AI Watermarking 101: Tools and Techniques














In recent months, we've seen multiple news stories involving ‘deepfakes’, or AI-generated content: from images of Taylor Swift to videos of Tom Hanks and recordings of US President Joe Biden. Whether they are selling products, manipulating images of people without their consent, supporting phishing for private information, or creating misinformation materials intended to mislead voters, deepfakes are increasingly being shared on social media platforms. This enables them to be quickly propagated and have a wider reach and therefore, the potential to cause long-lasting damage.
In this blog post, we will describe approaches to carry out watermarking of AI-generated content, discuss their pros and cons, and present some of the tools available on the Hugging Face Hub for adding/detecting watermarks.
What is watermarking and how does it work?

Watermarking is a method designed to mark content in order to convey additional information, such as authenticity. Watermarks in AI-generated content can range from fully visible (Figure 1) to invisible (Figure 2). In AI specifically, watermarking involves adding patterns to digital content (such as images), and conveying information regarding the provenance of the content; these patterns can then be recognized either by humans or algorithmically.
There are two primary methods for watermarking AI-generated content: the first occurs during content creation, which requires access to the model itself but can also be more robust given that it is automatically embedded as part of the generation process. The second method, which is implemented after the content is produced, can also be applied even to content from closed-source and proprietary models, with the caveat that it may not be applicable to all types of content (e.g., text).
Data Poisoning and Signing Techniques
In addition to watermarking, several related techniques have a role to play in limiting non-consensual image manipulation. Some imperceptibly alter images you share online so that AI algorithms don’t process them well. Even though people can see the images normally, AI algorithms can’t access comparable content, and as a result, can't create new images. Some tools that imperceptibly alter images include Glaze and Photoguard. Other tools work to “poison” images so that they break the assumptions inherent in AI algorithm training, making it impossible for AI systems to learn what people look like based on the images shared online – this makes it harder for these systems to generate fake images of people. These tools include Nightshade and Fawkes.
Maintaining content authenticity and reliability is also possible by utilizing "signing” techniques that link content to metadata about their provenance, such as the work of Truepic, which embeds metadata following the C2PA standard. Image signing can help understand where images come from. While metadata can be edited, systems such as Truepic help get around this limitation by 1) Providing certification to ensure that the validity of the metadata can be verified and 2) Integrating with watermarking techniques to make it harder to remove the information.
Open vs Closed Watermarks
There are pros and cons of providing different levels of access to both watermarkers and detectors for the general public. Openness helps stimulate innovation, as developers can iterate on key ideas and create better and better systems. However, this must be balanced against malicious use. With open code in an AI pipeline calling a watermarker, it is trivial to remove the watermarking step. Even if that aspect of the pipeline is closed, then if the watermark is known and the watermarking code is open, malicious actors may read the code to figure out how to edit generated content in a way where the watermarking doesn't work. If access to a detector is also available, it's possible to continue editing something synthetic until the detector returns low-confidence, undoing what the watermark provides. There are hybrid open-closed approaches that directly address these issues. For instance, the Truepic watermarking code is closed, but they provide a public JavaScript library that can verify Content Credentials. The IMATAG code to call a watermarker during generation is open, but the actual watermarker and the detector are private.
Watermarking Different Types of Data
While watermarking is an important tool across modalities (audio, images, text, etc.), each modality brings with it unique challenges and considerations. So, too, does the intent of the watermark: whether to prevent the usage of training data for training models, to protect content from being manipulated, to mark the output of models, or to detect AI-generated data. In the current section, we explore different modalities of data, the challenges they present for watermarking, and the open-source tools that exist on the Hugging Face Hub to carry out different types of watermarking.
Watermarking Images
Probably the best known type of watermarking (both for content created by humans or produced by AI) is carried out on images. There have been different approaches proposed to tag training data to impact the outputs of models trained on it: the best-known method for this kind of ‘image cloaking’ approach is “Nightshade”, which carries out tiny changes to images that are imperceptible to the human eye but that impact the quality of models trained on poisoned data. There are similar image cloaking tools available on the Hub - for instance, Fawkes, developed by the same lab that developed Nightshade, specifically targets images of people with the goal of thwarting facial recognition systems. Similarly, there’s also Photoguard, which aims to guard images against manipulation using generative AI tools, e.g., for the creation of deepfakes based on them.
