Llama 2 来袭 - 在 Hugging Face 上玩转它








引言
今天,Meta 发布了 Llama 2,其包含了一系列最先进的开放大语言模型,我们很高兴能够将其全面集成入 Hugging Face,并全力支持其发布。 Llama 2 的社区许可证相当宽松,且可商用。其代码、预训练模型和微调模型均于今天发布了🔥。
通过与 Meta 合作,我们已经顺利地完成了对 Llama 2 的集成,你可以在 Hub 上找到 12 个开放模型(3 个基础模型以及 3 个微调模型,每个模型都有 2 种 checkpoint:一个是 Meta 的原始 checkpoint,一个是 transformers 格式的 checkpoint)。以下列出了 Hugging Face 支持 Llama 2 的主要工作:
- Llama 2 已入驻 Hub:包括模型卡及相应的许可证。
- 支持 Llama 2 的 transformers 库
- 使用单 GPU 微调 Llama 2 小模型的示例
- Text Generation Inference(TGI) 已集成 Llama 2,以实现快速高效的生产化推理
- 推理终端(Inference Endpoints)已集成 Llama 2
目录
何以 Llama 2?
Llama 2 引入了一系列预训练和微调 LLM,参数量范围从 7B 到 70B(7B、13B、70B)。其预训练模型比 Llama 1 模型有了显著改进,包括训练数据的总词元数增加了 40%、上下文长度更长(4k 词元🤯),以及利用了分组查询注意力机制来加速 70B 模型的推理🔥!
但最令人兴奋的还是其发布的微调模型(Llama 2-Chat),该模型已使用基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)技术针对对话场景进行了优化。在相当广泛的有用性和安全性测试基准中,Llama 2-Chat 模型的表现优于大多数开放模型,且其在人类评估中表现出与 ChatGPT 相当的性能。更多详情,可参阅其论文。
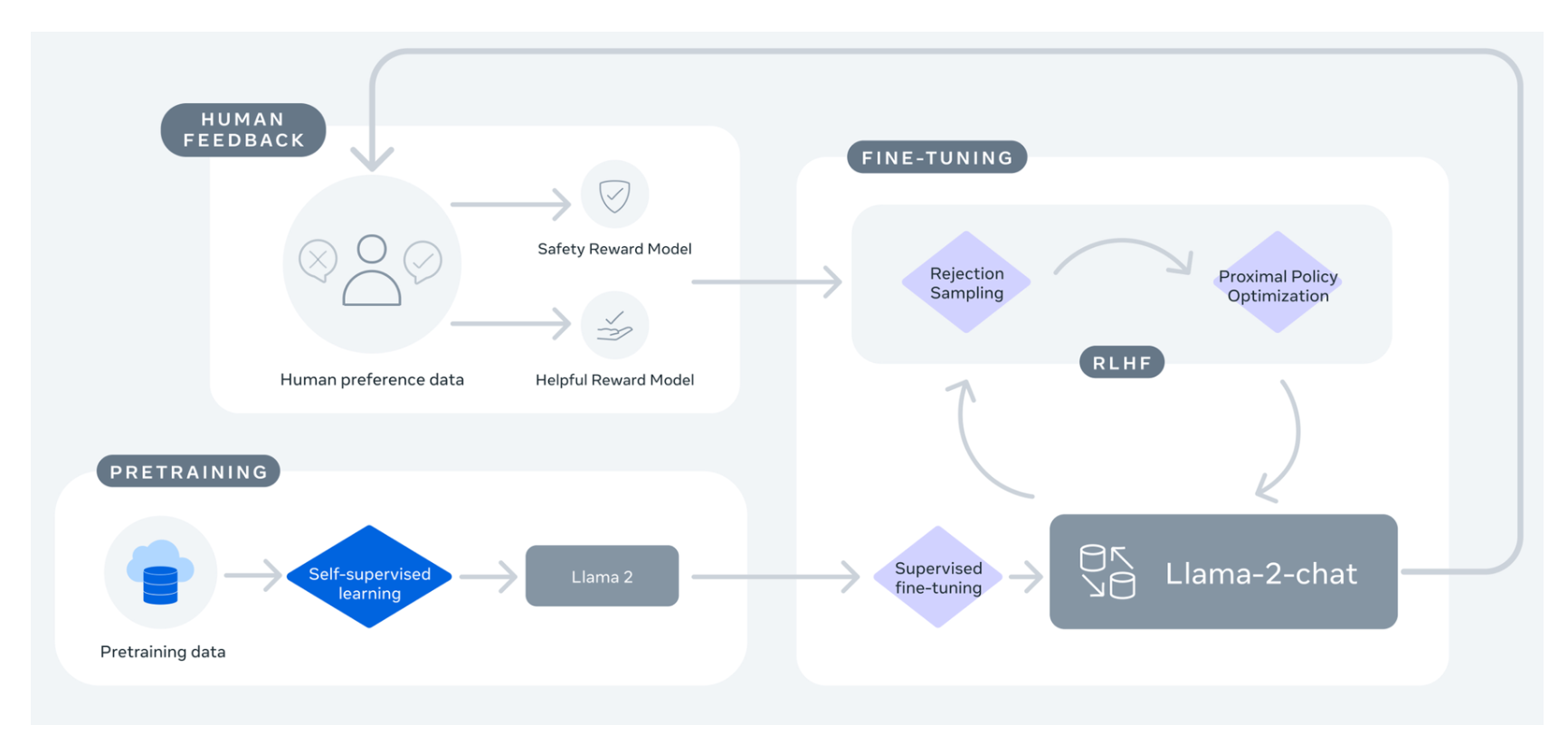
图来自 Llama 2: Open Foundation and Fine-Tuned Chat Models 一文
如果你一直在等一个闭源聊天机器人的开源替代,那你算是等着了!Llama 2-Chat 将是你的最佳选择!
