
Model Card for Silver-Multimodal
Model Details
The Silver-Multimodal model integrates both audio and video modalities for real-time situation classification.
This architecture allows it to process diverse inputs simultaneously and identify scenarios like daily activities, violence, and fall events with high precision.
The model leverages a Transformer-based architecture to combine features extracted from audio (MFCC) and video (MediaPipe keypoints), enabling robust multimodal learning.
Key Highlights:
- Multimodal Integration: Combines YOLO, MediaPipe, and MFCC features for comprehensive situation understanding.
- Middle Fusion: The extracted features are fused and passed through the Transformer model for context-aware classification.
- Output Classes:
- 0 Daily Activities: Normal indoor movements like walking or sitting.
- 1 Violence: Aggressive behaviors or physical conflicts.
- 2 Fall Down: Sudden fall or collapse.

Model Description
- Activity with: NIPA-Google(2024.10.23-20224.11.08), Kosa Hackathon(2024.12.9)
- Model type: Multimodal Transformer Model
- API used: Keras
- Dataset: HuggingFace Silver-Multimodal-Dataset
- Code: GitHub Silver Model Code
- Language(s) (NLP): Korean, English
Training Details
Dataset Preperation
- HuggingFace: HuggingFace Silver-Multimodal-Dataset
- Description:
- The dataset is designed to support the development of machine learning models for detecting daily activities, violence, and fall down scenarios from combined audio and video sources.
- The preprocessing pipeline leverages audio feature extraction, human keypoint detection, and relative positional encoding to generate a unified representation for training and inference.
- Classes:
- 0: Daily - Normal indoor activities
- 1: Violence - Aggressive behaviors
- 2: Fall Down - Sudden falls or collapses
Model Details
Model Structure:
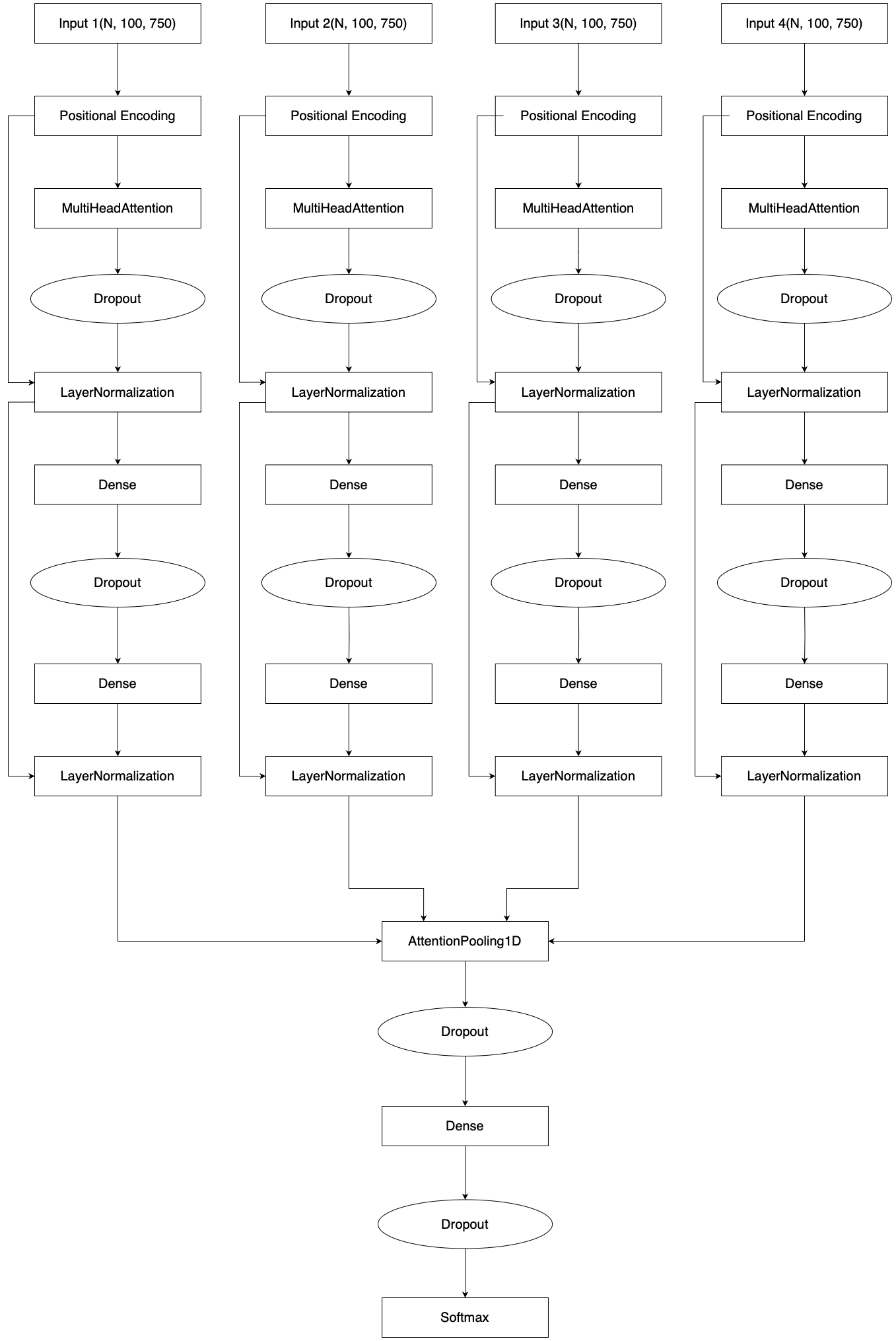
Input Shape and Division
- Input Shape:
- The input shape for each branch is (N, 100, 750), where:
- N: Batch size (number of sequences in a batch).
