VideoMamba: State Space Model for Efficient Video Understanding

The paper proposes VideoMamba, a state space model (SSM)-based approach for efficient video understanding. It aims to address the challenges of local redundancy and global dependencies in video data, leveraging the linear complexity of the Mamba operator for long-term modeling.
Method Overview
VideoMamba extends the bidirectional Mamba block, originally designed for 2D image processing, to handle 3D video sequences. It follows the architecture of vanilla Vision Transformers (ViT), with a 3D patch embedding layer that divides the input video into non-overlapping spatiotemporal patches. These patches are then flattened and mapped to a sequence of tokens, which are processed by stacked B-Mamba blocks.
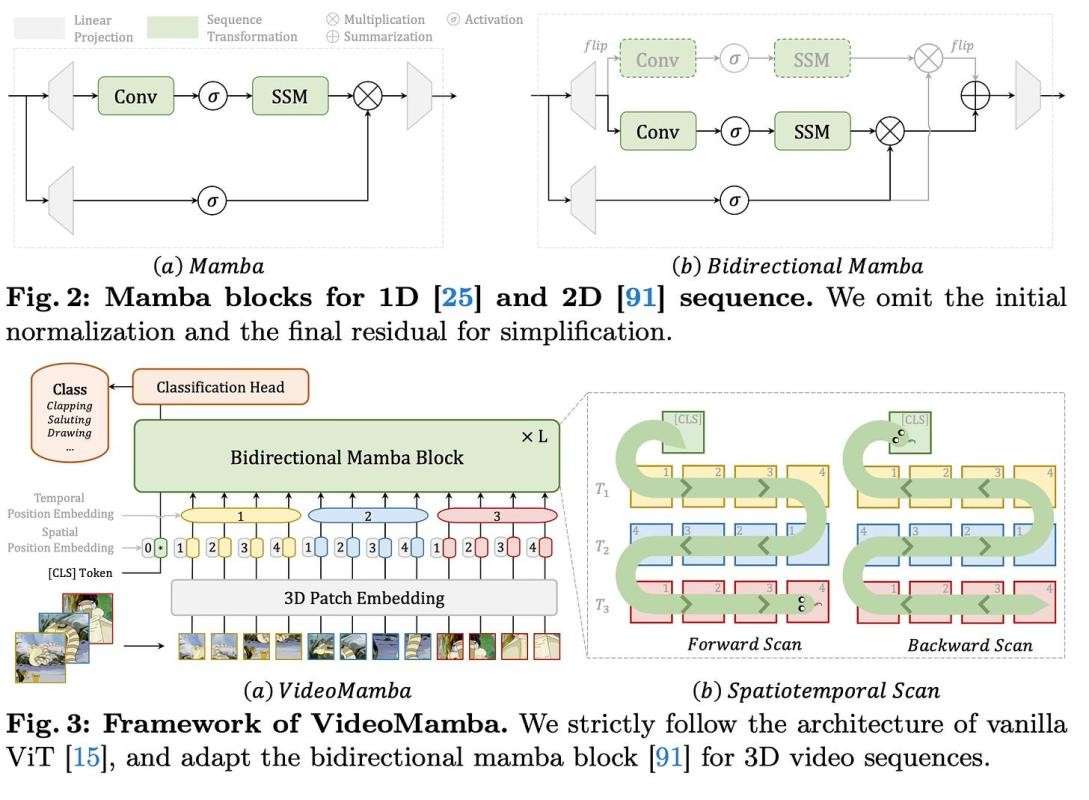
The authors explore different spatiotemporal scan orders for the B-Mamba blocks, including spatial-first, temporal-first, and hybrid scans. Through experiments, they find the spatial-first bidirectional scan to be the most effective, as it can seamlessly leverage 2D pretrained knowledge by scanning frame by frame.
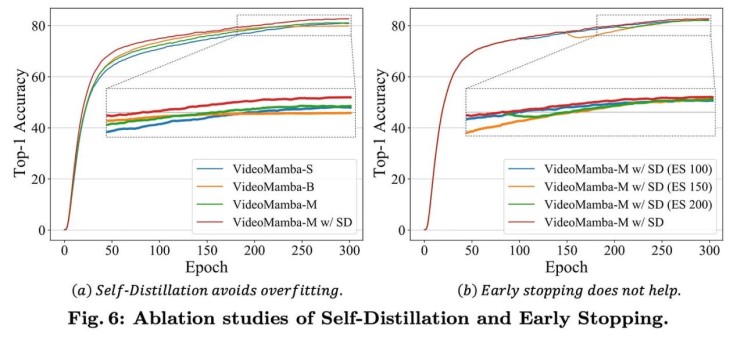
To enhance the scalability of larger VideoMamba models, the authors introduce a self-distillation technique. A smaller, well-trained model acts as a "teacher" to guide the training of a larger "student" model by aligning their final feature maps, mitigating overfitting issues observed in larger Mamba architectures.
