

Upload folder using huggingface_hub (#3)
Browse files- edc37da16a5ea802e0e25a96f90f7e72a616f154549c242fbb1f155f8ee10c88 (7481787b33ef326473e2406eac34f65e345eed31)
- 177e1567eb8fb97c77c6ca80393483bb4abe83c8c126a39372b923c86eae5b92 (e1b55c7a9a59e257b352918b061befebc4a979cf)
- README.md +1 -1
- config.json +1 -1
- plots.png +0 -0
- smash_config.json +1 -1
README.md
CHANGED
|
@@ -60,7 +60,7 @@ You can run the smashed model with these steps:
|
|
| 60 |
```python
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
|
| 63 |
-
model = AutoModelForCausalLM.from_pretrained("PrunaAI/huggyllama-llama-7b-
|
| 64 |
trust_remote_code=True, device_map='auto')
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
|
| 66 |
|
|
|
|
| 60 |
```python
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
|
| 63 |
+
model = AutoModelForCausalLM.from_pretrained("PrunaAI/huggyllama-llama-7b-bnb-4bit-smashed",
|
| 64 |
trust_remote_code=True, device_map='auto')
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
|
| 66 |
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpb4y27ufo",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
plots.png
CHANGED
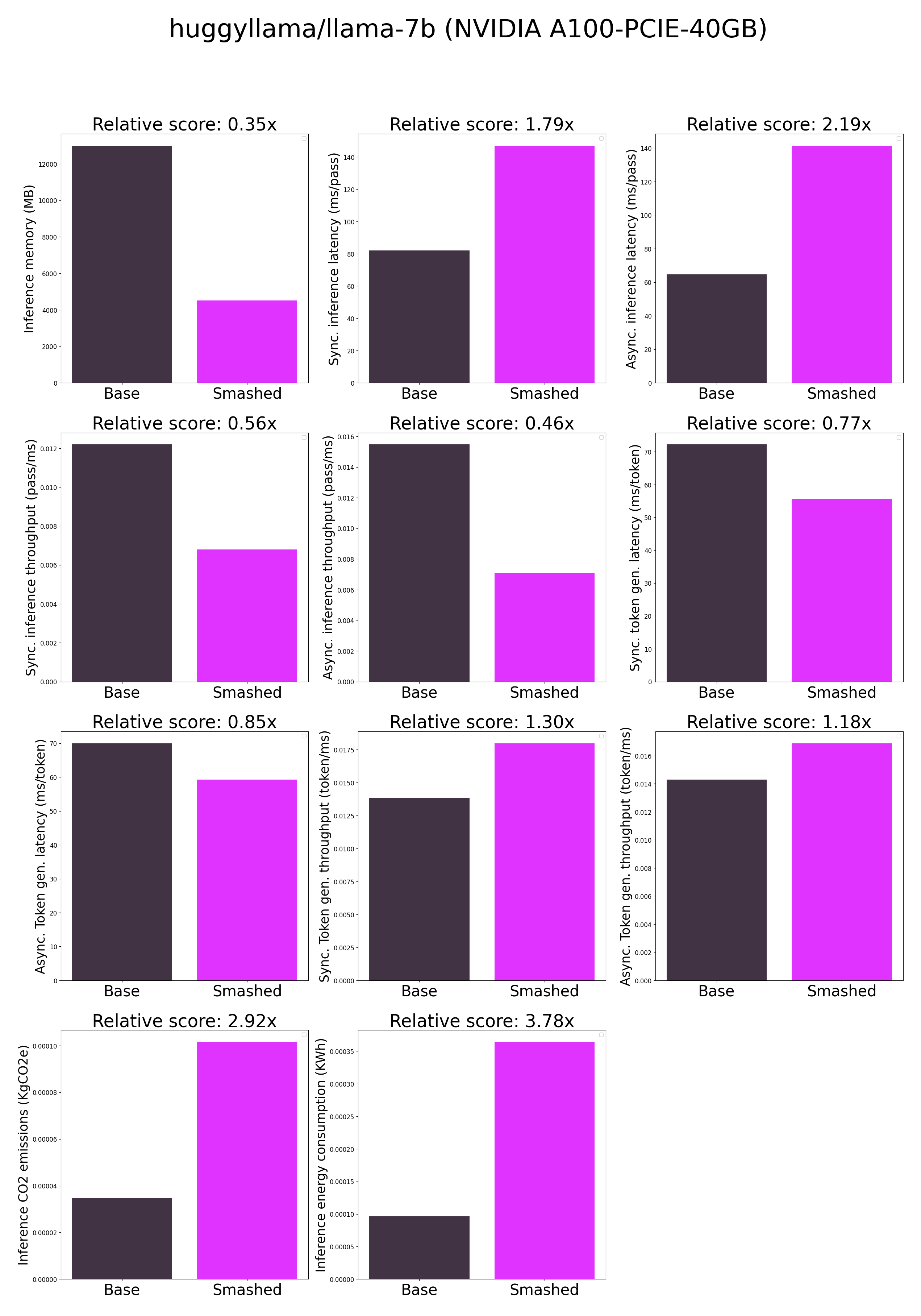
|

|
smash_config.json
CHANGED
|
@@ -8,7 +8,7 @@
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 12 |
"batch_size": 1,
|
| 13 |
"n_quantization_bits": 4,
|
| 14 |
"tokenizer": "LlamaTokenizerFast(name_or_path='huggyllama/llama-7b', vocab_size=32000, model_max_length=2048, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={\n\t0: AddedToken(\"<unk>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t1: AddedToken(\"<s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t2: AddedToken(\"</s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n}",
|
|
|
|
| 8 |
"compilers": "None",
|
| 9 |
"task": "text_text_generation",
|
| 10 |
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsy3nu9jue",
|
| 12 |
"batch_size": 1,
|
| 13 |
"n_quantization_bits": 4,
|
| 14 |
"tokenizer": "LlamaTokenizerFast(name_or_path='huggyllama/llama-7b', vocab_size=32000, model_max_length=2048, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>'}, clean_up_tokenization_spaces=False), added_tokens_decoder={\n\t0: AddedToken(\"<unk>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t1: AddedToken(\"<s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n\t2: AddedToken(\"</s>\", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),\n}",
|