Using Machine Learning to Aid Survivors and Race through Time








On February 6, 2023, earthquakes measuring 7.7 and 7.6 hit South Eastern Turkey, affecting 10 cities and resulting in more than 42,000 deaths and 120,000 injured as of February 21.
A few hours after the earthquake, a group of programmers started a Discord server to roll out an application called afetharita, literally meaning, disaster map. This application would serve search & rescue teams and volunteers to find survivors and bring them help. The need for such an app arose when survivors posted screenshots of texts with their addresses and what they needed (including rescue) on social media. Some survivors also tweeted what they needed so their relatives knew they were alive and that they need rescue. Needing to extract information from these tweets, we developed various applications to turn them into structured data and raced against time in developing and deploying these apps.
When I got invited to the discord server, there was quite a lot of chaos regarding how we (volunteers) would operate and what we would do. We decided to collaboratively train models so we needed a model and dataset registry. We opened a Hugging Face organization account and collaborated through pull requests as to build ML-based applications to receive and process information.
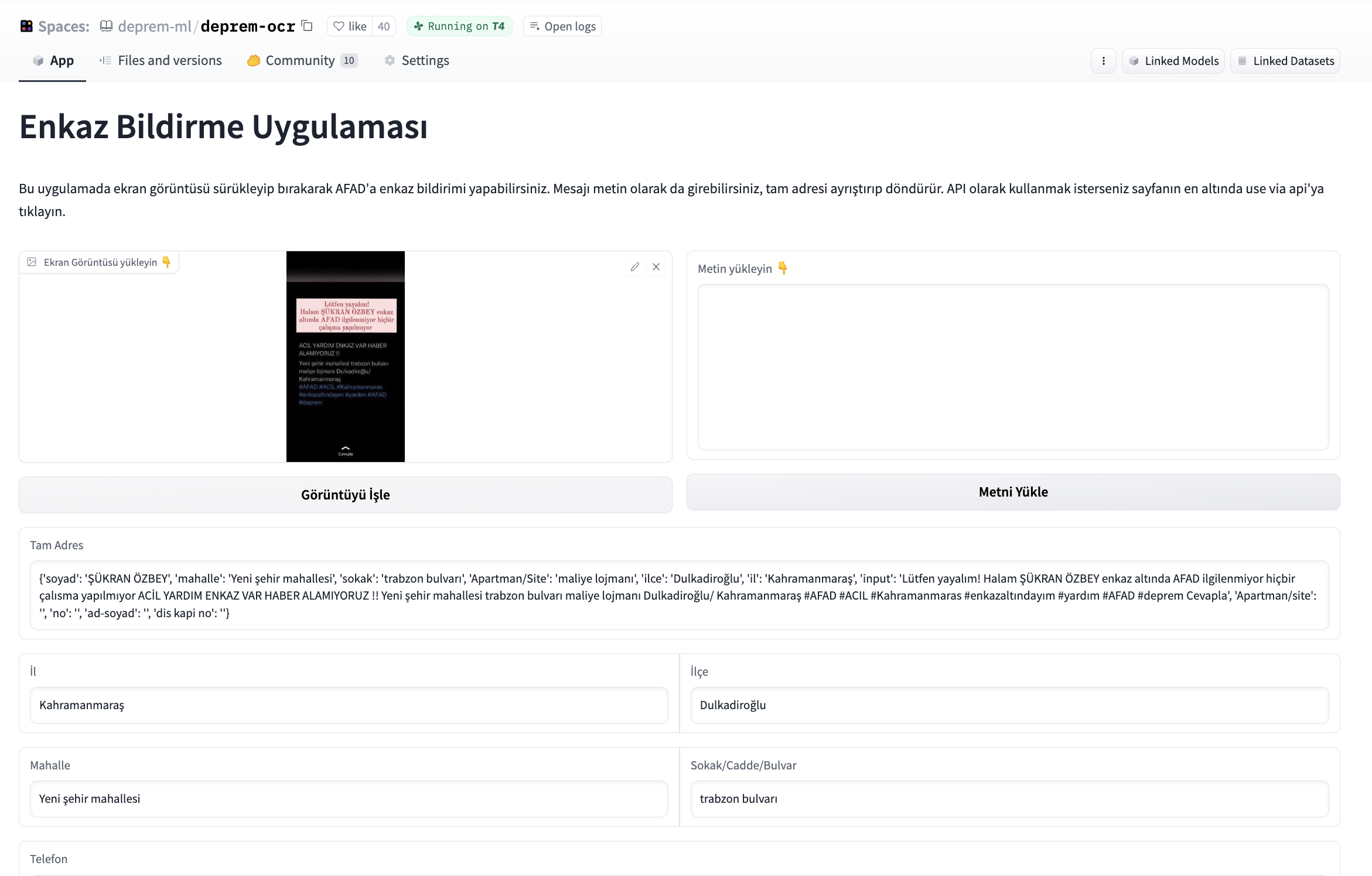
We had been told by volunteers in other teams that there's a need for an application to post screenshots, extract information from the screenshots, structure it and write the structured information to the database. We started developing an application that would take a given image, extract the text first, and from text, extract a name, telephone number, and address and write these informations to a database that would be handed to authorities. After experimenting with various open-source OCR tools, we started using easyocr for OCR part and Gradio for building an interface for this application. We were asked to build a standalone application for OCR as well so we opened endpoints from the interface. The text output from OCR is parsed using transformers-based fine-tuned NER model.
