
Target-Driven Distillation
Project Page | Paper | Code | Model | 🤗 TDD-SDXL Demo | 🤗 SVD-TDD Demo | 🤗 FLUX-TDD Demo
Target-Driven Distillation: Consistency Distillation with Target Timestep Selection and Decoupled Guidance

Samples generated by TDD-distilled SDXL, with only 4--8 steps.
Usage FLUX
from huggingface_hub import hf_hub_download
from diffusers import FluxPipeline
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16)
pipe.load_lora_weights(hf_hub_download("RED-AIGC/TDD", "FLUX.1-dev_tdd_adv_lora_weights.safetensors"))
pipe.fuse_lora(lora_scale=0.125)
pipe.to("cuda")
image_flux = pipe(
prompt=[prompt],
generator=torch.Generator().manual_seed(int(3413)),
num_inference_steps=8,
guidance_scale=2.0,
height=1024,
width=1024,
max_sequence_length=256
).images[0]
Usage SDXL
You can directly download the model in this repository. You also can download the model in python script:
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="RedAIGC/TDD", filename="sdxl_tdd_lora_weights.safetensors", local_dir="./tdd_lora")
# !pip install opencv-python transformers accelerate
import torch
import diffusers
from diffusers import StableDiffusionXLPipeline
from tdd_scheduler import TDDScheduler
device = "cuda"
tdd_lora_path = "tdd_lora/sdxl_tdd_lora_weights.safetensors"
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16").to(device)
pipe.scheduler = TDDSchedulerPlus.from_config(pipe.scheduler.config)
pipe.load_lora_weights(tdd_lora_path, adapter_name="accelerate")
pipe.fuse_lora()
prompt = "A photo of a cat made of water."
image = pipe(
prompt=prompt,
num_inference_steps=4,
guidance_scale=1.7,
eta=0.2,
generator=torch.Generator(device=device).manual_seed(546237),
).images[0]
image.save("tdd.png")
Update
- [2025.01.01]:Upload the TDD LoRA weights of FLUX-TDD-ADV
- [2024.09.20]:Upload the TDD LoRA weights of FLUX-TDD-BETA(4-8-steps)
- [2024.08.25]:Upload the TDD LoRA weights of SVD
- [2024.08.22]:Upload the TDD LoRA weights of Stable Diffusion XL, YamerMIX and RealVisXL-V4.0, fast text-to-image generation.
Thanks to Yamer and SG_161222 for developing YamerMIX and RealVisXL V4.0 respectively.
Introduction
Target-Driven Distillation (TDD) features three key designs, that differ from previous consistency distillation methods.
- TDD adopts a delicate selection strategy of target timesteps, increasing the training efficiency. Specifically, it first chooses from a predefined set of equidistant denoising schedules (e.g. 4--8 steps), then adds a stochatic offset to accomodate non-deterministic sampling (e.g. $\gamma$-sampling).
- TDD utilizes decoupled guidances during training, making itself open to post-tuning on guidance scale during inference periods. Specifically, it replaces a portion of the text conditions with unconditional (i.e. empty) prompts, in order to align with the standard training process using CFG.
- TDD can be optionally equipped with non-equidistant sampling and x0 clipping, enabling a more flexible and accurate way for image sampling.
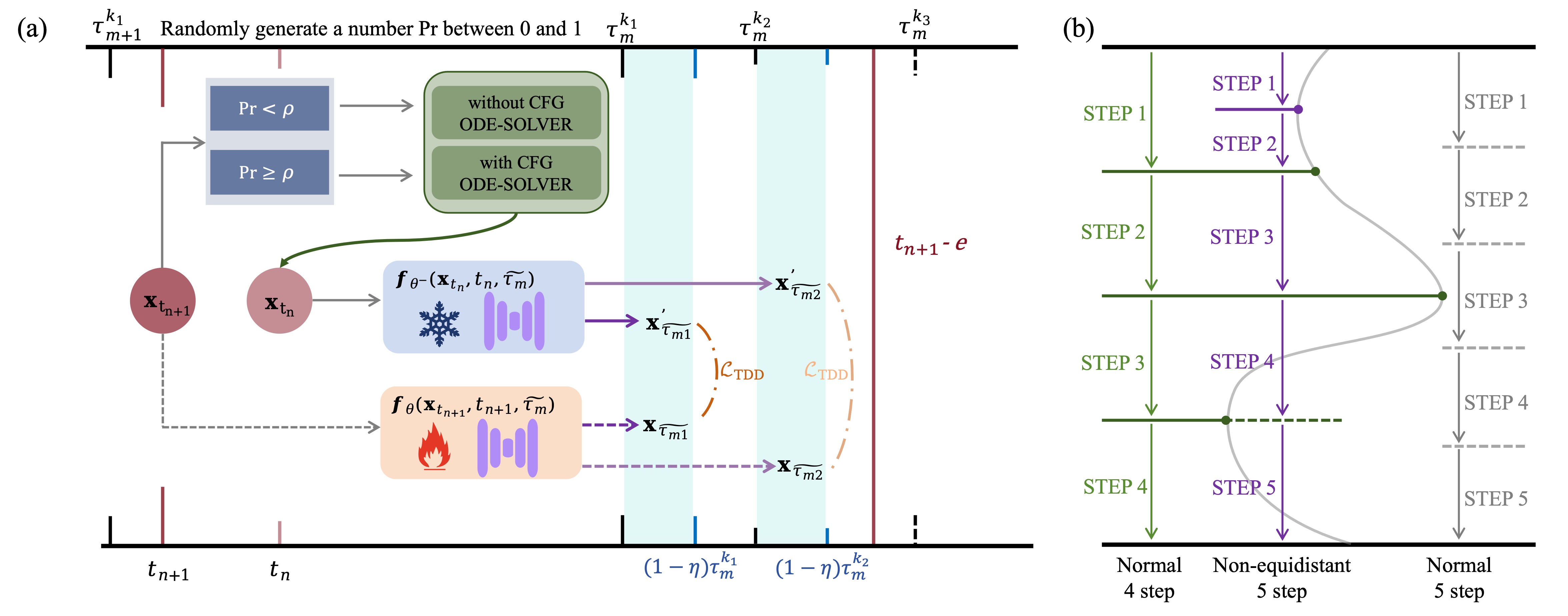
An overview of TDD. (a) The training process features target timestep selection and decoupled guidance. (b) The inference process can optionally adopt non-equidistant denoising schedules.

Samples generated by SDXL models distilled by mainstream consistency distillation methods LCM, PCM, TCD, and our TDD, from the same seeds. Our method demonstrates advantages in both image complexity and clarity.

Samples generated by TDD-distilled different base models, and by SDXL with different LoRA adapters or ControlNets.
Video samples generated by AnimateLCM-distilled (top) and TDD-distilled (bottom) SVD-xt 1.1, also with 4--8 steps.
- Downloads last month
- 439
Model tree for RED-AIGC/TDD
Base model
black-forest-labs/FLUX.1-dev