
![]()
SuperAnnotate
LLM Content Detector
Fine-Tuned RoBERTa Large
Description
The model designed to detect generated/synthetic text.
At the moment, such functionality is critical for determining the author of the text. It's critical for your training data, detecting fraud and cheating in scientific and educational areas.
Couple of articles about this problem: Problems with Synthetic Data | Risk of LLMs in Education
Model Details
Model Description
- Model type: The custom architecture for binary sequence classification based on pre-trained RoBERTa, with a single output label.
- Language(s): Primarily English.
- License: SAIPL
- Finetuned from model: RoBERTa Large
Model Sources
- Repository: GitHub for HTTP service
Training Data
The training data was sourced from two open datasets with different proportions and underwent filtering:
As a result, the training dataset contained approximately 20k pairs of text-label with an approximate balance of classes.
It's worth noting that the dataset's texts follow a logical structure:
Human-written and model-generated texts refer to a single prompt/instruction, though the prompts themselves were not used during training.
Furthermore, key n-grams (n ranging from 2 to 5) that exhibited the highest correlation with target labels were identified and subsequently removed from the training data utilizing the chi-squared test.
Peculiarity
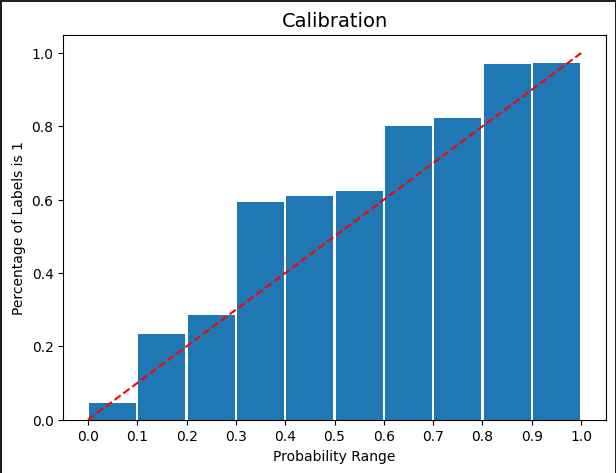
During training, one of the priorities was not only maximizing the quality of predictions but also avoiding overfitting and obtaining an adequately confident predictor.
We are pleased to achieve the following state of model calibration:
Usage
Pre-requirements:
Install generated_text_detector
Run following command: pip install git+https://github.com/superannotateai/generated_text_detector.git@v1.0.0
from generated_text_detector.utils.model.roberta_classifier import RobertaClassifier
from transformers import AutoTokenizer
import torch.nn.functional as F
model = RobertaClassifier.from_pretrained("SuperAnnotate/roberta-large-llm-content-detector")
tokenizer = AutoTokenizer.from_pretrained("SuperAnnotate/roberta-large-llm-content-detector")
text_example = "It's not uncommon for people to develop allergies or intolerances to certain foods as they get older. It's possible that you have always had a sensitivity to lactose (the sugar found in milk and other dairy products), but it only recently became a problem for you. This can happen because our bodies can change over time and become more or less able to tolerate certain things. It's also possible that you have developed an allergy or intolerance to something else that is causing your symptoms, such as a food additive or preservative. In any case, it's important to talk to a doctor if you are experiencing new allergy or intolerance symptoms, so they can help determine the cause and recommend treatment."
tokens = tokenizer.encode_plus(
text_example,
add_special_tokens=True,
max_length=512,
padding='longest',
truncation=True,
return_token_type_ids=True,
return_tensors="pt"
)
_, logits = model(**tokens)
proba = F.sigmoid(logits).squeeze(1).item()
print(proba)
Training Detailes
A custom architecture was chosen for its ability to perform binary classification while providing a single model output, as well as for its customizable settings for smoothing integrated into the loss function.
Training Arguments:
- Base Model: FacebookAI/roberta-large
- Epochs: 10
- Learning Rate: 5e-04
- Weight Decay: 0.05
- Label Smoothing: 0.1
- Warmup Epochs: 4
- Optimizer: SGD
- Scheduler: Linear schedule with warmup
Performance
The model was evaluated on a benchmark consisting of a holdout subset of training data, alongside a closed subset of SuperAnnotate data.
The benchmark comprises 1k samples, with 200 samples per category.
The model's performance is compared with open-source solutions and popular API detectors in the table below:
| Model/API | Wikipedia | Reddit QA | SA instruction | Papers | Average |
|---|---|---|---|---|---|
| Hello-SimpleAI | 0.97 | 0.95 | 0.82 | 0.69 | 0.86 |
| RADAR | 0.47 | 0.84 | 0.59 | 0.82 | 0.68 |
| GPTZero | 0.72 | 0.79 | 0.90 | 0.67 | 0.77 |
| Originality.ai | 0.91 | 0.97 | 0.77 | 0.93 | 0.89 |
| LLM content detector | 0.88 | 0.95 | 0.84 | 0.81 | 0.87 |
- Downloads last month
- 4,190