To collaborate and improve the application, we hosted it on Hugging Face Spaces and we've received a GPU grant to keep the application up and running. Hugging Face Hub team has set us up a CI bot for us to have an ephemeral environment, so we could see how a pull request would affect the Space, and it helped us during pull request reviews.
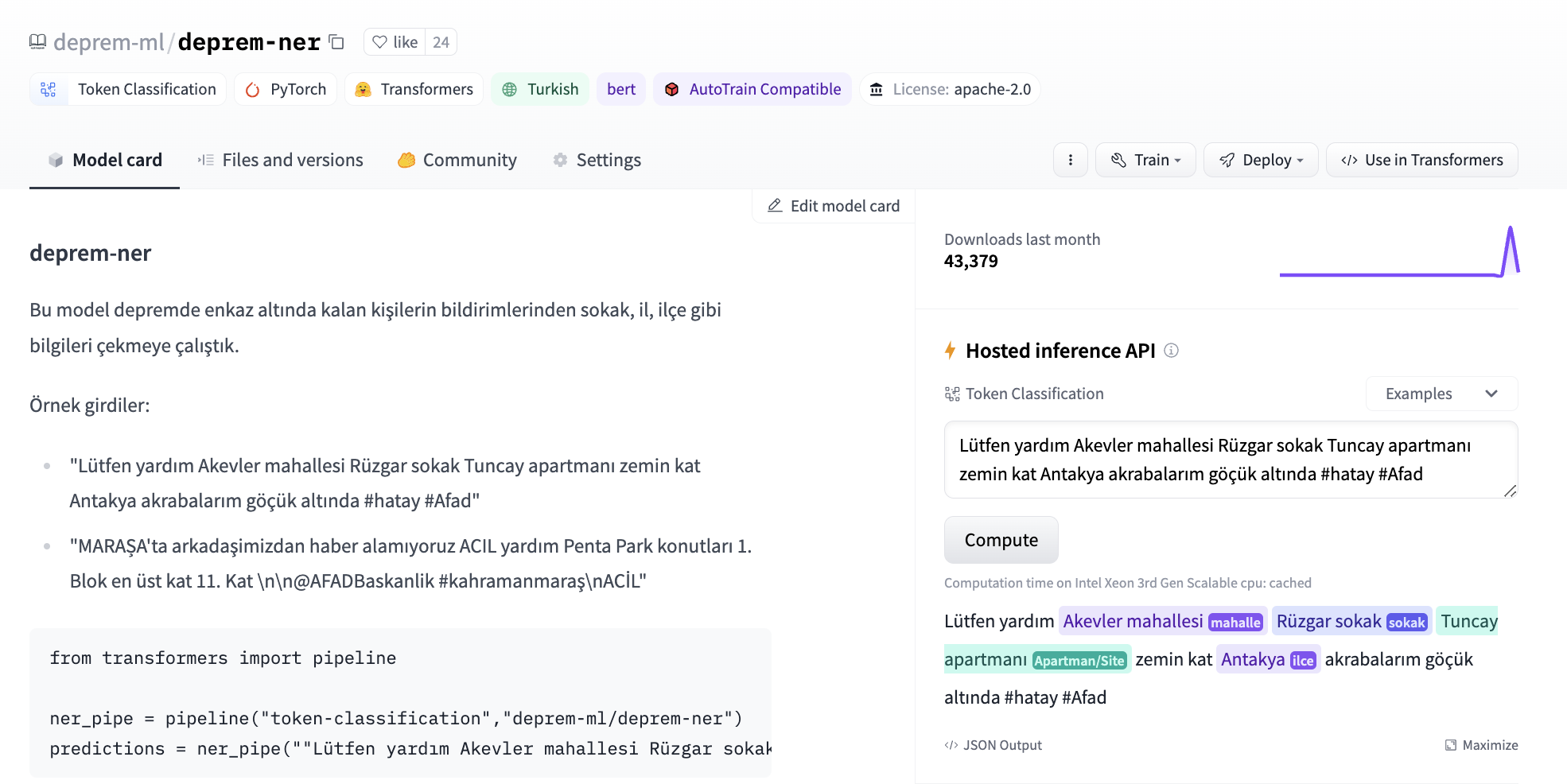
Later on, we were given labeled content from various channels (e.g. twitter, discord) with raw tweets of survivors' calls for help, along with the addresses and personal information extracted from them. We started experimenting both with few-shot prompting of closed-source models and fine-tuning our own token classification model from transformers. We’ve used bert-base-turkish-cased as a base model for token classification and came up with the first address extraction model.
