
anhdungitvn/vi-mistral-x
The model, referred to as anhdungitvn/vi-mistral-x, has been meticulously developed with an emphasis on processing the Vietnamese language.
This development was achieved through the method of continual pretraining on the mistralai/Mistral-7B-v0.1 model, which has been significantly specialized and adapted for the Vietnamese language with general domain capabilities. Furthermore, it possesses the flexibility to be fine-tuned for a wide range of specialized domains. This adaptability renders the model particularly suited to fulfilling the specific requirements of businesses, researchers, and developers engaged in work involving the Vietnamese language across various sectors.
Model Details
Model Description
- Developed by: James
- Model type: Mistral
- Model class MistralForCausalLM
- Language(s): Vietnamese
- License: Not yet decided
- Finetuned from model: mistralai/Mistral-7B-v0.1
Model Sources
- Repository: anhdungitvn/vi-mistral-x
- Paper: Enhancing Memory and Computational Efficiency in Training Transformer-Based Models (unpublished)
- Technical Report: Vi-Mistral-X: Building a Vietnamese Language Model with Advanced Continual Pre-training
Uses
Direct Use
from transfomers import AutoTokenizer
from transfomers import AutoModelForCausalLM
model_name_or_path = "anhdungitvn/vi-mistral-x"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
text = "Ngân hàng lớn nhất Việt Nam là"
outputs = model(**tokenizer(text, return_tensor='pt'))
Downstream Use
SFT
from transfomers import AutoTokenizer
from transfomers import AutoModelForCausalLM
model_name_or_path = "anhdungitvn/vi-mistral-x"
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
model_max_length=4096 # customize it yourself
)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
attn_implementation='sdpa' # customize it yourself
)
from peft import LoraConfig
from peft import PeftConfig
from peft import PeftModel
from peft import get_peft_model
config = LoraConfig(
r=64,
lora_alpha=128,
lora_dropout=0.00,
target_module=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"] # customize it yourself
)
model = get_peft_model(model, config)
from datasets import load_dataset
from transformers import DataCollatorForLanguageModeling
