Towards Encrypted Large Language Models with FHE







Large Language Models (LLM) have recently been proven as reliable tools for improving productivity in many areas such as programming, content creation, text analysis, web search, and distance learning.
The Impact of Large Language Models on Users' Privacy
Despite the appeal of LLMs, privacy concerns persist surrounding user queries that are processed by these models. On the one hand, leveraging the power of LLMs is desirable, but on the other hand, there is a risk of leaking sensitive information to the LLM service provider. In some areas, such as healthcare, finance, or law, this privacy risk is a showstopper.
One possible solution to this problem is on-premise deployment, where the LLM owner would deploy their model on the client’s machine. This is however not an optimal solution, as building an LLM may cost millions of dollars (4.6M$ for GPT3) and on-premise deployment runs the risk of leaking the model intellectual property (IP).
Zama believes you can get the best of both worlds: our ambition is to protect both the privacy of the user and the IP of the model. In this blog, you’ll see how to leverage the Hugging Face transformers library and have parts of these models run on encrypted data. The complete code can be found in this use case example.
Fully Homomorphic Encryption (FHE) Can Solve LLM Privacy Challenges
Zama’s solution to the challenges of LLM deployment is to use Fully Homomorphic Encryption (FHE) which enables the execution of functions on encrypted data. It is possible to achieve the goal of protecting the model owner’s IP while still maintaining the privacy of the user's data. This demo shows that an LLM model implemented in FHE maintains the quality of the original model’s predictions. To do this, it’s necessary to adapt the GPT2 implementation from the Hugging Face transformers library, reworking sections of the inference using Concrete-Python, which enables the conversion of Python functions into their FHE equivalents.
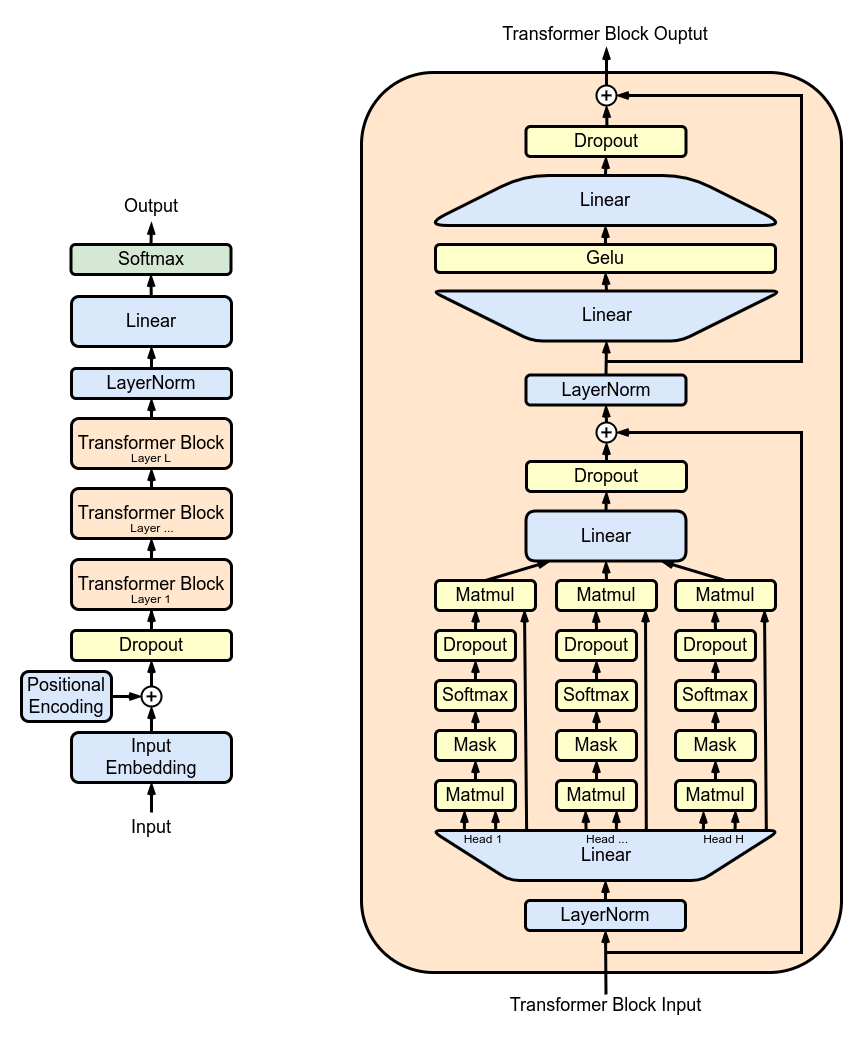
Figure 1 shows the GPT2 architecture which has a repeating structure: a series of multi-head attention (MHA) layers applied successively. Each MHA layer projects the inputs using the model weights, computes the attention mechanism, and re-projects the output of the attention into a new tensor.
In TFHE, model weights and activations are represented with integers. Nonlinear functions must be implemented with a Programmable Bootstrapping (PBS) operation. PBS implements a table lookup (TLU) operation on encrypted data while also refreshing ciphertexts to allow arbitrary computation. On the downside, the computation time of PBS dominates the one of linear operations. Leveraging these two types of operations, you can express any sub-part of, or, even the full LLM computation, in FHE.
