StarCoder2 及 The Stack v2 数据集正式发布





BigCode 正式推出 StarCoder2 —— 一系列新一代的开放源代码大语言模型(LLMs)。这些模型全部基于一个全新、大规模且高品质的代码数据集 The Stack v2 进行训练。我们不仅公开了所有的模型和数据集,还包括了数据处理和训练代码的详细信息,详情请参阅 相关论文。
StarCoder2 是什么?
StarCoder2 是一套面向代码的开放式大语言模型系列,提供3种规模的模型,分别包括 30 亿(3B)、70 亿(7B)和 150 亿(15B)参数。特别地,StarCoder2-15B 模型经过了超过 4 万亿 token 和 600 多种编程语言的训练,基于 The Stack v2 数据集。所有模型均采用分组查询注意力机制(Grouped Query Attention),具备 16384 个 token 的上下文窗口和 4096 个令牌的滑动窗口注意力,并通过“填充中间”(Fill-in-the-Middle)技术进行训练。
StarCoder2 包含三种规模的模型:ServiceNow 训练的30亿参数模型、Hugging Face 训练的 70 亿参数模型以及 NVIDIA 利用 NVIDIA NeMo 在 NVIDIA 加速基础架构上训练的150亿参数模型:
- StarCoder2-3B 基于 The Stack v2 的 17 种编程语言训练,处理了超过 3 万亿 token。
- StarCoder2-7B 基于 The Stack v2 的 17 种编程语言训练,处理了超过 3.5 万亿 token。
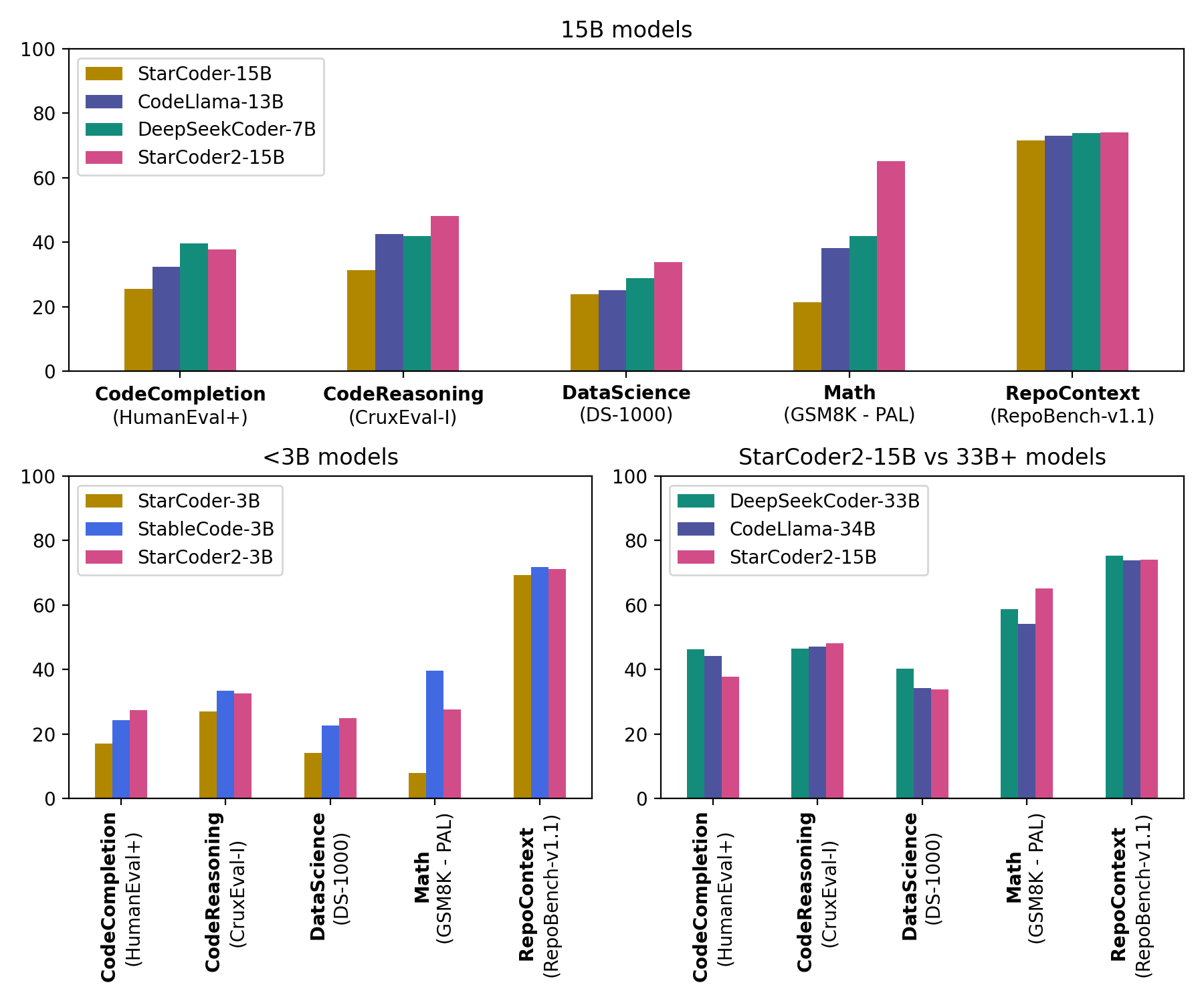
- StarCoder2-15B 基于 The Stack v2 的 600 多种编程语言训练,处理了超过 4 万亿 token。
StarCoder2-15B 模型在其级别中表现出色,与33亿以上参数的模型在多项评估中不相上下。StarCoder2-3B 的性能达到了 StarCoder1-15B 的水平:
The Stack v2 是什么?

