
license: apache-2.0
language:
- en
- az
- sw
- af
- ar
- ba
- be
- bxr
- bg
- bn
- cv
- hy
- da
- de
- el
- es
- eu
- fa
- fi
- fr
- he
- hi
- hu
- kk
- id
- it
- ja
- ka
- ky
- ko
- lt
- lv
- mn
- ml
- os
- mr
- ms
- my
- nl
- ro
- pl
- pt
- sah
- ru
- tg
- sv
- ta
- te
- tk
- th
- tr
- tl
- tt
- tyv
- uk
- en
- ur
- vi
- uz
- yo
- zh
- xal
pipeline_tag: text-generation
tags:
- PyTorch
- Transformers
- gpt3
- gpt2
- Deepspeed
- Megatron
datasets:
- mc4
- wikipedia
thumbnail: https://github.com/sberbank-ai/mgpt
Multilingual GPT model
We introduce family of autoregressive GPT-like models with 1.3 billion parameters trained on 60 languages from 25 language families using Wikipedia and Colossal Clean Crawled Corpus.
We reproduce the GPT-3 architecture using GPT-2 sources and the sparse attention mechanism, Deepspeed and Megatron frameworks allows us to effectively parallelize the training and inference steps. Resulting models show performance on par with the recently released XGLM models at the same time covering more languages and enhance NLP possibilities for low resource languages.
Code
The source code for the mGPT XL model is available on Github
Paper
Cite us:
bibtex
}
Languages
Model includes 60 languages: (iso codes)
az, sw, af, ar, ba, be, bxr, bg, bn, cv, hy, da, de, el, es, eu, fa, fi, fr, he, hi, hu, kk, id, it, ja, ka, ky, ko, lt, lv, mn, ml, os, mr, ms, my, nl, ro, pl, pt, sah, ru, tg, sv, ta, te, tk, th, tr, tl, tt, tyv, uk, en, ur, vi, uz, yo, zh, xal
Training Data Statistics
- Tokens: 559B
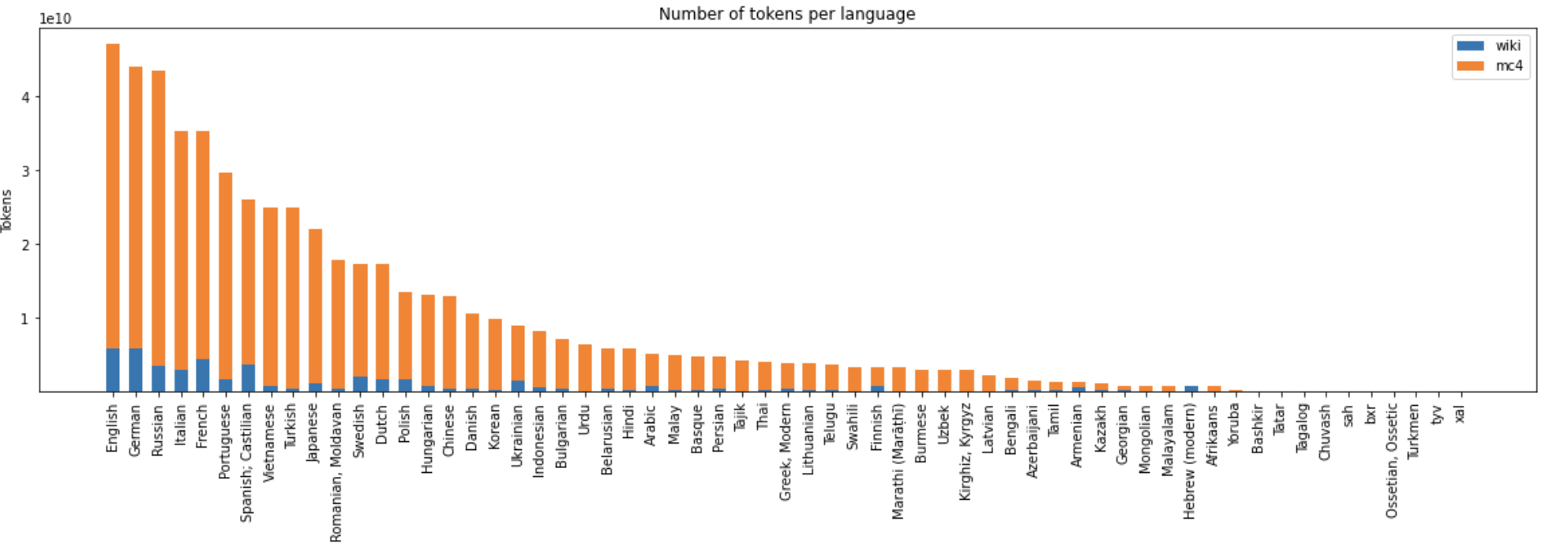 "General training corpus statistics"
"General training corpus statistics"
Details
Model was trained with sequence length 1024 using transformers lib by SberDevices team on 80B tokens for 3 epochs. After that model was finetuned 1 epoch with sequence length 2048.
Total training time was around n days on n GPUs for n context and few days on n GPUs for n context.