
bsmock/tatr-pubtables1m-v1.0
Updated
•
13
Error code: JobManagerCrashedError
Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
__key__
string | __url__
string | xml
unknown |
|---|---|---|
PMC1064082_1 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
48,
56,
50,
95,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
48,
56,
50,
95,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
56,
48,
53,
46,
52,
48,
55,
54,
54,
56,
54,
48,
52,
57,
57,
53,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
56,
48,
46,
51,
57,
54,
50,
53,
50,
50,
52,
49,
50,
57,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
56,
50,
46,
54,
55,
48,
56,
53,
53,
50,
56,
49,
51,
50,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064082_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
48,
56,
50,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
48,
56,
50,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
48,
52,
54,
52,
50,
53,
52,
48,
53,
49,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
55,
51,
46,
55,
48,
52,
54,
55,
56,
51,
57,
52,
55,
53,
53,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
49,
53,
46,
54,
50,
48,
55,
55,
54,
56,
54,
48,
52,
48,
48,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064098_6 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
48,
57,
56,
95,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
48,
57,
56,
95,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
52,
55,
55,
48,
48,
50,
55,
53,
51,
53,
56,
54,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
54,
53,
46,
48,
51,
55,
54,
49,
55,
53,
51,
56,
57,
49,
52,
53,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
56,
46,
52,
49,
48,
50,
51,
53,
50,
57,
53,
53,
51,
48,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
52,
51,
46,
54,
51,
54,
48,
50,
49,
52,
54,
57,
53,
55,
56,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064098_7 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
48,
57,
56,
95,
55,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
48,
57,
56,
95,
55,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
50,
57,
57,
56,
48,
48,
54,
56,
53,
49,
57,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
54,
53,
46,
48,
51,
55,
54,
49,
55,
53,
51,
56,
57,
49,
52,
53,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
51,
48,
52,
56,
54,
52,
54,
48,
50,
48,
49,
48,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
52,
51,
46,
54,
51,
54,
48,
50,
49,
52,
54,
57,
53,
55,
56,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064098_8 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
48,
57,
56,
95,
56,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
48,
57,
56,
95,
56,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
49,
51,
53,
57,
56,
56,
51,
50,
57,
50,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
54,
52,
46,
54,
53,
52,
57,
49,
52,
55,
55,
56,
56,
57,
50,
52,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
50,
52,
46,
54,
48,
54,
50,
48,
51,
54,
55,
51,
51,
49,
53,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
49,
53,
46,
57,
50,
56,
52,
52,
49,
56,
50,
55,
57,
52,
55,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
54,
51,
57,
46,
52,
50,
55,
53,
51,
49,
56,
52,
57,
50,
53,
52,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
54,
46,
53,
54,
54,
50,
50,
56,
49,
52,
55,
52,
49,
50,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
57,
56,
46,
53,
48,
51,
54,
50,
49,
52,
49,
57,
50,
55,
48,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064111_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
49,
49,
49,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
49,
49,
49,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
56,
53,
50,
53,
50,
49,
48,
50,
57,
51,
56,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
49,
48,
46,
48,
50,
53,
50,
48,
56,
53,
50,
48,
49,
48,
55,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
51,
55,
46,
51,
54,
55,
51,
52,
56,
55,
49,
57,
49,
50,
52,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064135_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
49,
51,
53,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
49,
51,
53,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
56,
53,
50,
53,
50,
49,
48,
50,
57,
51,
56,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
57,
46,
55,
57,
48,
50,
55,
55,
49,
57,
57,
54,
54,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
54,
51,
46,
51,
53,
50,
53,
57,
54,
51,
57,
56,
53,
53,
53,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064135_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
49,
51,
53,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
49,
51,
53,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
49,
46,
55,
52,
56,
56,
53,
50,
54,
53,
49,
54,
50,
55,
51,
51,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
57,
50,
49,
56,
48,
49,
56,
54,
53,
55,
48,
50,
57,
50,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
50,
46,
57,
48,
51,
53,
49,
51,
52,
50,
51,
55,
51,
50,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
53,
49,
46,
53,
57,
48,
55,
57,
56,
49,
49,
55,
56,
57,
55,
55,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
51,
52,
46,
49,
57,
53,
55,
53,
53,
52,
54,
55,
50,
55,
48,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
55,
46,
50,
52,
54,
54,
53,
55,
48,
55,
52,
52,
55,
52,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
56,
52,
46,
49,
56,
55,
49,
52,
55,
51,
53,
50,
52,
51,
48,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1064879_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
52,
56,
55,
57,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
52,
56,
55,
57,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
53,
56,
56,
54,
50,
52,
48,
52,
55,
52,
53,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
56,
53,
50,
53,
50,
49,
48,
50,
57,
51,
56,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
55,
51,
56,
49,
54,
50,
49,
56,
49,
52,
49,
54,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
57,
51,
46,
53,
55,
57,
52,
48,
57,
56,
50,
48,
56,
54,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065057_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
48,
53,
55,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
48,
53,
55,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
48,
52,
54,
52,
50,
53,
52,
48,
53,
49,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
48,
56,
46,
49,
54,
54,
57,
49,
55,
49,
52,
52,
50,
55,
53,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
54,
49,
46,
50,
51,
49,
48,
54,
50,
49,
52,
55,
51,
53,
50,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065063_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
56,
53,
50,
53,
50,
49,
48,
50,
57,
51,
56,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
54,
56,
46,
56,
51,
51,
49,
54,
50,
52,
48,
49,
53,
52,
51,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
52,
49,
46,
54,
56,
53,
57,
55,
57,
48,
53,
51,
50,
50,
55,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065063_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
56,
53,
50,
53,
50,
49,
48,
50,
57,
51,
56,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
53,
56,
46,
52,
51,
55,
48,
52,
52,
55,
51,
55,
55,
54,
56,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
55,
52,
46,
51,
51,
51,
57,
55,
54,
57,
55,
54,
55,
57,
57,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065063_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
56,
53,
50,
53,
50,
49,
48,
50,
57,
51,
56,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
51,
46,
54,
57,
52,
48,
50,
53,
50,
53,
56,
53,
52,
56,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
48,
56,
46,
50,
48,
48,
56,
55,
52,
55,
49,
51,
57,
51,
54,
50,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
49,
51,
53,
57,
56,
56,