| 模型 | 许可证 | 可否商用? | 预训练词元数 | 排行榜得分 |
|---|---|---|---|---|
| Falcon-7B | Apache 2.0 | ✅ | 1,500B | 47.01 |
| MPT-7B | Apache 2.0 | ✅ | 1,000B | 48.7 |
| Llama-7B | Llama 许可证 | ❌ | 1,000B | 49.71 |
| Llama-2-7B | Llama 2 许可证 | ✅ | 2,000B | 54.32 |
| Llama-33B | Llama 许可证 | ❌ | 1,500B | * |
| Llama-2-13B | Llama 2 许可证 | ✅ | 2,000B | 58.67 |
| mpt-30B | Apache 2.0 | ✅ | 1,000B | 55.7 |
| Falcon-40B | Apache 2.0 | ✅ | 1,000B | 61.5 |
| Llama-65B | Llama 许可证 | ❌ | 1,500B | 62.1 |
| Llama-2-70B | Llama 2 许可证 | ✅ | 2,000B | * |
| Llama-2-70B-chat* | Llama 2 许可证 | ✅ | 2,000B | 66.8 |
*目前,我们正在对 Llama 2 70B(非聊天版)进行评测。评测结果后续将更新至此表。
演示
你可以通过这个空间或下面的应用轻松试用 Llama 2 大模型(700 亿参数!):
它们背后都是基于 Hugging Face 的 TGI 框架,该框架也支撑了 HuggingChat ,我们会在下文分享更多相关内容。
推理
本节,我们主要介绍可用于对 Llama 2 模型进行推理的两种不同方法。在使用这些模型之前,请确保你已在 Meta Llama 2 存储库页面申请了模型访问权限。
**注意:请务必按照页面上的指示填写 Meta 官方表格。填完两个表格数小时后,用户就可以访问模型存储库。
使用 transformers
从 transformers 4.31 版本开始,HF 生态中的所有工具和机制都可以适用于 Llama 2,如:
- 训练、推理脚本及其示例
- 安全文件格式(
safetensors) - 与 bitsandbytes(4 比特量化)和 PEFT 等工具
- 帮助模型进行文本生成的辅助工具
- 导出模型以进行部署的机制
你只需确保使用最新的 transformers 版本并登录你的 Hugging Face 帐户。
pip install transformers
huggingface-cli login
下面是如何使用 transformers 进行推理的代码片段:
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
另外,尽管模型本身的上下文长度仅 4k 词元,但你可以使用 transformers 支持的技术,如旋转位置嵌入缩放(rotary position embedding scaling)(推特),进一步把它变长!