dataset = load_dataset("anhdungitvn/vi-bfsi-sft-dummy-1k") # customize it yourself
def process_function(examples):
# customize it yourself
return examples["text"]
dataset = dataset.map(
process_function,
batched=True,
num_proc=64,
remove_columns=dataset["train"].column_names,
desc="Preprocessing"
)
data_collator = DataCollatorForLanguageModeling(
tokenizer, mlm=False
)
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_preds):
preds, labels = eval_preds
labels = labels[:, 1:].reshape(-1)
preds = preds[:, :-1].reshape(-1)
return metric.compute(
predictions=preds,
references=labels
)
def preprocess_logits_for_metrics(logits, labels):
if isinstance(logits, tuple):
logits = logits[0]
return logits.argmax(dim=-1)
from transformers import TrainingArguments
from transformers import Trainer
args = TrainingArguments(
output_dir="output_dir",
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
gradient_accumulation_steps=1,
num_train_epochs=1,
max_steps=10, # for test
warmup_ratio=0.01, # warmup_steps
lr_scheduler_type='cosine', # cosine (fast), linear (stable), constant (test)
learning_rate=0.000010, # 10µ
weight_decay=0.0001,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": True},
fp16=False,
bf16=True,
remove_unused_columns=False,
dataloader_drop_last=True,
logging_strategy="steps",
logging_steps=logging_steps,
save_strategy="steps",
save_steps=save_steps,
save_total_limit=1,
evaluation_strategy="steps",
eval_steps=eval_steps,
push_to_hub=False,
# hub_private_repo=True,
# hub_model_id="anhdungitvn/my-model",
# hub_token=hf_token_write,
run_name='vi-mistral-x-sft'
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
compute_metrics=compute_metrics,
preprocess_logits_for_metrics=preprocess_logits_for_metrics
)
model.config.use_cache = False
trainer.train()
DPO
from datasets import load_dataset
dataset = load_dataset("anhdungitvn/vi-bfsi-dpo-dummy-1k") # customize it yourself
def process_function(examples):
# customize it yourself
return examples["text"]
from trl import DPOTrainer as
trainer = Trainer(
model,
model_ref,
**kwargs
)
KTO
from datasets import load_dataset
dataset = load_dataset("anhdungitvn/vi-bfsi-kto-dummy-1k") # customize it yourself
def process_function(examples):
# customize it yourself
return examples["text"]
