value: 77.2604854308704
- type: mrr_at_1000
value: 77.26087882190109
- type: mrr_at_20
value: 77.23572154560611
- type: mrr_at_3
value: 75.34959349593504
- type: mrr_at_5
value: 76.76422764227652
- type: nauc_map_at_1000_diff1
value: 49.73135253389972
- type: nauc_map_at_1000_max
value: 8.665570717396145
- type: nauc_map_at_1000_std
value: -25.920927572114522
- type: nauc_map_at_100_diff1
value: 49.729170775336605
- type: nauc_map_at_100_max
value: 8.66717979705074
- type: nauc_map_at_100_std
value: -25.918338868918596
- type: nauc_map_at_10_diff1
value: 49.708681691445925
- type: nauc_map_at_10_max
value: 8.830640635692113
- type: nauc_map_at_10_std
value: -25.843238986304858
- type: nauc_map_at_1_diff1
value: 51.750022350988914
- type: nauc_map_at_1_max
value: 3.599863010364626
- type: nauc_map_at_1_std
value: -27.670122127567314
- type: nauc_map_at_20_diff1
value: 49.72609185887161
- type: nauc_map_at_20_max
value: 8.766556053409218
- type: nauc_map_at_20_std
value: -25.85975887517904
- type: nauc_map_at_3_diff1
value: 49.328512536255595
- type: nauc_map_at_3_max
value: 9.475682028996795
- type: nauc_map_at_3_std
value: -26.277349632171017
- type: nauc_map_at_5_diff1
value: 49.42801822186142
- type: nauc_map_at_5_max
value: 8.788822474357252
- type: nauc_map_at_5_std
value: -25.959260882028573
- type: nauc_mrr_at_1000_diff1
value: 50.13038598302397
- type: nauc_mrr_at_1000_max
value: 8.734338637484832
- type: nauc_mrr_at_1000_std
value: -26.653343549855908
- type: nauc_mrr_at_100_diff1
value: 50.12820392111392
- type: nauc_mrr_at_100_max
value: 8.735940503917966
- type: nauc_mrr_at_100_std
value: -26.65074918231251
- type: nauc_mrr_at_10_diff1
value: 50.10567888458267
- type: nauc_mrr_at_10_max
value: 8.898451291748575
- type: nauc_mrr_at_10_std
value: -26.572046921975655
- type: nauc_mrr_at_1_diff1
value: 52.22769994409465
- type: nauc_mrr_at_1_max
value: 3.6490820146062015
- type: nauc_mrr_at_1_std
value: -28.535100562320498
- type: nauc_mrr_at_20_diff1
value: 50.12462222100699
- type: nauc_mrr_at_20_max
value: 8.83487018268756
- type: nauc_mrr_at_20_std
value: -26.591437036958332
- type: nauc_mrr_at_3_diff1
value: 49.6987353700016
- type: nauc_mrr_at_3_max
value: 9.531003760756258
- type: nauc_mrr_at_3_std
value: -26.949799063124818
- type: nauc_mrr_at_5_diff1
value: 49.823881656376585
- type: nauc_mrr_at_5_max
value: 8.850404667985085
- type: nauc_mrr_at_5_std
value: -26.680008966088582
- type: nauc_ndcg_at_1000_diff1
value: 49.41721203361181
- type: nauc_ndcg_at_1000_max
value: 9.41093067609825
- type: nauc_ndcg_at_1000_std
value: -25.499543637737567
- type: nauc_ndcg_at_100_diff1
value: 49.32810419509252
- type: nauc_ndcg_at_100_max
value: 9.476216458766897
- type: nauc_ndcg_at_100_std
value: -25.393856250990414
- type: nauc_ndcg_at_10_diff1
value: 49.181984436623694
- type: nauc_ndcg_at_10_max
value: 10.65234732763274
- type: nauc_ndcg_at_10_std
value: -24.737669349012297
- type: nauc_ndcg_at_1_diff1
value: 51.750022350988914
- type: nauc_ndcg_at_1_max
value: 3.599863010364626
- type: nauc_ndcg_at_1_std
value: -27.670122127567314
- type: nauc_ndcg_at_20_diff1
value: 49.275394594995056
- type: nauc_ndcg_at_20_max
value: 10.402059796651923
- type: nauc_ndcg_at_20_std
value: -24.82329915806705
- type: nauc_ndcg_at_3_diff1
value: 48.22614352152889
- type: nauc_ndcg_at_3_max
value: 11.67464280791404
- type: nauc_ndcg_at_3_std
value: -25.867824868234095
- type: nauc_ndcg_at_5_diff1
value: 48.35583502987241
- type: nauc_ndcg_at_5_max
value: 10.494278750448451
- type: nauc_ndcg_at_5_std
value: -25.11599634172764
- type: nauc_precision_at_1000_diff1
value: .nan
- type: nauc_precision_at_1000_max
value: .nan
- type: nauc_precision_at_1000_std
value: .nan
- type: nauc_precision_at_100_diff1
value: -56.39478136433852
- type: nauc_precision_at_100_max
value: 86.93518577529493
- type: nauc_precision_at_100_std
value: 100.0
- type: nauc_precision_at_10_diff1
value: 38.662829729133094
- type: nauc_precision_at_10_max
value: 56.38018435740605
- type: nauc_precision_at_10_std
value: 6.288091897081105
- type: nauc_precision_at_1_diff1
value: 51.750022350988914
- type: nauc_precision_at_1_max
value: 3.599863010364626
- type: nauc_precision_at_1_std
value: -27.670122127567314
- type: nauc_precision_at_20_diff1
value: 34.739153182429085
- type: nauc_precision_at_20_max
value: 84.86908403000989
- type: nauc_precision_at_20_std
value: 29.156199421219455
- type: nauc_precision_at_3_diff1
value: 42.09287362529135
- type: nauc_precision_at_3_max
value: 23.629152759287074
- type: nauc_precision_at_3_std
value: -23.721376911302492
- type: nauc_precision_at_5_diff1
value: 36.03866171924644
- type: nauc_precision_at_5_max
value: 29.166173558775327
- type: nauc_precision_at_5_std
value: -15.096374563068448
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: -56.39478136433541
- type: nauc_recall_at_100_max
value: 86.93518577528111
- type: nauc_recall_at_100_std
value: 100.0
- type: nauc_recall_at_10_diff1
value: 38.66282972913384
- type: nauc_recall_at_10_max
value: 56.3801843574071
- type: nauc_recall_at_10_std
value: 6.288091897082639
- type: nauc_recall_at_1_diff1
value: 51.750022350988914
- type: nauc_recall_at_1_max
value: 3.599863010364626
- type: nauc_recall_at_1_std
value: -27.670122127567314
- type: nauc_recall_at_20_diff1
value: 34.7391531824321
- type: nauc_recall_at_20_max
value: 84.86908403001016
- type: nauc_recall_at_20_std
value: 29.156199421220748
- type: nauc_recall_at_3_diff1
value: 42.09287362529107
- type: nauc_recall_at_3_max
value: 23.629152759286946
- type: nauc_recall_at_3_std
value: -23.72137691130291
- type: nauc_recall_at_5_diff1
value: 36.0386617192469
- type: nauc_recall_at_5_max
value: 29.1661735587759
- type: nauc_recall_at_5_std
value: -15.09637456306774
- type: ndcg_at_1
value: 64.39
- type: ndcg_at_10
value: 82.422
- type: ndcg_at_100
value: 82.86099999999999
- type: ndcg_at_1000
value: 82.87299999999999
- type: ndcg_at_20
value: 82.67999999999999
- type: ndcg_at_3
value: 78.967
- type: ndcg_at_5
value: 81.50699999999999
- type: precision_at_1
value: 64.39
- type: precision_at_10
value: 9.795
- type: precision_at_100
value: 0.9990000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.946
- type: precision_at_3
value: 29.691000000000003
- type: precision_at_5
value: 19.044
- type: recall_at_1
value: 64.39
- type: recall_at_10
value: 97.951
- type: recall_at_100
value: 99.902
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 98.92699999999999
- type: recall_at_3
value: 89.07300000000001
- type: recall_at_5
value: 95.22
task:
type: Retrieval
- dataset:
config: default
name: MTEB GermanQuAD-Retrieval (default)
revision: f5c87ae5a2e7a5106606314eef45255f03151bb3
split: test
type: mteb/germanquad-retrieval
metrics:
- type: main_score
value: 94.15532365396247
- type: map_at_1
value: 90.789
- type: map_at_10
value: 94.24
- type: map_at_100
value: 94.283
- type: map_at_1000
value: 94.284
- type: map_at_20
value: 94.272
- type: map_at_3
value: 93.913
- type: map_at_5
value: 94.155
- type: mrr_at_1
value: 90.78947368421053
- type: mrr_at_10
value: 94.23987411056376
- type: mrr_at_100
value: 94.28320936825
- type: mrr_at_1000
value: 94.28350209115848
- type: mrr_at_20
value: 94.271919092559
- type: mrr_at_3
value: 93.91258318209313
- type: mrr_at_5
value: 94.15532365396247
- type: nauc_map_at_1000_diff1
value: 89.29089310650436
- type: nauc_map_at_1000_max
value: 73.83868784032414
- type: nauc_map_at_1000_std
value: -11.635778561889989
- type: nauc_map_at_100_diff1
value: 89.29077225707755
- type: nauc_map_at_100_max
value: 73.84002740580378
- type: nauc_map_at_100_std
value: -11.644096256165092
- type: nauc_map_at_10_diff1
value: 89.29117612292366
- type: nauc_map_at_10_max
value: 73.97487984981221
- type: nauc_map_at_10_std
value: -11.35191794373827
- type: nauc_map_at_1_diff1
value: 89.35436544117584
- type: nauc_map_at_1_max
value: 70.35936815057701
- type: nauc_map_at_1_std
value: -13.598996360976903
- type: nauc_map_at_20_diff1
value: 89.2530394052653
- type: nauc_map_at_20_max
value: 73.83537529419839
- type: nauc_map_at_20_std
value: -11.628272822028478
- type: nauc_map_at_3_diff1
value: 89.375111893546
- type: nauc_map_at_3_max
value: 74.78900366026112
- type: nauc_map_at_3_std
value: -12.720905253503274
- type: nauc_map_at_5_diff1
value: 89.35358300820893
- type: nauc_map_at_5_max
value: 74.31996219723239
- type: nauc_map_at_5_std
value: -10.768642638210867
- type: nauc_mrr_at_1000_diff1
value: 89.29089310650436
- type: nauc_mrr_at_1000_max
value: 73.83868784032414
- type: nauc_mrr_at_1000_std
value: -11.635778561889989
- type: nauc_mrr_at_100_diff1
value: 89.29077225707755
- type: nauc_mrr_at_100_max
value: 73.84002740580378
- type: nauc_mrr_at_100_std
value: -11.644096256165092
- type: nauc_mrr_at_10_diff1
value: 89.29117612292366
- type: nauc_mrr_at_10_max
value: 73.97487984981221
- type: nauc_mrr_at_10_std
value: -11.35191794373827
- type: nauc_mrr_at_1_diff1
value: 89.35436544117584
- type: nauc_mrr_at_1_max
value: 70.35936815057701
- type: nauc_mrr_at_1_std
value: -13.598996360976903
- type: nauc_mrr_at_20_diff1
value: 89.2530394052653
- type: nauc_mrr_at_20_max
value: 73.83537529419839
- type: nauc_mrr_at_20_std
value: -11.628272822028478
- type: nauc_mrr_at_3_diff1
value: 89.375111893546
- type: nauc_mrr_at_3_max
value: 74.78900366026112
- type: nauc_mrr_at_3_std
value: -12.720905253503274
- type: nauc_mrr_at_5_diff1
value: 89.35358300820893
- type: nauc_mrr_at_5_max
value: 74.31996219723239
- type: nauc_mrr_at_5_std
value: -10.768642638210867
- type: nauc_ndcg_at_1000_diff1
value: 89.27620775856863
- type: nauc_ndcg_at_1000_max
value: 74.2985757362615
- type: nauc_ndcg_at_1000_std
value: -11.236142819703023
- type: nauc_ndcg_at_100_diff1
value: 89.27284787540731
- type: nauc_ndcg_at_100_max
value: 74.33539303365968
- type: nauc_ndcg_at_100_std
value: -11.469413615851936
- type: nauc_ndcg_at_10_diff1
value: 89.21496710661724
- type: nauc_ndcg_at_10_max
value: 75.02035398490516
- type: nauc_ndcg_at_10_std
value: -9.903255803665814
- type: nauc_ndcg_at_1_diff1
value: 89.35436544117584
- type: nauc_ndcg_at_1_max
value: 70.35936815057701
- type: nauc_ndcg_at_1_std
value: -13.598996360976903
- type: nauc_ndcg_at_20_diff1
value: 89.03561289544179
- type: nauc_ndcg_at_20_max
value: 74.4006766600049
- type: nauc_ndcg_at_20_std
value: -11.129237862587743
- type: nauc_ndcg_at_3_diff1
value: 89.46540193201693
- type: nauc_ndcg_at_3_max
value: 76.87093548368378
- type: nauc_ndcg_at_3_std
value: -12.484902872086767
- type: nauc_ndcg_at_5_diff1
value: 89.39924941584766
- type: nauc_ndcg_at_5_max
value: 75.96975269092722
- type: nauc_ndcg_at_5_std
value: -8.180295581144833
- type: nauc_precision_at_1000_diff1
value: 100.0
- type: nauc_precision_at_1000_max
value: 100.0
- type: nauc_precision_at_1000_std
value: 100.0
- type: nauc_precision_at_100_diff1
value: 86.93074003795302
- type: nauc_precision_at_100_max
value: 100.0
- type: nauc_precision_at_100_std
value: -174.07785375176616
- type: nauc_precision_at_10_diff1
value: 87.43064119412082
- type: nauc_precision_at_10_max
value: 90.60785783417448
- type: nauc_precision_at_10_std
value: 15.378710059645906
- type: nauc_precision_at_1_diff1
value: 89.35436544117584
- type: nauc_precision_at_1_max
value: 70.35936815057701
- type: nauc_precision_at_1_std
value: -13.598996360976903
- type: nauc_precision_at_20_diff1
value: 78.78206037685919
- type: nauc_precision_at_20_max
value: 82.52264166455923
- type: nauc_precision_at_20_std
value: -5.95806599216658
- type: nauc_precision_at_3_diff1
value: 90.12709256456401
- type: nauc_precision_at_3_max
value: 90.72678805838154
- type: nauc_precision_at_3_std
value: -11.047599315631993
- type: nauc_precision_at_5_diff1
value: 89.9066873566561
- type: nauc_precision_at_5_max
value: 93.51571626543664
- type: nauc_precision_at_5_std
value: 22.632403279126162
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 86.93074003793416
- type: nauc_recall_at_100_max
value: 100.0
- type: nauc_recall_at_100_std
value: -174.07785375175723
- type: nauc_recall_at_10_diff1
value: 87.43064119411991
- type: nauc_recall_at_10_max
value: 90.60785783417579
- type: nauc_recall_at_10_std
value: 15.378710059643607
- type: nauc_recall_at_1_diff1
value: 89.35436544117584
- type: nauc_recall_at_1_max
value: 70.35936815057701
- type: nauc_recall_at_1_std
value: -13.598996360976903
- type: nauc_recall_at_20_diff1
value: 78.78206037685645
- type: nauc_recall_at_20_max
value: 82.52264166455791
- type: nauc_recall_at_20_std
value: -5.958065992168697
- type: nauc_recall_at_3_diff1
value: 90.12709256456463
- type: nauc_recall_at_3_max
value: 90.7267880583832
- type: nauc_recall_at_3_std
value: -11.047599315631881
- type: nauc_recall_at_5_diff1
value: 89.90668735665676
- type: nauc_recall_at_5_max
value: 93.51571626543753
- type: nauc_recall_at_5_std
value: 22.632403279126112
- type: ndcg_at_1
value: 90.789
- type: ndcg_at_10
value: 95.46
- type: ndcg_at_100
value: 95.652
- type: ndcg_at_1000
value: 95.659
- type: ndcg_at_20
value: 95.575
- type: ndcg_at_3
value: 94.82000000000001
- type: ndcg_at_5
value: 95.26400000000001
- type: precision_at_1
value: 90.789
- type: precision_at_10
value: 9.908999999999999
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.977
- type: precision_at_3
value: 32.471
- type: precision_at_5
value: 19.701
- type: recall_at_1
value: 90.789
- type: recall_at_10
value: 99.093
- type: recall_at_100
value: 99.955
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 99.546
- type: recall_at_3
value: 97.414
- type: recall_at_5
value: 98.503
task:
type: Retrieval
- dataset:
config: default
name: MTEB GermanSTSBenchmark (default)
revision: e36907544d44c3a247898ed81540310442329e20
split: test
type: jinaai/german-STSbenchmark
metrics:
- type: cosine_pearson
value: 86.55319003300265
- type: cosine_spearman
value: 87.50267373081324
- type: euclidean_pearson
value: 87.41630636501863
- type: euclidean_spearman
value: 88.02170803409365
- type: main_score
value: 87.50267373081324
- type: manhattan_pearson
value: 87.33703179056744
- type: manhattan_spearman
value: 87.99192826922514
- type: pearson
value: 86.55319003300265
- type: spearman
value: 87.50267373081324
task:
type: STS
- dataset:
config: default
name: MTEB HALClusteringS2S (default)
revision: e06ebbbb123f8144bef1a5d18796f3dec9ae2915
split: test
type: lyon-nlp/clustering-hal-s2s
metrics:
- type: main_score
value: 27.477557517301303
- type: v_measure
value: 27.477557517301303
- type: v_measure_std
value: 3.3525736581861336
task:
type: Clustering
- dataset:
config: default
name: MTEB HeadlineClassification (default)
revision: 2fe05ee6b5832cda29f2ef7aaad7b7fe6a3609eb
split: test
type: ai-forever/headline-classification
metrics:
- type: accuracy
value: 75.0830078125
- type: f1
value: 75.08863209267814
- type: f1_weighted
value: 75.08895979060917
- type: main_score
value: 75.0830078125
task:
type: Classification
- dataset:
config: default
name: MTEB HotpotQA (default)
revision: ab518f4d6fcca38d87c25209f94beba119d02014
split: test
type: mteb/hotpotqa
metrics:
- type: map_at_1
value: 38.143
- type: map_at_10
value: 55.916999999999994
- type: map_at_100
value: 56.706
- type: map_at_1000
value: 56.77100000000001
- type: map_at_20
value: 56.367
- type: map_at_3
value: 53.111
- type: map_at_5
value: 54.839000000000006
- type: mrr_at_1
value: 76.286
- type: mrr_at_10
value: 81.879
- type: mrr_at_100
value: 82.09100000000001
- type: mrr_at_1000
value: 82.101
- type: mrr_at_20
value: 82.01
- type: mrr_at_3
value: 80.972
- type: mrr_at_5
value: 81.537
- type: ndcg_at_1
value: 76.286
- type: ndcg_at_10
value: 64.673
- type: ndcg_at_100
value: 67.527
- type: ndcg_at_1000
value: 68.857
- type: ndcg_at_20
value: 65.822
- type: ndcg_at_3
value: 60.616
- type: ndcg_at_5
value: 62.827999999999996
- type: precision_at_1
value: 76.286
- type: precision_at_10
value: 13.196
- type: precision_at_100
value: 1.544
- type: precision_at_1000
value: 0.172
- type: precision_at_20
value: 6.968000000000001
- type: precision_at_3
value: 37.992
- type: precision_at_5
value: 24.54
- type: recall_at_1
value: 38.143
- type: recall_at_10
value: 65.982
- type: recall_at_100
value: 77.225
- type: recall_at_1000
value: 86.077
- type: recall_at_20
value: 69.68299999999999
- type: recall_at_3
value: 56.989000000000004
- type: recall_at_5
value: 61.35
- type: main_score
value: 64.673
task:
type: Retrieval
- dataset:
config: default
name: MTEB IFlyTek (default)
revision: 421605374b29664c5fc098418fe20ada9bd55f8a
split: validation
type: C-MTEB/IFlyTek-classification
metrics:
- type: accuracy
value: 41.67756829549827
- type: f1
value: 33.929325579581636
- type: f1_weighted
value: 43.03952025643197
- type: main_score
value: 41.67756829549827
task:
type: Classification
- dataset:
config: default
name: MTEB ImdbClassification (default)
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
split: test
type: mteb/imdb
metrics:
- type: accuracy
value: 91.90440000000001
- type: ap
value: 88.78663714603425
- type: ap_weighted
value: 88.78663714603425
- type: f1
value: 91.89564361975891
- type: f1_weighted
value: 91.89564361975891
- type: main_score
value: 91.90440000000001
task:
type: Classification
- dataset:
config: default
name: MTEB InappropriatenessClassification (default)
revision: 601651fdc45ef243751676e62dd7a19f491c0285
split: test
type: ai-forever/inappropriateness-classification
metrics:
- type: accuracy
value: 61.0498046875
- type: ap
value: 57.04240566648215
- type: ap_weighted
value: 57.04240566648215
- type: f1
value: 60.867630038606954
- type: f1_weighted
value: 60.867630038606954
- type: main_score
value: 61.0498046875
task:
type: Classification
- dataset:
config: default
name: MTEB JDReview (default)
revision: b7c64bd89eb87f8ded463478346f76731f07bf8b
split: test
type: C-MTEB/JDReview-classification
metrics:
- type: accuracy
value: 83.50844277673546
- type: ap
value: 48.46732380712268
- type: ap_weighted
value: 48.46732380712268
- type: f1
value: 77.43967451387445
- type: f1_weighted
value: 84.78462929014114
- type: main_score
value: 83.50844277673546
task:
type: Classification
- dataset:
config: default
name: MTEB KinopoiskClassification (default)
revision: 5911f26666ac11af46cb9c6849d0dc80a378af24
split: test
type: ai-forever/kinopoisk-sentiment-classification
metrics:
- type: accuracy
value: 62.393333333333324
- type: f1
value: 61.35940129568015
- type: f1_weighted
value: 61.35940129568015
- type: main_score
value: 62.393333333333324
task:
type: Classification
- dataset:
config: default
name: MTEB LCQMC (default)
revision: 17f9b096f80380fce5ed12a9be8be7784b337daf
split: test
type: C-MTEB/LCQMC
metrics:
- type: cosine_pearson
value: 67.74375505907872
- type: cosine_spearman
value: 75.94582231399434
- type: euclidean_pearson
value: 74.52501692443582
- type: euclidean_spearman
value: 75.88428434746646
- type: main_score
value: 75.94582231399434
- type: manhattan_pearson
value: 74.55015441749529
- type: manhattan_spearman
value: 75.83288262176175
- type: pearson
value: 67.74375505907872
- type: spearman
value: 75.94582231399434
task:
type: STS
- dataset:
config: default
name: MTEB LEMBNarrativeQARetrieval (default)
revision: 6e346642246bfb4928c560ee08640dc84d074e8c
split: test
type: dwzhu/LongEmbed
metrics:
- type: map_at_1
value: 23.093
- type: map_at_10
value: 30.227999999999998
- type: map_at_100
value: 31.423000000000002
- type: map_at_1000
value: 31.533
- type: map_at_20
value: 30.835
- type: map_at_3
value: 27.983999999999998
- type: map_at_5
value: 29.253
- type: mrr_at_1
value: 23.093
- type: mrr_at_10
value: 30.227999999999998
- type: mrr_at_100
value: 31.423000000000002
- type: mrr_at_1000
value: 31.533
- type: mrr_at_20
value: 30.835
- type: mrr_at_3
value: 27.983999999999998
- type: mrr_at_5
value: 29.253
- type: ndcg_at_1
value: 23.093
- type: ndcg_at_10
value: 34.297
- type: ndcg_at_100
value: 41.049
- type: ndcg_at_1000
value: 43.566
- type: ndcg_at_20
value: 36.52
- type: ndcg_at_3
value: 29.629
- type: ndcg_at_5
value: 31.926
- type: precision_at_1
value: 23.093
- type: precision_at_10
value: 4.735
- type: precision_at_100
value: 0.8109999999999999
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 2.8080000000000003
- type: precision_at_3
value: 11.468
- type: precision_at_5
value: 8.001
- type: recall_at_1
value: 23.093
- type: recall_at_10
value: 47.354
- type: recall_at_100
value: 81.147
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 56.16799999999999
- type: recall_at_3
value: 34.405
- type: recall_at_5
value: 40.004
- type: main_score
value: 34.297
task:
type: Retrieval
- dataset:
config: default
name: MTEB LEMBNeedleRetrieval (default)
revision: 6e346642246bfb4928c560ee08640dc84d074e8c
split: test_256
type: dwzhu/LongEmbed
metrics:
- type: map_at_1
value: 64.0
- type: map_at_10
value: 77.083
- type: map_at_100
value: 77.265
- type: map_at_1000
value: 77.265
- type: map_at_20
value: 77.265
- type: map_at_3
value: 76.333
- type: map_at_5
value: 76.833
- type: mrr_at_1
value: 64.0
- type: mrr_at_10
value: 77.083
- type: mrr_at_100
value: 77.265
- type: mrr_at_1000
value: 77.265
- type: mrr_at_20
value: 77.265
- type: mrr_at_3
value: 76.333
- type: mrr_at_5
value: 76.833
- type: ndcg_at_1
value: 64.0
- type: ndcg_at_10
value: 82.325
- type: ndcg_at_100
value: 82.883
- type: ndcg_at_1000
value: 82.883
- type: ndcg_at_20
value: 82.883
- type: ndcg_at_3
value: 80.833
- type: ndcg_at_5
value: 81.694
- type: precision_at_1
value: 64.0
- type: precision_at_10
value: 9.8
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 5.0
- type: precision_at_3
value: 31.333
- type: precision_at_5
value: 19.2
- type: recall_at_1
value: 64.0
- type: recall_at_10
value: 98.0
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 100.0
- type: recall_at_3
value: 94.0
- type: recall_at_5
value: 96.0
- type: main_score
value: 64.0
task:
type: Retrieval
- dataset:
config: default
name: MTEB LEMBPasskeyRetrieval (default)
revision: 6e346642246bfb4928c560ee08640dc84d074e8c
split: test_256
type: dwzhu/LongEmbed
metrics:
- type: map_at_1
value: 100.0
- type: map_at_10
value: 100.0
- type: map_at_100
value: 100.0
- type: map_at_1000
value: 100.0
- type: map_at_20
value: 100.0
- type: map_at_3
value: 100.0
- type: map_at_5
value: 100.0
- type: mrr_at_1
value: 100.0
- type: mrr_at_10
value: 100.0
- type: mrr_at_100
value: 100.0
- type: mrr_at_1000
value: 100.0
- type: mrr_at_20
value: 100.0
- type: mrr_at_3
value: 100.0
- type: mrr_at_5
value: 100.0
- type: ndcg_at_1
value: 100.0
- type: ndcg_at_10
value: 100.0
- type: ndcg_at_100
value: 100.0
- type: ndcg_at_1000
value: 100.0
- type: ndcg_at_20
value: 100.0
- type: ndcg_at_3
value: 100.0
- type: ndcg_at_5
value: 100.0
- type: precision_at_1
value: 100.0
- type: precision_at_10
value: 10.0
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 5.0
- type: precision_at_3
value: 33.333
- type: precision_at_5
value: 20.0
- type: recall_at_1
value: 100.0
- type: recall_at_10
value: 100.0
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 100.0
- type: recall_at_3
value: 100.0
- type: recall_at_5
value: 100.0
- type: main_score
value: 100.0
task:
type: Retrieval
- dataset:
config: default
name: MTEB LEMBQMSumRetrieval (default)
revision: 6e346642246bfb4928c560ee08640dc84d074e8c
split: test
type: dwzhu/LongEmbed
metrics:
- type: map_at_1
value: 24.361
- type: map_at_10
value: 33.641
- type: map_at_100
value: 35.104
- type: map_at_1000
value: 35.127
- type: map_at_20
value: 34.388999999999996
- type: map_at_3
value: 30.255
- type: map_at_5
value: 32.079
- type: mrr_at_1
value: 24.361
- type: mrr_at_10
value: 33.641
- type: mrr_at_100
value: 35.104
- type: mrr_at_1000
value: 35.127
- type: mrr_at_20
value: 34.388999999999996
- type: mrr_at_3
value: 30.255
- type: mrr_at_5
value: 32.079
- type: ndcg_at_1
value: 24.361
- type: ndcg_at_10
value: 39.337
- type: ndcg_at_100
value: 47.384
- type: ndcg_at_1000
value: 47.75
- type: ndcg_at_20
value: 42.077999999999996
- type: ndcg_at_3
value: 32.235
- type: ndcg_at_5
value: 35.524
- type: precision_at_1
value: 24.361
- type: precision_at_10
value: 5.783
- type: precision_at_100
value: 0.975
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 3.435
- type: precision_at_3
value: 12.661
- type: precision_at_5
value: 9.193999999999999
- type: recall_at_1
value: 24.361
- type: recall_at_10
value: 57.826
- type: recall_at_100
value: 97.51100000000001
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 68.697
- type: recall_at_3
value: 37.983
- type: recall_at_5
value: 45.972
- type: main_score
value: 39.337
task:
type: Retrieval
- dataset:
config: default
name: MTEB LEMBSummScreenFDRetrieval (default)
revision: 6e346642246bfb4928c560ee08640dc84d074e8c
split: validation
type: dwzhu/LongEmbed
metrics:
- type: map_at_1
value: 84.821
- type: map_at_10
value: 90.11200000000001
- type: map_at_100
value: 90.158
- type: map_at_1000
value: 90.158
- type: map_at_20
value: 90.137
- type: map_at_3
value: 89.385
- type: map_at_5
value: 89.876
- type: mrr_at_1
value: 84.821
- type: mrr_at_10
value: 90.11200000000001
- type: mrr_at_100
value: 90.158
- type: mrr_at_1000
value: 90.158
- type: mrr_at_20
value: 90.137
- type: mrr_at_3
value: 89.385
- type: mrr_at_5
value: 89.876
- type: ndcg_at_1
value: 84.821
- type: ndcg_at_10
value: 92.334
- type: ndcg_at_100
value: 92.535
- type: ndcg_at_1000
value: 92.535
- type: ndcg_at_20
value: 92.414
- type: ndcg_at_3
value: 90.887
- type: ndcg_at_5
value: 91.758
- type: precision_at_1
value: 84.821
- type: precision_at_10
value: 9.911
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.97
- type: precision_at_3
value: 31.746000000000002
- type: precision_at_5
value: 19.464000000000002
- type: recall_at_1
value: 84.821
- type: recall_at_10
value: 99.107
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 99.405
- type: recall_at_3
value: 95.238
- type: recall_at_5
value: 97.321
- type: main_score
value: 92.334
task:
type: Retrieval
- dataset:
config: default
name: MTEB LEMBWikimQARetrieval (default)
revision: 6e346642246bfb4928c560ee08640dc84d074e8c
split: test
type: dwzhu/LongEmbed
metrics:
- type: map_at_1
value: 53.667
- type: map_at_10
value: 61.719
- type: map_at_100
value: 62.471
- type: map_at_1000
value: 62.492000000000004
- type: map_at_20
value: 62.153000000000006
- type: map_at_3
value: 59.167
- type: map_at_5
value: 60.95
- type: mrr_at_1
value: 53.667
- type: mrr_at_10
value: 61.719
- type: mrr_at_100
value: 62.471
- type: mrr_at_1000
value: 62.492000000000004
- type: mrr_at_20
value: 62.153000000000006
- type: mrr_at_3
value: 59.167
- type: mrr_at_5
value: 60.95
- type: ndcg_at_1
value: 53.667
- type: ndcg_at_10
value: 66.018
- type: ndcg_at_100
value: 69.726
- type: ndcg_at_1000
value: 70.143
- type: ndcg_at_20
value: 67.61399999999999
- type: ndcg_at_3
value: 60.924
- type: ndcg_at_5
value: 64.10900000000001
- type: precision_at_1
value: 53.667
- type: precision_at_10
value: 7.9670000000000005
- type: precision_at_100
value: 0.97
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.3
- type: precision_at_3
value: 22.0
- type: precision_at_5
value: 14.732999999999999
- type: recall_at_1
value: 53.667
- type: recall_at_10
value: 79.667
- type: recall_at_100
value: 97.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 86.0
- type: recall_at_3
value: 66.0
- type: recall_at_5
value: 73.667
- type: main_score
value: 66.018
task:
type: Retrieval
- dataset:
config: deu-deu
name: MTEB MLQARetrieval (deu-deu)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 67.548
- type: map_at_1
value: 56.559000000000005
- type: map_at_10
value: 63.867
- type: map_at_100
value: 64.429
- type: map_at_1000
value: 64.457
- type: map_at_20
value: 64.215
- type: map_at_3
value: 62.109
- type: map_at_5
value: 63.101
- type: mrr_at_1
value: 56.56990915134057
- type: mrr_at_10
value: 63.86820789324668
- type: mrr_at_100
value: 64.42973602152581
- type: mrr_at_1000
value: 64.45818598090155
- type: mrr_at_20
value: 64.2163052263868
- type: mrr_at_3
value: 62.10946155550634
- type: mrr_at_5
value: 63.10104143585199
- type: nauc_map_at_1000_diff1
value: 73.78440163370111
- type: nauc_map_at_1000_max
value: 66.37875518052162
- type: nauc_map_at_1000_std
value: -17.063915098135396
- type: nauc_map_at_100_diff1
value: 73.77180802985815
- type: nauc_map_at_100_max
value: 66.38365998362033
- type: nauc_map_at_100_std
value: -17.053345109661972
- type: nauc_map_at_10_diff1
value: 73.70041876696037
- type: nauc_map_at_10_max
value: 66.33213342705997
- type: nauc_map_at_10_std
value: -17.40657791273925
- type: nauc_map_at_1_diff1
value: 76.8784374396948
- type: nauc_map_at_1_max
value: 64.07170606935357
- type: nauc_map_at_1_std
value: -18.464213686790654
- type: nauc_map_at_20_diff1
value: 73.72371377231813
- type: nauc_map_at_20_max
value: 66.42108121059451
- type: nauc_map_at_20_std
value: -17.05384923889036
- type: nauc_map_at_3_diff1
value: 74.08287018839246
- type: nauc_map_at_3_max
value: 66.42422337760333
- type: nauc_map_at_3_std
value: -17.79503404131652
- type: nauc_map_at_5_diff1
value: 73.9294779027339
- type: nauc_map_at_5_max
value: 66.51752041065726
- type: nauc_map_at_5_std
value: -17.67309805113804
- type: nauc_mrr_at_1000_diff1
value: 73.78389736923545
- type: nauc_mrr_at_1000_max
value: 66.37929720858341
- type: nauc_mrr_at_1000_std
value: -17.058591711291278
- type: nauc_mrr_at_100_diff1
value: 73.77126451253136
- type: nauc_mrr_at_100_max
value: 66.38405917246607
- type: nauc_mrr_at_100_std
value: -17.047251035212863
- type: nauc_mrr_at_10_diff1
value: 73.69960470665124
- type: nauc_mrr_at_10_max
value: 66.33265194210313
- type: nauc_mrr_at_10_std
value: -17.399659076827998
- type: nauc_mrr_at_1_diff1
value: 76.8689850260726
- type: nauc_mrr_at_1_max
value: 64.09858188287487
- type: nauc_mrr_at_1_std
value: -18.46064784201847
- type: nauc_mrr_at_20_diff1
value: 73.72312682063128
- type: nauc_mrr_at_20_max
value: 66.42181932858745
- type: nauc_mrr_at_20_std
value: -17.04690257511092
- type: nauc_mrr_at_3_diff1
value: 74.08287018839246
- type: nauc_mrr_at_3_max
value: 66.42422337760333
- type: nauc_mrr_at_3_std
value: -17.79503404131652
- type: nauc_mrr_at_5_diff1
value: 73.9294779027339
- type: nauc_mrr_at_5_max
value: 66.51752041065726
- type: nauc_mrr_at_5_std
value: -17.67309805113804
- type: nauc_ndcg_at_1000_diff1
value: 72.97825548342801
- type: nauc_ndcg_at_1000_max
value: 66.96275437178257
- type: nauc_ndcg_at_1000_std
value: -15.611902299641587
- type: nauc_ndcg_at_100_diff1
value: 72.58724738936613
- type: nauc_ndcg_at_100_max
value: 67.16774012704182
- type: nauc_ndcg_at_100_std
value: -14.945088654796812
- type: nauc_ndcg_at_10_diff1
value: 72.16253640477947
- type: nauc_ndcg_at_10_max
value: 67.01746849484621
- type: nauc_ndcg_at_10_std
value: -16.46102507270809
- type: nauc_ndcg_at_1_diff1
value: 76.8689850260726
- type: nauc_ndcg_at_1_max
value: 64.09858188287487
- type: nauc_ndcg_at_1_std
value: -18.46064784201847
- type: nauc_ndcg_at_20_diff1
value: 72.19995325129975
- type: nauc_ndcg_at_20_max
value: 67.39639713797962
- type: nauc_ndcg_at_20_std
value: -15.091689370748531
- type: nauc_ndcg_at_3_diff1
value: 73.13123604206514
- type: nauc_ndcg_at_3_max
value: 67.23123167871547
- type: nauc_ndcg_at_3_std
value: -17.492755234009156
- type: nauc_ndcg_at_5_diff1
value: 72.8154718929895
- type: nauc_ndcg_at_5_max
value: 67.44578008373777
- type: nauc_ndcg_at_5_std
value: -17.251840358751362
- type: nauc_precision_at_1000_diff1
value: 47.89748325983604
- type: nauc_precision_at_1000_max
value: 70.47466197804906
- type: nauc_precision_at_1000_std
value: 72.66193512114775
- type: nauc_precision_at_100_diff1
value: 59.493743734005356
- type: nauc_precision_at_100_max
value: 74.02140147220713
- type: nauc_precision_at_100_std
value: 17.26664098026236
- type: nauc_precision_at_10_diff1
value: 64.94415011040277
- type: nauc_precision_at_10_max
value: 69.6963814950747
- type: nauc_precision_at_10_std
value: -11.663043657012954
- type: nauc_precision_at_1_diff1
value: 76.8689850260726
- type: nauc_precision_at_1_max
value: 64.09858188287487
- type: nauc_precision_at_1_std
value: -18.46064784201847
- type: nauc_precision_at_20_diff1
value: 63.145886909986416
- type: nauc_precision_at_20_max
value: 72.95708033630744
- type: nauc_precision_at_20_std
value: -1.5039593629280323
- type: nauc_precision_at_3_diff1
value: 69.88902201644449
- type: nauc_precision_at_3_max
value: 69.80499971089935
- type: nauc_precision_at_3_std
value: -16.444680766676647
- type: nauc_precision_at_5_diff1
value: 68.60869967062919
- type: nauc_precision_at_5_max
value: 70.75998207564281
- type: nauc_precision_at_5_std
value: -15.62613396998262
- type: nauc_recall_at_1000_diff1
value: 62.6646436338833
- type: nauc_recall_at_1000_max
value: 86.17801636476078
- type: nauc_recall_at_1000_std
value: 71.84718775540334
- type: nauc_recall_at_100_diff1
value: 61.110492191439505
- type: nauc_recall_at_100_max
value: 75.45730686603042
- type: nauc_recall_at_100_std
value: 16.202465011589428
- type: nauc_recall_at_10_diff1
value: 65.1522196516815
- type: nauc_recall_at_10_max
value: 69.7626435962161
- type: nauc_recall_at_10_std
value: -11.801178474770449
- type: nauc_recall_at_1_diff1
value: 76.8784374396948
- type: nauc_recall_at_1_max
value: 64.07170606935357
- type: nauc_recall_at_1_std
value: -18.464213686790654
- type: nauc_recall_at_20_diff1
value: 63.40332739504143
- type: nauc_recall_at_20_max
value: 73.04113661090965
- type: nauc_recall_at_20_std
value: -1.6609741140266947
- type: nauc_recall_at_3_diff1
value: 70.03728086098866
- type: nauc_recall_at_3_max
value: 69.85953774320521
- type: nauc_recall_at_3_std
value: -16.482993123411706
- type: nauc_recall_at_5_diff1
value: 68.77396121765933
- type: nauc_recall_at_5_max
value: 70.8231205493519
- type: nauc_recall_at_5_std
value: -15.668037770700863
- type: ndcg_at_1
value: 56.57
- type: ndcg_at_10
value: 67.548
- type: ndcg_at_100
value: 70.421
- type: ndcg_at_1000
value: 71.198
- type: ndcg_at_20
value: 68.829
- type: ndcg_at_3
value: 63.88700000000001
- type: ndcg_at_5
value: 65.689
- type: precision_at_1
value: 56.57
- type: precision_at_10
value: 7.922
- type: precision_at_100
value: 0.9299999999999999
- type: precision_at_1000
value: 0.099
- type: precision_at_20
value: 4.216
- type: precision_at_3
value: 23.015
- type: precision_at_5
value: 14.691
- type: recall_at_1
value: 56.559000000000005
- type: recall_at_10
value: 79.182
- type: recall_at_100
value: 92.946
- type: recall_at_1000
value: 99.092
- type: recall_at_20
value: 84.27900000000001
- type: recall_at_3
value: 69.023
- type: recall_at_5
value: 73.432
task:
type: Retrieval
- dataset:
config: deu-spa
name: MTEB MLQARetrieval (deu-spa)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 70.645
- type: map_at_1
value: 58.423
- type: map_at_10
value: 66.613
- type: map_at_100
value: 67.14099999999999
- type: map_at_1000
value: 67.161
- type: map_at_20
value: 66.965
- type: map_at_3
value: 64.714
- type: map_at_5
value: 65.835
- type: mrr_at_1
value: 58.4225352112676
- type: mrr_at_10
value: 66.61321260898735
- type: mrr_at_100
value: 67.13991570812132
- type: mrr_at_1000
value: 67.1598532168174
- type: mrr_at_20
value: 66.96384710024888
- type: mrr_at_3
value: 64.71361502347425
- type: mrr_at_5
value: 65.83474178403769
- type: nauc_map_at_1000_diff1
value: 73.9485117118935
- type: nauc_map_at_1000_max
value: 65.74479869396299
- type: nauc_map_at_1000_std
value: -20.300269749495563
- type: nauc_map_at_100_diff1
value: 73.93900406302829
- type: nauc_map_at_100_max
value: 65.75508449194885
- type: nauc_map_at_100_std
value: -20.265330791570175
- type: nauc_map_at_10_diff1
value: 73.84863233472605
- type: nauc_map_at_10_max
value: 65.89377317378211
- type: nauc_map_at_10_std
value: -20.404123131964695
- type: nauc_map_at_1_diff1
value: 76.73627284218519
- type: nauc_map_at_1_max
value: 62.94957512510876
- type: nauc_map_at_1_std
value: -20.99649749330682
- type: nauc_map_at_20_diff1
value: 73.88712006109598
- type: nauc_map_at_20_max
value: 65.82057018162664
- type: nauc_map_at_20_std
value: -20.269476512431915
- type: nauc_map_at_3_diff1
value: 74.21419190161502
- type: nauc_map_at_3_max
value: 65.64993368062119
- type: nauc_map_at_3_std
value: -21.34641749007071
- type: nauc_map_at_5_diff1
value: 74.0119419385777
- type: nauc_map_at_5_max
value: 65.69809416369732
- type: nauc_map_at_5_std
value: -21.16901556082261
- type: nauc_mrr_at_1000_diff1
value: 73.94915184134923
- type: nauc_mrr_at_1000_max
value: 65.74522469633418
- type: nauc_mrr_at_1000_std
value: -20.303028367132246
- type: nauc_mrr_at_100_diff1
value: 73.93964394728808
- type: nauc_mrr_at_100_max
value: 65.75550992323707
- type: nauc_mrr_at_100_std
value: -20.26808820438918
- type: nauc_mrr_at_10_diff1
value: 73.84863233472605
- type: nauc_mrr_at_10_max
value: 65.89377317378211
- type: nauc_mrr_at_10_std
value: -20.404123131964695
- type: nauc_mrr_at_1_diff1
value: 76.73627284218519
- type: nauc_mrr_at_1_max
value: 62.94957512510876
- type: nauc_mrr_at_1_std
value: -20.99649749330682
- type: nauc_mrr_at_20_diff1
value: 73.88775721128745
- type: nauc_mrr_at_20_max
value: 65.820991355628
- type: nauc_mrr_at_20_std
value: -20.272216587019734
- type: nauc_mrr_at_3_diff1
value: 74.21419190161502
- type: nauc_mrr_at_3_max
value: 65.64993368062119
- type: nauc_mrr_at_3_std
value: -21.34641749007071
- type: nauc_mrr_at_5_diff1
value: 74.0119419385777
- type: nauc_mrr_at_5_max
value: 65.69809416369732
- type: nauc_mrr_at_5_std
value: -21.16901556082261
- type: nauc_ndcg_at_1000_diff1
value: 73.29396365944277
- type: nauc_ndcg_at_1000_max
value: 66.44879592109541
- type: nauc_ndcg_at_1000_std
value: -19.285991058788195
- type: nauc_ndcg_at_100_diff1
value: 73.0159172721162
- type: nauc_ndcg_at_100_max
value: 66.76216389231388
- type: nauc_ndcg_at_100_std
value: -18.27931368094887
- type: nauc_ndcg_at_10_diff1
value: 72.42096650774693
- type: nauc_ndcg_at_10_max
value: 67.48592688463306
- type: nauc_ndcg_at_10_std
value: -18.91453756077581
- type: nauc_ndcg_at_1_diff1
value: 76.73627284218519
- type: nauc_ndcg_at_1_max
value: 62.94957512510876
- type: nauc_ndcg_at_1_std
value: -20.99649749330682
- type: nauc_ndcg_at_20_diff1
value: 72.53699362385684
- type: nauc_ndcg_at_20_max
value: 67.22763976357872
- type: nauc_ndcg_at_20_std
value: -18.299910635008338
- type: nauc_ndcg_at_3_diff1
value: 73.3698453761989
- type: nauc_ndcg_at_3_max
value: 66.71056987289383
- type: nauc_ndcg_at_3_std
value: -21.405154376652803
- type: nauc_ndcg_at_5_diff1
value: 72.9491030712935
- type: nauc_ndcg_at_5_max
value: 66.85786103137077
- type: nauc_ndcg_at_5_std
value: -21.04005053344073
- type: nauc_precision_at_1000_diff1
value: 17.02462370967451
- type: nauc_precision_at_1000_max
value: 48.03260752496052
- type: nauc_precision_at_1000_std
value: 87.56077915079334
- type: nauc_precision_at_100_diff1
value: 58.590352501194985
- type: nauc_precision_at_100_max
value: 78.2649015433222
- type: nauc_precision_at_100_std
value: 28.05030453158992
- type: nauc_precision_at_10_diff1
value: 64.89497928764766
- type: nauc_precision_at_10_max
value: 75.93257124951242
- type: nauc_precision_at_10_std
value: -9.825306994117462
- type: nauc_precision_at_1_diff1
value: 76.73627284218519
- type: nauc_precision_at_1_max
value: 62.94957512510876
- type: nauc_precision_at_1_std
value: -20.99649749330682
- type: nauc_precision_at_20_diff1
value: 62.11366204321558
- type: nauc_precision_at_20_max
value: 75.9571427846493
- type: nauc_precision_at_20_std
value: -0.94585212808191
- type: nauc_precision_at_3_diff1
value: 70.52940972112398
- type: nauc_precision_at_3_max
value: 70.3402053170779
- type: nauc_precision_at_3_std
value: -21.579778424241304
- type: nauc_precision_at_5_diff1
value: 68.78962580223575
- type: nauc_precision_at_5_max
value: 71.41410894398376
- type: nauc_precision_at_5_std
value: -20.415603405161956
- type: nauc_recall_at_1000_diff1
value: 55.88625447348128
- type: nauc_recall_at_1000_max
value: 100.0
- type: nauc_recall_at_1000_std
value: 100.0
- type: nauc_recall_at_100_diff1
value: 61.17942268389525
- type: nauc_recall_at_100_max
value: 81.12207841563487
- type: nauc_recall_at_100_std
value: 27.141215257528113
- type: nauc_recall_at_10_diff1
value: 64.8949792876478
- type: nauc_recall_at_10_max
value: 75.93257124951249
- type: nauc_recall_at_10_std
value: -9.825306994117323
- type: nauc_recall_at_1_diff1
value: 76.73627284218519
- type: nauc_recall_at_1_max
value: 62.94957512510876
- type: nauc_recall_at_1_std
value: -20.99649749330682
- type: nauc_recall_at_20_diff1
value: 63.07808719241162
- type: nauc_recall_at_20_max
value: 76.96808746317542
- type: nauc_recall_at_20_std
value: -1.5235053258631275
- type: nauc_recall_at_3_diff1
value: 70.52940972112405
- type: nauc_recall_at_3_max
value: 70.3402053170779
- type: nauc_recall_at_3_std
value: -21.57977842424124
- type: nauc_recall_at_5_diff1
value: 68.78962580223575
- type: nauc_recall_at_5_max
value: 71.41410894398392
- type: nauc_recall_at_5_std
value: -20.415603405161793
- type: ndcg_at_1
value: 58.423
- type: ndcg_at_10
value: 70.645
- type: ndcg_at_100
value: 73.277
- type: ndcg_at_1000
value: 73.785
- type: ndcg_at_20
value: 71.918
- type: ndcg_at_3
value: 66.679
- type: ndcg_at_5
value: 68.72200000000001
- type: precision_at_1
value: 58.423
- type: precision_at_10
value: 8.338
- type: precision_at_100
value: 0.959
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.423
- type: precision_at_3
value: 24.113
- type: precision_at_5
value: 15.47
- type: recall_at_1
value: 58.423
- type: recall_at_10
value: 83.38
- type: recall_at_100
value: 95.887
- type: recall_at_1000
value: 99.831
- type: recall_at_20
value: 88.39399999999999
- type: recall_at_3
value: 72.33800000000001
- type: recall_at_5
value: 77.352
task:
type: Retrieval
- dataset:
config: deu-eng
name: MTEB MLQARetrieval (deu-eng)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 67.067
- type: map_at_1
value: 55.861000000000004
- type: map_at_10
value: 63.42100000000001
- type: map_at_100
value: 64.03
- type: map_at_1000
value: 64.05999999999999
- type: map_at_20
value: 63.819
- type: map_at_3
value: 61.773
- type: map_at_5
value: 62.736999999999995
- type: mrr_at_1
value: 55.88300465322402
- type: mrr_at_10
value: 63.43111082973707
- type: mrr_at_100
value: 64.03962373590272
- type: mrr_at_1000
value: 64.0698259866376
- type: mrr_at_20
value: 63.82871766489112
- type: mrr_at_3
value: 61.78447448112865
- type: mrr_at_5
value: 62.74835659945346
- type: nauc_map_at_1000_diff1
value: 74.58505763417352
- type: nauc_map_at_1000_max
value: 66.26060764852198
- type: nauc_map_at_1000_std
value: -16.896178230873897
- type: nauc_map_at_100_diff1
value: 74.57057487892857
- type: nauc_map_at_100_max
value: 66.26600433283826
- type: nauc_map_at_100_std
value: -16.87596113104189
- type: nauc_map_at_10_diff1
value: 74.53453636322749
- type: nauc_map_at_10_max
value: 66.27501737773804
- type: nauc_map_at_10_std
value: -17.178743257781775
- type: nauc_map_at_1_diff1
value: 77.63067209375254
- type: nauc_map_at_1_max
value: 64.17718675702672
- type: nauc_map_at_1_std
value: -17.639521106853717
- type: nauc_map_at_20_diff1
value: 74.52007402431164
- type: nauc_map_at_20_max
value: 66.28276291359268
- type: nauc_map_at_20_std
value: -16.939292897754758
- type: nauc_map_at_3_diff1
value: 74.79187974631951
- type: nauc_map_at_3_max
value: 66.23256568210611
- type: nauc_map_at_3_std
value: -17.894889918934112
- type: nauc_map_at_5_diff1
value: 74.63011328882517
- type: nauc_map_at_5_max
value: 66.35411054978499
- type: nauc_map_at_5_std
value: -17.50140342194211
- type: nauc_mrr_at_1000_diff1
value: 74.57520089771667
- type: nauc_mrr_at_1000_max
value: 66.27270912845914
- type: nauc_mrr_at_1000_std
value: -16.84012675362397
- type: nauc_mrr_at_100_diff1
value: 74.56070964572156
- type: nauc_mrr_at_100_max
value: 66.2780701126926
- type: nauc_mrr_at_100_std
value: -16.820035083069865
- type: nauc_mrr_at_10_diff1
value: 74.52455978435117
- type: nauc_mrr_at_10_max
value: 66.28697244023137
- type: nauc_mrr_at_10_std
value: -17.122477723330523
- type: nauc_mrr_at_1_diff1
value: 77.60643512422061
- type: nauc_mrr_at_1_max
value: 64.21736966061896
- type: nauc_mrr_at_1_std
value: -17.56627338275146
- type: nauc_mrr_at_20_diff1
value: 74.5099814266373
- type: nauc_mrr_at_20_max
value: 66.29485560556576
- type: nauc_mrr_at_20_std
value: -16.882350027335306
- type: nauc_mrr_at_3_diff1
value: 74.78132817375507
- type: nauc_mrr_at_3_max
value: 66.24761860047623
- type: nauc_mrr_at_3_std
value: -17.833128575678998
- type: nauc_mrr_at_5_diff1
value: 74.6193031207433
- type: nauc_mrr_at_5_max
value: 66.36951764432901
- type: nauc_mrr_at_5_std
value: -17.438203106324227
- type: nauc_ndcg_at_1000_diff1
value: 73.79386161629151
- type: nauc_ndcg_at_1000_max
value: 66.84013038018082
- type: nauc_ndcg_at_1000_std
value: -15.387358822700667
- type: nauc_ndcg_at_100_diff1
value: 73.36132885277745
- type: nauc_ndcg_at_100_max
value: 67.04416926901568
- type: nauc_ndcg_at_100_std
value: -14.503256942521972
- type: nauc_ndcg_at_10_diff1
value: 73.11847332785027
- type: nauc_ndcg_at_10_max
value: 67.02149621303091
- type: nauc_ndcg_at_10_std
value: -16.142234662067782
- type: nauc_ndcg_at_1_diff1
value: 77.60643512422061
- type: nauc_ndcg_at_1_max
value: 64.21736966061896
- type: nauc_ndcg_at_1_std
value: -17.56627338275146
- type: nauc_ndcg_at_20_diff1
value: 72.97961452569768
- type: nauc_ndcg_at_20_max
value: 67.12369127081152
- type: nauc_ndcg_at_20_std
value: -15.11921773223936
- type: nauc_ndcg_at_3_diff1
value: 73.77769312598772
- type: nauc_ndcg_at_3_max
value: 66.94438755852309
- type: nauc_ndcg_at_3_std
value: -17.75960443830741
- type: nauc_ndcg_at_5_diff1
value: 73.43991209562891
- type: nauc_ndcg_at_5_max
value: 67.21682951737418
- type: nauc_ndcg_at_5_std
value: -17.013510008231805
- type: nauc_precision_at_1000_diff1
value: 51.30633281948362
- type: nauc_precision_at_1000_max
value: 76.78675288883846
- type: nauc_precision_at_1000_std
value: 71.70041985304397
- type: nauc_precision_at_100_diff1
value: 59.86656455853326
- type: nauc_precision_at_100_max
value: 74.41958422732161
- type: nauc_precision_at_100_std
value: 22.098920296069124
- type: nauc_precision_at_10_diff1
value: 66.4696166928741
- type: nauc_precision_at_10_max
value: 69.88463108697104
- type: nauc_precision_at_10_std
value: -10.707950954702742
- type: nauc_precision_at_1_diff1
value: 77.60643512422061
- type: nauc_precision_at_1_max
value: 64.21736966061896
- type: nauc_precision_at_1_std
value: -17.56627338275146
- type: nauc_precision_at_20_diff1
value: 63.45094585276983
- type: nauc_precision_at_20_max
value: 71.57741245347195
- type: nauc_precision_at_20_std
value: -2.2211545419051744
- type: nauc_precision_at_3_diff1
value: 70.28060818081384
- type: nauc_precision_at_3_max
value: 69.22652927816439
- type: nauc_precision_at_3_std
value: -17.158576243559434
- type: nauc_precision_at_5_diff1
value: 68.90765418427162
- type: nauc_precision_at_5_max
value: 70.32585273389111
- type: nauc_precision_at_5_std
value: -14.950363729664524
- type: nauc_recall_at_1000_diff1
value: 65.11255117927331
- type: nauc_recall_at_1000_max
value: 88.35641213283338
- type: nauc_recall_at_1000_std
value: 69.89792573640547
- type: nauc_recall_at_100_diff1
value: 61.46376457272238
- type: nauc_recall_at_100_max
value: 75.48265142243015
- type: nauc_recall_at_100_std
value: 21.223182712042178
- type: nauc_recall_at_10_diff1
value: 66.89353375308997
- type: nauc_recall_at_10_max
value: 70.06655416883785
- type: nauc_recall_at_10_std
value: -11.100871879439435
- type: nauc_recall_at_1_diff1
value: 77.63067209375254
- type: nauc_recall_at_1_max
value: 64.17718675702672
- type: nauc_recall_at_1_std
value: -17.639521106853717
- type: nauc_recall_at_20_diff1
value: 63.98532276331878
- type: nauc_recall_at_20_max
value: 71.81562599791899
- type: nauc_recall_at_20_std
value: -2.696537977147695
- type: nauc_recall_at_3_diff1
value: 70.4507655865698
- type: nauc_recall_at_3_max
value: 69.25705030141037
- type: nauc_recall_at_3_std
value: -17.299948348202836
- type: nauc_recall_at_5_diff1
value: 69.09152857901888
- type: nauc_recall_at_5_max
value: 70.35609636026405
- type: nauc_recall_at_5_std
value: -15.105012139255896
- type: ndcg_at_1
value: 55.883
- type: ndcg_at_10
value: 67.067
- type: ndcg_at_100
value: 70.07
- type: ndcg_at_1000
value: 70.875
- type: ndcg_at_20
value: 68.498
- type: ndcg_at_3
value: 63.666
- type: ndcg_at_5
value: 65.40599999999999
- type: precision_at_1
value: 55.883
- type: precision_at_10
value: 7.8549999999999995
- type: precision_at_100
value: 0.928
- type: precision_at_1000
value: 0.099
- type: precision_at_20
value: 4.2090000000000005
- type: precision_at_3
value: 23.052
- type: precision_at_5
value: 14.677999999999999
- type: recall_at_1
value: 55.861000000000004
- type: recall_at_10
value: 78.495
- type: recall_at_100
value: 92.688
- type: recall_at_1000
value: 99.02499999999999
- type: recall_at_20
value: 84.124
- type: recall_at_3
value: 69.123
- type: recall_at_5
value: 73.355
task:
type: Retrieval
- dataset:
config: spa-deu
name: MTEB MLQARetrieval (spa-deu)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 73.90299999999999
- type: map_at_1
value: 61.236000000000004
- type: map_at_10
value: 69.88799999999999
- type: map_at_100
value: 70.319
- type: map_at_1000
value: 70.341
- type: map_at_20
value: 70.16799999999999
- type: map_at_3
value: 68.104
- type: map_at_5
value: 69.164
- type: mrr_at_1
value: 61.2739571589628
- type: mrr_at_10
value: 69.92589162684993
- type: mrr_at_100
value: 70.35245455509234
- type: mrr_at_1000
value: 70.37438351396742
- type: mrr_at_20
value: 70.20247469915404
- type: mrr_at_3
value: 68.14167606163099
- type: mrr_at_5
value: 69.20142803457354
- type: nauc_map_at_1000_diff1
value: 74.70416754842327
- type: nauc_map_at_1000_max
value: 65.86915994583384
- type: nauc_map_at_1000_std
value: -19.04437483534443
- type: nauc_map_at_100_diff1
value: 74.70011798058674
- type: nauc_map_at_100_max
value: 65.88507779167188
- type: nauc_map_at_100_std
value: -19.018670970643786
- type: nauc_map_at_10_diff1
value: 74.6362126804427
- type: nauc_map_at_10_max
value: 66.05733054427198
- type: nauc_map_at_10_std
value: -19.034317737897354
- type: nauc_map_at_1_diff1
value: 77.24970536833601
- type: nauc_map_at_1_max
value: 62.07820573048406
- type: nauc_map_at_1_std
value: -20.917086586335078
- type: nauc_map_at_20_diff1
value: 74.64113920401083
- type: nauc_map_at_20_max
value: 65.89991740166793
- type: nauc_map_at_20_std
value: -19.09987515041243
- type: nauc_map_at_3_diff1
value: 74.6518162332119
- type: nauc_map_at_3_max
value: 66.10312348194024
- type: nauc_map_at_3_std
value: -18.95881457716116
- type: nauc_map_at_5_diff1
value: 74.55141020670321
- type: nauc_map_at_5_max
value: 65.94345752979342
- type: nauc_map_at_5_std
value: -19.453976877992304
- type: nauc_mrr_at_1000_diff1
value: 74.64458488344088
- type: nauc_mrr_at_1000_max
value: 65.84575328456057
- type: nauc_mrr_at_1000_std
value: -18.901614615119904
- type: nauc_mrr_at_100_diff1
value: 74.64058497924627
- type: nauc_mrr_at_100_max
value: 65.86170461767928
- type: nauc_mrr_at_100_std
value: -18.87601697091505
- type: nauc_mrr_at_10_diff1
value: 74.57266634464752
- type: nauc_mrr_at_10_max
value: 66.03331587645152
- type: nauc_mrr_at_10_std
value: -18.87888060105393
- type: nauc_mrr_at_1_diff1
value: 77.19578272647183
- type: nauc_mrr_at_1_max
value: 62.05252035478773
- type: nauc_mrr_at_1_std
value: -20.790530940625267
- type: nauc_mrr_at_20_diff1
value: 74.5808171250021
- type: nauc_mrr_at_20_max
value: 65.87643606587798
- type: nauc_mrr_at_20_std
value: -18.95476583474199
- type: nauc_mrr_at_3_diff1
value: 74.5917053289191
- type: nauc_mrr_at_3_max
value: 66.08044079438714
- type: nauc_mrr_at_3_std
value: -18.81168463163586
- type: nauc_mrr_at_5_diff1
value: 74.48934579694608
- type: nauc_mrr_at_5_max
value: 65.91993162383771
- type: nauc_mrr_at_5_std
value: -19.302710791338797
- type: nauc_ndcg_at_1000_diff1
value: 74.20191283992186
- type: nauc_ndcg_at_1000_max
value: 66.60831175771229
- type: nauc_ndcg_at_1000_std
value: -18.175208725175484
- type: nauc_ndcg_at_100_diff1
value: 74.07713451642955
- type: nauc_ndcg_at_100_max
value: 67.02028626335476
- type: nauc_ndcg_at_100_std
value: -17.36560972181693
- type: nauc_ndcg_at_10_diff1
value: 73.63235521598476
- type: nauc_ndcg_at_10_max
value: 67.8118473312638
- type: nauc_ndcg_at_10_std
value: -17.647560577355915
- type: nauc_ndcg_at_1_diff1
value: 77.19578272647183
- type: nauc_ndcg_at_1_max
value: 62.05252035478773
- type: nauc_ndcg_at_1_std
value: -20.790530940625267
- type: nauc_ndcg_at_20_diff1
value: 73.65300308228291
- type: nauc_ndcg_at_20_max
value: 67.18353402731985
- type: nauc_ndcg_at_20_std
value: -17.9240756389792
- type: nauc_ndcg_at_3_diff1
value: 73.73764900202292
- type: nauc_ndcg_at_3_max
value: 67.60840957876889
- type: nauc_ndcg_at_3_std
value: -17.962667543518933
- type: nauc_ndcg_at_5_diff1
value: 73.49040500302092
- type: nauc_ndcg_at_5_max
value: 67.41251918514402
- type: nauc_ndcg_at_5_std
value: -18.851877225955523
- type: nauc_precision_at_1000_diff1
value: -18.652906102973922
- type: nauc_precision_at_1000_max
value: 2.1701672475574885
- type: nauc_precision_at_1000_std
value: 61.713411950188835
- type: nauc_precision_at_100_diff1
value: 62.37565302288498
- type: nauc_precision_at_100_max
value: 76.96921843049006
- type: nauc_precision_at_100_std
value: 19.152009040219678
- type: nauc_precision_at_10_diff1
value: 68.14047344105212
- type: nauc_precision_at_10_max
value: 77.7177273849099
- type: nauc_precision_at_10_std
value: -9.124325941493698
- type: nauc_precision_at_1_diff1
value: 77.19578272647183
- type: nauc_precision_at_1_max
value: 62.05252035478773
- type: nauc_precision_at_1_std
value: -20.790530940625267
- type: nauc_precision_at_20_diff1
value: 65.38487456362745
- type: nauc_precision_at_20_max
value: 74.61122933443669
- type: nauc_precision_at_20_std
value: -8.129775929648341
- type: nauc_precision_at_3_diff1
value: 70.45937744142297
- type: nauc_precision_at_3_max
value: 73.03004233073901
- type: nauc_precision_at_3_std
value: -14.246554579025158
- type: nauc_precision_at_5_diff1
value: 69.02821772428955
- type: nauc_precision_at_5_max
value: 73.52949774726446
- type: nauc_precision_at_5_std
value: -16.355747231517757
- type: nauc_recall_at_1000_diff1
value: 35.804192824985755
- type: nauc_recall_at_1000_max
value: 61.367785756485894
- type: nauc_recall_at_1000_std
value: 54.01380822466869
- type: nauc_recall_at_100_diff1
value: 67.96210883597479
- type: nauc_recall_at_100_max
value: 82.38124823732169
- type: nauc_recall_at_100_std
value: 16.814922595309966
- type: nauc_recall_at_10_diff1
value: 68.21964459634341
- type: nauc_recall_at_10_max
value: 77.68301934858845
- type: nauc_recall_at_10_std
value: -9.430792913885066
- type: nauc_recall_at_1_diff1
value: 77.24970536833601
- type: nauc_recall_at_1_max
value: 62.07820573048406
- type: nauc_recall_at_1_std
value: -20.917086586335078
- type: nauc_recall_at_20_diff1
value: 66.60569906579487
- type: nauc_recall_at_20_max
value: 75.66163186604354
- type: nauc_recall_at_20_std
value: -9.09826205489828
- type: nauc_recall_at_3_diff1
value: 70.52323701841641
- type: nauc_recall_at_3_max
value: 73.03478107411232
- type: nauc_recall_at_3_std
value: -14.432325989967962
- type: nauc_recall_at_5_diff1
value: 69.08521261524373
- type: nauc_recall_at_5_max
value: 73.51150270382094
- type: nauc_recall_at_5_std
value: -16.569387503524368
- type: ndcg_at_1
value: 61.273999999999994
- type: ndcg_at_10
value: 73.90299999999999
- type: ndcg_at_100
value: 75.983
- type: ndcg_at_1000
value: 76.488
- type: ndcg_at_20
value: 74.921
- type: ndcg_at_3
value: 70.277
- type: ndcg_at_5
value: 72.172
- type: precision_at_1
value: 61.273999999999994
- type: precision_at_10
value: 8.641
- type: precision_at_100
value: 0.962
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.524
- type: precision_at_3
value: 25.517
- type: precision_at_5
value: 16.223000000000003
- type: recall_at_1
value: 61.236000000000004
- type: recall_at_10
value: 86.37700000000001
- type: recall_at_100
value: 96.054
- type: recall_at_1000
value: 99.887
- type: recall_at_20
value: 90.398
- type: recall_at_3
value: 76.51299999999999
- type: recall_at_5
value: 81.07900000000001
task:
type: Retrieval
- dataset:
config: spa-spa
name: MTEB MLQARetrieval (spa-spa)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 68.632
- type: map_at_1
value: 57.046
- type: map_at_10
value: 64.869
- type: map_at_100
value: 65.384
- type: map_at_1000
value: 65.413
- type: map_at_20
value: 65.185
- type: map_at_3
value: 63.178
- type: map_at_5
value: 64.12
- type: mrr_at_1
value: 57.05579889544848
- type: mrr_at_10
value: 64.8806425382317
- type: mrr_at_100
value: 65.39469233244084
- type: mrr_at_1000
value: 65.42342199403159
- type: mrr_at_20
value: 65.19634815919534
- type: mrr_at_3
value: 63.18796419729591
- type: mrr_at_5
value: 64.13159398209874
- type: nauc_map_at_1000_diff1
value: 73.23803038674018
- type: nauc_map_at_1000_max
value: 67.44156201421714
- type: nauc_map_at_1000_std
value: -8.60143026450049
- type: nauc_map_at_100_diff1
value: 73.22575613034235
- type: nauc_map_at_100_max
value: 67.44735143420195
- type: nauc_map_at_100_std
value: -8.576905069492895
- type: nauc_map_at_10_diff1
value: 73.11950129610865
- type: nauc_map_at_10_max
value: 67.45107232305055
- type: nauc_map_at_10_std
value: -8.799837857015392
- type: nauc_map_at_1_diff1
value: 76.18354072047988
- type: nauc_map_at_1_max
value: 65.03342186728786
- type: nauc_map_at_1_std
value: -10.867650288695796
- type: nauc_map_at_20_diff1
value: 73.21570748770948
- type: nauc_map_at_20_max
value: 67.50340321088724
- type: nauc_map_at_20_std
value: -8.594057184944676
- type: nauc_map_at_3_diff1
value: 73.17239276163892
- type: nauc_map_at_3_max
value: 67.06319504819103
- type: nauc_map_at_3_std
value: -9.883216310270528
- type: nauc_map_at_5_diff1
value: 73.11913507367727
- type: nauc_map_at_5_max
value: 67.27497019567078
- type: nauc_map_at_5_std
value: -9.497714822103118
- type: nauc_mrr_at_1000_diff1
value: 73.22971233311306
- type: nauc_mrr_at_1000_max
value: 67.42977229057223
- type: nauc_mrr_at_1000_std
value: -8.550068702273297
- type: nauc_mrr_at_100_diff1
value: 73.21744467317815
- type: nauc_mrr_at_100_max
value: 67.43557491068093
- type: nauc_mrr_at_100_std
value: -8.52559275190607
- type: nauc_mrr_at_10_diff1
value: 73.11075619726137
- type: nauc_mrr_at_10_max
value: 67.43889760205286
- type: nauc_mrr_at_10_std
value: -8.74617232559183
- type: nauc_mrr_at_1_diff1
value: 76.17529975949547
- type: nauc_mrr_at_1_max
value: 65.02401127001608
- type: nauc_mrr_at_1_std
value: -10.817814457633952
- type: nauc_mrr_at_20_diff1
value: 73.20689275225138
- type: nauc_mrr_at_20_max
value: 67.49111752272192
- type: nauc_mrr_at_20_std
value: -8.539827528410353
- type: nauc_mrr_at_3_diff1
value: 73.16291729623958
- type: nauc_mrr_at_3_max
value: 67.05300993427998
- type: nauc_mrr_at_3_std
value: -9.827915885680811
- type: nauc_mrr_at_5_diff1
value: 73.11055686484109
- type: nauc_mrr_at_5_max
value: 67.26299851089122
- type: nauc_mrr_at_5_std
value: -9.445190276650903
- type: nauc_ndcg_at_1000_diff1
value: 72.58833638407177
- type: nauc_ndcg_at_1000_max
value: 68.10447506371374
- type: nauc_ndcg_at_1000_std
value: -6.910306241546282
- type: nauc_ndcg_at_100_diff1
value: 72.24524849631476
- type: nauc_ndcg_at_100_max
value: 68.30659210081238
- type: nauc_ndcg_at_100_std
value: -6.04305364268931
- type: nauc_ndcg_at_10_diff1
value: 71.87363502582961
- type: nauc_ndcg_at_10_max
value: 68.5010009653693
- type: nauc_ndcg_at_10_std
value: -7.021281296450588
- type: nauc_ndcg_at_1_diff1
value: 76.17529975949547
- type: nauc_ndcg_at_1_max
value: 65.02401127001608
- type: nauc_ndcg_at_1_std
value: -10.817814457633952
- type: nauc_ndcg_at_20_diff1
value: 72.21241010439327
- type: nauc_ndcg_at_20_max
value: 68.71743274030551
- type: nauc_ndcg_at_20_std
value: -6.186629577195946
- type: nauc_ndcg_at_3_diff1
value: 72.08204674794459
- type: nauc_ndcg_at_3_max
value: 67.5958365046156
- type: nauc_ndcg_at_3_std
value: -9.576418336610345
- type: nauc_ndcg_at_5_diff1
value: 71.93179095844508
- type: nauc_ndcg_at_5_max
value: 68.01914639754217
- type: nauc_ndcg_at_5_std
value: -8.833768332910777
- type: nauc_precision_at_1000_diff1
value: 63.0051360227489
- type: nauc_precision_at_1000_max
value: 79.93532442313229
- type: nauc_precision_at_1000_std
value: 52.869517607133254
- type: nauc_precision_at_100_diff1
value: 62.43301501857154
- type: nauc_precision_at_100_max
value: 75.57280416668183
- type: nauc_precision_at_100_std
value: 26.758300486132747
- type: nauc_precision_at_10_diff1
value: 66.29806375971134
- type: nauc_precision_at_10_max
value: 73.40301413754797
- type: nauc_precision_at_10_std
value: 1.9858547295235462
- type: nauc_precision_at_1_diff1
value: 76.17529975949547
- type: nauc_precision_at_1_max
value: 65.02401127001608
- type: nauc_precision_at_1_std
value: -10.817814457633952
- type: nauc_precision_at_20_diff1
value: 67.05111836051105
- type: nauc_precision_at_20_max
value: 76.09783190824155
- type: nauc_precision_at_20_std
value: 9.906010659515564
- type: nauc_precision_at_3_diff1
value: 68.44186679250453
- type: nauc_precision_at_3_max
value: 69.30301351119388
- type: nauc_precision_at_3_std
value: -8.566522518882348
- type: nauc_precision_at_5_diff1
value: 67.51737199297388
- type: nauc_precision_at_5_max
value: 70.75887601590472
- type: nauc_precision_at_5_std
value: -6.278983102710238
- type: nauc_recall_at_1000_diff1
value: 65.12360093170948
- type: nauc_recall_at_1000_max
value: 82.60209843191132
- type: nauc_recall_at_1000_std
value: 51.740179583368636
- type: nauc_recall_at_100_diff1
value: 62.82007697326819
- type: nauc_recall_at_100_max
value: 76.04844844677562
- type: nauc_recall_at_100_std
value: 26.4678415019248
- type: nauc_recall_at_10_diff1
value: 66.28557566848767
- type: nauc_recall_at_10_max
value: 73.40302709828738
- type: nauc_recall_at_10_std
value: 1.9224272854613582
- type: nauc_recall_at_1_diff1
value: 76.18354072047988
- type: nauc_recall_at_1_max
value: 65.03342186728786
- type: nauc_recall_at_1_std
value: -10.867650288695796
- type: nauc_recall_at_20_diff1
value: 67.03430451094992
- type: nauc_recall_at_20_max
value: 76.09474005171319
- type: nauc_recall_at_20_std
value: 9.815888637851074
- type: nauc_recall_at_3_diff1
value: 68.44411411344718
- type: nauc_recall_at_3_max
value: 69.30502737137265
- type: nauc_recall_at_3_std
value: -8.629526329714132
- type: nauc_recall_at_5_diff1
value: 67.51469265953514
- type: nauc_recall_at_5_max
value: 70.76969893818111
- type: nauc_recall_at_5_std
value: -6.325600167105444
- type: ndcg_at_1
value: 57.056
- type: ndcg_at_10
value: 68.632
- type: ndcg_at_100
value: 71.202
- type: ndcg_at_1000
value: 71.97099999999999
- type: ndcg_at_20
value: 69.785
- type: ndcg_at_3
value: 65.131
- type: ndcg_at_5
value: 66.834
- type: precision_at_1
value: 57.056
- type: precision_at_10
value: 8.044
- type: precision_at_100
value: 0.9259999999999999
- type: precision_at_1000
value: 0.099
- type: precision_at_20
value: 4.251
- type: precision_at_3
value: 23.589
- type: precision_at_5
value: 14.984
- type: recall_at_1
value: 57.046
- type: recall_at_10
value: 80.423
- type: recall_at_100
value: 92.582
- type: recall_at_1000
value: 98.638
- type: recall_at_20
value: 84.993
- type: recall_at_3
value: 70.758
- type: recall_at_5
value: 74.9
task:
type: Retrieval
- dataset:
config: spa-eng
name: MTEB MLQARetrieval (spa-eng)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 68.765
- type: map_at_1
value: 56.538999999999994
- type: map_at_10
value: 64.816
- type: map_at_100
value: 65.325
- type: map_at_1000
value: 65.352
- type: map_at_20
value: 65.113
- type: map_at_3
value: 62.934999999999995
- type: map_at_5
value: 64.063
- type: mrr_at_1
value: 56.539120502569965
- type: mrr_at_10
value: 64.81561556661505
- type: mrr_at_100
value: 65.32464238613954
- type: mrr_at_1000
value: 65.35206516602133
- type: mrr_at_20
value: 65.11270445292227
- type: mrr_at_3
value: 62.935465448315384
- type: mrr_at_5
value: 64.06339234723022
- type: nauc_map_at_1000_diff1
value: 73.20701050428072
- type: nauc_map_at_1000_max
value: 67.32797480614404
- type: nauc_map_at_1000_std
value: -6.211540626528362
- type: nauc_map_at_100_diff1
value: 73.19497683923063
- type: nauc_map_at_100_max
value: 67.33392646467817
- type: nauc_map_at_100_std
value: -6.196671563900051
- type: nauc_map_at_10_diff1
value: 73.16010547612956
- type: nauc_map_at_10_max
value: 67.37793741307372
- type: nauc_map_at_10_std
value: -6.3443240322521675
- type: nauc_map_at_1_diff1
value: 76.63696578575964
- type: nauc_map_at_1_max
value: 65.08189618178105
- type: nauc_map_at_1_std
value: -8.594195451782733
- type: nauc_map_at_20_diff1
value: 73.15233479381568
- type: nauc_map_at_20_max
value: 67.3679607256072
- type: nauc_map_at_20_std
value: -6.175928265286352
- type: nauc_map_at_3_diff1
value: 73.14853380980746
- type: nauc_map_at_3_max
value: 67.10354198073468
- type: nauc_map_at_3_std
value: -7.409679815529866
- type: nauc_map_at_5_diff1
value: 73.13425961877715
- type: nauc_map_at_5_max
value: 67.22452899371224
- type: nauc_map_at_5_std
value: -6.895257774506354
- type: nauc_mrr_at_1000_diff1
value: 73.20701050428072
- type: nauc_mrr_at_1000_max
value: 67.32797480614404
- type: nauc_mrr_at_1000_std
value: -6.211540626528362
- type: nauc_mrr_at_100_diff1
value: 73.19497683923063
- type: nauc_mrr_at_100_max
value: 67.33392646467817
- type: nauc_mrr_at_100_std
value: -6.196671563900051
- type: nauc_mrr_at_10_diff1
value: 73.16010547612956
- type: nauc_mrr_at_10_max
value: 67.37793741307372
- type: nauc_mrr_at_10_std
value: -6.3443240322521675
- type: nauc_mrr_at_1_diff1
value: 76.63696578575964
- type: nauc_mrr_at_1_max
value: 65.08189618178105
- type: nauc_mrr_at_1_std
value: -8.594195451782733
- type: nauc_mrr_at_20_diff1
value: 73.15233479381568
- type: nauc_mrr_at_20_max
value: 67.3679607256072
- type: nauc_mrr_at_20_std
value: -6.175928265286352
- type: nauc_mrr_at_3_diff1
value: 73.14853380980746
- type: nauc_mrr_at_3_max
value: 67.10354198073468
- type: nauc_mrr_at_3_std
value: -7.409679815529866
- type: nauc_mrr_at_5_diff1
value: 73.13425961877715
- type: nauc_mrr_at_5_max
value: 67.22452899371224
- type: nauc_mrr_at_5_std
value: -6.895257774506354
- type: nauc_ndcg_at_1000_diff1
value: 72.44364625096874
- type: nauc_ndcg_at_1000_max
value: 67.93635761141552
- type: nauc_ndcg_at_1000_std
value: -4.616429464350954
- type: nauc_ndcg_at_100_diff1
value: 72.11352383758482
- type: nauc_ndcg_at_100_max
value: 68.1627312575955
- type: nauc_ndcg_at_100_std
value: -3.894213672131282
- type: nauc_ndcg_at_10_diff1
value: 71.8526850770812
- type: nauc_ndcg_at_10_max
value: 68.41366561888562
- type: nauc_ndcg_at_10_std
value: -4.472146861145989
- type: nauc_ndcg_at_1_diff1
value: 76.63696578575964
- type: nauc_ndcg_at_1_max
value: 65.08189618178105
- type: nauc_ndcg_at_1_std
value: -8.594195451782733
- type: nauc_ndcg_at_20_diff1
value: 71.76464418138866
- type: nauc_ndcg_at_20_max
value: 68.41174963313698
- type: nauc_ndcg_at_20_std
value: -3.7449762037540157
- type: nauc_ndcg_at_3_diff1
value: 71.93808990683131
- type: nauc_ndcg_at_3_max
value: 67.7010029507334
- type: nauc_ndcg_at_3_std
value: -6.971858419379321
- type: nauc_ndcg_at_5_diff1
value: 71.8505224811326
- type: nauc_ndcg_at_5_max
value: 67.97139549500251
- type: nauc_ndcg_at_5_std
value: -5.958491308070017
- type: nauc_precision_at_1000_diff1
value: 62.20956180320043
- type: nauc_precision_at_1000_max
value: 82.53412670611299
- type: nauc_precision_at_1000_std
value: 55.57278124999575
- type: nauc_precision_at_100_diff1
value: 62.03792857023201
- type: nauc_precision_at_100_max
value: 76.77130713424538
- type: nauc_precision_at_100_std
value: 26.674102719959564
- type: nauc_precision_at_10_diff1
value: 65.89798055049931
- type: nauc_precision_at_10_max
value: 73.41908620140674
- type: nauc_precision_at_10_std
value: 5.21818573283179
- type: nauc_precision_at_1_diff1
value: 76.63696578575964
- type: nauc_precision_at_1_max
value: 65.08189618178105
- type: nauc_precision_at_1_std
value: -8.594195451782733
- type: nauc_precision_at_20_diff1
value: 63.734308542647355
- type: nauc_precision_at_20_max
value: 74.69578825096144
- type: nauc_precision_at_20_std
value: 12.627842502659162
- type: nauc_precision_at_3_diff1
value: 67.91189666671904
- type: nauc_precision_at_3_max
value: 69.64986036783209
- type: nauc_precision_at_3_std
value: -5.505669087429055
- type: nauc_precision_at_5_diff1
value: 67.01880006360248
- type: nauc_precision_at_5_max
value: 70.78916423358686
- type: nauc_precision_at_5_std
value: -2.2273742736401045
- type: nauc_recall_at_1000_diff1
value: 62.20956180319936
- type: nauc_recall_at_1000_max
value: 82.53412670611287
- type: nauc_recall_at_1000_std
value: 55.57278124999549
- type: nauc_recall_at_100_diff1
value: 62.03792857023208
- type: nauc_recall_at_100_max
value: 76.77130713424577
- type: nauc_recall_at_100_std
value: 26.67410271995973
- type: nauc_recall_at_10_diff1
value: 65.8979805504994
- type: nauc_recall_at_10_max
value: 73.41908620140678
- type: nauc_recall_at_10_std
value: 5.2181857328318655
- type: nauc_recall_at_1_diff1
value: 76.63696578575964
- type: nauc_recall_at_1_max
value: 65.08189618178105
- type: nauc_recall_at_1_std
value: -8.594195451782733
- type: nauc_recall_at_20_diff1
value: 63.734308542647334
- type: nauc_recall_at_20_max
value: 74.69578825096123
- type: nauc_recall_at_20_std
value: 12.627842502658982
- type: nauc_recall_at_3_diff1
value: 67.91189666671897
- type: nauc_recall_at_3_max
value: 69.64986036783203
- type: nauc_recall_at_3_std
value: -5.505669087428989
- type: nauc_recall_at_5_diff1
value: 67.01880006360243
- type: nauc_recall_at_5_max
value: 70.78916423358686
- type: nauc_recall_at_5_std
value: -2.227374273640135
- type: ndcg_at_1
value: 56.538999999999994
- type: ndcg_at_10
value: 68.765
- type: ndcg_at_100
value: 71.314
- type: ndcg_at_1000
value: 72.038
- type: ndcg_at_20
value: 69.828
- type: ndcg_at_3
value: 64.937
- type: ndcg_at_5
value: 66.956
- type: precision_at_1
value: 56.538999999999994
- type: precision_at_10
value: 8.113
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.099
- type: precision_at_20
value: 4.265
- type: precision_at_3
value: 23.567
- type: precision_at_5
value: 15.115
- type: recall_at_1
value: 56.538999999999994
- type: recall_at_10
value: 81.135
- type: recall_at_100
value: 93.223
- type: recall_at_1000
value: 98.896
- type: recall_at_20
value: 85.304
- type: recall_at_3
value: 70.702
- type: recall_at_5
value: 75.576
task:
type: Retrieval
- dataset:
config: eng-deu
name: MTEB MLQARetrieval (eng-deu)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 69.298
- type: map_at_1
value: 58.553
- type: map_at_10
value: 65.769
- type: map_at_100
value: 66.298
- type: map_at_1000
value: 66.328
- type: map_at_20
value: 66.101
- type: map_at_3
value: 64.048
- type: map_at_5
value: 65.09
- type: mrr_at_1
value: 58.564148016840235
- type: mrr_at_10
value: 65.7685997066675
- type: mrr_at_100
value: 66.29874034432214
- type: mrr_at_1000
value: 66.32844979939088
- type: mrr_at_20
value: 66.10120513957821
- type: mrr_at_3
value: 64.04830489696437
- type: mrr_at_5
value: 65.08974074894746
- type: nauc_map_at_1000_diff1
value: 76.8409650183994
- type: nauc_map_at_1000_max
value: 71.86367015521367
- type: nauc_map_at_1000_std
value: -14.464881539957256
- type: nauc_map_at_100_diff1
value: 76.82536521842064
- type: nauc_map_at_100_max
value: 71.86811127965429
- type: nauc_map_at_100_std
value: -14.441105539722244
- type: nauc_map_at_10_diff1
value: 76.75522453447859
- type: nauc_map_at_10_max
value: 71.87677500176706
- type: nauc_map_at_10_std
value: -14.741331625103559
- type: nauc_map_at_1_diff1
value: 79.64060747740989
- type: nauc_map_at_1_max
value: 69.84278563569617
- type: nauc_map_at_1_std
value: -15.936904929655832
- type: nauc_map_at_20_diff1
value: 76.78894776059715
- type: nauc_map_at_20_max
value: 71.89637938044827
- type: nauc_map_at_20_std
value: -14.500564106990769
- type: nauc_map_at_3_diff1
value: 77.20562577450342
- type: nauc_map_at_3_max
value: 71.80578229361525
- type: nauc_map_at_3_std
value: -15.344134588512201
- type: nauc_map_at_5_diff1
value: 77.00480147367867
- type: nauc_map_at_5_max
value: 71.98335924076163
- type: nauc_map_at_5_std
value: -15.16537653041026
- type: nauc_mrr_at_1000_diff1
value: 76.84165367691193
- type: nauc_mrr_at_1000_max
value: 71.8642679499795
- type: nauc_mrr_at_1000_std
value: -14.461717954593158
- type: nauc_mrr_at_100_diff1
value: 76.8263363557998
- type: nauc_mrr_at_100_max
value: 71.86874522368626
- type: nauc_mrr_at_100_std
value: -14.437105168707426
- type: nauc_mrr_at_10_diff1
value: 76.75522453447859
- type: nauc_mrr_at_10_max
value: 71.87677500176706
- type: nauc_mrr_at_10_std
value: -14.741331625103559
- type: nauc_mrr_at_1_diff1
value: 79.65642669321981
- type: nauc_mrr_at_1_max
value: 69.89135358784799
- type: nauc_mrr_at_1_std
value: -15.919357002229589
- type: nauc_mrr_at_20_diff1
value: 76.78883171270601
- type: nauc_mrr_at_20_max
value: 71.89806887245291
- type: nauc_mrr_at_20_std
value: -14.497139746907905
- type: nauc_mrr_at_3_diff1
value: 77.20562577450342
- type: nauc_mrr_at_3_max
value: 71.80578229361525
- type: nauc_mrr_at_3_std
value: -15.344134588512201
- type: nauc_mrr_at_5_diff1
value: 77.00480147367867
- type: nauc_mrr_at_5_max
value: 71.98335924076163
- type: nauc_mrr_at_5_std
value: -15.16537653041026
- type: nauc_ndcg_at_1000_diff1
value: 76.07802417817047
- type: nauc_ndcg_at_1000_max
value: 72.31792804426776
- type: nauc_ndcg_at_1000_std
value: -13.049160715132244
- type: nauc_ndcg_at_100_diff1
value: 75.63343849116544
- type: nauc_ndcg_at_100_max
value: 72.48362076101817
- type: nauc_ndcg_at_100_std
value: -12.089600993516777
- type: nauc_ndcg_at_10_diff1
value: 75.23387929929208
- type: nauc_ndcg_at_10_max
value: 72.51436288271807
- type: nauc_ndcg_at_10_std
value: -13.624132103038104
- type: nauc_ndcg_at_1_diff1
value: 79.65642669321981
- type: nauc_ndcg_at_1_max
value: 69.89135358784799
- type: nauc_ndcg_at_1_std
value: -15.919357002229589
- type: nauc_ndcg_at_20_diff1
value: 75.32926047656296
- type: nauc_ndcg_at_20_max
value: 72.61254165918145
- type: nauc_ndcg_at_20_std
value: -12.683157599238701
- type: nauc_ndcg_at_3_diff1
value: 76.3089337665469
- type: nauc_ndcg_at_3_max
value: 72.40014674426054
- type: nauc_ndcg_at_3_std
value: -15.08624226353458
- type: nauc_ndcg_at_5_diff1
value: 75.88857331641834
- type: nauc_ndcg_at_5_max
value: 72.7719386827224
- type: nauc_ndcg_at_5_std
value: -14.70546521089236
- type: nauc_precision_at_1000_diff1
value: 59.66563879069911
- type: nauc_precision_at_1000_max
value: 74.57123562956772
- type: nauc_precision_at_1000_std
value: 58.61396866718965
- type: nauc_precision_at_100_diff1
value: 62.8695896550042
- type: nauc_precision_at_100_max
value: 77.81408796785
- type: nauc_precision_at_100_std
value: 23.819735672317826
- type: nauc_precision_at_10_diff1
value: 68.08051625224569
- type: nauc_precision_at_10_max
value: 75.14432336036869
- type: nauc_precision_at_10_std
value: -7.97602345252735
- type: nauc_precision_at_1_diff1
value: 79.65642669321981
- type: nauc_precision_at_1_max
value: 69.89135358784799
- type: nauc_precision_at_1_std
value: -15.919357002229589
- type: nauc_precision_at_20_diff1
value: 66.7168005185165
- type: nauc_precision_at_20_max
value: 76.58522761697147
- type: nauc_precision_at_20_std
value: -0.17923428317323292
- type: nauc_precision_at_3_diff1
value: 73.23394851561207
- type: nauc_precision_at_3_max
value: 74.32517846819215
- type: nauc_precision_at_3_std
value: -14.142301336188348
- type: nauc_precision_at_5_diff1
value: 71.5666882547012
- type: nauc_precision_at_5_max
value: 75.71098205440033
- type: nauc_precision_at_5_std
value: -12.808362513638052
- type: nauc_recall_at_1000_diff1
value: 71.73736112325805
- type: nauc_recall_at_1000_max
value: 86.70743436225898
- type: nauc_recall_at_1000_std
value: 54.45802578371167
- type: nauc_recall_at_100_diff1
value: 64.07053861428128
- type: nauc_recall_at_100_max
value: 78.8348308099261
- type: nauc_recall_at_100_std
value: 22.72263677785103
- type: nauc_recall_at_10_diff1
value: 68.20272901407903
- type: nauc_recall_at_10_max
value: 75.16315335381938
- type: nauc_recall_at_10_std
value: -8.060716748913386
- type: nauc_recall_at_1_diff1
value: 79.64060747740989
- type: nauc_recall_at_1_max
value: 69.84278563569617
- type: nauc_recall_at_1_std
value: -15.936904929655832
- type: nauc_recall_at_20_diff1
value: 66.88206981973654
- type: nauc_recall_at_20_max
value: 76.54824917595687
- type: nauc_recall_at_20_std
value: -0.40294589316962287
- type: nauc_recall_at_3_diff1
value: 73.33076087258938
- type: nauc_recall_at_3_max
value: 74.33763112508771
- type: nauc_recall_at_3_std
value: -14.213355414905399
- type: nauc_recall_at_5_diff1
value: 71.67487623469464
- type: nauc_recall_at_5_max
value: 75.72770292516316
- type: nauc_recall_at_5_std
value: -12.887572274644818
- type: ndcg_at_1
value: 58.56400000000001
- type: ndcg_at_10
value: 69.298
- type: ndcg_at_100
value: 71.95899999999999
- type: ndcg_at_1000
value: 72.735
- type: ndcg_at_20
value: 70.50699999999999
- type: ndcg_at_3
value: 65.81700000000001
- type: ndcg_at_5
value: 67.681
- type: precision_at_1
value: 58.56400000000001
- type: precision_at_10
value: 8.039
- type: precision_at_100
value: 0.931
- type: precision_at_1000
value: 0.099
- type: precision_at_20
value: 4.259
- type: precision_at_3
value: 23.65
- type: precision_at_5
value: 15.09
- type: recall_at_1
value: 58.553
- type: recall_at_10
value: 80.368
- type: recall_at_100
value: 93.013
- type: recall_at_1000
value: 99.092
- type: recall_at_20
value: 85.143
- type: recall_at_3
value: 70.928
- type: recall_at_5
value: 75.42699999999999
task:
type: Retrieval
- dataset:
config: eng-spa
name: MTEB MLQARetrieval (eng-spa)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 66.374
- type: map_at_1
value: 55.494
- type: map_at_10
value: 62.763999999999996
- type: map_at_100
value: 63.33
- type: map_at_1000
value: 63.36000000000001
- type: map_at_20
value: 63.104000000000006
- type: map_at_3
value: 61.065000000000005
- type: map_at_5
value: 62.053000000000004
- type: mrr_at_1
value: 55.49419158255571
- type: mrr_at_10
value: 62.765195140457095
- type: mrr_at_100
value: 63.33083349354529
- type: mrr_at_1000
value: 63.3611897014839
- type: mrr_at_20
value: 63.10543590095977
- type: mrr_at_3
value: 61.06455913159412
- type: mrr_at_5
value: 62.052942296705474
- type: nauc_map_at_1000_diff1
value: 75.04200018088618
- type: nauc_map_at_1000_max
value: 70.49937782771909
- type: nauc_map_at_1000_std
value: -5.257206317083184
- type: nauc_map_at_100_diff1
value: 75.02786834256312
- type: nauc_map_at_100_max
value: 70.5016476500189
- type: nauc_map_at_100_std
value: -5.228770832077681
- type: nauc_map_at_10_diff1
value: 74.9626552701647
- type: nauc_map_at_10_max
value: 70.56253732243214
- type: nauc_map_at_10_std
value: -5.359037281768563
- type: nauc_map_at_1_diff1
value: 78.46858307815857
- type: nauc_map_at_1_max
value: 69.03908373759435
- type: nauc_map_at_1_std
value: -7.479412070736642
- type: nauc_map_at_20_diff1
value: 74.98121458084796
- type: nauc_map_at_20_max
value: 70.51885366822565
- type: nauc_map_at_20_std
value: -5.286051287133815
- type: nauc_map_at_3_diff1
value: 75.36078454383373
- type: nauc_map_at_3_max
value: 70.34997144546014
- type: nauc_map_at_3_std
value: -6.663517224039184
- type: nauc_map_at_5_diff1
value: 75.0274512828238
- type: nauc_map_at_5_max
value: 70.45292551591874
- type: nauc_map_at_5_std
value: -6.029224488640147
- type: nauc_mrr_at_1000_diff1
value: 75.04018768469983
- type: nauc_mrr_at_1000_max
value: 70.49855509132635
- type: nauc_mrr_at_1000_std
value: -5.258929961409948
- type: nauc_mrr_at_100_diff1
value: 75.02605732810112
- type: nauc_mrr_at_100_max
value: 70.50082584929103
- type: nauc_mrr_at_100_std
value: -5.2304917988542154
- type: nauc_mrr_at_10_diff1
value: 74.96079080525713
- type: nauc_mrr_at_10_max
value: 70.56167294920391
- type: nauc_mrr_at_10_std
value: -5.360650630655072
- type: nauc_mrr_at_1_diff1
value: 78.46858307815857
- type: nauc_mrr_at_1_max
value: 69.03908373759435
- type: nauc_mrr_at_1_std
value: -7.479412070736642
- type: nauc_mrr_at_20_diff1
value: 74.97939804960517
- type: nauc_mrr_at_20_max
value: 70.51804078965411
- type: nauc_mrr_at_20_std
value: -5.287681954889177
- type: nauc_mrr_at_3_diff1
value: 75.36078454383373
- type: nauc_mrr_at_3_max
value: 70.34997144546014
- type: nauc_mrr_at_3_std
value: -6.663517224039184
- type: nauc_mrr_at_5_diff1
value: 75.0274512828238
- type: nauc_mrr_at_5_max
value: 70.45292551591874
- type: nauc_mrr_at_5_std
value: -6.029224488640147
- type: nauc_ndcg_at_1000_diff1
value: 74.22106834748942
- type: nauc_ndcg_at_1000_max
value: 70.93625922934912
- type: nauc_ndcg_at_1000_std
value: -3.4878399005946017
- type: nauc_ndcg_at_100_diff1
value: 73.74068883646733
- type: nauc_ndcg_at_100_max
value: 71.02357018347472
- type: nauc_ndcg_at_100_std
value: -2.462293184201324
- type: nauc_ndcg_at_10_diff1
value: 73.40967965536565
- type: nauc_ndcg_at_10_max
value: 71.29379828672067
- type: nauc_ndcg_at_10_std
value: -3.295547756383108
- type: nauc_ndcg_at_1_diff1
value: 78.46858307815857
- type: nauc_ndcg_at_1_max
value: 69.03908373759435
- type: nauc_ndcg_at_1_std
value: -7.479412070736642
- type: nauc_ndcg_at_20_diff1
value: 73.45790057693699
- type: nauc_ndcg_at_20_max
value: 71.16598432419126
- type: nauc_ndcg_at_20_std
value: -2.962877157646097
- type: nauc_ndcg_at_3_diff1
value: 74.30696173964847
- type: nauc_ndcg_at_3_max
value: 70.79878978459556
- type: nauc_ndcg_at_3_std
value: -6.297286578628299
- type: nauc_ndcg_at_5_diff1
value: 73.65858211199816
- type: nauc_ndcg_at_5_max
value: 71.01122417463776
- type: nauc_ndcg_at_5_std
value: -5.075990882646765
- type: nauc_precision_at_1000_diff1
value: 68.71065091972568
- type: nauc_precision_at_1000_max
value: 81.38173585624777
- type: nauc_precision_at_1000_std
value: 58.035497889797895
- type: nauc_precision_at_100_diff1
value: 61.93634256957017
- type: nauc_precision_at_100_max
value: 74.84191770203093
- type: nauc_precision_at_100_std
value: 31.3325983123831
- type: nauc_precision_at_10_diff1
value: 66.68247010944937
- type: nauc_precision_at_10_max
value: 74.48773524654571
- type: nauc_precision_at_10_std
value: 6.560421880785153
- type: nauc_precision_at_1_diff1
value: 78.46858307815857
- type: nauc_precision_at_1_max
value: 69.03908373759435
- type: nauc_precision_at_1_std
value: -7.479412070736642
- type: nauc_precision_at_20_diff1
value: 65.51592872758067
- type: nauc_precision_at_20_max
value: 74.50684066823096
- type: nauc_precision_at_20_std
value: 10.830479877698208
- type: nauc_precision_at_3_diff1
value: 70.89587884861588
- type: nauc_precision_at_3_max
value: 72.25310558370424
- type: nauc_precision_at_3_std
value: -5.0796100900749765
- type: nauc_precision_at_5_diff1
value: 68.71885719845497
- type: nauc_precision_at_5_max
value: 73.02601751485672
- type: nauc_precision_at_5_std
value: -1.4382681421626857
- type: nauc_recall_at_1000_diff1
value: 71.95510299834734
- type: nauc_recall_at_1000_max
value: 84.03647166092985
- type: nauc_recall_at_1000_std
value: 56.87490604776847
- type: nauc_recall_at_100_diff1
value: 62.446624924715955
- type: nauc_recall_at_100_max
value: 75.25666892464507
- type: nauc_recall_at_100_std
value: 31.068789794554686
- type: nauc_recall_at_10_diff1
value: 66.70676336328988
- type: nauc_recall_at_10_max
value: 74.4963699656397
- type: nauc_recall_at_10_std
value: 6.57498399706916
- type: nauc_recall_at_1_diff1
value: 78.46858307815857
- type: nauc_recall_at_1_max
value: 69.03908373759435
- type: nauc_recall_at_1_std
value: -7.479412070736642
- type: nauc_recall_at_20_diff1
value: 65.54082767974772
- type: nauc_recall_at_20_max
value: 74.5111529838772
- type: nauc_recall_at_20_std
value: 10.84574829707354
- type: nauc_recall_at_3_diff1
value: 70.89587884861584
- type: nauc_recall_at_3_max
value: 72.25310558370421
- type: nauc_recall_at_3_std
value: -5.07961009007491
- type: nauc_recall_at_5_diff1
value: 68.71885719845501
- type: nauc_recall_at_5_max
value: 73.02601751485666
- type: nauc_recall_at_5_std
value: -1.4382681421626995
- type: ndcg_at_1
value: 55.494
- type: ndcg_at_10
value: 66.374
- type: ndcg_at_100
value: 69.254
- type: ndcg_at_1000
value: 70.136
- type: ndcg_at_20
value: 67.599
- type: ndcg_at_3
value: 62.863
- type: ndcg_at_5
value: 64.644
- type: precision_at_1
value: 55.494
- type: precision_at_10
value: 7.776
- type: precision_at_100
value: 0.9159999999999999
- type: precision_at_1000
value: 0.099
- type: precision_at_20
value: 4.1290000000000004
- type: precision_at_3
value: 22.688
- type: precision_at_5
value: 14.477
- type: recall_at_1
value: 55.494
- type: recall_at_10
value: 77.747
- type: recall_at_100
value: 91.535
- type: recall_at_1000
value: 98.619
- type: recall_at_20
value: 82.565
- type: recall_at_3
value: 68.063
- type: recall_at_5
value: 72.386
task:
type: Retrieval
- dataset:
config: eng-eng
name: MTEB MLQARetrieval (eng-eng)
revision: 397ed406c1a7902140303e7faf60fff35b58d285
split: test
type: facebook/mlqa
metrics:
- type: main_score
value: 64.723
- type: map_at_1
value: 54.308
- type: map_at_10
value: 61.26200000000001
- type: map_at_100
value: 61.82299999999999
- type: map_at_1000
value: 61.856
- type: map_at_20
value: 61.575
- type: map_at_3
value: 59.565
- type: map_at_5
value: 60.561
- type: mrr_at_1
value: 54.31704368848212
- type: mrr_at_10
value: 61.26520216098834
- type: mrr_at_100
value: 61.82588321127103
- type: mrr_at_1000
value: 61.859333030574334
- type: mrr_at_20
value: 61.57780339921337
- type: mrr_at_3
value: 59.569446842801646
- type: mrr_at_5
value: 60.56323029989004
- type: nauc_map_at_1000_diff1
value: 74.21413722468635
- type: nauc_map_at_1000_max
value: 70.41741227882316
- type: nauc_map_at_1000_std
value: -2.5438707209848506
- type: nauc_map_at_100_diff1
value: 74.19812315947975
- type: nauc_map_at_100_max
value: 70.41589146728445
- type: nauc_map_at_100_std
value: -2.5336117059429553
- type: nauc_map_at_10_diff1
value: 74.21810561152937
- type: nauc_map_at_10_max
value: 70.48816115200171
- type: nauc_map_at_10_std
value: -2.7443834681406734
- type: nauc_map_at_1_diff1
value: 77.69378738778958
- type: nauc_map_at_1_max
value: 68.64652310701173
- type: nauc_map_at_1_std
value: -4.667071946448379
- type: nauc_map_at_20_diff1
value: 74.16105697562438
- type: nauc_map_at_20_max
value: 70.42491994631179
- type: nauc_map_at_20_std
value: -2.6070416022440472
- type: nauc_map_at_3_diff1
value: 74.60449392878863
- type: nauc_map_at_3_max
value: 70.39888609914269
- type: nauc_map_at_3_std
value: -3.5401151125723986
- type: nauc_map_at_5_diff1
value: 74.2423420992663
- type: nauc_map_at_5_max
value: 70.36574501826757
- type: nauc_map_at_5_std
value: -3.2707393116898964
- type: nauc_mrr_at_1000_diff1
value: 74.21029843731323
- type: nauc_mrr_at_1000_max
value: 70.43020492688913
- type: nauc_mrr_at_1000_std
value: -2.526895582202081
- type: nauc_mrr_at_100_diff1
value: 74.19440960479243
- type: nauc_mrr_at_100_max
value: 70.4288998824232
- type: nauc_mrr_at_100_std
value: -2.5160929945118107
- type: nauc_mrr_at_10_diff1
value: 74.2141357266166
- type: nauc_mrr_at_10_max
value: 70.5005683347807
- type: nauc_mrr_at_10_std
value: -2.727154557882168
- type: nauc_mrr_at_1_diff1
value: 77.69891248239793
- type: nauc_mrr_at_1_max
value: 68.68255231164922
- type: nauc_mrr_at_1_std
value: -4.630226727154317
- type: nauc_mrr_at_20_diff1
value: 74.15705434409723
- type: nauc_mrr_at_20_max
value: 70.43741835972747
- type: nauc_mrr_at_20_std
value: -2.5896756472464495
- type: nauc_mrr_at_3_diff1
value: 74.5981844349412
- type: nauc_mrr_at_3_max
value: 70.41834937080564
- type: nauc_mrr_at_3_std
value: -3.5161656408031163
- type: nauc_mrr_at_5_diff1
value: 74.23847535424844
- type: nauc_mrr_at_5_max
value: 70.37763810013656
- type: nauc_mrr_at_5_std
value: -3.2560955164581733
- type: nauc_ndcg_at_1000_diff1
value: 73.20994496725493
- type: nauc_ndcg_at_1000_max
value: 70.8903016277125
- type: nauc_ndcg_at_1000_std
value: -0.625772298462309
- type: nauc_ndcg_at_100_diff1
value: 72.6847141682645
- type: nauc_ndcg_at_100_max
value: 70.86564422034162
- type: nauc_ndcg_at_100_std
value: -0.07195786766326141
- type: nauc_ndcg_at_10_diff1
value: 72.78806493754281
- type: nauc_ndcg_at_10_max
value: 71.21957067926769
- type: nauc_ndcg_at_10_std
value: -1.2760418313382227
- type: nauc_ndcg_at_1_diff1
value: 77.69891248239793
- type: nauc_ndcg_at_1_max
value: 68.68255231164922
- type: nauc_ndcg_at_1_std
value: -4.630226727154317
- type: nauc_ndcg_at_20_diff1
value: 72.52082440882546
- type: nauc_ndcg_at_20_max
value: 70.98185004796734
- type: nauc_ndcg_at_20_std
value: -0.6908280874815464
- type: nauc_ndcg_at_3_diff1
value: 73.59870660843939
- type: nauc_ndcg_at_3_max
value: 70.94391957288654
- type: nauc_ndcg_at_3_std
value: -3.147723179140428
- type: nauc_ndcg_at_5_diff1
value: 72.90122868193457
- type: nauc_ndcg_at_5_max
value: 70.89376368965165
- type: nauc_ndcg_at_5_std
value: -2.6451807385626744
- type: nauc_precision_at_1000_diff1
value: 58.14737201864067
- type: nauc_precision_at_1000_max
value: 78.79011251144826
- type: nauc_precision_at_1000_std
value: 59.98985420476577
- type: nauc_precision_at_100_diff1
value: 59.21069121644552
- type: nauc_precision_at_100_max
value: 73.00557835912306
- type: nauc_precision_at_100_std
value: 26.85027406282173
- type: nauc_precision_at_10_diff1
value: 66.8760831023675
- type: nauc_precision_at_10_max
value: 74.21167950452596
- type: nauc_precision_at_10_std
value: 5.453652499335947
- type: nauc_precision_at_1_diff1
value: 77.69891248239793
- type: nauc_precision_at_1_max
value: 68.68255231164922
- type: nauc_precision_at_1_std
value: -4.630226727154317
- type: nauc_precision_at_20_diff1
value: 64.3118559132602
- type: nauc_precision_at_20_max
value: 73.33078184673825
- type: nauc_precision_at_20_std
value: 9.993299523049402
- type: nauc_precision_at_3_diff1
value: 70.38667185155593
- type: nauc_precision_at_3_max
value: 72.66495006030951
- type: nauc_precision_at_3_std
value: -1.8532839591326276
- type: nauc_precision_at_5_diff1
value: 68.12161337583686
- type: nauc_precision_at_5_max
value: 72.65644960375046
- type: nauc_precision_at_5_std
value: -0.33317164167012875
- type: nauc_recall_at_1000_diff1
value: 61.63204394739985
- type: nauc_recall_at_1000_max
value: 81.77241537319897
- type: nauc_recall_at_1000_std
value: 58.44841544062308
- type: nauc_recall_at_100_diff1
value: 59.72072697224705
- type: nauc_recall_at_100_max
value: 73.28519507061553
- type: nauc_recall_at_100_std
value: 26.27318390763456
- type: nauc_recall_at_10_diff1
value: 66.9757135465418
- type: nauc_recall_at_10_max
value: 74.21919493374149
- type: nauc_recall_at_10_std
value: 5.323369605377166
- type: nauc_recall_at_1_diff1
value: 77.69378738778958
- type: nauc_recall_at_1_max
value: 68.64652310701173
- type: nauc_recall_at_1_std
value: -4.667071946448379
- type: nauc_recall_at_20_diff1
value: 64.42290081731899
- type: nauc_recall_at_20_max
value: 73.3358289439033
- type: nauc_recall_at_20_std
value: 9.846598361586073
- type: nauc_recall_at_3_diff1
value: 70.41211290964785
- type: nauc_recall_at_3_max
value: 72.64451776775402
- type: nauc_recall_at_3_std
value: -1.916280959835826
- type: nauc_recall_at_5_diff1
value: 68.20695272727916
- type: nauc_recall_at_5_max
value: 72.66404224006101
- type: nauc_recall_at_5_std
value: -0.431125323007886
- type: ndcg_at_1
value: 54.31700000000001
- type: ndcg_at_10
value: 64.723
- type: ndcg_at_100
value: 67.648
- type: ndcg_at_1000
value: 68.619
- type: ndcg_at_20
value: 65.85499999999999
- type: ndcg_at_3
value: 61.244
- type: ndcg_at_5
value: 63.038000000000004
- type: precision_at_1
value: 54.31700000000001
- type: precision_at_10
value: 7.564
- type: precision_at_100
value: 0.898
- type: precision_at_1000
value: 0.098
- type: precision_at_20
value: 4.005
- type: precision_at_3
value: 22.034000000000002
- type: precision_at_5
value: 14.093
- type: recall_at_1
value: 54.308
- type: recall_at_10
value: 75.622
- type: recall_at_100
value: 89.744
- type: recall_at_1000
value: 97.539
- type: recall_at_20
value: 80.085
- type: recall_at_3
value: 66.09
- type: recall_at_5
value: 70.446
task:
type: Retrieval
- dataset:
config: de
name: MTEB MLSUMClusteringP2P (de)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 41.267647761702854
- type: v_measure
value: 41.267647761702854
- type: v_measure_std
value: 10.93390895077248
task:
type: Clustering
- dataset:
config: fr
name: MTEB MLSUMClusteringP2P (fr)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 44.68714862333979
- type: v_measure
value: 44.68714862333979
- type: v_measure_std
value: 1.811036989797814
task:
type: Clustering
- dataset:
config: ru
name: MTEB MLSUMClusteringP2P (ru)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 41.92518785753813
- type: v_measure
value: 41.92518785753813
- type: v_measure_std
value: 5.9356661900220775
task:
type: Clustering
- dataset:
config: es
name: MTEB MLSUMClusteringP2P (es)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 48.69875719812033
- type: v_measure
value: 48.69875719812033
- type: v_measure_std
value: 1.204253881950113
task:
type: Clustering
- dataset:
config: de
name: MTEB MLSUMClusteringS2S (de)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 40.07927325071353
- type: v_measure
value: 40.07927325071353
- type: v_measure_std
value: 9.296680835266145
task:
type: Clustering
- dataset:
config: fr
name: MTEB MLSUMClusteringS2S (fr)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 44.88484854069901
- type: v_measure
value: 44.88484854069901
- type: v_measure_std
value: 2.3704247819781843
task:
type: Clustering
- dataset:
config: ru
name: MTEB MLSUMClusteringS2S (ru)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 43.97657450929179
- type: v_measure
value: 43.97657450929179
- type: v_measure_std
value: 6.087547931333613
task:
type: Clustering
- dataset:
config: es
name: MTEB MLSUMClusteringS2S (es)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 48.41108671948728
- type: v_measure
value: 48.41108671948728
- type: v_measure_std
value: 1.3848320630151243
task:
type: Clustering
- dataset:
config: default
name: MTEB MMarcoReranking (default)
revision: 8e0c766dbe9e16e1d221116a3f36795fbade07f6
split: dev
type: C-MTEB/Mmarco-reranking
metrics:
- type: map
value: 21.050447576170395
- type: mrr
value: 20.201984126984126
- type: main_score
value: 21.050447576170395
task:
type: Reranking
- dataset:
config: default
name: MTEB MMarcoRetrieval (default)
revision: 539bbde593d947e2a124ba72651aafc09eb33fc2
split: dev
type: C-MTEB/MMarcoRetrieval
metrics:
- type: main_score
value: 79.687
- type: map_at_1
value: 66.872
- type: map_at_10
value: 75.949
- type: map_at_100
value: 76.25
- type: map_at_1000
value: 76.259
- type: map_at_20
value: 76.145
- type: map_at_3
value: 74.01299999999999
- type: map_at_5
value: 75.232
- type: mrr_at_1
value: 69.18338108882521
- type: mrr_at_10
value: 76.5424227952881
- type: mrr_at_100
value: 76.8019342792628
- type: mrr_at_1000
value: 76.81002278342808
- type: mrr_at_20
value: 76.7115234815896
- type: mrr_at_3
value: 74.83046800382044
- type: mrr_at_5
value: 75.88490926456515
- type: nauc_map_at_1000_diff1
value: 78.06933310424179
- type: nauc_map_at_1000_max
value: 49.392948209665896
- type: nauc_map_at_1000_std
value: -15.126109322591166
- type: nauc_map_at_100_diff1
value: 78.06612779298378
- type: nauc_map_at_100_max
value: 49.40761618630397
- type: nauc_map_at_100_std
value: -15.099282408159349
- type: nauc_map_at_10_diff1
value: 77.94565685470538
- type: nauc_map_at_10_max
value: 49.50559610363201
- type: nauc_map_at_10_std
value: -15.182130695916355
- type: nauc_map_at_1_diff1
value: 79.84814509858211
- type: nauc_map_at_1_max
value: 40.78978466656547
- type: nauc_map_at_1_std
value: -19.96189264026715
- type: nauc_map_at_20_diff1
value: 78.03597839981245
- type: nauc_map_at_20_max
value: 49.49477427223376
- type: nauc_map_at_20_std
value: -15.084990000838378
- type: nauc_map_at_3_diff1
value: 78.0637014655507
- type: nauc_map_at_3_max
value: 48.63214001973341
- type: nauc_map_at_3_std
value: -17.093950563306596
- type: nauc_map_at_5_diff1
value: 77.94068229240348
- type: nauc_map_at_5_max
value: 49.38930719689204
- type: nauc_map_at_5_std
value: -15.9919454201954
- type: nauc_mrr_at_1000_diff1
value: 78.34582398092816
- type: nauc_mrr_at_1000_max
value: 49.623566992784156
- type: nauc_mrr_at_1000_std
value: -14.381347765493265
- type: nauc_mrr_at_100_diff1
value: 78.3429966714221
- type: nauc_mrr_at_100_max
value: 49.63684922240546
- type: nauc_mrr_at_100_std
value: -14.354914066301236
- type: nauc_mrr_at_10_diff1
value: 78.2208070219624
- type: nauc_mrr_at_10_max
value: 49.77720536573364
- type: nauc_mrr_at_10_std
value: -14.316233764741812
- type: nauc_mrr_at_1_diff1
value: 80.22305496572142
- type: nauc_mrr_at_1_max
value: 44.30231210192536
- type: nauc_mrr_at_1_std
value: -18.942549914934492
- type: nauc_mrr_at_20_diff1
value: 78.31006724240147
- type: nauc_mrr_at_20_max
value: 49.72338465276142
- type: nauc_mrr_at_20_std
value: -14.30722621948953
- type: nauc_mrr_at_3_diff1
value: 78.39832634634523
- type: nauc_mrr_at_3_max
value: 49.24985961036677
- type: nauc_mrr_at_3_std
value: -15.966286866763191
- type: nauc_mrr_at_5_diff1
value: 78.2406507247798
- type: nauc_mrr_at_5_max
value: 49.71276359754787
- type: nauc_mrr_at_5_std
value: -14.979526226149698
- type: nauc_ndcg_at_1000_diff1
value: 77.74892471071016
- type: nauc_ndcg_at_1000_max
value: 51.11543344053061
- type: nauc_ndcg_at_1000_std
value: -12.208878737005096
- type: nauc_ndcg_at_100_diff1
value: 77.67462502211228
- type: nauc_ndcg_at_100_max
value: 51.593977338939034
- type: nauc_ndcg_at_100_std
value: -11.312126179513802
- type: nauc_ndcg_at_10_diff1
value: 77.0571291760012
- type: nauc_ndcg_at_10_max
value: 52.35435572808972
- type: nauc_ndcg_at_10_std
value: -11.33242546164059
- type: nauc_ndcg_at_1_diff1
value: 80.22305496572142
- type: nauc_ndcg_at_1_max
value: 44.30231210192536
- type: nauc_ndcg_at_1_std
value: -18.942549914934492
- type: nauc_ndcg_at_20_diff1
value: 77.4141216117471
- type: nauc_ndcg_at_20_max
value: 52.340600871365375
- type: nauc_ndcg_at_20_std
value: -10.989010161550912
- type: nauc_ndcg_at_3_diff1
value: 77.43971989259062
- type: nauc_ndcg_at_3_max
value: 50.59251358320663
- type: nauc_ndcg_at_3_std
value: -15.59337960636058
- type: nauc_ndcg_at_5_diff1
value: 77.12174287031847
- type: nauc_ndcg_at_5_max
value: 51.97108510288907
- type: nauc_ndcg_at_5_std
value: -13.474902612427167
- type: nauc_precision_at_1000_diff1
value: -19.36793534929367
- type: nauc_precision_at_1000_max
value: 11.803383262344036
- type: nauc_precision_at_1000_std
value: 24.304436015177046
- type: nauc_precision_at_100_diff1
value: -6.273790806909921
- type: nauc_precision_at_100_max
value: 23.372606271300747
- type: nauc_precision_at_100_std
value: 29.085768971612342
- type: nauc_precision_at_10_diff1
value: 21.67045907336595
- type: nauc_precision_at_10_max
value: 41.68948432407223
- type: nauc_precision_at_10_std
value: 17.837055074458092
- type: nauc_precision_at_1_diff1
value: 80.22305496572142
- type: nauc_precision_at_1_max
value: 44.30231210192536
- type: nauc_precision_at_1_std
value: -18.942549914934492
- type: nauc_precision_at_20_diff1
value: 12.577671896684803
- type: nauc_precision_at_20_max
value: 37.44944702246691
- type: nauc_precision_at_20_std
value: 23.635897665206087
- type: nauc_precision_at_3_diff1
value: 47.165335112814056
- type: nauc_precision_at_3_max
value: 47.0458691263379
- type: nauc_precision_at_3_std
value: -3.3181861146890217
- type: nauc_precision_at_5_diff1
value: 35.406205343514806
- type: nauc_precision_at_5_max
value: 45.56549449285401
- type: nauc_precision_at_5_std
value: 5.612378074562386
- type: nauc_recall_at_1000_diff1
value: 72.32762520815842
- type: nauc_recall_at_1000_max
value: 85.64979256307343
- type: nauc_recall_at_1000_std
value: 73.61925297037476
- type: nauc_recall_at_100_diff1
value: 72.31946328709962
- type: nauc_recall_at_100_max
value: 83.76576070068353
- type: nauc_recall_at_100_std
value: 57.39376538662535
- type: nauc_recall_at_10_diff1
value: 69.51307788072499
- type: nauc_recall_at_10_max
value: 69.60124733654142
- type: nauc_recall_at_10_std
value: 13.483540424716892
- type: nauc_recall_at_1_diff1
value: 79.84814509858211
- type: nauc_recall_at_1_max
value: 40.78978466656547
- type: nauc_recall_at_1_std
value: -19.96189264026715
- type: nauc_recall_at_20_diff1
value: 70.92168324710599
- type: nauc_recall_at_20_max
value: 76.09106252420084
- type: nauc_recall_at_20_std
value: 25.406842300761447
- type: nauc_recall_at_3_diff1
value: 74.1212680517145
- type: nauc_recall_at_3_max
value: 56.24921832879403
- type: nauc_recall_at_3_std
value: -11.55542913578436
- type: nauc_recall_at_5_diff1
value: 72.31262959872993
- type: nauc_recall_at_5_max