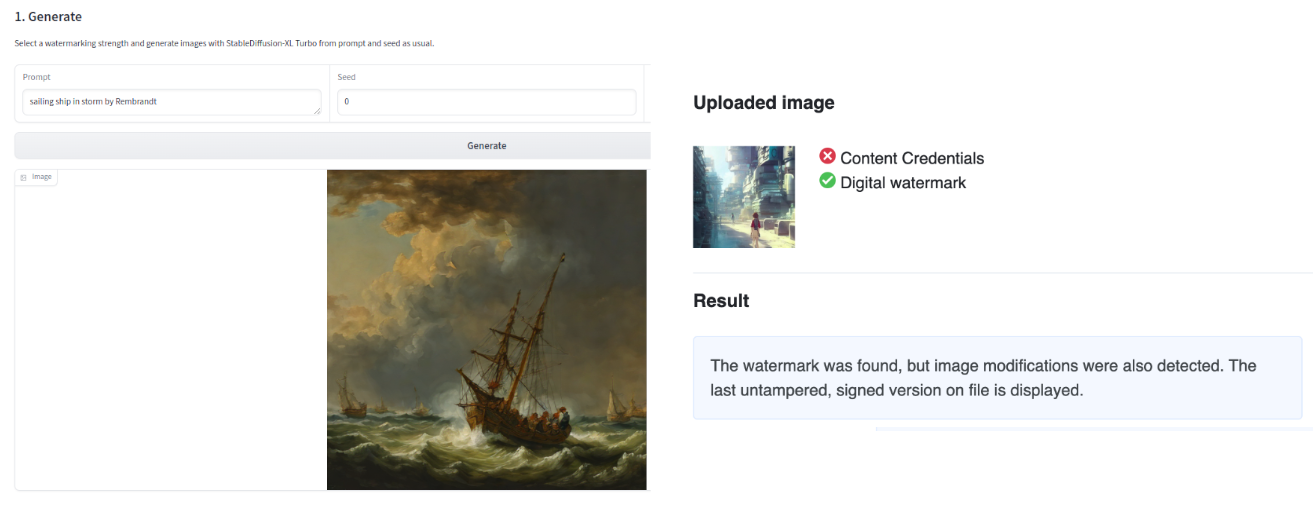
In terms of watermarking output images, there are two complementary approaches available on the Hub: IMATAG (see Fig 2), which carries out watermarking during the generation of content by leveraging modified versions of popular models such as Stable Diffusion XL Turbo, and Truepic, which adds invisible content credentials after an image has been generated.
TruePic also embeds C2PA content credentials into the images, which enables the storage of metadata regarding image provenance and generation in the image itself. Both the IMATAG and TruePic Spaces also allow for the detection of images watermarked by their systems. Both of these detection tools work with their respective approaches (i.e., they are approach-specific). There is an existing general deepfake detection Space on the Hub, but in our experience, we found that these solutions have variable performance depending on the quality of the image and the model used.
Watermarking Text
While watermarking AI-generated images can seem more intuitive – given the strongly visual nature of this content – text is a whole different story… How do you add watermarks to written words and numbers (tokens)? Well, the current approaches for watermarking rely on promoting sub-vocabularies based on the previous text. Let's dive into what this would look like for LLM-generated text.
During the generation process, an LLM outputs a list of logits for the next token before it carries out sampling or greedy decoding. Based on the previous generated text, most approaches split all candidate tokens into 2 groups – call them “red” and “green”. The “red” tokens will be restricted, and the “green” group will be promoted. This can happen by disallowing the red group tokens altogether (Hard Watermark), or by increasing the probability of the green group (Soft Watermark). The more we change the original probabilities, the higher our watermarking strength. WaterBench has created a benchmark dataset to facilitate comparison of performance across watermarking algorithms while controlling the watermarking strength for apples-to-apples comparisons.