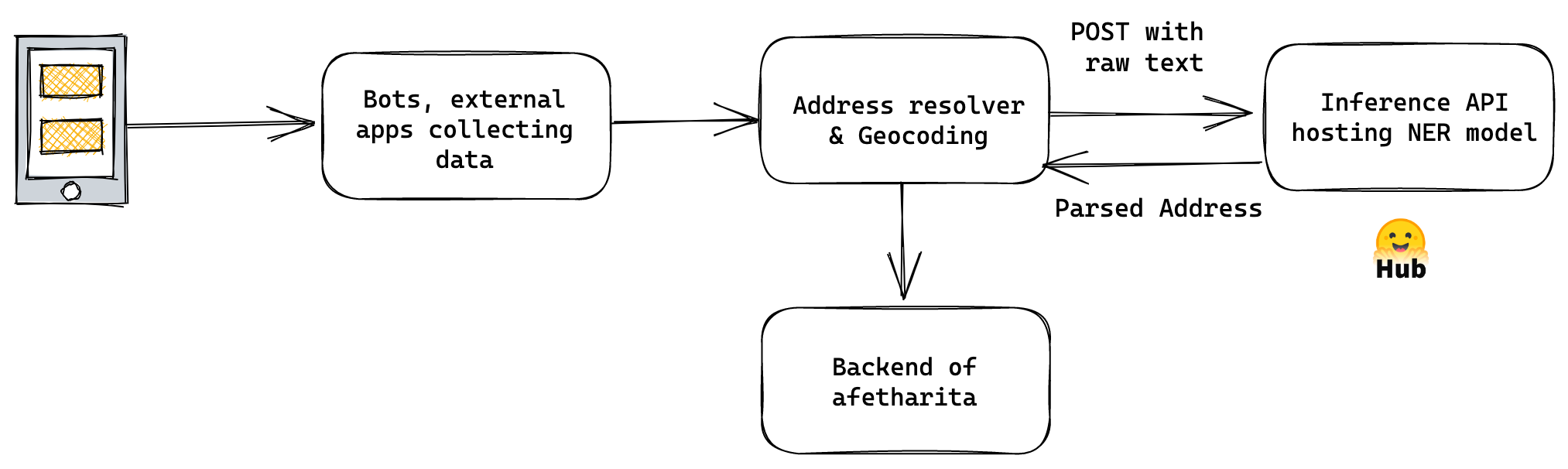
The model was later used in afetharita to extract addresses. The parsed addresses would be sent to a geocoding API to obtain longitude and latitude, and the geolocation would then be displayed on the front-end map. For inference, we have used Inference API, which is an API that hosts model for inference and is automatically enabled when the model is pushed to Hugging Face Hub. Using Inference API for serving has saved us from pulling the model, writing an app, building a docker image, setting up CI/CD, and deploying the model to a cloud instance, where it would be extra overhead work for the DevOps and cloud teams as well. Hugging Face teams have provided us with more replicas so that there would be no downtime and the application would be robust against a lot of traffic.
