

TheBloke's LLM work is generously supported by a grant from andreessen horowitz (a16z)
WizardCoder Python 13B V1.0 - GGML
- Model creator: WizardLM
- Original model: WizardCoder Python 13B V1.0
Description
This repo contains GGML format model files for WizardLM's WizardCoder Python 13B V1.0.
Important note regarding GGML files.
The GGML format has now been superseded by GGUF. As of August 21st 2023, llama.cpp no longer supports GGML models. Third party clients and libraries are expected to still support it for a time, but many may also drop support.
Please use the GGUF models instead.
About GGML
GGML files are for CPU + GPU inference using llama.cpp and libraries and UIs which support this format, such as:
- text-generation-webui, the most popular web UI. Supports NVidia CUDA GPU acceleration.
- KoboldCpp, a powerful GGML web UI with GPU acceleration on all platforms (CUDA and OpenCL). Especially good for story telling.
- LM Studio, a fully featured local GUI with GPU acceleration on both Windows (NVidia and AMD), and macOS.
- LoLLMS Web UI, a great web UI with CUDA GPU acceleration via the c_transformers backend.
- ctransformers, a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
- llama-cpp-python, a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
Repositories available
- GPTQ models for GPU inference, with multiple quantisation parameter options.
- 2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference
- 2, 3, 4, 5, 6 and 8-bit GGML models for CPU+GPU inference (deprecated)
- WizardLM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions
Prompt template: Alpaca
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
Compatibility
These quantised GGML files are compatible with llama.cpp between June 6th (commit 2d43387) and August 21st 2023.
For support with latest llama.cpp, please use GGUF files instead.
The final llama.cpp commit with support for GGML was: dadbed99e65252d79f81101a392d0d6497b86caa
As of August 23rd 2023 they are still compatible with all UIs, libraries and utilities which use GGML. This may change in the future.
Explanation of the new k-quant methods
Click to see details
The new methods available are:
- GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
- GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
- GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
- GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
- GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
- GGML_TYPE_Q8_K - "type-0" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existing Q8_0 is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
Refer to the Provided Files table below to see what files use which methods, and how.
Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
|---|---|---|---|---|---|
| wizardcoder-python-13b-v1.0.ggmlv3.Q2_K.bin | Q2_K | 2 | 5.74 GB | 8.24 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.vw and feed_forward.w2 tensors, GGML_TYPE_Q2_K for the other tensors. |
| wizardcoder-python-13b-v1.0.ggmlv3.Q3_K_S.bin | Q3_K_S | 3 | 5.87 GB | 8.37 GB | New k-quant method. Uses GGML_TYPE_Q3_K for all tensors |
| wizardcoder-python-13b-v1.0.ggmlv3.Q3_K_M.bin | Q3_K_M | 3 | 6.53 GB | 9.03 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| wizardcoder-python-13b-v1.0.ggmlv3.Q3_K_L.bin | Q3_K_L | 3 | 7.14 GB | 9.64 GB | New k-quant method. Uses GGML_TYPE_Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| wizardcoder-python-13b-v1.0.ggmlv3.Q4_0.bin | Q4_0 | 4 | 7.32 GB | 9.82 GB | Original quant method, 4-bit. |
| wizardcoder-python-13b-v1.0.ggmlv3.Q4_K_S.bin | Q4_K_S | 4 | 7.56 GB | 10.06 GB | New k-quant method. Uses GGML_TYPE_Q4_K for all tensors |
| wizardcoder-python-13b-v1.0.ggmlv3.Q4_K_M.bin | Q4_K_M | 4 | 8.06 GB | 10.56 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q4_K |
| wizardcoder-python-13b-v1.0.ggmlv3.Q4_1.bin | Q4_1 | 4 | 8.14 GB | 10.64 GB | Original quant method, 4-bit. Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models. |
| wizardcoder-python-13b-v1.0.ggmlv3.Q5_0.bin | Q5_0 | 5 | 8.95 GB | 11.45 GB | Original quant method, 5-bit. Higher accuracy, higher resource usage and slower inference. |
| wizardcoder-python-13b-v1.0.ggmlv3.Q5_K_S.bin | Q5_K_S | 5 | 9.14 GB | 11.64 GB | New k-quant method. Uses GGML_TYPE_Q5_K for all tensors |
| wizardcoder-python-13b-v1.0.ggmlv3.Q5_K_M.bin | Q5_K_M | 5 | 9.40 GB | 11.90 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q5_K |
| wizardcoder-python-13b-v1.0.ggmlv3.Q5_1.bin | Q5_1 | 5 | 9.76 GB | 12.26 GB | Original quant method, 5-bit. Even higher accuracy, resource usage and slower inference. |
| wizardcoder-python-13b-v1.0.ggmlv3.Q6_K.bin | Q6_K | 6 | 10.83 GB | 13.33 GB | New k-quant method. Uses GGML_TYPE_Q8_K for all tensors - 6-bit quantization |
| wizardcoder-python-13b-v1.0.ggmlv3.Q8_0.bin | Q8_0 | 8 | 13.83 GB | 16.33 GB | Original quant method, 8-bit. Almost indistinguishable from float16. High resource use and slow. Not recommended for most users. |
Note: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
How to run in llama.cpp
Make sure you are using llama.cpp from commit dadbed99e65252d79f81101a392d0d6497b86caa or earlier.