51,
50,
57,
50,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
56,
57,
46,
57,
53,
51,
49,
53,
48,
56,
57,
51,
55,
48,
50,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
54,
55,
46,
55,
52,
54,
56,
55,
53,
50,
48,
48,
49,
49,
53,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
53,
57,
46,
52,
56,
56,
50,
55,
55,
50,
52,
50,
54,
52,
49,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065063_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
48,
54,
51,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
48,
52,
54,
52,
50,
53,
52,
48,
53,
49,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
56,
51,
46,
52,
57,
50,
49,
54,
52,
57,
56,
55,
48,
51,
50,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
54,
49,
46,
50,
51,
48,
57,
52,
54,
53,
53,
48,
52,
54,
53,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
52,
51,
52,
46,
52,
57,
56,
54,
48,
51,
56,
57,
55,
56,
54,
53,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
56,
51,
46,
52,
57,
50,
49,
54,
52,
57,
56,
55,
48,
51,
50,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
50,
51,
46,
53,
48,
49,
52,
55,
57,
48,
50,
51,
54,
51,
52,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065107_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
49,
48,
55,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
49,
48,
55,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
48,
52,
54,
52,
50,
53,
52,
48,
53,
49,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
50,
48,
46,
50,
56,
55,
57,
52,
51,
51,
53,
53,
51,
55,
50,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
57,
56,
46,
49,
57,
54,
56,
52,
50,
54,
57,
52,
53,
50,
51,
51,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
57,
55,
46,
55,
54,
49,
48,
49,
57,
51,
49,
49,
55,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
52,
46,
48,
50,
57,
55,
55,
53,
49,
53,
48,
52,
56,
54,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
52,
57,
46,
51,
51,
55,
49,
54,
55,
52,
53,
48,
56,
55,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065107_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
49,
48,
55,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
49,
48,
55,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
48,
52,
54,
52,
50,
53,
52,
48,
53,
49,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
50,
53,
55,
49,
52,
51,
49,
49,
52,
52,
51,
51,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
50,
54,
46,
48,
48,
51,
55,
54,
50,
52,
52,
55,
52,
55,
50,
55,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1065333_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
54,
53,
51,
51,
51,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
54,
53,
51,
51,
51,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
48,
52,
54,
52,
50,
53,
52,
48,
53,
49,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
57,
46,
57,
50,
54,
53,
57,
53,
55,
49,
57,
49,
51,
52,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
52,
49,
46,
54,
56,
52,
57,
55,
55,
50,
49,
51,
53,
52,
49,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
52,
50,
52,
46,
55,
51,
57,
57,
57,
49,
55,
55,
53,
54,
54,
54,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
54,
51,
53,
54,
57,
51,
49,
53,
57,
50,
53,
57,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
51,
49,
46,
56,
49,
56,
50,
49,
50,
54,
52,
52,
48,
49,
56,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079800_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
51,
57,
57,
46,
48,
49,
49,
52,
56,
51,
49,
49,
52,
50,
55,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
53,
46,
48,
48,
52,
49,
54,
52,
56,
57,
56,
57,
56,
49,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
50,
49,
46,
48,
57,
57,
55,
50,
50,
53,
48,
53,
56,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079800_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
49,
49,
48,
57,
52,
51,
49,
56,
55,
51,
54,
54,
56,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
48,
46,
55,
48,
54,
53,
54,
55,
57,
56,
51,
49,
53,
56,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
54,
48,
46,
52,
57,
57,
57,
56,
49,
49,
57,
54,
50,
51,
57,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079800_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
54,
46,
48,
49,
48,
49,
55,
51,
56,
54,
48,
49,
52,
51,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
56,
56,
46,
54,
55,
54,
54,
55,
54,
49,
50,
52,
48,
51,
51,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
55,
50,
54,
50,
49,
51,
55,
57,
57,
49,
52,
57,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
56,
54,
46,
49,
57,
49,
52,
51,
53,
53,
51,
52,
53,
52,
52,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
54,
46,
52,
49,
53,
52,
55,
57,
51,
49,
54,
48,
56,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
49,
52,
46,
49,
51,
48,
53,
48,
49,
55,
57,
53,
50,
57,
54,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079800_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
48,
48,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
51,
52,
57,
48,
53,
55,
48,
53,
54,
56,
54,
52,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
53,
49,
46,
52,
48,
50,
54,
51,
55,
50,
49,
49,
57,
54,
51,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079832_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
51,
57,
57,
46,
48,
49,
49,
52,
56,
51,
49,
49,
52,
50,
55,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
50,
48,
49,
49,
54,
50,
56,
54,
57,
56,
49,
51,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
57,
49,
46,
52,
48,
55,
56,
55,
54,
48,
54,
50,
56,
55,
52,
56,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079832_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
49,
55,
51,
53,
56,
48,
57,
56,
50,
54,
52,
54,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
54,
49,
46,
56,
53,
55,
56,
49,
51,
48,
53,
52,
56,
54,
53,
48,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079832_6 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
53,
54,
46,
52,
50,
53,
56,
48,
49,
50,
54,
49,
53,
50,
54,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
55,
52,
46,
56,
49,
50,
54,
48,
50,
48,
51,
51,
53,
49,
56,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
57,
52,
46,
49,
52,
53,
57,
54,
53,
53,
55,
54,
49,
55,
49,
57,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
51,
46,
52,
57,
55,
51,
55,
49,
52,
56,
53,
57,
55,
53,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
49,
48,
46,
54,
52,
53,
56,
57,
53,
50,
57,
51,
50,
54,
52,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079832_7 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
55,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
55,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
54,
46,
57,
55,
51,
50,
50,
56,
53,
55,
57,
54,
54,
49,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
55,
51,
46,
53,
50,
52,
52,
54,
55,
51,
57,
49,
49,
57,
55,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079832_8 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
56,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
51,
50,
95,
56,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
49,
51,
56,
57,
56,
56,
48,
53,
55,
49,
50,
48,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
56,
57,
46,
57,
54,
51,
56,
56,
53,
57,
57,
49,
50,
54,
48,
50,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079868_16 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
54,
56,
95,
49,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
54,
56,
95,
49,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
56,
51,
53,
48,
51,
56,
57,
56,
50,
52,
53,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
50,
57,
46,
48,
54,
48,
55,
53,
53,
52,
57,
53,
49,
54,
53,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
57,
48,
46,
48,
52,
50,
56,
49,
53,
53,
52,
53,
53,
57,
50,