Later on, we were asked if we could extract what earthquake survivors need from a given tweet. We were given data with multiple labels for multiple needs in a given tweet, and these needs could be shelter, food, or logistics, as it was freezing cold over there. We’ve started experimenting first with zero-shot experimentations with open-source NLI models on Hugging Face Hub and few-shot experimentations with closed-source generative model endpoints. We have tried xlm-roberta-large-xnli and convbert-base-turkish-mc4-cased-allnli_tr. NLI models were particularly useful as we could directly infer with candidate labels and change the labels as data drift occurs, whereas generative models could have made up labels and cause mismatches when giving responses to the backend. We initially didn’t have labeled data so anything would work.
In the end, we decided to fine-tune our own model as it would take roughly three minutes to fine-tune BERT’s text classification head on a single GPU. We had a labelling effort to develop the dataset to train this model. We logged our experiments in the model card’s metadata so we could later come up with a leaderboard to keep track of which model should be deployed to production. For base model, we have tried bert-base-turkish-uncased and bert-base-turkish-128k-cased and realized they perform better than bert-base-turkish-cased. You can find our leaderboard here.
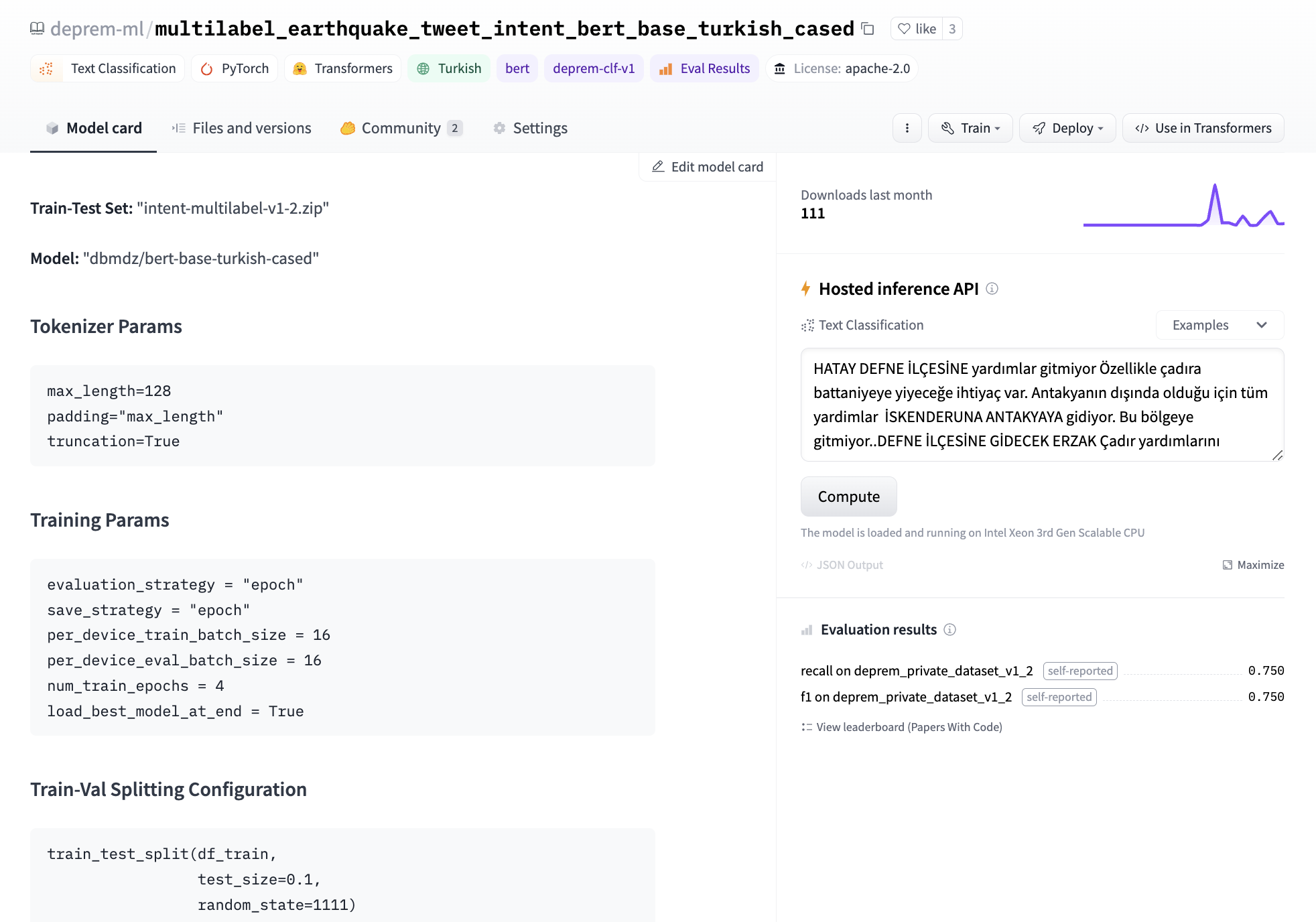
Considering the task at hand and the imbalance of our data classes, we focused on eliminating false negatives and created a Space to benchmark the recall and F1-scores of all models. To do this, we added the metadata tag deprem-clf-v1 to all relevant model repos and used this tag to automatically retrieve the logged F1 and recall scores and rank models. We had a separate benchmark set to avoid leakage to the train set and consistently benchmark our models. We also benchmarked each model to identify the best threshold per label for deployment.
