
The viewer is disabled because this dataset repo requires arbitrary Python code execution. Please consider
removing the
loading script
and relying on
automated data support
(you can use
convert_to_parquet
from the datasets library). If this is not possible, please
open a discussion
for direct help.
SPair-71k
This is an inofficial dataset loading script for the semantic correspondence dataset SPair-71k. It downloads the data from the original source and converts it to the huggingface format.
Official Description
Establishing visual correspondences under large intra-class variations, which is often referred to as semantic correspondence or semantic matching, remains a challenging problem in computer vision. Despite its significance, however, most of the datasets for semantic correspondence are limited to a small amount of image pairs with similar viewpoints and scales. In this paper, we present a new large-scale benchmark dataset of semantically paired images, SPair-71k, which contains 70,958 image pairs with diverse variations in viewpoint and scale. Compared to previous datasets, it is significantly larger in number and contains more accurate and richer annotations. We believe this dataset will provide a reliable testbed to study the problem of semantic correspondence and will help to advance research in this area. We provide the results of recent methods on our new dataset as baselines for further research.
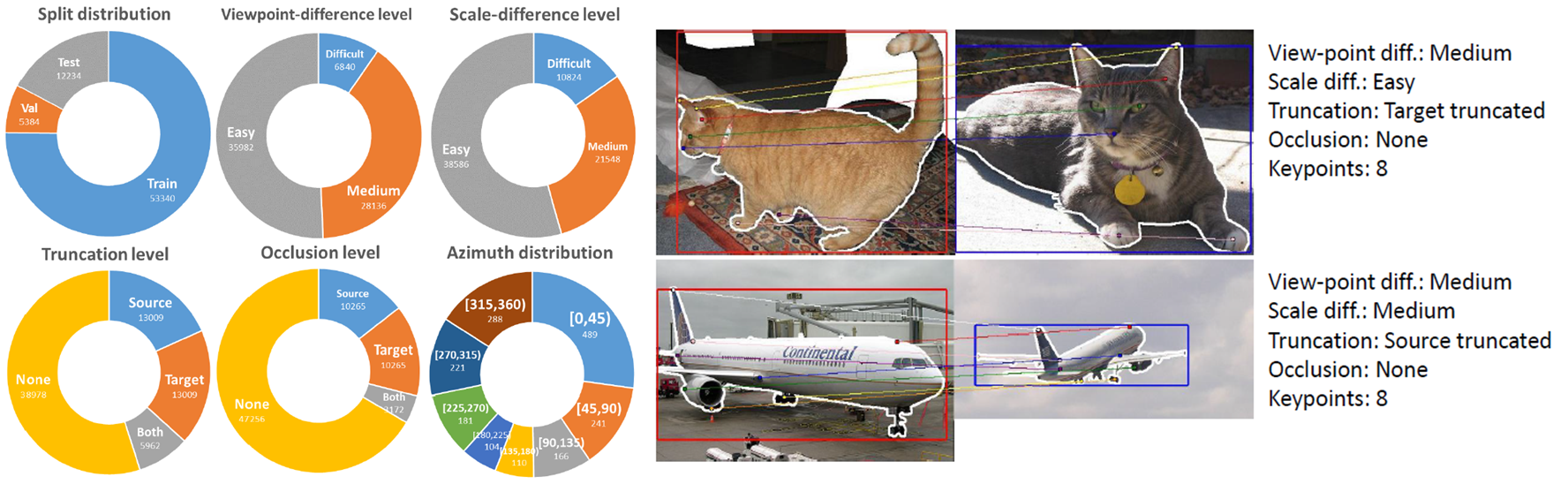
Usage
from datasets import load_dataset
# load image pairs for the semantic correspondence task
pairs = load_dataset("0jl/SPair-71k", trust_remote_code=True)
print('available splits:', pairs.keys()) # train, validation, test
print('exemplary sample:', pairs['train'][0])
# load only the data, i.e. images, segmentation and annotations
data = load_dataset("0jl/SPair-71k", "data", trust_remote_code=True)
print('available splits:', data.keys()) # only train, as the data is used in all splits
print('exemplary sample:', data['train'][0])
Output:
available splits: dict_keys(['train', 'validation', 'test'])
exemplary sample: {'pair_id': 35987, 'src_img': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x333 at ...>, 'src_segmentation': <PIL.PngImagePlugin.PngImageFile image mode=L size=500x333 at ...>, 'src_data_index': 1017, 'src_name': 'horse/2009_003294', 'src_imsize': [500, 333, 3], 'src_bndbox': [207, 38, 393, 310], 'src_pose': 0, 'src_kps': [[239, 42], [212, 45], [206, 100], [228, 51], [316, 265], [297, 259]], 'trg_img': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x375 at ...>, 'trg_segmentation': <PIL.PngImagePlugin.PngImageFile image mode=L size=500x375 at ...>, 'trg_data_index': 85, 'trg_name': 'horse/2007_006134', 'trg_imsize': [500, 375, 3], 'trg_bndbox': [125, 99, 442, 318], 'trg_pose': 4, 'trg_kps': [[401, 101], [385, 98], [408, 204], [380, 112], [138, 247], [160, 246]], 'kps_ids': [2, 3, 8, 9, 18, 19], 'category': 16, 'viewpoint_variation': 2, 'scale_variation': 0, 'truncation': 0, 'occlusion': 1}
available splits: dict_keys(['train'])