54,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
57,
52,
52,
52,
49,
53,
49,
55,
48,
54,
51,
56,
51,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
48,
52,
46,
52,
56,
52,
51,
49,
49,
52,
57,
56,
55,
55,
54,
56,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
51,
54,
51,
46,
49,
57,
55,
52,
52,
50,
55,
50,
55,
48,
49,
48,
55,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
54,
49,
46,
56,
53,
56,
50,
57,
56,
53,
54,
49,
55,
56,
57,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079894_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
56,
57,
52,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
56,
57,
52,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
49,
50,
54,
57,
54,
57,
49,
51,
52,
50,
50,
49,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
57,
49,
46,
51,
50,
57,
57,
52,
56,
51,
52,
56,
50,
50,
56,
51,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
52,
54,
55,
46,
54,
51,
48,
56,
50,
57,
52,
55,
51,
57,
51,
56,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
49,
46,
48,
56,
57,
51,
50,
52,
52,
53,
48,
56,
56,
51,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
56,
55,
46,
54,
49,
53,
51,
53,
48,
50,
56,
48,
49,
52,
53,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079913_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
57,
49,
51,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
57,
49,
51,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
53,
48,
46,
48,
49,
48,
52,
55,
48,
48,
51,
48,
55,
51,
55,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
49,
56,
50,
46,
57,
57,
51,
52,
53,
53,
51,
54,
54,
54,
53,
52,
56,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079913_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
57,
49,
51,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
57,
49,
51,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
50,
46,
57,
55,
51,
50,
51,
56,
53,
56,
53,
52,
50,
53,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
51,
49,
46,
50,
53,
49,
51,
55,
57,
52,
53,
54,
49,
56,
50,
57,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
50,
57,
46,
48,
55,
48,
48,
56,
49,
54,
49,
52,
52,
56,
52,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
56,
46,
54,
53,
51,
53,
52,
49,
52,
51,
57,
56,
54,
57,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
54,
57,
46,
50,
48,
53,
50,
56,
50,
49,
57,
50,
48,
51,
55,
53,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079941_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
51,
57,
57,
46,
48,
49,
49,
48,
53,
57,
51,
55,
48,
49,
57,
55,
50,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
52,
53,
54,
46,
52,
53,
51,
57,
57,
55,
54,
55,
57,
52,
51,
49,
48,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
48,
51,
56,
57,
48,
55,
52,
49,
48,
54,
54,
56,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
55,
54,
46,
50,
53,
49,
55,
49,
51,
57,
49,
54,
53,
48,
56,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079941_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
48,
46,
56,
51,
57,
57,
57,
56,
54,
53,
49,
55,
50,
51,
51,
57,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
50,
55,
46,
56,
49,
55,
54,
50,
48,
49,
55,
49,
52,
52,
48,
57,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
51,
54,
55,
46,
49,
49,
48,
49,
52,
49,
52,
52,
49,
52,
55,
48,
50,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
56,
48,
46,
55,
50,
48,
54,
56,
57,
53,
54,
49,
54,
51,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
54,
51,
53,
46,
55,
55,
50,
49,
54,
53,
54,
50,
53,
57,
56,
54,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
48,
55,
54,
48,
52,
50,
56,
48,
48,
54,
53,
51,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
54,
55,
46,
48,
49,
49,
48,
57,
57,
49,
53,
48,
54,
56,
54,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079941_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
56,
46,
56,
54,
49,
54,
54,
51,
51,
49,
56,
48,
55,
49,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
49,
57,
53,
46,
56,
55,
50,
52,
56,
57,
56,
53,
50,
49,
51,
52,
54,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
48,
56,
46,
52,
50,
51,
53,
55,
50,
49,
49,
54,
52,
50,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
54,
52,
48,
54,
50,
51,
57,
57,
57,
52,
50,
51,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
55,
50,
46,
57,
57,
51,
53,
56,
52,
56,
51,
53,
49,
54,
56,
48,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1079941_6 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
55,
57,
57,
52,
49,
95,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
50,
46,
48,
54,
48,
48,
55,
55,
53,
53,
49,
54,
51,
57,
52,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
57,
46,
53,
49,
54,
50,
51,
50,
51,
52,
57,
56,
51,
51,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
49,
57,
52,
46,
57,
54,
50,
57,
55,
51,
53,
52,
54,
53,
48,
48,
49,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
50,
57,
51,
46,
50,
55,
50,
50,
49,
49,
48,
57,
52,
48,
57,
53,
50,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
57,
46,
53,
49,
54,
50,
51,
50,
51,
52,
57,
56,
51,
51,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
52,
54,
46,
49,
55,
53,
50,
54,
49,
50,
49,
56,
49,
51,
56,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084248_1 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
50,
52,
56,
95,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
50,
52,
56,
95,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
56,
54,
46,
50,
49,
52,
55,
53,
55,
57,
53,
48,
53,
55,
57,
53,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
56,
46,
57,
51,
57,
51,
57,
57,
48,
57,
51,
56,
55,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
54,
57,
46,
56,
49,
49,
56,
49,
57,
48,
53,
55,
50,
55,
49,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084345_1 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
51,
52,
53,
95,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
51,
52,
53,
95,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
49,
53,
46,
54,
54,
49,
49,
52,
51,
50,
57,
51,
50,
56,
52,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
54,
46,
48,
53,
56,
55,
51,
54,
56,
51,
50,
52,
49,
53,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
55,
50,
46,
57,
57,
52,
57,
51,
51,
52,
54,
53,
53,
49,
52,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084345_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
51,
52,
53,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
51,
52,
53,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
56,
50,
56,
50,
57,
55,
53,
57,
57,
52,
49,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
49,
53,
46,
54,
54,
49,
49,
52,
51,
50,
57,
51,
50,
56,
52,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
54,
46,
48,
53,
56,
55,
51,
54,
56,
51,
50,
52,
49,
53,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
57,
56,
46,
57,
48,
50,
56,
49,
54,
48,
48,
49,
56,
49,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084351_1 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
49,
95,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
49,
95,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
56,
48,
51,
51,
49,
48,
55,
48,
54,
57,
54,
55,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
54,
54,
46,
50,
53,
48,
57,
56,
48,
50,
54,
49,
54,
48,
48,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084351_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
49,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
49,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
54,
49,
57,
46,
53,
50,
52,
54,
51,
55,
56,
53,
56,
48,
55,
50,
57,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
54,
46,
49,
49,
55,
55,
53,
50,
56,
50,
53,
54,
50,
55,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
54,
54,
46,
52,
48,
50,
52,
52,
51,
48,
48,
