Datasets:

content
stringlengths 0
1.88M
| url
stringlengths 0
5.28k
|
|---|---|
[Operationalizing a design] [Conditions]
Once you have a research question, hypothesis, and prediction, the next step is to develop the experimental design. In this section, we talk about the basics of experimental design, participants, and items.
Experimental design is the means by which hypotheses are operationalized. In other words, experimental design is how you collect controlled observations (i.e., data) about the relationship among the variables of interest. Note that our hypotheses often involve predictors that are continuous variables. The predictor variable we've discussed on the previous page—the relative frequency of words—is an example of a continuous predictor. For the purpose of experimental designs, continuous predictors are often binned into a small number of bins (though this is not always desirable, it is a common convention and for the current purpose, it will make it easier to talk about the design options you have for your experiment). Binning turns continuous variables into categorical variables. For example, we might bin words based on their relative frequency into "high" and "low" frequency words.
There are also variables that are naturally considered categorical. For example, if we hypothesized that nouns are read more quickly than verbs, "noun" vs. "verb" would be a categorical predictor.
Just like predictors, outcomes can be continuous or categorical. Reading times are an example of a continous outcome. The accuracy of an answer to a comprehension question (which is either true or false) is an example of a categorical outcome.
The first step in experimental design is to specify the conditions (e.g., test conditions and control conditions) that allow you to test your hypothesis. The conditions describe how we plan to manipulate our predictor variables. The goal of this manipulation is to test whether we will observe the change in the outcome variables predicted by our hypothesis.
To continue the example introduced above, consider that we plan to bin relative frequency into "high" and "low" frequency words. We would then design our experiment to have a high-frequency condition and a low-frequency condition. Our prediction would be that reading times will be faster in the high-frequency condition than in the low-frequency condition.
Without further additions, we would call this a by-2 design, because we have one predictor variable in two conditions and there are no other manipulations in the experiment. We will go through a more detailed example in Materials section, but first we'll establish a little bit more terminology.
1. What is a condition?
2. True or False: Many variables should be simultaneously changed to differentiate between conditions.
3. Researchers want to test whether a time delay between presentation of the first stimuli and the second stimuli will affect how fast and how accurately participants match them. Which type of design should they use?
4. Researchers want to test whether students who participated in sports performed better on different types of reading tasks than students who did not. Which type of design should they use? | https://www.hlp.rochester.edu/resources/BCS152-Tutorial/Design.html |
Great Burkhan Khaldun Mountain and its surrounding landscape, lies in the central part of the Khentii mountains chain that forms the watershed between the Arctic and Pacific Oceans, where the vast Central Asian steppe meets the coniferous forests of the Siberian taiga. Water from the permanently snow-capped mountains feed significant rivers flowing both to the north and south. High up the mountains are forests and lower down mountain steppe, while in the valley below are open grasslands dissected by rivers feeding swampy meadows.
Burkhan Khaldun is associated with Chinggis Khan, as his reputed burial site and more widely with his establishment of the Mongol Empire in 1206. It is one of four sacred mountains he designated during his lifetime, as part of the official status he gave to the traditions of mountain worship, based on long standing shamanic traditions associated with nomadic peoples. Traditions of mountain worship declined as Buddhism was adopted in the late 15th century and there appears to have been a lack of continuity of traditions and associations thereafter. Since the 1990s, the revival of mountain worship has been encouraged and old shamanist rituals are being revived and integrated with Buddhist rituals. State sponsored celebrations now take place at the mountain each summer around rivers and three stone ovoo-s (or rock cairns).
The Great Burkhan Khaldun Mountain has few structures other that three major stone ovoo-s alongside paths connected to a pilgrimage route. The cairns were apparently destroyed in the 17th century but have now been re-constructed with timber posts on top. The pilgrimage path starts some 20km from the mountain by a bridge over the Kherlen River at the Threshold Pass where there is also a major ovoo. Pilgrims ride on horseback from there to the large Beliin ovoo made of tree trunks and adorned with blue silk prayer scarves and thence to the main ovoo of heaven at the summit of the mountain. The sacredness of the mountain is strongly associated with its sense of isolation, and its perceived ‘pristine’ nature.
The Great Burkhan Khaldun Mountain and its surrounding sacred landscape, as a sacred mountain, were at the centre of events that profoundly changed Asia and Europe between the 12th and 14th and centuries and have direct links with Chinggis Khan and his formal recognition of mountain worship.
Criterion (iv): Burkhan Khaldun Sacred Mountain reflects the formalisation of mountain worship by Chinggis Khan, a key factor in his success in unifying the Mongol peoples during the creation of the Mongolian Empire, an event of vital historical significance for Asian and world history.
Criterion (vi): The Burkhan Khaldun Sacred Mountain is directly and tangibly associated with The Secret History of the Mongols, an historical and literary epic recognised as of world importance in its entry in the Memory of the World Register. The Secret History records the links between the mountain and Chinggis Khan, his formal recognition of mountain worship, and the formal status of Burkhan Khaldun as one of four sacred mountains designated during his lifetime.
The property has adequate attributes within its boundaries to reflect the scale and scope of the scared mountain, although the boundary needs to be marked in relation to natural features. An on-going programme of work needs to be undertaken on documenting and mapping archaeological sites that might strengthen associations with Chinggis Khan or traditions of mountain worship, and lead to their protection.
All the natural and cultural attributes of the Burkhan Khaldun Mountain display their value. Various parts of the mountain are vulnerable to an increase in tourism which could profoundly change its sense of isolation if not well managed, and to over-grazing that could impact on its ‘perceived’ pristine nature and on archaeological sites.
Although the majority of the Great Burkhan Khaldun Mountain is situated on the territory of the Khan Kentii Special Protected Area (KK SPA), a small area to the north-west and a much large area to the south lie outside this protected zone. There are plans to include the whole property and its buffer zone in the territory of the KK SPA in 2015. The KK SPA offers legal protection, but this is for natural and environmental protection rather than cultural heritage protection. Further protection needs to be established for cultural heritage and to ensure that no mining or extractive industry will be permitted within the property. The buffer zone is included within the buffer zone of the KK SPA. Currently the property buffer zone has no protection for cultural attributes nor does it have any regulatory procedures related to land-use or new construction and both need to be put in place.
Since 1990 and the renewal of older Mongolian practices related to sacred mountains, national traditions and customs of nature protection in Mongolia and the laws associated with “Khalkh Juram” have been revived and are now incorporated into State policy. On 16 May 1995, the first President of Mongolia issued a new Decree “Supporting initiatives to revive the tradition of worshiping Bogd Khan Khairkhan, Burkhan Khaldun (Khan Khentii), and Otgontenger Mountains”. The Decree pronounced the State’s support for initiatives to revive Mountain worship as described in the original Mongolian Legal Document and as “set out according to the official Decree”. A further Decree of the President on “Regulation of ceremony of worshipping and offering of state sacred mountains and ovoos” provides legal tools for visitor organization during the large state worshipping ceremonies. Any activity on Burkhan Khaldun Mountain itself, other than worshipping rituals, is traditionally forbidden. The KK reserve staff do however undertake fire-fighting, forest protection, forest clearing and renovation, and address illegal hunting and wood cutting.
At the national level, management of the site is under the responsibility of the Ministry of Nature, Environment and Green, and of the Ministry of Culture, Sports and Tourism. At the local level, local authorities at the levels of aimak-s, soum-s and bag-s have responsibility for providing local protection. Although soum administrations have people responsible for environmental protection, there appears not to be any formal arrangement for cultural heritage work. An Administration for the Protection of the World Heritage property responsible for both natural and cultural protection and conservation of the property is to be established, although no timescale has been provided for this, nor a commitment to the provision of adequate resources. Traditional protection is supported through the long standing tradition of worshipping nature and sacred places. For example, it is forbidden to disturb earth, waters, trees and all plants, animals and birds in sacred places, or hunt or cut wood for trading.
A draft Management Plan was submitted as part of the nomination dossier. This will run from 2015-2025 and covers both cultural and natural heritage. It includes both long-term (2015-2025), and medium-term (2015-2020) plans. The draft Management Plan has not yet been approved or implemented. Before completion and adoption, more work is needed to augment the Plan to allow it to provide an appropriate framework for management of the property and necessary funding has still to be put in place from stakeholder organisations together with further support from aid and international donor organizations. Archaeological sites on the mountain that may contribute to a wider understanding of mountain worship and have not been formally identified nor are they actively conserved. Both of these aspects should be addressed in the Plan.
Although a management plan exits for the Khan Khentii protected area and this is implemented by the Administration of Khan Khentii Special Protected Area, this is restricted to conservation of the natural environment and it appears that there is currently no active management for its cultural attributes, nor is work guided by specific cultural strategies and policies. These omissions need to be addressed. | https://whc.unesco.org/en/list/1440 |
Introduction Globalisation is the process that brings together the complaints nations of the world under a unique global village that takes different social & economic cultures in to consideration. First this essay will analyse globalisation in a broader term, second the history and foundation of globalisation that were intended to address poverty and inequality, third the causes that lead to globalisation and the impact that globalisation has on the world’s economy. The participation in the global economy was to solve economic problem such as poverty and inequality between the developed and developing nations. What is Globalisation?
When introduced to U.S. products and forced to accept them into their daily lives, it gives the U.S. another distinct advantage. Consumerism. Foreign citizens begin to grow attached to these U.S. products and when they have no need to receive them through aid any longer, they look elsewhere to find them. Consequently, businesses are encouraged to expand worldwide and promote globalization. Businesses go where demand is highest.
How has globalization influenced Canada's economy and cultural development? Trev Lau - Milliken Mills High School, York Region District School Board Globalization allows international companies free access to any country's marketplace. Countries like Canada pursue globalization because they want their businesses to have open access to other countries' marketplaces and be able to sell to more customers. In turn, Canada must open access to their markets.
It can be great and help the society because it can help advance the technology. For example Americans have devised straws that can instantly purify water, so they give this to many people n Africa. But globalization could also be bad because it can take away from cultural traditions. Part 2 1.
The Canadian GDP heavily relies on the contribution of foreign investments and therefore globalization is very important to the Canadian economy. Sometimes, Canadian owned businesses have to lower their prices due to foreign competition. There are also laws in Canada are put in place to ensure the protection of young (infant) industries, to make sure they survive the domestic competition that is as a result of foreign investments and globalization. Globalization affects almost all Canadian business decisions. Consumers benefit the most from this because they are the ones who get to make use of these products and they get to have a wider range of product variety due to globalization, this allows them to decide which of the many products
Globalization makes way for international investment and trade, there by establishing trade and bilateral relations between countries. 3. Technological diffusion and the distribution of economic development from rich to poor countries. 4. Globalization creates freedom to choose markets among globalized economy.
The founding of WTO in 1995 increased the conflict between economic globalisation and the protection of social norms until now because of WTO aims at further trade liberalisations. While there is no universally agreed definition of globalization, economists typically use the term to refer to international integration in commodity, capital and labour markets. There are many impacts that existed after the introducing of WTO. Firstly, the globalisation has changed the way of economic nowadays.
Moving on from a theory example, there are some other crucial factors that impact the progression of globalization. Important factors in globalization include transportation, technology, and an international currency system (Lecture 9-2). These are all important things needed for globalization. Transportation wise, the best method for transporting goods is through the use of containerized shipping. This method allows for ships to hold thousands of containers containing thousands of goods within those containers themselves (Lecture 9-2).
First of all, the most obvious advantage that the globalization brings about is that goods (such as car, laptop, smartphone, etc.) produced in one country can be sold in other countries .For the developed countries, now the can easily export their products and services to other countries to earn money. And for the developing countries, it can create opportunities of employment and reduce poverty, which is very good for the economy. The next positive aspect which is taken into consideration is that the developing countries now can receive sources of capital, new technologies from developed countries, which is very essential for the growth of a country. And in return, the developing countries let the developed countries’ companies do business in their countries.
Globalization allows countries in the world are free in trading without any barriers about tax, not only that the cost of domestic and imported goods are not too many differences cause major competition about commodity (The Impact, n.d.). That force developing nations have to make their product quality better, improve design of goods and reduce production cost. The next point is the pressure on the natural environment. Promoting the exploitation of natural resources in developing world depletes resources. The world is facing the fear of running out of natural resources like oil, natural gas, petroleum and coal because of overexploitation to meet the development needs (SÀIGÒN, 2010).
MINI REPORT ARE THE BENEFITS OF GLOBALISATION GREATER THAN THE DRAWBACKS? In my perspective, globalisation is a practice by which the world is becoming progressively connected as a result of immensely increased trade and cross culture diversity. Globalisation enhances the use of outsourcing and offshoring products.
Through globalization, people around the world share information as well as goods and services. As a result of globalization, consumers around the world enjoy a broader selection of products than they would have if they only had access to domestically made products. International trade has stimulated tremendous economic growth across the globe-creating jobs and reducing price. As globalization accelerates change in technology, more jobs are created and as a result more people are employed thus increasing their purchasing power. As the demand of consumers rise, more and more products are produced to suit the needs and wants of the people.
2. Main causes and drivers of globalization The treaty of Westphalia in 1648, has been known to be the beginning of the system of sovereign states. Unlike the previous treaties, the treaty of Westphalia drew up a list of core principles, which re-defined the conception of the state; territories were defined, and the lands uninfringeable. Supremacy of the nation-state became accepted as the norm and hence allowed growth of international relations (Pant, 2011). | https://www.ipl.org/essay/Factors-Influencing-The-Global-Economy-P396U4WBG5FV |
- We are seeking an experienced banker to help us develop and grow our Private Banking business across the North West of England.
- The role holder will be principally based in the Manchester office but is expected to work flexibly and remotely across the North West of England. They will report to the Regional Head, North and Midlands.
- When this role is filled, the team in the North West will comprise 2 Relationship managers
- The target market for the role holder will be UK Resident and UK Domiciled clients with investable assets of between $5m and $30m.
- The principal purpose is to provide wealth management services to these high-net-worth individual clients through the marketing of HSBC Private Bank services.
- It is a requirement to establish new client relationships and manage existing clients in order to generate new Assets Under Management (AUM) and increase overall portfolio revenues.
- The role holder will achieve this via a mixture of internal referrals as well as self generating leads from their own external introducer network
- The role holder will work alongside Investment Specialists, Strategic Financial Planners and Credit Specialists to deliver outstanding service and product solutions to the clients of HSBC Private Bank in Scotland
Key Accountabilities
Impact on the Business:
- Grow revenue, increase AUM of portfolio and increase inflows of net new money (NNM), achieving growth by leveraging brand, internal collaboration channels and RM’s own referral network.
Customers / Stakeholders
- Has regular contact and meetings with clients.
- Provides support to client’s portfolio management.
- Works with the Investment Specialist to ensures the client’s objectives are met through the portfolio allocation.
- Ensures clients understand and are aware of their level of risk.
- With the Investment Specialist, reviews portfolios on a regular basis and develops client’s profitability.
- Identifies opportunities to meet the credit needs of clients seeking secured and unsecured loans for a variety of purposes.
- Resolve basic enquiries, answers questions and provides documentation on client activities.
- Delivers fair outcomes for our clients and ensure own conduct maintains the orderly and transparent operation of financial markets.
- Identifies client’s financial planning needs and makes introductions to the Strategic Financial Planning (SFP) team.
Leadership & Teamwork
- Lead by example through financial results with excellent corporate behaviour.
- Provide assistance to fellow Relationship Managers.
- Bring motivation and support to the Regional Head.
- Work closely with other Bank Departments.
Operational Effectiveness & Control
- Works closely with other Bank Departments to maintain HSBC internal control standards, including timely implementation of internal and external audit points together with any issues raised by external regulators.
- Ensures follow-up on all risk and compliance issues (such as CCR, KYC, Compliance requests, Risk Management requests, Internal Audit requests).
- Minimize operational losses
Role Requirements
- Highly organized with a willingness to work under own supervision and remote from immediate line manager.
- Manage a portfolio of between 10 and 50 family Relationships.
