

f8a0b68f61f298f23c8d17d6b308fcaf71e02733fee948a5b38e124f27bfa18d
Browse files- README.md +84 -0
- config.json +51 -0
- configuration_gpt2_mq.py +201 -0
- generation_config.json +6 -0
- model.safetensors +3 -0
- modeling_gpt2_mq.py +346 -0
- plots.png +0 -0
- smash_config.json +27 -0
README.md
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
+
metrics:
|
| 4 |
+
- memory_disk
|
| 5 |
+
- memory_inference
|
| 6 |
+
- inference_latency
|
| 7 |
+
- inference_throughput
|
| 8 |
+
- inference_CO2_emissions
|
| 9 |
+
- inference_energy_consumption
|
| 10 |
+
tags:
|
| 11 |
+
- pruna-ai
|
| 12 |
+
---
|
| 13 |
+
<!-- header start -->
|
| 14 |
+
<!-- 200823 -->
|
| 15 |
+
<div style="width: auto; margin-left: auto; margin-right: auto">
|
| 16 |
+
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
|
| 17 |
+
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
|
| 18 |
+
</a>
|
| 19 |
+
</div>
|
| 20 |
+
<!-- header end -->
|
| 21 |
+
|
| 22 |
+
[](https://twitter.com/PrunaAI)
|
| 23 |
+
[](https://github.com/PrunaAI)
|
| 24 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 25 |
+
[](https://discord.gg/CP4VSgck)
|
| 26 |
+
|
| 27 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 28 |
+
|
| 29 |
+
- Give a thumbs up if you like this model!
|
| 30 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 31 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 32 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 33 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
|
| 34 |
+
|
| 35 |
+
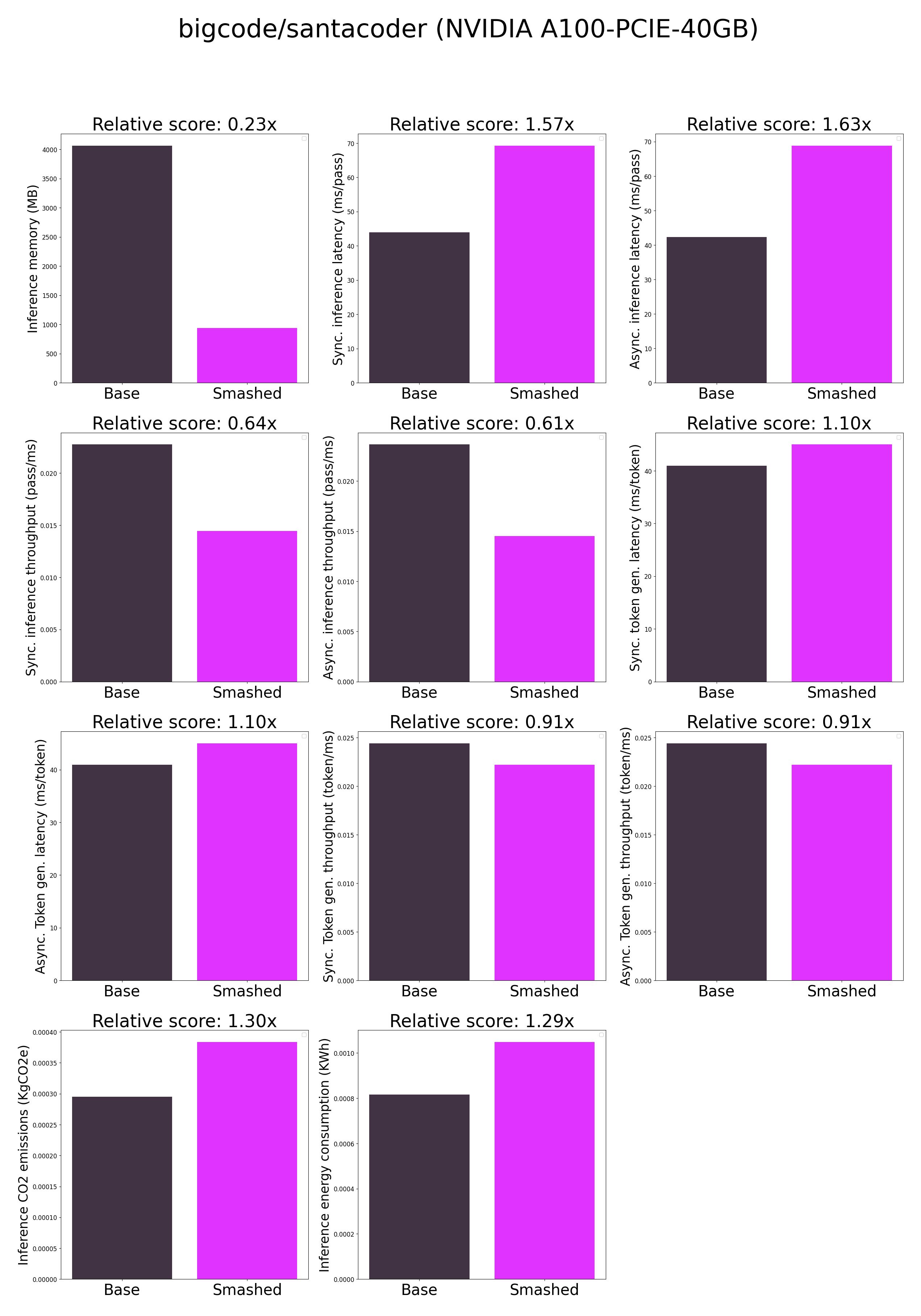
## Results
|
| 36 |
+
|
| 37 |
+

|
| 38 |
+
|
| 39 |
+
**Frequently Asked Questions**
|
| 40 |
+