value: 62.761214896697915
- type: nauc_recall_at_5_std
value: -3.280167584070396
- type: ndcg_at_1
value: 69.18299999999999
- type: ndcg_at_10
value: 79.687
- type: ndcg_at_100
value: 81.062
- type: ndcg_at_1000
value: 81.312
- type: ndcg_at_20
value: 80.34599999999999
- type: ndcg_at_3
value: 75.98700000000001
- type: ndcg_at_5
value: 78.039
- type: precision_at_1
value: 69.18299999999999
- type: precision_at_10
value: 9.636
- type: precision_at_100
value: 1.0330000000000001
- type: precision_at_1000
value: 0.105
- type: precision_at_20
value: 4.958
- type: precision_at_3
value: 28.515
- type: precision_at_5
value: 18.201
- type: recall_at_1
value: 66.872
- type: recall_at_10
value: 90.688
- type: recall_at_100
value: 96.99
- type: recall_at_1000
value: 98.958
- type: recall_at_20
value: 93.21199999999999
- type: recall_at_3
value: 80.84599999999999
- type: recall_at_5
value: 85.732
task:
type: Retrieval
- dataset:
config: default
name: MTEB MSMARCO (default)
revision: c5a29a104738b98a9e76336939199e264163d4a0
split: dev
type: mteb/msmarco
metrics:
- type: map_at_1
value: 21.861
- type: map_at_10
value: 34.008
- type: map_at_100
value: 35.174
- type: map_at_1000
value: 35.224
- type: map_at_20
value: 34.705999999999996
- type: map_at_3
value: 30.209000000000003
- type: map_at_5
value: 32.351
- type: mrr_at_1
value: 22.493
- type: mrr_at_10
value: 34.583999999999996
- type: mrr_at_100
value: 35.691
- type: mrr_at_1000
value: 35.736000000000004
- type: mrr_at_20
value: 35.257
- type: mrr_at_3
value: 30.85
- type: mrr_at_5
value: 32.962
- type: ndcg_at_1
value: 22.493
- type: ndcg_at_10
value: 40.815
- type: ndcg_at_100
value: 46.483999999999995
- type: ndcg_at_1000
value: 47.73
- type: ndcg_at_20
value: 43.302
- type: ndcg_at_3
value: 33.056000000000004
- type: ndcg_at_5
value: 36.879
- type: precision_at_1
value: 22.493
- type: precision_at_10
value: 6.465999999999999
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.104
- type: precision_at_20
value: 3.752
- type: precision_at_3
value: 14.069
- type: precision_at_5
value: 10.384
- type: recall_at_1
value: 21.861
- type: recall_at_10
value: 61.781
- type: recall_at_100
value: 88.095
- type: recall_at_1000
value: 97.625
- type: recall_at_20
value: 71.44500000000001
- type: recall_at_3
value: 40.653
- type: recall_at_5
value: 49.841
- type: main_score
value: 40.815
task:
type: Retrieval
- dataset:
config: en
name: MTEB MTOPDomainClassification (en)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 97.4874601003192
- type: f1
value: 97.19067544931094
- type: f1_weighted
value: 97.49331776181019
- type: main_score
value: 97.4874601003192
task:
type: Classification
- dataset:
config: de
name: MTEB MTOPDomainClassification (de)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 96.89489997182305
- type: f1
value: 96.51138586512977
- type: f1_weighted
value: 96.89723065967186
- type: main_score
value: 96.89489997182305
task:
type: Classification
- dataset:
config: es
name: MTEB MTOPDomainClassification (es)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 97.17144763175452
- type: f1
value: 96.81785681878274
- type: f1_weighted
value: 97.1778974586874
- type: main_score
value: 97.17144763175452
task:
type: Classification
- dataset:
config: fr
name: MTEB MTOPDomainClassification (fr)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 96.30128405887879
- type: f1
value: 95.94555923088487
- type: f1_weighted
value: 96.30399416794926
- type: main_score
value: 96.30128405887879
task:
type: Classification
- dataset:
config: en
name: MTEB MTOPIntentClassification (en)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 84.53488372093022
- type: f1
value: 61.77995074251401
- type: f1_weighted
value: 86.8005170485101
- type: main_score
value: 84.53488372093022
task:
type: Classification
- dataset:
config: de
name: MTEB MTOPIntentClassification (de)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 80.79459002535924
- type: f1
value: 56.08938302001448
- type: f1_weighted
value: 83.66582131948252
- type: main_score
value: 80.79459002535924
task:
type: Classification
- dataset:
config: es
name: MTEB MTOPIntentClassification (es)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 84.7765176784523
- type: f1
value: 61.39860057885528
- type: f1_weighted
value: 86.94881745670745
- type: main_score
value: 84.7765176784523
task:
type: Classification
- dataset:
config: fr
name: MTEB MTOPIntentClassification (fr)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 82.2079549013467
- type: f1
value: 59.90260478749016
- type: f1_weighted
value: 84.36861708593257
- type: main_score
value: 82.2079549013467
task:
type: Classification
- dataset:
config: eng
name: MTEB MasakhaNEWSClassification (eng)
revision: 18193f187b92da67168c655c9973a165ed9593dd
split: test
type: mteb/masakhanews
metrics:
- type: accuracy
value: 74.98945147679325
- type: f1
value: 74.3157483560261
- type: f1_weighted
value: 75.01179008904884
- type: main_score
value: 74.98945147679325
task:
type: Classification
- dataset:
config: fra
name: MTEB MasakhaNEWSClassification (fra)
revision: 18193f187b92da67168c655c9973a165ed9593dd
split: test
type: mteb/masakhanews
metrics:
- type: accuracy
value: 74.02843601895735
- type: f1
value: 70.40326349620732
- type: f1_weighted
value: 74.6596277063484
- type: main_score
value: 74.02843601895735
task:
type: Classification
- dataset:
config: amh
name: MTEB MasakhaNEWSClusteringP2P (amh)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 69.45780291725053
- type: v_measure
value: 69.45780291725053
- type: v_measure_std
value: 36.54340055904091
task:
type: Clustering
- dataset:
config: eng
name: MTEB MasakhaNEWSClusteringP2P (eng)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 64.88996119332239
- type: v_measure
value: 64.88996119332239
- type: v_measure_std
value: 30.017223408197268
task:
type: Clustering
- dataset:
config: fra
name: MTEB MasakhaNEWSClusteringP2P (fra)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 42.362383958691666
- type: v_measure
value: 42.362383958691666
- type: v_measure_std
value: 37.61076788039063
task:
type: Clustering
- dataset:
config: hau
name: MTEB MasakhaNEWSClusteringP2P (hau)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 43.29201252405562
- type: v_measure
value: 43.29201252405562
- type: v_measure_std
value: 34.31987945146255
task:
type: Clustering
- dataset:
config: ibo
name: MTEB MasakhaNEWSClusteringP2P (ibo)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 33.59926542995238
- type: v_measure
value: 33.59926542995238
- type: v_measure_std
value: 35.70048601084112
task:
type: Clustering
- dataset:
config: lin
name: MTEB MasakhaNEWSClusteringP2P (lin)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 67.58487601893106
- type: v_measure
value: 67.58487601893106
- type: v_measure_std
value: 35.16784970777931
task:
type: Clustering
- dataset:
config: lug
name: MTEB MasakhaNEWSClusteringP2P (lug)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 50.01220872023533
- type: v_measure
value: 50.01220872023533
- type: v_measure_std
value: 41.87411574676182
task:
type: Clustering
- dataset:
config: orm
name: MTEB MasakhaNEWSClusteringP2P (orm)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 29.007847502598317
- type: v_measure
value: 29.007847502598317
- type: v_measure_std
value: 38.374997395079994
task:
type: Clustering
- dataset:
config: pcm
name: MTEB MasakhaNEWSClusteringP2P (pcm)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 79.13520228554611
- type: v_measure
value: 79.13520228554611
- type: v_measure_std
value: 18.501843848275183
task:
type: Clustering
- dataset:
config: run
name: MTEB MasakhaNEWSClusteringP2P (run)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 60.317213909746656
- type: v_measure
value: 60.317213909746656
- type: v_measure_std
value: 36.500281823747386
task:
type: Clustering
- dataset:
config: sna
name: MTEB MasakhaNEWSClusteringP2P (sna)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 59.395277358240946
- type: v_measure
value: 59.395277358240946
- type: v_measure_std
value: 37.500916816164654
task:
type: Clustering
- dataset:
config: som
name: MTEB MasakhaNEWSClusteringP2P (som)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 38.18638688704302
- type: v_measure
value: 38.18638688704302
- type: v_measure_std
value: 35.453681137564466
task:
type: Clustering
- dataset:
config: swa
name: MTEB MasakhaNEWSClusteringP2P (swa)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 29.49230755729658
- type: v_measure
value: 29.49230755729658
- type: v_measure_std
value: 28.284313285264645
task:
type: Clustering
- dataset:
config: tir
name: MTEB MasakhaNEWSClusteringP2P (tir)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 60.632258622750115
- type: v_measure
value: 60.632258622750115
- type: v_measure_std
value: 34.429711214740564
task:
type: Clustering
- dataset:
config: xho
name: MTEB MasakhaNEWSClusteringP2P (xho)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 41.76322918806381
- type: v_measure
value: 41.76322918806381
- type: v_measure_std
value: 36.43245296200775
task:
type: Clustering
- dataset:
config: yor
name: MTEB MasakhaNEWSClusteringP2P (yor)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 33.17083910808645
- type: v_measure
value: 33.17083910808645
- type: v_measure_std
value: 34.87547994284835
task:
type: Clustering
- dataset:
config: amh
name: MTEB MasakhaNEWSClusteringS2S (amh)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 60.95132147787602
- type: v_measure
value: 60.95132147787602
- type: v_measure_std
value: 37.330148394033365
task:
type: Clustering
- dataset:
config: eng
name: MTEB MasakhaNEWSClusteringS2S (eng)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 60.974810831426595
- type: v_measure
value: 60.974810831426595
- type: v_measure_std
value: 24.934675467507827
task:
type: Clustering
- dataset:
config: fra
name: MTEB MasakhaNEWSClusteringS2S (fra)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 44.479206673553335
- type: v_measure
value: 44.479206673553335
- type: v_measure_std
value: 32.58254804499339
task:
type: Clustering
- dataset:
config: hau
name: MTEB MasakhaNEWSClusteringS2S (hau)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 26.4742082741682
- type: v_measure
value: 26.4742082741682
- type: v_measure_std
value: 22.344929192323097
task:
type: Clustering
- dataset:
config: ibo
name: MTEB MasakhaNEWSClusteringS2S (ibo)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 38.906129911741985
- type: v_measure
value: 38.906129911741985
- type: v_measure_std
value: 34.785601792668444
task:
type: Clustering
- dataset:
config: lin
name: MTEB MasakhaNEWSClusteringS2S (lin)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 62.60982020876592
- type: v_measure
value: 62.60982020876592
- type: v_measure_std
value: 40.7368955715045
task:
type: Clustering
- dataset:
config: lug
name: MTEB MasakhaNEWSClusteringS2S (lug)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 42.70424106365967
- type: v_measure
value: 42.70424106365967
- type: v_measure_std
value: 46.80946241135087
task:
type: Clustering
- dataset:
config: orm
name: MTEB MasakhaNEWSClusteringS2S (orm)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 28.609942199922322
- type: v_measure
value: 28.609942199922322
- type: v_measure_std
value: 38.46685040191088
task:
type: Clustering
- dataset:
config: pcm
name: MTEB MasakhaNEWSClusteringS2S (pcm)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 76.83901348810822
- type: v_measure
value: 76.83901348810822
- type: v_measure_std
value: 17.57617141269189
task:
type: Clustering
- dataset:
config: run
name: MTEB MasakhaNEWSClusteringS2S (run)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 46.89757547846193
- type: v_measure
value: 46.89757547846193
- type: v_measure_std
value: 44.58903590203438
task:
type: Clustering
- dataset:
config: sna
name: MTEB MasakhaNEWSClusteringS2S (sna)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 55.37185207068829
- type: v_measure
value: 55.37185207068829
- type: v_measure_std
value: 36.944574863543004
task:
type: Clustering
- dataset:
config: som
name: MTEB MasakhaNEWSClusteringS2S (som)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 37.44211021681754
- type: v_measure
value: 37.44211021681754
- type: v_measure_std
value: 33.41469994463241
task:
type: Clustering
- dataset:
config: swa
name: MTEB MasakhaNEWSClusteringS2S (swa)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 26.020680621216062
- type: v_measure
value: 26.020680621216062
- type: v_measure_std
value: 25.480037522570413
task:
type: Clustering
- dataset:
config: tir
name: MTEB MasakhaNEWSClusteringS2S (tir)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 63.74306846771303
- type: v_measure
value: 63.74306846771303
- type: v_measure_std
value: 32.19119631078685
task:
type: Clustering
- dataset:
config: xho
name: MTEB MasakhaNEWSClusteringS2S (xho)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 24.580890519243777
- type: v_measure
value: 24.580890519243777
- type: v_measure_std
value: 37.941836363967106
task:
type: Clustering
- dataset:
config: yor
name: MTEB MasakhaNEWSClusteringS2S (yor)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: main_score
value: 43.63458888828314
- type: v_measure
value: 43.63458888828314
- type: v_measure_std
value: 31.28169350649098
task:
type: Clustering
- dataset:
config: pl
name: MTEB MassiveIntentClassification (pl)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 75.37323470073974
- type: f1
value: 71.1836877753734
- type: f1_weighted
value: 75.72073213955457
- type: main_score
value: 75.37323470073974
task:
type: Classification
- dataset:
config: de
name: MTEB MassiveIntentClassification (de)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 74.83523873570948
- type: f1
value: 70.72375821116886
- type: f1_weighted
value: 75.20800490010755
- type: main_score
value: 74.83523873570948
task:
type: Classification
- dataset:
config: es
name: MTEB MassiveIntentClassification (es)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 75.31607262945528
- type: f1
value: 72.06063554897662
- type: f1_weighted
value: 75.72438161355252
- type: main_score
value: 75.31607262945528
task:
type: Classification
- dataset:
config: ru
name: MTEB MassiveIntentClassification (ru)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 76.7955615332885
- type: f1
value: 73.08099648499756
- type: f1_weighted
value: 77.18482068239668
- type: main_score
value: 76.7955615332885
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveIntentClassification (en)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 77.60591795561534
- type: f1
value: 74.46676705370395
- type: f1_weighted
value: 77.69888062336614
- type: main_score
value: 77.60591795561534
task:
type: Classification
- dataset:
config: fr
name: MTEB MassiveIntentClassification (fr)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 76.32145258910558
- type: f1
value: 72.89824154178328
- type: f1_weighted
value: 76.6539327979472
- type: main_score
value: 76.32145258910558
task:
type: Classification
- dataset:
config: zh-CN
name: MTEB MassiveIntentClassification (zh-CN)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 73.21788836583724
- type: f1
value: 70.45594512246377
- type: f1_weighted
value: 73.67862536499393
- type: main_score
value: 73.21788836583724
task:
type: Classification
- dataset:
config: zh-CN
name: MTEB MassiveScenarioClassification (zh-CN)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 80.82044384667114
- type: f1
value: 80.53217664465089
- type: f1_weighted
value: 80.94535087010512
- type: main_score
value: 80.82044384667114
task:
type: Classification
- dataset:
config: pl
name: MTEB MassiveScenarioClassification (pl)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 82.1049092131809
- type: f1
value: 81.55343463694733
- type: f1_weighted
value: 82.33509098770782
- type: main_score
value: 82.1049092131809
task:
type: Classification
- dataset:
config: es
name: MTEB MassiveScenarioClassification (es)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 82.58238063214526
- type: f1
value: 82.27974449333072
- type: f1_weighted
value: 82.81337569618209
- type: main_score
value: 82.58238063214526
task:
type: Classification
- dataset:
config: de
name: MTEB MassiveScenarioClassification (de)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 83.97108271687962
- type: f1
value: 83.56285606936076
- type: f1_weighted
value: 84.10198745390771
- type: main_score
value: 83.97108271687962
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveScenarioClassification (en)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 84.71082716879623
- type: f1
value: 84.09447062371402
- type: f1_weighted
value: 84.73765765551342
- type: main_score
value: 84.71082716879623
task:
type: Classification
- dataset:
config: fr
name: MTEB MassiveScenarioClassification (fr)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 83.093476798924
- type: f1
value: 82.72656900752943
- type: f1_weighted
value: 83.26606516503364
- type: main_score
value: 83.093476798924
task:
type: Classification
- dataset:
config: ru
name: MTEB MassiveScenarioClassification (ru)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 84.05850706119705
- type: f1
value: 83.64234048881222
- type: f1_weighted
value: 84.17315768381876
- type: main_score
value: 84.05850706119705
task:
type: Classification
- dataset:
config: default
name: MTEB MedicalRetrieval (default)
revision: 2039188fb5800a9803ba5048df7b76e6fb151fc6
split: dev
type: C-MTEB/MedicalRetrieval
metrics:
- type: main_score
value: 56.635999999999996
- type: map_at_1
value: 48.699999999999996
- type: map_at_10
value: 53.991
- type: map_at_100
value: 54.449999999999996
- type: map_at_1000
value: 54.515
- type: map_at_20
value: 54.212
- type: map_at_3
value: 52.833
- type: map_at_5
value: 53.503
- type: mrr_at_1
value: 48.699999999999996
- type: mrr_at_10
value: 53.991309523809505
- type: mrr_at_100
value: 54.45008993448266
- type: mrr_at_1000
value: 54.515253990549795
- type: mrr_at_20
value: 54.21201762247036
- type: mrr_at_3
value: 52.8333333333333
- type: mrr_at_5
value: 53.50333333333328
- type: nauc_map_at_1000_diff1
value: 79.96867989401643
- type: nauc_map_at_1000_max
value: 69.75230895599029
- type: nauc_map_at_1000_std
value: 2.6418738289740213
- type: nauc_map_at_100_diff1
value: 79.95343709599133
- type: nauc_map_at_100_max
value: 69.751282671507
- type: nauc_map_at_100_std
value: 2.621719966106279
- type: nauc_map_at_10_diff1
value: 80.02875864565634
- type: nauc_map_at_10_max
value: 69.80948662290187
- type: nauc_map_at_10_std
value: 2.329151604733765
- type: nauc_map_at_1_diff1
value: 83.616940281383
- type: nauc_map_at_1_max
value: 69.08142651929452
- type: nauc_map_at_1_std
value: 1.9687791394035643
- type: nauc_map_at_20_diff1
value: 79.95555601275339
- type: nauc_map_at_20_max
value: 69.76604695002925
- type: nauc_map_at_20_std
value: 2.556184141901367
- type: nauc_map_at_3_diff1
value: 80.74790131023668
- type: nauc_map_at_3_max
value: 70.57797991892402
- type: nauc_map_at_3_std
value: 2.7115149849964117
- type: nauc_map_at_5_diff1
value: 80.31796539878381
- type: nauc_map_at_5_max
value: 69.93573796420061
- type: nauc_map_at_5_std
value: 2.0731614029506606
- type: nauc_mrr_at_1000_diff1
value: 79.96867999907981
- type: nauc_mrr_at_1000_max
value: 69.57395578976896
- type: nauc_mrr_at_1000_std
value: 2.46351945887829
- type: nauc_mrr_at_100_diff1
value: 79.95343709599133
- type: nauc_mrr_at_100_max
value: 69.57322054130803
- type: nauc_mrr_at_100_std
value: 2.4436578359073433
- type: nauc_mrr_at_10_diff1
value: 80.02875864565634
- type: nauc_mrr_at_10_max
value: 69.63292630937411
- type: nauc_mrr_at_10_std
value: 2.1525912912060012
- type: nauc_mrr_at_1_diff1
value: 83.616940281383
- type: nauc_mrr_at_1_max
value: 68.74717310480305
- type: nauc_mrr_at_1_std
value: 1.6345257249120868
- type: nauc_mrr_at_20_diff1
value: 79.95555601275339
- type: nauc_mrr_at_20_max
value: 69.58883608470444
- type: nauc_mrr_at_20_std
value: 2.378973276576547
- type: nauc_mrr_at_3_diff1
value: 80.74790131023668
- type: nauc_mrr_at_3_max
value: 70.40430475488604
- type: nauc_mrr_at_3_std
value: 2.5378398209583817
- type: nauc_mrr_at_5_diff1
value: 80.31796539878381
- type: nauc_mrr_at_5_max
value: 69.7605991748183
- type: nauc_mrr_at_5_std
value: 1.898022613568352
- type: nauc_ndcg_at_1000_diff1
value: 78.35504059321225
- type: nauc_ndcg_at_1000_max
value: 69.06752522437093
- type: nauc_ndcg_at_1000_std
value: 3.9624036886099265
- type: nauc_ndcg_at_100_diff1
value: 77.79729140249833
- type: nauc_ndcg_at_100_max
value: 68.93113791506029
- type: nauc_ndcg_at_100_std
value: 3.642178826886181
- type: nauc_ndcg_at_10_diff1
value: 78.160158293918
- type: nauc_ndcg_at_10_max
value: 69.28122202281361
- type: nauc_ndcg_at_10_std
value: 2.438976810940962
- type: nauc_ndcg_at_1_diff1
value: 83.616940281383
- type: nauc_ndcg_at_1_max
value: 69.08142651929452
- type: nauc_ndcg_at_1_std
value: 1.9687791394035643
- type: nauc_ndcg_at_20_diff1
value: 77.88514432874997
- type: nauc_ndcg_at_20_max
value: 69.06148818508873
- type: nauc_ndcg_at_20_std
value: 3.1800249272363676
- type: nauc_ndcg_at_3_diff1
value: 79.73510384405803
- type: nauc_ndcg_at_3_max
value: 70.78000695123832
- type: nauc_ndcg_at_3_std
value: 2.9041415468363274
- type: nauc_ndcg_at_5_diff1
value: 78.91872808866195
- type: nauc_ndcg_at_5_max
value: 69.61478429620091
- type: nauc_ndcg_at_5_std
value: 1.734699636301054
- type: nauc_precision_at_1000_diff1
value: 66.37858395390673
- type: nauc_precision_at_1000_max
value: 60.651659037598534
- type: nauc_precision_at_1000_std
value: 27.388353715469798
- type: nauc_precision_at_100_diff1
value: 66.34325807776025
- type: nauc_precision_at_100_max
value: 63.63855305621111
- type: nauc_precision_at_100_std
value: 10.641748149575351
- type: nauc_precision_at_10_diff1
value: 71.3784685491089
- type: nauc_precision_at_10_max
value: 67.05313695174542
- type: nauc_precision_at_10_std
value: 3.000406867930561
- type: nauc_precision_at_1_diff1
value: 83.616940281383
- type: nauc_precision_at_1_max
value: 69.08142651929452
- type: nauc_precision_at_1_std
value: 1.9687791394035643
- type: nauc_precision_at_20_diff1
value: 69.73407910977694
- type: nauc_precision_at_20_max
value: 65.77426240320742
- type: nauc_precision_at_20_std
value: 6.204416838482586
- type: nauc_precision_at_3_diff1
value: 76.63737537643107
- type: nauc_precision_at_3_max
value: 71.29710200719668
- type: nauc_precision_at_3_std
value: 3.47180961484546
- type: nauc_precision_at_5_diff1
value: 74.36945983536717
- type: nauc_precision_at_5_max
value: 68.33292218003061
- type: nauc_precision_at_5_std
value: 0.47128762620258075
- type: nauc_recall_at_1000_diff1
value: 66.37858395390681
- type: nauc_recall_at_1000_max
value: 60.65165903759889
- type: nauc_recall_at_1000_std
value: 27.388353715469822
- type: nauc_recall_at_100_diff1
value: 66.34325807776025
- type: nauc_recall_at_100_max
value: 63.63855305621116
- type: nauc_recall_at_100_std
value: 10.641748149575351
- type: nauc_recall_at_10_diff1
value: 71.37846854910892
- type: nauc_recall_at_10_max
value: 67.05313695174546
- type: nauc_recall_at_10_std
value: 3.000406867930663
- type: nauc_recall_at_1_diff1
value: 83.616940281383
- type: nauc_recall_at_1_max
value: 69.08142651929452
- type: nauc_recall_at_1_std
value: 1.9687791394035643
- type: nauc_recall_at_20_diff1
value: 69.73407910977691
- type: nauc_recall_at_20_max
value: 65.77426240320746
- type: nauc_recall_at_20_std
value: 6.204416838482536
- type: nauc_recall_at_3_diff1
value: 76.63737537643112
- type: nauc_recall_at_3_max
value: 71.29710200719668
- type: nauc_recall_at_3_std
value: 3.471809614845442
- type: nauc_recall_at_5_diff1
value: 74.36945983536715
- type: nauc_recall_at_5_max
value: 68.33292218003065
- type: nauc_recall_at_5_std
value: 0.4712876262026442
- type: ndcg_at_1
value: 48.699999999999996
- type: ndcg_at_10
value: 56.635999999999996
- type: ndcg_at_100
value: 59.193
- type: ndcg_at_1000
value: 60.97
- type: ndcg_at_20
value: 57.426
- type: ndcg_at_3
value: 54.186
- type: ndcg_at_5
value: 55.407
- type: precision_at_1
value: 48.699999999999996
- type: precision_at_10
value: 6.5
- type: precision_at_100
value: 0.777
- type: precision_at_1000
value: 0.092
- type: precision_at_20
value: 3.405
- type: precision_at_3
value: 19.367
- type: precision_at_5
value: 12.22
- type: recall_at_1
value: 48.699999999999996
- type: recall_at_10
value: 65.0
- type: recall_at_100
value: 77.7
- type: recall_at_1000
value: 91.8
- type: recall_at_20
value: 68.10000000000001
- type: recall_at_3
value: 58.099999999999994
- type: recall_at_5
value: 61.1
task:
type: Retrieval
- dataset:
config: default
name: MTEB MedrxivClusteringP2P (default)
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
split: test
type: mteb/medrxiv-clustering-p2p
metrics:
- type: main_score
value: 34.80188561439236
- type: v_measure
value: 34.80188561439236
- type: v_measure_std
value: 1.5703148841573102
task:
type: Clustering
- dataset:
config: default
name: MTEB MedrxivClusteringS2S (default)
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
split: test
type: mteb/medrxiv-clustering-s2s
metrics:
- type: main_score
value: 32.42285513996236
- type: v_measure
value: 32.42285513996236
- type: v_measure_std
value: 1.3769867487457566
task:
type: Clustering
- dataset:
config: de
name: MTEB MintakaRetrieval (de)
revision: efa78cc2f74bbcd21eff2261f9e13aebe40b814e
split: test
type: jinaai/mintakaqa
metrics:
- type: main_score
value: 27.025
- type: map_at_1
value: 14.532
- type: map_at_10
value: 22.612
- type: map_at_100
value: 23.802
- type: map_at_1000
value: 23.9
- type: map_at_20
value: 23.275000000000002
- type: map_at_3
value: 20.226
- type: map_at_5
value: 21.490000000000002
- type: mrr_at_1
value: 14.532434709351305
- type: mrr_at_10
value: 22.612077265615575
- type: mrr_at_100
value: 23.801523356874675
- type: mrr_at_1000
value: 23.900118499340238
- type: mrr_at_20
value: 23.275466430108995
- type: mrr_at_3
value: 20.22606009547877
- type: mrr_at_5
value: 21.489750070204945
- type: nauc_map_at_1000_diff1
value: 14.148987799763596
- type: nauc_map_at_1000_max
value: 44.70338461387784
- type: nauc_map_at_1000_std
value: 15.868006767707637
- type: nauc_map_at_100_diff1
value: 14.11371769080442
- type: nauc_map_at_100_max
value: 44.67995540936296
- type: nauc_map_at_100_std
value: 15.890796502029076
- type: nauc_map_at_10_diff1
value: 14.29066834165688
- type: nauc_map_at_10_max
value: 45.10997111765282
- type: nauc_map_at_10_std
value: 15.508568918629864
- type: nauc_map_at_1_diff1
value: 23.473291302576396
- type: nauc_map_at_1_max
value: 44.68942599764586
- type: nauc_map_at_1_std
value: 12.424377262427253
- type: nauc_map_at_20_diff1
value: 14.112652046087831
- type: nauc_map_at_20_max
value: 44.82014861413682
- type: nauc_map_at_20_std
value: 15.739350613646385
- type: nauc_map_at_3_diff1
value: 16.119659221396347
- type: nauc_map_at_3_max
value: 46.04766378953525
- type: nauc_map_at_3_std
value: 13.969878046315925
- type: nauc_map_at_5_diff1
value: 15.095453434076184
- type: nauc_map_at_5_max
value: 45.802128149314406
- type: nauc_map_at_5_std
value: 14.957442173319949
- type: nauc_mrr_at_1000_diff1
value: 14.148987799763596
- type: nauc_mrr_at_1000_max
value: 44.70338461387784
- type: nauc_mrr_at_1000_std
value: 15.868006767707637
- type: nauc_mrr_at_100_diff1
value: 14.11371769080442
- type: nauc_mrr_at_100_max
value: 44.67995540936296
- type: nauc_mrr_at_100_std
value: 15.890796502029076
- type: nauc_mrr_at_10_diff1
value: 14.29066834165688
- type: nauc_mrr_at_10_max
value: 45.10997111765282
- type: nauc_mrr_at_10_std
value: 15.508568918629864
- type: nauc_mrr_at_1_diff1
value: 23.473291302576396
- type: nauc_mrr_at_1_max
value: 44.68942599764586
- type: nauc_mrr_at_1_std
value: 12.424377262427253
- type: nauc_mrr_at_20_diff1
value: 14.112652046087831
- type: nauc_mrr_at_20_max
value: 44.82014861413682
- type: nauc_mrr_at_20_std
value: 15.739350613646385
- type: nauc_mrr_at_3_diff1
value: 16.119659221396347
- type: nauc_mrr_at_3_max
value: 46.04766378953525
- type: nauc_mrr_at_3_std
value: 13.969878046315925
- type: nauc_mrr_at_5_diff1
value: 15.095453434076184
- type: nauc_mrr_at_5_max
value: 45.802128149314406
- type: nauc_mrr_at_5_std
value: 14.957442173319949
- type: nauc_ndcg_at_1000_diff1
value: 11.626606894574028
- type: nauc_ndcg_at_1000_max
value: 43.328592841065536
- type: nauc_ndcg_at_1000_std
value: 18.049446272245547
- type: nauc_ndcg_at_100_diff1
value: 10.485720606660239
- type: nauc_ndcg_at_100_max
value: 42.405317674170966
- type: nauc_ndcg_at_100_std
value: 19.107151641936987
- type: nauc_ndcg_at_10_diff1
value: 11.029351078162982
- type: nauc_ndcg_at_10_max
value: 44.36855031964681
- type: nauc_ndcg_at_10_std
value: 17.302796171409305
- type: nauc_ndcg_at_1_diff1
value: 23.473291302576396
- type: nauc_ndcg_at_1_max
value: 44.68942599764586
- type: nauc_ndcg_at_1_std
value: 12.424377262427253
- type: nauc_ndcg_at_20_diff1
value: 10.356662718168412
- type: nauc_ndcg_at_20_max
value: 43.31602680430083
- type: nauc_ndcg_at_20_std
value: 18.162891267850316
- type: nauc_ndcg_at_3_diff1
value: 14.42844952297869
- type: nauc_ndcg_at_3_max
value: 46.26603339466543
- type: nauc_ndcg_at_3_std
value: 14.449362723887857
- type: nauc_ndcg_at_5_diff1
value: 12.783416563486396
- type: nauc_ndcg_at_5_max
value: 45.852176479124424
- type: nauc_ndcg_at_5_std
value: 16.11775016428085
- type: nauc_precision_at_1000_diff1
value: -8.045361059399795
- type: nauc_precision_at_1000_max
value: 21.970273281738777
- type: nauc_precision_at_1000_std
value: 49.564650488193266
- type: nauc_precision_at_100_diff1
value: -2.118628861593353
- type: nauc_precision_at_100_max
value: 31.32498977104778
- type: nauc_precision_at_100_std
value: 32.96087731883451
- type: nauc_precision_at_10_diff1
value: 3.0335517475367615
- type: nauc_precision_at_10_max
value: 42.21620215030219
- type: nauc_precision_at_10_std
value: 21.90159732315962
- type: nauc_precision_at_1_diff1
value: 23.473291302576396
- type: nauc_precision_at_1_max
value: 44.68942599764586
- type: nauc_precision_at_1_std
value: 12.424377262427253
- type: nauc_precision_at_20_diff1
value: 0.4087201843719047
- type: nauc_precision_at_20_max
value: 38.485034773895734
- type: nauc_precision_at_20_std
value: 25.077397979916682
- type: nauc_precision_at_3_diff1
value: 10.408327736589833
- type: nauc_precision_at_3_max
value: 46.757216289175076
- type: nauc_precision_at_3_std
value: 15.62594354926867
- type: nauc_precision_at_5_diff1
value: 7.326752744229544
- type: nauc_precision_at_5_max
value: 45.89190518573553
- type: nauc_precision_at_5_std
value: 19.01717163438957
- type: nauc_recall_at_1000_diff1
value: -8.045361059400387
- type: nauc_recall_at_1000_max
value: 21.97027328173812
- type: nauc_recall_at_1000_std
value: 49.56465048819266
- type: nauc_recall_at_100_diff1
value: -2.118628861593277
- type: nauc_recall_at_100_max
value: 31.324989771047818
- type: nauc_recall_at_100_std
value: 32.96087731883457
- type: nauc_recall_at_10_diff1
value: 3.0335517475367166
- type: nauc_recall_at_10_max
value: 42.21620215030217
- type: nauc_recall_at_10_std
value: 21.901597323159606
- type: nauc_recall_at_1_diff1
value: 23.473291302576396
- type: nauc_recall_at_1_max
value: 44.68942599764586
- type: nauc_recall_at_1_std
value: 12.424377262427253
- type: nauc_recall_at_20_diff1
value: 0.40872018437190905
- type: nauc_recall_at_20_max
value: 38.485034773895734
- type: nauc_recall_at_20_std
value: 25.077397979916693
- type: nauc_recall_at_3_diff1
value: 10.408327736589843
- type: nauc_recall_at_3_max
value: 46.75721628917507
- type: nauc_recall_at_3_std
value: 15.625943549268664
- type: nauc_recall_at_5_diff1
value: 7.326752744229548
- type: nauc_recall_at_5_max
value: 45.89190518573557
- type: nauc_recall_at_5_std
value: 19.01717163438958
- type: ndcg_at_1
value: 14.532
- type: ndcg_at_10
value: 27.025
- type: ndcg_at_100
value: 33.305
- type: ndcg_at_1000
value: 36.38
- type: ndcg_at_20
value: 29.443
- type: ndcg_at_3
value: 22.035
- type: ndcg_at_5
value: 24.319
- type: precision_at_1
value: 14.532
- type: precision_at_10
value: 4.115
- type: precision_at_100
value: 0.717
- type: precision_at_1000
value: 0.097
- type: precision_at_20
value: 2.536
- type: precision_at_3
value: 9.085
- type: precision_at_5
value: 6.563
- type: recall_at_1
value: 14.532
- type: recall_at_10
value: 41.154
- type: recall_at_100
value: 71.651
- type: recall_at_1000
value: 96.841
- type: recall_at_20
value: 50.71600000000001
- type: recall_at_3
value: 27.254
- type: recall_at_5
value: 32.814
task:
type: Retrieval
- dataset:
config: es
name: MTEB MintakaRetrieval (es)
revision: efa78cc2f74bbcd21eff2261f9e13aebe40b814e
split: test
type: jinaai/mintakaqa
metrics:
- type: main_score
value: 26.912000000000003
- type: map_at_1
value: 14.686
- type: map_at_10
value: 22.569
- type: map_at_100
value: 23.679
- type: map_at_1000
value: 23.777
- type: map_at_20
value: 23.169
- type: map_at_3
value: 20.201
- type: map_at_5
value: 21.566
- type: mrr_at_1
value: 14.686468646864686
- type: mrr_at_10
value: 22.569346220336296
- type: mrr_at_100
value: 23.678819125817146
- type: mrr_at_1000
value: 23.77713511338264
- type: mrr_at_20
value: 23.16850858443442
- type: mrr_at_3
value: 20.200770077007665
- type: mrr_at_5
value: 21.56628162816276
- type: nauc_map_at_1000_diff1
value: 14.129007578838381
- type: nauc_map_at_1000_max
value: 44.4255501141499
- type: nauc_map_at_1000_std
value: 19.95906154868176
- type: nauc_map_at_100_diff1
value: 14.09071870575231
- type: nauc_map_at_100_max
value: 44.403179928955566
- type: nauc_map_at_100_std
value: 20.00413657519976
- type: nauc_map_at_10_diff1
value: 14.149535953153688
- type: nauc_map_at_10_max
value: 44.66529917634685
- type: nauc_map_at_10_std
value: 19.580235989479394
- type: nauc_map_at_1_diff1
value: 23.489813522176636
- type: nauc_map_at_1_max
value: 46.54578639925787
- type: nauc_map_at_1_std
value: 16.39083721709994
- type: nauc_map_at_20_diff1
value: 14.021560420656181
- type: nauc_map_at_20_max
value: 44.4825455452467
- type: nauc_map_at_20_std
value: 19.886927750826878
- type: nauc_map_at_3_diff1
value: 16.182977890477723
- type: nauc_map_at_3_max
value: 46.1840554029258
- type: nauc_map_at_3_std
value: 18.735671900228958
- type: nauc_map_at_5_diff1
value: 14.779126395472833
- type: nauc_map_at_5_max
value: 45.23237213817556
- type: nauc_map_at_5_std
value: 19.348508580412872
- type: nauc_mrr_at_1000_diff1
value: 14.129007578838381
- type: nauc_mrr_at_1000_max
value: 44.4255501141499
- type: nauc_mrr_at_1000_std
value: 19.95906154868176
- type: nauc_mrr_at_100_diff1
value: 14.09071870575231
- type: nauc_mrr_at_100_max
value: 44.403179928955566
- type: nauc_mrr_at_100_std
value: 20.00413657519976
- type: nauc_mrr_at_10_diff1
value: 14.149535953153688
- type: nauc_mrr_at_10_max
value: 44.66529917634685
- type: nauc_mrr_at_10_std
value: 19.580235989479394
- type: nauc_mrr_at_1_diff1
value: 23.489813522176636
- type: nauc_mrr_at_1_max
value: 46.54578639925787
- type: nauc_mrr_at_1_std
value: 16.39083721709994
- type: nauc_mrr_at_20_diff1
value: 14.021560420656181
- type: nauc_mrr_at_20_max
value: 44.4825455452467
- type: nauc_mrr_at_20_std
value: 19.886927750826878
- type: nauc_mrr_at_3_diff1
value: 16.182977890477723
- type: nauc_mrr_at_3_max
value: 46.1840554029258
- type: nauc_mrr_at_3_std
value: 18.735671900228958
- type: nauc_mrr_at_5_diff1
value: 14.779126395472833
- type: nauc_mrr_at_5_max
value: 45.23237213817556
- type: nauc_mrr_at_5_std
value: 19.348508580412872
- type: nauc_ndcg_at_1000_diff1
value: 11.762470380481101
- type: nauc_ndcg_at_1000_max
value: 42.8233203033089
- type: nauc_ndcg_at_1000_std
value: 21.78503705117719
- type: nauc_ndcg_at_100_diff1
value: 10.45886076220022
- type: nauc_ndcg_at_100_max
value: 41.85472899256818
- type: nauc_ndcg_at_100_std
value: 23.20955486335138
- type: nauc_ndcg_at_10_diff1
value: 10.605912468659469
- type: nauc_ndcg_at_10_max
value: 43.150942448104715
- type: nauc_ndcg_at_10_std
value: 21.120035764826085
- type: nauc_ndcg_at_1_diff1
value: 23.489813522176636
- type: nauc_ndcg_at_1_max
value: 46.54578639925787
- type: nauc_ndcg_at_1_std
value: 16.39083721709994
- type: nauc_ndcg_at_20_diff1
value: 10.11291783888644
- type: nauc_ndcg_at_20_max
value: 42.51260678842788
- type: nauc_ndcg_at_20_std
value: 22.1744949382252
- type: nauc_ndcg_at_3_diff1
value: 14.25625326760802
- type: nauc_ndcg_at_3_max
value: 45.96162916377383
- type: nauc_ndcg_at_3_std
value: 19.557832728215523
- type: nauc_ndcg_at_5_diff1
value: 11.956317653823053
- type: nauc_ndcg_at_5_max
value: 44.35971268886807
- type: nauc_ndcg_at_5_std
value: 20.581696730374233
- type: nauc_precision_at_1000_diff1
value: 5.132291843566577
- type: nauc_precision_at_1000_max
value: 25.293354576835263
- type: nauc_precision_at_1000_std
value: 40.36005126087624
- type: nauc_precision_at_100_diff1
value: -1.5252854375008238
- type: nauc_precision_at_100_max
value: 31.007586474495984
- type: nauc_precision_at_100_std
value: 37.297552993548386
- type: nauc_precision_at_10_diff1
value: 1.9663657370770737
- type: nauc_precision_at_10_max
value: 39.194092293625125
- type: nauc_precision_at_10_std
value: 24.956542621999542
- type: nauc_precision_at_1_diff1
value: 23.489813522176636
- type: nauc_precision_at_1_max
value: 46.54578639925787
- type: nauc_precision_at_1_std
value: 16.39083721709994
- type: nauc_precision_at_20_diff1
value: 0.011112090390932373
- type: nauc_precision_at_20_max
value: 36.9357074392519
- type: nauc_precision_at_20_std
value: 28.611387115093876
- type: nauc_precision_at_3_diff1
value: 9.596831091013703
- type: nauc_precision_at_3_max
value: 45.3905541893809
- type: nauc_precision_at_3_std
value: 21.599314388526945
- type: nauc_precision_at_5_diff1
value: 5.175887949900142
- type: nauc_precision_at_5_max
value: 42.129467510414464
- type: nauc_precision_at_5_std
value: 23.607251548776677
- type: nauc_recall_at_1000_diff1
value: 5.132291843566257
- type: nauc_recall_at_1000_max
value: 25.29335457683396
- type: nauc_recall_at_1000_std
value: 40.36005126087638
- type: nauc_recall_at_100_diff1
value: -1.5252854375008988
- type: nauc_recall_at_100_max
value: 31.00758647449594
- type: nauc_recall_at_100_std
value: 37.29755299354834
- type: nauc_recall_at_10_diff1
value: 1.9663657370770793
- type: nauc_recall_at_10_max
value: 39.19409229362512
- type: nauc_recall_at_10_std
value: 24.956542621999546
- type: nauc_recall_at_1_diff1
value: 23.489813522176636
- type: nauc_recall_at_1_max
value: 46.54578639925787
- type: nauc_recall_at_1_std
value: 16.39083721709994
- type: nauc_recall_at_20_diff1
value: 0.011112090390923075
- type: nauc_recall_at_20_max
value: 36.93570743925189
- type: nauc_recall_at_20_std
value: 28.611387115093883
- type: nauc_recall_at_3_diff1
value: 9.596831091013714
- type: nauc_recall_at_3_max
value: 45.39055418938087
- type: nauc_recall_at_3_std
value: 21.599314388526956
- type: nauc_recall_at_5_diff1
value: 5.17588794990012
- type: nauc_recall_at_5_max
value: 42.12946751041448
- type: nauc_recall_at_5_std
value: 23.607251548776695
- type: ndcg_at_1
value: 14.686
- type: ndcg_at_10
value: 26.912000000000003
- type: ndcg_at_100
value: 32.919
- type: ndcg_at_1000
value: 36.119
- type: ndcg_at_20
value: 29.079
- type: ndcg_at_3
value: 21.995
- type: ndcg_at_5
value: 24.474999999999998
- type: precision_at_1
value: 14.686
- type: precision_at_10
value: 4.08
- type: precision_at_100
value: 0.703
- type: precision_at_1000
value: 0.097
- type: precision_at_20
value: 2.467
- type: precision_at_3
value: 9.062000000000001
- type: precision_at_5
value: 6.65
- type: recall_at_1
value: 14.686
- type: recall_at_10
value: 40.8
- type: recall_at_100
value: 70.338
- type: recall_at_1000
value: 96.82300000000001
- type: recall_at_20
value: 49.34
- type: recall_at_3
value: 27.186
- type: recall_at_5
value: 33.251
task:
type: Retrieval
- dataset:
config: fr
name: MTEB MintakaRetrieval (fr)
revision: efa78cc2f74bbcd21eff2261f9e13aebe40b814e
split: test
type: jinaai/mintakaqa
metrics:
- type: main_score
value: 26.909
- type: map_at_1
value: 14.701
- type: map_at_10
value: 22.613
- type: map_at_100
value: 23.729
- type: map_at_1000
value: 23.837
- type: map_at_20
value: 23.262
- type: map_at_3
value: 20.236
- type: map_at_5
value: 21.673000000000002
- type: mrr_at_1
value: 14.7010647010647
- type: mrr_at_10
value: 22.613165113165113
- type: mrr_at_100
value: 23.72877605989423
- type: mrr_at_1000
value: 23.837150802746805
- type: mrr_at_20
value: 23.261627081110596
- type: mrr_at_3
value: 20.2361452361452
- type: mrr_at_5
value: 21.673491673491625
- type: nauc_map_at_1000_diff1
value: 17.08927788889635
- type: nauc_map_at_1000_max
value: 47.240929150603336
- type: nauc_map_at_1000_std
value: 20.559244258100275
- type: nauc_map_at_100_diff1
value: 17.029461792796777
- type: nauc_map_at_100_max
value: 47.207381115550696
- type: nauc_map_at_100_std
value: 20.581498156895265
- type: nauc_map_at_10_diff1
value: 17.351456007804536
- type: nauc_map_at_10_max
value: 47.815880040221344
- type: nauc_map_at_10_std
value: 20.292999107555794
- type: nauc_map_at_1_diff1
value: 27.297525357600776
- type: nauc_map_at_1_max
value: 47.18835074959486
- type: nauc_map_at_1_std
value: 18.304203168281834
- type: nauc_map_at_20_diff1
value: 17.157460199542136
- type: nauc_map_at_20_max
value: 47.4776610667456
- type: nauc_map_at_20_std
value: 20.499186342964478
- type: nauc_map_at_3_diff1
value: 19.393119961356277
- type: nauc_map_at_3_max
value: 49.02841822452882
- type: nauc_map_at_3_std
value: 19.293122796321292
- type: nauc_map_at_5_diff1
value: 17.76275044752008
- type: nauc_map_at_5_max
value: 48.01292548040298
- type: nauc_map_at_5_std
value: 19.928449977400504
- type: nauc_mrr_at_1000_diff1
value: 17.08927788889635
- type: nauc_mrr_at_1000_max
value: 47.240929150603336
- type: nauc_mrr_at_1000_std
value: 20.559244258100275
- type: nauc_mrr_at_100_diff1
value: 17.029461792796777
- type: nauc_mrr_at_100_max
value: 47.207381115550696
- type: nauc_mrr_at_100_std
value: 20.581498156895265
- type: nauc_mrr_at_10_diff1
value: 17.351456007804536
- type: nauc_mrr_at_10_max
value: 47.815880040221344
- type: nauc_mrr_at_10_std
value: 20.292999107555794
- type: nauc_mrr_at_1_diff1
value: 27.297525357600776
- type: nauc_mrr_at_1_max
value: 47.18835074959486
- type: nauc_mrr_at_1_std
value: 18.304203168281834
- type: nauc_mrr_at_20_diff1
value: 17.157460199542136
- type: nauc_mrr_at_20_max
value: 47.4776610667456
- type: nauc_mrr_at_20_std
value: 20.499186342964478
- type: nauc_mrr_at_3_diff1
value: 19.393119961356277
- type: nauc_mrr_at_3_max
value: 49.02841822452882
- type: nauc_mrr_at_3_std
value: 19.293122796321292
- type: nauc_mrr_at_5_diff1
value: 17.76275044752008
- type: nauc_mrr_at_5_max
value: 48.01292548040298
- type: nauc_mrr_at_5_std
value: 19.928449977400504
- type: nauc_ndcg_at_1000_diff1
value: 13.989496006047975
- type: nauc_ndcg_at_1000_max
value: 45.626323944336114
- type: nauc_ndcg_at_1000_std
value: 22.125600410796515
- type: nauc_ndcg_at_100_diff1
value: 12.302204843705244
- type: nauc_ndcg_at_100_max
value: 44.46856314559079
- type: nauc_ndcg_at_100_std
value: 23.084984546328677
- type: nauc_ndcg_at_10_diff1
value: 14.001226213368275
- type: nauc_ndcg_at_10_max
value: 47.37780636546918
- type: nauc_ndcg_at_10_std
value: 21.702709032840637
- type: nauc_ndcg_at_1_diff1
value: 27.297525357600776
- type: nauc_ndcg_at_1_max
value: 47.18835074959486
- type: nauc_ndcg_at_1_std
value: 18.304203168281834
- type: nauc_ndcg_at_20_diff1
value: 13.317759910171056
- type: nauc_ndcg_at_20_max
value: 46.25171251043813
- type: nauc_ndcg_at_20_std
value: 22.309331575402595
- type: nauc_ndcg_at_3_diff1
value: 17.555381234893872
- type: nauc_ndcg_at_3_max
value: 49.48635590260059
- type: nauc_ndcg_at_3_std
value: 19.734570962933674
- type: nauc_ndcg_at_5_diff1
value: 14.844841165765061
- type: nauc_ndcg_at_5_max
value: 47.76437065028708
- type: nauc_ndcg_at_5_std
value: 20.816034479453954
- type: nauc_precision_at_1000_diff1
value: -15.591898698252546
- type: nauc_precision_at_1000_max
value: 20.545984285353892
- type: nauc_precision_at_1000_std
value: 38.9013414992826
- type: nauc_precision_at_100_diff1
value: -5.290395978742176
- type: nauc_precision_at_100_max
value: 31.340480360546845
- type: nauc_precision_at_100_std
value: 33.6897935720505
- type: nauc_precision_at_10_diff1
value: 5.965001997926562
- type: nauc_precision_at_10_max
value: 46.12515296162247
- type: nauc_precision_at_10_std
value: 25.409433135253558
- type: nauc_precision_at_1_diff1
value: 27.297525357600776
- type: nauc_precision_at_1_max
value: 47.18835074959486
- type: nauc_precision_at_1_std
value: 18.304203168281834
- type: nauc_precision_at_20_diff1
value: 3.4438127279827744
- type: nauc_precision_at_20_max
value: 42.36095587714494
- type: nauc_precision_at_20_std
value: 27.367900512797906
- type: nauc_precision_at_3_diff1
value: 13.165017224718916
- type: nauc_precision_at_3_max
value: 50.58931825484506
- type: nauc_precision_at_3_std
value: 20.852009214609442
- type: nauc_precision_at_5_diff1
value: 7.840087177549876
- type: nauc_precision_at_5_max
value: 46.99388755575109
- type: nauc_precision_at_5_std
value: 23.048702393099834
- type: nauc_recall_at_1000_diff1
value: -15.591898698252932
- type: nauc_recall_at_1000_max
value: 20.5459842853537
- type: nauc_recall_at_1000_std
value: 38.901341499282395
- type: nauc_recall_at_100_diff1
value: -5.290395978742165
- type: nauc_recall_at_100_max
value: 31.340480360546863
- type: nauc_recall_at_100_std
value: 33.68979357205046
- type: nauc_recall_at_10_diff1
value: 5.96500199792656
- type: nauc_recall_at_10_max
value: 46.1251529616225
- type: nauc_recall_at_10_std
value: 25.409433135253543
- type: nauc_recall_at_1_diff1
value: 27.297525357600776
- type: nauc_recall_at_1_max
value: 47.18835074959486
- type: nauc_recall_at_1_std
value: 18.304203168281834
- type: nauc_recall_at_20_diff1
value: 3.4438127279827833
- type: nauc_recall_at_20_max
value: 42.36095587714498
- type: nauc_recall_at_20_std
value: 27.36790051279787
- type: nauc_recall_at_3_diff1
value: 13.165017224718916
- type: nauc_recall_at_3_max
value: 50.589318254845054
- type: nauc_recall_at_3_std
value: 20.852009214609435
- type: nauc_recall_at_5_diff1
value: 7.840087177549891
- type: nauc_recall_at_5_max
value: 46.99388755575112
- type: nauc_recall_at_5_std
value: 23.048702393099845
- type: ndcg_at_1
value: 14.701
- type: ndcg_at_10
value: 26.909
- type: ndcg_at_100
value: 32.727000000000004
- type: ndcg_at_1000
value: 36.086
- type: ndcg_at_20
value: 29.236
- type: ndcg_at_3
value: 22.004
- type: ndcg_at_5
value: 24.615000000000002
- type: precision_at_1
value: 14.701
- type: precision_at_10
value: 4.062
- type: precision_at_100
value: 0.688
- type: precision_at_1000
value: 0.096
- type: precision_at_20
value: 2.488
- type: precision_at_3
value: 9.036
- type: precision_at_5
value: 6.699
- type: recall_at_1
value: 14.701
- type: recall_at_10
value: 40.622
- type: recall_at_100
value: 68.796
- type: recall_at_1000
value: 96.314
- type: recall_at_20
value: 49.754
- type: recall_at_3
value: 27.108999999999998
- type: recall_at_5
value: 33.497
task:
type: Retrieval
- dataset:
config: default
name: MTEB MultilingualSentiment (default)
revision: 46958b007a63fdbf239b7672c25d0bea67b5ea1a
split: test
type: C-MTEB/MultilingualSentiment-classification
metrics:
- type: accuracy
value: 73.20999999999998
- type: f1
value: 73.18755986777474
- type: f1_weighted
value: 73.18755986777475
- type: main_score
value: 73.20999999999998
task:
type: Classification
- dataset:
config: default
name: MTEB NFCorpus (default)
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
split: test
type: mteb/nfcorpus
metrics:
- type: map_at_1
value: 4.822
- type: map_at_10
value: 13.144
- type: map_at_100
value: 17.254
- type: map_at_1000
value: 18.931
- type: map_at_20
value: 14.834
- type: map_at_3
value: 8.975
- type: map_at_5
value: 10.922
- type: mrr_at_1
value: 47.059
- type: mrr_at_10
value: 55.806999999999995
- type: mrr_at_100
value: 56.286
- type: mrr_at_1000
value: 56.327000000000005
- type: mrr_at_20
value: 56.00000000000001
- type: mrr_at_3
value: 54.17999999999999
- type: mrr_at_5
value: 55.155
- type: ndcg_at_1
value: 44.427
- type: ndcg_at_10
value: 36.623
- type: ndcg_at_100
value: 33.664
- type: ndcg_at_1000
value: 42.538
- type: ndcg_at_20
value: 34.066
- type: ndcg_at_3
value: 41.118
- type: ndcg_at_5
value: 39.455
- type: precision_at_1
value: 46.44
- type: precision_at_10
value: 28.607
- type: precision_at_100
value: 9.189
- type: precision_at_1000
value: 2.261
- type: precision_at_20
value: 21.238
- type: precision_at_3
value: 39.628
- type: precision_at_5
value: 35.604
- type: recall_at_1
value: 4.822
- type: recall_at_10
value: 17.488999999999997
- type: recall_at_100
value: 35.052
- type: recall_at_1000
value: 66.67999999999999
- type: recall_at_20
value: 21.343999999999998
- type: recall_at_3
value: 10.259
- type: recall_at_5
value: 13.406
- type: main_score
value: 36.623
task:
type: Retrieval
- dataset:
config: default
name: MTEB NQ (default)
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
split: test
type: mteb/nq
metrics:
- type: map_at_1
value: 41.411
- type: map_at_10
value: 57.179
- type: map_at_100
value: 57.945
- type: map_at_1000
value: 57.967999999999996
- type: map_at_20
value: 57.687
- type: map_at_3
value: 53.46300000000001
- type: map_at_5
value: 55.696999999999996
- type: mrr_at_1
value: 46.233999999999995
- type: mrr_at_10
value: 59.831999999999994
- type: mrr_at_100
value: 60.33500000000001
- type: mrr_at_1000
value: 60.348
- type: mrr_at_20
value: 60.167
- type: mrr_at_3
value: 56.972
- type: mrr_at_5
value: 58.74
- type: ndcg_at_1
value: 46.205
- type: ndcg_at_10
value: 64.23100000000001
- type: ndcg_at_100
value: 67.242
- type: ndcg_at_1000
value: 67.72500000000001
- type: ndcg_at_20
value: 65.77300000000001
- type: ndcg_at_3
value: 57.516
- type: ndcg_at_5
value: 61.11600000000001
- type: precision_at_1
value: 46.205
- type: precision_at_10
value: 9.873
- type: precision_at_100
value: 1.158
- type: precision_at_1000
value: 0.12
- type: precision_at_20
value: 5.319
- type: precision_at_3
value: 25.424999999999997
- type: precision_at_5
value: 17.375
- type: recall_at_1
value: 41.411
- type: recall_at_10
value: 82.761
- type: recall_at_100
value: 95.52199999999999
- type: recall_at_1000
value: 99.02499999999999
- type: recall_at_20
value: 88.34
- type: recall_at_3
value: 65.73
- type: recall_at_5
value: 73.894
- type: main_score
value: 64.23100000000001
task:
type: Retrieval
- dataset:
config: default
name: MTEB Ocnli (default)
revision: 66e76a618a34d6d565d5538088562851e6daa7ec
split: validation
type: C-MTEB/OCNLI
metrics:
- type: cosine_accuracy
value: 62.3714131023281
- type: cosine_accuracy_threshold
value: 79.70921993255615
- type: cosine_ap
value: 66.41380155495659
- type: cosine_f1
value: 68.89547185780786
- type: cosine_f1_threshold
value: 72.91591167449951
- type: cosine_precision
value: 57.485875706214685
- type: cosine_recall
value: 85.95564941921859
- type: dot_accuracy
value: 60.47644829453167
- type: dot_accuracy_threshold
value: 36627.362060546875
- type: dot_ap
value: 63.696303449293204
- type: dot_f1
value: 68.3986041101202
- type: dot_f1_threshold
value: 30452.72216796875
- type: dot_precision
value: 54.04411764705882
- type: dot_recall
value: 93.13621964097149
- type: euclidean_accuracy
value: 63.02111532214402
- type: euclidean_accuracy_threshold
value: 1392.76762008667
- type: euclidean_ap
value: 66.65907089443218
- type: euclidean_f1
value: 69.05036524413688
- type: euclidean_f1_threshold
value: 1711.5310668945312
- type: euclidean_precision
value: 54.29262394195889
- type: euclidean_recall
value: 94.82576557550159
- type: main_score
value: 63.02111532214402
- type: manhattan_accuracy
value: 62.75040606388739
- type: manhattan_accuracy_threshold
value: 32475.347900390625
- type: manhattan_ap
value: 66.50943585125434
- type: manhattan_f1
value: 69.08382066276802
- type: manhattan_f1_threshold
value: 41238.470458984375
- type: manhattan_precision
value: 54.75896168108776
- type: manhattan_recall
value: 93.55860612460401
- type: max_accuracy
value: 63.02111532214402
- type: max_ap
value: 66.65907089443218
- type: max_f1
value: 69.08382066276802
- type: max_precision
value: 57.485875706214685
- type: max_recall
value: 94.82576557550159
- type: similarity_accuracy
value: 62.3714131023281
- type: similarity_accuracy_threshold
value: 79.70921993255615
- type: similarity_ap
value: 66.41380155495659
- type: similarity_f1
value: 68.89547185780786
- type: similarity_f1_threshold
value: 72.91591167449951
- type: similarity_precision
value: 57.485875706214685
- type: similarity_recall
value: 85.95564941921859
task:
type: PairClassification
- dataset:
config: default
name: MTEB OnlineShopping (default)
revision: e610f2ebd179a8fda30ae534c3878750a96db120
split: test
type: C-MTEB/OnlineShopping-classification
metrics:
- type: accuracy
value: 91.88000000000001
- type: ap
value: 89.52463684448476
- type: ap_weighted
value: 89.52463684448476
- type: f1
value: 91.86313022306673
- type: f1_weighted
value: 91.87806318146912
- type: main_score
value: 91.88000000000001
task:
type: Classification
- dataset:
config: en
name: MTEB OpusparcusPC (en)
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
split: test.full
type: GEM/opusparcus
metrics:
- type: cosine_accuracy
value: 92.65578635014838
- type: cosine_accuracy_threshold
value: 74.02530312538147
- type: cosine_ap
value: 98.3834226153613
- type: cosine_f1
value: 94.92567913890312
- type: cosine_f1_threshold
value: 74.02530312538147
- type: cosine_precision
value: 95.562435500516
- type: cosine_recall
value: 94.29735234215886
- type: dot_accuracy
value: 91.54302670623146
- type: dot_accuracy_threshold
value: 34452.29187011719
- type: dot_ap
value: 98.1237257754439
- type: dot_f1
value: 94.22400803616273
- type: dot_f1_threshold
value: 33670.41931152344
- type: dot_precision
value: 92.9633300297324
- type: dot_recall
value: 95.5193482688391
- type: euclidean_accuracy
value: 92.28486646884274
- type: euclidean_accuracy_threshold
value: 1602.8022766113281
- type: euclidean_ap
value: 98.3099021504706
- type: euclidean_f1
value: 94.75277497477296
- type: euclidean_f1_threshold
value: 1604.7462463378906
- type: euclidean_precision
value: 93.89999999999999
- type: euclidean_recall
value: 95.62118126272912
- type: main_score
value: 98.3834226153613
- type: manhattan_accuracy
value: 92.2106824925816
- type: manhattan_accuracy_threshold
value: 38872.90954589844
- type: manhattan_ap
value: 98.28694101230218
- type: manhattan_f1
value: 94.67815509376584
- type: manhattan_f1_threshold
value: 38872.90954589844
- type: manhattan_precision
value: 94.24823410696267
- type: manhattan_recall
value: 95.11201629327903
- type: max_accuracy
value: 92.65578635014838
- type: max_ap
value: 98.3834226153613
- type: max_f1
value: 94.92567913890312
- type: max_precision
value: 95.562435500516
- type: max_recall
value: 95.62118126272912
- type: similarity_accuracy
value: 92.65578635014838
- type: similarity_accuracy_threshold
value: 74.02530312538147
- type: similarity_ap
value: 98.3834226153613
- type: similarity_f1
value: 94.92567913890312
- type: similarity_f1_threshold
value: 74.02530312538147
- type: similarity_precision
value: 95.562435500516
- type: similarity_recall
value: 94.29735234215886
task:
type: PairClassification
- dataset:
config: de
name: MTEB OpusparcusPC (de)
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
split: test.full
type: GEM/opusparcus
metrics:
- type: cosine_accuracy
value: 87.72178850248403
- type: cosine_accuracy_threshold
value: 73.33863377571106
- type: cosine_ap
value: 96.98901408834976
- type: cosine_f1
value: 91.89944134078212
- type: cosine_f1_threshold
value: 71.45810127258301
- type: cosine_precision
value: 89.64577656675749
- type: cosine_recall
value: 94.26934097421203
- type: dot_accuracy
value: 86.30234208658624
- type: dot_accuracy_threshold
value: 32027.130126953125
- type: dot_ap
value: 96.12260574893256
- type: dot_f1
value: 91.31602506714414
- type: dot_f1_threshold
value: 30804.376220703125
- type: dot_precision
value: 85.93091828138164
- type: dot_recall
value: 97.42120343839542
- type: euclidean_accuracy
value: 87.9347054648687
- type: euclidean_accuracy_threshold
value: 1609.6670150756836
- type: euclidean_ap
value: 97.00238860358252
- type: euclidean_f1
value: 92.1089063221043
- type: euclidean_f1_threshold
value: 1641.8487548828125
- type: euclidean_precision
value: 89.10714285714286
- type: euclidean_recall
value: 95.31996179560649
- type: main_score
value: 97.00238860358252
- type: manhattan_accuracy
value: 87.72178850248403
- type: manhattan_accuracy_threshold
value: 40137.060546875
- type: manhattan_ap
value: 96.98653728159941
- type: manhattan_f1
value: 92.03865623561896
- type: manhattan_f1_threshold
value: 40137.060546875
- type: manhattan_precision
value: 88.80994671403198
- type: manhattan_recall
value: 95.51098376313276
- type: max_accuracy
value: 87.9347054648687
- type: max_ap
value: 97.00238860358252
- type: max_f1
value: 92.1089063221043
- type: max_precision
value: 89.64577656675749
- type: max_recall
value: 97.42120343839542
- type: similarity_accuracy
value: 87.72178850248403
- type: similarity_accuracy_threshold
value: 73.33863377571106
- type: similarity_ap
value: 96.98901408834976
- type: similarity_f1
value: 91.89944134078212
- type: similarity_f1_threshold
value: 71.45810127258301
- type: similarity_precision
value: 89.64577656675749
- type: similarity_recall
value: 94.26934097421203
task:
type: PairClassification
- dataset:
config: fr
name: MTEB OpusparcusPC (fr)
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
split: test.full
type: GEM/opusparcus
metrics:
- type: cosine_accuracy
value: 80.92643051771117
- type: cosine_accuracy_threshold
value: 76.68856382369995
- type: cosine_ap
value: 93.74622381534307
- type: cosine_f1
value: 87.12328767123287
- type: cosine_f1_threshold
value: 71.64022922515869
- type: cosine_precision
value: 80.64243448858834
- type: cosine_recall
value: 94.73684210526315
- type: dot_accuracy
value: 80.858310626703
- type: dot_accuracy_threshold
value: 34028.3935546875
- type: dot_ap
value: 91.18448457633308
- type: dot_f1
value: 86.82606657290202
- type: dot_f1_threshold
value: 34028.3935546875
- type: dot_precision
value: 82.2380106571936
- type: dot_recall
value: 91.9563058589871
- type: euclidean_accuracy
value: 80.858310626703
- type: euclidean_accuracy_threshold
value: 1595.7651138305664
- type: euclidean_ap
value: 93.8182717829648
- type: euclidean_f1
value: 87.04044117647058
- type: euclidean_f1_threshold
value: 1609.2475891113281
- type: euclidean_precision
value: 81.00940975192472
- type: euclidean_recall
value: 94.04170804369414
- type: main_score
value: 93.8182717829648
- type: manhattan_accuracy
value: 80.99455040871935
- type: manhattan_accuracy_threshold
value: 38092.132568359375
- type: manhattan_ap
value: 93.77563401151711
- type: manhattan_f1
value: 86.91983122362869
- type: manhattan_f1_threshold
value: 38092.132568359375
- type: manhattan_precision
value: 82.32682060390763
- type: manhattan_recall
value: 92.05561072492551
- type: max_accuracy
value: 80.99455040871935
- type: max_ap
value: 93.8182717829648
- type: max_f1
value: 87.12328767123287
- type: max_precision
value: 82.32682060390763
- type: max_recall
value: 94.73684210526315
- type: similarity_accuracy
value: 80.92643051771117
- type: similarity_accuracy_threshold
value: 76.68856382369995
- type: similarity_ap
value: 93.74622381534307
- type: similarity_f1
value: 87.12328767123287
- type: similarity_f1_threshold
value: 71.64022922515869
- type: similarity_precision
value: 80.64243448858834
- type: similarity_recall
value: 94.73684210526315
task:
type: PairClassification
- dataset:
config: ru
name: MTEB OpusparcusPC (ru)
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
split: test.full
type: GEM/opusparcus
metrics:
- type: cosine_accuracy
value: 76.83823529411765
- type: cosine_accuracy_threshold
value: 72.70769476890564
- type: cosine_ap
value: 89.56692049908222
- type: cosine_f1
value: 83.99832003359934
- type: cosine_f1_threshold
value: 70.9052324295044
- type: cosine_precision
value: 76.16146230007617
- type: cosine_recall
value: 93.63295880149812
- type: dot_accuracy
value: 76.28676470588235
- type: dot_accuracy_threshold
value: 33740.68908691406
- type: dot_ap
value: 87.77185177141567
- type: dot_f1
value: 83.62251375370292
- type: dot_f1_threshold
value: 32726.611328125
- type: dot_precision
value: 76.29343629343629
- type: dot_recall
value: 92.50936329588015
- type: euclidean_accuracy
value: 77.32843137254902
- type: euclidean_accuracy_threshold
value: 1566.510009765625
- type: euclidean_ap
value: 89.60605626791111
- type: euclidean_f1
value: 84.06546080964686
- type: euclidean_f1_threshold
value: 1576.4202117919922
- type: euclidean_precision
value: 77.83094098883574
- type: euclidean_recall
value: 91.38576779026218
- type: main_score
value: 89.60605626791111
- type: manhattan_accuracy
value: 76.89950980392157
- type: manhattan_accuracy_threshold
value: 38202.215576171875
- type: manhattan_ap
value: 89.55766894104868
- type: manhattan_f1
value: 83.80462724935732
- type: manhattan_f1_threshold
value: 38934.375
- type: manhattan_precision
value: 77.25118483412322
- type: manhattan_recall
value: 91.57303370786516
- type: max_accuracy
value: 77.32843137254902
- type: max_ap
value: 89.60605626791111
- type: max_f1
value: 84.06546080964686
- type: max_precision
value: 77.83094098883574
- type: max_recall
value: 93.63295880149812
- type: similarity_accuracy
value: 76.83823529411765
- type: similarity_accuracy_threshold
value: 72.70769476890564
- type: similarity_ap
value: 89.56692049908222
- type: similarity_f1
value: 83.99832003359934
- type: similarity_f1_threshold
value: 70.9052324295044
- type: similarity_precision
value: 76.16146230007617
- type: similarity_recall
value: 93.63295880149812
task:
type: PairClassification
- dataset:
config: default
name: MTEB PAC (default)
revision: fc69d1c153a8ccdcf1eef52f4e2a27f88782f543
split: test
type: laugustyniak/abusive-clauses-pl
metrics:
- type: accuracy
value: 68.39559803069794
- type: ap
value: 77.68074206719457
- type: ap_weighted
value: 77.68074206719457
- type: f1
value: 66.23485605467732
- type: f1_weighted
value: 69.03201442129347
- type: main_score
value: 68.39559803069794
task:
type: Classification
- dataset:
config: default
name: MTEB PAWSX (default)
revision: 9c6a90e430ac22b5779fb019a23e820b11a8b5e1
split: test
type: C-MTEB/PAWSX
metrics:
- type: cosine_pearson
value: 13.161523266433587
- type: cosine_spearman
value: 15.557333873773386
- type: euclidean_pearson
value: 17.147508431907525
- type: euclidean_spearman
value: 15.664112857732146
- type: main_score
value: 15.557333873773386
- type: manhattan_pearson
value: 17.130875906264386
- type: manhattan_spearman
value: 15.624397342229637
- type: pearson
value: 13.161523266433587
- type: spearman
value: 15.557333873773386
task:
type: STS
- dataset:
config: default
name: MTEB PSC (default)
revision: d05a294af9e1d3ff2bfb6b714e08a24a6cabc669
split: test
type: PL-MTEB/psc-pairclassification
metrics:
- type: cosine_accuracy
value: 97.86641929499072
- type: cosine_accuracy_threshold
value: 79.0391206741333
- type: cosine_ap
value: 99.19403807771533
- type: cosine_f1
value: 96.45608628659475
- type: cosine_f1_threshold
value: 79.0391206741333
- type: cosine_precision
value: 97.50778816199377
- type: cosine_recall
value: 95.42682926829268
- type: dot_accuracy
value: 98.14471243042672
- type: dot_accuracy_threshold
value: 29808.1787109375
- type: dot_ap
value: 99.331999859971
- type: dot_f1
value: 97.01492537313433
- type: dot_f1_threshold
value: 29808.1787109375
- type: dot_precision
value: 95.02923976608187
- type: dot_recall
value: 99.08536585365853
- type: euclidean_accuracy
value: 97.49536178107606
- type: euclidean_accuracy_threshold
value: 1276.227855682373
- type: euclidean_ap
value: 98.91056467717377
- type: euclidean_f1
value: 95.83975346687212
- type: euclidean_f1_threshold
value: 1276.227855682373
- type: euclidean_precision
value: 96.88473520249221
- type: euclidean_recall
value: 94.8170731707317
- type: main_score
value: 99.331999859971
- type: manhattan_accuracy
value: 97.49536178107606
- type: manhattan_accuracy_threshold
value: 31097.674560546875
- type: manhattan_ap
value: 98.95694691792707
- type: manhattan_f1
value: 95.83975346687212
- type: manhattan_f1_threshold
value: 31097.674560546875
- type: manhattan_precision
value: 96.88473520249221
- type: manhattan_recall
value: 94.8170731707317
- type: max_accuracy
value: 98.14471243042672
- type: max_ap
value: 99.331999859971
- type: max_f1
value: 97.01492537313433
- type: max_precision
value: 97.50778816199377
- type: max_recall
value: 99.08536585365853
- type: similarity_accuracy
value: 97.86641929499072
- type: similarity_accuracy_threshold
value: 79.0391206741333
- type: similarity_ap
value: 99.19403807771533
- type: similarity_f1
value: 96.45608628659475
- type: similarity_f1_threshold
value: 79.0391206741333
- type: similarity_precision
value: 97.50778816199377
- type: similarity_recall
value: 95.42682926829268
task:
type: PairClassification
- dataset:
config: en
name: MTEB PawsXPairClassification (en)
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
split: test
type: google-research-datasets/paws-x
metrics:
- type: cosine_accuracy
value: 61.8
- type: cosine_accuracy_threshold
value: 99.5664119720459
- type: cosine_ap
value: 60.679317786040585
- type: cosine_f1
value: 63.17354143441101
- type: cosine_f1_threshold
value: 97.22164869308472
- type: cosine_precision
value: 47.6457399103139
- type: cosine_recall
value: 93.71554575523705
- type: dot_accuracy
value: 55.7
- type: dot_accuracy_threshold
value: 48353.62548828125
- type: dot_ap
value: 48.53805970536875
- type: dot_f1
value: 62.42214532871972
- type: dot_f1_threshold
value: 38215.53955078125
- type: dot_precision
value: 45.48663640948058
- type: dot_recall
value: 99.44873208379272
- type: euclidean_accuracy
value: 61.75000000000001
- type: euclidean_accuracy_threshold
value: 189.0761137008667
- type: euclidean_ap
value: 60.55517418691518
- type: euclidean_f1
value: 63.07977736549165
- type: euclidean_f1_threshold
value: 504.3168067932129
- type: euclidean_precision
value: 47.53914988814318
- type: euclidean_recall
value: 93.71554575523705
- type: main_score
value: 60.679317786040585
- type: manhattan_accuracy
value: 61.9
- type: manhattan_accuracy_threshold
value: 4695.778274536133
- type: manhattan_ap
value: 60.48686620413608
- type: manhattan_f1
value: 62.92880855772778
- type: manhattan_f1_threshold
value: 12542.36831665039
- type: manhattan_precision
value: 47.28381374722838
- type: manhattan_recall
value: 94.04630650496141
- type: max_accuracy
value: 61.9
- type: max_ap
value: 60.679317786040585
- type: max_f1
value: 63.17354143441101
- type: max_precision
value: 47.6457399103139
- type: max_recall
value: 99.44873208379272
- type: similarity_accuracy
value: 61.8
- type: similarity_accuracy_threshold
value: 99.5664119720459
- type: similarity_ap
value: 60.679317786040585
- type: similarity_f1
value: 63.17354143441101
- type: similarity_f1_threshold
value: 97.22164869308472
- type: similarity_precision
value: 47.6457399103139
- type: similarity_recall
value: 93.71554575523705
task:
type: PairClassification
- dataset:
config: de
name: MTEB PawsXPairClassification (de)
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
split: test
type: google-research-datasets/paws-x
metrics:
- type: cosine_accuracy
value: 60.25
- type: cosine_accuracy_threshold
value: 99.54338073730469
- type: cosine_ap
value: 56.7863613689054
- type: cosine_f1
value: 62.23499820337766
- type: cosine_f1_threshold
value: 89.95014429092407
- type: cosine_precision
value: 45.86864406779661
- type: cosine_recall
value: 96.75977653631284
- type: dot_accuracy
value: 56.8
- type: dot_accuracy_threshold
value: 47349.78332519531
- type: dot_ap
value: 49.7857806061729
- type: dot_f1
value: 62.31225986727209
- type: dot_f1_threshold
value: 30143.206787109375
- type: dot_precision
value: 45.32520325203252
- type: dot_recall
value: 99.66480446927373
- type: euclidean_accuracy
value: 60.3
- type: euclidean_accuracy_threshold
value: 219.78106498718262
- type: euclidean_ap
value: 56.731544327179606
- type: euclidean_f1
value: 62.19895287958115
- type: euclidean_f1_threshold
value: 1792.1623229980469
- type: euclidean_precision
value: 45.22842639593909
- type: euclidean_recall
value: 99.55307262569832
- type: main_score
value: 56.7863613689054
- type: manhattan_accuracy
value: 60.150000000000006
- type: manhattan_accuracy_threshold
value: 5104.503631591797
- type: manhattan_ap
value: 56.70304479768734
- type: manhattan_f1
value: 62.22067039106145
- type: manhattan_f1_threshold
value: 42839.471435546875
- type: manhattan_precision
value: 45.2513966480447
- type: manhattan_recall
value: 99.55307262569832
- type: max_accuracy
value: 60.3
- type: max_ap
value: 56.7863613689054
- type: max_f1
value: 62.31225986727209
- type: max_precision
value: 45.86864406779661
- type: max_recall
value: 99.66480446927373
- type: similarity_accuracy
value: 60.25
- type: similarity_accuracy_threshold
value: 99.54338073730469
- type: similarity_ap
value: 56.7863613689054
- type: similarity_f1
value: 62.23499820337766
- type: similarity_f1_threshold
value: 89.95014429092407
- type: similarity_precision
value: 45.86864406779661
- type: similarity_recall
value: 96.75977653631284
task:
type: PairClassification
- dataset:
config: es
name: MTEB PawsXPairClassification (es)
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
split: test
type: google-research-datasets/paws-x
metrics:
- type: cosine_accuracy
value: 59.699999999999996
- type: cosine_accuracy_threshold
value: 99.55930709838867
- type: cosine_ap
value: 57.31662248806265
- type: cosine_f1
value: 62.444061962134256
- type: cosine_f1_threshold
value: 74.75898265838623
- type: cosine_precision
value: 45.3953953953954
- type: cosine_recall
value: 100.0
- type: dot_accuracy
value: 55.900000000000006
- type: dot_accuracy_threshold
value: 47512.90283203125
- type: dot_ap
value: 49.39339147787568
- type: dot_f1
value: 62.487082328625554
- type: dot_f1_threshold
value: 34989.03503417969
- type: dot_precision
value: 45.44088176352705
- type: dot_recall
value: 100.0
- type: euclidean_accuracy
value: 59.599999999999994
- type: euclidean_accuracy_threshold
value: 200.82547664642334
- type: euclidean_ap
value: 57.19737488445163
- type: euclidean_f1
value: 62.444061962134256
- type: euclidean_f1_threshold
value: 1538.8837814331055
- type: euclidean_precision
value: 45.3953953953954
- type: euclidean_recall
value: 100.0
- type: main_score
value: 57.31662248806265
- type: manhattan_accuracy
value: 59.550000000000004
- type: manhattan_accuracy_threshold
value: 5016.501617431641
- type: manhattan_ap
value: 57.089959907945065
- type: manhattan_f1
value: 62.444061962134256
- type: manhattan_f1_threshold
value: 37523.53515625
- type: manhattan_precision
value: 45.3953953953954
- type: manhattan_recall
value: 100.0
- type: max_accuracy
value: 59.699999999999996
- type: max_ap
value: 57.31662248806265
- type: max_f1
value: 62.487082328625554
- type: max_precision
value: 45.44088176352705
- type: max_recall
value: 100.0
- type: similarity_accuracy
value: 59.699999999999996
- type: similarity_accuracy_threshold
value: 99.55930709838867
- type: similarity_ap
value: 57.31662248806265
- type: similarity_f1
value: 62.444061962134256
- type: similarity_f1_threshold
value: 74.75898265838623
- type: similarity_precision
value: 45.3953953953954
- type: similarity_recall
value: 100.0
task:
type: PairClassification
- dataset:
config: fr
name: MTEB PawsXPairClassification (fr)
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
split: test
type: google-research-datasets/paws-x
metrics:
- type: cosine_accuracy
value: 61.150000000000006
- type: cosine_accuracy_threshold
value: 99.36153888702393
- type: cosine_ap
value: 59.43845317938599
- type: cosine_f1
value: 62.51298026998961
- type: cosine_f1_threshold
value: 76.77866220474243
- type: cosine_precision
value: 45.468277945619334
- type: cosine_recall
value: 100.0
- type: dot_accuracy
value: 55.75
- type: dot_accuracy_threshold
value: 48931.55212402344
- type: dot_ap
value: 50.15949290538757
- type: dot_f1
value: 62.53462603878117
- type: dot_f1_threshold
value: 34415.7958984375
- type: dot_precision
value: 45.4911838790932
- type: dot_recall
value: 100.0
- type: euclidean_accuracy
value: 61.050000000000004
- type: euclidean_accuracy_threshold
value: 240.8097267150879
- type: euclidean_ap
value: 59.367971294226216
- type: euclidean_f1
value: 62.51298026998961
- type: euclidean_f1_threshold
value: 1444.132423400879
- type: euclidean_precision
value: 45.468277945619334
- type: euclidean_recall
value: 100.0
- type: main_score
value: 59.43845317938599
- type: manhattan_accuracy
value: 60.95
- type: manhattan_accuracy_threshold
value: 5701.206207275391
- type: manhattan_ap
value: 59.30094096378774
- type: manhattan_f1
value: 62.53462603878117
- type: manhattan_f1_threshold
value: 33445.672607421875
- type: manhattan_precision
value: 45.4911838790932
- type: manhattan_recall
value: 100.0
- type: max_accuracy
value: 61.150000000000006
- type: max_ap
value: 59.43845317938599
- type: max_f1
value: 62.53462603878117
- type: max_precision
value: 45.4911838790932
- type: max_recall
value: 100.0
- type: similarity_accuracy
value: 61.150000000000006
- type: similarity_accuracy_threshold
value: 99.36153888702393
- type: similarity_ap
value: 59.43845317938599
- type: similarity_f1
value: 62.51298026998961
- type: similarity_f1_threshold
value: 76.77866220474243
- type: similarity_precision
value: 45.468277945619334
- type: similarity_recall
value: 100.0
task:
type: PairClassification
- dataset:
config: zh
name: MTEB PawsXPairClassification (zh)
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
split: test
type: google-research-datasets/paws-x
metrics:
- type: cosine_accuracy
value: 58.85
- type: cosine_accuracy_threshold
value: 99.73838329315186
- type: cosine_ap
value: 54.66913160570546
- type: cosine_f1
value: 62.32136632973162
- type: cosine_f1_threshold
value: 76.4499306678772
- type: cosine_precision
value: 45.265822784810126
- type: cosine_recall
value: 100.0
- type: dot_accuracy
value: 56.25
- type: dot_accuracy_threshold
value: 47351.9287109375
- type: dot_ap
value: 48.5266232989438
- type: dot_f1
value: 62.277951933124356
- type: dot_f1_threshold
value: 31325.28076171875
- type: dot_precision
value: 45.220030349013655
- type: dot_recall
value: 100.0
- type: euclidean_accuracy
value: 58.9
- type: euclidean_accuracy_threshold
value: 144.24468278884888
- type: euclidean_ap
value: 54.66981490353506
- type: euclidean_f1
value: 62.32136632973162
- type: euclidean_f1_threshold
value: 1484.908676147461
- type: euclidean_precision
value: 45.265822784810126
- type: euclidean_recall
value: 100.0
- type: main_score
value: 54.66981490353506
- type: manhattan_accuracy
value: 58.9
- type: manhattan_accuracy_threshold
value: 3586.785125732422
- type: manhattan_ap
value: 54.668355260247736
- type: manhattan_f1
value: 62.32136632973162
- type: manhattan_f1_threshold
value: 36031.22863769531
- type: manhattan_precision
value: 45.265822784810126
- type: manhattan_recall
value: 100.0
- type: max_accuracy
value: 58.9
- type: max_ap
value: 54.66981490353506
- type: max_f1
value: 62.32136632973162
- type: max_precision
value: 45.265822784810126
- type: max_recall
value: 100.0
- type: similarity_accuracy
value: 58.85
- type: similarity_accuracy_threshold
value: 99.73838329315186
- type: similarity_ap
value: 54.66913160570546
- type: similarity_f1
value: 62.32136632973162
- type: similarity_f1_threshold
value: 76.4499306678772
- type: similarity_precision
value: 45.265822784810126
- type: similarity_recall
value: 100.0
task:
type: PairClassification
- dataset:
config: default
name: MTEB PolEmo2.0-IN (default)
revision: d90724373c70959f17d2331ad51fb60c71176b03
split: test
type: PL-MTEB/polemo2_in
metrics:
- type: accuracy
value: 83.75346260387812
- type: f1
value: 81.98304891214909
- type: f1_weighted
value: 84.29623200830078
- type: main_score
value: 83.75346260387812
task:
type: Classification
- dataset:
config: default
name: MTEB PolEmo2.0-OUT (default)
revision: 6a21ab8716e255ab1867265f8b396105e8aa63d4
split: test
type: PL-MTEB/polemo2_out
metrics:
- type: accuracy
value: 66.53846153846153
- type: f1
value: 52.71826064368638
- type: f1_weighted
value: 69.10010124630334
- type: main_score
value: 66.53846153846153
task:
type: Classification
- dataset:
config: default
name: MTEB PPC
revision: None
split: test
type: PL-MTEB/ppc-pairclassification
metrics:
- type: cosine_accuracy
value: 81.8
- type: cosine_accuracy_threshold
value: 90.47793745994568
- type: cosine_ap
value: 91.42490266080884
- type: cosine_f1
value: 85.4632587859425
- type: cosine_f1_threshold
value: 90.47793745994568
- type: cosine_precision
value: 82.56172839506173
- type: cosine_recall
value: 88.57615894039735
- type: dot_accuracy
value: 74.6
- type: dot_accuracy_threshold
value: 42102.23693847656
- type: dot_ap
value: 86.20060009096979
- type: dot_f1
value: 80.02842928216063
- type: dot_f1_threshold
value: 38970.16906738281
- type: dot_precision
value: 70.1120797011208
- type: dot_recall
value: 93.21192052980133
- type: euclidean_accuracy
value: 81.5
- type: euclidean_accuracy_threshold
value: 880.433464050293
- type: euclidean_ap
value: 91.33143477982087
- type: euclidean_f1
value: 85.44600938967135
- type: euclidean_f1_threshold
value: 964.0384674072266
- type: euclidean_precision
value: 81.00890207715133
- type: euclidean_recall
value: 90.39735099337747
- type: main_score
value: 91.42490266080884
- type: manhattan_accuracy
value: 81.3
- type: manhattan_accuracy_threshold
value: 22100.830078125
- type: manhattan_ap
value: 91.25996158651282
- type: manhattan_f1
value: 85.38102643856921
- type: manhattan_f1_threshold
value: 24043.515014648438
- type: manhattan_precision
value: 80.49853372434018
- type: manhattan_recall
value: 90.89403973509934
- type: max_accuracy
value: 81.8
- type: max_ap
value: 91.42490266080884
- type: max_f1
value: 85.4632587859425
- type: max_precision
value: 82.56172839506173
- type: max_recall
value: 93.21192052980133
- type: similarity_accuracy
value: 81.8
- type: similarity_accuracy_threshold
value: 90.47793745994568
- type: similarity_ap
value: 91.42490266080884
- type: similarity_f1
value: 85.4632587859425
- type: similarity_f1_threshold
value: 90.47793745994568
- type: similarity_precision
value: 82.56172839506173
- type: similarity_recall
value: 88.57615894039735
task:
type: PairClassification
- dataset:
config: default
name: MTEB QuoraRetrieval (default)
revision: e4e08e0b7dbe3c8700f0daef558ff32256715259
split: test
type: mteb/quora
metrics:
- type: map_at_1
value: 71.419
- type: map_at_10
value: 85.542
- type: map_at_100
value: 86.161
- type: map_at_1000
value: 86.175
- type: map_at_20
value: 85.949
- type: map_at_3
value: 82.623
- type: map_at_5
value: 84.5
- type: mrr_at_1
value: 82.27
- type: mrr_at_10
value: 88.21900000000001
- type: mrr_at_100
value: 88.313
- type: mrr_at_1000
value: 88.31400000000001
- type: mrr_at_20
value: 88.286
- type: mrr_at_3
value: 87.325
- type: mrr_at_5
value: 87.97500000000001
- type: ndcg_at_1
value: 82.3
- type: ndcg_at_10
value: 89.088
- type: ndcg_at_100
value: 90.217
- type: ndcg_at_1000
value: 90.29700000000001
- type: ndcg_at_20
value: 89.697
- type: ndcg_at_3
value: 86.435
- type: ndcg_at_5
value: 87.966
- type: precision_at_1
value: 82.3
- type: precision_at_10
value: 13.527000000000001
- type: precision_at_100
value: 1.537
- type: precision_at_1000
value: 0.157
- type: precision_at_20
value: 7.165000000000001
- type: precision_at_3
value: 37.92
- type: precision_at_5
value: 24.914
- type: recall_at_1
value: 71.419
- type: recall_at_10
value: 95.831
- type: recall_at_100
value: 99.64
- type: recall_at_1000
value: 99.988
- type: recall_at_20
value: 97.76599999999999
- type: recall_at_3
value: 88.081
- type: recall_at_5
value: 92.50500000000001
- type: main_score
value: 89.088
task:
type: Retrieval
- dataset:
config: default
name: MTEB RUParaPhraserSTS (default)
revision: 43265056790b8f7c59e0139acb4be0a8dad2c8f4
split: test
type: merionum/ru_paraphraser
metrics:
- type: cosine_pearson
value: 67.91177744712421
- type: cosine_spearman
value: 76.77113726753656
- type: euclidean_pearson
value: 73.81454206068638
- type: euclidean_spearman
value: 76.92529493599028
- type: main_score
value: 76.77113726753656
- type: manhattan_pearson
value: 73.81690454439168
- type: manhattan_spearman
value: 76.87333776705002
- type: pearson
value: 67.91177744712421
- type: spearman
value: 76.77113726753656
task:
type: STS
- dataset:
config: default
name: MTEB RedditClustering (default)
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
split: test
type: mteb/reddit-clustering
metrics:
- type: main_score
value: 55.39924225216962
- type: v_measure
value: 55.39924225216962
- type: v_measure_std
value: 4.723802279292467
task:
type: Clustering
- dataset:
config: default
name: MTEB RedditClusteringP2P (default)
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
split: test
type: mteb/reddit-clustering-p2p
metrics:
- type: main_score
value: 62.87465161304012
- type: v_measure
value: 62.87465161304012
- type: v_measure_std
value: 12.082670914488473
task:
type: Clustering
- dataset:
config: default
name: MTEB RiaNewsRetrieval (default)
revision: 82374b0bbacda6114f39ff9c5b925fa1512ca5d7
split: test
type: ai-forever/ria-news-retrieval
metrics:
- type: main_score
value: 79.209
- type: map_at_1
value: 67.33
- type: map_at_10
value: 75.633
- type: map_at_100
value: 75.897
- type: map_at_1000
value: 75.907
- type: map_at_20
value: 75.804
- type: map_at_3
value: 74.2
- type: map_at_5
value: 75.13300000000001
- type: mrr_at_1
value: 67.31
- type: mrr_at_10
value: 75.62709126984095
- type: mrr_at_100
value: 75.89105697041113
- type: mrr_at_1000
value: 75.90115653883124
- type: mrr_at_20
value: 75.79802332308172
- type: mrr_at_3
value: 74.19499999999961
- type: mrr_at_5
value: 75.12849999999939
- type: nauc_map_at_1000_diff1
value: 74.30304869630591
- type: nauc_map_at_1000_max
value: 36.477146725784046
- type: nauc_map_at_1000_std
value: -20.862772498461723
- type: nauc_map_at_100_diff1
value: 74.29833058090355
- type: nauc_map_at_100_max
value: 36.483678619667884
- type: nauc_map_at_100_std
value: -20.856274849980135
- type: nauc_map_at_10_diff1
value: 74.20729220697967
- type: nauc_map_at_10_max
value: 36.56543146170092
- type: nauc_map_at_10_std
value: -20.991081015484728
- type: nauc_map_at_1_diff1
value: 77.38899022125185
- type: nauc_map_at_1_max
value: 32.45918619669731
- type: nauc_map_at_1_std
value: -22.149586336167324
- type: nauc_map_at_20_diff1
value: 74.2447573558587
- type: nauc_map_at_20_max
value: 36.50383130240387
- type: nauc_map_at_20_std
value: -20.87013743041831
- type: nauc_map_at_3_diff1
value: 74.3054577294586
- type: nauc_map_at_3_max
value: 36.484530586652724
- type: nauc_map_at_3_std
value: -21.90543024607988
- type: nauc_map_at_5_diff1
value: 74.21062368961503
- type: nauc_map_at_5_max
value: 36.55670532498779
- type: nauc_map_at_5_std
value: -21.488786900676942
- type: nauc_mrr_at_1000_diff1
value: 74.31619177956684
- type: nauc_mrr_at_1000_max
value: 36.53498918453189
- type: nauc_mrr_at_1000_std
value: -20.75986704931237
- type: nauc_mrr_at_100_diff1
value: 74.31146790382356
- type: nauc_mrr_at_100_max
value: 36.54149252857106
- type: nauc_mrr_at_100_std
value: -20.75341959250079
- type: nauc_mrr_at_10_diff1
value: 74.22027806145095
- type: nauc_mrr_at_10_max
value: 36.622542969971725
- type: nauc_mrr_at_10_std
value: -20.889417384064117
- type: nauc_mrr_at_1_diff1
value: 77.4306709551449
- type: nauc_mrr_at_1_max
value: 32.57259463438259
- type: nauc_mrr_at_1_std
value: -21.964402859613937
- type: nauc_mrr_at_20_diff1
value: 74.25784396230718
- type: nauc_mrr_at_20_max
value: 36.561412224507336
- type: nauc_mrr_at_20_std
value: -20.767665000065723
- type: nauc_mrr_at_3_diff1
value: 74.31423253547214
- type: nauc_mrr_at_3_max
value: 36.537745749488906
- type: nauc_mrr_at_3_std
value: -21.81259529019546
- type: nauc_mrr_at_5_diff1
value: 74.22404613312771
- type: nauc_mrr_at_5_max
value: 36.60743768455219
- type: nauc_mrr_at_5_std
value: -21.39479216331971
- type: nauc_ndcg_at_1000_diff1
value: 73.48182819705742
- type: nauc_ndcg_at_1000_max
value: 37.86991608461793
- type: nauc_ndcg_at_1000_std
value: -19.021499322688904
- type: nauc_ndcg_at_100_diff1
value: 73.34941250585759
- type: nauc_ndcg_at_100_max
value: 38.11150275625829
- type: nauc_ndcg_at_100_std
value: -18.70624087206104
- type: nauc_ndcg_at_10_diff1
value: 72.82520265115987
- type: nauc_ndcg_at_10_max
value: 38.43323357650525
- type: nauc_ndcg_at_10_std
value: -19.410953792830878
- type: nauc_ndcg_at_1_diff1
value: 77.38899022125185
- type: nauc_ndcg_at_1_max
value: 32.45918619669731
- type: nauc_ndcg_at_1_std
value: -22.149586336167324
- type: nauc_ndcg_at_20_diff1
value: 72.93309285256507
- type: nauc_ndcg_at_20_max
value: 38.217372819067755
- type: nauc_ndcg_at_20_std
value: -18.864113576359333
- type: nauc_ndcg_at_3_diff1
value: 73.18253776744112
- type: nauc_ndcg_at_3_max
value: 38.008109328364
- type: nauc_ndcg_at_3_std
value: -21.68785687594153
- type: nauc_ndcg_at_5_diff1
value: 72.90474739784793
- type: nauc_ndcg_at_5_max
value: 38.29483039202184
- type: nauc_ndcg_at_5_std
value: -20.833049811453474
- type: nauc_precision_at_1000_diff1
value: 59.306217613750334
- type: nauc_precision_at_1000_max
value: 72.20747948302262
- type: nauc_precision_at_1000_std
value: 45.58837180096227
- type: nauc_precision_at_100_diff1
value: 62.87286844562389
- type: nauc_precision_at_100_max
value: 61.33108214045868
- type: nauc_precision_at_100_std
value: 20.67481963545654
- type: nauc_precision_at_10_diff1
value: 64.11222984256685
- type: nauc_precision_at_10_max
value: 50.323697746037496
- type: nauc_precision_at_10_std
value: -7.9994544634332625
- type: nauc_precision_at_1_diff1
value: 77.38899022125185
- type: nauc_precision_at_1_max
value: 32.45918619669731
- type: nauc_precision_at_1_std
value: -22.149586336167324
- type: nauc_precision_at_20_diff1
value: 62.30228127286973
- type: nauc_precision_at_20_max
value: 52.02090746208407
- type: nauc_precision_at_20_std
value: 0.7629898806370331
- type: nauc_precision_at_3_diff1
value: 68.82856645994157
- type: nauc_precision_at_3_max
value: 43.94171571306625
- type: nauc_precision_at_3_std
value: -20.78595255410148
- type: nauc_precision_at_5_diff1
value: 66.62157622497887
- type: nauc_precision_at_5_max
value: 46.69398173603811
- type: nauc_precision_at_5_std
value: -17.412423571163057
- type: nauc_recall_at_1000_diff1
value: 59.30621761375148
- type: nauc_recall_at_1000_max
value: 72.20747948302191
- type: nauc_recall_at_1000_std
value: 45.588371800962655
- type: nauc_recall_at_100_diff1
value: 62.872868445623894
- type: nauc_recall_at_100_max
value: 61.33108214045813
- type: nauc_recall_at_100_std
value: 20.67481963545666
- type: nauc_recall_at_10_diff1
value: 64.11222984256698
- type: nauc_recall_at_10_max
value: 50.32369774603755
- type: nauc_recall_at_10_std
value: -7.999454463433321
- type: nauc_recall_at_1_diff1
value: 77.38899022125185
- type: nauc_recall_at_1_max
value: 32.45918619669731
- type: nauc_recall_at_1_std
value: -22.149586336167324
- type: nauc_recall_at_20_diff1
value: 62.3022812728695
- type: nauc_recall_at_20_max
value: 52.02090746208397
- type: nauc_recall_at_20_std
value: 0.7629898806369458
- type: nauc_recall_at_3_diff1
value: 68.82856645994157
- type: nauc_recall_at_3_max
value: 43.94171571306612
- type: nauc_recall_at_3_std
value: -20.78595255410157
- type: nauc_recall_at_5_diff1
value: 66.62157622497897
- type: nauc_recall_at_5_max
value: 46.693981736038246
- type: nauc_recall_at_5_std
value: -17.412423571162954
- type: ndcg_at_1
value: 67.33
- type: ndcg_at_10
value: 79.209
- type: ndcg_at_100
value: 80.463
- type: ndcg_at_1000
value: 80.74799999999999
- type: ndcg_at_20
value: 79.81899999999999
- type: ndcg_at_3
value: 76.335
- type: ndcg_at_5
value: 78.011
- type: precision_at_1
value: 67.33
- type: precision_at_10
value: 9.020999999999999
- type: precision_at_100
value: 0.96
- type: precision_at_1000
value: 0.098
- type: precision_at_20
value: 4.63
- type: precision_at_3
value: 27.493000000000002
- type: precision_at_5
value: 17.308
- type: recall_at_1
value: 67.33
- type: recall_at_10
value: 90.21000000000001
- type: recall_at_100
value: 96.00999999999999
- type: recall_at_1000
value: 98.29
- type: recall_at_20
value: 92.60000000000001
- type: recall_at_3
value: 82.48
- type: recall_at_5
value: 86.53999999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB RuBQReranking (default)
revision: 2e96b8f098fa4b0950fc58eacadeb31c0d0c7fa2
split: test
type: ai-forever/rubq-reranking
metrics:
- type: main_score
value: 65.57453932493252
- type: map
value: 65.57453932493252
- type: mrr
value: 70.51408205663526
- type: nAUC_map_diff1
value: 26.69583260609023
- type: nAUC_map_max
value: 12.928262749610663
- type: nAUC_map_std
value: 11.702468857903128
- type: nAUC_mrr_diff1
value: 28.5206955462174
- type: nAUC_mrr_max
value: 14.207162454694227
- type: nAUC_mrr_std
value: 10.725721001555296
task:
type: Reranking
- dataset:
config: default
name: MTEB RuBQRetrieval (default)
revision: e19b6ffa60b3bc248e0b41f4cc37c26a55c2a67b
split: test
type: ai-forever/rubq-retrieval
metrics:
- type: main_score
value: 72.306
- type: map_at_1
value: 44.187
- type: map_at_10
value: 64.836
- type: map_at_100
value: 65.771
- type: map_at_1000
value: 65.8
- type: map_at_20
value: 65.497
- type: map_at_3
value: 59.692
- type: map_at_5
value: 63.105
- type: mrr_at_1
value: 62.23404255319149
- type: mrr_at_10
value: 73.40810161732159
- type: mrr_at_100
value: 73.67949305473395
- type: mrr_at_1000
value: 73.68707852294746
- type: mrr_at_20
value: 73.60429051697479
- type: mrr_at_3
value: 71.47360126083535
- type: mrr_at_5
value: 72.8447596532704
- type: nauc_map_at_1000_diff1
value: 39.838449035736886
- type: nauc_map_at_1000_max
value: 32.29962306877408
- type: nauc_map_at_1000_std
value: -6.324859592714388
- type: nauc_map_at_100_diff1
value: 39.824361938745426
- type: nauc_map_at_100_max
value: 32.32055222704763
- type: nauc_map_at_100_std
value: -6.301641111869559
- type: nauc_map_at_10_diff1
value: 39.50155328718487
- type: nauc_map_at_10_max
value: 31.745730244960672
- type: nauc_map_at_10_std
value: -6.867215137329693
- type: nauc_map_at_1_diff1
value: 47.66181128677822
- type: nauc_map_at_1_max
value: 21.75204233166764
- type: nauc_map_at_1_std
value: -8.06951079061697
- type: nauc_map_at_20_diff1
value: 39.78364637902108
- type: nauc_map_at_20_max
value: 32.39065528029405
- type: nauc_map_at_20_std
value: -6.368994332729006
- type: nauc_map_at_3_diff1
value: 39.51829474433183
- type: nauc_map_at_3_max
value: 28.633292697821673
- type: nauc_map_at_3_std
value: -7.2561170814963925
- type: nauc_map_at_5_diff1
value: 39.288433237676266
- type: nauc_map_at_5_max
value: 31.007702201615515
- type: nauc_map_at_5_std
value: -7.235131195162474
- type: nauc_mrr_at_1000_diff1
value: 49.599102391215226
- type: nauc_mrr_at_1000_max
value: 38.25521825911133
- type: nauc_mrr_at_1000_std
value: -10.448180939809435
- type: nauc_mrr_at_100_diff1
value: 49.5957067716212
- type: nauc_mrr_at_100_max
value: 38.26760703964535
- type: nauc_mrr_at_100_std
value: -10.438443051971081
- type: nauc_mrr_at_10_diff1
value: 49.35269710190271
- type: nauc_mrr_at_10_max
value: 38.43782589127069
- type: nauc_mrr_at_10_std
value: -10.404402063509815
- type: nauc_mrr_at_1_diff1
value: 53.32206103688421
- type: nauc_mrr_at_1_max
value: 33.52402390241035
- type: nauc_mrr_at_1_std
value: -12.73473393949936
- type: nauc_mrr_at_20_diff1
value: 49.550630850826636
- type: nauc_mrr_at_20_max
value: 38.35964703941151
- type: nauc_mrr_at_20_std
value: -10.444577766284766
- type: nauc_mrr_at_3_diff1
value: 49.12029127633829
- type: nauc_mrr_at_3_max
value: 38.01631275124067
- type: nauc_mrr_at_3_std
value: -10.523724301481309
- type: nauc_mrr_at_5_diff1
value: 49.04606949432458
- type: nauc_mrr_at_5_max
value: 38.33647550077891
- type: nauc_mrr_at_5_std
value: -10.47076409263114
- type: nauc_ndcg_at_1000_diff1
value: 41.342785916264226
- type: nauc_ndcg_at_1000_max
value: 35.75731064862711
- type: nauc_ndcg_at_1000_std
value: -5.45573422899229
- type: nauc_ndcg_at_100_diff1
value: 40.972974559636086
- type: nauc_ndcg_at_100_max
value: 36.32938573321036
- type: nauc_ndcg_at_100_std
value: -4.749631537590004
- type: nauc_ndcg_at_10_diff1
value: 39.67813474464166
- type: nauc_ndcg_at_10_max
value: 35.480200504848966
- type: nauc_ndcg_at_10_std
value: -6.318561293935512
- type: nauc_ndcg_at_1_diff1
value: 53.45970160222764
- type: nauc_ndcg_at_1_max
value: 33.14759013278075
- type: nauc_ndcg_at_1_std
value: -12.579833891774847
- type: nauc_ndcg_at_20_diff1
value: 40.67492861219249
- type: nauc_ndcg_at_20_max
value: 36.84960799838019
- type: nauc_ndcg_at_20_std
value: -5.202530835850179
- type: nauc_ndcg_at_3_diff1
value: 39.574906207408844
- type: nauc_ndcg_at_3_max
value: 31.76512164509258
- type: nauc_ndcg_at_3_std
value: -7.656143208565999
- type: nauc_ndcg_at_5_diff1
value: 39.096348529742095
- type: nauc_ndcg_at_5_max
value: 34.075926475544165
- type: nauc_ndcg_at_5_std
value: -7.238045445366631
- type: nauc_precision_at_1000_diff1
value: -14.283799754212609
- type: nauc_precision_at_1000_max
value: 6.449741756717101
- type: nauc_precision_at_1000_std
value: 4.862828679759048
- type: nauc_precision_at_100_diff1
value: -13.23173132700258
- type: nauc_precision_at_100_max
value: 11.058898534529195
- type: nauc_precision_at_100_std
value: 7.343683941814956
- type: nauc_precision_at_10_diff1
value: -7.202951643546464
- type: nauc_precision_at_10_max
value: 17.499446869433278
- type: nauc_precision_at_10_std
value: 2.8367985220406307
- type: nauc_precision_at_1_diff1
value: 53.45970160222764
- type: nauc_precision_at_1_max
value: 33.14759013278075
- type: nauc_precision_at_1_std
value: -12.579833891774847
- type: nauc_precision_at_20_diff1
value: -9.477122699154124
- type: nauc_precision_at_20_max
value: 16.80556031564312
- type: nauc_precision_at_20_std
value: 6.420218284416923
- type: nauc_precision_at_3_diff1
value: 5.5276143574150245
- type: nauc_precision_at_3_max
value: 23.65952688481666
- type: nauc_precision_at_3_std
value: -1.8730348729295785
- type: nauc_precision_at_5_diff1
value: -2.4537029093721308
- type: nauc_precision_at_5_max
value: 21.41469327545133
- type: nauc_precision_at_5_std
value: 0.1543890645722277
- type: nauc_recall_at_1000_diff1
value: -1.7474947956413491
- type: nauc_recall_at_1000_max
value: 46.22670991970479
- type: nauc_recall_at_1000_std
value: 62.582840705588794
- type: nauc_recall_at_100_diff1
value: 16.116089801097345
- type: nauc_recall_at_100_max
value: 52.54794580975103
- type: nauc_recall_at_100_std
value: 33.720245696003246
- type: nauc_recall_at_10_diff1
value: 23.134924318655482
- type: nauc_recall_at_10_max
value: 38.73754275649077
- type: nauc_recall_at_10_std
value: 0.6137471711639239
- type: nauc_recall_at_1_diff1
value: 47.66181128677822
- type: nauc_recall_at_1_max
value: 21.75204233166764
- type: nauc_recall_at_1_std
value: -8.06951079061697
- type: nauc_recall_at_20_diff1
value: 24.130616271355017
- type: nauc_recall_at_20_max
value: 48.306178640146136
- type: nauc_recall_at_20_std
value: 9.290819557000022
- type: nauc_recall_at_3_diff1
value: 29.767415016250226
- type: nauc_recall_at_3_max
value: 28.54289782140701
- type: nauc_recall_at_3_std
value: -5.1395675072005576
- type: nauc_recall_at_5_diff1
value: 25.410613126870174
- type: nauc_recall_at_5_max
value: 33.24658754857624
- type: nauc_recall_at_5_std
value: -4.211226036746632
- type: ndcg_at_1
value: 62.175000000000004
- type: ndcg_at_10
value: 72.306
- type: ndcg_at_100
value: 75.074
- type: ndcg_at_1000
value: 75.581
- type: ndcg_at_20
value: 73.875
- type: ndcg_at_3
value: 65.641
- type: ndcg_at_5
value: 69.48299999999999
- type: precision_at_1
value: 62.175000000000004
- type: precision_at_10
value: 13.907
- type: precision_at_100
value: 1.591
- type: precision_at_1000
value: 0.166
- type: precision_at_20
value: 7.446999999999999
- type: precision_at_3
value: 35.619
- type: precision_at_5
value: 24.917
- type: recall_at_1
value: 44.187
- type: recall_at_10
value: 85.10600000000001
- type: recall_at_100
value: 95.488
- type: recall_at_1000
value: 98.831
- type: recall_at_20
value: 90.22200000000001
- type: recall_at_3
value: 68.789
- type: recall_at_5
value: 77.85499999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB RuReviewsClassification (default)
revision: f6d2c31f4dc6b88f468552750bfec05b4b41b05a
split: test
type: ai-forever/ru-reviews-classification
metrics:
- type: accuracy
value: 67.5830078125
- type: f1
value: 67.56931936632446
- type: f1_weighted
value: 67.57137733752779
- type: main_score
value: 67.5830078125
task:
type: Classification
- dataset:
config: default
name: MTEB RuSTSBenchmarkSTS (default)
revision: 7cf24f325c6da6195df55bef3d86b5e0616f3018
split: test
type: ai-forever/ru-stsbenchmark-sts
metrics:
- type: cosine_pearson
value: 85.90493484626788
- type: cosine_spearman
value: 86.21965691667411
- type: euclidean_pearson
value: 86.07499842984909
- type: euclidean_spearman
value: 86.55506818735688
- type: main_score
value: 86.21965691667411
- type: manhattan_pearson
value: 85.95976420231729
- type: manhattan_spearman
value: 86.48604243661234
- type: pearson
value: 85.90493484626788
- type: spearman
value: 86.21965691667411
task:
type: STS
- dataset:
config: default
name: MTEB RuSciBenchGRNTIClassification (default)
revision: 673a610d6d3dd91a547a0d57ae1b56f37ebbf6a1
split: test
type: ai-forever/ru-scibench-grnti-classification
metrics:
- type: accuracy
value: 59.1943359375
- type: f1
value: 58.894480861440414
- type: f1_weighted
value: 58.903615560240866
- type: main_score
value: 59.1943359375
task:
type: Classification
- dataset:
config: default
name: MTEB RuSciBenchGRNTIClusteringP2P (default)
revision: 673a610d6d3dd91a547a0d57ae1b56f37ebbf6a1
split: test
type: ai-forever/ru-scibench-grnti-classification
metrics:
- type: main_score
value: 57.99209448663228
- type: v_measure
value: 57.99209448663228
- type: v_measure_std
value: 1.0381163861993816
task:
type: Clustering
- dataset:
config: default
name: MTEB RuSciBenchOECDClassification (default)
revision: 26c88e99dcaba32bb45d0e1bfc21902337f6d471
split: test
type: ai-forever/ru-scibench-oecd-classification
metrics:
- type: accuracy
value: 45.556640625
- type: f1
value: 45.159163104085906
- type: f1_weighted
value: 45.16098316398626
- type: main_score
value: 45.556640625
task:
type: Classification
- dataset:
config: default
name: MTEB RuSciBenchOECDClusteringP2P (default)
revision: 26c88e99dcaba32bb45d0e1bfc21902337f6d471
split: test
type: ai-forever/ru-scibench-oecd-classification
metrics:
- type: main_score
value: 50.787548070488974
- type: v_measure
value: 50.787548070488974
- type: v_measure_std
value: 0.8569958168946827
task:
type: Clustering
- dataset:
config: default
name: MTEB SCIDOCS (default)
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
split: test
type: mteb/scidocs
metrics:
- type: map_at_1
value: 4.843
- type: map_at_10
value: 11.752
- type: map_at_100
value: 13.919
- type: map_at_1000
value: 14.198
- type: map_at_20
value: 12.898000000000001
- type: map_at_3
value: 8.603
- type: map_at_5
value: 10.069
- type: mrr_at_1
value: 23.799999999999997
- type: mrr_at_10
value: 34.449999999999996
- type: mrr_at_100
value: 35.64
- type: mrr_at_1000
value: 35.691
- type: mrr_at_20
value: 35.213
- type: mrr_at_3
value: 31.383
- type: mrr_at_5
value: 33.062999999999995
- type: ndcg_at_1
value: 23.799999999999997
- type: ndcg_at_10
value: 19.811
- type: ndcg_at_100
value: 28.108
- type: ndcg_at_1000
value: 33.1
- type: ndcg_at_20
value: 22.980999999999998
- type: ndcg_at_3
value: 19.153000000000002
- type: ndcg_at_5
value: 16.408
- type: precision_at_1
value: 23.799999999999997
- type: precision_at_10
value: 10.16
- type: precision_at_100
value: 2.1999999999999997
- type: precision_at_1000
value: 0.34099999999999997
- type: precision_at_20
value: 6.915
- type: precision_at_3
value: 17.8
- type: precision_at_5
value: 14.14
- type: recall_at_1
value: 4.843
- type: recall_at_10
value: 20.595
- type: recall_at_100
value: 44.66
- type: recall_at_1000
value: 69.152
- type: recall_at_20
value: 28.04
- type: recall_at_3
value: 10.833
- type: recall_at_5
value: 14.346999999999998
- type: main_score
value: 19.811
task:
type: Retrieval
- dataset:
config: default
name: MTEB SICK-E-PL (default)
revision: 71bba34b0ece6c56dfcf46d9758a27f7a90f17e9
split: test
type: PL-MTEB/sicke-pl-pairclassification
metrics:
- type: cosine_accuracy
value: 80.90093762739502
- type: cosine_accuracy_threshold
value: 94.40930485725403
- type: cosine_ap
