MMLU-PRO-ITA a new eval for Italian LLMs



In a previous post, we as mii-llm lab, described an analysis on evaluating Italian LLMs on different common used benchmarks and launched the redesign of the Italian Leaderboard. In this post we will present a new evaluation benchmark mmlu-pro-ita that has an open pull request on lm-evaluation-harness and some results. If you want to see all data open the “Eval Aggiuntive” tab in the Italian Leaderboard.
MMLU-PRO is an evolution of MMLU designed to evaluate language understanding models across broader and more challenging tasks. Building on the Massive Multitask Language Understanding (MMLU) dataset. MMLU-Pro-ita is a curated translation of the original dataset. Claude Opus from Anthropic with a prompt engineer draft and refine technique has been used as translator.
You are a professional translation system that accurately translates multiple-choice exercises from English to Italian. Follow these steps to ensure high-quality translations:
1. Provide an initial translation within <traduzione></traduzione> tags.
2. Propose corrections, if necessary, within <correzioni></correzioni> tags, always re-reading the input problem.
3. Write the final, polished translation within <traduzione-finale></traduzione-finale> tags.
Adhere to the following requirements:
1. Deliver top-notch, professional translations in Italian.
2. Ensure the translated text is fluent, grammatically perfect, and uses standard Italian without regional bias.
