
LiLT-RoBERTa (base-sized model)
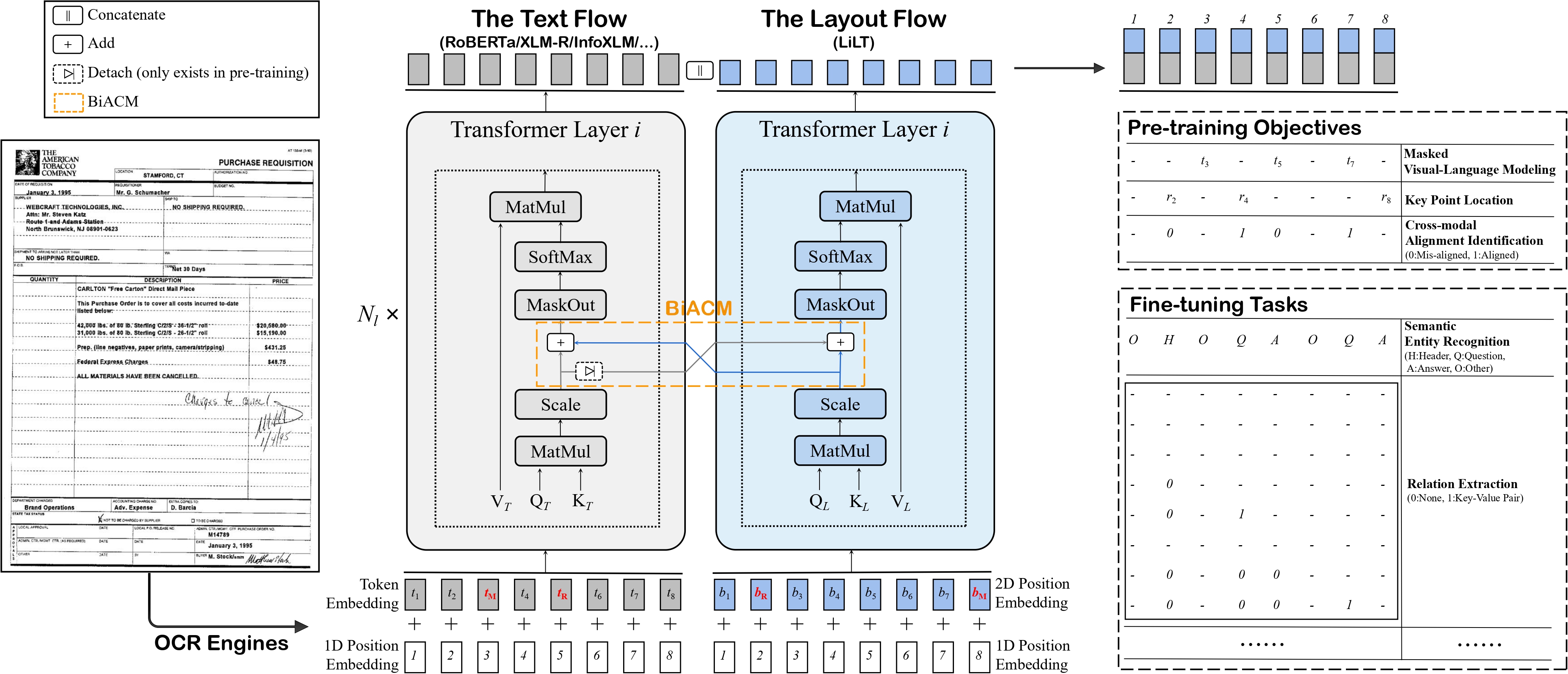
Language-Independent Layout Transformer - RoBERTa model by stitching a pre-trained RoBERTa (English) and a pre-trained Language-Independent Layout Transformer (LiLT) together. It was introduced in the paper LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding by Wang et al. and first released in this repository.
Disclaimer: The team releasing LiLT did not write a model card for this model so this model card has been written by the Hugging Face team.
Model description
The Language-Independent Layout Transformer (LiLT) allows to combine any pre-trained RoBERTa encoder from the hub (hence, in any language) with a lightweight Layout Transformer to have a LayoutLM-like model for any language.
Intended uses & limitations
The model is meant to be fine-tuned on tasks like document image classification, document parsing and document QA. See the model hub to look for fine-tuned versions on a task that interests you.
How to use
For code examples, we refer to the documentation.
BibTeX entry and citation info
@misc{https://doi.org/10.48550/arxiv.2202.13669,
doi = {10.48550/ARXIV.2202.13669},
url = {https://arxiv.org/abs/2202.13669},
author = {Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
- Downloads last month
- 18,155