- Ability to travel to meet clients and internal stakeholders.
- Manage own time to meet demanding new client acquisition objectives.
- Represent the Private Bank with internal stakeholders and in the professional community across the North West of England
- Work as part of a highly effective client team.
Observation of Internal Controls
- The jobholder will adhere to, and be able to demonstrate adherence to, internal controls and will implement the Group compliance policy by adhering to all relevant processes/procedures.
- The term ‘compliance’ embraces all relevant financial services laws, rules and codes with which the business has to comply. This will be achieved by adherence to all relevant procedures, keeping appropriate records and, where appropriate, by the timely implementation of internal and external audit points, including issues raised by external regulators.
- The following statement is only for roles with managerial or specific Compliance responsibilities
- The jobholder will implement measures to contain compliance risk across the business area. This will be achieved by liaising with Compliance department about business initiatives at the earliest opportunity. Also and when applicable, by ensuring adequate resources are in place and training is provided, fostering a compliance culture and optimising relations with regulators.
Management Risk
- The jobholder will ensure the fair treatment of our customers is at the heart of everything we do, both personally and as an organisation.
- This will be achieved by consistently displaying the behaviours that form part of the HSBC Values and culture and adhering to HSBC risk policies and procedures, including notification and escalation of any concerns and taking required action in relation to points raised by audit and/or external regulators.
- The jobholder is responsible for managing and mitigating operational risks in their day to day operations. In executing these responsibilities, the Group has adopted risk management and internal control structure referred to as the ‘Three Lines of Defence’. The jobholder should ensure they understand their position within the Three Lines of Defence, and act accordingly in line with operational risk policy, escalating in a timely manner where they are unsure of actions required.
- Through the implementation the Global AML, Sanctions and ABC Policies, supporting Guidance, and Line of Business Procedures the jobholder will make informed decisions in accordance with the core principles of HSBC's Financial Crime Risk Appetite.
- The following statement is only for roles with core responsibilities in Operational Risk Management (Risk Owner, Control Owner, Risk Steward, BRCM, and Operational Risk Function
- The jobholder has responsibility for overseeing and ensuring that Operational risks are managed in accordance with the Group Standards Manual, Risk FIM, & relevant guidelines & standards. The jobholder should comply with the detailed expectations and responsibilities for their core role in operational risk management through ensuring all actions take account of operational risks, and through using the Operational Risk Management Framework appropriately to manage those risks.
- This will be achieved by:
- Continuously reassessing risks associated with the role and inherent in the business, taking account of changing economic or market conditions, legal and regulatory requirements, operating procedures and practices, management restructurings, and the impact of new technology.
- Ensuring all actions take account of the likelihood of operational risk occurring, addressing areas of concern in conjunction with Risk and relevant line colleagues, and also by ensuring that actions resulting from points raised by internal or external audits, and external regulators, are correctly implemented in a timely fashion. | https://uk.work180.co/job/185474/relationship-manager |
LITTLE ROCK, Ark. — Arkansas Boys State has named Andrew Brodsky as Director of Staff for the program, which has transformed the lives of young men throughout the state and beyond since 1940.
Brodsky has been part of Arkansas Boys State since his delegate year in 2013, in which he represented Lakeside High School and was elected as Arkansas Boys State Speaker of the House. He has served the program since as a junior counselor, state counselor, senior counselor and, most recently, as assistant director of operations.
“Arkansas Boys State is able to provide a world-class program because of the staff who volunteer their time and return year after year to mentor our state’s next generation of leaders,” Brodsky said. “It is these volunteers who facilitate every aspect of the program so that it can truly be a week that shapes a lifetime. By ensuring that our staff is supported, trained and well-resourced, we can continue to excel as our state’s premier youth leadership and civic engagement program.”
Brodsky is a Higher Education Consulting Associate for Huron Consulting Group and holds a Master of Education in Higher Education Administration and a Bachelor of Science in Human and Organizational Development, both from Vanderbilt University.
“Arkansas Boys State alumni and staff hold an array of experiences, backgrounds and interests, and each provides exceptional perspective and skills — often with new and innovative approaches to our program,” Brodsky said. “My goal is to create a structure where every member of our staff is empowered to revolutionize Arkansas Boys State in a way that only they are able to do.”
Lloyd Jackson, executive director of Arkansas Boys State, said he looks forward to seeing the program’s top-tier staff grow and succeed under Brodsky’s leadership.
“Young men who attend Arkansas Boys State know that one of the most memorable and life-changing experiences of the program is being mentored, challenged and celebrated by our incredible staff, which develops relationships that last long beyond our week-long program,” Jackson said. “Andrew’s vision for supporting and growing our staff will ensure that Arkansas Boys State’s legacy of excellence and transformation thrives well into the future. We’re excited to have him on board.”
Arkansas Boys State is an immersive program in civics education designed for high school juniors. Since 1940, the week-long summer program has transformed the next generation of leaders throughout the state and beyond. These men have become state, national, and international leaders, including Pres. Bill Clinton, former Arkansas Gov. Mike Huckabee, former White House Chiefs of Staff Mack McLarty and Jack Watson Jr., Sen. Tom Cotton, Sen. John Boozman and Arkansas Chief Justice John Dan Kemp.
During their week at Arkansas Boys State, delegates are assigned a political party, city, and county. Throughout the week, delegates, from the ground up, administer this mock government as if it were real: they run for office, draft and pass legislation, solve municipal challenges, and engage constituents. By the week’s end, the delegates have experienced civic responsibility and engagement firsthand while making life-long memories and friends — all with the guiding principle that “Democracy Depends on Me.” Learn more at arboysstate.org. | https://arboysstate.org/brodsky-appointed-to-arkansas-boys-state-leadership/ |
The Example of Ingrid Schroffner: Any Exemplary Government Lawyer, Advocate for Diversity, and Mentor by Renée M. Landers
This series paying tribute to exemplary government workers is a fitting way for the Section and Notice & Comment to observe Public Service Recognition Week. Coverage of excessive use of force by police nationally, too often resulting in death, has shared the headlines in Massachusetts with police fraud in accounting for overtime. The attention these failures receive makes taking the time to remind the public of the countless public servants who are essential to effective government really important. Because they perform their responsibilities with integrity and dedication, the work of these impressive individuals often goes unnoticed. In addition, the recent examination of the role of systemic racism in the legal system and the larger society has caused us once again to consider and address the continued lack of racial and ethnic diversity in the ranks of the legal profession and the legal academy.
I am grateful for this opportunity to express appreciation for my friend Ingrid Schroffner’s distinguished contributions to the legal profession and public service. Ingrid’s career in government embodies a record of mentoring generations of law students, and reflects her commitment to advancing diversity, equity, and inclusion in the legal profession and society.
I have known Ingrid since we both served as members of the Steering Committee of the Boston Bar Association’s Diversity, Equity, and Inclusion Section for which I served as Co-Chair from 2010-2012 after having served as the first legal academic and woman of color as BBA President. For more than a decade, Ingrid was a leader in the General Counsel’s Office of the Massachusetts Executive Office of Human Services (EHS)—advancing from Assistant General Counsel to Associate General Counsel to Acting Deputy General Counsel. During that time, I engaged with Ingrid on a regular basis as she considered applications from Suffolk University Law students for internship positions with the EHS Internship Program. From these associations, I learned that Ingrid possesses the dynamic personal qualities, engaging communication skills, and deep experience in the legal profession and community service which are an example for other public servants and allow the public to have confidence in government.
Ingrid’s professional career reflects substantial experience in government for which she prepared by spending significant time in private practice. She was an effective advocate and manager for a litigation unit for MassHealth, the Massachusetts Medicaid program, in which she provided advice on the administration of the program and providing quality services to MassHealth members. In her role as Chair of the EHS Diversity Council, she provided extensive leadership on efforts to create a diverse staff and to promote agency policies aimed at meeting the needs and concerns of immigrants, religious minorities, veterans, and other vulnerable populations, and addressing disparities and implicit bias. This spirit of making a place at the table for everyone carries through her involvement in the Boston Bar Association mentioned earlier. In addition, she served as a member of the Board of Directors and President of the Asian American Lawyers Association of Massachusetts. That she rose to leadership positions in the organizations in which she has been involved is a testament to the authenticity of her commitment to issues of diversity, equity, and inclusion, and her ability to inspire the confidence of other lawyers.
Ingrid brought these prodigious skills and sensibilities to bear in her leadership of the EHS Legal Intern Program. First, with a colleague, she revived a dormant program in 2010 and applied rigor to working with law schools to promote the internships, the process of recruiting interns, and screening interns. Second, having selected interns, Ingrid insured that all received a comprehensive variety of work assignments, effective supervision, constructive evaluation, and supportive mentoring. During the summer she arranged for speakers for the Legal Intern Speaker Series. To institutionalize program principles, she created and updated a Legal Intern Protocol and Handbook for the program. She actively coordinated with the area law schools and their clinics to provide internship opportunities during the school year as well as the summer, for both students and new attorneys.
The internship program she managed was important for students enrolled in the Health and Biomedical Law Concentration for which I serve as the Faculty Director because it gave students exposure to the public sector considerations relevant in the field. The structure and rigor of the program made it easy for law professors like me to recommend the EHS Internship Program as an essential experience for students aspiring to practice in the field of health law. The internship provides valuable experience for students in a professional environment and imparts important lawyering skills and values. Every student who participated found Ingrid to be an attentive and exacting presence and valued the role the internship played in their individual development. Following the internships, Ingrid was a reliable and supportive source of recommendations for these students as they sought future internships or job opportunities. The structure and regularity of the program is unusual in the universe of internship opportunities available to the students.
As the COVID-19 pandemic, as well as the focus on police misconduct, have focused the national attention on disparities, providing more information about Ingrid’s work as the Chair and Co-Chair of the EHS Diversity Council is especially relevant to understanding her impact on the profession. This work demonstrated the importance of focused attention on fostering inclusive and respectful work environments. In Ingrid’s words, such environments recognize “the progress that results from employees’ diversity . . . that reflects the population served.” Making available training opportunities and education and identifying best practices helped MassHealth programs serve the members better. Under Ingrid’s leadership, the EHS Diversity Council regularly created publications entitled “Prisms of Diversity” featuring various geographic areas with cultural history and cuisine. Beginning in 2015, the Council provided quarterly brown bag speaker events for EHS employees on “hot topics” relating to health care, including Immigrant Advancement, Muslim Access to Health Care, Unconscious Bias, Veterans’ Issues, the Opioid Crisis, Aging Population, Vulnerable Workers, and Health and Racial Health Disparities. Ingrid also has written regularly about diversity and cultural competency and is a sought-after speaker on these topics—as well as on the work of litigating estate recovery for the MassHealth program.
Ingrid is now continuing her career in public service as a Senior Associate Attorney in the Office of Management at the University of Massachusetts Medical School. Massachusetts state government is so fortunate that she will continue to impart her experiences working in government programs serving low-income and vulnerable populations and with a large public academic medical center—as well as her service with bar and other organizations serving the legal and larger communities, to inculcate a culture of public service among future generations of law students and recent law graduates. She is an exemplary government lawyer and mentor. In The Measure of Our Success: A Letter to My Children and Yours,” Marian Wright Edelman, the founder of the Children’s Defense Fund, wrote that you do not need “to be a big dog to make a difference . . . . You just need to be a flea for justice bent on building a more decent home life, neighborhood, work place, and America.” Ingrid has lived this exhortation through the example of her career in public service.
Renée M. Landers is Professor of Law at Suffolk University Law School and Faculty Director of the Health and Biomedical Law Concentration and Master of Science in Law: Life Sciences Program. This post is part of the ABA Administrative Law Section Series Celebrating Public Service; all the posts in the series are collected here. | https://www.yalejreg.com/nc/the-example-of-ingrid-schroffner-any-exemplary-government-lawyer-advocate-for-diversity-and-mentor-by-renee-m-landers/ |
Well, can you reuse coffee grounds?
Sure, you can, but it’s not really the best option if you’re crazy about coffee. You found this article, which leads me to believe you deeply care about your coffee and how it tastes.
Let’s discuss what’s going to happen when you reuse grounds, and see if it’s something that’s worth doing for its budget effectiveness, or just not worth sacrificing the flavor for.
Contents
- 1 Can You Reuse Coffee Grounds?
- 2 Benefits of Reusing Coffee Grounds
- 3 Drawbacks of Reusing Coffee Grounds
- 4 What Type of Coffee is Best for Reusing?
- 5 Being Economic About Your Coffee
Can You Reuse Coffee Grounds?
You can reuse grinds, and this is how you are going to do it.
Your grinds are going to come out of the brew basket completely wet, but you don’t want to just leave those lying around so build up mildew and bacterial growth.
While coffee is very acidic and it’s not likely that bacteria will grow on it in a short amount of time, it’s still a process that begins once the grinds exit the temperature safe zone of about 140° F.
To continue, you have to dry out those grinds. First thing’s first: lay them out on a pan and put them in the oven for about fifteen minutes on 275° F.
This starts getting most of the excess moisture out, just don’t layer the pan too high. You want about half an inch worth of depth.
Thing is, you don’t want to over roast the grounds for too long. Eventually, they’ll just end up tasting burnt. Take them out of the oven at this point and prepare to transfer them to a pan that’s lined with tin foil.
That pan is going to sit out in the sunlight for about two to three days.
If you’re going to do this on a routine basis, you should have a spot where you can put up to four pans at a time (since you don’t want wet grounds sitting around until you can build up a big batch).
Slap a timestamp on each of them so you know how long they’ve been there. Another thing to consider is having the upcoming weather forecast handy.
You might not be able to reuse all of the grounds due to inclement weather, but reusing about 70% of your grounds isn’t uncommon.
If you’re wondering how it’s going to work out in your favor, we’ve listed the benefits of reusing coffee grounds below.
Benefits of Reusing Coffee Grounds
While it’s not everyone’s preferred method of saving on coffee, reusing your grounds has a few major benefits for your wallet, and the environment as well.
Saving Money
Everyone likes saving money. If you buy a 16 oz bag of coffee beans, and let’s say that’s about $8.99 for a medium-quality roast, then you can double down on the money you’ve spent.
You grind them up, use them, and let’s say that you’re using about 1 oz per cup in a single-cup machine.
That’s sixteen cups of coffee at about $0.57 each, but if you’re able to salvage enough for another 12 cups (you can’t save all the grinds), you’d only be spending about $0.33 per cup.
That could equal roughly a hundred dollars a year in savings, depending on how much coffee you drink.
Environmentally Conscious
Coffee grounds can either help the soil in ways that we almost can’t image or add methane gas to the atmosphere if we let them rot in the landfills.
When it gets mixed in with other kitchen food scrap waste, it ends up being a blight on the earth.
If you just spread wet coffee grounds across your lawn, or more specifically, use them for gardening, they’re aerated enough to actually provide nutritional benefits to the soil.
Try New Flavors
Once you’re familiar enough with the taste of reused coffee grounds, you should be able to start toying with how they taste.
You’ll see in our drawbacks that reused grounds, as you might expect, lack the flavor of freshly ground coffee.
That’s okay; you can spice it up by adding flavor components into your brewed coffee.
Or, you can actually spice it up by adding spices into the reused grinds to bring some of that coffee zing back to life.
Try cinnamon, nutmeg, and even pumpkin pie spice if you’re feeling a bit adventurous. It makes a world of difference without wasting a full cup of freshly ground coffee.
Drawbacks of Reusing Coffee Grounds
There are some good reasons to reuse coffee grounds, but if you’re like us, sometimes these drawbacks are just a bit too much to trade-off in exchange for the economic boost.
Less Flavor
It’s an undeniable fact, and the very thing you expected to see when you came here: there’s just a lot less flavor in reused coffee grounds.
While that might not come as a shock, the flavor will diminish in accordance with your brewing method. If you’re making strong coffee in a percolator, the grinds are going to have almost no flavor left.
If you use a French press, your grinds are bigger, so they might actually have some more life to them.
