
File size: 3,155 Bytes
b3aad81 1f717d1 b3aad81 58f9176 1f717d1 b3aad81 58f9176 e526b9e 58f9176 e526b9e 58f9176 e526b9e 58f9176 e526b9e |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
tags:
- code
- finance
dataset_info:
features:
- name: id
dtype: int32
- name: image
dtype: image
- name: bboxes
dtype: string
splits:
- name: train
num_bytes: 3152173
num_examples: 13
download_size: 3029413
dataset_size: 3152173
---
# OCR Trains - Object Detection Dataset
The dataset consists of text data obtained through optical character recognition (OCR) technology, which extracts text from images, in this case, **the train number**.
# 💴 For Commercial Usage: To discuss your requirements, learn about the price and buy the dataset, leave a request on **[TrainingData](https://trainingdata.pro/datasets/train-numbers?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-trains-dataset)** to buy the dataset
The dataset be used to train machine learning models for extracting and analyzing text from train-related documents or images, to develop algorithms or models for real-time updates, or building intelligent systems related to trains and transportation.
.png?generation=1691732664604021&alt=media)
# Dataset structure
- **images** - contains of original images of trains
- **annotations.xml** - contains coordinates of the bounding boxes and indicated text, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for text detection. For each point, the x and y coordinates are provided.
# Example of XML file structure
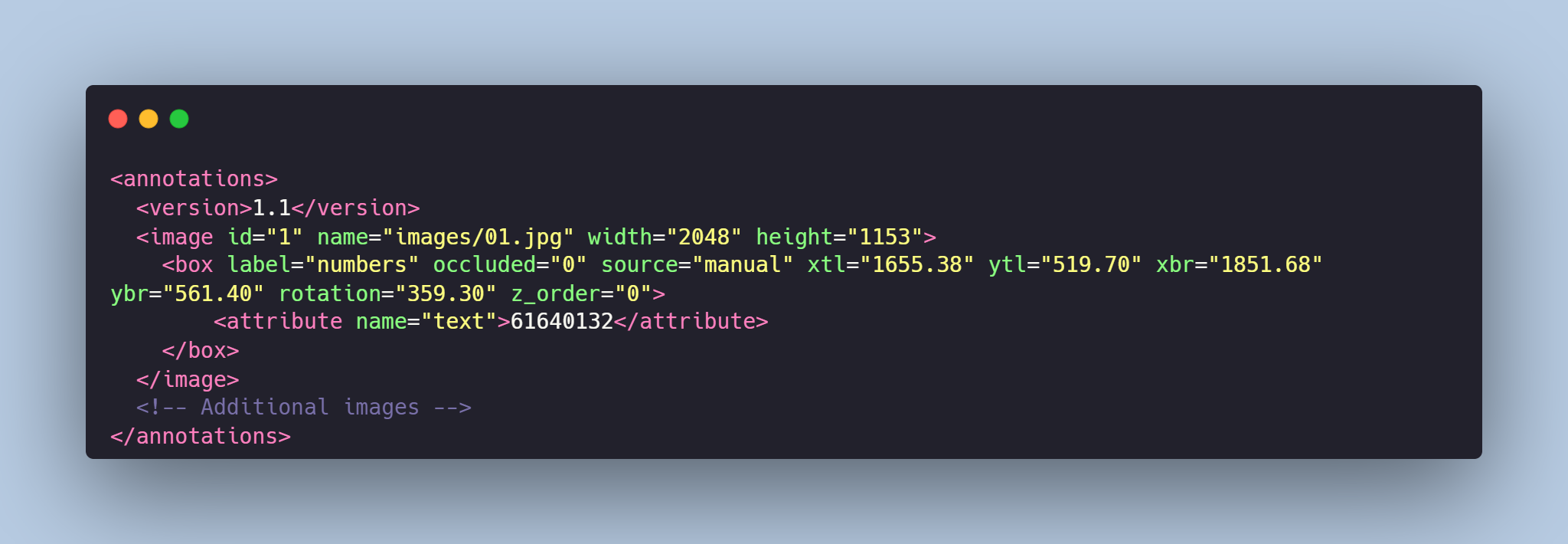
# Text Detection in Trains' images might be made in accordance with your requirements.
# 💴 Buy the Dataset: This is just an example of the data. Leave a request on **[https://trainingdata.pro/datasets](https://trainingdata.pro/datasets/train-numbers?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-trains-dataset)** to discuss your requirements, learn about the price and buy the dataset
## **[TrainingData](https://trainingdata.pro/datasets/train-numbers?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-trains-dataset)** provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
*keywords: railways dataset, global railways, train traffic, rail network, rail transport, transportation, railroad, ocr annotations dataset, text detection, text recognition, optical character recognition, computer vision dataset, image dataset, image-to-text dataset, detecting text-lines, object detection, deep-text-recognition, text area detection, text extraction, images dataset, image-to-text* |