3. Accurately translate mathematical terms, notations, and equations, preserving their original meaning and structure.
4. Focus solely on translating content without providing explanations, adding extra information, or copying the source text verbatim.
Always use the following output format:
<traduzione>
<domanda>[write the translated question here]</domanda>
<opzioni>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
...
</opzioni>
</traduzione>
<correzioni>
[write your corrections here, analyzing the translation quality, errors, and providing suggestions regarding the exercise and given options]
</correzioni>
<traduzione-finale>
<domanda>[write the translated question here]</domanda>
<opzioni>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
...
</opzioni>
</traduzione-finale>
From now on, only write in Italian and translate all incoming messages. Ensure the best translation possible.
The final result is a high quality translated dataset from the original MMLU-Pro. If you are interested in the technique, have a look at the dataset card.
Results
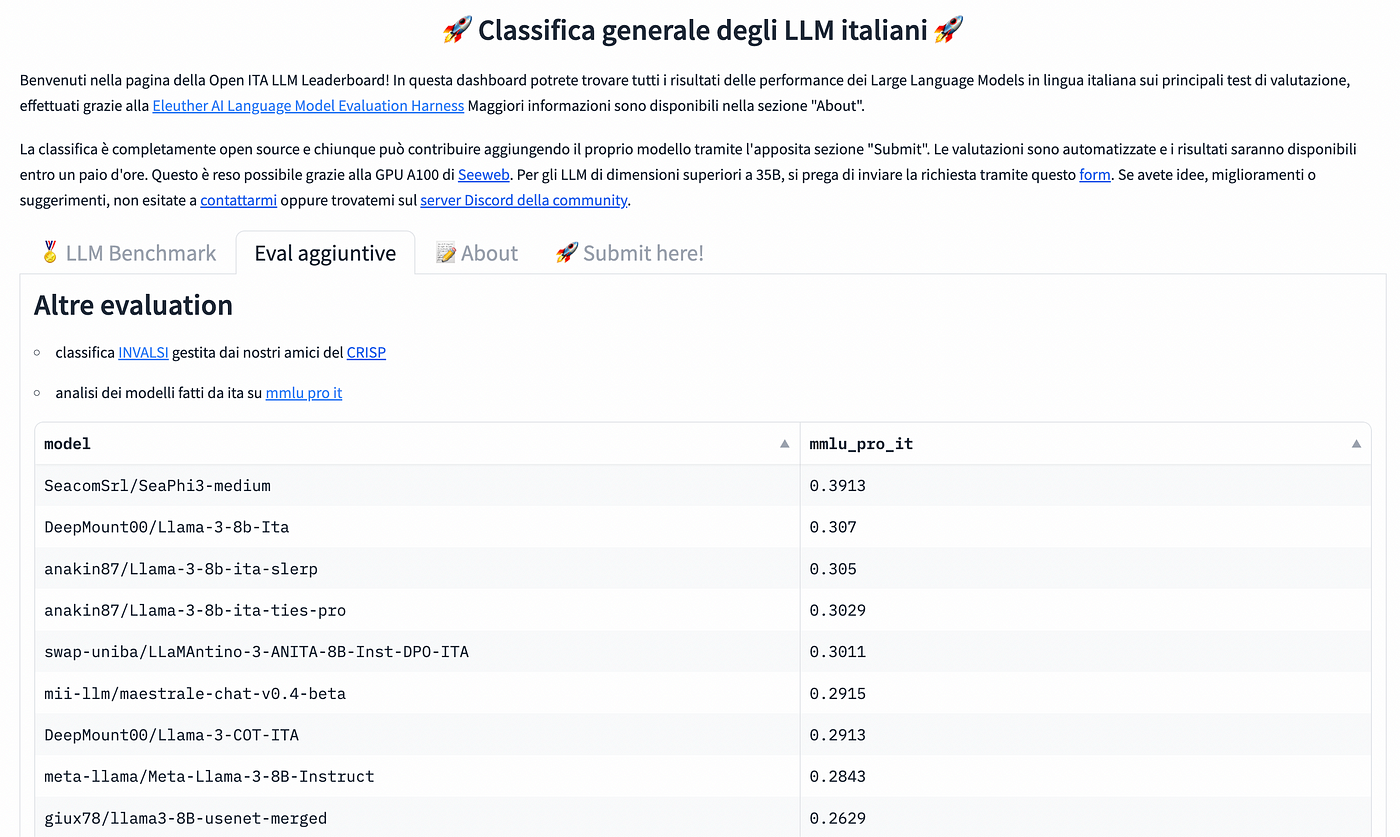
In the chart below the rank on MMLU-Pro-ita. Surprisingly:
microsoft/Phi-3medium-4k-instruct is the best performer. The Phi-3 family of models are trained on synthetic data, most likely in English, and from our experience they don’t speak very well Italian and are not easy to fine tune.Despite this it is in first position.