For the most common type of brewing method, being a drip coffee maker, the results rest somewhere in the middle.
You get a mix between the flavor being sapped out, and the grinds being big enough to still have just a little bit more life in them.
Easy to Mess Up
If you don’t do this properly, your grounds are going to gather mildew and mold. It’s not good. You can’t just scoop out that one part that’s starting to grow green fuzz.
Since coffee grounds are acidic, they’re harder for bacteria to start growing on.
That means that it’s severe, and the other grounds are likely a day or two away from completely molding as well.
Time-Consuming
It’s not exactly a simple task to constantly be rotating your coffee out while trying to dry it. Carving out that time, and doing it properly, is something you have to commit to.
Sure, you can save some money every year, but in your busy life is it really the best way to be spending your time?
We don’t particularly advocate for or against reusing your own coffee grinds, but it’s important to note how long it can take, especially at the beginning.
Bye-Bye to Caffeine
Caffeine is water-soluble, meaning once water is introduced to the grounds and run through them, the caffeine comes rushing out.
That’s good for your first cup or pot of coffee, but you’re just going to be drinking coffee-flavored water after the fact.
The health benefits are basically microscopic in comparison to what they were before, and you won’t get a jolt or a buzz off of your coffee the same way that you’re used to.
If you immediately rebrew your coffee in the coffeemaker, you might still get a hint of caffeine in that second pot.
What Type of Coffee is Best for Reusing?
For starters, you need to make sure it’s freshly ground.
If you’re reusing pre-ground coffee, you’ll be left with a bitter flavor in your cup.
If you’re grinding it yourself every morning, you can most certainly reuse your grounds with little to no problem.
But what type of coffee beans should you use?
You can use arabica, robusta, or even Liberian coffee beans if you want—there’s no major difference between reusing these.
That being said, you should aim to reuse light roast or medium roast coffee grounds only, and avoid dark roast altogether.
During the roasting process, oils and co2 are extracted from each coffee bean (commonly referred to as the first and second “crack,” which indicates the cracking sound it makes during roasting).
When this happens, there’s fewer oils and hydration to each bean. That’s good for storage, but it’s not good for reusing them.
The beans are cooked at higher temperatures for longer. There is more flavor, to some, but it’s quickly diminished after the grounds are used one time.
Since light roast and medium roast beans are roasted for less time, there’s arguably more coffee flavor and actual oils/co2 in each bean. That’s going to contribute to flavor.
Being Economic About Your Coffee
If you’re eccentric about your coffee flavor, then we don’t recommend reusing your grounds.
It’s just not going to create the same flavor profiles, and it will certainly give you inconsistency in your daily coffee regimen.
Every other cup of coffee you have will be watered down or lacking in flavor.
However, if you want to be economic about your coffee grounds, you can simply use a little less at a time when you make your coffee in the morning.
If you usually use five teaspoons in your drip brewer, use four, or four-and-a-half, then put the additional amount of coffee grounds in a separate container.
Somewhere between five to ten times of doing this, you’ll have enough for another pot. | https://insidethehub.com/can-you-reuse-coffee-grounds/ |
|Sem 2 2010,
|
Sem 1 2011,
Sem 2 2011,
Sem 1 2012,
Sem 1 2013,
Sem 1 2014
Course Coordinator: Tony Skinner
Course Coordinator Phone: +61 3 9925 4444
Course Coordinator Email: tony.skinner@rmit.edu.au
Pre-requisite Courses and Assumed Knowledge and Capabilities
Nil.
Course Description
This course illustrates the effects on the earth’s environment of various types of pollution, the impact of engineering works and investigates management techniques to minimise degradation.
Objectives/Learning Outcomes/Capability Development
You will gain or improve capabilities in:
1. Technical competence
Ability to establish technical skills appropriate to the diversity of practice in the engineering industry.
• Ability to demonstrate critical thinking in relation to industry structure and practices
• Ability to apply knowledge of basic science and industry practice fundamentals
2. Integrative perspective
Developed broader perspectives, within the engineering industry and external to it, and also to demonstrate ability to work with complex systems.
• Ability to undertake problem identification, formulation and solution
3. Professional skills
Recognise and apply engineering industry skills, attitudes and professional standards.
• Ability to communicate effectively, not only within the engineering sector, but also with the community at large
• Ability to function effectively as an individual and in multi-disciplinary and multi-cultural teams, with the capacity to be an effective team member as well as to take on roles of responsibility
• Understanding of the social, cultural, global and environmental responsibilities associated with the engineering industry, and the principles of sustainability
• Understanding of, and commitment to, professional and ethical responsibilities
• Expectation and capacity to undertake lifelong learning
On successful completion of this course, you will be able to :
• describe the major components of the earth’s environment and their inter-relationships
• identify environmental degradation problems and solutions
• compare the benefits and adverse effects of engineering works
• describe the role of government authorities in monitoring and controlling the environment
• explain the principles involved in rehabilitation, restoration and reclamation
• demonstrate an understanding of ecologically sustainable development
Overview of Learning Activities
The learning activities included in this course are:
• attendance at lectures and laboratory sessions where syllabus material will be presented and explained, and the subject will be illustrated with demonstrations and examples;
• completion of tutorial questions and workshop projects designed to give further practice in the application of theory and procedures, and to give feedback on student progress and understanding;
• completion of written and practical assignments, individually or in teams intended to develop effectiveness in a team environment; this will consist of numerical and other problems requiring an integrated understanding of the subject matter; and
• private study, working through the course as presented in classes, laboratories and supplementary learning materials, and gaining practice at solving conceptual and numerical problems.
Overview of Learning Resources
Students will be able to access course information and learning materials through the Learning Hub (also known as online@RMIT) and will be provided with copies of additional materials in class. Lists of relevant reference texts, resources in the library and accessible Internet sites will be provided where applicable. Students will also use laboratory equipment for experiments within the School during project and assignment work.
Overview of Assessment
The assessment for this course comprises of a mixture of written and assessable practical assignments, progress tests and a final exam in either short answer, multi choice or a mixture of the two. Written assignments and combined team project work will be used to provide feedback on progress through the course. | http://www1.rmit.edu.au/browse;ID=041997heparta |
To ask Her Majesty's Government what assessment they have made of the impact of light pollution on wildlife and the environment.
Answered on
20 January 2021
Defra has published or contributed to a range of assessments of the impact of artificial light on insects and wider biodiversity, as well as global and national assessments of the drivers of biodiversity loss more generally.
Following publication of the Royal Commission on Environmental Pollution’s report, ‘Artificial light in the environment’ in 2009, Defra has supported assessments of impacts of artificial light on insects and on other organisms such as bats. These are published on our science website. Defra has also funded or co-funded national and international assessments of drivers of change on insects and wider biodiversity such as the global IPBES Assessment Report on Pollinators, Pollination and Food Production, which notes effects of light on nocturnal insects may be growing and identifies the need for further study.
There have been a number of externally funded studies which have highlighted potential impacts of artificial light pollution on insects, but based on the current available evidence, artificial light is not considered one of the main drivers of species decline. We are confident that we are focusing and taking action on the issues that will make a real difference to insect pollinators.
We recognise that there is ongoing research into the topic and together with our academic partners, we will keep this under review. | https://questions-statements.parliament.uk/written-questions/detail/2021-01-06/HL11814/ |
The National Educational Psychological Service (NEPS) of the Department provides a comprehensive, school-based psychological service to all primary and post primary schools through the application of psychological theory and practice to support the wellbeing, academic, social and emotional development of all learners. NEPS provides its service to schools through casework and through support and development work for schools. Individual casework service involves a high level of psychologist collaboration with teachers and parents, often also working directly with the child/young person. NEPS may become involved with supporting individual students where the school’s Special Education Teaching team or Student Support Team feels that the involvement of the psychologist is needed. Psychologists may provide consultation in relation to appropriate therapeutic interventions to be delivered in the school setting and engage in direct work with an individual student as appropriate.
At post primary level, counselling is a key part of the role of the Guidance Counsellor, offered on an individual or group basis as part of a developmental learning process, at moments of personal crisis but also at key transition points. Each post primary school currently receives an allocation in respect of guidance provision, calculated by reference to the approved enrolment. Guidance allocations for all schools were increased in the 2020/21 school year in response to Covid 19. The Guidance Counsellor also identifies and supports the referral of students to external counselling agencies and professionals, as required. The Guidance Counsellor is key in developing and implementing innovative approaches to wellbeing promotion on a whole schools basis though the school’s Guidance Plan.
In the event that the need for a more specialised intervention or counselling is identified by the NEPS psychologist, a referral is made to an outside agency for evaluation and ongoing support. The NEPS psychologist can in consultation with the Guidance Counsellor identify the most appropriate referral pathway and support schools with the onward referral to Child and Adolescent Mental Health Team (CAMHS), HSE Primary Care/Community Psychology teams, or an identified local community based specialist mental health service.
In addition to casework NEPS psychologists work with teachers to build their capacity/capability to promote the wellbeing and mental health of children and young people in schools. NEPS teams offer training and guidance for teachers in the provision of universal and targeted evidence-informed approaches and early intervention to promote children’s wellbeing, social, emotional and academic development. Initiatives such as the Incredible Years Social Emotional learning Programmes and the FRIENDS Resilience Programmes. These programmes have been welcomed by schools and their impact positively evaluated.
NEPS is currently developing a range of workshops on the promotion of wellbeing and resilience in schools which includes trauma informed approaches. The approaches outlined in the workshops are based on research findings, on the experience of experts in their fields and on the experience of practicing psychologists working in schools. The workshops will be available to build the capability of school staff in both primary and post-primary settings, including for school leaders, teachers and SNAs. Work is underway to identify schools for inclusion in a pilot of the workshops.In selecting schools, a mix of DEIS, non DEIS and urban and rural schools will be included. Following the pilot a national roll-out is planned during the next academic year.
Pádraig O'Sullivan (Cork North Central, Fianna Fail)
Link to this: Individually | In context | Oireachtas source
207. To ask the Minister for Education and Skills the current level of service from NEPS at primary and post-primary level; and her plans to increase the NEPS support to schools. [17729/21]
Norma Foley (Kerry, Fianna Fail)
Link to this: Individually | In context | Oireachtas source
NEPS’ sanctioned psychologist numbers have grown from a base of 173 whole-time equivalent psychologists (w.t.e.) in 2016, through the intervening Budget increases in 2017-2019 to 204 w.t.e. psychologist posts. This Government remains firmly committed to the maintenance of a robust and effective educational psychological service. In this connection, as part of a package of measures to support the reopening of our schools the provision of an additional seventeen psychologist posts to NEPS was announced bringing overall sanctioned numbers to 221 w.t.e. psychologist posts.
Currently NEPS has 206 w.t.e. psychologist. NEPS is actively recruiting to achieve sanctioned numbers in NEPS. The Department has engaged with teh Public Appointments Service who are planning a recruitment compeition for NEPS in Q2 of 2021. | https://www.kildarestreet.com/wrans/?id=2021-04-01a.551 |
The Energy Drone Coalition and DRONEII.COM recently released a joint report, “Drones in the Energy Industry,” an industry-specific benchmark of the use of UAVs in the energy industry and analysis of potential future developments.
A mix of UAV leaders from the energy and engineering industries, including energy asset owners using drones as well as drone-as-a-service providers (DSPs), participated in this study.
“This survey was created in July 2018 and distributed within the Energy Drone Coalition network in the North American region with 214 total surveys completed,” said director, Sean Guerre. “The survey is planned to be conducted again in 2019 to assess operational changes, market growth and technological developments of commercial drones in the energy industry, and we look forward to having even more respondents share their insights.”
Key areas include:
- The Drone Market (time in market, organization UAV setup)
- Operational Setup (in-house, outsource or hybrid)
- Technology Stack (hardware, software, payloads)
- Operations (types of UAV use cases, frequency of flights)
The report discovered that about two-thirds of the energy companies who responded to the survey are currently operating drones, 50% of which are in-house operations, but that the majority of current drone operations during 2018 are in the “proof of concept” phase (60% have fewer than ten flights per month). Multi-copters are the most utilized drone configuration and the use of infrared sensors is prevalent in comparison to other industry sectors. Endurance, range, reliability, and flexible utilization are cited as the core developments required by the respondents to grow or scale their drone operations.
The complimentary report is available for download here. | https://defensetechconnect.com/2019/04/05/the-energy-drone-coalition-releases-joint-report-drones-in-the-energy-industry/ |
Updated Friday November 9, 10:48am:
Feminine prettiness was in the air last night as stars adopted the most romantic of dresses for their public appearances. The Duchess of Cambridge attended a gala celebrating the birthday of St Andrews University wearing a floor-length Temperley London lace dress, while Laetitia Casta chose a Chanel tulle confection to support Karl Lagerfeld at the Paris opening of Chanel's touring exhibition The Little Black Jacket.
Contrarily, Kristen Stewart wore a form-fitting A.L.C. black leather dress to promote On The Road and Hilary Rhoda adopted the boyish trouser suit trend for a dinner in New York.
Updated Thursday November 8, 11.09am:
Red carpet film premieres took centre stage last night. Cameron Diaz arrived in a monochrome Stella McCartney dress - on the arm of co-star Colin Firth - for the London premiere of Gambit. In New York, Keira Knightley chose a lace Valentino Couture autumn/winter 2012-13 gown to attend a screening of Anna Karenina, while burgeoning fashion icon Elle Fanning chose a strapless Oscar de la Renta gown for a Ginger and Rosa screening in LA.
Updated Wednesday November 7, 10.22am:
President Barack Obama won his second term in office and America's stars ensured they all had their say, arriving in droves at the polling stations; Sarah Jessica Parker professed her Obama loyalty wearing a slogan T-shirt, while Milla Jovovich and January Jones took a more laid back approach - opting for skinny jeans and flats.
Anticipation continues to build around tonight's Victoria's Secret show - Miranda Kerr was spotted arriving for rehearsals looking impeccably groomed - while Rihanna, emerging after an intense rehearsal of her live performance, left the venue in a signature streetwear and heels ensemble.
Updated Tuesday November 6, 10.53am:
Kristen Stewart flew the flag for British style while appearing on The Tonight Show with Jay Leno, wearing a Peter Pilotto pre-spring/summer 2013 dress to face the famed interviewer.
Meanwhile, it was a night of premieres - Marion Cotillard chose a Dior gown for the AFI Fest screening of Rust And Bone, Halle Berry was in Helmut Lang for the Cloud Atlas Berlin premiere and Penelope Cruz opted for Versace to walk the red carpet in Rome for Venuto Al Mondo.
Updated Monday November 5, 11.17am:
Feminine style came to the fore over the weekend as an array of stars stepped out in the girliest of designs. Jessica Alba attended a charity gala in a pale pink gown by Valentino, covered in intricate embroidery, while Amy Adams wore a full-skirted Dolce & Gabbana prom dress to the LA premiere of On The Road and Rita Ora showed off McQ's autumn/winter 2012-13 florals at the Mobo Awards.
At the other end of the spectrum, Kristen Stewart erred on the more boyish side in a Balenciaga jumpsuit for her latest red carpet outing.
November 8 2012
To attend the University of St Andrews 600th Anniversary Fundraising Auction, the Duchess of Cambridge wore a Temperley London black lace dress and carried a red clutch.
© Rex Features
November 8 2012
She wore an A.L.C. black leather and jersey dress with strappy Barbara Bui sandals to a screening of On The Road in New York.
© Rex Features
November 8 2012
She wore a grey dress with a navy coat and Aperlai red velvet shoes for an appearance on Good Morning America.
© Rex Features
November 8 2012
Laetitia Casta wore a black feathered Chanel dress with stiletto heels to attend the Paris opening of Chanel’s The Little Black Jacket exhibition.
© Rex Features
November 8 2012
For a night out in New York, she wore a shearling coat with a camouflage shirt, skinny jeans and tan boots.
© Rex Features
November 8 2012
Pixie Geldof wore a long black dress to attend the Uniqlo and Conde Nast in-store event where she performed live with her band, Violet.