The Stack v2 是迄今为止最大的开放代码数据集,非常适合进行大语言模型的预训练。与 The Stack v1 相比,The Stack v2 拥有更大的数据规模,采用了更先进的语言和许可证检测流程以及更优的过滤机制。此外,训练数据集按照仓库进行了分组,使得模型训练能够获得仓库上下文的支持。
| 数据集对比 | The Stack v1 | The Stack v2 |
|---|---|---|
| 全部数据量 | 6.4TB | 67.5TB |
| 去重后数据量 | 2.9TB | 32.1TB |
| 训练数据集大小 | 约 2000 亿token | 约9000亿token |
该数据集源自软件遗产档案(Software Heritage archive),这是一个包含了丰富软件源代码及其开发历史的公共档案库。作为一个开放和非盈利的项目,软件遗产由 Inria 与 UNESCO 合作发起,旨在收集、保存并共享所有公开可用的软件源代码。我们对软件遗产提供这一无价资源表示感
谢。欲了解更多信息,请访问 软件遗产网站。
您可以通过 Hugging Face Hub 访问 The Stack v2 数据集。
关于 BigCode
BigCode 是由 Hugging Face 和 ServiceNow 联合领导的一个开放科研合作项目,致力于负责任地开发代码用大语言模型。
相关链接
模型资源
- 研究论文:详细介绍 StarCoder2 和 The Stack v2 的技术报告。
- GitHub 仓库:提供使用或微调 StarCoder2 的完整指南。
- StarCoder2-3B:规模较小的 StarCoder2 模型。
- StarCoder2-7B:规模中等的 StarCoder2 模型。
- StarCoder2-15B:规模较大的 StarCoder2 模型。
数据及治理
- StarCoder2 许可协议:模型基于 BigCode OpenRAIL-M v1 许可协议授权。
- StarCoder2 代码搜索:对预训练数据集中的代码进行全文搜索。
- StarCoder2 成员资格测试:快速验证代码是否包含在预训练数据集中。
其他资源
- VSCode 扩展:使用 StarCoder 进行编码的插件。
- 大型代码模型排行榜:比较不同模型的性能。 所有资源和链接均可在 huggingface.co/bigcode 查阅!