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 41 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 42 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 43 |
+
- ***What is the model format?*** We use safetensors.
|
| 44 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 45 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 46 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 47 |
+
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 48 |
+
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 49 |
+
|
| 50 |
+
## Setup
|
| 51 |
+
|
| 52 |
+
You can run the smashed model with these steps:
|
| 53 |
+
|
| 54 |
+
0. Check requirements from the original repo bigcode/santacoder installed. In particular, check python, cuda, and transformers versions.
|
| 55 |
+
1. Make sure that you have installed quantization related packages.
|
| 56 |
+
```bash
|
| 57 |
+
pip install transformers accelerate bitsandbytes>0.37.0
|
| 58 |
+
```
|
| 59 |
+
2. Load & run the model.
|
| 60 |
+
```python
|
| 61 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
+
|
| 63 |
+
model = AutoModelForCausalLM.from_pretrained("PrunaAI/bigcode-santacoder-bnb-4bit-smashed",
|
| 64 |
+
trust_remote_code=True)
|
| 65 |
+
tokenizer = AutoTokenizer.from_pretrained("bigcode/santacoder")
|
| 66 |
+
|
| 67 |
+
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 68 |
+
|
| 69 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 70 |
+
tokenizer.decode(outputs[0])
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
## Configurations
|
| 74 |
+
|
| 75 |
+
The configuration info are in `smash_config.json`.
|
| 76 |
+
|
| 77 |
+
## Credits & License
|
| 78 |
+
|
| 79 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model bigcode/santacoder before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 80 |