November 8 2012
Berenice Marlohe arrived to see Skyfall co-star Javier Bardem receive a star on LA's Hollywood Walk Of Fame wearing an Elie Saab nude lace dress and gold stiletto heels.
© Rex Features
November 8 2012
For an LA screening of Ginger & Rosa, Christina Hendricks wore a burgundy dress with black boots.
© Wenn
November 8 2012
She attended a special New York screening of Rust & Bone hosted by Christian Dior wearing a crystal-embellished gown and black stiletto heels by the fashion house.
© Rex Features
November 8 2012
To attend the LA premiere of Lincoln during the AFI Film Festival, Lucy Liu wore a printed Roberto Cavalli cape over a Roland Mouret dress and carried a clutch.
© Rex Features
November 8 2012
Elle Fanning wore a Dolce & Gabbana white shirt, a black skirt, lace court shoes and a beaded headband to attend a screening of Ginger & Rosa in LA.
© Wenn
November 8 2012
Hilary Rhoda attended a dinner to celebrate the Engine Blocks Installation by Shelter Serra wearing a mottled suit with black stiletto heels. | https://www.vogue.co.uk/gallery/12-14 |
Pieces from the Zuahir Murad Spring/Summer ’17 Collection where among the designs to be displayed at the “Haute Dentelle” designer lace exhibition at the Museum of Fashion and Lace Calais, France.
Zuahir Murad pieces showcased at the exhibition include, a see-through long sleeved metallic lace dress with crystal studded chromatic bursts and raised ruffles, held together by a bow shaped black belt; a tea length, champagne colored tulle dress with long sleeves and a neck and decorated with floral appliqués.
The “Haute Dentelle” exhibition is designed by the Museum of Fashion and Lace to offer “a unique insight into the contemporary uses by fashion designers of lace woven on Leavers loom. The exhibition is curated by Sylvie Marot and also displays works from Dior, Iris Van Herpen and Chanel. The exhibition runs from 9 June, 2018 to 6 January, 2019. | https://belijose.com/2018/09/11/the-museum-of-fashion-and-lace-showcases-zuhair-murads-beautiful-lace-designs/?shared=email&msg=fail |
It was a rainy day in autumn as I was sitting on the love seat by my window that looked out into the city. I was content and cozy drinking my hot cup of Earl Grey tea, watching the orange, yellow, and red leaves fall from the trees. My cat Izzy was happily purring in my lap. The only thing that was disconcerting was that I had been noticing more and more stuff disappearing from the apartment. None of my personal stuff, but stuff that my roommate and I communally shared, and stuff that was just hers.
Lily and I were best friends and had been best friends for years now. Lily had always been a very quirky person. She grew up poor, and at the age of 13 her mother killed herself and her father had abandoned Lily and her sister. After that, Lily basically fended for herself, living on the streets until her grandmother had heard that her daughter died and her granddaughters were wondering the streets of New York City.
Lily was tough, street-smart, and a very loyal friend. She was sweet but had a temper that could flicker to the other side faster than a blink. She was a hippie, a vegetarian, and a masseuse. She played guitar and sang odd songs.
Was I going crazy or had all of Lily's plants in the living room disappeared? Where were the creepy paintings that she had hung up, that she bought from a flea market? And shouldn't she be home by now, baking cookies and singing in the kitchen?
Maybe I was overthinking it. She was probably at the farmers' market, talking to some homeless people, or had met some cute guy at the coffee shop downstairs and was getting lucky.
I should do some things to distract myself from thinking maybe Lily got murdered and raped, I thought. So, I got up from the window seat, my cat annoyed that I woke him up from such a peaceful slumber and made another cup of tea. I went to my room, put on my coat and scarf, and left the apartment to take a walk around the city and maybe do some errands.
The autumn air was cool and crisp. Autumn was my favorite time of year. It's cool, but not freezing, and everything is so beautiful. The sky is the brightest blue I have ever seen it all year. I love smelling the smell of firewood, cinnamon, and the smell of hot coffee pouring out of the local coffee shops.
The cool air felt amazing on my face as I walked briskly past bookstores and restaurants. Geese were flying through the air in a V-formation, migrating for the winter. Squirrels were running about Central Park, gathering bundles of acorns for their upcoming hibernation. Leaves were falling everywhere and being blown in all directions. The wet smell of the leaves was intoxicating.
I went to the farmers' market and bought some apples to make apple pie, two pumpkins to carve with Lily, and the tomato sauce I always purchased for making spaghetti. I went to the bookstore down the street, bought two books that caught my eye, and walked home.
When I got into the apartment, I noticed that the fall-scented candles on the kitchen counter and living room table had been lit and that the dishwasher was running.
"Lily?" I called out, hoping this wasn't another chapter of Chloe Goes Crazy.
"I'm here, love!" Lily replied. "I'll be out there in a second. Just straightening up my room a bit."
I breathed out a sigh, relieved my mental state was intact and that my best friend and roommate was home safe.
Lily came out of her bedroom, smiling nervously.
"Hi hun," she said. "How was your day?"
"Good, typical day at work," I answered. I thought this would be an opportune time to bring up the subject of Lily's vanishing items. I was either going to risk appearing insane or get some helpful, reassuring answers.
"So Lily, I was wondering, where did all your plants go? And where is the curtain of beads that hung from your bedroom doorway? Where's the toaster, and half of the refrigerator magnets? Are you giving things away to charity?"
"Look, Chloe," she replied. "I bought an apartment a couple weeks ago and I've been moving my things out bit by bit over the last few weeks, hoping you wouldn't notice and hoping to wait until the last minute to bring the difficult subject of me moving out".
"What? But why? Why are you moving out? I thought you liked living together," I said, bewildered.
"I do like living with you Chloe, but sometimes I don't. We fight about roommate stuff like cleanliness and orderliness, and I'm just not as clean and orderly as you. I want us to stay friends, best friends, and I couldn't see that lasting with us being roommates. I love you."
"You're the best friend to be so considerate and sweet. I love you too, Lil'."
And we have the best friendship two women could ever have, and we always will. | https://www.theodysseyonline.com/chloe-and-lilys-autumn-in-manhattan |
Uric acid is a substance produced naturally by the breakdown of purine (a type of dietary protein) . When it is in excess in the body, crystals composed of these substances are formed.
These crystals are deposited in various parts of the body, mainly in the joints and kidneys, causing pain and other aggravations.
The lack or excess of uric acid in the body is caused by some diseases (such as leukemia , obesity , kidney diseases and anemia ) and factors related to lifestyle (consumption of alcohol and processed foods , for example).
Contents
- 1 Where does purine come from?
- 2 Where is uric acid found?
- 3 What is high uric acid?
- 4 What can high uric acid cause?
- 5 What is low uric acid?
- 6 Tests: how to know uric acid levels?
Where does purine come from?
Purine is produced and released into the bloodstream when an amino acid is broken down by digestion.
Therefore, it is produced naturally in the body.
Purine is also found in foods such as red meat, seafood, some types of grains ( beans , for example) and in alcoholic beverages (mainly beer).
Therefore, anyone who has high rates of uric acid should avoid eating foods that contain purine.
However, normal levels are necessary for the proper functioning of the body, as they are fundamental for the construction of genetic material (DNA), in addition to being responsible for the coloring of urine and the dilation of blood vessels.
Where is uric acid found?
Once produced in the body, part of the uric acid remains in the bloodstream and the other part is filtered by the kidneys and eliminated in the urine. Understand:
On urine
Uric acid is found in the urine due to the filtering process done by the kidneys. But when this substance is produced in excess, only urine cannot eliminate it from the body.
To avoid damage caused by excess of the substance, it is important to monitor the amount of uric acid present in the urine. This can be done through laboratory tests.
In addition to the test, drinking a lot of water during the day also helps to prevent uric acid crystals, because the liquid helps the kidneys to eliminate the substance that prevents crystallization.
In the blood
Urine eliminates some of the uric acid. The other part remains circulating throughout the body through the blood.
The levels of uric acid in the blood can be high or low. Studies have shown that if uric acid is high in the blood, a person is more likely to develop cardiovascular disease .
To identify the amount of uric acid in the blood, laboratory tests are also required.
What is high uric acid?
When the amount of uric acid is high in the body, it is called hyperuricemia. In general, excess is represented by values above 6 mg / dL (in women) and above 7 mg / dL (in men) .
This condition can happen for two reasons: the production of this acid has increased or the elimination, through the urine, is not being enough.
The uric acid highest is a result of a modern and stirred life, consumption of processed foods, little water intake and physical inactivity that atrophy of joints. The use of some medications can also have an influence.
The diagnosis is made by laboratory tests that measure the amount of uric acid in the blood.
What can high uric acid cause?
Uric acid, when missing or in excess, is related to various diseases and health complications. Between them:
Crystals in the kidneys or joints
When uric acid is in excess, the kidneys are unable to properly filter the blood and, therefore, crystals composed of this acid are formed.
They stay in the joints, kidneys and gallbladder, are difficult to eliminate and cause severe pain.
In general, they are eliminated naturally in the urine, which causes pain and discomfort. Therefore, consuming plenty of water can help eliminate these crystals more quickly.
Purine-free eating and exercise can also facilitate the process.
In some more complex situations, uric acid will be eliminated with the help of medications, which can be prescribed by a rheumatologist or nephrologist.
Kidney problems
Under normal conditions, the kidney filters uric acid and eliminates excess uric acid in the urine.
But when uric acid crystals form in the kidneys, there is a greater chance that diseases and complications will develop in this kidney, such as kidney stones and chronic or acute kidney failure.
This is because the crystallization of the substance remains inside the kidney, which prevents the organ from filtering the blood properly.
Gout and arthritis
The drop is a type of arthritis inflammation caused by uric acid crystals in the joint accumulation. This disease is prevalent among adult men.
About 20% of people who have hyperuricemia (excess uric acid) will develop gout.
The initial symptom is characterized by a crisis that lasts between 3 and 10 days with swelling in the joints of the foot accompanied by severe pain. Seizures naturally normalize within a week, on average.
Another gout crisis can take months or even years to happen again. Therefore, many people end up choosing not to have the treatment.
But if gout is not treated, the joints affected by the disease can suffer permanent deformations in the long run.
Heart problems
People who already have gout are more likely to develop cardiovascular disease.
This is because the condition stimulates constant inflammation that ends up damaging the arteries.
Blood pressure can also increase, as uric acid helps with sodium retention, causing pressure fluctuations.
What is low uric acid?
When there is a lack of uric acid in the body, it is called hypouricemia. The condition is usually characterized when the levels of the substance are below 2.4 mg / dL (in women) and 3.4 mg / dL (in men) .
This is a rare condition that usually does not cause any symptoms.
Low uric acid can happen when there is drug use or kidney and liver problems. It is divided into two types:
- Primary: when the disease is permanent. The hereditary factor is related to this type of hypouricemia;
- Acquired: when the condition is intermittent, that is, “come and go”. This type can be triggered by drug use or changes in the functioning of the kidneys and liver.
Tests: how to know uric acid levels?
Some tests may be ordered by your doctor to check the amount of uric acid in your body. To perform this analysis, laboratory tests of blood and urine collection can be done.
The blood test requires fasting for at least 3 hours. For the urine test, the first of the day should be collected or as instructed by the laboratory.
Before making a diagnosis, tell the doctor if you take any medication or dietary supplement. In some cases, it will be necessary to stop that treatment.
Results vary between laboratories and only a medical analysis can accurately interpret these tests.
Uric acid, in shortage or in excess, can cause a lot of damage to the body.
In addition to forming the crystals and causing pain and swelling in the joints, this substance is also related to gout, anemia and cardiovascular diseases.
The Healthy Minute also brings content about exams and medicines that can guarantee more quality of life! | https://hickeysolution.com/what-is-uric-acid/ |
One of our common goals in the rehabilitation of a multitude of conditions is to increase range of motion. In this months’ Research Refresh we looked at a systematic review of human research that compares strength training with stretching to improve range of motion.
According to the review, both strength training and stretching resulted in improvements in range of motion, in both short-term and long-term interventions. The decision with regard to which programme to pursue for an individual patient may hinge on the additional benefits, goals and requirements of that patient.
Do you know how strengthening and stretching programmes differ, yet can affect the same outcome measure?
A reduced range of motion
A reduction in range of motion can occur as a result of many conditions or pathologies, and can be divided into the following categories:
Mechanical
Muscle injury or pathology
Ligament/tendon injury or pathology
Osteoarthritis
Pain
Neurological
Loss of proprioception
Nerve injury or dysfunction
Central sensitisation
Hypertonicity
Muscle weakness or atrophy
Infection
Swelling
Pain
Joint infection
Range of motion can be reduced actively, referring to a reduced range of motion in the active movement of the patient. A restriction in active movement can be as a result of muscle weakness or restriction, pain, a physical inability to complete the full range of motion, or instability of the region.
Passive range can be restricted as a result of pain, contracture of the muscle or joint capsule, or restrictions within the joint. When we test range of motion in our patients, we are testing the passive range.
An understanding of the cause of the reduced range of motion can guide us in our choice of whether to opt for stretching or strengthening as a treatment intervention.
Stretching to increase range of motion
We will commonly use stretching in our patients to increase range of motion, both during treatment and as part of the home programme.
Static stretching is performed by the therapist or owner stretching out the limb or muscle group and holding it for a period of time. Dynamic stretching requires the patient to move into and hold a stretched position. This can be specific to the sport or function that the patient needs to perform. An example of a dynamic stretch would be placing the forelimbs on a raised surface such as a peanut ball and doing cookie stretches to increase the extension of the back and hips.
Dynamic stretching will impact the whole body, increasing full body circulation and cardiovascular rates, and improving neuromuscular control and proprioception. It can help us to achieve specific goals in addition to increasing range of motion.
Stretching will improve range of motion in a number of ways, increasing stretch tolerance through neuromodulation, and through histological changes at the level of the musculotendinous unit.
Strengthening to increase range of motion
Strengthening is primarily used to address muscle weakness or asymmetry, or to improve function. There are many ways to incorporate strength training into our patients’ routines. All that is required is the addition of resistance to an exercise, which can include increasing the load on a limb through lifting another limb/s, the use of the theraband, or hydrotherapy.
Strength training has been shown to increase fascicle length, improve muscle coordination, improve reciprocal inhibition, and improve stretch-shortening cycles, as well as to increase range of motion, but studies comparing strengthening to stretching have shown conflicting results.
Strengthening VS Stretching
In Strength Training versus Stretching for Improving Range of Motion: A Systematic Review and Meta-Analysis, 194 peer reviewed journal articles were evaluated, and 11 were finally eligible for inclusion in the review. In this review, no statistical difference could be shown between the use of strengthening or stretching to promote range of motion, and one protocol could not be favoured or recommended above another.
The articles reviewed were all human-based, and this certainly does add some complications as we try to extrapolate these findings to our animal patients. For one, there are limitations in both stretching and strengthening protocols in animals, with many of the techniques used in humans not relevant to our equine or small animal practices simply because they are impractical to perform.
Considering other factors
As we make decisions clinically to guide our treatment interventions, we must consider the preferences of the patient, the concurrent treatment goals, the cause of reduced range of motion, and the ability and compliance of the owner. In some cases, static stretching may be simple, easy and enjoyable for both owner and patient, and can be incorporated into a leisurely massage and cuddle session.
For other owners and patients, a more active approach will be more enjoyable, and incorporating active stretches into a training routine or exercise routine may be far more beneficial.
Strengthening exercises can have the additional advantages of improving neurological deficits, improving muscle symmetry, strengthening specific muscle groups, improving joint health, and addressing functional or competition goals.
Conclusion
Both strengthening protocols and stretching protocols can improve range of motion in our patients. It is up to us to use sound clinical reasoning to establish the cause of the dysfunction and the goals of the patient when deciding which intervention to prioritise.