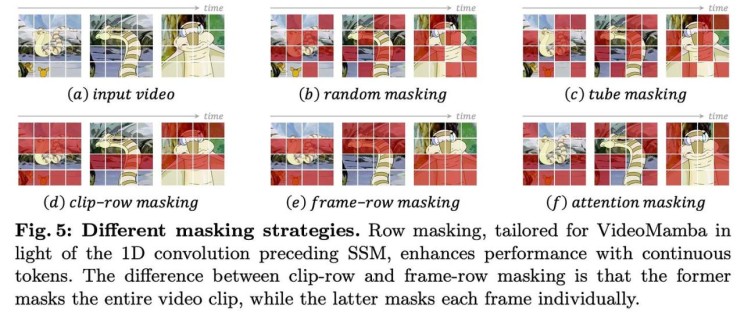
Additionally, VideoMamba adapts masked modeling techniques to improve its temporal sensitivity and multi-modal compatibility. The authors propose row masking strategies tailored to the 1D convolution within B-Mamba blocks, exploring random, tube, clip-row, frame-row, and attention-based masking. They also investigate aligning only the final outputs between the student and teacher models due to architectural differences.
Results
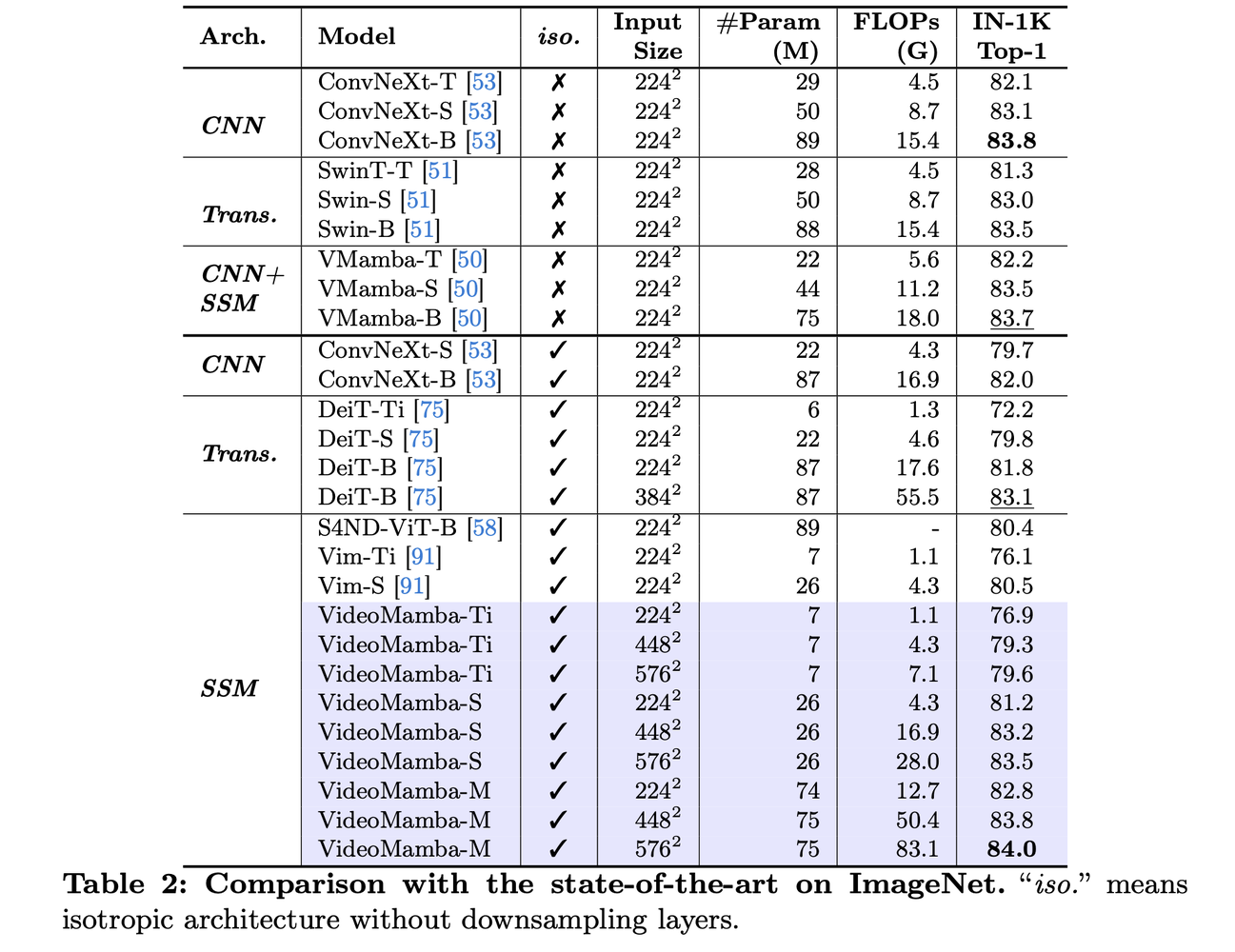
- Scalability: VideoMamba outperforms other isotropic architectures on ImageNet-1K, achieving 84.0% top-1 accuracy with only 74M parameters.
