Fit More and Train Faster With ZeRO via DeepSpeed and FairScale





A guest blog post by Hugging Face fellow Stas Bekman
As recent Machine Learning models have been growing much faster than the amount of GPU memory added to newly released cards, many users are unable to train or even just load some of those huge models onto their hardware. While there is an ongoing effort to distill some of those huge models to be of a more manageable size -- that effort isn't producing models small enough soon enough.
In the fall of 2019 Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase and Yuxiong He published a paper: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, which contains a plethora of ingenious new ideas on how one could make their hardware do much more than what it was thought possible before. A short time later DeepSpeed has been released and it gave to the world the open source implementation of most of the ideas in that paper (a few ideas are still in works) and in parallel a team from Facebook released FairScale which also implemented some of the core ideas from the ZeRO paper.
If you use the Hugging Face Trainer, as of transformers v4.2.0 you have the experimental support for DeepSpeed's and FairScale's ZeRO features. The new --sharded_ddp and --deepspeed command line Trainer arguments provide FairScale and DeepSpeed integration respectively. Here is the full documentation.
This blog post will describe how you can benefit from ZeRO regardless of whether you own just a single GPU or a whole stack of them.
Huge Speedups with Multi-GPU Setups
Let's do a small finetuning with translation task experiment, using a t5-large model and the finetune_trainer.py script which you can find under examples/seq2seq in the transformers GitHub repo.
We have 2x 24GB (Titan RTX) GPUs to test with.
This is just a proof of concept benchmarks so surely things can be improved further, so we will benchmark on a small sample of 2000 items for training and 500 items for evalulation to perform the comparisons. Evaluation does by default a beam search of size 4, so it's slower than training with the same number of samples, that's why 4x less eval items were used in these tests.
Here are the key command line arguments of our baseline:
export BS=16
python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py \
--model_name_or_path t5-large --n_train 2000 --n_val 500 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro [...]
We are just using the DistributedDataParallel (DDP) and nothing else to boost the performance for the baseline. I was able to fit a batch size (BS) of 16 before hitting Out of Memory (OOM) error.
Note, that for simplicity and to make it easier to understand, I have only shown the command line arguments important for this demonstration. You will find the complete command line at this post.
Next, we are going to re-run the benchmark every time adding one of the following:
--fp16--sharded_ddp(fairscale)--sharded_ddp --fp16(fairscale)--deepspeedwithout cpu offloading--deepspeedwith cpu offloading
Since the key optimization here is that each technique deploys GPU RAM more efficiently, we will try to continually increase the batch size and expect the training and evaluation to complete faster (while keeping the metrics steady or even improving some, but we won't focus on these here).
Remember that training and evaluation stages are very different from each other, because during training model weights are being modified, gradients are being calculated, and optimizer states are stored. During evaluation, none of these happen, but in this particular task of translation the model will try to search for the best hypothesis, so it actually has to do multiple runs before it's satisfied. That's why it's not fast, especially when a model is large.
Let's look at the results of these six test runs:
| Method | max BS | train time | eval time |
|---|---|---|---|
| baseline | 16 | 30.9458 | 56.3310 |
| fp16 | 20 | 21.4943 | 53.4675 |
| sharded_ddp | 30 | 25.9085 | 47.5589 |
| sharded_ddp+fp16 | 30 | 17.3838 | 45.6593 |
| deepspeed w/o cpu offload | 40 | 10.4007 | 34.9289 |
| deepspeed w/ cpu offload | 50 | 20.9706 | 32.1409 |
It's easy to see that both FairScale and DeepSpeed provide great improvements over the baseline, in the total train and evaluation time, but also in the batch size. DeepSpeed implements more magic as of this writing and seems to be the short term winner, but Fairscale is easier to deploy. For DeepSpeed you need to write a simple configuration file and change your command line's launcher, with Fairscale you only need to add the --sharded_ddp command line argument, so you may want to try it first as it's the most low-hanging fruit.