Resources
If you would like to learn more about clinical reasoning or exercise protocols, there are some phenomenal webinars in our members platforms for you to learn from:
- Understanding Exercise Physiology, a four-part series with Lesie Eide
- Therapeutic Exercise for Every Dog, with Debbie Gross Torraca
- Force-Free Exercise in the Canine, with Robert J Porter
- Biomechanics of Tissue Healing and its Relationship to Therapeutic Exercise, with Carrie Adrian
References
JOIN OUR
FACEBOOK GROUP
for Vetrehabbers ONLY
JOIN OUR
FACEBOOK GROUP
for Vetrehabbers ONLY
JOIN OUR
FACEBOOK GROUP
for Vetrehabbers ONLY
JOIN OUR
FACEBOOK GROUP
for Vetrehabbers ONLY
#VETREHABBERSSHARE: DID YOU ENJOY THIS BLOG?
If you found this blog interesting please share it with your friends and vetrehabber colleagues.
Use the share buttons below: | https://onlinepethealth.com/2021/10/14/stretching-or-strengthening-for-improving-range-of-motion/ |
McGrath, Alister E. Christian Theology: An Introduction (5th ed.). Wiley-Blackwell, 2011.
This book was comprehensive but not exhaustive. Christian Theology is indisputably a “textbook” proper, i.e., “a book used as a standard work for the study of a particular subject.” What the book lacks in imagination, i.e., style, tone, voice, allusion, etc., McGrath compensates for with factoid and reference factors, e.g., a useful (shock!!!) index, glossary, and primary source citations. Such being the case, the book will sit on my bookcase next to other useful theological reference works, e.g., Lewis and DeMarest’s Integrative Theology (3 vol.), Beeke and Ferguson’s Reformed Confessions Harmonized, Hodge’s Outlines of Theology, Beeke and Jones’s A Puritan Theology, etc.
The book is truly comprehensive: “The present volume therefore assumes that its reader knows nothing about Christian theology. . . . This book is ideally placed to help its reader gain an appreciation of the rich resources of the Christian tradition. Although this is not a work of Catholic, Orthodox, or Protestant theology, great care has been taken to ensure that Catholic, Orthodox, and Protestant perspectives and insights are represented and explored” (xxii-xxiii). McGrath gladly admits “My aim in this work has not be to persuade but to explain” (xxiii). That is good in one sense, but bad in the sense that McGrath does not provide direction on what ideas the reader’s mind-trap ought to go “slam!” on.
In addition to the already mentioned “factoid and reference factors” the book’s structure was very helpful. McGrath wants to expose readers the “themes of Christian theology” but he also wants to “enable them to understand them” (xxvii). Thus, the book is split into three parts: Part I covers the “landmarks” of Christian theology, i.e., the historical development of Christian theology neatly broken into four parts (Patristic c. 100-700; Middle Ages/Renaissance, c. 700-1500; Reformation, c. 1500-1750; Modern, c. 1750-the Present); Part 2 covers “Sources and Methods,” i.e., Prolegomena; the quadrilateral of Scripture, Tradition, Reason, Religious Experience; the ideas/categories of divine revelation and natural theology; and a high overview of different approaches to the relationship between Philosophy and Theology); Part 3 covers “Christian Theology” in its traditional creedal outline, i.e., “We shall use the structure of the traditional Christian creeds as a framework for our exploration of the leading topics of Christian theology” (197). This structure is where the book is at its strongest–the author’s aim for his readers to know and understand the themes of Christian theology.
My undergraduate degree is in Religion and Philosophy, so I enjoyed Part 2 – Chapter 8, “Philosophy and Theology: Dialogue and Debate,” and Part 3 – Chapter 17, “Christianity and the World Religions.” Nothing new therein, but thoroughly enjoyable–like shaking up and searching through the catch-all, “junk drawer” in a home, revisiting those chapters stirred up a bunch lost, “junk drawer — “wellwouldyoulookatthat” and “ha, cool!” — philosophic ideas and memories. 😉
It was a bit of a chore to trudge through 450+ pages of dry academic prose that attempted to be objective, but it was well worth it. To have another good reference work that has been thumbed through and heavily underlined with marginal notes is always a good thing to have; later on in life when the brain-gears are getting rusty and the recall and recollection skills are taxed with the weight of decades I will be even more thankful.
My 8 word aphoristic review: A non-scintillating but thorough rehearsal of Christian theology. As McGrath may say, Cheers! | http://treeandtheseed.com/reading-notes-christian-theology-by-alister-e-mcgrath/ |
From phone camera snapshots to lifesaving medical scans, digital images play an important role in the way humans communicate information. But digital images are subject to a range of imperfections such as blurriness, grainy noise, missing pixels and color corruption.
A group led by a University of Maryland computer scientist has designed a new algorithm that incorporates artificial neural networks to simultaneously apply a wide range of fixes to corrupted digital images. Because the algorithm can be “trained” to recognize what an ideal, uncorrupted image should look like, it is able to address multiple flaws in a single image.
The research team, which included members from the University of Bern in Switzerland, tested their algorithm by taking high-quality, uncorrupted images, purposely introducing severe degradations, then using the algorithm to repair the damage. In many cases, the algorithm outperformed competitors’ techniques, very nearly returning the images to their original state.
The researchers presented their findings on December 5, 2017, at the 31st Conference on Neural Information Processing Systems in Long Beach, California.
Artificial neural networks are a type of artificial intelligence algorithm inspired by the structure of the human brain. They can assemble patterns of behavior based on input data, in a process that resembles the way a human brain learns new information. For example, human brains can learn a new language through repeated exposure to words and sentences in specific contexts.
Zwicker and his colleagues can “train” their algorithm by exposing it to a large database of high-quality, uncorrupted images widely used for research with artificial neural networks. Because the algorithm can take in a large amount of data and extrapolate the complex parameters that define images—including variations in texture, color, light, shadows and edges—it is able to predict what an ideal, uncorrupted image should look like. Then, it can recognize and fix deviations from these ideal parameters in a new image.
Zwicker noted that several other research groups are working along the same lines and have designed algorithms that achieve similar results. Many of the research groups noticed that if their algorithms were tasked with only removing noise (or graininess) from an image, the algorithm would automatically address many of the other imperfections as well. But Zwicker’s group proposed a new theoretical explanation for this effect that leads to a very simple and effective algorithm.
Zwicker also said that the new algorithm, while powerful, still has room for improvement. Currently, the algorithm works well for fixing easily recognizable “low-level” structures in images, such as sharp edges. The researchers hope to push the algorithm to recognize and repair “high-level” features, including complex textures such as hair and water. | https://jpralves.net/post/2017/12/11/new-algorithm-repairs-corrupted-digital-images-in-one-step.html |
We have a new obsession around here. It’s Monopoly.
At any given opportunity, my children will pull it out and begin playing. It’s surprising to me, really, how often they will beg me to play it with them and I find myself saying, “Are you kidding? We have to leave in thirty minutes!”
“Please?” they will whine then, “please, please, please?” with the blithe carelessness children have for time.
I usually cave and we end up forgetting lunch and extend bedtime. I play with them, but not only because I usually win. (And they still want to play. I’m in awe.) And not even because I’ve waited a long time to find anyone else as in love with it as I was as a kid.
I agree to play it so much because Monopoly has some fantastic lessons. (And before you roll your eyes, let me say, of course it’s okay to play it just for fun. Not everything has to have a lesson.)
However, if you’re an overthinker like me and you appreciate myriad reminders of frugality, budgeting, cash reserves, you’ll know where I’m coming from. Otherwise, maybe it’s best to go read about how to win at Monopoly each and every time.
Here are three lessons “the world’s most popular game” has taught me.
Pay attention
Children (did I say that out loud? I meant people – in general, but let’s stay focused) tend to have tunnel vision, especially when something looks fun. I find that Monopoly is a fantastic reminder to get them to be aware of their surroundings.
When a property goes to an auction, my children almost always reject if they’re not actively seeking it out as a monopoly or if they think it’s unimportant for whatever reason. (The light blue properties, for instance, are treated like trash and sold back to the bank with the least hesitation.) Here’s where I remind them.
“Look, I’m picking it up for a song.”
Shrug.
“No, look!” I insist, as I turn back around and resell the property to the bank and make some extra cash or hold it until it becomes obvious that it’s valuable to someone else wanting a monopoly. It’s been a hard lesson for my children to learn that even if they’re not interested in a property and it isn’t as expensive or high rent as Park Place or Boardwalk, it’s still a great way to make some money by what we now call “flipping.”
Also related to the auction is keeping an eye on what the other players have in terms of money and / or properties. Many a time, it is a good idea to let a property go to auction and not buy it for asking price if the other players don’t have ready cash available. My children rarely notice this and happily pay asking price if they’re excited about landing on a past favorite.
In terms of developing the art of paying attention, Monopoly is as good as a game as the Where’s Waldo puzzle books or playing Spot It and Spot It Jr. with younger children.
It teaches them that gathering information at all stages of the game – not just when it’s your turn – is a fantastic skill to develop.
Currency is not Value
My children never, ever want to part with their hundred dollar notes. Never. Ever. And this is not an exaggeration.
If there is ever a time that they have to pay fifty dollars, they would rather gather up all their change in five and one dollar notes rather than break the hundred dollar notes.
Also, once they own a specific property, even if they owe another player rent, they will get rid of all their cash and refuse to liquidate it, claiming they have “no money.”
Indeed, they will make all kinds of arrangements to simply keep playing. It’s fascinating to watch the odd combinations and permutations they come up with – including debts, forgiveness of said debts, even paying each others’ rents!
At some point, my husband declares, they’re not even playing Monopoly; they’re playing “rotten economy,” if such a game exists.
“So what is money?” my daughter finally asked at the dinner table the other day after a long conversation with my husband trying to explain the concepts of money, price, value and currency.
She may not have got it all, but at least the conversation had begun. And I understood that based on the classical model of education, they are still in the grammar stage and money versus currency is definitely a logic stage conversation, but there had been a hint in that direction.
“What is money, then?” she asked. I wanted to applaud. She’s only eight. It took me until I was in my mid-twenties to ask that question.
Fortunes change, be kind
This is one we all stumble on, but one specific child (I won’t mention who) really, really likes to win. I mean, really. And this specific child likes to rub our noses in the dirt when such a victory is about to take place, takes place and after it takes place.
I’m all for celebrating, but learning to be kind has been one of the best lessons from this game. And yes, while I will say that there is a tipping point after which fortunes certainly can not change, we have had some very interesting reversals.
Helping my children to manage their emotions and temper both their wins and losses has been challenging, to say the least. What are the chances that I would get one of each child who loves to win and one who hates to lose? (That sounds redundant, but I assure you, it’s not.)
So we have to learn, I guess, in one word, humility. Me too.
This is one subject with no lesson plan. I can’t put “kindness” in our daily planner. So we practice when we play. And when the winner loses, we remember the quote I had glued above my desk when I was much, much younger, a quote from Kipling’s poem If that I still recall with fondness. | http://purvabrown.com/three-lessons-monopoly/ |
What Is Behavioral Economics?
1:58
What is Behavioural Economics?
0:15
Behavioral Economics, Explained
3:43
Behavioural Economics - Introduction
2:45
Economic Psychology V Behavioral Economics
Behavioral economics studies the effects of psychological, cognitive, emotional, cultural and social factors on the economic decisions of individuals and institutions and how those decisions vary from those implied by classical theory.
Explore contextually related video stories in a new eye-catching way. Try Combster now!
Open web
History
Classical economics
Writers
Adam Smith
The Theory of Moral Sentiments
load more
Criticism
Applied issues
Related fields
Notable people
Video encyclopedia
About us
|
Privacy
Home
Flashback
Categories
About us
Privacy | https://www.spectroom.com/10254212-behavioral-economics |
The US Centers for Disease Control and Prevention (CDC) today announced a $77 million investment in efforts to track and fight antibiotic resistance.
The money will be distributed to public health departments in all 50 states and Puerto Rico to help them combat antibiotic resistant bacteria in food, healthcare facilities, and communities, with a particular focus on enhancing testing capabilities in the agency's regional antibiotic resistance labs. It will also help fund a new surveillance center for tuberculosis (TB).
The money comes from the CDC's Epidemiology and Laboratory Capacity for Infectious Diseases (ELC) Cooperative Agreement, which is awarding more than $200 million to help state and local health departments respond to infectious disease threats. ELC money will also support improved surveillance and response to outbreaks of foodborne infections caused by antibiotic-resistant bacteria.
Enhanced testing for Candida auris, gonorrhea
With the investments, the seven regional labs—part of the CDC's Antibiotic Resistance Lab Network (AR Lab Network)—will be able to expand antibiotic susceptibility testing for Candida auris, the multidrug-resistant fungal infection that has emerged in US healthcare facilities over the past year. C auris has shown resistance to all three classes of drugs typically used to treat Candida infections and can cause serious invasive infections, with mortality rates as high as 50%.
"We've asked this year that all of the seven regional laboratories be able to do Candida antibiotic susceptibility testing, and that means we do the kind of testing necessary to find the right drug for treatment, and to look for new types of resistance," Jean Patel, PhD, the CDC's science lead for antibiotic resistance, told CIDRAP News. Patel said the role of the regional labs in monitoring C auris is critical, since many smaller and clinical laboratories lack the capability to properly identify the fungus and perform susceptibility testing.
The seven regional labs will also be able to do more advanced surveillance, using whole-genome sequencing (WGS), to identify emerging strains of drug-resistant gonorrhea, another major concern for public health officials. Last month, World Health Organization officials said that resistance to the only remaining treatment for the sexually transmitted infection is on the rise, and that widespread treatment failure is on the horizon unless action is taken. The first US cases of highly resistant gonorrhea were identified in Hawaii in September.
"We really think whole-genome sequencing of Neisseria gonorrhea is going to be critical for early detection of new resistance," Patel said. "We anticipate seeing very drug-resistant forms of Neisseria gonorrhea in the United States, and we want to make sure when that occurs, we detect it early and respond early."
WGS is a form of testing that looks at the entire genetic blueprint of an organism. It can help epidemiologists track development of antibiotic resistance in gonorrhea, identify the mechanisms of resistance, understand how the infection spreads from one person to another, and trace the origins of an outbreak.
New TB surveillance center
WGS will also be a core capability of the new National TB Molecular Surveillance Center, based in Michigan. The lab will perform WGS an all TB isolates in the United States, which sees roughly 9,000 cases of TB a year. Patel said the sequencing will provide critical information on transmission dynamics and antibiotic resistance in Mycobacterium tuberculosis, and that information will help guide treatment and prevention efforts.
Although the number of TB cases in the United States has steadily declined since 1992, the disease remains a major global health problem, and Patel says the rise in multidrug-resistant TB in other parts of the world is a cause for concern.
"This increasing threat internationally is the reason why we're investing in TB testing here at home," Patel said.
See also: | https://www.cidrap.umn.edu/antimicrobial-stewardship/cdc-invest-millions-enhanced-antibiotic-resistance-testing |
“Sorrow is better than fear. Fear is a journey, a terrible journey, but sorrow is, at least, an arriving.” So says Father Vincent in “Cry, the Beloved Country,” Alan Paton’s celebrated novel about South Africa. Share on Pinterest Which way to go? Not knowing the outcome can be tougher than the outcome itself. Now, research published in Nature Communications suggests that knowing that something bad is going to happen is better than not knowing whether it will happen or not. Findings show that a small possibility of receiving a painful electric shock causes people more stress than knowing for sure that a shock was on the way. Researchers from University College London (UCL), in the UK, enlisted 45 volunteers to play a computer game, which involved turning over rocks under which snakes might lurk. The aim was to guess whether or not there would be a snake. Turning over a rock with a snake underneath led to a small electric shock on the hand. As the participants became more familiar with the game, the chance of a particular rock harboring a snake changed, resulting in fluctuating levels of uncertainty.