57,
49,
57,
51,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084351_6 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
49,
95,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
49,
95,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
56,
53,
52,
51,
57,
49,
49,
50,
57,
50,
57,
48,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
48,
56,
46,
56,
50,
55,
50,
55,
56,
56,
51,
48,
55,
56,
56,
51,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084353_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
51,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
51,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
56,
54,
46,
57,
52,
57,
48,
49,
49,
50,
57,
50,
49,
50,
48,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
50,
46,
55,
54,
52,
51,
52,
54,
50,
54,
51,
52,
52,
55,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
54,
49,
46,
57,
51,
50,
54,
48,
52,
50,
52,
48,
54,
52,
56,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1084353_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
51,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
52,
51,
53,
51,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
53,
46,
52,
50,
53,
49,
53,
48,
56,
56,
54,
57,
49,
48,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
51,
57,
46,
56,
56,
55,
49,
49,
52,
50,
52,
53,
52,
56,
50,
49,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087471_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
52,
55,
49,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
52,
55,
49,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
53,
49,
56,
49,
54,
57,
52,
54,
53,
54,
49,
50,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
56,
51,
46,
49,
52,
53,
55,
48,
52,
49,
55,
51,
48,
55,
56,
52,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087471_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
52,
55,
49,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
52,
55,
49,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
55,
51,
52,
56,
56,
49,
50,
57,
49,
54,
50,
53,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
55,
54,
55,
55,
49,
54,
50,
48,
52,
53,
51,
51,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
52,
49,
46,
49,
56,
48,
49,
56,
49,
48,
50,
49,
54,
52,
50,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087471_6 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
52,
55,
49,
95,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
52,
55,
49,
95,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
49,
46,
50,
52,
53,
52,
52,
49,
51,
55,
52,
50,
51,
49,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
53,
49,
46,
49,
55,
56,
52,
52,
56,
54,
48,
57,
54,
51,
49,
52,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087851_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
56,
53,
49,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
56,
53,
49,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
51,
57,
57,
46,
48,
49,
49,
51,
50,
57,
48,
50,
53,
53,
49,
56,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
49,
46,
52,
50,
56,
54,
48,
50,
56,
55,
53,
50,
53,
54,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
51,
52,
46,
55,
51,
54,
53,
52,
56,
53,
50,
57,
55,
51,
48,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087851_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
56,
53,
49,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
56,
53,
49,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
56,
56,
49,
50,
54,
53,
54,
48,
56,
57,
57,
49,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
49,
49,
49,
49,
54,
52,
53,
49,
54,
56,
55,
50,
56,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
49,
46,
56,
56,
49,
49,
48,
57,
53,
49,
57,
48,
56,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
54,
48,
46,
54,
52,
53,
52,
51,
50,
57,
48,
53,
55,
49,
55,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
56,
55,
57,
51,
51,
57,
52,
57,
57,
53,
53,
50,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
52,
48,
49,
46,
50,
52,
55,
53,
48,
54,
49,
56,
57,
56,
50,
55,
57,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
49,
46,
55,
51,
54,
51,
49,
54,
49,
49,
56,
48,
56,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
53,
55,
46,
54,
57,
49,
49,
51,
48,
57,
55,
53,
50,
56,
48,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087860_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
56,
54,
48,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
56,
54,
48,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
55,
50,
51,
46,
53,
55,
53,
50,
52,
53,
50,
53,
48,
51,
53,
53,
49,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
57,
46,
48,
55,
52,
48,
57,
57,
54,
56,
49,
52,
49,
54,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
55,
54,
46,
52,
48,
50,
52,
56,
51,
48,
56,
50,
55,
56,
48,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087872_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
56,
55,
50,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
56,
55,
50,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
55,
46,
55,
52,
56,
55,
51,
50,
50,
54,
57,
55,
56,
55,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
55,
54,
46,
52,
53,
49,
53,
49,
53,
52,
50,
56,
57,
52,
55,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
55,
54,
46,
57,
48,
56,
53,
52,
51,
49,
51,
51,
57,
55,
54,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
55,
46,
51,
54,
51,
52,
53,
56,
51,
53,
50,
48,
49,
48,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
54,
49,
46,
52,
56,
48,
50,
48,
52,
50,
54,
52,
51,
50,
50,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1087888_1 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
56,
55,
56,
56,
56,
95,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
56,
55,
56,
56,
56,
95,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
51,
46,
51,
53,
56,
53,
56,
57,
53,
52,
55,
53,
55,
57,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
49,
57,
46,
52,
51,
57,
49,
57,
54,
51,
52,
53,
55,
56,
50,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1090608_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
57,
48,
54,
48,
56,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
57,
48,
54,
48,
56,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
48,
50,
52,
53,
50,
56,
49,
50,
56,
50,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
50,
49,
56,
46,
57,
49,
56,
55,
51,
50,
57,
50,
50,
52,
56,
54,
53,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
49,
50,
57,
57,
55,
51,
56,
54,
52,
57,
52,
54,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
51,
54,
46,
49,
48,
48,
51,
51,
55,
52,
56,
49,
50,
53,
55,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1090608_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
48,
57,
48,
54,
48,
56,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
48,
57,
48,
54,
48,
56,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
55,
53,
50,
48,
57,
49,
50,
48,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
52,
51,
51,
56,
54,
50,
56,
53,
57,
53,
53,
50,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
52,
46,
57,
53,
50,
52,
56,
51,
54,
51,
48,
53,
55,
49,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
57,
57,
46,
56,
49,
50,
51,
54,
51,
49,
51,
51,
50,
56,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1112589_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
49,
50,
53,
56,
57,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
49,
50,
53,
56,
57,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
48,
46,
56,
55,
55,
56,
51,
55,
54,
51,
52,
52,
55,
55,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
57,
55,
46,
48,
57,
49,
56,
54,
55,
52,
54,
54,
49,
54,
53,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1112589_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
49,
