
Uh oh, the "q's"...

Could you please give us the lowdown on all of these q's, I'm totally lost? What kinds of benefits are in using the new k-quant methods (if any) over what we are used to so far?
I read the model card and, but I don't understand now what should I be using. Maybe offer suggestions for those who do GPU+CPU vs CPU with GGML...
TIA!

I was trying to figure out the same. I was lurking around llamacpp github page to find the answer, but what I found only led me to more confusion lol, so I second this. I would like to know the definitive answer what are the benefits if any, because according to what I've read there, the benefit might be speed, but that depends on the version of k-quantizer and hardware, there were some tests which showed some performance improvement and then there were other tests which showed performance decrease, so yeah. I would wait for a good explanation and avoid these new versions until them. Also, if you're using KoboldCpp like I do, avoid it from the simple principle that KoboldCpp hasn't been updated to use the latest version of llamacpp which introduced support for these new k-quantizers. Hopefully a new version will be out soon enough in couple of next days.
Here's a table:

Here's a simplified view of the table:

Comparing the figures in this table to the same data for the original quant types in the llama.cpp README:

Gives some idea of where we are.
Beyond that I don't know specifics, which is one reason why I'm including everything, so that people can experiment and then maybe in a week or two there will be some consensus as to what formats are worth using longer term.
I wouldn't be surprised if the original methods were dropped at some point, leaving 'just' the newer methods to choose between.
Here's a brief snippet from the llama.cpp PR that introduced the new quants that may be illuminating as to how one might decide what method to use, and how this decision will be personal to a given piece of hardware, and a user's own requirements:
"As we can see from this graph, generation performance as measured by perplexity is basically a fairly smooth function of quantized model size, and the quantization types added by the PR allow the user to pick the best performing quantized model, given the limits of their compute resources (in terms of being able to fully load the model into memory, but also in terms of inference speed, which tends to depend on the model size). As a specific example, the 2-bit quantization of the 30B model fits on the 16 GB RTX 4080 GPU that I have available, while the others do not, resulting in a large difference in inference performance."
From my POV, performance isn't everything, and I would not trade performance over accuracy. I'm definitely interested in knowing are we trading in more hallucination for couple of extra tokens per second.
Perhaps a simplification could be:
- If you don't care about speed - eg because accuracy is of paramount importance to you, and/or because you run queries in the background without waiting for responses - then pick the largest model your hardware can physically run.
- If you do care about speed, pick the largest model you can completely fit into your GPU
This doesn't answer every case, eg it doesn't necessarily help us choose between models of different types. Eg should you use WizardLM 30B or Hermes 13B? That's a much more complex question, because the models are trained on different data and may have very different performance for a given use case.
But in the 'easy' case of for example "what should I use out of Guanaco 7B, 13B, 33B, or 65B", you should theoretically be able to apply the above logic and find the optimum model for your HW and use case.
From my POV, performance isn't everything, and I would not trade performance over accuracy. I'm definitely interested in knowing are we trading in more hallucination for couple of extra tokens per second.
That's harder to answer. All we know is the synthetic perplexity benchmark scores. We don't know how that translates into real world performance - and how it translates may well vary by use case.
A difference of 0.1 on perplexity might have no noticeable difference for use case X, but might have quite a difference for use case Y. Or it might have no difference for either.
I don't think we'll know that unless and until more comprehensive benchmarking is done, over the coming days and weeks.
For now you just to rely on your own and others' anecdotal experiences.
So looking at the tables with my layman's eyes, on a 13B model a Q6_K seems to be the best bet if you have 24GB VRAM since it has about the same perplexity score as Q8_0, but 3-4x faster.
Going to give it a try and report!
So looking at the table just comparing performance of ms/t in 7B's, Q6_K against Q8_0, it looks like Q8_0 performs slightly better in 4th scenario, but slightly worse in 8th scenario. I mean lower is better, right? And Q6_K has a file size of 5.15GB, whereas Q8_0 has a file size of 6.7GB. I'd say that's expectable, but when it comes to VRAM offloading in times when most users would have at least 8GB GPU nowadays, I don't see much of a benefit that would convince me to use Q6_K over Q8_0. I would always think of Q8_0 being probably more precise, because higher is better, right? And if the performance is comparable, there's no reason to go lower to Q6_K. Still I would probably give it a try, because those 8th scenarios caught my eyes, because doing my own tests on my hardware, I did notice some models actually perform better with 4 threads only instead of 8 threads, which I found pretty weird, but if these new k-quantizers performed better on more threads than the old versions, that would be something I would like to look at and test.
But in the 'easy' case of for example "what should I use out of Guanaco 7B, 13B, 33B, or 65B", you should theoretically be able to apply the above logic and find the optimum model for your HW and use case.
Well, it's easier than that with Guanaco, there are no k-quantizer versions for it yet, so the choice is pretty much straightforward. 😁
:P

