Introducing Storage Regions on the Hub



![[object Object]'s avatar](https://cdn-avatars.huggingface.co/v1/production/uploads/61a5dcedf14aa6d7c74925f7/ZbVN8MsvjWwanqOwUdIeC.png)



As part of our Enterprise Hub plan, we recently released support for Storage Regions.
Regions let you decide where your org's models and datasets will be stored. This has two main benefits, which we'll briefly go over in this blog post:
- Regulatory and legal compliance, and more generally, better digital sovereignty
- Performance (improved download and upload speeds and latency)
Currently we support the following regions:
- US 🇺🇸
- EU 🇪🇺
- coming soon: Asia-Pacific 🌏
But first, let's see how to setup this feature in your organization's settings 🔥
Org settings
If your organization is not an Enterprise Hub org yet, you will see the following screen:
As soon as you subscribe, you will be able to see the Regions settings page:
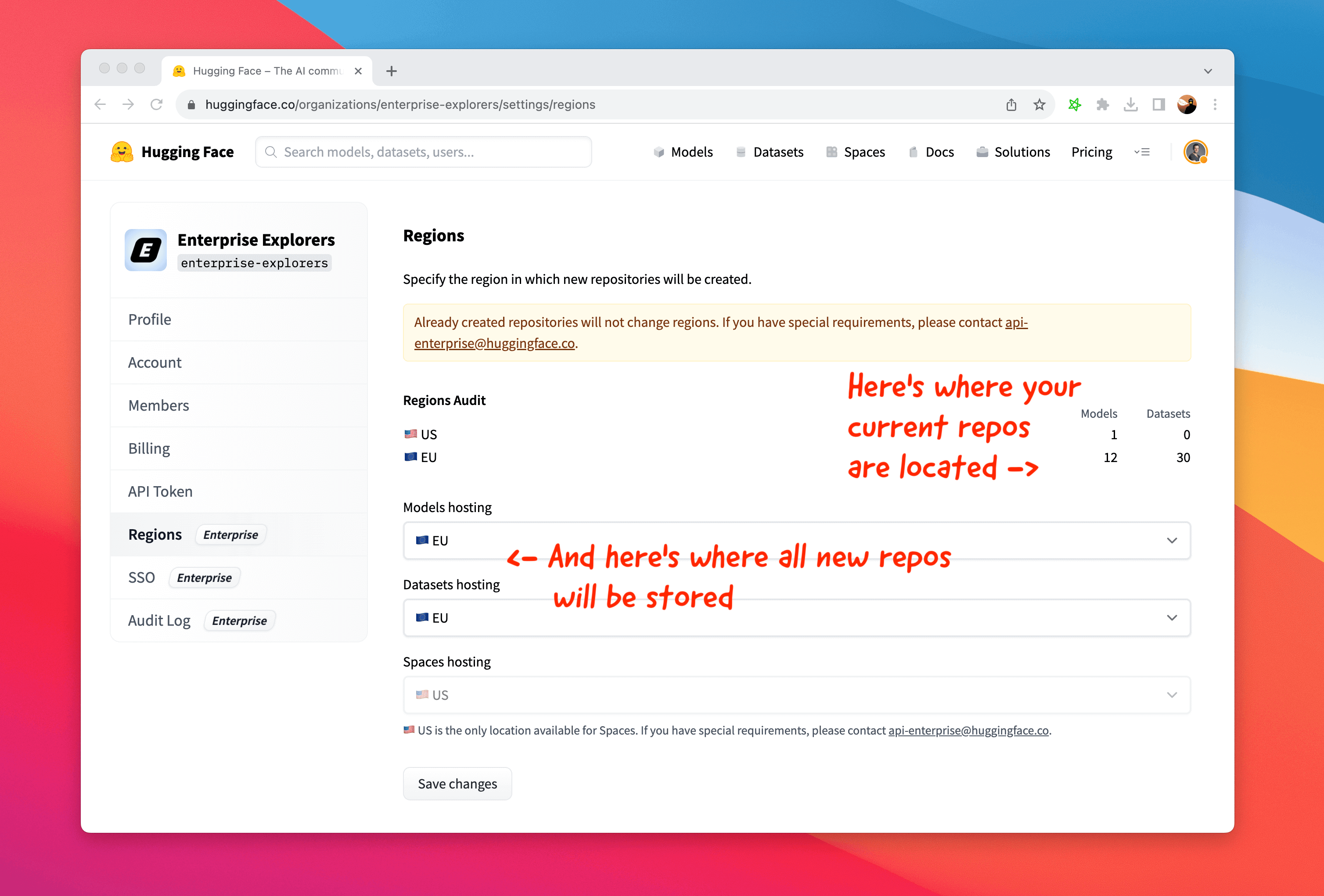
On that page you can see:
- an audit of where your orgs' repos are currently located
- dropdowns to select where your repos will be created
Repository Tag
Any repo (model or dataset) stored in a non-default location will display its Region directly as a tag. That way your organization's members can see at a glance where repos are located.

Regulatory and legal compliance
In many regulated industries, you may have a requirement to store your data in a specific area.
For companies in the EU, that means you can use the Hub to build ML in a GDPR compliant way: with datasets, models and inference endpoints all stored within EU data centers.
If you are an Enterprise Hub customer and have further questions about this, please get in touch!
Performance
Storing your models or your datasets closer to your team and infrastructure also means significantly improved performance, for both uploads and downloads.
This makes a big difference considering model weights and dataset files are usually very large.

As an example, if you are located in Europe and store your repositories in the EU region, you can expect to see ~4-5x faster upload and download speeds vs. if they were stored in the US.