For compatibility with latest llama.cpp, please use GGUF files instead.
./main -t 10 -ngl 32 -m wizardcoder-python-13b-v1.0.ggmlv3.q4_K_M.bin --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWrite a story about llamas\n\n### Response:"
Change -t 10 to the number of physical CPU cores you have. For example if your system has 8 cores/16 threads, use -t 8.
Change -ngl 32 to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change -c 2048 to the desired sequence length for this model. For example, -c 4096 for a Llama 2 model. For models that use RoPE, add --rope-freq-base 10000 --rope-freq-scale 0.5 for doubled context, or --rope-freq-base 10000 --rope-freq-scale 0.25 for 4x context.
If you want to have a chat-style conversation, replace the -p <PROMPT> argument with -i -ins
For other parameters and how to use them, please refer to the llama.cpp documentation
How to run in text-generation-webui
Further instructions here: text-generation-webui/docs/llama.cpp.md.
Discord
For further support, and discussions on these models and AI in general, join us at:
Thanks, and how to contribute.
Thanks to the chirper.ai team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
- Patreon: https://patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI
Special thanks to: Aemon Algiz.
Patreon special mentions: Russ Johnson, J, alfie_i, Alex, NimbleBox.ai, Chadd, Mandus, Nikolai Manek, Ken Nordquist, ya boyyy, Illia Dulskyi, Viktor Bowallius, vamX, Iucharbius, zynix, Magnesian, Clay Pascal, Pierre Kircher, Enrico Ros, Tony Hughes, Elle, Andrey, knownsqashed, Deep Realms, Jerry Meng, Lone Striker, Derek Yates, Pyrater, Mesiah Bishop, James