Cool! What's the smallest file size of 65B with these new k-quantizers? Still not fitting in 16GB of RAM? 🤔 Just kidding (although that would be cool lol), but I guess 33B could fit with these new k-quantizers, no? 😀
LOL, it was inevitable!
I'm getting about 115ms/t with q6_K on my 3090 in WSL2. Loading all 40 layers into the GPU, with 8 threads (2x XeonE5v3)
With 10 threads I get ~128ms/t, with 6 threads I get ~105ms/t and with 4 threads ~130ms/t.
More is not better, and it depends on the model, too.
26GB for q2_K, meaning around 29GB RAM usage assuming no GPU offload.
With GPU offload you can reduce that, but you'd need a a 16GB GPU to be able to offload enough to get under 16GB RAM usage. And I'm assuming that with 16GB RAM, it's unlikely you have 16GB VRAM :)
But yeah, 33B should definitely be do-able.
LOL, it was inevitable!
I'm getting about 115ms/t with q6_K on my 3090 in WSL2. Loading all 40 layers into the GPU, with 8 threads (2x XeonE5v3)
With 10 threads I get ~128ms/t, with 6 threads I get ~105ms/t and with 4 threads ~130ms/t.
More is not better, and it depends on the model, too.
Interesting. On my 18-core Intel i9-10980XE, without GPU offload, I found it scaled acceptably up to 12 cores. 14 cores was a little faster but not by enough to be worth the extra electricity. And 16 was such a tiny increase from 14 to be even less worth it. Then at 18 threads it was slower than 16.
So I'm wondering if you get diminishing returns earlier with GPU offload. Although it could also just vary by CPU. What CPU is that?