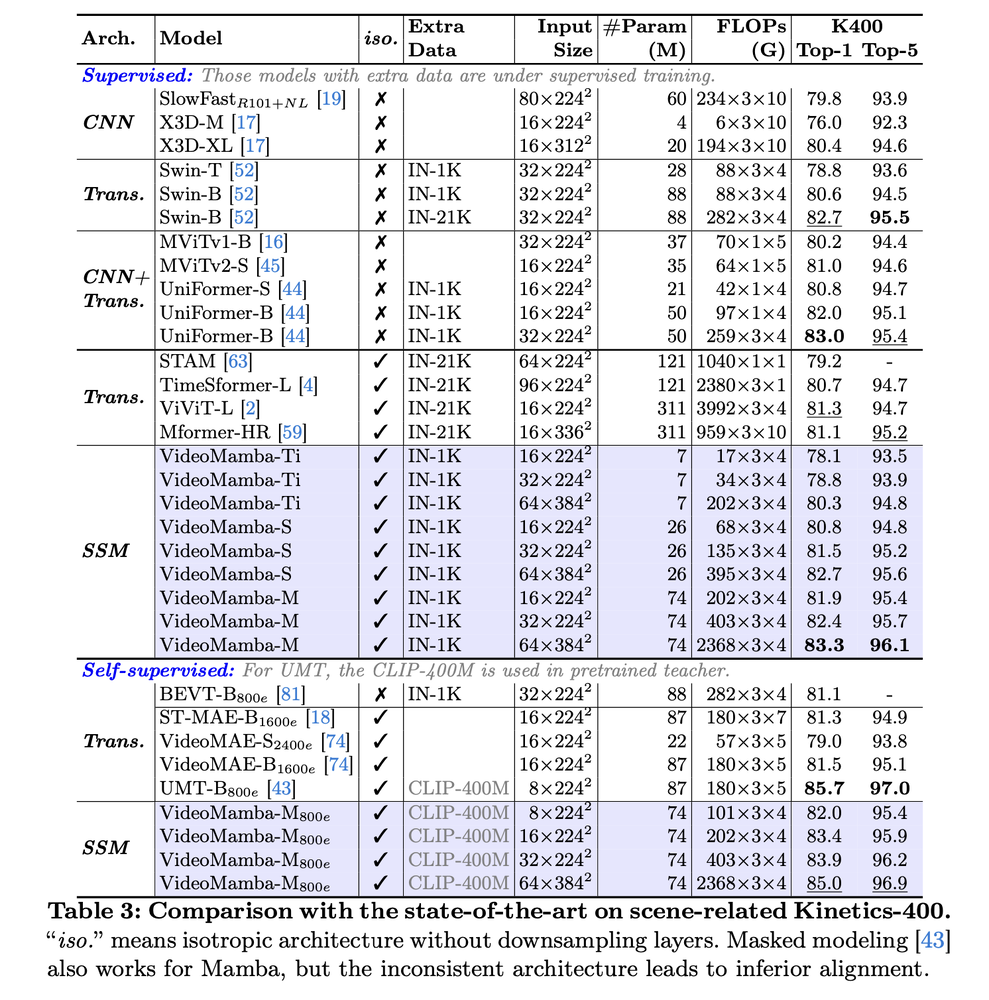
- Short-term Action Recognition: On Kinetics-400 and Something-Something V2, VideoMamba surpasses attention-based models like ViViT and TimeSformer, with reduced computational demands.