We wanted our NER model to be evaluated and crowd-sourced the effort because the data labelers were working to give us better and updated intent datasets. To evaluate the NER model, we’ve set up a labeling interface using Argilla and Gradio, where people could input a tweet and flag the output as correct/incorrect/ambiguous.
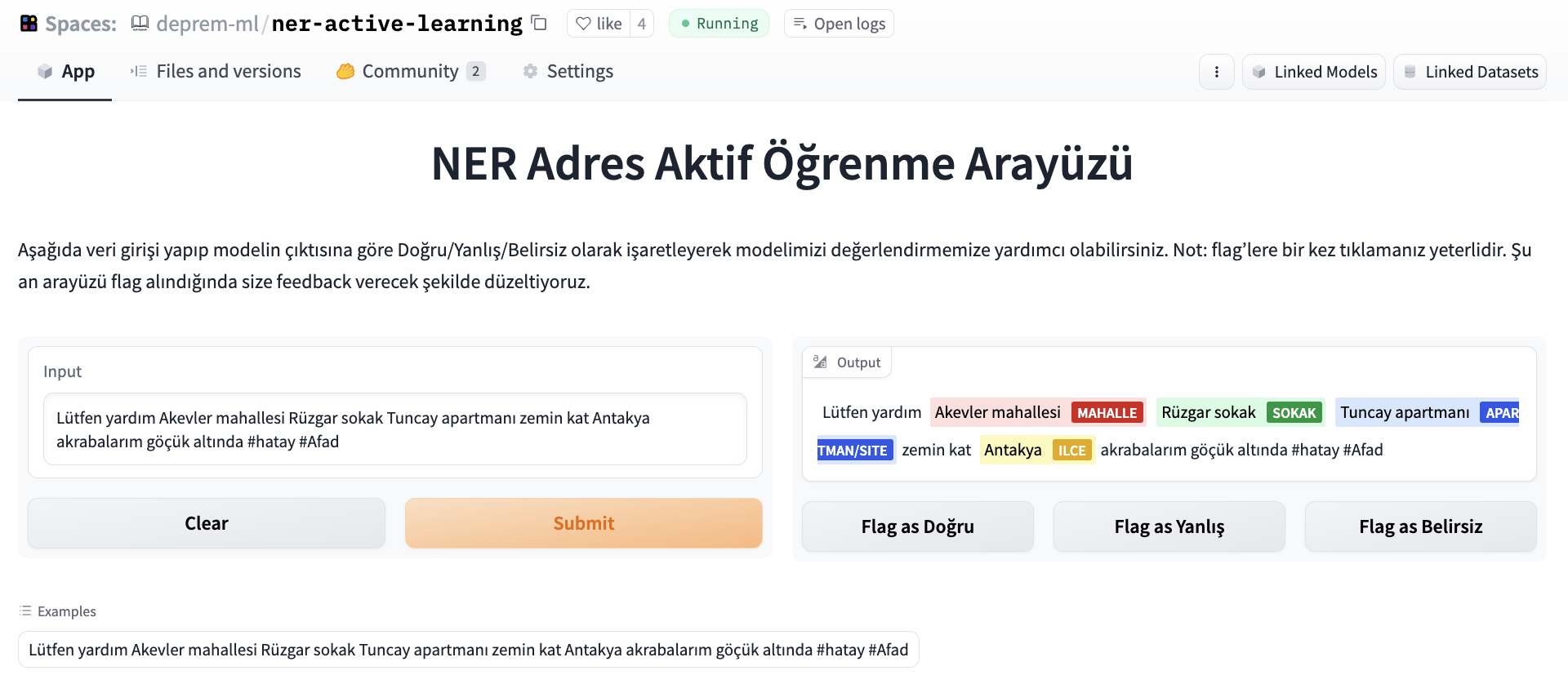
Later, the dataset was deduplicated and used to benchmark our further experiments.