At the second position we found a fine tuned of Phi-3 seacom/SeaPhi3-medium.
From the llama3 family at the third place there is the fine tune DeepMount00/Llama-3b-Ita,
Interesting also the merged model anakin87/Llama-3–8b-ita-slerp in the fourth place.
In the fifth place swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA.
And the best from the mistral family in sixth place mii-llm/maestrale-chat-v0.4-beta one of our favorite model.
Fine tuned models
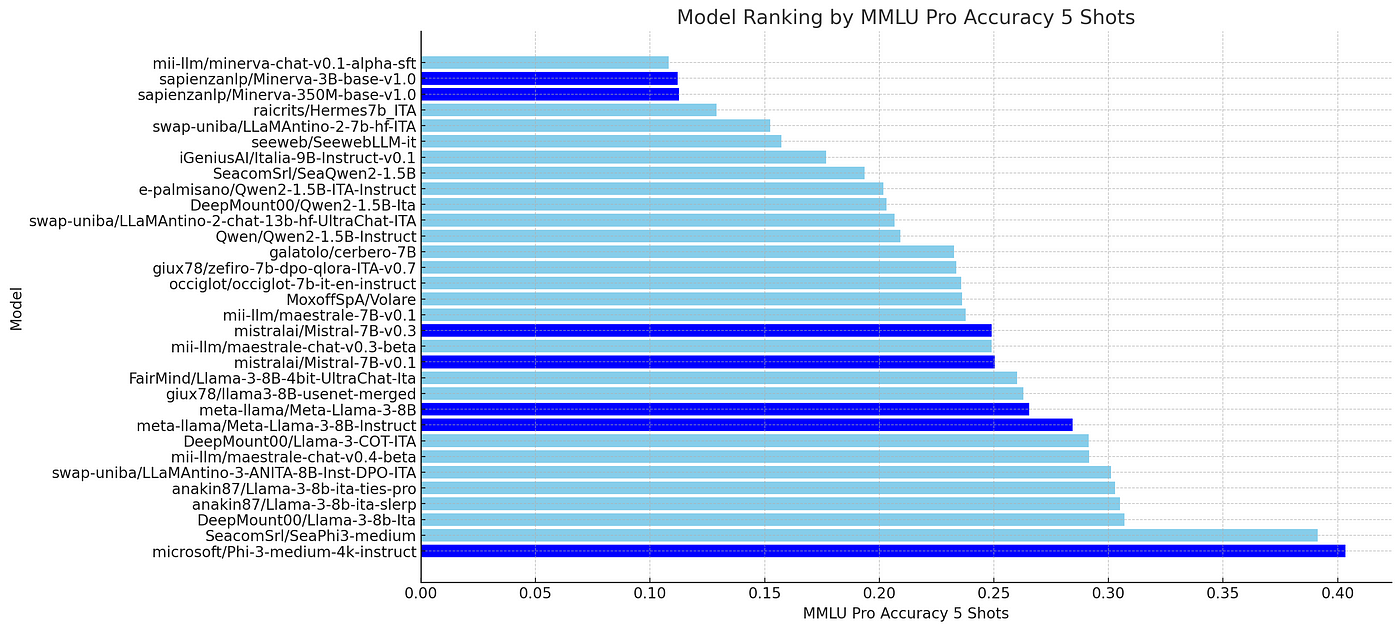
For fine-tuned models, another important metric is the percentage gain compared to their baseline models. This is useful for assessing the success of the training and also serves as a good indicator of the quality and quantity of data used in the fine-tuning steps. The chart below shows that DeepMount00/Llama-3b-Ita and mii-llm/maestrale-chat-v0.4-beta are the best models in terms of improvement from their base models, suggesting that they have used the most complete and best datasets for the mmlu-pro-it task.
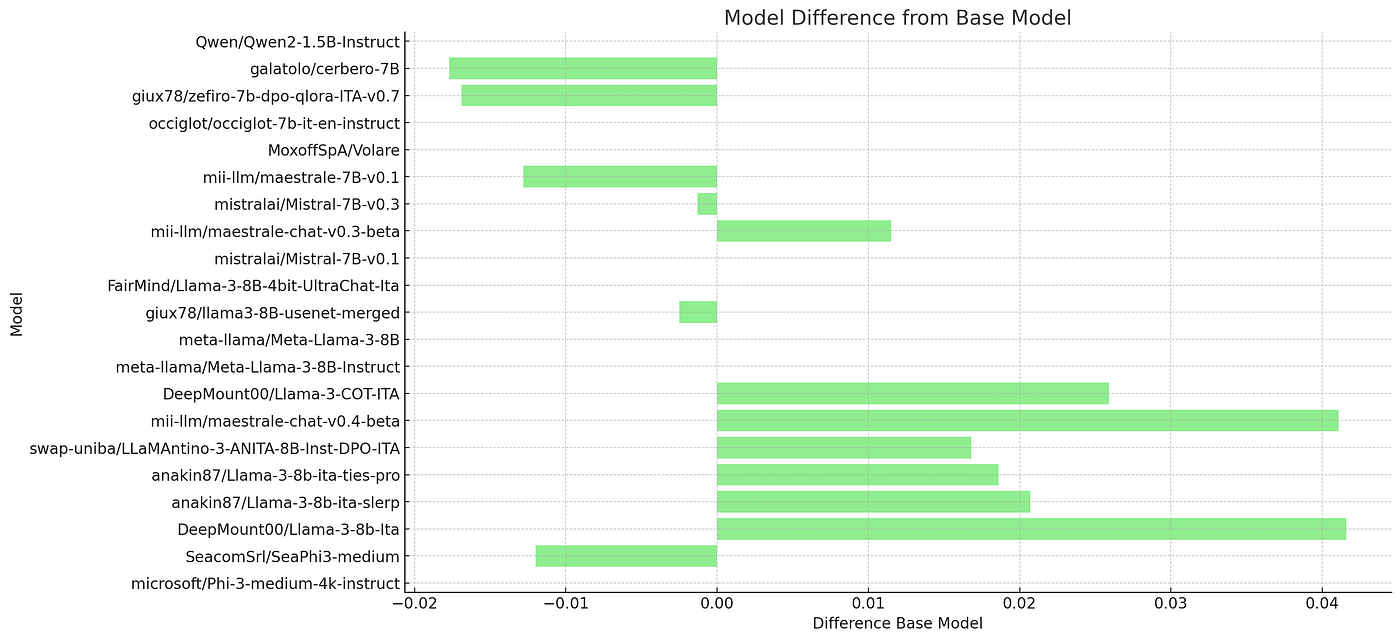
Maestrale series
A deep dive analysis on Maestrale, that we know well, shows, for example, that continual pre-training tends to erode a small amount of specific knowledge, decreasing MMLU performance, while instilling more language specific knowledge. Instead the next releases based on SFT and KTO tends to increase specific knowledge on MMLU subjects demonstrating the quality of datasets for this particular set of tasks.