50,
53,
56,
57,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
49,
50,
53,
56,
57,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
48,
51,
56,
49,
51,
57,
57,
54,
56,
54,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
57,
46,
56,
57,
50,
56,
50,
53,
50,
54,
55,
51,
53,
51,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
56,
52,
46,
50,
49,
50,
56,
51,
50,
57,
56,
48,
54,
56,
53,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1112589_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
49,
50,
53,
56,
57,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
49,
50,
53,
56,
57,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
49,
48,
46,
53,
57,
50,
52,
56,
54,
50,
55,
50,
48,
57,
50,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
51,
50,
46,
51,
57,
51,
57,
56,
53,
51,
50,
52,
52,
51,
53,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1127019_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
50,
55,
48,
49,
57,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
50,
55,
48,
49,
57,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
55,
50,
55,
49,
55,
54,
56,
53,
51,
56,
54,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
53,
56,
49,
46,
51,
57,
57,
50,
49,
53,
57,
52,
56,
51,
56,
54,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
50,
49,
46,
55,
56,
50,
48,
54,
55,
56,
48,
57,
52,
52,
50,
48,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
50,
50,
46,
57,
54,
57,
50,
48,
53,
52,
53,
49,
55,
51,
52,
49,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
48,
46,
56,
52,
52,
53,
50,
55,
52,
52,
55,
56,
48,
57,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
49,
52,
46,
54,
54,
48,
56,
50,
57,
52,
56,
54,
50,
54,
56,
57,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
49,
53,
46,
56,
52,
55,
57,
52,
55,
56,
54,
50,
52,
49,
51,
50,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
51,
55,
46,
56,
53,
57,
54,
52,
55,
49,
53,
54,
55,
54,
50,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
56,
49,
46,
54,
51,
48,
48,
49,
51,
50,
48,
53,
55,
56,
56,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
54,
56,
56,
46,
52,
57,
57,
53,
50,
55,
55,
52,
56,
49,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
48,
51,
46,
56,
56,
53,
50,
55,
50,
52,
49,
54,
57,
49,
50,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
49,
57,
46,
48,
53,
53,
52,
57,
57,
52,
53,
50,
53,
51,
51,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1127019_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
50,
55,
48,
49,
57,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
50,
55,
48,
49,
57,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
55,
50,
51,
46,
53,
55,
53,
50,
52,
53,
50,
53,
48,
51,
53,
53,
49,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
50,
52,
46,
50,
51,
57,
57,
55,
51,
50,
50,
52,
53,
55,
55,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
49,
53,
46,
50,
54,
54,
56,
53,
48,
48,
49,
56,
55,
52,
50,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1131895_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
51,
49,
56,
57,
53,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
51,
49,
56,
57,
53,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
52,
53,
46,
50,
56,
50,
51,
52,
52,
54,
50,
53,
52,
53,
51,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
56,
46,
54,
49,
51,
51,
52,
55,
50,
56,
56,
48,
51,
55,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
51,
57,
46,
53,
48,
57,
53,
48,
53,
52,
53,
52,
57,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1131908_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
51,
49,
57,
48,
56,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
51,
49,
57,
48,
56,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
49,
51,
52,
52,
52,
53,
52,
52,
48,
54,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
49,
50,
46,
54,
52,
49,
53,
57,
55,
48,
53,
57,
57,
48,
54,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
49,
50,
46,
51,
49,
52,
51,
51,
53,
57,
56,
54,
56,
50,
49,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1131908_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
51,
49,
57,
48,
56,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
51,
49,
57,
48,
56,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
53,
55,
46,
55,
56,
48,
54,
50,
54,
54,
52,
48,
57,
52,
53,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
50,
49,
46,
55,
56,
49,
55,
53,
57,
53,
53,
49,
48,
55,
55,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
50,
57,
54,
46,
52,
53,
52,
48,
53,
51,
57,
51,
54,
53,
56,
50,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
50,
46,
55,
55,
56,
51,
52,
51,
51,
50,
53,
55,
53,
53,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
48,
56,
46,
49,
52,
56,
56,
54,
51,
56,
50,
49,
51,
49,
56,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1131908_6 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
51,
49,
57,
48,
56,
95,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
51,
49,
57,
48,
56,
95,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
49,
46,
50,
48,
56,
51,
48,
53,
57,
56,
52,
50,
52,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
52,
55,
46,
54,
57,
49,
54,
52,
53,
55,
54,
54,
55,
52,
57,
53,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1140076_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
52,
48,
48,
55,
54,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
52,
48,
48,
55,
54,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
55,
51,
53,
46,
53,
52,
52,
56,
52,
48,
52,
57,
52,
55,
57,
49,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
54,
46,
56,
50,
52,
53,
48,
55,
57,
49,
54,
53,
53,
57,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
56,
49,
46,
50,
53,
49,
52,
55,
57,
54,
52,
48,
49,
53,
49,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1140076_8 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
52,
48,
48,
55,
54,
95,
56,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
52,
48,
48,
55,
54,
95,
56,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
49,
48,
55,
46,
53,
55,
50,
52,
55,
48,
54,
49,
56,
48,
55,
54,
48,
49,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
55,
46,
48,
50,
55,
53,
52,
50,
56,
54,
52,
54,
57,
48,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
48,
56,
46,
56,
50,
55,
50,
55,
56,
56,
51,
48,
55,
56,
56,
51,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
49,
48,
55,
46,
53,
55,
50,
52,
55,
48,
54,
49,
56,
48,
55,
54,
48,
49,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
50,
57,
51,
46,
56,
48,
50,
52,
57,
50,
53,
52,
54,
51,
49,
50,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
55,
46,
48,
50,
55,
53,
52,
50,
56,
54,
52,
54,
57,
48,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
55,
50,
46,
53,
51,
57,
50,
49,
50,
48,
48,
53,
51,
48,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1140076_9 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
52,
48,
48,
55,
54,
95,
57,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
52,
48,
48,
55,
54,
95,
57,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
56,
49,
46,
48,
54,
52,
49,
48,
48,
53,
52,
54,
57,
49,
53,
48,
51,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
52,
46,
49,
48,
53,
52,
50,
55,
50,
56,
57,
50,
52,
57,
57,
50,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
54,
46,
52,
55,
52,
54,
55,
50,
52,
49,
49,
51,
48,
56,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
56,
52,
46,
53,
56,
53,
55,
55,
57,
51,
54,
51,
52,
53,
56,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1142327_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
52,
50,
51,
50,
55,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
52,
50,
51,
50,
55,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
51,
54,
46,
53,
48,
52,
52,
55,
53,