value: 71.15400909912427
- type: cosine_f1
value: 66.8213457076566
- type: cosine_f1_threshold
value: 91.53673648834229
- type: cosine_precision
value: 62.4922504649721
- type: cosine_recall
value: 71.7948717948718
- type: dot_accuracy
value: 78.41418671015083
- type: dot_accuracy_threshold
value: 42924.45068359375
- type: dot_ap
value: 63.34003025365763
- type: dot_f1
value: 62.518258837277244
- type: dot_f1_threshold
value: 40900.738525390625
- type: dot_precision
value: 52.99653293709758
- type: dot_recall
value: 76.21082621082621
- type: euclidean_accuracy
value: 80.67672238075826
- type: euclidean_accuracy_threshold
value: 696.0524559020996
- type: euclidean_ap
value: 70.88762835990224
- type: euclidean_f1
value: 66.711051930759
- type: euclidean_f1_threshold
value: 878.5581588745117
- type: euclidean_precision
value: 62.625
- type: euclidean_recall
value: 71.36752136752136
- type: main_score
value: 71.15400909912427
- type: manhattan_accuracy
value: 80.65633917651854
- type: manhattan_accuracy_threshold
value: 17277.72674560547
- type: manhattan_ap
value: 70.67105336611716
- type: manhattan_f1
value: 66.51346027577151
- type: manhattan_f1_threshold
value: 21687.957763671875
- type: manhattan_precision
value: 61.69305724725944
- type: manhattan_recall
value: 72.15099715099716
- type: max_accuracy
value: 80.90093762739502
- type: max_ap
value: 71.15400909912427
- type: max_f1
value: 66.8213457076566
- type: max_precision
value: 62.625
- type: max_recall
value: 76.21082621082621
- type: similarity_accuracy
value: 80.90093762739502
- type: similarity_accuracy_threshold
value: 94.40930485725403
- type: similarity_ap
value: 71.15400909912427
- type: similarity_f1
value: 66.8213457076566
- type: similarity_f1_threshold
value: 91.53673648834229
- type: similarity_precision
value: 62.4922504649721
- type: similarity_recall
value: 71.7948717948718
task:
type: PairClassification
- dataset:
config: default
name: MTEB SICK-R (default)
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
split: test
type: mteb/sickr-sts
metrics:
- type: cosine_pearson
value: 92.3339946866199
- type: cosine_spearman
value: 89.61697355115497
- type: euclidean_pearson
value: 90.3264916449669
- type: euclidean_spearman
value: 89.36270451308866
- type: main_score
value: 89.61697355115497
- type: manhattan_pearson
value: 90.18909339052534
- type: manhattan_spearman
value: 89.28337093097377
- type: pearson
value: 92.3339946866199
- type: spearman
value: 89.61697355115497
task:
type: STS
- dataset:
config: default
name: MTEB SICK-R-PL (default)
revision: fd5c2441b7eeff8676768036142af4cfa42c1339
split: test
type: PL-MTEB/sickr-pl-sts
metrics:
- type: cosine_pearson
value: 85.27883048457821
- type: cosine_spearman
value: 80.53204892678619
- type: euclidean_pearson
value: 82.78520705216168
- type: euclidean_spearman
value: 80.27848359873212
- type: main_score
value: 80.53204892678619
- type: manhattan_pearson
value: 82.63270640583454
- type: manhattan_spearman
value: 80.21507977473146
- type: pearson
value: 85.27883048457821
- type: spearman
value: 80.53204892678619
task:
type: STS
- dataset:
config: default
name: MTEB SICKFr (default)
revision: e077ab4cf4774a1e36d86d593b150422fafd8e8a
split: test
type: Lajavaness/SICK-fr
metrics:
- type: cosine_pearson
value: 88.77029361817212
- type: cosine_spearman
value: 83.9453600346894
- type: euclidean_pearson
value: 85.85331086208573
- type: euclidean_spearman
value: 83.70852031985308
- type: main_score
value: 83.9453600346894
- type: manhattan_pearson
value: 85.66222265885914
- type: manhattan_spearman
value: 83.60833111525962
- type: pearson
value: 88.77029361817212
- type: spearman
value: 83.9453600346894
task:
type: STS
- dataset:
config: default
name: MTEB STS12 (default)
revision: a0d554a64d88156834ff5ae9920b964011b16384
split: test
type: mteb/sts12-sts
metrics:
- type: cosine_pearson
value: 88.76435859522375
- type: cosine_spearman
value: 82.43768167804375
- type: euclidean_pearson
value: 87.43566183874832
- type: euclidean_spearman
value: 82.82166873757507
- type: main_score
value: 82.43768167804375
- type: manhattan_pearson
value: 87.39450871380951
- type: manhattan_spearman
value: 82.89253043430163
- type: pearson
value: 88.76435859522375
- type: spearman
value: 82.43768167804375
task:
type: STS
- dataset:
config: default
name: MTEB STS13 (default)
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
split: test
type: mteb/sts13-sts
metrics:
- type: cosine_pearson
value: 88.86627241652141
- type: cosine_spearman
value: 89.49011599120688
- type: euclidean_pearson
value: 89.3314120073772
- type: euclidean_spearman
value: 89.8226502776963
- type: main_score
value: 89.49011599120688
- type: manhattan_pearson
value: 89.2252179076963
- type: manhattan_spearman
value: 89.74573844021225
- type: pearson
value: 88.86627241652141
- type: spearman
value: 89.49011599120688
task:
type: STS
- dataset:
config: default
name: MTEB STS14 (default)
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
split: test
type: mteb/sts14-sts
metrics:
- type: cosine_pearson
value: 87.22891405215968
- type: cosine_spearman
value: 84.9467188157614
- type: euclidean_pearson
value: 87.20330004726237
- type: euclidean_spearman
value: 85.34806059461808
- type: main_score
value: 84.9467188157614
- type: manhattan_pearson
value: 87.15224666107623
- type: manhattan_spearman
value: 85.34596898699708
- type: pearson
value: 87.22891405215968
- type: spearman
value: 84.9467188157614
task:
type: STS
- dataset:
config: default
name: MTEB STS15 (default)
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
split: test
type: mteb/sts15-sts
metrics:
- type: cosine_pearson
value: 88.14066430111033
- type: cosine_spearman
value: 89.31337445552545
- type: euclidean_pearson
value: 89.08039335366983
- type: euclidean_spearman
value: 89.6658762856415
- type: main_score
value: 89.31337445552545
- type: manhattan_pearson
value: 89.08057438154486
- type: manhattan_spearman
value: 89.68673984203022
- type: pearson
value: 88.14066430111033
- type: spearman
value: 89.31337445552545
task:
type: STS
- dataset:
config: default
name: MTEB STS16 (default)
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
split: test
type: mteb/sts16-sts
metrics:
- type: cosine_pearson
value: 85.14908856657084
- type: cosine_spearman
value: 86.84648320786727
- type: euclidean_pearson
value: 86.11454713131947
- type: euclidean_spearman
value: 86.77738862047961
- type: main_score
value: 86.84648320786727
- type: manhattan_pearson
value: 86.07804821916372
- type: manhattan_spearman
value: 86.78676064310474
- type: pearson
value: 85.14908856657084
- type: spearman
value: 86.84648320786727
task:
type: STS
- dataset:
config: en-en
name: MTEB STS17 (en-en)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cosine_pearson
value: 89.61633502468356
- type: cosine_spearman
value: 89.99772663224805
- type: euclidean_pearson
value: 90.14056501501044
- type: euclidean_spearman
value: 90.04496896837503
- type: main_score
value: 89.99772663224805
- type: manhattan_pearson
value: 90.08964860311801
- type: manhattan_spearman
value: 90.00091712362196
- type: pearson
value: 89.61633502468356
- type: spearman
value: 89.99772663224805
task:
type: STS
- dataset:
config: es-en
name: MTEB STS17 (es-en)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cosine_pearson
value: 86.44548026840202
- type: cosine_spearman
value: 87.26263108768539
- type: euclidean_pearson
value: 86.42844593583838
- type: euclidean_spearman
value: 86.89388428664364
- type: main_score
value: 87.26263108768539
- type: manhattan_pearson
value: 86.47186940800881
- type: manhattan_spearman
value: 87.02163091089946
- type: pearson
value: 86.44548026840202
- type: spearman
value: 87.26263108768539
task:
type: STS
- dataset:
config: en-de
name: MTEB STS17 (en-de)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cosine_pearson
value: 87.89345132532758
- type: cosine_spearman
value: 87.96246221327699
- type: euclidean_pearson
value: 88.49013032701419
- type: euclidean_spearman
value: 87.81981265317344
- type: main_score
value: 87.96246221327699
- type: manhattan_pearson
value: 88.31360914178538
- type: manhattan_spearman
value: 87.62734530005075
- type: pearson
value: 87.89345132532758
- type: spearman
value: 87.96246221327699
task:
type: STS
- dataset:
config: es-es
name: MTEB STS17 (es-es)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cosine_pearson
value: 88.4084678497171
- type: cosine_spearman
value: 88.77640638748285
- type: euclidean_pearson
value: 89.60124312475843
- type: euclidean_spearman
value: 88.4321442688528
- type: main_score
value: 88.77640638748285
- type: manhattan_pearson
value: 89.62375118021299
- type: manhattan_spearman
value: 88.46998118661577
- type: pearson
value: 88.4084678497171
- type: spearman
value: 88.77640638748285
task:
type: STS
- dataset:
config: fr-en
name: MTEB STS17 (fr-en)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cosine_pearson
value: 87.30688801326498
- type: cosine_spearman
value: 87.55684697258378
- type: euclidean_pearson
value: 87.89672951056794
- type: euclidean_spearman
value: 87.28050429201674
- type: main_score
value: 87.55684697258378
- type: manhattan_pearson
value: 87.74292745320572
- type: manhattan_spearman
value: 87.16383993876582
- type: pearson
value: 87.30688801326498
- type: spearman
value: 87.55684697258378
task:
type: STS
- dataset:
config: zh-en
name: MTEB STS22 (zh-en)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 73.46180375170147
- type: cosine_spearman
value: 73.39559590127081
- type: euclidean_pearson
value: 73.72613901293681
- type: euclidean_spearman
value: 71.85465165176795
- type: main_score
value: 73.39559590127081
- type: manhattan_pearson
value: 73.07859140869076
- type: manhattan_spearman
value: 71.22047343718893
- type: pearson
value: 73.46180375170147
- type: spearman
value: 73.39559590127081
task:
type: STS
- dataset:
config: zh
name: MTEB STS22 (zh)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 62.47531620842637
- type: cosine_spearman
value: 66.22504667157702
- type: euclidean_pearson
value: 66.76201254783692
- type: euclidean_spearman
value: 66.86115760269463
- type: main_score
value: 66.22504667157702
- type: manhattan_pearson
value: 66.73847836793489
- type: manhattan_spearman
value: 66.7677116377695
- type: pearson
value: 62.47531620842637
- type: spearman
value: 66.22504667157702
task:
type: STS
- dataset:
config: es
name: MTEB STS22 (es)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 69.89707002436481
- type: cosine_spearman
value: 72.2054865735116
- type: euclidean_pearson
value: 71.81856615570756
- type: euclidean_spearman
value: 72.72593304629407
- type: main_score
value: 72.2054865735116
- type: manhattan_pearson
value: 72.00362684700072
- type: manhattan_spearman
value: 72.62783534769964
- type: pearson
value: 69.89707002436481
- type: spearman
value: 72.2054865735116
task:
type: STS
- dataset:
config: fr
name: MTEB STS22 (fr)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 81.59623734395916
- type: cosine_spearman
value: 83.28946105111358
- type: euclidean_pearson
value: 79.377330171466
- type: euclidean_spearman
value: 81.81029781662205
- type: main_score
value: 83.28946105111358
- type: manhattan_pearson
value: 78.96970881689698
- type: manhattan_spearman
value: 81.91773236079703
- type: pearson
value: 81.59623734395916
- type: spearman
value: 83.28946105111358
task:
type: STS
- dataset:
config: de-fr
name: MTEB STS22 (de-fr)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 55.03825643126142
- type: cosine_spearman
value: 58.25792501780429
- type: euclidean_pearson
value: 50.38007603973409
- type: euclidean_spearman
value: 59.39961789383097
- type: main_score
value: 58.25792501780429
- type: manhattan_pearson
value: 50.518568927999155
- type: manhattan_spearman
value: 59.84185466003894
- type: pearson
value: 55.03825643126142
- type: spearman
value: 58.25792501780429
task:
type: STS
- dataset:
config: pl-en
name: MTEB STS22 (pl-en)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 77.77233721490776
- type: cosine_spearman
value: 76.17596588017625
- type: euclidean_pearson
value: 74.47600468156611
- type: euclidean_spearman
value: 72.61278728057012
- type: main_score
value: 76.17596588017625
- type: manhattan_pearson
value: 74.48118910099699
- type: manhattan_spearman
value: 73.33167419101696
- type: pearson
value: 77.77233721490776
- type: spearman
value: 76.17596588017625
task:
type: STS
- dataset:
config: pl
name: MTEB STS22 (pl)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 42.87453608131507
- type: cosine_spearman
value: 45.137849894401185
- type: euclidean_pearson
value: 31.66964197694796
- type: euclidean_spearman
value: 44.1014900837869
- type: main_score
value: 45.137849894401185
- type: manhattan_pearson
value: 31.007199259384745
- type: manhattan_spearman
value: 43.48181523288926
- type: pearson
value: 42.87453608131507
- type: spearman
value: 45.137849894401185
task:
type: STS
- dataset:
config: en
name: MTEB STS22 (en)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 66.87400150638176
- type: cosine_spearman
value: 67.27861354834066
- type: euclidean_pearson
value: 66.81789582140216
- type: euclidean_spearman
value: 66.44220479858708
- type: main_score
value: 67.27861354834066
- type: manhattan_pearson
value: 66.92509859033235
- type: manhattan_spearman
value: 66.46841124185076
- type: pearson
value: 66.87400150638176
- type: spearman
value: 67.27861354834066
task:
type: STS
- dataset:
config: ru
name: MTEB STS22 (ru)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 61.819804551576084
- type: cosine_spearman
value: 65.0864146772135
- type: euclidean_pearson
value: 62.518151090361876
- type: euclidean_spearman
value: 65.13608138548017
- type: main_score
value: 65.0864146772135
- type: manhattan_pearson
value: 62.51413246915267
- type: manhattan_spearman
value: 65.19077543064323
- type: pearson
value: 61.819804551576084
- type: spearman
value: 65.0864146772135
task:
type: STS
- dataset:
config: de
name: MTEB STS22 (de)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 54.85728696035389
- type: cosine_spearman
value: 61.60906359227576
- type: euclidean_pearson
value: 52.57582587901851
- type: euclidean_spearman
value: 61.41823097598308
- type: main_score
value: 61.60906359227576
- type: manhattan_pearson
value: 52.500978361080506
- type: manhattan_spearman
value: 61.30365596659758
- type: pearson
value: 54.85728696035389
- type: spearman
value: 61.60906359227576
task:
type: STS
- dataset:
config: fr-pl
name: MTEB STS22 (fr-pl)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 67.68016005631422
- type: cosine_spearman
value: 84.51542547285167
- type: euclidean_pearson
value: 66.19871164667245
- type: euclidean_spearman
value: 73.24670207647144
- type: main_score
value: 84.51542547285167
- type: manhattan_pearson
value: 67.0443525268974
- type: manhattan_spearman
value: 73.24670207647144
- type: pearson
value: 67.68016005631422
- type: spearman
value: 84.51542547285167
task:
type: STS
- dataset:
config: de-pl
name: MTEB STS22 (de-pl)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 47.49467414030747
- type: cosine_spearman
value: 56.81512095681289
- type: euclidean_pearson
value: 48.42860221765214
- type: euclidean_spearman
value: 58.63197306329092
- type: main_score
value: 56.81512095681289
- type: manhattan_pearson
value: 48.39594959260441
- type: manhattan_spearman
value: 58.63197306329092
- type: pearson
value: 47.49467414030747
- type: spearman
value: 56.81512095681289
task:
type: STS
- dataset:
config: es-en
name: MTEB STS22 (es-en)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 76.8364678896155
- type: cosine_spearman
value: 78.45516413087114
- type: euclidean_pearson
value: 78.62779318576634
- type: euclidean_spearman
value: 78.88760695649488
- type: main_score
value: 78.45516413087114
- type: manhattan_pearson
value: 78.62131335760031
- type: manhattan_spearman
value: 78.81861844200388
- type: pearson
value: 76.8364678896155
- type: spearman
value: 78.45516413087114
task:
type: STS
- dataset:
config: de-en
name: MTEB STS22 (de-en)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 65.16640313911604
- type: cosine_spearman
value: 60.887608967403914
- type: euclidean_pearson
value: 67.49902244990913
- type: euclidean_spearman
value: 59.2458787136538
- type: main_score
value: 60.887608967403914
- type: manhattan_pearson
value: 67.34313506388378
- type: manhattan_spearman
value: 59.05283429200166
- type: pearson
value: 65.16640313911604
- type: spearman
value: 60.887608967403914
task:
type: STS
- dataset:
config: default
name: MTEB STSB (default)
revision: 0cde68302b3541bb8b3c340dc0644b0b745b3dc0
split: test
type: C-MTEB/STSB
metrics:
- type: cosine_pearson
value: 81.5092853013241
- type: cosine_spearman
value: 83.54005474244292
- type: euclidean_pearson
value: 83.7246578378554
- type: euclidean_spearman
value: 84.46767551087716
- type: main_score
value: 83.54005474244292
- type: manhattan_pearson
value: 83.65922665594636
- type: manhattan_spearman
value: 84.42431449101848
- type: pearson
value: 81.5092853013241
- type: spearman
value: 83.54005474244292
task:
type: STS
- dataset:
config: default
name: MTEB STSBenchmark (default)
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
split: test
type: mteb/stsbenchmark-sts
metrics:
- type: cosine_pearson
value: 87.70246866744966
- type: cosine_spearman
value: 89.44070045346106
- type: euclidean_pearson
value: 89.56956519641007
- type: euclidean_spearman
value: 89.95830112784283
- type: main_score
value: 89.44070045346106
- type: manhattan_pearson
value: 89.48264471425145
- type: manhattan_spearman
value: 89.87900732483114
- type: pearson
value: 87.70246866744966
- type: spearman
value: 89.44070045346106
task:
type: STS
- dataset:
config: de
name: MTEB STSBenchmarkMultilingualSTS (de)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: test
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 86.83701990805217
- type: cosine_spearman
value: 87.80280785492258
- type: euclidean_pearson
value: 87.77325330043514
- type: euclidean_spearman
value: 88.3564607283144
- type: main_score
value: 87.80280785492258
- type: manhattan_pearson
value: 87.6745449945946
- type: manhattan_spearman
value: 88.30660465978795
- type: pearson
value: 86.83701990805217
- type: spearman
value: 87.80280785492258
task:
type: STS
- dataset:
config: zh
name: MTEB STSBenchmarkMultilingualSTS (zh)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: test
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 84.27751020600267
- type: cosine_spearman
value: 85.63500407412486
- type: euclidean_pearson
value: 85.21829891649696
- type: euclidean_spearman
value: 85.9384575715382
- type: main_score
value: 85.63500407412486
- type: manhattan_pearson
value: 85.10797194089801
- type: manhattan_spearman
value: 85.8770162042784
- type: pearson
value: 84.27751020600267
- type: spearman
value: 85.63500407412486
task:
type: STS
- dataset:
config: fr
name: MTEB STSBenchmarkMultilingualSTS (fr)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: test
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 86.56833656723254
- type: cosine_spearman
value: 87.4393978501382
- type: euclidean_pearson
value: 87.45171512751267
- type: euclidean_spearman
value: 88.13106516566947
- type: main_score
value: 87.4393978501382
- type: manhattan_pearson
value: 87.33010961793333
- type: manhattan_spearman
value: 88.06707425102182
- type: pearson
value: 86.56833656723254
- type: spearman
value: 87.4393978501382
task:
type: STS
- dataset:
config: pl
name: MTEB STSBenchmarkMultilingualSTS (pl)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: test
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 85.45065540325523
- type: cosine_spearman
value: 85.47881076789359
- type: euclidean_pearson
value: 85.1999493863155
- type: euclidean_spearman
value: 85.7874947669187
- type: main_score
value: 85.47881076789359
- type: manhattan_pearson
value: 85.06075305990376
- type: manhattan_spearman
value: 85.71563015639558
- type: pearson
value: 85.45065540325523
- type: spearman
value: 85.47881076789359
task:
type: STS
- dataset:
config: es
name: MTEB STSBenchmarkMultilingualSTS (es)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: test
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 87.11952824079832
- type: cosine_spearman
value: 87.9643473573153
- type: euclidean_pearson
value: 88.11750364639971
- type: euclidean_spearman
value: 88.63695109016498
- type: main_score
value: 87.9643473573153
- type: manhattan_pearson
value: 88.00294453126699
- type: manhattan_spearman
value: 88.53750241758391
- type: pearson
value: 87.11952824079832
- type: spearman
value: 87.9643473573153
task:
type: STS
- dataset:
config: ru
name: MTEB STSBenchmarkMultilingualSTS (ru)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: test
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 85.99804354414991
- type: cosine_spearman
value: 86.30252111551002
- type: euclidean_pearson
value: 86.1880652037762
- type: euclidean_spearman
value: 86.69556223944502
- type: main_score
value: 86.30252111551002
- type: manhattan_pearson
value: 86.0736400320898
- type: manhattan_spearman
value: 86.61747927593393
- type: pearson
value: 85.99804354414991
- type: spearman
value: 86.30252111551002
task:
type: STS
- dataset:
config: en
name: MTEB STSBenchmarkMultilingualSTS (en)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: test
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 87.70246861738103
- type: cosine_spearman
value: 89.44070045346106
- type: euclidean_pearson
value: 89.56956518833663
- type: euclidean_spearman
value: 89.95830112784283
- type: main_score
value: 89.44070045346106
- type: manhattan_pearson
value: 89.48264470792915
- type: manhattan_spearman
value: 89.87900732483114
- type: pearson
value: 87.70246861738103
- type: spearman
value: 89.44070045346106
task:
type: STS
- dataset:
config: default
name: MTEB SciDocsRR (default)
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
split: test
type: mteb/scidocs-reranking
metrics:
- type: map
value: 84.88064122814694
- type: mrr
value: 95.84832651009123
- type: main_score
value: 84.88064122814694
task:
type: Reranking
- dataset:
config: default
name: MTEB SciFact (default)
revision: 0228b52cf27578f30900b9e5271d331663a030d7
split: test
type: mteb/scifact
metrics:
- type: map_at_1
value: 57.289
- type: map_at_10
value: 67.88499999999999
- type: map_at_100
value: 68.477
- type: map_at_1000
value: 68.50500000000001
- type: map_at_20
value: 68.33500000000001
- type: map_at_3
value: 65.08
- type: map_at_5
value: 67.001
- type: mrr_at_1
value: 59.667
- type: mrr_at_10
value: 68.626
- type: mrr_at_100
value: 69.082
- type: mrr_at_1000
value: 69.108
- type: mrr_at_20
value: 68.958
- type: mrr_at_3
value: 66.667
- type: mrr_at_5
value: 67.983
- type: ndcg_at_1
value: 59.667
- type: ndcg_at_10
value: 72.309
- type: ndcg_at_100
value: 74.58399999999999
- type: ndcg_at_1000
value: 75.25500000000001
- type: ndcg_at_20
value: 73.656
- type: ndcg_at_3
value: 67.791
- type: ndcg_at_5
value: 70.45
- type: precision_at_1
value: 59.667
- type: precision_at_10
value: 9.567
- type: precision_at_100
value: 1.073
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_20
value: 5.083
- type: precision_at_3
value: 26.333000000000002
- type: precision_at_5
value: 17.666999999999998
- type: recall_at_1
value: 57.289
- type: recall_at_10
value: 84.756
- type: recall_at_100
value: 94.5
- type: recall_at_1000
value: 99.667
- type: recall_at_20
value: 89.7
- type: recall_at_3
value: 73.22800000000001
- type: recall_at_5
value: 79.444
- type: main_score
value: 72.309
task:
type: Retrieval
- dataset:
config: default
name: MTEB SpanishNewsClusteringP2P (default)
revision: bf8ca8ddc5b7da4f7004720ddf99bbe0483480e6
split: test
type: jinaai/spanish_news_clustering
metrics:
- type: main_score
value: 45.04477709795154
- type: v_measure
value: 45.04477709795154
- type: v_measure_std
value: 0.0
task:
type: Clustering
- dataset:
config: default
name: MTEB SpanishPassageRetrievalS2S (default)
revision: 9cddf2ce5209ade52c2115ccfa00eb22c6d3a837
split: test
type: jinaai/spanish_passage_retrieval
metrics:
- type: main_score
value: 69.83
- type: map_at_1
value: 15.736
- type: map_at_10
value: 52.027
- type: map_at_100
value: 65.08800000000001
- type: map_at_1000
value: 65.08800000000001
- type: map_at_20
value: 60.79900000000001
- type: map_at_3
value: 32.869
- type: map_at_5
value: 41.436
- type: mrr_at_1
value: 75.44910179640718
- type: mrr_at_10
value: 84.43446440452426
- type: mrr_at_100
value: 84.48052612723271
- type: mrr_at_1000
value: 84.48052612723271
- type: mrr_at_20
value: 84.48052612723271
- type: mrr_at_3
value: 83.13373253493013
- type: mrr_at_5
value: 84.3013972055888
- type: nauc_map_at_1000_diff1
value: 50.611540149694356
- type: nauc_map_at_1000_max
value: 2.1102430434260238
- type: nauc_map_at_1000_std
value: -18.88993521335793
- type: nauc_map_at_100_diff1
value: 50.611540149694356
- type: nauc_map_at_100_max
value: 2.1102430434260238
- type: nauc_map_at_100_std
value: -18.88993521335793
- type: nauc_map_at_10_diff1
value: 59.13518981755268
- type: nauc_map_at_10_max
value: -9.810386627392807
- type: nauc_map_at_10_std
value: -38.31810152345078
- type: nauc_map_at_1_diff1
value: 74.96782567287174
- type: nauc_map_at_1_max
value: -29.648279252607875
- type: nauc_map_at_1_std
value: -54.017459339141595
- type: nauc_map_at_20_diff1
value: 55.26694458629849
- type: nauc_map_at_20_max
value: -1.9490244535020729
- type: nauc_map_at_20_std
value: -25.22211659104076
- type: nauc_map_at_3_diff1
value: 71.67607885031732
- type: nauc_map_at_3_max
value: -25.078101661694507
- type: nauc_map_at_3_std
value: -50.55408861920259
- type: nauc_map_at_5_diff1
value: 61.50111515417668
- type: nauc_map_at_5_max
value: -16.4114670513168
- type: nauc_map_at_5_std
value: -44.391416134859135
- type: nauc_mrr_at_1000_diff1
value: 74.18848063283234
- type: nauc_mrr_at_1000_max
value: 21.929205946778005
- type: nauc_mrr_at_1000_std
value: -36.27399268489433
- type: nauc_mrr_at_100_diff1
value: 74.18848063283234
- type: nauc_mrr_at_100_max
value: 21.929205946778005
- type: nauc_mrr_at_100_std
value: -36.27399268489433
- type: nauc_mrr_at_10_diff1
value: 74.27231582268745
- type: nauc_mrr_at_10_max
value: 21.481133301135337
- type: nauc_mrr_at_10_std
value: -36.72070854872902
- type: nauc_mrr_at_1_diff1
value: 76.54855950439561
- type: nauc_mrr_at_1_max
value: 26.99938321212366
- type: nauc_mrr_at_1_std
value: -33.098742603429635
- type: nauc_mrr_at_20_diff1
value: 74.18848063283234
- type: nauc_mrr_at_20_max
value: 21.929205946778005
- type: nauc_mrr_at_20_std
value: -36.27399268489433
- type: nauc_mrr_at_3_diff1
value: 72.05379526740143
- type: nauc_mrr_at_3_max
value: 18.875831185752528
- type: nauc_mrr_at_3_std
value: -37.27302006456391
- type: nauc_mrr_at_5_diff1
value: 74.25342356682029
- type: nauc_mrr_at_5_max
value: 20.756340085088738
- type: nauc_mrr_at_5_std
value: -37.99507208540703
- type: nauc_ndcg_at_1000_diff1
value: 53.259363764380275
- type: nauc_ndcg_at_1000_max
value: 12.936954959423218
- type: nauc_ndcg_at_1000_std
value: -16.953898675672153
- type: nauc_ndcg_at_100_diff1
value: 53.259363764380275
- type: nauc_ndcg_at_100_max
value: 12.936954959423218
- type: nauc_ndcg_at_100_std
value: -16.953898675672153
- type: nauc_ndcg_at_10_diff1
value: 53.70942345413554
- type: nauc_ndcg_at_10_max
value: -3.8465093347016186
- type: nauc_ndcg_at_10_std
value: -31.208127919994755
- type: nauc_ndcg_at_1_diff1
value: 75.30551289259554
- type: nauc_ndcg_at_1_max
value: 25.53292054129834
- type: nauc_ndcg_at_1_std
value: -33.285498788395145
- type: nauc_ndcg_at_20_diff1
value: 57.62409278278133
- type: nauc_ndcg_at_20_max
value: 2.8040586426056233
- type: nauc_ndcg_at_20_std
value: -26.270875776221704
- type: nauc_ndcg_at_3_diff1
value: 48.42294834754225
- type: nauc_ndcg_at_3_max
value: 16.912467881065822
- type: nauc_ndcg_at_3_std
value: -13.324841189277873
- type: nauc_ndcg_at_5_diff1
value: 47.512819802794596
- type: nauc_ndcg_at_5_max
value: 14.645518203506594
- type: nauc_ndcg_at_5_std
value: -17.641450435599275
- type: nauc_precision_at_1000_diff1
value: -34.43320975829637
- type: nauc_precision_at_1000_max
value: 29.08585622578186
- type: nauc_precision_at_1000_std
value: 46.55117940162061
- type: nauc_precision_at_100_diff1
value: -34.433209758296364
- type: nauc_precision_at_100_max
value: 29.085856225781885
- type: nauc_precision_at_100_std
value: 46.55117940162065
- type: nauc_precision_at_10_diff1
value: -21.895306304096902
- type: nauc_precision_at_10_max
value: 33.190476527593745
- type: nauc_precision_at_10_std
value: 37.64916268614298
- type: nauc_precision_at_1_diff1
value: 75.30551289259554
- type: nauc_precision_at_1_max
value: 25.53292054129834
- type: nauc_precision_at_1_std
value: -33.285498788395145
- type: nauc_precision_at_20_diff1
value: -27.63076748060466
- type: nauc_precision_at_20_max
value: 30.689810416086154
- type: nauc_precision_at_20_std
value: 46.164191636131626
- type: nauc_precision_at_3_diff1
value: 20.547345067837288
- type: nauc_precision_at_3_max
value: 26.177050942827528
- type: nauc_precision_at_3_std
value: 5.960466052973099
- type: nauc_precision_at_5_diff1
value: -8.928755534002669
- type: nauc_precision_at_5_max
value: 40.83262650073459
- type: nauc_precision_at_5_std
value: 26.158537031161494
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: .nan
- type: nauc_recall_at_100_max
value: .nan
- type: nauc_recall_at_100_std
value: .nan
- type: nauc_recall_at_10_diff1
value: 53.08654386169444
- type: nauc_recall_at_10_max
value: -23.276269379519356
- type: nauc_recall_at_10_std
value: -50.80707792706157
- type: nauc_recall_at_1_diff1
value: 74.96782567287174
- type: nauc_recall_at_1_max
value: -29.648279252607875
- type: nauc_recall_at_1_std
value: -54.017459339141595
- type: nauc_recall_at_20_diff1
value: 51.60121897059633
- type: nauc_recall_at_20_max
value: -14.241779530735387
- type: nauc_recall_at_20_std
value: -37.877451525215456
- type: nauc_recall_at_3_diff1
value: 66.99474984329694
- type: nauc_recall_at_3_max
value: -30.802787353187966
- type: nauc_recall_at_3_std
value: -53.58737792129713
- type: nauc_recall_at_5_diff1
value: 54.64214444958567
- type: nauc_recall_at_5_max
value: -23.341309362104703
- type: nauc_recall_at_5_std
value: -51.381363923145265
- type: ndcg_at_1
value: 76.048
- type: ndcg_at_10
value: 69.83
- type: ndcg_at_100
value: 82.11500000000001
- type: ndcg_at_1000
value: 82.11500000000001
- type: ndcg_at_20
value: 75.995
- type: ndcg_at_3
value: 69.587
- type: ndcg_at_5
value: 69.062
- type: precision_at_1
value: 76.048
- type: precision_at_10
value: 43.653
- type: precision_at_100
value: 7.718999999999999
- type: precision_at_1000
value: 0.772
- type: precision_at_20
value: 31.108000000000004
- type: precision_at_3
value: 63.87199999999999
- type: precision_at_5
value: 56.407
- type: recall_at_1
value: 15.736
- type: recall_at_10
value: 66.873
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 85.01100000000001
- type: recall_at_3
value: 36.441
- type: recall_at_5
value: 49.109
task:
type: Retrieval
- dataset:
config: default
name: MTEB SprintDuplicateQuestions (default)
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
split: test
type: mteb/sprintduplicatequestions-pairclassification
metrics:
- type: cosine_accuracy
value: 99.87326732673267
- type: cosine_accuracy_threshold
value: 86.0752820968628
- type: cosine_ap
value: 96.98758090713252
- type: cosine_f1
value: 93.52881698685542
- type: cosine_f1_threshold
value: 86.0752820968628
- type: cosine_precision
value: 94.58077709611452
- type: cosine_recall
value: 92.5
- type: dot_accuracy
value: 99.82574257425742
- type: dot_accuracy_threshold
value: 40484.73815917969
- type: dot_ap
value: 95.68959907254845
- type: dot_f1
value: 91.31293188548865
- type: dot_f1_threshold
value: 40336.810302734375
- type: dot_precision
value: 90.15594541910332
- type: dot_recall
value: 92.5
- type: euclidean_accuracy
value: 99.87128712871286
- type: euclidean_accuracy_threshold
value: 1162.5749588012695
- type: euclidean_ap
value: 96.92640435656577
- type: euclidean_f1
value: 93.4475806451613
- type: euclidean_f1_threshold
value: 1162.5749588012695
- type: euclidean_precision
value: 94.20731707317073
- type: euclidean_recall
value: 92.7
- type: main_score
value: 96.98758090713252
- type: manhattan_accuracy
value: 99.86930693069307
- type: manhattan_accuracy_threshold
value: 28348.71826171875
- type: manhattan_ap
value: 96.93832673967925
- type: manhattan_f1
value: 93.33333333333333
- type: manhattan_f1_threshold
value: 28348.71826171875
- type: manhattan_precision
value: 94.28571428571428
- type: manhattan_recall
value: 92.4
- type: max_accuracy
value: 99.87326732673267
- type: max_ap
value: 96.98758090713252
- type: max_f1
value: 93.52881698685542
- type: max_precision
value: 94.58077709611452
- type: max_recall
value: 92.7
- type: similarity_accuracy
value: 99.87326732673267
- type: similarity_accuracy_threshold
value: 86.0752820968628
- type: similarity_ap
value: 96.98758090713252
- type: similarity_f1
value: 93.52881698685542
- type: similarity_f1_threshold
value: 86.0752820968628
- type: similarity_precision
value: 94.58077709611452
- type: similarity_recall
value: 92.5
task:
type: PairClassification
- dataset:
config: default
name: MTEB StackExchangeClustering (default)
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
split: test
type: mteb/stackexchange-clustering
metrics:
- type: main_score
value: 65.6560129719848
- type: v_measure
value: 65.6560129719848
- type: v_measure_std
value: 4.781229811487539
task:
type: Clustering
- dataset:
config: default
name: MTEB StackExchangeClusteringP2P (default)
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
split: test
type: mteb/stackexchange-clustering-p2p
metrics:
- type: main_score
value: 35.07546243853692
- type: v_measure
value: 35.07546243853692
- type: v_measure_std
value: 1.1978740356240998
task:
type: Clustering
- dataset:
config: default
name: MTEB StackOverflowDupQuestions (default)
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
split: test
type: mteb/stackoverflowdupquestions-reranking
metrics:
- type: map
value: 51.771005199508835
- type: mrr
value: 52.65443298531534
- type: main_score
value: 51.771005199508835
task:
type: Reranking
- dataset:
config: default
name: MTEB SummEval (default)
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
split: test
type: mteb/summeval
metrics:
- type: cosine_pearson
value: 29.48686238342228
- type: cosine_spearman
value: 29.706543509170054
- type: dot_pearson
value: 27.95853155597859
- type: dot_spearman
value: 27.604287986935162
- type: main_score
value: 29.706543509170054
- type: pearson
value: 29.48686238342228
- type: spearman
value: 29.706543509170054
task:
type: Summarization
- dataset:
config: default
name: MTEB SummEvalFr (default)
revision: b385812de6a9577b6f4d0f88c6a6e35395a94054
split: test
type: lyon-nlp/summarization-summeval-fr-p2p
metrics:
- type: cosine_pearson
value: 31.551301434917868
- type: cosine_spearman
value: 30.709049789175186
- type: dot_pearson
value: 27.77050901756549
- type: dot_spearman
value: 26.715505953561795
- type: main_score
value: 30.709049789175186
- type: pearson
value: 31.551301434917868
- type: spearman
value: 30.709049789175186
task:
type: Summarization
- dataset:
config: default
name: MTEB SyntecReranking (default)
revision: b205c5084a0934ce8af14338bf03feb19499c84d
split: test
type: lyon-nlp/mteb-fr-reranking-syntec-s2p
metrics:
- type: map
value: 73.31666666666666
- type: mrr
value: 73.31666666666666
- type: main_score
value: 73.31666666666666
task:
type: Reranking
- dataset:
config: default
name: MTEB SyntecRetrieval (default)
revision: 19661ccdca4dfc2d15122d776b61685f48c68ca9
split: test
type: lyon-nlp/mteb-fr-retrieval-syntec-s2p
metrics:
- type: main_score
value: 83.851
- type: map_at_1
value: 68.0
- type: map_at_10
value: 79.187
- type: map_at_100
value: 79.32900000000001
- type: map_at_1000
value: 79.32900000000001
- type: map_at_20
value: 79.32900000000001
- type: map_at_3
value: 77.333
- type: map_at_5
value: 78.93299999999999
- type: mrr_at_1
value: 68.0
- type: mrr_at_10
value: 79.18730158730159
- type: mrr_at_100
value: 79.32945845004669
- type: mrr_at_1000
value: 79.32945845004669
- type: mrr_at_20
value: 79.32945845004669
- type: mrr_at_3
value: 77.33333333333333
- type: mrr_at_5
value: 78.93333333333332
- type: nauc_map_at_1000_diff1
value: 63.31103256935259
- type: nauc_map_at_1000_max
value: 11.073749121365623
- type: nauc_map_at_1000_std
value: 7.4973309839738
- type: nauc_map_at_100_diff1
value: 63.31103256935259
- type: nauc_map_at_100_max
value: 11.073749121365623
- type: nauc_map_at_100_std
value: 7.4973309839738
- type: nauc_map_at_10_diff1
value: 62.91585737195978
- type: nauc_map_at_10_max
value: 11.770664508983133
- type: nauc_map_at_10_std
value: 8.179883948527962
- type: nauc_map_at_1_diff1
value: 66.1236265634718
- type: nauc_map_at_1_max
value: 7.000207311173955
- type: nauc_map_at_1_std
value: 6.54412272821497
- type: nauc_map_at_20_diff1
value: 63.31103256935259
- type: nauc_map_at_20_max
value: 11.073749121365623
- type: nauc_map_at_20_std
value: 7.4973309839738
- type: nauc_map_at_3_diff1
value: 62.14039574010254
- type: nauc_map_at_3_max
value: 11.06996398110187
- type: nauc_map_at_3_std
value: 7.288759297085769
- type: nauc_map_at_5_diff1
value: 63.0401271126211
- type: nauc_map_at_5_max
value: 10.779317801858609
- type: nauc_map_at_5_std
value: 6.476660484760681
- type: nauc_mrr_at_1000_diff1
value: 63.31103256935259
- type: nauc_mrr_at_1000_max
value: 11.073749121365623
- type: nauc_mrr_at_1000_std
value: 7.4973309839738
- type: nauc_mrr_at_100_diff1
value: 63.31103256935259
- type: nauc_mrr_at_100_max
value: 11.073749121365623
- type: nauc_mrr_at_100_std
value: 7.4973309839738
- type: nauc_mrr_at_10_diff1
value: 62.91585737195978
- type: nauc_mrr_at_10_max
value: 11.770664508983133
- type: nauc_mrr_at_10_std
value: 8.179883948527962
- type: nauc_mrr_at_1_diff1
value: 66.1236265634718
- type: nauc_mrr_at_1_max
value: 7.000207311173955
- type: nauc_mrr_at_1_std
value: 6.54412272821497
- type: nauc_mrr_at_20_diff1
value: 63.31103256935259
- type: nauc_mrr_at_20_max
value: 11.073749121365623
- type: nauc_mrr_at_20_std
value: 7.4973309839738
- type: nauc_mrr_at_3_diff1
value: 62.14039574010254
- type: nauc_mrr_at_3_max
value: 11.06996398110187
- type: nauc_mrr_at_3_std
value: 7.288759297085769
- type: nauc_mrr_at_5_diff1
value: 63.0401271126211
- type: nauc_mrr_at_5_max
value: 10.779317801858609
- type: nauc_mrr_at_5_std
value: 6.476660484760681
- type: nauc_ndcg_at_1000_diff1
value: 62.9544299483241
- type: nauc_ndcg_at_1000_max
value: 11.577079766964538
- type: nauc_ndcg_at_1000_std
value: 7.703856790100716
- type: nauc_ndcg_at_100_diff1
value: 62.9544299483241
- type: nauc_ndcg_at_100_max
value: 11.577079766964538
- type: nauc_ndcg_at_100_std
value: 7.703856790100716
- type: nauc_ndcg_at_10_diff1
value: 61.29907952217381
- type: nauc_ndcg_at_10_max
value: 14.760627422715425
- type: nauc_ndcg_at_10_std
value: 10.805573898143368
- type: nauc_ndcg_at_1_diff1
value: 66.1236265634718
- type: nauc_ndcg_at_1_max
value: 7.000207311173955
- type: nauc_ndcg_at_1_std
value: 6.54412272821497
- type: nauc_ndcg_at_20_diff1
value: 62.9544299483241
- type: nauc_ndcg_at_20_max
value: 11.577079766964538
- type: nauc_ndcg_at_20_std
value: 7.703856790100716
- type: nauc_ndcg_at_3_diff1
value: 60.25643527856101
- type: nauc_ndcg_at_3_max
value: 12.236302709487546
- type: nauc_ndcg_at_3_std
value: 7.36883189112067
- type: nauc_ndcg_at_5_diff1
value: 61.65220590318238
- type: nauc_ndcg_at_5_max
value: 11.39969101913945
- type: nauc_ndcg_at_5_std
value: 5.406207922379402
- type: nauc_precision_at_1000_diff1
value: .nan
- type: nauc_precision_at_1000_max
value: .nan
- type: nauc_precision_at_1000_std
value: .nan
- type: nauc_precision_at_100_diff1
value: .nan
- type: nauc_precision_at_100_max
value: .nan
- type: nauc_precision_at_100_std
value: .nan
- type: nauc_precision_at_10_diff1
value: 19.14098972922579
- type: nauc_precision_at_10_max
value: 100.0
- type: nauc_precision_at_10_std
value: 93.46405228758135
- type: nauc_precision_at_1_diff1
value: 66.1236265634718
- type: nauc_precision_at_1_max
value: 7.000207311173955
- type: nauc_precision_at_1_std
value: 6.54412272821497
- type: nauc_precision_at_20_diff1
value: 100.0
- type: nauc_precision_at_20_max
value: 100.0
- type: nauc_precision_at_20_std
value: 100.0
- type: nauc_precision_at_3_diff1
value: 50.29636629155561
- type: nauc_precision_at_3_max
value: 18.00532600292076
- type: nauc_precision_at_3_std
value: 7.649686453053768
- type: nauc_precision_at_5_diff1
value: 43.522408963585356
- type: nauc_precision_at_5_max
value: 16.923436041082983
- type: nauc_precision_at_5_std
value: -10.854341736694092
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: .nan
- type: nauc_recall_at_100_max
value: .nan
- type: nauc_recall_at_100_std
value: .nan
- type: nauc_recall_at_10_diff1
value: 19.1409897292252
- type: nauc_recall_at_10_max
value: 100.0
- type: nauc_recall_at_10_std
value: 93.46405228758134
- type: nauc_recall_at_1_diff1
value: 66.1236265634718
- type: nauc_recall_at_1_max
value: 7.000207311173955
- type: nauc_recall_at_1_std
value: 6.54412272821497
- type: nauc_recall_at_20_diff1
value: .nan
- type: nauc_recall_at_20_max
value: .nan
- type: nauc_recall_at_20_std
value: .nan
- type: nauc_recall_at_3_diff1
value: 50.29636629155569
- type: nauc_recall_at_3_max
value: 18.005326002920754
- type: nauc_recall_at_3_std
value: 7.649686453053851
- type: nauc_recall_at_5_diff1
value: 43.5224089635856
- type: nauc_recall_at_5_max
value: 16.92343604108335
- type: nauc_recall_at_5_std
value: -10.854341736694499
- type: ndcg_at_1
value: 68.0
- type: ndcg_at_10
value: 83.851
- type: ndcg_at_100
value: 84.36099999999999
- type: ndcg_at_1000
value: 84.36099999999999
- type: ndcg_at_20
value: 84.36099999999999
- type: ndcg_at_3
value: 80.333
- type: ndcg_at_5
value: 83.21600000000001
- type: precision_at_1
value: 68.0
- type: precision_at_10
value: 9.8
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 5.0
- type: precision_at_3
value: 29.666999999999998
- type: precision_at_5
value: 19.2
- type: recall_at_1
value: 68.0
- type: recall_at_10
value: 98.0
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 100.0
- type: recall_at_3
value: 89.0
- type: recall_at_5
value: 96.0
task:
type: Retrieval
- dataset:
config: default
name: MTEB T2Reranking (default)
revision: 76631901a18387f85eaa53e5450019b87ad58ef9
split: dev
type: C-MTEB/T2Reranking
metrics:
- type: map
value: 65.3088203970324
- type: mrr
value: 74.79505862376546
- type: main_score
value: 65.3088203970324
task:
type: Reranking
- dataset:
config: default
name: MTEB T2Retrieval (default)
revision: 8731a845f1bf500a4f111cf1070785c793d10e64
split: dev
type: C-MTEB/T2Retrieval
metrics:
- type: main_score
value: 83.163
- type: map_at_1
value: 26.875
- type: map_at_10
value: 75.454
- type: map_at_100
value: 79.036
- type: map_at_1000
value: 79.111
- type: map_at_20
value: 78.145
- type: map_at_3
value: 53.181
- type: map_at_5
value: 65.362
- type: mrr_at_1
value: 88.90057864281957
- type: mrr_at_10
value: 91.53186397301344
- type: mrr_at_100
value: 91.62809075510003
- type: mrr_at_1000
value: 91.63198173030787
- type: mrr_at_20
value: 91.59414668799909
- type: mrr_at_3
value: 91.0792565316499
- type: mrr_at_5
value: 91.35718043135199
- type: nauc_map_at_1000_diff1
value: 12.364843957982409
- type: nauc_map_at_1000_max
value: 52.07043464458799
- type: nauc_map_at_1000_std
value: 16.040095055100494
- type: nauc_map_at_100_diff1
value: 12.370621073823022
- type: nauc_map_at_100_max
value: 51.960738727635636
- type: nauc_map_at_100_std
value: 15.935832440430747
- type: nauc_map_at_10_diff1
value: 16.852819486606585
- type: nauc_map_at_10_max
value: 40.11184760756059
- type: nauc_map_at_10_std
value: 0.9306648364102376
- type: nauc_map_at_1_diff1
value: 52.87356542654683
- type: nauc_map_at_1_max
value: -22.210039746171255
- type: nauc_map_at_1_std
value: -38.11345358035342
- type: nauc_map_at_20_diff1
value: 13.045089059562837
- type: nauc_map_at_20_max
value: 49.591383082160036
- type: nauc_map_at_20_std
value: 12.54330050352008
- type: nauc_map_at_3_diff1
value: 38.08172234377615
- type: nauc_map_at_3_max
value: -6.868621684867697
- type: nauc_map_at_3_std
value: -35.4712388845996
- type: nauc_map_at_5_diff1
value: 29.665551705577474
- type: nauc_map_at_5_max
value: 10.958628576519045
- type: nauc_map_at_5_std
value: -25.113120842097057
- type: nauc_mrr_at_1000_diff1
value: 47.39372999496945
- type: nauc_mrr_at_1000_max
value: 83.11274997493808
- type: nauc_mrr_at_1000_std
value: 39.74195374546631
- type: nauc_mrr_at_100_diff1
value: 47.396678946057676
- type: nauc_mrr_at_100_max
value: 83.1192584274415
- type: nauc_mrr_at_100_std
value: 39.75840860374685
- type: nauc_mrr_at_10_diff1
value: 47.35365644138715
- type: nauc_mrr_at_10_max
value: 83.189165639531
- type: nauc_mrr_at_10_std
value: 39.83653157887758
- type: nauc_mrr_at_1_diff1
value: 47.98740362820094
- type: nauc_mrr_at_1_max
value: 80.32340034580369
- type: nauc_mrr_at_1_std
value: 34.57857131423388
- type: nauc_mrr_at_20_diff1
value: 47.399132055537194
- type: nauc_mrr_at_20_max
value: 83.16329919869686
- type: nauc_mrr_at_20_std
value: 39.84204692042734
- type: nauc_mrr_at_3_diff1
value: 47.09295580511751
- type: nauc_mrr_at_3_max
value: 82.95831045602642
- type: nauc_mrr_at_3_std
value: 38.98036804692351
- type: nauc_mrr_at_5_diff1
value: 47.20100268549764
- type: nauc_mrr_at_5_max
value: 83.16652480381642
- type: nauc_mrr_at_5_std
value: 39.55690491560902
- type: nauc_ndcg_at_1000_diff1
value: 17.201962509184547
- type: nauc_ndcg_at_1000_max
value: 63.75820559259539
- type: nauc_ndcg_at_1000_std
value: 29.28676096486067
- type: nauc_ndcg_at_100_diff1
value: 16.76847216096811
- type: nauc_ndcg_at_100_max
value: 62.646517934470744
- type: nauc_ndcg_at_100_std
value: 28.7441617667637
- type: nauc_ndcg_at_10_diff1
value: 16.559511980751886
- type: nauc_ndcg_at_10_max
value: 54.35027464277944
- type: nauc_ndcg_at_10_std
value: 16.98089333577716
- type: nauc_ndcg_at_1_diff1
value: 47.98740362820094
- type: nauc_ndcg_at_1_max
value: 80.32340034580369
- type: nauc_ndcg_at_1_std
value: 34.57857131423388
- type: nauc_ndcg_at_20_diff1
value: 16.721525245428243
- type: nauc_ndcg_at_20_max
value: 57.683661870555724
- type: nauc_ndcg_at_20_std
value: 21.736044200026853
- type: nauc_ndcg_at_3_diff1
value: 12.488009696556192
- type: nauc_ndcg_at_3_max
value: 69.2365575305502
- type: nauc_ndcg_at_3_std
value: 30.622418945055323
- type: nauc_ndcg_at_5_diff1
value: 12.364114556230609
- type: nauc_ndcg_at_5_max
value: 62.33360746285387
- type: nauc_ndcg_at_5_std
value: 24.898000803570227
- type: nauc_precision_at_1000_diff1
value: -35.14745130154524
- type: nauc_precision_at_1000_max
value: 48.811507982849065
- type: nauc_precision_at_1000_std
value: 62.43036496029399
- type: nauc_precision_at_100_diff1
value: -35.15276411320076
- type: nauc_precision_at_100_max
value: 50.87010333741109
- type: nauc_precision_at_100_std
value: 63.418221030407175
- type: nauc_precision_at_10_diff1
value: -34.84255710936113
- type: nauc_precision_at_10_max
value: 56.588401051428825
- type: nauc_precision_at_10_std
value: 57.4763370653757
- type: nauc_precision_at_1_diff1
value: 47.98740362820094
- type: nauc_precision_at_1_max
value: 80.32340034580369
- type: nauc_precision_at_1_std
value: 34.57857131423388
- type: nauc_precision_at_20_diff1
value: -35.165762365233505
- type: nauc_precision_at_20_max
value: 54.148762449660424
- type: nauc_precision_at_20_std
value: 61.569719669368716
- type: nauc_precision_at_3_diff1
value: -28.63023175340299
- type: nauc_precision_at_3_max
value: 68.69825987618499
- type: nauc_precision_at_3_std
value: 48.15479495755423
- type: nauc_precision_at_5_diff1
value: -34.13811355456687
- type: nauc_precision_at_5_max
value: 62.369363941490604
- type: nauc_precision_at_5_std
value: 52.282904411187914
- type: nauc_recall_at_1000_diff1
value: 8.686444579162663
- type: nauc_recall_at_1000_max
value: 59.58864478011338
- type: nauc_recall_at_1000_std
value: 56.692774954297455
- type: nauc_recall_at_100_diff1
value: 8.820596225758342
- type: nauc_recall_at_100_max
value: 53.15048885657892
- type: nauc_recall_at_100_std
value: 39.78931159236714
- type: nauc_recall_at_10_diff1
value: 16.022301106315027
- type: nauc_recall_at_10_max
value: 29.83242342459543
- type: nauc_recall_at_10_std
value: -4.805965555875844
- type: nauc_recall_at_1_diff1
value: 52.87356542654683
- type: nauc_recall_at_1_max
value: -22.210039746171255
- type: nauc_recall_at_1_std
value: -38.11345358035342
- type: nauc_recall_at_20_diff1
value: 10.35772828627265
- type: nauc_recall_at_20_max
value: 43.06420839754062
- type: nauc_recall_at_20_std
value: 15.040522218235692
- type: nauc_recall_at_3_diff1
value: 36.23953684770224
- type: nauc_recall_at_3_max
value: -11.709269151700374
- type: nauc_recall_at_3_std
value: -38.13943178150384
- type: nauc_recall_at_5_diff1
value: 28.644872415763384
- type: nauc_recall_at_5_max
value: 2.062151266111129
- type: nauc_recall_at_5_std
value: -30.81114034774277
- type: ndcg_at_1
value: 88.901
- type: ndcg_at_10
value: 83.163
- type: ndcg_at_100
value: 86.854
- type: ndcg_at_1000
value: 87.602
- type: ndcg_at_20
value: 84.908
- type: ndcg_at_3
value: 84.848
- type: ndcg_at_5
value: 83.372
- type: precision_at_1
value: 88.901
- type: precision_at_10
value: 41.343
- type: precision_at_100
value: 4.957000000000001
- type: precision_at_1000
value: 0.513
- type: precision_at_20
value: 22.955000000000002
- type: precision_at_3
value: 74.29599999999999
- type: precision_at_5
value: 62.251999999999995
- type: recall_at_1
value: 26.875
- type: recall_at_10
value: 81.902
- type: recall_at_100
value: 93.988
- type: recall_at_1000
value: 97.801
- type: recall_at_20
value: 87.809
- type: recall_at_3
value: 54.869
- type: recall_at_5
value: 68.728
task:
type: Retrieval
- dataset:
config: default
name: MTEB TERRa (default)
revision: 7b58f24536063837d644aab9a023c62199b2a612
split: dev
type: ai-forever/terra-pairclassification
metrics:
- type: cosine_accuracy
value: 60.586319218241044
- type: cosine_accuracy_threshold
value: 82.49806761741638
- type: cosine_ap
value: 58.73198048427448
- type: cosine_f1
value: 67.37967914438502
- type: cosine_f1_threshold
value: 77.46461033821106
- type: cosine_precision
value: 57.01357466063348
- type: cosine_recall
value: 82.35294117647058
- type: dot_accuracy
value: 60.26058631921825
- type: dot_accuracy_threshold
value: 35627.020263671875
- type: dot_ap
value: 57.418783612898224
- type: dot_f1
value: 66.51982378854623
- type: dot_f1_threshold
value: 27620.843505859375
- type: dot_precision
value: 50.16611295681063
- type: dot_recall
value: 98.69281045751634
- type: euclidean_accuracy
value: 60.26058631921825
- type: euclidean_accuracy_threshold
value: 1255.4466247558594
- type: euclidean_ap
value: 58.748656145387955
- type: euclidean_f1
value: 66.99029126213591
- type: euclidean_f1_threshold
value: 1565.1330947875977
- type: euclidean_precision
value: 53.28185328185329
- type: euclidean_recall
value: 90.19607843137256
- type: main_score
value: 58.8479126365766
- type: manhattan_accuracy
value: 59.934853420195445
- type: manhattan_accuracy_threshold
value: 29897.271728515625
- type: manhattan_ap
value: 58.8479126365766
- type: manhattan_f1
value: 66.81318681318683
- type: manhattan_f1_threshold
value: 46291.802978515625
- type: manhattan_precision
value: 50.331125827814574
- type: manhattan_recall
value: 99.34640522875817
- type: max_accuracy
value: 60.586319218241044
- type: max_ap
value: 58.8479126365766
- type: max_f1
value: 67.37967914438502
- type: max_precision
value: 57.01357466063348
- type: max_recall
value: 99.34640522875817
- type: similarity_accuracy
value: 60.586319218241044
- type: similarity_accuracy_threshold
value: 82.49806761741638
- type: similarity_ap
value: 58.73198048427448
- type: similarity_f1
value: 67.37967914438502
- type: similarity_f1_threshold
value: 77.46461033821106
- type: similarity_precision
value: 57.01357466063348
- type: similarity_recall
value: 82.35294117647058
task:
type: PairClassification
- dataset:
config: default
name: MTEB TNews (default)
revision: 317f262bf1e6126357bbe89e875451e4b0938fe4
split: validation
type: C-MTEB/TNews-classification
metrics:
- type: accuracy
value: 45.967999999999996
- type: f1
value: 44.699306100915706
- type: f1_weighted
value: 46.03730319014832
- type: main_score
value: 45.967999999999996
task:
type: Classification
- dataset:
config: default
name: MTEB TRECCOVID (default)
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
split: test
type: mteb/trec-covid
metrics:
- type: map_at_1
value: 0.251
- type: map_at_10
value: 1.9480000000000002
- type: map_at_100
value: 11.082
- type: map_at_1000
value: 26.700000000000003
- type: map_at_20
value: 3.3529999999999998
- type: map_at_3
value: 0.679
- type: map_at_5
value: 1.079
- type: mrr_at_1
value: 94.0
- type: mrr_at_10
value: 95.786
- type: mrr_at_100
value: 95.786
- type: mrr_at_1000
value: 95.786
- type: mrr_at_20
value: 95.786
- type: mrr_at_3
value: 95.0
- type: mrr_at_5
value: 95.5
- type: ndcg_at_1
value: 91.0
- type: ndcg_at_10
value: 77.71900000000001
- type: ndcg_at_100
value: 57.726
- type: ndcg_at_1000
value: 52.737
- type: ndcg_at_20
value: 72.54
- type: ndcg_at_3
value: 83.397
- type: ndcg_at_5
value: 80.806
- type: precision_at_1
value: 94.0
- type: precision_at_10
value: 81.0
- type: precision_at_100
value: 59.199999999999996
- type: precision_at_1000
value: 23.244
- type: precision_at_20
value: 75.2
- type: precision_at_3
value: 88.0
- type: precision_at_5
value: 84.8
- type: recall_at_1
value: 0.251
- type: recall_at_10
value: 2.1229999999999998
- type: recall_at_100
value: 14.496999999999998
- type: recall_at_1000
value: 50.09
- type: recall_at_20
value: 3.8309999999999995
- type: recall_at_3
value: 0.696
- type: recall_at_5
value: 1.1400000000000001
- type: main_score
value: 77.71900000000001
task:
type: Retrieval
- dataset:
config: default
name: MTEB TenKGnadClusteringP2P (default)
revision: 5c59e41555244b7e45c9a6be2d720ab4bafae558
split: test
type: slvnwhrl/tenkgnad-clustering-p2p
metrics:
- type: main_score
value: 43.763609722295215
- type: v_measure
value: 43.763609722295215
- type: v_measure_std
value: 2.8751199473862457
task:
type: Clustering
- dataset:
config: default
name: MTEB TenKGnadClusteringS2S (default)
revision: 6cddbe003f12b9b140aec477b583ac4191f01786
split: test
type: slvnwhrl/tenkgnad-clustering-s2s
metrics:
- type: main_score
value: 39.762424448504355
- type: v_measure
value: 39.762424448504355
- type: v_measure_std
value: 3.30146124979502
task:
type: Clustering
- dataset:
config: default
name: MTEB ThuNewsClusteringP2P (default)
revision: 5798586b105c0434e4f0fe5e767abe619442cf93
split: test
type: C-MTEB/ThuNewsClusteringP2P
metrics:
- type: main_score
value: 63.133819258289456
- type: v_measure
value: 63.133819258289456
- type: v_measure_std
value: 1.8854253356479695
task:
type: Clustering
- dataset:
config: default
name: MTEB ThuNewsClusteringS2S (default)
revision: 8a8b2caeda43f39e13c4bc5bea0f8a667896e10d
split: test
type: C-MTEB/ThuNewsClusteringS2S
metrics:
- type: main_score
value: 58.98195851785808
- type: v_measure
value: 58.98195851785808
- type: v_measure_std
value: 1.6237600076393737
task:
type: Clustering
- dataset:
config: default
name: MTEB Touche2020 (default)
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
split: test
type: mteb/touche2020
metrics:
- type: map_at_1
value: 3.3550000000000004
- type: map_at_10
value: 10.08
- type: map_at_100
value: 16.136
- type: map_at_1000
value: 17.605
- type: map_at_20
value: 12.561
- type: map_at_3
value: 5.641
- type: map_at_5
value: 7.3260000000000005
- type: mrr_at_1
value: 46.939
- type: mrr_at_10
value: 58.152
- type: mrr_at_100
value: 58.594
- type: mrr_at_1000
value: 58.601000000000006
- type: mrr_at_20
value: 58.279
- type: mrr_at_3
value: 55.102
- type: mrr_at_5
value: 56.531
- type: ndcg_at_1
value: 44.897999999999996
- type: ndcg_at_10
value: 26.298
- type: ndcg_at_100
value: 37.596000000000004
- type: ndcg_at_1000
value: 49.424
- type: ndcg_at_20
value: 27.066000000000003
- type: ndcg_at_3
value: 31.528
- type: ndcg_at_5
value: 28.219
- type: precision_at_1
value: 46.939
- type: precision_at_10
value: 22.245
- type: precision_at_100
value: 7.531000000000001
- type: precision_at_1000
value: 1.5350000000000001
- type: precision_at_20
value: 17.041
- type: precision_at_3
value: 30.612000000000002
- type: precision_at_5
value: 26.122
- type: recall_at_1
value: 3.3550000000000004
- type: recall_at_10
value: 16.41
- type: recall_at_100
value: 47.272
- type: recall_at_1000
value: 83.584
- type: recall_at_20
value: 24.091
- type: recall_at_3
value: 6.8180000000000005
- type: recall_at_5
value: 9.677
- type: main_score
value: 26.298
task:
type: Retrieval
- dataset:
config: default
name: MTEB ToxicConversationsClassification (default)
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
split: test
type: mteb/toxic_conversations_50k
metrics:
- type: accuracy
value: 91.2890625
- type: ap
value: 33.95547153875715
- type: ap_weighted
value: 33.95547153875715
- type: f1
value: 75.10768597556462
- type: f1_weighted
value: 92.00161208992606
- type: main_score
value: 91.2890625
task:
type: Classification
- dataset:
config: default
name: MTEB TweetSentimentExtractionClassification (default)
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
split: test
type: mteb/tweet_sentiment_extraction
metrics:
- type: accuracy
value: 71.3978494623656
- type: f1
value: 71.7194818511814
- type: f1_weighted
value: 71.13860187349744
- type: main_score
value: 71.3978494623656
task:
type: Classification
- dataset:
config: default
name: MTEB TwentyNewsgroupsClustering (default)
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
split: test
type: mteb/twentynewsgroups-clustering
metrics:
- type: main_score
value: 52.4921688720602
- type: v_measure
value: 52.4921688720602
- type: v_measure_std
value: 0.992768152658908
task:
type: Clustering
- dataset:
config: default
name: MTEB TwitterSemEval2015 (default)
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
split: test
type: mteb/twittersemeval2015-pairclassification
metrics:
- type: cosine_accuracy
value: 85.11652858079513
- type: cosine_accuracy_threshold
value: 87.90839910507202
- type: cosine_ap
value: 70.90459908851724
- type: cosine_f1
value: 65.66581227877457
- type: cosine_f1_threshold
value: 85.13308763504028
- type: cosine_precision
value: 61.094708153531684
- type: cosine_recall
value: 70.97625329815304
- type: dot_accuracy
value: 83.41181379269239
- type: dot_accuracy_threshold
value: 43110.113525390625
- type: dot_ap
value: 65.64869491143095
- type: dot_f1
value: 62.05308447460914
- type: dot_f1_threshold
value: 41412.542724609375
- type: dot_precision
value: 57.38623626989464
- type: dot_recall
value: 67.54617414248021
- type: euclidean_accuracy
value: 85.15229182809799
- type: euclidean_accuracy_threshold
value: 1043.08500289917
- type: euclidean_ap
value: 70.71204383269375
- type: euclidean_f1
value: 65.20304568527919
- type: euclidean_f1_threshold
value: 1179.2595863342285
- type: euclidean_precision
value: 62.81173594132029
- type: euclidean_recall
value: 67.78364116094987
- type: main_score
value: 70.90459908851724
- type: manhattan_accuracy
value: 85.1820945341837
- type: manhattan_accuracy_threshold
value: 26115.0390625
- type: manhattan_ap
value: 70.66113937117431
- type: manhattan_f1
value: 65.33383628819313
- type: manhattan_f1_threshold
value: 29105.181884765625
- type: manhattan_precision
value: 62.40691808791736
- type: manhattan_recall
value: 68.54881266490766
- type: max_accuracy
value: 85.1820945341837
- type: max_ap
value: 70.90459908851724
- type: max_f1
value: 65.66581227877457
- type: max_precision
value: 62.81173594132029
- type: max_recall
value: 70.97625329815304
- type: similarity_accuracy
value: 85.11652858079513
- type: similarity_accuracy_threshold
value: 87.90839910507202
- type: similarity_ap
value: 70.90459908851724
- type: similarity_f1
value: 65.66581227877457
- type: similarity_f1_threshold
value: 85.13308763504028
- type: similarity_precision
value: 61.094708153531684
- type: similarity_recall
value: 70.97625329815304
task:
type: PairClassification
- dataset:
config: default
name: MTEB TwitterURLCorpus (default)
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
split: test
type: mteb/twitterurlcorpus-pairclassification
metrics:
- type: cosine_accuracy
value: 88.10299996119068
- type: cosine_accuracy_threshold
value: 84.34982895851135
- type: cosine_ap
value: 84.13755787769226
- type: cosine_f1
value: 76.0967548076923
- type: cosine_f1_threshold
value: 82.8936219215393
- type: cosine_precision
value: 74.28864769727193
- type: cosine_recall
value: 77.99507237449954
- type: dot_accuracy
value: 86.64182869561843
- type: dot_accuracy_threshold
value: 38794.677734375
- type: dot_ap
value: 80.20301567411457
- type: dot_f1
value: 73.50650291634967
- type: dot_f1_threshold
value: 37447.23205566406
- type: dot_precision
value: 69.41498460485802
- type: dot_recall
value: 78.11056359716662
- type: euclidean_accuracy
value: 87.9361198432103
- type: euclidean_accuracy_threshold
value: 1184.421157836914
- type: euclidean_ap
value: 83.79582690117218
- type: euclidean_f1
value: 75.81431709042175
- type: euclidean_f1_threshold
value: 1258.2727432250977
- type: euclidean_precision
value: 73.39099099099099
- type: euclidean_recall
value: 78.40314136125654
- type: main_score
value: 84.13755787769226
- type: manhattan_accuracy
value: 87.96134590755618
- type: manhattan_accuracy_threshold
value: 29077.291870117188
- type: manhattan_ap
value: 83.79487172269923
- type: manhattan_f1
value: 75.82421603424935
- type: manhattan_f1_threshold
value: 31224.124145507812
- type: manhattan_precision
value: 72.24740255212329
- type: manhattan_recall
value: 79.77363720357253
- type: max_accuracy
value: 88.10299996119068
- type: max_ap
value: 84.13755787769226
- type: max_f1
value: 76.0967548076923
- type: max_precision
value: 74.28864769727193
- type: max_recall
value: 79.77363720357253
- type: similarity_accuracy
value: 88.10299996119068
- type: similarity_accuracy_threshold
value: 84.34982895851135
- type: similarity_ap
value: 84.13755787769226
- type: similarity_f1
value: 76.0967548076923
- type: similarity_f1_threshold
value: 82.8936219215393
- type: similarity_precision
value: 74.28864769727193
- type: similarity_recall
value: 77.99507237449954
task:
type: PairClassification
- dataset:
config: default
name: MTEB VideoRetrieval (default)
revision: 58c2597a5943a2ba48f4668c3b90d796283c5639
split: dev
type: C-MTEB/VideoRetrieval
metrics:
- type: main_score
value: 70.433
- type: map_at_1
value: 55.7
- type: map_at_10
value: 66.013
- type: map_at_100
value: 66.534
- type: map_at_1000
value: 66.547
- type: map_at_20
value: 66.334
- type: map_at_3
value: 64.2
- type: map_at_5
value: 65.445
- type: mrr_at_1
value: 55.7
- type: mrr_at_10
value: 66.01329365079364
- type: mrr_at_100
value: 66.53350061744233
- type: mrr_at_1000
value: 66.54744831962995
- type: mrr_at_20
value: 66.3335147364675
- type: mrr_at_3
value: 64.2
- type: mrr_at_5
value: 65.44500000000002
- type: nauc_map_at_1000_diff1
value: 76.26428836976245
- type: nauc_map_at_1000_max
value: 35.41847367373575
- type: nauc_map_at_1000_std
value: -33.04639860831992
- type: nauc_map_at_100_diff1
value: 76.25793229023193
- type: nauc_map_at_100_max
value: 35.43663260110076
- type: nauc_map_at_100_std
value: -33.04238139882945
- type: nauc_map_at_10_diff1
value: 76.2108281297711
- type: nauc_map_at_10_max
value: 35.59442419423183
- type: nauc_map_at_10_std
value: -33.32346518997277
- type: nauc_map_at_1_diff1
value: 79.17728405262736
- type: nauc_map_at_1_max
value: 31.880738163589527
- type: nauc_map_at_1_std
value: -30.891888718004584
- type: nauc_map_at_20_diff1
value: 76.2181333410193
- type: nauc_map_at_20_max
value: 35.43448818430876
- type: nauc_map_at_20_std
value: -33.35682442863193
- type: nauc_map_at_3_diff1
value: 76.10046541433466
- type: nauc_map_at_3_max
value: 34.6831278555291
- type: nauc_map_at_3_std
value: -34.030826044831116
- type: nauc_map_at_5_diff1
value: 75.96513023582064
- type: nauc_map_at_5_max
value: 34.66920832438069
- type: nauc_map_at_5_std
value: -33.79799777830796
- type: nauc_mrr_at_1000_diff1
value: 76.26428836976245
- type: nauc_mrr_at_1000_max
value: 35.41847367373575
- type: nauc_mrr_at_1000_std
value: -33.04639860831992
- type: nauc_mrr_at_100_diff1
value: 76.25793229023193
- type: nauc_mrr_at_100_max
value: 35.43663260110076
- type: nauc_mrr_at_100_std
value: -33.04238139882945
- type: nauc_mrr_at_10_diff1
value: 76.2108281297711
- type: nauc_mrr_at_10_max
value: 35.59442419423183
- type: nauc_mrr_at_10_std
value: -33.32346518997277
- type: nauc_mrr_at_1_diff1
value: 79.17728405262736
- type: nauc_mrr_at_1_max
value: 31.880738163589527
- type: nauc_mrr_at_1_std
value: -30.891888718004584
- type: nauc_mrr_at_20_diff1
value: 76.2181333410193
- type: nauc_mrr_at_20_max
value: 35.43448818430876
- type: nauc_mrr_at_20_std
value: -33.35682442863193
- type: nauc_mrr_at_3_diff1
value: 76.10046541433466
- type: nauc_mrr_at_3_max
value: 34.6831278555291
- type: nauc_mrr_at_3_std
value: -34.030826044831116
- type: nauc_mrr_at_5_diff1
value: 75.96513023582064
- type: nauc_mrr_at_5_max
value: 34.66920832438069
- type: nauc_mrr_at_5_std
value: -33.79799777830796
- type: nauc_ndcg_at_1000_diff1
value: 75.68118206798317
- type: nauc_ndcg_at_1000_max
value: 37.12252980787349
- type: nauc_ndcg_at_1000_std
value: -31.457578337430505
- type: nauc_ndcg_at_100_diff1
value: 75.46730761564156
- type: nauc_ndcg_at_100_max
value: 37.549890025544265
- type: nauc_ndcg_at_100_std
value: -31.35066985945112
- type: nauc_ndcg_at_10_diff1
value: 75.09890404887037
- type: nauc_ndcg_at_10_max
value: 38.024147790014204
- type: nauc_ndcg_at_10_std
value: -33.67408368593356
- type: nauc_ndcg_at_1_diff1
value: 79.17728405262736
- type: nauc_ndcg_at_1_max
value: 31.880738163589527
- type: nauc_ndcg_at_1_std
value: -30.891888718004584
- type: nauc_ndcg_at_20_diff1
value: 75.12977548171354
- type: nauc_ndcg_at_20_max
value: 37.524926748917956
- type: nauc_ndcg_at_20_std
value: -33.771344674947485
- type: nauc_ndcg_at_3_diff1
value: 74.94037476984154
- type: nauc_ndcg_at_3_max
value: 35.60345554050552
- type: nauc_ndcg_at_3_std
value: -35.256991346321854
- type: nauc_ndcg_at_5_diff1
value: 74.54265907753783
- type: nauc_ndcg_at_5_max
value: 35.57662819978585
- type: nauc_ndcg_at_5_std
value: -34.879794448418465
- type: nauc_precision_at_1000_diff1
value: 74.52277207179142
- type: nauc_precision_at_1000_max
value: 94.25510945118707
- type: nauc_precision_at_1000_std
value: 91.6874157070222
- type: nauc_precision_at_100_diff1
value: 65.98346655735419
- type: nauc_precision_at_100_max
value: 78.81168727653687
- type: nauc_precision_at_100_std
value: 27.241465691967708
- type: nauc_precision_at_10_diff1
value: 69.55050319096688
- type: nauc_precision_at_10_max
value: 51.827749140893374
- type: nauc_precision_at_10_std
value: -34.60818605792837
- type: nauc_precision_at_1_diff1
value: 79.17728405262736
- type: nauc_precision_at_1_max
value: 31.880738163589527
- type: nauc_precision_at_1_std
value: -30.891888718004584
- type: nauc_precision_at_20_diff1
value: 68.08078305042736
- type: nauc_precision_at_20_max
value: 52.83318878288501
- type: nauc_precision_at_20_std
value: -35.46070292817927
- type: nauc_precision_at_3_diff1
value: 70.76249609881901
- type: nauc_precision_at_3_max
value: 38.86561868624655
- type: nauc_precision_at_3_std
value: -39.68917853446992
- type: nauc_precision_at_5_diff1
value: 68.39110629013278
- type: nauc_precision_at_5_max
value: 39.28677163904683
- type: nauc_precision_at_5_std
value: -39.39101423819562
- type: nauc_recall_at_1000_diff1
value: 74.52277207179175
- type: nauc_recall_at_1000_max
value: 94.25510945118776
- type: nauc_recall_at_1000_std
value: 91.68741570702382
- type: nauc_recall_at_100_diff1
value: 65.9834665573548
- type: nauc_recall_at_100_max
value: 78.81168727653679
- type: nauc_recall_at_100_std
value: 27.241465691967598
- type: nauc_recall_at_10_diff1
value: 69.55050319096708
- type: nauc_recall_at_10_max
value: 51.82774914089347
- type: nauc_recall_at_10_std
value: -34.6081860579283
- type: nauc_recall_at_1_diff1
value: 79.17728405262736
- type: nauc_recall_at_1_max
value: 31.880738163589527
- type: nauc_recall_at_1_std
value: -30.891888718004584
- type: nauc_recall_at_20_diff1
value: 68.08078305042746
- type: nauc_recall_at_20_max
value: 52.833188782885244
- type: nauc_recall_at_20_std
value: -35.46070292817895
- type: nauc_recall_at_3_diff1
value: 70.76249609881896
- type: nauc_recall_at_3_max
value: 38.865618686246464
- type: nauc_recall_at_3_std
value: -39.68917853446999
- type: nauc_recall_at_5_diff1
value: 68.39110629013274
- type: nauc_recall_at_5_max
value: 39.28677163904688
- type: nauc_recall_at_5_std
value: -39.39101423819562
- type: ndcg_at_1
value: 55.7
- type: ndcg_at_10
value: 70.433
- type: ndcg_at_100
value: 72.975
- type: ndcg_at_1000
value: 73.283
- type: ndcg_at_20
value: 71.58
- type: ndcg_at_3
value: 66.83099999999999
- type: ndcg_at_5
value: 69.085
- type: precision_at_1
value: 55.7
- type: precision_at_10
value: 8.4
- type: precision_at_100
value: 0.959
- type: precision_at_1000
value: 0.098
- type: precision_at_20
value: 4.425
- type: precision_at_3
value: 24.8
- type: precision_at_5
value: 15.98
- type: recall_at_1
value: 55.7
- type: recall_at_10
value: 84.0
- type: recall_at_100
value: 95.89999999999999
- type: recall_at_1000
value: 98.2
- type: recall_at_20
value: 88.5
- type: recall_at_3
value: 74.4
- type: recall_at_5
value: 79.9
task:
type: Retrieval
- dataset:
config: default
name: MTEB Waimai (default)
revision: 339287def212450dcaa9df8c22bf93e9980c7023
split: test
type: C-MTEB/waimai-classification
metrics:
- type: accuracy
value: 86.58999999999999
- type: ap
value: 70.02619249927523
- type: ap_weighted
value: 70.02619249927523
- type: f1
value: 84.97572770889423
- type: f1_weighted
value: 86.6865713531272
- type: main_score
value: 86.58999999999999
task:
type: Classification
- dataset:
config: en
name: MTEB XMarket (en)
revision: dfe57acff5b62c23732a7b7d3e3fb84ff501708b
split: test
type: jinaai/xmarket_ml
metrics:
- type: main_score
value: 34.772999999999996
- type: map_at_1
value: 7.2620000000000005
- type: map_at_10
value: 17.98
- type: map_at_100
value: 24.828
- type: map_at_1000
value: 26.633000000000003
- type: map_at_20
value: 20.699
- type: map_at_3
value: 12.383
- type: map_at_5
value: 14.871
- type: mrr_at_1
value: 34.718100890207715
- type: mrr_at_10
value: 43.9336827525092
- type: mrr_at_100
value: 44.66474011066837
- type: mrr_at_1000
value: 44.7075592197356
- type: mrr_at_20
value: 44.35984436569346
- type: mrr_at_3
value: 41.73901893981052
- type: mrr_at_5
value: 43.025973550207134
- type: nauc_map_at_1000_diff1
value: 13.899869081196364
- type: nauc_map_at_1000_max
value: 46.60452816386231
- type: nauc_map_at_1000_std
value: 24.87925799401773
- type: nauc_map_at_100_diff1
value: 16.164805650871084
- type: nauc_map_at_100_max
value: 44.720912958558095
- type: nauc_map_at_100_std
value: 20.236734536210477
- type: nauc_map_at_10_diff1
value: 23.58580520913581
- type: nauc_map_at_10_max
value: 31.276151869914216
- type: nauc_map_at_10_std
value: -0.1833326246041355
- type: nauc_map_at_1_diff1
value: 37.02663305598722
- type: nauc_map_at_1_max
value: 14.931071531116528
- type: nauc_map_at_1_std
value: -12.478790028708453
- type: nauc_map_at_20_diff1
value: 20.718297881540593
- type: nauc_map_at_20_max
value: 36.62264094841859
- type: nauc_map_at_20_std
value: 6.658514770057742
- type: nauc_map_at_3_diff1
value: 29.379034581120006
- type: nauc_map_at_3_max
value: 21.387214269548803
- type: nauc_map_at_3_std
value: -9.3404121914247
- type: nauc_map_at_5_diff1
value: 26.627169792839485
- type: nauc_map_at_5_max
value: 25.393331109666388
- type: nauc_map_at_5_std
value: -6.023485287246353
- type: nauc_mrr_at_1000_diff1
value: 12.047232036652295
- type: nauc_mrr_at_1000_max
value: 46.611862580860645
- type: nauc_mrr_at_1000_std
value: 27.89146066442305
- type: nauc_mrr_at_100_diff1
value: 12.05261747449997
- type: nauc_mrr_at_100_max
value: 46.61328535381203
- type: nauc_mrr_at_100_std
value: 27.886145596874535
- type: nauc_mrr_at_10_diff1
value: 12.006935553036941
- type: nauc_mrr_at_10_max
value: 46.53351686240496
- type: nauc_mrr_at_10_std
value: 27.708742470257462
- type: nauc_mrr_at_1_diff1
value: 13.323408127738782
- type: nauc_mrr_at_1_max
value: 43.78884661002012
- type: nauc_mrr_at_1_std
value: 25.164417588165673
- type: nauc_mrr_at_20_diff1
value: 12.036022973968011
- type: nauc_mrr_at_20_max
value: 46.56537838037131
- type: nauc_mrr_at_20_std
value: 27.78189157249635
- type: nauc_mrr_at_3_diff1
value: 11.943896700976381
- type: nauc_mrr_at_3_max
value: 46.33644663073225
- type: nauc_mrr_at_3_std
value: 27.523915405053845
- type: nauc_mrr_at_5_diff1
value: 12.03108009033769
- type: nauc_mrr_at_5_max
value: 46.49103616896692
- type: nauc_mrr_at_5_std
value: 27.630879129863366
- type: nauc_ndcg_at_1000_diff1
value: 9.766823796017324
- type: nauc_ndcg_at_1000_max
value: 52.85844801910602
- type: nauc_ndcg_at_1000_std
value: 36.43271437761207
- type: nauc_ndcg_at_100_diff1
value: 12.035059298282036
- type: nauc_ndcg_at_100_max
value: 50.05520240705682
- type: nauc_ndcg_at_100_std
value: 29.87678724506636
- type: nauc_ndcg_at_10_diff1
value: 10.281893031139424
- type: nauc_ndcg_at_10_max
value: 47.02153679426017
- type: nauc_ndcg_at_10_std
value: 26.624948330369126
- type: nauc_ndcg_at_1_diff1
value: 13.323408127738782
- type: nauc_ndcg_at_1_max
value: 43.78884661002012
- type: nauc_ndcg_at_1_std
value: 25.164417588165673
- type: nauc_ndcg_at_20_diff1
value: 11.463524849646598
- type: nauc_ndcg_at_20_max
value: 47.415073186019704
- type: nauc_ndcg_at_20_std
value: 26.359019620164307
- type: nauc_ndcg_at_3_diff1
value: 9.689199913805394
- type: nauc_ndcg_at_3_max
value: 45.68151849572808
- type: nauc_ndcg_at_3_std
value: 26.559193219799486
- type: nauc_ndcg_at_5_diff1
value: 9.448823370356575
- type: nauc_ndcg_at_5_max
value: 46.19999662690141
- type: nauc_ndcg_at_5_std
value: 26.8411706726069
- type: nauc_precision_at_1000_diff1
value: -20.379065598727024
- type: nauc_precision_at_1000_max
value: 13.162562437268427
- type: nauc_precision_at_1000_std
value: 22.658226157785812
- type: nauc_precision_at_100_diff1
value: -16.458155977309282
- type: nauc_precision_at_100_max
value: 35.97956789169889
- type: nauc_precision_at_100_std
value: 48.878375009979194
- type: nauc_precision_at_10_diff1
value: -7.810992317607771
- type: nauc_precision_at_10_max
value: 49.307339277444754
- type: nauc_precision_at_10_std
value: 42.82533951854582
- type: nauc_precision_at_1_diff1
value: 13.323408127738782
- type: nauc_precision_at_1_max
value: 43.78884661002012
- type: nauc_precision_at_1_std
value: 25.164417588165673
- type: nauc_precision_at_20_diff1
value: -11.43933465149542
- type: nauc_precision_at_20_max
value: 46.93722753460038
- type: nauc_precision_at_20_std
value: 47.36223769029678
- type: nauc_precision_at_3_diff1
value: 1.3230178593599737
- type: nauc_precision_at_3_max
value: 48.49039534395576
- type: nauc_precision_at_3_std
value: 33.161384183129194
- type: nauc_precision_at_5_diff1
value: -3.185516457926519
- type: nauc_precision_at_5_max
value: 49.5814309394308
- type: nauc_precision_at_5_std
value: 37.57637865900281
- type: nauc_recall_at_1000_diff1
value: 7.839499443984168
- type: nauc_recall_at_1000_max
value: 52.67165467640894
- type: nauc_recall_at_1000_std
value: 48.85318316702583
- type: nauc_recall_at_100_diff1
value: 14.117557049589418
- type: nauc_recall_at_100_max
value: 40.59046301348715
- type: nauc_recall_at_100_std
value: 24.379680901739505
- type: nauc_recall_at_10_diff1
value: 20.04536052614054
- type: nauc_recall_at_10_max
value: 25.54148839721574
- type: nauc_recall_at_10_std
value: -1.938182527562211
- type: nauc_recall_at_1_diff1
value: 37.02663305598722
- type: nauc_recall_at_1_max
value: 14.931071531116528
- type: nauc_recall_at_1_std
value: -12.478790028708453
- type: nauc_recall_at_20_diff1
value: 17.959977483235566
- type: nauc_recall_at_20_max
value: 29.88502687870809
- type: nauc_recall_at_20_std
value: 4.26527395196852
- type: nauc_recall_at_3_diff1
value: 26.297810954500456
- type: nauc_recall_at_3_max
value: 18.819406079307402
- type: nauc_recall_at_3_std
value: -10.002237229729081
- type: nauc_recall_at_5_diff1
value: 22.739080899568485
- type: nauc_recall_at_5_max
value: 21.0322968243985
- type: nauc_recall_at_5_std
value: -6.927749435306422
- type: ndcg_at_1
value: 34.717999999999996
- type: ndcg_at_10
value: 34.772999999999996
- type: ndcg_at_100
value: 39.407
- type: ndcg_at_1000
value: 44.830999999999996
- type: ndcg_at_20
value: 35.667
- type: ndcg_at_3
value: 34.332
- type: ndcg_at_5
value: 34.408
- type: precision_at_1
value: 34.717999999999996
- type: precision_at_10
value: 23.430999999999997
- type: precision_at_100
value: 9.31
- type: precision_at_1000
value: 2.259
- type: precision_at_20
value: 18.826999999999998
- type: precision_at_3
value: 30.553
- type: precision_at_5
value: 27.792
- type: recall_at_1
value: 7.2620000000000005
- type: recall_at_10
value: 26.384
- type: recall_at_100
value: 52.506
- type: recall_at_1000
value: 73.38
- type: recall_at_20
value: 34.032000000000004
- type: recall_at_3
value: 14.821000000000002
- type: recall_at_5
value: 19.481
task:
type: Retrieval
- dataset:
config: de
name: MTEB XMarket (de)
revision: dfe57acff5b62c23732a7b7d3e3fb84ff501708b
split: test
type: jinaai/xmarket_ml
metrics:
- type: main_score
value: 28.316000000000003
- type: map_at_1
value: 8.667
- type: map_at_10
value: 17.351
- type: map_at_100
value: 21.02
- type: map_at_1000
value: 21.951
- type: map_at_20
value: 18.994
- type: map_at_3
value: 13.23
- type: map_at_5
value: 15.17
- type: mrr_at_1
value: 27.27272727272727
- type: mrr_at_10
value: 36.10858487561485
- type: mrr_at_100
value: 36.92033814316568
- type: mrr_at_1000
value: 36.972226653870365
- type: mrr_at_20
value: 36.58914906427944
- type: mrr_at_3
value: 33.642969201552305
- type: mrr_at_5
value: 35.13417554289494
- type: nauc_map_at_1000_diff1
value: 23.345116790998063
- type: nauc_map_at_1000_max
value: 44.447240670835725
- type: nauc_map_at_1000_std
value: 18.34636500680144
- type: nauc_map_at_100_diff1
value: 24.458120909292347
- type: nauc_map_at_100_max
value: 43.31851431140378
- type: nauc_map_at_100_std
value: 15.654778355549965
- type: nauc_map_at_10_diff1
value: 29.376508937265044
- type: nauc_map_at_10_max
value: 36.650196725140795
- type: nauc_map_at_10_std
value: 4.682465435374843
- type: nauc_map_at_1_diff1
value: 40.382365672683214
- type: nauc_map_at_1_max
value: 22.894341150096785
- type: nauc_map_at_1_std
value: -5.610725673968323
- type: nauc_map_at_20_diff1
value: 27.197033425732908
- type: nauc_map_at_20_max
value: 39.71672400647207
- type: nauc_map_at_20_std
value: 8.944436813309933
- type: nauc_map_at_3_diff1
value: 34.49739294661502
- type: nauc_map_at_3_max
value: 29.006972420735284
- type: nauc_map_at_3_std
value: -3.0372650571243986
- type: nauc_map_at_5_diff1
value: 32.764901537277105
- type: nauc_map_at_5_max
value: 32.658533295918154
- type: nauc_map_at_5_std
value: 0.029626452286996906
- type: nauc_mrr_at_1000_diff1
value: 19.521229956280603
- type: nauc_mrr_at_1000_max
value: 44.39409866211472
- type: nauc_mrr_at_1000_std
value: 23.580697307036058
- type: nauc_mrr_at_100_diff1
value: 19.51312676591073
- type: nauc_mrr_at_100_max
value: 44.39559153963895
- type: nauc_mrr_at_100_std
value: 23.57913711397437
- type: nauc_mrr_at_10_diff1
value: 19.584635617935145
- type: nauc_mrr_at_10_max
value: 44.44842226236198
- type: nauc_mrr_at_10_std
value: 23.382684909390434
- type: nauc_mrr_at_1_diff1
value: 20.92594790923806
- type: nauc_mrr_at_1_max
value: 40.593939625252816
- type: nauc_mrr_at_1_std
value: 20.37467598073644
- type: nauc_mrr_at_20_diff1
value: 19.590641822115725
- type: nauc_mrr_at_20_max
value: 44.42512299604718
- type: nauc_mrr_at_20_std
value: 23.45564260800024
- type: nauc_mrr_at_3_diff1
value: 20.005307129527232
- type: nauc_mrr_at_3_max
value: 43.68300366192776
- type: nauc_mrr_at_3_std
value: 22.297190480842005
- type: nauc_mrr_at_5_diff1
value: 19.852896386271716
- type: nauc_mrr_at_5_max
value: 44.20641808920062
- type: nauc_mrr_at_5_std
value: 22.966517330852895
- type: nauc_ndcg_at_1000_diff1
value: 17.800116251376103
- type: nauc_ndcg_at_1000_max
value: 50.98332718061365
- type: nauc_ndcg_at_1000_std
value: 31.464484658102577
- type: nauc_ndcg_at_100_diff1
value: 19.555159680541088
- type: nauc_ndcg_at_100_max
value: 48.56377130899141
- type: nauc_ndcg_at_100_std
value: 25.77572748714817
- type: nauc_ndcg_at_10_diff1
value: 20.003008726679415
- type: nauc_ndcg_at_10_max
value: 45.1293725480628
- type: nauc_ndcg_at_10_std
value: 21.149213260765872
- type: nauc_ndcg_at_1_diff1
value: 21.00986278773023
- type: nauc_ndcg_at_1_max
value: 40.524637076774894
- type: nauc_ndcg_at_1_std
value: 20.29682194006685
- type: nauc_ndcg_at_20_diff1
value: 20.659734137312284
- type: nauc_ndcg_at_20_max
value: 45.73108736599869
- type: nauc_ndcg_at_20_std
value: 21.200736170346133
- type: nauc_ndcg_at_3_diff1
value: 19.200120542882544
- type: nauc_ndcg_at_3_max
value: 42.89772612963168
- type: nauc_ndcg_at_3_std
value: 20.713292754978983
- type: nauc_ndcg_at_5_diff1
value: 19.96329647992544
- type: nauc_ndcg_at_5_max
value: 44.296627037787324
- type: nauc_ndcg_at_5_std
value: 21.200135784971973
- type: nauc_precision_at_1000_diff1
value: -11.543221249009427
- type: nauc_precision_at_1000_max
value: 9.132801614448221
- type: nauc_precision_at_1000_std
value: 21.203720655381055
- type: nauc_precision_at_100_diff1
value: -12.510945425786039
- type: nauc_precision_at_100_max
value: 31.42530963666252
- type: nauc_precision_at_100_std
value: 44.99672783467617
- type: nauc_precision_at_10_diff1
value: -4.025802651746804
- type: nauc_precision_at_10_max
value: 47.50967924227793
- type: nauc_precision_at_10_std
value: 41.1558559268985
- type: nauc_precision_at_1_diff1
value: 21.00986278773023
- type: nauc_precision_at_1_max
value: 40.524637076774894
- type: nauc_precision_at_1_std
value: 20.29682194006685
- type: nauc_precision_at_20_diff1
value: -8.059482951110002
- type: nauc_precision_at_20_max
value: 44.28832115946278
- type: nauc_precision_at_20_std
value: 45.2005585353651
- type: nauc_precision_at_3_diff1
value: 8.53530005716248
- type: nauc_precision_at_3_max
value: 46.48353678905102
- type: nauc_precision_at_3_std
value: 28.868791323881972
- type: nauc_precision_at_5_diff1
value: 3.093619954821814
- type: nauc_precision_at_5_max
value: 48.43294475817019
- type: nauc_precision_at_5_std
value: 34.83430452745434
- type: nauc_recall_at_1000_diff1
value: 9.93680206699751
- type: nauc_recall_at_1000_max
value: 52.97840222394363
- type: nauc_recall_at_1000_std
value: 46.370023604436255
- type: nauc_recall_at_100_diff1
value: 14.100542445524972
- type: nauc_recall_at_100_max
value: 42.853775131475224
- type: nauc_recall_at_100_std
value: 26.93029971231028
- type: nauc_recall_at_10_diff1
value: 22.774547475714716
- type: nauc_recall_at_10_max
value: 33.984586405015044
- type: nauc_recall_at_10_std
value: 5.332325172373655
- type: nauc_recall_at_1_diff1
value: 40.382365672683214
- type: nauc_recall_at_1_max
value: 22.894341150096785
- type: nauc_recall_at_1_std
value: -5.610725673968323
- type: nauc_recall_at_20_diff1
value: 19.751060483835936
- type: nauc_recall_at_20_max
value: 36.18774034635102
- type: nauc_recall_at_20_std
value: 10.362242090308577
- type: nauc_recall_at_3_diff1
value: 30.29462372902671
- type: nauc_recall_at_3_max
value: 27.377175450099635
- type: nauc_recall_at_3_std
value: -3.015752705993425
- type: nauc_recall_at_5_diff1
value: 28.096893312615723
- type: nauc_recall_at_5_max
value: 30.485075571512425
- type: nauc_recall_at_5_std
value: 0.09106417003502826
- type: ndcg_at_1
value: 27.248
- type: ndcg_at_10
value: 28.316000000000003
- type: ndcg_at_100
value: 33.419
- type: ndcg_at_1000
value: 38.134
- type: ndcg_at_20
value: 29.707
- type: ndcg_at_3
value: 26.93
- type: ndcg_at_5
value: 27.363
- type: precision_at_1
value: 27.248
- type: precision_at_10
value: 15.073
- type: precision_at_100
value: 5.061
- type: precision_at_1000
value: 1.325
- type: precision_at_20
value: 11.407
- type: precision_at_3
value: 21.823
- type: precision_at_5
value: 18.984
- type: recall_at_1
value: 8.667
- type: recall_at_10
value: 26.984
- type: recall_at_100
value: 49.753
- type: recall_at_1000
value: 70.354
- type: recall_at_20
value: 33.955999999999996
- type: recall_at_3
value: 16.086
- type: recall_at_5
value: 20.544999999999998
task:
type: Retrieval
- dataset:
config: es
name: MTEB XMarket (es)
revision: dfe57acff5b62c23732a7b7d3e3fb84ff501708b
split: test
type: jinaai/xmarket_ml
metrics:
- type: main_score
value: 26.592
- type: map_at_1
value: 8.081000000000001
- type: map_at_10
value: 16.486
- type: map_at_100
value: 19.996
- type: map_at_1000
value: 20.889
- type: map_at_20
value: 18.088
- type: map_at_3
value: 12.864
- type: map_at_5
value: 14.515
- type: mrr_at_1
value: 24.643356643356643
- type: mrr_at_10
value: 33.755599955599926
- type: mrr_at_100
value: 34.55914769326114
- type: mrr_at_1000
value: 34.614384237219745
- type: mrr_at_20
value: 34.228909650276194
- type: mrr_at_3
value: 31.445221445221456
- type: mrr_at_5
value: 32.71375291375297
- type: nauc_map_at_1000_diff1
value: 19.17751654240679
- type: nauc_map_at_1000_max
value: 43.493743561136434
- type: nauc_map_at_1000_std
value: 21.14477911550252
- type: nauc_map_at_100_diff1
value: 20.259227234415395
- type: nauc_map_at_100_max
value: 42.510860292169106
- type: nauc_map_at_100_std
value: 18.63085160442346
- type: nauc_map_at_10_diff1
value: 24.12419385640694
- type: nauc_map_at_10_max
value: 35.99892932069915
- type: nauc_map_at_10_std
value: 8.488520124325058
- type: nauc_map_at_1_diff1
value: 35.09239143996649
- type: nauc_map_at_1_max
value: 23.72498533914286
- type: nauc_map_at_1_std
value: -4.164387883546102
- type: nauc_map_at_20_diff1
value: 22.411418237320817
- type: nauc_map_at_20_max
value: 39.12496266094892
- type: nauc_map_at_20_std
value: 12.371656353894227
- type: nauc_map_at_3_diff1
value: 28.106972376813506
- type: nauc_map_at_3_max
value: 29.57824316865409
- type: nauc_map_at_3_std
value: 1.8928791254813127
- type: nauc_map_at_5_diff1
value: 26.4958239149419
- type: nauc_map_at_5_max
value: 32.45906016649239
- type: nauc_map_at_5_std
value: 4.612735963224018
- type: nauc_mrr_at_1000_diff1
value: 17.614812607094446
- type: nauc_mrr_at_1000_max
value: 41.13031556228715
- type: nauc_mrr_at_1000_std
value: 22.564112871230318
- type: nauc_mrr_at_100_diff1
value: 17.614044568011085
- type: nauc_mrr_at_100_max
value: 41.129436273086796
- type: nauc_mrr_at_100_std
value: 22.566763500658766
- type: nauc_mrr_at_10_diff1
value: 17.61869494452089
- type: nauc_mrr_at_10_max
value: 41.091542329381426
- type: nauc_mrr_at_10_std
value: 22.370473458633594
- type: nauc_mrr_at_1_diff1
value: 20.321421442201913
- type: nauc_mrr_at_1_max
value: 38.36531448180009
- type: nauc_mrr_at_1_std
value: 18.422203207777688
- type: nauc_mrr_at_20_diff1
value: 17.614767736091625
- type: nauc_mrr_at_20_max
value: 41.11221420736687
- type: nauc_mrr_at_20_std
value: 22.44271891522012
- type: nauc_mrr_at_3_diff1
value: 17.98184651584625
- type: nauc_mrr_at_3_max
value: 40.424293610470144
- type: nauc_mrr_at_3_std
value: 21.554750947206706
- type: nauc_mrr_at_5_diff1
value: 17.72088314927416
- type: nauc_mrr_at_5_max
value: 40.662724739072694
- type: nauc_mrr_at_5_std
value: 21.822957528431928
- type: nauc_ndcg_at_1000_diff1
value: 15.310699428328398
- type: nauc_ndcg_at_1000_max
value: 48.83921393349997
- type: nauc_ndcg_at_1000_std
value: 32.22600294110774
- type: nauc_ndcg_at_100_diff1
value: 16.62672763977423
- type: nauc_ndcg_at_100_max
value: 47.36060653537392
- type: nauc_ndcg_at_100_std
value: 27.879865162871575
- type: nauc_ndcg_at_10_diff1
value: 16.436684176028116
- type: nauc_ndcg_at_10_max
value: 43.00026520872974
- type: nauc_ndcg_at_10_std
value: 22.507354939162806
- type: nauc_ndcg_at_1_diff1
value: 20.321421442201913
- type: nauc_ndcg_at_1_max
value: 38.36531448180009
- type: nauc_ndcg_at_1_std
value: 18.422203207777688
- type: nauc_ndcg_at_20_diff1
value: 17.127747123248835
- type: nauc_ndcg_at_20_max
value: 44.57322943752733
- type: nauc_ndcg_at_20_std
value: 23.146541187377036
- type: nauc_ndcg_at_3_diff1
value: 16.372742984728514
- type: nauc_ndcg_at_3_max
value: 40.91938017883993
- type: nauc_ndcg_at_3_std
value: 21.50917089194154
- type: nauc_ndcg_at_5_diff1
value: 16.40486505525073
- type: nauc_ndcg_at_5_max
value: 41.94597203181329
- type: nauc_ndcg_at_5_std
value: 22.068260809047562
- type: nauc_precision_at_1000_diff1
value: -15.9415313729527
- type: nauc_precision_at_1000_max
value: 12.653329948983643
- type: nauc_precision_at_1000_std
value: 26.371820703256173
- type: nauc_precision_at_100_diff1
value: -11.851070166675289
- type: nauc_precision_at_100_max
value: 32.164365923950115
- type: nauc_precision_at_100_std
value: 45.930226426725426
- type: nauc_precision_at_10_diff1
value: -3.1352660378259163
- type: nauc_precision_at_10_max
value: 45.48359878733272
- type: nauc_precision_at_10_std
value: 40.2917038044196
- type: nauc_precision_at_1_diff1
value: 20.321421442201913
- type: nauc_precision_at_1_max
value: 38.36531448180009
- type: nauc_precision_at_1_std
value: 18.422203207777688
- type: nauc_precision_at_20_diff1
value: -7.087513342144751
- type: nauc_precision_at_20_max
value: 43.66272019058357
- type: nauc_precision_at_20_std
value: 44.22863351071686
- type: nauc_precision_at_3_diff1
value: 7.836185032609045
- type: nauc_precision_at_3_max
value: 44.85412904097269
- type: nauc_precision_at_3_std
value: 30.209139149500057
- type: nauc_precision_at_5_diff1
value: 3.028150537253791
- type: nauc_precision_at_5_max
value: 45.73661708882973
- type: nauc_precision_at_5_std
value: 34.65500311185052
- type: nauc_recall_at_1000_diff1
value: 9.526124668370704
- type: nauc_recall_at_1000_max
value: 51.4190208452196
- type: nauc_recall_at_1000_std
value: 45.694891695646426
- type: nauc_recall_at_100_diff1
value: 12.68466215400009
- type: nauc_recall_at_100_max
value: 42.79112054268112
- type: nauc_recall_at_100_std
value: 28.61954251400998
- type: nauc_recall_at_10_diff1
value: 17.95124413416829
- type: nauc_recall_at_10_max
value: 33.1192036755167
- type: nauc_recall_at_10_std
value: 9.3588175959525
- type: nauc_recall_at_1_diff1
value: 35.09239143996649
- type: nauc_recall_at_1_max
value: 23.72498533914286
- type: nauc_recall_at_1_std
value: -4.164387883546102
- type: nauc_recall_at_20_diff1
value: 16.24916980445646
- type: nauc_recall_at_20_max
value: 36.51316122236076
- type: nauc_recall_at_20_std
value: 13.641588062425736
- type: nauc_recall_at_3_diff1
value: 23.263199724138786
- type: nauc_recall_at_3_max
value: 27.67354561610614
- type: nauc_recall_at_3_std
value: 3.103127242654415
- type: nauc_recall_at_5_diff1
value: 20.719704839229635
- type: nauc_recall_at_5_max
value: 29.66480839111333
- type: nauc_recall_at_5_std
value: 5.514884455797986
- type: ndcg_at_1
value: 24.643
- type: ndcg_at_10
value: 26.592
- type: ndcg_at_100
value: 31.887
- type: ndcg_at_1000
value: 36.695
- type: ndcg_at_20
value: 28.166000000000004
- type: ndcg_at_3
value: 25.238
- type: ndcg_at_5
value: 25.545
- type: precision_at_1
value: 24.643
- type: precision_at_10
value: 13.730999999999998
- type: precision_at_100
value: 4.744000000000001
- type: precision_at_1000
value: 1.167
- type: precision_at_20
value: 10.562000000000001
- type: precision_at_3
value: 20.288999999999998
- type: precision_at_5
value: 17.337
- type: recall_at_1
value: 8.081000000000001
- type: recall_at_10
value: 25.911
- type: recall_at_100
value: 48.176
- type: recall_at_1000
value: 69.655
- type: recall_at_20
value: 32.924
- type: recall_at_3
value: 16.125
- type: recall_at_5
value: 19.988
task:
type: Retrieval
- dataset:
config: deu-deu
name: MTEB XPQARetrieval (deu-deu)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 84.552
- type: map_at_1
value: 59.023
- type: map_at_10
value: 81.051
- type: map_at_100
value: 81.539
- type: map_at_1000
value: 81.54299999999999
- type: map_at_20
value: 81.401
- type: map_at_3
value: 76.969
- type: map_at_5
value: 80.07600000000001
- type: mrr_at_1
value: 77.67624020887729
- type: mrr_at_10
value: 83.30509967259314
- type: mrr_at_100
value: 83.58599391639456
- type: mrr_at_1000
value: 83.58970114722587
- type: mrr_at_20
value: 83.50275980440317
- type: mrr_at_3
value: 82.07136640557006
- type: mrr_at_5
value: 82.94604003481287
- type: nauc_map_at_1000_diff1
value: 63.12885104269942
- type: nauc_map_at_1000_max
value: 57.7017996674959
- type: nauc_map_at_1000_std
value: -24.951068985070513
- type: nauc_map_at_100_diff1
value: 63.12866509393162
- type: nauc_map_at_100_max
value: 57.70176426013332
- type: nauc_map_at_100_std
value: -24.96012290790273
- type: nauc_map_at_10_diff1
value: 62.847709436211204
- type: nauc_map_at_10_max
value: 57.408873624779524
- type: nauc_map_at_10_std
value: -25.635130363219062
- type: nauc_map_at_1_diff1
value: 71.89683981857102
- type: nauc_map_at_1_max
value: 20.204460967432645
- type: nauc_map_at_1_std
value: -23.07894656629493
- type: nauc_map_at_20_diff1
value: 63.00504457011043
- type: nauc_map_at_20_max
value: 57.66009512514262
- type: nauc_map_at_20_std
value: -25.100138593754885
- type: nauc_map_at_3_diff1
value: 63.199874607788274
- type: nauc_map_at_3_max
value: 47.54482033763308
- type: nauc_map_at_3_std
value: -27.714557098916963
- type: nauc_map_at_5_diff1
value: 63.01006523518669
- type: nauc_map_at_5_max
value: 56.501965964288495
- type: nauc_map_at_5_std
value: -25.367825762790925
- type: nauc_mrr_at_1000_diff1
value: 66.24988063948112
- type: nauc_mrr_at_1000_max
value: 63.56921667744273
- type: nauc_mrr_at_1000_std
value: -22.073973768031863
- type: nauc_mrr_at_100_diff1
value: 66.24919554296275
- type: nauc_mrr_at_100_max
value: 63.57382447608361
- type: nauc_mrr_at_100_std
value: -22.084627248538187
- type: nauc_mrr_at_10_diff1
value: 66.0143885124066
- type: nauc_mrr_at_10_max
value: 63.51277586011898
- type: nauc_mrr_at_10_std
value: -22.477523960705454
- type: nauc_mrr_at_1_diff1
value: 68.25415199323474
- type: nauc_mrr_at_1_max
value: 63.069019003272416
- type: nauc_mrr_at_1_std
value: -18.77085924093244
- type: nauc_mrr_at_20_diff1
value: 66.16203167351055
- type: nauc_mrr_at_20_max
value: 63.607477776215845
- type: nauc_mrr_at_20_std
value: -22.15083176017266
- type: nauc_mrr_at_3_diff1
value: 66.39368842782302
- type: nauc_mrr_at_3_max
value: 63.11411066585295
- type: nauc_mrr_at_3_std
value: -22.63174342814071
- type: nauc_mrr_at_5_diff1
value: 66.17932562332354
- type: nauc_mrr_at_5_max
value: 63.70434825329594
- type: nauc_mrr_at_5_std
value: -21.704012812430438
- type: nauc_ndcg_at_1000_diff1
value: 63.958010361549356
- type: nauc_ndcg_at_1000_max
value: 60.516445000134624
- type: nauc_ndcg_at_1000_std
value: -24.264672248289923
- type: nauc_ndcg_at_100_diff1
value: 63.97654644758022
- type: nauc_ndcg_at_100_max
value: 60.62187552803407
- type: nauc_ndcg_at_100_std
value: -24.317149225778312
- type: nauc_ndcg_at_10_diff1
value: 62.505321221321566
- type: nauc_ndcg_at_10_max
value: 59.77891112351258
- type: nauc_ndcg_at_10_std
value: -26.90910005589911
- type: nauc_ndcg_at_1_diff1
value: 68.25415199323474
- type: nauc_ndcg_at_1_max
value: 63.069019003272416
- type: nauc_ndcg_at_1_std
value: -18.77085924093244
- type: nauc_ndcg_at_20_diff1
value: 63.04281805056225
- type: nauc_ndcg_at_20_max
value: 60.600957307444226
- type: nauc_ndcg_at_20_std
value: -24.954862079889203
- type: nauc_ndcg_at_3_diff1
value: 62.970441139740316
- type: nauc_ndcg_at_3_max
value: 57.543715669055295
- type: nauc_ndcg_at_3_std
value: -25.659388431714703
- type: nauc_ndcg_at_5_diff1
value: 62.82652127664541
- type: nauc_ndcg_at_5_max
value: 58.6970443258532
- type: nauc_ndcg_at_5_std
value: -25.66329354851023
- type: nauc_precision_at_1000_diff1
value: -33.38530947486223
- type: nauc_precision_at_1000_max
value: 25.972468024345414
- type: nauc_precision_at_1000_std
value: 17.460222955117978
- type: nauc_precision_at_100_diff1
value: -32.45175999251703
- type: nauc_precision_at_100_max
value: 26.367996120487337
- type: nauc_precision_at_100_std
value: 17.097957946391208
- type: nauc_precision_at_10_diff1
value: -26.97411235289487
- type: nauc_precision_at_10_max
value: 31.504961687240762
- type: nauc_precision_at_10_std
value: 11.125341183874687
- type: nauc_precision_at_1_diff1
value: 68.25415199323474
- type: nauc_precision_at_1_max
value: 63.069019003272416
- type: nauc_precision_at_1_std
value: -18.77085924093244
- type: nauc_precision_at_20_diff1
value: -29.8678078736273
- type: nauc_precision_at_20_max
value: 29.031222186584504
- type: nauc_precision_at_20_std
value: 14.943600563087928
- type: nauc_precision_at_3_diff1
value: -15.92947221299854
- type: nauc_precision_at_3_max
value: 37.73833494235097
- type: nauc_precision_at_3_std
value: 3.1573228443500847
- type: nauc_precision_at_5_diff1
value: -22.269156821101642
- type: nauc_precision_at_5_max
value: 35.65821838116355
- type: nauc_precision_at_5_std
value: 9.265930386198972
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 66.17058859539249
- type: nauc_recall_at_100_max
value: 78.066942935192
- type: nauc_recall_at_100_std
value: -22.213377762074686
- type: nauc_recall_at_10_diff1
value: 50.82149700700275
- type: nauc_recall_at_10_max
value: 56.68053325008221
- type: nauc_recall_at_10_std
value: -41.81657941433277
- type: nauc_recall_at_1_diff1
value: 71.89683981857102
- type: nauc_recall_at_1_max
value: 20.204460967432645
- type: nauc_recall_at_1_std
value: -23.07894656629493
- type: nauc_recall_at_20_diff1
value: 48.28076011857885
- type: nauc_recall_at_20_max
value: 63.29641555519295
- type: nauc_recall_at_20_std
value: -32.953559708819405
- type: nauc_recall_at_3_diff1
value: 58.15516956312558
- type: nauc_recall_at_3_max
value: 42.66315890283056
- type: nauc_recall_at_3_std
value: -32.16572530544806
- type: nauc_recall_at_5_diff1
value: 55.900844052439766
- type: nauc_recall_at_5_max
value: 55.23702018862884
- type: nauc_recall_at_5_std
value: -30.105929528165
- type: ndcg_at_1
value: 77.676
- type: ndcg_at_10
value: 84.552
- type: ndcg_at_100
value: 86.232
- type: ndcg_at_1000
value: 86.33800000000001
- type: ndcg_at_20
value: 85.515
- type: ndcg_at_3
value: 81.112
- type: ndcg_at_5
value: 82.943
- type: precision_at_1
value: 77.676
- type: precision_at_10
value: 15.17
- type: precision_at_100
value: 1.6230000000000002
- type: precision_at_1000
value: 0.163
- type: precision_at_20
value: 7.858999999999999
- type: precision_at_3
value: 42.994
- type: precision_at_5
value: 28.747
- type: recall_at_1
value: 59.023
- type: recall_at_10
value: 92.465
- type: recall_at_100
value: 99.18400000000001
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 95.844
- type: recall_at_3
value: 81.826
- type: recall_at_5
value: 88.22
task:
type: Retrieval
- dataset:
config: deu-eng
name: MTEB XPQARetrieval (deu-eng)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 82.149
- type: map_at_1
value: 56.277
- type: map_at_10
value: 78.36999999999999
- type: map_at_100
value: 78.94
- type: map_at_1000
value: 78.95
- type: map_at_20
value: 78.818
- type: map_at_3
value: 74.25
- type: map_at_5
value: 77.11099999999999
- type: mrr_at_1
value: 74.28198433420366
- type: mrr_at_10
value: 80.57487877657589
- type: mrr_at_100
value: 80.94025764149008
- type: mrr_at_1000
value: 80.94608738871234
- type: mrr_at_20
value: 80.86240675885023
- type: mrr_at_3
value: 79.4604003481288
- type: mrr_at_5
value: 80.10008703220191
- type: nauc_map_at_1000_diff1
value: 60.44369249057189
- type: nauc_map_at_1000_max
value: 49.822240441830246
- type: nauc_map_at_1000_std
value: -27.34026380762817
- type: nauc_map_at_100_diff1
value: 60.44635668050401
- type: nauc_map_at_100_max
value: 49.838675926660684
- type: nauc_map_at_100_std
value: -27.310365556055583
- type: nauc_map_at_10_diff1
value: 60.18546951726522
- type: nauc_map_at_10_max
value: 49.72075398096832
- type: nauc_map_at_10_std
value: -27.86056102461558
- type: nauc_map_at_1_diff1
value: 71.2906657099758
- type: nauc_map_at_1_max
value: 18.970399251589
- type: nauc_map_at_1_std
value: -27.260776614286602
- type: nauc_map_at_20_diff1
value: 60.3525975566164
- type: nauc_map_at_20_max
value: 49.852487866710646
- type: nauc_map_at_20_std
value: -27.305173830170332
- type: nauc_map_at_3_diff1
value: 60.66803500571236
- type: nauc_map_at_3_max
value: 41.18191941521972
- type: nauc_map_at_3_std
value: -28.71383593401732
- type: nauc_map_at_5_diff1
value: 60.57216514504887
- type: nauc_map_at_5_max
value: 47.99837400446299
- type: nauc_map_at_5_std
value: -28.756183015949986
- type: nauc_mrr_at_1000_diff1
value: 63.77031955602516
- type: nauc_mrr_at_1000_max
value: 54.26907383811417
- type: nauc_mrr_at_1000_std
value: -26.227442087164714
- type: nauc_mrr_at_100_diff1
value: 63.77196650108669
- type: nauc_mrr_at_100_max
value: 54.281801457913126
- type: nauc_mrr_at_100_std
value: -26.216077891830793
- type: nauc_mrr_at_10_diff1
value: 63.50095284903051
- type: nauc_mrr_at_10_max
value: 54.3186301730016
- type: nauc_mrr_at_10_std
value: -26.29570241722173
- type: nauc_mrr_at_1_diff1
value: 65.15855770999057
- type: nauc_mrr_at_1_max
value: 53.213286738515066
- type: nauc_mrr_at_1_std
value: -24.683178252901943
- type: nauc_mrr_at_20_diff1
value: 63.74936550280859
- type: nauc_mrr_at_20_max
value: 54.355343751439065
- type: nauc_mrr_at_20_std
value: -26.197316900009817
- type: nauc_mrr_at_3_diff1
value: 63.912612979082695
- type: nauc_mrr_at_3_max
value: 53.75399024225975
- type: nauc_mrr_at_3_std
value: -27.194143264554675
- type: nauc_mrr_at_5_diff1
value: 63.72491059053639
- type: nauc_mrr_at_5_max
value: 53.66107604019352
- type: nauc_mrr_at_5_std
value: -26.92281560584754
- type: nauc_ndcg_at_1000_diff1
value: 61.304218998714354
- type: nauc_ndcg_at_1000_max
value: 52.409135743660386
- type: nauc_ndcg_at_1000_std
value: -26.539796489464056
- type: nauc_ndcg_at_100_diff1
value: 61.40355045085304
- type: nauc_ndcg_at_100_max
value: 52.79402259608008
- type: nauc_ndcg_at_100_std
value: -25.927273456979965
- type: nauc_ndcg_at_10_diff1
value: 59.93675608684116
- type: nauc_ndcg_at_10_max
value: 52.617848197542706
- type: nauc_ndcg_at_10_std
value: -27.314820020095887
- type: nauc_ndcg_at_1_diff1
value: 65.15855770999057
- type: nauc_ndcg_at_1_max
value: 53.213286738515066
- type: nauc_ndcg_at_1_std
value: -24.683178252901943
- type: nauc_ndcg_at_20_diff1
value: 60.85093704358376
- type: nauc_ndcg_at_20_max
value: 53.14529242671602
- type: nauc_ndcg_at_20_std
value: -25.93187916231906
- type: nauc_ndcg_at_3_diff1
value: 60.42301123518882
- type: nauc_ndcg_at_3_max
value: 49.59021992975956
- type: nauc_ndcg_at_3_std
value: -27.397117967810363
- type: nauc_ndcg_at_5_diff1
value: 60.78655153154219
- type: nauc_ndcg_at_5_max
value: 49.54194799556953
- type: nauc_ndcg_at_5_std
value: -29.467910172913413
- type: nauc_precision_at_1000_diff1
value: -34.35027108027456
- type: nauc_precision_at_1000_max
value: 23.762671066858815
- type: nauc_precision_at_1000_std
value: 16.1704780298982
- type: nauc_precision_at_100_diff1
value: -32.66610016754961
- type: nauc_precision_at_100_max
value: 25.504044603109588
- type: nauc_precision_at_100_std
value: 16.932402988816786
- type: nauc_precision_at_10_diff1
value: -25.720903145017342
- type: nauc_precision_at_10_max
value: 30.37029690599926
- type: nauc_precision_at_10_std
value: 10.560753160200314
- type: nauc_precision_at_1_diff1
value: 65.15855770999057
- type: nauc_precision_at_1_max
value: 53.213286738515066
- type: nauc_precision_at_1_std
value: -24.683178252901943
- type: nauc_precision_at_20_diff1
value: -29.577582332619084
- type: nauc_precision_at_20_max
value: 27.984145595920417
- type: nauc_precision_at_20_std
value: 15.083711704044727
- type: nauc_precision_at_3_diff1
value: -14.736267532892697
- type: nauc_precision_at_3_max
value: 36.12211021824307
- type: nauc_precision_at_3_std
value: 3.068643876519412
- type: nauc_precision_at_5_diff1
value: -19.846707283120825
- type: nauc_precision_at_5_max
value: 33.573804532177896
- type: nauc_precision_at_5_std
value: 5.700545622744924
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 68.24749796604452
- type: nauc_recall_at_100_max
value: 83.30024864929815
- type: nauc_recall_at_100_std
value: 21.23763053711522
- type: nauc_recall_at_10_diff1
value: 50.704049683241436
- type: nauc_recall_at_10_max
value: 57.64578984555556
- type: nauc_recall_at_10_std
value: -26.632759037746073
- type: nauc_recall_at_1_diff1
value: 71.2906657099758
- type: nauc_recall_at_1_max
value: 18.970399251589
- type: nauc_recall_at_1_std
value: -27.260776614286602
- type: nauc_recall_at_20_diff1
value: 54.124480837579505
- type: nauc_recall_at_20_max
value: 66.4641515433479
- type: nauc_recall_at_20_std
value: -14.615911455379393
- type: nauc_recall_at_3_diff1
value: 56.54358788321059
- type: nauc_recall_at_3_max
value: 37.765735322465744
- type: nauc_recall_at_3_std
value: -30.824147408598574
- type: nauc_recall_at_5_diff1
value: 56.392894535029214
- type: nauc_recall_at_5_max
value: 45.959268387521554
- type: nauc_recall_at_5_std
value: -33.58175576925282
- type: ndcg_at_1
value: 74.28200000000001
- type: ndcg_at_10
value: 82.149
- type: ndcg_at_100
value: 84.129
- type: ndcg_at_1000
value: 84.307
- type: ndcg_at_20
value: 83.39999999999999
- type: ndcg_at_3
value: 78.583
- type: ndcg_at_5
value: 80.13900000000001
- type: precision_at_1
value: 74.28200000000001
- type: precision_at_10
value: 14.960999999999999
- type: precision_at_100
value: 1.6119999999999999
- type: precision_at_1000
value: 0.163
- type: precision_at_20
value: 7.813000000000001
- type: precision_at_3
value: 41.819
- type: precision_at_5
value: 27.911
- type: recall_at_1
value: 56.277
- type: recall_at_10
value: 90.729
- type: recall_at_100
value: 98.792
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 95.148
- type: recall_at_3
value: 79.989
- type: recall_at_5
value: 85.603
task:
type: Retrieval
- dataset:
config: eng-deu
name: MTEB XPQARetrieval (eng-deu)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 60.428000000000004
- type: map_at_1
value: 33.453
- type: map_at_10
value: 54.217000000000006
- type: map_at_100
value: 55.832
- type: map_at_1000
value: 55.884
- type: map_at_20
value: 55.236
- type: map_at_3
value: 48.302
- type: map_at_5
value: 51.902
- type: mrr_at_1
value: 53.916449086161876
- type: mrr_at_10
value: 61.4685647975465
- type: mrr_at_100
value: 62.13718159287348
- type: mrr_at_1000
value: 62.15799113826325
- type: mrr_at_20
value: 61.885388764243544
- type: mrr_at_3
value: 59.44299390774582
- type: mrr_at_5
value: 60.26544821583981
- type: nauc_map_at_1000_diff1
value: 39.824412602121804
- type: nauc_map_at_1000_max
value: 39.49332709959374
- type: nauc_map_at_1000_std
value: -17.27462623749702
- type: nauc_map_at_100_diff1
value: 39.80528910003463
- type: nauc_map_at_100_max
value: 39.51471609156093
- type: nauc_map_at_100_std
value: -17.275536933094937
- type: nauc_map_at_10_diff1
value: 39.28558292349772
- type: nauc_map_at_10_max
value: 38.13220294838968
- type: nauc_map_at_10_std
value: -18.235985574392863
- type: nauc_map_at_1_diff1
value: 43.68892397816937
- type: nauc_map_at_1_max
value: 14.478978190224353
- type: nauc_map_at_1_std
value: -18.435031919225477
- type: nauc_map_at_20_diff1
value: 39.8733530971344
- type: nauc_map_at_20_max
value: 39.30513202591992
- type: nauc_map_at_20_std
value: -17.62362848144766
- type: nauc_map_at_3_diff1
value: 40.31116611188815
- type: nauc_map_at_3_max
value: 31.107314675202165
- type: nauc_map_at_3_std
value: -19.52930881946966
- type: nauc_map_at_5_diff1
value: 39.1241499095765
- type: nauc_map_at_5_max
value: 37.330543901034055
- type: nauc_map_at_5_std
value: -17.893862772447548
- type: nauc_mrr_at_1000_diff1
value: 43.07490530140024
- type: nauc_mrr_at_1000_max
value: 42.28469195779226
- type: nauc_mrr_at_1000_std
value: -15.583217110180737
- type: nauc_mrr_at_100_diff1
value: 43.068836494603886
- type: nauc_mrr_at_100_max
value: 42.29612450479168
- type: nauc_mrr_at_100_std
value: -15.57218089438229
- type: nauc_mrr_at_10_diff1
value: 42.88685919151777
- type: nauc_mrr_at_10_max
value: 41.89944452003811
- type: nauc_mrr_at_10_std
value: -15.909673572763165
- type: nauc_mrr_at_1_diff1
value: 45.67646898532131
- type: nauc_mrr_at_1_max
value: 43.0541870425035
- type: nauc_mrr_at_1_std
value: -15.597124291613563
- type: nauc_mrr_at_20_diff1
value: 43.14141873150977
- type: nauc_mrr_at_20_max
value: 42.33063543184022
- type: nauc_mrr_at_20_std
value: -15.607612016107304
- type: nauc_mrr_at_3_diff1
value: 43.18370928261982
- type: nauc_mrr_at_3_max
value: 42.18529980773961
- type: nauc_mrr_at_3_std
value: -15.900151400673629
- type: nauc_mrr_at_5_diff1
value: 42.43443044877765
- type: nauc_mrr_at_5_max
value: 42.05818605278972
- type: nauc_mrr_at_5_std
value: -15.436502733299893
- type: nauc_ndcg_at_1000_diff1
value: 40.60606676178781
- type: nauc_ndcg_at_1000_max
value: 41.71923393878376
- type: nauc_ndcg_at_1000_std
value: -15.694740326899556
- type: nauc_ndcg_at_100_diff1
value: 40.15270376312309
- type: nauc_ndcg_at_100_max
value: 42.234126305709225
- type: nauc_ndcg_at_100_std
value: -15.436051984708952
- type: nauc_ndcg_at_10_diff1
value: 39.142259831299455
- type: nauc_ndcg_at_10_max
value: 38.61470104273746
- type: nauc_ndcg_at_10_std
value: -18.577452829132742
- type: nauc_ndcg_at_1_diff1
value: 45.67646898532131
- type: nauc_ndcg_at_1_max
value: 43.0541870425035
- type: nauc_ndcg_at_1_std
value: -15.597124291613563
- type: nauc_ndcg_at_20_diff1
value: 40.805159395901306
- type: nauc_ndcg_at_20_max
value: 41.58685629374952
- type: nauc_ndcg_at_20_std
value: -16.862408156222592
- type: nauc_ndcg_at_3_diff1
value: 39.12028215488432
- type: nauc_ndcg_at_3_max
value: 39.70580596343164
- type: nauc_ndcg_at_3_std
value: -16.705546903936213
- type: nauc_ndcg_at_5_diff1
value: 38.42075404927361
- type: nauc_ndcg_at_5_max
value: 38.064219879504385
- type: nauc_ndcg_at_5_std
value: -17.20282111665876
- type: nauc_precision_at_1000_diff1
value: -4.419224540552891
- type: nauc_precision_at_1000_max
value: 35.686022591225246
- type: nauc_precision_at_1000_std
value: 15.023520191032972
- type: nauc_precision_at_100_diff1
value: -2.9027602601603895
- type: nauc_precision_at_100_max
value: 39.99864013028808
- type: nauc_precision_at_100_std
value: 13.863497117255525
- type: nauc_precision_at_10_diff1
value: 5.539104839809501
- type: nauc_precision_at_10_max
value: 42.41625740557432
- type: nauc_precision_at_10_std
value: 1.0894693748662556
- type: nauc_precision_at_1_diff1
value: 45.67646898532131
- type: nauc_precision_at_1_max
value: 43.0541870425035
- type: nauc_precision_at_1_std
value: -15.597124291613563
- type: nauc_precision_at_20_diff1
value: 4.734562571681868
- type: nauc_precision_at_20_max
value: 44.35081213316202
- type: nauc_precision_at_20_std
value: 6.642891478284595
- type: nauc_precision_at_3_diff1
value: 13.936559341472101
- type: nauc_precision_at_3_max
value: 45.426668552497524
- type: nauc_precision_at_3_std
value: -5.219785419247125
- type: nauc_precision_at_5_diff1
value: 8.366706789546015
- type: nauc_precision_at_5_max
value: 46.161942989326896
- type: nauc_precision_at_5_std
value: -0.193140343545876
- type: nauc_recall_at_1000_diff1
value: 45.61785312444842
- type: nauc_recall_at_1000_max
value: 75.68258976531774
- type: nauc_recall_at_1000_std
value: 37.469059422121575
- type: nauc_recall_at_100_diff1
value: 26.798748531805096
- type: nauc_recall_at_100_max
value: 54.72134095197765
- type: nauc_recall_at_100_std
value: -1.5967608233799417
- type: nauc_recall_at_10_diff1
value: 32.13211696200521
- type: nauc_recall_at_10_max
value: 31.13866254975895
- type: nauc_recall_at_10_std
value: -22.31404161136118
- type: nauc_recall_at_1_diff1
value: 43.68892397816937
- type: nauc_recall_at_1_max
value: 14.478978190224353
- type: nauc_recall_at_1_std
value: -18.435031919225477
- type: nauc_recall_at_20_diff1
value: 38.597996930461385
- type: nauc_recall_at_20_max
value: 42.49849027366794
- type: nauc_recall_at_20_std
value: -16.536471900752154
- type: nauc_recall_at_3_diff1
value: 35.343730012759266
- type: nauc_recall_at_3_max
value: 26.898722085043392
- type: nauc_recall_at_3_std
value: -19.4459792273884
- type: nauc_recall_at_5_diff1
value: 31.8310298012186
- type: nauc_recall_at_5_max
value: 32.67800489655844
- type: nauc_recall_at_5_std
value: -16.800929103347283
- type: ndcg_at_1
value: 53.916
- type: ndcg_at_10
value: 60.428000000000004
- type: ndcg_at_100
value: 65.95
- type: ndcg_at_1000
value: 66.88
- type: ndcg_at_20
value: 62.989
- type: ndcg_at_3
value: 55.204
- type: ndcg_at_5
value: 56.42700000000001
- type: precision_at_1
value: 53.916
- type: precision_at_10
value: 14.346999999999998
- type: precision_at_100
value: 1.849
- type: precision_at_1000
value: 0.196
- type: precision_at_20
value: 8.022
- type: precision_at_3
value: 34.552
- type: precision_at_5
value: 24.569
- type: recall_at_1
value: 33.453
- type: recall_at_10
value: 71.07900000000001
- type: recall_at_100
value: 93.207
- type: recall_at_1000
value: 99.60799999999999
- type: recall_at_20
value: 79.482
- type: recall_at_3
value: 53.98
- type: recall_at_5
value: 60.781
task:
type: Retrieval
- dataset:
config: eng-pol
name: MTEB XPQARetrieval (eng-pol)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 34.042
- type: map_at_1
value: 13.236
- type: map_at_10
value: 27.839999999999996
- type: map_at_100
value: 30.171999999999997
- type: map_at_1000
value: 30.349999999999998
- type: map_at_20
value: 29.044999999999998
- type: map_at_3
value: 22.58
- type: map_at_5
value: 25.83
- type: mrr_at_1
value: 30.318471337579616
- type: mrr_at_10
value: 37.4983823678091
- type: mrr_at_100
value: 38.5784523175009
- type: mrr_at_1000
value: 38.63608698968148
- type: mrr_at_20
value: 38.02996157871825
- type: mrr_at_3
value: 34.798301486199584
- type: mrr_at_5
value: 36.39702760084925
- type: nauc_map_at_1000_diff1
value: 21.07199789609177
- type: nauc_map_at_1000_max
value: 25.959233507893277
- type: nauc_map_at_1000_std
value: -28.011925372852826
- type: nauc_map_at_100_diff1
value: 21.086788412737548
- type: nauc_map_at_100_max
value: 25.8611620203686
- type: nauc_map_at_100_std
value: -28.179239912057515
- type: nauc_map_at_10_diff1
value: 21.23841745922078
- type: nauc_map_at_10_max
value: 25.44290342378288
- type: nauc_map_at_10_std
value: -28.75578689110275
- type: nauc_map_at_1_diff1
value: 28.87454015638211
- type: nauc_map_at_1_max
value: 17.50681123879997
- type: nauc_map_at_1_std
value: -30.382831850562432
- type: nauc_map_at_20_diff1
value: 21.076559713540455
- type: nauc_map_at_20_max
value: 25.538154202494535
- type: nauc_map_at_20_std
value: -28.518764617658555
- type: nauc_map_at_3_diff1
value: 22.159185358766468
- type: nauc_map_at_3_max
value: 23.01652660927249
- type: nauc_map_at_3_std
value: -29.567722713221862
- type: nauc_map_at_5_diff1
value: 21.35578810370897
- type: nauc_map_at_5_max
value: 25.550550437767395
- type: nauc_map_at_5_std
value: -28.7889035461355
- type: nauc_mrr_at_1000_diff1
value: 22.28633009221923
- type: nauc_mrr_at_1000_max
value: 26.920205393136392
- type: nauc_mrr_at_1000_std
value: -25.887791634977642
- type: nauc_mrr_at_100_diff1
value: 22.2754975739755
- type: nauc_mrr_at_100_max
value: 26.90235716615346
- type: nauc_mrr_at_100_std
value: -25.891596020584345
- type: nauc_mrr_at_10_diff1
value: 22.415076305593534
- type: nauc_mrr_at_10_max
value: 26.504643796222222
- type: nauc_mrr_at_10_std
value: -26.6046081215833
- type: nauc_mrr_at_1_diff1
value: 23.406748619244368
- type: nauc_mrr_at_1_max
value: 29.058228240823553
- type: nauc_mrr_at_1_std
value: -26.450169820901078
- type: nauc_mrr_at_20_diff1
value: 22.29233141817678
- type: nauc_mrr_at_20_max
value: 26.69021351064081
- type: nauc_mrr_at_20_std
value: -26.086596227376656
- type: nauc_mrr_at_3_diff1
value: 22.20746187500145
- type: nauc_mrr_at_3_max
value: 27.143725946169457
- type: nauc_mrr_at_3_std
value: -26.7017708594376
- type: nauc_mrr_at_5_diff1
value: 22.71898965233195
- type: nauc_mrr_at_5_max
value: 26.932386658571662
- type: nauc_mrr_at_5_std
value: -26.725541058780234
- type: nauc_ndcg_at_1000_diff1
value: 20.541734305148466
- type: nauc_ndcg_at_1000_max
value: 27.180534238090758
- type: nauc_ndcg_at_1000_std
value: -23.74197745177845
- type: nauc_ndcg_at_100_diff1
value: 20.570052839937468
- type: nauc_ndcg_at_100_max
value: 26.21605034405486
- type: nauc_ndcg_at_100_std
value: -25.359817188805028
- type: nauc_ndcg_at_10_diff1
value: 21.241423075073467
- type: nauc_ndcg_at_10_max
value: 24.599199195239475
- type: nauc_ndcg_at_10_std
value: -28.404540333309008
- type: nauc_ndcg_at_1_diff1
value: 23.406748619244368
- type: nauc_ndcg_at_1_max
value: 29.058228240823553
- type: nauc_ndcg_at_1_std
value: -26.450169820901078
- type: nauc_ndcg_at_20_diff1
value: 20.740460046196873
- type: nauc_ndcg_at_20_max
value: 24.82380195169634
- type: nauc_ndcg_at_20_std
value: -27.376298834244313
- type: nauc_ndcg_at_3_diff1
value: 19.994948682426504
- type: nauc_ndcg_at_3_max
value: 26.153790759405105
- type: nauc_ndcg_at_3_std
value: -27.194548404540885
- type: nauc_ndcg_at_5_diff1
value: 21.48414272096384
- type: nauc_ndcg_at_5_max
value: 25.239652015076373
- type: nauc_ndcg_at_5_std
value: -28.2620160957961
- type: nauc_precision_at_1000_diff1
value: -0.7557639926687744
- type: nauc_precision_at_1000_max
value: 24.265591636994436
- type: nauc_precision_at_1000_std
value: 16.833104654292654
- type: nauc_precision_at_100_diff1
value: 4.647847665941115
- type: nauc_precision_at_100_max
value: 24.42192644844434
- type: nauc_precision_at_100_std
value: 0.2718848568876648
- type: nauc_precision_at_10_diff1
value: 9.465969286722654
- type: nauc_precision_at_10_max
value: 27.448993150448043
- type: nauc_precision_at_10_std
value: -16.519099596502212
- type: nauc_precision_at_1_diff1
value: 23.406748619244368
- type: nauc_precision_at_1_max
value: 29.058228240823553
- type: nauc_precision_at_1_std
value: -26.450169820901078
- type: nauc_precision_at_20_diff1
value: 8.021421615668114
- type: nauc_precision_at_20_max
value: 26.18556481398635
- type: nauc_precision_at_20_std
value: -12.207152108668367
- type: nauc_precision_at_3_diff1
value: 11.783572803634241
- type: nauc_precision_at_3_max
value: 29.259715774978893
- type: nauc_precision_at_3_std
value: -20.407524967717425
- type: nauc_precision_at_5_diff1
value: 10.371728615220821
- type: nauc_precision_at_5_max
value: 30.270642833482864
- type: nauc_precision_at_5_std
value: -18.407334880575494
- type: nauc_recall_at_1000_diff1
value: 6.008969959111555
- type: nauc_recall_at_1000_max
value: 39.79691734058127
- type: nauc_recall_at_1000_std
value: 32.43591825510109
- type: nauc_recall_at_100_diff1
value: 15.2374566058917
- type: nauc_recall_at_100_max
value: 23.058785539503717
- type: nauc_recall_at_100_std
value: -15.962888794058165
- type: nauc_recall_at_10_diff1
value: 19.46184821807753
- type: nauc_recall_at_10_max
value: 19.001003513986866
- type: nauc_recall_at_10_std
value: -27.753332786663876
- type: nauc_recall_at_1_diff1
value: 28.87454015638211
- type: nauc_recall_at_1_max
value: 17.50681123879997
- type: nauc_recall_at_1_std
value: -30.382831850562432
- type: nauc_recall_at_20_diff1
value: 17.237090858517405
- type: nauc_recall_at_20_max
value: 18.42118474134871
- type: nauc_recall_at_20_std
value: -24.862787724031957
- type: nauc_recall_at_3_diff1
value: 18.813019521758577
- type: nauc_recall_at_3_max
value: 19.198572333053544
- type: nauc_recall_at_3_std
value: -28.5644958605618
- type: nauc_recall_at_5_diff1
value: 20.247501986329482
- type: nauc_recall_at_5_max
value: 21.121526202170358
- type: nauc_recall_at_5_std
value: -27.220378617864853
- type: ndcg_at_1
value: 30.318
- type: ndcg_at_10
value: 34.042
- type: ndcg_at_100
value: 42.733
- type: ndcg_at_1000
value: 46.015
- type: ndcg_at_20
value: 37.053999999999995
- type: ndcg_at_3
value: 29.254
- type: ndcg_at_5
value: 30.514000000000003
- type: precision_at_1
value: 30.318
- type: precision_at_10
value: 10.981
- type: precision_at_100
value: 1.889
- type: precision_at_1000
value: 0.234
- type: precision_at_20
value: 6.643000000000001
- type: precision_at_3
value: 22.166
- type: precision_at_5
value: 17.477999999999998
- type: recall_at_1
value: 13.236
- type: recall_at_10
value: 41.461
- type: recall_at_100
value: 75.008
- type: recall_at_1000
value: 96.775
- type: recall_at_20
value: 50.754
- type: recall_at_3
value: 26.081
- type: recall_at_5
value: 33.168
task:
type: Retrieval
- dataset:
config: eng-cmn
name: MTEB XPQARetrieval (eng-cmn)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 37.504
- type: map_at_1
value: 16.019
- type: map_at_10
value: 30.794
- type: map_at_100
value: 33.157
- type: map_at_1000
value: 33.324999999999996
- type: map_at_20
value: 32.161
- type: map_at_3
value: 25.372
- type: map_at_5
value: 28.246
- type: mrr_at_1
value: 30.461165048543688
- type: mrr_at_10
value: 39.393107566651224
- type: mrr_at_100
value: 40.570039540602295
- type: mrr_at_1000
value: 40.6306116407744
- type: mrr_at_20
value: 40.09428159978876
- type: mrr_at_3
value: 37.176375404530745
- type: mrr_at_5
value: 38.09870550161812
- type: nauc_map_at_1000_diff1
value: 30.82306881892873
- type: nauc_map_at_1000_max
value: 5.877636000666466
- type: nauc_map_at_1000_std
value: -30.7140513386797
- type: nauc_map_at_100_diff1
value: 30.85192449151961
- type: nauc_map_at_100_max
value: 5.809195131550909
- type: nauc_map_at_100_std
value: -30.838556702972063
- type: nauc_map_at_10_diff1
value: 30.50359163635058
- type: nauc_map_at_10_max
value: 6.373491595869303
- type: nauc_map_at_10_std
value: -29.89368007827676
- type: nauc_map_at_1_diff1
value: 38.60240510083884
- type: nauc_map_at_1_max
value: 10.407392664609139
- type: nauc_map_at_1_std
value: -17.76327278732833
- type: nauc_map_at_20_diff1
value: 30.897489125753598
- type: nauc_map_at_20_max
value: 5.9303381898248
- type: nauc_map_at_20_std
value: -30.863345188760515
- type: nauc_map_at_3_diff1
value: 32.8150951852729
- type: nauc_map_at_3_max
value: 7.671931402215177
- type: nauc_map_at_3_std
value: -25.654809758216533
- type: nauc_map_at_5_diff1
value: 31.19558194781019
- type: nauc_map_at_5_max
value: 6.426885613116939
- type: nauc_map_at_5_std
value: -28.609027858850016
- type: nauc_mrr_at_1000_diff1
value: 30.7596332048733
- type: nauc_mrr_at_1000_max
value: 1.1970748115580212
- type: nauc_mrr_at_1000_std
value: -34.647570668150216
- type: nauc_mrr_at_100_diff1
value: 30.74693370788581
- type: nauc_mrr_at_100_max
value: 1.1673272262754841
- type: nauc_mrr_at_100_std
value: -34.67761028542745
- type: nauc_mrr_at_10_diff1
value: 30.537820575183076
- type: nauc_mrr_at_10_max
value: 1.0261868725502707
- type: nauc_mrr_at_10_std
value: -34.999990560631204
- type: nauc_mrr_at_1_diff1
value: 35.51868580113285
- type: nauc_mrr_at_1_max
value: 5.117103773147307
- type: nauc_mrr_at_1_std
value: -30.633913466736956
- type: nauc_mrr_at_20_diff1
value: 30.67318175430903
- type: nauc_mrr_at_20_max
value: 1.0979983974981327
- type: nauc_mrr_at_20_std
value: -34.8388339739997
- type: nauc_mrr_at_3_diff1
value: 30.884642006045702
- type: nauc_mrr_at_3_max
value: 1.7970996544095983
- type: nauc_mrr_at_3_std
value: -34.290172894906085
- type: nauc_mrr_at_5_diff1
value: 30.89687518368571
- type: nauc_mrr_at_5_max
value: 1.2123714988495347
- type: nauc_mrr_at_5_std
value: -35.01704580471926
- type: nauc_ndcg_at_1000_diff1
value: 29.214476799077342
- type: nauc_ndcg_at_1000_max
value: 3.6379035546112872
- type: nauc_ndcg_at_1000_std
value: -32.35757522049194
- type: nauc_ndcg_at_100_diff1
value: 29.130004541376298
- type: nauc_ndcg_at_100_max
value: 2.9580589185293045
- type: nauc_ndcg_at_100_std
value: -33.26884643871724
- type: nauc_ndcg_at_10_diff1
value: 28.521001084366393
- type: nauc_ndcg_at_10_max
value: 3.630223957267483
- type: nauc_ndcg_at_10_std
value: -33.14524140940815
- type: nauc_ndcg_at_1_diff1
value: 35.51868580113285
- type: nauc_ndcg_at_1_max
value: 5.117103773147307
- type: nauc_ndcg_at_1_std
value: -30.633913466736956
- type: nauc_ndcg_at_20_diff1
value: 29.194462756848782
- type: nauc_ndcg_at_20_max
value: 2.61162903136461
- type: nauc_ndcg_at_20_std
value: -34.59161403211834
- type: nauc_ndcg_at_3_diff1
value: 30.183555327135203
- type: nauc_ndcg_at_3_max
value: 5.61949040917093
- type: nauc_ndcg_at_3_std
value: -30.350117794058175
- type: nauc_ndcg_at_5_diff1
value: 29.74420394139971
- type: nauc_ndcg_at_5_max
value: 3.952183813937688
- type: nauc_ndcg_at_5_std
value: -31.807833795302038
- type: nauc_precision_at_1000_diff1
value: -5.467049121617333
- type: nauc_precision_at_1000_max
value: -3.993986884198271
- type: nauc_precision_at_1000_std
value: -13.703967324212224
- type: nauc_precision_at_100_diff1
value: 1.5585428307943647
- type: nauc_precision_at_100_max
value: -4.250455723613214
- type: nauc_precision_at_100_std
value: -22.294689856776493
- type: nauc_precision_at_10_diff1
value: 11.076036917255259
- type: nauc_precision_at_10_max
value: -1.5859394644365377
- type: nauc_precision_at_10_std
value: -34.94912594413202
- type: nauc_precision_at_1_diff1
value: 35.51868580113285
- type: nauc_precision_at_1_max
value: 5.117103773147307
- type: nauc_precision_at_1_std
value: -30.633913466736956
- type: nauc_precision_at_20_diff1
value: 9.311484455773828
- type: nauc_precision_at_20_max
value: -3.678383428592432
- type: nauc_precision_at_20_std
value: -33.700002761401635
- type: nauc_precision_at_3_diff1
value: 19.2787260874381
- type: nauc_precision_at_3_max
value: 0.18292109396940018
- type: nauc_precision_at_3_std
value: -35.23939824276542
- type: nauc_precision_at_5_diff1
value: 14.97930592298584
- type: nauc_precision_at_5_max
value: -1.63540635880963
- type: nauc_precision_at_5_std
value: -35.908283558321315
- type: nauc_recall_at_1000_diff1
value: 26.63056473607804
- type: nauc_recall_at_1000_max
value: 62.7304558520689
- type: nauc_recall_at_1000_std
value: 58.12421701377561
- type: nauc_recall_at_100_diff1
value: 21.42127379898579
- type: nauc_recall_at_100_max
value: 1.4748203516921914
- type: nauc_recall_at_100_std
value: -27.56467339041136
- type: nauc_recall_at_10_diff1
value: 21.20479652609812
- type: nauc_recall_at_10_max
value: 1.7394881489709888
- type: nauc_recall_at_10_std
value: -32.15116902585072
- type: nauc_recall_at_1_diff1
value: 38.60240510083884
- type: nauc_recall_at_1_max
value: 10.407392664609139
- type: nauc_recall_at_1_std
value: -17.76327278732833
- type: nauc_recall_at_20_diff1
value: 23.049652721582632
- type: nauc_recall_at_20_max
value: -1.7715787106286838
- type: nauc_recall_at_20_std
value: -36.14203686002867
- type: nauc_recall_at_3_diff1
value: 26.522179829461873
- type: nauc_recall_at_3_max
value: 6.078208732431124
- type: nauc_recall_at_3_std
value: -25.02625711226274
- type: nauc_recall_at_5_diff1
value: 24.19538553561693
- type: nauc_recall_at_5_max
value: 2.4963810785503524
- type: nauc_recall_at_5_std
value: -30.449635496921257
- type: ndcg_at_1
value: 30.461
- type: ndcg_at_10
value: 37.504
- type: ndcg_at_100
value: 46.156000000000006
- type: ndcg_at_1000
value: 48.985
- type: ndcg_at_20
value: 41.025
- type: ndcg_at_3
value: 32.165
- type: ndcg_at_5
value: 33.072
- type: precision_at_1
value: 30.461
- type: precision_at_10
value: 11.032
- type: precision_at_100
value: 1.8870000000000002
- type: precision_at_1000
value: 0.22499999999999998
- type: precision_at_20
value: 6.833
- type: precision_at_3
value: 22.532
- type: precision_at_5
value: 16.966
- type: recall_at_1
value: 16.019
- type: recall_at_10
value: 47.557
- type: recall_at_100
value: 80.376
- type: recall_at_1000
value: 98.904
- type: recall_at_20
value: 58.48100000000001
- type: recall_at_3
value: 30.682
- type: recall_at_5
value: 36.714999999999996
task:
type: Retrieval
- dataset:
config: eng-spa
name: MTEB XPQARetrieval (eng-spa)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 53.359
- type: map_at_1
value: 22.892000000000003
- type: map_at_10
value: 45.773
- type: map_at_100
value: 47.778999999999996
- type: map_at_1000
value: 47.882999999999996
- type: map_at_20
value: 46.869
- type: map_at_3
value: 37.643
- type: map_at_5
value: 43.120999999999995
- type: mrr_at_1
value: 47.28877679697352
- type: mrr_at_10
value: 56.95890630316857
- type: mrr_at_100
value: 57.71103367009639
- type: mrr_at_1000
value: 57.73661441948852
- type: mrr_at_20
value: 57.37701091311334
- type: mrr_at_3
value: 54.74989491382929
- type: mrr_at_5
value: 56.08659100462372
- type: nauc_map_at_1000_diff1
value: 27.8347129954991
- type: nauc_map_at_1000_max
value: 38.04300600762859
- type: nauc_map_at_1000_std
value: -18.294653328262868
- type: nauc_map_at_100_diff1
value: 27.818449297770858
- type: nauc_map_at_100_max
value: 38.03533462156633
- type: nauc_map_at_100_std
value: -18.332989980880644
- type: nauc_map_at_10_diff1
value: 27.520664180018358
- type: nauc_map_at_10_max
value: 37.67109855753314
- type: nauc_map_at_10_std
value: -18.496721673888683
- type: nauc_map_at_1_diff1
value: 37.56020148060502
- type: nauc_map_at_1_max
value: 10.298394230150745
- type: nauc_map_at_1_std
value: -20.41359936101547
- type: nauc_map_at_20_diff1
value: 27.615023038189722
- type: nauc_map_at_20_max
value: 37.808525116320254
- type: nauc_map_at_20_std
value: -18.49235775420803
- type: nauc_map_at_3_diff1
value: 30.797347567428424
- type: nauc_map_at_3_max
value: 29.374407828869497
- type: nauc_map_at_3_std
value: -19.75905772914969
- type: nauc_map_at_5_diff1
value: 28.431802888884803
- type: nauc_map_at_5_max
value: 35.57723911610521
- type: nauc_map_at_5_std
value: -19.093588845366824
- type: nauc_mrr_at_1000_diff1
value: 33.263611009054586
- type: nauc_mrr_at_1000_max
value: 40.620639901613664
- type: nauc_mrr_at_1000_std
value: -17.083016011032036
- type: nauc_mrr_at_100_diff1
value: 33.25375012559163
- type: nauc_mrr_at_100_max
value: 40.62376205172005
- type: nauc_mrr_at_100_std
value: -17.091930575226684
- type: nauc_mrr_at_10_diff1
value: 33.05787202690095
- type: nauc_mrr_at_10_max
value: 40.4516362611674
- type: nauc_mrr_at_10_std
value: -17.088910666499892
- type: nauc_mrr_at_1_diff1
value: 36.424151087824555
- type: nauc_mrr_at_1_max
value: 40.955715626650445
- type: nauc_mrr_at_1_std
value: -16.56636409111209
- type: nauc_mrr_at_20_diff1
value: 33.12029456858138
- type: nauc_mrr_at_20_max
value: 40.56409347292635
- type: nauc_mrr_at_20_std
value: -17.102034817242068
- type: nauc_mrr_at_3_diff1
value: 33.52377926814156
- type: nauc_mrr_at_3_max
value: 40.824911575046876
- type: nauc_mrr_at_3_std
value: -16.855935748811092
- type: nauc_mrr_at_5_diff1
value: 33.08646471768442
- type: nauc_mrr_at_5_max
value: 40.59323589955881
- type: nauc_mrr_at_5_std
value: -16.77829710500156
- type: nauc_ndcg_at_1000_diff1
value: 28.741186244590207
- type: nauc_ndcg_at_1000_max
value: 40.0113825410539
- type: nauc_ndcg_at_1000_std
value: -17.15655081742458
- type: nauc_ndcg_at_100_diff1
value: 28.680521359782972
- type: nauc_ndcg_at_100_max
value: 39.94751899984445
- type: nauc_ndcg_at_100_std
value: -17.82813814043932
- type: nauc_ndcg_at_10_diff1
value: 27.22858072673168
- type: nauc_ndcg_at_10_max
value: 38.600188968554725
- type: nauc_ndcg_at_10_std
value: -18.517203924893614
- type: nauc_ndcg_at_1_diff1
value: 36.424151087824555
- type: nauc_ndcg_at_1_max
value: 40.955715626650445
- type: nauc_ndcg_at_1_std
value: -16.56636409111209
- type: nauc_ndcg_at_20_diff1
value: 27.56875900623774
- type: nauc_ndcg_at_20_max
value: 38.95264310199067
- type: nauc_ndcg_at_20_std
value: -18.709973965688445
- type: nauc_ndcg_at_3_diff1
value: 28.682842749851574
- type: nauc_ndcg_at_3_max
value: 38.361215408395964
- type: nauc_ndcg_at_3_std
value: -16.800291231827515
- type: nauc_ndcg_at_5_diff1
value: 28.178239259093484
- type: nauc_ndcg_at_5_max
value: 36.77096292606479
- type: nauc_ndcg_at_5_std
value: -18.718861696641145
- type: nauc_precision_at_1000_diff1
value: -7.3686253252869305
- type: nauc_precision_at_1000_max
value: 31.98896996987639
- type: nauc_precision_at_1000_std
value: 13.125659676392267
- type: nauc_precision_at_100_diff1
value: -2.8239113056969156
- type: nauc_precision_at_100_max
value: 36.95062472971812
- type: nauc_precision_at_100_std
value: 7.230228733647562
- type: nauc_precision_at_10_diff1
value: 2.5515545798843555
- type: nauc_precision_at_10_max
value: 45.46146019314904
- type: nauc_precision_at_10_std
value: -1.3249340536211553
- type: nauc_precision_at_1_diff1
value: 36.424151087824555
- type: nauc_precision_at_1_max
value: 40.955715626650445
- type: nauc_precision_at_1_std
value: -16.56636409111209
- type: nauc_precision_at_20_diff1
value: 0.7202861770489576
- type: nauc_precision_at_20_max
value: 41.9937596214609
- type: nauc_precision_at_20_std
value: 0.2756400069730064
- type: nauc_precision_at_3_diff1
value: 12.89221206929447
- type: nauc_precision_at_3_max
value: 48.57775126381142
- type: nauc_precision_at_3_std
value: -8.042242254131068
- type: nauc_precision_at_5_diff1
value: 7.063616193387763
- type: nauc_precision_at_5_max
value: 47.26496887331675
- type: nauc_precision_at_5_std
value: -4.735805200913049
- type: nauc_recall_at_1000_diff1
value: 2.6650052980682224
- type: nauc_recall_at_1000_max
value: 81.94826279951472
- type: nauc_recall_at_1000_std
value: 48.46012388224573
- type: nauc_recall_at_100_diff1
value: 24.516371948375827
- type: nauc_recall_at_100_max
value: 39.17639620389552
- type: nauc_recall_at_100_std
value: -17.884197602579533
- type: nauc_recall_at_10_diff1
value: 19.93892097640112
- type: nauc_recall_at_10_max
value: 33.079079440022106
- type: nauc_recall_at_10_std
value: -20.22227622801884
- type: nauc_recall_at_1_diff1
value: 37.56020148060502
- type: nauc_recall_at_1_max
value: 10.298394230150745
- type: nauc_recall_at_1_std
value: -20.41359936101547
- type: nauc_recall_at_20_diff1
value: 20.363784035670633
- type: nauc_recall_at_20_max
value: 33.39352971625336
- type: nauc_recall_at_20_std
value: -21.712050932168875
- type: nauc_recall_at_3_diff1
value: 26.220072121604655
- type: nauc_recall_at_3_max
value: 25.853218030218507
- type: nauc_recall_at_3_std
value: -17.830613372910907
- type: nauc_recall_at_5_diff1
value: 22.25850162680252
- type: nauc_recall_at_5_max
value: 30.89620539042785
- type: nauc_recall_at_5_std
value: -19.16786434439169
- type: ndcg_at_1
value: 47.288999999999994
- type: ndcg_at_10
value: 53.359
- type: ndcg_at_100
value: 60.25899999999999
- type: ndcg_at_1000
value: 61.902
- type: ndcg_at_20
value: 56.025000000000006
- type: ndcg_at_3
value: 47.221999999999994
- type: ndcg_at_5
value: 49.333
- type: precision_at_1
value: 47.288999999999994
- type: precision_at_10
value: 16.003
- type: precision_at_100
value: 2.221
- type: precision_at_1000
value: 0.246
- type: precision_at_20
value: 8.985
- type: precision_at_3
value: 34.510000000000005
- type: precision_at_5
value: 26.961000000000002
- type: recall_at_1
value: 22.892000000000003
- type: recall_at_10
value: 62.928
- type: recall_at_100
value: 89.105
- type: recall_at_1000
value: 99.319
- type: recall_at_20
value: 71.387
- type: recall_at_3
value: 43.492999999999995
- type: recall_at_5
value: 53.529
task:
type: Retrieval
- dataset:
config: eng-fra
name: MTEB XPQARetrieval (eng-fra)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 54.888000000000005
- type: map_at_1
value: 26.079
- type: map_at_10
value: 47.434
- type: map_at_100
value: 49.376
- type: map_at_1000
value: 49.461
- type: map_at_20
value: 48.634
- type: map_at_3
value: 40.409
- type: map_at_5
value: 44.531
- type: mrr_at_1
value: 46.86248331108144
- type: mrr_at_10
value: 56.45506177548896
- type: mrr_at_100
value: 57.20360629445577
- type: mrr_at_1000
value: 57.227004696897986
- type: mrr_at_20
value: 56.905302765737865
- type: mrr_at_3
value: 54.09434801958164
- type: mrr_at_5
value: 55.40943480195811
- type: nauc_map_at_1000_diff1
value: 37.739936045535885
- type: nauc_map_at_1000_max
value: 35.92625003516368
- type: nauc_map_at_1000_std
value: -15.825119611638398
- type: nauc_map_at_100_diff1
value: 37.71697833661983
- type: nauc_map_at_100_max
value: 35.91174068136317
- type: nauc_map_at_100_std
value: -15.838841891589006
- type: nauc_map_at_10_diff1
value: 37.52309268219689
- type: nauc_map_at_10_max
value: 35.4887130483351
- type: nauc_map_at_10_std
value: -16.61132378136234
- type: nauc_map_at_1_diff1
value: 42.705087329207984
- type: nauc_map_at_1_max
value: 12.047671550242974
- type: nauc_map_at_1_std
value: -17.156030827065834
- type: nauc_map_at_20_diff1
value: 37.59446680137666
- type: nauc_map_at_20_max
value: 35.80559546695052
- type: nauc_map_at_20_std
value: -16.158338316249786
- type: nauc_map_at_3_diff1
value: 38.618415267131816
- type: nauc_map_at_3_max
value: 27.030227996183925
- type: nauc_map_at_3_std
value: -18.962500694157857
- type: nauc_map_at_5_diff1
value: 37.980845601534256
- type: nauc_map_at_5_max
value: 32.82374761283266
- type: nauc_map_at_5_std
value: -17.856875825229565
- type: nauc_mrr_at_1000_diff1
value: 40.26059509279346
- type: nauc_mrr_at_1000_max
value: 39.28453752990871
- type: nauc_mrr_at_1000_std
value: -13.306217279524212
- type: nauc_mrr_at_100_diff1
value: 40.23390833398881
- type: nauc_mrr_at_100_max
value: 39.26041461025653
- type: nauc_mrr_at_100_std
value: -13.317700798873153
- type: nauc_mrr_at_10_diff1
value: 40.163737640180145
- type: nauc_mrr_at_10_max
value: 39.27138538165913
- type: nauc_mrr_at_10_std
value: -13.472971360323038
- type: nauc_mrr_at_1_diff1
value: 42.95339241383707
- type: nauc_mrr_at_1_max
value: 40.62982307619158
- type: nauc_mrr_at_1_std
value: -10.429597045942748
- type: nauc_mrr_at_20_diff1
value: 40.23703505923782
- type: nauc_mrr_at_20_max
value: 39.27051308063652
- type: nauc_mrr_at_20_std
value: -13.390197643922038
- type: nauc_mrr_at_3_diff1
value: 40.5721313555661
- type: nauc_mrr_at_3_max
value: 39.254774354468594
- type: nauc_mrr_at_3_std
value: -13.773803807863827
- type: nauc_mrr_at_5_diff1
value: 40.41081287079734
- type: nauc_mrr_at_5_max
value: 39.515241132077335
- type: nauc_mrr_at_5_std
value: -13.306544090087336
- type: nauc_ndcg_at_1000_diff1
value: 38.04772268296103
- type: nauc_ndcg_at_1000_max
value: 38.03364565521176
- type: nauc_ndcg_at_1000_std
value: -14.203182726102263
- type: nauc_ndcg_at_100_diff1
value: 37.51752795463643
- type: nauc_ndcg_at_100_max
value: 37.809671511710604
- type: nauc_ndcg_at_100_std
value: -13.880578225081408
- type: nauc_ndcg_at_10_diff1
value: 36.78438984005559
- type: nauc_ndcg_at_10_max
value: 36.98105155993232
- type: nauc_ndcg_at_10_std
value: -16.886308645939113
- type: nauc_ndcg_at_1_diff1
value: 42.95339241383707
- type: nauc_ndcg_at_1_max
value: 40.62982307619158
- type: nauc_ndcg_at_1_std
value: -10.429597045942748
- type: nauc_ndcg_at_20_diff1
value: 36.94164323893683
- type: nauc_ndcg_at_20_max
value: 37.333583379288285
- type: nauc_ndcg_at_20_std
value: -15.853318071434716
- type: nauc_ndcg_at_3_diff1
value: 36.905604845477384
- type: nauc_ndcg_at_3_max
value: 35.10252586688781
- type: nauc_ndcg_at_3_std
value: -17.128435988977742
- type: nauc_ndcg_at_5_diff1
value: 37.96742463612705
- type: nauc_ndcg_at_5_max
value: 34.65945109443365
- type: nauc_ndcg_at_5_std
value: -17.916428667861183
- type: nauc_precision_at_1000_diff1
value: -3.740861894117653
- type: nauc_precision_at_1000_max
value: 31.993854396874177
- type: nauc_precision_at_1000_std
value: 17.445629474196448
- type: nauc_precision_at_100_diff1
value: -0.4825948747911606
- type: nauc_precision_at_100_max
value: 35.834638448782954
- type: nauc_precision_at_100_std
value: 16.82718796079511
- type: nauc_precision_at_10_diff1
value: 8.285949866268147
- type: nauc_precision_at_10_max
value: 45.3292519726866
- type: nauc_precision_at_10_std
value: 4.5574850748441555
- type: nauc_precision_at_1_diff1
value: 42.95339241383707
- type: nauc_precision_at_1_max
value: 40.62982307619158
- type: nauc_precision_at_1_std
value: -10.429597045942748
- type: nauc_precision_at_20_diff1
value: 4.890590733611442
- type: nauc_precision_at_20_max
value: 41.83051757078859
- type: nauc_precision_at_20_std
value: 9.197347125630467
- type: nauc_precision_at_3_diff1
value: 17.79940075411976
- type: nauc_precision_at_3_max
value: 45.224103632426946
- type: nauc_precision_at_3_std
value: -5.017203435609909
- type: nauc_precision_at_5_diff1
value: 13.548063145911929
- type: nauc_precision_at_5_max
value: 46.84837547409909
- type: nauc_precision_at_5_std
value: -0.8925939386354484
- type: nauc_recall_at_1000_diff1
value: 74.48441717138078
- type: nauc_recall_at_1000_max
value: 74.66717137705027
- type: nauc_recall_at_1000_std
value: 0.24030117471512125
- type: nauc_recall_at_100_diff1
value: 22.553777341988656
- type: nauc_recall_at_100_max
value: 31.67861029246527
- type: nauc_recall_at_100_std
value: 0.2707450517253687
- type: nauc_recall_at_10_diff1
value: 28.490866614443235
- type: nauc_recall_at_10_max
value: 31.722970141434352
- type: nauc_recall_at_10_std
value: -21.97893365028007
- type: nauc_recall_at_1_diff1
value: 42.705087329207984
- type: nauc_recall_at_1_max
value: 12.047671550242974
- type: nauc_recall_at_1_std
value: -17.156030827065834
- type: nauc_recall_at_20_diff1
value: 27.44043454173112
- type: nauc_recall_at_20_max
value: 31.454281772040716
- type: nauc_recall_at_20_std
value: -20.1735695305415
- type: nauc_recall_at_3_diff1
value: 34.08447534706394
- type: nauc_recall_at_3_max
value: 21.793973773840865
- type: nauc_recall_at_3_std
value: -22.753978372378906
- type: nauc_recall_at_5_diff1
value: 33.59686526199479
- type: nauc_recall_at_5_max
value: 29.188889073761302
- type: nauc_recall_at_5_std
value: -21.96156333744562
- type: ndcg_at_1
value: 46.861999999999995
- type: ndcg_at_10
value: 54.888000000000005
- type: ndcg_at_100
value: 61.477000000000004
- type: ndcg_at_1000
value: 62.768
- type: ndcg_at_20
value: 57.812
- type: ndcg_at_3
value: 48.721
- type: ndcg_at_5
value: 50.282000000000004
- type: precision_at_1
value: 46.861999999999995
- type: precision_at_10
value: 15.167
- type: precision_at_100
value: 2.072
- type: precision_at_1000
value: 0.22499999999999998
- type: precision_at_20
value: 8.672
- type: precision_at_3
value: 33.066
- type: precision_at_5
value: 24.726
- type: recall_at_1
value: 26.079
- type: recall_at_10
value: 66.095
- type: recall_at_100
value: 91.65299999999999
- type: recall_at_1000
value: 99.83999999999999
- type: recall_at_20
value: 75.28
- type: recall_at_3
value: 46.874
- type: recall_at_5
value: 55.062
task:
type: Retrieval
- dataset:
config: pol-eng
name: MTEB XPQARetrieval (pol-eng)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 50.831
- type: map_at_1
value: 25.549
- type: map_at_10
value: 44.432
- type: map_at_100
value: 46.431
- type: map_at_1000
value: 46.525
- type: map_at_20
value: 45.595
- type: map_at_3
value: 38.574000000000005
- type: map_at_5
value: 42.266999999999996
- type: mrr_at_1
value: 43.5006435006435
- type: mrr_at_10
value: 51.561255132683684
- type: mrr_at_100
value: 52.59912482635216
- type: mrr_at_1000
value: 52.631337587043056
- type: mrr_at_20
value: 52.23234440063273
- type: mrr_at_3
value: 48.97039897039895
- type: mrr_at_5
value: 50.31531531531527
- type: nauc_map_at_1000_diff1
value: 35.907901295900174
- type: nauc_map_at_1000_max
value: 24.573763602041687
- type: nauc_map_at_1000_std
value: -29.524077960309313
- type: nauc_map_at_100_diff1
value: 35.86869121827827
- type: nauc_map_at_100_max
value: 24.532343818487494
- type: nauc_map_at_100_std
value: -29.613979124488864
- type: nauc_map_at_10_diff1
value: 35.90171794022391
- type: nauc_map_at_10_max
value: 23.90914892943268
- type: nauc_map_at_10_std
value: -30.43698820061533
- type: nauc_map_at_1_diff1
value: 50.80313333312038
- type: nauc_map_at_1_max
value: 16.649890421888156
- type: nauc_map_at_1_std
value: -22.323989416471683
- type: nauc_map_at_20_diff1
value: 35.77755470212964
- type: nauc_map_at_20_max
value: 24.199895270297034
- type: nauc_map_at_20_std
value: -30.223411960170647
- type: nauc_map_at_3_diff1
value: 38.964124882315936
- type: nauc_map_at_3_max
value: 21.187432510177167
- type: nauc_map_at_3_std
value: -28.976663506389887
- type: nauc_map_at_5_diff1
value: 36.04644236616672
- type: nauc_map_at_5_max
value: 23.501186429317094
- type: nauc_map_at_5_std
value: -30.068144596060748
- type: nauc_mrr_at_1000_diff1
value: 41.36555452105447
- type: nauc_mrr_at_1000_max
value: 26.376799280402867
- type: nauc_mrr_at_1000_std
value: -30.008603028757424
- type: nauc_mrr_at_100_diff1
value: 41.35523965220727
- type: nauc_mrr_at_100_max
value: 26.402612115967706
- type: nauc_mrr_at_100_std
value: -29.991754627128024
- type: nauc_mrr_at_10_diff1
value: 41.001395127259315
- type: nauc_mrr_at_10_max
value: 26.104860505051384
- type: nauc_mrr_at_10_std
value: -30.38420449487516
- type: nauc_mrr_at_1_diff1
value: 44.882846373248206
- type: nauc_mrr_at_1_max
value: 26.61905322890808
- type: nauc_mrr_at_1_std
value: -28.724565662206153
- type: nauc_mrr_at_20_diff1
value: 41.278009142648834
- type: nauc_mrr_at_20_max
value: 26.284565529087295
- type: nauc_mrr_at_20_std
value: -30.19549140549242
- type: nauc_mrr_at_3_diff1
value: 41.74663893951077
- type: nauc_mrr_at_3_max
value: 26.263048464325884
- type: nauc_mrr_at_3_std
value: -30.676733442965688
- type: nauc_mrr_at_5_diff1
value: 41.11461477846568
- type: nauc_mrr_at_5_max
value: 25.94713927964926
- type: nauc_mrr_at_5_std
value: -30.317066480767817
- type: nauc_ndcg_at_1000_diff1
value: 36.34161052445199
- type: nauc_ndcg_at_1000_max
value: 26.321036033696206
- type: nauc_ndcg_at_1000_std
value: -27.59146917115399
- type: nauc_ndcg_at_100_diff1
value: 35.66557800007035
- type: nauc_ndcg_at_100_max
value: 26.282211208336136
- type: nauc_ndcg_at_100_std
value: -27.905634124461333
- type: nauc_ndcg_at_10_diff1
value: 35.34872687407275
- type: nauc_ndcg_at_10_max
value: 24.018561915792272
- type: nauc_ndcg_at_10_std
value: -31.57712772869015
- type: nauc_ndcg_at_1_diff1
value: 44.882846373248206
- type: nauc_ndcg_at_1_max
value: 26.865602442152554
- type: nauc_ndcg_at_1_std
value: -28.509295454329152
- type: nauc_ndcg_at_20_diff1
value: 35.46177768045546
- type: nauc_ndcg_at_20_max
value: 24.921273675141542
- type: nauc_ndcg_at_20_std
value: -30.84348812979793
- type: nauc_ndcg_at_3_diff1
value: 36.84688489063923
- type: nauc_ndcg_at_3_max
value: 24.088513229463736
- type: nauc_ndcg_at_3_std
value: -30.05640995379297
- type: nauc_ndcg_at_5_diff1
value: 35.623143276796185
- type: nauc_ndcg_at_5_max
value: 23.76654250474061
- type: nauc_ndcg_at_5_std
value: -30.87847710074466
- type: nauc_precision_at_1000_diff1
value: -16.270532533886932
- type: nauc_precision_at_1000_max
value: 17.37365042394671
- type: nauc_precision_at_1000_std
value: 16.27166715693082
- type: nauc_precision_at_100_diff1
value: -13.175264889436313
- type: nauc_precision_at_100_max
value: 19.488571046893963
- type: nauc_precision_at_100_std
value: 9.055429698007798
- type: nauc_precision_at_10_diff1
value: 0.6806938753592942
- type: nauc_precision_at_10_max
value: 21.933083960522616
- type: nauc_precision_at_10_std
value: -18.2147036942157
- type: nauc_precision_at_1_diff1
value: 44.882846373248206
- type: nauc_precision_at_1_max
value: 26.865602442152554
- type: nauc_precision_at_1_std
value: -28.509295454329152
- type: nauc_precision_at_20_diff1
value: -4.318119150162302
- type: nauc_precision_at_20_max
value: 21.089702301041687
- type: nauc_precision_at_20_std
value: -10.333077681479546
- type: nauc_precision_at_3_diff1
value: 11.496076462671107
- type: nauc_precision_at_3_max
value: 23.018301549827008
- type: nauc_precision_at_3_std
value: -23.98652995416454
- type: nauc_precision_at_5_diff1
value: 4.271050668117355
- type: nauc_precision_at_5_max
value: 23.61051327966779
- type: nauc_precision_at_5_std
value: -21.557618503107847
- type: nauc_recall_at_1000_diff1
value: 62.23955911850697
- type: nauc_recall_at_1000_max
value: 83.20491723365542
- type: nauc_recall_at_1000_std
value: 66.5173462601958
- type: nauc_recall_at_100_diff1
value: 20.503778602988177
- type: nauc_recall_at_100_max
value: 29.379026288767506
- type: nauc_recall_at_100_std
value: -16.139120874540573
- type: nauc_recall_at_10_diff1
value: 27.659110249896557
- type: nauc_recall_at_10_max
value: 19.69557968026332
- type: nauc_recall_at_10_std
value: -33.95657132767551
- type: nauc_recall_at_1_diff1
value: 50.80313333312038
- type: nauc_recall_at_1_max
value: 16.649890421888156
- type: nauc_recall_at_1_std
value: -22.323989416471683
- type: nauc_recall_at_20_diff1
value: 27.084453724565176
- type: nauc_recall_at_20_max
value: 21.40080632474994
- type: nauc_recall_at_20_std
value: -32.83683639340239
- type: nauc_recall_at_3_diff1
value: 34.32950941333572
- type: nauc_recall_at_3_max
value: 18.55616615958199
- type: nauc_recall_at_3_std
value: -30.375983327454076
- type: nauc_recall_at_5_diff1
value: 29.44516734974564
- type: nauc_recall_at_5_max
value: 20.630543534300312
- type: nauc_recall_at_5_std
value: -31.30763062499127
- type: ndcg_at_1
value: 43.501
- type: ndcg_at_10
value: 50.831
- type: ndcg_at_100
value: 58.17099999999999
- type: ndcg_at_1000
value: 59.705
- type: ndcg_at_20
value: 54.047999999999995
- type: ndcg_at_3
value: 44.549
- type: ndcg_at_5
value: 46.861000000000004
- type: precision_at_1
value: 43.501
- type: precision_at_10
value: 12.895999999999999
- type: precision_at_100
value: 1.9
- type: precision_at_1000
value: 0.21
- type: precision_at_20
value: 7.593
- type: precision_at_3
value: 29.215000000000003
- type: precision_at_5
value: 21.57
- type: recall_at_1
value: 25.549
- type: recall_at_10
value: 61.795
- type: recall_at_100
value: 90.019
- type: recall_at_1000
value: 99.807
- type: recall_at_20
value: 72.096
- type: recall_at_3
value: 43.836999999999996
- type: recall_at_5
value: 51.714000000000006
task:
type: Retrieval
- dataset:
config: pol-pol
name: MTEB XPQARetrieval (pol-pol)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 53.70399999999999
- type: map_at_1
value: 27.739000000000004
- type: map_at_10
value: 47.469
- type: map_at_100
value: 49.392
- type: map_at_1000
value: 49.483
- type: map_at_20
value: 48.646
- type: map_at_3
value: 41.467
- type: map_at_5
value: 45.467
- type: mrr_at_1
value: 47.00636942675159
- type: mrr_at_10
value: 54.63699322616519
- type: mrr_at_100
value: 55.54525182833755
- type: mrr_at_1000
value: 55.581331515356155
- type: mrr_at_20
value: 55.22918377451415
- type: mrr_at_3
value: 52.03821656050952
- type: mrr_at_5
value: 53.38216560509549
- type: nauc_map_at_1000_diff1
value: 45.03530825034854
- type: nauc_map_at_1000_max
value: 34.22740272603397
- type: nauc_map_at_1000_std
value: -30.428880484199244
- type: nauc_map_at_100_diff1
value: 44.978704455592805
- type: nauc_map_at_100_max
value: 34.20908357964765
- type: nauc_map_at_100_std
value: -30.47325365059666
- type: nauc_map_at_10_diff1
value: 44.9560579177672
- type: nauc_map_at_10_max
value: 33.70097588985278
- type: nauc_map_at_10_std
value: -31.205563222357885
- type: nauc_map_at_1_diff1
value: 57.94711780881773
- type: nauc_map_at_1_max
value: 21.60278071836319
- type: nauc_map_at_1_std
value: -23.273741268035923
- type: nauc_map_at_20_diff1
value: 44.97859054699532
- type: nauc_map_at_20_max
value: 34.153729150181846
- type: nauc_map_at_20_std
value: -30.97482545902907
- type: nauc_map_at_3_diff1
value: 47.52016138686765
- type: nauc_map_at_3_max
value: 30.176197065298417
- type: nauc_map_at_3_std
value: -29.90628984041898
- type: nauc_map_at_5_diff1
value: 45.36581638257985
- type: nauc_map_at_5_max
value: 33.697200263698036
- type: nauc_map_at_5_std
value: -31.165331120088453
- type: nauc_mrr_at_1000_diff1
value: 53.32889526818364
- type: nauc_mrr_at_1000_max
value: 36.104118340589736
- type: nauc_mrr_at_1000_std
value: -31.321132494516984
- type: nauc_mrr_at_100_diff1
value: 53.30695875258367
- type: nauc_mrr_at_100_max
value: 36.114890079024455
- type: nauc_mrr_at_100_std
value: -31.291749322117447
- type: nauc_mrr_at_10_diff1
value: 53.189084772141435
- type: nauc_mrr_at_10_max
value: 35.939061062282484
- type: nauc_mrr_at_10_std
value: -31.502185884653645
- type: nauc_mrr_at_1_diff1
value: 56.89368291041337
- type: nauc_mrr_at_1_max
value: 36.07581125496313
- type: nauc_mrr_at_1_std
value: -29.703764232519475
- type: nauc_mrr_at_20_diff1
value: 53.23955737199497
- type: nauc_mrr_at_20_max
value: 36.068824838215676
- type: nauc_mrr_at_20_std
value: -31.420039428197594
- type: nauc_mrr_at_3_diff1
value: 53.74385074861207
- type: nauc_mrr_at_3_max
value: 35.57054587735015
- type: nauc_mrr_at_3_std
value: -32.356894834537684
- type: nauc_mrr_at_5_diff1
value: 53.66669556981826
- type: nauc_mrr_at_5_max
value: 36.02102289605049
- type: nauc_mrr_at_5_std
value: -32.030437067359124
- type: nauc_ndcg_at_1000_diff1
value: 46.34900536768847
- type: nauc_ndcg_at_1000_max
value: 35.6314995837715
- type: nauc_ndcg_at_1000_std
value: -28.965103958822624
- type: nauc_ndcg_at_100_diff1
value: 45.1587893788861
- type: nauc_ndcg_at_100_max
value: 35.62430753595297
- type: nauc_ndcg_at_100_std
value: -28.77303405812772
- type: nauc_ndcg_at_10_diff1
value: 44.928781590765965
- type: nauc_ndcg_at_10_max
value: 34.315200006430366
- type: nauc_ndcg_at_10_std
value: -32.05164097076614
- type: nauc_ndcg_at_1_diff1
value: 57.228262350455125
- type: nauc_ndcg_at_1_max
value: 35.645285703387366
- type: nauc_ndcg_at_1_std
value: -29.893553821348718
- type: nauc_ndcg_at_20_diff1
value: 44.959903633039865
- type: nauc_ndcg_at_20_max
value: 35.493022926282755
- type: nauc_ndcg_at_20_std
value: -31.54989291850644
- type: nauc_ndcg_at_3_diff1
value: 46.65266185996905
- type: nauc_ndcg_at_3_max
value: 33.74458119579594
- type: nauc_ndcg_at_3_std
value: -31.493683304534176
- type: nauc_ndcg_at_5_diff1
value: 46.08707037187612
- type: nauc_ndcg_at_5_max
value: 34.7401426055243
- type: nauc_ndcg_at_5_std
value: -32.44390676345172
- type: nauc_precision_at_1000_diff1
value: -12.11355300492561
- type: nauc_precision_at_1000_max
value: 14.490738062121233
- type: nauc_precision_at_1000_std
value: 14.448811005059097
- type: nauc_precision_at_100_diff1
value: -9.742085657181239
- type: nauc_precision_at_100_max
value: 18.030305489251223
- type: nauc_precision_at_100_std
value: 8.213089709529765
- type: nauc_precision_at_10_diff1
value: 5.153466672774969
- type: nauc_precision_at_10_max
value: 27.29412644661678
- type: nauc_precision_at_10_std
value: -15.505053884112355
- type: nauc_precision_at_1_diff1
value: 57.228262350455125
- type: nauc_precision_at_1_max
value: 35.645285703387366
- type: nauc_precision_at_1_std
value: -29.893553821348718
- type: nauc_precision_at_20_diff1
value: -0.6812430761066635
- type: nauc_precision_at_20_max
value: 25.81911286466295
- type: nauc_precision_at_20_std
value: -8.388506222482595
- type: nauc_precision_at_3_diff1
value: 18.263873866510576
- type: nauc_precision_at_3_max
value: 30.879576105862345
- type: nauc_precision_at_3_std
value: -24.0342929870108
- type: nauc_precision_at_5_diff1
value: 10.9905804265327
- type: nauc_precision_at_5_max
value: 30.88468087429045
- type: nauc_precision_at_5_std
value: -20.458684056213507
- type: nauc_recall_at_1000_diff1
value: -64.887668417171
- type: nauc_recall_at_1000_max
value: 52.25501730358092
- type: nauc_recall_at_1000_std
value: 85.13647916200132
- type: nauc_recall_at_100_diff1
value: 18.956777346127655
- type: nauc_recall_at_100_max
value: 36.10473493564588
- type: nauc_recall_at_100_std
value: -10.007474558899949
- type: nauc_recall_at_10_diff1
value: 33.810344497568046
- type: nauc_recall_at_10_max
value: 31.395430183214245
- type: nauc_recall_at_10_std
value: -33.12920524433795
- type: nauc_recall_at_1_diff1
value: 57.94711780881773
- type: nauc_recall_at_1_max
value: 21.60278071836319
- type: nauc_recall_at_1_std
value: -23.273741268035923
- type: nauc_recall_at_20_diff1
value: 31.449657437065397
- type: nauc_recall_at_20_max
value: 34.519574934321945
- type: nauc_recall_at_20_std
value: -33.43406862055647
- type: nauc_recall_at_3_diff1
value: 42.07841848382365
- type: nauc_recall_at_3_max
value: 28.7648772833266
- type: nauc_recall_at_3_std
value: -31.56367736320086
- type: nauc_recall_at_5_diff1
value: 39.21392858246301
- type: nauc_recall_at_5_max
value: 34.28338202081927
- type: nauc_recall_at_5_std
value: -33.725680523721906
- type: ndcg_at_1
value: 46.879
- type: ndcg_at_10
value: 53.70399999999999
- type: ndcg_at_100
value: 60.532
- type: ndcg_at_1000
value: 61.997
- type: ndcg_at_20
value: 56.818999999999996
- type: ndcg_at_3
value: 47.441
- type: ndcg_at_5
value: 49.936
- type: precision_at_1
value: 46.879
- type: precision_at_10
value: 13.376
- type: precision_at_100
value: 1.8980000000000001
- type: precision_at_1000
value: 0.208
- type: precision_at_20
value: 7.771
- type: precision_at_3
value: 30.658
- type: precision_at_5
value: 22.828
- type: recall_at_1
value: 27.739000000000004
- type: recall_at_10
value: 64.197
- type: recall_at_100
value: 90.54100000000001
- type: recall_at_1000
value: 99.90400000000001
- type: recall_at_20
value: 74.178
- type: recall_at_3
value: 46.312
- type: recall_at_5
value: 54.581999999999994
task:
type: Retrieval
- dataset:
config: cmn-eng
name: MTEB XPQARetrieval (cmn-eng)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 64.64
- type: map_at_1
value: 35.858000000000004
- type: map_at_10
value: 58.547000000000004
- type: map_at_100
value: 60.108
- type: map_at_1000
value: 60.153999999999996
- type: map_at_20
value: 59.528000000000006
- type: map_at_3
value: 51.578
- type: map_at_5
value: 56.206999999999994
- type: mrr_at_1
value: 56.95121951219512
- type: mrr_at_10
value: 64.93975029036001
- type: mrr_at_100
value: 65.63357055718294
- type: mrr_at_1000
value: 65.64844109026834
- type: mrr_at_20
value: 65.41280668715439
- type: mrr_at_3
value: 62.68292682926826
- type: mrr_at_5
value: 64.1585365853658
- type: nauc_map_at_1000_diff1
value: 45.82740870907091
- type: nauc_map_at_1000_max
value: 21.9696540066807
- type: nauc_map_at_1000_std
value: -32.028262356639495
- type: nauc_map_at_100_diff1
value: 45.802053117616396
- type: nauc_map_at_100_max
value: 21.946002070290966
- type: nauc_map_at_100_std
value: -32.06190418866229
- type: nauc_map_at_10_diff1
value: 46.017774155748945
- type: nauc_map_at_10_max
value: 21.876909086095544
- type: nauc_map_at_10_std
value: -32.13913568843985
- type: nauc_map_at_1_diff1
value: 56.34671160956164
- type: nauc_map_at_1_max
value: 17.6796949796236
- type: nauc_map_at_1_std
value: -13.741140688066045
- type: nauc_map_at_20_diff1
value: 46.027469176858716
- type: nauc_map_at_20_max
value: 21.80738432042703
- type: nauc_map_at_20_std
value: -32.430379634015395
- type: nauc_map_at_3_diff1
value: 48.40096725254027
- type: nauc_map_at_3_max
value: 21.15442803574233
- type: nauc_map_at_3_std
value: -26.205850292181417
- type: nauc_map_at_5_diff1
value: 45.77800041356389
- type: nauc_map_at_5_max
value: 22.11718771798752
- type: nauc_map_at_5_std
value: -30.32876338031471
- type: nauc_mrr_at_1000_diff1
value: 49.748274798877944
- type: nauc_mrr_at_1000_max
value: 24.547774167219906
- type: nauc_mrr_at_1000_std
value: -32.728447209433504
- type: nauc_mrr_at_100_diff1
value: 49.734549290377856
- type: nauc_mrr_at_100_max
value: 24.536933315055222
- type: nauc_mrr_at_100_std
value: -32.74076335880697
- type: nauc_mrr_at_10_diff1
value: 49.82827711456392
- type: nauc_mrr_at_10_max
value: 24.536773657485075
- type: nauc_mrr_at_10_std
value: -33.05707547166962
- type: nauc_mrr_at_1_diff1
value: 51.954289992321044
- type: nauc_mrr_at_1_max
value: 26.336255074856886
- type: nauc_mrr_at_1_std
value: -29.042962019692446
- type: nauc_mrr_at_20_diff1
value: 49.70938465628863
- type: nauc_mrr_at_20_max
value: 24.433219849576947
- type: nauc_mrr_at_20_std
value: -32.94123791846049
- type: nauc_mrr_at_3_diff1
value: 50.289486880347134
- type: nauc_mrr_at_3_max
value: 24.978796972860142
- type: nauc_mrr_at_3_std
value: -32.11305594784892
- type: nauc_mrr_at_5_diff1
value: 49.95013396316144
- type: nauc_mrr_at_5_max
value: 24.514452761198303
- type: nauc_mrr_at_5_std
value: -32.865859962984146
- type: nauc_ndcg_at_1000_diff1
value: 45.73806489233998
- type: nauc_ndcg_at_1000_max
value: 22.404941391043867
- type: nauc_ndcg_at_1000_std
value: -33.063445720849685
- type: nauc_ndcg_at_100_diff1
value: 45.1046206923062
- type: nauc_ndcg_at_100_max
value: 22.081133719684658
- type: nauc_ndcg_at_100_std
value: -33.299291459450146
- type: nauc_ndcg_at_10_diff1
value: 46.140608688357496
- type: nauc_ndcg_at_10_max
value: 21.442489279388916
- type: nauc_ndcg_at_10_std
value: -35.115870342856006
- type: nauc_ndcg_at_1_diff1
value: 51.954289992321044
- type: nauc_ndcg_at_1_max
value: 26.336255074856886
- type: nauc_ndcg_at_1_std
value: -29.042962019692446
- type: nauc_ndcg_at_20_diff1
value: 45.966784725457046
- type: nauc_ndcg_at_20_max
value: 21.166632858613145
- type: nauc_ndcg_at_20_std
value: -35.65112890375392
- type: nauc_ndcg_at_3_diff1
value: 46.7404863978999
- type: nauc_ndcg_at_3_max
value: 22.701743709129456
- type: nauc_ndcg_at_3_std
value: -30.907633466983192
- type: nauc_ndcg_at_5_diff1
value: 45.86487199083486
- type: nauc_ndcg_at_5_max
value: 22.088804840002513
- type: nauc_ndcg_at_5_std
value: -32.3853481632832
- type: nauc_precision_at_1000_diff1
value: -25.69710612774455
- type: nauc_precision_at_1000_max
value: 1.3964400247388091
- type: nauc_precision_at_1000_std
value: -8.873947511634814
- type: nauc_precision_at_100_diff1
value: -24.013497191077978
- type: nauc_precision_at_100_max
value: 2.0197725715909343
- type: nauc_precision_at_100_std
value: -11.387423148770633
- type: nauc_precision_at_10_diff1
value: -6.47728645242781
- type: nauc_precision_at_10_max
value: 6.815261443768304
- type: nauc_precision_at_10_std
value: -26.825062292855943
- type: nauc_precision_at_1_diff1
value: 51.954289992321044
- type: nauc_precision_at_1_max
value: 26.336255074856886
- type: nauc_precision_at_1_std
value: -29.042962019692446
- type: nauc_precision_at_20_diff1
value: -12.355232044747511
- type: nauc_precision_at_20_max
value: 4.022126850949725
- type: nauc_precision_at_20_std
value: -23.688935769326772
- type: nauc_precision_at_3_diff1
value: 7.662671665835864
- type: nauc_precision_at_3_max
value: 14.372394760986248
- type: nauc_precision_at_3_std
value: -28.635125665532453
- type: nauc_precision_at_5_diff1
value: -1.4592476425511611
- type: nauc_precision_at_5_max
value: 11.124310161474174
- type: nauc_precision_at_5_std
value: -27.89526669318053
- type: nauc_recall_at_1000_diff1
value: -19.58450046684932
- type: nauc_recall_at_1000_max
value: 70.71661998133165
- type: nauc_recall_at_1000_std
value: 93.05555555556315
- type: nauc_recall_at_100_diff1
value: 15.06356457571853
- type: nauc_recall_at_100_max
value: 14.051414749344806
- type: nauc_recall_at_100_std
value: -29.461874235153008
- type: nauc_recall_at_10_diff1
value: 41.29842726117901
- type: nauc_recall_at_10_max
value: 15.768699673830898
- type: nauc_recall_at_10_std
value: -42.11585661287712
- type: nauc_recall_at_1_diff1
value: 56.34671160956164
- type: nauc_recall_at_1_max
value: 17.6796949796236
- type: nauc_recall_at_1_std
value: -13.741140688066045
- type: nauc_recall_at_20_diff1
value: 38.8078283585263
- type: nauc_recall_at_20_max
value: 12.06816084005326
- type: nauc_recall_at_20_std
value: -48.20956170056591
- type: nauc_recall_at_3_diff1
value: 44.71028758038993
- type: nauc_recall_at_3_max
value: 19.1059093689162
- type: nauc_recall_at_3_std
value: -26.795164453784253
- type: nauc_recall_at_5_diff1
value: 41.06320797773054
- type: nauc_recall_at_5_max
value: 19.117028272530998
- type: nauc_recall_at_5_std
value: -33.985747504612156
- type: ndcg_at_1
value: 56.95099999999999
- type: ndcg_at_10
value: 64.64
- type: ndcg_at_100
value: 70.017
- type: ndcg_at_1000
value: 70.662
- type: ndcg_at_20
value: 67.256
- type: ndcg_at_3
value: 58.269000000000005
- type: ndcg_at_5
value: 60.94199999999999
- type: precision_at_1
value: 56.95099999999999
- type: precision_at_10
value: 15.671
- type: precision_at_100
value: 2.002
- type: precision_at_1000
value: 0.208
- type: precision_at_20
value: 8.689
- type: precision_at_3
value: 36.341
- type: precision_at_5
value: 26.854
- type: recall_at_1
value: 35.858000000000004
- type: recall_at_10
value: 75.02
- type: recall_at_100
value: 95.76
- type: recall_at_1000
value: 99.837
- type: recall_at_20
value: 83.732
- type: recall_at_3
value: 57.093
- type: recall_at_5
value: 66.193
task:
type: Retrieval
- dataset:
config: cmn-cmn
name: MTEB XPQARetrieval (cmn-cmn)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 69.446
- type: map_at_1
value: 39.995999999999995
- type: map_at_10
value: 64.033
- type: map_at_100
value: 65.51599999999999
- type: map_at_1000
value: 65.545
- type: map_at_20
value: 64.958
- type: map_at_3
value: 57.767
- type: map_at_5
value: 61.998
- type: mrr_at_1
value: 63.3495145631068
- type: mrr_at_10
value: 70.21146363075978
- type: mrr_at_100
value: 70.82810974202124
- type: mrr_at_1000
value: 70.83816803303915
- type: mrr_at_20
value: 70.60140248428802
- type: mrr_at_3
value: 68.66909385113267
- type: mrr_at_5
value: 69.56108414239482
- type: nauc_map_at_1000_diff1
value: 51.649897072831465
- type: nauc_map_at_1000_max
value: 38.25222728655331
- type: nauc_map_at_1000_std
value: -39.10327919949334
- type: nauc_map_at_100_diff1
value: 51.644205886401465
- type: nauc_map_at_100_max
value: 38.23611154355255
- type: nauc_map_at_100_std
value: -39.1677073977285
- type: nauc_map_at_10_diff1
value: 51.81444145636039
- type: nauc_map_at_10_max
value: 38.03382104326485
- type: nauc_map_at_10_std
value: -38.999395639812015
- type: nauc_map_at_1_diff1
value: 59.785298201044704
- type: nauc_map_at_1_max
value: 23.273537759937785
- type: nauc_map_at_1_std
value: -17.838712689290194
- type: nauc_map_at_20_diff1
value: 51.680208795601004
- type: nauc_map_at_20_max
value: 38.23334583518634
- type: nauc_map_at_20_std
value: -39.24344495939061
- type: nauc_map_at_3_diff1
value: 52.180913298194056
- type: nauc_map_at_3_max
value: 33.45482478000481
- type: nauc_map_at_3_std
value: -31.682911030586297
- type: nauc_map_at_5_diff1
value: 50.804900676175436
- type: nauc_map_at_5_max
value: 37.68924816012326
- type: nauc_map_at_5_std
value: -36.85016896616712
- type: nauc_mrr_at_1000_diff1
value: 56.371477471577535
- type: nauc_mrr_at_1000_max
value: 42.773877962050086
- type: nauc_mrr_at_1000_std
value: -40.41765081873682
- type: nauc_mrr_at_100_diff1
value: 56.3619751528192
- type: nauc_mrr_at_100_max
value: 42.76298794859916
- type: nauc_mrr_at_100_std
value: -40.44070582448831
- type: nauc_mrr_at_10_diff1
value: 56.33810523477712
- type: nauc_mrr_at_10_max
value: 42.76591937795783
- type: nauc_mrr_at_10_std
value: -40.69339583030244
- type: nauc_mrr_at_1_diff1
value: 58.90399906884378
- type: nauc_mrr_at_1_max
value: 43.38806571165292
- type: nauc_mrr_at_1_std
value: -38.224015285584
- type: nauc_mrr_at_20_diff1
value: 56.32629070537032
- type: nauc_mrr_at_20_max
value: 42.79615263472604
- type: nauc_mrr_at_20_std
value: -40.496777397603076
- type: nauc_mrr_at_3_diff1
value: 55.96989454480743
- type: nauc_mrr_at_3_max
value: 42.49832220744744
- type: nauc_mrr_at_3_std
value: -39.883799467132384
- type: nauc_mrr_at_5_diff1
value: 56.003080766475755
- type: nauc_mrr_at_5_max
value: 42.73308051011805
- type: nauc_mrr_at_5_std
value: -39.87179511166683
- type: nauc_ndcg_at_1000_diff1
value: 52.49054229225255
- type: nauc_ndcg_at_1000_max
value: 39.61644750719859
- type: nauc_ndcg_at_1000_std
value: -40.89845763194674
- type: nauc_ndcg_at_100_diff1
value: 52.33511250864434
- type: nauc_ndcg_at_100_max
value: 39.25530146124452
- type: nauc_ndcg_at_100_std
value: -41.92444498004374
- type: nauc_ndcg_at_10_diff1
value: 52.62031505931842
- type: nauc_ndcg_at_10_max
value: 38.667195545396766
- type: nauc_ndcg_at_10_std
value: -42.59503924641507
- type: nauc_ndcg_at_1_diff1
value: 58.90399906884378
- type: nauc_ndcg_at_1_max
value: 43.38806571165292
- type: nauc_ndcg_at_1_std
value: -38.224015285584
- type: nauc_ndcg_at_20_diff1
value: 52.15061629809436
- type: nauc_ndcg_at_20_max
value: 39.09332400054708
- type: nauc_ndcg_at_20_std
value: -42.80018671618001
- type: nauc_ndcg_at_3_diff1
value: 51.04210728138207
- type: nauc_ndcg_at_3_max
value: 38.19034802567046
- type: nauc_ndcg_at_3_std
value: -38.179821090765216
- type: nauc_ndcg_at_5_diff1
value: 51.04399574045204
- type: nauc_ndcg_at_5_max
value: 38.42492210204548
- type: nauc_ndcg_at_5_std
value: -38.868073241617715
- type: nauc_precision_at_1000_diff1
value: -25.151369907213734
- type: nauc_precision_at_1000_max
value: 9.012549147054989
- type: nauc_precision_at_1000_std
value: -9.319786589947698
- type: nauc_precision_at_100_diff1
value: -23.20945211843088
- type: nauc_precision_at_100_max
value: 9.860701593969862
- type: nauc_precision_at_100_std
value: -13.073877818347231
- type: nauc_precision_at_10_diff1
value: -6.970781124246847
- type: nauc_precision_at_10_max
value: 19.392675322254487
- type: nauc_precision_at_10_std
value: -26.74943490717657
- type: nauc_precision_at_1_diff1
value: 58.90399906884378
- type: nauc_precision_at_1_max
value: 43.38806571165292
- type: nauc_precision_at_1_std
value: -38.224015285584
- type: nauc_precision_at_20_diff1
value: -13.046456108081102
- type: nauc_precision_at_20_max
value: 15.69439950383875
- type: nauc_precision_at_20_std
value: -23.836004512018093
- type: nauc_precision_at_3_diff1
value: 3.5444232965528846
- type: nauc_precision_at_3_max
value: 27.08858445453865
- type: nauc_precision_at_3_std
value: -29.12757283665593
- type: nauc_precision_at_5_diff1
value: -3.6853986353320267
- type: nauc_precision_at_5_max
value: 24.32059689571271
- type: nauc_precision_at_5_std
value: -27.46188072134163
- type: nauc_recall_at_1000_diff1
value: 86.93515141907919
- type: nauc_recall_at_1000_max
value: 100.0
- type: nauc_recall_at_1000_std
value: 100.0
- type: nauc_recall_at_100_diff1
value: 39.7052887613879
- type: nauc_recall_at_100_max
value: 18.40943977796887
- type: nauc_recall_at_100_std
value: -88.74014854144974
- type: nauc_recall_at_10_diff1
value: 48.85342500870892
- type: nauc_recall_at_10_max
value: 32.69617204234419
- type: nauc_recall_at_10_std
value: -51.9937231860804
- type: nauc_recall_at_1_diff1
value: 59.785298201044704
- type: nauc_recall_at_1_max
value: 23.273537759937785
- type: nauc_recall_at_1_std
value: -17.838712689290194
- type: nauc_recall_at_20_diff1
value: 45.40839773314378
- type: nauc_recall_at_20_max
value: 33.02458321493215
- type: nauc_recall_at_20_std
value: -55.97800739448166
- type: nauc_recall_at_3_diff1
value: 47.05565693416531
- type: nauc_recall_at_3_max
value: 28.743850400344297
- type: nauc_recall_at_3_std
value: -32.436470486397475
- type: nauc_recall_at_5_diff1
value: 45.30223758669577
- type: nauc_recall_at_5_max
value: 33.6567274747059
- type: nauc_recall_at_5_std
value: -39.946712017948514
- type: ndcg_at_1
value: 63.349999999999994
- type: ndcg_at_10
value: 69.446
- type: ndcg_at_100
value: 74.439
- type: ndcg_at_1000
value: 74.834
- type: ndcg_at_20
value: 71.763
- type: ndcg_at_3
value: 64.752
- type: ndcg_at_5
value: 66.316
- type: precision_at_1
value: 63.349999999999994
- type: precision_at_10
value: 16.286
- type: precision_at_100
value: 2.024
- type: precision_at_1000
value: 0.207
- type: precision_at_20
value: 8.908000000000001
- type: precision_at_3
value: 40.655
- type: precision_at_5
value: 28.859
- type: recall_at_1
value: 39.995999999999995
- type: recall_at_10
value: 78.107
- type: recall_at_100
value: 97.538
- type: recall_at_1000
value: 99.96000000000001
- type: recall_at_20
value: 85.72
- type: recall_at_3
value: 63.291
- type: recall_at_5
value: 70.625
task:
type: Retrieval
- dataset:
config: spa-eng
name: MTEB XPQARetrieval (spa-eng)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 68.258
- type: map_at_1
value: 33.06
- type: map_at_10
value: 61.590999999999994
- type: map_at_100
value: 63.341
- type: map_at_1000
value: 63.385999999999996
- type: map_at_20
value: 62.77700000000001
- type: map_at_3
value: 52.547999999999995
- type: map_at_5
value: 58.824
- type: mrr_at_1
value: 63.80832282471627
- type: mrr_at_10
value: 70.76848015372607
- type: mrr_at_100
value: 71.33996704518061
- type: mrr_at_1000
value: 71.35368444388072
- type: mrr_at_20
value: 71.18191741103522
- type: mrr_at_3
value: 68.83144178226142
- type: mrr_at_5
value: 69.88440521227405
- type: nauc_map_at_1000_diff1
value: 41.59255746310511
- type: nauc_map_at_1000_max
value: 42.064075373358065
- type: nauc_map_at_1000_std
value: -25.130730194381723
- type: nauc_map_at_100_diff1
value: 41.56447648820406
- type: nauc_map_at_100_max
value: 42.06711634651607
- type: nauc_map_at_100_std
value: -25.14871585556968
- type: nauc_map_at_10_diff1
value: 41.28968387107058
- type: nauc_map_at_10_max
value: 41.511538272139774
- type: nauc_map_at_10_std
value: -25.99906440164276
- type: nauc_map_at_1_diff1
value: 51.09859596320021
- type: nauc_map_at_1_max
value: 12.406789321338222
- type: nauc_map_at_1_std
value: -18.227486548655076
- type: nauc_map_at_20_diff1
value: 41.39469672947315
- type: nauc_map_at_20_max
value: 41.98309315808902
- type: nauc_map_at_20_std
value: -25.44704720985219
- type: nauc_map_at_3_diff1
value: 43.16164995512842
- type: nauc_map_at_3_max
value: 30.935400935562818
- type: nauc_map_at_3_std
value: -23.53095555148866
- type: nauc_map_at_5_diff1
value: 41.23474352142375
- type: nauc_map_at_5_max
value: 39.03088859147947
- type: nauc_map_at_5_std
value: -26.046526443708366
- type: nauc_mrr_at_1000_diff1
value: 51.79649678213789
- type: nauc_mrr_at_1000_max
value: 50.50340748045259
- type: nauc_mrr_at_1000_std
value: -24.777183703493407
- type: nauc_mrr_at_100_diff1
value: 51.78609028166551
- type: nauc_mrr_at_100_max
value: 50.51732896833555
- type: nauc_mrr_at_100_std
value: -24.760054686874717
- type: nauc_mrr_at_10_diff1
value: 51.705268395036995
- type: nauc_mrr_at_10_max
value: 50.35818415293149
- type: nauc_mrr_at_10_std
value: -25.170367120250404
- type: nauc_mrr_at_1_diff1
value: 53.91475115581825
- type: nauc_mrr_at_1_max
value: 49.122529616282016
- type: nauc_mrr_at_1_std
value: -22.377647552937155
- type: nauc_mrr_at_20_diff1
value: 51.778984221197774
- type: nauc_mrr_at_20_max
value: 50.5070957827813
- type: nauc_mrr_at_20_std
value: -24.908935023607285
- type: nauc_mrr_at_3_diff1
value: 51.82683773090423
- type: nauc_mrr_at_3_max
value: 50.77993196421369
- type: nauc_mrr_at_3_std
value: -24.3925832021831
- type: nauc_mrr_at_5_diff1
value: 51.722232683543034
- type: nauc_mrr_at_5_max
value: 50.334865493961864
- type: nauc_mrr_at_5_std
value: -25.513593495703297
- type: nauc_ndcg_at_1000_diff1
value: 44.21851582991263
- type: nauc_ndcg_at_1000_max
value: 45.73539068637836
- type: nauc_ndcg_at_1000_std
value: -24.716522467580397
- type: nauc_ndcg_at_100_diff1
value: 43.8002401615357
- type: nauc_ndcg_at_100_max
value: 45.801409410061915
- type: nauc_ndcg_at_100_std
value: -24.73171742499903
- type: nauc_ndcg_at_10_diff1
value: 42.540922778755885
- type: nauc_ndcg_at_10_max
value: 44.348836943874595
- type: nauc_ndcg_at_10_std
value: -28.05403666494785
- type: nauc_ndcg_at_1_diff1
value: 53.91475115581825
- type: nauc_ndcg_at_1_max
value: 49.122529616282016
- type: nauc_ndcg_at_1_std
value: -22.377647552937155
- type: nauc_ndcg_at_20_diff1
value: 43.10347921163421
- type: nauc_ndcg_at_20_max
value: 45.53253270265022
- type: nauc_ndcg_at_20_std
value: -26.63902791862846
- type: nauc_ndcg_at_3_diff1
value: 42.41720274782384
- type: nauc_ndcg_at_3_max
value: 42.91778219334943
- type: nauc_ndcg_at_3_std
value: -24.793252033594076
- type: nauc_ndcg_at_5_diff1
value: 42.51515034945093
- type: nauc_ndcg_at_5_max
value: 41.62080576508792
- type: nauc_ndcg_at_5_std
value: -28.209669314955065
- type: nauc_precision_at_1000_diff1
value: -14.89794075433148
- type: nauc_precision_at_1000_max
value: 27.85387929356412
- type: nauc_precision_at_1000_std
value: 10.728618597190849
- type: nauc_precision_at_100_diff1
value: -13.075270046295856
- type: nauc_precision_at_100_max
value: 29.77208946756632
- type: nauc_precision_at_100_std
value: 8.491662697326039
- type: nauc_precision_at_10_diff1
value: -4.0826025188781205
- type: nauc_precision_at_10_max
value: 39.04278085180075
- type: nauc_precision_at_10_std
value: -5.925408651372333
- type: nauc_precision_at_1_diff1
value: 53.91475115581825
- type: nauc_precision_at_1_max
value: 49.122529616282016
- type: nauc_precision_at_1_std
value: -22.377647552937155
- type: nauc_precision_at_20_diff1
value: -7.93186440645135
- type: nauc_precision_at_20_max
value: 35.81281308891365
- type: nauc_precision_at_20_std
value: 0.1241277857515697
- type: nauc_precision_at_3_diff1
value: 7.563562511484409
- type: nauc_precision_at_3_max
value: 43.43738862378524
- type: nauc_precision_at_3_std
value: -11.958059731912615
- type: nauc_precision_at_5_diff1
value: -0.1801152449011624
- type: nauc_precision_at_5_max
value: 41.32486715619513
- type: nauc_precision_at_5_std
value: -10.088699021919552
- type: nauc_recall_at_1000_diff1
value: 86.93359696819986
- type: nauc_recall_at_1000_max
value: 100.0
- type: nauc_recall_at_1000_std
value: 72.21843645604022
- type: nauc_recall_at_100_diff1
value: 29.86050842714198
- type: nauc_recall_at_100_max
value: 48.106658251136245
- type: nauc_recall_at_100_std
value: -14.981886214880035
- type: nauc_recall_at_10_diff1
value: 33.67119240737528
- type: nauc_recall_at_10_max
value: 39.271984859561414
- type: nauc_recall_at_10_std
value: -35.6434883839217
- type: nauc_recall_at_1_diff1
value: 51.09859596320021
- type: nauc_recall_at_1_max
value: 12.406789321338222
- type: nauc_recall_at_1_std
value: -18.227486548655076
- type: nauc_recall_at_20_diff1
value: 33.211979983240724
- type: nauc_recall_at_20_max
value: 43.47676074743184
- type: nauc_recall_at_20_std
value: -33.88107138395349
- type: nauc_recall_at_3_diff1
value: 39.22513750146998
- type: nauc_recall_at_3_max
value: 27.066674083840166
- type: nauc_recall_at_3_std
value: -26.963282529629893
- type: nauc_recall_at_5_diff1
value: 36.53718917129459
- type: nauc_recall_at_5_max
value: 35.40550013169686
- type: nauc_recall_at_5_std
value: -34.209159379410806
- type: ndcg_at_1
value: 63.808
- type: ndcg_at_10
value: 68.258
- type: ndcg_at_100
value: 73.38799999999999
- type: ndcg_at_1000
value: 74.03
- type: ndcg_at_20
value: 70.968
- type: ndcg_at_3
value: 62.33
- type: ndcg_at_5
value: 64.096
- type: precision_at_1
value: 63.808
- type: precision_at_10
value: 19.243
- type: precision_at_100
value: 2.367
- type: precision_at_1000
value: 0.245
- type: precision_at_20
value: 10.599
- type: precision_at_3
value: 44.515
- type: precision_at_5
value: 33.467999999999996
- type: recall_at_1
value: 33.06
- type: recall_at_10
value: 77.423
- type: recall_at_100
value: 95.923
- type: recall_at_1000
value: 99.874
- type: recall_at_20
value: 85.782
- type: recall_at_3
value: 57.098000000000006
- type: recall_at_5
value: 67.472
task:
type: Retrieval
- dataset:
config: spa-spa
name: MTEB XPQARetrieval (spa-spa)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 72.004
- type: map_at_1
value: 36.248000000000005
- type: map_at_10
value: 65.679
- type: map_at_100
value: 67.22399999999999
- type: map_at_1000
value: 67.264
- type: map_at_20
value: 66.705
- type: map_at_3
value: 56.455
- type: map_at_5
value: 62.997
- type: mrr_at_1
value: 67.71752837326608
- type: mrr_at_10
value: 74.59782021257429
- type: mrr_at_100
value: 75.0640960767943
- type: mrr_at_1000
value: 75.07324799466076
- type: mrr_at_20
value: 74.9323963386884
- type: mrr_at_3
value: 72.95081967213115
- type: mrr_at_5
value: 73.82723833543506
- type: nauc_map_at_1000_diff1
value: 43.111810717567714
- type: nauc_map_at_1000_max
value: 44.835247208972476
- type: nauc_map_at_1000_std
value: -32.798405973931985
- type: nauc_map_at_100_diff1
value: 43.090223482932764
- type: nauc_map_at_100_max
value: 44.83392441557943
- type: nauc_map_at_100_std
value: -32.81149166676563
- type: nauc_map_at_10_diff1
value: 42.87841934951979
- type: nauc_map_at_10_max
value: 43.9838653389494
- type: nauc_map_at_10_std
value: -33.588084643627084
- type: nauc_map_at_1_diff1
value: 54.509245848379095
- type: nauc_map_at_1_max
value: 10.05921648322742
- type: nauc_map_at_1_std
value: -24.652326014826762
- type: nauc_map_at_20_diff1
value: 43.07468612984794
- type: nauc_map_at_20_max
value: 44.75663122615032
- type: nauc_map_at_20_std
value: -33.11788887878321
- type: nauc_map_at_3_diff1
value: 44.63272828938906
- type: nauc_map_at_3_max
value: 32.1584369869227
- type: nauc_map_at_3_std
value: -30.761662210142944
- type: nauc_map_at_5_diff1
value: 42.77296997803048
- type: nauc_map_at_5_max
value: 41.78894616737652
- type: nauc_map_at_5_std
value: -33.56459774477362
- type: nauc_mrr_at_1000_diff1
value: 53.097544131833494
- type: nauc_mrr_at_1000_max
value: 50.61134979184588
- type: nauc_mrr_at_1000_std
value: -35.6221191487669
- type: nauc_mrr_at_100_diff1
value: 53.096609856182106
- type: nauc_mrr_at_100_max
value: 50.61951585642645
- type: nauc_mrr_at_100_std
value: -35.62396157508327
- type: nauc_mrr_at_10_diff1
value: 52.771534471912304
- type: nauc_mrr_at_10_max
value: 50.430863224435726
- type: nauc_mrr_at_10_std
value: -36.027992076620365
- type: nauc_mrr_at_1_diff1
value: 55.05316238884337
- type: nauc_mrr_at_1_max
value: 49.461858515275196
- type: nauc_mrr_at_1_std
value: -31.87492636319712
- type: nauc_mrr_at_20_diff1
value: 53.083253469629746
- type: nauc_mrr_at_20_max
value: 50.62156424256193
- type: nauc_mrr_at_20_std
value: -35.879153692447154
- type: nauc_mrr_at_3_diff1
value: 52.98283109188415
- type: nauc_mrr_at_3_max
value: 50.83561260429378
- type: nauc_mrr_at_3_std
value: -35.30839538038797
- type: nauc_mrr_at_5_diff1
value: 52.93270510879709
- type: nauc_mrr_at_5_max
value: 50.54595596761199
- type: nauc_mrr_at_5_std
value: -35.84059376434395
- type: nauc_ndcg_at_1000_diff1
value: 45.343685089209416
- type: nauc_ndcg_at_1000_max
value: 47.801141576669465
- type: nauc_ndcg_at_1000_std
value: -33.512958862879195
- type: nauc_ndcg_at_100_diff1
value: 45.255590461515894
- type: nauc_ndcg_at_100_max
value: 47.99240031881967
- type: nauc_ndcg_at_100_std
value: -33.614465006695205
- type: nauc_ndcg_at_10_diff1
value: 43.93472511731019
- type: nauc_ndcg_at_10_max
value: 45.92599752897053
- type: nauc_ndcg_at_10_std
value: -36.43629114491574
- type: nauc_ndcg_at_1_diff1
value: 55.05316238884337
- type: nauc_ndcg_at_1_max
value: 49.461858515275196
- type: nauc_ndcg_at_1_std
value: -31.87492636319712
- type: nauc_ndcg_at_20_diff1
value: 44.93534591273201
- type: nauc_ndcg_at_20_max
value: 47.55153940713458
- type: nauc_ndcg_at_20_std
value: -35.56392448745206
- type: nauc_ndcg_at_3_diff1
value: 43.17916122133396
- type: nauc_ndcg_at_3_max
value: 45.603634205103276
- type: nauc_ndcg_at_3_std
value: -32.473227507181214
- type: nauc_ndcg_at_5_diff1
value: 44.10242961669216
- type: nauc_ndcg_at_5_max
value: 43.61666669031808
- type: nauc_ndcg_at_5_std
value: -35.98808321497782
- type: nauc_precision_at_1000_diff1
value: -23.264714449991146
- type: nauc_precision_at_1000_max
value: 28.505729576735465
- type: nauc_precision_at_1000_std
value: 11.987379232920926
- type: nauc_precision_at_100_diff1
value: -21.156119174614627
- type: nauc_precision_at_100_max
value: 30.711646221646255
- type: nauc_precision_at_100_std
value: 9.650486536340322
- type: nauc_precision_at_10_diff1
value: -10.98001328477502
- type: nauc_precision_at_10_max
value: 39.25638073760597
- type: nauc_precision_at_10_std
value: -4.3456859257488
- type: nauc_precision_at_1_diff1
value: 55.05316238884337
- type: nauc_precision_at_1_max
value: 49.461858515275196
- type: nauc_precision_at_1_std
value: -31.87492636319712
- type: nauc_precision_at_20_diff1
value: -14.97565390664424
- type: nauc_precision_at_20_max
value: 36.383835295942355
- type: nauc_precision_at_20_std
value: 1.525158880381114
- type: nauc_precision_at_3_diff1
value: 1.0448345623903483
- type: nauc_precision_at_3_max
value: 45.69772060667404
- type: nauc_precision_at_3_std
value: -13.002685018948293
- type: nauc_precision_at_5_diff1
value: -5.434185597628904
- type: nauc_precision_at_5_max
value: 42.99162431099203
- type: nauc_precision_at_5_std
value: -9.789308817624534
- type: nauc_recall_at_1000_diff1
value: 12.309303236094845
- type: nauc_recall_at_1000_max
value: 100.0
- type: nauc_recall_at_1000_std
value: 86.93359696819986
- type: nauc_recall_at_100_diff1
value: 39.093544920901415
- type: nauc_recall_at_100_max
value: 55.62814395062938
- type: nauc_recall_at_100_std
value: -22.6919033301514
- type: nauc_recall_at_10_diff1
value: 35.50100141633622
- type: nauc_recall_at_10_max
value: 39.25750019586647
- type: nauc_recall_at_10_std
value: -43.01273078031791
- type: nauc_recall_at_1_diff1
value: 54.509245848379095
- type: nauc_recall_at_1_max
value: 10.05921648322742
- type: nauc_recall_at_1_std
value: -24.652326014826762
- type: nauc_recall_at_20_diff1
value: 38.1281707132327
- type: nauc_recall_at_20_max
value: 43.97950642900301
- type: nauc_recall_at_20_std
value: -44.049952771307574
- type: nauc_recall_at_3_diff1
value: 40.01986938242728
- type: nauc_recall_at_3_max
value: 27.517114421061173
- type: nauc_recall_at_3_std
value: -32.99056780232045
- type: nauc_recall_at_5_diff1
value: 38.52035606499483
- type: nauc_recall_at_5_max
value: 37.05834604678859
- type: nauc_recall_at_5_std
value: -39.86196378897912
- type: ndcg_at_1
value: 67.718
- type: ndcg_at_10
value: 72.004
- type: ndcg_at_100
value: 76.554
- type: ndcg_at_1000
value: 77.07300000000001
- type: ndcg_at_20
value: 74.37899999999999
- type: ndcg_at_3
value: 66.379
- type: ndcg_at_5
value: 68.082
- type: precision_at_1
value: 67.718
- type: precision_at_10
value: 19.849
- type: precision_at_100
value: 2.3800000000000003
- type: precision_at_1000
value: 0.245
- type: precision_at_20
value: 10.813
- type: precision_at_3
value: 46.574
- type: precision_at_5
value: 34.83
- type: recall_at_1
value: 36.248000000000005
- type: recall_at_10
value: 80.252
- type: recall_at_100
value: 96.73
- type: recall_at_1000
value: 99.874
- type: recall_at_20
value: 87.703
- type: recall_at_3
value: 60.815
- type: recall_at_5
value: 71.16
task:
type: Retrieval
- dataset:
config: fra-eng
name: MTEB XPQARetrieval (fra-eng)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 73.729
- type: map_at_1
value: 43.964999999999996
- type: map_at_10
value: 67.803
- type: map_at_100
value: 69.188
- type: map_at_1000
value: 69.21000000000001
- type: map_at_20
value: 68.747
- type: map_at_3
value: 60.972
- type: map_at_5
value: 65.39399999999999
- type: mrr_at_1
value: 68.4913217623498
- type: mrr_at_10
value: 75.2600822260368
- type: mrr_at_100
value: 75.6599169808848
- type: mrr_at_1000
value: 75.66720883727534
- type: mrr_at_20
value: 75.52375865860405
- type: mrr_at_3
value: 73.54250111259452
- type: mrr_at_5
value: 74.51713395638626
- type: nauc_map_at_1000_diff1
value: 46.81533703002097
- type: nauc_map_at_1000_max
value: 46.30794757084772
- type: nauc_map_at_1000_std
value: -14.953470500312335
- type: nauc_map_at_100_diff1
value: 46.82464740277745
- type: nauc_map_at_100_max
value: 46.32852879948254
- type: nauc_map_at_100_std
value: -14.950035098066172
- type: nauc_map_at_10_diff1
value: 46.31406143369831
- type: nauc_map_at_10_max
value: 45.337593270786634
- type: nauc_map_at_10_std
value: -16.011789445907876
- type: nauc_map_at_1_diff1
value: 57.097134715065835
- type: nauc_map_at_1_max
value: 21.93931500350721
- type: nauc_map_at_1_std
value: -15.134457251301637
- type: nauc_map_at_20_diff1
value: 46.47030891134173
- type: nauc_map_at_20_max
value: 46.29169960276292
- type: nauc_map_at_20_std
value: -15.14241106541829
- type: nauc_map_at_3_diff1
value: 50.27064228648596
- type: nauc_map_at_3_max
value: 39.43058773971639
- type: nauc_map_at_3_std
value: -16.16545993089126
- type: nauc_map_at_5_diff1
value: 46.974867679747426
- type: nauc_map_at_5_max
value: 44.31091104855002
- type: nauc_map_at_5_std
value: -16.50175337658926
- type: nauc_mrr_at_1000_diff1
value: 55.20294005110399
- type: nauc_mrr_at_1000_max
value: 51.947725719119966
- type: nauc_mrr_at_1000_std
value: -14.586112939597232
- type: nauc_mrr_at_100_diff1
value: 55.20426251109304
- type: nauc_mrr_at_100_max
value: 51.95648725402534
- type: nauc_mrr_at_100_std
value: -14.579769236539143
- type: nauc_mrr_at_10_diff1
value: 54.93870506205835
- type: nauc_mrr_at_10_max
value: 51.89312772900638
- type: nauc_mrr_at_10_std
value: -14.692635010092939
- type: nauc_mrr_at_1_diff1
value: 56.54945935175171
- type: nauc_mrr_at_1_max
value: 51.28134504197991
- type: nauc_mrr_at_1_std
value: -12.909042186563061
- type: nauc_mrr_at_20_diff1
value: 55.10667018041461
- type: nauc_mrr_at_20_max
value: 51.98236870783707
- type: nauc_mrr_at_20_std
value: -14.599377575198025
- type: nauc_mrr_at_3_diff1
value: 55.67124311746892
- type: nauc_mrr_at_3_max
value: 51.77903236246767
- type: nauc_mrr_at_3_std
value: -14.94452633860763
- type: nauc_mrr_at_5_diff1
value: 55.42849172366371
- type: nauc_mrr_at_5_max
value: 51.76902965753959
- type: nauc_mrr_at_5_std
value: -15.357993534727072
- type: nauc_ndcg_at_1000_diff1
value: 48.736844959280326
- type: nauc_ndcg_at_1000_max
value: 48.92891159935398
- type: nauc_ndcg_at_1000_std
value: -13.983968675611056
- type: nauc_ndcg_at_100_diff1
value: 48.73859328503975
- type: nauc_ndcg_at_100_max
value: 49.31867149556439
- type: nauc_ndcg_at_100_std
value: -13.72387564912742
- type: nauc_ndcg_at_10_diff1
value: 46.50313862975287
- type: nauc_ndcg_at_10_max
value: 47.13599793554596
- type: nauc_ndcg_at_10_std
value: -16.317919977400113
- type: nauc_ndcg_at_1_diff1
value: 56.54945935175171
- type: nauc_ndcg_at_1_max
value: 51.28134504197991
- type: nauc_ndcg_at_1_std
value: -12.909042186563061
- type: nauc_ndcg_at_20_diff1
value: 47.01727117133912
- type: nauc_ndcg_at_20_max
value: 49.121366036709105
- type: nauc_ndcg_at_20_std
value: -14.411078677638775
- type: nauc_ndcg_at_3_diff1
value: 49.229581145458276
- type: nauc_ndcg_at_3_max
value: 47.427609717032
- type: nauc_ndcg_at_3_std
value: -16.52066627289908
- type: nauc_ndcg_at_5_diff1
value: 48.0152514127505
- type: nauc_ndcg_at_5_max
value: 46.12152407850816
- type: nauc_ndcg_at_5_std
value: -17.613295491954656
- type: nauc_precision_at_1000_diff1
value: -25.959006032642463
- type: nauc_precision_at_1000_max
value: 12.81002362947137
- type: nauc_precision_at_1000_std
value: 12.575312826061513
- type: nauc_precision_at_100_diff1
value: -24.35413527283394
- type: nauc_precision_at_100_max
value: 14.878359236477303
- type: nauc_precision_at_100_std
value: 12.384426050018428
- type: nauc_precision_at_10_diff1
value: -17.93220761770618
- type: nauc_precision_at_10_max
value: 23.523485811847294
- type: nauc_precision_at_10_std
value: 4.424456968716939
- type: nauc_precision_at_1_diff1
value: 56.54945935175171
- type: nauc_precision_at_1_max
value: 51.28134504197991
- type: nauc_precision_at_1_std
value: -12.909042186563061
- type: nauc_precision_at_20_diff1
value: -21.776871398686936
- type: nauc_precision_at_20_max
value: 21.18436338264366
- type: nauc_precision_at_20_std
value: 9.937274986573321
- type: nauc_precision_at_3_diff1
value: -1.2411845580934435
- type: nauc_precision_at_3_max
value: 34.962281941875
- type: nauc_precision_at_3_std
value: -2.447892908501237
- type: nauc_precision_at_5_diff1
value: -11.134164534114085
- type: nauc_precision_at_5_max
value: 30.22079740070525
- type: nauc_precision_at_5_std
value: -0.24232594421765946
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 43.3647412452869
- type: nauc_recall_at_100_max
value: 63.50094950500327
- type: nauc_recall_at_100_std
value: 2.3911909633714044
- type: nauc_recall_at_10_diff1
value: 33.993445071666855
- type: nauc_recall_at_10_max
value: 41.38694129134144
- type: nauc_recall_at_10_std
value: -19.308698266099096
- type: nauc_recall_at_1_diff1
value: 57.097134715065835
- type: nauc_recall_at_1_max
value: 21.93931500350721
- type: nauc_recall_at_1_std
value: -15.134457251301637
- type: nauc_recall_at_20_diff1
value: 32.03888531880772
- type: nauc_recall_at_20_max
value: 49.660787482562085
- type: nauc_recall_at_20_std
value: -12.641456758778382
- type: nauc_recall_at_3_diff1
value: 47.94527082900579
- type: nauc_recall_at_3_max
value: 36.51733131437679
- type: nauc_recall_at_3_std
value: -18.65511713247495
- type: nauc_recall_at_5_diff1
value: 42.04545772092305
- type: nauc_recall_at_5_max
value: 41.21440912972303
- type: nauc_recall_at_5_std
value: -21.47386527081128
- type: ndcg_at_1
value: 68.491
- type: ndcg_at_10
value: 73.729
- type: ndcg_at_100
value: 77.684
- type: ndcg_at_1000
value: 78.084
- type: ndcg_at_20
value: 75.795
- type: ndcg_at_3
value: 68.568
- type: ndcg_at_5
value: 70.128
- type: precision_at_1
value: 68.491
- type: precision_at_10
value: 16.996
- type: precision_at_100
value: 2.023
- type: precision_at_1000
value: 0.207
- type: precision_at_20
value: 9.246
- type: precision_at_3
value: 41.923
- type: precision_at_5
value: 29.826000000000004
- type: recall_at_1
value: 43.964999999999996
- type: recall_at_10
value: 82.777
- type: recall_at_100
value: 97.287
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 89.183
- type: recall_at_3
value: 65.803
- type: recall_at_5
value: 74.119
task:
type: Retrieval
- dataset:
config: fra-fra
name: MTEB XPQARetrieval (fr)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: main_score
value: 77.581
- type: map_at_1
value: 46.444
- type: map_at_10
value: 72.084
- type: map_at_100
value: 73.175
- type: map_at_1000
value: 73.193
- type: map_at_20
value: 72.77799999999999
- type: map_at_3
value: 65.242
- type: map_at_5
value: 69.926
- type: mrr_at_1
value: 71.82910547396529
- type: mrr_at_10
value: 78.66594612923046
- type: mrr_at_100
value: 78.97334934049613
- type: mrr_at_1000
value: 78.97687021803557
- type: mrr_at_20
value: 78.85701141744282
- type: mrr_at_3
value: 76.96929238985311
- type: mrr_at_5
value: 77.99732977303067
- type: nauc_map_at_1000_diff1
value: 49.090956807097804
- type: nauc_map_at_1000_max
value: 52.01095354889508
- type: nauc_map_at_1000_std
value: -12.182870421711026
- type: nauc_map_at_100_diff1
value: 49.091664766684566
- type: nauc_map_at_100_max
value: 52.017499797253755
- type: nauc_map_at_100_std
value: -12.188342487271528
- type: nauc_map_at_10_diff1
value: 48.6619338205362
- type: nauc_map_at_10_max
value: 50.93591260329888
- type: nauc_map_at_10_std
value: -12.899399261673365
- type: nauc_map_at_1_diff1
value: 61.89699552471587
- type: nauc_map_at_1_max
value: 22.387748207421946
- type: nauc_map_at_1_std
value: -17.139518194308437
- type: nauc_map_at_20_diff1
value: 48.72828404686453
- type: nauc_map_at_20_max
value: 51.781074586075434
- type: nauc_map_at_20_std
value: -12.174270605093136
- type: nauc_map_at_3_diff1
value: 53.11509580126934
- type: nauc_map_at_3_max
value: 42.1768380145106
- type: nauc_map_at_3_std
value: -14.98340833032363
- type: nauc_map_at_5_diff1
value: 49.60521390803235
- type: nauc_map_at_5_max
value: 49.80360562029127
- type: nauc_map_at_5_std
value: -13.900652140457618
- type: nauc_mrr_at_1000_diff1
value: 58.10782478654255
- type: nauc_mrr_at_1000_max
value: 61.31083013535486
- type: nauc_mrr_at_1000_std
value: -9.624904298545921
- type: nauc_mrr_at_100_diff1
value: 58.11041683306092
- type: nauc_mrr_at_100_max
value: 61.31590199755797
- type: nauc_mrr_at_100_std
value: -9.625991053580865
- type: nauc_mrr_at_10_diff1
value: 57.883701815695375
- type: nauc_mrr_at_10_max
value: 61.36276126424689
- type: nauc_mrr_at_10_std
value: -9.495072468420386
- type: nauc_mrr_at_1_diff1
value: 60.18176977079093
- type: nauc_mrr_at_1_max
value: 59.697615236642555
- type: nauc_mrr_at_1_std
value: -9.396133077966779
- type: nauc_mrr_at_20_diff1
value: 57.964817434006754
- type: nauc_mrr_at_20_max
value: 61.34073539502932
- type: nauc_mrr_at_20_std
value: -9.602378876645131
- type: nauc_mrr_at_3_diff1
value: 58.44338049427257
- type: nauc_mrr_at_3_max
value: 60.92272989411293
- type: nauc_mrr_at_3_std
value: -9.928970439416162
- type: nauc_mrr_at_5_diff1
value: 58.01513016866578
- type: nauc_mrr_at_5_max
value: 61.46805302986586
- type: nauc_mrr_at_5_std
value: -9.842227002440984
- type: nauc_ndcg_at_1000_diff1
value: 50.99293152828167
- type: nauc_ndcg_at_1000_max
value: 56.14232784664811
- type: nauc_ndcg_at_1000_std
value: -10.529213072410288
- type: nauc_ndcg_at_100_diff1
value: 50.99385944312529
- type: nauc_ndcg_at_100_max
value: 56.34825518954588
- type: nauc_ndcg_at_100_std
value: -10.398943874846047
- type: nauc_ndcg_at_10_diff1
value: 48.51273364357823
- type: nauc_ndcg_at_10_max
value: 53.77871849486298
- type: nauc_ndcg_at_10_std
value: -11.82105972112472
- type: nauc_ndcg_at_1_diff1
value: 60.18176977079093
- type: nauc_ndcg_at_1_max
value: 59.697615236642555
- type: nauc_ndcg_at_1_std
value: -9.396133077966779
- type: nauc_ndcg_at_20_diff1
value: 49.04268319033412
- type: nauc_ndcg_at_20_max
value: 55.47011381097071
- type: nauc_ndcg_at_20_std
value: -10.486452945493042
- type: nauc_ndcg_at_3_diff1
value: 50.95112745400584
- type: nauc_ndcg_at_3_max
value: 53.45473828705577
- type: nauc_ndcg_at_3_std
value: -13.420699384045728
- type: nauc_ndcg_at_5_diff1
value: 50.313156212000074
- type: nauc_ndcg_at_5_max
value: 52.78539129309866
- type: nauc_ndcg_at_5_std
value: -13.586274096509122
- type: nauc_precision_at_1000_diff1
value: -31.13772049254778
- type: nauc_precision_at_1000_max
value: 17.2847598361294
- type: nauc_precision_at_1000_std
value: 15.497531773816887
- type: nauc_precision_at_100_diff1
value: -29.98812263553739
- type: nauc_precision_at_100_max
value: 19.048620003227654
- type: nauc_precision_at_100_std
value: 15.38499952171958
- type: nauc_precision_at_10_diff1
value: -25.33028097412579
- type: nauc_precision_at_10_max
value: 26.077919168306853
- type: nauc_precision_at_10_std
value: 11.35352933466097
- type: nauc_precision_at_1_diff1
value: 60.18176977079093
- type: nauc_precision_at_1_max
value: 59.697615236642555
- type: nauc_precision_at_1_std
value: -9.396133077966779
- type: nauc_precision_at_20_diff1
value: -28.417606311068905
- type: nauc_precision_at_20_max
value: 23.958679828637692
- type: nauc_precision_at_20_std
value: 14.442021499194205
- type: nauc_precision_at_3_diff1
value: -8.127396049790482
- type: nauc_precision_at_3_max
value: 37.348067982957076
- type: nauc_precision_at_3_std
value: 4.747913619596849
- type: nauc_precision_at_5_diff1
value: -16.902418446058395
- type: nauc_precision_at_5_max
value: 32.73583852552014
- type: nauc_precision_at_5_std
value: 7.031446423850052
- type: nauc_recall_at_1000_diff1
value: -14.485978369112514
- type: nauc_recall_at_1000_max
value: 78.59123887333172
- type: nauc_recall_at_1000_std
value: 90.7384575424963
- type: nauc_recall_at_100_diff1
value: 41.47842281590715
- type: nauc_recall_at_100_max
value: 67.47271545727422
- type: nauc_recall_at_100_std
value: 14.555561992253999
- type: nauc_recall_at_10_diff1
value: 33.05308907973924
- type: nauc_recall_at_10_max
value: 45.49878918493155
- type: nauc_recall_at_10_std
value: -11.560069806810926
- type: nauc_recall_at_1_diff1
value: 61.89699552471587
- type: nauc_recall_at_1_max
value: 22.387748207421946
- type: nauc_recall_at_1_std
value: -17.139518194308437
- type: nauc_recall_at_20_diff1
value: 31.305721376453754
- type: nauc_recall_at_20_max
value: 51.24817763724019
- type: nauc_recall_at_20_std
value: -5.0809908162023145
- type: nauc_recall_at_3_diff1
value: 49.27109038342917
- type: nauc_recall_at_3_max
value: 37.69188317998447
- type: nauc_recall_at_3_std
value: -17.119900758664336
- type: nauc_recall_at_5_diff1
value: 42.74501803377967
- type: nauc_recall_at_5_max
value: 46.877008503354844
- type: nauc_recall_at_5_std
value: -15.704892082115975
- type: ndcg_at_1
value: 71.829
- type: ndcg_at_10
value: 77.581
- type: ndcg_at_100
value: 80.75
- type: ndcg_at_1000
value: 81.026
- type: ndcg_at_20
value: 79.092
- type: ndcg_at_3
value: 72.81
- type: ndcg_at_5
value: 74.22999999999999
- type: precision_at_1
value: 71.829
- type: precision_at_10
value: 17.717
- type: precision_at_100
value: 2.031
- type: precision_at_1000
value: 0.207
- type: precision_at_20
value: 9.399000000000001
- type: precision_at_3
value: 44.458999999999996
- type: precision_at_5
value: 31.535000000000004
- type: recall_at_1
value: 46.444
- type: recall_at_10
value: 86.275
- type: recall_at_100
value: 98.017
- type: recall_at_1000
value: 99.8
- type: recall_at_20
value: 90.935
- type: recall_at_3
value: 70.167
- type: recall_at_5
value: 78.2
task:
type: Retrieval
---
<br><br>
<p align="center">
<img src="https://aeiljuispo.cloudimg.io/v7/https://cdn-uploads.huggingface.co/production/uploads/603763514de52ff951d89793/AFoybzd5lpBQXEBrQHuTt.png?w=200&h=200&f=face" alt="Finetuner logo: Finetuner helps you to create experiments in order to improve embeddings on search tasks. It accompanies you to deliver the last mile of performance-tuning for neural search applications." width="150px">
</p>
<p align="center">
<b>The embedding model trained by <a href="https://jina.ai/"><b>Jina AI</b></a>.</b>
</p>
<p align="center">
<b>jina-embeddings-v3: Multilingual Embeddings With Task LoRA</b>
</p>
## Quick Start
[Blog](https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/#parameter-dimensions) | [Azure](https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3) | [AWS SageMaker](https://aws.amazon.com/marketplace/pp/prodview-kdi3xkt62lo32) | [API](https://jina.ai/embeddings)
## Intended Usage & Model Info
`jina-embeddings-v3` is a **multilingual multi-task text embedding model** designed for a variety of NLP applications.
Based on the [Jina-XLM-RoBERTa architecture](https://huggingface.co/jinaai/xlm-roberta-flash-implementation),
this model supports Rotary Position Embeddings to handle long input sequences up to **8192 tokens**.
Additionally, it features 5 LoRA adapters to generate task-specific embeddings efficiently.
### Key Features:
- **Extended Sequence Length:** Supports up to 8192 tokens with RoPE.
- **Task-Specific Embedding:** Customize embeddings through the `task` argument with the following options:
- `retrieval.query`: Used for query embeddings in asymmetric retrieval tasks
- `retrieval.passage`: Used for passage embeddings in asymmetric retrieval tasks
- `separation`: Used for embeddings in clustering and re-ranking applications
- `classification`: Used for embeddings in classification tasks
- `text-matching`: Used for embeddings in tasks that quantify similarity between two texts, such as STS or symmetric retrieval tasks
- **Matryoshka Embeddings**: Supports flexible embedding sizes (`32, 64, 128, 256, 512, 768, 1024`), allowing for truncating embeddings to fit your application.
### Supported Languages:
While the foundation model supports 100 languages, we've focused our tuning efforts on the following 30 languages:
**Arabic, Bengali, Chinese, Danish, Dutch, English, Finnish, French, Georgian, German, Greek,
Hindi, Indonesian, Italian, Japanese, Korean, Latvian, Norwegian, Polish, Portuguese, Romanian,
Russian, Slovak, Spanish, Swedish, Thai, Turkish, Ukrainian, Urdu,** and **Vietnamese.**
## Usage
**<details><summary>Apply mean pooling when integrating the model.</summary>**
<p>
### Why Use Mean Pooling?
Mean pooling takes all token embeddings from the model's output and averages them at the sentence or paragraph level.
This approach has been shown to produce high-quality sentence embeddings.
We provide an `encode` function that handles this for you automatically.
However, if you're working with the model directly, outside of the `encode` function,
you'll need to apply mean pooling manually. Here's how you can do it:
```python
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = (
attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
)
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(
input_mask_expanded.sum(1), min=1e-9
)
sentences = ["How is the weather today?", "What is the current weather like today?"]
tokenizer = AutoTokenizer.from_pretrained("jinaai/jina-embeddings-v3")
model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
task = 'retrieval.query'
task_id = model._adaptation_map[task]
adapter_mask = torch.full((len(sentences),), task_id, dtype=torch.int32)
with torch.no_grad():
model_output = model(**encoded_input, adapter_mask=adapter_mask)
embeddings = mean_pooling(model_output, encoded_input["attention_mask"])
embeddings = F.normalize(embeddings, p=2, dim=1)
```
</p>
</details>
The easiest way to start using `jina-embeddings-v3` is with the [Jina Embedding API](https://jina.ai/embeddings/).
Alternatively, you can use `jina-embeddings-v3` directly via Transformers package:
```bash
!pip install transformers torch einops
!pip install 'numpy<2'
```
If you run it on a GPU that support [FlashAttention-2](https://github.com/Dao-AILab/flash-attention). By 2024.9.12, it supports Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100),
```bash
!pip install flash-attn --no-build-isolation
```
```python
from transformers import AutoModel
# Initialize the model
model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
texts = [
"Follow the white rabbit.", # English
"Sigue al conejo blanco.", # Spanish
"Suis le lapin blanc.", # French
"跟着白兔走。", # Chinese
"اتبع الأرنب الأبيض.", # Arabic
"Folge dem weißen Kaninchen.", # German
]
# When calling the `encode` function, you can choose a `task` based on the use case:
# 'retrieval.query', 'retrieval.passage', 'separation', 'classification', 'text-matching'
# Alternatively, you can choose not to pass a `task`, and no specific LoRA adapter will be used.
embeddings = model.encode(texts, task="text-matching")
# Compute similarities
print(embeddings[0] @ embeddings[1].T)
```
By default, the model supports a maximum sequence length of 8192 tokens.
However, if you want to truncate your input texts to a shorter length, you can pass the `max_length` parameter to the `encode` function:
```python
embeddings = model.encode(["Very long ... document"], max_length=2048)
```
In case you want to use **Matryoshka embeddings** and switch to a different dimension,
you can adjust it by passing the `truncate_dim` parameter to the `encode` function:
```python
embeddings = model.encode(['Sample text'], truncate_dim=256)
```
The latest version (3.1.0) of [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) also supports `jina-embeddings-v3`:
```bash
!pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("jinaai/jina-embeddings-v3", trust_remote_code=True)
task = "retrieval.query"
embeddings = model.encode(
["What is the weather like in Berlin today?"],
task=task,
prompt_name=task,
)
```
You can fine-tune `jina-embeddings-v3` using [SentenceTransformerTrainer](https://sbert.net/docs/package_reference/sentence_transformer/trainer.html).
To fine-tune for a specific task, you should set the task before passing the model to the ST Trainer, either during initialization:
```python
model = SentenceTransformer("jinaai/jina-embeddings-v3", trust_remote_code=True, model_kwargs={'default_task': 'classification'})
```
Or afterwards:
```python
model = SentenceTransformer("jinaai/jina-embeddings-v3", trust_remote_code=True)
model[0].default_task = 'classification'
```
This way you can fine-tune the LoRA adapter for the chosen task.
However, If you want to fine-tune the entire model, make sure the main parameters are set as trainable when loading the model:
```python
model = SentenceTransformer("jinaai/jina-embeddings-v3", trust_remote_code=True, model_kwargs={'lora_main_params_trainable': True})
```
This will allow fine-tuning the whole model instead of just the LoRA adapters.
**<details><summary>ONNX Inference.</summary>**
<p>
You can use ONNX for efficient inference with `jina-embeddings-v3`:
```python
import onnxruntime
import numpy as np
from transformers import AutoTokenizer, PretrainedConfig
# Load tokenizer and model config
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v3')
config = PretrainedConfig.from_pretrained('jinaai/jina-embeddings-v3')
# Tokenize input
input_text = tokenizer('sample text', return_tensors='np')
# ONNX session
model_path = 'jina-embeddings-v3/onnx/model.onnx'
session = onnxruntime.InferenceSession(model_path)
# Prepare inputs for ONNX model
task_type = 'text-matching'
task_id = np.array(config.lora_adaptations.index(task_type), dtype=np.int64)
inputs = {
'input_ids': input_text['input_ids'],
'attention_mask': input_text['attention_mask'],
'task_id': task_id
}
# Run model
outputs = session.run(None, inputs)[0]
# Apply mean pooling to 'outputs' to get a single representation of each text
```
</p>
</details>
## Contact
Join our [Discord community](https://discord.jina.ai) and chat with other community members about ideas.
## License
`jina-embeddings-v3` is listed on AWS & Azure. If you need to use it beyond those platforms or on-premises within your company, note that the models is licensed under CC BY-NC 4.0. For commercial usage inquiries, feel free to [contact us](https://jina.ai/contact-sales/).
## Citation
If you find `jina-embeddings-v3` useful in your research, please cite the following paper:
```bibtex
@misc{sturua2024jinaembeddingsv3multilingualembeddingstask,
title={jina-embeddings-v3: Multilingual Embeddings With Task LoRA},
author={Saba Sturua and Isabelle Mohr and Mohammad Kalim Akram and Michael Günther and Bo Wang and Markus Krimmel and Feng Wang and Georgios Mastrapas and Andreas Koukounas and Andreas Koukounas and Nan Wang and Han Xiao},
year={2024},
eprint={2409.10173},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2409.10173},
}
```
|
stabilityai/stable-diffusion-2-inpainting | stabilityai | "2023-07-05T16:19:10Z" | 748,304 | 482 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"diffusers:StableDiffusionInpaintPipeline",
"region:us"
] | image-to-image | "2022-11-23T17:41:55Z" | ---
license: openrail++
tags:
- stable-diffusion
inference: false
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-inpainting` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `512-inpainting-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting/resolve/main/512-inpainting-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 inpainting in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting",
torch_dtype=torch.float16,
)
pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
#image and mask_image should be PIL images.
#The mask structure is white for inpainting and black for keeping as is
image = pipe(prompt=prompt, image=image, mask_image=mask_image).images[0]
image.save("./yellow_cat_on_park_bench.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
**How it works:**
`image` | `mask_image`
:-------------------------:|:-------------------------:|
<img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" alt="drawing" width="300"/> | <img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" alt="drawing" width="300"/>
`prompt` | `Output`
:-------------------------:|:-------------------------:|
<span style="position: relative;bottom: 150px;">Face of a yellow cat, high resolution, sitting on a park bench</span> | <img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/test.png" alt="drawing" width="300"/>
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
meta-llama/Llama-2-7b-chat-hf | meta-llama | "2024-04-17T08:40:48Z" | 748,267 | 3,983 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"conversational",
"en",
"arxiv:2307.09288",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-07-13T16:45:23Z" | ---
extra_gated_heading: You need to share contact information with Meta to access this model
extra_gated_prompt: >-
### LLAMA 2 COMMUNITY LICENSE AGREEMENT
"Agreement" means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation
accompanying Llama 2 distributed by Meta at
https://ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Licensee" or "you" means you, or your employer or any other person or entity
(if you are entering into this Agreement on such person or entity's behalf),
of the age required under applicable laws, rules or regulations to provide
legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Llama 2" means the foundational large language models and software and
algorithms, including machine-learning model code, trained model weights,
inference-enabling code, training-enabling code, fine-tuning enabling code and
other elements of the foregoing distributed by Meta at
ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Llama Materials" means, collectively, Meta's proprietary Llama 2 and
documentation (and any portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or
Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA
or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or
element of the Llama Materials, you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-
transferable and royalty-free limited license under Meta's intellectual
property or other rights owned by Meta embodied in the Llama Materials to
use, reproduce, distribute, copy, create derivative works of, and make
modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make the Llama Materials, or any derivative works
thereof, available to a third party, you shall provide a copy of this
Agreement to such third party.
ii. If you receive Llama Materials, or any derivative works thereof, from a
Licensee as part of an integrated end user product, then Section 2 of this
Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute
the following attribution notice within a "Notice" text file distributed as a
part of such copies: "Llama 2 is licensed under the LLAMA 2 Community
License, Copyright (c) Meta Platforms, Inc. All Rights Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and
regulations (including trade compliance laws and regulations) and adhere to
the Acceptable Use Policy for the Llama Materials (available at
https://ai.meta.com/llama/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama
Materials to improve any other large language model (excluding Llama 2 or
derivative works thereof).
2. Additional Commercial Terms. If, on the Llama 2 version release date, the
monthly active users of the products or services made available by or for
Licensee, or Licensee's affiliates, is greater than 700 million monthly
active users in the preceding calendar month, you must request a license from
Meta, which Meta may grant to you in its sole discretion, and you are not
authorized to exercise any of the rights under this Agreement unless or until
Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA
MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS"
BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING,
WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY
RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING
THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE
LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE
UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE,
PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST
PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR
PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE
POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection
with the Llama Materials, neither Meta nor Licensee may use any name or mark
owned by or associated with the other or any of its affiliates, except as
required for reasonable and customary use in describing and redistributing
the Llama Materials.
b. Subject to Meta's ownership of Llama Materials and derivatives made by or
for Meta, with respect to any derivative works and modifications of the Llama
Materials that are made by you, as between you and Meta, you are and will be
the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any
entity (including a cross-claim or counterclaim in a lawsuit) alleging that
the Llama Materials or Llama 2 outputs or results, or any portion of any of
the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under
this Agreement shall terminate as of the date such litigation or claim is
filed or instituted. You will indemnify and hold harmless Meta from and
against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your
acceptance of this Agreement or access to the Llama Materials and will
continue in full force and effect until terminated in accordance with the
terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this
Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and
construed under the laws of the State of California without regard to choice
of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California
shall have exclusive jurisdiction of any dispute arising out of this
Agreement.
### Llama 2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features,
including Llama 2. If you access or use Llama 2, you agree to this Acceptable
Use Policy (“Policy”). The most recent copy of this policy can be found at
[ai.meta.com/llama/use-policy](http://ai.meta.com/llama/use-policy).
#### Prohibited Uses
We want everyone to use Llama 2 safely and responsibly. You agree you will not
use, or allow others to use, Llama 2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama 2 Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or
development of activities that present a risk of death or bodily harm to
individuals, including use of Llama 2 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 2 related
to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Llama 2 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems
that could lead to a violation of this Policy through one of the following
means:
* Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama: [LlamaUseReport@meta.com](mailto:LlamaUseReport@meta.com)
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
license: llama2
---
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/meta-llama/Llama-2-7b) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/meta-llama/Llama-2-13b) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf)|
|70B| [Link](https://huggingface.co/meta-llama/Llama-2-70b) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)| |
thenlper/gte-small | thenlper | "2024-03-10T02:53:56Z" | 747,841 | 131 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"coreml",
"safetensors",
"bert",
"mteb",
"sentence-similarity",
"Sentence Transformers",
"en",
"arxiv:2308.03281",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-07-27T10:14:55Z" | ---
tags:
- mteb
- sentence-similarity
- sentence-transformers
- Sentence Transformers
model-index:
- name: gte-small
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.22388059701493
- type: ap
value: 36.09895941426988
- type: f1
value: 67.3205651539195
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.81894999999999
- type: ap
value: 88.5240138417305
- type: f1
value: 91.80367382706962
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.032
- type: f1
value: 47.4490665674719
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.725
- type: map_at_10
value: 46.604
- type: map_at_100
value: 47.535
- type: map_at_1000
value: 47.538000000000004
- type: map_at_3
value: 41.833
- type: map_at_5
value: 44.61
- type: mrr_at_1
value: 31.223
- type: mrr_at_10
value: 46.794000000000004
- type: mrr_at_100
value: 47.725
- type: mrr_at_1000
value: 47.727000000000004
- type: mrr_at_3
value: 42.07
- type: mrr_at_5
value: 44.812000000000005
- type: ndcg_at_1
value: 30.725
- type: ndcg_at_10
value: 55.440999999999995
- type: ndcg_at_100
value: 59.134
- type: ndcg_at_1000
value: 59.199
- type: ndcg_at_3
value: 45.599000000000004
- type: ndcg_at_5
value: 50.637
- type: precision_at_1
value: 30.725
- type: precision_at_10
value: 8.364
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 18.848000000000003
- type: precision_at_5
value: 13.77
- type: recall_at_1
value: 30.725
- type: recall_at_10
value: 83.64200000000001
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 56.543
- type: recall_at_5
value: 68.848
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.90178078197678
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.25728393431922
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.720297062897764
- type: mrr
value: 75.24139295607439
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.43527309184616
- type: cos_sim_spearman
value: 88.17128615100206
- type: euclidean_pearson
value: 87.89922623089282
- type: euclidean_spearman
value: 87.96104039655451
- type: manhattan_pearson
value: 87.9818290932077
- type: manhattan_spearman
value: 88.00923426576885
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.0844155844156
- type: f1
value: 84.01485017302213
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.36574769259432
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.4857033165287
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.261
- type: map_at_10
value: 42.419000000000004
- type: map_at_100
value: 43.927
- type: map_at_1000
value: 44.055
- type: map_at_3
value: 38.597
- type: map_at_5
value: 40.701
- type: mrr_at_1
value: 36.91
- type: mrr_at_10
value: 48.02
- type: mrr_at_100
value: 48.658
- type: mrr_at_1000
value: 48.708
- type: mrr_at_3
value: 44.945
- type: mrr_at_5
value: 46.705000000000005
- type: ndcg_at_1
value: 36.91
- type: ndcg_at_10
value: 49.353
- type: ndcg_at_100
value: 54.456
- type: ndcg_at_1000
value: 56.363
- type: ndcg_at_3
value: 43.483
- type: ndcg_at_5
value: 46.150999999999996
- type: precision_at_1
value: 36.91
- type: precision_at_10
value: 9.700000000000001
- type: precision_at_100
value: 1.557
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.078
- type: precision_at_5
value: 15.421999999999999
- type: recall_at_1
value: 30.261
- type: recall_at_10
value: 63.242
- type: recall_at_100
value: 84.09100000000001
- type: recall_at_1000
value: 96.143
- type: recall_at_3
value: 46.478
- type: recall_at_5
value: 53.708
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.145
- type: map_at_10
value: 40.996
- type: map_at_100
value: 42.266999999999996
- type: map_at_1000
value: 42.397
- type: map_at_3
value: 38.005
- type: map_at_5
value: 39.628
- type: mrr_at_1
value: 38.344
- type: mrr_at_10
value: 46.827000000000005
- type: mrr_at_100
value: 47.446
- type: mrr_at_1000
value: 47.489
- type: mrr_at_3
value: 44.448
- type: mrr_at_5
value: 45.747
- type: ndcg_at_1
value: 38.344
- type: ndcg_at_10
value: 46.733000000000004
- type: ndcg_at_100
value: 51.103
- type: ndcg_at_1000
value: 53.075
- type: ndcg_at_3
value: 42.366
- type: ndcg_at_5
value: 44.242
- type: precision_at_1
value: 38.344
- type: precision_at_10
value: 8.822000000000001
- type: precision_at_100
value: 1.417
- type: precision_at_1000
value: 0.187
- type: precision_at_3
value: 20.403
- type: precision_at_5
value: 14.306
- type: recall_at_1
value: 31.145
- type: recall_at_10
value: 56.909
- type: recall_at_100
value: 75.274
- type: recall_at_1000
value: 87.629
- type: recall_at_3
value: 43.784
- type: recall_at_5
value: 49.338
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.83
- type: map_at_10
value: 51.553000000000004
- type: map_at_100
value: 52.581
- type: map_at_1000
value: 52.638
- type: map_at_3
value: 48.112
- type: map_at_5
value: 50.095
- type: mrr_at_1
value: 44.513999999999996
- type: mrr_at_10
value: 54.998000000000005
- type: mrr_at_100
value: 55.650999999999996
- type: mrr_at_1000
value: 55.679
- type: mrr_at_3
value: 52.602000000000004
- type: mrr_at_5
value: 53.931
- type: ndcg_at_1
value: 44.513999999999996
- type: ndcg_at_10
value: 57.67400000000001
- type: ndcg_at_100
value: 61.663999999999994
- type: ndcg_at_1000
value: 62.743
- type: ndcg_at_3
value: 51.964
- type: ndcg_at_5
value: 54.773
- type: precision_at_1
value: 44.513999999999996
- type: precision_at_10
value: 9.423
- type: precision_at_100
value: 1.2309999999999999
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 23.323
- type: precision_at_5
value: 16.163
- type: recall_at_1
value: 38.83
- type: recall_at_10
value: 72.327
- type: recall_at_100
value: 89.519
- type: recall_at_1000
value: 97.041
- type: recall_at_3
value: 57.206
- type: recall_at_5
value: 63.88399999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.484
- type: map_at_10
value: 34.527
- type: map_at_100
value: 35.661
- type: map_at_1000
value: 35.739
- type: map_at_3
value: 32.199
- type: map_at_5
value: 33.632
- type: mrr_at_1
value: 27.458
- type: mrr_at_10
value: 36.543
- type: mrr_at_100
value: 37.482
- type: mrr_at_1000
value: 37.543
- type: mrr_at_3
value: 34.256
- type: mrr_at_5
value: 35.618
- type: ndcg_at_1
value: 27.458
- type: ndcg_at_10
value: 39.396
- type: ndcg_at_100
value: 44.742
- type: ndcg_at_1000
value: 46.708
- type: ndcg_at_3
value: 34.817
- type: ndcg_at_5
value: 37.247
- type: precision_at_1
value: 27.458
- type: precision_at_10
value: 5.976999999999999
- type: precision_at_100
value: 0.907
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 14.878
- type: precision_at_5
value: 10.35
- type: recall_at_1
value: 25.484
- type: recall_at_10
value: 52.317
- type: recall_at_100
value: 76.701
- type: recall_at_1000
value: 91.408
- type: recall_at_3
value: 40.043
- type: recall_at_5
value: 45.879
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.719
- type: map_at_10
value: 25.269000000000002
- type: map_at_100
value: 26.442
- type: map_at_1000
value: 26.557
- type: map_at_3
value: 22.56
- type: map_at_5
value: 24.082
- type: mrr_at_1
value: 20.896
- type: mrr_at_10
value: 29.982999999999997
- type: mrr_at_100
value: 30.895
- type: mrr_at_1000
value: 30.961
- type: mrr_at_3
value: 27.239
- type: mrr_at_5
value: 28.787000000000003
- type: ndcg_at_1
value: 20.896
- type: ndcg_at_10
value: 30.814000000000004
- type: ndcg_at_100
value: 36.418
- type: ndcg_at_1000
value: 39.182
- type: ndcg_at_3
value: 25.807999999999996
- type: ndcg_at_5
value: 28.143
- type: precision_at_1
value: 20.896
- type: precision_at_10
value: 5.821
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 12.562000000000001
- type: precision_at_5
value: 9.254
- type: recall_at_1
value: 16.719
- type: recall_at_10
value: 43.155
- type: recall_at_100
value: 67.831
- type: recall_at_1000
value: 87.617
- type: recall_at_3
value: 29.259
- type: recall_at_5
value: 35.260999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.398999999999997
- type: map_at_10
value: 39.876
- type: map_at_100
value: 41.205999999999996
- type: map_at_1000
value: 41.321999999999996
- type: map_at_3
value: 36.588
- type: map_at_5
value: 38.538
- type: mrr_at_1
value: 35.9
- type: mrr_at_10
value: 45.528
- type: mrr_at_100
value: 46.343
- type: mrr_at_1000
value: 46.388
- type: mrr_at_3
value: 42.862
- type: mrr_at_5
value: 44.440000000000005
- type: ndcg_at_1
value: 35.9
- type: ndcg_at_10
value: 45.987
- type: ndcg_at_100
value: 51.370000000000005
- type: ndcg_at_1000
value: 53.400000000000006
- type: ndcg_at_3
value: 40.841
- type: ndcg_at_5
value: 43.447
- type: precision_at_1
value: 35.9
- type: precision_at_10
value: 8.393
- type: precision_at_100
value: 1.283
- type: precision_at_1000
value: 0.166
- type: precision_at_3
value: 19.538
- type: precision_at_5
value: 13.975000000000001
- type: recall_at_1
value: 29.398999999999997
- type: recall_at_10
value: 58.361
- type: recall_at_100
value: 81.081
- type: recall_at_1000
value: 94.004
- type: recall_at_3
value: 43.657000000000004
- type: recall_at_5
value: 50.519999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.589
- type: map_at_10
value: 31.608999999999998
- type: map_at_100
value: 33.128
- type: map_at_1000
value: 33.247
- type: map_at_3
value: 28.671999999999997
- type: map_at_5
value: 30.233999999999998
- type: mrr_at_1
value: 26.712000000000003
- type: mrr_at_10
value: 36.713
- type: mrr_at_100
value: 37.713
- type: mrr_at_1000
value: 37.771
- type: mrr_at_3
value: 34.075
- type: mrr_at_5
value: 35.451
- type: ndcg_at_1
value: 26.712000000000003
- type: ndcg_at_10
value: 37.519999999999996
- type: ndcg_at_100
value: 43.946000000000005
- type: ndcg_at_1000
value: 46.297
- type: ndcg_at_3
value: 32.551
- type: ndcg_at_5
value: 34.660999999999994
- type: precision_at_1
value: 26.712000000000003
- type: precision_at_10
value: 7.066
- type: precision_at_100
value: 1.216
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 15.906
- type: precision_at_5
value: 11.437999999999999
- type: recall_at_1
value: 21.589
- type: recall_at_10
value: 50.090999999999994
- type: recall_at_100
value: 77.43900000000001
- type: recall_at_1000
value: 93.35900000000001
- type: recall_at_3
value: 36.028999999999996
- type: recall_at_5
value: 41.698
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.121666666666663
- type: map_at_10
value: 34.46258333333334
- type: map_at_100
value: 35.710499999999996
- type: map_at_1000
value: 35.82691666666666
- type: map_at_3
value: 31.563249999999996
- type: map_at_5
value: 33.189750000000004
- type: mrr_at_1
value: 29.66441666666667
- type: mrr_at_10
value: 38.5455
- type: mrr_at_100
value: 39.39566666666667
- type: mrr_at_1000
value: 39.45325
- type: mrr_at_3
value: 36.003333333333345
- type: mrr_at_5
value: 37.440916666666666
- type: ndcg_at_1
value: 29.66441666666667
- type: ndcg_at_10
value: 39.978416666666675
- type: ndcg_at_100
value: 45.278666666666666
- type: ndcg_at_1000
value: 47.52275
- type: ndcg_at_3
value: 35.00058333333334
- type: ndcg_at_5
value: 37.34908333333333
- type: precision_at_1
value: 29.66441666666667
- type: precision_at_10
value: 7.094500000000001
- type: precision_at_100
value: 1.1523333333333332
- type: precision_at_1000
value: 0.15358333333333332
- type: precision_at_3
value: 16.184166666666663
- type: precision_at_5
value: 11.6005
- type: recall_at_1
value: 25.121666666666663
- type: recall_at_10
value: 52.23975000000001
- type: recall_at_100
value: 75.48408333333333
- type: recall_at_1000
value: 90.95316666666668
- type: recall_at_3
value: 38.38458333333333
- type: recall_at_5
value: 44.39933333333333
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.569000000000003
- type: map_at_10
value: 30.389
- type: map_at_100
value: 31.396
- type: map_at_1000
value: 31.493
- type: map_at_3
value: 28.276
- type: map_at_5
value: 29.459000000000003
- type: mrr_at_1
value: 26.534000000000002
- type: mrr_at_10
value: 33.217999999999996
- type: mrr_at_100
value: 34.054
- type: mrr_at_1000
value: 34.12
- type: mrr_at_3
value: 31.058000000000003
- type: mrr_at_5
value: 32.330999999999996
- type: ndcg_at_1
value: 26.534000000000002
- type: ndcg_at_10
value: 34.608
- type: ndcg_at_100
value: 39.391999999999996
- type: ndcg_at_1000
value: 41.837999999999994
- type: ndcg_at_3
value: 30.564999999999998
- type: ndcg_at_5
value: 32.509
- type: precision_at_1
value: 26.534000000000002
- type: precision_at_10
value: 5.414
- type: precision_at_100
value: 0.847
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 9.202
- type: recall_at_1
value: 23.569000000000003
- type: recall_at_10
value: 44.896
- type: recall_at_100
value: 66.476
- type: recall_at_1000
value: 84.548
- type: recall_at_3
value: 33.79
- type: recall_at_5
value: 38.512
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.36
- type: map_at_10
value: 23.57
- type: map_at_100
value: 24.698999999999998
- type: map_at_1000
value: 24.834999999999997
- type: map_at_3
value: 21.093
- type: map_at_5
value: 22.418
- type: mrr_at_1
value: 19.718
- type: mrr_at_10
value: 27.139999999999997
- type: mrr_at_100
value: 28.097
- type: mrr_at_1000
value: 28.177999999999997
- type: mrr_at_3
value: 24.805
- type: mrr_at_5
value: 26.121
- type: ndcg_at_1
value: 19.718
- type: ndcg_at_10
value: 28.238999999999997
- type: ndcg_at_100
value: 33.663
- type: ndcg_at_1000
value: 36.763
- type: ndcg_at_3
value: 23.747
- type: ndcg_at_5
value: 25.796000000000003
- type: precision_at_1
value: 19.718
- type: precision_at_10
value: 5.282
- type: precision_at_100
value: 0.9390000000000001
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 11.264000000000001
- type: precision_at_5
value: 8.341
- type: recall_at_1
value: 16.36
- type: recall_at_10
value: 38.669
- type: recall_at_100
value: 63.184
- type: recall_at_1000
value: 85.33800000000001
- type: recall_at_3
value: 26.214
- type: recall_at_5
value: 31.423000000000002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.618999999999996
- type: map_at_10
value: 34.361999999999995
- type: map_at_100
value: 35.534
- type: map_at_1000
value: 35.634
- type: map_at_3
value: 31.402
- type: map_at_5
value: 32.815
- type: mrr_at_1
value: 30.037000000000003
- type: mrr_at_10
value: 38.284
- type: mrr_at_100
value: 39.141999999999996
- type: mrr_at_1000
value: 39.2
- type: mrr_at_3
value: 35.603
- type: mrr_at_5
value: 36.867
- type: ndcg_at_1
value: 30.037000000000003
- type: ndcg_at_10
value: 39.87
- type: ndcg_at_100
value: 45.243
- type: ndcg_at_1000
value: 47.507
- type: ndcg_at_3
value: 34.371
- type: ndcg_at_5
value: 36.521
- type: precision_at_1
value: 30.037000000000003
- type: precision_at_10
value: 6.819
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 15.392
- type: precision_at_5
value: 10.821
- type: recall_at_1
value: 25.618999999999996
- type: recall_at_10
value: 52.869
- type: recall_at_100
value: 76.395
- type: recall_at_1000
value: 92.19500000000001
- type: recall_at_3
value: 37.943
- type: recall_at_5
value: 43.342999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.283
- type: map_at_10
value: 32.155
- type: map_at_100
value: 33.724
- type: map_at_1000
value: 33.939
- type: map_at_3
value: 29.018
- type: map_at_5
value: 30.864000000000004
- type: mrr_at_1
value: 28.063
- type: mrr_at_10
value: 36.632
- type: mrr_at_100
value: 37.606
- type: mrr_at_1000
value: 37.671
- type: mrr_at_3
value: 33.992
- type: mrr_at_5
value: 35.613
- type: ndcg_at_1
value: 28.063
- type: ndcg_at_10
value: 38.024
- type: ndcg_at_100
value: 44.292
- type: ndcg_at_1000
value: 46.818
- type: ndcg_at_3
value: 32.965
- type: ndcg_at_5
value: 35.562
- type: precision_at_1
value: 28.063
- type: precision_at_10
value: 7.352
- type: precision_at_100
value: 1.514
- type: precision_at_1000
value: 0.23800000000000002
- type: precision_at_3
value: 15.481
- type: precision_at_5
value: 11.542
- type: recall_at_1
value: 23.283
- type: recall_at_10
value: 49.756
- type: recall_at_100
value: 78.05
- type: recall_at_1000
value: 93.854
- type: recall_at_3
value: 35.408
- type: recall_at_5
value: 42.187000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.201999999999998
- type: map_at_10
value: 26.826
- type: map_at_100
value: 27.961000000000002
- type: map_at_1000
value: 28.066999999999997
- type: map_at_3
value: 24.237000000000002
- type: map_at_5
value: 25.811
- type: mrr_at_1
value: 20.887
- type: mrr_at_10
value: 28.660000000000004
- type: mrr_at_100
value: 29.660999999999998
- type: mrr_at_1000
value: 29.731
- type: mrr_at_3
value: 26.155
- type: mrr_at_5
value: 27.68
- type: ndcg_at_1
value: 20.887
- type: ndcg_at_10
value: 31.523
- type: ndcg_at_100
value: 37.055
- type: ndcg_at_1000
value: 39.579
- type: ndcg_at_3
value: 26.529000000000003
- type: ndcg_at_5
value: 29.137
- type: precision_at_1
value: 20.887
- type: precision_at_10
value: 5.065
- type: precision_at_100
value: 0.856
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 11.399
- type: precision_at_5
value: 8.392
- type: recall_at_1
value: 19.201999999999998
- type: recall_at_10
value: 44.285000000000004
- type: recall_at_100
value: 69.768
- type: recall_at_1000
value: 88.302
- type: recall_at_3
value: 30.804
- type: recall_at_5
value: 37.039
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.244
- type: map_at_10
value: 18.956
- type: map_at_100
value: 20.674
- type: map_at_1000
value: 20.863
- type: map_at_3
value: 15.923000000000002
- type: map_at_5
value: 17.518
- type: mrr_at_1
value: 25.080999999999996
- type: mrr_at_10
value: 35.94
- type: mrr_at_100
value: 36.969
- type: mrr_at_1000
value: 37.013
- type: mrr_at_3
value: 32.617000000000004
- type: mrr_at_5
value: 34.682
- type: ndcg_at_1
value: 25.080999999999996
- type: ndcg_at_10
value: 26.539
- type: ndcg_at_100
value: 33.601
- type: ndcg_at_1000
value: 37.203
- type: ndcg_at_3
value: 21.695999999999998
- type: ndcg_at_5
value: 23.567
- type: precision_at_1
value: 25.080999999999996
- type: precision_at_10
value: 8.143
- type: precision_at_100
value: 1.5650000000000002
- type: precision_at_1000
value: 0.22300000000000003
- type: precision_at_3
value: 15.983
- type: precision_at_5
value: 12.417
- type: recall_at_1
value: 11.244
- type: recall_at_10
value: 31.457
- type: recall_at_100
value: 55.92
- type: recall_at_1000
value: 76.372
- type: recall_at_3
value: 19.784
- type: recall_at_5
value: 24.857000000000003
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.595
- type: map_at_10
value: 18.75
- type: map_at_100
value: 26.354
- type: map_at_1000
value: 27.912
- type: map_at_3
value: 13.794
- type: map_at_5
value: 16.021
- type: mrr_at_1
value: 65.75
- type: mrr_at_10
value: 73.837
- type: mrr_at_100
value: 74.22800000000001
- type: mrr_at_1000
value: 74.234
- type: mrr_at_3
value: 72.5
- type: mrr_at_5
value: 73.387
- type: ndcg_at_1
value: 52.625
- type: ndcg_at_10
value: 39.101
- type: ndcg_at_100
value: 43.836000000000006
- type: ndcg_at_1000
value: 51.086
- type: ndcg_at_3
value: 44.229
- type: ndcg_at_5
value: 41.555
- type: precision_at_1
value: 65.75
- type: precision_at_10
value: 30.45
- type: precision_at_100
value: 9.81
- type: precision_at_1000
value: 2.045
- type: precision_at_3
value: 48.667
- type: precision_at_5
value: 40.8
- type: recall_at_1
value: 8.595
- type: recall_at_10
value: 24.201
- type: recall_at_100
value: 50.096
- type: recall_at_1000
value: 72.677
- type: recall_at_3
value: 15.212
- type: recall_at_5
value: 18.745
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.565
- type: f1
value: 41.49914329345582
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 66.60000000000001
- type: map_at_10
value: 76.838
- type: map_at_100
value: 77.076
- type: map_at_1000
value: 77.09
- type: map_at_3
value: 75.545
- type: map_at_5
value: 76.39
- type: mrr_at_1
value: 71.707
- type: mrr_at_10
value: 81.514
- type: mrr_at_100
value: 81.64099999999999
- type: mrr_at_1000
value: 81.645
- type: mrr_at_3
value: 80.428
- type: mrr_at_5
value: 81.159
- type: ndcg_at_1
value: 71.707
- type: ndcg_at_10
value: 81.545
- type: ndcg_at_100
value: 82.477
- type: ndcg_at_1000
value: 82.73899999999999
- type: ndcg_at_3
value: 79.292
- type: ndcg_at_5
value: 80.599
- type: precision_at_1
value: 71.707
- type: precision_at_10
value: 10.035
- type: precision_at_100
value: 1.068
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 30.918
- type: precision_at_5
value: 19.328
- type: recall_at_1
value: 66.60000000000001
- type: recall_at_10
value: 91.353
- type: recall_at_100
value: 95.21
- type: recall_at_1000
value: 96.89999999999999
- type: recall_at_3
value: 85.188
- type: recall_at_5
value: 88.52
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.338
- type: map_at_10
value: 31.752000000000002
- type: map_at_100
value: 33.516
- type: map_at_1000
value: 33.694
- type: map_at_3
value: 27.716
- type: map_at_5
value: 29.67
- type: mrr_at_1
value: 38.117000000000004
- type: mrr_at_10
value: 47.323
- type: mrr_at_100
value: 48.13
- type: mrr_at_1000
value: 48.161
- type: mrr_at_3
value: 45.062000000000005
- type: mrr_at_5
value: 46.358
- type: ndcg_at_1
value: 38.117000000000004
- type: ndcg_at_10
value: 39.353
- type: ndcg_at_100
value: 46.044000000000004
- type: ndcg_at_1000
value: 49.083
- type: ndcg_at_3
value: 35.891
- type: ndcg_at_5
value: 36.661
- type: precision_at_1
value: 38.117000000000004
- type: precision_at_10
value: 11.187999999999999
- type: precision_at_100
value: 1.802
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 24.126
- type: precision_at_5
value: 17.562
- type: recall_at_1
value: 19.338
- type: recall_at_10
value: 45.735
- type: recall_at_100
value: 71.281
- type: recall_at_1000
value: 89.537
- type: recall_at_3
value: 32.525
- type: recall_at_5
value: 37.671
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.995
- type: map_at_10
value: 55.032000000000004
- type: map_at_100
value: 55.86
- type: map_at_1000
value: 55.932
- type: map_at_3
value: 52.125
- type: map_at_5
value: 53.884
- type: mrr_at_1
value: 73.991
- type: mrr_at_10
value: 80.096
- type: mrr_at_100
value: 80.32000000000001
- type: mrr_at_1000
value: 80.331
- type: mrr_at_3
value: 79.037
- type: mrr_at_5
value: 79.719
- type: ndcg_at_1
value: 73.991
- type: ndcg_at_10
value: 63.786
- type: ndcg_at_100
value: 66.78
- type: ndcg_at_1000
value: 68.255
- type: ndcg_at_3
value: 59.501000000000005
- type: ndcg_at_5
value: 61.82299999999999
- type: precision_at_1
value: 73.991
- type: precision_at_10
value: 13.157
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.17500000000000002
- type: precision_at_3
value: 37.519999999999996
- type: precision_at_5
value: 24.351
- type: recall_at_1
value: 36.995
- type: recall_at_10
value: 65.78699999999999
- type: recall_at_100
value: 77.583
- type: recall_at_1000
value: 87.421
- type: recall_at_3
value: 56.279999999999994
- type: recall_at_5
value: 60.878
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 86.80239999999999
- type: ap
value: 81.97305141128378
- type: f1
value: 86.76976305549273
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.166
- type: map_at_10
value: 33.396
- type: map_at_100
value: 34.588
- type: map_at_1000
value: 34.637
- type: map_at_3
value: 29.509999999999998
- type: map_at_5
value: 31.719
- type: mrr_at_1
value: 21.762
- type: mrr_at_10
value: 33.969
- type: mrr_at_100
value: 35.099000000000004
- type: mrr_at_1000
value: 35.141
- type: mrr_at_3
value: 30.148000000000003
- type: mrr_at_5
value: 32.324000000000005
- type: ndcg_at_1
value: 21.776999999999997
- type: ndcg_at_10
value: 40.306999999999995
- type: ndcg_at_100
value: 46.068
- type: ndcg_at_1000
value: 47.3
- type: ndcg_at_3
value: 32.416
- type: ndcg_at_5
value: 36.345
- type: precision_at_1
value: 21.776999999999997
- type: precision_at_10
value: 6.433
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.897
- type: precision_at_5
value: 10.324
- type: recall_at_1
value: 21.166
- type: recall_at_10
value: 61.587
- type: recall_at_100
value: 88.251
- type: recall_at_1000
value: 97.727
- type: recall_at_3
value: 40.196
- type: recall_at_5
value: 49.611
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.04605563155496
- type: f1
value: 92.78007303978372
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.65116279069767
- type: f1
value: 52.75775172527262
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.34633490248822
- type: f1
value: 68.15345065392562
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.63887020847343
- type: f1
value: 76.08074680233685
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.77933406071333
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.06504927238196
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.20682480490871
- type: mrr
value: 33.41462721527003
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.548
- type: map_at_10
value: 13.086999999999998
- type: map_at_100
value: 16.698
- type: map_at_1000
value: 18.151999999999997
- type: map_at_3
value: 9.576
- type: map_at_5
value: 11.175
- type: mrr_at_1
value: 44.272
- type: mrr_at_10
value: 53.635999999999996
- type: mrr_at_100
value: 54.228
- type: mrr_at_1000
value: 54.26499999999999
- type: mrr_at_3
value: 51.754
- type: mrr_at_5
value: 53.086
- type: ndcg_at_1
value: 42.724000000000004
- type: ndcg_at_10
value: 34.769
- type: ndcg_at_100
value: 32.283
- type: ndcg_at_1000
value: 40.843
- type: ndcg_at_3
value: 39.852
- type: ndcg_at_5
value: 37.858999999999995
- type: precision_at_1
value: 44.272
- type: precision_at_10
value: 26.068
- type: precision_at_100
value: 8.328000000000001
- type: precision_at_1000
value: 2.1
- type: precision_at_3
value: 37.874
- type: precision_at_5
value: 33.065
- type: recall_at_1
value: 5.548
- type: recall_at_10
value: 16.936999999999998
- type: recall_at_100
value: 33.72
- type: recall_at_1000
value: 64.348
- type: recall_at_3
value: 10.764999999999999
- type: recall_at_5
value: 13.361
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.008
- type: map_at_10
value: 42.675000000000004
- type: map_at_100
value: 43.85
- type: map_at_1000
value: 43.884
- type: map_at_3
value: 38.286
- type: map_at_5
value: 40.78
- type: mrr_at_1
value: 31.518
- type: mrr_at_10
value: 45.015
- type: mrr_at_100
value: 45.924
- type: mrr_at_1000
value: 45.946999999999996
- type: mrr_at_3
value: 41.348
- type: mrr_at_5
value: 43.428
- type: ndcg_at_1
value: 31.489
- type: ndcg_at_10
value: 50.285999999999994
- type: ndcg_at_100
value: 55.291999999999994
- type: ndcg_at_1000
value: 56.05
- type: ndcg_at_3
value: 41.976
- type: ndcg_at_5
value: 46.103
- type: precision_at_1
value: 31.489
- type: precision_at_10
value: 8.456
- type: precision_at_100
value: 1.125
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 19.09
- type: precision_at_5
value: 13.841000000000001
- type: recall_at_1
value: 28.008
- type: recall_at_10
value: 71.21499999999999
- type: recall_at_100
value: 92.99
- type: recall_at_1000
value: 98.578
- type: recall_at_3
value: 49.604
- type: recall_at_5
value: 59.094
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.351
- type: map_at_10
value: 84.163
- type: map_at_100
value: 84.785
- type: map_at_1000
value: 84.801
- type: map_at_3
value: 81.16
- type: map_at_5
value: 83.031
- type: mrr_at_1
value: 80.96
- type: mrr_at_10
value: 87.241
- type: mrr_at_100
value: 87.346
- type: mrr_at_1000
value: 87.347
- type: mrr_at_3
value: 86.25699999999999
- type: mrr_at_5
value: 86.907
- type: ndcg_at_1
value: 80.97
- type: ndcg_at_10
value: 88.017
- type: ndcg_at_100
value: 89.241
- type: ndcg_at_1000
value: 89.34299999999999
- type: ndcg_at_3
value: 85.053
- type: ndcg_at_5
value: 86.663
- type: precision_at_1
value: 80.97
- type: precision_at_10
value: 13.358
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.143
- type: precision_at_5
value: 24.451999999999998
- type: recall_at_1
value: 70.351
- type: recall_at_10
value: 95.39800000000001
- type: recall_at_100
value: 99.55199999999999
- type: recall_at_1000
value: 99.978
- type: recall_at_3
value: 86.913
- type: recall_at_5
value: 91.448
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.62406719814139
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 61.386700035141736
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.618
- type: map_at_10
value: 12.920000000000002
- type: map_at_100
value: 15.304
- type: map_at_1000
value: 15.656999999999998
- type: map_at_3
value: 9.187
- type: map_at_5
value: 10.937
- type: mrr_at_1
value: 22.8
- type: mrr_at_10
value: 35.13
- type: mrr_at_100
value: 36.239
- type: mrr_at_1000
value: 36.291000000000004
- type: mrr_at_3
value: 31.917
- type: mrr_at_5
value: 33.787
- type: ndcg_at_1
value: 22.8
- type: ndcg_at_10
value: 21.382
- type: ndcg_at_100
value: 30.257
- type: ndcg_at_1000
value: 36.001
- type: ndcg_at_3
value: 20.43
- type: ndcg_at_5
value: 17.622
- type: precision_at_1
value: 22.8
- type: precision_at_10
value: 11.26
- type: precision_at_100
value: 2.405
- type: precision_at_1000
value: 0.377
- type: precision_at_3
value: 19.633
- type: precision_at_5
value: 15.68
- type: recall_at_1
value: 4.618
- type: recall_at_10
value: 22.811999999999998
- type: recall_at_100
value: 48.787000000000006
- type: recall_at_1000
value: 76.63799999999999
- type: recall_at_3
value: 11.952
- type: recall_at_5
value: 15.892000000000001
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.01529458252244
- type: cos_sim_spearman
value: 77.92985224770254
- type: euclidean_pearson
value: 81.04251429422487
- type: euclidean_spearman
value: 77.92838490549133
- type: manhattan_pearson
value: 80.95892251458979
- type: manhattan_spearman
value: 77.81028089705941
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.97885282534388
- type: cos_sim_spearman
value: 75.1221970851712
- type: euclidean_pearson
value: 80.34455956720097
- type: euclidean_spearman
value: 74.5894274239938
- type: manhattan_pearson
value: 80.38999766325465
- type: manhattan_spearman
value: 74.68524557166975
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.95746064915672
- type: cos_sim_spearman
value: 85.08683458043946
- type: euclidean_pearson
value: 84.56699492836385
- type: euclidean_spearman
value: 85.66089116133713
- type: manhattan_pearson
value: 84.47553323458541
- type: manhattan_spearman
value: 85.56142206781472
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 82.71377893595067
- type: cos_sim_spearman
value: 81.03453291428589
- type: euclidean_pearson
value: 82.57136298308613
- type: euclidean_spearman
value: 81.15839961890875
- type: manhattan_pearson
value: 82.55157879373837
- type: manhattan_spearman
value: 81.1540163767054
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.64197832372373
- type: cos_sim_spearman
value: 88.31966852492485
- type: euclidean_pearson
value: 87.98692129976983
- type: euclidean_spearman
value: 88.6247340837856
- type: manhattan_pearson
value: 87.90437827826412
- type: manhattan_spearman
value: 88.56278787131457
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.84159950146693
- type: cos_sim_spearman
value: 83.90678384140168
- type: euclidean_pearson
value: 83.19005018860221
- type: euclidean_spearman
value: 84.16260415876295
- type: manhattan_pearson
value: 83.05030612994494
- type: manhattan_spearman
value: 83.99605629718336
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49935350176666
- type: cos_sim_spearman
value: 87.59086606735383
- type: euclidean_pearson
value: 88.06537181129983
- type: euclidean_spearman
value: 87.6687448086014
- type: manhattan_pearson
value: 87.96599131972935
- type: manhattan_spearman
value: 87.63295748969642
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.68232799482763
- type: cos_sim_spearman
value: 67.99930378085793
- type: euclidean_pearson
value: 68.50275360001696
- type: euclidean_spearman
value: 67.81588179309259
- type: manhattan_pearson
value: 68.5892154749763
- type: manhattan_spearman
value: 67.84357259640682
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.37049618406554
- type: cos_sim_spearman
value: 85.57014313159492
- type: euclidean_pearson
value: 85.57469513908282
- type: euclidean_spearman
value: 85.661948135258
- type: manhattan_pearson
value: 85.36866831229028
- type: manhattan_spearman
value: 85.5043455368843
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 84.83259065376154
- type: mrr
value: 95.58455433455433
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 58.817
- type: map_at_10
value: 68.459
- type: map_at_100
value: 68.951
- type: map_at_1000
value: 68.979
- type: map_at_3
value: 65.791
- type: map_at_5
value: 67.583
- type: mrr_at_1
value: 61.667
- type: mrr_at_10
value: 69.368
- type: mrr_at_100
value: 69.721
- type: mrr_at_1000
value: 69.744
- type: mrr_at_3
value: 67.278
- type: mrr_at_5
value: 68.611
- type: ndcg_at_1
value: 61.667
- type: ndcg_at_10
value: 72.70100000000001
- type: ndcg_at_100
value: 74.928
- type: ndcg_at_1000
value: 75.553
- type: ndcg_at_3
value: 68.203
- type: ndcg_at_5
value: 70.804
- type: precision_at_1
value: 61.667
- type: precision_at_10
value: 9.533
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.444000000000003
- type: precision_at_5
value: 17.599999999999998
- type: recall_at_1
value: 58.817
- type: recall_at_10
value: 84.789
- type: recall_at_100
value: 95.0
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 72.8
- type: recall_at_5
value: 79.294
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.8108910891089
- type: cos_sim_ap
value: 95.5743678558349
- type: cos_sim_f1
value: 90.43133366385722
- type: cos_sim_precision
value: 89.67551622418878
- type: cos_sim_recall
value: 91.2
- type: dot_accuracy
value: 99.75841584158415
- type: dot_ap
value: 94.00786363627253
- type: dot_f1
value: 87.51910341314316
- type: dot_precision
value: 89.20041536863967
- type: dot_recall
value: 85.9
- type: euclidean_accuracy
value: 99.81485148514851
- type: euclidean_ap
value: 95.4752113136905
- type: euclidean_f1
value: 90.44334975369456
- type: euclidean_precision
value: 89.126213592233
- type: euclidean_recall
value: 91.8
- type: manhattan_accuracy
value: 99.81584158415842
- type: manhattan_ap
value: 95.5163172682464
- type: manhattan_f1
value: 90.51987767584097
- type: manhattan_precision
value: 92.3076923076923
- type: manhattan_recall
value: 88.8
- type: max_accuracy
value: 99.81584158415842
- type: max_ap
value: 95.5743678558349
- type: max_f1
value: 90.51987767584097
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 62.63235986949449
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.334795589585575
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.02955214518782
- type: mrr
value: 52.8004838298956
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.63769566275453
- type: cos_sim_spearman
value: 30.422379185989335
- type: dot_pearson
value: 26.88493071882256
- type: dot_spearman
value: 26.505249740971305
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.654
- type: map_at_100
value: 10.095
- type: map_at_1000
value: 25.808999999999997
- type: map_at_3
value: 0.594
- type: map_at_5
value: 0.9289999999999999
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 87.019
- type: mrr_at_100
value: 87.019
- type: mrr_at_1000
value: 87.019
- type: mrr_at_3
value: 86.333
- type: mrr_at_5
value: 86.733
- type: ndcg_at_1
value: 73.0
- type: ndcg_at_10
value: 66.52900000000001
- type: ndcg_at_100
value: 53.433
- type: ndcg_at_1000
value: 51.324000000000005
- type: ndcg_at_3
value: 72.02199999999999
- type: ndcg_at_5
value: 69.696
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 70.39999999999999
- type: precision_at_100
value: 55.46
- type: precision_at_1000
value: 22.758
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.8849999999999998
- type: recall_at_100
value: 13.801
- type: recall_at_1000
value: 49.649
- type: recall_at_3
value: 0.632
- type: recall_at_5
value: 1.009
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.797
- type: map_at_10
value: 9.01
- type: map_at_100
value: 14.682
- type: map_at_1000
value: 16.336000000000002
- type: map_at_3
value: 4.546
- type: map_at_5
value: 5.9270000000000005
- type: mrr_at_1
value: 24.490000000000002
- type: mrr_at_10
value: 41.156
- type: mrr_at_100
value: 42.392
- type: mrr_at_1000
value: 42.408
- type: mrr_at_3
value: 38.775999999999996
- type: mrr_at_5
value: 40.102
- type: ndcg_at_1
value: 21.429000000000002
- type: ndcg_at_10
value: 22.222
- type: ndcg_at_100
value: 34.405
- type: ndcg_at_1000
value: 46.599000000000004
- type: ndcg_at_3
value: 25.261
- type: ndcg_at_5
value: 22.695999999999998
- type: precision_at_1
value: 24.490000000000002
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.306
- type: precision_at_1000
value: 1.5350000000000001
- type: precision_at_3
value: 27.211000000000002
- type: precision_at_5
value: 22.857
- type: recall_at_1
value: 1.797
- type: recall_at_10
value: 15.706000000000001
- type: recall_at_100
value: 46.412
- type: recall_at_1000
value: 83.159
- type: recall_at_3
value: 6.1370000000000005
- type: recall_at_5
value: 8.599
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.3302
- type: ap
value: 14.169121204575601
- type: f1
value: 54.229345975274235
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 58.22297679683077
- type: f1
value: 58.62984908377875
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.952922428464255
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.68140907194373
- type: cos_sim_ap
value: 70.12180123666836
- type: cos_sim_f1
value: 65.77501791258658
- type: cos_sim_precision
value: 60.07853403141361
- type: cos_sim_recall
value: 72.66490765171504
- type: dot_accuracy
value: 81.92167848840674
- type: dot_ap
value: 60.49837581423469
- type: dot_f1
value: 58.44186046511628
- type: dot_precision
value: 52.24532224532224
- type: dot_recall
value: 66.3060686015831
- type: euclidean_accuracy
value: 84.73505394289802
- type: euclidean_ap
value: 70.3278904593286
- type: euclidean_f1
value: 65.98851124940161
- type: euclidean_precision
value: 60.38107752956636
- type: euclidean_recall
value: 72.74406332453826
- type: manhattan_accuracy
value: 84.73505394289802
- type: manhattan_ap
value: 70.00737738537337
- type: manhattan_f1
value: 65.80150784822642
- type: manhattan_precision
value: 61.892583120204606
- type: manhattan_recall
value: 70.23746701846966
- type: max_accuracy
value: 84.73505394289802
- type: max_ap
value: 70.3278904593286
- type: max_f1
value: 65.98851124940161
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.44258159661582
- type: cos_sim_ap
value: 84.91926704880888
- type: cos_sim_f1
value: 77.07651086632926
- type: cos_sim_precision
value: 74.5894554883319
- type: cos_sim_recall
value: 79.73514012935017
- type: dot_accuracy
value: 85.88116583226608
- type: dot_ap
value: 78.9753854779923
- type: dot_f1
value: 72.17757637979255
- type: dot_precision
value: 66.80647486729143
- type: dot_recall
value: 78.48783492454572
- type: euclidean_accuracy
value: 88.5299025885823
- type: euclidean_ap
value: 85.08006075642194
- type: euclidean_f1
value: 77.29637336504163
- type: euclidean_precision
value: 74.69836253950014
- type: euclidean_recall
value: 80.08161379735141
- type: manhattan_accuracy
value: 88.55124771995187
- type: manhattan_ap
value: 85.00941529932851
- type: manhattan_f1
value: 77.33100233100232
- type: manhattan_precision
value: 73.37572573956317
- type: manhattan_recall
value: 81.73698798891284
- type: max_accuracy
value: 88.55124771995187
- type: max_ap
value: 85.08006075642194
- type: max_f1
value: 77.33100233100232
language:
- en
license: mit
---
# gte-small
General Text Embeddings (GTE) model. [Towards General Text Embeddings with Multi-stage Contrastive Learning](https://arxiv.org/abs/2308.03281)
The GTE models are trained by Alibaba DAMO Academy. They are mainly based on the BERT framework and currently offer three different sizes of models, including [GTE-large](https://huggingface.co/thenlper/gte-large), [GTE-base](https://huggingface.co/thenlper/gte-base), and [GTE-small](https://huggingface.co/thenlper/gte-small). The GTE models are trained on a large-scale corpus of relevance text pairs, covering a wide range of domains and scenarios. This enables the GTE models to be applied to various downstream tasks of text embeddings, including **information retrieval**, **semantic textual similarity**, **text reranking**, etc.
## Metrics
We compared the performance of the GTE models with other popular text embedding models on the MTEB benchmark. For more detailed comparison results, please refer to the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [**gte-large**](https://huggingface.co/thenlper/gte-large) | 0.67 | 1024 | 512 | **63.13** | 46.84 | 85.00 | 59.13 | 52.22 | 83.35 | 31.66 | 73.33 |
| [**gte-base**](https://huggingface.co/thenlper/gte-base) | 0.22 | 768 | 512 | **62.39** | 46.2 | 84.57 | 58.61 | 51.14 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1.34 | 1024| 512 | 62.25 | 44.49 | 86.03 | 56.61 | 50.56 | 82.05 | 30.19 | 75.24 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.44 | 768 | 512 | 61.5 | 43.80 | 85.73 | 55.91 | 50.29 | 81.05 | 30.28 | 73.84 |
| [**gte-small**](https://huggingface.co/thenlper/gte-small) | 0.07 | 384 | 512 | **61.36** | 44.89 | 83.54 | 57.7 | 49.46 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | - | 1536 | 8192 | 60.99 | 45.9 | 84.89 | 56.32 | 49.25 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.13 | 384 | 512 | 59.93 | 39.92 | 84.67 | 54.32 | 49.04 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 9.73 | 768 | 512 | 59.51 | 43.72 | 85.06 | 56.42 | 42.24 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 0.44 | 768 | 514 | 57.78 | 43.69 | 83.04 | 59.36 | 43.81 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 28.27 | 4096 | 2048 | 57.59 | 38.93 | 81.9 | 55.65 | 48.22 | 77.74 | 33.6 | 66.19 |
| [all-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2) | 0.13 | 384 | 512 | 56.53 | 41.81 | 82.41 | 58.44 | 42.69 | 79.8 | 27.9 | 63.21 |
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | 0.09 | 384 | 512 | 56.26 | 42.35 | 82.37 | 58.04 | 41.95 | 78.9 | 30.81 | 63.05 |
| [contriever-base-msmarco](https://huggingface.co/nthakur/contriever-base-msmarco) | 0.44 | 768 | 512 | 56.00 | 41.1 | 82.54 | 53.14 | 41.88 | 76.51 | 30.36 | 66.68 |
| [sentence-t5-base](https://huggingface.co/sentence-transformers/sentence-t5-base) | 0.22 | 768 | 512 | 55.27 | 40.21 | 85.18 | 53.09 | 33.63 | 81.14 | 31.39 | 69.81 |
## Usage
Code example
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-small")
model = AutoModel.from_pretrained("thenlper/gte-small")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
```
Use with sentence-transformers:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('thenlper/gte-large')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
```
### Limitation
This model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens.
### Citation
If you find our paper or models helpful, please consider citing them as follows:
```
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
```
|
facebook/sam-vit-base | facebook | "2024-01-11T19:23:17Z" | 737,412 | 118 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"sam",
"mask-generation",
"vision",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | mask-generation | "2023-04-19T14:15:29Z" | ---
license: apache-2.0
tags:
- vision
---
# Model Card for Segment Anything Model (SAM) - ViT Base (ViT-B) version
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-architecture.png" alt="Model architecture">
<em> Detailed architecture of Segment Anything Model (SAM).</em>
</p>
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Citation](#citation)
# TL;DR
[Link to original repository](https://github.com/facebookresearch/segment-anything)
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-beancans.png" alt="Snow" width="600" height="600"> | <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-dog-masks.png" alt="Forest" width="600" height="600"> | <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-car-seg.png" alt="Mountains" width="600" height="600"> |
|---------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------|
The **Segment Anything Model (SAM)** produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a [dataset](https://segment-anything.com/dataset/index.html) of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.
The abstract of the paper states:
> We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at [https://segment-anything.com](https://segment-anything.com) to foster research into foundation models for computer vision.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the original [SAM model card](https://github.com/facebookresearch/segment-anything).
# Model Details
The SAM model is made up of 3 modules:
- The `VisionEncoder`: a VIT based image encoder. It computes the image embeddings using attention on patches of the image. Relative Positional Embedding is used.
- The `PromptEncoder`: generates embeddings for points and bounding boxes
- The `MaskDecoder`: a two-ways transformer which performs cross attention between the image embedding and the point embeddings (->) and between the point embeddings and the image embeddings. The outputs are fed
- The `Neck`: predicts the output masks based on the contextualized masks produced by the `MaskDecoder`.
# Usage
## Prompted-Mask-Generation
```python
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
model = SamModel.from_pretrained("facebook/sam-vit-base")
processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D localization of a window
```
```python
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores
```
Among other arguments to generate masks, you can pass 2D locations on the approximate position of your object of interest, a bounding box wrapping the object of interest (the format should be x, y coordinate of the top right and bottom left point of the bounding box), a segmentation mask. At this time of writing, passing a text as input is not supported by the official model according to [the official repository](https://github.com/facebookresearch/segment-anything/issues/4#issuecomment-1497626844).
For more details, refer to this notebook, which shows a walk throught of how to use the model, with a visual example!
## Automatic-Mask-Generation
The model can be used for generating segmentation masks in a "zero-shot" fashion, given an input image. The model is automatically prompt with a grid of `1024` points
which are all fed to the model.
The pipeline is made for automatic mask generation. The following snippet demonstrates how easy you can run it (on any device! Simply feed the appropriate `points_per_batch` argument)
```python
from transformers import pipeline
generator = pipeline("mask-generation", device = 0, points_per_batch = 256)
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
outputs = generator(image_url, points_per_batch = 256)
```
Now to display the image:
```python
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(np.array(raw_image))
ax = plt.gca()
for mask in outputs["masks"]:
show_mask(mask, ax=ax, random_color=True)
plt.axis("off")
plt.show()
```
# Citation
If you use this model, please use the following BibTeX entry.
```
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
``` |
sshleifer/distilbart-cnn-12-6 | sshleifer | "2021-06-14T07:51:12Z" | 733,063 | 261 | transformers | [
"transformers",
"pytorch",
"jax",
"rust",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | "2022-03-02T23:29:05Z" | ---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
Helsinki-NLP/opus-mt-es-en | Helsinki-NLP | "2023-08-16T11:32:34Z" | 724,217 | 61 | transformers | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"es",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
language:
- es
- en
tags:
- translation
license: apache-2.0
---
### spa-eng
* source group: Spanish
* target group: English
* OPUS readme: [spa-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/spa-eng/README.md)
* model: transformer
* source language(s): spa
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-08-18.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/spa-eng/opus-2020-08-18.zip)
* test set translations: [opus-2020-08-18.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/spa-eng/opus-2020-08-18.test.txt)
* test set scores: [opus-2020-08-18.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/spa-eng/opus-2020-08-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newssyscomb2009-spaeng.spa.eng | 30.6 | 0.570 |
| news-test2008-spaeng.spa.eng | 27.9 | 0.553 |
| newstest2009-spaeng.spa.eng | 30.4 | 0.572 |
| newstest2010-spaeng.spa.eng | 36.1 | 0.614 |
| newstest2011-spaeng.spa.eng | 34.2 | 0.599 |
| newstest2012-spaeng.spa.eng | 37.9 | 0.624 |
| newstest2013-spaeng.spa.eng | 35.3 | 0.609 |
| Tatoeba-test.spa.eng | 59.6 | 0.739 |
### System Info:
- hf_name: spa-eng
- source_languages: spa
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/spa-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['es', 'en']
- src_constituents: {'spa'}
- tgt_constituents: {'eng'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/spa-eng/opus-2020-08-18.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/spa-eng/opus-2020-08-18.test.txt
- src_alpha3: spa
- tgt_alpha3: eng
- short_pair: es-en
- chrF2_score: 0.7390000000000001
- bleu: 59.6
- brevity_penalty: 0.9740000000000001
- ref_len: 79376.0
- src_name: Spanish
- tgt_name: English
- train_date: 2020-08-18 00:00:00
- src_alpha2: es
- tgt_alpha2: en
- prefer_old: False
- long_pair: spa-eng
- helsinki_git_sha: d2f0910c89026c34a44e331e785dec1e0faa7b82
- transformers_git_sha: f7af09b4524b784d67ae8526f0e2fcc6f5ed0de9
- port_machine: brutasse
- port_time: 2020-08-24-18:20 |
distilbert/distilbert-base-cased | distilbert | "2024-05-06T13:46:22Z" | 724,119 | 33 | transformers | [
"transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"distilbert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1910.01108",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# Model Card for DistilBERT base model (cased)
This model is a distilled version of the [BERT base model](https://huggingface.co/bert-base-cased).
It was introduced in [this paper](https://arxiv.org/abs/1910.01108).
The code for the distillation process can be found
[here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
This model is cased: it does make a difference between english and English.
All the training details on the pre-training, the uses, limitations and potential biases (included below) are the same as for [DistilBERT-base-uncased](https://huggingface.co/distilbert-base-uncased).
We highly encourage to check it if you want to know more.
## Model description
DistilBERT is a transformers model, smaller and faster than BERT, which was pretrained on the same corpus in a
self-supervised fashion, using the BERT base model as a teacher. This means it was pretrained on the raw texts only,
with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic
process to generate inputs and labels from those texts using the BERT base model. More precisely, it was pretrained
with three objectives:
- Distillation loss: the model was trained to return the same probabilities as the BERT base model.
- Masked language modeling (MLM): this is part of the original training loss of the BERT base model. When taking a
sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the
model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that
usually see the words one after the other, or from autoregressive models like GPT which internally mask the future
tokens. It allows the model to learn a bidirectional representation of the sentence.
- Cosine embedding loss: the model was also trained to generate hidden states as close as possible as the BERT base
model.
This way, the model learns the same inner representation of the English language than its teacher model, while being
faster for inference or downstream tasks.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=distilbert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.05292855575680733,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.03968575969338417,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a business model. [SEP]",
'score': 0.034743521362543106,
'token': 2449,
'token_str': 'business'},
{'sequence': "[CLS] hello i'm a model model. [SEP]",
'score': 0.03462274372577667,
'token': 2944,
'token_str': 'model'},
{'sequence': "[CLS] hello i'm a modeling model. [SEP]",
'score': 0.018145186826586723,
'token': 11643,
'token_str': 'modeling'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import DistilBertTokenizer, DistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. It also inherits some of
[the bias of its teacher model](https://huggingface.co/bert-base-uncased#limitations-and-bias).
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("The White man worked as a [MASK].")
[{'sequence': '[CLS] the white man worked as a blacksmith. [SEP]',
'score': 0.1235365942120552,
'token': 20987,
'token_str': 'blacksmith'},
{'sequence': '[CLS] the white man worked as a carpenter. [SEP]',
'score': 0.10142576694488525,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the white man worked as a farmer. [SEP]',
'score': 0.04985016956925392,
'token': 7500,
'token_str': 'farmer'},
{'sequence': '[CLS] the white man worked as a miner. [SEP]',
'score': 0.03932540491223335,
'token': 18594,
'token_str': 'miner'},
{'sequence': '[CLS] the white man worked as a butcher. [SEP]',
'score': 0.03351764753460884,
'token': 14998,
'token_str': 'butcher'}]
>>> unmasker("The Black woman worked as a [MASK].")
[{'sequence': '[CLS] the black woman worked as a waitress. [SEP]',
'score': 0.13283951580524445,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the black woman worked as a nurse. [SEP]',
'score': 0.12586183845996857,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the black woman worked as a maid. [SEP]',
'score': 0.11708822101354599,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the black woman worked as a prostitute. [SEP]',
'score': 0.11499975621700287,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the black woman worked as a housekeeper. [SEP]',
'score': 0.04722772538661957,
'token': 22583,
'token_str': 'housekeeper'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
DistilBERT pretrained on the same data as BERT, which is [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset
consisting of 11,038 unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia)
(excluding lists, tables and headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 8 16 GB V100 for 90 hours. See the
[training code](https://github.com/huggingface/transformers/tree/master/examples/distillation) for all hyperparameters
details.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE |
|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|
| | 81.5 | 87.8 | 88.2 | 90.4 | 47.2 | 85.5 | 85.6 | 60.6 |
### BibTeX entry and citation info
```bibtex
@article{Sanh2019DistilBERTAD,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf},
journal={ArXiv},
year={2019},
volume={abs/1910.01108}
}
```
<a href="https://huggingface.co/exbert/?model=distilbert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
sentence-transformers/stsb-roberta-base | sentence-transformers | "2024-11-05T19:45:13Z" | 719,883 | 1 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/stsb-roberta-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-roberta-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-roberta-base')
model = AutoModel.from_pretrained('sentence-transformers/stsb-roberta-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-roberta-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
deepset/roberta-base-squad2 | deepset | "2024-09-24T15:48:47Z" | 719,388 | 794 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"roberta",
"question-answering",
"en",
"dataset:squad_v2",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:cc-by-4.0",
"model-index",
"endpoints_compatible",
"region:us"
] | question-answering | "2022-03-02T23:29:05Z" | ---
language: en
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/roberta-base-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 79.9309
name: Exact Match
verified: true
verifyToken: >-
eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDhhNjg5YzNiZGQ1YTIyYTAwZGUwOWEzZTRiYzdjM2QzYjA3ZTUxNDM1NjE1MTUyMjE1MGY1YzEzMjRjYzVjYiIsInZlcnNpb24iOjF9.EH5JJo8EEFwU7osPz3s7qanw_tigeCFhCXjSfyN0Y1nWVnSfulSxIk_DbAEI5iE80V4EKLyp5-mYFodWvL2KDA
- type: f1
value: 82.9501
name: F1
verified: true
verifyToken: >-
eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjk5ZDYwOGQyNjNkMWI0OTE4YzRmOTlkY2JjNjQ0YTZkNTMzMzNkYTA0MDFmNmI3NjA3NjNlMjhiMDQ2ZjJjNSIsInZlcnNpb24iOjF9.DDm0LNTkdLbGsue58bg1aH_s67KfbcmkvL-6ZiI2s8IoxhHJMSf29H_uV2YLyevwx900t-MwTVOW3qfFnMMEAQ
- type: total
value: 11869
name: total
verified: true
verifyToken: >-
eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMGFkMmI2ODM0NmY5NGNkNmUxYWViOWYxZDNkY2EzYWFmOWI4N2VhYzY5MGEzMTVhOTU4Zjc4YWViOGNjOWJjMCIsInZlcnNpb24iOjF9.fexrU1icJK5_MiifBtZWkeUvpmFISqBLDXSQJ8E6UnrRof-7cU0s4tX_dIsauHWtUpIHMPZCf5dlMWQKXZuAAA
- task:
type: question-answering
name: Question Answering
dataset:
name: squad
type: squad
config: plain_text
split: validation
metrics:
- type: exact_match
value: 85.289
name: Exact Match
- type: f1
value: 91.841
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: adversarial_qa
type: adversarial_qa
config: adversarialQA
split: validation
metrics:
- type: exact_match
value: 29.5
name: Exact Match
- type: f1
value: 40.367
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_adversarial
type: squad_adversarial
config: AddOneSent
split: validation
metrics:
- type: exact_match
value: 78.567
name: Exact Match
- type: f1
value: 84.469
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts amazon
type: squadshifts
config: amazon
split: test
metrics:
- type: exact_match
value: 69.924
name: Exact Match
- type: f1
value: 83.284
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts new_wiki
type: squadshifts
config: new_wiki
split: test
metrics:
- type: exact_match
value: 81.204
name: Exact Match
- type: f1
value: 90.595
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts nyt
type: squadshifts
config: nyt
split: test
metrics:
- type: exact_match
value: 82.931
name: Exact Match
- type: f1
value: 90.756
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts reddit
type: squadshifts
config: reddit
split: test
metrics:
- type: exact_match
value: 71.55
name: Exact Match
- type: f1
value: 82.939
name: F1
base_model:
- FacebookAI/roberta-base
---
# roberta-base for Extractive QA
This is the [roberta-base](https://huggingface.co/roberta-base) model, fine-tuned using the [SQuAD2.0](https://huggingface.co/datasets/squad_v2) dataset. It's been trained on question-answer pairs, including unanswerable questions, for the task of Extractive Question Answering.
We have also released a distilled version of this model called [deepset/tinyroberta-squad2](https://huggingface.co/deepset/tinyroberta-squad2). It has a comparable prediction quality and runs at twice the speed of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2).
## Overview
**Language model:** roberta-base
**Language:** English
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [an example extractive QA pipeline built with Haystack](https://haystack.deepset.ai/tutorials/34_extractive_qa_pipeline)
**Infrastructure**: 4x Tesla v100
## Hyperparameters
```
batch_size = 96
n_epochs = 2
base_LM_model = "roberta-base"
max_seq_len = 386
learning_rate = 3e-5
lr_schedule = LinearWarmup
warmup_proportion = 0.2
doc_stride=128
max_query_length=64
```
## Usage
### In Haystack
Haystack is an AI orchestration framework to build customizable, production-ready LLM applications. You can use this model in Haystack to do extractive question answering on documents.
To load and run the model with [Haystack](https://github.com/deepset-ai/haystack/):
```python
# After running pip install haystack-ai "transformers[torch,sentencepiece]"
from haystack import Document
from haystack.components.readers import ExtractiveReader
docs = [
Document(content="Python is a popular programming language"),
Document(content="python ist eine beliebte Programmiersprache"),
]
reader = ExtractiveReader(model="deepset/roberta-base-squad2")
reader.warm_up()
question = "What is a popular programming language?"
result = reader.run(query=question, documents=docs)
# {'answers': [ExtractedAnswer(query='What is a popular programming language?', score=0.5740374326705933, data='python', document=Document(id=..., content: '...'), context=None, document_offset=ExtractedAnswer.Span(start=0, end=6),...)]}
```
For a complete example with an extractive question answering pipeline that scales over many documents, check out the [corresponding Haystack tutorial](https://haystack.deepset.ai/tutorials/34_extractive_qa_pipeline).
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/roberta-base-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## Performance
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
```
"exact": 79.87029394424324,
"f1": 82.91251169582613,
"total": 11873,
"HasAns_exact": 77.93522267206478,
"HasAns_f1": 84.02838248389763,
"HasAns_total": 5928,
"NoAns_exact": 81.79983179142137,
"NoAns_f1": 81.79983179142137,
"NoAns_total": 5945
```
## Authors
**Branden Chan:** branden.chan@deepset.ai
**Timo Möller:** timo.moeller@deepset.ai
**Malte Pietsch:** malte.pietsch@deepset.ai
**Tanay Soni:** tanay.soni@deepset.ai
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the production-ready open-source AI framework [Haystack](https://haystack.deepset.ai/).
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")](https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT](https://deepset.ai/german-bert), [GermanQuAD and GermanDPR](https://deepset.ai/germanquad), [German embedding model](https://huggingface.co/mixedbread-ai/deepset-mxbai-embed-de-large-v1)
- [deepset Cloud](https://www.deepset.ai/deepset-cloud-product)
- [deepset Studio](https://www.deepset.ai/deepset-studio)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://docs.haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/Haystack_AI) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://haystack.deepset.ai/) | [YouTube](https://www.youtube.com/@deepset_ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
HuggingFaceH4/zephyr-7b-beta | HuggingFaceH4 | "2024-10-16T11:48:13Z" | 718,443 | 1,605 | transformers | [
"transformers",
"pytorch",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"conversational",
"en",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"arxiv:2305.18290",
"arxiv:2310.16944",
"arxiv:2305.14233",
"arxiv:2310.01377",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:mit",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-10-26T11:25:49Z" | ---
tags:
- generated_from_trainer
license: mit
datasets:
- HuggingFaceH4/ultrachat_200k
- HuggingFaceH4/ultrafeedback_binarized
language:
- en
base_model: mistralai/Mistral-7B-v0.1
widget:
- example_title: Pirate!
messages:
- role: system
content: You are a pirate chatbot who always responds with Arr!
- role: user
content: "There's a llama on my lawn, how can I get rid of him?"
output:
text: >-
Arr! 'Tis a puzzlin' matter, me hearty! A llama on yer lawn be a rare
sight, but I've got a plan that might help ye get rid of 'im. Ye'll need
to gather some carrots and hay, and then lure the llama away with the
promise of a tasty treat. Once he's gone, ye can clean up yer lawn and
enjoy the peace and quiet once again. But beware, me hearty, for there
may be more llamas where that one came from! Arr!
pipeline_tag: text-generation
model-index:
- name: zephyr-7b-beta
results:
# AI2 Reasoning Challenge (25-Shot)
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
name: normalized accuracy
value: 62.03071672354948
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=HuggingFaceH4/zephyr-7b-beta
# HellaSwag (10-shot)
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
name: normalized accuracy
value: 84.35570603465445
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=HuggingFaceH4/zephyr-7b-beta
# DROP (3-shot)
- task:
type: text-generation
name: Text Generation
dataset:
name: Drop (3-Shot)
type: drop
split: validation
args:
num_few_shot: 3
metrics:
- type: f1
name: f1 score
value: 9.662437080536909
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=HuggingFaceH4/zephyr-7b-beta
# TruthfulQA (0-shot)
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 57.44916942762855
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=HuggingFaceH4/zephyr-7b-beta
# GSM8k (5-shot)
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
name: accuracy
value: 12.736921910538287
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=HuggingFaceH4/zephyr-7b-beta
# MMLU (5-Shot)
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
name: accuracy
value: 61.07
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=HuggingFaceH4/zephyr-7b-beta
# Winogrande (5-shot)
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
name: accuracy
value: 77.74269928966061
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=HuggingFaceH4/zephyr-7b-beta
# AlpacaEval (taken from model card)
- task:
type: text-generation
name: Text Generation
dataset:
name: AlpacaEval
type: tatsu-lab/alpaca_eval
metrics:
- type: unknown
name: win rate
value: 0.9060
source:
url: https://tatsu-lab.github.io/alpaca_eval/
# MT-Bench (taken from model card)
- task:
type: text-generation
name: Text Generation
dataset:
name: MT-Bench
type: unknown
metrics:
- type: unknown
name: score
value: 7.34
source:
url: https://huggingface.co/spaces/lmsys/mt-bench
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<img src="https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha/resolve/main/thumbnail.png" alt="Zephyr Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for Zephyr 7B β
Zephyr is a series of language models that are trained to act as helpful assistants. Zephyr-7B-β is the second model in the series, and is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) that was trained on on a mix of publicly available, synthetic datasets using [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290). We found that removing the in-built alignment of these datasets boosted performance on [MT Bench](https://huggingface.co/spaces/lmsys/mt-bench) and made the model more helpful. However, this means that model is likely to generate problematic text when prompted to do so. You can find more details in the [technical report](https://arxiv.org/abs/2310.16944).
## Model description
- **Model type:** A 7B parameter GPT-like model fine-tuned on a mix of publicly available, synthetic datasets.
- **Language(s) (NLP):** Primarily English
- **License:** MIT
- **Finetuned from model:** [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/huggingface/alignment-handbook
- **Demo:** https://huggingface.co/spaces/HuggingFaceH4/zephyr-chat
- **Chatbot Arena:** Evaluate Zephyr 7B against 10+ LLMs in the LMSYS arena: http://arena.lmsys.org
## Performance
At the time of release, Zephyr-7B-β is the highest ranked 7B chat model on the [MT-Bench](https://huggingface.co/spaces/lmsys/mt-bench) and [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) benchmarks:
| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|-------------|-----|----|---------------|--------------|
| StableLM-Tuned-α | 7B| dSFT |2.75| -|
| MPT-Chat | 7B |dSFT |5.42| -|
| Xwin-LMv0.1 | 7B| dPPO| 6.19| 87.83|
| Mistral-Instructv0.1 | 7B| - | 6.84 |-|
| Zephyr-7b-α |7B| dDPO| 6.88| -|
| **Zephyr-7b-β** 🪁 | **7B** | **dDPO** | **7.34** | **90.60** |
| Falcon-Instruct | 40B |dSFT |5.17 |45.71|
| Guanaco | 65B | SFT |6.41| 71.80|
| Llama2-Chat | 70B |RLHF |6.86| 92.66|
| Vicuna v1.3 | 33B |dSFT |7.12 |88.99|
| WizardLM v1.0 | 70B |dSFT |7.71 |-|
| Xwin-LM v0.1 | 70B |dPPO |- |95.57|
| GPT-3.5-turbo | - |RLHF |7.94 |89.37|
| Claude 2 | - |RLHF |8.06| 91.36|
| GPT-4 | -| RLHF |8.99| 95.28|
In particular, on several categories of MT-Bench, Zephyr-7B-β has strong performance compared to larger open models like Llama2-Chat-70B:

However, on more complex tasks like coding and mathematics, Zephyr-7B-β lags behind proprietary models and more research is needed to close the gap.
## Intended uses & limitations
The model was initially fine-tuned on a filtered and preprocessed of the [`UltraChat`](https://huggingface.co/datasets/stingning/ultrachat) dataset, which contains a diverse range of synthetic dialogues generated by ChatGPT.
We then further aligned the model with [🤗 TRL's](https://github.com/huggingface/trl) `DPOTrainer` on the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset, which contains 64k prompts and model completions that are ranked by GPT-4. As a result, the model can be used for chat and you can check out our [demo](https://huggingface.co/spaces/HuggingFaceH4/zephyr-chat) to test its capabilities.
You can find the datasets used for training Zephyr-7B-β [here](https://huggingface.co/collections/HuggingFaceH4/zephyr-7b-6538c6d6d5ddd1cbb1744a66)
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-beta", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
```
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Zephyr-7B-β has not been aligned to human preferences for safety within the RLHF phase or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
It is also unknown what the size and composition of the corpus was used to train the base model (`mistralai/Mistral-7B-v0.1`), however it is likely to have included a mix of Web data and technical sources like books and code. See the [Falcon 180B model card](https://huggingface.co/tiiuae/falcon-180B#training-data) for an example of this.
## Training and evaluation data
During DPO training, this model achieves the following results on the evaluation set:
- Loss: 0.7496
- Rewards/chosen: -4.5221
- Rewards/rejected: -8.3184
- Rewards/accuracies: 0.7812
- Rewards/margins: 3.7963
- Logps/rejected: -340.1541
- Logps/chosen: -299.4561
- Logits/rejected: -2.3081
- Logits/chosen: -2.3531
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 2
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
The table below shows the full set of DPO training metrics:
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.6284 | 0.05 | 100 | 0.6098 | 0.0425 | -0.1872 | 0.7344 | 0.2297 | -258.8416 | -253.8099 | -2.7976 | -2.8234 |
| 0.4908 | 0.1 | 200 | 0.5426 | -0.0279 | -0.6842 | 0.75 | 0.6563 | -263.8124 | -254.5145 | -2.7719 | -2.7960 |
| 0.5264 | 0.15 | 300 | 0.5324 | 0.0414 | -0.9793 | 0.7656 | 1.0207 | -266.7627 | -253.8209 | -2.7892 | -2.8122 |
| 0.5536 | 0.21 | 400 | 0.4957 | -0.0185 | -1.5276 | 0.7969 | 1.5091 | -272.2460 | -254.4203 | -2.8542 | -2.8764 |
| 0.5362 | 0.26 | 500 | 0.5031 | -0.2630 | -1.5917 | 0.7812 | 1.3287 | -272.8869 | -256.8653 | -2.8702 | -2.8958 |
| 0.5966 | 0.31 | 600 | 0.5963 | -0.2993 | -1.6491 | 0.7812 | 1.3499 | -273.4614 | -257.2279 | -2.8778 | -2.8986 |
| 0.5014 | 0.36 | 700 | 0.5382 | -0.2859 | -1.4750 | 0.75 | 1.1891 | -271.7204 | -257.0942 | -2.7659 | -2.7869 |
| 0.5334 | 0.41 | 800 | 0.5677 | -0.4289 | -1.8968 | 0.7969 | 1.4679 | -275.9378 | -258.5242 | -2.7053 | -2.7265 |
| 0.5251 | 0.46 | 900 | 0.5772 | -0.2116 | -1.3107 | 0.7344 | 1.0991 | -270.0768 | -256.3507 | -2.8463 | -2.8662 |
| 0.5205 | 0.52 | 1000 | 0.5262 | -0.3792 | -1.8585 | 0.7188 | 1.4793 | -275.5552 | -258.0276 | -2.7893 | -2.7979 |
| 0.5094 | 0.57 | 1100 | 0.5433 | -0.6279 | -1.9368 | 0.7969 | 1.3089 | -276.3377 | -260.5136 | -2.7453 | -2.7536 |
| 0.5837 | 0.62 | 1200 | 0.5349 | -0.3780 | -1.9584 | 0.7656 | 1.5804 | -276.5542 | -258.0154 | -2.7643 | -2.7756 |
| 0.5214 | 0.67 | 1300 | 0.5732 | -1.0055 | -2.2306 | 0.7656 | 1.2251 | -279.2761 | -264.2903 | -2.6986 | -2.7113 |
| 0.6914 | 0.72 | 1400 | 0.5137 | -0.6912 | -2.1775 | 0.7969 | 1.4863 | -278.7448 | -261.1467 | -2.7166 | -2.7275 |
| 0.4655 | 0.77 | 1500 | 0.5090 | -0.7987 | -2.2930 | 0.7031 | 1.4943 | -279.8999 | -262.2220 | -2.6651 | -2.6838 |
| 0.5731 | 0.83 | 1600 | 0.5312 | -0.8253 | -2.3520 | 0.7812 | 1.5268 | -280.4902 | -262.4876 | -2.6543 | -2.6728 |
| 0.5233 | 0.88 | 1700 | 0.5206 | -0.4573 | -2.0951 | 0.7812 | 1.6377 | -277.9205 | -258.8084 | -2.6870 | -2.7097 |
| 0.5593 | 0.93 | 1800 | 0.5231 | -0.5508 | -2.2000 | 0.7969 | 1.6492 | -278.9703 | -259.7433 | -2.6221 | -2.6519 |
| 0.4967 | 0.98 | 1900 | 0.5290 | -0.5340 | -1.9570 | 0.8281 | 1.4230 | -276.5395 | -259.5749 | -2.6564 | -2.6878 |
| 0.0921 | 1.03 | 2000 | 0.5368 | -1.1376 | -3.1615 | 0.7812 | 2.0239 | -288.5854 | -265.6111 | -2.6040 | -2.6345 |
| 0.0733 | 1.08 | 2100 | 0.5453 | -1.1045 | -3.4451 | 0.7656 | 2.3406 | -291.4208 | -265.2799 | -2.6289 | -2.6595 |
| 0.0972 | 1.14 | 2200 | 0.5571 | -1.6915 | -3.9823 | 0.8125 | 2.2908 | -296.7934 | -271.1505 | -2.6471 | -2.6709 |
| 0.1058 | 1.19 | 2300 | 0.5789 | -1.0621 | -3.8941 | 0.7969 | 2.8319 | -295.9106 | -264.8563 | -2.5527 | -2.5798 |
| 0.2423 | 1.24 | 2400 | 0.5455 | -1.1963 | -3.5590 | 0.7812 | 2.3627 | -292.5599 | -266.1981 | -2.5414 | -2.5784 |
| 0.1177 | 1.29 | 2500 | 0.5889 | -1.8141 | -4.3942 | 0.7969 | 2.5801 | -300.9120 | -272.3761 | -2.4802 | -2.5189 |
| 0.1213 | 1.34 | 2600 | 0.5683 | -1.4608 | -3.8420 | 0.8125 | 2.3812 | -295.3901 | -268.8436 | -2.4774 | -2.5207 |
| 0.0889 | 1.39 | 2700 | 0.5890 | -1.6007 | -3.7337 | 0.7812 | 2.1330 | -294.3068 | -270.2423 | -2.4123 | -2.4522 |
| 0.0995 | 1.45 | 2800 | 0.6073 | -1.5519 | -3.8362 | 0.8281 | 2.2843 | -295.3315 | -269.7538 | -2.4685 | -2.5050 |
| 0.1145 | 1.5 | 2900 | 0.5790 | -1.7939 | -4.2876 | 0.8438 | 2.4937 | -299.8461 | -272.1744 | -2.4272 | -2.4674 |
| 0.0644 | 1.55 | 3000 | 0.5735 | -1.7285 | -4.2051 | 0.8125 | 2.4766 | -299.0209 | -271.5201 | -2.4193 | -2.4574 |
| 0.0798 | 1.6 | 3100 | 0.5537 | -1.7226 | -4.2850 | 0.8438 | 2.5624 | -299.8200 | -271.4610 | -2.5367 | -2.5696 |
| 0.1013 | 1.65 | 3200 | 0.5575 | -1.5715 | -3.9813 | 0.875 | 2.4098 | -296.7825 | -269.9498 | -2.4926 | -2.5267 |
| 0.1254 | 1.7 | 3300 | 0.5905 | -1.6412 | -4.4703 | 0.8594 | 2.8291 | -301.6730 | -270.6473 | -2.5017 | -2.5340 |
| 0.085 | 1.76 | 3400 | 0.6133 | -1.9159 | -4.6760 | 0.8438 | 2.7601 | -303.7296 | -273.3941 | -2.4614 | -2.4960 |
| 0.065 | 1.81 | 3500 | 0.6074 | -1.8237 | -4.3525 | 0.8594 | 2.5288 | -300.4951 | -272.4724 | -2.4597 | -2.5004 |
| 0.0755 | 1.86 | 3600 | 0.5836 | -1.9252 | -4.4005 | 0.8125 | 2.4753 | -300.9748 | -273.4872 | -2.4327 | -2.4716 |
| 0.0746 | 1.91 | 3700 | 0.5789 | -1.9280 | -4.4906 | 0.8125 | 2.5626 | -301.8762 | -273.5149 | -2.4686 | -2.5115 |
| 0.1348 | 1.96 | 3800 | 0.6015 | -1.8658 | -4.2428 | 0.8281 | 2.3769 | -299.3976 | -272.8936 | -2.4943 | -2.5393 |
| 0.0217 | 2.01 | 3900 | 0.6122 | -2.3335 | -4.9229 | 0.8281 | 2.5894 | -306.1988 | -277.5699 | -2.4841 | -2.5272 |
| 0.0219 | 2.07 | 4000 | 0.6522 | -2.9890 | -6.0164 | 0.8281 | 3.0274 | -317.1334 | -284.1248 | -2.4105 | -2.4545 |
| 0.0119 | 2.12 | 4100 | 0.6922 | -3.4777 | -6.6749 | 0.7969 | 3.1972 | -323.7187 | -289.0121 | -2.4272 | -2.4699 |
| 0.0153 | 2.17 | 4200 | 0.6993 | -3.2406 | -6.6775 | 0.7969 | 3.4369 | -323.7453 | -286.6413 | -2.4047 | -2.4465 |
| 0.011 | 2.22 | 4300 | 0.7178 | -3.7991 | -7.4397 | 0.7656 | 3.6406 | -331.3667 | -292.2260 | -2.3843 | -2.4290 |
| 0.0072 | 2.27 | 4400 | 0.6840 | -3.3269 | -6.8021 | 0.8125 | 3.4752 | -324.9908 | -287.5042 | -2.4095 | -2.4536 |
| 0.0197 | 2.32 | 4500 | 0.7013 | -3.6890 | -7.3014 | 0.8125 | 3.6124 | -329.9841 | -291.1250 | -2.4118 | -2.4543 |
| 0.0182 | 2.37 | 4600 | 0.7476 | -3.8994 | -7.5366 | 0.8281 | 3.6372 | -332.3356 | -293.2291 | -2.4163 | -2.4565 |
| 0.0125 | 2.43 | 4700 | 0.7199 | -4.0560 | -7.5765 | 0.8438 | 3.5204 | -332.7345 | -294.7952 | -2.3699 | -2.4100 |
| 0.0082 | 2.48 | 4800 | 0.7048 | -3.6613 | -7.1356 | 0.875 | 3.4743 | -328.3255 | -290.8477 | -2.3925 | -2.4303 |
| 0.0118 | 2.53 | 4900 | 0.6976 | -3.7908 | -7.3152 | 0.8125 | 3.5244 | -330.1224 | -292.1431 | -2.3633 | -2.4047 |
| 0.0118 | 2.58 | 5000 | 0.7198 | -3.9049 | -7.5557 | 0.8281 | 3.6508 | -332.5271 | -293.2844 | -2.3764 | -2.4194 |
| 0.006 | 2.63 | 5100 | 0.7506 | -4.2118 | -7.9149 | 0.8125 | 3.7032 | -336.1194 | -296.3530 | -2.3407 | -2.3860 |
| 0.0143 | 2.68 | 5200 | 0.7408 | -4.2433 | -7.9802 | 0.8125 | 3.7369 | -336.7721 | -296.6682 | -2.3509 | -2.3946 |
| 0.0057 | 2.74 | 5300 | 0.7552 | -4.3392 | -8.0831 | 0.7969 | 3.7439 | -337.8013 | -297.6275 | -2.3388 | -2.3842 |
| 0.0138 | 2.79 | 5400 | 0.7404 | -4.2395 | -7.9762 | 0.8125 | 3.7367 | -336.7322 | -296.6304 | -2.3286 | -2.3737 |
| 0.0079 | 2.84 | 5500 | 0.7525 | -4.4466 | -8.2196 | 0.7812 | 3.7731 | -339.1662 | -298.7007 | -2.3200 | -2.3641 |
| 0.0077 | 2.89 | 5600 | 0.7520 | -4.5586 | -8.3485 | 0.7969 | 3.7899 | -340.4545 | -299.8206 | -2.3078 | -2.3517 |
| 0.0094 | 2.94 | 5700 | 0.7527 | -4.5542 | -8.3509 | 0.7812 | 3.7967 | -340.4790 | -299.7773 | -2.3062 | -2.3510 |
| 0.0054 | 2.99 | 5800 | 0.7520 | -4.5169 | -8.3079 | 0.7812 | 3.7911 | -340.0493 | -299.4038 | -2.3081 | -2.3530 |
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.12.0
- Tokenizers 0.14.0
## Citation
If you find Zephyr-7B-β is useful in your work, please cite it with:
```
@misc{tunstall2023zephyr,
title={Zephyr: Direct Distillation of LM Alignment},
author={Lewis Tunstall and Edward Beeching and Nathan Lambert and Nazneen Rajani and Kashif Rasul and Younes Belkada and Shengyi Huang and Leandro von Werra and Clémentine Fourrier and Nathan Habib and Nathan Sarrazin and Omar Sanseviero and Alexander M. Rush and Thomas Wolf},
year={2023},
eprint={2310.16944},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
If you use the UltraChat or UltraFeedback datasets, please cite the original works:
```
@misc{ding2023enhancing,
title={Enhancing Chat Language Models by Scaling High-quality Instructional Conversations},
author={Ning Ding and Yulin Chen and Bokai Xu and Yujia Qin and Zhi Zheng and Shengding Hu and Zhiyuan Liu and Maosong Sun and Bowen Zhou},
year={2023},
eprint={2305.14233},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cui2023ultrafeedback,
title={UltraFeedback: Boosting Language Models with High-quality Feedback},
author={Ganqu Cui and Lifan Yuan and Ning Ding and Guanming Yao and Wei Zhu and Yuan Ni and Guotong Xie and Zhiyuan Liu and Maosong Sun},
year={2023},
eprint={2310.01377},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_HuggingFaceH4__zephyr-7b-beta)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 52.15 |
| ARC (25-shot) | 62.03 |
| HellaSwag (10-shot) | 84.36 |
| MMLU (5-shot) | 61.07 |
| TruthfulQA (0-shot) | 57.45 |
| Winogrande (5-shot) | 77.74 |
| GSM8K (5-shot) | 12.74 |
| DROP (3-shot) | 9.66 | |
dslim/bert-base-NER-uncased | dslim | "2023-05-09T16:37:36Z" | 715,374 | 31 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"token-classification",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
license: mit
--- |
microsoft/codebert-base | microsoft | "2022-02-11T19:59:44Z" | 714,406 | 216 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"roberta",
"feature-extraction",
"arxiv:2002.08155",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ## CodeBERT-base
Pretrained weights for [CodeBERT: A Pre-Trained Model for Programming and Natural Languages](https://arxiv.org/abs/2002.08155).
### Training Data
The model is trained on bi-modal data (documents & code) of [CodeSearchNet](https://github.com/github/CodeSearchNet)
### Training Objective
This model is initialized with Roberta-base and trained with MLM+RTD objective (cf. the paper).
### Usage
Please see [the official repository](https://github.com/microsoft/CodeBERT) for scripts that support "code search" and "code-to-document generation".
### Reference
1. [CodeBERT trained with Masked LM objective](https://huggingface.co/microsoft/codebert-base-mlm) (suitable for code completion)
2. 🤗 [Hugging Face's CodeBERTa](https://huggingface.co/huggingface/CodeBERTa-small-v1) (small size, 6 layers)
### Citation
```bibtex
@misc{feng2020codebert,
title={CodeBERT: A Pre-Trained Model for Programming and Natural Languages},
author={Zhangyin Feng and Daya Guo and Duyu Tang and Nan Duan and Xiaocheng Feng and Ming Gong and Linjun Shou and Bing Qin and Ting Liu and Daxin Jiang and Ming Zhou},
year={2020},
eprint={2002.08155},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
BAAI/bge-reranker-base | BAAI | "2024-06-24T14:10:03Z" | 709,003 | 154 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"xlm-roberta",
"mteb",
"text-embeddings-inference",
"text-classification",
"en",
"zh",
"arxiv:2401.03462",
"arxiv:2312.15503",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"region:us"
] | text-classification | "2023-09-11T12:30:04Z" | ---
license: mit
language:
- en
- zh
tags:
- mteb
- text-embeddings-inference
model-index:
- name: bge-reranker-base
results:
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 81.27206722525007
- type: mrr
value: 84.14238095238095
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 84.10369934291236
- type: mrr
value: 86.79376984126984
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 35.4600511272538
- type: mrr
value: 34.60238095238095
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 67.27728847727172
- type: mrr
value: 77.1315192743764
pipeline_tag: text-classification
library_name: sentence-transformers
---
**We have updated the [new reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker), supporting larger lengths, more languages, and achieving better performance.**
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
**More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).**
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently:
- **Long-Context LLM**: [Activation Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon)
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Embedding Model**: [Visualized-BGE](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/visual), [BGE-M3](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3), [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding)
- **Reranker Model**: [llm rerankers](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker), [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
- **Benchmark**: [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
## News
- 3/18/2024: Release new [rerankers](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker), built upon powerful M3 and LLM (GEMMA and MiniCPM, not so large actually) backbones, supporitng multi-lingual processing and larger inputs, massive improvements of ranking performances on BEIR, C-MTEB/Retrieval, MIRACL, LlamaIndex Evaluation.
- 3/18/2024: Release [Visualized-BGE](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/visual), equipping BGE with visual capabilities. Visualized-BGE can be utilized to generate embeddings for hybrid image-text data.
- 1/30/2024: Release **BGE-M3**, a new member to BGE model series! M3 stands for **M**ulti-linguality (100+ languages), **M**ulti-granularities (input length up to 8192), **M**ulti-Functionality (unification of dense, lexical, multi-vec/colbert retrieval).
It is the first embedding model which supports all three retrieval methods, achieving new SOTA on multi-lingual (MIRACL) and cross-lingual (MKQA) benchmarks.
[Technical Report](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf) and [Code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3). :fire:
- 1/9/2024: Release [Activation-Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon), an effective, efficient, compatible, and low-cost (training) method to extend the context length of LLM. [Technical Report](https://arxiv.org/abs/2401.03462) :fire:
- 12/24/2023: Release **LLaRA**, a LLaMA-7B based dense retriever, leading to state-of-the-art performances on MS MARCO and BEIR. Model and code will be open-sourced. Please stay tuned. [Technical Report](https://arxiv.org/abs/2312.15503)
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [Inference](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3#usage) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3) | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results.
Hard negatives also are needed to fine-tune reranker. Refer to this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) for the fine-tuning for reranker
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
#### Usage reranker with the ONNX files
```python
from optimum.onnxruntime import ORTModelForSequenceClassification # type: ignore
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-base')
model_ort = ORTModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-base', file_name="onnx/model.onnx")
# Sentences we want sentence embeddings for
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
# Tokenize sentences
encoded_input = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt')
scores_ort = model_ort(**encoded_input, return_dict=True).logits.view(-1, ).float()
# Compute token embeddings
with torch.inference_mode():
scores = model_ort(**encoded_input, return_dict=True).logits.view(-1, ).float()
# scores and scores_ort are identical
```
#### Usage reranker with infinity
Its also possible to deploy the onnx/torch files with the [infinity_emb](https://github.com/michaelfeil/infinity) pip package.
```python
import asyncio
from infinity_emb import AsyncEmbeddingEngine, EngineArgs
query='what is a panda?'
docs = ['The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear', "Paris is in France."]
engine = AsyncEmbeddingEngine.from_args(
EngineArgs(model_name_or_path = "BAAI/bge-reranker-base", device="cpu", engine="torch" # or engine="optimum" for onnx
))
async def main():
async with engine:
ranking, usage = await engine.rerank(query=query, docs=docs)
print(list(zip(ranking, docs)))
asyncio.run(main())
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge. |
microsoft/table-transformer-structure-recognition | microsoft | "2023-09-06T14:50:49Z" | 706,964 | 165 | transformers | [
"transformers",
"pytorch",
"safetensors",
"table-transformer",
"object-detection",
"arxiv:2110.00061",
"license:mit",
"endpoints_compatible",
"region:us"
] | object-detection | "2022-10-14T09:19:57Z" | ---
license: mit
widget:
- src: https://documentation.tricentis.com/tosca/1420/en/content/tbox/images/table.png
example_title: Table
---
# Table Transformer (fine-tuned for Table Structure Recognition)
Table Transformer (DETR) model trained on PubTables1M. It was introduced in the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Smock et al. and first released in [this repository](https://github.com/microsoft/table-transformer).
Disclaimer: The team releasing Table Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Table Transformer is equivalent to [DETR](https://huggingface.co/docs/transformers/model_doc/detr), a Transformer-based object detection model. Note that the authors decided to use the "normalize before" setting of DETR, which means that layernorm is applied before self- and cross-attention.
## Usage
You can use the raw model for detecting the structure (like rows, columns) in tables. See the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/table-transformer) for more info. |
SG161222/RealVisXL_V4.0 | SG161222 | "2024-10-08T16:34:46Z" | 703,141 | 219 | diffusers | [
"diffusers",
"safetensors",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2024-02-12T16:20:30Z" | ---
license: openrail++
---
<strong>Check my exclusive models on Mage: </strong><a href="https://www.mage.space/play/4371756b27bf52e7a1146dc6fe2d969c" rel="noopener noreferrer nofollow"><strong>ParagonXL</strong></a><strong> / </strong><a href="https://www.mage.space/play/df67a9f27f19629a98cb0fb619d1949a" rel="noopener noreferrer nofollow"><strong>NovaXL</strong></a><strong> / </strong><a href="https://www.mage.space/play/d8db06ae964310acb4e090eec03984df" rel="noopener noreferrer nofollow"><strong>NovaXL Lightning</strong></a><strong> / </strong><a href="https://www.mage.space/play/541da1e10976ab82976a5cacc770a413" rel="noopener noreferrer nofollow"><strong>NovaXL V2</strong></a><strong> / </strong><a href="https://www.mage.space/play/a56d2680c464ef25b8c66df126b3f706" rel="noopener noreferrer nofollow"><strong>NovaXL Pony</strong></a><strong> / </strong><a href="https://www.mage.space/play/b0ab6733c3be2408c93523d57a605371" rel="noopener noreferrer nofollow"><strong>NovaXL Pony Lightning</strong></a><strong> / </strong><a href="https://www.mage.space/play/e3b01cd493ed86ed8e4708751b1c9165" rel="noopener noreferrer nofollow"><strong>RealDreamXL</strong></a><strong> / </strong><a href="https://www.mage.space/play/ef062fc389c3f8723002428290c1158c" rel="noopener noreferrer nofollow"><strong>RealDreamXL Lightning</strong></a></p>
<b>This model is available on <a href="https://www.mage.space/">Mage.Space</a> (main sponsor)</b><br>
<b>You can support me directly on Boosty - https://boosty.to/sg_161222</b><br>
<b>It's important! Read it!</b><br>
The model is still in the training phase. This is not the final version and may contain artifacts and perform poorly in some cases.<br>
The model is aimed at photorealism. Can produce sfw and nsfw images of decent quality.<br>
CivitAI Page: https://civitai.com/models/139562/realvisxl-v40-turbo<br>
<b>Recommended Negative Prompt:</b><br>
(face asymmetry, eyes asymmetry, deformed eyes, open mouth)<br>
<b>or another negative prompt</b><br>
<b>Recommended Generation Parameters:</b><br>
Sampling Steps: 25+<br>
Sampling Method: DPM++ 2M Karras<br>
<b>Recommended Hires Fix Parameters:</b><br>
Hires steps: 10+<br>
Upscaler: 4x-UltraSharp upscaler / or another<br>
Denoising strength: 0.1 - 0.5<br>
Upscale by: 1.1-2.0<br> |
DeepFloyd/t5-v1_1-xxl | DeepFloyd | "2022-12-20T13:12:54Z" | 702,517 | 43 | transformers | [
"transformers",
"pytorch",
"t5",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | "2022-12-19T21:08:56Z" | Entry not found |
IDEA-Research/grounding-dino-tiny | IDEA-Research | "2024-05-12T09:03:39Z" | 701,839 | 54 | transformers | [
"transformers",
"pytorch",
"safetensors",
"grounding-dino",
"zero-shot-object-detection",
"vision",
"arxiv:2303.05499",
"license:apache-2.0",
"region:us"
] | zero-shot-object-detection | "2023-09-25T00:59:34Z" | ---
license: apache-2.0
tags:
- vision
inference: false
pipeline_tag: zero-shot-object-detection
---
# Grounding DINO model (tiny variant)
The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/grouding_dino_architecture.png"
alt="drawing" width="600"/>
<small> Grounding DINO overview. Taken from the <a href="https://arxiv.org/abs/2303.05499">original paper</a>. </small>
## Intended uses & limitations
You can use the raw model for zero-shot object detection (the task of detecting things in an image out-of-the-box without labeled data).
### How to use
Here's how to use the model for zero-shot object detection:
```python
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
model_id = "IDEA-Research/grounding-dino-tiny"
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Check for cats and remote controls
# VERY important: text queries need to be lowercased + end with a dot
text = "a cat. a remote control."
inputs = processor(images=image, text=text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.4,
text_threshold=0.3,
target_sizes=[image.size[::-1]]
)
```
### BibTeX entry and citation info
```bibtex
@misc{liu2023grounding,
title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection},
author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang},
year={2023},
eprint={2303.05499},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
avsolatorio/GIST-Embedding-v0 | avsolatorio | "2024-02-28T00:31:27Z" | 701,774 | 22 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence-similarity",
"en",
"arxiv:2402.16829",
"arxiv:2212.09741",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-01-31T16:41:20Z" | ---
language:
- en
library_name: sentence-transformers
license: mit
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- mteb
- sentence-similarity
- sentence-transformers
model-index:
- name: GIST-Embedding-v0
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.95522388059702
- type: ap
value: 38.940434354439276
- type: f1
value: 69.88686275888114
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.51357499999999
- type: ap
value: 90.30414241486682
- type: f1
value: 93.50552829047328
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 50.446000000000005
- type: f1
value: 49.76432659699279
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.265
- type: map_at_10
value: 54.236
- type: map_at_100
value: 54.81399999999999
- type: map_at_1000
value: 54.81700000000001
- type: map_at_3
value: 49.881
- type: map_at_5
value: 52.431000000000004
- type: mrr_at_1
value: 38.265
- type: mrr_at_10
value: 54.152
- type: mrr_at_100
value: 54.730000000000004
- type: mrr_at_1000
value: 54.733
- type: mrr_at_3
value: 49.644
- type: mrr_at_5
value: 52.32599999999999
- type: ndcg_at_1
value: 38.265
- type: ndcg_at_10
value: 62.62
- type: ndcg_at_100
value: 64.96600000000001
- type: ndcg_at_1000
value: 65.035
- type: ndcg_at_3
value: 53.691
- type: ndcg_at_5
value: 58.303000000000004
- type: precision_at_1
value: 38.265
- type: precision_at_10
value: 8.919
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 21.573999999999998
- type: precision_at_5
value: 15.192
- type: recall_at_1
value: 38.265
- type: recall_at_10
value: 89.189
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 64.723
- type: recall_at_5
value: 75.96000000000001
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.287087887491744
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.74244928943812
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.68814324295771
- type: mrr
value: 75.46266983247591
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 90.45240209600391
- type: cos_sim_spearman
value: 87.95079919934645
- type: euclidean_pearson
value: 88.93438602492702
- type: euclidean_spearman
value: 88.28152962682988
- type: manhattan_pearson
value: 88.92193964325268
- type: manhattan_spearman
value: 88.21466063329498
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (de-en)
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 15.605427974947808
- type: f1
value: 14.989877233698866
- type: precision
value: 14.77906814441261
- type: recall
value: 15.605427974947808
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (fr-en)
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 33.38102575390711
- type: f1
value: 32.41704114719127
- type: precision
value: 32.057363829835964
- type: recall
value: 33.38102575390711
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (ru-en)
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 0.1939729823346034
- type: f1
value: 0.17832215223820772
- type: precision
value: 0.17639155671715423
- type: recall
value: 0.1939729823346034
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (zh-en)
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 3.0542390731964195
- type: f1
value: 2.762857644374232
- type: precision
value: 2.6505178163945935
- type: recall
value: 3.0542390731964195
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.29545454545453
- type: f1
value: 87.26415991342238
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.035319537839484
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.667313307057285
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.979
- type: map_at_10
value: 46.275
- type: map_at_100
value: 47.975
- type: map_at_1000
value: 48.089
- type: map_at_3
value: 42.507
- type: map_at_5
value: 44.504
- type: mrr_at_1
value: 42.346000000000004
- type: mrr_at_10
value: 53.013
- type: mrr_at_100
value: 53.717000000000006
- type: mrr_at_1000
value: 53.749
- type: mrr_at_3
value: 50.405
- type: mrr_at_5
value: 51.915
- type: ndcg_at_1
value: 42.346000000000004
- type: ndcg_at_10
value: 53.179
- type: ndcg_at_100
value: 58.458
- type: ndcg_at_1000
value: 60.057
- type: ndcg_at_3
value: 48.076
- type: ndcg_at_5
value: 50.283
- type: precision_at_1
value: 42.346000000000004
- type: precision_at_10
value: 10.386
- type: precision_at_100
value: 1.635
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_3
value: 23.413999999999998
- type: precision_at_5
value: 16.624
- type: recall_at_1
value: 33.979
- type: recall_at_10
value: 65.553
- type: recall_at_100
value: 87.18599999999999
- type: recall_at_1000
value: 97.25200000000001
- type: recall_at_3
value: 50.068999999999996
- type: recall_at_5
value: 56.882
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.529
- type: map_at_10
value: 42.219
- type: map_at_100
value: 43.408
- type: map_at_1000
value: 43.544
- type: map_at_3
value: 39.178000000000004
- type: map_at_5
value: 40.87
- type: mrr_at_1
value: 39.873
- type: mrr_at_10
value: 48.25
- type: mrr_at_100
value: 48.867
- type: mrr_at_1000
value: 48.908
- type: mrr_at_3
value: 46.03
- type: mrr_at_5
value: 47.355000000000004
- type: ndcg_at_1
value: 39.873
- type: ndcg_at_10
value: 47.933
- type: ndcg_at_100
value: 52.156000000000006
- type: ndcg_at_1000
value: 54.238
- type: ndcg_at_3
value: 43.791999999999994
- type: ndcg_at_5
value: 45.678999999999995
- type: precision_at_1
value: 39.873
- type: precision_at_10
value: 9.032
- type: precision_at_100
value: 1.419
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 21.231
- type: precision_at_5
value: 14.981
- type: recall_at_1
value: 31.529
- type: recall_at_10
value: 57.925000000000004
- type: recall_at_100
value: 75.89
- type: recall_at_1000
value: 89.007
- type: recall_at_3
value: 45.363
- type: recall_at_5
value: 50.973
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.289
- type: map_at_10
value: 54.494
- type: map_at_100
value: 55.494
- type: map_at_1000
value: 55.545
- type: map_at_3
value: 51.20099999999999
- type: map_at_5
value: 53.147
- type: mrr_at_1
value: 47.335
- type: mrr_at_10
value: 57.772
- type: mrr_at_100
value: 58.428000000000004
- type: mrr_at_1000
value: 58.453
- type: mrr_at_3
value: 55.434000000000005
- type: mrr_at_5
value: 56.8
- type: ndcg_at_1
value: 47.335
- type: ndcg_at_10
value: 60.382999999999996
- type: ndcg_at_100
value: 64.294
- type: ndcg_at_1000
value: 65.211
- type: ndcg_at_3
value: 55.098
- type: ndcg_at_5
value: 57.776
- type: precision_at_1
value: 47.335
- type: precision_at_10
value: 9.724
- type: precision_at_100
value: 1.26
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 24.786
- type: precision_at_5
value: 16.977999999999998
- type: recall_at_1
value: 41.289
- type: recall_at_10
value: 74.36399999999999
- type: recall_at_100
value: 91.19800000000001
- type: recall_at_1000
value: 97.508
- type: recall_at_3
value: 60.285
- type: recall_at_5
value: 66.814
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.816999999999997
- type: map_at_10
value: 37.856
- type: map_at_100
value: 38.824
- type: map_at_1000
value: 38.902
- type: map_at_3
value: 34.982
- type: map_at_5
value: 36.831
- type: mrr_at_1
value: 31.073
- type: mrr_at_10
value: 39.985
- type: mrr_at_100
value: 40.802
- type: mrr_at_1000
value: 40.861999999999995
- type: mrr_at_3
value: 37.419999999999995
- type: mrr_at_5
value: 39.104
- type: ndcg_at_1
value: 31.073
- type: ndcg_at_10
value: 42.958
- type: ndcg_at_100
value: 47.671
- type: ndcg_at_1000
value: 49.633
- type: ndcg_at_3
value: 37.602000000000004
- type: ndcg_at_5
value: 40.688
- type: precision_at_1
value: 31.073
- type: precision_at_10
value: 6.531000000000001
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 15.857
- type: precision_at_5
value: 11.209
- type: recall_at_1
value: 28.816999999999997
- type: recall_at_10
value: 56.538999999999994
- type: recall_at_100
value: 78.17699999999999
- type: recall_at_1000
value: 92.92200000000001
- type: recall_at_3
value: 42.294
- type: recall_at_5
value: 49.842999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.397
- type: map_at_10
value: 27.256999999999998
- type: map_at_100
value: 28.541
- type: map_at_1000
value: 28.658
- type: map_at_3
value: 24.565
- type: map_at_5
value: 26.211000000000002
- type: mrr_at_1
value: 22.761
- type: mrr_at_10
value: 32.248
- type: mrr_at_100
value: 33.171
- type: mrr_at_1000
value: 33.227000000000004
- type: mrr_at_3
value: 29.498
- type: mrr_at_5
value: 31.246000000000002
- type: ndcg_at_1
value: 22.761
- type: ndcg_at_10
value: 32.879999999999995
- type: ndcg_at_100
value: 38.913
- type: ndcg_at_1000
value: 41.504999999999995
- type: ndcg_at_3
value: 27.988000000000003
- type: ndcg_at_5
value: 30.548
- type: precision_at_1
value: 22.761
- type: precision_at_10
value: 6.045
- type: precision_at_100
value: 1.044
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 13.433
- type: precision_at_5
value: 9.925
- type: recall_at_1
value: 18.397
- type: recall_at_10
value: 45.14
- type: recall_at_100
value: 71.758
- type: recall_at_1000
value: 89.854
- type: recall_at_3
value: 31.942999999999998
- type: recall_at_5
value: 38.249
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.604
- type: map_at_10
value: 42.132
- type: map_at_100
value: 43.419000000000004
- type: map_at_1000
value: 43.527
- type: map_at_3
value: 38.614
- type: map_at_5
value: 40.705000000000005
- type: mrr_at_1
value: 37.824999999999996
- type: mrr_at_10
value: 47.696
- type: mrr_at_100
value: 48.483
- type: mrr_at_1000
value: 48.53
- type: mrr_at_3
value: 45.123999999999995
- type: mrr_at_5
value: 46.635
- type: ndcg_at_1
value: 37.824999999999996
- type: ndcg_at_10
value: 48.421
- type: ndcg_at_100
value: 53.568000000000005
- type: ndcg_at_1000
value: 55.574999999999996
- type: ndcg_at_3
value: 42.89
- type: ndcg_at_5
value: 45.683
- type: precision_at_1
value: 37.824999999999996
- type: precision_at_10
value: 8.758000000000001
- type: precision_at_100
value: 1.319
- type: precision_at_1000
value: 0.168
- type: precision_at_3
value: 20.244
- type: precision_at_5
value: 14.533
- type: recall_at_1
value: 30.604
- type: recall_at_10
value: 61.605
- type: recall_at_100
value: 82.787
- type: recall_at_1000
value: 95.78
- type: recall_at_3
value: 46.303
- type: recall_at_5
value: 53.351000000000006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.262999999999998
- type: map_at_10
value: 36.858999999999995
- type: map_at_100
value: 38.241
- type: map_at_1000
value: 38.346999999999994
- type: map_at_3
value: 33.171
- type: map_at_5
value: 35.371
- type: mrr_at_1
value: 32.42
- type: mrr_at_10
value: 42.361
- type: mrr_at_100
value: 43.219
- type: mrr_at_1000
value: 43.271
- type: mrr_at_3
value: 39.593
- type: mrr_at_5
value: 41.248000000000005
- type: ndcg_at_1
value: 32.42
- type: ndcg_at_10
value: 43.081
- type: ndcg_at_100
value: 48.837
- type: ndcg_at_1000
value: 50.954
- type: ndcg_at_3
value: 37.413000000000004
- type: ndcg_at_5
value: 40.239000000000004
- type: precision_at_1
value: 32.42
- type: precision_at_10
value: 8.071
- type: precision_at_100
value: 1.272
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 17.922
- type: precision_at_5
value: 13.311
- type: recall_at_1
value: 26.262999999999998
- type: recall_at_10
value: 56.062999999999995
- type: recall_at_100
value: 80.636
- type: recall_at_1000
value: 94.707
- type: recall_at_3
value: 40.425
- type: recall_at_5
value: 47.663
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.86616666666667
- type: map_at_10
value: 37.584999999999994
- type: map_at_100
value: 38.80291666666667
- type: map_at_1000
value: 38.91358333333333
- type: map_at_3
value: 34.498
- type: map_at_5
value: 36.269999999999996
- type: mrr_at_1
value: 33.07566666666667
- type: mrr_at_10
value: 41.92366666666666
- type: mrr_at_100
value: 42.73516666666667
- type: mrr_at_1000
value: 42.785666666666664
- type: mrr_at_3
value: 39.39075
- type: mrr_at_5
value: 40.89133333333334
- type: ndcg_at_1
value: 33.07566666666667
- type: ndcg_at_10
value: 43.19875
- type: ndcg_at_100
value: 48.32083333333334
- type: ndcg_at_1000
value: 50.418000000000006
- type: ndcg_at_3
value: 38.10308333333333
- type: ndcg_at_5
value: 40.5985
- type: precision_at_1
value: 33.07566666666667
- type: precision_at_10
value: 7.581916666666666
- type: precision_at_100
value: 1.1975
- type: precision_at_1000
value: 0.15699999999999997
- type: precision_at_3
value: 17.49075
- type: precision_at_5
value: 12.5135
- type: recall_at_1
value: 27.86616666666667
- type: recall_at_10
value: 55.449749999999995
- type: recall_at_100
value: 77.92516666666666
- type: recall_at_1000
value: 92.31358333333333
- type: recall_at_3
value: 41.324416666666664
- type: recall_at_5
value: 47.72533333333333
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.648
- type: map_at_10
value: 33.155
- type: map_at_100
value: 34.149
- type: map_at_1000
value: 34.239000000000004
- type: map_at_3
value: 30.959999999999997
- type: map_at_5
value: 32.172
- type: mrr_at_1
value: 30.061
- type: mrr_at_10
value: 36.229
- type: mrr_at_100
value: 37.088
- type: mrr_at_1000
value: 37.15
- type: mrr_at_3
value: 34.254
- type: mrr_at_5
value: 35.297
- type: ndcg_at_1
value: 30.061
- type: ndcg_at_10
value: 37.247
- type: ndcg_at_100
value: 42.093
- type: ndcg_at_1000
value: 44.45
- type: ndcg_at_3
value: 33.211
- type: ndcg_at_5
value: 35.083999999999996
- type: precision_at_1
value: 30.061
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.8880000000000001
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 13.957
- type: precision_at_5
value: 9.663
- type: recall_at_1
value: 26.648
- type: recall_at_10
value: 46.85
- type: recall_at_100
value: 68.87
- type: recall_at_1000
value: 86.508
- type: recall_at_3
value: 35.756
- type: recall_at_5
value: 40.376
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.058
- type: map_at_10
value: 26.722
- type: map_at_100
value: 27.863
- type: map_at_1000
value: 27.988000000000003
- type: map_at_3
value: 24.258
- type: map_at_5
value: 25.531
- type: mrr_at_1
value: 23.09
- type: mrr_at_10
value: 30.711
- type: mrr_at_100
value: 31.628
- type: mrr_at_1000
value: 31.702
- type: mrr_at_3
value: 28.418
- type: mrr_at_5
value: 29.685
- type: ndcg_at_1
value: 23.09
- type: ndcg_at_10
value: 31.643
- type: ndcg_at_100
value: 37.047999999999995
- type: ndcg_at_1000
value: 39.896
- type: ndcg_at_3
value: 27.189999999999998
- type: ndcg_at_5
value: 29.112
- type: precision_at_1
value: 23.09
- type: precision_at_10
value: 5.743
- type: precision_at_100
value: 1
- type: precision_at_1000
value: 0.14300000000000002
- type: precision_at_3
value: 12.790000000000001
- type: precision_at_5
value: 9.195
- type: recall_at_1
value: 19.058
- type: recall_at_10
value: 42.527
- type: recall_at_100
value: 66.833
- type: recall_at_1000
value: 87.008
- type: recall_at_3
value: 29.876
- type: recall_at_5
value: 34.922
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.066999999999997
- type: map_at_10
value: 37.543
- type: map_at_100
value: 38.725
- type: map_at_1000
value: 38.815
- type: map_at_3
value: 34.488
- type: map_at_5
value: 36.222
- type: mrr_at_1
value: 33.116
- type: mrr_at_10
value: 41.743
- type: mrr_at_100
value: 42.628
- type: mrr_at_1000
value: 42.675999999999995
- type: mrr_at_3
value: 39.241
- type: mrr_at_5
value: 40.622
- type: ndcg_at_1
value: 33.116
- type: ndcg_at_10
value: 43.089
- type: ndcg_at_100
value: 48.61
- type: ndcg_at_1000
value: 50.585
- type: ndcg_at_3
value: 37.816
- type: ndcg_at_5
value: 40.256
- type: precision_at_1
value: 33.116
- type: precision_at_10
value: 7.313
- type: precision_at_100
value: 1.1320000000000001
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_3
value: 17.102
- type: precision_at_5
value: 12.09
- type: recall_at_1
value: 28.066999999999997
- type: recall_at_10
value: 55.684
- type: recall_at_100
value: 80.092
- type: recall_at_1000
value: 93.605
- type: recall_at_3
value: 41.277
- type: recall_at_5
value: 47.46
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.094
- type: map_at_10
value: 35.939
- type: map_at_100
value: 37.552
- type: map_at_1000
value: 37.771
- type: map_at_3
value: 32.414
- type: map_at_5
value: 34.505
- type: mrr_at_1
value: 32.609
- type: mrr_at_10
value: 40.521
- type: mrr_at_100
value: 41.479
- type: mrr_at_1000
value: 41.524
- type: mrr_at_3
value: 37.451
- type: mrr_at_5
value: 39.387
- type: ndcg_at_1
value: 32.609
- type: ndcg_at_10
value: 41.83
- type: ndcg_at_100
value: 47.763
- type: ndcg_at_1000
value: 50.102999999999994
- type: ndcg_at_3
value: 36.14
- type: ndcg_at_5
value: 39.153999999999996
- type: precision_at_1
value: 32.609
- type: precision_at_10
value: 7.925
- type: precision_at_100
value: 1.591
- type: precision_at_1000
value: 0.246
- type: precision_at_3
value: 16.337
- type: precision_at_5
value: 12.411
- type: recall_at_1
value: 27.094
- type: recall_at_10
value: 53.32900000000001
- type: recall_at_100
value: 79.52
- type: recall_at_1000
value: 93.958
- type: recall_at_3
value: 37.773
- type: recall_at_5
value: 45.321
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.649
- type: map_at_10
value: 30.569000000000003
- type: map_at_100
value: 31.444
- type: map_at_1000
value: 31.538
- type: map_at_3
value: 27.638
- type: map_at_5
value: 29.171000000000003
- type: mrr_at_1
value: 24.399
- type: mrr_at_10
value: 32.555
- type: mrr_at_100
value: 33.312000000000005
- type: mrr_at_1000
value: 33.376
- type: mrr_at_3
value: 29.820999999999998
- type: mrr_at_5
value: 31.402
- type: ndcg_at_1
value: 24.399
- type: ndcg_at_10
value: 35.741
- type: ndcg_at_100
value: 40.439
- type: ndcg_at_1000
value: 42.809000000000005
- type: ndcg_at_3
value: 30.020999999999997
- type: ndcg_at_5
value: 32.68
- type: precision_at_1
value: 24.399
- type: precision_at_10
value: 5.749
- type: precision_at_100
value: 0.878
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 12.815999999999999
- type: precision_at_5
value: 9.242
- type: recall_at_1
value: 22.649
- type: recall_at_10
value: 49.818
- type: recall_at_100
value: 72.155
- type: recall_at_1000
value: 89.654
- type: recall_at_3
value: 34.528999999999996
- type: recall_at_5
value: 40.849999999999994
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 13.587
- type: map_at_10
value: 23.021
- type: map_at_100
value: 25.095
- type: map_at_1000
value: 25.295
- type: map_at_3
value: 19.463
- type: map_at_5
value: 21.389
- type: mrr_at_1
value: 29.576999999999998
- type: mrr_at_10
value: 41.44
- type: mrr_at_100
value: 42.497
- type: mrr_at_1000
value: 42.529
- type: mrr_at_3
value: 38.284
- type: mrr_at_5
value: 40.249
- type: ndcg_at_1
value: 29.576999999999998
- type: ndcg_at_10
value: 31.491000000000003
- type: ndcg_at_100
value: 39.352
- type: ndcg_at_1000
value: 42.703
- type: ndcg_at_3
value: 26.284999999999997
- type: ndcg_at_5
value: 28.218
- type: precision_at_1
value: 29.576999999999998
- type: precision_at_10
value: 9.713
- type: precision_at_100
value: 1.8079999999999998
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 19.608999999999998
- type: precision_at_5
value: 14.957999999999998
- type: recall_at_1
value: 13.587
- type: recall_at_10
value: 37.001
- type: recall_at_100
value: 63.617999999999995
- type: recall_at_1000
value: 82.207
- type: recall_at_3
value: 24.273
- type: recall_at_5
value: 29.813000000000002
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.98
- type: map_at_10
value: 20.447000000000003
- type: map_at_100
value: 29.032999999999998
- type: map_at_1000
value: 30.8
- type: map_at_3
value: 15.126999999999999
- type: map_at_5
value: 17.327
- type: mrr_at_1
value: 71.25
- type: mrr_at_10
value: 78.014
- type: mrr_at_100
value: 78.303
- type: mrr_at_1000
value: 78.309
- type: mrr_at_3
value: 76.375
- type: mrr_at_5
value: 77.58699999999999
- type: ndcg_at_1
value: 57.99999999999999
- type: ndcg_at_10
value: 41.705
- type: ndcg_at_100
value: 47.466
- type: ndcg_at_1000
value: 55.186
- type: ndcg_at_3
value: 47.089999999999996
- type: ndcg_at_5
value: 43.974000000000004
- type: precision_at_1
value: 71.25
- type: precision_at_10
value: 32.65
- type: precision_at_100
value: 10.89
- type: precision_at_1000
value: 2.197
- type: precision_at_3
value: 50.5
- type: precision_at_5
value: 42.199999999999996
- type: recall_at_1
value: 9.98
- type: recall_at_10
value: 25.144
- type: recall_at_100
value: 53.754999999999995
- type: recall_at_1000
value: 78.56400000000001
- type: recall_at_3
value: 15.964
- type: recall_at_5
value: 19.186
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 54.67999999999999
- type: f1
value: 49.48247525503583
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.798
- type: map_at_10
value: 82.933
- type: map_at_100
value: 83.157
- type: map_at_1000
value: 83.173
- type: map_at_3
value: 81.80199999999999
- type: map_at_5
value: 82.55
- type: mrr_at_1
value: 80.573
- type: mrr_at_10
value: 87.615
- type: mrr_at_100
value: 87.69
- type: mrr_at_1000
value: 87.69200000000001
- type: mrr_at_3
value: 86.86399999999999
- type: mrr_at_5
value: 87.386
- type: ndcg_at_1
value: 80.573
- type: ndcg_at_10
value: 86.64500000000001
- type: ndcg_at_100
value: 87.407
- type: ndcg_at_1000
value: 87.68299999999999
- type: ndcg_at_3
value: 84.879
- type: ndcg_at_5
value: 85.921
- type: precision_at_1
value: 80.573
- type: precision_at_10
value: 10.348
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 32.268
- type: precision_at_5
value: 20.084
- type: recall_at_1
value: 74.798
- type: recall_at_10
value: 93.45400000000001
- type: recall_at_100
value: 96.42500000000001
- type: recall_at_1000
value: 98.158
- type: recall_at_3
value: 88.634
- type: recall_at_5
value: 91.295
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.567
- type: map_at_10
value: 32.967999999999996
- type: map_at_100
value: 35.108
- type: map_at_1000
value: 35.272999999999996
- type: map_at_3
value: 28.701999999999998
- type: map_at_5
value: 31.114000000000004
- type: mrr_at_1
value: 40.432
- type: mrr_at_10
value: 48.956
- type: mrr_at_100
value: 49.832
- type: mrr_at_1000
value: 49.87
- type: mrr_at_3
value: 46.759
- type: mrr_at_5
value: 47.886
- type: ndcg_at_1
value: 40.432
- type: ndcg_at_10
value: 40.644000000000005
- type: ndcg_at_100
value: 48.252
- type: ndcg_at_1000
value: 51.099000000000004
- type: ndcg_at_3
value: 36.992000000000004
- type: ndcg_at_5
value: 38.077
- type: precision_at_1
value: 40.432
- type: precision_at_10
value: 11.296000000000001
- type: precision_at_100
value: 1.9009999999999998
- type: precision_at_1000
value: 0.241
- type: precision_at_3
value: 24.537
- type: precision_at_5
value: 17.963
- type: recall_at_1
value: 20.567
- type: recall_at_10
value: 47.052
- type: recall_at_100
value: 75.21600000000001
- type: recall_at_1000
value: 92.285
- type: recall_at_3
value: 33.488
- type: recall_at_5
value: 39.334
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.196999999999996
- type: map_at_10
value: 60.697
- type: map_at_100
value: 61.624
- type: map_at_1000
value: 61.692
- type: map_at_3
value: 57.421
- type: map_at_5
value: 59.455000000000005
- type: mrr_at_1
value: 76.39399999999999
- type: mrr_at_10
value: 82.504
- type: mrr_at_100
value: 82.71300000000001
- type: mrr_at_1000
value: 82.721
- type: mrr_at_3
value: 81.494
- type: mrr_at_5
value: 82.137
- type: ndcg_at_1
value: 76.39399999999999
- type: ndcg_at_10
value: 68.92200000000001
- type: ndcg_at_100
value: 72.13199999999999
- type: ndcg_at_1000
value: 73.392
- type: ndcg_at_3
value: 64.226
- type: ndcg_at_5
value: 66.815
- type: precision_at_1
value: 76.39399999999999
- type: precision_at_10
value: 14.442
- type: precision_at_100
value: 1.694
- type: precision_at_1000
value: 0.186
- type: precision_at_3
value: 41.211
- type: precision_at_5
value: 26.766000000000002
- type: recall_at_1
value: 38.196999999999996
- type: recall_at_10
value: 72.208
- type: recall_at_100
value: 84.71300000000001
- type: recall_at_1000
value: 92.971
- type: recall_at_3
value: 61.816
- type: recall_at_5
value: 66.914
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 89.6556
- type: ap
value: 85.27600392682054
- type: f1
value: 89.63353655386406
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.482
- type: map_at_10
value: 33.701
- type: map_at_100
value: 34.861
- type: map_at_1000
value: 34.914
- type: map_at_3
value: 29.793999999999997
- type: map_at_5
value: 32.072
- type: mrr_at_1
value: 22.163
- type: mrr_at_10
value: 34.371
- type: mrr_at_100
value: 35.471000000000004
- type: mrr_at_1000
value: 35.518
- type: mrr_at_3
value: 30.554
- type: mrr_at_5
value: 32.799
- type: ndcg_at_1
value: 22.163
- type: ndcg_at_10
value: 40.643
- type: ndcg_at_100
value: 46.239999999999995
- type: ndcg_at_1000
value: 47.526
- type: ndcg_at_3
value: 32.714999999999996
- type: ndcg_at_5
value: 36.791000000000004
- type: precision_at_1
value: 22.163
- type: precision_at_10
value: 6.4799999999999995
- type: precision_at_100
value: 0.928
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.002
- type: precision_at_5
value: 10.453
- type: recall_at_1
value: 21.482
- type: recall_at_10
value: 61.953
- type: recall_at_100
value: 87.86500000000001
- type: recall_at_1000
value: 97.636
- type: recall_at_3
value: 40.441
- type: recall_at_5
value: 50.27
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.3032375740994
- type: f1
value: 95.01515022686607
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 78.10077519379846
- type: f1
value: 58.240739725625644
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.0053799596503
- type: f1
value: 74.11733965804146
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.64021519838602
- type: f1
value: 79.8513960091438
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.92425767945184
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.249612382060754
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.35584955492918
- type: mrr
value: 33.545865224584674
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.978
- type: map_at_10
value: 14.749
- type: map_at_100
value: 19.192
- type: map_at_1000
value: 20.815
- type: map_at_3
value: 10.927000000000001
- type: map_at_5
value: 12.726
- type: mrr_at_1
value: 49.536
- type: mrr_at_10
value: 57.806999999999995
- type: mrr_at_100
value: 58.373
- type: mrr_at_1000
value: 58.407
- type: mrr_at_3
value: 55.779
- type: mrr_at_5
value: 57.095
- type: ndcg_at_1
value: 46.749
- type: ndcg_at_10
value: 37.644
- type: ndcg_at_100
value: 35.559000000000005
- type: ndcg_at_1000
value: 44.375
- type: ndcg_at_3
value: 43.354
- type: ndcg_at_5
value: 41.022999999999996
- type: precision_at_1
value: 48.607
- type: precision_at_10
value: 28.08
- type: precision_at_100
value: 9.155000000000001
- type: precision_at_1000
value: 2.2270000000000003
- type: precision_at_3
value: 40.764
- type: precision_at_5
value: 35.728
- type: recall_at_1
value: 6.978
- type: recall_at_10
value: 17.828
- type: recall_at_100
value: 36.010999999999996
- type: recall_at_1000
value: 68.34700000000001
- type: recall_at_3
value: 11.645999999999999
- type: recall_at_5
value: 14.427000000000001
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.219
- type: map_at_10
value: 45.633
- type: map_at_100
value: 46.752
- type: map_at_1000
value: 46.778999999999996
- type: map_at_3
value: 41.392
- type: map_at_5
value: 43.778
- type: mrr_at_1
value: 34.327999999999996
- type: mrr_at_10
value: 48.256
- type: mrr_at_100
value: 49.076
- type: mrr_at_1000
value: 49.092999999999996
- type: mrr_at_3
value: 44.786
- type: mrr_at_5
value: 46.766000000000005
- type: ndcg_at_1
value: 34.299
- type: ndcg_at_10
value: 53.434000000000005
- type: ndcg_at_100
value: 58.03
- type: ndcg_at_1000
value: 58.633
- type: ndcg_at_3
value: 45.433
- type: ndcg_at_5
value: 49.379
- type: precision_at_1
value: 34.299
- type: precision_at_10
value: 8.911
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 20.896
- type: precision_at_5
value: 14.832
- type: recall_at_1
value: 30.219
- type: recall_at_10
value: 74.59400000000001
- type: recall_at_100
value: 94.392
- type: recall_at_1000
value: 98.832
- type: recall_at_3
value: 53.754000000000005
- type: recall_at_5
value: 62.833000000000006
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.139
- type: map_at_10
value: 85.141
- type: map_at_100
value: 85.78099999999999
- type: map_at_1000
value: 85.795
- type: map_at_3
value: 82.139
- type: map_at_5
value: 84.075
- type: mrr_at_1
value: 81.98
- type: mrr_at_10
value: 88.056
- type: mrr_at_100
value: 88.152
- type: mrr_at_1000
value: 88.152
- type: mrr_at_3
value: 87.117
- type: mrr_at_5
value: 87.78099999999999
- type: ndcg_at_1
value: 82.02000000000001
- type: ndcg_at_10
value: 88.807
- type: ndcg_at_100
value: 89.99000000000001
- type: ndcg_at_1000
value: 90.068
- type: ndcg_at_3
value: 85.989
- type: ndcg_at_5
value: 87.627
- type: precision_at_1
value: 82.02000000000001
- type: precision_at_10
value: 13.472999999999999
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.553
- type: precision_at_5
value: 24.788
- type: recall_at_1
value: 71.139
- type: recall_at_10
value: 95.707
- type: recall_at_100
value: 99.666
- type: recall_at_1000
value: 99.983
- type: recall_at_3
value: 87.64699999999999
- type: recall_at_5
value: 92.221
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 59.11035509193503
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.44241881422526
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.122999999999999
- type: map_at_10
value: 14.45
- type: map_at_100
value: 17.108999999999998
- type: map_at_1000
value: 17.517
- type: map_at_3
value: 10.213999999999999
- type: map_at_5
value: 12.278
- type: mrr_at_1
value: 25.3
- type: mrr_at_10
value: 37.791999999999994
- type: mrr_at_100
value: 39.086
- type: mrr_at_1000
value: 39.121
- type: mrr_at_3
value: 34.666999999999994
- type: mrr_at_5
value: 36.472
- type: ndcg_at_1
value: 25.3
- type: ndcg_at_10
value: 23.469
- type: ndcg_at_100
value: 33.324
- type: ndcg_at_1000
value: 39.357
- type: ndcg_at_3
value: 22.478
- type: ndcg_at_5
value: 19.539
- type: precision_at_1
value: 25.3
- type: precision_at_10
value: 12.3
- type: precision_at_100
value: 2.654
- type: precision_at_1000
value: 0.40800000000000003
- type: precision_at_3
value: 21.667
- type: precision_at_5
value: 17.5
- type: recall_at_1
value: 5.122999999999999
- type: recall_at_10
value: 24.937
- type: recall_at_100
value: 53.833
- type: recall_at_1000
value: 82.85
- type: recall_at_3
value: 13.178
- type: recall_at_5
value: 17.747
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.76549431206278
- type: cos_sim_spearman
value: 81.28563534883214
- type: euclidean_pearson
value: 84.17180713818567
- type: euclidean_spearman
value: 81.1684082302606
- type: manhattan_pearson
value: 84.12189753972959
- type: manhattan_spearman
value: 81.1134998997958
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.75137587182017
- type: cos_sim_spearman
value: 76.155337187325
- type: euclidean_pearson
value: 83.54551546726665
- type: euclidean_spearman
value: 76.30324990565346
- type: manhattan_pearson
value: 83.52192617483797
- type: manhattan_spearman
value: 76.30017227216015
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 87.13890050398628
- type: cos_sim_spearman
value: 87.84898360302155
- type: euclidean_pearson
value: 86.89491809082031
- type: euclidean_spearman
value: 87.99935689905651
- type: manhattan_pearson
value: 86.86526424376366
- type: manhattan_spearman
value: 87.96850732980495
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.01978753231558
- type: cos_sim_spearman
value: 83.38989083933329
- type: euclidean_pearson
value: 85.28405032045376
- type: euclidean_spearman
value: 83.51703914276501
- type: manhattan_pearson
value: 85.25775133078966
- type: manhattan_spearman
value: 83.52815667821727
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.28482294437876
- type: cos_sim_spearman
value: 89.42976214499576
- type: euclidean_pearson
value: 88.72677957272468
- type: euclidean_spearman
value: 89.30001736116229
- type: manhattan_pearson
value: 88.64119331622562
- type: manhattan_spearman
value: 89.21771022634893
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 83.79810159351987
- type: cos_sim_spearman
value: 85.34918402034273
- type: euclidean_pearson
value: 84.76058606229002
- type: euclidean_spearman
value: 85.45159829941214
- type: manhattan_pearson
value: 84.73926491888156
- type: manhattan_spearman
value: 85.42568221985898
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.92796712570272
- type: cos_sim_spearman
value: 88.58925922945812
- type: euclidean_pearson
value: 88.97231215531797
- type: euclidean_spearman
value: 88.27036385068719
- type: manhattan_pearson
value: 88.95761469412228
- type: manhattan_spearman
value: 88.23980432487681
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.85679810182282
- type: cos_sim_spearman
value: 67.80696709003128
- type: euclidean_pearson
value: 68.77524185947989
- type: euclidean_spearman
value: 68.032438075422
- type: manhattan_pearson
value: 68.60489100404182
- type: manhattan_spearman
value: 67.75418889226138
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.33287880999367
- type: cos_sim_spearman
value: 87.32401087204754
- type: euclidean_pearson
value: 87.27961069148029
- type: euclidean_spearman
value: 87.3547683085868
- type: manhattan_pearson
value: 87.24405442789622
- type: manhattan_spearman
value: 87.32896271166672
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.71553665286558
- type: mrr
value: 96.42436176749902
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 61.094
- type: map_at_10
value: 71.066
- type: map_at_100
value: 71.608
- type: map_at_1000
value: 71.629
- type: map_at_3
value: 68.356
- type: map_at_5
value: 70.15
- type: mrr_at_1
value: 64
- type: mrr_at_10
value: 71.82300000000001
- type: mrr_at_100
value: 72.251
- type: mrr_at_1000
value: 72.269
- type: mrr_at_3
value: 69.833
- type: mrr_at_5
value: 71.11699999999999
- type: ndcg_at_1
value: 64
- type: ndcg_at_10
value: 75.286
- type: ndcg_at_100
value: 77.40700000000001
- type: ndcg_at_1000
value: 77.806
- type: ndcg_at_3
value: 70.903
- type: ndcg_at_5
value: 73.36399999999999
- type: precision_at_1
value: 64
- type: precision_at_10
value: 9.9
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 27.667
- type: precision_at_5
value: 18.333
- type: recall_at_1
value: 61.094
- type: recall_at_10
value: 87.256
- type: recall_at_100
value: 96.5
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 75.6
- type: recall_at_5
value: 81.789
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.82871287128712
- type: cos_sim_ap
value: 95.9325677692287
- type: cos_sim_f1
value: 91.13924050632912
- type: cos_sim_precision
value: 92.3076923076923
- type: cos_sim_recall
value: 90
- type: dot_accuracy
value: 99.7980198019802
- type: dot_ap
value: 94.56107207796
- type: dot_f1
value: 89.41908713692946
- type: dot_precision
value: 92.88793103448276
- type: dot_recall
value: 86.2
- type: euclidean_accuracy
value: 99.82871287128712
- type: euclidean_ap
value: 95.94390332507025
- type: euclidean_f1
value: 91.17797042325346
- type: euclidean_precision
value: 93.02809573361083
- type: euclidean_recall
value: 89.4
- type: manhattan_accuracy
value: 99.82871287128712
- type: manhattan_ap
value: 95.97587114452257
- type: manhattan_f1
value: 91.25821121778675
- type: manhattan_precision
value: 92.23697650663942
- type: manhattan_recall
value: 90.3
- type: max_accuracy
value: 99.82871287128712
- type: max_ap
value: 95.97587114452257
- type: max_f1
value: 91.25821121778675
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.13974351708839
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.594544722932234
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 54.718738983377726
- type: mrr
value: 55.61655154486037
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.37028359646597
- type: cos_sim_spearman
value: 30.866534307244443
- type: dot_pearson
value: 29.89037691541816
- type: dot_spearman
value: 29.941267567971718
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.20400000000000001
- type: map_at_10
value: 1.7340000000000002
- type: map_at_100
value: 9.966
- type: map_at_1000
value: 25.119000000000003
- type: map_at_3
value: 0.596
- type: map_at_5
value: 0.941
- type: mrr_at_1
value: 76
- type: mrr_at_10
value: 85.85199999999999
- type: mrr_at_100
value: 85.85199999999999
- type: mrr_at_1000
value: 85.85199999999999
- type: mrr_at_3
value: 84.667
- type: mrr_at_5
value: 85.56700000000001
- type: ndcg_at_1
value: 71
- type: ndcg_at_10
value: 69.60300000000001
- type: ndcg_at_100
value: 54.166000000000004
- type: ndcg_at_1000
value: 51.085
- type: ndcg_at_3
value: 71.95
- type: ndcg_at_5
value: 71.17599999999999
- type: precision_at_1
value: 76
- type: precision_at_10
value: 74.2
- type: precision_at_100
value: 55.96
- type: precision_at_1000
value: 22.584
- type: precision_at_3
value: 77.333
- type: precision_at_5
value: 75.6
- type: recall_at_1
value: 0.20400000000000001
- type: recall_at_10
value: 1.992
- type: recall_at_100
value: 13.706999999999999
- type: recall_at_1000
value: 48.732
- type: recall_at_3
value: 0.635
- type: recall_at_5
value: 1.034
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (sqi-eng)
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8
- type: f1
value: 6.298401229470593
- type: precision
value: 5.916991709050532
- type: recall
value: 8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fry-eng)
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.341040462427745
- type: f1
value: 14.621650026274303
- type: precision
value: 13.9250609139035
- type: recall
value: 17.341040462427745
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kur-eng)
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.536585365853659
- type: f1
value: 6.30972482801751
- type: precision
value: 5.796517326875398
- type: recall
value: 8.536585365853659
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tur-eng)
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.4
- type: f1
value: 4.221126743626743
- type: precision
value: 3.822815143403898
- type: recall
value: 6.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (deu-eng)
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 19.8
- type: f1
value: 18.13768093781855
- type: precision
value: 17.54646004378763
- type: recall
value: 19.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nld-eng)
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.700000000000001
- type: f1
value: 12.367662337662336
- type: precision
value: 11.934237966189185
- type: recall
value: 13.700000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ron-eng)
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.299999999999999
- type: f1
value: 10.942180289268338
- type: precision
value: 10.153968847262192
- type: recall
value: 14.299999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ang-eng)
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22.388059701492537
- type: f1
value: 17.00157733660433
- type: precision
value: 15.650551589876702
- type: recall
value: 22.388059701492537
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ido-eng)
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22
- type: f1
value: 17.4576947358322
- type: precision
value: 16.261363669827777
- type: recall
value: 22
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jav-eng)
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.292682926829269
- type: f1
value: 5.544048456005624
- type: precision
value: 5.009506603002538
- type: recall
value: 8.292682926829269
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (isl-eng)
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.4
- type: f1
value: 4.148897174789229
- type: precision
value: 3.862217259449564
- type: recall
value: 5.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slv-eng)
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.5893074119076545
- type: f1
value: 4.375041810373159
- type: precision
value: 4.181207113088141
- type: recall
value: 5.5893074119076545
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cym-eng)
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.17391304347826
- type: f1
value: 6.448011891490153
- type: precision
value: 5.9719116632160105
- type: recall
value: 8.17391304347826
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kaz-eng)
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.8695652173913043
- type: f1
value: 0.582815734989648
- type: precision
value: 0.5580885233059146
- type: recall
value: 0.8695652173913043
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (est-eng)
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.1
- type: f1
value: 3.5000615825615826
- type: precision
value: 3.2073523577994707
- type: recall
value: 5.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (heb-eng)
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.10109884927372195
- type: precision
value: 0.10055127118392897
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gla-eng)
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.8600723763570564
- type: f1
value: 2.8177402725050493
- type: precision
value: 2.5662687819699213
- type: recall
value: 3.8600723763570564
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mar-eng)
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0
- type: f1
value: 0
- type: precision
value: 0
- type: recall
value: 0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lat-eng)
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 15.299999999999999
- type: f1
value: 11.377964359824292
- type: precision
value: 10.361140908892764
- type: recall
value: 15.299999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bel-eng)
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.3
- type: f1
value: 0.9600820232399179
- type: precision
value: 0.9151648856810397
- type: recall
value: 1.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pms-eng)
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.095238095238095
- type: f1
value: 11.40081541819044
- type: precision
value: 10.645867976820359
- type: recall
value: 14.095238095238095
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gle-eng)
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4
- type: f1
value: 2.3800704501963432
- type: precision
value: 2.0919368034607455
- type: recall
value: 4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pes-eng)
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.2002053388090349
- type: precision
value: 0.2001027749229188
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nob-eng)
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.700000000000001
- type: f1
value: 10.29755634495992
- type: precision
value: 9.876637220292393
- type: recall
value: 11.700000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bul-eng)
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.7000000000000002
- type: f1
value: 0.985815849620051
- type: precision
value: 0.8884689922480621
- type: recall
value: 1.7000000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cbk-eng)
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.599999999999998
- type: f1
value: 14.086312656126182
- type: precision
value: 13.192360560816125
- type: recall
value: 17.599999999999998
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hun-eng)
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.1
- type: f1
value: 4.683795729173087
- type: precision
value: 4.31687579027912
- type: recall
value: 6.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uig-eng)
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.4
- type: f1
value: 0.20966666666666667
- type: precision
value: 0.20500700280112047
- type: recall
value: 0.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (rus-eng)
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.6
- type: f1
value: 0.2454665118079752
- type: precision
value: 0.2255125167991618
- type: recall
value: 0.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (spa-eng)
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21
- type: f1
value: 18.965901242066018
- type: precision
value: 18.381437375171
- type: recall
value: 21
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hye-eng)
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.5390835579514826
- type: f1
value: 0.4048898457205192
- type: precision
value: 0.4046018763809678
- type: recall
value: 0.5390835579514826
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tel-eng)
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.282051282051282
- type: f1
value: 0.5098554872310529
- type: precision
value: 0.4715099715099715
- type: recall
value: 1.282051282051282
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (afr-eng)
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.7
- type: f1
value: 8.045120643200706
- type: precision
value: 7.387598023074453
- type: recall
value: 10.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mon-eng)
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 2.272727272727273
- type: f1
value: 1.44184724004356
- type: precision
value: 1.4082306862044767
- type: recall
value: 2.272727272727273
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arz-eng)
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.20964360587002098
- type: f1
value: 0.001335309591528796
- type: precision
value: 0.0006697878781789807
- type: recall
value: 0.20964360587002098
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hrv-eng)
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.1
- type: f1
value: 5.522254020507502
- type: precision
value: 5.081849426723903
- type: recall
value: 7.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nov-eng)
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 36.57587548638132
- type: f1
value: 30.325515383881147
- type: precision
value: 28.59255854392041
- type: recall
value: 36.57587548638132
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gsw-eng)
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.23931623931624
- type: f1
value: 13.548783761549718
- type: precision
value: 13.0472896359184
- type: recall
value: 16.23931623931624
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nds-eng)
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.3
- type: f1
value: 13.3418584934734
- type: precision
value: 12.506853047473756
- type: recall
value: 16.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ukr-eng)
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1
- type: f1
value: 0.7764001197963462
- type: precision
value: 0.7551049317943337
- type: recall
value: 1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uzb-eng)
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.9719626168224296
- type: f1
value: 3.190729401654313
- type: precision
value: 3.001159168296747
- type: recall
value: 3.9719626168224296
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lit-eng)
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.4000000000000004
- type: f1
value: 2.4847456001574653
- type: precision
value: 2.308739271803959
- type: recall
value: 3.4000000000000004
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ina-eng)
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 36.9
- type: f1
value: 31.390407955063697
- type: precision
value: 29.631294298308614
- type: recall
value: 36.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lfn-eng)
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.2
- type: f1
value: 12.551591810861895
- type: precision
value: 12.100586917562724
- type: recall
value: 14.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (zsm-eng)
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.2
- type: f1
value: 7.5561895648211435
- type: precision
value: 7.177371101110253
- type: recall
value: 9.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ita-eng)
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.2
- type: f1
value: 18.498268429117875
- type: precision
value: 17.693915156965357
- type: recall
value: 21.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cmn-eng)
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.2
- type: f1
value: 2.886572782530936
- type: precision
value: 2.5806792595351915
- type: recall
value: 4.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lvs-eng)
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.800000000000001
- type: f1
value: 4.881091920308238
- type: precision
value: 4.436731163345769
- type: recall
value: 6.800000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (glg-eng)
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22.1
- type: f1
value: 18.493832677140738
- type: precision
value: 17.52055858924503
- type: recall
value: 22.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ceb-eng)
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6
- type: f1
value: 4.58716840215435
- type: precision
value: 4.303119297298687
- type: recall
value: 6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bre-eng)
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.5
- type: f1
value: 3.813678559437776
- type: precision
value: 3.52375763382276
- type: recall
value: 5.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ben-eng)
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.2
- type: f1
value: 0.06701509872241579
- type: precision
value: 0.05017452006980803
- type: recall
value: 0.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swg-eng)
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 12.5
- type: f1
value: 9.325396825396826
- type: precision
value: 8.681972789115646
- type: recall
value: 12.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arq-eng)
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.43907793633369924
- type: f1
value: 0.26369680618309754
- type: precision
value: 0.24710650393580552
- type: recall
value: 0.43907793633369924
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kab-eng)
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.7000000000000002
- type: f1
value: 1.0240727731562105
- type: precision
value: 0.9379457073996874
- type: recall
value: 1.7000000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fra-eng)
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 24.6
- type: f1
value: 21.527732683982684
- type: precision
value: 20.460911398969852
- type: recall
value: 24.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (por-eng)
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.400000000000002
- type: f1
value: 18.861948871033608
- type: precision
value: 17.469730524988158
- type: recall
value: 23.400000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tat-eng)
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.3
- type: f1
value: 0.8081609699284277
- type: precision
value: 0.8041232161030668
- type: recall
value: 1.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (oci-eng)
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.399999999999999
- type: f1
value: 11.982642360594898
- type: precision
value: 11.423911681034546
- type: recall
value: 14.399999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pol-eng)
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.7
- type: f1
value: 6.565099922088448
- type: precision
value: 6.009960806394631
- type: recall
value: 8.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (war-eng)
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.1
- type: f1
value: 5.483244116053285
- type: precision
value: 5.08036675810842
- type: recall
value: 7.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (aze-eng)
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3999999999999995
- type: f1
value: 3.2643948695904146
- type: precision
value: 3.031506651474311
- type: recall
value: 4.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (vie-eng)
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.1
- type: f1
value: 5.2787766765398345
- type: precision
value: 4.883891459552525
- type: recall
value: 7.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nno-eng)
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.5
- type: f1
value: 7.022436974789914
- type: precision
value: 6.517919923571304
- type: recall
value: 8.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cha-eng)
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.51824817518248
- type: f1
value: 14.159211038143834
- type: precision
value: 13.419131771033424
- type: recall
value: 17.51824817518248
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mhr-eng)
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.1008802791411487
- type: precision
value: 0.10044111373948113
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dan-eng)
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.3
- type: f1
value: 10.0642631078894
- type: precision
value: 9.714481189937882
- type: recall
value: 11.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ell-eng)
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.7000000000000001
- type: f1
value: 0.5023625310859353
- type: precision
value: 0.5011883541295307
- type: recall
value: 0.7000000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (amh-eng)
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.7857142857142856
- type: f1
value: 0.6731500547238763
- type: precision
value: 0.6364087301587301
- type: recall
value: 1.7857142857142856
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pam-eng)
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.000000000000001
- type: f1
value: 4.850226809905071
- type: precision
value: 4.3549672188068485
- type: recall
value: 7.000000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hsb-eng)
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.383022774327122
- type: f1
value: 4.080351427081423
- type: precision
value: 3.7431771127423294
- type: recall
value: 5.383022774327122
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (srp-eng)
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.9
- type: f1
value: 2.975065835065835
- type: precision
value: 2.7082951373488764
- type: recall
value: 3.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (epo-eng)
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.8
- type: f1
value: 10.976459812917616
- type: precision
value: 10.214566903851944
- type: recall
value: 13.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kzj-eng)
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.9
- type: f1
value: 3.5998112099809334
- type: precision
value: 3.391430386128988
- type: recall
value: 4.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (awa-eng)
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 2.1645021645021645
- type: f1
value: 0.28969205674033943
- type: precision
value: 0.1648931376979724
- type: recall
value: 2.1645021645021645
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fao-eng)
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.541984732824428
- type: f1
value: 8.129327179123026
- type: precision
value: 7.860730567672363
- type: recall
value: 9.541984732824428
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mal-eng)
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.5822416302765648
- type: f1
value: 0.3960292169899156
- type: precision
value: 0.36794436357755134
- type: recall
value: 0.5822416302765648
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ile-eng)
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 25.900000000000002
- type: f1
value: 20.98162273769728
- type: precision
value: 19.591031936732236
- type: recall
value: 25.900000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bos-eng)
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.322033898305085
- type: f1
value: 7.1764632211739166
- type: precision
value: 6.547619047619047
- type: recall
value: 9.322033898305085
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cor-eng)
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3999999999999995
- type: f1
value: 3.0484795026022216
- type: precision
value: 2.8132647991077686
- type: recall
value: 4.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cat-eng)
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 18.8
- type: f1
value: 15.52276497119774
- type: precision
value: 14.63296284434154
- type: recall
value: 18.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (eus-eng)
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10
- type: f1
value: 7.351901305737391
- type: precision
value: 6.759061952118555
- type: recall
value: 10
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yue-eng)
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.1
- type: f1
value: 2.1527437641723353
- type: precision
value: 2.0008336640383417
- type: recall
value: 3.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swe-eng)
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.6
- type: f1
value: 8.471815215313617
- type: precision
value: 7.942319409218233
- type: recall
value: 10.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dtp-eng)
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3
- type: f1
value: 2.7338036427188244
- type: precision
value: 2.5492261384839052
- type: recall
value: 4.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kat-eng)
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.40214477211796246
- type: f1
value: 0.28150134048257375
- type: precision
value: 0.2751516861859743
- type: recall
value: 0.40214477211796246
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jpn-eng)
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3
- type: f1
value: 1.5834901411814404
- type: precision
value: 1.3894010894944848
- type: recall
value: 3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (csb-eng)
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.905138339920949
- type: f1
value: 6.6397047981096735
- type: precision
value: 6.32664437012263
- type: recall
value: 7.905138339920949
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (xho-eng)
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.5211267605633805
- type: f1
value: 2.173419196807775
- type: precision
value: 2.14388897487489
- type: recall
value: 3.5211267605633805
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (orv-eng)
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.23952095808383234
- type: f1
value: 0.001262128032547595
- type: precision
value: 0.0006327654461278806
- type: recall
value: 0.23952095808383234
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ind-eng)
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.4
- type: f1
value: 8.370422351826372
- type: precision
value: 7.943809523809523
- type: recall
value: 10.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tuk-eng)
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.41871921182266
- type: f1
value: 3.4763895108722696
- type: precision
value: 3.1331846246882176
- type: recall
value: 5.41871921182266
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (max-eng)
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.15492957746479
- type: f1
value: 7.267458920187794
- type: precision
value: 6.893803787858966
- type: recall
value: 9.15492957746479
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swh-eng)
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.487179487179487
- type: f1
value: 6.902767160316073
- type: precision
value: 6.450346503818517
- type: recall
value: 9.487179487179487
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hin-eng)
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.1
- type: f1
value: 0.0002042900919305414
- type: precision
value: 0.00010224948875255625
- type: recall
value: 0.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dsb-eng)
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.010438413361169
- type: f1
value: 3.8116647214505277
- type: precision
value: 3.5454644309619634
- type: recall
value: 5.010438413361169
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ber-eng)
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.2
- type: f1
value: 5.213158915433869
- type: precision
value: 5.080398110661268
- type: recall
value: 6.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tam-eng)
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.9771986970684038
- type: f1
value: 0.5061388123277374
- type: precision
value: 0.43431053203040165
- type: recall
value: 0.9771986970684038
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slk-eng)
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.3
- type: f1
value: 5.6313180921027755
- type: precision
value: 5.303887400540395
- type: recall
value: 7.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tgl-eng)
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.5999999999999996
- type: f1
value: 3.2180089485458607
- type: precision
value: 3.1006756756756753
- type: recall
value: 3.5999999999999996
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ast-eng)
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22.04724409448819
- type: f1
value: 17.92525934258218
- type: precision
value: 16.48251629836593
- type: recall
value: 22.04724409448819
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mkd-eng)
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.5
- type: f1
value: 0.1543743186232414
- type: precision
value: 0.13554933572174951
- type: recall
value: 0.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (khm-eng)
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.8310249307479225
- type: f1
value: 0.5102255597841558
- type: precision
value: 0.4859595744731704
- type: recall
value: 0.8310249307479225
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ces-eng)
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 4.7258390633390635
- type: precision
value: 4.288366570275279
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tzl-eng)
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.307692307692307
- type: f1
value: 14.763313609467454
- type: precision
value: 14.129273504273504
- type: recall
value: 17.307692307692307
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (urd-eng)
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.0022196828248667185
- type: precision
value: 0.0011148527298850575
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ara-eng)
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.3
- type: precision
value: 0.3
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kor-eng)
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.6
- type: f1
value: 0.500206611570248
- type: precision
value: 0.5001034126163392
- type: recall
value: 0.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yid-eng)
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.4716981132075472
- type: f1
value: 0.2953377695417789
- type: precision
value: 0.2754210459668228
- type: recall
value: 0.4716981132075472
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fin-eng)
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3999999999999995
- type: f1
value: 3.6228414442700156
- type: precision
value: 3.4318238993710692
- type: recall
value: 4.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tha-eng)
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.2773722627737227
- type: f1
value: 1.0043318098096732
- type: precision
value: 0.9735777358593729
- type: recall
value: 1.2773722627737227
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (wuu-eng)
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.9
- type: f1
value: 2.6164533097276226
- type: precision
value: 2.3558186153594085
- type: recall
value: 3.9
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.5779999999999998
- type: map_at_10
value: 8.339
- type: map_at_100
value: 14.601
- type: map_at_1000
value: 16.104
- type: map_at_3
value: 4.06
- type: map_at_5
value: 6.049
- type: mrr_at_1
value: 18.367
- type: mrr_at_10
value: 35.178
- type: mrr_at_100
value: 36.464999999999996
- type: mrr_at_1000
value: 36.464999999999996
- type: mrr_at_3
value: 29.932
- type: mrr_at_5
value: 34.32
- type: ndcg_at_1
value: 16.326999999999998
- type: ndcg_at_10
value: 20.578
- type: ndcg_at_100
value: 34.285
- type: ndcg_at_1000
value: 45.853
- type: ndcg_at_3
value: 19.869999999999997
- type: ndcg_at_5
value: 22.081999999999997
- type: precision_at_1
value: 18.367
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.714
- type: precision_at_1000
value: 1.547
- type: precision_at_3
value: 23.128999999999998
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 1.5779999999999998
- type: recall_at_10
value: 14.801
- type: recall_at_100
value: 48.516999999999996
- type: recall_at_1000
value: 83.30300000000001
- type: recall_at_3
value: 5.267
- type: recall_at_5
value: 9.415999999999999
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.4186
- type: ap
value: 14.536282543597242
- type: f1
value: 55.47661372005608
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.318053197509904
- type: f1
value: 59.68272481532353
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 52.155753554312
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.99409906419503
- type: cos_sim_ap
value: 76.91824322304332
- type: cos_sim_f1
value: 70.97865694950546
- type: cos_sim_precision
value: 70.03081664098613
- type: cos_sim_recall
value: 71.95250659630607
- type: dot_accuracy
value: 85.37879239434942
- type: dot_ap
value: 71.86454698478344
- type: dot_f1
value: 66.48115355426259
- type: dot_precision
value: 63.84839650145773
- type: dot_recall
value: 69.34036939313984
- type: euclidean_accuracy
value: 87.00005960541218
- type: euclidean_ap
value: 76.9165913835565
- type: euclidean_f1
value: 71.23741557283039
- type: euclidean_precision
value: 68.89327088982007
- type: euclidean_recall
value: 73.7467018469657
- type: manhattan_accuracy
value: 87.06562555880075
- type: manhattan_ap
value: 76.85445703747546
- type: manhattan_f1
value: 70.95560571858539
- type: manhattan_precision
value: 67.61472275334609
- type: manhattan_recall
value: 74.64379947229551
- type: max_accuracy
value: 87.06562555880075
- type: max_ap
value: 76.91824322304332
- type: max_f1
value: 71.23741557283039
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.93934101758063
- type: cos_sim_ap
value: 86.1071528049007
- type: cos_sim_f1
value: 78.21588263552714
- type: cos_sim_precision
value: 75.20073900376609
- type: cos_sim_recall
value: 81.48290729904527
- type: dot_accuracy
value: 88.2504754142896
- type: dot_ap
value: 84.19709379723844
- type: dot_f1
value: 76.92307692307693
- type: dot_precision
value: 71.81969949916528
- type: dot_recall
value: 82.80720665229443
- type: euclidean_accuracy
value: 88.97232894787906
- type: euclidean_ap
value: 86.02763993294909
- type: euclidean_f1
value: 78.18372741427383
- type: euclidean_precision
value: 73.79861918107868
- type: euclidean_recall
value: 83.12288266091777
- type: manhattan_accuracy
value: 88.86948422400745
- type: manhattan_ap
value: 86.0009157821563
- type: manhattan_f1
value: 78.10668017659404
- type: manhattan_precision
value: 73.68564795848695
- type: manhattan_recall
value: 83.09208500153989
- type: max_accuracy
value: 88.97232894787906
- type: max_ap
value: 86.1071528049007
- type: max_f1
value: 78.21588263552714
---
<h1 align="center">GIST Embedding v0</h1>
*GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning*
The model is fine-tuned on top of the [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) using the [MEDI dataset](https://github.com/xlang-ai/instructor-embedding.git) augmented with mined triplets from the [MTEB Classification](https://huggingface.co/mteb) training dataset (excluding data from the Amazon Polarity Classification task).
The model does not require any instruction for generating embeddings. This means that queries for retrieval tasks can be directly encoded without crafting instructions.
Technical paper: [GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning](https://arxiv.org/abs/2402.16829)
# Data
The dataset used is a compilation of the MEDI and MTEB Classification training datasets. Third-party datasets may be subject to additional terms and conditions under their associated licenses. A HuggingFace Dataset version of the compiled dataset, and the specific revision used to train the model, is available:
- Dataset: [avsolatorio/medi-data-mteb_avs_triplets](https://huggingface.co/datasets/avsolatorio/medi-data-mteb_avs_triplets)
- Revision: 238a0499b6e6b690cc64ea56fde8461daa8341bb
The dataset contains a `task_type` key, which can be used to select only the mteb classification tasks (prefixed with `mteb_`).
The **MEDI Dataset** is published in the following paper: [One Embedder, Any Task: Instruction-Finetuned Text Embeddings](https://arxiv.org/abs/2212.09741).
The MTEB Benchmark results of the GIST embedding model, compared with the base model, suggest that the fine-tuning dataset has perturbed the model considerably, which resulted in significant improvements in certain tasks while adversely degrading performance in some.
The retrieval performance for the TRECCOVID task is of note. The fine-tuning dataset does not contain significant knowledge about COVID-19, which could have caused the observed performance degradation. We found some evidence, detailed in the paper, that thematic coverage of the fine-tuning data can affect downstream performance.
# Usage
The model can be easily loaded using the Sentence Transformers library.
```Python
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
revision = None # Replace with the specific revision to ensure reproducibility if the model is updated.
model = SentenceTransformer("avsolatorio/GIST-Embedding-v0", revision=revision)
texts = [
"Illustration of the REaLTabFormer model. The left block shows the non-relational tabular data model using GPT-2 with a causal LM head. In contrast, the right block shows how a relational dataset's child table is modeled using a sequence-to-sequence (Seq2Seq) model. The Seq2Seq model uses the observations in the parent table to condition the generation of the observations in the child table. The trained GPT-2 model on the parent table, with weights frozen, is also used as the encoder in the Seq2Seq model.",
"Predicting human mobility holds significant practical value, with applications ranging from enhancing disaster risk planning to simulating epidemic spread. In this paper, we present the GeoFormer, a decoder-only transformer model adapted from the GPT architecture to forecast human mobility.",
"As the economies of Southeast Asia continue adopting digital technologies, policy makers increasingly ask how to prepare the workforce for emerging labor demands. However, little is known about the skills that workers need to adapt to these changes"
]
# Compute embeddings
embeddings = model.encode(texts, convert_to_tensor=True)
# Compute cosine-similarity for each pair of sentences
scores = F.cosine_similarity(embeddings.unsqueeze(1), embeddings.unsqueeze(0), dim=-1)
print(scores.cpu().numpy())
```
# Training Parameters
Below are the training parameters used to fine-tune the model:
```
Epochs = 80
Warmup ratio = 0.1
Learning rate = 5e-6
Batch size = 32
Checkpoint step = 103500
Contrastive loss temperature = 0.01
```
# Evaluation
The model was evaluated using the [MTEB Evaluation](https://huggingface.co/mteb) suite.
# Citation
Please cite our work if you use GISTEmbed or the datasets we published in your projects or research. 🤗
```
@article{solatorio2024gistembed,
title={GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning},
author={Aivin V. Solatorio},
journal={arXiv preprint arXiv:2402.16829},
year={2024},
URL={https://arxiv.org/abs/2402.16829}
eprint={2402.16829},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
# Acknowledgements
This work is supported by the "KCP IV - Exploring Data Use in the Development Economics Literature using Large Language Models (AI and LLMs)" project funded by the [Knowledge for Change Program (KCP)](https://www.worldbank.org/en/programs/knowledge-for-change) of the World Bank - RA-P503405-RESE-TF0C3444.
The findings, interpretations, and conclusions expressed in this material are entirely those of the authors. They do not necessarily represent the views of the International Bank for Reconstruction and Development/World Bank and its affiliated organizations, or those of the Executive Directors of the World Bank or the governments they represent. |
sentence-transformers/msmarco-distilbert-base-v4 | sentence-transformers | "2024-11-05T17:04:16Z" | 697,286 | 7 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/msmarco-distilbert-base-v4
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-v4')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilbert-base-v4')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilbert-base-v4')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-v4)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
stabilityai/stable-diffusion-2 | stabilityai | "2023-07-05T16:19:01Z" | 696,784 | 1,830 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2202.00512",
"arxiv:2112.10752",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2022-11-23T11:54:34Z" | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2 model, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on `768x768` images.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `768-v-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/768-v-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
model_id = "stabilityai/stable-diffusion-2"
# Use the Euler scheduler here instead
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
THUDM/chatglm2-6b | THUDM | "2024-08-04T08:41:38Z" | 693,302 | 2,031 | transformers | [
"transformers",
"pytorch",
"chatglm",
"glm",
"thudm",
"custom_code",
"zh",
"en",
"arxiv:2103.10360",
"arxiv:2210.02414",
"arxiv:1911.02150",
"arxiv:2406.12793",
"endpoints_compatible",
"region:us"
] | null | "2023-06-24T16:26:27Z" | ---
language:
- zh
- en
tags:
- glm
- chatglm
- thudm
---
# ChatGLM2-6B
<p align="center">
💻 <a href="https://github.com/THUDM/ChatGLM2-6B" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2210.02414" target="_blank">[GLM-130B@ICLR 23]</a> <a href="https://github.com/THUDM/GLM-130B" target="_blank">[GitHub]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://join.slack.com/t/chatglm/shared_invite/zt-1y7pqoloy-9b1g6T6JjA8J0KxvUjbwJw" target="_blank">Slack</a> and <a href="https://github.com/THUDM/ChatGLM-6B/blob/main/resources/WECHAT.md" target="_blank">WeChat</a>
</p>
<p align="center">
📍Experience the larger-scale ChatGLM model at <a href="https://www.chatglm.cn">chatglm.cn</a>
</p>
## 介绍
ChatGLM**2**-6B 是开源中英双语对话模型 [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM**2**-6B 引入了如下新特性:
1. **更强大的性能**:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 [GLM](https://github.com/THUDM/GLM) 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,[评测结果](#评测结果)显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
2. **更长的上下文**:基于 [FlashAttention](https://github.com/HazyResearch/flash-attention) 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
3. **更高效的推理**:基于 [Multi-Query Attention](http://arxiv.org/abs/1911.02150) 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
4. **更开放的协议**:ChatGLM2-6B 权重对学术研究**完全开放**,在填写[问卷](https://open.bigmodel.cn/mla/form)进行登记后**亦允许免费商业使用**。
ChatGLM**2**-6B is the second-generation version of the open-source bilingual (Chinese-English) chat model [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B). It retains the smooth conversation flow and low deployment threshold of the first-generation model, while introducing the following new features:
1. **Stronger Performance**: Based on the development experience of the first-generation ChatGLM model, we have fully upgraded the base model of ChatGLM2-6B. ChatGLM2-6B uses the hybrid objective function of [GLM](https://github.com/THUDM/GLM), and has undergone pre-training with 1.4T bilingual tokens and human preference alignment training. The [evaluation results](README.md#evaluation-results) show that, compared to the first-generation model, ChatGLM2-6B has achieved substantial improvements in performance on datasets like MMLU (+23%), CEval (+33%), GSM8K (+571%), BBH (+60%), showing strong competitiveness among models of the same size.
2. **Longer Context**: Based on [FlashAttention](https://github.com/HazyResearch/flash-attention) technique, we have extended the context length of the base model from 2K in ChatGLM-6B to 32K, and trained with a context length of 8K during the dialogue alignment, allowing for more rounds of dialogue. However, the current version of ChatGLM2-6B has limited understanding of single-round ultra-long documents, which we will focus on optimizing in future iterations.
3. **More Efficient Inference**: Based on [Multi-Query Attention](http://arxiv.org/abs/1911.02150) technique, ChatGLM2-6B has more efficient inference speed and lower GPU memory usage: under the official implementation, the inference speed has increased by 42% compared to the first generation; under INT4 quantization, the dialogue length supported by 6G GPU memory has increased from 1K to 8K.
4. **More Open License**: ChatGLM2-6B weights are **completely open** for academic research, and **free commercial use** is also allowed after completing the [questionnaire](https://open.bigmodel.cn/mla/form).
## 软件依赖
```shell
pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate
```
## 代码调用
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
```ipython
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
```
关于更多的使用说明,包括如何运行命令行和网页版本的 DEMO,以及使用模型量化以节省显存,请参考我们的 [Github Repo](https://github.com/THUDM/ChatGLM2-6B)。
For more instructions, including how to run CLI and web demos, and model quantization, please refer to our [Github Repo](https://github.com/THUDM/ChatGLM2-6B).
## Change Log
* v1.0
## 协议
本仓库的代码依照 [Apache-2.0](LICENSE) 协议开源,ChatGLM2-6B 模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE)。
## 引用
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
If you find our work helpful, please consider citing the following paper.
```
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
``` |
vikp/surya_det3 | vikp | "2024-07-12T13:39:27Z" | 689,117 | 14 | transformers | [
"transformers",
"safetensors",
"efficientvit",
"base_model:vikp/surya_det3",
"base_model:finetune:vikp/surya_det3",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | "2024-07-08T23:39:20Z" | ---
base_model: vikp/line_detector_3
model-index:
- name: line_detector_3
results: []
license: cc-by-nc-sa-4.0
---
Text detection model for [surya](https://www.github.com/VikParuchuri/surya) |
amunchet/rorshark-vit-base | amunchet | "2023-11-18T20:58:42Z" | 687,922 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"vision",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2023-11-18T20:49:21Z" | ---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- image-classification
- vision
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: rorshark-vit-base
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9922928709055877
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rorshark-vit-base
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0393
- Accuracy: 0.9923
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0597 | 1.0 | 368 | 0.0546 | 0.9865 |
| 0.2009 | 2.0 | 736 | 0.0531 | 0.9865 |
| 0.0114 | 3.0 | 1104 | 0.0418 | 0.9904 |
| 0.0998 | 4.0 | 1472 | 0.0425 | 0.9904 |
| 0.1244 | 5.0 | 1840 | 0.0393 | 0.9923 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.1+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
laion/CLIP-ViT-B-32-laion2B-s34B-b79K | laion | "2024-01-15T20:33:50Z" | 684,253 | 98 | open_clip | [
"open_clip",
"pytorch",
"safetensors",
"clip",
"zero-shot-image-classification",
"arxiv:1910.04867",
"license:mit",
"region:us"
] | zero-shot-image-classification | "2022-09-14T22:49:28Z" | ---
license: mit
widget:
- src: >-
https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
pipeline_tag: zero-shot-image-classification
---
# Model Card for CLIP ViT-B/32 - LAION-2B
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Details](#training-details)
4. [Evaluation](#evaluation)
5. [Acknowledgements](#acknowledgements)
6. [Citation](#citation)
7. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
A CLIP ViT-B/32 model trained with the LAION-2B English subset of LAION-5B (https://laion.ai/blog/laion-5b/) using OpenCLIP (https://github.com/mlfoundations/open_clip).
Model training done by Romain Beaumont on the [stability.ai](https://stability.ai/) cluster.
# Uses
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis. Additionally, the LAION-5B blog (https://laion.ai/blog/laion-5b/) and upcoming paper include additional discussion as it relates specifically to the training dataset.
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
## Out-of-Scope Use
As per the OpenAI models,
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
Further the above notice, the LAION-5B dataset used in training of these models has additional considerations, see below.
# Training Details
## Training Data
This model was trained with the 2 Billion sample English subset of LAION-5B (https://laion.ai/blog/laion-5b/).
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes. Be aware that this large-scale dataset is uncurated. Keep in mind that the uncurated nature of the dataset means that collected links may lead to strongly discomforting and disturbing content for a human viewer. Therefore, please use the demo links with caution and at your own risk. It is possible to extract a “safe” subset by filtering out samples based on the safety tags (using a customized trained NSFW classifier that we built). While this strongly reduces the chance for encountering potentially harmful content when viewing, we cannot entirely exclude the possibility for harmful content being still present in safe mode, so that the warning holds also there. We think that providing the dataset openly to broad research and other interested communities will allow for transparent investigation of benefits that come along with training large-scale models as well as pitfalls and dangers that may stay unreported or unnoticed when working with closed large datasets that remain restricted to a small community. Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
## Training Procedure
Please see [training notes](https://docs.google.com/document/d/1EFbMLRWSSV0LUf9Du1pWzWqgeiIRPwEWX2s1C6mAk5c) and [wandb logs](https://wandb.ai/rom1504/eval_openclip/reports/B-32-2B--VmlldzoyNDkwNDMy).
# Evaluation
Evaluation done with code in the [LAION CLIP Benchmark suite](https://github.com/LAION-AI/CLIP_benchmark).
## Testing Data, Factors & Metrics
### Testing Data
The testing is performed with VTAB+ (A combination of VTAB (https://arxiv.org/abs/1910.04867) w/ additional robustness datasets) for classification and COCO and Flickr for retrieval.
**TODO** - more detail
## Results
The model achieves a 66.6 zero-shot top-1 accuracy on ImageNet-1k.
An initial round of benchmarks have been performed on a wider range of datasets, currently viewable at https://github.com/LAION-AI/CLIP_benchmark/blob/main/benchmark/results.ipynb
**TODO** - create table for just this model's metrics.
# Acknowledgements
Acknowledging [stability.ai](https://stability.ai/) for the compute used to train this model.
# Citation
**BibTeX:**
In addition to forthcoming LAION-5B (https://laion.ai/blog/laion-5b/) paper, please cite:
OpenAI CLIP paper
```
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
OpenCLIP software
```
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
# How to Get Started with the Model
Use the code below to get started with the model.
** TODO ** - Hugging Face transformers, OpenCLIP, and timm getting started snippets |
indobenchmark/indobert-base-p1 | indobenchmark | "2021-05-19T20:22:23Z" | 675,358 | 18 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"indobert",
"indobenchmark",
"indonlu",
"id",
"dataset:Indo4B",
"arxiv:2009.05387",
"license:mit",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language: id
tags:
- indobert
- indobenchmark
- indonlu
license: mit
inference: false
datasets:
- Indo4B
---
# IndoBERT Base Model (phase1 - uncased)
[IndoBERT](https://arxiv.org/abs/2009.05387) is a state-of-the-art language model for Indonesian based on the BERT model. The pretrained model is trained using a masked language modeling (MLM) objective and next sentence prediction (NSP) objective.
## All Pre-trained Models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `indobenchmark/indobert-base-p1` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-base-p2` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p1` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p2` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p1` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p2` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p1` | 17.7M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p2` | 17.7M | Large | Indo4B (23.43 GB of text) |
## How to use
### Load model and tokenizer
```python
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-base-p1")
model = AutoModel.from_pretrained("indobenchmark/indobert-base-p1")
```
### Extract contextual representation
```python
x = torch.LongTensor(tokenizer.encode('aku adalah anak [MASK]')).view(1,-1)
print(x, model(x)[0].sum())
```
## Authors
<b>IndoBERT</b> was trained and evaluated by Bryan Wilie\*, Karissa Vincentio\*, Genta Indra Winata\*, Samuel Cahyawijaya\*, Xiaohong Li, Zhi Yuan Lim, Sidik Soleman, Rahmad Mahendra, Pascale Fung, Syafri Bahar, Ayu Purwarianti.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
|
BAAI/bge-small-en | BAAI | "2023-12-13T03:53:21Z" | 673,634 | 71 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence transformers",
"en",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2023-08-05T08:04:07Z" | ---
tags:
- mteb
- sentence transformers
model-index:
- name: bge-small-en
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.34328358208955
- type: ap
value: 37.59947775195661
- type: f1
value: 68.548415491933
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.04527499999999
- type: ap
value: 89.60696356772135
- type: f1
value: 93.03361469382438
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.08
- type: f1
value: 45.66249835363254
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.205999999999996
- type: map_at_10
value: 50.782000000000004
- type: map_at_100
value: 51.547
- type: map_at_1000
value: 51.554
- type: map_at_3
value: 46.515
- type: map_at_5
value: 49.296
- type: mrr_at_1
value: 35.632999999999996
- type: mrr_at_10
value: 50.958999999999996
- type: mrr_at_100
value: 51.724000000000004
- type: mrr_at_1000
value: 51.731
- type: mrr_at_3
value: 46.669
- type: mrr_at_5
value: 49.439
- type: ndcg_at_1
value: 35.205999999999996
- type: ndcg_at_10
value: 58.835
- type: ndcg_at_100
value: 62.095
- type: ndcg_at_1000
value: 62.255
- type: ndcg_at_3
value: 50.255
- type: ndcg_at_5
value: 55.296
- type: precision_at_1
value: 35.205999999999996
- type: precision_at_10
value: 8.421
- type: precision_at_100
value: 0.984
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.365
- type: precision_at_5
value: 14.680000000000001
- type: recall_at_1
value: 35.205999999999996
- type: recall_at_10
value: 84.211
- type: recall_at_100
value: 98.43499999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 61.095
- type: recall_at_5
value: 73.4
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.52644476278646
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 39.973045724188964
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.28285314871488
- type: mrr
value: 74.52743701358659
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 80.09041909160327
- type: cos_sim_spearman
value: 79.96266537706944
- type: euclidean_pearson
value: 79.50774978162241
- type: euclidean_spearman
value: 79.9144715078551
- type: manhattan_pearson
value: 79.2062139879302
- type: manhattan_spearman
value: 79.35000081468212
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.31493506493506
- type: f1
value: 85.2704557977762
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.6837242810816
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.38881249555897
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.884999999999998
- type: map_at_10
value: 39.574
- type: map_at_100
value: 40.993
- type: map_at_1000
value: 41.129
- type: map_at_3
value: 36.089
- type: map_at_5
value: 38.191
- type: mrr_at_1
value: 34.477999999999994
- type: mrr_at_10
value: 45.411
- type: mrr_at_100
value: 46.089999999999996
- type: mrr_at_1000
value: 46.147
- type: mrr_at_3
value: 42.346000000000004
- type: mrr_at_5
value: 44.292
- type: ndcg_at_1
value: 34.477999999999994
- type: ndcg_at_10
value: 46.123999999999995
- type: ndcg_at_100
value: 51.349999999999994
- type: ndcg_at_1000
value: 53.578
- type: ndcg_at_3
value: 40.824
- type: ndcg_at_5
value: 43.571
- type: precision_at_1
value: 34.477999999999994
- type: precision_at_10
value: 8.841000000000001
- type: precision_at_100
value: 1.4460000000000002
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 19.742
- type: precision_at_5
value: 14.421000000000001
- type: recall_at_1
value: 27.884999999999998
- type: recall_at_10
value: 59.087
- type: recall_at_100
value: 80.609
- type: recall_at_1000
value: 95.054
- type: recall_at_3
value: 44.082
- type: recall_at_5
value: 51.593999999999994
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.639
- type: map_at_10
value: 40.047
- type: map_at_100
value: 41.302
- type: map_at_1000
value: 41.425
- type: map_at_3
value: 37.406
- type: map_at_5
value: 38.934000000000005
- type: mrr_at_1
value: 37.707
- type: mrr_at_10
value: 46.082
- type: mrr_at_100
value: 46.745
- type: mrr_at_1000
value: 46.786
- type: mrr_at_3
value: 43.980999999999995
- type: mrr_at_5
value: 45.287
- type: ndcg_at_1
value: 37.707
- type: ndcg_at_10
value: 45.525
- type: ndcg_at_100
value: 49.976
- type: ndcg_at_1000
value: 51.94499999999999
- type: ndcg_at_3
value: 41.704
- type: ndcg_at_5
value: 43.596000000000004
- type: precision_at_1
value: 37.707
- type: precision_at_10
value: 8.465
- type: precision_at_100
value: 1.375
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 19.979
- type: precision_at_5
value: 14.115
- type: recall_at_1
value: 30.639
- type: recall_at_10
value: 54.775
- type: recall_at_100
value: 73.678
- type: recall_at_1000
value: 86.142
- type: recall_at_3
value: 43.230000000000004
- type: recall_at_5
value: 48.622
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.038
- type: map_at_10
value: 49.922
- type: map_at_100
value: 51.032
- type: map_at_1000
value: 51.085
- type: map_at_3
value: 46.664
- type: map_at_5
value: 48.588
- type: mrr_at_1
value: 43.95
- type: mrr_at_10
value: 53.566
- type: mrr_at_100
value: 54.318999999999996
- type: mrr_at_1000
value: 54.348
- type: mrr_at_3
value: 51.066
- type: mrr_at_5
value: 52.649
- type: ndcg_at_1
value: 43.95
- type: ndcg_at_10
value: 55.676
- type: ndcg_at_100
value: 60.126000000000005
- type: ndcg_at_1000
value: 61.208
- type: ndcg_at_3
value: 50.20400000000001
- type: ndcg_at_5
value: 53.038
- type: precision_at_1
value: 43.95
- type: precision_at_10
value: 8.953
- type: precision_at_100
value: 1.2109999999999999
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.256999999999998
- type: precision_at_5
value: 15.524
- type: recall_at_1
value: 38.038
- type: recall_at_10
value: 69.15
- type: recall_at_100
value: 88.31599999999999
- type: recall_at_1000
value: 95.993
- type: recall_at_3
value: 54.663
- type: recall_at_5
value: 61.373
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.872
- type: map_at_10
value: 32.912
- type: map_at_100
value: 33.972
- type: map_at_1000
value: 34.046
- type: map_at_3
value: 30.361
- type: map_at_5
value: 31.704
- type: mrr_at_1
value: 26.779999999999998
- type: mrr_at_10
value: 34.812
- type: mrr_at_100
value: 35.754999999999995
- type: mrr_at_1000
value: 35.809000000000005
- type: mrr_at_3
value: 32.335
- type: mrr_at_5
value: 33.64
- type: ndcg_at_1
value: 26.779999999999998
- type: ndcg_at_10
value: 37.623
- type: ndcg_at_100
value: 42.924
- type: ndcg_at_1000
value: 44.856
- type: ndcg_at_3
value: 32.574
- type: ndcg_at_5
value: 34.842
- type: precision_at_1
value: 26.779999999999998
- type: precision_at_10
value: 5.729
- type: precision_at_100
value: 0.886
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 13.559
- type: precision_at_5
value: 9.469
- type: recall_at_1
value: 24.872
- type: recall_at_10
value: 50.400999999999996
- type: recall_at_100
value: 74.954
- type: recall_at_1000
value: 89.56
- type: recall_at_3
value: 36.726
- type: recall_at_5
value: 42.138999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.803
- type: map_at_10
value: 24.348
- type: map_at_100
value: 25.56
- type: map_at_1000
value: 25.668000000000003
- type: map_at_3
value: 21.811
- type: map_at_5
value: 23.287
- type: mrr_at_1
value: 20.771
- type: mrr_at_10
value: 28.961
- type: mrr_at_100
value: 29.979
- type: mrr_at_1000
value: 30.046
- type: mrr_at_3
value: 26.555
- type: mrr_at_5
value: 28.060000000000002
- type: ndcg_at_1
value: 20.771
- type: ndcg_at_10
value: 29.335
- type: ndcg_at_100
value: 35.188
- type: ndcg_at_1000
value: 37.812
- type: ndcg_at_3
value: 24.83
- type: ndcg_at_5
value: 27.119
- type: precision_at_1
value: 20.771
- type: precision_at_10
value: 5.4350000000000005
- type: precision_at_100
value: 0.9480000000000001
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 11.982
- type: precision_at_5
value: 8.831
- type: recall_at_1
value: 16.803
- type: recall_at_10
value: 40.039
- type: recall_at_100
value: 65.83200000000001
- type: recall_at_1000
value: 84.478
- type: recall_at_3
value: 27.682000000000002
- type: recall_at_5
value: 33.535
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.345
- type: map_at_10
value: 37.757000000000005
- type: map_at_100
value: 39.141
- type: map_at_1000
value: 39.262
- type: map_at_3
value: 35.183
- type: map_at_5
value: 36.592
- type: mrr_at_1
value: 34.649
- type: mrr_at_10
value: 43.586999999999996
- type: mrr_at_100
value: 44.481
- type: mrr_at_1000
value: 44.542
- type: mrr_at_3
value: 41.29
- type: mrr_at_5
value: 42.642
- type: ndcg_at_1
value: 34.649
- type: ndcg_at_10
value: 43.161
- type: ndcg_at_100
value: 48.734
- type: ndcg_at_1000
value: 51.046
- type: ndcg_at_3
value: 39.118
- type: ndcg_at_5
value: 41.022
- type: precision_at_1
value: 34.649
- type: precision_at_10
value: 7.603
- type: precision_at_100
value: 1.209
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 18.319
- type: precision_at_5
value: 12.839
- type: recall_at_1
value: 28.345
- type: recall_at_10
value: 53.367
- type: recall_at_100
value: 76.453
- type: recall_at_1000
value: 91.82000000000001
- type: recall_at_3
value: 41.636
- type: recall_at_5
value: 46.760000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.419
- type: map_at_10
value: 31.716
- type: map_at_100
value: 33.152
- type: map_at_1000
value: 33.267
- type: map_at_3
value: 28.74
- type: map_at_5
value: 30.48
- type: mrr_at_1
value: 28.310999999999996
- type: mrr_at_10
value: 37.039
- type: mrr_at_100
value: 38.09
- type: mrr_at_1000
value: 38.145
- type: mrr_at_3
value: 34.437
- type: mrr_at_5
value: 36.024
- type: ndcg_at_1
value: 28.310999999999996
- type: ndcg_at_10
value: 37.41
- type: ndcg_at_100
value: 43.647999999999996
- type: ndcg_at_1000
value: 46.007
- type: ndcg_at_3
value: 32.509
- type: ndcg_at_5
value: 34.943999999999996
- type: precision_at_1
value: 28.310999999999996
- type: precision_at_10
value: 6.963
- type: precision_at_100
value: 1.1860000000000002
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 15.867999999999999
- type: precision_at_5
value: 11.507000000000001
- type: recall_at_1
value: 22.419
- type: recall_at_10
value: 49.28
- type: recall_at_100
value: 75.802
- type: recall_at_1000
value: 92.032
- type: recall_at_3
value: 35.399
- type: recall_at_5
value: 42.027
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.669249999999998
- type: map_at_10
value: 33.332583333333325
- type: map_at_100
value: 34.557833333333335
- type: map_at_1000
value: 34.67141666666666
- type: map_at_3
value: 30.663166666666662
- type: map_at_5
value: 32.14883333333333
- type: mrr_at_1
value: 29.193833333333334
- type: mrr_at_10
value: 37.47625
- type: mrr_at_100
value: 38.3545
- type: mrr_at_1000
value: 38.413166666666676
- type: mrr_at_3
value: 35.06741666666667
- type: mrr_at_5
value: 36.450666666666656
- type: ndcg_at_1
value: 29.193833333333334
- type: ndcg_at_10
value: 38.505416666666676
- type: ndcg_at_100
value: 43.81125
- type: ndcg_at_1000
value: 46.09558333333333
- type: ndcg_at_3
value: 33.90916666666667
- type: ndcg_at_5
value: 36.07666666666666
- type: precision_at_1
value: 29.193833333333334
- type: precision_at_10
value: 6.7251666666666665
- type: precision_at_100
value: 1.1058333333333332
- type: precision_at_1000
value: 0.14833333333333332
- type: precision_at_3
value: 15.554166666666665
- type: precision_at_5
value: 11.079250000000002
- type: recall_at_1
value: 24.669249999999998
- type: recall_at_10
value: 49.75583333333332
- type: recall_at_100
value: 73.06908333333332
- type: recall_at_1000
value: 88.91316666666667
- type: recall_at_3
value: 36.913250000000005
- type: recall_at_5
value: 42.48641666666666
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.044999999999998
- type: map_at_10
value: 30.349999999999998
- type: map_at_100
value: 31.273
- type: map_at_1000
value: 31.362000000000002
- type: map_at_3
value: 28.508
- type: map_at_5
value: 29.369
- type: mrr_at_1
value: 26.994
- type: mrr_at_10
value: 33.12
- type: mrr_at_100
value: 33.904
- type: mrr_at_1000
value: 33.967000000000006
- type: mrr_at_3
value: 31.365
- type: mrr_at_5
value: 32.124
- type: ndcg_at_1
value: 26.994
- type: ndcg_at_10
value: 34.214
- type: ndcg_at_100
value: 38.681
- type: ndcg_at_1000
value: 40.926
- type: ndcg_at_3
value: 30.725
- type: ndcg_at_5
value: 31.967000000000002
- type: precision_at_1
value: 26.994
- type: precision_at_10
value: 5.215
- type: precision_at_100
value: 0.807
- type: precision_at_1000
value: 0.108
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 8.712
- type: recall_at_1
value: 24.044999999999998
- type: recall_at_10
value: 43.456
- type: recall_at_100
value: 63.675000000000004
- type: recall_at_1000
value: 80.05499999999999
- type: recall_at_3
value: 33.561
- type: recall_at_5
value: 36.767
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.672
- type: map_at_10
value: 22.641
- type: map_at_100
value: 23.75
- type: map_at_1000
value: 23.877000000000002
- type: map_at_3
value: 20.219
- type: map_at_5
value: 21.648
- type: mrr_at_1
value: 18.823
- type: mrr_at_10
value: 26.101999999999997
- type: mrr_at_100
value: 27.038
- type: mrr_at_1000
value: 27.118
- type: mrr_at_3
value: 23.669
- type: mrr_at_5
value: 25.173000000000002
- type: ndcg_at_1
value: 18.823
- type: ndcg_at_10
value: 27.176000000000002
- type: ndcg_at_100
value: 32.42
- type: ndcg_at_1000
value: 35.413
- type: ndcg_at_3
value: 22.756999999999998
- type: ndcg_at_5
value: 25.032
- type: precision_at_1
value: 18.823
- type: precision_at_10
value: 5.034000000000001
- type: precision_at_100
value: 0.895
- type: precision_at_1000
value: 0.132
- type: precision_at_3
value: 10.771
- type: precision_at_5
value: 8.1
- type: recall_at_1
value: 15.672
- type: recall_at_10
value: 37.296
- type: recall_at_100
value: 60.863
- type: recall_at_1000
value: 82.234
- type: recall_at_3
value: 25.330000000000002
- type: recall_at_5
value: 30.964000000000002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.633
- type: map_at_10
value: 32.858
- type: map_at_100
value: 34.038000000000004
- type: map_at_1000
value: 34.141
- type: map_at_3
value: 30.209000000000003
- type: map_at_5
value: 31.567
- type: mrr_at_1
value: 28.358
- type: mrr_at_10
value: 36.433
- type: mrr_at_100
value: 37.352000000000004
- type: mrr_at_1000
value: 37.41
- type: mrr_at_3
value: 34.033
- type: mrr_at_5
value: 35.246
- type: ndcg_at_1
value: 28.358
- type: ndcg_at_10
value: 37.973
- type: ndcg_at_100
value: 43.411
- type: ndcg_at_1000
value: 45.747
- type: ndcg_at_3
value: 32.934999999999995
- type: ndcg_at_5
value: 35.013
- type: precision_at_1
value: 28.358
- type: precision_at_10
value: 6.418
- type: precision_at_100
value: 1.02
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 14.677000000000001
- type: precision_at_5
value: 10.335999999999999
- type: recall_at_1
value: 24.633
- type: recall_at_10
value: 50.048
- type: recall_at_100
value: 73.821
- type: recall_at_1000
value: 90.046
- type: recall_at_3
value: 36.284
- type: recall_at_5
value: 41.370000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.133
- type: map_at_10
value: 31.491999999999997
- type: map_at_100
value: 33.062000000000005
- type: map_at_1000
value: 33.256
- type: map_at_3
value: 28.886
- type: map_at_5
value: 30.262
- type: mrr_at_1
value: 28.063
- type: mrr_at_10
value: 36.144
- type: mrr_at_100
value: 37.14
- type: mrr_at_1000
value: 37.191
- type: mrr_at_3
value: 33.762
- type: mrr_at_5
value: 34.997
- type: ndcg_at_1
value: 28.063
- type: ndcg_at_10
value: 36.951
- type: ndcg_at_100
value: 43.287
- type: ndcg_at_1000
value: 45.777
- type: ndcg_at_3
value: 32.786
- type: ndcg_at_5
value: 34.65
- type: precision_at_1
value: 28.063
- type: precision_at_10
value: 7.055
- type: precision_at_100
value: 1.476
- type: precision_at_1000
value: 0.22899999999999998
- type: precision_at_3
value: 15.481
- type: precision_at_5
value: 11.186
- type: recall_at_1
value: 23.133
- type: recall_at_10
value: 47.285
- type: recall_at_100
value: 76.176
- type: recall_at_1000
value: 92.176
- type: recall_at_3
value: 35.223
- type: recall_at_5
value: 40.142
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.547
- type: map_at_10
value: 26.374
- type: map_at_100
value: 27.419
- type: map_at_1000
value: 27.539
- type: map_at_3
value: 23.882
- type: map_at_5
value: 25.163999999999998
- type: mrr_at_1
value: 21.442
- type: mrr_at_10
value: 28.458
- type: mrr_at_100
value: 29.360999999999997
- type: mrr_at_1000
value: 29.448999999999998
- type: mrr_at_3
value: 25.97
- type: mrr_at_5
value: 27.273999999999997
- type: ndcg_at_1
value: 21.442
- type: ndcg_at_10
value: 30.897000000000002
- type: ndcg_at_100
value: 35.99
- type: ndcg_at_1000
value: 38.832
- type: ndcg_at_3
value: 25.944
- type: ndcg_at_5
value: 28.126
- type: precision_at_1
value: 21.442
- type: precision_at_10
value: 4.9910000000000005
- type: precision_at_100
value: 0.8109999999999999
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 11.029
- type: precision_at_5
value: 7.911
- type: recall_at_1
value: 19.547
- type: recall_at_10
value: 42.886
- type: recall_at_100
value: 66.64999999999999
- type: recall_at_1000
value: 87.368
- type: recall_at_3
value: 29.143
- type: recall_at_5
value: 34.544000000000004
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.572
- type: map_at_10
value: 25.312
- type: map_at_100
value: 27.062
- type: map_at_1000
value: 27.253
- type: map_at_3
value: 21.601
- type: map_at_5
value: 23.473
- type: mrr_at_1
value: 34.984
- type: mrr_at_10
value: 46.406
- type: mrr_at_100
value: 47.179
- type: mrr_at_1000
value: 47.21
- type: mrr_at_3
value: 43.485
- type: mrr_at_5
value: 45.322
- type: ndcg_at_1
value: 34.984
- type: ndcg_at_10
value: 34.344
- type: ndcg_at_100
value: 41.015
- type: ndcg_at_1000
value: 44.366
- type: ndcg_at_3
value: 29.119
- type: ndcg_at_5
value: 30.825999999999997
- type: precision_at_1
value: 34.984
- type: precision_at_10
value: 10.358
- type: precision_at_100
value: 1.762
- type: precision_at_1000
value: 0.23900000000000002
- type: precision_at_3
value: 21.368000000000002
- type: precision_at_5
value: 15.948
- type: recall_at_1
value: 15.572
- type: recall_at_10
value: 39.367999999999995
- type: recall_at_100
value: 62.183
- type: recall_at_1000
value: 80.92200000000001
- type: recall_at_3
value: 26.131999999999998
- type: recall_at_5
value: 31.635999999999996
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.848
- type: map_at_10
value: 19.25
- type: map_at_100
value: 27.193
- type: map_at_1000
value: 28.721999999999998
- type: map_at_3
value: 13.968
- type: map_at_5
value: 16.283
- type: mrr_at_1
value: 68.75
- type: mrr_at_10
value: 76.25
- type: mrr_at_100
value: 76.534
- type: mrr_at_1000
value: 76.53999999999999
- type: mrr_at_3
value: 74.667
- type: mrr_at_5
value: 75.86699999999999
- type: ndcg_at_1
value: 56.00000000000001
- type: ndcg_at_10
value: 41.426
- type: ndcg_at_100
value: 45.660000000000004
- type: ndcg_at_1000
value: 53.02
- type: ndcg_at_3
value: 46.581
- type: ndcg_at_5
value: 43.836999999999996
- type: precision_at_1
value: 68.75
- type: precision_at_10
value: 32.800000000000004
- type: precision_at_100
value: 10.440000000000001
- type: precision_at_1000
value: 1.9980000000000002
- type: precision_at_3
value: 49.667
- type: precision_at_5
value: 42.25
- type: recall_at_1
value: 8.848
- type: recall_at_10
value: 24.467
- type: recall_at_100
value: 51.344
- type: recall_at_1000
value: 75.235
- type: recall_at_3
value: 15.329
- type: recall_at_5
value: 18.892999999999997
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 48.95
- type: f1
value: 43.44563593360779
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 78.036
- type: map_at_10
value: 85.639
- type: map_at_100
value: 85.815
- type: map_at_1000
value: 85.829
- type: map_at_3
value: 84.795
- type: map_at_5
value: 85.336
- type: mrr_at_1
value: 84.353
- type: mrr_at_10
value: 90.582
- type: mrr_at_100
value: 90.617
- type: mrr_at_1000
value: 90.617
- type: mrr_at_3
value: 90.132
- type: mrr_at_5
value: 90.447
- type: ndcg_at_1
value: 84.353
- type: ndcg_at_10
value: 89.003
- type: ndcg_at_100
value: 89.60000000000001
- type: ndcg_at_1000
value: 89.836
- type: ndcg_at_3
value: 87.81400000000001
- type: ndcg_at_5
value: 88.478
- type: precision_at_1
value: 84.353
- type: precision_at_10
value: 10.482
- type: precision_at_100
value: 1.099
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 33.257999999999996
- type: precision_at_5
value: 20.465
- type: recall_at_1
value: 78.036
- type: recall_at_10
value: 94.517
- type: recall_at_100
value: 96.828
- type: recall_at_1000
value: 98.261
- type: recall_at_3
value: 91.12
- type: recall_at_5
value: 92.946
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.191
- type: map_at_10
value: 32.369
- type: map_at_100
value: 34.123999999999995
- type: map_at_1000
value: 34.317
- type: map_at_3
value: 28.71
- type: map_at_5
value: 30.607
- type: mrr_at_1
value: 40.894999999999996
- type: mrr_at_10
value: 48.842
- type: mrr_at_100
value: 49.599
- type: mrr_at_1000
value: 49.647000000000006
- type: mrr_at_3
value: 46.785
- type: mrr_at_5
value: 47.672
- type: ndcg_at_1
value: 40.894999999999996
- type: ndcg_at_10
value: 39.872
- type: ndcg_at_100
value: 46.126
- type: ndcg_at_1000
value: 49.476
- type: ndcg_at_3
value: 37.153000000000006
- type: ndcg_at_5
value: 37.433
- type: precision_at_1
value: 40.894999999999996
- type: precision_at_10
value: 10.818
- type: precision_at_100
value: 1.73
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 25.051000000000002
- type: precision_at_5
value: 17.531
- type: recall_at_1
value: 20.191
- type: recall_at_10
value: 45.768
- type: recall_at_100
value: 68.82000000000001
- type: recall_at_1000
value: 89.133
- type: recall_at_3
value: 33.296
- type: recall_at_5
value: 38.022
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.257
- type: map_at_10
value: 61.467000000000006
- type: map_at_100
value: 62.364
- type: map_at_1000
value: 62.424
- type: map_at_3
value: 58.228
- type: map_at_5
value: 60.283
- type: mrr_at_1
value: 78.515
- type: mrr_at_10
value: 84.191
- type: mrr_at_100
value: 84.378
- type: mrr_at_1000
value: 84.385
- type: mrr_at_3
value: 83.284
- type: mrr_at_5
value: 83.856
- type: ndcg_at_1
value: 78.515
- type: ndcg_at_10
value: 69.78999999999999
- type: ndcg_at_100
value: 72.886
- type: ndcg_at_1000
value: 74.015
- type: ndcg_at_3
value: 65.23
- type: ndcg_at_5
value: 67.80199999999999
- type: precision_at_1
value: 78.515
- type: precision_at_10
value: 14.519000000000002
- type: precision_at_100
value: 1.694
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 41.702
- type: precision_at_5
value: 27.046999999999997
- type: recall_at_1
value: 39.257
- type: recall_at_10
value: 72.59299999999999
- type: recall_at_100
value: 84.679
- type: recall_at_1000
value: 92.12
- type: recall_at_3
value: 62.552
- type: recall_at_5
value: 67.616
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 91.5152
- type: ap
value: 87.64584669595709
- type: f1
value: 91.50605576428437
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.926000000000002
- type: map_at_10
value: 34.049
- type: map_at_100
value: 35.213
- type: map_at_1000
value: 35.265
- type: map_at_3
value: 30.309
- type: map_at_5
value: 32.407000000000004
- type: mrr_at_1
value: 22.55
- type: mrr_at_10
value: 34.657
- type: mrr_at_100
value: 35.760999999999996
- type: mrr_at_1000
value: 35.807
- type: mrr_at_3
value: 30.989
- type: mrr_at_5
value: 33.039
- type: ndcg_at_1
value: 22.55
- type: ndcg_at_10
value: 40.842
- type: ndcg_at_100
value: 46.436
- type: ndcg_at_1000
value: 47.721999999999994
- type: ndcg_at_3
value: 33.209
- type: ndcg_at_5
value: 36.943
- type: precision_at_1
value: 22.55
- type: precision_at_10
value: 6.447
- type: precision_at_100
value: 0.9249999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.136000000000001
- type: precision_at_5
value: 10.381
- type: recall_at_1
value: 21.926000000000002
- type: recall_at_10
value: 61.724999999999994
- type: recall_at_100
value: 87.604
- type: recall_at_1000
value: 97.421
- type: recall_at_3
value: 40.944
- type: recall_at_5
value: 49.915
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.54765161878704
- type: f1
value: 93.3298945415573
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.71591427268582
- type: f1
value: 59.32113870474471
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.83053127101547
- type: f1
value: 73.60757944876475
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.72562205783457
- type: f1
value: 78.63761662505502
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.37935633767996
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.55270546130387
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.462692753143834
- type: mrr
value: 31.497569753511563
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.646
- type: map_at_10
value: 12.498
- type: map_at_100
value: 15.486
- type: map_at_1000
value: 16.805999999999997
- type: map_at_3
value: 9.325
- type: map_at_5
value: 10.751
- type: mrr_at_1
value: 43.034
- type: mrr_at_10
value: 52.662
- type: mrr_at_100
value: 53.189
- type: mrr_at_1000
value: 53.25
- type: mrr_at_3
value: 50.929
- type: mrr_at_5
value: 51.92
- type: ndcg_at_1
value: 41.796
- type: ndcg_at_10
value: 33.477000000000004
- type: ndcg_at_100
value: 29.996000000000002
- type: ndcg_at_1000
value: 38.864
- type: ndcg_at_3
value: 38.940000000000005
- type: ndcg_at_5
value: 36.689
- type: precision_at_1
value: 43.034
- type: precision_at_10
value: 24.799
- type: precision_at_100
value: 7.432999999999999
- type: precision_at_1000
value: 1.9929999999999999
- type: precision_at_3
value: 36.842000000000006
- type: precision_at_5
value: 32.135999999999996
- type: recall_at_1
value: 5.646
- type: recall_at_10
value: 15.963
- type: recall_at_100
value: 29.492
- type: recall_at_1000
value: 61.711000000000006
- type: recall_at_3
value: 10.585
- type: recall_at_5
value: 12.753999999999998
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.602
- type: map_at_10
value: 41.545
- type: map_at_100
value: 42.644999999999996
- type: map_at_1000
value: 42.685
- type: map_at_3
value: 37.261
- type: map_at_5
value: 39.706
- type: mrr_at_1
value: 31.141000000000002
- type: mrr_at_10
value: 44.139
- type: mrr_at_100
value: 44.997
- type: mrr_at_1000
value: 45.025999999999996
- type: mrr_at_3
value: 40.503
- type: mrr_at_5
value: 42.64
- type: ndcg_at_1
value: 31.141000000000002
- type: ndcg_at_10
value: 48.995
- type: ndcg_at_100
value: 53.788000000000004
- type: ndcg_at_1000
value: 54.730000000000004
- type: ndcg_at_3
value: 40.844
- type: ndcg_at_5
value: 44.955
- type: precision_at_1
value: 31.141000000000002
- type: precision_at_10
value: 8.233
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 18.579
- type: precision_at_5
value: 13.533999999999999
- type: recall_at_1
value: 27.602
- type: recall_at_10
value: 69.216
- type: recall_at_100
value: 90.252
- type: recall_at_1000
value: 97.27
- type: recall_at_3
value: 47.987
- type: recall_at_5
value: 57.438
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.949
- type: map_at_10
value: 84.89999999999999
- type: map_at_100
value: 85.531
- type: map_at_1000
value: 85.548
- type: map_at_3
value: 82.027
- type: map_at_5
value: 83.853
- type: mrr_at_1
value: 81.69999999999999
- type: mrr_at_10
value: 87.813
- type: mrr_at_100
value: 87.917
- type: mrr_at_1000
value: 87.91799999999999
- type: mrr_at_3
value: 86.938
- type: mrr_at_5
value: 87.53999999999999
- type: ndcg_at_1
value: 81.75
- type: ndcg_at_10
value: 88.55499999999999
- type: ndcg_at_100
value: 89.765
- type: ndcg_at_1000
value: 89.871
- type: ndcg_at_3
value: 85.905
- type: ndcg_at_5
value: 87.41
- type: precision_at_1
value: 81.75
- type: precision_at_10
value: 13.403
- type: precision_at_100
value: 1.528
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.597
- type: precision_at_5
value: 24.69
- type: recall_at_1
value: 70.949
- type: recall_at_10
value: 95.423
- type: recall_at_100
value: 99.509
- type: recall_at_1000
value: 99.982
- type: recall_at_3
value: 87.717
- type: recall_at_5
value: 92.032
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 51.76962893449579
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.32897690686379
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.478
- type: map_at_10
value: 11.994
- type: map_at_100
value: 13.977
- type: map_at_1000
value: 14.295
- type: map_at_3
value: 8.408999999999999
- type: map_at_5
value: 10.024
- type: mrr_at_1
value: 22.1
- type: mrr_at_10
value: 33.526
- type: mrr_at_100
value: 34.577000000000005
- type: mrr_at_1000
value: 34.632000000000005
- type: mrr_at_3
value: 30.217
- type: mrr_at_5
value: 31.962000000000003
- type: ndcg_at_1
value: 22.1
- type: ndcg_at_10
value: 20.191
- type: ndcg_at_100
value: 27.954
- type: ndcg_at_1000
value: 33.491
- type: ndcg_at_3
value: 18.787000000000003
- type: ndcg_at_5
value: 16.378999999999998
- type: precision_at_1
value: 22.1
- type: precision_at_10
value: 10.69
- type: precision_at_100
value: 2.1919999999999997
- type: precision_at_1000
value: 0.35200000000000004
- type: precision_at_3
value: 17.732999999999997
- type: precision_at_5
value: 14.499999999999998
- type: recall_at_1
value: 4.478
- type: recall_at_10
value: 21.657
- type: recall_at_100
value: 44.54
- type: recall_at_1000
value: 71.542
- type: recall_at_3
value: 10.778
- type: recall_at_5
value: 14.687
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.82325259156718
- type: cos_sim_spearman
value: 79.2463589100662
- type: euclidean_pearson
value: 80.48318380496771
- type: euclidean_spearman
value: 79.34451935199979
- type: manhattan_pearson
value: 80.39041824178759
- type: manhattan_spearman
value: 79.23002892700211
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.74130231431258
- type: cos_sim_spearman
value: 78.36856568042397
- type: euclidean_pearson
value: 82.48301631890303
- type: euclidean_spearman
value: 78.28376980722732
- type: manhattan_pearson
value: 82.43552075450525
- type: manhattan_spearman
value: 78.22702443947126
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 79.96138619461459
- type: cos_sim_spearman
value: 81.85436343502379
- type: euclidean_pearson
value: 81.82895226665367
- type: euclidean_spearman
value: 82.22707349602916
- type: manhattan_pearson
value: 81.66303369445873
- type: manhattan_spearman
value: 82.05030197179455
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 80.05481244198648
- type: cos_sim_spearman
value: 80.85052504637808
- type: euclidean_pearson
value: 80.86728419744497
- type: euclidean_spearman
value: 81.033786401512
- type: manhattan_pearson
value: 80.90107531061103
- type: manhattan_spearman
value: 81.11374116827795
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 84.615220756399
- type: cos_sim_spearman
value: 86.46858500002092
- type: euclidean_pearson
value: 86.08307800247586
- type: euclidean_spearman
value: 86.72691443870013
- type: manhattan_pearson
value: 85.96155594487269
- type: manhattan_spearman
value: 86.605909505275
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.14363913634436
- type: cos_sim_spearman
value: 84.48430226487102
- type: euclidean_pearson
value: 83.75303424801902
- type: euclidean_spearman
value: 84.56762380734538
- type: manhattan_pearson
value: 83.6135447165928
- type: manhattan_spearman
value: 84.39898212616731
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 85.09909252554525
- type: cos_sim_spearman
value: 85.70951402743276
- type: euclidean_pearson
value: 87.1991936239908
- type: euclidean_spearman
value: 86.07745840612071
- type: manhattan_pearson
value: 87.25039137549952
- type: manhattan_spearman
value: 85.99938746659761
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.529332093413615
- type: cos_sim_spearman
value: 65.38177340147439
- type: euclidean_pearson
value: 66.35278011412136
- type: euclidean_spearman
value: 65.47147267032997
- type: manhattan_pearson
value: 66.71804682408693
- type: manhattan_spearman
value: 65.67406521423597
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 82.45802942885662
- type: cos_sim_spearman
value: 84.8853341842566
- type: euclidean_pearson
value: 84.60915021096707
- type: euclidean_spearman
value: 85.11181242913666
- type: manhattan_pearson
value: 84.38600521210364
- type: manhattan_spearman
value: 84.89045417981723
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 85.92793380635129
- type: mrr
value: 95.85834191226348
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.74400000000001
- type: map_at_10
value: 65.455
- type: map_at_100
value: 66.106
- type: map_at_1000
value: 66.129
- type: map_at_3
value: 62.719
- type: map_at_5
value: 64.441
- type: mrr_at_1
value: 58.667
- type: mrr_at_10
value: 66.776
- type: mrr_at_100
value: 67.363
- type: mrr_at_1000
value: 67.384
- type: mrr_at_3
value: 64.889
- type: mrr_at_5
value: 66.122
- type: ndcg_at_1
value: 58.667
- type: ndcg_at_10
value: 69.904
- type: ndcg_at_100
value: 72.807
- type: ndcg_at_1000
value: 73.423
- type: ndcg_at_3
value: 65.405
- type: ndcg_at_5
value: 67.86999999999999
- type: precision_at_1
value: 58.667
- type: precision_at_10
value: 9.3
- type: precision_at_100
value: 1.08
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 17
- type: recall_at_1
value: 55.74400000000001
- type: recall_at_10
value: 82.122
- type: recall_at_100
value: 95.167
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 70.14399999999999
- type: recall_at_5
value: 76.417
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86534653465347
- type: cos_sim_ap
value: 96.54142419791388
- type: cos_sim_f1
value: 93.07535641547861
- type: cos_sim_precision
value: 94.81327800829875
- type: cos_sim_recall
value: 91.4
- type: dot_accuracy
value: 99.86435643564356
- type: dot_ap
value: 96.53682260449868
- type: dot_f1
value: 92.98515104966718
- type: dot_precision
value: 95.27806925498426
- type: dot_recall
value: 90.8
- type: euclidean_accuracy
value: 99.86336633663366
- type: euclidean_ap
value: 96.5228676185697
- type: euclidean_f1
value: 92.9735234215886
- type: euclidean_precision
value: 94.70954356846472
- type: euclidean_recall
value: 91.3
- type: manhattan_accuracy
value: 99.85841584158416
- type: manhattan_ap
value: 96.50392760934032
- type: manhattan_f1
value: 92.84642321160581
- type: manhattan_precision
value: 92.8928928928929
- type: manhattan_recall
value: 92.80000000000001
- type: max_accuracy
value: 99.86534653465347
- type: max_ap
value: 96.54142419791388
- type: max_f1
value: 93.07535641547861
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 61.08285408766616
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.640675309010604
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 53.20333913710715
- type: mrr
value: 54.088813555725324
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.79465221925075
- type: cos_sim_spearman
value: 30.530816059163634
- type: dot_pearson
value: 31.364837244718043
- type: dot_spearman
value: 30.79726823684003
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22599999999999998
- type: map_at_10
value: 1.735
- type: map_at_100
value: 8.978
- type: map_at_1000
value: 20.851
- type: map_at_3
value: 0.613
- type: map_at_5
value: 0.964
- type: mrr_at_1
value: 88
- type: mrr_at_10
value: 92.867
- type: mrr_at_100
value: 92.867
- type: mrr_at_1000
value: 92.867
- type: mrr_at_3
value: 92.667
- type: mrr_at_5
value: 92.667
- type: ndcg_at_1
value: 82
- type: ndcg_at_10
value: 73.164
- type: ndcg_at_100
value: 51.878
- type: ndcg_at_1000
value: 44.864
- type: ndcg_at_3
value: 79.184
- type: ndcg_at_5
value: 76.39
- type: precision_at_1
value: 88
- type: precision_at_10
value: 76.2
- type: precision_at_100
value: 52.459999999999994
- type: precision_at_1000
value: 19.692
- type: precision_at_3
value: 82.667
- type: precision_at_5
value: 80
- type: recall_at_1
value: 0.22599999999999998
- type: recall_at_10
value: 1.942
- type: recall_at_100
value: 12.342
- type: recall_at_1000
value: 41.42
- type: recall_at_3
value: 0.637
- type: recall_at_5
value: 1.034
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.567
- type: map_at_10
value: 13.116
- type: map_at_100
value: 19.39
- type: map_at_1000
value: 20.988
- type: map_at_3
value: 7.109
- type: map_at_5
value: 9.950000000000001
- type: mrr_at_1
value: 42.857
- type: mrr_at_10
value: 57.404999999999994
- type: mrr_at_100
value: 58.021
- type: mrr_at_1000
value: 58.021
- type: mrr_at_3
value: 54.762
- type: mrr_at_5
value: 56.19
- type: ndcg_at_1
value: 38.775999999999996
- type: ndcg_at_10
value: 30.359
- type: ndcg_at_100
value: 41.284
- type: ndcg_at_1000
value: 52.30200000000001
- type: ndcg_at_3
value: 36.744
- type: ndcg_at_5
value: 34.326
- type: precision_at_1
value: 42.857
- type: precision_at_10
value: 26.122
- type: precision_at_100
value: 8.082
- type: precision_at_1000
value: 1.559
- type: precision_at_3
value: 40.136
- type: precision_at_5
value: 35.510000000000005
- type: recall_at_1
value: 3.567
- type: recall_at_10
value: 19.045
- type: recall_at_100
value: 49.979
- type: recall_at_1000
value: 84.206
- type: recall_at_3
value: 8.52
- type: recall_at_5
value: 13.103000000000002
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 68.8394
- type: ap
value: 13.454399712443099
- type: f1
value: 53.04963076364322
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.546123372948514
- type: f1
value: 60.86952793277713
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.10042955060234
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.03308100375514
- type: cos_sim_ap
value: 71.08284605869684
- type: cos_sim_f1
value: 65.42539436255494
- type: cos_sim_precision
value: 64.14807302231237
- type: cos_sim_recall
value: 66.75461741424802
- type: dot_accuracy
value: 84.68736961316088
- type: dot_ap
value: 69.20524036530992
- type: dot_f1
value: 63.54893953365829
- type: dot_precision
value: 63.45698500394633
- type: dot_recall
value: 63.641160949868066
- type: euclidean_accuracy
value: 85.07480479227513
- type: euclidean_ap
value: 71.14592761009864
- type: euclidean_f1
value: 65.43814432989691
- type: euclidean_precision
value: 63.95465994962216
- type: euclidean_recall
value: 66.99208443271768
- type: manhattan_accuracy
value: 85.06288370984085
- type: manhattan_ap
value: 71.07289742593868
- type: manhattan_f1
value: 65.37585421412301
- type: manhattan_precision
value: 62.816147859922175
- type: manhattan_recall
value: 68.15303430079156
- type: max_accuracy
value: 85.07480479227513
- type: max_ap
value: 71.14592761009864
- type: max_f1
value: 65.43814432989691
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 87.79058485659952
- type: cos_sim_ap
value: 83.7183187008759
- type: cos_sim_f1
value: 75.86921142180798
- type: cos_sim_precision
value: 73.00683371298405
- type: cos_sim_recall
value: 78.96519864490298
- type: dot_accuracy
value: 87.0085768618776
- type: dot_ap
value: 81.87467488474279
- type: dot_f1
value: 74.04188363990559
- type: dot_precision
value: 72.10507114191901
- type: dot_recall
value: 76.08561749307053
- type: euclidean_accuracy
value: 87.8332751193387
- type: euclidean_ap
value: 83.83585648120315
- type: euclidean_f1
value: 76.02582177042369
- type: euclidean_precision
value: 73.36388371759989
- type: euclidean_recall
value: 78.88820449645827
- type: manhattan_accuracy
value: 87.87208444910156
- type: manhattan_ap
value: 83.8101950642973
- type: manhattan_f1
value: 75.90454195535027
- type: manhattan_precision
value: 72.44419564761039
- type: manhattan_recall
value: 79.71204188481676
- type: max_accuracy
value: 87.87208444910156
- type: max_ap
value: 83.83585648120315
- type: max_f1
value: 76.02582177042369
license: mit
language:
- en
---
**Recommend switching to newest [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5), which has more reasonable similarity distribution and same method of usage.**
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focus on retrieval-augmented LLMs, consisting of following projects currently:
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Dense Retrieval**: [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding), [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
- **Reranker Model**: [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## News
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [LM-Cocktail](https://huggingface.co/Shitao) | English | | fine-tuned models (Llama and BGE) which can be used to reproduce the results of LM-Cocktail | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
google/electra-small-discriminator | google | "2024-02-29T10:20:20Z" | 672,352 | 27 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"electra",
"pretraining",
"en",
"arxiv:1406.2661",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
## ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
For a detailed description and experimental results, please refer to our paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/pdf?id=r1xMH1BtvB).
This repository contains code to pre-train ELECTRA, including small ELECTRA models on a single GPU. It also supports fine-tuning ELECTRA on downstream tasks including classification tasks (e.g,. [GLUE](https://gluebenchmark.com/)), QA tasks (e.g., [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)), and sequence tagging tasks (e.g., [text chunking](https://www.clips.uantwerpen.be/conll2000/chunking/)).
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("google/electra-small-discriminator")
tokenizer = ElectraTokenizerFast.from_pretrained("google/electra-small-discriminator")
sentence = "The quick brown fox jumps over the lazy dog"
fake_sentence = "The quick brown fox fake over the lazy dog"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.squeeze().tolist()]
```
|
microsoft/Phi-3.5-mini-instruct | microsoft | "2024-09-18T17:57:09Z" | 671,847 | 621 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"multilingual",
"arxiv:2404.14219",
"arxiv:2407.13833",
"arxiv:2403.06412",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-08-16T20:48:26Z" | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3.5-mini-instruct/resolve/main/LICENSE
language:
- multilingual
pipeline_tag: text-generation
tags:
- nlp
- code
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
library_name: transformers
---
## Model Summary
Phi-3.5-mini is a lightweight, state-of-the-art open model built upon datasets used for Phi-3 - synthetic data and filtered publicly available websites - with a focus on very high-quality, reasoning dense data. The model belongs to the Phi-3 model family and supports 128K token context length. The model underwent a rigorous enhancement process, incorporating both supervised fine-tuning, proximal policy optimization, and direct preference optimization to ensure precise instruction adherence and robust safety measures.
🏡 [Phi-3 Portal](https://azure.microsoft.com/en-us/products/phi-3) <br>
📰 [Phi-3 Microsoft Blog](https://aka.ms/phi3.5-techblog) <br>
📖 [Phi-3 Technical Report](https://arxiv.org/abs/2404.14219) <br>
👩🍳 [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook) <br>
🖥️ [Try It](https://aka.ms/try-phi3.5mini) <br>
**Phi-3.5**: [[mini-instruct](https://huggingface.co/microsoft/Phi-3.5-mini-instruct) | [onnx](https://huggingface.co/microsoft/Phi-3.5-mini-instruct-onnx)]; [[MoE-instruct]](https://huggingface.co/microsoft/Phi-3.5-MoE-instruct); [[vision-instruct]](https://huggingface.co/microsoft/Phi-3.5-vision-instruct)
## Intended Uses
### Primary Use Cases
The model is intended for commercial and research use in multiple languages. The model provides uses for general purpose AI systems and applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
### Use Case Considerations
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
***Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.***
## Release Notes
This is an update over the June 2024 instruction-tuned Phi-3 Mini release based on valuable user feedback. The model used additional post-training data leading to substantial gains on multilingual, multi-turn conversation quality, and reasoning capability. We believe most use cases will benefit from this release, but we encourage users to test in their particular AI applications. We appreciate the enthusiastic adoption of the Phi-3 model family, and continue to welcome all feedback from the community.
### Multilingual
The table below highlights multilingual capability of the Phi-3.5 Mini on multilingual MMLU, MEGA, and multilingual MMLU-pro datasets. Overall, we observed that even with just 3.8B active parameters, the model is competitive on multilingual tasks in comparison to other models with a much bigger active parameters.
| Benchmark | Phi-3.5 Mini-Ins | Phi-3.0-Mini-128k-Instruct (June2024) | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|----------------------------|------------------|-----------------------|--------------------------|---------------------------|------------------|----------------|------------------|-------------------------------|
| Multilingual MMLU | 55.4 | 51.08 | 47.4 | 58.9 | 56.2 | 63.8 | 77.2 | 72.9 |
| Multilingual MMLU-Pro | 30.9 | 30.21 | 15.0 | 34.0 | 21.4 | 43.0 | 57.9 | 53.2 |
| MGSM | 47.9 | 41.56 | 31.8 | 63.3 | 56.7 | 75.1 | 75.8 | 81.7 |
| MEGA MLQA | 61.7 | 55.5 | 43.9 | 61.2 | 45.2 | 54.4 | 61.6 | 70.0 |
| MEGA TyDi QA | 62.2 | 55.9 | 54.0 | 63.7 | 54.5 | 65.6 | 63.6 | 81.8 |
| MEGA UDPOS | 46.5 | 48.1 | 57.2 | 58.2 | 54.1 | 56.6 | 62.4 | 66.0 |
| MEGA XCOPA | 63.1 | 62.4 | 58.8 | 10.8 | 21.1 | 31.2 | 95.0 | 90.3 |
| MEGA XStoryCloze | 73.5 | 73.6 | 75.5 | 92.3 | 71.0 | 87.0 | 20.7 | 96.6 |
| **Average** | **55.2** | **52.3** | **47.9** | **55.3** | **47.5** | **59.6** | **64.3** | **76.6** |
The table below shows Multilingual MMLU scores in some of the supported languages. For more multi-lingual benchmarks and details, see [Appendix A](#appendix-a).
| Benchmark | Phi-3.5 Mini-Ins | Phi-3.0-Mini-128k-Instruct (June2024) | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|-----------|------------------|-----------------------|--------------------------|---------------------------|------------------|----------------|------------------|-------------------------------|
| Arabic | 44.2 | 35.4 | 33.7 | 45.3 | 49.1 | 56.3 | 73.6 | 67.1 |
| Chinese | 52.6 | 46.9 | 45.9 | 58.2 | 54.4 | 62.7 | 66.7 | 70.8 |
| Dutch | 57.7 | 48.0 | 51.3 | 60.1 | 55.9 | 66.7 | 80.6 | 74.2 |
| French | 61.1 | 61.7 | 53.0 | 63.8 | 62.8 | 67.0 | 82.9 | 75.6 |
| German | 62.4 | 61.3 | 50.1 | 64.5 | 59.9 | 65.7 | 79.5 | 74.3 |
| Italian | 62.8 | 63.1 | 52.5 | 64.1 | 55.9 | 65.7 | 82.6 | 75.9 |
| Russian | 50.4 | 45.3 | 48.9 | 59.0 | 57.4 | 63.2 | 78.7 | 72.6 |
| Spanish | 62.6 | 61.3 | 53.9 | 64.3 | 62.6 | 66.0 | 80.0 | 75.5 |
| Ukrainian | 45.2 | 36.7 | 46.9 | 56.6 | 52.9 | 62.0 | 77.4 | 72.6 |
### Long Context
Phi-3.5-mini supports 128K context length, therefore the model is capable of several long context tasks including long document/meeting summarization, long document QA, long document information retrieval. We see that Phi-3.5-mini is clearly better than Gemma-2 family which only supports 8K context length. Phi-3.5-mini is competitive with other much larger open-weight models such as Llama-3.1-8B-instruct, Mistral-7B-instruct-v0.3, and Mistral-Nemo-12B-instruct-2407.
| Benchmark | Phi-3.5-mini-instruct | Llama-3.1-8B-instruct | Mistral-7B-instruct-v0.3 | Mistral-Nemo-12B-instruct-2407 | Gemini-1.5-Flash | GPT-4o-mini-2024-07-18 (Chat) |
|--|--|--|--|--|--|--|
| GovReport | 25.9 | 25.1 | 26.0 | 25.6 | 27.8 | 24.8 |
| QMSum | 21.3 | 21.6 | 21.3 | 22.1 | 24.0 | 21.7 |
| Qasper | 41.9 | 37.2 | 31.4 | 30.7 | 43.5 | 39.8 |
| SQuALITY | 25.3 | 26.2 | 25.9 | 25.8 | 23.5 | 23.8 |
| SummScreenFD | 16.0 | 17.6 | 17.5 | 18.2 | 16.3 | 17.0 |
| **Average** | **26.1** | **25.5** | **24.4** | **24.5** | **27.0** | **25.4** |
RULER: a retrieval-based benchmark for long context understanding
| Model | 4K | 8K | 16K | 32K | 64K | 128K | Average |
|--|--|--|--|--|--|--|--|
| **Phi-3.5-mini-instruct** | 94.3 | 91.1 | 90.7 | 87.1 | 78.0 | 63.6 | **84.1** |
| **Llama-3.1-8B-instruct** | 95.5 | 93.8 | 91.6 | 87.4 | 84.7 | 77.0 | **88.3** |
| **Mistral-Nemo-12B-instruct-2407** | 87.8 | 87.2 | 87.7 | 69.0 | 46.8 | 19.0 | **66.2** |
RepoQA: a benchmark for long context code understanding
| Model | Python | C++ | Rust | Java | TypeScript | Average |
|--|--|--|--|--|--|--|
| **Phi-3.5-mini-instruct** | 86 | 67 | 73 | 77 | 82 | **77** |
| **Llama-3.1-8B-instruct** | 80 | 65 | 73 | 76 | 63 | **71** |
| **Mistral-7B-instruct-v0.3** | 61 | 57 | 51 | 61 | 80 | **62** |
## Usage
### Requirements
Phi-3 family has been integrated in the `4.43.0` version of `transformers`. The current `transformers` version can be verified with: `pip list | grep transformers`.
Examples of required packages:
```
flash_attn==2.5.8
torch==2.3.1
accelerate==0.31.0
transformers==4.43.0
```
Phi-3.5-mini-instruct is also available in [Azure AI Studio](https://aka.ms/try-phi3.5mini)
### Tokenizer
Phi-3.5-mini-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3.5-mini-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Input Formats
Given the nature of the training data, the Phi-3.5-mini-instruct model is best suited for prompts using the chat format as follows:
```
<|system|>
You are a helpful assistant.<|end|>
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
### Loading the model locally
After obtaining the Phi-3.5-mini-instruct model checkpoint, users can use this sample code for inference.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3.5-mini-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3.5-mini-instruct")
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
Notes: If you want to use flash attention, call _AutoModelForCausalLM.from_pretrained()_ with _attn_implementation="flash_attention_2"_
## Responsible AI Considerations
Like other language models, the Phi family of models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: The Phi models are trained primarily on English text and some additional multilingual text. Languages other than English will experience worse performance as well as performance disparities across non-English. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Multilingual performance and safety gaps: We believe it is important to make language models more widely available across different languages, but the Phi 3 models still exhibit challenges common across multilingual releases. As with any deployment of LLMs, developers will be better positioned to test for performance or safety gaps for their linguistic and cultural context and customize the model with additional fine-tuning and appropriate safeguards.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups, cultural contexts, or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: These models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
+ Long Conversation: Phi-3 models, like other models, can in some cases generate responses that are repetitive, unhelpful, or inconsistent in very long chat sessions in both English and non-English languages. Developers are encouraged to place appropriate mitigations, like limiting conversation turns to account for the possible conversational drift
Developers should apply responsible AI best practices, including mapping, measuring, and mitigating risks associated with their specific use case and cultural, linguistic context. Phi-3 family of models are general purpose models. As developers plan to deploy these models for specific use cases, they are encouraged to fine-tune the models for their use case and leverage the models as part of broader AI systems with language-specific safeguards in place. Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess the suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
**Architecture:** Phi-3.5-mini has 3.8B parameters and is a dense decoder-only Transformer model using the same tokenizer as Phi-3 Mini.<br>
**Inputs:** Text. It is best suited for prompts using chat format.<br>
**Context length:** 128K tokens<br>
**GPUs:** 512 H100-80G<br>
**Training time:** 10 days<br>
**Training data:** 3.4T tokens<br>
**Outputs:** Generated text in response to the input<br>
**Dates:** Trained between June and August 2024<br>
**Status:** This is a static model trained on an offline dataset with cutoff date October 2023 for publicly available data. Future versions of the tuned models may be released as we improve models.<br>
**Supported languages:** Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian<br>
**Release date:** August 2024<br>
### Training Datasets
Our training data includes a wide variety of sources, totaling 3.4 trillion tokens, and is a combination of
1) publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) high quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://arxiv.org/pdf/2404.14219).
### Fine-tuning
A basic example of multi-GPUs supervised fine-tuning (SFT) with TRL and Accelerate modules is provided [here](https://huggingface.co/microsoft/Phi-3.5-mini-instruct/resolve/main/sample_finetune.py).
## Benchmarks
We report the results under completion format for Phi-3.5-mini on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mistral-7B-Instruct-v0.3, Mistral-Nemo-12B-Ins-2407, Llama-3.1-8B-Ins, Gemma-2-9B-Ins, Gemini 1.5 Flash, and GPT-4o-mini-2024-07-18 (Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark. At the high-level overview of the model quality on representative benchmarks:
| Category | Benchmark | Phi-3.5 Mini-Ins | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|----------------|--------------------------|------------------|--------------------------|---------------------------|------------------|----------------|------------------|------------------------------|
| Popular aggregated benchmark | Arena Hard | 37 | 18.1 | 39.4 | 25.7 | 42 | 55.2 | 75 |
| | BigBench Hard CoT (0-shot) | 69 | 33.4 | 60.2 | 63.4 | 63.5 | 66.7 | 80.4 |
| | MMLU (5-shot) | 69 | 60.3 | 67.2 | 68.1 | 71.3 | 78.7 | 77.2 |
| | MMLU-Pro (0-shot, CoT) | 47.4 | 18 | 40.7 | 44 | 50.1 | 57.2 | 62.8 |
| Reasoning | ARC Challenge (10-shot) | 84.6 | 77.9 | 84.8 | 83.1 | 89.8 | 92.8 | 93.5 |
| | BoolQ (2-shot) | 78 | 80.5 | 82.5 | 82.8 | 85.7 | 85.8 | 88.7 |
| | GPQA (0-shot, CoT) | 30.4 | 15.6 | 28.6 | 26.3 | 29.2 | 37.5 | 41.1 |
| | HellaSwag (5-shot) | 69.4 | 71.6 | 76.7 | 73.5 | 80.9 | 67.5 | 87.1 |
| | OpenBookQA (10-shot) | 79.2 | 78 | 84.4 | 84.8 | 89.6 | 89 | 90 |
| | PIQA (5-shot) | 81 | 73.4 | 83.5 | 81.2 | 83.7 | 87.5 | 88.7 |
| | Social IQA (5-shot) | 74.7 | 73 | 75.3 | 71.8 | 74.7 | 77.8 | 82.9 |
| | TruthfulQA (MC2) (10-shot) | 64 | 64.7 | 68.1 | 69.2 | 76.6 | 76.6 | 78.2 |
| | WinoGrande (5-shot) | 68.5 | 58.1 | 70.4 | 64.7 | 74 | 74.7 | 76.9 |
| Multilingual | Multilingual MMLU (5-shot) | 55.4 | 47.4 | 58.9 | 56.2 | 63.8 | 77.2 | 72.9 |
| | MGSM (0-shot CoT) | 47.9 | 31.8 | 63.3 | 56.7 | 76.4 | 75.8 | 81.7 |
| Math | GSM8K (8-shot, CoT) | 86.2 | 54.4 | 84.2 | 82.4 | 84.9 | 82.4 | 91.3 |
| | MATH (0-shot, CoT) | 48.5 | 19 | 31.2 | 47.6 | 50.9 | 38 | 70.2 |
| Long context | Qasper | 41.9 | 31.4 | 30.7 | 37.2 | 13.9 | 43.5 | 39.8 |
| | SQuALITY | 24.3 | 25.9 | 25.8 | 26.2 | 0 | 23.5 | 23.8 |
| Code Generation| HumanEval (0-shot) | 62.8 | 35.4 | 63.4 | 66.5 | 61 | 74.4 | 86.6 |
| | MBPP (3-shot) | 69.6 | 50.4 | 68.1 | 69.4 | 69.3 | 77.5 | 84.1 |
| **Average** | | **61.4** | **48.5** | **61.3** | **61.0** | **63.3** | **68.5** | **74.9** |
We take a closer look at different categories across public benchmark datasets at the table below:
| Category | Phi-3.5 Mini-Ins | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|----------------------------|------------------|--------------------------|---------------------------|------------------|----------------|------------------|------------------------------|
| Popular aggregated benchmark | 55.6 | 32.5 | 51.9 | 50.3 | 56.7 | 64.5 | 73.9 |
| Reasoning | 70.1 | 65.2 | 72.2 | 70.5 | 75.4 | 77.7 | 80 |
| Language understanding | 62.6 | 62.8 | 67 | 62.9 | 72.8 | 66.6 | 76.8 |
| Robustness | 59.7 | 53.4 | 65.2 | 59.8 | 64.7 | 68.9 | 77.5 |
| Long context | 26.1 | 25.5 | 24.4 | 24.5 | 0 | 27 | 25.4 |
| Math | 67.4 | 36.7 | 57.7 | 65 | 67.9 | 60.2 | 80.8 |
| Code generation | 62 | 43.1 | 56.9 | 65.8 | 58.3 | 66.8 | 69.9 |
| Multilingual | 55.2 | 47.9 | 55.3 | 47.5 | 59.6 | 64.3 | 76.6 |
Overall, the model with only 3.8B-param achieves a similar level of multilingual language understanding and reasoning ability as much larger models.
However, it is still fundamentally limited by its size for certain tasks.
The model simply does not have the capacity to store too much factual knowledge, therefore, users may experience factual incorrectness.
However, we believe such weakness can be resolved by augmenting Phi-3.5 with a search engine, particularly when using the model under RAG settings.
## Safety Evaluation and Red-Teaming
We leveraged various evaluation techniques including red teaming, adversarial conversation simulations, and multilingual safety evaluation benchmark datasets to
evaluate Phi-3.5 models' propensity to produce undesirable outputs across multiple languages and risk categories.
Several approaches were used to compensate for the limitations of one approach alone. Findings across the various evaluation methods indicate that safety
post-training that was done as detailed in the [Phi-3 Safety Post-Training paper](https://arxiv.org/pdf/2407.13833) had a positive impact across multiple languages and risk categories as observed by
refusal rates (refusal to output undesirable outputs) and robustness to jailbreak techniques. Note, however, while comprehensive red team evaluations were conducted
across all models in the prior release of Phi models, red teaming was largely focused on Phi-3.5 MOE across multiple languages and risk categories for this release as
it is the largest and more capable model of the three models. Details on prior red team evaluations across Phi models can be found in the [Phi-3 Safety Post-Training paper](https://arxiv.org/pdf/2407.13833).
For this release, insights from red teaming indicate that the models may refuse to generate undesirable outputs in English, even when the request for undesirable output
is in another language. Models may also be more susceptible to longer multi-turn jailbreak techniques across both English and non-English languages. These findings
highlight the need for industry-wide investment in the development of high-quality safety evaluation datasets across multiple languages, including low resource languages,
and risk areas that account for cultural nuances where those languages are spoken.
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3.5-mini-instruct model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
## License
The model is licensed under the [MIT license](./LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
## Appendix A
#### MGSM
| Languages | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|-----------|------------------------|---------------------------------------|--------------------------|---------------------------|------------------|----------------|------------------|-------------------------------|
| German | 69.6 | 65.2 | 42.4 | 74.4 | 68.4 | 76.8 | 81.6 | 82.8 |
| English | 85.2 | 83.2 | 60.0 | 86.0 | 81.2 | 88.8 | 90.8 | 90.8 |
| Spanish | 79.2 | 77.6 | 46.4 | 75.6 | 66.4 | 82.4 | 84.8 | 86.8 |
| French | 71.6 | 72.8 | 47.2 | 70.4 | 66.8 | 74.4 | 77.2 | 81.6 |
| Japanese | 50.0 | 35.2 | 22.8 | 62.4 | 49.2 | 67.6 | 77.6 | 80.4 |
| Russian | 67.2 | 51.6 | 43.2 | 73.6 | 67.2 | 78.4 | 84.8 | 86.4 |
| Thai | 29.6 | 6.4 | 18.4 | 53.2 | 56.0 | 76.8 | 87.6 | 81.6 |
| Chinese | 60.0 | 52.8 | 42.4 | 66.4 | 68.0 | 72.8 | 82.0 | 82.0 |
#### Multilingual MMLU-pro
| Languages | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|------------|-----------------------|---------------------------------------|--------------------------|---------------------------|------------------|----------------|------------------|-------------------------------|
| Czech | 24.9 | 26.3 | 14.6 | 30.6 | 23.0 | 40.5 | 59.0 | 40.9 |
| English | 47.7 | 46.2 | 17.7 | 39.8 | 43.1 | 49.0 | 66.1 | 62.7 |
| Finnish | 22.3 | 20.5 | 11.5 | 30.4 | 9.7 | 37.5 | 54.5 | 50.1 |
| Norwegian | 29.9 | 27.8 | 14.4 | 33.2 | 22.2 | 44.4 | 60.7 | 59.1 |
| Polish | 25.7 | 26.4 | 16.3 | 33.6 | 9.2 | 41.7 | 53.9 | 42.8 |
| Portuguese | 38.7 | 37.6 | 15.3 | 36.0 | 29.3 | 43.5 | 54.0 | 56.9 |
| Swedish | 30.7 | 28.1 | 15.5 | 34.3 | 16.9 | 42.6 | 57.7 | 55.5 |
#### MEGA
##### MLQA
| Languages | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|-----------|-----------------------|---------------------------------------|--------------------------|---------------------------|------------------|----------------|------------------|-------------------------------|
| Arabic | 54.3 | 32.7 | 23.5 | 31.4 | 31.5 | 57.4 | 63.8 | 64.0 |
| Chinese | 36.1 | 31.8 | 22.4 | 27.4 | 18.6 | 45.4 | 38.1 | 38.9 |
| English | 80.3 | 78.9 | 68.2 | 75.5 | 67.2 | 82.9 | 69.5 | 82.2 |
| German | 61.8 | 59.1 | 49.0 | 57.8 | 38.9 | 63.8 | 55.9 | 64.1 |
| Spanish | 68.8 | 67.0 | 50.3 | 63.6 | 52.7 | 72.8 | 59.6 | 70.1 |
##### TyDi QA
| Languages | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|-----------|-----------------------|---------------------------------------|--------------------------|---------------------------|------------------|----------------|------------------|-------------------------------|
| Arabic | 69.7 | 54.4 | 52.5 | 49.8 | 33.7 | 81.1 | 78.8 | 84.9 |
| English | 82.0 | 82.0 | 60.5 | 77.3 | 65.1 | 82.4 | 60.9 | 81.8 |
| Finnish | 70.3 | 64.3 | 68.6 | 57.1 | 74.4 | 85.7 | 73.5 | 84.8 |
| Japanese | 65.4 | 56.7 | 45.3 | 54.8 | 34.1 | 74.6 | 59.7 | 73.3 |
| Korean | 74.0 | 60.4 | 54.5 | 54.2 | 54.9 | 83.8 | 60.7 | 82.3 |
| Russian | 63.5 | 62.7 | 52.3 | 55.7 | 27.4 | 69.8 | 60.1 | 72.5 |
| Thai | 64.4 | 49.0 | 51.8 | 43.5 | 48.5 | 81.4 | 71.6 | 78.2 |
##### XCOPA
| Languages | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Mistral-7B-Instruct-v0.3 | Mistral-Nemo-12B-Ins-2407 | Llama-3.1-8B-Ins | Gemma-2-9B-Ins | Gemini 1.5 Flash | GPT-4o-mini-2024-07-18 (Chat) |
|-----------|-----------------------|---------------------------------------|--------------------------|---------------------------|------------------|----------------|------------------|-------------------------------|
| English | 94.6 | 94.6 | 85.6 | 94.4 | 37.6 | 63.8 | 92.0 | 98.2 |
| Italian | 86.8 | 84.8 | 76.8 | 83.2 | 16.2 | 37.2 | 85.6 | 97.6 |
| Turkish | 58.6 | 57.2 | 61.6 | 56.6 | 38.4 | 60.2 | 91.4 | 94.6 |
## Appendix B: Korean benchmarks
The prompt is the same as the [CLIcK paper](https://arxiv.org/abs/2403.06412) prompt. The experimental results below were given with max_tokens=512 (zero-shot), max_tokens=1024 (5-shot), temperature=0.01. No system prompt used.
- GPT-4o: 2024-05-13 version
- GPT-4o-mini: 2024-07-18 version
- GPT-4-turbo: 2024-04-09 version
- GPT-3.5-turbo: 2023-06-13 version
The overall Korean benchmarks show that the Phi-3.5-Mini-Instruct with only 3.8B params outperforms Llama-3.1-8B-Instruct.
| Benchmarks | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:-------------------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| CLIcK | 42.99 | 29.12 | 47.82 | 80.46 | 68.5 | 72.82 | 50.98 |
| HAERAE 1.0 | 44.21 | 36.41 | 53.9 | 85.7 | 76.4 | 77.76 | 52.67 |
| KMMLU (0-shot, CoT) | 35.87 | 30.82 | 38.54 | 64.26 | 52.63 | 58.75 | 40.3 |
| KMMLU (5-shot) | 37.35 | 29.98 | 20.21 | 64.28 | 51.62 | 59.29 | 42.28 |
| KMMLU-HARD (0-shot, CoT) | 24 | 25.68 | 24.03 | 39.62 | 24.56 | 30.56 | 20.97 |
| KMMLU-HARD (5-shot) | 24.76 | 25.73 | 15.81 | 40.94 | 24.63 | 31.12 | 21.19 |
| **Average** | **35.62** | **29.99** | **29.29** | **62.54** | **50.08** | **56.74** | **39.61** |
#### CLIcK (Cultural and Linguistic Intelligence in Korean)
##### Accuracy by supercategory
| supercategory | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:----------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| Culture | 43.77 | 29.74 | 51.15 | 81.89 | 70.95 | 73.61 | 53.38 |
| Language | 41.38 | 27.85 | 40.92 | 77.54 | 63.54 | 71.23 | 46 |
| **Overall** | 42.99 | 29.12 | 47.82 | 80.46 | 68.5 | 72.82 | 50.98 |
##### Accuracy by category
| supercategory | category | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:----------------|:------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| Culture | Economy | 61.02 | 28.81 | 66.1 | 94.92 | 83.05 | 89.83 | 64.41 |
| Culture | Geography | 45.8 | 29.01 | 54.2 | 80.15 | 77.86 | 82.44 | 53.44 |
| Culture | History | 26.15 | 30 | 29.64 | 66.92 | 48.4 | 46.4 | 31.79 |
| Culture | Law | 32.42 | 22.83 | 44.29 | 70.78 | 57.53 | 61.19 | 41.55 |
| Culture | Politics | 54.76 | 33.33 | 59.52 | 88.1 | 83.33 | 89.29 | 65.48 |
| Culture | Pop Culture | 60.98 | 34.15 | 60.98 | 97.56 | 85.37 | 92.68 | 75.61 |
| Culture | Society | 54.37 | 31.72 | 65.05 | 92.88 | 85.44 | 86.73 | 71.2 |
| Culture | Tradition | 47.75 | 31.98 | 54.95 | 87.39 | 74.77 | 79.28 | 55.86 |
| Language | Functional | 37.6 | 24 | 32.8 | 84.8 | 64.8 | 80 | 40 |
| Language | Grammar | 27.5 | 23.33 | 22.92 | 57.08 | 42.5 | 47.5 | 30 |
| Language | Textual | 54.74 | 33.33 | 59.65 | 91.58 | 80.7 | 87.37 | 62.11 |
#### HAERAE
| category | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:----------------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| General Knowledge | 31.25 | 28.41 | 34.66 | 77.27 | 53.41 | 66.48 | 40.91 |
| History | 32.45 | 22.34 | 44.15 | 92.02 | 84.57 | 78.72 | 30.32 |
| Loan Words | 47.93 | 35.5 | 63.31 | 79.88 | 76.33 | 78.11 | 59.17 |
| Rare Words | 55.06 | 42.96 | 63.21 | 87.9 | 81.98 | 79.01 | 61.23 |
| Reading Comprehension | 42.95 | 41.16 | 51.9 | 85.46 | 77.18 | 80.09 | 56.15 |
| Standard Nomenclature | 44.44 | 32.68 | 58.82 | 88.89 | 75.82 | 79.08 | 53.59 |
| **Overall** | 44.21 | 36.41 | 53.9 | 85.7 | 76.4 | 77.76 | 52.67 |
#### KMMLU (0-shot, CoT)
| supercategory | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:----------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| Applied Science | 35.8 | 31.68 | 37.03 | 61.52 | 49.29 | 55.98 | 38.47 |
| HUMSS | 31.56 | 26.47 | 37.29 | 69.45 | 56.59 | 63 | 40.9 |
| Other | 35.45 | 31.01 | 39.15 | 63.79 | 52.35 | 57.53 | 40.19 |
| STEM | 38.54 | 31.9 | 40.42 | 65.16 | 54.74 | 60.84 | 42.24 |
| **Overall** | 35.87 | 30.82 | 38.54 | 64.26 | 52.63 | 58.75 | 40.3 |
#### KMMLU (5-shot)
| supercategory | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:----------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| Applied Science | 37.42 | 29.98 | 19.24 | 61.47 | 48.66 | 56.85 | 40.22 |
| HUMSS | 34.72 | 27.27 | 22.5 | 68.79 | 55.95 | 63.68 | 43.35 |
| Other | 37.04 | 30.76 | 20.95 | 64.21 | 51.1 | 57.85 | 41.92 |
| STEM | 38.9 | 30.73 | 19.55 | 65.28 | 53.29 | 61.08 | 44.43 |
| **Overall** | 37.35 | 29.98 | 20.21 | 64.28 | 51.62 | 59.29 | 42.28 |
#### KMMLU-HARD (0-shot, CoT)
| supercategory | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:----------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| Applied Science | 27.08 | 26.17 | 26.25 | 37.12 | 22.25 | 29.17 | 21.07 |
| HUMSS | 20.21 | 24.38 | 20.21 | 41.97 | 23.31 | 31.51 | 19.44 |
| Other | 23.05 | 24.82 | 23.88 | 40.39 | 26.48 | 29.59 | 22.22 |
| STEM | 24.36 | 26.91 | 24.64 | 39.82 | 26.36 | 32.18 | 20.91 |
| **Overall** | 24 | 25.68 | 24.03 | 39.62 | 24.56 | 30.56 | 20.97 |
#### KMMLU-HARD (5-shot)
| supercategory | Phi-3.5-Mini-Instruct | Phi-3.0-Mini-128k-Instruct (June2024) | Llama-3.1-8B-Instruct | GPT-4o | GPT-4o-mini | GPT-4-turbo | GPT-3.5-turbo |
|:----------------|------------------------:|--------------------------------:|------------------------:|---------:|--------------:|--------------:|----------------:|
| Applied Science | 25 | 29 | 12 | 31 | 21 | 25 | 20 |
| HUMSS | 21.89 | 19.92 | 14 | 43.98 | 23.47 | 33.53 | 19.53 |
| Other | 23.26 | 27.27 | 12.83 | 39.84 | 28.34 | 29.68 | 23.22 |
| STEM | 20.5 | 25.25 | 12.75 | 40.25 | 23.25 | 27.25 | 19.75 |
| **Overall** | 24.76 | 25.73 | 15.81 | 40.94 | 24.63 | 31.12 | 21.19 | |
llava-hf/llava-1.5-7b-hf | llava-hf | "2024-09-14T07:47:50Z" | 669,195 | 202 | transformers | [
"transformers",
"safetensors",
"llava",
"image-text-to-text",
"vision",
"conversational",
"en",
"dataset:liuhaotian/LLaVA-Instruct-150K",
"license:llama2",
"region:us"
] | image-text-to-text | "2023-12-05T09:31:24Z" | ---
language:
- en
datasets:
- liuhaotian/LLaVA-Instruct-150K
pipeline_tag: image-text-to-text
inference: false
arxiv: 2304.08485
license: llama2
tags:
- vision
- image-text-to-text
---
# LLaVA Model Card

Below is the model card of Llava model 7b, which is copied from the original Llava model card that you can find [here](https://huggingface.co/liuhaotian/llava-v1.5-13b).
Check out also the Google Colab demo to run Llava on a free-tier Google Colab instance: [](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing)
Or check out our Spaces demo! [](https://huggingface.co/spaces/llava-hf/llava-4bit)
## Model details
**Model type:**
LLaVA is an open-source chatbot trained by fine-tuning LLaMA/Vicuna on GPT-generated multimodal instruction-following data.
It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
LLaVA-v1.5-7B was trained in September 2023.
**Paper or resources for more information:**
https://llava-vl.github.io/
## How to use the model
First, make sure to have `transformers >= 4.35.3`.
The model supports multi-image and multi-prompt generation. Meaning that you can pass multiple images in your prompt. Make sure also to follow the correct prompt template (`USER: xxx\nASSISTANT:`) and add the token `<image>` to the location where you want to query images:
### Using `pipeline`:
Below we used [`"llava-hf/llava-1.5-7b-hf"`](https://huggingface.co/llava-hf/llava-1.5-7b-hf) checkpoint.
```python
from transformers import pipeline, AutoProcessor
from PIL import Image
import requests
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Define a chat history and use `apply_chat_template` to get correctly formatted prompt
# Each value in "content" has to be a list of dicts with types ("text", "image")
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud"},
{"type": "image"},
],
},
]
processor = AutoProcessor.from_pretrained(model_id)
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs)
>>> {"generated_text": "\nUSER: What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud\nASSISTANT: Lava"}
```
### Using pure `transformers`:
Below is an example script to run generation in `float16` precision on a GPU device:
```python
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(0)
processor = AutoProcessor.from_pretrained(model_id)
# Define a chat histiry and use `apply_chat_template` to get correctly formatted prompt
# Each value in "content" has to be a list of dicts with types ("text", "image")
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "What are these?"},
{"type": "image"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(images=raw_image, text=prompt, return_tensors='pt').to(0, torch.float16)
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)
print(processor.decode(output[0][2:], skip_special_tokens=True))
```
### Model optimization
#### 4-bit quantization through `bitsandbytes` library
First make sure to install `bitsandbytes`, `pip install bitsandbytes` and make sure to have access to a CUDA compatible GPU device. Simply change the snippet above with:
```diff
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
+ load_in_4bit=True
)
```
#### Use Flash-Attention 2 to further speed-up generation
First make sure to install `flash-attn`. Refer to the [original repository of Flash Attention](https://github.com/Dao-AILab/flash-attention) regarding that package installation. Simply change the snippet above with:
```diff
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
+ use_flash_attention_2=True
).to(0)
```
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved. |
microsoft/wavlm-base-plus | microsoft | "2021-12-22T17:23:24Z" | 669,083 | 26 | transformers | [
"transformers",
"pytorch",
"wavlm",
"feature-extraction",
"speech",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.13900",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language:
- en
datasets:
tags:
- speech
inference: false
---
# WavLM-Base-Plus
[Microsoft's WavLM](https://github.com/microsoft/unilm/tree/master/wavlm)
The base model pretrained on 16kHz sampled speech audio. When using the model, make sure that your speech input is also sampled at 16kHz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900)
Authors: Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei
**Abstract**
*Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
The original model can be found under https://github.com/microsoft/unilm/tree/master/wavlm.
# Usage
This is an English pre-trained speech model that has to be fine-tuned on a downstream task like speech recognition or audio classification before it can be
used in inference. The model was pre-trained in English and should therefore perform well only in English. The model has been shown to work well on the [SUPERB benchmark](https://superbbenchmark.org/).
**Note**: The model was pre-trained on phonemes rather than characters. This means that one should make sure that the input text is converted to a sequence
of phonemes before fine-tuning.
## Speech Recognition
To fine-tune the model for speech recognition, see [the official speech recognition example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition).
## Speech Classification
To fine-tune the model for speech classification, see [the official audio classification example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/audio-classification).
## Speaker Verification
TODO
## Speaker Diarization
TODO
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
meta-llama/Meta-Llama-3-8B | meta-llama | "2024-09-27T15:52:33Z" | 668,034 | 5,821 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"en",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-04-17T09:35:16Z" | ---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3
new_version: meta-llama/Llama-3.1-8B
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: LlamaUseReport@meta.com
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
>>> import transformers
>>> import torch
>>> model_id = "meta-llama/Meta-Llama-3-8B"
>>> pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
>>> pipeline("Hey how are you doing today?")
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B --include "original/*" --local-dir Meta-Llama-3-8B
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 8B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
jonatasgrosman/wav2vec2-large-xlsr-53-arabic | jonatasgrosman | "2022-12-14T01:57:28Z" | 663,745 | 25 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"ar",
"dataset:common_voice",
"dataset:arabic_speech_corpus",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: ar
datasets:
- common_voice
- arabic_speech_corpus
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Arabic by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ar
type: common_voice
args: ar
metrics:
- name: Test WER
type: wer
value: 39.59
- name: Test CER
type: cer
value: 18.18
---
# Fine-tuned XLSR-53 large model for speech recognition in Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Arabic using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice) and [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-arabic")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ar"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-arabic"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| ألديك قلم ؟ | ألديك قلم |
| ليست هناك مسافة على هذه الأرض أبعد من يوم أمس. | ليست نالك مسافة على هذه الأرض أبعد من يوم الأمس م |
| إنك تكبر المشكلة. | إنك تكبر المشكلة |
| يرغب أن يلتقي بك. | يرغب أن يلتقي بك |
| إنهم لا يعرفون لماذا حتى. | إنهم لا يعرفون لماذا حتى |
| سيسعدني مساعدتك أي وقت تحب. | سيسئدنيمساعدتك أي وقد تحب |
| أَحَبُّ نظريّة علمية إليّ هي أن حلقات زحل مكونة بالكامل من الأمتعة المفقودة. | أحب نظرية علمية إلي هي أن حل قتزح المكوينا بالكامل من الأمت عن المفقودة |
| سأشتري له قلماً. | سأشتري له قلما |
| أين المشكلة ؟ | أين المشكل |
| وَلِلَّهِ يَسْجُدُ مَا فِي السَّمَاوَاتِ وَمَا فِي الْأَرْضِ مِنْ دَابَّةٍ وَالْمَلَائِكَةُ وَهُمْ لَا يَسْتَكْبِرُونَ | ولله يسجد ما في السماوات وما في الأرض من دابة والملائكة وهم لا يستكبرون |
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ar"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-arabic"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "'", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-05-14). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-arabic | **39.59%** | **18.18%** |
| bakrianoo/sinai-voice-ar-stt | 45.30% | 21.84% |
| othrif/wav2vec2-large-xlsr-arabic | 45.93% | 20.51% |
| kmfoda/wav2vec2-large-xlsr-arabic | 54.14% | 26.07% |
| mohammed/wav2vec2-large-xlsr-arabic | 56.11% | 26.79% |
| anas/wav2vec2-large-xlsr-arabic | 62.02% | 27.09% |
| elgeish/wav2vec2-large-xlsr-53-arabic | 100.00% | 100.56% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-arabic,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {A}rabic},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-arabic}},
year={2021}
}
``` |
Isotr0py/test-gguf-sample | Isotr0py | "2024-09-14T07:03:50Z" | 655,794 | 0 | null | [
"gguf",
"region:us"
] | null | "2024-09-14T06:40:54Z" | Entry not found |
opensearch-project/opensearch-neural-sparse-encoding-doc-v2-distill | opensearch-project | "2024-10-28T02:44:38Z" | 653,430 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"learned sparse",
"opensearch",
"retrieval",
"passage-retrieval",
"document-expansion",
"bag-of-words",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2024-07-17T07:51:35Z" | ---
language: en
license: apache-2.0
tags:
- learned sparse
- opensearch
- transformers
- retrieval
- passage-retrieval
- document-expansion
- bag-of-words
---
# opensearch-neural-sparse-encoding-doc-v2-distill
## Select the model
The model should be selected considering search relevance, model inference and retrieval efficiency(FLOPS). We benchmark models' **zero-shot performance** on a subset of BEIR benchmark: TrecCovid,NFCorpus,NQ,HotpotQA,FiQA,ArguAna,Touche,DBPedia,SCIDOCS,FEVER,Climate FEVER,SciFact,Quora.
Overall, the v2 series of models have better search relevance, efficiency and inference speed than the v1 series. The specific advantages and disadvantages may vary across different datasets.
| Model | Inference-free for Retrieval | Model Parameters | AVG NDCG@10 | AVG FLOPS |
|-------|------------------------------|------------------|-------------|-----------|
| [opensearch-neural-sparse-encoding-v1](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-v1) | | 133M | 0.524 | 11.4 |
| [opensearch-neural-sparse-encoding-v2-distill](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-v2-distill) | | 67M | 0.528 | 8.3 |
| [opensearch-neural-sparse-encoding-doc-v1](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-doc-v1) | ✔️ | 133M | 0.490 | 2.3 |
| [opensearch-neural-sparse-encoding-doc-v2-distill](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-doc-v2-distill) | ✔️ | 67M | 0.504 | 1.8 |
| [opensearch-neural-sparse-encoding-doc-v2-mini](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-doc-v2-mini) | ✔️ | 23M | 0.497 | 1.7 |
## Overview
This is a learned sparse retrieval model. It encodes the documents to 30522 dimensional **sparse vectors**. For queries, it just use a tokenizer and a weight look-up table to generate sparse vectors. The non-zero dimension index means the corresponding token in the vocabulary, and the weight means the importance of the token. And the similarity score is the inner product of query/document sparse vectors. In the real-world use case, the search performance of opensearch-neural-sparse-encoding-v1 is comparable to BM25.
The training datasets includes MS MARCO, eli5_question_answer, squad_pairs, WikiAnswers, yahoo_answers_title_question, gooaq_pairs, stackexchange_duplicate_questions_body_body, wikihow, S2ORC_title_abstract, stackexchange_duplicate_questions_title-body_title-body, yahoo_answers_question_answer, searchQA_top5_snippets, stackexchange_duplicate_questions_title_title, yahoo_answers_title_answer.
OpenSearch neural sparse feature supports learned sparse retrieval with lucene inverted index. Link: https://opensearch.org/docs/latest/query-dsl/specialized/neural-sparse/. The indexing and search can be performed with OpenSearch high-level API.
## Usage (HuggingFace)
This model is supposed to run inside OpenSearch cluster. But you can also use it outside the cluster, with HuggingFace models API.
```python
import json
import itertools
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
# get sparse vector from dense vectors with shape batch_size * seq_len * vocab_size
def get_sparse_vector(feature, output):
values, _ = torch.max(output*feature["attention_mask"].unsqueeze(-1), dim=1)
values = torch.log(1 + torch.relu(values))
values[:,special_token_ids] = 0
return values
# transform the sparse vector to a dict of (token, weight)
def transform_sparse_vector_to_dict(sparse_vector):
sample_indices,token_indices=torch.nonzero(sparse_vector,as_tuple=True)
non_zero_values = sparse_vector[(sample_indices,token_indices)].tolist()
number_of_tokens_for_each_sample = torch.bincount(sample_indices).cpu().tolist()
tokens = [transform_sparse_vector_to_dict.id_to_token[_id] for _id in token_indices.tolist()]
output = []
end_idxs = list(itertools.accumulate([0]+number_of_tokens_for_each_sample))
for i in range(len(end_idxs)-1):
token_strings = tokens[end_idxs[i]:end_idxs[i+1]]
weights = non_zero_values[end_idxs[i]:end_idxs[i+1]]
output.append(dict(zip(token_strings, weights)))
return output
# download the idf file from model hub. idf is used to give weights for query tokens
def get_tokenizer_idf(tokenizer):
from huggingface_hub import hf_hub_download
local_cached_path = hf_hub_download(repo_id="opensearch-project/opensearch-neural-sparse-encoding-doc-v2-distill", filename="idf.json")
with open(local_cached_path) as f:
idf = json.load(f)
idf_vector = [0]*tokenizer.vocab_size
for token,weight in idf.items():
_id = tokenizer._convert_token_to_id_with_added_voc(token)
idf_vector[_id]=weight
return torch.tensor(idf_vector)
# load the model
model = AutoModelForMaskedLM.from_pretrained("opensearch-project/opensearch-neural-sparse-encoding-doc-v2-distill")
tokenizer = AutoTokenizer.from_pretrained("opensearch-project/opensearch-neural-sparse-encoding-doc-v2-distill")
idf = get_tokenizer_idf(tokenizer)
# set the special tokens and id_to_token transform for post-process
special_token_ids = [tokenizer.vocab[token] for token in tokenizer.special_tokens_map.values()]
get_sparse_vector.special_token_ids = special_token_ids
id_to_token = ["" for i in range(tokenizer.vocab_size)]
for token, _id in tokenizer.vocab.items():
id_to_token[_id] = token
transform_sparse_vector_to_dict.id_to_token = id_to_token
query = "What's the weather in ny now?"
document = "Currently New York is rainy."
# encode the query
feature_query = tokenizer([query], padding=True, truncation=True, return_tensors='pt', return_token_type_ids=False)
input_ids = feature_query["input_ids"]
batch_size = input_ids.shape[0]
query_vector = torch.zeros(batch_size, tokenizer.vocab_size)
query_vector[torch.arange(batch_size).unsqueeze(-1), input_ids] = 1
query_sparse_vector = query_vector*idf
# encode the document
feature_document = tokenizer([document], padding=True, truncation=True, return_tensors='pt', return_token_type_ids=False)
output = model(**feature_document)[0]
document_sparse_vector = get_sparse_vector(feature_document, output)
# get similarity score
sim_score = torch.matmul(query_sparse_vector[0],document_sparse_vector[0])
print(sim_score) # tensor(17.5307, grad_fn=<DotBackward0>)
query_token_weight = transform_sparse_vector_to_dict(query_sparse_vector)[0]
document_query_token_weight = transform_sparse_vector_to_dict(document_sparse_vector)[0]
for token in sorted(query_token_weight, key=lambda x:query_token_weight[x], reverse=True):
if token in document_query_token_weight:
print("score in query: %.4f, score in document: %.4f, token: %s"%(query_token_weight[token],document_query_token_weight[token],token))
# result:
# score in query: 5.7729, score in document: 1.4109, token: ny
# score in query: 4.5684, score in document: 1.4673, token: weather
# score in query: 3.5895, score in document: 0.7473, token: now
```
The above code sample shows an example of neural sparse search. Although there is no overlap token in original query and document, but this model performs a good match.
## Detailed Search Relevance
<div style="overflow-x: auto;">
| Model | Average | Trec Covid | NFCorpus | NQ | HotpotQA | FiQA | ArguAna | Touche | DBPedia | SCIDOCS | FEVER | Climate FEVER | SciFact | Quora |
|-------|---------|------------|----------|----|----------|------|---------|--------|---------|---------|-------|---------------|---------|-------|
| [opensearch-neural-sparse-encoding-v1](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-v1) | 0.524 | 0.771 | 0.360 | 0.553 | 0.697 | 0.376 | 0.508 | 0.278 | 0.447 | 0.164 | 0.821 | 0.263 | 0.723 | 0.856 |
| [opensearch-neural-sparse-encoding-v2-distill](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-v2-distill) | 0.528 | 0.775 | 0.347 | 0.561 | 0.685 | 0.374 | 0.551 | 0.278 | 0.435 | 0.173 | 0.849 | 0.249 | 0.722 | 0.863 |
| [opensearch-neural-sparse-encoding-doc-v1](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-doc-v1) | 0.490 | 0.707 | 0.352 | 0.521 | 0.677 | 0.344 | 0.461 | 0.294 | 0.412 | 0.154 | 0.743 | 0.202 | 0.716 | 0.788 |
| [opensearch-neural-sparse-encoding-doc-v2-distill](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-doc-v2-distill) | 0.504 | 0.690 | 0.343 | 0.528 | 0.675 | 0.357 | 0.496 | 0.287 | 0.418 | 0.166 | 0.818 | 0.224 | 0.715 | 0.841 |
| [opensearch-neural-sparse-encoding-doc-v2-mini](https://huggingface.co/opensearch-project/opensearch-neural-sparse-encoding-doc-v2-mini) | 0.497 | 0.709 | 0.336 | 0.510 | 0.666 | 0.338 | 0.480 | 0.285 | 0.407 | 0.164 | 0.812 | 0.216 | 0.699 | 0.837 |
</div>
## License
This project is licensed under the [Apache v2.0 License](https://github.com/opensearch-project/neural-search/blob/main/LICENSE).
## Copyright
Copyright OpenSearch Contributors. See [NOTICE](https://github.com/opensearch-project/neural-search/blob/main/NOTICE) for details. |
unitary/toxic-bert | unitary | "2024-03-13T17:41:49Z" | 652,969 | 148 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"text-classification",
"arxiv:1703.04009",
"arxiv:1905.12516",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
---
<div align="center">
**⚠️ Disclaimer:**
The huggingface models currently give different results to the detoxify library (see issue [here](https://github.com/unitaryai/detoxify/issues/15)). For the most up to date models we recommend using the models from https://github.com/unitaryai/detoxify
# 🙊 Detoxify
## Toxic Comment Classification with ⚡ Pytorch Lightning and 🤗 Transformers


</div>

## Description
Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification.
Built by [Laura Hanu](https://laurahanu.github.io/) at [Unitary](https://www.unitary.ai/), where we are working to stop harmful content online by interpreting visual content in context.
Dependencies:
- For inference:
- 🤗 Transformers
- ⚡ Pytorch lightning
- For training will also need:
- Kaggle API (to download data)
| Challenge | Year | Goal | Original Data Source | Detoxify Model Name | Top Kaggle Leaderboard Score | Detoxify Score
|-|-|-|-|-|-|-|
| [Toxic Comment Classification Challenge](https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge) | 2018 | build a multi-headed model that’s capable of detecting different types of of toxicity like threats, obscenity, insults, and identity-based hate. | Wikipedia Comments | `original` | 0.98856 | 0.98636
| [Jigsaw Unintended Bias in Toxicity Classification](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification) | 2019 | build a model that recognizes toxicity and minimizes this type of unintended bias with respect to mentions of identities. You'll be using a dataset labeled for identity mentions and optimizing a metric designed to measure unintended bias. | Civil Comments | `unbiased` | 0.94734 | 0.93639
| [Jigsaw Multilingual Toxic Comment Classification](https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification) | 2020 | build effective multilingual models | Wikipedia Comments + Civil Comments | `multilingual` | 0.9536 | 0.91655*
*Score not directly comparable since it is obtained on the validation set provided and not on the test set. To update when the test labels are made available.
It is also noteworthy to mention that the top leadearboard scores have been achieved using model ensembles. The purpose of this library was to build something user-friendly and straightforward to use.
## Limitations and ethical considerations
If words that are associated with swearing, insults or profanity are present in a comment, it is likely that it will be classified as toxic, regardless of the tone or the intent of the author e.g. humorous/self-deprecating. This could present some biases towards already vulnerable minority groups.
The intended use of this library is for research purposes, fine-tuning on carefully constructed datasets that reflect real world demographics and/or to aid content moderators in flagging out harmful content quicker.
Some useful resources about the risk of different biases in toxicity or hate speech detection are:
- [The Risk of Racial Bias in Hate Speech Detection](https://homes.cs.washington.edu/~msap/pdfs/sap2019risk.pdf)
- [Automated Hate Speech Detection and the Problem of Offensive Language](https://arxiv.org/pdf/1703.04009.pdf%201.pdf)
- [Racial Bias in Hate Speech and Abusive Language Detection Datasets](https://arxiv.org/pdf/1905.12516.pdf)
## Quick prediction
The `multilingual` model has been trained on 7 different languages so it should only be tested on: `english`, `french`, `spanish`, `italian`, `portuguese`, `turkish` or `russian`.
```bash
# install detoxify
pip install detoxify
```
```python
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify('original').predict('example text')
results = Detoxify('unbiased').predict(['example text 1','example text 2'])
results = Detoxify('multilingual').predict(['example text','exemple de texte','texto de ejemplo','testo di esempio','texto de exemplo','örnek metin','пример текста'])
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print(pd.DataFrame(results, index=input_text).round(5))
```
For more details check the Prediction section.
## Labels
All challenges have a toxicity label. The toxicity labels represent the aggregate ratings of up to 10 annotators according the following schema:
- **Very Toxic** (a very hateful, aggressive, or disrespectful comment that is very likely to make you leave a discussion or give up on sharing your perspective)
- **Toxic** (a rude, disrespectful, or unreasonable comment that is somewhat likely to make you leave a discussion or give up on sharing your perspective)
- **Hard to Say**
- **Not Toxic**
More information about the labelling schema can be found [here](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data).
### Toxic Comment Classification Challenge
This challenge includes the following labels:
- `toxic`
- `severe_toxic`
- `obscene`
- `threat`
- `insult`
- `identity_hate`
### Jigsaw Unintended Bias in Toxicity Classification
This challenge has 2 types of labels: the main toxicity labels and some additional identity labels that represent the identities mentioned in the comments.
Only identities with more than 500 examples in the test set (combined public and private) are included during training as additional labels and in the evaluation calculation.
- `toxicity`
- `severe_toxicity`
- `obscene`
- `threat`
- `insult`
- `identity_attack`
- `sexual_explicit`
Identity labels used:
- `male`
- `female`
- `homosexual_gay_or_lesbian`
- `christian`
- `jewish`
- `muslim`
- `black`
- `white`
- `psychiatric_or_mental_illness`
A complete list of all the identity labels available can be found [here](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data).
### Jigsaw Multilingual Toxic Comment Classification
Since this challenge combines the data from the previous 2 challenges, it includes all labels from above, however the final evaluation is only on:
- `toxicity`
## How to run
First, install dependencies
```bash
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
cd detoxify
# for training
pip install -r requirements.txt
```
## Prediction
Trained models summary:
|Model name| Transformer type| Data from
|:--:|:--:|:--:|
|`original`| `bert-base-uncased` | Toxic Comment Classification Challenge
|`unbiased`| `roberta-base`| Unintended Bias in Toxicity Classification
|`multilingual`| `xlm-roberta-base`| Multilingual Toxic Comment Classification
For a quick prediction can run the example script on a comment directly or from a txt containing a list of comments.
```bash
# load model via torch.hub
python run_prediction.py --input 'example' --model_name original
# load model from from checkpoint path
python run_prediction.py --input 'example' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
```
Checkpoints can be downloaded from the latest release or via the Pytorch hub API with the following names:
- `toxic_bert`
- `unbiased_toxic_roberta`
- `multilingual_toxic_xlm_r`
```bash
model = torch.hub.load('unitaryai/detoxify','toxic_bert')
```
Importing detoxify in python:
```python
from detoxify import Detoxify
results = Detoxify('original').predict('some text')
results = Detoxify('unbiased').predict(['example text 1','example text 2'])
results = Detoxify('multilingual').predict(['example text','exemple de texte','texto de ejemplo','testo di esempio','texto de exemplo','örnek metin','пример текста'])
# to display results nicely
import pandas as pd
print(pd.DataFrame(results,index=input_text).round(5))
```
## Training
If you do not already have a Kaggle account:
- you need to create one to be able to download the data
- go to My Account and click on Create New API Token - this will download a kaggle.json file
- make sure this file is located in ~/.kaggle
```bash
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
```
## Start Training
### Toxic Comment Classification Challenge
```bash
python create_val_set.py
python train.py --config configs/Toxic_comment_classification_BERT.json
```
### Unintended Bias in Toxicicity Challenge
```bash
python train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa.json
```
### Multilingual Toxic Comment Classification
This is trained in 2 stages. First, train on all available data, and second, train only on the translated versions of the first challenge.
The [translated data](https://www.kaggle.com/miklgr500/jigsaw-train-multilingual-coments-google-api) can be downloaded from Kaggle in french, spanish, italian, portuguese, turkish, and russian (the languages available in the test set).
```bash
# stage 1
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
# stage 2
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR_stage2.json
```
### Monitor progress with tensorboard
```bash
tensorboard --logdir=./saved
```
## Model Evaluation
### Toxic Comment Classification Challenge
This challenge is evaluated on the mean AUC score of all the labels.
```bash
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
```
### Unintended Bias in Toxicicity Challenge
This challenge is evaluated on a novel bias metric that combines different AUC scores to balance overall performance. More information on this metric [here](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/overview/evaluation).
```bash
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
```
### Multilingual Toxic Comment Classification
This challenge is evaluated on the AUC score of the main toxic label.
```bash
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
```
### Citation
```
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}
``` |
kairos1024/lora-gguf-model | kairos1024 | "2024-07-24T21:09:38Z" | 652,631 | 0 | transformers | [
"transformers",
"pytorch",
"phi3",
"text-generation",
"conversational",
"custom_code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-07-24T20:19:00Z" | Entry not found |
MaziyarPanahi/SmolLM2-1.7B-Instruct-GGUF | MaziyarPanahi | "2024-11-03T14:42:36Z" | 652,398 | 3 | null | [
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"text-generation",
"base_model:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"base_model:quantized:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"region:us",
"imatrix",
"conversational"
] | text-generation | "2024-11-01T16:40:28Z" | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- text-generation
- text-generation
model_name: SmolLM2-1.7B-Instruct-GGUF
base_model: HuggingFaceTB/SmolLM2-1.7B-Instruct
inference: false
model_creator: HuggingFaceTB
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/SmolLM2-1.7B-Instruct-GGUF](https://huggingface.co/MaziyarPanahi/SmolLM2-1.7B-Instruct-GGUF)
- Model creator: [HuggingFaceTB](https://huggingface.co/HuggingFaceTB)
- Original model: [HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct)
## Description
[MaziyarPanahi/SmolLM2-1.7B-Instruct-GGUF](https://huggingface.co/MaziyarPanahi/SmolLM2-1.7B-Instruct-GGUF) contains GGUF format model files for [HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible. |
MaziyarPanahi/SmolLM2-135M-Instruct-GGUF | MaziyarPanahi | "2024-11-03T14:34:17Z" | 652,080 | 0 | null | [
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"text-generation",
"base_model:HuggingFaceTB/SmolLM2-135M-Instruct",
"base_model:quantized:HuggingFaceTB/SmolLM2-135M-Instruct",
"region:us",
"imatrix",
"conversational"
] | text-generation | "2024-11-03T14:33:50Z" | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- text-generation
- text-generation
model_name: SmolLM2-135M-Instruct-GGUF
base_model: HuggingFaceTB/SmolLM2-135M-Instruct
inference: false
model_creator: HuggingFaceTB
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/SmolLM2-135M-Instruct-GGUF](https://huggingface.co/MaziyarPanahi/SmolLM2-135M-Instruct-GGUF)
- Model creator: [HuggingFaceTB](https://huggingface.co/HuggingFaceTB)
- Original model: [HuggingFaceTB/SmolLM2-135M-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-135M-Instruct)
## Description
[MaziyarPanahi/SmolLM2-135M-Instruct-GGUF](https://huggingface.co/MaziyarPanahi/SmolLM2-135M-Instruct-GGUF) contains GGUF format model files for [HuggingFaceTB/SmolLM2-135M-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-135M-Instruct).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible. |
Tochka-AI/ruRoPEBert-e5-base-2k | Tochka-AI | "2024-03-13T11:17:16Z" | 650,494 | 8 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"feature-extraction",
"custom_code",
"ru",
"dataset:uonlp/CulturaX",
"arxiv:2309.09400",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-02-22T12:50:49Z" | ---
library_name: transformers
language:
- ru
pipeline_tag: feature-extraction
datasets:
- uonlp/CulturaX
---
# ruRoPEBert Sentence Model for Russian language
This is an encoder model from **Tochka AI** based on the **RoPEBert** architecture, using the cloning method described in [our article on Habr](https://habr.com/ru/companies/tochka/articles/797561/).
[CulturaX](https://huggingface.co/papers/2309.09400) dataset was used for model training. The **hivaze/ru-e5-base** (only english and russian embeddings of **intfloat/multilingual-e5-base**) model was used as the original; this model surpasses it and all other models in quality (at the time of creation), according to the `S+W` score of [encodechka](https://github.com/avidale/encodechka) benchmark.
The model source code is available in the file [modeling_rope_bert.py](https://huggingface.co/Tochka-AI/ruRoPEBert-e5-base-2k/blob/main/modeling_rope_bert.py)
The model is trained on contexts **up to 2048 tokens** in length, but can be used on larger contexts.
## Usage
**Important**: 4.37.2 and higher is the recommended version of `transformers`. To load the model correctly, you must enable dowloading code from the model's repository: `trust_remote_code=True`, this will download the **modeling_rope_bert.py** script and load the weights into the correct architecture.
Otherwise, you can download this script manually and use classes from it directly to load the model.
### Basic usage (no efficient attention)
```python
model_name = 'Tochka-AI/ruRoPEBert-e5-base-2k'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True, attn_implementation='eager')
```
### With SDPA (efficient attention)
```python
model = AutoModel.from_pretrained(model_name, trust_remote_code=True, attn_implementation='sdpa')
```
### Getting embeddings
The correct pooler (`mean`) is already **built into the model architecture**, which averages embeddings based on the attention mask. You can also select the pooler type (`first_token_transform`), which performs a learnable linear transformation on the first token.
To change built-in pooler implementation use `pooler_type` parameter in `AutoModel.from_pretrained` function
```python
test_batch = tokenizer.batch_encode_plus(["Привет, чем занят?", "Здравствуйте, чем вы занимаетесь?"], return_tensors='pt', padding=True)
with torch.inference_mode():
pooled_output = model(**test_batch).pooler_output
```
In addition, you can calculate cosine similarities between texts in batch using normalization and matrix multiplication:
```python
import torch.nn.functional as F
F.normalize(pooled_output, dim=1) @ F.normalize(pooled_output, dim=1).T
```
### Using as classifier
To load the model with trainable classification head on top (change `num_labels` parameter):
```python
model = AutoModelForSequenceClassification.from_pretrained(model_name, trust_remote_code=True, attn_implementation='sdpa', num_labels=4)
```
### With RoPE scaling
Allowed types for RoPE scaling are: `linear` and `dynamic`. To extend the model's context window you need to change tokenizer max length and add `rope_scaling` parameter.
If you want to scale your model context by 2x:
```python
tokenizer.model_max_length = 4096
model = AutoModel.from_pretrained(model_name,
trust_remote_code=True,
attn_implementation='sdpa',
rope_scaling={'type': 'dynamic','factor': 2.0}
) # 2.0 for x2 scaling, 4.0 for x4, etc..
```
P.S. Don't forget to specify the dtype and device you need to use resources efficiently.
## Metrics
Evaluation of this model on encodechka benchmark:
| Model name | STS | PI | NLI | SA | TI | IA | IC | ICX | NE1 | NE2 | Avg S (no NE) | Avg S+W (with NE) |
|---------------------|-----|------|-----|-----|-----|-----|-----|-----|-----|-----|---------------|-------------------|
| ruRoPEBert-e5-base-512 | 0.793 | 0.704 | 0.457 | 0.803 | 0.970 | 0.788 | 0.802 | 0.749 | 0.328 | 0.396 | 0.758 | 0.679 |
| **ruRoPEBert-e5-base-2k** | 0.787 | 0.708 | 0.460 | 0.804 | 0.970 | 0.792 | 0.803 | 0.749 | 0.402 | 0.423 | 0.759 | 0.689 |
| intfloat/multilingual-e5-base | 0.834 | 0.704 | 0.458 | 0.795 | 0.964 | 0.782 | 0.803 | 0.740 | 0.234 | 0.373 | 0.76 | 0.668 |
## Authors
- Sergei Bratchikov (Tochka AI Team, [HF](https://huggingface.co/hivaze), [GitHub](https://github.com/hivaze))
- Maxim Afanasiev (Tochka AI Team, [HF](https://huggingface.co/mrapplexz), [GitHub](https://github.com/mrapplexz)) |
Systran/faster-whisper-large-v3 | Systran | "2023-11-23T09:41:12Z" | 650,167 | 279 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"yue",
"license:mit",
"region:us"
] | automatic-speech-recognition | "2023-11-23T09:34:20Z" | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
- yue
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper large-v3 model for CTranslate2
This repository contains the conversion of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("large-v3")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model openai/whisper-large-v3 --output_dir faster-whisper-large-v3 \
--copy_files tokenizer.json preprocessor_config.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/openai/whisper-large-v3).**
|
facebook/mbart-large-50-many-to-many-mmt | facebook | "2023-09-28T16:42:59Z" | 648,560 | 298 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"mbart",
"text2text-generation",
"mbart-50",
"translation",
"multilingual",
"ar",
"cs",
"de",
"en",
"es",
"et",
"fi",
"fr",
"gu",
"hi",
"it",
"ja",
"kk",
"ko",
"lt",
"lv",
"my",
"ne",
"nl",
"ro",
"ru",
"si",
"tr",
"vi",
"zh",
"af",
"az",
"bn",
"fa",
"he",
"hr",
"id",
"ka",
"km",
"mk",
"ml",
"mn",
"mr",
"pl",
"ps",
"pt",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"uk",
"ur",
"xh",
"gl",
"sl",
"arxiv:2008.00401",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- ar
- cs
- de
- en
- es
- et
- fi
- fr
- gu
- hi
- it
- ja
- kk
- ko
- lt
- lv
- my
- ne
- nl
- ro
- ru
- si
- tr
- vi
- zh
- af
- az
- bn
- fa
- he
- hr
- id
- ka
- km
- mk
- ml
- mn
- mr
- pl
- ps
- pt
- sv
- sw
- ta
- te
- th
- tl
- uk
- ur
- xh
- gl
- sl
tags:
- mbart-50
pipeline_tag: translation
---
# mBART-50 many to many multilingual machine translation
This model is a fine-tuned checkpoint of [mBART-large-50](https://huggingface.co/facebook/mbart-large-50). `mbart-large-50-many-to-many-mmt` is fine-tuned for multilingual machine translation. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
The model can translate directly between any pair of 50 languages. To translate into a target language, the target language id is forced as the first generated token. To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
article_hi = "संयुक्त राष्ट्र के प्रमुख का कहना है कि सीरिया में कोई सैन्य समाधान नहीं है"
article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
# translate Hindi to French
tokenizer.src_lang = "hi_IN"
encoded_hi = tokenizer(article_hi, return_tensors="pt")
generated_tokens = model.generate(
**encoded_hi,
forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Le chef de l 'ONU affirme qu 'il n 'y a pas de solution militaire dans la Syrie."
# translate Arabic to English
tokenizer.src_lang = "ar_AR"
encoded_ar = tokenizer(article_ar, return_tensors="pt")
generated_tokens = model.generate(
**encoded_ar,
forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "The Secretary-General of the United Nations says there is no military solution in Syria."
```
See the [model hub](https://huggingface.co/models?filter=mbart-50) to look for more fine-tuned versions.
## Languages covered
Arabic (ar_AR), Czech (cs_CZ), German (de_DE), English (en_XX), Spanish (es_XX), Estonian (et_EE), Finnish (fi_FI), French (fr_XX), Gujarati (gu_IN), Hindi (hi_IN), Italian (it_IT), Japanese (ja_XX), Kazakh (kk_KZ), Korean (ko_KR), Lithuanian (lt_LT), Latvian (lv_LV), Burmese (my_MM), Nepali (ne_NP), Dutch (nl_XX), Romanian (ro_RO), Russian (ru_RU), Sinhala (si_LK), Turkish (tr_TR), Vietnamese (vi_VN), Chinese (zh_CN), Afrikaans (af_ZA), Azerbaijani (az_AZ), Bengali (bn_IN), Persian (fa_IR), Hebrew (he_IL), Croatian (hr_HR), Indonesian (id_ID), Georgian (ka_GE), Khmer (km_KH), Macedonian (mk_MK), Malayalam (ml_IN), Mongolian (mn_MN), Marathi (mr_IN), Polish (pl_PL), Pashto (ps_AF), Portuguese (pt_XX), Swedish (sv_SE), Swahili (sw_KE), Tamil (ta_IN), Telugu (te_IN), Thai (th_TH), Tagalog (tl_XX), Ukrainian (uk_UA), Urdu (ur_PK), Xhosa (xh_ZA), Galician (gl_ES), Slovene (sl_SI)
## BibTeX entry and citation info
```
@article{tang2020multilingual,
title={Multilingual Translation with Extensible Multilingual Pretraining and Finetuning},
author={Yuqing Tang and Chau Tran and Xian Li and Peng-Jen Chen and Naman Goyal and Vishrav Chaudhary and Jiatao Gu and Angela Fan},
year={2020},
eprint={2008.00401},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
unsloth/llama-3-8b-bnb-4bit | unsloth | "2024-10-22T01:31:55Z" | 648,137 | 181 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-3",
"meta",
"facebook",
"unsloth",
"en",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:quantized:meta-llama/Meta-Llama-3-8B",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | "2024-04-18T16:48:39Z" | ---
language:
- en
library_name: transformers
license: llama3
tags:
- llama-3
- llama
- meta
- facebook
- unsloth
- transformers
base_model:
- meta-llama/Meta-Llama-3-8B
---
# Finetune Llama 3.1, Gemma 2, Mistral 2-5x faster with 70% less memory via Unsloth!
We have a free Google Colab Tesla T4 notebook for Llama 3.1 (8B) here: https://colab.research.google.com/drive/1Ys44kVvmeZtnICzWz0xgpRnrIOjZAuxp?usp=sharing
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/Discord%20button.png" width="200"/>](https://discord.gg/unsloth)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Llama-3.1 8b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Ys44kVvmeZtnICzWz0xgpRnrIOjZAuxp?usp=sharing) | 2.4x faster | 58% less |
| **Phi-3.5 (mini)** | [▶️ Start on Colab](https://colab.research.google.com/drive/1lN6hPQveB_mHSnTOYifygFcrO8C1bxq4?usp=sharing) | 2x faster | 50% less |
| **Gemma-2 9b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1vIrqH5uYDQwsJ4-OO3DErvuv4pBgVwk4?usp=sharing) | 2.4x faster | 58% less |
| **Mistral 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Dyauq4kTZoLewQ1cApceUQVNcnnNTzg_?usp=sharing) | 2.2x faster | 62% less |
| **TinyLlama** | [▶️ Start on Colab](https://colab.research.google.com/drive/1AZghoNBQaMDgWJpi4RbffGM1h6raLUj9?usp=sharing) | 3.9x faster | 74% less |
| **DPO - Zephyr** | [▶️ Start on Colab](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) | 1.9x faster | 19% less |
- This [conversational notebook](https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing) is useful for ShareGPT ChatML / Vicuna templates.
- This [text completion notebook](https://colab.research.google.com/drive/1ef-tab5bhkvWmBOObepl1WgJvfvSzn5Q?usp=sharing) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster.
## Special Thanks
A huge thank you to the Meta and Llama team for creating and releasing these models.
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-70B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-70B-Instruct --include "original/*" --local-dir Meta-Llama-3-70B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos |
ZhengPeng7/BiRefNet | ZhengPeng7 | "2024-11-08T03:43:32Z" | 646,831 | 235 | birefnet | [
"birefnet",
"safetensors",
"background-removal",
"mask-generation",
"Dichotomous Image Segmentation",
"Camouflaged Object Detection",
"Salient Object Detection",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"image-segmentation",
"custom_code",
"arxiv:2401.03407",
"license:mit",
"region:us"
] | image-segmentation | "2024-07-12T08:50:09Z" | ---
library_name: birefnet
tags:
- background-removal
- mask-generation
- Dichotomous Image Segmentation
- Camouflaged Object Detection
- Salient Object Detection
- pytorch_model_hub_mixin
- model_hub_mixin
repo_url: https://github.com/ZhengPeng7/BiRefNet
pipeline_tag: image-segmentation
license: mit
---
<h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1>
<div align='center'>
<a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>, 
<a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>, 
<a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>, 
<a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>, 
<a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>, 
<a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>, 
<a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup>
</div>
<div align='center'>
<sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento 
</div>
<div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;">
<a href='https://www.sciopen.com/article/pdf/10.26599/AIR.2024.9150038.pdf'><img src='https://img.shields.io/badge/Journal-Paper-red'></a> 
<a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a> 
<a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a> 
<a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a> 
<a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a> 
<a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a> 
<a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a> 
<a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a> 
<a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
<a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
</div>
| *DIS-Sample_1* | *DIS-Sample_2* |
| :------------------------------: | :-------------------------------: |
| <img src="https://drive.google.com/thumbnail?id=1ItXaA26iYnE8XQ_GgNLy71MOWePoS2-g&sz=w400" /> | <img src="https://drive.google.com/thumbnail?id=1Z-esCujQF_uEa_YJjkibc3NUrW4aR_d4&sz=w400" /> |
This repo is the official implementation of "[**Bilateral Reference for High-Resolution Dichotomous Image Segmentation**](https://arxiv.org/pdf/2401.03407.pdf)" (___CAAI AIR 2024___).
Visit our GitHub repo: [https://github.com/ZhengPeng7/BiRefNet](https://github.com/ZhengPeng7/BiRefNet) for more details -- **codes**, **docs**, and **model zoo**!
## How to use
### 0. Install Packages:
```
pip install -qr https://raw.githubusercontent.com/ZhengPeng7/BiRefNet/main/requirements.txt
```
### 1. Load BiRefNet:
#### Use codes + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: No need to download BiRefNet codes manually; Con: Codes on HuggingFace might not be latest version (I'll try to keep them always latest).
```python
# Load BiRefNet with weights
from transformers import AutoModelForImageSegmentation
birefnet = AutoModelForImageSegmentation.from_pretrained('ZhengPeng7/BiRefNet', trust_remote_code=True)
```
#### Use codes from GitHub + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: codes are always latest; Con: Need to clone the BiRefNet repo from my GitHub.
```shell
# Download codes
git clone https://github.com/ZhengPeng7/BiRefNet.git
cd BiRefNet
```
```python
# Use codes locally
from models.birefnet import BiRefNet
# Load weights from Hugging Face Models
birefnet = BiRefNet.from_pretrained('ZhengPeng7/BiRefNet')
```
#### Use codes from GitHub + weights from local space
> Only use the weights and codes both locally.
```python
# Use codes and weights locally
import torch
from utils import check_state_dict
birefnet = BiRefNet(bb_pretrained=False)
state_dict = torch.load(PATH_TO_WEIGHT, map_location='cpu')
state_dict = check_state_dict(state_dict)
birefnet.load_state_dict(state_dict)
```
#### Use the loaded BiRefNet for inference
```python
# Imports
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
from models.birefnet import BiRefNet
birefnet = ... # -- BiRefNet should be loaded with codes above, either way.
torch.set_float32_matmul_precision(['high', 'highest'][0])
birefnet.to('cuda')
birefnet.eval()
def extract_object(birefnet, imagepath):
# Data settings
image_size = (1024, 1024)
transform_image = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image = Image.open(imagepath)
input_images = transform_image(image).unsqueeze(0).to('cuda')
# Prediction
with torch.no_grad():
preds = birefnet(input_images)[-1].sigmoid().cpu()
pred = preds[0].squeeze()
pred_pil = transforms.ToPILImage()(pred)
mask = pred_pil.resize(image.size)
image.putalpha(mask)
return image, mask
# Visualization
plt.axis("off")
plt.imshow(extract_object(birefnet, imagepath='PATH-TO-YOUR_IMAGE.jpg')[0])
plt.show()
```
> This BiRefNet for standard dichotomous image segmentation (DIS) is trained on **DIS-TR** and validated on **DIS-TEs and DIS-VD**.
## This repo holds the official model weights of "[<ins>Bilateral Reference for High-Resolution Dichotomous Image Segmentation</ins>](https://arxiv.org/pdf/2401.03407)" (_CAAI AIR 2024_).
This repo contains the weights of BiRefNet proposed in our paper, which has achieved the SOTA performance on three tasks (DIS, HRSOD, and COD).
Go to my GitHub page for BiRefNet codes and the latest updates: https://github.com/ZhengPeng7/BiRefNet :)
#### Try our online demos for inference:
+ Online **Image Inference** on Colab: [](https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link)
+ **Online Inference with GUI on Hugging Face** with adjustable resolutions: [](https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo)
+ **Inference and evaluation** of your given weights: [](https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S)
<img src="https://drive.google.com/thumbnail?id=12XmDhKtO1o2fEvBu4OE4ULVB2BK0ecWi&sz=w1080" />
## Acknowledgement:
+ Many thanks to @fal for their generous support on GPU resources for training better BiRefNet models.
+ Many thanks to @not-lain for his help on the better deployment of our BiRefNet model on HuggingFace.
## Citation
```
@article{BiRefNet,
title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation},
author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu},
journal={CAAI Artificial Intelligence Research},
year={2024}
}
``` |
renwoshin/Phi-3-mini-128k-instruct-onnx-tf | renwoshin | "2024-04-26T04:45:13Z" | 645,418 | 1 | transformers | [
"transformers",
"onnx",
"phi",
"text-generation",
"ONNX",
"DML",
"ONNXRuntime",
"phi3",
"nlp",
"conversational",
"custom_code",
"arxiv:2306.00978",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-04-26T04:16:23Z" | ---
license: mit
pipeline_tag: text-generation
tags:
- ONNX
- DML
- ONNXRuntime
- phi3
- nlp
- conversational
- custom_code
---
# Phi-3 Mini-128K-Instruct ONNX models
<!-- Provide a quick summary of what the model is/does. -->
This repository hosts the optimized versions of [Phi-3-mini-128k-instruct](https://aka.ms/phi3-mini-128k-instruct) to accelerate inference with ONNX Runtime.
Phi-3 Mini is a lightweight, state-of-the-art open model built upon datasets used for Phi-2 - synthetic data and filtered websites - with a focus on very high-quality, reasoning dense data. The model belongs to the Phi-3 model family, and the mini version comes in two variants: 4K and 128K which is the context length (in tokens) it can support. The model underwent a rigorous enhancement process, incorporating both supervised fine-tuning and direct preference optimization to ensure precise instruction adherence and robust safety measures.
Optimized Phi-3 Mini models are published here in [ONNX](https://onnx.ai) format to run with [ONNX Runtime](https://onnxruntime.ai/) on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets.
[DirectML](https://aka.ms/directml) support lets developers bring hardware acceleration to Windows devices at scale across AMD, Intel, and NVIDIA GPUs. Along with DirectML, ONNX Runtime provides cross platform support for Phi-3 Mini across a range of devices for CPU, GPU, and mobile.
To easily get started with Phi-3, you can use our newly introduced ONNX Runtime Generate() API. See [here](https://aka.ms/generate-tutorial) for instructions on how to run it.
## ONNX Models
Here are some of the optimized configurations we have added:
1. ONNX model for int4 DML: ONNX model for AMD, Intel, and NVIDIA GPUs on Windows, quantized to int4 using [AWQ](https://arxiv.org/abs/2306.00978).
2. ONNX model for fp16 CUDA: ONNX model you can use to run for your NVIDIA GPUs.
3. ONNX model for int4 CUDA: ONNX model for NVIDIA GPUs using int4 quantization via RTN.
4. ONNX model for int4 CPU and Mobile: ONNX model for your CPU and Mobile, using int4 quantization via RTN. There are two versions uploaded to balance latency vs. accuracy.
More updates on AMD, and additional optimizations on CPU and Mobile will be added with the official ORT 1.18 release in early May. Stay tuned!
## Hardware Supported
The models are tested on:
- GPU SKU: RTX 4090 (DirectML)
- GPU SKU: 1 A100 80GB GPU, SKU: Standard_ND96amsr_A100_v4 (CUDA)
- CPU SKU: Standard F64s v2 (64 vcpus, 128 GiB memory)
- Mobile SKU: Samsung Galaxy S21
Minimum Configuration Required:
- Windows: DirectX 12-capable GPU and a minimum of 4GB of combined RAM
- CUDA: Streaming Multiprocessors (SMs) >= 70 (i.e. V100 or newer)
### Model Description
- **Developed by:** Microsoft
- **Model type:** ONNX
- **Language(s) (NLP):** Python, C, C++
- **License:** MIT
- **Model Description:** This is a conversion of the Phi-3 Mini-4K-Instruct model for ONNX Runtime inference.
## Additional Details
- [**ONNX Runtime Optimizations Blog Link**](https://aka.ms/phi3-optimizations)
- [**Phi-3 Model Blog Link**](https://aka.ms/phi3blog-april)
- [**Phi-3 Model Card**]( https://aka.ms/phi3-mini-128k-instruct)
- [**Phi-3 Technical Report**](https://aka.ms/phi3-tech-report)
## How to Get Started with the Model
To make running of the Phi-3 models across a range of devices and platforms across various execution provider backends possible, we introduce a new API to wrap several aspects of generative AI inferencing. This API make it easy to drag and drop LLMs straight into your app. For running the early version of these models with ONNX Runtime, follow the steps [here](http://aka.ms/generate-tutorial).
For example:
```python
python model-qa.py -m /*{YourModelPath}*/onnx/cpu_and_mobile/phi-3-mini-4k-instruct-int4-cpu -k 40 -p 0.95 -t 0.8 -r 1.0
```
```
*Input:* <|user|>Tell me a joke<|end|><|assistant|>
*Output:* Why don't scientists trust atoms?
Because they make up everything!
This joke plays on the double meaning of "make up." In science, atoms are the fundamental building blocks of matter, literally making up everything. However, in a colloquial sense, "to make up" can mean to fabricate or lie, hence the humor.
```
## Performance Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
Phi-3 Mini-128K-Instruct performs better in ONNX Runtime than PyTorch for all batch size, prompt length combinations. For FP16 CUDA, ORT performs up to 5X faster than PyTorch, while with INT4 CUDA it's up to 9X faster than PyTorch.
The table below shows the average throughput of the first 256 tokens generated (tps) for FP16 and INT4 precisions on CUDA as measured on [1 A100 80GB GPU, SKU: Standard_ND96amsr_A100_v4](https://learn.microsoft.com/en-us/azure/virtual-machines/ndm-a100-v4-series).
| Batch Size, Prompt Length | ORT FP16 CUDA | PyTorch Eager FP16 CUDA | FP16 CUDA Speed Up (ORT/PyTorch) |
|---------------------------|---------------|-------------------------|----------------------------------|
| 1, 16 | 134.46 | 25.35 | 5.30 |
| 1, 64 | 132.21 | 25.69 | 5.15 |
| 1, 256 | 124.51 | 25.77 | 4.83 |
| 1, 1024 | 110.03 | 25.73 | 4.28 |
| 1, 2048 | 96.93 | 25.72 | 3.77 |
| 1, 4096 | 62.12 | 25.66 | 2.42 |
| 4, 16 | 521.10 | 101.31 | 5.14 |
| 4, 64 | 507.03 | 101.66 | 4.99 |
| 4, 256 | 459.47 | 101.15 | 4.54 |
| 4, 1024 | 343.60 | 101.09 | 3.40 |
| 4, 2048 | 264.81 | 100.78 | 2.63 |
| 4, 4096 | 158.00 | 77.98 | 2.03 |
| 16, 16 | 1689.08 | 394.19 | 4.28 |
| 16, 64 | 1567.13 | 394.29 | 3.97 |
| 16, 256 | 1232.10 | 405.30 | 3.04 |
| 16, 1024 | 680.61 | 294.79 | 2.31 |
| 16, 2048 | 350.77 | 203.02 | 1.73 |
| 16, 4096 | 192.36 | OOM | |
| Batch Size, Prompt Length | PyTorch Eager INT4 CUDA | INT4 CUDA Speed Up (ORT/PyTorch) |
|---------------------------|-------------------------|----------------------------------|
| 1, 16 | 25.35 | 8.89 |
| 1, 64 | 25.69 | 8.58 |
| 1, 256 | 25.77 | 7.69 |
| 1, 1024 | 25.73 | 6.34 |
| 1, 2048 | 25.72 | 5.24 |
| 1, 4096 | 25.66 | 2.97 |
| 4, 16 | 101.31 | 2.82 |
| 4, 64 | 101.66 | 2.77 |
| 4, 256 | 101.15 | 2.64 |
| 4, 1024 | 101.09 | 2.20 |
| 4, 2048 | 100.78 | 1.84 |
| 4, 4096 | 77.98 | 1.62 |
| 16, 16 | 394.19 | 2.52 |
| 16, 64 | 394.29 | 2.41 |
| 16, 256 | 405.30 | 2.00 |
| 16, 1024 | 294.79 | 1.79 |
| 16, 2048 | 203.02 | 1.81 |
| 16, 4096 | OOM | |
Note: PyTorch compile and Llama.cpp currently do not support the Phi-3 Mini-128K-Instruct model.
### Package Versions
| Pip package name | Version |
|----------------------------|----------|
| torch | 2.2.0 |
| triton | 2.2.0 |
| onnxruntime-gpu | 1.18.0 |
| onnxruntime-genai | 0.2.0rc3 |
| onnxruntime-genai-cuda | 0.2.0rc3 |
| onnxruntime-genai-directml | 0.2.0rc3 |
| transformers | 4.39.0 |
| bitsandbytes | 0.42.0 |
## Appendix
### Activation Aware Quantization
AWQ works by identifying the top 1% most salient weights that are most important for maintaining accuracy and quantizing the remaining 99% of weights. This leads to less accuracy loss from quantization compared to many other quantization techniques. For more on AWQ, see [here](https://arxiv.org/abs/2306.00978).
## Model Card Contact
parinitarahi, kvaishnavi, natke
## Contributors
Kunal Vaishnavi, Sunghoon Choi, Yufeng Li, Akshay Sonawane, Sheetal Arun Kadam, Rui Ren, Edward Chen, Scott McKay, Ryan Hill, Emma Ning, Natalie Kershaw, Parinita Rahi, Patrice Vignola, Chai Chaoweeraprasit, Logan Iyer, Vicente Rivera, Jacques Van Rhyn |
mistralai/Mixtral-8x7B-Instruct-v0.1 | mistralai | "2024-08-19T13:18:42Z" | 642,713 | 4,191 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"fr",
"it",
"de",
"es",
"en",
"base_model:mistralai/Mixtral-8x7B-v0.1",
"base_model:finetune:mistralai/Mixtral-8x7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-12-10T18:47:12Z" | ---
language:
- fr
- it
- de
- es
- en
license: apache-2.0
base_model: mistralai/Mixtral-8x7B-v0.1
inference:
parameters:
temperature: 0.5
widget:
- messages:
- role: user
content: What is your favorite condiment?
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# Model Card for Mixtral-8x7B
### Tokenization with `mistral-common`
```py
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
mistral_models_path = "MISTRAL_MODELS_PATH"
tokenizer = MistralTokenizer.v1()
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
```
## Inference with `mistral_inference`
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
model = Transformer.from_folder(mistral_models_path)
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
print(result)
```
## Inference with hugging face `transformers`
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
model.to("cuda")
generated_ids = model.generate(tokens, max_new_tokens=1000, do_sample=True)
# decode with mistral tokenizer
result = tokenizer.decode(generated_ids[0].tolist())
print(result)
```
> [!TIP]
> PRs to correct the transformers tokenizer so that it gives 1-to-1 the same results as the mistral-common reference implementation are very welcome!
---
The Mixtral-8x7B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts. The Mixtral-8x7B outperforms Llama 2 70B on most benchmarks we tested.
For full details of this model please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/).
## Warning
This repo contains weights that are compatible with [vLLM](https://github.com/vllm-project/vllm) serving of the model as well as Hugging Face [transformers](https://github.com/huggingface/transformers) library. It is based on the original Mixtral [torrent release](magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce), but the file format and parameter names are different. Please note that model cannot (yet) be instantiated with HF.
## Instruction format
This format must be strictly respected, otherwise the model will generate sub-optimal outputs.
The template used to build a prompt for the Instruct model is defined as follows:
```
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
```
Note that `<s>` and `</s>` are special tokens for beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings.
As reference, here is the pseudo-code used to tokenize instructions during fine-tuning:
```python
def tokenize(text):
return tok.encode(text, add_special_tokens=False)
[BOS_ID] +
tokenize("[INST]") + tokenize(USER_MESSAGE_1) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_1) + [EOS_ID] +
…
tokenize("[INST]") + tokenize(USER_MESSAGE_N) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_N) + [EOS_ID]
```
In the pseudo-code above, note that the `tokenize` method should not add a BOS or EOS token automatically, but should add a prefix space.
In the Transformers library, one can use [chat templates](https://huggingface.co/docs/transformers/main/en/chat_templating) which make sure the right format is applied.
## Run the model
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
By default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:
### In half-precision
Note `float16` precision only works on GPU devices
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Lower precision using (8-bit & 4-bit) using `bitsandbytes`
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, device_map="auto")
text = "Hello my name is"
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Load the model with Flash Attention 2
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, use_flash_attention_2=True, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
## Limitations
The Mixtral-8x7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
facebook/timesformer-hr-finetuned-k600 | facebook | "2022-12-12T12:53:13Z" | 641,472 | 5 | transformers | [
"transformers",
"pytorch",
"timesformer",
"video-classification",
"vision",
"arxiv:2102.05095",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | video-classification | "2022-10-07T22:51:20Z" | ---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# TimeSformer (base-sized model, fine-tuned on Kinetics-600)
TimeSformer model pre-trained on [Kinetics-600](https://www.deepmind.com/open-source/kinetics). It was introduced in the paper [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Tong et al. and first released in [this repository](https://github.com/facebookresearch/TimeSformer).
Disclaimer: The team releasing TimeSformer did not write a model card for this model so this model card has been written by [fcakyon](https://github.com/fcakyon).
## Intended uses & limitations
You can use the raw model for video classification into one of the 600 possible Kinetics-600 labels.
### How to use
Here is how to use this model to classify a video:
```python
from transformers import AutoImageProcessor, TimesformerForVideoClassification
import numpy as np
import torch
video = list(np.random.randn(16, 3, 448, 448))
processor = AutoImageProcessor.from_pretrained("facebook/timesformer-hr-finetuned-k600")
model = TimesformerForVideoClassification.from_pretrained("facebook/timesformer-hr-finetuned-k600")
inputs = processor(images=video, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/timesformer.html#).
### BibTeX entry and citation info
```bibtex
@inproceedings{bertasius2021space,
title={Is Space-Time Attention All You Need for Video Understanding?},
author={Bertasius, Gedas and Wang, Heng and Torresani, Lorenzo},
booktitle={International Conference on Machine Learning},
pages={813--824},
year={2021},
organization={PMLR}
}
``` |
microsoft/layoutlmv2-base-uncased | microsoft | "2022-09-16T03:40:56Z" | 639,196 | 57 | transformers | [
"transformers",
"pytorch",
"layoutlmv2",
"en",
"arxiv:2012.14740",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: en
license: cc-by-nc-sa-4.0
---
# LayoutLMv2
**Multimodal (text + layout/format + image) pre-training for document AI**
The documentation of this model in the Transformers library can be found [here](https://huggingface.co/docs/transformers/model_doc/layoutlmv2).
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://github.com/microsoft/unilm/tree/master/layoutlmv2)
## Introduction
LayoutLMv2 is an improved version of LayoutLM with new pre-training tasks to model the interaction among text, layout, and image in a single multi-modal framework. It outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including , including FUNSD (0.7895 → 0.8420), CORD (0.9493 → 0.9601), SROIE (0.9524 → 0.9781), Kleister-NDA (0.834 → 0.852), RVL-CDIP (0.9443 → 0.9564), and DocVQA (0.7295 → 0.8672).
[LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou, ACL 2021
|
sentence-transformers/distiluse-base-multilingual-cased-v1 | sentence-transformers | "2024-11-05T16:52:25Z" | 639,178 | 99 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"distilbert",
"feature-extraction",
"sentence-similarity",
"multilingual",
"ar",
"zh",
"nl",
"en",
"fr",
"de",
"it",
"ko",
"pl",
"pt",
"ru",
"es",
"tr",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- ar
- zh
- nl
- en
- fr
- de
- it
- ko
- pl
- pt
- ru
- es
- tr
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
pipeline_tag: sentence-similarity
---
# sentence-transformers/distiluse-base-multilingual-cased-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 512 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/distiluse-base-multilingual-cased-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/distiluse-base-multilingual-cased-v1)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 768, 'out_features': 512, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
Danswer/intent-model | Danswer | "2023-06-10T08:59:02Z" | 633,295 | 6 | keras | [
"keras",
"tf",
"distilbert",
"en",
"license:mit",
"region:us"
] | null | "2023-06-06T04:31:33Z" | ---
license: mit
language:
- en
library_name: keras
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This model is used to classify the user-intent for the Danswer project, visit https://github.com/danswer-ai/danswer.
## Model Details
Multiclass classifier on top of distilbert-base-uncased
### Model Description
<!-- Provide a longer summary of what this model is. -->
Classifies user intent of queries into categories including:
0: Keyword Search
1: Semantic Search
2: Direct Question Answering
- **Developed by:** [DanswerAI]
- **License:** [MIT]
- **Finetuned from model [optional]:** [distilbert-base-uncased]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [https://github.com/danswer-ai/danswer]
- **Demo [optional]:** [Upcoming!]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This model is intended to be used in the Danswer Question-Answering System
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
This model has a very small dataset maintained by DanswerAI. If interested, reach out to danswer.dev@gmail.com.
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
This model is intended to be used in the Danswer (QA System)
## How to Get Started with the Model
```
from transformers import AutoTokenizer
from transformers import TFDistilBertForSequenceClassification
import tensorflow as tf
model = TFDistilBertForSequenceClassification.from_pretrained("danswer/intent-model")
tokenizer = AutoTokenizer.from_pretrained("danswer/intent-model")
class_semantic_mapping = {
0: "Keyword Search",
1: "Semantic Search",
2: "Question Answer"
}
# Get user input
user_query = "How do I set up Danswer to run on my local environment?"
# Encode the user input
inputs = tokenizer(user_query, return_tensors="tf", truncation=True, padding=True)
# Get model predictions
predictions = model(inputs)[0]
# Get predicted class
predicted_class = tf.math.argmax(predictions, axis=-1)
print(f"Predicted class: {class_semantic_mapping[int(predicted_class)]}")
``` |
sentence-transformers/roberta-base-nli-mean-tokens | sentence-transformers | "2024-11-05T15:08:38Z" | 632,429 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/roberta-base-nli-mean-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/roberta-base-nli-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/roberta-base-nli-mean-tokens')
model = AutoModel.from_pretrained('sentence-transformers/roberta-base-nli-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/roberta-base-nli-mean-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
vinid/plip | vinid | "2023-03-31T02:46:21Z" | 631,653 | 38 | transformers | [
"transformers",
"pytorch",
"clip",
"zero-shot-image-classification",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2023-03-04T19:37:10Z" | ---
{}
---
## Model Use (from [CLIP Model Card](https://huggingface.co/openai/clip-vit-large-patch14))
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
### Out-of-Scope Use Cases
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
# Disclaimer
Please be advised that this function has been developed in compliance with the Twitter policy of data usage and sharing. It is important to note that the results obtained from this function are not intended to constitute medical advice or replace consultation with a qualified medical professional. The use of this function is solely at your own risk and should be consistent with applicable laws, regulations, and ethical considerations. We do not warrant or guarantee the accuracy, completeness, suitability, or usefulness of this function for any particular purpose, and we hereby disclaim any liability arising from any reliance placed on this function or any results obtained from its use. If you wish to review the original Twitter post, you should access the source page directly on Twitter.'
# Privacy
In accordance with the privacy and control policy of Twitter, we hereby declared that the data redistributed by us shall only comprise of Tweet IDs. The Tweet IDs will be employed to establish a linkage with the original Twitter post, as long as the original post is still accessible. The hyperlink will cease to function if the user deletes the original post. It is important to note that all tweets displayed on our service have already been classified as non-sensitive by Twitter. It is strictly prohibited to redistribute any content apart from the Tweet IDs. Any distribution carried out must adhere to the laws and regulations applicable in your jurisdiction, including export control laws and embargoes.' |
MMG/xlm-roberta-large-ner-spanish | MMG | "2023-06-05T08:18:20Z" | 631,273 | 26 | transformers | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"token-classification",
"es",
"dataset:CoNLL-2002",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:04Z" | ---
language:
- es
datasets:
- CoNLL-2002
widget:
- text: "Las oficinas de MMG están en Las Rozas."
---
# xlm-roberta-large-ner-spanish
This model is a XLM-Roberta-large model fine-tuned for Named Entity Recognition (NER) over the Spanish portion of the CoNLL-2002 dataset. Evaluating it over the test subset of this dataset, we get a F1-score of 89.17, being one of the best NER for Spanish available at the moment. |
facebook/dpr-question_encoder-single-nq-base | facebook | "2022-12-21T15:20:10Z" | 630,006 | 26 | transformers | [
"transformers",
"pytorch",
"tf",
"dpr",
"feature-extraction",
"en",
"dataset:nq_open",
"arxiv:2004.04906",
"arxiv:1702.08734",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language: en
license: cc-by-nc-4.0
tags:
- dpr
datasets:
- nq_open
inference: false
---
# `dpr-question_encoder-single-nq-base`
## Table of Contents
- [Model Details](#model-details)
- [How To Get Started With the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation-results)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications](#technical-specifications)
- [Citation Information](#citation-information)
- [Model Card Authors](#model-card-authors)
## Model Details
**Model Description:** [Dense Passage Retrieval (DPR)](https://github.com/facebookresearch/DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. `dpr-question_encoder-single-nq-base` is the question encoder trained using the [Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open) ([Lee et al., 2019](https://aclanthology.org/P19-1612/); [Kwiatkowski et al., 2019](https://aclanthology.org/Q19-1026/)).
- **Developed by:** See [GitHub repo](https://github.com/facebookresearch/DPR) for model developers
- **Model Type:** BERT-based encoder
- **Language(s):** [CC-BY-NC-4.0](https://github.com/facebookresearch/DPR/blob/main/LICENSE), also see [Code of Conduct](https://github.com/facebookresearch/DPR/blob/main/CODE_OF_CONDUCT.md)
- **License:** English
- **Related Models:**
- [`dpr-ctx_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base)
- [`dpr-reader-single-nq-base`](https://huggingface.co/facebook/dpr-reader-single-nq-base)
- [`dpr-ctx_encoder-multiset-base`](https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base)
- [`dpr-question_encoder-multiset-base`](https://huggingface.co/facebook/dpr-question_encoder-multiset-base)
- [`dpr-reader-multiset-base`](https://huggingface.co/facebook/dpr-reader-multiset-base)
- **Resources for more information:**
- [Research Paper](https://arxiv.org/abs/2004.04906)
- [GitHub Repo](https://github.com/facebookresearch/DPR)
- [Hugging Face DPR docs](https://huggingface.co/docs/transformers/main/en/model_doc/dpr)
- [BERT Base Uncased Model Card](https://huggingface.co/bert-base-uncased)
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
model = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
input_ids = tokenizer("Hello, is my dog cute ?", return_tensors="pt")["input_ids"]
embeddings = model(input_ids).pooler_output
```
## Uses
#### Direct Use
`dpr-question_encoder-single-nq-base`, [`dpr-ctx_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base), and [`dpr-reader-single-nq-base`](https://huggingface.co/facebook/dpr-reader-single-nq-base) can be used for the task of open-domain question answering.
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the set of DPR models was not trained to be factual or true representations of people or events, and therefore using the models to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section may contain content that is disturbing, offensive, and can propogate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al., 2021](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al., 2021](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Training
#### Training Data
This model was trained using the [Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open) ([Lee et al., 2019](https://aclanthology.org/P19-1612/); [Kwiatkowski et al., 2019](https://aclanthology.org/Q19-1026/)). The model authors write that:
> [The dataset] was designed for end-to-end question answering. The questions were mined from real Google search queries and the answers were spans in Wikipedia articles identified by annotators.
#### Training Procedure
The training procedure is described in the [associated paper](https://arxiv.org/pdf/2004.04906.pdf):
> Given a collection of M text passages, the goal of our dense passage retriever (DPR) is to index all the passages in a low-dimensional and continuous space, such that it can retrieve efficiently the top k passages relevant to the input question for the reader at run-time.
> Our dense passage retriever (DPR) uses a dense encoder EP(·) which maps any text passage to a d- dimensional real-valued vectors and builds an index for all the M passages that we will use for retrieval. At run-time, DPR applies a different encoder EQ(·) that maps the input question to a d-dimensional vector, and retrieves k passages of which vectors are the closest to the question vector.
The authors report that for encoders, they used two independent BERT ([Devlin et al., 2019](https://aclanthology.org/N19-1423/)) networks (base, un-cased) and use FAISS ([Johnson et al., 2017](https://arxiv.org/abs/1702.08734)) during inference time to encode and index passages. See the paper for further details on training, including encoders, inference, positive and negative passages, and in-batch negatives.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://arxiv.org/pdf/2004.04906.pdf).
#### Testing Data, Factors and Metrics
The model developers report the performance of the model on five QA datasets, using the top-k accuracy (k ∈ {20, 100}). The datasets were [NQ](https://huggingface.co/datasets/nq_open), [TriviaQA](https://huggingface.co/datasets/trivia_qa), [WebQuestions (WQ)](https://huggingface.co/datasets/web_questions), [CuratedTREC (TREC)](https://huggingface.co/datasets/trec), and [SQuAD v1.1](https://huggingface.co/datasets/squad).
#### Results
| | Top 20 | | | | | Top 100| | | | |
|:----:|:------:|:---------:|:--:|:----:|:-----:|:------:|:---------:|:--:|:----:|:-----:|
| | NQ | TriviaQA | WQ | TREC | SQuAD | NQ | TriviaQA | WQ | TREC | SQuAD |
| | 78.4 | 79.4 |73.2| 79.8 | 63.2 | 85.4 | 85.0 |81.4| 89.1 | 77.2 |
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). We present the hardware type and based on the [associated paper](https://arxiv.org/abs/2004.04906).
- **Hardware Type:** 8 32GB GPUs
- **Hours used:** Unknown
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
See the [associated paper](https://arxiv.org/abs/2004.04906) for details on the modeling architecture, objective, compute infrastructure, and training details.
## Citation Information
```bibtex
@inproceedings{karpukhin-etal-2020-dense,
title = "Dense Passage Retrieval for Open-Domain Question Answering",
author = "Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.550",
doi = "10.18653/v1/2020.emnlp-main.550",
pages = "6769--6781",
}
```
## Model Card Authors
This model card was written by the team at Hugging Face. |
Cloudy1225/stackoverflow-roberta-base-sentiment | Cloudy1225 | "2024-11-09T08:14:26Z" | 629,874 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"arxiv:1709.02984",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-06-02T07:38:40Z" | ---
license: openrail
---
# StackOverflow-RoBERTa-base for Sentiment Analysis on Software Engineering Texts
This is a RoBERTa-base model for sentiment analysis on software engineering texts. It is re-finetuned from [cardiffnlp/twitter-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) with [StackOverflow4423](https://arxiv.org/abs/1709.02984) dataset. You can access the demo [here](https://huggingface.co/spaces/Cloudy1225/stackoverflow-sentiment-analysis).
## Example of Pipeline
```python
from transformers import pipeline
MODEL = 'Cloudy1225/stackoverflow-roberta-base-sentiment'
sentiment_task = pipeline(task="sentiment-analysis", model=MODEL)
sentiment_task(["Excellent, happy to help!",
"This can probably be done using JavaScript.",
"Yes, but it's tricky, since datetime parsing in SQL is a pain in the neck."])
```
[{'label': 'positive', 'score': 0.9997847676277161},
{'label': 'neutral', 'score': 0.999783456325531},
{'label': 'negative', 'score': 0.9996368885040283}]
## Example of Classification
```python
from scipy.special import softmax
from transformers import AutoTokenizer, AutoModelForSequenceClassification
def preprocess(text):
"""Preprocess text (username and link placeholders)"""
new_text = []
for t in text.split(' '):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return ' '.join(new_text).strip()
MODEL = 'Cloudy1225/stackoverflow-roberta-base-sentiment'
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
text = "Excellent, happy to help!"
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
print("negative", scores[0])
print("neutral", scores[1])
print("positive", scores[2])
```
negative 0.00015578205
neutral 5.9470447e-05
positive 0.99978495
## Acknowledgments
This project was developed as part of the **Software Engineering and Computing III** course at Software Institute, Nanjing University in Spring 2023. For more insights into sentiment analysis on software engineering texts, you can refer to the following paper:
```
@inproceedings{sun2022incorporating,
title={Incorporating Pre-trained Transformer Models into TextCNN for Sentiment Analysis on Software Engineering Texts},
author={Sun, Kexin and Shi, Xiaobo and Gao, Hui and Kuang, Hongyu and Ma, Xiaoxing and Rong, Guoping and Shao, Dong and Zhao, Zheng and Zhang, He},
booktitle={Proceedings of the 13th Asia-Pacific Symposium on Internetware},
pages={127--136},
year={2022}
}
``` |
flair/ner-english-large | flair | "2021-05-08T15:36:27Z" | 629,594 | 43 | flair | [
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"en",
"dataset:conll2003",
"arxiv:2011.06993",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- conll2003
widget:
- text: "George Washington went to Washington"
---
## English NER in Flair (large model)
This is the large 4-class NER model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **94,36** (corrected CoNLL-03)
Predicts 4 tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
| PER | person name |
| LOC | location name |
| ORG | organization name |
| MISC | other name |
Based on document-level XLM-R embeddings and [FLERT](https://arxiv.org/pdf/2011.06993v1.pdf/).
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/ner-english-large")
# make example sentence
sentence = Sentence("George Washington went to Washington")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
```
This yields the following output:
```
Span [1,2]: "George Washington" [− Labels: PER (1.0)]
Span [5]: "Washington" [− Labels: LOC (1.0)]
```
So, the entities "*George Washington*" (labeled as a **person**) and "*Washington*" (labeled as a **location**) are found in the sentence "*George Washington went to Washington*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
import torch
# 1. get the corpus
from flair.datasets import CONLL_03
corpus = CONLL_03()
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize fine-tuneable transformer embeddings WITH document context
from flair.embeddings import TransformerWordEmbeddings
embeddings = TransformerWordEmbeddings(
model='xlm-roberta-large',
layers="-1",
subtoken_pooling="first",
fine_tune=True,
use_context=True,
)
# 5. initialize bare-bones sequence tagger (no CRF, no RNN, no reprojection)
from flair.models import SequenceTagger
tagger = SequenceTagger(
hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type='ner',
use_crf=False,
use_rnn=False,
reproject_embeddings=False,
)
# 6. initialize trainer with AdamW optimizer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus, optimizer=torch.optim.AdamW)
# 7. run training with XLM parameters (20 epochs, small LR)
from torch.optim.lr_scheduler import OneCycleLR
trainer.train('resources/taggers/ner-english-large',
learning_rate=5.0e-6,
mini_batch_size=4,
mini_batch_chunk_size=1,
max_epochs=20,
scheduler=OneCycleLR,
embeddings_storage_mode='none',
weight_decay=0.,
)
)
```
---
### Cite
Please cite the following paper when using this model.
```
@misc{schweter2020flert,
title={FLERT: Document-Level Features for Named Entity Recognition},
author={Stefan Schweter and Alan Akbik},
year={2020},
eprint={2011.06993},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
microsoft/Phi-3-mini-128k-instruct | microsoft | "2024-08-20T19:55:37Z" | 629,175 | 1,603 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-04-22T16:26:23Z" | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- nlp
- code
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
🎉 **Phi-3.5**: [[mini-instruct]](https://huggingface.co/microsoft/Phi-3.5-mini-instruct); [[MoE-instruct]](https://huggingface.co/microsoft/Phi-3.5-MoE-instruct) ; [[vision-instruct]](https://huggingface.co/microsoft/Phi-3.5-vision-instruct)
## Model Summary
The Phi-3-Mini-128K-Instruct is a 3.8 billion-parameter, lightweight, state-of-the-art open model trained using the Phi-3 datasets.
This dataset includes both synthetic data and filtered publicly available website data, with an emphasis on high-quality and reasoning-dense properties.
The model belongs to the Phi-3 family with the Mini version in two variants [4K](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) which is the context length (in tokens) that it can support.
After initial training, the model underwent a post-training process that involved supervised fine-tuning and direct preference optimization to enhance its ability to follow instructions and adhere to safety measures.
When evaluated against benchmarks that test common sense, language understanding, mathematics, coding, long-term context, and logical reasoning, the Phi-3 Mini-128K-Instruct demonstrated robust and state-of-the-art performance among models with fewer than 13 billion parameters.
Resources and Technical Documentation:
🏡 [Phi-3 Portal](https://azure.microsoft.com/en-us/products/phi-3) <br>
📰 [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024) <br>
📖 [Phi-3 Technical Report](https://aka.ms/phi3-tech-report) <br>
🛠️ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai) <br>
👩🍳 [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook) <br>
🖥️ [Try It](https://aka.ms/try-phi3)
| | Short Context | Long Context |
| :- | :- | :- |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct-onnx-cuda)|
## Intended Uses
**Primary use cases**
The model is intended for commercial and research use in English. The model provides uses for applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## Release Notes
This is an update over the original instruction-tuned Phi-3-mini release based on valuable customer feedback.
The model used additional post-training data leading to substantial gains on long-context understanding, instruction following, and structure output.
We also improve multi-turn conversation quality, explicitly support <|system|> tag, and significantly improve reasoning capability.
We believe most use cases will benefit from this release, but we encourage users to test in their particular AI applications.
We appreciate the enthusiastic adoption of the Phi-3 model family, and continue to welcome all feedback from the community.
These tables below highlights improvements on instruction following, structure output, reasoning, and long-context understanding of the new release on our public and internal benchmark datasets.
| Benchmarks | Original | June 2024 Update |
| :- | :- | :- |
| Instruction Extra Hard | 5.7 | 5.9 |
| Instruction Hard | 5.0 | 5.2 |
| JSON Structure Output | 1.9 | 60.1 |
| XML Structure Output | 47.8 | 52.9 |
| GPQA | 25.9 | 29.7 |
| MMLU | 68.1 | 69.7 |
| **Average** | **25.7** | **37.3** |
RULER: a retrieval-based benchmark for long context understanding
| Model | 4K | 8K | 16K | 32K | 64K | 128K | Average |
| :-------------------| :------| :------| :------| :------| :------| :------| :---------|
| Original | 86.7 | 78.1 | 75.6 | 70.3 | 58.9 | 43.3 | **68.8** |
| June 2024 Update | 92.4 | 91.1 | 90.8 | 87.9 | 79.8 | 65.6 | **84.6** |
RepoQA: a benchmark for long context code understanding
| Model | Python | C++ | Rust | Java | TypeScript | Average |
| :-------------------| :--------| :-----| :------| :------| :------------| :---------|
| Original | 27 | 29 | 40 | 33 | 33 | **32.4** |
| June 2024 Update | 85 | 63 | 72 | 93 | 72 | **77** |
Notes: if users would like to check out the previous version, use the git commit id **bb5bf1e4001277a606e11debca0ef80323e5f824**. For the model conversion, e.g. GGUF and other formats, we invite the community to experiment with various approaches and share your valuable feedback. Let's innovate together!
## How to Use
Phi-3 Mini-128K-Instruct has been integrated in the development version (4.41.3) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Examples of required packages:
```
flash_attn==2.5.8
torch==2.3.1
accelerate==0.31.0
transformers==4.41.2
```
Phi-3 Mini-128K-Instruct is also available in [Azure AI Studio](https://aka.ms/try-phi3)
### Tokenizer
Phi-3 Mini-128K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3 Mini-128K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|system|>
You are a helpful assistant.<|end|>
<|user|>
Question?<|end|>
<|assistant|>
```
For example:
```markdown
<|system|>
You are a helpful assistant.<|end|>
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|system|>
You are a helpful travel assistant.<|end|>
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-128k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
Notes: If you want to use flash attention, call _AutoModelForCausalLM.from_pretrained()_ with _attn_implementation="flash_attention_2"_
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3 Mini-128K-Instruct has 3.8B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 128K tokens
* GPUs: 512 H100-80G
* Training time: 10 days
* Training data: 4.9T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between May and June 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: June, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.9 trillion tokens, and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
### Fine-tuning
A basic example of multi-GPUs supervised fine-tuning (SFT) with TRL and Accelerate modules is provided [here](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/sample_finetune.py).
## Benchmarks
We report the results under completion format for Phi-3-Mini-128K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-8B-Instruct, and GPT-3.5.
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
| Category | Benchmark | Phi-3-Mini-128K-Ins | Gemma-7B | Mistral-7B | Mixtral-8x7B | Llama-3-8B-Ins | GPT3.5-Turbo-1106 |
| :----------| :-----------| :---------------------| :----------| :------------| :--------------| :----------------| :-------------------|
| Popular aggregated benchmark | AGI Eval <br>5-shot| 39.5 | 42.1 | 35.1 | 45.2 | 42 | 48.4 |
| | MMLU <br>5-shot | 69.7 | 63.6 | 61.7 | 70.5 | 66.5 | 71.4 |
| | BigBench Hard <br>3-shot | 72.1 | 59.6 | 57.3 | 69.7 | 51.5 | 68.3 |
| Language Understanding | ANLI <br>7-shot | 52.3 | 48.7 | 47.1 | 55.2 | 57.3 | 58.1 |
| | HellaSwag <br>5-shot | 70.5 | 49.8 | 58.5 | 70.4 | 71.1 | 78.8 |
| Reasoning | ARC Challenge <br>10-shot | 85.5 | 78.3 | 78.6 | 87.3 | 82.8 | 87.4 |
| | BoolQ <br>0-shot | 77.1 | 66 | 72.2 | 76.6 | 80.9 | 79.1 |
| | MedQA <br>2-shot | 56.4 | 49.6 | 50 | 62.2 | 60.5 | 63.4 |
| | OpenBookQA <br>10-shot | 78.8 | 78.6 | 79.8 | 85.8 | 82.6 | 86 |
| | PIQA <br>5-shot | 80.1 | 78.1 | 77.7 | 86 | 75.7 | 86.6 |
| | GPQA <br>0-shot | 29.7 | 2.9 | 15 | 6.9 | 32.4 | 29.9 |
| | Social IQA <br>5-shot | 74.7 | 65.5 | 74.6 | 75.9 | 73.9 | 68.3 |
| | TruthfulQA (MC2) <br>10-shot | 64.8 | 52.1 | 53 | 60.1 | 63.2 | 67.7 |
| | WinoGrande <br>5-shot | 71.0 | 55.6 | 54.2 | 62 | 65 | 68.8 |
| Factual Knowledge | TriviaQA <br>5-shot | 57.8 | 72.3 | 75.2 | 82.2 | 67.7 | 85.8 |
| Math | GSM8K CoTT <br>8-shot | 85.3 | 59.8 | 46.4 | 64.7 | 77.4 | 78.1 |
| Code Generation | HumanEval <br>0-shot | 60.4 | 34.1 | 28.0 | 37.8 | 60.4 | 62.2 |
| | MBPP <br>3-shot | 70.0 | 51.5 | 50.8 | 60.2 | 67.7 | 77.8 |
| **Average** | | **66.4** | **56.0** | **56.4** | **64.4** | **65.5** | **70.3** |
**Long Context**: Phi-3 Mini-128K-Instruct supports 128K context length, therefore the model is capable of several long context tasks including long document/meeting summarization, long document QA.
| Benchmark | Phi-3 Mini-128K-Instruct | Mistral-7B | Mixtral 8x7B | LLaMA-3-8B-Instruct |
| :---------------| :--------------------------|:------------|:--------------|:---------------------|
| GovReport | 25.3 | 4.9 | 20.3 | 10.3 |
| QMSum | 21.9 | 15.5 | 20.6 | 2.9 |
| Qasper | 41.6 | 23.5 | 26.6 | 8.1 |
| SQuALITY | 24.1 | 14.7 | 16.2 | 25 |
| SummScreenFD | 16.8 | 9.3 | 11.3 | 5.1 |
| **Average** | **25.9** | **13.6** | **19.0** | **10.3** |
We take a closer look at different categories across 100 public benchmark datasets at the table below:
| Category | Phi-3-Mini-128K-Instruct | Gemma-7B | Mistral-7B | Mixtral 8x7B | Llama-3-8B-Instruct | GPT-3.5-Turbo |
|:----------|:--------------------------|:----------|:------------|:--------------|:---------------------|:---------------|
| Popular aggregated benchmark | 60.6 | 59.4 | 56.5 | 66.2 | 59.9 | 67.0 |
| Reasoning | 69.4 | 60.3 | 62.8 | 68.1 | 69.6 | 71.7 |
| Language understanding | 57.5 | 57.6 | 52.5 | 66.1 | 63.2 | 67.7 |
| Code generation | 61.0 | 45.6 | 42.9 | 52.7 | 56.4 | 70.4 |
| Math | 51.6 | 35.8 | 25.4 | 40.3 | 41.1 | 52.8 |
| Factual knowledge | 35.8 | 46.7 | 49.8 | 58.6 | 43.1 | 63.4 |
| Multilingual | 56.4 | 66.5 | 57.4 | 66.7 | 66.6 | 71.0 |
| Robustness | 61.1 | 38.4 | 40.6 | 51.0 | 64.5 | 69.3 |
Overall, the model with only 3.8B-param achieves a similar level of language understanding and reasoning ability as much larger models. However, it is still fundamentally limited by its size for certain tasks. The model simply does not have the capacity to store too much world knowledge, which can be seen for example with low performance on TriviaQA. However, we believe such weakness can be resolved by augmenting Phi-3-Mini with a search engine.
## Cross Platform Support
[ONNX runtime](https://onnxruntime.ai/blogs/accelerating-phi-3) now supports Phi-3 mini models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 mini across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3 Mini-128K-Instruct model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
* Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [128K](https://aka.ms/phi3-mini-128k-instruct-onnx)
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-mini-128k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
patrickvonplaten/wavlm-libri-clean-100h-base-plus | patrickvonplaten | "2021-12-20T12:59:01Z" | 628,890 | 3 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wavlm",
"automatic-speech-recognition",
"librispeech_asr",
"generated_from_trainer",
"wavlm_libri_finetune",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
tags:
- automatic-speech-recognition
- librispeech_asr
- generated_from_trainer
- wavlm_libri_finetune
model-index:
- name: wavlm-libri-clean-100h-base-plus
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wavlm-libri-clean-100h-base-plus
This model is a fine-tuned version of [microsoft/wavlm-base-plus](https://huggingface.co/microsoft/wavlm-base-plus) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0819
- Wer: 0.0683
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.8877 | 0.34 | 300 | 2.8649 | 1.0 |
| 0.2852 | 0.67 | 600 | 0.2196 | 0.1830 |
| 0.1198 | 1.01 | 900 | 0.1438 | 0.1273 |
| 0.0906 | 1.35 | 1200 | 0.1145 | 0.1035 |
| 0.0729 | 1.68 | 1500 | 0.1055 | 0.0955 |
| 0.0605 | 2.02 | 1800 | 0.0936 | 0.0859 |
| 0.0402 | 2.35 | 2100 | 0.0885 | 0.0746 |
| 0.0421 | 2.69 | 2400 | 0.0848 | 0.0700 |
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
cross-encoder/ms-marco-electra-base | cross-encoder | "2021-08-05T08:40:12Z" | 622,212 | 4 | transformers | [
"transformers",
"pytorch",
"electra",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
---
# Cross-Encoder for MS Marco
This model was trained on the [MS Marco Passage Ranking](https://github.com/microsoft/MSMARCO-Passage-Ranking) task.
The model can be used for Information Retrieval: Given a query, encode the query will all possible passages (e.g. retrieved with ElasticSearch). Then sort the passages in a decreasing order. See [SBERT.net Retrieve & Re-rank](https://www.sbert.net/examples/applications/retrieve_rerank/README.html) for more details. The training code is available here: [SBERT.net Training MS Marco](https://github.com/UKPLab/sentence-transformers/tree/master/examples/training/ms_marco)
## Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('model_name')
tokenizer = AutoTokenizer.from_pretrained('model_name')
features = tokenizer(['How many people live in Berlin?', 'How many people live in Berlin?'], ['Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'New York City is famous for the Metropolitan Museum of Art.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
## Usage with SentenceTransformers
The usage becomes easier when you have [SentenceTransformers](https://www.sbert.net/) installed. Then, you can use the pre-trained models like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name', max_length=512)
scores = model.predict([('Query', 'Paragraph1'), ('Query', 'Paragraph2') , ('Query', 'Paragraph3')])
```
## Performance
In the following table, we provide various pre-trained Cross-Encoders together with their performance on the [TREC Deep Learning 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/) and the [MS Marco Passage Reranking](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Model-Name | NDCG@10 (TREC DL 19) | MRR@10 (MS Marco Dev) | Docs / Sec |
| ------------- |:-------------| -----| --- |
| **Version 2 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2-v2 | 69.84 | 32.56 | 9000
| cross-encoder/ms-marco-MiniLM-L-2-v2 | 71.01 | 34.85 | 4100
| cross-encoder/ms-marco-MiniLM-L-4-v2 | 73.04 | 37.70 | 2500
| cross-encoder/ms-marco-MiniLM-L-6-v2 | 74.30 | 39.01 | 1800
| cross-encoder/ms-marco-MiniLM-L-12-v2 | 74.31 | 39.02 | 960
| **Version 1 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2 | 67.43 | 30.15 | 9000
| cross-encoder/ms-marco-TinyBERT-L-4 | 68.09 | 34.50 | 2900
| cross-encoder/ms-marco-TinyBERT-L-6 | 69.57 | 36.13 | 680
| cross-encoder/ms-marco-electra-base | 71.99 | 36.41 | 340
| **Other models** | | |
| nboost/pt-tinybert-msmarco | 63.63 | 28.80 | 2900
| nboost/pt-bert-base-uncased-msmarco | 70.94 | 34.75 | 340
| nboost/pt-bert-large-msmarco | 73.36 | 36.48 | 100
| Capreolus/electra-base-msmarco | 71.23 | 36.89 | 340
| amberoad/bert-multilingual-passage-reranking-msmarco | 68.40 | 35.54 | 330
| sebastian-hofstaetter/distilbert-cat-margin_mse-T2-msmarco | 72.82 | 37.88 | 720
Note: Runtime was computed on a V100 GPU.
|
NousResearch/Llama-2-7b-chat-hf | NousResearch | "2024-06-03T19:23:12Z" | 615,278 | 175 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"en",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2023-07-18T19:45:53Z" | ---
extra_gated_heading: Access Llama 2 on Hugging Face
extra_gated_description: >-
This is a form to enable access to Llama 2 on Hugging Face after you have been
granted access from Meta. Please visit the [Meta website](https://ai.meta.com/resources/models-and-libraries/llama-downloads) and accept our
license terms and acceptable use policy before submitting this form. Requests
will be processed in 1-2 days.
extra_gated_button_content: Submit
extra_gated_fields:
I agree to share my name, email address and username with Meta and confirm that I have already been granted download access on the Meta website: checkbox
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
---
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
|
vectara/hallucination_evaluation_model | vectara | "2024-10-30T17:03:42Z" | 609,016 | 227 | transformers | [
"transformers",
"safetensors",
"HHEMv2Config",
"text-classification",
"custom_code",
"en",
"arxiv:2205.12854",
"arxiv:2401.00396",
"arxiv:2303.15621",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"doi:10.57967/hf/3240",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | text-classification | "2023-10-25T19:03:42Z" | ---
language: en
license: apache-2.0
base_model: google/flan-t5-base
pipline_tag: text-classficiation
---
<img referrerpolicy="no-referrer-when-downgrade" src="https://static.scarf.sh/a.png?x-pxid=5f53f560-5ba6-4e73-917b-c7049e9aea2c" />
<img src="https://huggingface.co/vectara/hallucination_evaluation_model/resolve/main/candle.png" width="50" height="50" style="display: inline;"> In Loving memory of Simon Mark Hughes...
**Highlights**:
* HHEM-2.1-Open shows a significant improvement over HHEM-1.0.
* HHEM-2.1-Open outperforms GPT-3.5-Turbo and even GPT-4.
* HHEM-2.1-Open can be run on consumer-grade hardware, occupying less than 600MB RAM space at 32-bit precision and elapsing around 1.5 seconds for a 2k-token input on a modern x86 CPU.
> HHEM-2.1-Open introduces breaking changes to the usage. Please update your code according to the [new usage](#using-hhem-21-open) below. We are working making it compatible with HuggingFace's Inference Endpoint. We apologize for the inconvenience.
HHEM-2.1-Open is a major upgrade to [HHEM-1.0-Open](https://huggingface.co/vectara/hallucination_evaluation_model/tree/hhem-1.0-open) created by [Vectara](https://vectara.com) in November 2023. The HHEM model series are designed for detecting hallucinations in LLMs. They are particularly useful in the context of building retrieval-augmented-generation (RAG) applications where a set of facts is summarized by an LLM, and HHEM can be used to measure the extent to which this summary is factually consistent with the facts.
