
I2VGen-XL高清图像生成视频大模型
本项目I2VGen-XL旨在解决根据输入图像生成高清视频任务。I2VGen-XL由达摩院研发的高清视频生成基础模型之一,其核心部分包含两个阶段,分别解决语义一致性和清晰度的问题,参数量共计约37亿,模型经过在大规模视频和图像数据混合预训练,并在少量精品数据上微调得到,该数据分布广泛、类别多样化,模型对不同的数据均有良好的泛化性。项目相比于现有视频生成模型,I2VGen-XL在清晰度、质感、语义、时序连续性等方面均具有明显的优势。
此外,I2VGen-XL的许多设计理念和设计细节(比如核心的UNet部分)都继承于我们已经公开的工作VideoComposer,您可以参考我们的VideoComposer和本项目ModelScope的了解详细细节。
The I2VGen-XL project aims to address the task of HD video generation based on input images. I2VGen-XL is one of the HQ video generation base models developed by DAMO Academy. Its core components consist of two stages, each addressing the issues of semantic consistency and video quality. The total number of parameters is approximately 3.7 billion. The model has been pre-trained on a large-scale mixture of video and image data and fine-tuned on a small amount of high-quality data. This data distribution is extensive and diverse, and the model demonstrates good generalization to different types of data. Compared to existing video generation models, the I2VGen-XL project has significant advantages in terms of quality, texture, semantics, and temporal continuity.
Additionally, many design concepts and details of I2VGen-XL (such as the core UNet) are inherited from our publicly available work, VideoComposer. For detailed information, please refer to our VideoComposer and the Github code repository for this ModelScope project.
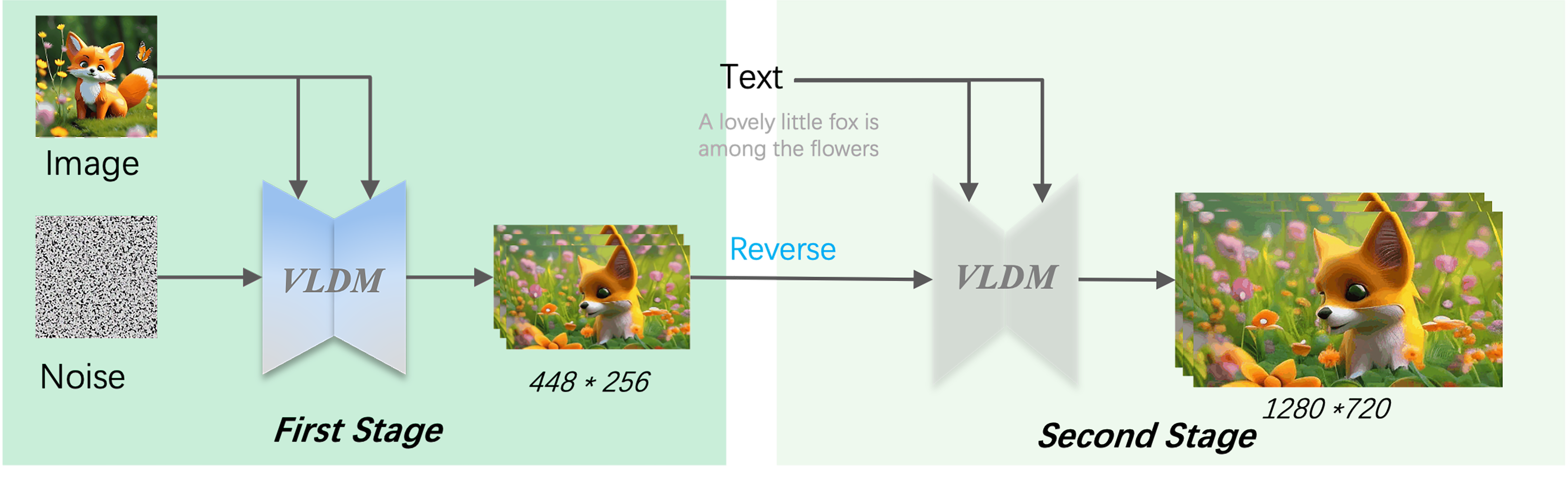
Fig.1 I2VGen-XL
体验地址(Project experience address): https://modelscope.cn/studios/damo/I2VGen-XL-Demo/summary
模型介绍 (Introduction)
如图Fig.2所示,I2VGen-XL是一种基于隐空间的视频扩散模型(VLDM),其通过我们专门设计的时空UNet(ST-UNet)在隐空间中进行时空建模并通过解码器重建出最终视频(具体模型结构可以参考VideoComposer)。为能够生成720P视频,我们将I2VGen-XL分为两个阶段,第一阶段是在低分辨率条件下保证语义一致性,第二阶是利用新的VLDM进行去噪以提高视频分辨率以及同时提升时间和空间上的一致性。通过在模型、数据和训练上的联合优化,I2VGen-XL主要具有以下几个特点:
- 高清&宽屏,可以直接生成720P(1280*720)分辨率的视频,且相比于现有的开源项目,不仅分辨率得到有效提高,其生产的宽屏视频可以适合更多的场景
- 连续性,通过特定训练和推理策略,在视频的细节生成的稳定性上(时间和空间维度)有明显提高
- 质感好,通过收集特定的风格的视频数据训练,使得生成的视频在质感上得到明显提升,可以生成科技感、电影色、卡通风格和素描等类型视频
- 无水印,模型通过我们内部大规模无水印视频/图像训练,并在高质量数据微调得到,生成的无水印视频可适用更多视频平台,减少许多限制
以下为生成的部分案例:
As shown in Fig.2, I2VGen-XL is a video latent diffusion model. It utilizes our designed ST-UNet ((for model details, please refer to VideoComposer)) to perform spatio-temporal modeling in the latent space and reconstruct the generated video through a decoder. In order to generate 720P videos, we divide I2VGen-XL into two stages. The first stage ensures semantic consistency with low resolutions, while the second stage utilizes the new VLDM to denoise and improve video resolution, as well as enhance temporal and spatial consistency. Through joint optimization of the model, data, and training, I2VGen-XL has the following characteristics.
- High-definition & widescreen, can directly generate 720P (1280*720) resolution videos, and compared to existing open source projects, not only is the resolution effectively improved, but the widescreen videos it produces can also be suitable for more scenarios.
- Continuity, through specific training and inference strategies, there is a significant improvement in the stability of detail generation in videos (in the time and space dimensions).
- Good texture, by collecting specific style video data for training, the generated model has a significant improvement in texture and can generate technology, film color, cartoon style, sketch and other types of videos.
- No watermark, the model is trained on a large-scale watermark-free video/image dataset internally and fine-tuned on high-quality data, generating watermark-free videos that can be applied to more video platforms and reducing many restrictions.
Below are some examples generated by the model:
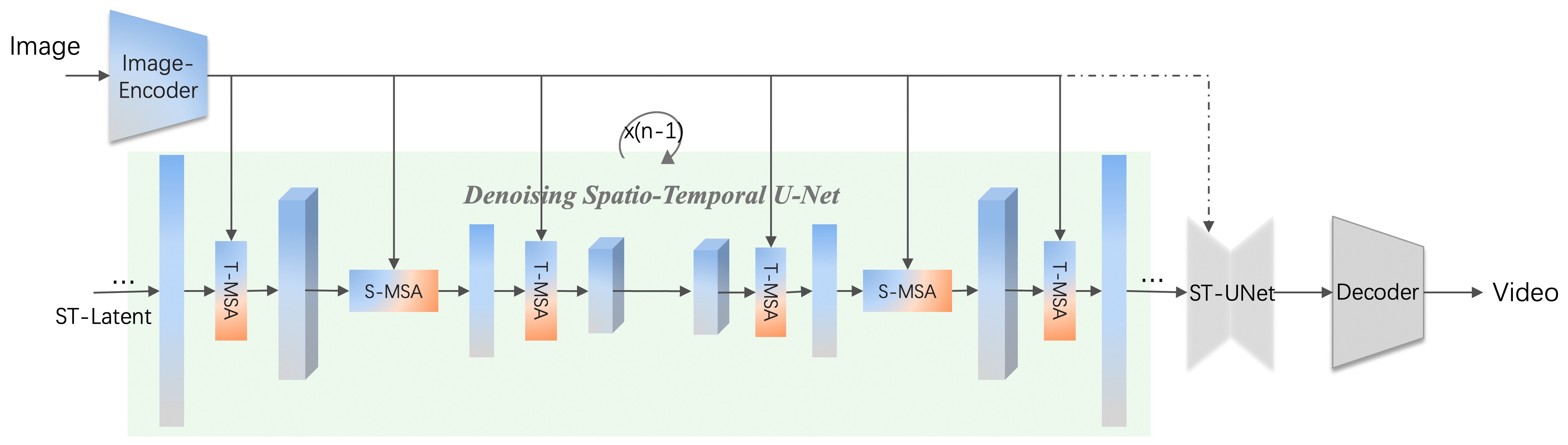
Fig.2 VLDM
为方便展示,本页面展示为低分辨率GIF格式,但是GIF会下降视频质量,720P的视频效果可以参下面对应的视频链接
For display purposes, this page shows low-resolution GIF format. However, GIF format may reduce video quality. For specific effects, please refer to the video link below.

|
|

|
|
[2023.08.25 更新] ModelScope发布1.8.4版本,I2VGen-XL模型更新到模型参数文件 v1.1.0;
依赖项 (Dependency)
首先你需要确定你的系统安装了ffmpeg命令,如果没有,可以通过以下命令来安装:
First, you need to ensure that your system has installed the ffmpeg command. If it is not installed, you can install it using the following command:
sudo apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
其次,本I2VGen-XL项目适配ModelScope代码库,以下是本项目需要安装的部分依赖项。
The I2VGen-XL project is compatible with the ModelScope codebase, and the following are some of the dependencies that need to be installed for this project.
pip install modelscope==1.8.4
pip install xformers==0.0.20
pip install torch==2.0.1
pip install open_clip_torch>=2.0.2
pip install opencv-python-headless
pip install opencv-python
pip install einops>=0.4
pip install rotary-embedding-torch
pip install fairscale
pip install scipy
pip install imageio
pip install pytorch-lightning
pip install torchsde
快速使用 (Inference)
关于更多的尝试,请关注我们将公开的技术报告和开源代码。
For more experiments, please stay tuned for our upcoming technical report and open-source code release.
代码范例 (Code example)
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
pipe = pipeline(task='image-to-video', model='damo/Image-to-Video', model_revision='v1.1.0')
# IMG_PATH: your image path (url or local file)
output_video_path = pipe(IMG_PATH, output_video='./output.mp4')[OutputKeys.OUTPUT_VIDEO]
print(output_video_path)
如果想生成超分视频的话, 示例见下:
If you want to generate high-resolution video, please use the following code:
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
# if you only have one GPU, please make it's GPU memory bigger than 50G, or you can use two GPUs, and set them by device
pipe1 = pipeline(task='image-to-video', model='damo/Image-to-Video', model_revision='v1.1.0', device='cuda:0')
pipe2 = pipeline(task='video-to-video', model='damo/Video-to-Video', model_revision='v1.1.0', device='cuda:0')
# image to video
output_video_path = pipe1("test.jpg", output_video='./i2v_output.mp4')[OutputKeys.OUTPUT_VIDEO]
# video resolution
p_input = {'video_path': output_video_path}
new_output_video_path = pipe2(p_input, output_video='./v2v_output.mp4')[OutputKeys.OUTPUT_VIDEO]
更多超分细节, 请访问 Video-to-Video。 我们也提供了用户接口,请移步I2VGen-XL-Demo。
Please visit Video-to-Video for more details. We also provide user interface:I2VGen-XL-Demo.
