
Intro
This study, based on deep learning technology, draws inspiration from classical backbone network structures in the computer vision domain to construct an innovative 8-class piano timbre discriminator model through audio data processing. The model focuses on eight brands and types of pianos, including Kawai, Kawai Grand, YOUNG CHANG, HSINGHAI, Steinway Theatre, Steinway Grand, Pearl River, and Yamaha. By transforming audio data into Mel spectrograms and conducting supervised learning in the fine-tuning phase, the model accurately distinguishes different piano timbres and performs well in practical testing. In the training process, a large-scale annotated audio dataset is utilized, and the introduction of deep learning technology provides crucial support for improving the model's performance by progressively learning to extract key features from audio. The piano timbre discriminator model has broad potential applications in music assessment, audio engineering, and other fields, offering an advanced and reliable solution for piano timbre discrimination. This study expands new possibilities for the application of deep learning in the audio domain, providing valuable references for future research and applications in related fields.
Demo (inference code)
https://huggingface.co/spaces/ccmusic-database/pianos
Usage
from huggingface_hub import snapshot_download
model_dir = snapshot_download("ccmusic-database/pianos")
Maintenance
GIT_LFS_SKIP_SMUDGE=1 git clone git@hf.co:ccmusic-database/pianos
cd pianos
Results
A demo result of SqueezeNet fine-tuning:
| Loss curve | 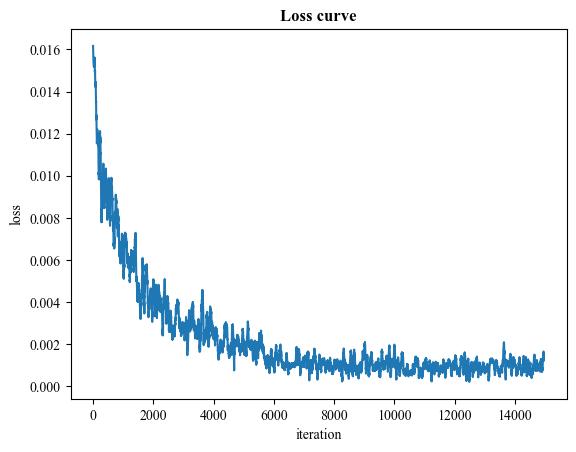 |
|---|---|
| Training and validation accuracy | 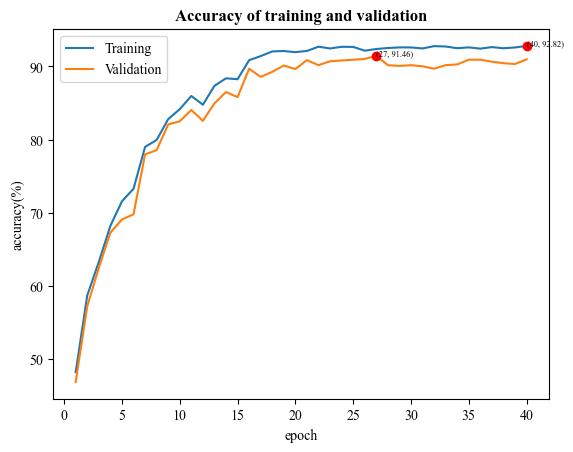 |
| Confusion matrix | 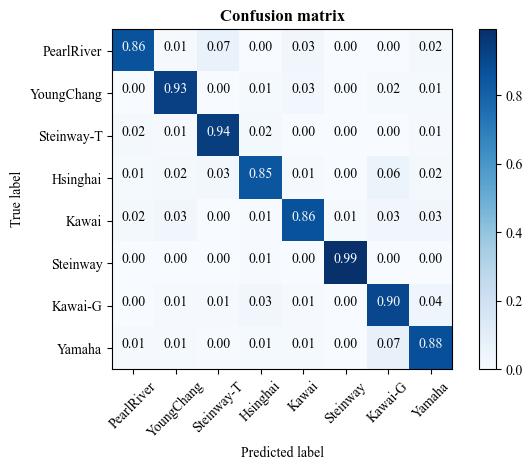 |
Dataset
https://huggingface.co/datasets/ccmusic-database/pianos
Mirror
https://www.modelscope.cn/models/ccmusic-database/pianos
Evaluation
https://github.com/monetjoe/pianos
Cite
@inproceedings{zhou2023holistic,
title = {A Holistic Evaluation of Piano Sound Quality},
author = {Monan Zhou and Shangda Wu and Shaohua Ji and Zijin Li and Wei Li},
booktitle = {National Conference on Sound and Music Technology},
pages = {3--17},
year = {2023},
organization = {Springer}
}