48,
55,
55,
54,
52,
52,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
49,
53,
46,
57,
53,
50,
51,
57,
51,
53,
48,
50,
57,
48,
48,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1142327_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
52,
50,
51,
50,
55,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
52,
50,
51,
50,
55,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
52,
46,
56,
57,
55,
55,
50,
56,
48,
57,
49,
51,
56,
48,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
54,
49,
46,
56,
54,
54,
49,
53,
57,
49,
53,
48,
48,
57,
52,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1142330_1 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
52,
50,
51,
51,
48,
95,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
52,
50,
51,
51,
48,
95,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
54,
55,
56,
46,
56,
52,
51,
48,
50,
54,
50,
48,
57,
51,
53,
57,
50,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
48,
46,
56,
57,
52,
57,
54,
54,
53,
48,
48,
55,
48,
52,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
54,
49,
46,
57,
56,
51,
48,
57,
54,
57,
54,
48,
56,
49,
57,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1145186_7 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
52,
53,
49,
56,
54,
95,
55,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
52,
53,
49,
56,
54,
95,
55,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
50,
46,
54,
57,
50,
50,
48,
53,
55,
49,
48,
52,
56,
57,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
49,
49,
46,
48,
50,
51,
54,
57,
54,
55,
52,
53,
50,
56,
52,
56,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
49,
48,
53,
46,
49,
52,
57,
49,
56,
52,
49,
56,
48,
48,
56,
55,
55,
51,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
48,
50,
46,
50,
53,
50,
48,
54,
54,
50,
53,
53,
56,
49,
57,
57,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
54,
46,
56,
53,
49,
54,
53,
50,
53,
53,
49,
56,
54,
57,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
57,
54,
46,
51,
50,
55,
48,
48,
57,
49,
48,
52,
55,
49,
57,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156875_1 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
50,
46,
48,
54,
48,
48,
55,
55,
53,
53,
49,
54,
51,
57,
52,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
53,
46,
51,
56,
51,
55,
50,
54,
48,
50,
54,
49,
57,
49,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
54,
56,
46,
48,
55,
50,
56,
49,
48,
51,
49,
55,
53,
51,
48,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156875_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
52,
46,
49,
48,
53,
52,
50,
55,
50,
56,
57,
50,
52,
57,
57,
50,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
51,
54,
52,
46,
56,
50,
49,
55,
51,
48,
56,
49,
54,
57,
53,
48,
53,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
49,
49,
46,
56,
54,
48,
51,
52,
48,
55,
55,
51,
52,
53,
55,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156875_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
50,
46,
50,
57,
57,
53,
55,
53,
52,
57,
50,
57,
56,
51,
57,
54,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
50,
46,
48,
54,
48,
48,
55,
55,
53,
53,
49,
54,
51,
57,
52,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
53,
46,
54,
56,
52,
54,
51,
54,
51,
53,
48,
53,
51,
55,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
50,
53,
46,
53,
55,
48,
49,
51,
57,
50,
53,
56,
55,
57,
56,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156875_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
56,
55,
53,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
48,
46,
56,
51,
55,
51,
55,
52,
51,
50,
55,
54,
49,
50,
55,
49,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
57,
50,
55,
52,
51,
48,
49,
50,
51,
57,
57,
51,
56,
52,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
52,
50,
48,
55,
51,
57,
51,
52,
53,
56,
54,
51,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
49,
55,
46,
51,
49,
54,
51,
55,
53,
49,
49,
53,
57,
48,
53,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156893_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
56,
57,
51,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
56,
57,
51,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
56,
56,
56,
57,
55,
48,
48,
52,
54,
55,
52,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
55,
46,
50,
54,
57,
50,
48,
56,
48,
54,
51,
56,
52,
52,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
56,
55,
46,
54,
57,
53,
56,
57,
56,
49,
57,
48,
56,
57,
51,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156893_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
56,
57,
51,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
56,
57,
51,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
49,
46,
56,
55,
51,
50,
53,
51,
55,
49,
54,
51,
54,
50,
56,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
51,
46,
48,
49,
57,
49,
48,
53,
48,
48,
52,
52,
56,
50,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
57,
54,
46,
49,
56,
50,
53,
56,
50,
51,
53,
52,
51,
48,
52,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156909_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
57,
48,
57,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
57,
48,
57,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
53,
46,
56,
48,
49,
51,
56,
49,
53,
57,
53,
55,
57,
57,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
53,
57,
46,
51,
53,
56,
52,
53,
52,
50,
51,
50,
50,
54,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156909_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
57,
48,
57,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
57,
48,
57,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
57,
46,
57,
50,
55,
51,
49,
54,
49,
51,
52,
48,
57,
51,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
52,
54,
46,
52,
48,
51,
54,
54,
53,
50,
53,
51,
54,
49,
48,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
53,
51,
46,
48,
56,
53,
51,
55,
51,
51,
56,
55,
49,
57,
50,
50,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
55,
46,
54,
51,
48,
48,
51,
49,
56,
57,
56,
51,
55,
51,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
50,
50,
46,
51,
56,
55,
49,
50,
53,
48,
51,
52,
53,
50,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156909_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
57,
48,
57,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
57,
48,
57,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
49,
51,
52,
52,
52,
53,
52,
52,
48,
54,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
49,
46,
50,
48,
53,
54,
54,
49,
52,
54,
49,
48,
48,
49,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
52,
55,
46,
54,
57,
49,
54,
52,
53,
55,
54,
54,
55,
52,
57,
53,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156955_11 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
49,
49,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
49,
49,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
56,
54,
46,
53,
49,
55,
55,
48,
54,
48,
55,
51,
54,
57,
56,
52,
53,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
53,
46,
55,
51,
54,
56,
54,
53,
52,
49,
57,
51,
51,
48,
48,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
48,
46,
53,
50,
56,
55,
55,
52,
53,
55,
52,
49,
53,
52,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
54,
50,
46,
55,
54,
54,
52,
56,
49,
54,
52,
57,
57,
57,
54,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
50,
55,
52,
57,
50,
50,
51,
53,
53,
50,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
54,
49,
46,
48,
51,
50,
53,
56,
50,
50,
57,
50,
54,
53,
51,
49,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
50,
46,
57,
54,
53,
56,
54,
57,
51,
52,
48,
55,
52,
48,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
52,
48,
46,
56,
55,
50,
54,
57,
51,
51,
48,
50,
54,
53,
53,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156955_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