exemplary sample: {'img': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x332 at ...>, 'segmentation': <PIL.PngImagePlugin.PngImageFile image mode=L size=500x332 at ...>, 'annotation': '{"filename": "2007_000175.jpg", "src_database": "The VOC2007 Database", "src_annotation": "PASCAL VOC2007", "src_image": "flickr", "image_width": 500, "image_height": 332, "image_depth": 3, "category": "sheep", "pose": "Unspecified", "truncated": 0, "occluded": 0, "difficult": 0, "bndbox": [25, 34, 419, 271], "kps": {"0": [211, 100], "1": [347, 87], "2": [132, 99], "3": [423, 72], "4": [245, 91], "5": [329, 88], "6": [282, 137], "7": [304, 138], "8": [295, 162], "9": null, "10": null, "11": null, "12": null, "13": null, "14": null, "15": [173, 247], "16": null, "17": [45, 205], "18": null, "19": null, "20": null, "21": null, "22": null, "23": null, "24": null, "25": null, "26": null, "27": null, "28": null, "29": null}, "azimuth_id": 7}', 'name': 'sheep/2007_000175'}
Featues for pairs (default)
pairs = load_dataset("0jl/SPair-71k", name='pairs', trust_remote_code=True)
splits: train, validation, test
pair_id:Value(dtype='uint32')src_img:Image(decode=True)src_segmentation:Image(decode=True)src_data_index:Value(dtype='uint32')src_name:Value(dtype='string')src_imsize:Sequence(feature=Value(dtype='uint32'), length=3)src_bndbox:Sequence(feature=Value(dtype='uint32'), length=4)src_pose:ClassLabel(names=['Unspecified', 'Frontal', 'Left', 'Rear', 'Right'])src_kps:Array2D(shape=(None, 2), dtype='uint32')trg_img:Image(decode=True)trg_segmentation:Image(decode=True)trg_data_index:Value(dtype='uint32')trg_name:Value(dtype='string')trg_imsize:Sequence(feature=Value(dtype='uint32'), length=3)trg_bndbox:Sequence(feature=Value(dtype='uint32'), length=4)trg_pose:ClassLabel(names=['Unspecified', 'Frontal', 'Left', 'Rear', 'Right'])trg_kps:Array2D(shape=(None, 2), dtype='uint32')kps_ids:Sequence(feature=Value(dtype='uint32'), length=-1)category:Value(dtype='string')category_id:ClassLabel(names=['cat', 'pottedplant', 'train', 'bicycle', 'car', 'bus', 'aeroplane', 'dog', 'bird', 'chair', 'motorbike', 'cow', 'bottle', 'person', 'boat', 'sheep', 'horse', 'tvmonitor'])viewpoint_variation:Value(dtype='uint8')scale_variation:Value(dtype='uint8')truncation:Value(dtype='uint8')occlusion:Value(dtype='uint8')
Features for data
data = load_dataset("0jl/SPair-71k", name='data', trust_remote_code=True)
splits: train
img:Image(decode=True)name:Value(dtype='string')segmentation:Image(decode=True)filename:Value(dtype='string')src_database:Value(dtype='string')src_annotation:Value(dtype='string')src_image:Value(dtype='string')image_width:Value(dtype='uint32')image_height:Value(dtype='uint32')image_depth:Value(dtype='uint32')category:Value(dtype='string')category_id:ClassLabel(names=['cat', 'pottedplant', 'train', 'bicycle', 'car', 'bus', 'aeroplane', 'dog', 'bird', 'chair', 'motorbike', 'cow', 'bottle', 'person', 'boat', 'sheep', 'horse', 'tvmonitor'])pose:Value(dtype='string')truncated:Value(dtype='uint8')occluded:Value(dtype='uint8')difficult:Value(dtype='uint8')bndbox:Sequence(feature=Value(dtype='uint32'), length=4)kps:Array2D(shape=(None, 2), dtype='int32')azimuth_id:Value(dtype='uint8')
Terms of Use
The SPair-71k data includes images and metadata obtained from the PASCAL-VOC and flickr website. Use of these images and metadata must respect the corresponding terms of use.
Citation of original dataset
@article{min2019spair,
title={SPair-71k: A Large-scale Benchmark for Semantic Correspondence},
author={Juhong Min and Jongmin Lee and Jean Ponce and Minsu Cho},
journal={arXiv prepreint arXiv:1908.10543},
year={2019}
}
- Downloads last month
- 38