
[ICCV 2023] StyleLipSync: Style-based Personalized Lip-sync Video Generation
ProjectPage | Paper | ArXiv
An official pytorch implementation of StyleLipSync: Style-based Personalized Lip-sync Video Generation by Taekyung Ki* and Dongchan Min*.
Abstract
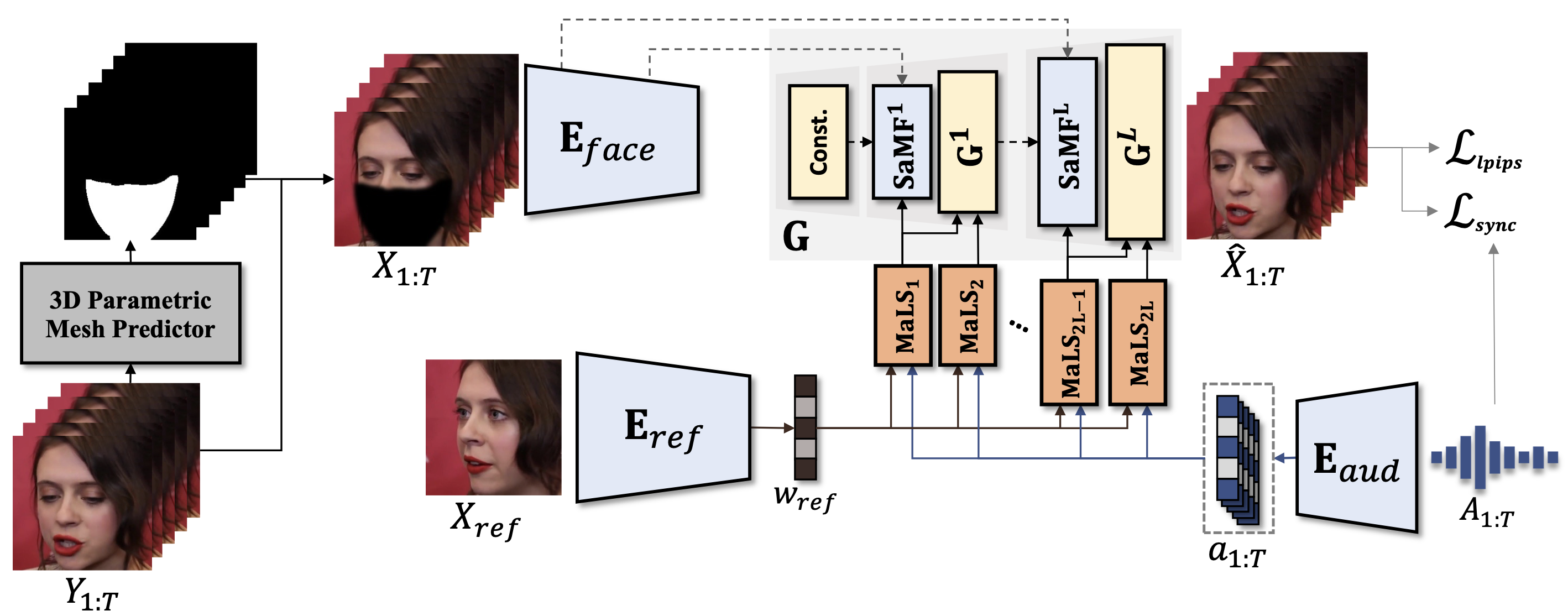
In this paper, we present StyleLipSync, a style-based personalized lip-sync video generative model that can generate identity-agnostic lip-synchronizing video from arbitrary audio. To generate a video of arbitrary identities, we leverage expressive lip prior from the semantically rich latent space of a pre-trained StyleGAN, where we can also design a video consistency with a linear transformation. In contrast to the previous lip-sync methods, we introduce pose-aware masking that dynamically locates the mask to improve the naturalness over frames by utilizing a 3D parametric mesh predictor frame by frame. Moreover, we propose a few-shot lip-sync adaptation method for an arbitrary person by introducing a sync regularizer that preserves lip-sync generalization while enhancing the person-specific visual information. Extensive experiments demonstrate that our model can generate accurate lip-sync videos even with the zero-shot setting and enhance characteristics of an unseen face using a few seconds of target video through the proposed adaptation method.
Requirements
We recommend using Python 3.8.13 and Pytorch 1.7.1+cu110.
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
Demo
We provide a simple demonstration script with a personalized model where a target person AlexandriaOcasioCortez_0 is in HDTF.
sh prepare_hdtf.sh
You can get the preprocessed frames (.jpg) and their pose-aware masks of the person by running prepare_hdtf.sh.
For arbitrary audio, you can generate a lip-synchronizing video of the target person by running:
CUDA_VISIBLE_DEVICES=0 python run_demo.py --audio [path/to/audio] --person [person/for/demo] --res_dir [path/to/save/results]
You can adjust the following options for inference:
--audio: an audio file (.wav).--person: person for infernece, folder name indata. (default: AlexandriaOcasioCortez_0)--res_dir: a directory to save results video. (default: results)
The results video will be res_dir/person#audio.mp4. The sample audio files are provided in data/audio. You can also use your audio file. If you want to evaluate the lip-sync metrics (LSE-C and LSE-D), please refer to this repository.
Disclaimer
This repository is only for the research purpose.
Acknowledgements
Citation
@InProceedings{Ki_2023_ICCV,
author = {Ki, Taekyung and Min, Dongchan},
title = {StyleLipSync: Style-based Personalized Lip-sync Video Generation},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {22841-22850}
}
- Downloads last month
- 0