Another team under machine learning has worked with generative models (behind a gated API) to get the specific needs (as labels were too broad) as free text and pass the text as an additional context to each posting. For this, they’ve done prompt engineering and wrapped the API endpoints as a separate API, and deployed them on the cloud. We found that using few-shot prompting with LLMs helps adjust to fine-grained needs in the presence of rapidly developing data drift, as the only thing we need to adjust is the prompt and we do not need any labeled data for this.
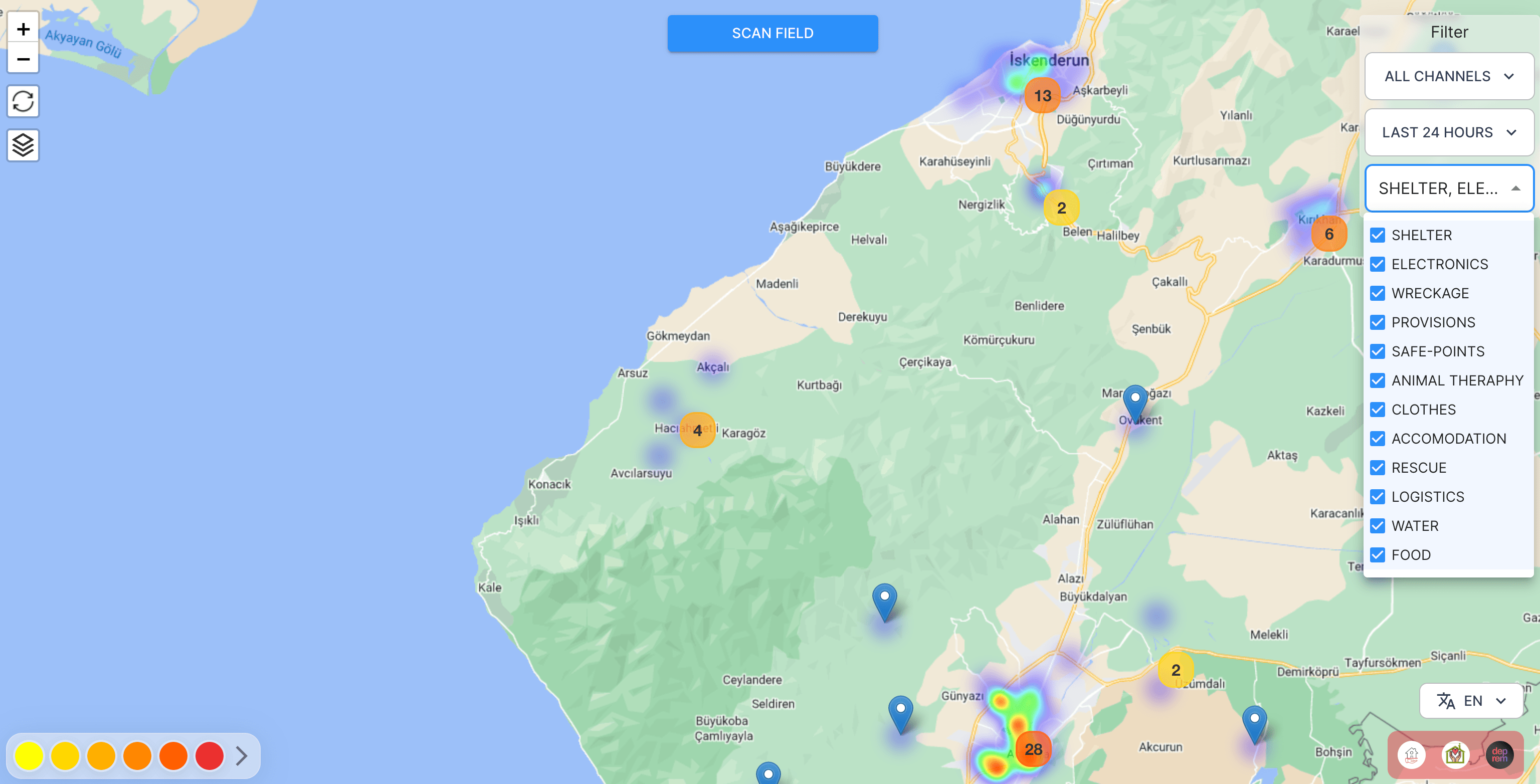
These models are currently being used in production to create the points in the heat map below so that volunteers and search and rescue teams can bring the needs to survivors.