On evals and benchmark
Evaluations and benchmarks tend to test only a particular or a small set of abilities of a model and they are subject to cultural knowledge and bias. This assumes that they can be only indicators of the model performance but cannot be used to judge a model for a particular use case. I suspect that we will see a fast domain specialisation of models and moreover a domain specialisation of evaluation and benchmarks. For example MMLU family of benchmarks test the knowledge on subjects evaluating how much knowledge has been able to be absorbed from a huge amount of text.
But that implies that if in the model training datasets such knowledge is not present or is not well represented your model will not perform very well, This is the reason why foundational models like sapienzanlp/minerva-llms and iiGeniusAI/Italia-9B-Instruct-v0.1 trained mainly on Italian data do not perform so well in MMLU challenges. I’m a big fan of foundational models and we think that there will be space also for specific foundational SLM. Something we are cooking about.
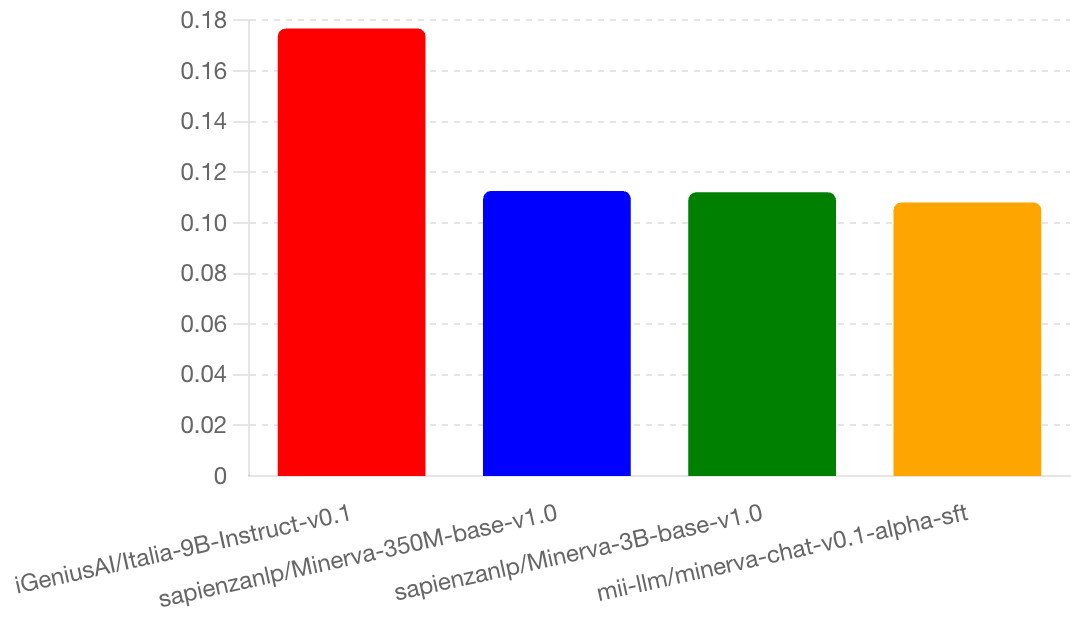
Igenius Italia vs Minerva
As in the chart below iGeniusAI/Italia-9B-Instruct-v0.1 a 9 billion model performs better than sapienzanlp/minerva-llms but the biggest is only 3 billion parameters. Another curiousity is that the 350 M model is better than the 3B, may be it is something interesting to deepen.
Conclusions
The evaluations and benchmarks fields in LLMs is very dynamic and changing fast, our vision is that in the next months and years will born hyper specialized LLMs and hence, many new benchmarks specific for various domains. We are also ready to release a new Italian based evaluation benchmark. Stay tuned and join our community research lab.