Implementation of a LLM layer with FHE
Next, you’ll see how to encrypt a single attention head of the multi-head attention (MHA) block. You can also find an example for the full MHA block in this use case example.

Figure 2. shows a simplified overview of the underlying implementation. A client starts the inference locally up to the first layer which has been removed from the shared model. The user encrypts the intermediate operations and sends them to the server. The server applies part of the attention mechanism and the results are then returned to the client who can decrypt them and continue the local inference.
Quantization
First, in order to perform the model inference on encrypted values, the weights and activations of the model must be quantized and converted to integers. The ideal is to use post-training quantization which does not require re-training the model. The process is to implement an FHE compatible attention mechanism, use integers and PBS, and then examine the impact on LLM accuracy.
To evaluate the impact of quantization, run the full GPT2 model with a single LLM Head operating over encrypted data. Then, evaluate the accuracy obtained when varying the number of quantization bits for both weights and activations.
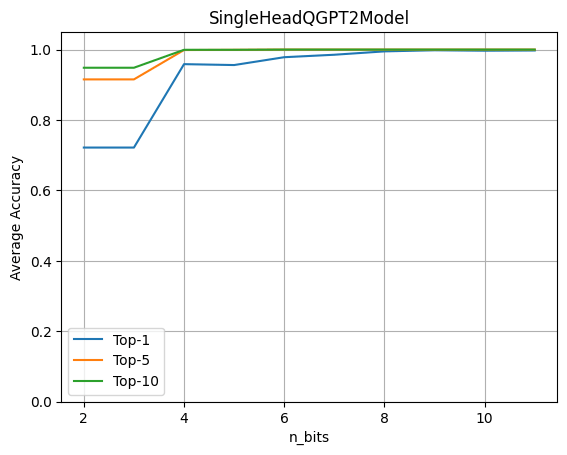
This graph shows that 4-bit quantization maintains 96% of the original accuracy. The experiment is done using a data-set of ~80 sentences. The metrics are computed by comparing the logits prediction from the original model against the model with the quantized head model.
Applying FHE to the Hugging Face GPT2 model
Building upon the transformers library from Hugging Face, rewrite the forward pass of modules that you want to encrypt, in order to include the quantized operators. Build a SingleHeadQGPT2Model instance by first loading a GPT2LMHeadModel and then manually replace the first multi-head attention module as following using a QGPT2SingleHeadAttention module. The complete implementation can be found here.
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)
The forward pass is then overwritten so that the first head of the multi-head attention mechanism, including the projections made for building the query, keys and value matrices, is performed with FHE-friendly operators. The following QGPT2 module can be found here.
class SingleHeadAttention(QGPT2):
"""Class representing a single attention head implemented with quantization methods."""
def run_numpy(self, q_hidden_states: np.ndarray):
# Convert the input to a DualArray instance
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# Extract the attention base module name
mha_weights_name = f"transformer.h.{self.layer}.attn."
# Extract the query, key and value weight and bias values using the proper indices
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# Apply the first projection in order to extract Q, K and V as a single array
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# Extract the queries, keys and vales
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# Compute attention mechanism
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)
Other computations in the model remain in floating point, non-encrypted and are expected to be executed by the client on-premise.
Loading pre-trained weights into the GPT2 model modified in this way, you can then call the generate method:
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)
As an example, you can ask the quantized model to complete the phrase ”Cryptography is a”. With sufficient quantization precision when running the model in FHE, the output of the generation is:
“Cryptography is a very important part of the security of your computer”
When quantization precision is too low you will get:
“Cryptography is a great way to learn about the world around you”
Compilation to FHE
You can now compile the attention head using the following Concrete-ML code:
circuit_head = qgpt2_model.compile(input_ids)
Running this, you will see the following print out: “Circuit compiled with 8 bit-width”. This configuration, compatible with FHE, shows the maximum bit-width necessary to perform operations in FHE.
Complexity
In transformer models, the most computationally intensive operation is the attention mechanism which multiplies the queries, keys, and values. In FHE, the cost is compounded by the specificity of multiplications in the encrypted domain. Furthermore, as the sequence length increases, the number of these challenging multiplications increases quadratically.
For the encrypted head, a sequence of length 6 requires 11,622 PBS operations. This is a first experiment that has not been optimized for performance. While it can run in a matter of seconds, it would require quite a lot of computing power. Fortunately, hardware will improve latency by 1000x to 10000x, making things go from several minutes on CPU to < 100ms on ASIC once they are available in a few years. For more information about these projections, see this blog post.
Conclusion
Large Language Models are great assistance tools in a wide variety of use cases but their implementation raises major issues for user privacy. In this blog, you saw a first step toward having the whole LLM work on encrypted data where the model would run entirely in the cloud while users' privacy would be fully respected.
This step includes the conversion of a specific part in a model like GPT2 to the FHE realm. This implementation leverages the transformers library and allows you to evaluate the impact on the accuracy when part of the model runs on encrypted data. In addition to preserving user privacy, this approach also allows a model owner to keep a major part of their model private. The complete code can be found in this use case example.
Zama libraries Concrete and Concrete-ML (Don't forget to star the repos on GitHub ⭐️💛) allow straightforward ML model building and conversion to the FHE equivalent to being able to compute and predict over encrypted data.
Hope you enjoyed this post; feel free to share your thoughts/feedback!