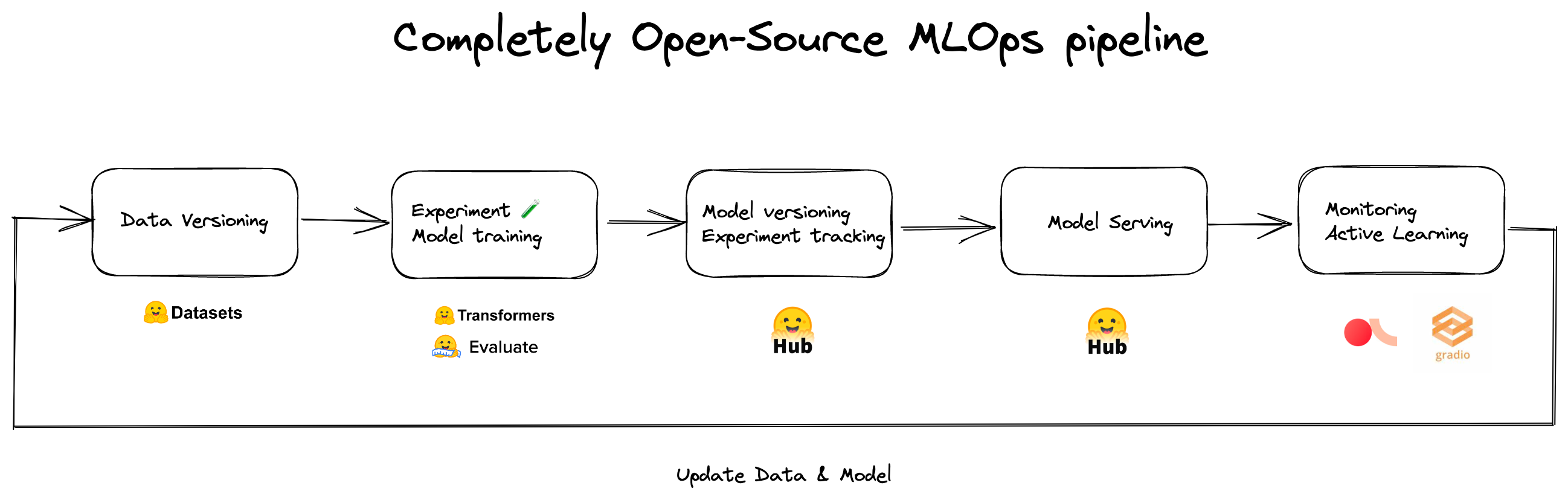
We’ve realized that if it wasn’t for Hugging Face Hub and the ecosystem, we wouldn’t be able to collaborate, prototype, and deploy this fast. Below is our MLOps pipeline for address recognition and intent classification models.
There are tens of volunteers behind this application and its individual components, who worked with no sleep to get these out in such a short time.
Remote Sensing Applications
Other teams worked on remote sensing applications to assess the damage to buildings and infrastructure in an effort to direct search and rescue operations. The lack of electricity and stable mobile networks during the first 48 hours of the earthquake, combined with collapsed roads, made it extremely difficult to assess the extent of the damage and where help was needed. The search and rescue operations were also heavily affected by false reports of collapsed and damaged buildings due to the difficulties in communication and transportation.
To address these issues and create open source tools that can be leveraged in the future, we started by collecting pre and post-earthquake satellite images of the affected zones from Planet Labs, Maxar and Copernicus Open Access Hub.

Our initial approach was to rapidly label satellite images for object detection and instance segmentation, with a single category for "buildings". The aim was to evaluate the extent of damage by comparing the number of surviving buildings in pre- and post-earthquake images collected from the same area. In order to make it easier to train models, we started by cropping 1080x1080 satellite images into smaller 640x640 chunks. Next, we fine-tuned YOLOv5, YOLOv8 and EfficientNet models for building detection and a SegFormer model for semantic segmentation of buildings, and deployed these apps as Hugging Face Spaces.