Any reco's on 65B models on a 4090 24VRAM + 64GIG system?
Also, what wondering what would work best on an M1 Mac with Metal ( 16 core GPU ) 32GIG Ram.
These are dual Xeon E5-2690 v3 in Supermicro X10DAi board. RTX 3090 is definitely sitting in a PCIe x16 slot but all I ever see is x8 connection. I don't know if there's a penalty for x8 connection, but according to some charts on the web, my CPUs are bottlenecking the RTX 3090.
And as you mentioned before, single threaded higher clock on more modern CPU works better for the current code and models. I'm waiting for some SSDs to arrive then I can install native Linux and see just how much WSL2 slows things down. :)
Some motherboards have slots that are PCIe x16 size, but only electrically connected at x8. Or, the connection depends on other cards connected. CPUs have a finite number of PCIe lanes. So it can be the case that a motherboard can support installing multiple PCIe x16 cards, but one or more of them will run at x8 if there are multiple installed.
It can also be the case that the CPUs supported by the motherboard have a varying number of PCIe lanes. Some CPUs support X lanes, and others only support Y, which could be 4 or 8 fewer perhaps. So the motherboard may support 4 x PCIe x16 with one CPU, but will run one or more slots at x8 with another CPU.
Or, slots can share resources with other things on the motherboard. For example, I have an old Westmere-generation Tian motherboard where one of the PCIe slots shares resources with the SATA ports. So if I plug in a bunch of SATA drives as well as a PCIe card in that specific slot, the PCIe card runs at x2 or something like that.
Or it can be the case that certain slots are always x8. So it could be that swapping the card to another slot might get x16. Or it can even be the slot is damaged and not detecting some pins, causing it to drop to x8.
In the manual for your motherboard you should find an explanation for what slot will run at what speed, under what circumstance.
All that said, I don't believe running at x8 is going to be making a huge difference in GPTQ testing, especially as you're already CPU bottlenecked
That's a pretty old CPU, and it's a server CPU. So it's going to have pretty poor single-core performance compared to a modern gaming CPU, which are the kings of pytorch/GPTQ at the moment. And yes, WSL may be contributing to some slowdown as well.
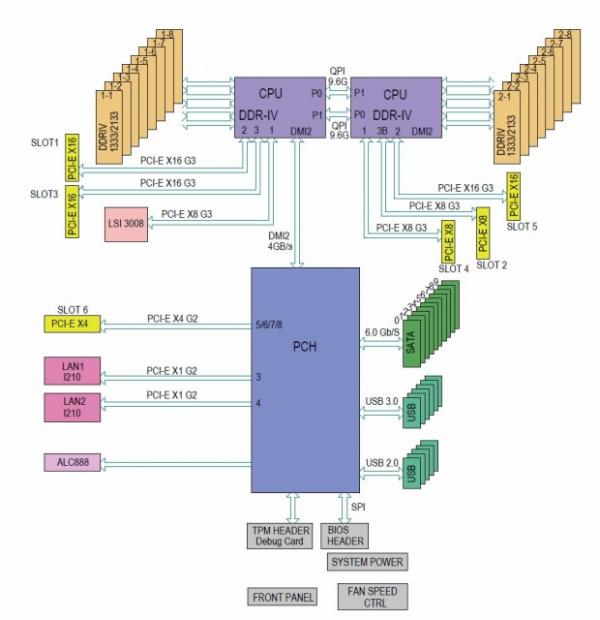
I got 2 Xeon CPUs and I've ensured that the 3090 is in a x16 slot.
According to this diagram PCH doesn't even drive x16 slots: https://static.tweaktown.com/content/6/7/6750_03_supermicro_x10dai_intel_c612_workstation_motherboard_review.jpg
But yeah, I guess should've upgraded to a gaming system. I stuck with 2011-3 because everything is watercooled (incl. 3090) and 2011 CPU blocks are compatible with 2011-3 CPUs. :)
So in your opinion what would be a good (local/home) setup for ML from presently available hardware that would cover most bases (both on GPU inference and on CPU/llama.cpp)?
Would CPUs like Intel i7-13700KF or AMD 7900X do, or older gen like Intel i7-12700 and AMD 5900X?
Problem I see is that most consumer motherboards only have 4 DIMM slots and RAM limit of 128GB which might not be enough.
Is it worth getting some of those older AMD Ryzen Threadripper combos (CPU/mobo/RAM) that are appearing on eBay?
Also, I finally installed Ubuntu 22.04 LTS onto a seprate SSD and I am not seeing much of an improvement over running in WSL2, maybe +1 t/s or less.
But, what surfaced up was that there's now less VRAM available for the models because X is running, and so I can't load the Falcon-40B anymore.
I can load the 40B model and run it just fine in WSL2, so unless native Linux is running headless, I see no benefit (for me at least) running it over WSL2.
@Nurb432
Yes, but then I don't have a browser to connect to the text-gen-webui so I'm stuck in the CLI.
I think my whole setup is wrong...I upgraded from dual Xeon E5v2 to a dual Xeon E5v3 thinking a single generation step-up adding AVX2 and DDR4 would do it. And because I wanted to reuse my existing CPU waterblocks and the watercooling setup.
Then I found out that I need better single thread performance, and that multiple cores aren't where it's at for PyTorch. In hindsight, I should've spent more money, and go for a single Threadripper 39xx or 59xx.
20/20

i think the most important thing is memory bandwidth, so if you take a Threadripper PRO 5955WX for example, and use the 8 memory channel, you may have better t/s than using the ryzen 9 7950x but i wish there was a benchmark, though it is ddr4 instead of ddr5 so i'm really curious which would beat the other.

@TheBloke can you help me, I'm looking for LLM models which can easily run on CPU. I'm not able to find any examples, kindly help me
For me, oddly, using the GGML version for just CPU is faster than using GPU for the same thing with a regular bin/safetensor file. ( even if the model is smaller than availble Vram ). Unless i using SD, then CPU is dreadful slow, but GPU flies.

{kind=link}