
File size: 3,004 Bytes
14b6eef 3f73376 7450c86 57ab6cc 7450c86 0319bd9 7450c86 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
---
license: other
---
# PubTables-1M
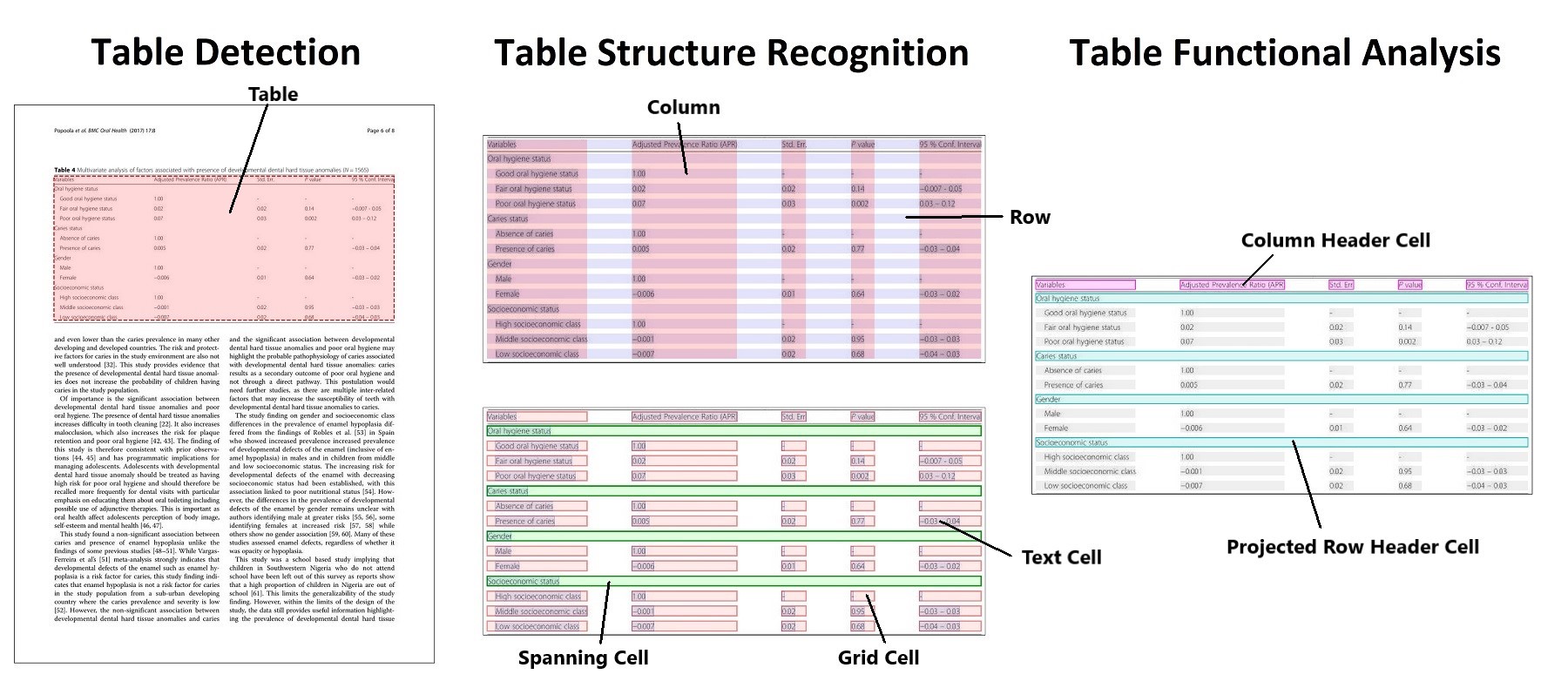
- GitHub: [https://github.com/microsoft/table-transformer](https://github.com/microsoft/table-transformer)
- Paper: ["PubTables-1M: Towards comprehensive table extraction from unstructured documents"](https://openaccess.thecvf.com/content/CVPR2022/html/Smock_PubTables-1M_Towards_Comprehensive_Table_Extraction_From_Unstructured_Documents_CVPR_2022_paper.html)
- Hugging Face:
- [Detection model](https://huggingface.co/microsoft/table-transformer-detection)
- [Structure recognition model](https://huggingface.co/microsoft/table-transformer-structure-recognition)
Currently we only support downloading the dataset as tar.gz files. Integrating with HuggingFace Datasets is something we hope to support in the future!
Please switch to the "Files and versions" tab to download all of the files or use a command such as wget to download from the command line.
Once downloaded, use the included script "extract_structure_dataset.sh" to extract and organize all of the data.
## Files
It comes in 18 tar.gz files:
Training and evaluation data for the structure recognition model (947,642 total cropped table instances):
- PubTables-1M-Structure_Filelists.tar.gz
- PubTables-1M-Structure_Annotations_Test.tar.gz: 93,834 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Annotations_Train.tar.gz: 758,849 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Annotations_Val.tar.gz: 94,959 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Images_Test.tar.gz
- PubTables-1M-Structure_Images_Train.tar.gz
- PubTables-1M-Structure_Images_Val.tar.gz
- PubTables-1M-Structure_Table_Words.tar.gz: Bounding boxes and text content for all of the words in each cropped table image
Training and evaluation data for the detection model (575,305 total document page instances):
- PubTables-1M-Detection_Filelists.tar.gz
- PubTables-1M-Detection_Annotations_Test.tar.gz: 57,125 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Annotations_Train.tar.gz: 460,589 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Annotations_Val.tar.gz: 57,591 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Images_Test.tar.gz
- PubTables-1M-Detection_Images_Train_Part1.tar.gz
- PubTables-1M-Detection_Images_Train_Part2.tar.gz
- PubTables-1M-Detection_Images_Val.tar.gz
- PubTables-1M-Detection_Page_Words.tar.gz: Bounding boxes and text content for all of the words in each page image (plus some unused files)
Full table annotations for the source PDF files:
- PubTables-1M-PDF_Annotations.tar.gz: Detailed annotations for all of the tables appearing in the source PubMed PDFs. All annotations are in PDF coordinates.
- 401,733 JSON files, one per source PDF document |