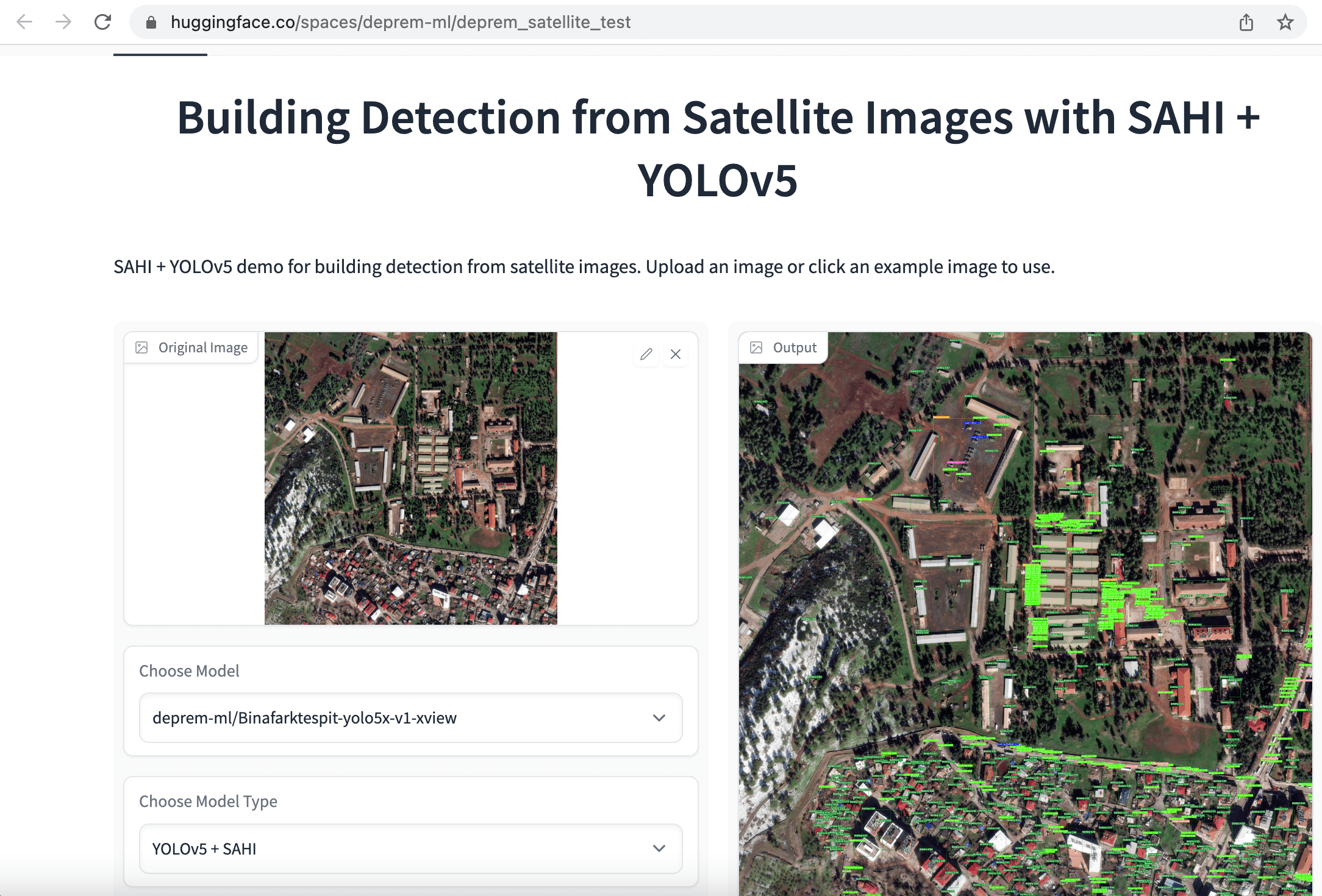
Once again, dozens of volunteers worked on labeling, preparing data, and training models. In addition to individual volunteers, companies like Co-One volunteered to label satellite data with more detailed annotations for buildings and infrastructure, including no damage, destroyed, damaged, damaged facility, and undamaged facility labels. Our current objective is to release an extensive open-source dataset that can expedite search and rescue operations worldwide in the future.

Wrapping Up
For this extreme use case, we had to move fast and optimize over classification metrics where even one percent improvement mattered. There were many ethical discussions in the progress, as even picking the metric to optimize over was an ethical question. We have seen how open-source machine learning and democratization enables individuals to build life-saving applications. We are thankful for the community behind Hugging Face for releasing these models and datasets, and team at Hugging Face for their infrastructure and MLOps support.