+
|
| 81 |
+
## Want to compress other models?
|
| 82 |
+
|
| 83 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 84 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
config.json
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/tmp/tmppkofl_7p",
|
| 3 |
+
"activation_function": "gelu_fast",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"GPT2LMHeadCustomModel"
|
| 6 |
+
],
|
| 7 |
+
"attention_head_type": "multiquery",
|
| 8 |
+
"attn_pdrop": 0.1,
|
| 9 |
+
"auto_map": {
|
| 10 |
+
"AutoConfig": "configuration_gpt2_mq.GPT2CustomConfig",
|
| 11 |
+
"AutoModelForCausalLM": "modeling_gpt2_mq.GPT2LMHeadCustomModel"
|
| 12 |
+
},
|
| 13 |
+
"bos_token_id": 49152,
|
| 14 |
+
"embd_pdrop": 0.1,
|
| 15 |
+
"eos_token_id": 49152,
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"layer_norm_epsilon": 1e-05,
|
| 18 |
+
"model_type": "gpt2",
|
| 19 |
+
"n_embd": 2048,
|
| 20 |
+
"n_head": 16,
|
| 21 |
+
"n_inner": 8192,
|
| 22 |
+
"n_layer": 24,
|
| 23 |
+
"n_positions": 2048,
|
| 24 |
+
"quantization_config": {
|
| 25 |
+
"bnb_4bit_compute_dtype": "bfloat16",
|
| 26 |
+
"bnb_4bit_quant_type": "fp4",
|
| 27 |
+
"bnb_4bit_use_double_quant": true,
|
| 28 |
+
"llm_int8_enable_fp32_cpu_offload": false,
|
| 29 |
+
"llm_int8_has_fp16_weight": false,
|
| 30 |
+
"llm_int8_skip_modules": [
|
| 31 |
+
"lm_head"
|
| 32 |
+
],
|
| 33 |
+
"llm_int8_threshold": 6.0,
|
| 34 |
+
"load_in_4bit": true,
|
| 35 |
+
"load_in_8bit": false,
|
| 36 |
+
"quant_method": "bitsandbytes"
|
| 37 |
+
},
|
| 38 |
+
"reorder_and_upcast_attn": false,
|
| 39 |
+
"resid_pdrop": 0.1,
|
| 40 |
+
"scale_attn_by_inverse_layer_idx": false,
|
| 41 |
+
"scale_attn_weights": true,
|
| 42 |
+
"summary_activation": null,
|
| 43 |
+
"summary_first_dropout": 0.1,
|
| 44 |
+
"summary_proj_to_labels": true,
|
| 45 |
+
"summary_type": "cls_index",
|
| 46 |
+
"summary_use_proj": true,
|
| 47 |
+
"torch_dtype": "float16",
|
| 48 |
+
"transformers_version": "4.37.1",
|
| 49 |
+
"use_cache": true,
|
| 50 |
+
"vocab_size": 49280
|
| 51 |
+
}
|
configuration_gpt2_mq.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The OpenAI Team Authors and Hugging Face Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
""" Custom GPT-2 configuration"""
|
| 17 |
+
from collections import OrderedDict
|
| 18 |
+
from typing import Any, List, Mapping, Optional
|
| 19 |
+
from enum import Enum
|
| 20 |
+
|
| 21 |
+
from transformers import PreTrainedTokenizer, TensorType, is_torch_available
|
| 22 |
+
|
| 23 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 24 |
+
from transformers.onnx import OnnxConfigWithPast, PatchingSpec
|
| 25 |
+
from transformers.utils import logging
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
logger = logging.get_logger(__name__)
|
| 29 |
+
|
| 30 |
+
GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
| 31 |
+
"gpt2": "https://huggingface.co/gpt2/resolve/main/config.json",
|
| 32 |
+
"gpt2-medium": "https://huggingface.co/gpt2-medium/resolve/main/config.json",
|
| 33 |
+
"gpt2-large": "https://huggingface.co/gpt2-large/resolve/main/config.json",
|
| 34 |
+
"gpt2-xl": "https://huggingface.co/gpt2-xl/resolve/main/config.json",
|
| 35 |
+
"distilgpt2": "https://huggingface.co/distilgpt2/resolve/main/config.json",
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
MULTI_HEAD = "multihead"
|
| 39 |
+
MULTI_QUERY = "multiquery"
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class GPT2CustomConfig(PretrainedConfig):
|
| 43 |
+
"""
|
| 44 |
+
This is the configuration class to store the configuration of a [`GPT2Model`] or a [`TFGPT2Model`]. It is used to
|
| 45 |
+
instantiate a GPT-2 model according to the specified arguments, defining the model architecture. Instantiating a
|
| 46 |
+
configuration with the defaults will yield a similar configuration to that of the GPT-2
|
| 47 |
+
[gpt2](https://huggingface.co/gpt2) architecture.