Stress levels match levels of uncertainty An elaborate computer model measured participants’ uncertainty that a snake would be hiding under any specific rock. To measure stress, the researchers looked at pupil dilation, perspiration and reports by participants. The higher the levels of uncertainty, say the findings, the more stress people experienced. The most stressful moments were when subjects had a 50% chance of receiving a shock, while a 0% or 100% chance produced the least stress. People whose stress levels correlated closely with their uncertainty levels were better at guessing whether or not they would receive a shock, suggesting that stress may help us to judge how risky something is. Lead author Archy de Berker comments: “It turns out that it’s much worse not knowing you are going to get a shock than knowing you definitely will or won’t. We saw exactly the same effects in our physiological measures: people sweat more, and their pupils get bigger when they are more uncertain.” While many people will find the concept familiar, this is the first time for research to quantify the effect of uncertainty on stress. Coauthor Dr. Robb Rutledge notes that people who are applying for a job will normally be more relaxed if they know they either will or will not get the job. “The most stressful scenario,” he says, “is when you really don’t know. It’s the uncertainty that makes us anxious.”
| |
Outcome Questionnaire: item sensitivity to change.
Although high levels of reliability are emphasized in the construction of many measures of psychological traits, tests that are intended to measure patient change following psychotherapy need to emphasize sensitivity to change as a central and primary property. This study proposes 2 criteria for evaluating the degree to which an item on a test is sensitive to change: (a) that an item changes in the theoretically proposed direction following an intervention and (b) that the change measured on an item is significantly greater in treated than in untreated individuals. Outcome Questionnaire (Lambert et al., 1996) items were subjected to item analysis by examining change rates in 284 untreated control participants and in 1,176 individuals undergoing psychotherapy. Results analyzed through multilevel or hierarchical linear modeling suggest the majority of items on this frequently used measure of psychotherapy outcome meet both criteria. Implications for test development and future research are discussed.
| |
This study employs a randomized controlled trial of an established intervention, Mindfulness Based Cognitive Therapy (MBCT) adapted for pregnancy, to examine effects on various aspects of maternal psychological stress during pregnancy (magnitude and trajectories of stress) and offspring brain systems integral to healthy and maladaptive emotion regulation. This study considers other potential influences on maternal stress and psychiatric symptomatology, and infant behavior and brain development. The study population is pregnant women aged 21-45, and their infants.
The study will involve an online screen of potentially eligible pregnant women. If women are eligible after the online screen, they will be invited in for an in-person assessment, including cognitive testing and a diagnostic interview, to further determine eligibility. After the assessment, they will be informed of their eligibility status and, if applicable, randomized to a Mindfulness Based Cognitive Therapy (MBCT) group involving an 8-session group-based intervention or to treatment as usual (TAU) during pregnancy followed by one mindfulness psychoeducation session postpartum. Eligible participants will then be invited in for a study visit during which they will give blood, urine, and saliva samples. Participants in the MBCT group will complete questionnaires prior to the 1st group session, after the 4th session, and after the 8th/final session. Participants in the TAU group will complete the same questionnaires at equivalent time points. All participants will come in for an in-person session at 34 weeks GA, during which they will complete questionnaires, a brief clinical interview and provide blood, urine, and saliva samples again. Participants will then come in with their infant for the infant MRI scan within one month of giving birth. Study staff will collect a hair and saliva sample from the infant at this time. Participants will have a remote visit at 6 weeks postpartum, during which time they will complete questionnaires and a clinical interview. At 6 months postpartum, participants will return for their final visit, during which they will complete questionnaires and a clinical interview. Mothers and infants will also provide a hair sample at this time.
Masking Description: Given the use of a psychotherapeutic intervention involving participation in group sessions, participants and interventionists cannot be blinded to group assignment. The study is designed to minimize the extent to which study staff, aside from interventionists and the primary Study Coordinator(s), are aware of group assignment. The Study Coordinator(s) needs to know group assignment because they will inform participants of their group assignment and will communicate with participants regarding group attendance. The Study Coordinator(s) will be the main point of contact for participants throughout the study to reduce risk of participants revealing their group assignment to other study staff. Participants will be informed that only the Study Coordinator(s) and interventionists, if applicable, are aware of their group assignment. Therefore, in order to ensure the integrity of the research study, they should refrain from discussing their group assignment with other staff members.
MBCT adapted for pregnancy includes 8 sequential, weekly 2-hour group sessions co-led by two master's level therapists. Sessions include: 1) introducing new mindfulness skills through in-session practice, 2) reviewing mindfulness practices and troubleshooting barriers to practice, 3) reinforcing mindfulness skills through in-session practice and debriefing, 4) learning about how thoughts influence feelings and behaviors (not all sessions), 5) providing psychoeducational information to support skills, and 6) encouraging the establishment of social support. The intervention is focused on skill development through active engagement in mindfulness practices and exercises to increase awareness of thoughts, feelings and behavior in session, and assignment and review of daily home practices.
Maternal psychological stress will be a composite of the Perceived Stress Scale (PSS), Beck Anxiety Inventory (BAI), and Center for Epidemiologic Studies Depression Scale - Revised (CESD-R). This composite measure includes the degree to which situation's in one's life are appraised as stressful, perception of one's capacity to manage potentially stressful situations, as well as anxiety and depressive symptomatology. The magnitude and trajectory of maternal psychological stress will be examined.
Levels of IL6 assayed from maternal blood samples. Difference in magnitude of inflammation between groups at T5 after adjusting for inflammation prior to the intervention.
The cortisol levels obtained from participant's hair samples to assess cumulative cortisol from pre- to post-intervention.
MRI scans with neonates will occur during natural sleep. Resting state functional connectivity will be the outcome of interest.
MRI scans with neonates will occur during natural sleep. Neonatal subcortical brain structure volume will be the outcome of interest.
The Prenatal Distress Questionnaire (PDQ) is a short measure designed to assess specific worries and concerns related to pregnancy.
Inclusion and exclusion criteria for pregnant women/ mothers will be determined by a combination of the initial screen and intake assessment.
have a history of a mood or anxiety disorder.
not meeting any of the exclusion criteria below.
We are using GA equivalent rather than postnatal age because infants born pre-term will not be scanned prior to term equivalent (37 weeks GA). Therefore, infants who are born preterm may be older in terms of postnatal age, but will be similar to infants born at term with regard to time since conception. The time since conception is more pertinent to our measures of brain development versus postnatal age.
medical complications following birth requiring ongoing hospitalization.
a clinical psychology graduate students or psychiatry trainee (resident or fellow), who will be supervised by the PI or other licensed psychologist, psychiatrist or clinical social worker with expertise in MBCT-PD. Two therapists will participate/lead each group.
(1) If the therapists meet inclusion criteria, there is no other exclusion criteria.
Plan Description: We propose to share individual participant data in accord with the NIMH Data Archive Data Submission Agreement.
Time Frame: In accord with the NIMH Data Archive Data Submission Agreement policies we will share data on a semi-annual basis beginning 6-months after initiating data collection and through the end of the study.
Access Criteria: Data will be available through the NIMH Data Archive by following the procedures for Data Use Certification. | https://www.clinicaltrials.gov/ct2/show/NCT03809598?rank=80 |
Let’s be honest, Episode 11: Businesses and sustainability
Let’s be honest is a Food Circle’s project with the aim to open up the conversation about the challenges when being or becoming a member of the SC (Sustainability Club). This series will shine a light on the different approaches to make life more sustainable, as well as the step-backs and difficulties that arise. Being more kind and understanding, instead of critical, will hopefully help to encourage us to try, instead of giving up when facing a step-back or failure. This is made possible thanks to Sapient, the mother company of Food Circle, which every year offers internships to students from all around the world creating a uniquely multicultural environment.
Let’s celebrate the achievements and give room for honesty and struggles!
Having an enterprise nowadays comes along with a large variety of responsibilities for the owners. Entering the market requires hard work and determination on the entrepreneurs’ behalf. It is also of paramount importance that the right resources are obtained: labour, time, capital, etc. “The problem is that it isn’t hard to start a business, but it’s very hard to make it work.”(Matthews, 2019)
Given all these challenges that entrepreneurs have to overcome while climbing the ladder of success, governments still encourage them to also shift towards an eco-friendly approach in their business. That adds up more responsibilities to their schedules.Is it, though, convoluted to minimize the negative impact your business could have on the environment? Does it consume a significant amount of the firm’s resources? The purpose of this article is to try and provide answers to this question and present the challenges of implementing eco-friendly solutions for your business.
I find it relevant, to begin with, the definition of sustainability in a business context to be able to analyze the concept further.
“In business, sustainability refers to doing business without negatively impacting the environment, community, or society as a whole.” (Spiliakos, 2018)
That is equivalent to aiming to make a positive impact on the environment and society in which your business operates. With their focus on both increasing the revenues and being eco-friendly, businesses need to take into consideration a large variety of factors and solutions.
The first challenge - time
Even though it might be quite hard to explain and understand, time is familiar to everyone. According to Gallup's Dec. 2-6 Lifestyle poll, around 48% of the Americans subject to an experiment consider that they do not have enough time to fulfill their desires. That means that time is a limited resource and the lack of it could represent an impediment. Especially for the ones who need to get more tasks done.
When it comes to businesses, time is considered even more precious. Nevertheless, does the desire to protect the environment pose a threat to it?
The answer is, usually, yes. In order to shift towards a more sustainable business, efforts need to be done and decisions to be made. Choosing the best alternatives for a business to require planning, budgeting and controlling for the results. Especially at the beginning, it is fair to assume that time is one of the essential resources to be invested. It is not possible to minimize the usage of natural resources and emissions of waste, for example in a very short time. Everything takes time to plan in advance.
Nevertheless, once the business embraces the concept of sustainability, it will be less time consuming to identify solutions. All it takes is bringing sustainability among the core values of the business.
The second challenge – Employees and their habits.
According to Ian Hutchinson, a Life & Work engagement strategist, “Employee engagement is an investment we make for the privilege of staying in business.” (Hutchinson, n.d.) That means that the labour force has a say in case the change needs to be done. That is mainly because whenever a change needs to be made, resistance from the employees’ side could be an impediment. Whether the resistance has an organisational or personal source, there are many ways to overcome it.
Keeping employees motivated by incentives or making them understand the necessity of change could be two solutions. It is sometimes the fact that employees are not aware of the reasoning behind the changes that generate resistance. Individuals have habits and personal beliefs and the change should begin with the workforce.
The third challenge – Money
One of the most evident questions that a business has when they try to “go green” is if they can afford it. The answer depends on many factors.
It has been discussed in previous articles that some eco-friendly products are more expensive than their regular alternatives. However, when it comes to businesses, sustainability could end up being a good investment. The beauty of protecting-the-environment measures is that they could actually cut the costs instead of increasing them. That if research is done thoroughly and such solutions are implemented.
Take for example the initiative that some restaurants have of not offering straws. This reduces the amount of plastic discharged in the environment and also saves the business some money. At the same time, becoming eco-friendly might lead to increased revenues for some businesses. That since customers might be more incentivised to buy something if they know they are protecting the environment at the same time.
Still, sometimes it might appear that “going green” is a roller coaster of endless spendings.
In conclusion, we can be honest with ourselves and say that implementing sustainable solutions is not all milk and honey. Nevertheless, going green could prove to be a valuable investment for the business.
Author and Editor: Anda Codreanu, Henry Mitchell
References
Hutchinson, a. (n.d.). | https://www.foodcirclenl.org/post/let-s-be-honest-episode-11-businesses-and-sustainability |
RGD advocates best practices for both graphic designers and their clients. Our primary focus is on fighting spec work and crowdsourcing of design; promoting accessible design best practices; and providing best practices in the areas of salaries and billing practices, pro bono work and internships. If you have questions about RGD's advocacy efforts or would like the Association's assistance responding to a request for spec, please email Executive Director, Hilary Ashworth, at
RGD writes to Mayor and key officials to explain the negatives of spec work both to the design community and clients. News Talk 610 CKTB and Niagara This Week reported on the Association's position.
- 06/04/2016
The comprehensive report includes how design impacts productivity, turnover, employment and the financial performance of businesses. | https://www.rgd.ca/about/advocacy/main/18/news_post/2016-04.php |
1.
Critical thinkers are
flexible
3.
Critical thinkers are
skeptical
4.
Critical thinkers separate
facts
from
opinions
5.
Critical thinkers
don't oversimplify
Remember:
There is no "my side" or "your side". We must always remain open and flexible. The fields of social sciences are constantly changing and adapting with the world around us. What you learn in this class may become discarded in 10 years, years, or even in a few months. What's important is that we always pursue truth aggressively and that we don't allow our own preconceptions to blind us to real knowledge.
2.
Critical thinkers can identify
biases and assumptions
(including their own!)
6.
Critical Thinkers use
logical inference
Critical Thinking in Social Sciences: 6 TIPS
The
s
ocial sciences
are about thinking critically.
Life
is about about thinking critically.
Many issues we cover in the social sciences can be confusing, controversial and garner a wide variety of
opinions
,
which people try to support or discredit with
facts.
Critical Thinking
is the process of investigating an issue, while simultaneously
avoiding one's preconceptions.
Why is critical thinking important?
1. You must be able to think critically to be
well-educated:
-
higher
order thinking (explore ideas deeply)
- working in jobs that don't yet exist (
new challenges
)
2. We live in the
information age:
- determine what's
"junk information"
(not correct, beneficial, or useful)
3. Helps with
practical problems
related to social sciences:
- ex. coping with
stress
, dealing with
relationships
, understanding a person's
motives
If you enjoy mysteries and complexities you have one of the most important qualities of a critical thinker!
Sherlock Holmes doesn't jump to conclusions
"All people on welfare are lazy and cheating the government..."
Have you ever heard someone say something like this?
- person works hard
- resents rising taxes
- knows person who has abused system
Important:
biases don't make an opinion wrong, but we need to be aware of the possibility that they can cause people to avoid evidence that contradicts their opinions.
"vegetables will make you grow up big and strong"
As a kid you may have believed everything you were told:
But as you get older..
""yeah right" "prove it!"
Mr. Walker's mother told him all the vitamins were trapped at the bottom of his bowl of soup!
We must question
all
information and ideas and not just when they go against our own. Even when they come from someone we like and respect (like a teacher or our parents)
As social scientists we require evidence when making a decision.
We need to be
objective
and remain
emotionally detached
when dealing with controversial issues
Social scientists view the world as a complicated place of
cause and effect.
We need to look beyond simple and easy answers when pursuing
truth.
When we draw logical conclusions from our
understanding of evidence
ex.
If your friend tells you that he is going to be at
9:00pm
, when his usual bed time is at
midnight
, what logical inferences could you conclude?
Why would building a wall across the Mexican border not solve all of the U.S/Mexico immigration issues
Present Remotely
Send the link below via email or IMCopy
Present to your audienceStart remote presentation
- Invited audience members will follow you as you navigate and present
- People invited to a presentation do not need a Prezi account
- This link expires 10 minutes after you close the presentation
- A maximum of 30 users can follow your presentation
- Learn more about this feature in our knowledge base article
Critical Thinking in Social Sciences
No description
byTweet
Jermaine Walkeron 11 January 2017
Comments (0)
Please log in to add your comment. | https://prezi.com/aqnddmry9-dz/critical-thinking-in-social-sciences/ |
Recently, Rob co-authored three popularising papers related to our research topics. In the last issue of Živa, a popularising journal of the Czech Academy of Sciences, there are two papers written together with Jana Jersáková. The main paper focuses on mutual relationships of flowering plants and their pollinators, including its evolution. The second paper describes and discusses pollination syndromes. A week ago, a brief description of the projects on dynamics of biodiversity in the Kruger National Park in relation to water stress and herbivores was published in Botanika, a popularising journal of the Institute of Botany CAS. All three papers are freely accessible, click the links above. Although in Czech, there are some nice pictures. | http://www.insect-communities.cz/popularising-articles-on-our-work/ |
Ownership of mobile phones, especially smartphones, is spreading rapidly across the globe.
Yet, there are still many people in emerging economies who do not own a mobile phone, or who share one with others. According to the Pew Research Center, in 2019 mobile divides were most pronounced in Venezuela, India, and the Philippines, countries where three-in-10 adults do not own a mobile phone.
