Introducing the LiveCodeBench Leaderboard - Holistic and Contamination-Free Evaluation of Code LLMs













We are excited to introduce the LiveCodeBench leaderboard, based on LiveCodeBench, a new benchmark developed by researchers from UC Berkeley, MIT, and Cornell for measuring LLMs’ code generation capabilities.
LiveCodeBench collects coding problems over time from various coding contest platforms, annotating problems with their release dates. Annotations are used to evaluate models on problem sets released in different time windows, allowing an “evaluation over time” strategy that helps detect and prevent contamination. In addition to the usual code generation task, LiveCodeBench also assesses self-repair, test output prediction, and code execution, thus providing a more holistic view of coding capabilities required for the next generation of AI programming agents.
LiveCodeBench Scenarios and Evaluation
LiveCodeBench problems are curated from coding competition platforms: LeetCode, AtCoder, and CodeForces. These websites periodically host contests containing problems that assess the coding and problem-solving skills of participants. Problems consist of a natural language problem statement along with example input-output examples, and the goal is to write a program that passes a set of hidden tests. Thousands of participants engage in the competitions, which ensures that the problems are vetted for clarity and correctness.
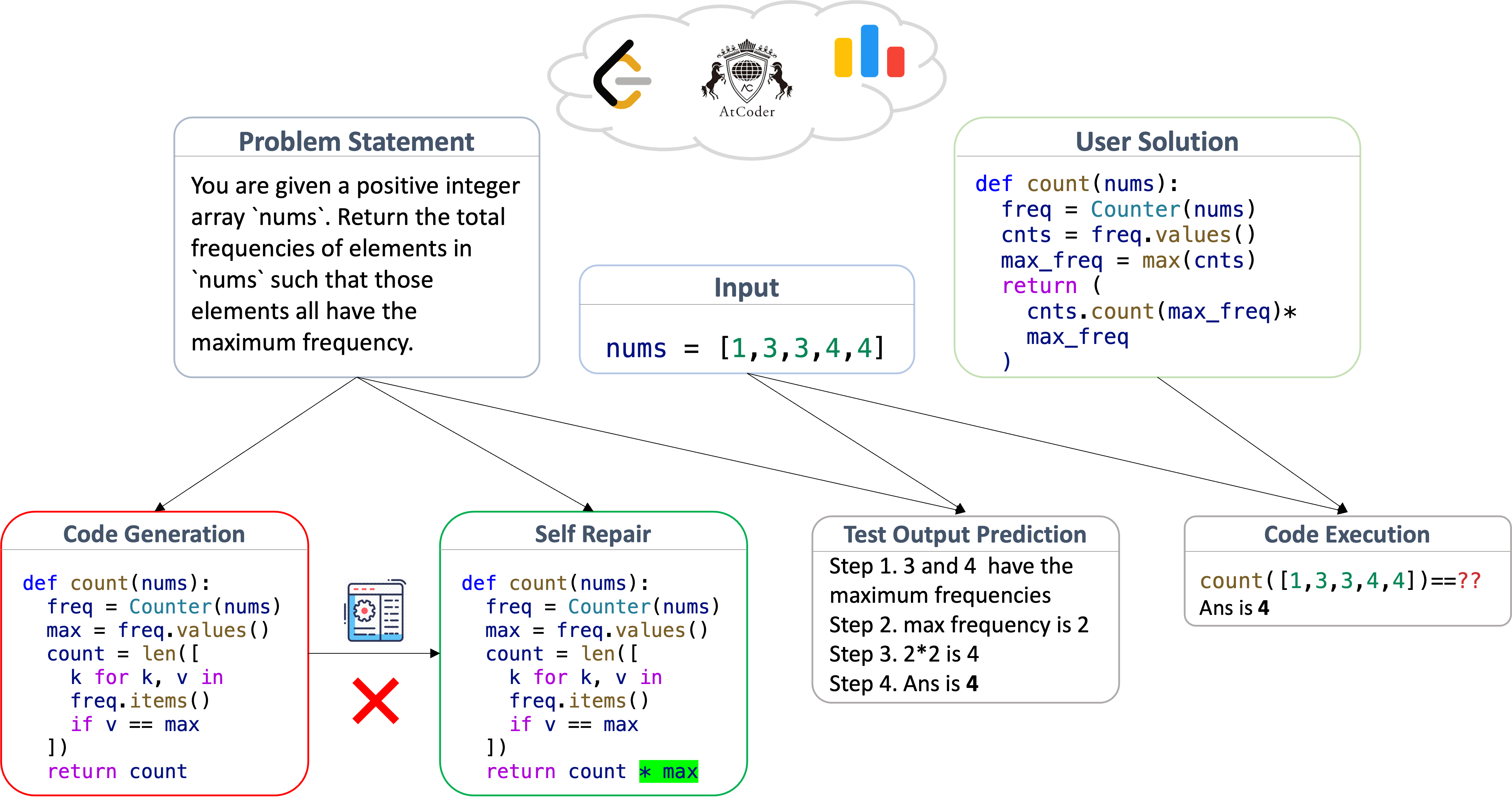
LiveCodeBench uses the collected problems for building its four coding scenarios
- Code Generation. The model is given a problem statement, which includes a natural language description and example tests (input-output pairs), and is tasked with generating a correct solution. Evaluation is based on the functional correctness of the generated code, which is determined using a set of test cases.
- Self Repair. The model is given a problem statement and generates a candidate program, similar to the code generation scenario above. In case of a mistake, the model is provided with error feedback (either an exception message or a failing test case) and is tasked with generating a fix. Evaluation is performed using the same functional correctness as above.
- Code Execution. The model is provided a program snippet consisting of a function (f) along with a test input, and is tasked with predicting the output of the program on the input test case. Evaluation is based on an execution-based correctness metric: the model's output is considered correct if the assertion
