

Upload folder using huggingface_hub (#2)
Browse files- b8c18c3cd2c60ec3be4ce18201d524e9105da816b53728ce1eb6dcbcdaeba920 (1b6b23a1829e01efe10e4fde75555ac7fe62626b)
- 05dce499639c97d78137f8b8c6645892272c5526013edac8f21fb992351dd25a (dcf5d6fdca5da9a654fd8005fe1f97f2ac7c9156)
- README.md +5 -3
- config.json +2 -2
- model.safetensors +2 -2
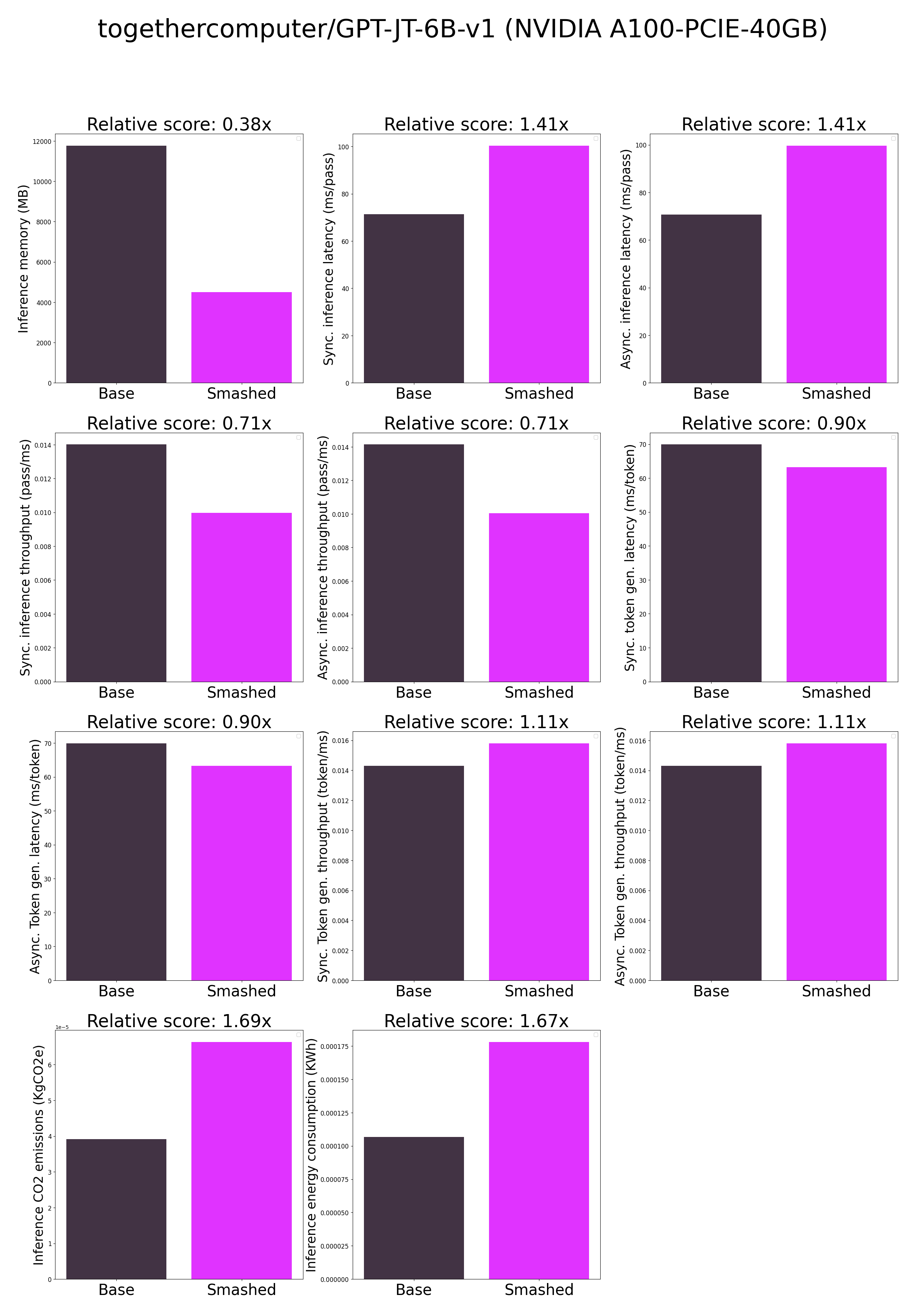
- plots.png +0 -0
- smash_config.json +1 -1
README.md
CHANGED
|
@@ -1,5 +1,4 @@
|
|
| 1 |
---
|
| 2 |
-
library_name: pruna-engine
|
| 3 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 4 |
metrics:
|
| 5 |
- memory_disk
|
|
@@ -8,6 +7,8 @@ metrics:
|
|
| 8 |
- inference_throughput
|
| 9 |
- inference_CO2_emissions
|
| 10 |
- inference_energy_consumption
|
|
|
|
|
|
|
| 11 |
---
|
| 12 |
<!-- header start -->
|
| 13 |
<!-- 200823 -->
|
|
@@ -33,7 +34,7 @@ metrics:
|
|
| 33 |
|
| 34 |
## Results
|
| 35 |
|
| 36 |
-
|
| 37 |
|
| 38 |
**Frequently Asked Questions**
|
| 39 |
- ***How does the compression work?*** The model is compressed with llm-int8.