from trl import KTOTrainer as Trainer
from trl import KTOConfig
args = KTOConfig(
beta=0.1,
desirable_weight=1.0,
undesirable_weight=1.0,
)
trainer = Trainer(
model,
model_ref,
args=args,
**kwargs
)
QLoRA
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
model = AutoModelForCausalLM.from_pretrained(
"anhdungitvn/vi-mistral-x",
load_in_4bit=True, # GPU Quantization
quantization_config=bnb_config,
torch_dtype=torch.bfloat16, # GPU
)
Evaluation on VMLU
VMLU: https://vmlu.ai
from transformers import AutoTokenizer
from transformers import AutoModelForCausalLM
model_name_or_path = "anhdungitvn/vi-mistral-x"
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
padding_side = "left"
)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16
)
class InferModel:
def __init__(self, model, tokenizer, **kwargs):
self.model = model
self.tokenizer = tokenizer
def __call__(self, prompt, **kwargs):
outputs = self.model.generate(**self.tokenizer(prompt, return_tensors="pt"))
text = self.tokenizer.batch_decode(outputs)[0]
text = text.split("Đáp án: ")[-1].lstrip()
return text
infer = InferModel(model=model, tokenizer=tokenizer)
from datasets import load_dataset
dataset_name_or_path = "anhdungitvn/vmlu_v1.5"
dataset = load_dataset(dataset_name_or_path)
test_dataset = dataset["test"]
import re
import os
import pandas as pd
from tqdm.auto import tqdm
all_res = []
with tqdm(total=len(test_dataset)) as pbar:
for example in test_dataset:
answer = infer(example["prompt"])
all_res.append({
"id": example['id'],
"prompt": example["prompt"],
"question": example["question"],
"answer": answer
})
pbar.update(1)
df = pd.DataFrame(all_res)
df['answer'] = df.answer.map(lambda x: x[0].lower())
df['answer'] = df['answer'].map(lambda x: re.sub(r'[^abcde]', '', x))
submission_csv = df[['id', 'answer']].to_csv('submission.csv', index=None)
Training
Hyperparams:
- Learning rate: 20μ, 5μ (PT); 50μ, 20μ (SFT)
- per_device_train_batch_size: 4
Progress: ⬛⬛⬜⬜⬜⬜⬜⬜⬜⬜ 16%
- Epoch: 0/1
- Steps: 10000/63500
- Tokens: 1310720000/8323137536
- Data: ~3GB/20GB


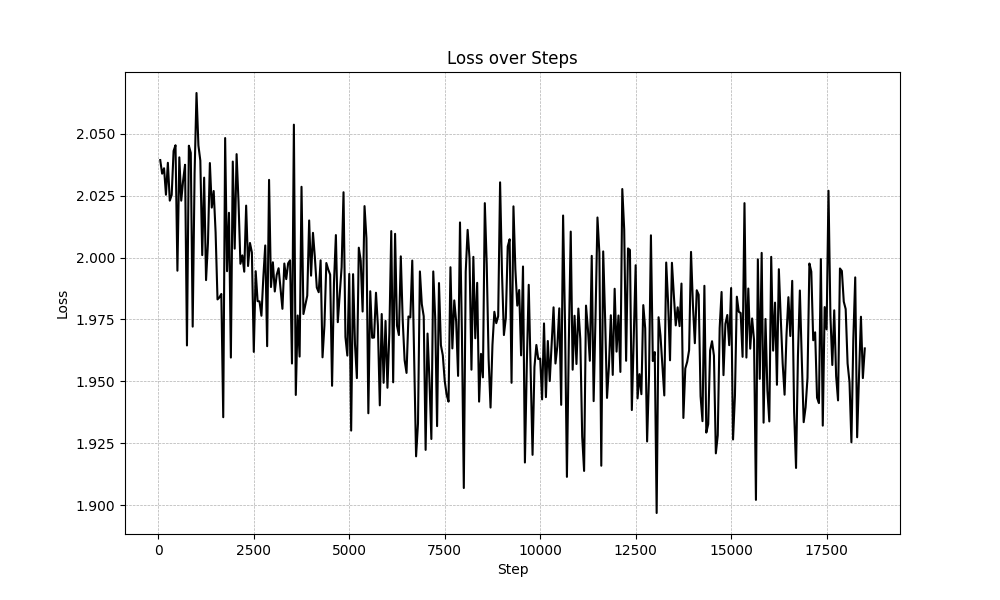



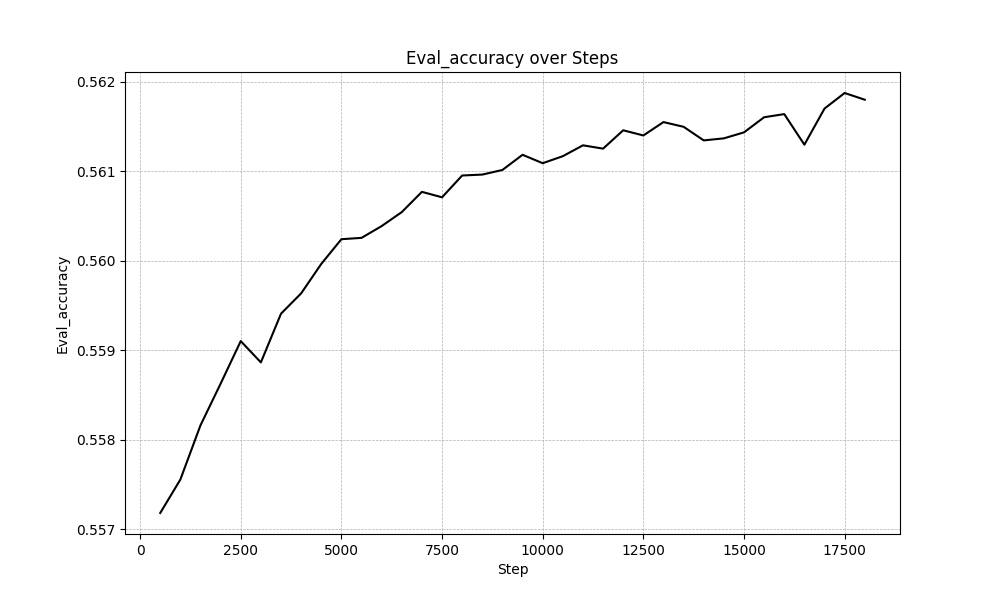
This session is being updated...
Alignment
SFT_1


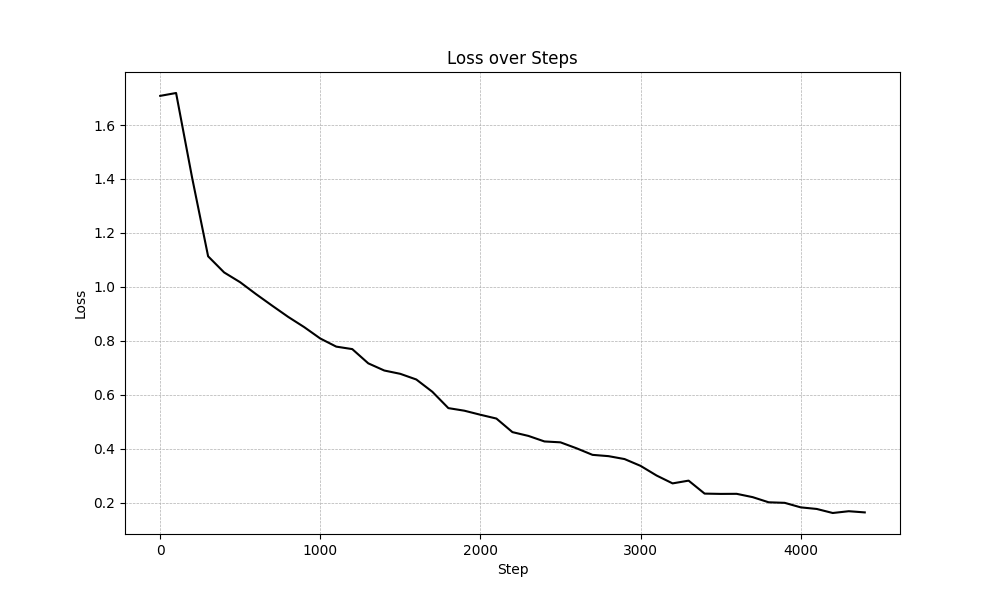



SFT_2
This session is being updated...