51,
50,
55,
48,
53,
54,
51,
56,
52,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
51,
46,
51,
56,
56,
52,
50,
48,
54,
52,
52,
52,
51,
50,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
49,
46,
49,
52,
52,
55,
52,
52,
51,
55,
50,
55,
53,
56,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
49,
53,
46,
49,
57,
50,
48,
53,
56,
56,
51,
50,
57,
53,
56,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156955_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
49,
48,
50,
46,
52,
50,
50,
54,
50,
50,
49,
56,
48,
51,
55,
53,
57,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
51,
46,
54,
57,
49,
52,
51,
56,
54,
49,
55,
49,
50,
56,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
53,
46,
52,
51,
56,
48,
49,
55,
50,
57,
55,
57,
54,
51,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
57,
48,
46,
53,
54,
57,
49,
53,
49,
50,
57,
48,
55,
51,
57,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1156955_7 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
55,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
53,
54,
57,
53,
53,
95,
55,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
52,
51,
46,
51,
56,
49,
48,
52,
49,
55,
48,
57,
56,
50,
50,
56,
50,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
48,
46,
57,
56,
55,
50,
49,
51,
54,
51,
53,
48,
53,
51,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
51,
56,
46,
50,
57,
54,
55,
48,
49,
52,
53,
48,
53,
52,
48,
53,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166540_10 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
48,
95,
49,
48,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
48,
95,
49,
48,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
52,
46,
49,
48,
48,
57,
54,
52,
49,
53,
53,
51,
53,
51,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
51,
52,
46,
55,
51,
54,
56,
53,
54,
55,
56,
56,
48,
57,
53,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166541_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
49,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
49,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
52,
46,
48,
54,
51,
57,
48,
56,
55,
52,
48,
55,
50,
55,
53,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
53,
56,
46,
53,
49,
53,
50,
52,
52,
55,
56,
48,
57,
57,
51,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
51,
48,
46,
51,
52,
50,
49,
55,
49,
52,
48,
56,
57,
49,
51,
51,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166549_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
57,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
57,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
50,
46,
57,
56,
57,
57,
48,
55,
49,
56,
54,
53,
51,
57,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
57,
51,
46,
49,
52,
52,
55,
50,
54,
57,
57,
52,
48,
54,
49,
55,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166549_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
57,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
52,
57,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
56,
54,
57,
53,
48,
56,
55,
55,
52,
53,
53,
52,
49,
53,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
53,
46,
53,
56,
55,
57,
57,
55,
54,
56,
54,
54,
54,
55,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
55,
50,
46,
49,
54,
54,
55,
49,
50,
53,
57,
55,
49,
54,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166566_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
54,
54,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
54,
54,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
52,
57,
48,
56,
55,
56,
57,
57,
54,
51,
48,
49,
56,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
51,
54,
54,
46,
57,
54,
56,
54,
49,
48,
57,
49,
57,
56,
56,
57,
56,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
52,
54,
46,
52,
48,
50,
53,
48,
57,
50,
56,
52,
55,
52,
49,
57,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166566_6 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
54,
54,
95,
54,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
54,
54,
95,
54,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
49,
48,
56,
46,
53,
53,
54,
57,
49,
52,
55,
56,
50,
57,
49,
52,
57,
54,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
54,
46,
49,
56,
55,
56,
54,
51,
50,
48,
57,
50,
48,
56,
54,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
56,
56,
46,
54,
55,
54,
54,
55,
54,
49,
50,
52,
48,
51,
51,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166568_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
54,
56,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
54,
56,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
55,
50,
51,
46,
51,
56,
56,
51,
54,
51,
54,
49,
54,
54,
51,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
52,
46,
49,
50,
55,
52,
57,
50,
52,
51,
53,
54,
52,
50,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
56,
55,
51,
46,
54,
55,
54,
52,
57,
50,
55,
49,
48,
51,
48,
54,
50,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166581_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
56,
49,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
56,
49,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
57,
52,
53,
50,
52,
56,
50,
49,
50,
57,
55,
48,
54,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
52,
56,
56,
56,
54,
54,
57,
52,
48,
56,
57,
51,
51,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
52,
54,
52,
48,
48,
55,
50,
54,
56,
49,
56,
54,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
51,
50,
46,
54,
57,
48,
49,
50,
57,
49,
51,
53,
53,
57,
52,
50,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
54,
46,
55,
52,
53,
53,
54,
48,
57,
52,
51,
49,
48,
51,
50,
51,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
53,
49,
48,
46,
49,
54,
54,
49,
50,
57,
54,
56,
48,
53,
57,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
56,
54,
46,
55,
48,
54,
53,
53,
50,
57,
55,
52,
53,
49,
51,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
52,
48,
46,
54,
52,
54,
51,
56,
53,
52,
50,
52,
48,
54,
52,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1166581_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
54,
53,
56,
49,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
54,
53,
56,
49,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
50,
57,
46,
57,
48,
51,
53,
56,
49,
52,
48,
55,
51,
51,
53,
48,
56,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
56,
46,
52,
51,
48,
57,
48,
56,
50,
48,
51,
49,
50,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
50,
54,
56,
46,
53,
50,
53,
48,
53,
54,
49,
54,
52,
54,
55,
52,
49,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1168893_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
48,
46,
53,
50,
52,
49,
55,
56,
57,
50,
55,
48,
54,
49,
57,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
54,
53,
46,
56,
55,
50,
49,
49,
53,
51,
49,
56,
50,
50,
49,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1168893_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
51,
57,
54,
46,
52,
51,
54,
51,
57,
48,
51,
54,
48,
56,
52,
55,
56,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
49,
46,
51,
48,
55,
55,
50,
48,
50,
52,
54,
56,
54,
50,
50,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
50,
56,
46,
57,
48,
55,
49,
56,
50,
52,
56,
49,
53,
53,
51,
56,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1168893_5 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
53,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
53,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
51,
57,
53,
46,
50,
50,
52,
53,
57,
55,
56,
54,
56,
51,
55,
50,
50,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
54,
46,
57,
50,
54,
49,
56,
49,
52,
56,
48,
53,
51,
50,
56,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
48,
49,
46,
49,
55,
54,
53,
56,
51,
54,
52,
54,
53,
50,
51,