Detection works by determining what “color” each token is, and then calculating the probability that the input text comes from the model in question. It’s worth noting that shorter texts have a much lower confidence, since there are less tokens to examine.

There are a couple of ways you can easily implement watermarking for LLMs on the Hugging Face Hub. The Watermark for LLMs Space (see Fig. 3) demonstrates this, using an LLM watermarking approach on models such as OPT and Flan-T5. For production level workloads, you can use our Text Generation Inference toolkit, which implements the same watermarking algorithm and sets the corresponding parameters and can be used with any of the latest models!
Similar to universal watermarking of AI-generated images, it is yet to be proven whether universally watermarking text is possible. Approaches such as GLTR are meant to be robust for any accessible language model (given that they rely upon comparing the logits of generated text to those of different models). Detecting whether a given text was generated using a language model without having access to that model (either because it’s closed-source or because you don’t know which model was used to generate the text) is currently impossible.
As we discussed above, detection methods for generated text require a large amount of text to be reliable. Even then, detectors can have high false positive rates, incorrectly labeling text written by people as synthetic. Indeed, OpenAI removed their in-house detection tool in 2023 given low accuracy rate, which came with unintended consequences when it was used by teachers to gauge whether the assignments submitted by their students were generated using ChatGPT or not.
Watermarking Audio
The data extracted from a person's voice (voiceprint), is often used as a biometric security authentication mechanism to identify an individual. While generally paired with other security factors such as PIN or password, a breach of this biometric data still presents a risk and can be used to gain access to, e.g., bank accounts, given that many banks use voice recognition technologies to verify clients over the phone. As voice becomes easier to replicate with AI, we must also improve the techniques to validate the authenticity of voice audio. Watermarking audio content is similar to watermarking images in the sense that there is a multidimensional output space that can be used to inject metadata regarding provenance. In the case of audio, the watermarking is usually carried out on frequencies that are imperceptible to human ears (below ~20 or above ~20,000 Hz), which can then be detected using AI-driven approaches.
Given the high-stakes nature of audio output, watermarking audio content is an active area of research, and multiple approaches (e.g., WaveFuzz, Venomave) have been proposed over the last few years.
AudioSeal is a method for speech localized watermarking, with state-of-the-art detector speed without compromising the watermarking robustness. It jointly trains a generator that embeds a watermark in the audio, and a detector that detects the watermarked fragments in longer audios, even in the presence of editing. Audioseal achieves state-of-the-art detection performance of both natural and synthetic speech at the sample level (1/16k second resolution), it generates limited alteration of signal quality and is robust to many types of audio editing.

AudioSeal was also used to release SeamlessExpressive and SeamlessStreaming demos with mechanisms for safety.
Conclusion
Disinformation, being accused of producing synthetic content when it's real, and instances of inappropriate representations of people without their consent can be difficult and time-consuming; much of the damage is done before corrections and clarifications can be made. As such, as part of our mission to democratize good machine learning, we at Hugging Face believe that having mechanisms to identify AI-Generated content quickly and systematically are important. AI watermarking is not foolproof, but can be a powerful tool in the fight against malicious and misleading uses of AI.
Relevant press stories
- It Doesn't End With Taylor Swift: How to Protect Against AI Deepfakes and Sexual Harassment | PopSugar (@meg)
- Three ways we can fight deepfake porn | MIT Technology Review (@sasha)
- Gun violence killed them. Now, their voices will lobby Congress to do more using AI | NPR (@irenesolaiman)
- Google DeepMind has launched a watermarking tool for AI-generated images | MIT Technology Review (@sasha)
- Invisible AI watermarks won’t stop bad actors. But they are a ‘really big deal’ for good ones | VentureBeat (@meg)
- A watermark for chatbots can expose text written by an AI | MIT Technology Review (@irenesolaiman)
- Hugging Face empowers users with deepfake detection tools | Mashable (@meg)