Of course, when a crisis strikes, such digital technologies can make all the difference. As Samira Sadeque points out in “COVID-19: The Digital Divide Grows Wider Amid Global Lockdown“: “The digital divide has become more pronounced than ever amid the global coronavirus lockdown, but experts are concerned that in the current circumstances this divide, where over 46 per cent of the world’s population remain without technology or internet access, could grow wider — particularly among women.”
Health care is one of the arenas where digital technologies have taken on a vital role. There is a growing need for high capacity health-care systems and related internet-based services such as telemedicine. Unequal access to technologies, as well as issues around affordability, will exclude people and might prevent them from accessing medical treatment as well as trusted online information about reducing exposure to viruses such as COVID-19.
Today, there is more and more media coverage of this global digital divide and how the experience of the coronavirus virus ought to contribute to the creation of a more egalitarian world. Recently, in an editorial last month, the Financial Times commented:
“Some countries, such as Estonia, have long championed digital sovereignty, arguing that the ability to operate online is an essential part of modern life. Post-pandemic, this understanding should be more widely spread. But this will depend on upgrading digital infrastructure so that it serves all citizens … Governments should ensure they expand digital access to [include] those who only make limited use of basic services. That may require them to review pricing structures that currently exclude the most vulnerable, who could gain the most from access to digital resources.”
In Canada, 76 per cent of the population owns a smartphone, according to Statistics Canada’s 2016 data. However, an annual wireless price comparison study commissioned by the federal government since 2007 has consistently shown that Canada’s mobile phone rates rank among the highest when compared to other G7 countries.
“Prices in France, the U.K. and Italy are noticeably lower than most other countries,” according to the 2019 Price Comparison Study of Telecommunications Services in Canada and with Foreign Jurisdictions. The study showed, for example, that one gigabyte of data costs an average $64.80 in Canada, compared to $22.89 in Germany, $35.56 in the U.K., $50.17 in the U.S., and $57.82 in Japan.
As a result, Canadian households — particularly those in the low-income level — choose to subscribe either to mobile services only or to landline services only. In 2016, 32.5 per cent of Canadian households subscribed to mobile services only and 11.4 per cent of households subscribed to landline services only, according to Statistics Canada.
Both the digital divide and social inclusion need to be addressed by governments and by civil society organizations. The right to communicate is never more urgent than when lives and livelihoods are at stake because access to trustworthy information and news is blocked.
Marginalized and vulnerable communities, especially women in the Global South, deserve preferential treatment.
Philip Lee is WACC general secretary and editor of its international journal Media Development. His edited publications include The Democratization of Communication (1995), Many Voices, One Vision: The Right to Communicate in Practice (2004); Communicating Peace: Entertaining Angels Unawares (2008); and Public Memory, Public Media, and the Politics of Justice (ed. with Pradip N. Thomas) (2012). WACC Global is an international NGO that promotes communication as a basic human right, essential to people’s dignity and community. The article originally appeared on the WACC blog. | https://rabble.ca/technology/upgrading-digital-infrastructure-serve-all-people-everywhere/ |
The Municipality of North Cowichan (population 30,000) is located in the beautiful Cowichan Valley on Southern Vancouver Island, between Nanaimo and Victoria. Our communities of Chemainus, Crofton, Maple Bay, and the South End including University Village, are home to a multitude of artistic, cultural and outdoor recreational activities. The Municipality provides a stable and varied work environment, competitive pay and benefits.
We are inviting applications from candidates with the proven skills, qualifications and abilities for the position of Assistant Fire Chief of inspections and investigations. If you are self-motivated, looking to take on a new challenge where you can make a difference, enjoy both responsibility and accountability, and are ready to join one of British Columbia’s most inclusive and environmentally conscious municipalities, we look forward to receiving your application!
Reporting directly to the Manager, Fire and Bylaw Services (Fire Chief), the Assistant Fire Chief provides support with the strategic direction, leadership, and management of North Cowichan’s Fire Services. This position will be responsible for fire investigations and fire inspections; however, this may change in the future to provide for developmental opportunities. As an Assistant Fire Chief, you will fulfill requirements as a Local Assistant to the Fire Commissioner.
The ideal candidate will possess relevant post-secondary education augmented by NFPA Level 2 certifications for Inspector and Investigator, along with several years of experience as a Fire Officer in a leadership role. You possess management qualifications that will clearly demonstrate your ability to manage the strategic leadership, administrative and operational functions of a complex organization, as well as in building effective relationships with all stakeholders and the public. You are an effective communicator and a leader of innovation and change, and your values align with the Municipality’s core values of fiscal accountability, commitment, inclusion, collaboration, continuous improvement, environmental stewardship, sustainability and service excellence.
We require a candidate that can develop an inspection program from the ground up utilizing all the latest technology and resources afforded by the Municipality, along with the experience of conducting fire investigations and inspections. You must confidently organize the fire ground and related emergencies using the incident command model, incorporating strategies and tactics to ensure life safety of all first responders and the public. The successful candidate will possess practical operational experience as an Incident Commander at a wide range of events.
You have exceptional communications abilities, including presentation and report writing skills, and the ability to communicate complex information to a diverse group of people in an easy-to-understand manner. You possess an open, team-oriented leadership style and welcome the challenge of seeking continuous improvements in organizational efficiency. You work collaboratively with senior management, Council and staff across the Municipality. You are respected for your ability to gain commitment on department priorities, you bring a distinguished customer service philosophy and are recognized for your positive corporate contribution.
The ideal candidate for this position will maintain a successful police information check, including a vulnerable sector check; agree to share Chief responsibilities after regular work hours; and, possess and maintain a valid Class 3 B.C. driver’s license with an acceptable driving record.
A competitive salary and comprehensive benefit package is offered. This position is excluded from union membership.
Candidates being considered will be required to undergo a comprehensive evaluation of skills, qualifications and abilities.
To Apply:
Visit the Municipality of North Cowichan Career Portal at www.northcowichan.ca/jobs to apply for this position.
Please note that all candidates must apply via the Career Portal; we do not accept resumes via email or hard copy.
Application Deadline: | https://vancouverjobs.me/job-postings/assistant-fire-chief-municipality-of-north-cowichan-duncan-bc/ |
a graph with points plotted to show a possible relationship between two sets of data.
slope intercept form
y=mx+b
point slope form
y-y1 = m(x-x1), where m is the slope and (x1,y1) is the point the line is passing through.
midpoint formula
(x₁+x₂)/2, (y₁+y₂)/2
slope formula
y2-y1/x2-x1
standard form
Ax + By=C, where A, B, and C are not decimals or fractions, where A and B are not both zero, and where A is not a negative
function notation
To write a rule in function notation, you use the symbol f(x) in place of y. | https://quizlet.com/6116787/algebra-2-trig-vocab-flash-cards/ |
You desire a position in robotics. What a fantastic idea! Robotics is a field with a promising future and a wealth of untapped potential. But how may one find employment in robotics? What should you research? Which academic backgrounds best prepare you for a career?
I’ll try to answer those questions for you in this post. In the field of robotics, numerous persons with various majors are employed. Although we will focus on technical positions, there are several degrees that can prepare you to become a robotics developer. I’ll concentrate on the most prevalent ones and highlight the useful abilities they impart for various robotics fields. The degrees are not listed in any particular order because they will prepare you for many, equally significant and enjoyable sectors of robotics. Let’s begin, then!
1. Mechanical Engineering for Robotics
The mechanical design serves as the cornerstone for all robot development. A degree in mechanical engineering is the best preparation for it. You will gain knowledge of mechanical system design and manufacturing processes. You will learn about various materials and how to evaluate the system’s characteristics. All of this will assist you in creating the ideal robot design by determining the proper robot kinematics, doing structural analyses, and much more.
But this isn’t the end of it. Control theory, which focuses on how to instruct the robot’s motors so that it moves in the correct manner, is one of the most crucial subjects for designing robots. The control of the robot is closely related to its mechanical structure, making mechanical engineering particularly well-suited for this area of work. Control theory specialties are common in mechanical engineering degrees, and there are even distinct degrees just for it that are typically offered by the mechanical engineering faculty.
2. Electrical Engineering for Robotics
The robot’s movement is actually caused by electronics. It is in charge of establishing communication, managing electricity, and managing the robot motors. By creating electrical circuits and planning the layout for the electric boards, you will learn how to create electronics as part of an electrical engineering degree (PCBs).
These, however, are typically merely phases within a protracted growth process. A robot has a large number of sensors, both for sensing the environment and for monitoring and managing the robot’s internal status. The tough job of the electrical engineer is to analyze and integrate these sensors. Close cooperation with the other disciplines is required for this. To create their control algorithms, mechanical engineers are interested in sensors found inside motors, such as current or position readings. The sensors that computer scientists use for perception and their machine learning algorithms are important to them (e.g. cameras). Generally speaking, electrical engineering often works at the junction of other fields, therefore collaboration with them is crucial.
Finally, embedded programming employs a large number of electrical engineers. The software needed to combine the sensors and actuate the motors is created by embedded software developers. As a result, they require a thorough knowledge of the hardware, which is ideal for electrical engineers.
3. Computer Science for Robotics
The robot runs a ton of software, thus many computer experts are required tremendous create it. Motion planning algorithms are required to program the robot to move in the desired manner. To ensure that the robot is aware of its surroundings, perception is crucial. As a result, you must create the computer vision algorithms that analyze the data from your cameras.
A user interface that makes it simple to control the robot is also necessary. The software infrastructure needs to be improved in all larger software initiatives. This facilitates development and ensures that everything goes without a hitch. Software architects are crucial for organizing the various software modules and ensuring that everything works well together.
The aforementioned are only a few instances of the various jobs that computer scientists are involved in when developing robots. A computer science major will teach you all about the various components of quality software and give you a thorough understanding of how the execution process operates. Even if you don’t have a lot of experience in the field of robotics yet, it will provide you with all the fundamental tools you need to work on the different difficulties in that field. Simply pick a discipline that interests you, and the rest will come to you as you go.
4. Artificial Intelligence for Robotics
It is undeniable that artificial intelligence is a current hot topic. There is a cause behind this, too. The robot’s artificial intelligence is actually created by these algorithms. Additionally, it is probably where the majority of robotics innovation occurs.
In a normal AI course, you first master a significant amount of algebra and probability-based mathematics before moving on to the fundamentals of machine learning algorithms. You learn how to create machine learning models, how to train them, and how the performance of these models is influenced by the data you feed them. A subset of artificial intelligence (AI), deep learning, focuses on multi-layered machine learning models with many well-known applications, such as object detection or tracking. Reinforcement Learning is a unique area of artificial intelligence that has a significant impact on robotics. The basic goal of this strategy is to train the model by making mistakes and learning from them. This aims to emulate how people learn, and many see it as a potential strategy for resolving challenging robotics problems.
AI is crucial for human-robot interactions as well. It is employed in both voice recognition and the analysis of human face expressions. All of this makes the interaction more natural and aids the robot in understanding what the user intends.
There are numerous challenges that have not yet been solved in the area of artificial intelligence in robotics. Separate degrees in AI are being established by more and more universities. A specialization in more broad degrees like computer science is also common.
5. Mathematics/Physics for Robotics
A degree in physics or mathematics can lead to several opportunities. Even if they lack domain-specific knowledge, graduates are in high demand if they have a solid mathematical background and experience approaching and solving challenging problems.
Graduates in mathematics and physics who are interested in programming can certainly work on any of the several algorithms that we already covered for the Computer Science degree (motion planning, Computer Vision, etc.). Many graduates go on to work on machine learning-related issues. A solid mathematical foundation is necessary once you begin researching machine learning techniques in depth.
After your studies, you will undoubtedly be able to enter the robots industry if mathematics or physics are your passions.
degrees in robotics
Universities that specialize in robotics are popping up everywhere. That is a fantastic chance to learn about a certain industry before beginning your career. But it’s crucial to pay great attention to the design and narrow concentration of these degrees.
Some programs place a greater emphasis on mechanical engineering, leading students to frequently study advanced control theory for robotics. Others are concentrating on the (artificial) intelligence component, which includes machine learning, perception, etc.
A degree in robotics can be a terrific way to get started on your future profession. As different robotics degrees have different emphasis, make sure the courses offered match your interests.
Conclusion
This list demonstrates the diversity of degrees that can lead to a career in robotics. Which one ought to you ultimately select? I made an effort to explain the little emphasis these degrees place on various branches of robotics. Therefore, you should ultimately determine whatever field most interests you.
How do you go about that? by putting a bunch of different things to the test! Investigate a topic if you believe you might be interested in it. Look for home-based tasks to work on (you can draw some inspiration from the article on projects to learn robotics). Start with tutorials on a topic and decide if you want to learn more about it. For example, check at the tutorials overview to learn about various robotics themes. If you are a newbie, you should read my comprehensive post on Where to Begin With Robotics.
Nothing is definite in the end. Even if the aforementioned descriptions give some indications of the potential directions a particular degree path can take you, there are just as many counterexamples. It is simple to transfer across fields because robotics is such an interdisciplinary field.
The setting in which you study is a different consideration that is equally significant to your degree of choice. A institution that allows its students to obtain experience in a quality robotics lab is extremely important. Use the chance you have if you have it!
If you decide to work in robots in the future, no matter what degree you are currently pursuing, you will unavoidably wind up doing it and you will love it! I swear.
Did you like this article?
There are no reviews yet. Be the first one to write one. | https://www.awerobotics.com/home/where-to-begin-with-robotics/top-courses-degrees-to-get-into-the-field-of-robotics/ |
Kaizen Private Equity Fund
Kaizen Private Equity will invest in opportunities along the education market value chain in India: from school management companies in the core education segment, to vocational training providers in the parallel education segment, and to education-specific technology providers in the ancillary education segment. Beside direct development effects, such as job creation and increased tax revenue, investing in the Indian education sector is expected to result in substantial indirect development effects, such as raising literacy levels and improving the employability of India’s youth.
Kaizen Private Equity is the first private equity fund with a sole focus on the Indian education sector. It is advised by Kaizen Management Advisors, based in Mumbai. The management team consists of both private equity professionals and education sector specialists, allowing them to add substantial value to investee companies with their knowledge of the education sector. | https://sifem.ch/investments/portfolio/detail/kaizen-private-equity-fund |
A drought is caused by prolonged dry conditions that threaten to deplete the country's water resources. It results from lack of rain; snow; or sleet, which affects the ability of water reservoirs to replenish. Drought is effectively a prolonged hot temperature that causes moisture to evaporate from the soil, rivers and streams to dry up, and plants and livestock begin to die. Droughts are a natural phenomenon but there is a significant contribution of human activity, like water misuse and mismanagement, which deepen the impact of the drought and of course greenhouse emission that causes global warming.
Today, Cape Town's six major water dams are full. This, however, was the case even in 2014. Then came three consecutive years of little to no winter rains, unchanging water demand and use, inability to take advice about preparing for an impending disaster, and the inevitable happened: Day Zero knocked at the door. There is never a time to be complacent when it comes to water supply, especially in South Africa. This is what Eastern Cape, Limpopo and Northern Cape are learning.
After a drought, an equally prolonged period of rainfall is required for the soil to soak and absorb water sufficiently to be able to reproduce and be fruitful. Western Cape is currently enjoying regular and sufficient winter rainfalls, dams are overflowing and the soil is moist. Western Cape is the prime example that it takes enough and regular rain to end a drought.
What causes droughts?
Droughts do not happen overnight. Only a prolonged dry and hot season qualifies as a drought. High temperatures affect ocean temperatures, which generally dictate in land weather patterns. Drastic changes in oceanic temperatures directly correlate to weather changes inland. The drier the land the less moisture is evaporated into the atmosphere and the less likelihood for that evaporation comes back as rain.