- 100: Temporal dimension (time steps).
- 750: Feature dimension, representing extracted features for each input modality.
- The input shape for each branch is (N, 100, 750), where:
- Why Four Inputs?:
- The model processes four distinct inputs, each corresponding to a specific set of features derived from video keypoints. Here’s how they are divided:
- Input 1, Input 2, Input 3:
- For each detected individual (up to 3 people), the model extracts 30 keypoints using MediaPipe.
- Each keypoint contains 3 features (x, y, z), resulting in 30 x 3 = 90 features per frame.
- Input 4:
- Represents relative positional coordinates calculated from the 10 most important key joints (e.g., shoulders, elbows, knees) for all 3 individuals.
- These relative coordinates capture spatial relationships among individuals, crucial for contextual understanding.
- Input Shape:
Detailed Explanation of Architecture
- Positional Encoding:
- Adds temporal position information to the input embeddings, allowing the transformer to consider the sequence order.
- Multi-Head Attention:
- Captures interdependencies and relationships across the temporal dimension within each input.
- Ensures the model focuses on the most relevant frames or segments of the sequence.
- Dropout:
- Applies dropout regularization to prevent overfitting and improve generalization.
- LayerNormalization:
- Normalizes the output of each layer to stabilize training and accelerate convergence.
- Dense Layers:
- Extracts higher-level features after the attention mechanism.
- The first dense layer processes features from attention, followed by another dropout and dense layer to refine features further.
- AttentionPooling1D:
- Combines outputs from all four inputs into a unified representation.
- Aggregates temporal features using an attention mechanism, emphasizing the most important segments across modalities.
- Final Dense Layers:
- The combined representation is passed through dense layers and a softmax activation function for final classification into target classes:
- 0: Daily Activities
- 1: Violence
- 2: Fall Down
- The combined representation is passed through dense layers and a softmax activation function for final classification into target classes:
- Positional Encoding:
Model Performance:
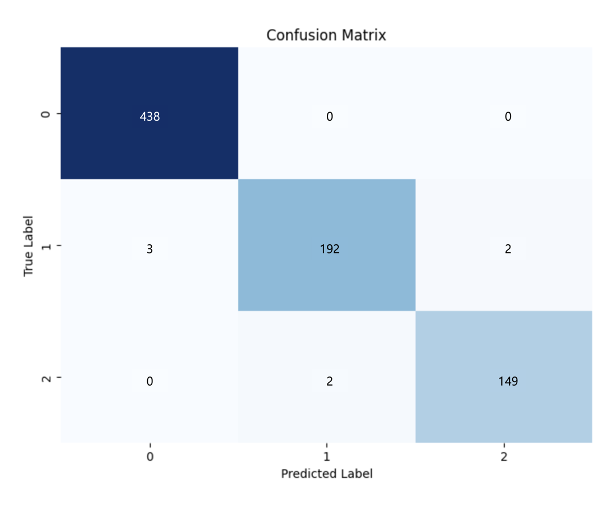
- Confusion Matrix Insights:
- Class 0 (Daily): 100% accuracy with no misclassifications.
- Class 1 (Violence): 96.96% accuracy with minimal false positives or false negatives.
- Class 2 (Fall Down): 98.67% accuracy, highlighting the model’s robustness in detecting falls.
- The overall accuracy is 98.37%, indicating the model’s reliability for real-time applications.
- Confusion Matrix Insights:


Model Usage
Silver AssistantProject
Load Model For Inference
# Hugging Face Hub에서 모델 다운로드
MODEL_PATH="silver_assistant_transformer.keras"
model_path = hf_hub_download(repo_id="SilverAvocado/Silver-Multimodal", filename=MODEL_PATH)
# 사용자 정의 클래스 로드
model = load_model(
model_path,
custom_objects={
"PositionalEncoding": PositionalEncoding,
"AttentionPooling1D": AttentionPooling1D
}
)
y_pred = np.argmax(model.predict([X_test1, X_test2, X_test3, X_test4]), axis=1)
accuracy = accuracy_score(y_test, y_pred)
print(f"Test Accuracy: {accuracy:.4f}")
Conclusion
The Silver-Multimodal model demonstrates exceptional capabilities in multimodal learning for situation classification.
Its ability to effectively integrate audio and video modalities ensures:
- High Accuracy: Consistent performance across all classes.
- Real-World Applicability: Suitable for applications like healthcare monitoring, safety systems, and smart homes.
- Scalable Architecture: Transformer-based design allows future enhancements and additional modality integration.
This model sets a new benchmark for multimodal AI systems, empowering safety-critical projects like
Silver Assistantwith state-of-the-art situation awareness.
- Downloads last month
- 106