
Model Card for FLAN-T5 base
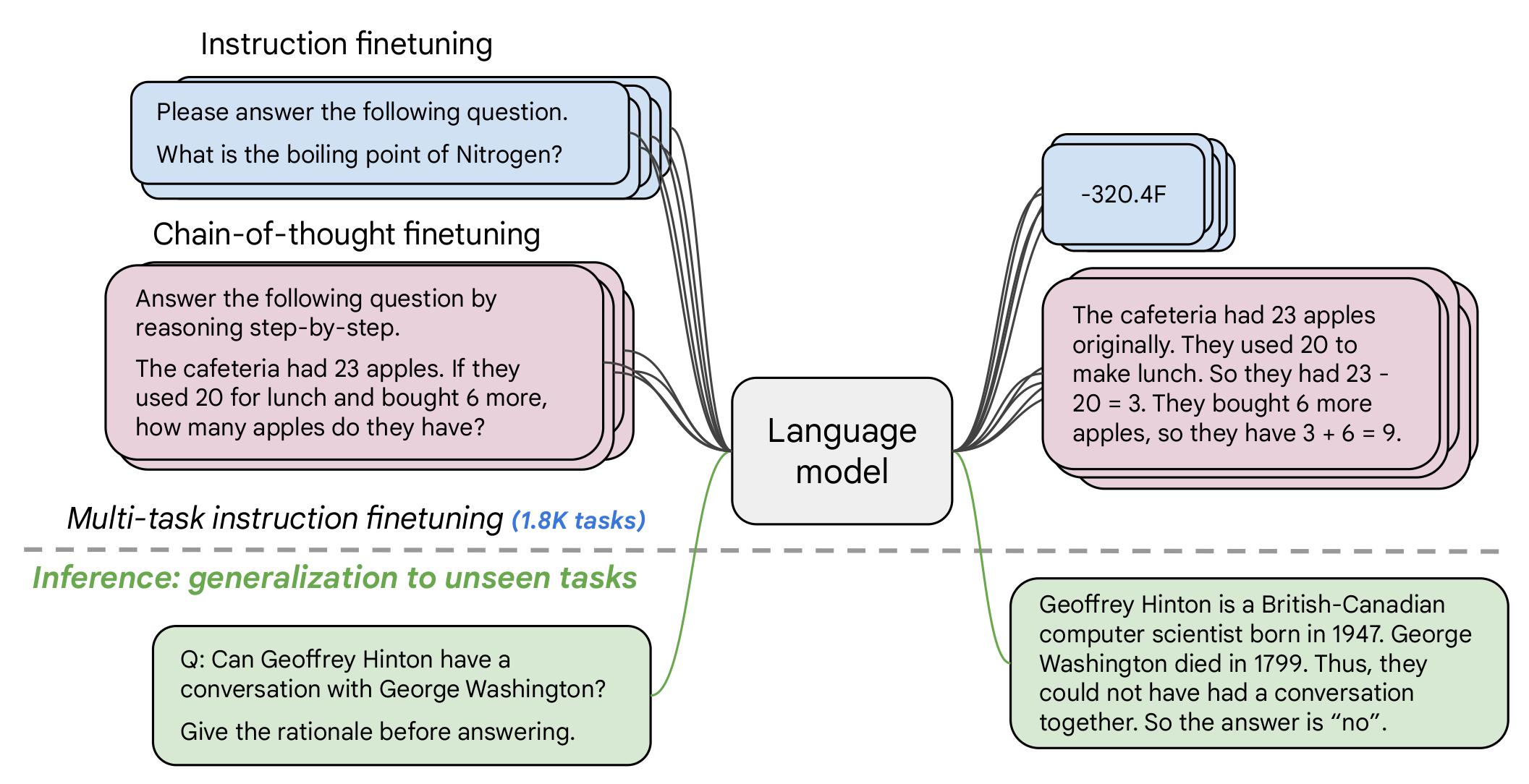
Table of Contents
- TL;DR
- Model Details
- Usage
- Uses
- Bias, Risks, and Limitations
- Training Details
- Evaluation
- Environmental Impact
- Citation
- Model Card Authors
TL;DR
later
Usage
Find below some example scripts on how to use the model in transformers:
Using the Pytorch model
Running the model on a CPU
Click to expand
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("AlexWortega/Flan_base_translated")
model = T5ForConditionalGeneration.from_pretrained("AlexWortega/Flan_base_translated")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
Running the model on a GPU
Click to expand
# pip install accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("AlexWortega/Flan_base_translated")
model = T5ForConditionalGeneration.from_pretrained("AlexWortega/Flan_base_translated", device_map="auto")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
Running the model on a GPU using different precisions
FP16
Click to expand
# pip install accelerate
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("AlexWortega/Flan_base_translated")
model = T5ForConditionalGeneration.from_pretrained("AlexWortega/Flan_base_translated", device_map="auto", torch_dtype=torch.float16)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
INT8
Click to expand
# pip install bitsandbytes accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("AlexWortega/Flan_base_translated")
model = T5ForConditionalGeneration.from_pretrained("AlexWortega/Flan_base_translated", device_map="auto", load_in_8bit=True)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
Uses
Direct Use and Downstream Use
The authors write in the original paper's model card that:
The primary use is research on language models, including: research on zero-shot NLP tasks and in-context few-shot learning NLP tasks, such as reasoning, and question answering; advancing fairness and safety research, and understanding limitations of current large language models
See the research paper for further details.
Out-of-Scope Use
More information needed.
Bias, Risks, and Limitations
The information below in this section are copied from the model's official model card:
Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
Ethical considerations and risks
Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
Known Limitations
Flan-T5 has not been tested in real world applications.
Sensitive Use:
Flan-T5 should not be applied for any unacceptable use cases, e.g., generation of abusive speech.
Training Details
Training Data
Training Procedure
Evaluation
Testing Data, Factors & Metrics
BibTeX:
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
- Downloads last month
- 81