Drought, of course, is a natural phenomenon, but things like greenhouse gas emissions are having an impact on the likelihood of drought and its intensity. This is climate change and global warming. It causes rising temperatures, which make dry regions even more dry. Climate change also alters weather patens from their typical path so that an expectation of winter rains in Western Cape and Summer rains in the rest of the country is no longer guaranteed.
Humanity's role in deepening the drought and water crisis is very clear. Population growth and intensive agricultural water use contribute to imbalance in water supply and demand. Studies in countries like the United States have shown that between 1960 and 2010, consumption of water increased by 25%. This means there was more pumping of groundwater, extraction in rivers and reservoirs matched with less than expected rains, which inevitably results in water stress in many areas. Irrigation and hydroelectric dams have also dried lakes and rivers and downstream water sources.
Deforestation and extensive farming can destroy the quality of land and its ability to absorb and retain water, causing less water to feed into the water cycle, resulting in possible drought.
How do we monitor droughts? One way is to check weather satellites in space. For example, satellite data was used to develop a tool that alerts farmers about upcoming flash droughts. This information can be used to estimate evapotranspiration, which is a measure of how much water is being transferred from the land to the atmosphere through the soil and plants.
Solutions
The natural phenomenon of drought is beyond our control but the deepening of it through human effort is within our reach. For starters, we can start using water wisely and using it more efficiently, helping us stretch the litres of water we have and prepare for no-rain days.
The most important thing for South Africa is to fix our aging and crumbling water infrastructure. We continue to lose drinkable water due to aging infrastructure, faulty meters, crumbling pipes and leaky water mains. The Water Research Council estimated this loss to be above 25%.
Secondly, businesses can also be smart and use water and energy efficient technologies. Farmers can plant drought tolerant plants and apply water-efficient irrigation techniques. The biggest consumer of water of course is agriculture and it is said to withdraw 70% of water from any nation's water supply. This means water efficiency in the agricultural sector holds a key to sustainable water for everyone. There needs to be drastic improvements in irrigation techniques, moving from flood irrigation to drip irrigation, and better irrigation scheduling for different stages of crops.
Much of industrial activity can use recycled water and help us protect drinkable and fresh water from wastage. Recycled water is water that comes from sinks, shower drains, washing machines that could be reclaimed and recycled if we had proper functioning treatment works.
However, with so many water treatment works in dysfunctional state in many provinces, this means treated water that could be used as cooling water for power and oil refineries, watering public parks and golf courses, and replenishing groundwater supplies is not sufficiently available.
Thirdly, we need strong water governance. Water governance is largely the responsibility of the local government. It is critically important for local governments to have strong water governance for water management to succeed. Local governments must be able to manage the water supply and demand in order to protect water resources and ensure the stretch of available litres.
At the current level of water management, which is loose and poorly regulated, South Africa is said to face a water deficit of 17% by 2030. It becomes important to leverage all stakeholders, from public, private, schools, businesses, communities, scientists and other water experts in order to ensure water consciousness becomes our daily lived reality and water conservation becomes everyone's responsibility.
South Africa has low rainfall and low per capital water availability compared to other countries. We have an average of 500mm annual rainfall. This is while water demand has been increasing at a high rate with main economic sectors behind the rising demand. In South Africa, agriculture accounts for 63% of water consumption, followed by municipal use at 26% and then industrial use at 11%.
We therefore need effective water management but as Voge et al 2000 said: "Effective drought management strategies have been impeded by coordination problems and a lack of ability of government."
We need our water authorities to be much stronger on water governance. Otherwise, when summer rains finally come, we will not store and keep as much water as we should.
Yonela Diko is spokesperson to Minister of Human Settlements, Water and Sanitation Lindiwe Sisulu. You can follow him on Twitter on @yonela_diko. | https://ewn.co.za/2020/09/28/yonela-diko-the-creeping-disaster-how-to-prepare-for-country-s-droughts |
Genetic resources are global assets of inestimable value to human kind, which holds the key to increasing food security. The loss of variation in crops due to the modernization of agriculture has been described as genetic erosion. The current status of the genetic diversity and erosion in spice crops is discussed in this chapter. Human intervention into the natural habitats of wild and related species in centers of diversity, diseases, and pests plays an important role in the loss of older species and varieties. This is further complicated by climate change and reproductive behavior of crop species. The Genetic erosion of cultivated diversity is reflected in a modernization bottleneck in the diversity levels that occurred during the history of the crop. Two stages in this bottleneck are recognized: the initial replacement of landraces by modern cultivars and further trends in diversity as a consequence of modern breeding practices. The factors contributing to erosion is due to the enormous diversity in cultivated plants, population growth, deforestation, erosion, changing land use, and climate factors are major threats to the existing biodiversity of the region. Urbanization is increasing and agriculture is changing from subsistence based on highly market-driven farming. Although these changes have increased incomes of the populations of wild habitants to certain extent, not all of them are for the good. In particular, biodiversity is declining as a result of some of these changes. It is mandate to conserve the vanishing plant genetic resources and to understand better the linkages between agricultural and economic system that affect diversity and sustainable production. Genetic erosion may occur at three levels of integration: crop, variety, and allele. Thus, genetic erosion is reflected in the reduction of allelic richness in conjunction with events at variety level. This requires immediate efforts to understand and implement the effective multiplication and conservation strategies using both conventional and modern technologies to save the loss of the valuable genetic resources and preserve them for posterity. An important aspect is also to include genetic resource conservation as an important part in our social life. | https://rd.springer.com/chapter/10.1007/978-3-319-25637-5_9 |
- The Wallace's giant bee has been found in the wild 38 years since its last sighting.
- It's the largest bee in the world, at about the size of human thumb. The bee boasts a wingspan of 2.5 inches and has two large pincers.
- In January, a group of scientists and nature photographers successfully located the bee in Indonesia.
- The species is listed as vulnerable to extinction by the International Union for Conservation of Nature.
Wallace's giant bee had been flying under the radar since its last known sighting in 1981. Until a few months ago.
At 1.5 inches long, the bee is the world's largest. It has a wingspan of 2.5 inches and enormous jaws, making it a fearsome sight.
But Wallace's giant bee — officially called Megachile pluto — had been rather camera shy for the last 38 years. The scientific community feared it had disappeared altogether, but an expedition in the Indonesian jungle caught the elusive insect on camera in January.
"I dreamed of seeing this bee—the sound of its wings, its nest, a living individual," natural history photographer Clay Bolt told Business Insider. "When we achieved our goal, we simply couldn't believe it."
The bee was on the 'most wanted' list
Four times larger than a European honey bee, Wallace's giant bee is about the size of a human thumb.
It boasts a set of intimidating mandibles, but these jaws aren't for eating other bugs — the bee is vegetarian, preferring nectar and pollen. The giant bees use their mandibles to scrap sticky resin off of trees. They then use that resin to construct burrows inside termite nests, and female bees use those shelters to raise their babies.
The bee was last seen alive by entomologist Adam Messer in 1981 on North Moluccas, part of an Indonesian archipelago west of Papua New Guinea. (Another French scientist named Roch Desmier de Chenon collected a specimen seven years later, but failed to photograph or document the animal, according to National Geographic.)
Before Messer's sighting, the previous documented encounter happened more than 100 years earlier, when scientist Alfred Russel Wallace discovered and named the insect on the Indonesian island of Bacan in 1859.
That elusive history landed Wallace's giant bee on Global Wildlife Conservation’s list of the planet's top 25 "most wanted" species. The list is part of the environmental organization's Search for Lost Species program, which partners with locals around the world to find and protect species that have not been seen in decades. The full list includes 1,200 missing animals and plants.
Now, Wallace's giant bee is no longer on there.
'An animal that had only lived in my imagination'
Bolt said his fascination with the bee started after his colleague Eli Wyman, a biologist from Princeton University, showed him a rare specimen of the bee at the American Museum of Natural History. Bolt and Wyman then spent years researching the most promising habitat in which to search for the insect.
In January, Bold and Wyman joined a team of biologists and photographers who traveled to the forests of North Moluccas in an attempt to find and photograph the bee alive in the wild.
The group spent five days in hot, humid conditions, braving occasional torrential downpours as they searched for termite nests suspended from tree trunks. They examined dozens of termite mounds, but the expedition kept coming up empty.
Then on the last day, the team struck gold.
In a termite nest 8 feet off the ground, they found a single female giant bee.
"It was such a humbling experience, and to have the distinct honor of being the first person to photograph this creature in the wild is something that I'll likely never top," Bolt said.
Bolt and his colleagues placed the female in small rectangular flight box in order to photograph and observe her, then released the bee back into the nest.
According to National Geographic, Bolt and Wyman said the sound of the bee's 2.5-inch wings fluttering was striking: A “deep, slow thrum that you could almost feel as well as hear,” Bolt said.
Wyman told National Geographic that the finding was “an incredible, tangible experience from an animal that had only lived in my imagination for years.”
Why the Wallace's giant bee is under threat
The bee’s fearsome size and rare status make it especially interesting to wildlife collectors and traders.
In fact, while Bolt, Wyman, and their colleagues prepared for their expedition to Indonesia last year, an Indonesian eBay user sold two dead specimens of Wallace's giant bee on eBay for thousands of dollars.
Though the species is listed as vulnerable to extinction by the International Union for Conservation of Nature, there are no legal protections in place regulating how the bee is sold and traded online or otherwise.
“We know that putting the news out about this rediscovery could seem like a big risk given the demand, but the reality is that unscrupulous collectors already know that the bee is out there,” Robin Moore, who leads the Lost Species program, said in a press release.
But overzealous collectors aren't the bees' only threats.
Because the giant bees rely on termite nests in forests, they are particularly vulnerable to deforestation and habitat loss. Between 2001 and 2017, Indonesia lost 15% of its tree cover as forests were destroyed to make room for agricultural land, according to Global Forest Watch.
Read More: Meet the first species to go extinct because of climate change — it was tiny, cute, and fluffy
The members of the latest expedition are hoping to use their rediscovery of the bee to push the Indonesian government to institute conservation measures that would protect its habitat.
"I hope that Wallace's giant bee's newfound fame will lead to its protection by the Indonesian government, scientific institutions, and the local communities in which it is found," Bolt said."It should be a symbol, like the beautiful standard wing bird of paradise, of the life that thrives in this miraculous corner of the world."
Scientists hope it might even stave off collectors, too.
"By making the bee a world-famous flagship for conservation, we are confident that the species has a brighter future than if we just let them quietly be collected into oblivion,” Moore said. | https://www.insider.com/worlds-largest-bee-found-38-years-after-last-sighting-2019-3 |
Retrieve-Pile (Knowledge-Pile) is a knowledge-related data leveraging Retrieve-from-CC (We also called this method as "Query of CC"),a total of 735GB disk size and 188B tokens (using Llama2 tokenizer).
Retrieve-from-CC
Just like the figure below, we initially collected seed information in some specific domains, such as keywords, frequently asked questions, and textbooks, to serve as inputs for the Query Bootstrapping stage. Leveraging the great generalization capability of large language models, we can effortlessly expand the initial seed information and extend it to an amount of domain-relevant queries. Inspiration from Self-instruct and WizardLM, we encompassed two stages of expansion, namely Question Extension and Thought Generation, which respectively extend the queries in terms of breadth and depth, for retrieving the domain-related data with a broader scope and deeper thought. Subsequently, based on the queries, we retrieved relevant documents from public corpora, and after performing operations such as duplicate data removal and filtering, we formed the final training dataset.
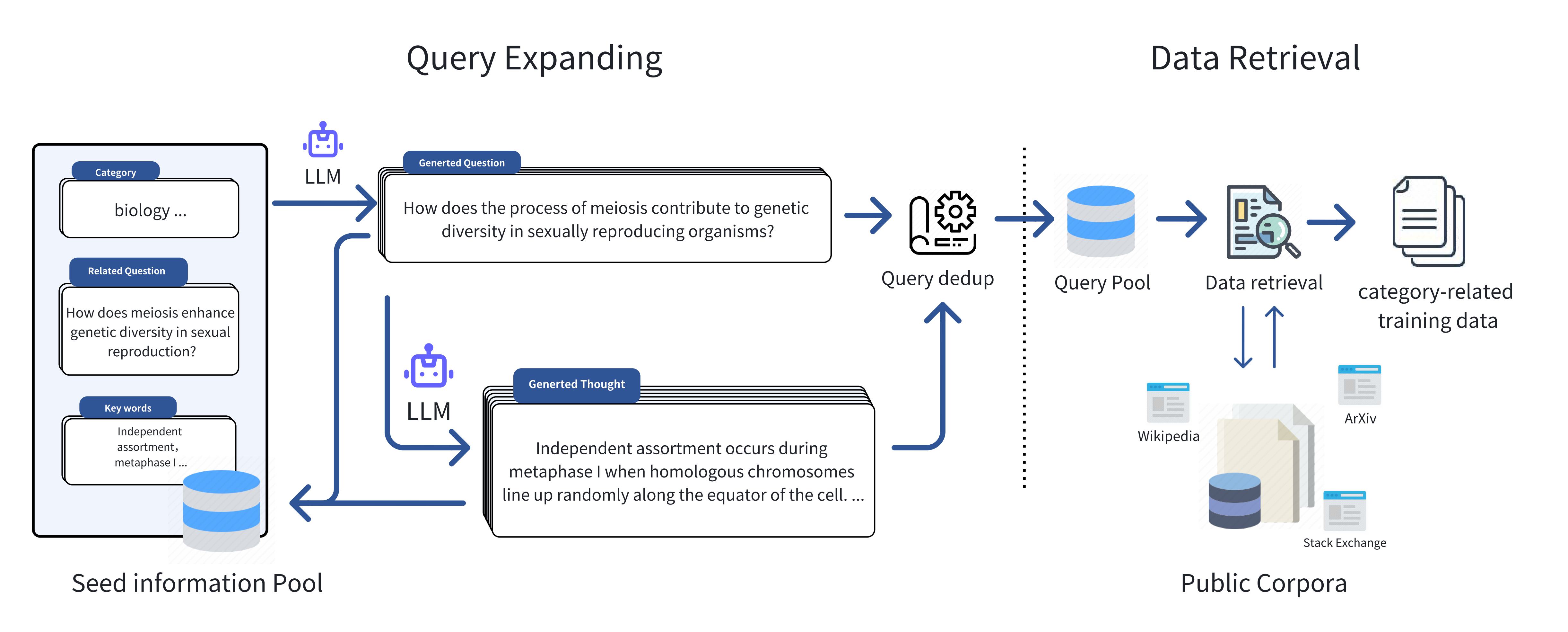
Retrieve-Pile Statistics
Based on Retrieve-from-CC , we have formed a high-quality knowledge dataset Retrieve-Pile. As shown in Figure below, comparing with other datasets in academic and mathematical reasoning domains, we have acquired a large-scale, high-quality knowledge dataset at a lower cost, without the need for manual intervention. Through automated query bootstrapping, we efficiently capture the information about the seed query. Retrieve-Pile not only covers mathematical reasoning data but also encompasses rich knowledge-oriented corpora spanning various fields such as biology, physics, etc., enhancing its comprehensive research and application potential.

This table presents the top 10 web domains with the highest proportion of Retrieve-Pile, primarily including academic websites, high-quality forums, and some knowledge domain sites. Table provides a breakdown of the data sources' timestamps in Retrieve-Pile, with statistics conducted on an annual basis. It is evident that a significant portion of Retrieve-Pile is sourced from recent years, with a decreasing proportion for earlier timestamps. This trend can be attributed to the exponential growth of internet data and the inherent timeliness introduced by the Retrieve-Pile.
| Web Domain | Count |
|---|---|
| en.wikipedia.org | 398833 |
| www.semanticscholar.org | 141268 |
| slideplayer.com | 108177 |
| www.ncbi.nlm.nih.gov | 97009 |
| link.springer.com | 85357 |
| www.ipl.org | 84084 |
| pubmed.ncbi.nlm.nih.gov | 68934 |
| www.reference.com | 61658 |
| www.bartleby.com | 60097 |
| quizlet.com | 56752 |
- Downloads last month
- 1,033