56,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1168893_7 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
55,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
54,
56,
56,
57,
51,
95,
55,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
51,
46,
48,
52,
54,
54,
56,
56,
56,
57,
50,
56,
48,
50,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
50,
50,
46,
53,
51,
57,
56,
51,
54,
50,
50,
56,
52,
57,
53,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1174879_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
55,
52,
56,
55,
57,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
55,
52,
56,
55,
57,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
51,
46,
51,
51,
57,
51,
52,
50,
51,
51,
54,
49,
56,
53,
54,
52,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
51,
48,
46,
48,
57,
48,
52,
48,
53,
50,
52,
50,
54,
49,
49,
54,
55,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
51,
56,
46,
52,
52,
50,
55,
49,
57,
48,
48,
54,
49,
52,
55,
53,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
52,
48,
50,
46,
57,
57,
55,
54,
48,
52,
53,
50,
52,
50,
52,
54,
51,
54,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1174953_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
55,
52,
57,
53,
51,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
55,
52,
57,
53,
51,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
57,
57,
50,
49,
49,
51,
54,
55,
50,
49,
50,
49,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
50,
46,
52,
53,
57,
56,
52,
49,
56,
54,
56,
57,
49,
54,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
56,
54,
46,
52,
51,
57,
50,
51,
54,
55,
50,
55,
54,
50,
55,
56,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1174953_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
55,
52,
57,
53,
51,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
55,
52,
57,
53,
51,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
49,
46,
55,
52,
56,
56,
52,
55,
56,
51,
54,
51,
53,
51,
55,
53,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
57,
57,
50,
49,
49,
51,
54,
55,
50,
49,
50,
49,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
57,
54,
46,
50,
57,
53,
49,
56,
56,
48,
50,
56,
51,
48,
52,
51,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
53,
49,
49,
46,
52,
51,
56,
48,
48,
51,
54,
57,
52,
49,
54,
56,
50,
51,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1174953_4 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
55,
52,
57,
53,
51,
95,
52,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
55,
52,
57,
53,
51,
95,
52,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
56,
53,
50,
53,
50,
49,
48,
50,
57,
51,
56,
53,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
52,
56,
46,
50,
53,
53,
55,
56,
52,
51,
51,
49,
55,
55,
53,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
57,
48,
46,
57,
50,
55,
50,
48,
56,
55,
57,
52,
52,
56,
55,
56,
53,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1174962_2 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
55,
52,
57,
54,
50,
95,
50,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
55,
52,
57,
54,
50,
95,
50,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
54,
48,
52,
54,
52,
50,
53,
52,
48,
53,
49,
55,
53,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
54,
48,
46,
53,
57,
49,
53,
49,
51,
55,
49,
49,
56,
57,
56,
49,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
54,
51,
53,
46,
50,
52,
54,
53,
48,
56,
48,
52,
57,
50,
52,
50,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
PMC1174962_3 | hf://datasets/bsmock/pubtables-1m@35b1c097807e0b07ec5313879b85956b7b3890db/PubTables-1M-Detection_Annotations_Test.tar.gz | [
60,
63,
120,
109,
108,
32,
118,
101,
114,
115,
105,
111,
110,
61,
34,
49,
46,
48,
34,
32,
63,
62,
10,
60,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10,
32,
32,
32,
60,
102,
111,
108,
100,
101,
114,
47,
62,
10,
32,
32,
32,
60,
102,
105,
108,
101,
110,
97,
109,
101,
62,
80,
77,
67,
49,
49,
55,
52,
57,
54,
50,
95,
51,
46,
106,
112,
103,
60,
47,
102,
105,
108,
101,
110,
97,
109,
101,
62,
10,
32,
32,
32,
60,
112,
97,
116,
104,
62,
80,
77,
67,
49,
49,
55,
52,
57,
54,
50,
95,
51,
46,
106,
112,
103,
60,
47,
112,
97,
116,
104,
62,
10,
32,
32,
32,
60,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
97,
116,
97,
98,
97,
115,
101,
62,
80,
117,
98,
84,
97,
98,
108,
101,
115,
49,
77,
45,
68,
101,
116,
101,
99,
116,
105,
111,
110,
60,
47,
100,
97,
116,
97,
98,
97,
115,
101,
62,
10,
32,
32,
32,
60,
47,
115,
111,
117,
114,
99,
101,
62,
10,
32,
32,
32,
60,
115,
105,
122,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
119,
105,
100,
116,
104,
62,
55,
55,
49,
60,
47,
119,
105,
100,
116,
104,
62,
10,
32,
32,
32,
32,
32,
32,
60,
104,
101,
105,
103,
104,
116,
62,
49,
48,
48,
48,
60,
47,
104,
101,
105,
103,
104,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
101,
112,
116,
104,
62,
51,
60,
47,
100,
101,
112,
116,
104,
62,
10,
32,
32,
32,
60,
47,
115,
105,
122,
101,
62,
10,
32,
32,
32,
60,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
48,
60,
47,
115,
101,
103,
109,
101,
110,
116,
101,
100,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
55,
56,
57,
55,
53,
50,
56,
57,
55,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
49,
53,
50,
46,
57,
57,
50,
49,
49,
51,
54,
55,
50,
49,
50,
49,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
54,
46,
53,
49,
57,
50,
56,
51,
49,
48,
55,
48,
54,
57,
55,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
51,
48,
52,
46,
51,
57,
51,
55,
52,
57,
48,
52,
52,
51,
57,
57,
48,
52,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
60,
111,
98,
106,
101,
99,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
110,
97,
109,
101,
62,
116,
97,
98,
108,
101,
60,
47,
110,
97,
109,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
112,
111,
115,
101,
62,
70,
114,
111,
110,
116,
97,
108,
60,
47,
112,
111,
115,
101,
62,
10,
32,
32,
32,
32,
32,
32,
60,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
48,
60,
47,
116,
114,
117,
110,
99,
97,
116,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
48,
60,
47,
100,
105,
102,
102,
105,
99,
117,
108,
116,
62,
10,
32,
32,
32,
32,
32,
32,
60,
111,
99,
99,
108,
117,
100,
101,
100,
62,
48,
60,
47,
111,
99,
99,
108,
117,
100,
101,
100,
62,
10,
32,
32,
32,
32,
32,
32,
60,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
105,
110,
62,
55,
53,
46,
53,
51,
53,
55,
51,
51,
48,
56,
50,
50,
53,
53,
51,
56,
60,
47,
120,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
105,
110,
62,
51,
57,
53,
46,
52,
56,
51,
54,
53,
50,
55,
53,
48,
54,
53,
49,
48,
54,
60,
47,
121,
109,
105,
110,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
120,
109,
97,
120,
62,
54,
55,
49,
46,
49,
57,
48,
56,
49,
54,
57,
49,
48,
53,
52,
48,
52,
60,
47,
120,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
32,
32,
32,
60,
121,
109,
97,
120,
62,
55,
51,
49,
46,
54,
56,
53,
50,
57,
49,
54,
51,
55,
48,
55,
51,
57,
60,
47,
121,
109,
97,
120,
62,
10,
32,
32,
32,
32,
32,
32,
60,
47,
98,
110,
100,
98,
111,
120,
62,
10,
32,
32,
32,
60,
47,
111,
98,
106,
101,
99,
116,
62,
10,
60,
47,
97,
110,
110,
111,
116,
97,
116,
105,
111,
110,
62,
10
] |
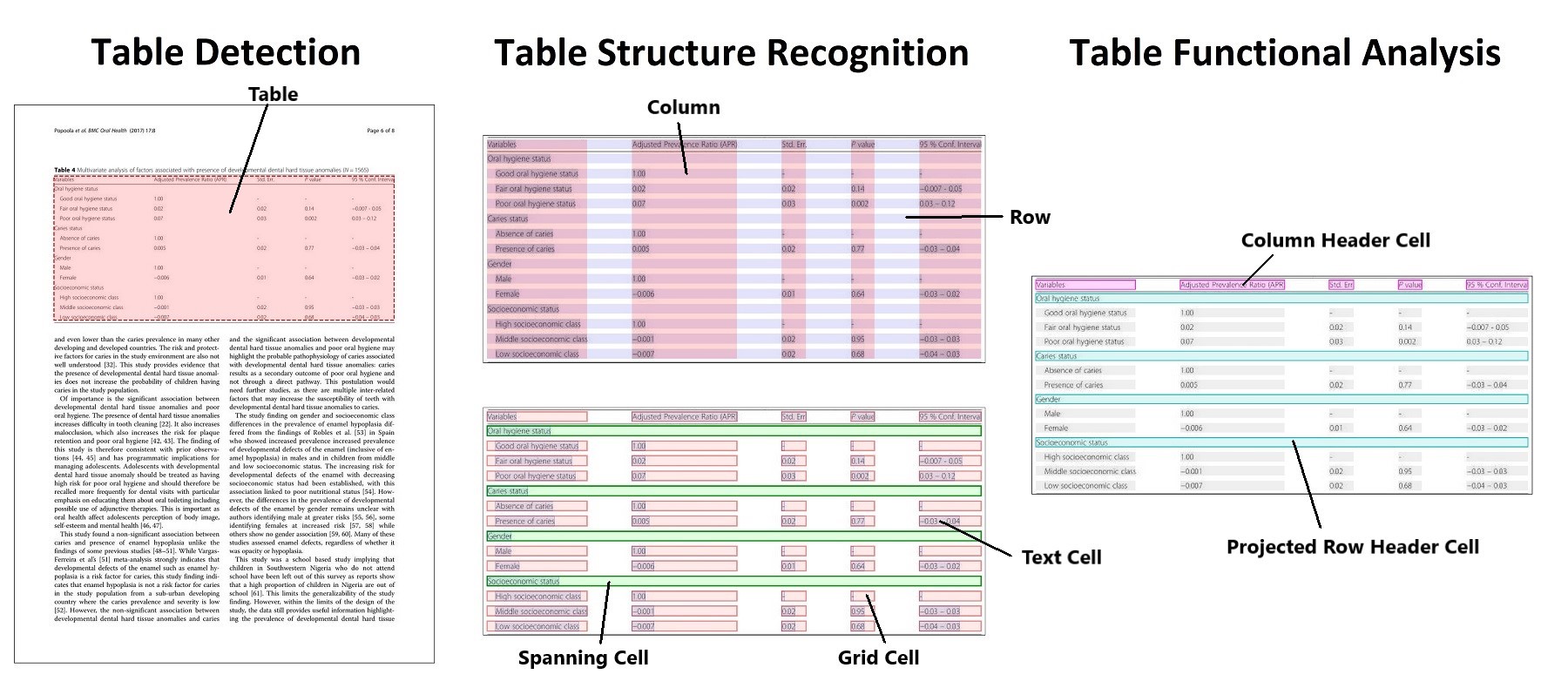
Currently we only support downloading the dataset as tar.gz files. Integrating with HuggingFace Datasets is something we hope to support in the future!
Please switch to the "Files and versions" tab to download all of the files or use a command such as wget to download from the command line.
Once downloaded, use the included script "extract_structure_dataset.sh" to extract and organize all of the data.
It comes in 18 tar.gz files:
Training and evaluation data for the structure recognition model (947,642 total cropped table instances):
Training and evaluation data for the detection model (575,305 total document page instances):
Full table annotations for the source PDF files:

