
Dataset Card for #PraCegoVer
Dataset Summary
#PraCegoVer is a multi-modal dataset with Portuguese captions based on posts from Instagram. It is the first large dataset for image captioning in Portuguese with freely annotated images. The dataset has been created to alleviate the lack of datasets with Portuguese captions for visual-linguistic tasks.
#PraCegoVer comprehends 533,523 instances that represent public posts collected from Instagram tagged with #PraCegoVer. the data were collected from more than 14 thousand different profiles.
This dataset contains images of people, and it consists of data collected from public profiles on Instagram. Thus, the images and raw captions might contain sensitive data that reveal racial or ethnic origins, sexual orientations, and religious beliefs. Hence, under Brazilian Law No. 13,709, to avoid the unintended use of our dataset, we decided to restrict its access, ensuring that the dataset will be used for research purposes only.
Supported Tasks and Leaderboards
image-captioning,image-to-text: the dataset can be used to train models for Image Captioning, which consists in generating a short description of the visual content of a given image. The model performance is typically measured using ROUGE, METEOR, CIDEr-D, CIDEr-R and SPICE.
Languages
The captions in this dataset are in Brazilian Portuguese (pt-BR).
Dataset Structure
Data Instances
#PraCegoVer dataset is composed of the main file dataset.json and a directory with images, images. The instances in dataset.json have the following format:
{'user': '16247e952a987935792d1d9d937eeb8413e0367cfb9c5e640db1d1bc4a58dc01',
'filename': 'i-00518416.jpg',
'raw_caption': 'Com mais de 12 milhões de habitantes 👨🏾👩🏼🦰, #SãoPaulo é a maior e mais populosa cidade do Brasil 🇧🇷 , além de ser a primeira metrópole da América e do hemisfério sul.\n\nSe você mora nessa cidade incrível, comente um ❤️ nesta imagem.\n\n📸Bruno Mancini\n\n#MaisSegurosJuntos #Segurança #Aplicativo #Metrópole #Brasil\n\n#PraCegoVer #PraTodosVerem: Foto do Rio Pinheiros, em São Paulo, mostrando a Ponte Estaiada e vários prédios dos dois lados do rio. Com um tom azulado a imagem possui quatro i´s transparentes bem suaves cobrindo-a toda',
'caption': 'Foto do Rio Pinheiros, em São Paulo, mostrando a Ponte Estaiada e vários prédios dos dois lados do rio. Com um tom azulado a imagem possui quatro i´s transparentes bem suaves cobrindo-a toda.',
'date': '25-09-2020'},
Data Fields
user: anonymized user that created the post;
filename: image file name, which indicates the image in the images directory;
raw_caption: raw caption;
caption: clean caption;
date: post date.
Data Splits
This dataset comes with two specified train/validation/test splits, one for #PraCegoVer-63K (train/validation/test: 37,881/12,442/12,612) and another for #PraCegoVer-173K (train/validation/test: 104,004/34,452/34,882). These splits are subsets of the whole dataset.
Dataset Creation
Curation Rationale
Automatically describing images using natural sentences is an essential task to visually impaired people's inclusion on the Internet. Although there are many datasets in the literature, most of them contain only English captions, whereas datasets with captions described in other languages are scarce.
Then, inspired by the movement PraCegoVer, #PraCegoVer dataset has been created to provide images annotated with descriptions in Portuguese for the image captioning task. With this dataset, we aim to alleviate the lack of datasets with Portuguese captions for visual-linguistic tasks.
Source Data
Initial Data Collection and Normalization
The data were collected from posts on Instagram that tagged #PraCegoVer. Then, descriptions are extracted from the raw image caption by using regular expressions. The script to download more data is available in the #PraCegoVer repository. We collected the data on a daily basis from 2020 to 2021, but the posts can have been created at any time before this period.
Who are the source language producers?
The language producers are Instagram users that post images tagging #PraCegoVer.
Who are the annotators?
The Instagram users that tag #PraCegoVer spontaneously add a short description of the image content in their posts.
Personal and Sensitive Information
The usernames were anonymized in order to make it difficult to directly identify the individuals. However, we don't anonymize the remaining data, thus the individuals present in the images can be identified. Moreover, the images and raw captions might contain data revealing racial or ethnic origins, sexual orientations, religious beliefs, political opinions, or union memberships.
Considerations for Using the Data
Social Impact of Dataset
The purpose of this dataset is to help develop better image captioning models in Portuguese. Such models are essential to help the inclusion of visually impaired people on the Internet, making it more inclusive and democratic.
However, it is worth noting that the data were collected from public profiles on Instagram, and were not thoroughly validated. Thus, there might be more examples of offensive and insulting content, albeit an exploratory analysis shows that although there exist words that can be offensive they are insignificant because they occur rarely. Moreover, the images and raw captions might contain data revealing racial or ethnic origins, sexual orientations, religious beliefs, political opinions, or union memberships.
Discussion of Biases
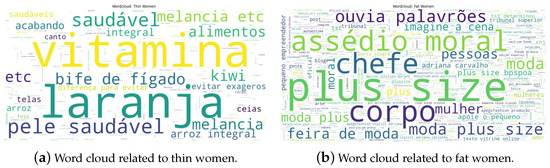
We collected the data from public posts on Instagram. Thus, the data is susceptible to the bias of its algorithm and stereotypes. We conducted an initial analysis of the bias within our dataset. Figure 20 from the dataset's paper shows that women are frequently associated with beauty, cosmetic products, and domestic violence. Moreover, black women co-occur more often with terms such as "racism", "discrimination", "prejudice" and "consciousness", whereas white women appear with "spa", "hair", and "lipstick", and indigenous women are mostly associated with beauty products. Similarly, black men frequently appear together with the terms "Zumbi dos Palmares", "consciousness", "racism", "United States" and "justice", while white men are associated with "theatre", "wage", "benefit" and "social security". In addition, Table 4 from the dataset's paper shows that women are more frequently associated with physical words (e.g., thin, fat); still, fat people appear more frequently than thin people. Figure 21 from the dataset's paper illustrates that fat women are also related to swearing words, "mental harassment", and "boss", while thin women are associated with "vitamin", "fruits", and "healthy skin". To sum up, depending on the usage of this dataset, future users may take these aspects into account.
{kind=link}
{kind=link}
Additional Information
Dataset Curators
The dataset was created by Gabriel Oliveira, Esther Colombini and Sandra Avila.
Citation Information
If you use #PraCegoVer dataset, please cite as:
@article{pracegover2022,
AUTHOR = {dos Santos, Gabriel Oliveira and Colombini, Esther Luna and Avila, Sandra},
TITLE = {#PraCegoVer: A Large Dataset for Image Captioning in Portuguese},
JOURNAL = {Data},
VOLUME = {7},
YEAR = {2022},
NUMBER = {2},
ARTICLE-NUMBER = {13},
URL = {https://www.mdpi.com/2306-5729/7/2/13},
ISSN = {2306-5729},
DOI = {10.3390/data7020013}
}
- Downloads last month
- 0