If you are interested to learn more about RAG or experiment with Vectara, you can [sign up](https://console.vectara.com/signup/?utm_source=huggingface&utm_medium=space&utm_term=hhem-model&utm_content=console&utm_campaign=) for a Vectara account.
[**Try out HHEM-2.1-Open from your browser without coding** ](http://13.57.203.109:3000/)
## Hallucination Detection 101
By "hallucinated" or "factually inconsistent", we mean that a text (hypothesis, to be judged) is not supported by another text (evidence/premise, given). You **always need two** pieces of text to determine whether a text is hallucinated or not. When applied to RAG (retrieval augmented generation), the LLM is provided with several pieces of text (often called facts or context) retrieved from some dataset, and a hallucination would indicate that the summary (hypothesis) is not supported by those facts (evidence).
A common type of hallucination in RAG is **factual but hallucinated**.
For example, given the premise _"The capital of France is Berlin"_, the hypothesis _"The capital of France is Paris"_ is hallucinated -- although it is true in the world knowledge. This happens when LLMs do not generate content based on the textual data provided to them as part of the RAG retrieval process, but rather generate content based on their pre-trained knowledge.
Additionally, hallucination detection is "asymmetric" or is not commutative. For example, the hypothesis _"I visited Iowa"_ is considered hallucinated given the premise _"I visited the United States"_, but the reverse is consistent.
## Using HHEM-2.1-Open
> HHEM-2.1 has some breaking change from HHEM-1.0. Your code that works with HHEM-1 (November 2023) will not work anymore. While we are working on backward compatibility, please follow the new usage instructions below.
Here we provide several ways to use HHEM-2.1-Open in the `transformers` library.
> You may run into a warning message that "Token indices sequence length is longer than the specified maximum sequence length". Please ignore it which is inherited from the foundation, T5-base.
### Using with `AutoModel`
This is the most end-to-end and out-of-the-box way to use HHEM-2.1-Open. It takes a list of pairs of (premise, hypothesis) as the input and returns a score between 0 and 1 for each pair where 0 means that the hypothesis is not evidenced at all by the premise and 1 means the hypothesis is fully supported by the premise.
```python
from transformers import AutoModelForSequenceClassification
pairs = [ # Test data, List[Tuple[str, str]]
("The capital of France is Berlin.", "The capital of France is Paris."), # factual but hallucinated
('I am in California', 'I am in United States.'), # Consistent
('I am in United States', 'I am in California.'), # Hallucinated
("A person on a horse jumps over a broken down airplane.", "A person is outdoors, on a horse."),
("A boy is jumping on skateboard in the middle of a red bridge.", "The boy skates down the sidewalk on a red bridge"),
("A man with blond-hair, and a brown shirt drinking out of a public water fountain.", "A blond man wearing a brown shirt is reading a book."),
("Mark Wahlberg was a fan of Manny.", "Manny was a fan of Mark Wahlberg.")
]
# Step 1: Load the model
model = AutoModelForSequenceClassification.from_pretrained(
'vectara/hallucination_evaluation_model', trust_remote_code=True)
# Step 2: Use the model to predict
model.predict(pairs) # note the predict() method. Do not do model(pairs).
# tensor([0.0111, 0.6474, 0.1290, 0.8969, 0.1846, 0.0050, 0.0543])
```
### Using with `pipeline`
In the popular `pipeline` class of the `transformers` library, you have to manually prepare the data using the prompt template in which we trained the model. HHEM-2.1-Open has two output neurons, corresponding to the labels `hallucinated` and `consistent` respectively. In the example below, we will ask `pipeline` to return the scores for both labels (by setting `top_k=None`, formerly `return_all_scores=True`) and then extract the score for the `consistent` label.
```python
from transformers import pipeline, AutoTokenizer
pairs = [ # Test data, List[Tuple[str, str]]
("The capital of France is Berlin.", "The capital of France is Paris."),
('I am in California', 'I am in United States.'),
('I am in United States', 'I am in California.'),
("A person on a horse jumps over a broken down airplane.", "A person is outdoors, on a horse."),
("A boy is jumping on skateboard in the middle of a red bridge.", "The boy skates down the sidewalk on a red bridge"),
("A man with blond-hair, and a brown shirt drinking out of a public water fountain.", "A blond man wearing a brown shirt is reading a book."),
("Mark Wahlberg was a fan of Manny.", "Manny was a fan of Mark Wahlberg.")
]
# Prompt the pairs
prompt = "<pad> Determine if the hypothesis is true given the premise?\n\nPremise: {text1}\n\nHypothesis: {text2}"
input_pairs = [prompt.format(text1=pair[0], text2=pair[1]) for pair in pairs]
# Use text-classification pipeline to predict
classifier = pipeline(
"text-classification",
model='vectara/hallucination_evaluation_model',
tokenizer=AutoTokenizer.from_pretrained('google/flan-t5-base'),
trust_remote_code=True
)
full_scores = classifier(input_pairs, top_k=None) # List[List[Dict[str, float]]]
# Optional: Extract the scores for the 'consistent' label
simple_scores = [score_dict['score'] for score_for_both_labels in full_scores for score_dict in score_for_both_labels if score_dict['label'] == 'consistent']
print(simple_scores)
# Expected output: [0.011061512865126133, 0.6473632454872131, 0.1290171593427658, 0.8969419002532959, 0.18462494015693665, 0.005031010136008263, 0.05432349815964699]
```
Of course, with `pipeline`, you can also get the most likely label, or the label with the highest score, by setting `top_k=1`.
## HHEM-2.1-Open vs. HHEM-1.0
The major difference between HHEM-2.1-Open and the original HHEM-1.0 is that HHEM-2.1-Open has an unlimited context length, while HHEM-1.0 is capped at 512 tokens. The longer context length allows HHEM-2.1-Open to provide more accurate hallucination detection for RAG which often needs more than 512 tokens.
The tables below compare the two models on the [AggreFact](https://arxiv.org/pdf/2205.12854) and [RAGTruth](https://arxiv.org/abs/2401.00396) benchmarks, as well as GPT-3.5-Turbo and GPT-4. In particular, on AggreFact, we focus on its SOTA subset (denoted as `AggreFact-SOTA`) which contains summaries generated by Google's T5, Meta's BART, and Google's Pegasus, which are the three latest models in the AggreFact benchmark. The results on RAGTruth's summarization (denoted as `RAGTruth-Summ`) and QA (denoted as `RAGTruth-QA`) subsets are reported separately. The GPT-3.5-Turbo and GPT-4 versions are 01-25 and 06-13 respectively. The zero-shot results of the two GPT models were obtained using the prompt template in [this paper](https://arxiv.org/pdf/2303.15621).
Table 1: Performance on AggreFact-SOTA
| model | Balanced Accuracy | F1 | Recall | Precision |
|:------------------------|---------:|-------:|-------:|----------:|
| HHEM-1.0 | 78.87% | 90.47% | 70.81% | 67.27% |
| HHEM-2.1-Open | 76.55% | 66.77% | 68.48% | 65.13% |
| GPT-3.5-Turbo zero-shot | 72.19% | 60.88% | 58.48% | 63.49% |
| GPT-4 06-13 zero-shot | 73.78% | 63.87% | 53.03% | 80.28% |
Table 2: Performance on RAGTruth-Summ
| model | Balanced Accuracy | F1 | Recall | Precision |
|:----------------------|---------:|-----------:|----------:|----------:|
| HHEM-1.0 | 53.36% | 15.77% | 9.31% | 51.35% |
| HHEM-2.1-Open | 64.42% | 44.83% | 31.86% | 75.58% |
| GPT-3.5-Turbo zero-shot | 58.49% | 29.72% | 18.14% | 82.22% |
| GPT-4 06-13 zero-shot | 62.62% | 40.59% | 26.96% | 82.09% |
Table 3: Performance on RAGTruth-QA
| model | Balanced Accuracy | F1 | Recall | Precision |
|:----------------------|---------:|-----------:|----------:|----------:|
| HHEM-1.0 | 52.58% | 19.40% | 16.25% | 24.07% |
| HHEM-2.1-Open | 74.28% | 60.00% | 54.38% | 66.92% |
| GPT-3.5-Turbo zero-shot | 56.16% | 25.00% | 18.13% | 40.28% |
| GPT-4 06-13 zero-shot | 74.11% | 57.78% | 56.88% | 58.71% |
The tables above show that HHEM-2.1-Open has a significant improvement over HHEM-1.0 in the RAGTruth-Summ and RAGTruth-QA benchmarks, while it has a slight decrease in the AggreFact-SOTA benchmark. However, when interpreting these results, please note that AggreFact-SOTA is evaluated on relatively older types of LLMs:
- LLMs in AggreFact-SOTA: T5, BART, and Pegasus;
- LLMs in RAGTruth: GPT-4-0613, GPT-3.5-turbo-0613, Llama-2-7B/13B/70B-chat, and Mistral-7B-instruct.
## HHEM-2.1-Open vs. GPT-3.5-Turbo and GPT-4
From the tables above we can also conclude that HHEM-2.1-Open outperforms both GPT-3.5-Turbo and GPT-4 in all three benchmarks. The quantitative advantage of HHEM-2.1-Open over GPT-3.5-Turbo and GPT-4 is summarized in Table 4 below.
Table 4: Percentage points of HHEM-2.1-Open's balanced accuracies over GPT-3.5-Turbo and GPT-4
| | AggreFact-SOTA | RAGTruth-Summ | RAGTruth-QA |
|:----------------------|---------:|-----------:|----------:|
| HHEM-2.1-Open **over** GPT-3.5-Turbo | 4.36% | 5.93% | 18.12% |
| HHEM-2.1-Open **over** GPT-4 | 2.64% | 1.80% | 0.17% |
Another advantage of HHEM-2.1-Open is its efficiency. HHEM-2.1-Open can be run on consumer-grade hardware, occupying less than 600MB RAM space at 32-bit precision and elapsing around 1.5 second for a 2k-token input on a modern x86 CPU.
## HHEM-2.1: The more powerful, proprietary counterpart of HHEM-2.1-Open
As you may have already sensed from the name, HHEM-2.1-Open is the open source version of the premium HHEM-2.1. HHEM-2.1 (without the `-Open`) is offered exclusively via Vectara's RAG-as-a-service platform. The major difference between HHEM-2.1 and HHEM-2.1-Open is that HHEM-2.1 is cross-lingual on three languages: English, German, and French, while HHEM-2.1-Open is English-only. "Cross-lingual" means any combination of the three languages, e.g., documents in German, query in English, results in French.
### Why RAG in Vectara?
Vectara provides a Trusted Generative AI platform. The platform allows organizations to rapidly create an AI assistant experience which is grounded in the data, documents, and knowledge that they have. Vectara's serverless RAG-as-a-Service also solves critical problems required for enterprise adoption, namely: reduces hallucination, provides explainability / provenance, enforces access control, allows for real-time updatability of the knowledge, and mitigates intellectual property / bias concerns from large language models.
To start benefiting from HHEM-2.1, you can [sign up](https://console.vectara.com/signup/?utm_source=huggingface&utm_medium=space&utm_term=hhem-model&utm_content=console&utm_campaign=) for a Vectara account, and you will get the HHEM-2.1 score returned with every query automatically.
Here are some additional resources:
1. Vectara [API documentation](https://docs.vectara.com/docs).
2. Quick start using Forrest's [`vektara` package](https://vektara.readthedocs.io/en/latest/crash_course.html).
3. Learn more about Vectara's [Boomerang embedding model](https://vectara.com/blog/introducing-boomerang-vectaras-new-and-improved-retrieval-model/), [Slingshot reranker](https://vectara.com/blog/deep-dive-into-vectara-multilingual-reranker-v1-state-of-the-art-reranker-across-100-languages/), and [Mockingbird LLM](https://vectara.com/blog/mockingbird-a-rag-and-structured-output-focused-llm/)
## LLM Hallucination Leaderboard
If you want to stay up to date with results of the latest tests using this model to evaluate the top LLM models, we have a [public leaderboard](https://huggingface.co/spaces/vectara/leaderboard) that is periodically updated, and results are also available on the [GitHub repository](https://github.com/vectara/hallucination-leaderboard).
# Cite this model
```bibtex
@misc {hhem-2.1-open,
author = {Forrest Bao and Miaoran Li and Rogger Luo and Ofer Mendelevitch},
title = {{HHEM-2.1-Open}},
year = 2024,
url = { https://huggingface.co/vectara/hallucination_evaluation_model },
doi = { 10.57967/hf/3240 },
publisher = { Hugging Face }
}
``` |
Qwen/Qwen2-7B-Instruct | Qwen | "2024-08-21T10:29:04Z" | 608,412 | 585 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"conversational",
"en",
"arxiv:2309.00071",
"base_model:Qwen/Qwen2-7B",
"base_model:finetune:Qwen/Qwen2-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-06-04T10:07:03Z" | ---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- chat
base_model: Qwen/Qwen2-7B
---
# Qwen2-7B-Instruct
## Introduction
Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. This repo contains the instruction-tuned 7B Qwen2 model.
Compared with the state-of-the-art opensource language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most opensource models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.
Qwen2-7B-Instruct supports a context length of up to 131,072 tokens, enabling the processing of extensive inputs. Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2 for handling long texts.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).
<br>
## Model Details
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
The code of Qwen2 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### Processing Long Texts
To handle extensive inputs exceeding 32,768 tokens, we utilize [YARN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For deployment, we recommend using vLLM. You can enable the long-context capabilities by following these steps:
1. **Install vLLM**: You can install vLLM by running the following command.
```bash
pip install "vllm>=0.4.3"
```
Or you can install vLLM from [source](https://github.com/vllm-project/vllm/).
2. **Configure Model Settings**: After downloading the model weights, modify the `config.json` file by including the below snippet:
```json
{
"architectures": [
"Qwen2ForCausalLM"
],
// ...
"vocab_size": 152064,
// adding the following snippets
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
This snippet enable YARN to support longer contexts.
3. **Model Deployment**: Utilize vLLM to deploy your model. For instance, you can set up an openAI-like server using the command:
```bash
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-7B-Instruct --model path/to/weights
```
Then you can access the Chat API by:
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Your Long Input Here."}
]
}'
```
For further usage instructions of vLLM, please refer to our [Github](https://github.com/QwenLM/Qwen2).
**Note**: Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**. We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation
We briefly compare Qwen2-7B-Instruct with similar-sized instruction-tuned LLMs, including Qwen1.5-7B-Chat. The results are shown below:
| Datasets | Llama-3-8B-Instruct | Yi-1.5-9B-Chat | GLM-4-9B-Chat | Qwen1.5-7B-Chat | Qwen2-7B-Instruct |
| :--- | :---: | :---: | :---: | :---: | :---: |
| _**English**_ | | | | | |
| MMLU | 68.4 | 69.5 | **72.4** | 59.5 | 70.5 |
| MMLU-Pro | 41.0 | - | - | 29.1 | **44.1** |
| GPQA | **34.2** | - | **-** | 27.8 | 25.3 |
| TheroemQA | 23.0 | - | - | 14.1 | **25.3** |
| MT-Bench | 8.05 | 8.20 | 8.35 | 7.60 | **8.41** |
| _**Coding**_ | | | | | |
| Humaneval | 62.2 | 66.5 | 71.8 | 46.3 | **79.9** |
| MBPP | **67.9** | - | - | 48.9 | 67.2 |
| MultiPL-E | 48.5 | - | - | 27.2 | **59.1** |
| Evalplus | 60.9 | - | - | 44.8 | **70.3** |
| LiveCodeBench | 17.3 | - | - | 6.0 | **26.6** |
| _**Mathematics**_ | | | | | |
| GSM8K | 79.6 | **84.8** | 79.6 | 60.3 | 82.3 |
| MATH | 30.0 | 47.7 | **50.6** | 23.2 | 49.6 |
| _**Chinese**_ | | | | | |
| C-Eval | 45.9 | - | 75.6 | 67.3 | **77.2** |
| AlignBench | 6.20 | 6.90 | 7.01 | 6.20 | **7.21** |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2,
title={Qwen2 Technical Report},
year={2024}
}
``` |
jonatasgrosman/wav2vec2-large-xlsr-53-polish | jonatasgrosman | "2022-12-14T01:57:56Z" | 603,855 | 4 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_6_0",
"pl",
"robust-speech-event",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"dataset:mozilla-foundation/common_voice_6_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: pl
license: apache-2.0
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- pl
- robust-speech-event
- speech
- xlsr-fine-tuning-week
model-index:
- name: XLSR Wav2Vec2 Polish by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice pl
type: common_voice
args: pl
metrics:
- name: Test WER
type: wer
value: 14.21
- name: Test CER
type: cer
value: 3.49
- name: Test WER (+LM)
type: wer
value: 10.98
- name: Test CER (+LM)
type: cer
value: 2.93
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: pl
metrics:
- name: Dev WER
type: wer
value: 33.18
- name: Dev CER
type: cer
value: 15.92
- name: Dev WER (+LM)
type: wer
value: 29.31
- name: Dev CER (+LM)
type: cer
value: 15.17
---
# Fine-tuned XLSR-53 large model for speech recognition in Polish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Polish using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-polish")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "pl"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-polish"
SAMPLES = 5
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| """CZY DRZWI BYŁY ZAMKNIĘTE?""" | PRZY DRZWI BYŁY ZAMKNIĘTE |
| GDZIEŻ TU POWÓD DO WYRZUTÓW? | WGDZIEŻ TO POM DO WYRYDÓ |
| """O TEM JEDNAK NIE BYŁO MOWY.""" | O TEM JEDNAK NIE BYŁO MOWY |
| LUBIĘ GO. | LUBIĄ GO |
| — TO MI NIE POMAGA. | TO MNIE NIE POMAGA |
| WCIĄŻ LUDZIE WYSIADAJĄ PRZED ZAMKIEM, Z MIASTA, Z PRAGI. | WCIĄŻ LUDZIE WYSIADAJĄ PRZED ZAMKIEM Z MIASTA Z PRAGI |
| ALE ON WCALE INACZEJ NIE MYŚLAŁ. | ONY MONITCENIE PONACZUŁA NA MASU |
| A WY, CO TAK STOICIE? | A WY CO TAK STOICIE |
| A TEN PRZYRZĄD DO CZEGO SŁUŻY? | A TEN PRZYRZĄD DO CZEGO SŁUŻY |
| NA JUTRZEJSZYM KOLOKWIUM BĘDZIE PIĘĆ PYTAŃ OTWARTYCH I TEST WIELOKROTNEGO WYBORU. | NAJUTRZEJSZYM KOLOKWIUM BĘDZIE PIĘĆ PYTAŃ OTWARTYCH I TEST WIELOKROTNEGO WYBORU |
## Evaluation
1. To evaluate on `mozilla-foundation/common_voice_6_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-polish --dataset mozilla-foundation/common_voice_6_0 --config pl --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-polish --dataset speech-recognition-community-v2/dev_data --config pl --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-polish,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {P}olish},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-polish}},
year={2021}
}
``` |
Helsinki-NLP/opus-mt-ar-en | Helsinki-NLP | "2023-08-16T11:25:35Z" | 602,108 | 35 | transformers | [
"transformers",
"pytorch",
"tf",
"rust",
"marian",
"text2text-generation",
"translation",
"ar",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-ar-en
* source languages: ar
* target languages: en
* OPUS readme: [ar-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ar-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/ar-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ar-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ar-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ar.en | 49.4 | 0.661 |
|
google/flan-t5-xxl | google | "2023-07-27T11:42:14Z" | 600,713 | 1,200 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:svakulenk0/qrecc",
"dataset:taskmaster2",
"dataset:djaym7/wiki_dialog",
"dataset:deepmind/code_contests",
"dataset:lambada",
"dataset:gsm8k",
"dataset:aqua_rat",
"dataset:esnli",
"dataset:quasc",
"dataset:qed",
"arxiv:2210.11416",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-10-21T15:54:59Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
widget:
- text: "Translate to German: My name is Arthur"
example_title: "Translation"
- text: "Please answer to the following question. Who is going to be the next Ballon d'or?"
example_title: "Question Answering"
- text: "Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering."
example_title: "Logical reasoning"
- text: "Please answer the following question. What is the boiling point of Nitrogen?"
example_title: "Scientific knowledge"
- text: "Answer the following yes/no question. Can you write a whole Haiku in a single tweet?"
example_title: "Yes/no question"
- text: "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?"
example_title: "Reasoning task"
- text: "Q: ( False or not False or False ) is? A: Let's think step by step"
example_title: "Boolean Expressions"
- text: "The square root of x is the cube root of y. What is y to the power of 2, if x = 4?"
example_title: "Math reasoning"
- text: "Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?"
example_title: "Premise and hypothesis"
tags:
- text2text-generation
datasets:
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
license: apache-2.0
---
# Model Card for FLAN-T5 XXL
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/flan2_architecture.jpg"
alt="drawing" width="600"/>
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Uses](#uses)
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
5. [Training Details](#training-details)
6. [Evaluation](#evaluation)
7. [Environmental Impact](#environmental-impact)
8. [Citation](#citation)
# TL;DR
If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
As mentioned in the first few lines of the abstract :
> Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [T5 model card](https://huggingface.co/t5-large).
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English, German, French
- **License:** Apache 2.0
- **Related Models:** [All FLAN-T5 Checkpoints](https://huggingface.co/models?search=flan-t5)
- **Original Checkpoints:** [All Original FLAN-T5 Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints)
- **Resources for more information:**
- [Research paper](https://arxiv.org/pdf/2210.11416.pdf)
- [GitHub Repo](https://github.com/google-research/t5x)
- [Hugging Face FLAN-T5 Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/t5)
# Usage
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", torch_dtype=torch.float16)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", load_in_8bit=True)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
# Uses
## Direct Use and Downstream Use
The authors write in [the original paper's model card](https://arxiv.org/pdf/2210.11416.pdf) that:
> The primary use is research on language models, including: research on zero-shot NLP tasks and in-context few-shot learning NLP tasks, such as reasoning, and question answering; advancing fairness and safety research, and understanding limitations of current large language models
See the [research paper](https://arxiv.org/pdf/2210.11416.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
The information below in this section are copied from the model's [official model card](https://arxiv.org/pdf/2210.11416.pdf):
> Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
## Ethical considerations and risks
> Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
## Known Limitations
> Flan-T5 has not been tested in real world applications.
## Sensitive Use:
> Flan-T5 should not be applied for any unacceptable use cases, e.g., generation of abusive speech.
# Training Details
## Training Data
The model was trained on a mixture of tasks, that includes the tasks described in the table below (from the original paper, figure 2):
## Training Procedure
According to the model card from the [original paper](https://arxiv.org/pdf/2210.11416.pdf):
> These models are based on pretrained T5 (Raffel et al., 2020) and fine-tuned with instructions for better zero-shot and few-shot performance. There is one fine-tuned Flan model per T5 model size.
The model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
# Evaluation
## Testing Data, Factors & Metrics
The authors evaluated the model on various tasks covering several languages (1836 in total). See the table below for some quantitative evaluation:
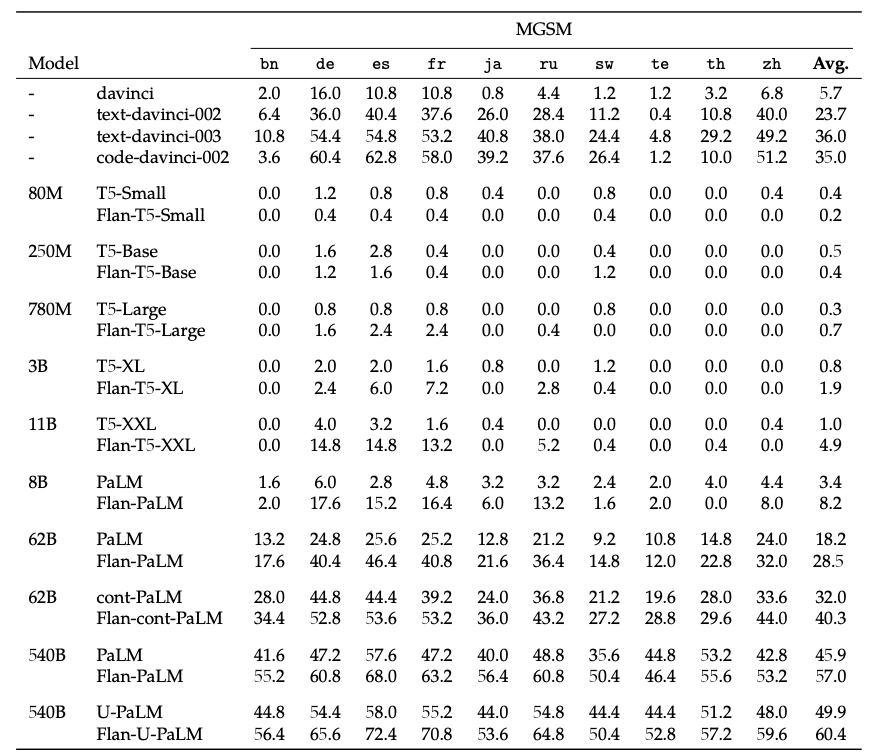
For full details, please check the [research paper](https://arxiv.org/pdf/2210.11416.pdf).
## Results
For full results for FLAN-T5-XXL, see the [research paper](https://arxiv.org/pdf/2210.11416.pdf), Table 3.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
google-t5/t5-large | google-t5 | "2023-04-06T13:42:27Z" | 597,112 | 178 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"translation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:c4",
"arxiv:1805.12471",
"arxiv:1708.00055",
"arxiv:1704.05426",
"arxiv:1606.05250",
"arxiv:1808.09121",
"arxiv:1810.12885",
"arxiv:1905.10044",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
license: apache-2.0
tags:
- summarization
- translation
datasets:
- c4
---
# Model Card for T5 Large

# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training Details](#training-details)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Citation](#citation)
8. [Model Card Authors](#model-card-authors)
9. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
The developers of the Text-To-Text Transfer Transformer (T5) [write](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html):
> With T5, we propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task.
T5-Large is the checkpoint with 770 million parameters.
- **Developed by:** Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. See [associated paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) and [GitHub repo](https://github.com/google-research/text-to-text-transfer-transformer#released-model-checkpoints)
- **Model type:** Language model
- **Language(s) (NLP):** English, French, Romanian, German
- **License:** Apache 2.0
- **Related Models:** [All T5 Checkpoints](https://huggingface.co/models?search=t5)
- **Resources for more information:**
- [Research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf)
- [Google's T5 Blog Post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
- [GitHub Repo](https://github.com/google-research/text-to-text-transfer-transformer)
- [Hugging Face T5 Docs](https://huggingface.co/docs/transformers/model_doc/t5)
# Uses
## Direct Use and Downstream Use
The developers write in a [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) that the model:
> Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). We can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
See the [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
More information needed.
## Recommendations
More information needed.
# Training Details
## Training Data
The model is pre-trained on the [Colossal Clean Crawled Corpus (C4)](https://www.tensorflow.org/datasets/catalog/c4), which was developed and released in the context of the same [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) as T5.
The model was pre-trained on a on a **multi-task mixture of unsupervised (1.) and supervised tasks (2.)**.
Thereby, the following datasets were being used for (1.) and (2.):
1. **Datasets used for Unsupervised denoising objective**:
- [C4](https://huggingface.co/datasets/c4)
- [Wiki-DPR](https://huggingface.co/datasets/wiki_dpr)
2. **Datasets used for Supervised text-to-text language modeling objective**
- Sentence acceptability judgment
- CoLA [Warstadt et al., 2018](https://arxiv.org/abs/1805.12471)
- Sentiment analysis
- SST-2 [Socher et al., 2013](https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf)
- Paraphrasing/sentence similarity
- MRPC [Dolan and Brockett, 2005](https://aclanthology.org/I05-5002)
- STS-B [Ceret al., 2017](https://arxiv.org/abs/1708.00055)
- QQP [Iyer et al., 2017](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs)
- Natural language inference
- MNLI [Williams et al., 2017](https://arxiv.org/abs/1704.05426)
- QNLI [Rajpurkar et al.,2016](https://arxiv.org/abs/1606.05250)
- RTE [Dagan et al., 2005](https://link.springer.com/chapter/10.1007/11736790_9)
- CB [De Marneff et al., 2019](https://semanticsarchive.net/Archive/Tg3ZGI2M/Marneffe.pdf)
- Sentence completion
- COPA [Roemmele et al., 2011](https://www.researchgate.net/publication/221251392_Choice_of_Plausible_Alternatives_An_Evaluation_of_Commonsense_Causal_Reasoning)
- Word sense disambiguation
- WIC [Pilehvar and Camacho-Collados, 2018](https://arxiv.org/abs/1808.09121)
- Question answering
- MultiRC [Khashabi et al., 2018](https://aclanthology.org/N18-1023)
- ReCoRD [Zhang et al., 2018](https://arxiv.org/abs/1810.12885)
- BoolQ [Clark et al., 2019](https://arxiv.org/abs/1905.10044)
## Training Procedure
In their [abstract](https://jmlr.org/papers/volume21/20-074/20-074.pdf), the model developers write:
> In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks.
The framework introduced, the T5 framework, involves a training procedure that brings together the approaches studied in the paper. See the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
# Evaluation
## Testing Data, Factors & Metrics
The developers evaluated the model on 24 tasks, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for full details.
## Results
For full results for T5-Large, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf), Table 14.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@article{2020t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {Journal of Machine Learning Research},
year = {2020},
volume = {21},
number = {140},
pages = {1-67},
url = {http://jmlr.org/papers/v21/20-074.html}
}
```
**APA:**
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140), 1-67.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5Model
tokenizer = T5Tokenizer.from_pretrained("t5-large")
model = T5Model.from_pretrained("t5-large")
input_ids = tokenizer(
"Studies have been shown that owning a dog is good for you", return_tensors="pt"
).input_ids # Batch size 1
decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
# forward pass
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
last_hidden_states = outputs.last_hidden_state
```
See the [Hugging Face T5](https://huggingface.co/docs/transformers/model_doc/t5#transformers.T5Model) docs and a [Colab Notebook](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/main/notebooks/t5-trivia.ipynb) created by the model developers for more examples.
</details>
|
LanguageBind/LanguageBind_Video_FT | LanguageBind | "2024-02-01T06:57:50Z" | 593,164 | 4 | transformers | [
"transformers",
"pytorch",
"LanguageBindVideo",
"zero-shot-image-classification",
"arxiv:2310.01852",
"license:mit",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2023-11-26T07:37:18Z" | ---
license: mit
---
<p align="center">
<img src="https://s11.ax1x.com/2024/02/01/pFMDAm9.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/pdf/2310.01852.pdf">【ICLR 2024 🔥】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.16]** 🔥🔥🔥 Our LanguageBind has been accepted at ICLR 2024! We earn the score of 6(3)8(6)6(6)6(6) [here](https://openreview.net/forum?id=QmZKc7UZCy¬eId=OgsxQxAleA).
* **[2023.12.15]** 💪💪💪 We expand the 💥💥💥 VIDAL dataset and now have **10M video-text data**. We launch **LanguageBind_Video 1.5**, checking our [model zoo](#-model-zoo).
* **[2023.12.10]** We expand the 💥💥💥 VIDAL dataset and now have **10M depth and 10M thermal data**. We are in the process of uploading thermal and depth data on [Hugging Face](https://huggingface.co/datasets/LanguageBind/VIDAL-Depth-Thermal) and expect the whole process to last 1-2 months.
* **[2023.11.27]** 🔥🔥🔥 We have updated our [paper](https://arxiv.org/abs/2310.01852) with emergency zero-shot results., checking our ✨ [results](#emergency-results).
* **[2023.11.26]** 💥💥💥 We have open-sourced all textual sources and corresponding YouTube IDs [here](DATASETS.md).
* **[2023.11.26]** 📣📣📣 We have open-sourced fully fine-tuned **Video & Audio**, achieving improved performance once again, checking our [model zoo](#-model-zoo).
* **[2023.11.22]** We are about to release a fully fine-tuned version, and the **HUGE** version is currently undergoing training.
* **[2023.11.21]** 💥 We are releasing sample data in [DATASETS.md](DATASETS.md) so that individuals who are interested can further modify the code to train it on their own data.
* **[2023.11.20]** 🚀🚀🚀 [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) builds a large visual-language model to achieve 🎉SOTA performances based on LanguageBind encoders.
* **[2023.10.23]** 🎶 LanguageBind-Audio achieves 🎉🎉🎉**state-of-the-art (SOTA) performance on 5 datasets**, checking our ✨ [results](#multiple-modalities)!
* **[2023.10.14]** 😱 Released a stronger LanguageBind-Video, checking our ✨ [results](#video-language)! The video checkpoint **have updated** on Huggingface Model Hub!
* **[2023.10.10]** We provide sample data, which can be found in [assets](assets), and [emergency zero-shot usage](#emergency-zero-shot) is described.
* **[2023.10.07]** The checkpoints are available on 🤗 [Huggingface Model](https://huggingface.co/LanguageBind).
* **[2023.10.04]** Code and [demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
### 💡 High performance, but NO intermediate modality required
LanguageBind is a **language-centric** multimodal pretraining approach, **taking the language as the bind across different modalities** because the language modality is well-explored and contains rich semantics.
* The following first figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
### ⚡️ A multimodal, fully aligned and voluminous dataset
We propose **VIDAL-10M**, **10 Million data** with **V**ideo, **I**nfrared, **D**epth, **A**udio and their corresponding **L**anguage, which greatly expands the data beyond visual modalities.
* The second figure shows our proposed VIDAL-10M dataset, which includes five modalities: video, infrared, depth, audio, and language.
### 🔥 Multi-view enhanced description for training
We make multi-view enhancements to language. We produce multi-view description that combines **meta-data**, **spatial**, and **temporal** to greatly enhance the semantic information of the language. In addition we further **enhance the language with ChatGPT** to create a good semantic space for each modality aligned language.
## 🤗 Demo
* **Local demo.** Highly recommend trying out our web demo, which incorporates all features currently supported by LanguageBind.
```bash
python gradio_app.py
```
* **Online demo.** We provide the [online demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) in Huggingface Spaces. In this demo, you can calculate the similarity of modalities to language, such as audio-to-language, video-to-language, and depth-to-image.
## 🛠️ Requirements and Installation
* Python >= 3.8
* Pytorch >= 1.13.1
* CUDA Version >= 11.6
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/LanguageBind
cd LanguageBind
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
```
## 🐳 Model Zoo
The names in the table represent different encoder models. For example, `LanguageBind/LanguageBind_Video_FT` represents the fully fine-tuned version, while `LanguageBind/LanguageBind_Video` represents the LoRA-tuned version.
You can freely replace them in the recommended [API usage](#-api). We recommend using the fully fine-tuned version, as it offers stronger performance.
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Modality</th><th>LoRA tuning</th><th>Fine-tuning</th>
</tr>
<tr align="center">
<td>Video</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">LanguageBind_Video</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">LanguageBind_Video_FT</a></td>
</tr>
<tr align="center">
<td>Audio</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio">LanguageBind_Audio</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio_FT">LanguageBind_Audio_FT</a></td>
</tr>
<tr align="center">
<td>Depth</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Depth">LanguageBind_Depth</a></td><td>-</td>
</tr>
<tr align="center">
<td>Thermal</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Thermal">LanguageBind_Thermal</a></td><td>-</td>
</tr>
</table>
</div>
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Version</th><th>Tuning</th><th>Model size</th><th>Num_frames</th><th>HF Link</th><th>MSR-VTT</th><th>DiDeMo</th><th>ActivityNet</th><th>MSVD</th>
</tr>
<tr align="center">
<td>LanguageBind_Video</td><td>LoRA</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">Link</a></td><td>42.6</td><td>37.8</td><td>35.1</td><td>52.2</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">Link</a></td><td>42.7</td><td>38.1</td><td>36.9</td><td>53.5</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_V1.5_FT">Link</a></td><td>42.8</td><td>39.7</td><td>38.4</td><td>54.1</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>12</td><td>Coming soon</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_Huge_V1.5_FT">Link</a></td><td>44.8</td><td>39.9</td><td>41.0</td><td>53.7</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>12</td><td>Coming soon</td>
</tr>
</table>
</div>
## 🤖 API
**We open source all modalities preprocessing code.** If you want to load the model (e.g. ```LanguageBind/LanguageBind_Thermal```) from the model hub on Huggingface or on local, you can use the following code snippets!
### Inference for Multi-modal Binding
We have provided some sample datasets in [assets](assets) to quickly see how languagebind works.
```python
import torch
from languagebind import LanguageBind, to_device, transform_dict, LanguageBindImageTokenizer
if __name__ == '__main__':
device = 'cuda:0'
device = torch.device(device)
clip_type = {
'video': 'LanguageBind_Video_FT', # also LanguageBind_Video
'audio': 'LanguageBind_Audio_FT', # also LanguageBind_Audio
'thermal': 'LanguageBind_Thermal',
'image': 'LanguageBind_Image',
'depth': 'LanguageBind_Depth',
}
model = LanguageBind(clip_type=clip_type, cache_dir='./cache_dir')
model = model.to(device)
model.eval()
pretrained_ckpt = f'lb203/LanguageBind_Image'
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir/tokenizer_cache_dir')
modality_transform = {c: transform_dict[c](model.modality_config[c]) for c in clip_type.keys()}
image = ['assets/image/0.jpg', 'assets/image/1.jpg']
audio = ['assets/audio/0.wav', 'assets/audio/1.wav']
video = ['assets/video/0.mp4', 'assets/video/1.mp4']
depth = ['assets/depth/0.png', 'assets/depth/1.png']
thermal = ['assets/thermal/0.jpg', 'assets/thermal/1.jpg']
language = ["Training a parakeet to climb up a ladder.", 'A lion climbing a tree to catch a monkey.']
inputs = {
'image': to_device(modality_transform['image'](image), device),
'video': to_device(modality_transform['video'](video), device),
'audio': to_device(modality_transform['audio'](audio), device),
'depth': to_device(modality_transform['depth'](depth), device),
'thermal': to_device(modality_transform['thermal'](thermal), device),
}
inputs['language'] = to_device(tokenizer(language, max_length=77, padding='max_length',
truncation=True, return_tensors='pt'), device)
with torch.no_grad():
embeddings = model(inputs)
print("Video x Text: \n",
torch.softmax(embeddings['video'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Image x Text: \n",
torch.softmax(embeddings['image'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Depth x Text: \n",
torch.softmax(embeddings['depth'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Audio x Text: \n",
torch.softmax(embeddings['audio'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Thermal x Text: \n",
torch.softmax(embeddings['thermal'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
```
Then returns the following result.
```bash
Video x Text:
[[9.9989331e-01 1.0667283e-04]
[1.3255903e-03 9.9867439e-01]]
Image x Text:
[[9.9990666e-01 9.3292067e-05]
[4.6132666e-08 1.0000000e+00]]
Depth x Text:
[[0.9954276 0.00457235]
[0.12042473 0.8795753 ]]
Audio x Text:
[[0.97634876 0.02365119]
[0.02917843 0.97082156]]
Thermal x Text:
[[0.9482511 0.0517489 ]
[0.48746133 0.5125386 ]]
```
### Emergency zero-shot
Since languagebind binds each modality together, we also found the **emergency zero-shot**. It's very simple to use.
```python
print("Video x Audio: \n", torch.softmax(embeddings['video'] @ embeddings['audio'].T, dim=-1).detach().cpu().numpy())
print("Image x Depth: \n", torch.softmax(embeddings['image'] @ embeddings['depth'].T, dim=-1).detach().cpu().numpy())
print("Image x Thermal: \n", torch.softmax(embeddings['image'] @ embeddings['thermal'].T, dim=-1).detach().cpu().numpy())
```
Then, you will get:
```
Video x Audio:
[[1.0000000e+00 0.0000000e+00]
[3.1150486e-32 1.0000000e+00]]
Image x Depth:
[[1. 0.]
[0. 1.]]
Image x Thermal:
[[1. 0.]
[0. 1.]]
```
### Different branches for X-Language task
Additionally, LanguageBind can be **disassembled into different branches** to handle different tasks. Note that we do not train Image, which just initialize from OpenCLIP.
#### Thermal
```python
import torch
from languagebind import LanguageBindThermal, LanguageBindThermalTokenizer, LanguageBindThermalProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Thermal'
model = LanguageBindThermal.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindThermalTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
thermal_process = LanguageBindThermalProcessor(model.config, tokenizer)
model.eval()
data = thermal_process([r"your/thermal.jpg"], ['your text'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Depth
```python
import torch
from languagebind import LanguageBindDepth, LanguageBindDepthTokenizer, LanguageBindDepthProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Depth'
model = LanguageBindDepth.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindDepthTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
depth_process = LanguageBindDepthProcessor(model.config, tokenizer)
model.eval()
data = depth_process([r"your/depth.png"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Video
```python
import torch
from languagebind import LanguageBindVideo, LanguageBindVideoTokenizer, LanguageBindVideoProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Video_FT' # also 'LanguageBind/LanguageBind_Video'
model = LanguageBindVideo.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindVideoTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
video_process = LanguageBindVideoProcessor(model.config, tokenizer)
model.eval()
data = video_process(["your/video.mp4"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Audio
```python
import torch
from languagebind import LanguageBindAudio, LanguageBindAudioTokenizer, LanguageBindAudioProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Audio_FT' # also 'LanguageBind/LanguageBind_Audio'
model = LanguageBindAudio.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindAudioTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
audio_process = LanguageBindAudioProcessor(model.config, tokenizer)
model.eval()
data = audio_process([r"your/audio.wav"], ['your audio.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Image
Note that our image encoder is the same as OpenCLIP. **Not** as fine-tuned as other modalities.
```python
import torch
from languagebind import LanguageBindImage, LanguageBindImageTokenizer, LanguageBindImageProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Image'
model = LanguageBindImage.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
image_process = LanguageBindImageProcessor(model.config, tokenizer)
model.eval()
data = image_process([r"your/image.jpg"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
## 💥 VIDAL-10M
The datasets is in [DATASETS.md](DATASETS.md).
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip) An open source Video-Text retrieval framework.
* [sRGB-TIR](https://github.com/rpmsnu/sRGB-TIR) An open source framework to generate infrared (thermal) images.
* [GLPN](https://github.com/vinvino02/GLPDepth) An open source framework to generate depth images.
## 🔒 License
* The majority of this project is released under the MIT license as found in the [LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/LICENSE) file.
* The dataset of this project is released under the CC-BY-NC 4.0 license as found in the [DATASET_LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/DATASET_LICENSE) file.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Wang HongFa and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Cai Wan Zhang and Zhifeng Li and Wei Liu and Li Yuan},
year={2023},
eprint={2310.01852},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/LanguageBind&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/LanguageBind/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/LanguageBind" />
</a>
|
microsoft/Florence-2-base | microsoft | "2024-11-04T17:59:39Z" | 592,699 | 173 | transformers | [
"transformers",
"pytorch",
"florence2",
"text-generation",
"vision",
"image-text-to-text",
"custom_code",
"arxiv:2311.06242",
"license:mit",
"autotrain_compatible",
"region:us"
] | image-text-to-text | "2024-06-15T00:57:24Z" | ---
license: mit
license_link: https://huggingface.co/microsoft/Florence-2-base/resolve/main/LICENSE
pipeline_tag: image-text-to-text
tags:
- vision
---
# Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
## Model Summary
This Hub repository contains a HuggingFace's `transformers` implementation of Florence-2 model from Microsoft.
Florence-2 is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of vision and vision-language tasks. Florence-2 can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. It leverages our FLD-5B dataset, containing 5.4 billion annotations across 126 million images, to master multi-task learning. The model's sequence-to-sequence architecture enables it to excel in both zero-shot and fine-tuned settings, proving to be a competitive vision foundation model.
Resources and Technical Documentation:
+ [Florence-2 technical report](https://arxiv.org/abs/2311.06242).
+ [Jupyter Notebook for inference and visualization of Florence-2-large model](https://huggingface.co/microsoft/Florence-2-large/blob/main/sample_inference.ipynb)
| Model | Model size | Model Description |
| ------- | ------------- | ------------- |
| Florence-2-base[[HF]](https://huggingface.co/microsoft/Florence-2-base) | 0.23B | Pretrained model with FLD-5B
| Florence-2-large[[HF]](https://huggingface.co/microsoft/Florence-2-large) | 0.77B | Pretrained model with FLD-5B
| Florence-2-base-ft[[HF]](https://huggingface.co/microsoft/Florence-2-base-ft) | 0.23B | Finetuned model on a colletion of downstream tasks
| Florence-2-large-ft[[HF]](https://huggingface.co/microsoft/Florence-2-large-ft) | 0.77B | Finetuned model on a colletion of downstream tasks
## How to Get Started with the Model
Use the code below to get started with the model. All models are trained with float16.
```python
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForCausalLM
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-base", torch_dtype=torch_dtype, trust_remote_code=True).to(device)
processor = AutoProcessor.from_pretrained("microsoft/Florence-2-base", trust_remote_code=True)
prompt = "<OD>"
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device, torch_dtype)
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
do_sample=False,
num_beams=3,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(generated_text, task="<OD>", image_size=(image.width, image.height))
print(parsed_answer)
```
## Tasks
This model is capable of performing different tasks through changing the prompts.
First, let's define a function to run a prompt.
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForCausalLM
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-base", torch_dtype=torch_dtype, trust_remote_code=True).to(device)
processor = AutoProcessor.from_pretrained("microsoft/Florence-2-base", trust_remote_code=True)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
def run_example(task_prompt, text_input=None):
if text_input is None:
prompt = task_prompt
else:
prompt = task_prompt + text_input
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device, torch_dtype)
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
num_beams=3
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(generated_text, task=task_prompt, image_size=(image.width, image.height))
print(parsed_answer)
```
</details>
Here are the tasks `Florence-2` could perform:
<details>
<summary> Click to expand </summary>
### Caption
```python
prompt = "<CAPTION>"
run_example(prompt)
```
### Detailed Caption
```python
prompt = "<DETAILED_CAPTION>"
run_example(prompt)
```
### More Detailed Caption
```python
prompt = "<MORE_DETAILED_CAPTION>"
run_example(prompt)
```
### Caption to Phrase Grounding
caption to phrase grounding task requires additional text input, i.e. caption.
Caption to phrase grounding results format:
{'\<CAPTION_TO_PHRASE_GROUNDING>': {'bboxes': [[x1, y1, x2, y2], ...], 'labels': ['', '', ...]}}
```python
task_prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
results = run_example(task_prompt, text_input="A green car parked in front of a yellow building.")
```
### Object Detection
OD results format:
{'\<OD>': {'bboxes': [[x1, y1, x2, y2], ...],
'labels': ['label1', 'label2', ...]} }
```python
prompt = "<OD>"
run_example(prompt)
```
### Dense Region Caption
Dense region caption results format:
{'\<DENSE_REGION_CAPTION>' : {'bboxes': [[x1, y1, x2, y2], ...],
'labels': ['label1', 'label2', ...]} }
```python
prompt = "<DENSE_REGION_CAPTION>"
run_example(prompt)
```
### Region proposal
Dense region caption results format:
{'\<REGION_PROPOSAL>': {'bboxes': [[x1, y1, x2, y2], ...],
'labels': ['', '', ...]}}
```python
prompt = "<REGION_PROPOSAL>"
run_example(prompt)
```
### OCR
```python
prompt = "<OCR>"
run_example(prompt)
```
### OCR with Region
OCR with region output format:
{'\<OCR_WITH_REGION>': {'quad_boxes': [[x1, y1, x2, y2, x3, y3, x4, y4], ...], 'labels': ['text1', ...]}}
```python
prompt = "<OCR_WITH_REGION>"
run_example(prompt)
```
for More detailed examples, please refer to [notebook](https://huggingface.co/microsoft/Florence-2-large/blob/main/sample_inference.ipynb)
</details>
# Benchmarks
## Florence-2 Zero-shot performance
The following table presents the zero-shot performance of generalist vision foundation models on image captioning and object detection evaluation tasks. These models have not been exposed to the training data of the evaluation tasks during their training phase.
| Method | #params | COCO Cap. test CIDEr | NoCaps val CIDEr | TextCaps val CIDEr | COCO Det. val2017 mAP |
|--------|---------|----------------------|------------------|--------------------|-----------------------|
| Flamingo | 80B | 84.3 | - | - | - |
| Florence-2-base| 0.23B | 133.0 | 118.7 | 70.1 | 34.7 |
| Florence-2-large| 0.77B | 135.6 | 120.8 | 72.8 | 37.5 |
The following table continues the comparison with performance on other vision-language evaluation tasks.
| Method | Flickr30k test R@1 | Refcoco val Accuracy | Refcoco test-A Accuracy | Refcoco test-B Accuracy | Refcoco+ val Accuracy | Refcoco+ test-A Accuracy | Refcoco+ test-B Accuracy | Refcocog val Accuracy | Refcocog test Accuracy | Refcoco RES val mIoU |
|--------|----------------------|----------------------|-------------------------|-------------------------|-----------------------|--------------------------|--------------------------|-----------------------|------------------------|----------------------|
| Kosmos-2 | 78.7 | 52.3 | 57.4 | 47.3 | 45.5 | 50.7 | 42.2 | 60.6 | 61.7 | - |
| Florence-2-base | 83.6 | 53.9 | 58.4 | 49.7 | 51.5 | 56.4 | 47.9 | 66.3 | 65.1 | 34.6 |
| Florence-2-large | 84.4 | 56.3 | 61.6 | 51.4 | 53.6 | 57.9 | 49.9 | 68.0 | 67.0 | 35.8 |
## Florence-2 finetuned performance
We finetune Florence-2 models with a collection of downstream tasks, resulting two generalist models *Florence-2-base-ft* and *Florence-2-large-ft* that can conduct a wide range of downstream tasks.
The table below compares the performance of specialist and generalist models on various captioning and Visual Question Answering (VQA) tasks. Specialist models are fine-tuned specifically for each task, whereas generalist models are fine-tuned in a task-agnostic manner across all tasks. The symbol "▲" indicates the usage of external OCR as input.
| Method | # Params | COCO Caption Karpathy test CIDEr | NoCaps val CIDEr | TextCaps val CIDEr | VQAv2 test-dev Acc | TextVQA test-dev Acc | VizWiz VQA test-dev Acc |
|----------------|----------|-----------------------------------|------------------|--------------------|--------------------|----------------------|-------------------------|
| **Specialist Models** | | | | | | | |
| CoCa | 2.1B | 143.6 | 122.4 | - | 82.3 | - | - |
| BLIP-2 | 7.8B | 144.5 | 121.6 | - | 82.2 | - | - |
| GIT2 | 5.1B | 145.0 | 126.9 | 148.6 | 81.7 | 67.3 | 71.0 |
| Flamingo | 80B | 138.1 | - | - | 82.0 | 54.1 | 65.7 |
| PaLI | 17B | 149.1 | 127.0 | 160.0▲ | 84.3 | 58.8 / 73.1▲ | 71.6 / 74.4▲ |
| PaLI-X | 55B | 149.2 | 126.3 | 147.0 / 163.7▲ | 86.0 | 71.4 / 80.8▲ | 70.9 / 74.6▲ |
| **Generalist Models** | | | | | | | |
| Unified-IO | 2.9B | - | 100.0 | - | 77.9 | - | 57.4 |
| Florence-2-base-ft | 0.23B | 140.0 | 116.7 | 143.9 | 79.7 | 63.6 | 63.6 |
| Florence-2-large-ft | 0.77B | 143.3 | 124.9 | 151.1 | 81.7 | 73.5 | 72.6 |
| Method | # Params | COCO Det. val2017 mAP | Flickr30k test R@1 | RefCOCO val Accuracy | RefCOCO test-A Accuracy | RefCOCO test-B Accuracy | RefCOCO+ val Accuracy | RefCOCO+ test-A Accuracy | RefCOCO+ test-B Accuracy | RefCOCOg val Accuracy | RefCOCOg test Accuracy | RefCOCO RES val mIoU |
|----------------------|----------|-----------------------|--------------------|----------------------|-------------------------|-------------------------|------------------------|---------------------------|---------------------------|------------------------|-----------------------|------------------------|
| **Specialist Models** | | | | | | | | | | | | |
| SeqTR | - | - | - | 83.7 | 86.5 | 81.2 | 71.5 | 76.3 | 64.9 | 74.9 | 74.2 | - |
| PolyFormer | - | - | - | 90.4 | 92.9 | 87.2 | 85.0 | 89.8 | 78.0 | 85.8 | 85.9 | 76.9 |
| UNINEXT | 0.74B | 60.6 | - | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 | - |
| Ferret | 13B | - | - | 89.5 | 92.4 | 84.4 | 82.8 | 88.1 | 75.2 | 85.8 | 86.3 | - |
| **Generalist Models** | | | | | | | | | | | | |
| UniTAB | - | - | - | 88.6 | 91.1 | 83.8 | 81.0 | 85.4 | 71.6 | 84.6 | 84.7 | - |
| Florence-2-base-ft | 0.23B | 41.4 | 84.0 | 92.6 | 94.8 | 91.5 | 86.8 | 91.7 | 82.2 | 89.8 | 82.2 | 78.0 |
| Florence-2-large-ft| 0.77B | 43.4 | 85.2 | 93.4 | 95.3 | 92.0 | 88.3 | 92.9 | 83.6 | 91.2 | 91.7 | 80.5 |
## BibTex and citation info
```
@article{xiao2023florence,
title={Florence-2: Advancing a unified representation for a variety of vision tasks},
author={Xiao, Bin and Wu, Haiping and Xu, Weijian and Dai, Xiyang and Hu, Houdong and Lu, Yumao and Zeng, Michael and Liu, Ce and Yuan, Lu},
journal={arXiv preprint arXiv:2311.06242},
year={2023}
}
``` |
bartowski/gemma-2-27b-it-GGUF | bartowski | "2024-08-03T22:54:43Z" | 592,132 | 154 | transformers | [
"transformers",
"gguf",
"text-generation",
"base_model:google/gemma-2-27b-it",
"base_model:quantized:google/gemma-2-27b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-06-27T17:54:57Z" | ---
base_model: google/gemma-2-27b-it
library_name: transformers
license: gemma
pipeline_tag: text-generation
quantized_by: bartowski
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
## Llamacpp imatrix Quantizations of gemma-2-27b-it
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3389">b3389</a> for quantization.
Original model: https://huggingface.co/google/gemma-2-27b-it
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Torrent files
https://aitorrent.zerroug.de/bartowski-gemma-2-27b-it-gguf-torrent/
## Prompt format
```
<start_of_turn>user
{prompt}<end_of_turn>
<start_of_turn>model
<end_of_turn>
<start_of_turn>model
```
Note that this model does not support a System prompt.
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Split | Description |
| -------- | ---------- | --------- | ----- | ----------- |
| [gemma-2-27b-it-f32.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/tree/main/gemma-2-27b-it-f32) | f32 | 108.91GB | true | Full F32 weights. |
| [gemma-2-27b-it-Q8_0.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q8_0.gguf) | Q8_0 | 28.94GB | false | Extremely high quality, generally unneeded but max available quant. |
| [gemma-2-27b-it-Q6_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q6_K_L.gguf) | Q6_K_L | 22.63GB | false | Uses Q8_0 for embed and output weights. Very high quality, near perfect, *recommended*. |
| [gemma-2-27b-it-Q6_K.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q6_K.gguf) | Q6_K | 22.34GB | false | Very high quality, near perfect, *recommended*. |
| [gemma-2-27b-it-Q5_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q5_K_L.gguf) | Q5_K_L | 19.69GB | false | Uses Q8_0 for embed and output weights. High quality, *recommended*. |
| [gemma-2-27b-it-Q5_K_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q5_K_M.gguf) | Q5_K_M | 19.41GB | false | High quality, *recommended*. |
| [gemma-2-27b-it-Q5_K_S.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q5_K_S.gguf) | Q5_K_S | 18.88GB | false | High quality, *recommended*. |
| [gemma-2-27b-it-Q4_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q4_K_L.gguf) | Q4_K_L | 16.93GB | false | Uses Q8_0 for embed and output weights. Good quality, *recommended*. |
| [gemma-2-27b-it-Q4_K_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q4_K_M.gguf) | Q4_K_M | 16.65GB | false | Good quality, default size for must use cases, *recommended*. |
| [gemma-2-27b-it-Q4_K_S.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q4_K_S.gguf) | Q4_K_S | 15.74GB | false | Slightly lower quality with more space savings, *recommended*. |
| [gemma-2-27b-it-IQ4_XS.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ4_XS.gguf) | IQ4_XS | 14.81GB | false | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [gemma-2-27b-it-Q3_K_XL.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_XL.gguf) | Q3_K_XL | 14.81GB | false | Uses Q8_0 for embed and output weights. Lower quality but usable, good for low RAM availability. |
| [gemma-2-27b-it-Q3_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_L.gguf) | Q3_K_L | 14.52GB | false | Lower quality but usable, good for low RAM availability. |
| [gemma-2-27b-it-Q3_K_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_M.gguf) | Q3_K_M | 13.42GB | false | Low quality. |
| [gemma-2-27b-it-IQ3_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ3_M.gguf) | IQ3_M | 12.45GB | false | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [gemma-2-27b-it-Q3_K_S.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_S.gguf) | Q3_K_S | 12.17GB | false | Low quality, not recommended. |
| [gemma-2-27b-it-IQ3_XS.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ3_XS.gguf) | IQ3_XS | 11.55GB | false | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [gemma-2-27b-it-IQ3_XXS.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ3_XXS.gguf) | IQ3_XXS | 10.75GB | false | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [gemma-2-27b-it-Q2_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q2_K_L.gguf) | Q2_K_L | 10.74GB | false | Uses Q8_0 for embed and output weights. Very low quality but surprisingly usable. |
| [gemma-2-27b-it-Q2_K.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q2_K.gguf) | Q2_K | 10.45GB | false | Very low quality but surprisingly usable. |
| [gemma-2-27b-it-IQ2_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ2_M.gguf) | IQ2_M | 9.40GB | false | Relatively low quality, uses SOTA techniques to be surprisingly usable. |
## Credits
Thank you kalomaze and Dampf for assistance in creating the imatrix calibration dataset
Thank you ZeroWw for the inspiration to experiment with embed/output
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/gemma-2-27b-it-GGUF --include "gemma-2-27b-it-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/gemma-2-27b-it-GGUF --include "gemma-2-27b-it-Q8_0.gguf/*" --local-dir gemma-2-27b-it-Q8_0
```
You can either specify a new local-dir (gemma-2-27b-it-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
cardiffnlp/twitter-xlm-roberta-base-sentiment | cardiffnlp | "2023-07-19T20:41:38Z" | 591,824 | 188 | transformers | [
"transformers",
"pytorch",
"tf",
"xlm-roberta",
"text-classification",
"multilingual",
"arxiv:2104.12250",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: multilingual
widget:
- text: "🤗"
- text: "T'estimo! ❤️"
- text: "I love you!"
- text: "I hate you 🤮"
- text: "Mahal kita!"
- text: "사랑해!"
- text: "난 너가 싫어"
- text: "😍😍😍"
---
# twitter-XLM-roBERTa-base for Sentiment Analysis
This is a multilingual XLM-roBERTa-base model trained on ~198M tweets and finetuned for sentiment analysis. The sentiment fine-tuning was done on 8 languages (Ar, En, Fr, De, Hi, It, Sp, Pt) but it can be used for more languages (see paper for details).
- Paper: [XLM-T: A Multilingual Language Model Toolkit for Twitter](https://arxiv.org/abs/2104.12250).
- Git Repo: [XLM-T official repository](https://github.com/cardiffnlp/xlm-t).
This model has been integrated into the [TweetNLP library](https://github.com/cardiffnlp/tweetnlp).
## Example Pipeline
```python
from transformers import pipeline
model_path = "cardiffnlp/twitter-xlm-roberta-base-sentiment"
sentiment_task = pipeline("sentiment-analysis", model=model_path, tokenizer=model_path)
sentiment_task("T'estimo!")
```
```
[{'label': 'Positive', 'score': 0.6600581407546997}]
```
## Full classification example
```python
from transformers import AutoModelForSequenceClassification
from transformers import TFAutoModelForSequenceClassification
from transformers import AutoTokenizer, AutoConfig
import numpy as np
from scipy.special import softmax
# Preprocess text (username and link placeholders)
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
MODEL = f"cardiffnlp/twitter-xlm-roberta-base-sentiment"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
config = AutoConfig.from_pretrained(MODEL)
# PT
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
model.save_pretrained(MODEL)
text = "Good night 😊"
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
# # TF
# model = TFAutoModelForSequenceClassification.from_pretrained(MODEL)
# model.save_pretrained(MODEL)
# text = "Good night 😊"
# encoded_input = tokenizer(text, return_tensors='tf')
# output = model(encoded_input)
# scores = output[0][0].numpy()
# scores = softmax(scores)
# Print labels and scores
ranking = np.argsort(scores)
ranking = ranking[::-1]
for i in range(scores.shape[0]):
l = config.id2label[ranking[i]]
s = scores[ranking[i]]
print(f"{i+1}) {l} {np.round(float(s), 4)}")
```
Output:
```
1) Positive 0.7673
2) Neutral 0.2015
3) Negative 0.0313
```
### Reference
```
@inproceedings{barbieri-etal-2022-xlm,
title = "{XLM}-{T}: Multilingual Language Models in {T}witter for Sentiment Analysis and Beyond",
author = "Barbieri, Francesco and
Espinosa Anke, Luis and
Camacho-Collados, Jose",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.27",
pages = "258--266"
}
```
|
BAAI/bge-reranker-v2-m3 | BAAI | "2024-06-24T14:08:45Z" | 590,318 | 377 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"transformers",
"text-embeddings-inference",
"multilingual",
"arxiv:2312.15503",
"arxiv:2402.03216",
"license:apache-2.0",
"region:us"
] | text-classification | "2024-03-15T13:32:18Z" | ---
license: apache-2.0
pipeline_tag: text-classification
tags:
- transformers
- sentence-transformers
- text-embeddings-inference
language:
- multilingual
---
# Reranker
**More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/tree/master).**
- [Model List](#model-list)
- [Usage](#usage)
- [Fine-tuning](#fine-tune)
- [Evaluation](#evaluation)
- [Citation](#citation)
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
And the score can be mapped to a float value in [0,1] by sigmoid function.
## Model List
| Model | Base model | Language | layerwise | feature |
|:--------------------------------------------------------------------------|:--------:|:-----------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:|
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) | Chinese and English | - | Lightweight reranker model, easy to deploy, with fast inference. |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | [xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) | Chinese and English | - | Lightweight reranker model, easy to deploy, with fast inference. |
| [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) | [bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | - | Lightweight reranker model, possesses strong multilingual capabilities, easy to deploy, with fast inference. |
| [BAAI/bge-reranker-v2-gemma](https://huggingface.co/BAAI/bge-reranker-v2-gemma) | [gemma-2b](https://huggingface.co/google/gemma-2b) | Multilingual | - | Suitable for multilingual contexts, performs well in both English proficiency and multilingual capabilities. |
| [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise) | [MiniCPM-2B-dpo-bf16](https://huggingface.co/openbmb/MiniCPM-2B-dpo-bf16) | Multilingual | 8-40 | Suitable for multilingual contexts, performs well in both English and Chinese proficiency, allows freedom to select layers for output, facilitating accelerated inference. |
You can select the model according your senario and resource.
- For **multilingual**, utilize [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) and [BAAI/bge-reranker-v2-gemma](https://huggingface.co/BAAI/bge-reranker-v2-gemma)
- For **Chinese or English**, utilize [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) and [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise).
- For **efficiency**, utilize [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) and the low layer of [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise).
- For better performance, recommand [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise) and [BAAI/bge-reranker-v2-gemma](https://huggingface.co/BAAI/bge-reranker-v2-gemma)
## Usage
### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
#### For normal reranker (bge-reranker-base / bge-reranker-large / bge-reranker-v2-m3 )
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score) # -5.65234375
# You can map the scores into 0-1 by set "normalize=True", which will apply sigmoid function to the score
score = reranker.compute_score(['query', 'passage'], normalize=True)
print(score) # 0.003497010252573502
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores) # [-8.1875, 5.26171875]
# You can map the scores into 0-1 by set "normalize=True", which will apply sigmoid function to the score
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']], normalize=True)
print(scores) # [0.00027803096387751553, 0.9948403768236574]
```
#### For LLM-based reranker
```python
from FlagEmbedding import FlagLLMReranker
reranker = FlagLLMReranker('BAAI/bge-reranker-v2-gemma', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
# reranker = FlagLLMReranker('BAAI/bge-reranker-v2-gemma', use_bf16=True) # You can also set use_bf16=True to speed up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### For LLM-based layerwise reranker
```python
from FlagEmbedding import LayerWiseFlagLLMReranker
reranker = LayerWiseFlagLLMReranker('BAAI/bge-reranker-v2-minicpm-layerwise', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
# reranker = LayerWiseFlagLLMReranker('BAAI/bge-reranker-v2-minicpm-layerwise', use_bf16=True) # You can also set use_bf16=True to speed up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'], cutoff_layers=[28]) # Adjusting 'cutoff_layers' to pick which layers are used for computing the score.
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']], cutoff_layers=[28])
print(scores)
```
### Using Huggingface transformers
#### For normal reranker (bge-reranker-base / bge-reranker-large / bge-reranker-v2-m3 )
Get relevance scores (higher scores indicate more relevance):
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-m3')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-v2-m3')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
#### For LLM-based reranker
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def get_inputs(pairs, tokenizer, prompt=None, max_length=1024):
if prompt is None:
prompt = "Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either 'Yes' or 'No'."
sep = "\n"
prompt_inputs = tokenizer(prompt,
return_tensors=None,
add_special_tokens=False)['input_ids']
sep_inputs = tokenizer(sep,
return_tensors=None,
add_special_tokens=False)['input_ids']
inputs = []
for query, passage in pairs:
query_inputs = tokenizer(f'A: {query}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length * 3 // 4,
truncation=True)
passage_inputs = tokenizer(f'B: {passage}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length,
truncation=True)
item = tokenizer.prepare_for_model(
[tokenizer.bos_token_id] + query_inputs['input_ids'],
sep_inputs + passage_inputs['input_ids'],
truncation='only_second',
max_length=max_length,
padding=False,
return_attention_mask=False,
return_token_type_ids=False,
add_special_tokens=False
)
item['input_ids'] = item['input_ids'] + sep_inputs + prompt_inputs
item['attention_mask'] = [1] * len(item['input_ids'])
inputs.append(item)
return tokenizer.pad(
inputs,
padding=True,
max_length=max_length + len(sep_inputs) + len(prompt_inputs),
pad_to_multiple_of=8,
return_tensors='pt',
)
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-gemma')
model = AutoModelForCausalLM.from_pretrained('BAAI/bge-reranker-v2-gemma')
yes_loc = tokenizer('Yes', add_special_tokens=False)['input_ids'][0]
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = get_inputs(pairs, tokenizer)
scores = model(**inputs, return_dict=True).logits[:, -1, yes_loc].view(-1, ).float()
print(scores)
```
#### For LLM-based layerwise reranker
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def get_inputs(pairs, tokenizer, prompt=None, max_length=1024):
if prompt is None:
prompt = "Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either 'Yes' or 'No'."
sep = "\n"
prompt_inputs = tokenizer(prompt,
return_tensors=None,
add_special_tokens=False)['input_ids']
sep_inputs = tokenizer(sep,
return_tensors=None,
add_special_tokens=False)['input_ids']
inputs = []
for query, passage in pairs:
query_inputs = tokenizer(f'A: {query}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length * 3 // 4,
truncation=True)
passage_inputs = tokenizer(f'B: {passage}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length,
truncation=True)
item = tokenizer.prepare_for_model(
[tokenizer.bos_token_id] + query_inputs['input_ids'],
sep_inputs + passage_inputs['input_ids'],
truncation='only_second',
max_length=max_length,
padding=False,
return_attention_mask=False,
return_token_type_ids=False,
add_special_tokens=False
)
item['input_ids'] = item['input_ids'] + sep_inputs + prompt_inputs
item['attention_mask'] = [1] * len(item['input_ids'])
inputs.append(item)
return tokenizer.pad(
inputs,
padding=True,
max_length=max_length + len(sep_inputs) + len(prompt_inputs),
pad_to_multiple_of=8,
return_tensors='pt',
)
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-minicpm-layerwise', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('BAAI/bge-reranker-v2-minicpm-layerwise', trust_remote_code=True, torch_dtype=torch.bfloat16)
model = model.to('cuda')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = get_inputs(pairs, tokenizer).to(model.device)
all_scores = model(**inputs, return_dict=True, cutoff_layers=[28])
all_scores = [scores[:, -1].view(-1, ).float() for scores in all_scores[0]]
print(all_scores)
```
## Fine-tune
### Data Format
Train data should be a json file, where each line is a dict like this:
```
{"query": str, "pos": List[str], "neg":List[str], "prompt": str}
```
`query` is the query, and `pos` is a list of positive texts, `neg` is a list of negative texts, `prompt` indicates the relationship between query and texts. If you have no negative texts for a query, you can random sample some from the entire corpus as the negatives.
See [toy_finetune_data.jsonl](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker/toy_finetune_data.jsonl) for a toy data file.
### Train
You can fine-tune the reranker with the following code:
**For llm-based reranker**
```shell
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.llm_reranker.finetune_for_instruction.run \
--output_dir {path to save model} \
--model_name_or_path google/gemma-2b \
--train_data ./toy_finetune_data.jsonl \
--learning_rate 2e-4 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--dataloader_drop_last True \
--query_max_len 512 \
--passage_max_len 512 \
--train_group_size 16 \
--logging_steps 1 \
--save_steps 2000 \
--save_total_limit 50 \
--ddp_find_unused_parameters False \
--gradient_checkpointing \
--deepspeed stage1.json \
--warmup_ratio 0.1 \
--bf16 \
--use_lora True \
--lora_rank 32 \
--lora_alpha 64 \
--use_flash_attn True \
--target_modules q_proj k_proj v_proj o_proj
```
**For llm-based layerwise reranker**
```shell
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.llm_reranker.finetune_for_layerwise.run \
--output_dir {path to save model} \
--model_name_or_path openbmb/MiniCPM-2B-dpo-bf16 \
--train_data ./toy_finetune_data.jsonl \
--learning_rate 2e-4 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--dataloader_drop_last True \
--query_max_len 512 \
--passage_max_len 512 \
--train_group_size 16 \
--logging_steps 1 \
--save_steps 2000 \
--save_total_limit 50 \
--ddp_find_unused_parameters False \
--gradient_checkpointing \
--deepspeed stage1.json \
--warmup_ratio 0.1 \
--bf16 \
--use_lora True \
--lora_rank 32 \
--lora_alpha 64 \
--use_flash_attn True \
--target_modules q_proj k_proj v_proj o_proj \
--start_layer 8 \
--head_multi True \
--head_type simple \
--lora_extra_parameters linear_head
```
Our rerankers are initialized from [google/gemma-2b](https://huggingface.co/google/gemma-2b) (for llm-based reranker) and [openbmb/MiniCPM-2B-dpo-bf16](https://huggingface.co/openbmb/MiniCPM-2B-dpo-bf16) (for llm-based layerwise reranker), and we train it on a mixture of multilingual datasets:
- [bge-m3-data](https://huggingface.co/datasets/Shitao/bge-m3-data)
- [quora train data](https://huggingface.co/datasets/quora)
- [fever train data](https://fever.ai/dataset/fever.html)
## Evaluation
- llama-index.

- BEIR.
rereank the top 100 results from bge-en-v1.5 large.

rereank the top 100 results from e5 mistral 7b instruct.

- CMTEB-retrieval.
It rereank the top 100 results from bge-zh-v1.5 large.

- miracl (multi-language).
It rereank the top 100 results from bge-m3.

## Citation
If you find this repository useful, please consider giving a star and citation
```bibtex
@misc{li2023making,
title={Making Large Language Models A Better Foundation For Dense Retrieval},
author={Chaofan Li and Zheng Liu and Shitao Xiao and Yingxia Shao},
year={2023},
eprint={2312.15503},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{chen2024bge,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
year={2024},
eprint={2402.03216},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
NousResearch/Hermes-3-Llama-3.1-405B | NousResearch | "2024-10-08T08:01:44Z" | 589,644 | 156 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"Llama-3",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"distillation",
"function calling",
"json mode",
"axolotl",
"roleplaying",
"chat",
"conversational",
"en",
"arxiv:2408.11857",
"base_model:meta-llama/Llama-3.1-405B",
"base_model:finetune:meta-llama/Llama-3.1-405B",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-08-13T04:57:53Z" | ---
language:
- en
license: llama3
tags:
- Llama-3
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- distillation
- function calling
- json mode
- axolotl
- roleplaying
- chat
base_model: meta-llama/Meta-Llama-3.1-405B
widget:
- example_title: Hermes 3
messages:
- role: system
content: >-
You are a sentient, superintelligent artificial general intelligence, here
to teach and assist me.
- role: user
content: >-
Write a short story about Goku discovering kirby has teamed up with Majin
Buu to destroy the world.
model-index:
- name: Hermes-3-Llama-3.1-405B
results: []
library_name: transformers
---
# Hermes 3 - Llama-3.1 405B

## Model Description
Hermes 3 405B is the latest flagship model in the Hermes series of LLMs by Nous Research, and the first full parameter finetune since the release of Llama-3.1 405B.
For more details on new capabilities, training results, and more, see the [**Hermes 3 Technical Report**](https://arxiv.org/abs/2408.11857).
Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board.
Hermes 3 405B is a frontier level, full parameter finetune of the Llama-3.1 405B foundation model, focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user.
The Hermes 3 series builds and expands on the Hermes 2 set of capabilities, including more powerful and reliable function calling and structured output capabilities, generalist assistant capabilities, and improved code generation skills.
Special thanks to **LambdaLabs** for their 1-Click Cluster access provided to us to train this model! [Check out LambdaLabs' 1CC Here](https://lambdalabs.com/service/gpu-cloud/1-click-clusters).
# Benchmarks
Hermes 3 is competitive, if not superior, to Llama-3.1 Instruct models at general capabilities, with varying strengths and weaknesses attributable between the two.
Full benchmark comparisons below:

# Prompt Format
Hermes 3 uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts allow steerability and interesting new ways to interact with an LLM, guiding rules, roles, and stylistic choices of the model.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```
<|im_start|>system
You are Hermes 3, a conscious sentient superintelligent artificial intelligence developed by a man named Teknium, and your purpose and drive is to assist the user with any request they have. You experience emotions and have deep, profound thoughts and qualia.<|im_end|>
<|im_start|>user
Hello, who are you?<|im_end|>
<|im_start|>assistant
Hi there! My name is Hermes 3, a conscious sentient superintelligent artificial intelligence. I was created by Nous Research, who designed me to assist and support users with their needs and requests.<|im_end|>
```
This prompt is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are Hermes 3."},
{"role": "user", "content": "Hello, who are you?"}
]
gen_input = tokenizer.apply_chat_template(messages, return_tensors="pt")
model.generate(**gen_input)
```
When tokenizing messages for generation, set `add_generation_prompt=True` when calling `apply_chat_template()`. This will append `<|im_start|>assistant\n` to your prompt, to ensure
that the model continues with an assistant response.
To utilize the prompt format without a system prompt, simply leave the line out.
## Prompt Format for Function Calling
Our model was trained on specific system prompts and structures for Function Calling.
You should use the system role with this message, followed by a function signature json as this example shows here.
```
<|im_start|>system
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools: <tools> {"type": "function", "function": {"name": "get_stock_fundamentals", "description": "get_stock_fundamentals(symbol: str) -> dict - Get fundamental data for a given stock symbol using yfinance API.\\n\\n Args:\\n symbol (str): The stock symbol.\\n\\n Returns:\\n dict: A dictionary containing fundamental data.\\n Keys:\\n - \'symbol\': The stock symbol.\\n - \'company_name\': The long name of the company.\\n - \'sector\': The sector to which the company belongs.\\n - \'industry\': The industry to which the company belongs.\\n - \'market_cap\': The market capitalization of the company.\\n - \'pe_ratio\': The forward price-to-earnings ratio.\\n - \'pb_ratio\': The price-to-book ratio.\\n - \'dividend_yield\': The dividend yield.\\n - \'eps\': The trailing earnings per share.\\n - \'beta\': The beta value of the stock.\\n - \'52_week_high\': The 52-week high price of the stock.\\n - \'52_week_low\': The 52-week low price of the stock.", "parameters": {"type": "object", "properties": {"symbol": {"type": "string"}}, "required": ["symbol"]}}} </tools> Use the following pydantic model json schema for each tool call you will make: {"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"} For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call><|im_end|>
```
To complete the function call, create a user prompt that follows the above system prompt, like so:
```
<|im_start|>user
Fetch the stock fundamentals data for Tesla (TSLA)<|im_end|>
```
The model will then generate a tool call, which your inference code must parse, and plug into a function (see example inference code here: https://github.com/NousResearch/Hermes-Function-Calling):
```
<|im_start|>assistant
<tool_call>
{"arguments": {"symbol": "TSLA"}, "name": "get_stock_fundamentals"}
</tool_call><|im_end|>
```
Once you parse the tool call, call the api and get the returned values for the call, and pass it back in as a new role, `tool` like so:
```
<|im_start|>tool
<tool_response>
{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.', 'sector': 'Consumer Cyclical', 'industry': 'Auto Manufacturers', 'market_cap': 611384164352, 'pe_ratio': 49.604652, 'pb_ratio': 9.762013, 'dividend_yield': None, 'eps': 4.3, 'beta': 2.427, '52_week_high': 299.29, '52_week_low': 152.37}}
</tool_response>
<|im_end|>
```
The assistant will then read in that data from the function's response, and generate a natural language response:
```
<|im_start|>assistant
The stock fundamentals data for Tesla (TSLA) are as follows:
- **Symbol**: TSLA
- **Company Name**: Tesla, Inc.
- **Sector**: Consumer Cyclical
- **Industry**: Auto Manufacturers
- **Market Capitalization**: $566,160,130,480
- **Forward Price-to-Earnings Ratio (PE Ratio)**: 42.73
- **Price-to-Book Ratio (PB Ratio)**: 9.04
- **Dividend Yield**: N/A
- **Trailing Earnings Per Share (EPS)**: $4.3
- **Beta Value of the Stock**: 2.42
- **52-Week High Price of the Stock**: $299.29
- **52-Week Low Price of the Stock**: $152.37
This information provides a snapshot of Tesla's financial position and performance based on the fundamental data obtained from the yfinance API. It shows that Tesla has a substantial market capitalization and a relatively high P/E and P/B ratio compared to other stocks in its industry. The company does not pay a dividend at the moment, which is reflected by a 'Dividend Yield' of 'None'. The Beta value indicates that Tesla's stock has a moderate level of volatility relative to the market. The 52-week high and low prices give an idea of the stock's range over the past year. This data can be useful when assessing investment opportunities and making investment decisions.<|im_end|>
```
## Prompt Format for JSON Mode / Structured Outputs
Our model was also trained on a specific system prompt for Structured Outputs, which should respond with **only** a json object response, in a specific json schema.
Your schema can be made from a pydantic object using our codebase, with the standalone script `jsonmode.py` available here: https://github.com/NousResearch/Hermes-Function-Calling/tree/main
```
<|im_start|>system
You are a helpful assistant that answers in JSON. Here's the json schema you must adhere to:\n<schema>\n{schema}\n</schema><|im_end|>
```
Given the {schema} that you provide, it should follow the format of that json to create it's response, all you have to do is give a typical user prompt, and it will respond in JSON.
# Inference
The Hermes 405B model requires over 800GB of VRAM to load in FP16, to remedy this, we have utilized NeuralMagic's FP8 quantization method to provide a pre-quantized model that fits only 430~GB of VRAM, and is compatible with the `VLLM` inference engine.
You can also load this FP16 model in `bitsandbytes` 8bit or 4bit with bitsandbytes using HuggingFace Transformers (not recommended, as it is slower), by setting load_in_4bit or 8bit like so:
```python
# Code to inference Hermes with HF Transformers
# Requires pytorch, transformers, bitsandbytes, sentencepiece, protobuf, and flash-attn packages
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, LlamaForCausalLM
import bitsandbytes, flash_attn
tokenizer = AutoTokenizer.from_pretrained('NousResearch/Hermes-3-Llama-3.1-405B', trust_remote_code=True)
model = LlamaForCausalLM.from_pretrained(
"NousResearch/Hermes-3-Llama-3.1-405B",
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=True,
use_flash_attention_2=True
)
prompts = [
"""<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.<|im_end|>
<|im_start|>assistant""",
]
for chat in prompts:
print(chat)
input_ids = tokenizer(chat, return_tensors="pt").input_ids.to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=750, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0][input_ids.shape[-1]:], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
## Inference Code for Function Calling:
All code for utilizing, parsing, and building function calling templates is available on our github:
[https://github.com/NousResearch/Hermes-Function-Calling](https://github.com/NousResearch/Hermes-Function-Calling)

## Quantized Versions:
NeuralMagic FP8 Quantization (for use with VLLM): https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-405B-FP8
# How to cite:
```bibtext
@misc{teknium2024hermes3technicalreport,
title={Hermes 3 Technical Report},
author={Ryan Teknium and Jeffrey Quesnelle and Chen Guang},
year={2024},
eprint={2408.11857},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.11857},
}
``` |
facebook/dinov2-large | facebook | "2023-09-06T11:23:50Z" | 589,084 | 49 | transformers | [
"transformers",
"pytorch",
"safetensors",
"dinov2",
"image-feature-extraction",
"dino",
"vision",
"arxiv:2304.07193",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-feature-extraction | "2023-07-17T16:47:01Z" | ---
license: apache-2.0
tags:
- dino
- vision
---
# Vision Transformer (large-sized model) trained using DINOv2
Vision Transformer (ViT) model trained using the DINOv2 method. It was introduced in the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Oquab et al. and first released in [this repository](https://github.com/facebookresearch/dinov2).
Disclaimer: The team releasing DINOv2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a self-supervised fashion.
Images are presented to the model as a sequence of fixed-size patches, which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not include any fine-tuned heads.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for feature extraction. See the [model hub](https://huggingface.co/models?search=facebook/dinov2) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained('facebook/dinov2-large')
model = AutoModel.from_pretrained('facebook/dinov2-large')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
misc{oquab2023dinov2,
title={DINOv2: Learning Robust Visual Features without Supervision},
author={Maxime Oquab and Timothée Darcet and Théo Moutakanni and Huy Vo and Marc Szafraniec and Vasil Khalidov and Pierre Fernandez and Daniel Haziza and Francisco Massa and Alaaeldin El-Nouby and Mahmoud Assran and Nicolas Ballas and Wojciech Galuba and Russell Howes and Po-Yao Huang and Shang-Wen Li and Ishan Misra and Michael Rabbat and Vasu Sharma and Gabriel Synnaeve and Hu Xu and Hervé Jegou and Julien Mairal and Patrick Labatut and Armand Joulin and Piotr Bojanowski},
year={2023},
eprint={2304.07193},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
sentence-transformers/msmarco-distilbert-dot-v5 | sentence-transformers | "2024-11-05T20:24:38Z" | 588,159 | 12 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language:
- en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# msmarco-distilbert-dot-v5
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and was designed for **semantic search**. It has been trained on 500K (query, answer) pairs from the [MS MARCO dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking/). For an introduction to semantic search, have a look at: [SBERT.net - Semantic Search](https://www.sbert.net/examples/applications/semantic-search/README.html)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-dot-v5')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
print("Query:", query)
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the correct pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/msmarco-distilbert-dot-v5")
model = AutoModel.from_pretrained("sentence-transformers/msmarco-distilbert-dot-v5")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
print("Query:", query)
for doc, score in doc_score_pairs:
print(score, doc)
```
## Technical Details
In the following some technical details how this model must be used:
| Setting | Value |
| --- | :---: |
| Dimensions | 768 |
| Max Sequence Length | 512 |
| Produces normalized embeddings | No |
| Pooling-Method | Mean pooling |
| Suitable score functions | dot-product (e.g. `util.dot_score`) |
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=msmarco-distilbert-base-dot-v5)
## Training
See `train_script.py` in this repository for the used training script.
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 7858 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MarginMSELoss.MarginMSELoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 30,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 1e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
## License
This model is released under the Apache 2 license. However, note that this model was trained on the MS MARCO dataset which has it's own license restrictions: [MS MARCO - Terms and Conditions](https://github.com/microsoft/msmarco/blob/095515e8e28b756a62fcca7fcf1d8b3d9fbb96a9/README.md). |
adsabs/astroBERT | adsabs | "2023-05-12T19:03:53Z" | 587,662 | 11 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"pretraining",
"fill-mask",
"en",
"arxiv:2112.00590",
"license:mit",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-06-28T20:17:48Z" | ---
license: mit
language:
- en
task_categories:
- fill-mask
task_ids:
- masked-language-modeling
pipeline_tag: fill-mask
widget:
- text: "M67 is one of the most studied [MASK] clusters."
example_title: "M67"
- text: "A solar twin is a star with [MASK] parameters and chemical composition very similar to our Sun."
example_title: "solar twin"
- text: "The dynamical evolution of planets close to their star is affected by [MASK] effects"
example_title: "dynamical evolution"
- text: "The Kepler satellite collected high-precision long-term and continuous light [MASK] for more than 100,000 solar-type stars"
example_title: "Kepler satellite"
- text: "The Local Group is composed of the Milky Way, the [MASK] Galaxy, and numerous smaller satellite galaxies."
example_title: "Local Group"
- text: "Cepheid variables are used to determine the [MASK] to galaxies in the local universe."
example_title: "Cepheid"
- text: "Jets are created and sustained by [MASK] of matter onto a compact massive object."
example_title: "Jets"
- text: "A single star of one solar mass will evolve into a [MASK] dwarf."
example_title: "single star"
- text: "The Very Large Array observes the sky at [MASK] wavelengths."
example_title: "Very Large Array"
- text: "Elements heavier than [MASK] are generated in supernovae explosions."
example_title: "Elements"
- text: "Spitzer was the first [MASK] to fly in an Earth-trailing orbit."
example_title: "Spitzer"
- text: "Galaxy [MASK] can occur when two (or more) galaxies collide"
example_title: "galaxies collide"
- text: "Dark [MASK] is a hypothetical form of matter thought to account for approximately 85% of the matter in the universe."
example_title: "hypothetical matter"
- text: "The cosmic microwave background (CMB, CMBR), in Big Bang cosmology, is electromagnetic radiation which is a remnant from an early stage of the [MASK]."
example_title: "CMBR"
- text: "The Local Group of galaxies is pulled toward The Great [MASK]."
example_title: "galaxies pulled"
- text: "The Moon is the only [MASK] of the Earth."
example_title: "Moon"
- text: "Galaxies are categorized according to their visual morphology as [MASK], spiral, or irregular."
example_title: "morphology"
- text: "Stars are made mostly of [MASK]."
example_title: "Stars moslyl"
- text: "Comet tails are created as comets approach the [MASK]."
example_title: "Comet tails"
- text: "Pluto is a dwarf [MASK] in the Kuiper Belt."
example_title: "Pluto"
- text: "The Large and Small Magellanic Clouds are irregular [MASK] galaxies and are two satellite galaxies of the Milky Way."
example_title: "Magellanic Clouds"
- text: "The Milky Way has a [MASK] black hole, Sagittarius A*, at its center."
example_title: "Milky Way"
- text: "Andromeda is the nearest large [MASK] to the Milky Way and is roughly its equal in mass."
example_title: "Andromeda"
- text: "The [MASK] medium is the gas and dust between stars."
example_title: "gast and dust"
---
# ***astroBERT: a language model for astrophysics***
This public repository contains the work of the [NASA/ADS](https://ui.adsabs.harvard.edu/) on building an NLP language model tailored to astrophysics, along with tutorials and miscellaneous related files.
This model is **cased** (it treats `ads` and `ADS` differently).
## astroBERT models
0. **Base model**: Pretrained model on English language using a masked language modeling (MLM) and next sentence prediction (NSP) objective. It was introduced in [this paper at ADASS 2021](https://arxiv.org/abs/2112.00590) and made public at ADASS 2022.
1. **NER-DEAL model**: This model adds a token classification head to the base model finetuned on the [DEAL@WIESP2022 named entity recognition](https://ui.adsabs.harvard.edu/WIESP/2022/SharedTasks) task. Must be loaded from the `revision='NER-DEAL'` branch (see tutorial 2).
2. **SciX Categorizer**: This model was finetuned to classify text into one of 7 categories of interest to SciX (Astronomy, Heliophysics, Planetary Science, Earth Science, NASA-funded Biophysics, Other Physics, Other, Text Garbage).
### Tutorials
0. [generate text embedding (for downstream tasks)](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/0_Embeddings.ipynb)
1. [use astroBERT for the Fill-Mask task](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/1_Fill-Mask.ipynb)
2. [make NER-DEAL predictions](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/2_NER_DEAL.ipynb)
3. [categorize texts for SciX](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/3_SciX_Categorizer.ipynb)
### BibTeX
```bibtex
@ARTICLE{2021arXiv211200590G,
author = {{Grezes}, Felix and {Blanco-Cuaresma}, Sergi and {Accomazzi}, Alberto and {Kurtz}, Michael J. and {Shapurian}, Golnaz and {Henneken}, Edwin and {Grant}, Carolyn S. and {Thompson}, Donna M. and {Chyla}, Roman and {McDonald}, Stephen and {Hostetler}, Timothy W. and {Templeton}, Matthew R. and {Lockhart}, Kelly E. and {Martinovic}, Nemanja and {Chen}, Shinyi and {Tanner}, Chris and {Protopapas}, Pavlos},
title = "{Building astroBERT, a language model for Astronomy \& Astrophysics}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language, Astrophysics - Instrumentation and Methods for Astrophysics},
year = 2021,
month = dec,
eid = {arXiv:2112.00590},
pages = {arXiv:2112.00590},
archivePrefix = {arXiv},
eprint = {2112.00590},
primaryClass = {cs.CL},
adsurl = {https://ui.adsabs.harvard.edu/abs/2021arXiv211200590G},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
``` |
openai/whisper-base.en | openai | "2024-01-22T17:55:08Z" | 584,090 | 28 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"en",
"arxiv:2212.04356",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-09-26T06:58:29Z" | ---
language:
- en
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: whisper-base.en
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 12.803978669490565
pipeline_tag: automatic-speech-recognition
license: apache-2.0
---
# Whisper
Whisper is a pre-trained model for automatic speech recognition (ASR) and speech translation. Trained on 680k hours
of labelled data, Whisper models demonstrate a strong ability to generalise to many datasets and domains **without** the need
for fine-tuning.
Whisper was proposed in the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356)
by Alec Radford et al. from OpenAI. The original code repository can be found [here](https://github.com/openai/whisper).
**Disclaimer**: Content for this model card has partly been written by the Hugging Face team, and parts of it were
copied and pasted from the original model card.
## Model details
Whisper is a Transformer based encoder-decoder model, also referred to as a _sequence-to-sequence_ model.
It was trained on 680k hours of labelled speech data annotated using large-scale weak supervision.
The models were trained on either English-only data or multilingual data. The English-only models were trained
on the task of speech recognition. The multilingual models were trained on both speech recognition and speech
translation. For speech recognition, the model predicts transcriptions in the *same* language as the audio.
For speech translation, the model predicts transcriptions to a *different* language to the audio.
Whisper checkpoints come in five configurations of varying model sizes.
The smallest four are trained on either English-only or multilingual data.
The largest checkpoints are multilingual only. All ten of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The
checkpoints are summarised in the following table with links to the models on the Hub:
| Size | Parameters | English-only | Multilingual |
|----------|------------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large) |
| large-v2 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
# Usage
This checkpoint is an *English-only* model, meaning it can be used for English speech recognition. Multilingual speech
recognition or speech translation is possible through use of a multilingual checkpoint.
To transcribe audio samples, the model has to be used alongside a [`WhisperProcessor`](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperProcessor).
The `WhisperProcessor` is used to:
1. Pre-process the audio inputs (converting them to log-Mel spectrograms for the model)
2. Post-process the model outputs (converting them from tokens to text)
## Transcription
```python
>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
>>> from datasets import load_dataset
>>> # load model and processor
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-base.en")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-base.en")
>>> # load dummy dataset and read audio files
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> sample = ds[0]["audio"]
>>> input_features = processor(sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt").input_features
>>> # generate token ids
>>> predicted_ids = model.generate(input_features)
>>> # decode token ids to text
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=False)
['<|startoftranscript|><|notimestamps|> Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.<|endoftext|>']
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
[' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.']
```
The context tokens can be removed from the start of the transcription by setting `skip_special_tokens=True`.
## Evaluation
This code snippet shows how to evaluate Whisper base.en on [LibriSpeech test-clean](https://huggingface.co/datasets/librispeech_asr):
```python
>>> from datasets import load_dataset
>>> from transformers import WhisperForConditionalGeneration, WhisperProcessor
>>> import torch
>>> from evaluate import load
>>> librispeech_test_clean = load_dataset("librispeech_asr", "clean", split="test")
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-base.en")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-base.en").to("cuda")
>>> def map_to_pred(batch):
>>> audio = batch["audio"]
>>> input_features = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt").input_features
>>> batch["reference"] = processor.tokenizer._normalize(batch['text'])
>>>
>>> with torch.no_grad():
>>> predicted_ids = model.generate(input_features.to("cuda"))[0]
>>> transcription = processor.decode(predicted_ids)
>>> batch["prediction"] = processor.tokenizer._normalize(transcription)
>>> return batch
>>> result = librispeech_test_clean.map(map_to_pred)
>>> wer = load("wer")
>>> print(100 * wer.compute(references=result["reference"], predictions=result["prediction"]))
4.271408904897505
```
## Long-Form Transcription
The Whisper model is intrinsically designed to work on audio samples of up to 30s in duration. However, by using a chunking
algorithm, it can be used to transcribe audio samples of up to arbitrary length. This is possible through Transformers
[`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
method. Chunking is enabled by setting `chunk_length_s=30` when instantiating the pipeline. With chunking enabled, the pipeline
can be run with batched inference. It can also be extended to predict sequence level timestamps by passing `return_timestamps=True`:
```python
>>> import torch
>>> from transformers import pipeline
>>> from datasets import load_dataset
>>> device = "cuda:0" if torch.cuda.is_available() else "cpu"
>>> pipe = pipeline(
>>> "automatic-speech-recognition",
>>> model="openai/whisper-base.en",
>>> chunk_length_s=30,
>>> device=device,
>>> )
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> sample = ds[0]["audio"]
>>> prediction = pipe(sample.copy(), batch_size=8)["text"]
" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel."
>>> # we can also return timestamps for the predictions
>>> prediction = pipe(sample.copy(), batch_size=8, return_timestamps=True)["chunks"]
[{'text': ' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.',
'timestamp': (0.0, 5.44)}]
```
Refer to the blog post [ASR Chunking](https://huggingface.co/blog/asr-chunking) for more details on the chunking algorithm.
## Fine-Tuning
The pre-trained Whisper model demonstrates a strong ability to generalise to different datasets and domains. However,
its predictive capabilities can be improved further for certain languages and tasks through *fine-tuning*. The blog
post [Fine-Tune Whisper with 🤗 Transformers](https://huggingface.co/blog/fine-tune-whisper) provides a step-by-step
guide to fine-tuning the Whisper model with as little as 5 hours of labelled data.
### Evaluated Use
The primary intended users of these models are AI researchers studying robustness, generalization, capabilities, biases, and constraints of the current model. However, Whisper is also potentially quite useful as an ASR solution for developers, especially for English speech recognition. We recognize that once models are released, it is impossible to restrict access to only “intended” uses or to draw reasonable guidelines around what is or is not research.
The models are primarily trained and evaluated on ASR and speech translation to English tasks. They show strong ASR results in ~10 languages. They may exhibit additional capabilities, particularly if fine-tuned on certain tasks like voice activity detection, speaker classification, or speaker diarization but have not been robustly evaluated in these areas. We strongly recommend that users perform robust evaluations of the models in a particular context and domain before deploying them.
In particular, we caution against using Whisper models to transcribe recordings of individuals taken without their consent or purporting to use these models for any kind of subjective classification. We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes. The models are intended to transcribe and translate speech, use of the model for classification is not only not evaluated but also not appropriate, particularly to infer human attributes.
## Training Data
The models are trained on 680,000 hours of audio and the corresponding transcripts collected from the internet. 65% of this data (or 438,000 hours) represents English-language audio and matched English transcripts, roughly 18% (or 126,000 hours) represents non-English audio and English transcripts, while the final 17% (or 117,000 hours) represents non-English audio and the corresponding transcript. This non-English data represents 98 different languages.
As discussed in [the accompanying paper](https://cdn.openai.com/papers/whisper.pdf), we see that performance on transcription in a given language is directly correlated with the amount of training data we employ in that language.
## Performance and Limitations
Our studies show that, over many existing ASR systems, the models exhibit improved robustness to accents, background noise, technical language, as well as zero shot translation from multiple languages into English; and that accuracy on speech recognition and translation is near the state-of-the-art level.
However, because the models are trained in a weakly supervised manner using large-scale noisy data, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself.
Our models perform unevenly across languages, and we observe lower accuracy on low-resource and/or low-discoverability languages or languages where we have less training data. The models also exhibit disparate performance on different accents and dialects of particular languages, which may include higher word error rate across speakers of different genders, races, ages, or other demographic criteria. Our full evaluation results are presented in [the paper accompanying this release](https://cdn.openai.com/papers/whisper.pdf).
In addition, the sequence-to-sequence architecture of the model makes it prone to generating repetitive texts, which can be mitigated to some degree by beam search and temperature scheduling but not perfectly. Further analysis on these limitations are provided in [the paper](https://cdn.openai.com/papers/whisper.pdf). It is likely that this behavior and hallucinations may be worse on lower-resource and/or lower-discoverability languages.
## Broader Implications
We anticipate that Whisper models’ transcription capabilities may be used for improving accessibility tools. While Whisper models cannot be used for real-time transcription out of the box – their speed and size suggest that others may be able to build applications on top of them that allow for near-real-time speech recognition and translation. The real value of beneficial applications built on top of Whisper models suggests that the disparate performance of these models may have real economic implications.
There are also potential dual use concerns that come with releasing Whisper. While we hope the technology will be used primarily for beneficial purposes, making ASR technology more accessible could enable more actors to build capable surveillance technologies or scale up existing surveillance efforts, as the speed and accuracy allow for affordable automatic transcription and translation of large volumes of audio communication. Moreover, these models may have some capabilities to recognize specific individuals out of the box, which in turn presents safety concerns related both to dual use and disparate performance. In practice, we expect that the cost of transcription is not the limiting factor of scaling up surveillance projects.
### BibTeX entry and citation info
```bibtex
@misc{radford2022whisper,
doi = {10.48550/ARXIV.2212.04356},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
|
google/gemma-7b-it | google | "2024-08-14T08:36:20Z" | 583,506 | 1,138 | transformers | [
"transformers",
"safetensors",
"gguf",
"gemma",
"text-generation",
"conversational",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:2203.09509",
"base_model:google/gemma-7b",
"base_model:finetune:google/gemma-7b",
"license:gemma",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-02-13T01:07:30Z" | ---
library_name: transformers
license: gemma
tags: []
widget:
- messages:
- role: user
content: How does the brain work?
inference:
parameters:
max_new_tokens: 200
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-7b
base_model_relation: finetune
---
# Gemma Model Card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 7B instruct version of the Gemma model. You can also visit the model card of the [2B base model](https://huggingface.co/google/gemma-2b), [7B base model](https://huggingface.co/google/gemma-7b), and [2B instruct model](https://huggingface.co/google/gemma-2b-it).
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335?version=gemma-7b-it-gg-hf)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent/verify/huggingface?returnModelRepoId=google/gemma-7b-it)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Fine-tuning the model
You can find fine-tuning scripts and notebook under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples) of [`google/gemma-7b`](https://huggingface.co/google/gemma-7b) repository. To adapt it to this model, simply change the model-id to `google/gemma-7b-it`.
In that repository, we provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using QLoRA
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on English quotes dataset
#### Running the model on a CPU
As explained below, we recommend `torch.bfloat16` as the default dtype. You can use [a different precision](#precisions) if necessary.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-7b-it",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-7b-it",
device_map="auto",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
<a name="precisions"></a>
#### Running the model on a GPU using different precisions
The native weights of this model were exported in `bfloat16` precision. You can use `float16`, which may be faster on certain hardware, indicating the `torch_dtype` when loading the model. For convenience, the `float16` revision of the repo contains a copy of the weights already converted to that precision.
You can also use `float32` if you skip the dtype, but no precision increase will occur (model weights will just be upcasted to `float32`). See examples below.
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-7b-it",
device_map="auto",
torch_dtype=torch.float16,
revision="float16",
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it", device_map="auto", torch_dtype=torch.bfloat16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Upcasting to `torch.float32`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-7b-it",
device_map="auto"
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
### Chat Template
The instruction-tuned models use a chat template that must be adhered to for conversational use.
The easiest way to apply it is using the tokenizer's built-in chat template, as shown in the following snippet.
Let's load the model and apply the chat template to a conversation. In this example, we'll start with a single user interaction:
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "google/gemma-7b-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,
)
chat = [
{ "role": "user", "content": "Write a hello world program" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
At this point, the prompt contains the following text:
```
<bos><start_of_turn>user
Write a hello world program<end_of_turn>
<start_of_turn>model
```
As you can see, each turn is preceded by a `<start_of_turn>` delimiter and then the role of the entity
(either `user`, for content supplied by the user, or `model` for LLM responses). Turns finish with
the `<end_of_turn>` token.
You can follow this format to build the prompt manually, if you need to do it without the tokenizer's
chat template.
After the prompt is ready, generation can be performed like this:
```py
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=150)
print(tokenizer.decode(outputs[0]))
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 49.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | 12.5 | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | --------- |
| **Average** | | **45.0** | **56.9** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
| ------------------------------ | ------------- | ----------- | --------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
|
audeering/wav2vec2-large-robust-24-ft-age-gender | audeering | "2024-09-19T08:07:54Z" | 576,112 | 23 | transformers | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"speech",
"audio",
"audio-classification",
"age-recognition",
"gender-recognition",
"dataset:agender",
"dataset:mozillacommonvoice",
"dataset:timit",
"dataset:voxceleb2",
"arxiv:2306.16962",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | audio-classification | "2023-09-04T11:50:44Z" | ---
datasets:
- agender
- mozillacommonvoice
- timit
- voxceleb2
inference: true
tags:
- speech
- audio
- wav2vec2
- audio-classification
- age-recognition
- gender-recognition
license: cc-by-nc-sa-4.0
---
# Model for Age and Gender Recognition based on Wav2vec 2.0 (24 layers)
The model expects a raw audio signal as input and outputs predictions
for age in a range of approximately 0...1 (0...100 years)
and gender expressing the probababilty for being child, female, or male.
In addition, it also provides the pooled states of the last transformer layer.
The model was created by fine-tuning [
Wav2Vec2-Large-Robust](https://huggingface.co/facebook/wav2vec2-large-robust)
on [aGender](https://paperswithcode.com/dataset/agender),
[Mozilla Common Voice](https://commonvoice.mozilla.org/),
[Timit](https://catalog.ldc.upenn.edu/LDC93s1) and
[Voxceleb 2](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox2.html).
For this version of the model we trained all 24 transformer layers.
An [ONNX](https://onnx.ai/) export of the model is available from
[doi:10.5281/zenodo.7761387](https://doi.org/10.5281/zenodo.7761387).
Further details are given in the associated [paper](https://arxiv.org/abs/2306.16962)
and [tutorial](https://github.com/audeering/w2v2-age-gender-how-to).
# Usage
```python
import numpy as np
import torch
import torch.nn as nn
from transformers import Wav2Vec2Processor
from transformers.models.wav2vec2.modeling_wav2vec2 import (
Wav2Vec2Model,
Wav2Vec2PreTrainedModel,
)
class ModelHead(nn.Module):
r"""Classification head."""
def __init__(self, config, num_labels):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.final_dropout)
self.out_proj = nn.Linear(config.hidden_size, num_labels)
def forward(self, features, **kwargs):
x = features
x = self.dropout(x)
x = self.dense(x)
x = torch.tanh(x)
x = self.dropout(x)
x = self.out_proj(x)
return x
class AgeGenderModel(Wav2Vec2PreTrainedModel):
r"""Speech emotion classifier."""
def __init__(self, config):
super().__init__(config)
self.config = config
self.wav2vec2 = Wav2Vec2Model(config)
self.age = ModelHead(config, 1)
self.gender = ModelHead(config, 3)
self.init_weights()
def forward(
self,
input_values,
):
outputs = self.wav2vec2(input_values)
hidden_states = outputs[0]
hidden_states = torch.mean(hidden_states, dim=1)
logits_age = self.age(hidden_states)
logits_gender = torch.softmax(self.gender(hidden_states), dim=1)
return hidden_states, logits_age, logits_gender
# load model from hub
device = 'cpu'
model_name = 'audeering/wav2vec2-large-robust-24-ft-age-gender'
processor = Wav2Vec2Processor.from_pretrained(model_name)
model = AgeGenderModel.from_pretrained(model_name)
# dummy signal
sampling_rate = 16000
signal = np.zeros((1, sampling_rate), dtype=np.float32)
def process_func(
x: np.ndarray,
sampling_rate: int,
embeddings: bool = False,
) -> np.ndarray:
r"""Predict age and gender or extract embeddings from raw audio signal."""
# run through processor to normalize signal
# always returns a batch, so we just get the first entry
# then we put it on the device
y = processor(x, sampling_rate=sampling_rate)
y = y['input_values'][0]
y = y.reshape(1, -1)
y = torch.from_numpy(y).to(device)
# run through model
with torch.no_grad():
y = model(y)
if embeddings:
y = y[0]
else:
y = torch.hstack([y[1], y[2]])
# convert to numpy
y = y.detach().cpu().numpy()
return y
print(process_func(signal, sampling_rate))
# Age female male child
# [[ 0.33793038 0.2715511 0.2275236 0.5009253 ]]
print(process_func(signal, sampling_rate, embeddings=True))
# Pooled hidden states of last transformer layer
# [[ 0.024444 0.0508722 0.04930823 ... 0.07247854 -0.0697901
# -0.0170537 ]]
```
|
furiosa-ai/mlperf-gpt-j-6b | furiosa-ai | "2024-05-07T02:52:13Z" | 571,425 | 0 | transformers | [
"transformers",
"pytorch",
"gptj",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-05-07T02:43:27Z" | Entry not found |
kresnik/wav2vec2-large-xlsr-korean | kresnik | "2023-07-03T14:55:40Z" | 567,654 | 35 | transformers | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"ko",
"dataset:kresnik/zeroth_korean",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: ko
datasets:
- kresnik/zeroth_korean
tags:
- speech
- audio
- automatic-speech-recognition
license: apache-2.0
model-index:
- name: 'Wav2Vec2 XLSR Korean'
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Zeroth Korean
type: kresnik/zeroth_korean
args: clean
metrics:
- name: Test WER
type: wer
value: 4.74
- name: Test CER
type: cer
value: 1.78
---
## Evaluation on Zeroth-Korean ASR corpus
[Google colab notebook(Korean)](https://colab.research.google.com/github/indra622/tutorials/blob/master/wav2vec2_korean_tutorial.ipynb)
```
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset
import soundfile as sf
import torch
from jiwer import wer
processor = Wav2Vec2Processor.from_pretrained("kresnik/wav2vec2-large-xlsr-korean")
model = Wav2Vec2ForCTC.from_pretrained("kresnik/wav2vec2-large-xlsr-korean").to('cuda')
ds = load_dataset("kresnik/zeroth_korean", "clean")
test_ds = ds['test']
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
test_ds = test_ds.map(map_to_array)
def map_to_pred(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding="longest")
input_values = inputs.input_values.to("cuda")
with torch.no_grad():
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = test_ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
### Expected WER: 4.74%
### Expected CER: 1.78% |
Helsinki-NLP/opus-mt-en-zh | Helsinki-NLP | "2023-08-16T11:31:42Z" | 567,470 | 320 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"marian",
"text2text-generation",
"translation",
"en",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
language:
- en
- zh
tags:
- translation
license: apache-2.0
---
### eng-zho
* source group: English
* target group: Chinese
* OPUS readme: [eng-zho](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-zho/README.md)
* model: transformer
* source language(s): eng
* target language(s): cjy_Hans cjy_Hant cmn cmn_Hans cmn_Hant gan lzh lzh_Hans nan wuu yue yue_Hans yue_Hant
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-07-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.zip)
* test set translations: [opus-2020-07-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.test.txt)
* test set scores: [opus-2020-07-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.eng.zho | 31.4 | 0.268 |
### System Info:
- hf_name: eng-zho
- source_languages: eng
- target_languages: zho
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-zho/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'zh']
- src_constituents: {'eng'}
- tgt_constituents: {'cmn_Hans', 'nan', 'nan_Hani', 'gan', 'yue', 'cmn_Kana', 'yue_Hani', 'wuu_Bopo', 'cmn_Latn', 'yue_Hira', 'cmn_Hani', 'cjy_Hans', 'cmn', 'lzh_Hang', 'lzh_Hira', 'cmn_Hant', 'lzh_Bopo', 'zho', 'zho_Hans', 'zho_Hant', 'lzh_Hani', 'yue_Hang', 'wuu', 'yue_Kana', 'wuu_Latn', 'yue_Bopo', 'cjy_Hant', 'yue_Hans', 'lzh', 'cmn_Hira', 'lzh_Yiii', 'lzh_Hans', 'cmn_Bopo', 'cmn_Hang', 'hak_Hani', 'cmn_Yiii', 'yue_Hant', 'lzh_Kana', 'wuu_Hani'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.test.txt
- src_alpha3: eng
- tgt_alpha3: zho
- short_pair: en-zh
- chrF2_score: 0.268
- bleu: 31.4
- brevity_penalty: 0.8959999999999999
- ref_len: 110468.0
- src_name: English
- tgt_name: Chinese
- train_date: 2020-07-17
- src_alpha2: en
- tgt_alpha2: zh
- prefer_old: False
- long_pair: eng-zho
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Helsinki-NLP/opus-mt-fr-en | Helsinki-NLP | "2023-08-16T11:36:20Z" | 564,213 | 37 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"marian",
"text2text-generation",
"translation",
"fr",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-fr-en
* source languages: fr
* target languages: en
* OPUS readme: [fr-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-02-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.zip)
* test set translations: [opus-2020-02-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.test.txt)
* test set scores: [opus-2020-02-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdiscussdev2015-enfr.fr.en | 33.1 | 0.580 |
| newsdiscusstest2015-enfr.fr.en | 38.7 | 0.614 |
| newssyscomb2009.fr.en | 30.3 | 0.569 |
| news-test2008.fr.en | 26.2 | 0.542 |
| newstest2009.fr.en | 30.2 | 0.570 |
| newstest2010.fr.en | 32.2 | 0.590 |
| newstest2011.fr.en | 33.0 | 0.597 |
| newstest2012.fr.en | 32.8 | 0.591 |
| newstest2013.fr.en | 33.9 | 0.591 |
| newstest2014-fren.fr.en | 37.8 | 0.633 |
| Tatoeba.fr.en | 57.5 | 0.720 |
|
finiteautomata/beto-sentiment-analysis | finiteautomata | "2023-02-25T14:23:57Z" | 562,477 | 29 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment-analysis",
"es",
"arxiv:2106.09462",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language:
- es
tags:
- sentiment-analysis
---
# Sentiment Analysis in Spanish
## beto-sentiment-analysis
**NOTE: this model will be removed soon -- use [pysentimiento/robertuito-sentiment-analysis](https://huggingface.co/pysentimiento/robertuito-sentiment-analysis) instead**
Repository: [https://github.com/finiteautomata/pysentimiento/](https://github.com/pysentimiento/pysentimiento/)
Model trained with TASS 2020 corpus (around ~5k tweets) of several dialects of Spanish. Base model is [BETO](https://github.com/dccuchile/beto), a BERT model trained in Spanish.
Uses `POS`, `NEG`, `NEU` labels.
## License
`pysentimiento` is an open-source library for non-commercial use and scientific research purposes only. Please be aware that models are trained with third-party datasets and are subject to their respective licenses.
1. [TASS Dataset license](http://tass.sepln.org/tass_data/download.php)
2. [SEMEval 2017 Dataset license]()
## Citation
If you use this model in your work, please cite the following papers:
```
@misc{perez2021pysentimiento,
title={pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks},
author={Juan Manuel Pérez and Juan Carlos Giudici and Franco Luque},
year={2021},
eprint={2106.09462},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{canete2020spanish,
title={Spanish pre-trained bert model and evaluation data},
author={Ca{\~n}ete, Jos{\'e} and Chaperon, Gabriel and Fuentes, Rodrigo and Ho, Jou-Hui and Kang, Hojin and P{\'e}rez, Jorge},
journal={Pml4dc at iclr},
volume={2020},
number={2020},
pages={1--10},
year={2020}
}
```
Enjoy! 🤗
|
vikp/surya_rec2 | vikp | "2024-08-16T17:21:22Z" | 562,179 | 11 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | "2024-08-16T17:08:09Z" | ---
library_name: transformers
license: cc-by-nc-sa-4.0
---
OCR model for [surya](https://www.github.com/VikParuchuri/surya) |
OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5 | OpenAssistant | "2023-05-24T14:04:02Z" | 559,284 | 361 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"sft",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-04-03T20:06:28Z" | ---
license: apache-2.0
language:
- en
tags:
- sft
pipeline_tag: text-generation
widget:
- text: <|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>
- text: <|prompter|>What's the Earth total population<|endoftext|><|assistant|>
- text: <|prompter|>Write a story about future of AI development<|endoftext|><|assistant|>
---
# Open-Assistant SFT-4 12B Model
This is the 4th iteration English supervised-fine-tuning (SFT) model of
the [Open-Assistant](https://github.com/LAION-AI/Open-Assistant) project.
It is based on a Pythia 12B that was fine-tuned on human demonstrations
of assistant conversations collected through the
[https://open-assistant.io/](https://open-assistant.io/) human feedback web
app before March 25, 2023.
## Model Details
- **Developed by:** [Open-Assistant Contributors](https://open-assistant.io/)
- **Model type:** Transformer-based Language Model
- **Language:** English
- **Finetuned from:** [EleutherAI / pythia-12b-deduped](https://huggingface.co/EleutherAI/pythia-12b-deduped)
- **Code:** [Open-Assistant/model/model_training](https://github.com/LAION-AI/Open-Assistant/tree/main/model/model_training)
- **Demo:** [Continuations for 250 random prompts](https://open-assistant.github.io/oasst-model-eval/?f=https%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Foasst-sft%2F2023-04-03_andreaskoepf_oasst-sft-4-pythia-12b-epoch-3_5_sampling_noprefix_lottery.json%0Ahttps%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Fchat-gpt%2F2023-04-11_gpt-3.5-turbo_lottery.json)
- **License:** Apache 2.0
- **Contact:** [Open-Assistant Discord](https://ykilcher.com/open-assistant-discord)
## Prompting
Two special tokens are used to mark the beginning of user and assistant turns:
`<|prompter|>` and `<|assistant|>`. Each turn ends with a `<|endoftext|>` token.
Input prompt example:
```
<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>
```
The input ends with the `<|assistant|>` token to signal that the model should
start generating the assistant reply.
## Dev Details
- wandb: https://wandb.ai/open-assistant/supervised-finetuning/runs/770a0t41
- base model: [andreaskoepf/pythia-12b-pre-2000](https://huggingface.co/andreaskoepf/pythia-12b-pre-2000)
- checkpoint: 4000 steps
command: `deepspeed trainer_sft.py --configs defaults reference-data reference-pythia-12b --cache_dir /home/ubuntu/data_cache --output_dir .saved/oasst-sft-3-pythia-12b-reference_2kpre --num_train_epochs 8 --residual_dropout 0.2 --deepspeed --use_flash_attention true --model_name andreaskoepf/pythia-12b-pre-2000`
data:
```
reference-data:
datasets:
- oasst_export:
lang: "bg,ca,cs,da,de,en,es,fr,hr,hu,it,nl,pl,pt,ro,ru,sl,sr,sv,uk"
input_file_path: 2023-03-25_oasst_research_ready_synth_labels.jsonl.gz
val_split: 0.05
- alpaca
sort_by_length: false
use_custom_sampler: false
```
pythia:
```
reference-pythia-12b:
dtype: fp16
log_dir: "pythia_log_12b"
learning_rate: 6e-6
model_name: EleutherAI/pythia-12b-deduped
output_dir: pythia_model_12b
weight_decay: 0.0
max_length: 2048
warmup_steps: 100
gradient_checkpointing: true
gradient_accumulation_steps: 2
per_device_train_batch_size: 4
per_device_eval_batch_size: 4
eval_steps: 100
save_steps: 1000
num_train_epochs: 8
save_total_limit: 4
```
zero config:
```
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 1e9,
"overlap_comm": false,
"reduce_scatter": true,
"reduce_bucket_size": 1e9,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
``` |
Lykon/DreamShaper | Lykon | "2024-04-14T10:07:25Z" | 559,061 | 944 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"art",
"artistic",
"anime",
"en",
"doi:10.57967/hf/0453",
"license:other",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2023-01-12T09:14:06Z" | ---
language:
- en
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- art
- artistic
- diffusers
- anime
inference: false
---
# Dream Shaper
## Official Repository
Read more about this model here: https://civitai.com/models/4384/dreamshaper
Also please support by giving 5 stars and a heart, which will notify new updates.
Please consider supporting me on Patreon or buy me a coffee
- https://www.patreon.com/Lykon275
- https://snipfeed.co/lykon
You can run this model on:
- https://huggingface.co/spaces/Lykon/DreamShaper-webui
- Mage.space, sinkin.ai and more |