模型局限 (Limitation)
本I2VGen-XL项目的模型在处理以下情况会存在局限性:
- 小目标生成能力有限,在生成较小目标的时候,会存在一定的错误
- 快速运动目标生成能力有限,当生成快速运动目标时,可能会出现一些假象和不合理的情况
- 生成速度较慢,生成高清视频会明显导致生成速度减慢
此外,我们研究也发现,生成的视频空间上的质量和时序上的变化速度在一定程度上存在互斥现象,在本项目我们选择了其折中的模型,兼顾两者间的平衡。
The model of the I2VGen-XL project still have some following limitations:
- Limited ability to generate small objects, there may be some errors when generating smaller objects.
- Limited ability to generate fast-moving objects, there may be some artifacts when generating fast-moving objects.
- Slow generation speed, generating high-definition videos significantly slows down the generation speed.
In addition, our research has also found that there is a trade-off between the quality of the generated video in spatial and temporal changes. In this project, we have chosen a model that strikes a balance between the two.
如果您正在尝试使用我们的模型,我们建议您首先在第一阶段中得到语义符合预期的视频后(离线运行的时候可以修改configuration.json文件中的Seed生成不同视频),再尝试第二阶段的视频修正(因为该过程比较耗时),这样可以提高您的使用效率,也更容易得到更好的结果。
If you are trying to use our model, we suggest that you first obtain semantic-expected videos in the first stage (you can modify the Seed in the configuration.json file when running offline to generate different videos). Then, you can try video refining in the second stage (as this process takes more time). This will improve your efficiency and make it easier to achieve better results.
训练数据介绍 (Training Data)
我们训练数据主要来源来源广泛,具备以下几个属性:
- 混合训练,模型有按照视频图像比7:1训练模型,以此保证视频生成质量
- 类别分布广,数据数十亿的总体量涵盖人、动物、机车、科幻、场景等等绝大多数的实际数据
- 来源分布广,数据来源于开源数据、视频网站以及其他内部数据,具有多分辨率、长宽比等
- 精品数据构建,为了提升模型生成的质量,我们构建了约20w的精品数据对预训练模型进行微调
Our training data mainly comes from various sources and has the following attributes:
- Mixed training: The model is trained with a 7:1 ratio of video to image to ensure the quality of video generation.
- Wide class distribution: The data set covers most real-world categories, including people, animals, locomotives, science fiction, scenes, etc. with a total volume of billions of data points.
- Wide source distribution: The data comes from open-source data, video websites, and other internal sources, with varying resolutions and aspect ratios.
- High-quality data construction: To improve the quality of the model-generated videos, we constructed approximately 200,000 high-quality data pairs for fine-tuning the pre-training model.
更强更灵活的视频生成模型会持续发布,及其背后技术报告正在撰写中,欢迎及时关注。
More powerful models will continue to be released, and the technical report behind them are currently being written. Please stay tuned for updates and timely information.
相关论文以及引用信息 (Reference)
@article{videocomposer2023,
title={VideoComposer: Compositional Video Synthesis with Motion Controllability},
author={Wang, Xiang* and Yuan, Hangjie* and Zhang, Shiwei* and Chen, Dayou* and Wang, Jiuniu and Zhang, Yingya and Shen, Yujun and Zhao, Deli and Zhou, Jingren},
journal={arXiv preprint arXiv:2306.02018},
year={2023}
}
@inproceedings{videofusion2023,
title={VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation},
author={Luo, Zhengxiong and Chen, Dayou and Zhang, Yingya and Huang, Yan and Wang, Liang and Shen, Yujun and Zhao, Deli and Zhou, Jingren and Tan, Tieniu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
使用协议 (License Agreement)
我们的代码和模型权重仅可用于个人/学术研究,暂不支持商用。
Our code and model weights are only available for personal/academic research use and are currently not supported for commercial use.
联系我们 (Contact Us)
如果你想联系我们的算法/产品同学, 或者想加入我们的算法团队(实习/正式), 欢迎发邮件至: yingya.zyy@alibaba-inc.com。
If you would like to contact us, or join our team (internship/formal), please feel free to email us at yingya.zyy@alibaba-inc.com.
- Downloads last month
- 19