Bentley, Femi Adebogun, Brandon Frisco, SuperWojo, Alps Aficionado, Michael Dempsey, Vitor Caleffi, Will Dee, Edmond Seymore, usrbinkat, LangChain4j, Kacper Wikieł, Luke Pendergrass, John Detwiler, theTransient, Nathan LeClaire, Tiffany J. Kim, biorpg, Eugene Pentland, Stanislav Ovsiannikov, Fred von Graf, terasurfer, Kalila, Dan Guido, Nitin Borwankar, 阿明, Ai Maven, John Villwock, Gabriel Puliatti, Stephen Murray, Asp the Wyvern, danny, Chris Smitley, ReadyPlayerEmma, S_X, Daniel P. Andersen, Olakabola, Jeffrey Morgan, Imad Khwaja, Caitlyn Gatomon, webtim, Alicia Loh, Trenton Dambrowitz, Swaroop Kallakuri, Erik Bjäreholt, Leonard Tan, Spiking Neurons AB, Luke @flexchar, Ajan Kanaga, Thomas Belote, Deo Leter, RoA, Willem Michiel, transmissions 11, subjectnull, Matthew Berman, Joseph William Delisle, David Ziegler, Michael Davis, Johann-Peter Hartmann, Talal Aujan, senxiiz, Artur Olbinski, Rainer Wilmers, Spencer Kim, Fen Risland, Cap'n Zoog, Rishabh Srivastava, Michael Levine, Geoffrey Montalvo, Sean Connelly, Alexandros Triantafyllidis, Pieter, Gabriel Tamborski, Sam, Subspace Studios, Junyu Yang, Pedro Madruga, Vadim, Cory Kujawski, K, Raven Klaugh, Randy H, Mano Prime, Sebastain Graf, Space Cruiser
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
Original model card: WizardLM's WizardCoder Python 13B V1.0
🤗 HF Repo •🐱 Github Repo • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Join our Discord
News
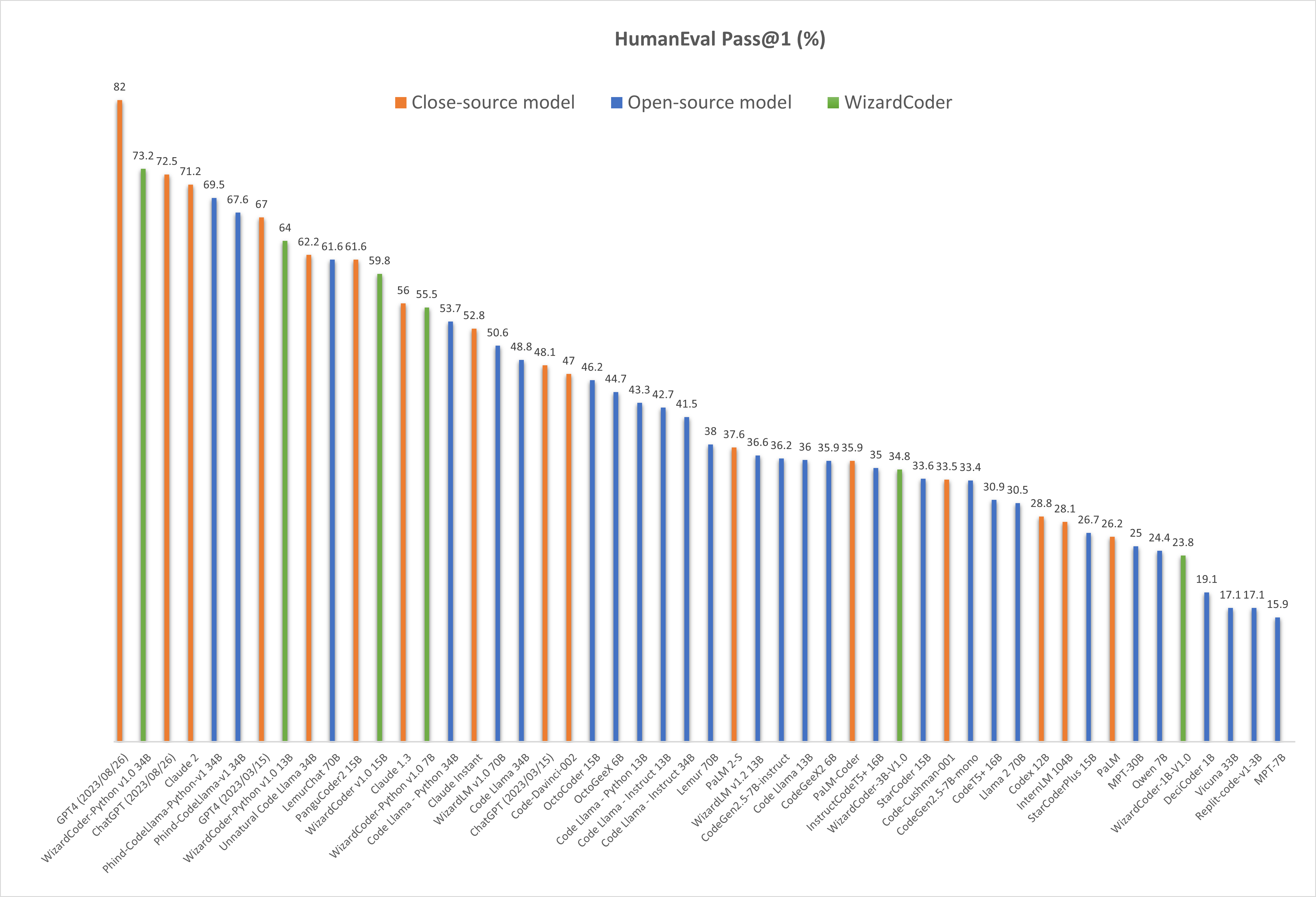
- 🔥🔥🔥[2023/08/26] We released WizardCoder-Python-34B-V1.0 , which achieves the 73.2 pass@1 and surpasses GPT4 (2023/03/15), ChatGPT-3.5, and Claude2 on the HumanEval Benchmarks.