Long-term Video Understanding: VideoMamba demonstrates remarkable superiority over traditional feature-based methods on the Breakfast, COIN, and LVU benchmarks, setting new state-of-the-art results.
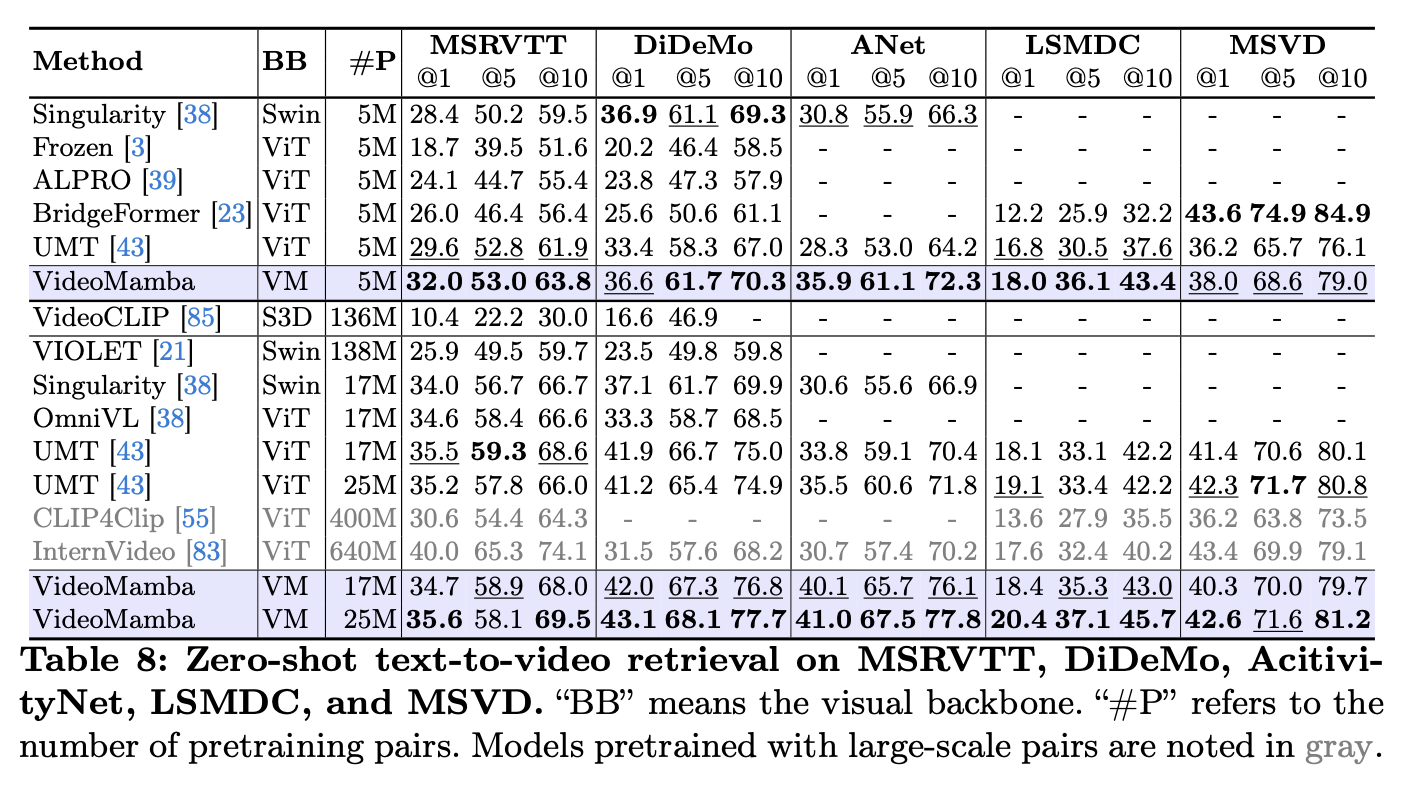
Multi-modality: VideoMamba achieves improved performance in zero-shot video-text retrieval tasks, showcasing its robustness in multi-modal contexts.
Conclusion
VideoMamba adapts the Mamba architecture for efficient long-term video modeling, outperforming existing methods in various video understanding tasks. For more details please consult the full paper or the code.
Congrats to the authors for their work!
Model: https://huggingface.co/OpenGVLab/VideoMamba
Li, Kunchang, et al. "VideoMamba: State Space Model for Efficient Video Understanding." arXiv preprint arXiv:2403.06977, 2023.