|
| 48 |
+
|
| 49 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 50 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
vocab_size (`int`, *optional*, defaults to 50257):
|
| 55 |
+
Vocabulary size of the GPT-2 model. Defines the number of different tokens that can be represented by the
|
| 56 |
+
`inputs_ids` passed when calling [`GPT2Model`] or [`TFGPT2Model`].
|
| 57 |
+
n_positions (`int`, *optional*, defaults to 1024):
|
| 58 |
+
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
| 59 |
+
just in case (e.g., 512 or 1024 or 2048).
|
| 60 |
+
n_embd (`int`, *optional*, defaults to 768):
|
| 61 |
+
Dimensionality of the embeddings and hidden states.
|
| 62 |
+
n_layer (`int`, *optional*, defaults to 12):
|
| 63 |
+
Number of hidden layers in the Transformer encoder.
|
| 64 |
+
n_head (`int`, *optional*, defaults to 12):
|
| 65 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 66 |
+
n_inner (`int`, *optional*, defaults to None):
|
| 67 |
+
Dimensionality of the inner feed-forward layers. `None` will set it to 4 times n_embd
|
| 68 |
+
activation_function (`str`, *optional*, defaults to `"gelu"`):
|
| 69 |
+
Activation function, to be selected in the list `["relu", "silu", "gelu", "tanh", "gelu_new"]`.
|
| 70 |
+
resid_pdrop (`float`, *optional*, defaults to 0.1):
|
| 71 |
+
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
| 72 |
+
embd_pdrop (`int`, *optional*, defaults to 0.1):
|
| 73 |
+
The dropout ratio for the embeddings.
|
| 74 |
+
attn_pdrop (`float`, *optional*, defaults to 0.1):
|
| 75 |
+
The dropout ratio for the attention.
|
| 76 |
+
layer_norm_epsilon (`float`, *optional*, defaults to 1e-5):
|
| 77 |
+
The epsilon to use in the layer normalization layers.
|
| 78 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 79 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 80 |
+
summary_type (`string`, *optional*, defaults to `"cls_index"`):
|
| 81 |
+
Argument used when doing sequence summary, used in the models [`GPT2DoubleHeadsModel`] and
|
| 82 |
+
[`TFGPT2DoubleHeadsModel`].
|
| 83 |
+
|
| 84 |
+
Has to be one of the following options:
|
| 85 |
+
|
| 86 |
+
- `"last"`: Take the last token hidden state (like XLNet).
|
| 87 |
+
- `"first"`: Take the first token hidden state (like BERT).
|
| 88 |
+
- `"mean"`: Take the mean of all tokens hidden states.
|
| 89 |
+
- `"cls_index"`: Supply a Tensor of classification token position (like GPT/GPT-2).
|
| 90 |
+
- `"attn"`: Not implemented now, use multi-head attention.
|
| 91 |
+
summary_use_proj (`bool`, *optional*, defaults to `True`):
|
| 92 |
+
Argument used when doing sequence summary, used in the models [`GPT2DoubleHeadsModel`] and
|
| 93 |
+
[`TFGPT2DoubleHeadsModel`].
|
| 94 |
+
|
| 95 |
+
Whether or not to add a projection after the vector extraction.
|
| 96 |
+
summary_activation (`str`, *optional*):
|
| 97 |
+
Argument used when doing sequence summary. Used in for the multiple choice head in
|
| 98 |
+
[`GPT2DoubleHeadsModel`].
|
| 99 |
+
|
| 100 |
+
Pass `"tanh"` for a tanh activation to the output, any other value will result in no activation.
|
| 101 |
+
summary_proj_to_labels (`bool`, *optional*, defaults to `True`):
|
| 102 |
+
Argument used when doing sequence summary, used in the models [`GPT2DoubleHeadsModel`] and
|
| 103 |
+
[`TFGPT2DoubleHeadsModel`].
|
| 104 |
+
|
| 105 |
+
Whether the projection outputs should have `config.num_labels` or `config.hidden_size` classes.