Evaluation
VNLU
Pretrained Model
| # | MODEL | CREATOR | ACCESS | EVALUATION DATE | STEM | SOCIAL SCIENCE | HUMANITIES | OTHERS | AVG |
|----|----------------|---------------|--------|-----------------|-------|----------------|------------|--------|-------|
| 1 | GPT-4 | OpenAI | API | 08/01/2024 | 63.84 | 71.78 | 66.14 | 60.37 | 65.53 |
| 2 | gemini | Google | API | 30/01/2024 | 42.8 | 60.31 | 55.35 | 51.30 | 51.03 |
| 3 | ChatGPT | OpenAI | API | 08/01/2024 | 43.24 | 51.67 | 46.96 | 46.32 | 46.33 |
| 4 | ViGPT-1.6B-v1 | Vin BigData | Private| 08/01/2024 | 35.06 | 48.72 | 47.20 | 42.54 | 42.34 |
| 5 | gemma-7b-it | Google | Weight | 22/02/2024 | 39.95 | 44.93 | 43.39 | 40.11 | 41.9 |
| 6 | Qwen-7B | Alibaba Cloud | Weight | 08/01/2024 | 30.64 | 35.07 | 34.15 | 32.68 | 32.81 |
| 7 | vi-mistral-x | James | Private| 10/04/2024 | 24.88 | 34.08 | 35.11 | 29.26 | 30.32 |
| 8 | gemma-2b-it | Google | Weight | 22/02/2024 | 24.39 | 29.59 | 31.01 | 26.81 | 27.72 |
| 9 | sealion7b | AI Singapore | Weight | 08/01/2024 | 26.28 | 28.57 | 27.66 | 27.34 | 26.73 |
| 10 | bloom-1b7 | BigScience | Weight | 08/01/2024 | 25.13 | 25.09 | 26.34 | 25.19 | 25.51 |
Aligned Model
| # | MODEL | CREATOR | ACCESS | BASE MODEL | EVALUATION DATE | STEM | SOCIAL SCIENCE | HUMANITIES | OTHERS | AVG |
|----|------------------------|-----------------------|--------|---------------------|-----------------|-------|----------------|------------|--------|-------|
| 1 | VNPTAI.IO-14B | VNPT AI | Private| Qwen1.5-14B-Chat | 11/03/2024 | 51.64 | 61.75 | 58.09 | 54.51 | 55.83 |
| 2 | Vistral-7B-Chat | UONLP x Ontocord | Weight | Mistral-7B-v0.1 | 16/01/2024 | 43.32 | 57.02 | 55.12 | 48.01 | 50.07 |
| 3 | SeaLLM-7b-v2 | DAMO Academy | Weight | llama-2-7b | 15/02/2024 | 39.95 | 52.02 | 49.38 | 45.27 | 45.79 |
| 4 | vi-mistral-x | James | Private| vi-mistral-x | 10/04/2024 | 31.13 | 48.81 | 48.36 | 40.44 | 40.97 |
| 5 | bloomz-7b1 | BigScience | Weight | Bloom-7b1 | 08/01/2024 | 32.63 | 45.73 | 41.85 | 39.89 | 38.87 |
| 6 | T-Llama | FPTU HCM | Weight | llama-2-7b | 18/03/2024 | 32.2 | 43.15 | 40.31 | 36.57 | 37.28 |
| 7 | vbd-llama2-7b-50b-chat | Vin BigData | Weight | llama-2-7b | 08/01/2024 | 31.45 | 40.34 | 40.24 | 39.62 | 36.98 |
| 8 | vietcuna-3b | Virtual Interactive | Weight | bloomz-3b | 08/01/2024 | 30.12 | 39.92 | 37.86 | 33.83 | 34.79 |
| 9 | bloomz-1b7 | BigScience | Weight | Bloom-1b7 | 08/01/2024 | 29.72 | 40.17 | 34.73 | 33.41 | 33.65 |
| 10 | SeaLLM-7B-Hybrid | DAMO Academy | Weight | llama-2-7b | 08/01/2024 | 29.49 | 34.61 | 36.68 | 34.52 | 33.39 |
|category_subcategory |score_PT|score_SFT|diff |
|----------------------------------------------------------------|--------|---------|------|
|total |30.32 |40.97 |10.65 |
|stem_applied_informatics |39.44 |30.36 |-9.08 |
|stem_computer_architecture |31.11 |39.77 |8.66 |
|stem_computer_network |34.64 |36.67 |2.03 |
|stem_discrete_mathematics |23.64 |61.99 |38.35 |
|stem_electrical_engineering |22.73 |33.33 |10.6 |
|stem_elementary_mathematics |19.44 |39.18 |19.74 |