|
|
@@ -60,12 +61,13 @@ You can run the smashed model with these steps:
|
|
| 60 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 61 |
|
| 62 |
model = AutoModelForCausalLM.from_pretrained("PrunaAI/togethercomputer-GPT-JT-6B-v1-bnb-4bit-smashed",
|
| 63 |
-
trust_remote_code=True)
|
| 64 |
tokenizer = AutoTokenizer.from_pretrained("togethercomputer/GPT-JT-6B-v1")
|
| 65 |
|
| 66 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 67 |
|
| 68 |
outputs = model.generate(input_ids, max_new_tokens=216)
|
|
|
|
| 69 |
```
|
| 70 |
|
| 71 |
## Configurations
|
|
|
|
| 1 |
---
|
|
|
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
metrics:
|
| 4 |
- memory_disk
|
|
|
|
| 7 |
- inference_throughput
|
| 8 |
- inference_CO2_emissions
|
| 9 |
- inference_energy_consumption
|
| 10 |
+
tags:
|
| 11 |
+
- pruna-ai
|
| 12 |
---
|
| 13 |
<!-- header start -->
|
| 14 |
<!-- 200823 -->
|
|
|
|
| 34 |
|
| 35 |
## Results
|
| 36 |
|
| 37 |
+

|
| 38 |
|
| 39 |
**Frequently Asked Questions**
|
| 40 |
- ***How does the compression work?*** The model is compressed with llm-int8.
|
|
|
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
|
| 63 |
model = AutoModelForCausalLM.from_pretrained("PrunaAI/togethercomputer-GPT-JT-6B-v1-bnb-4bit-smashed",
|
| 64 |
+
trust_remote_code=True, device_map='auto')
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("togethercomputer/GPT-JT-6B-v1")
|
| 66 |
|
| 67 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 68 |
|
| 69 |
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 70 |
+
tokenizer.decode(outputs[0])
|
| 71 |
```
|
| 72 |
|
| 73 |
## Configurations
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"activation_function": "gelu_new",
|
| 4 |
"architectures": [
|
| 5 |
"GPTJForCausalLM"
|
|
@@ -20,7 +20,7 @@
|
|
| 20 |
"quantization_config": {
|
| 21 |
"bnb_4bit_compute_dtype": "bfloat16",
|
| 22 |
"bnb_4bit_quant_type": "fp4",
|
| 23 |
-
"bnb_4bit_use_double_quant":
|
| 24 |
"llm_int8_enable_fp32_cpu_offload": false,
|
| 25 |
"llm_int8_has_fp16_weight": false,
|
| 26 |
"llm_int8_skip_modules": [
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmps08uljpf",
|
| 3 |
"activation_function": "gelu_new",
|
| 4 |
"architectures": [
|
| 5 |
"GPTJForCausalLM"
|
|
|
|
| 20 |
"quantization_config": {
|
| 21 |
"bnb_4bit_compute_dtype": "bfloat16",
|
| 22 |
"bnb_4bit_quant_type": "fp4",
|
| 23 |
+
"bnb_4bit_use_double_quant": false,
|
| 24 |
"llm_int8_enable_fp32_cpu_offload": false,
|
| 25 |
"llm_int8_has_fp16_weight": false,
|
| 26 |
"llm_int8_skip_modules": [
|
model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8cb0afced4b790d2eae8aa6623e91d404fce5acf688ac784ac1fc5993f65d000
|
| 3 |
+
size 3998485888
|
plots.png
ADDED
|
smash_config.json
CHANGED
|
@@ -8,7 +8,7 @@
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 12 |
"batch_size": 1,
|
| 13 |
"model_name": "togethercomputer/GPT-JT-6B-v1",
|
| 14 |
"pruning_ratio": 0.0,
|
|
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/models17a99hiq",
|
| 12 |
"batch_size": 1,
|
| 13 |
"model_name": "togethercomputer/GPT-JT-6B-v1",
|
| 14 |
"pruning_ratio": 0.0,
|