- [2023/06/16] We released WizardCoder-15B-V1.0 , which achieves the 57.3 pass@1 and surpasses Claude-Plus (+6.8), Bard (+15.3) and InstructCodeT5+ (+22.3) on the HumanEval Benchmarks.
❗Note: There are two HumanEval results of GPT4 and ChatGPT-3.5. The 67.0 and 48.1 are reported by the official GPT4 Report (2023/03/15) of OpenAI. The 82.0 and 72.5 are tested by ourselves with the latest API (2023/08/26).
| Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License |
|---|---|---|---|---|---|---|
| WizardCoder-Python-34B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 73.2 | 61.2 | Demo | Llama2 |
| WizardCoder-15B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 59.8 | 50.6 | -- | OpenRAIL-M |
| WizardCoder-Python-13B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 64.0 | 55.6 | -- | Llama2 |
| WizardCoder-Python-7B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 55.5 | 51.6 | Demo | Llama2 |
| WizardCoder-3B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 34.8 | 37.4 | -- | OpenRAIL-M |
| WizardCoder-1B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 23.8 | 28.6 | -- | OpenRAIL-M |
- Our WizardMath-70B-V1.0 model slightly outperforms some closed-source LLMs on the GSM8K, including ChatGPT 3.5, Claude Instant 1 and PaLM 2 540B.
- Our WizardMath-70B-V1.0 model achieves 81.6 pass@1 on the GSM8k Benchmarks, which is 24.8 points higher than the SOTA open-source LLM, and achieves 22.7 pass@1 on the MATH Benchmarks, which is 9.2 points higher than the SOTA open-source LLM.
| Model | Checkpoint | Paper | GSM8k | MATH | Online Demo | License |
|---|---|---|---|---|---|---|
| WizardMath-70B-V1.0 | 🤗 HF Link | 📃 [WizardMath] | 81.6 | 22.7 | Demo | Llama 2 |
| WizardMath-13B-V1.0 | 🤗 HF Link | 📃 [WizardMath] | 63.9 | 14.0 | Demo | Llama 2 |
| WizardMath-7B-V1.0 | 🤗 HF Link | 📃 [WizardMath] | 54.9 | 10.7 | Demo | Llama 2 |
- [08/09/2023] We released WizardLM-70B-V1.0 model. Here is Full Model Weight.
| Model | Checkpoint | Paper | MT-Bench | AlpacaEval | GSM8k | HumanEval | License |
|---|---|---|---|---|---|---|---|
| WizardLM-70B-V1.0 | 🤗 HF Link | 📃Coming Soon | 7.78 | 92.91% | 77.6% | 50.6 | Llama 2 License |
| WizardLM-13B-V1.2 | 🤗 HF Link | 7.06 | 89.17% | 55.3% | 36.6 | Llama 2 License | |
| WizardLM-13B-V1.1 | 🤗 HF Link | 6.76 | 86.32% | 25.0 | Non-commercial | ||
| WizardLM-30B-V1.0 | 🤗 HF Link | 7.01 | 37.8 | Non-commercial | |||
| WizardLM-13B-V1.0 | 🤗 HF Link | 6.35 | 75.31% | 24.0 | Non-commercial | ||
| WizardLM-7B-V1.0 | 🤗 HF Link | 📃 [WizardLM] | 19.1 | Non-commercial | |||
Comparing WizardCoder-Python-34B-V1.0 with Other LLMs.
🔥 The following figure shows that our WizardCoder-Python-34B-V1.0 attains the second position in this benchmark, surpassing GPT4 (2023/03/15, 73.2 vs. 67.0), ChatGPT-3.5 (73.2 vs. 72.5) and Claude2 (73.2 vs. 71.2).
Prompt Format
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
Inference Demo Script
We provide the inference demo code here.
Note: This script supports WizardLM/WizardCoder-Python-34B/13B/7B-V1.0. If you want to inference with WizardLM/WizardCoder-15B/3B/1B-V1.0, please change the stop_tokens = ['</s>'] to stop_tokens = ['<|endoftext|>'] in the script.
Citation
Please cite the repo if you use the data, method or code in this repo.
@misc{luo2023wizardcoder,
title={WizardCoder: Empowering Code Large Language Models with Evol-Instruct},
author={Ziyang Luo and Can Xu and Pu Zhao and Qingfeng Sun and Xiubo Geng and Wenxiang Hu and Chongyang Tao and Jing Ma and Qingwei Lin and Daxin Jiang},
year={2023},
}
- Downloads last month
- 5