
![]()
This model requires the Vocex library, which is available using
pip install vocex
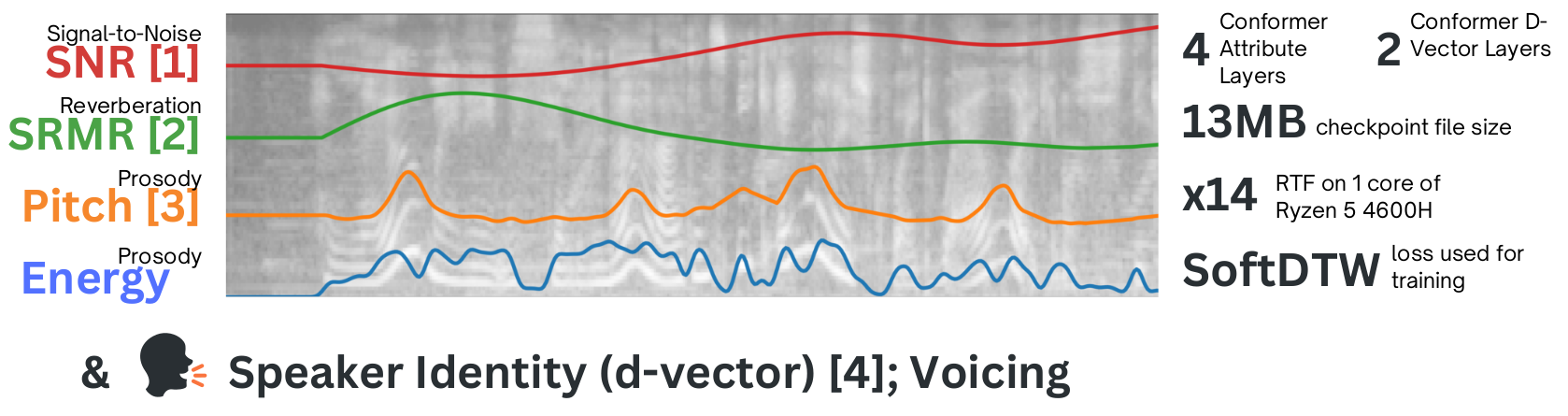
Vocex extracts several measures (as well as d-vectors) from audio.
 You can read more here:
https://github.com/minixc/vocex
You can read more here:
https://github.com/minixc/vocex
Usage
from vocex import Vocex
import torchaudio # or any other audio loading library
model = Vocex.from_pretrained('cdminix/vocex') # an fp16 model is loaded by default
model = Vocex.from_pretrained('cdminix/vocex', fp16=False) # to load a fp32 model
model = Vocex.from_pretrained('some/path/model.ckpt') # to load local checkpoint
audio = ... # a numpy or torch array is required with shape [batch_size, length_in_samples] or just [length_in_samples]
sample_rate = ... # we need to specify a sample rate if the audio is not sampled at 22050
outputs = model(audio, sample_rate)
pitch, energy, snr, srmr = (
outputs["measures"]["pitch"],
outputs["measures"]["energy"],
outputs["measures"]["snr"],
outputs["measures"]["srmr"],
)
d_vector = outputs["d_vector"] # a torch tensor with shape [batch_size, 256]
# you can also get activations and attention weights at all layers of the model
outputs = model(audio, sample_rate, return_activations=True, return_attention=True)
activations = outputs["activations"] # a list of torch tensors with shape [batch_size, layers, ...]
attention = outputs["attention"] # a list of torch tensors with shape [batch_size, layers, ...]
# there are also speaker avatars, which are a 2D representation of the speaker's voice
outputs = model(audio, sample_rate, return_avatar=True)
avatar = outputs["avatars"] # a torch tensor with shape [batch_size, 256, 256]
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.