|stem_elementary_science |55.0 |52.94 |-2.06 |
|stem_high_school_biology |15.0 |24.14 |9.14 |
|stem_high_school_chemistry |22.78 |45.61 |22.83 |
|stem_high_school_mathematics |16.22 |40.44 |24.22 |
|stem_high_school_physics |23.33 |37.78 |14.45 |
|stem_introduction_to_chemistry |14.53 |71.91 |57.38 |
|stem_introduction_to_physics |23.12 |61.22 |38.1 |
|stem_introduction_to_programming |29.05 |40.56 |11.51 |
|stem_metrology_engineer |22.7 |51.69 |28.99 |
|stem_middle_school_biology |31.18 |48.81 |17.63 |
|stem_middle_school_chemistry |18.33 |33.91 |15.58 |
|stem_middle_school_mathematics |17.59 |60.56 |42.97 |
|stem_middle_school_physics |21.67 |46.3 |24.63 |
|stem_operating_system |30.56 |45.25 |14.69 |
|stem_statistics_and_probability |10.34 |38.89 |28.55 |
|stem_total |24.88 |41.67 |16.79 |
|other_clinical_pharmacology |26.11 |30.56 |4.45 |
|other_driving_license_certificate |45.61 |34.64 |-10.97|
|other_environmental_engineering |11.7 |20.61 |8.91 |
|other_internal_basic_medicine |34.5 |30.11 |-4.39 |
|other_preschool_pedagogy |34.31 |10.56 |-23.75|
|other_tax_accountant |20.69 |68.33 |47.64 |
|other_tax_civil_servant |41.52 |26.11 |-15.41|
|other_total |29.26 |32.22 |2.96 |
|other_accountant |21.43 |22.97 |1.54 |
|other_civil_servant |27.49 |24.44 |-3.05 |
|humanity_economic_law |29.81 |26.82 |-2.99 |
|humanity_education_law |33.13 |26.01 |-7.12 |
|humanity_elementary_history |49.72 |30.17 |-19.55|
|humanity_high_school_history |31.11 |37.59 |6.48 |
|humanity_high_school_literature |25.56 |46.47 |20.91 |
|humanity_history_of_world_civilization |41.11 |27.78 |-13.33|
|humanity_idealogical_and_moral_cultivation |49.44 |16.67 |-32.77|
|humanity_introduction_to_laws |39.68 |24.44 |-15.24|
|humanity_introduction_to_vietnam_culture |28.33 |41.11 |12.78 |
|humanity_logic |18.97 |34.48 |15.51 |
|humanity_middle_school_history |37.78 |31.13 |-6.65 |
|humanity_middle_school_literature |37.36 |45.81 |8.45 |
|humanity_revolutionary_policy_of_the_vietnamese_commununist_part|36.67 |53.33 |16.66 |
|humanity_vietnamese_language_and_literature |17.24 |57.06 |39.82 |
|humanity_total |35.11 |37.27 |2.16 |
|humanity_administrative_law |37.78 |43.37 |5.59 |
|humanity_business_law |39.11 |53.11 |14.0 |
|humanity_civil_law |41.11 |44.44 |3.33 |
|humanity_criminal_law |38.04 |43.89 |5.85 |
|social_science_middle_school_geography |27.21 |58.33 |31.12 |
|social_science_principles_of_marxism_and_leninism |36.67 |61.67 |25.0 |
|social_science_sociology |39.89 |47.62 |7.73 |
|social_science_business_administration |20.69 |47.78 |27.09 |
|social_science_high_school_civil_education |43.89 |27.59 |-16.3 |
|social_science_high_school_geography |33.33 |56.11 |22.78 |
|social_science_ho_chi_minh_ideology |41.34 |55.17 |13.83 |
|social_science_macroeconomics |21.67 |50.0 |28.33 |
|social_science_microeconomics |23.89 |39.08 |15.19 |
|social_science_middle_school_civil_education |52.25 |48.36 |-3.89 |
|social_science_total |34.08 |48.89 |14.81 |
This session is being updated...
```
- Downloads last month
- 0