
Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
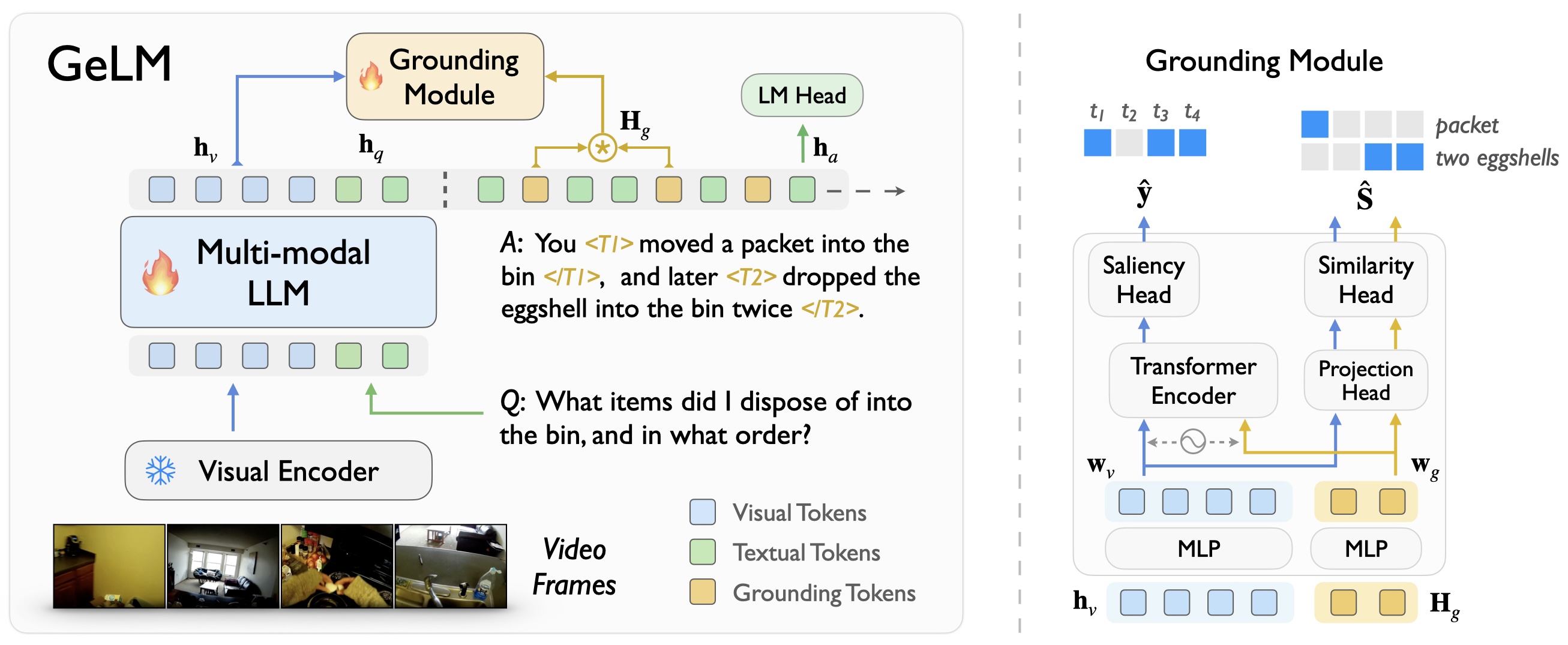
GeLM Model
We propose a novel architecture, termed as GeLM for MH-VidQA, to leverage the world knowledge reasoning capabilities of multi-modal large language models (LLMs), while incorporating a grounding module to retrieve temporal evidence in the video with flexible grounding tokens.
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.