Following the 80:20 rule, I have only spent a few hours on these benchmarks and I haven't tried to squeeze every MB and second by refining the command line arguments and configuration, since it's pretty obvious from the simple table what you'd want to try next. When you will face a real project that will be running for hours and perhaps days, definitely spend more time to make sure you use the most optimal hyper-parameters to get your job done faster and at a minimal cost.
If you would like to experiment with this benchmark yourself or want to know more details about the hardware and software used to run it, please, refer to this post.
Fitting A Huge Model Onto One GPU
While Fairscale gives us a boost only with multiple GPUs, DeepSpeed has a gift even for those of us with a single GPU.
Let's try the impossible - let's train t5-3b on a 24GB RTX-3090 card.
First let's try to finetune the huge t5-3b using the normal single GPU setup:
export BS=1
CUDA_VISIBLE_DEVICES=0 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 [...]
No cookie, even with BS=1 we get:
RuntimeError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 23.70 GiB total capacity;
21.37 GiB already allocated; 45.69 MiB free; 22.05 GiB reserved in total by PyTorch)
Note, as earlier I'm showing only the important parts and the full command line arguments can be found here.
Now update your transformers to v4.2.0 or higher, then install DeepSpeed:
pip install deepspeed
and let's try again, this time adding DeepSpeed to the command line:
export BS=20
CUDA_VISIBLE_DEVICES=0 deepspeed --num_gpus=1 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 --deepspeed ds_config_1gpu.json [...]
et voila! We get a batch size of 20 trained just fine. I could probably push it even further. The program failed with OOM at BS=30.
Here are the relevant results:
2021-01-12 19:06:31 | INFO | __main__ | train_n_objs = 60
2021-01-12 19:06:31 | INFO | __main__ | train_runtime = 8.8511
2021-01-12 19:06:35 | INFO | __main__ | val_n_objs = 10
2021-01-12 19:06:35 | INFO | __main__ | val_runtime = 3.5329
We can't compare these to the baseline, since the baseline won't even start and immediately failed with OOM.
Simply amazing!
I used only a tiny sample since I was primarily interested in being able to train and evaluate with this huge model that normally won't fit onto a 24GB GPU.
If you would like to experiment with this benchmark yourself or want to know more details about the hardware and software used to run it, please, refer to this post.
The Magic Behind ZeRO
Since transformers only integrated these fabulous solutions and wasn't part of their invention I will share the resources where you can discover all the details for yourself. But here are a few quick insights that may help understand how ZeRO manages these amazing feats.
The key feature of ZeRO is adding distributed data storage to the quite familiar concept of data parallel training.
The computation on each GPU is exactly the same as data parallel training, but the parameter, gradients and optimizer states are stored in a distributed/partitioned fashion across all the GPUs and fetched only when needed.
The following diagram, coming from this blog post illustrates how this works:
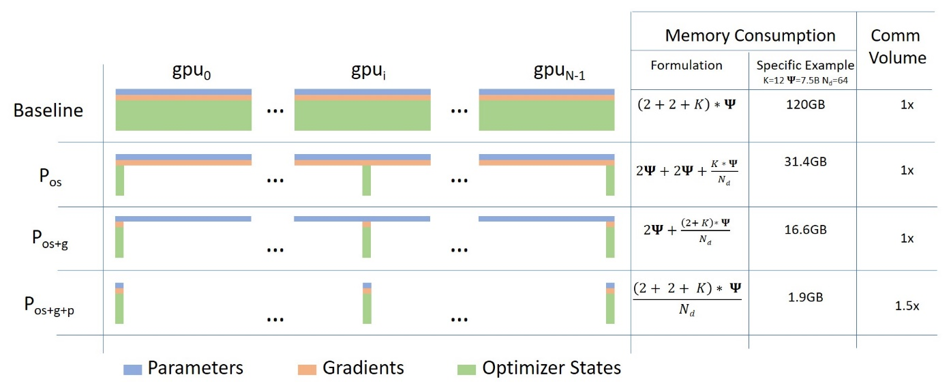
ZeRO's ingenious approach is to partition the params, gradients and optimizer states equally across all GPUs and give each GPU just a single partition (also referred to as a shard). This leads to zero overlap in data storage between GPUs. At runtime each GPU builds up each layer's data on the fly by asking participating GPUs to send the information it's lacking.