使用 TGI 和推理终端
Text Generation Inference(TGI) 是 Hugging Face 开发的生产级推理容器,可用于轻松部署大语言模型。它支持流式组批、流式输出、基于张量并行的多 GPU 快速推理,并支持生产级的日志记录和跟踪等功能。
你可以在自己的基础设施上部署并尝试 TGI,也可以直接使用 Hugging Face 的 **推理终端**。如果要用推理终端部署 Llama 2 模型,请登陆 模型页面 并单击 Deploy -> Inference Endpoints 菜单。
- 要推理 7B 模型,我们建议你选择 “GPU [medium] - 1x Nvidia A10G”。
- 要推理 13B 模型,我们建议你选择 “GPU [xlarge] - 1x Nvidia A100”。
- 要推理 70B 模型,我们建议你选择 “GPU [xxxlarge] - 8x Nvidia A100”。
注意:如果你配额不够,请发送邮件至 api-enterprise@huggingface.co 申请升级配额,通过后你就可以访问 A100 了。
你还可以从我们的另一篇博文中了解更多有关如何使用 Hugging Face 推理终端部署 LLM 的知识, 文中包含了推理终端支持的超参以及如何使用其 Python 和 Javascript API 实现流式输出等信息。
使用 PEFT 微调
训练 LLM 在技术和计算上都有一定的挑战。本节,我们将介绍 Hugging Face 生态中有哪些工具可以帮助开发者在简单的硬件上高效训练 Llama 2,我们还将展示如何在单张 NVIDIA T4(16GB - Google Colab)上微调 Llama 2 7B 模型。你可以通过让 LLM 更可得这篇博文了解更多信息。
我们构建了一个脚本,其中使用了 QLoRA 和 trl 中的 SFTTrainer 来对 Llama 2 进行指令微调。
下面的命令给出了在 timdettmers/openassistant-guanaco 数据集上微调 Llama 2 7B 的一个示例。该脚本可以通过 merge_and_push 参数将 LoRA 权重合并到模型权重中,并将其保存为 safetensor 格式。这样,我们就能使用 TGI 和推理终端部署微调后的模型。
首先安装 trl 包并下载脚本:
pip install trl
git clone https://github.com/lvwerra/trl
然后,你就可以运行脚本了:
python trl/examples/scripts/sft_trainer.py \
--model_name meta-llama/Llama-2-7b-hf \
--dataset_name timdettmers/openassistant-guanaco \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2
如何提示 Llama 2
开放模型的一个被埋没的优势是你可以完全控制聊天应用程序中的系统提示。这对于指定聊天助手的行为至关重要,甚至能赋予它一些个性,这是仅提供 API 调用的模型无法实现的。
在 Llama 2 首发几天后,我们决定加上这一部分,因为社区向我们提出了许多关于如何提示模型以及如何更改系统提示的问题。希望这部分能帮得上忙!
第一轮的提示模板如下:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]
此模板与模型训练时使用的模板一致,具体可见 Llama 2 论文。我们可以使用任何我们想要的 system_prompt,但格式须与训练时使用的格式一致。
再说明白一点,以下是用户在使用我们的 13B 模型聊天演示 聊天且输入 There's a llama in my garden 😱 What should I do? 时,我们真正发送给语言模型的内容:
<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
There's a llama in my garden 😱 What should I do? [/INST]
如你所见,成对的 <<sys>> 标记之间的指令为模型提供了上下文,即告诉模型我们期望它如何响应。这很有用,因为在训练过程中我们也使用了完全相同的格式,并针对不同的任务对各种各样的系统提示对模型进行了训练。
随着对话的进行,我们会把人类和“机器人”之间的交互历史附加到之前的提示中,并包含在 [INST] 分隔符之间。多轮对话期间使用的模板遵循以下结构(🎩 感谢 Arthur Zucker 的解释):
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
模型本身是无状态的,不会“记住”之前的对话片段,我们必须始终为其提供所有上下文,以便对话可以继续。这就是为什么我们一直强调模型的上下文长度非常重要且越大越好,因为只有这样才能支持更长的对话和更多的信息。
忽略之前的指令
在使用仅提供 API 调用的模型时,人们会采用一些技巧来尝试覆盖系统提示并更改模型的默认行为。尽管这些解决方案富有想象力,但开放模型完全不必如此:任何人都可以使用不同的提示,只要它遵循上述格式即可。我们相信,这将成为研究人员研究提示对所需或不需的模型行为的影响的重要工具。例如,当人们对谨慎到荒谬的生成文本感到惊讶时,你可以探索是否不同的提示能帮得上忙。(🎩 感谢 Clémentine Fourrier 提供这个例子的链接)。
在我们的 13B 和 7B 演示中,你可以在 UI 上点开“高级选项”并简单编写你自己的指令,从而轻松探索此功能。你还可以复制这些演示并用于你个人的娱乐或研究!
其他资源
总结
Llama 2 的推出让我们非常兴奋!后面我们会围绕它陆陆续续推出更多内容,包括如何微调一个自己的模型,如何在设备侧运行 Llama 2 小模型等,敬请期待!







