
File size: 3,725 Bytes
5edd837 1bb4dd7 5edd837 1bb4dd7 6133853 20a59e1 1121266 6133853 ba098a0 1121266 1bb4dd7 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
---
language:
- en
license: apache-2.0
tags:
- openllama
- 3b
datasets:
- totally-not-an-llm/EverythingLM-data-V3
model-index:
- name: open-llama-3b-v2-elmv3
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 42.06
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 73.28
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 27.61
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 35.54
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.96
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 3.41
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
---
Trained on 3 epoch of the EverythingLM data.
Eval Results :
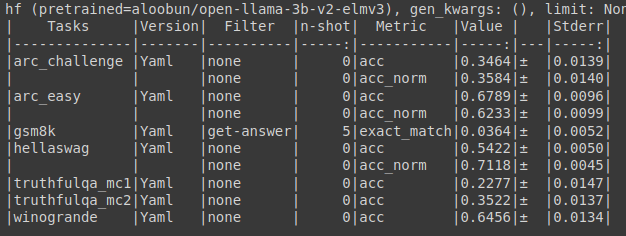
I like to tweak smaller models than 3B and mix loras, but now I'm trying my hand at finetuning a 3B model. Lets see how it goes.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_aloobun__open-llama-3b-v2-elmv3)
| Metric |Value|
|---------------------------------|----:|
|Avg. |41.14|
|AI2 Reasoning Challenge (25-Shot)|42.06|
|HellaSwag (10-Shot) |73.28|
|MMLU (5-Shot) |27.61|
|TruthfulQA (0-shot) |35.54|
|Winogrande (5-shot) |64.96|
|GSM8k (5-shot) | 3.41|
|