This idea could be difficult to grasp, and you will find my attempt at an explanation here.
As of this writing FairScale and DeepSpeed only perform Partitioning (Sharding) for the optimizer states and gradients. Model parameters sharding is supposedly coming soon in DeepSpeed and FairScale.
The other powerful feature is ZeRO-Offload (paper). This feature offloads some of the processing and memory needs to the host's CPU, thus allowing more to be fit onto the GPU. You saw its dramatic impact in the success at running t5-3b on a 24GB GPU.
One other problem that a lot of people complain about on pytorch forums is GPU memory fragmentation. One often gets an OOM error that may look like this:
RuntimeError: CUDA out of memory. Tried to allocate 1.48 GiB (GPU 0; 23.65 GiB total capacity;
16.22 GiB already allocated; 111.12 MiB free; 22.52 GiB reserved in total by PyTorch)
The program wants to allocate ~1.5GB and the GPU still has some 6-7GBs of unused memory, but it reports to have only ~100MB of contiguous free memory and it fails with the OOM error. This happens as chunks of different size get allocated and de-allocated again and again, and over time holes get created leading to memory fragmentation, where there is a lot of unused memory but no contiguous chunks of the desired size. In the example above the program could probably allocate 100MB of contiguous memory, but clearly it can't get 1.5GB in a single chunk.
DeepSpeed attacks this problem by managing GPU memory by itself and ensuring that long term memory allocations don't mix with short-term ones and thus there is much less fragmentation. While the paper doesn't go into details, the source code is available, so it's possible to see how DeepSpeed accomplishes that.
As ZeRO stands for Zero Redundancy Optimizer, it's easy to see that it lives up to its name.
The Future
Besides the anticipated upcoming support for model params sharding in DeepSpeed, it already released new features that we haven't explored yet. These include DeepSpeed Sparse Attention and 1-bit Adam, which are supposed to decrease memory usage and dramatically reduce inter-GPU communication overhead, which should lead to an even faster training and support even bigger models.
I trust we are going to see new gifts from the FairScale team as well. I think they are working on ZeRO stage 3 as well.
Even more exciting, ZeRO is being integrated into pytorch.
Deployment
If you found the results shared in this blog post enticing, please proceed here for details on how to use DeepSpeed and FairScale with the transformers Trainer.
You can, of course, modify your own trainer to integrate DeepSpeed and FairScale, based on each project's instructions or you can "cheat" and see how we did it in the transformers Trainer. If you go for the latter, to find your way around grep the source code for deepspeed and/or sharded_ddp.
The good news is that ZeRO requires no model modification. The only required modifications are in the training code.
Issues
If you encounter any issues with the integration part of either of these projects please open an Issue in transformers.
But if you have problems with DeepSpeed and FairScale installation, configuration and deployment - you need to ask the experts in their domains, therefore, please, use DeepSpeed Issue or FairScale Issue instead.
Resources
While you don't really need to understand how any of these projects work and you can just deploy them via the transformers Trainer, should you want to figure out the whys and hows please refer to the following resources.
Paper: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. The paper is very interesting, but it's very terse.
Here is a good video discussion of the paper with visuals
Paper: ZeRO-Offload: Democratizing Billion-Scale Model Training. Just published - this one goes into the details of ZeRO Offload feature.
DeepSpeed configuration and tutorials
In addition to the paper, I highly recommend to read the following detailed blog posts with diagrams:
DeepSpeed examples on GitHub
Gratitude
We were quite astonished at the amazing level of support we received from the FairScale and DeepSpeed developer teams while working on integrating those projects into transformers.
In particular I'd like to thank:
- Benjamin Lefaudeux @blefaudeux
- Mandeep Baines @msbaines
from the FairScale team and:
from the DeepSpeed team for your generous and caring support and prompt resolution of the issues we have encountered.
And HuggingFace for providing access to hardware the benchmarks were run on.
Sylvain Gugger @sgugger and Stas Bekman @stas00 worked on the integration of these projects.