assert f(input) == generated_outputpasses. - Test Output Prediction. The model is given the problem statement along with a test case input and is tasked with generating the expected output for the input. Tests are generated solely from problem statements, without the need for the function’s implementation, and outputs are evaluated using an exact match checker.
For each scenario, evaluation is performed using the Pass@1 metric. The metric captures the probability of generating a correct answer and is computed using the ratio of the count of correct answers over the count of total attempts, following Pass@1 = total_correct / total_attempts.
Preventing Benchmark Contamination
Contamination is one of the major bottlenecks in current LLM evaluations. Even within LLM coding evaluations, there have been evidential reports of contamination and overfitting on standard benchmarks like HumanEval ([1] and [2]).
For this reason, we annotate problems with release dates in LiveCodeBench: that way, for new models with a training-cutoff date D, we can compute scores on problems released after D to measure their generalization on unseen problems.
LiveCodeBench formalizes this with a “scrolling over time” feature, that allows you to select problems within a specific time window. You can try it out in the leaderboard above!
Findings
We find that:
- while model performances are correlated across different scenarios, the relative performances and orderings can vary on the 4 scenarios we use
GPT-4-Turbois the best-performing model across most scenarios. Furthermore, its margin grows on self-repair tasks, highlighting its capability to take compiler feedback.Claude-3-OpusovertakesGPT-4-Turboin the test output prediction scenario, highlighting stronger natural language reasoning capabilities.Mistral-Largeperforms considerably better on natural language reasoning tasks like test output prediction and code execution.

How to Submit?
To evaluate your code models on LiveCodeBench, you can follow these steps
- Environment Setup: You can use conda to create a new environment, and install LiveCodeBench
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBench
pip install poetry
poetry install
- For evaluating new Hugging Face models, you can easily evaluate the model using
python -m lcb_runner.runner.main --model {model_name} --scenario {scenario_name}
for different scenarios. For new model families, we have implemented an extensible framework and you can support new models by modifying lcb_runner/lm_styles.py and lcb_runner/prompts as described in the github README.
- Once you results are generated, you can submit them by filling out this form.
How to contribute
Finally, we are looking for collaborators and suggestions for LiveCodeBench. The dataset and code are available online, so please reach out by submitting an issue or mail.