|
| 106 |
+
summary_first_dropout (`float`, *optional*, defaults to 0.1):
|
| 107 |
+
Argument used when doing sequence summary, used in the models [`GPT2DoubleHeadsModel`] and
|
| 108 |
+
[`TFGPT2DoubleHeadsModel`].
|
| 109 |
+
|
| 110 |
+
The dropout ratio to be used after the projection and activation.
|
| 111 |
+
scale_attn_weights (`bool`, *optional*, defaults to `True`):
|
| 112 |
+
Scale attention weights by dividing by sqrt(head_dim)..
|
| 113 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 114 |
+
Whether or not the model should return the last key/values attentions (not used by all models).
|
| 115 |
+
scale_attn_by_inverse_layer_idx (`bool`, *optional*, defaults to `False`):
|
| 116 |
+
Whether to additionally scale attention weights by `1 / layer_idx + 1`.
|
| 117 |
+
reorder_and_upcast_attn (`bool`, *optional*, defaults to `False`):
|
| 118 |
+
Whether to scale keys (K) prior to computing attention (dot-product) and upcast attention
|
| 119 |
+
dot-product/softmax to float() when training with mixed precision.
|
| 120 |
+
|
| 121 |
+
Example:
|
| 122 |
+
|
| 123 |
+
```python
|
| 124 |
+
>>> from transformers import GPT2Config, GPT2Model
|
| 125 |
+
|
| 126 |
+
>>> # Initializing a GPT2 configuration
|
| 127 |
+
>>> configuration = GPT2Config()
|
| 128 |
+
|
| 129 |
+
>>> # Initializing a model (with random weights) from the configuration
|
| 130 |
+
>>> model = GPT2Model(configuration)
|
| 131 |
+
|
| 132 |
+
>>> # Accessing the model configuration
|
| 133 |
+
>>> configuration = model.config
|
| 134 |
+
```"""
|
| 135 |
+
|
| 136 |
+
model_type = "gpt2"
|
| 137 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 138 |
+
attribute_map = {
|
| 139 |
+
"hidden_size": "n_embd",
|
| 140 |
+
"max_position_embeddings": "n_positions",
|
| 141 |
+
"num_attention_heads": "n_head",
|
| 142 |
+
"num_hidden_layers": "n_layer",
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
def __init__(
|
| 146 |
+
self,
|
| 147 |
+
vocab_size=50257,
|
| 148 |
+
n_positions=1024,
|
| 149 |
+
n_embd=768,
|
| 150 |
+
n_layer=12,
|
| 151 |
+
n_head=12,
|
| 152 |
+
n_inner=None,
|
| 153 |
+
activation_function="gelu_new",
|
| 154 |
+
resid_pdrop=0.1,
|
| 155 |
+
embd_pdrop=0.1,
|
| 156 |
+
attn_pdrop=0.1,
|
| 157 |
+
layer_norm_epsilon=1e-5,
|
| 158 |
+
initializer_range=0.02,
|
| 159 |
+
summary_type="cls_index",
|
| 160 |
+
summary_use_proj=True,
|
| 161 |
+
summary_activation=None,
|
| 162 |
+
summary_proj_to_labels=True,
|
| 163 |
+
summary_first_dropout=0.1,
|
| 164 |
+
scale_attn_weights=True,
|
| 165 |
+
use_cache=True,
|
| 166 |
+
bos_token_id=50256,
|
| 167 |
+
eos_token_id=50256,
|
| 168 |
+
scale_attn_by_inverse_layer_idx=False,
|
| 169 |
+
reorder_and_upcast_attn=False,
|
| 170 |
+
attention_head_type=MULTI_HEAD,
|
| 171 |
+
**kwargs,
|
| 172 |
+
):
|
| 173 |
+
self.vocab_size = vocab_size
|
| 174 |
+
self.n_positions = n_positions
|
| 175 |
+
self.n_embd = n_embd
|
| 176 |
+
self.n_layer = n_layer
|
| 177 |
+
self.n_head = n_head
|
| 178 |
+
self.n_inner = n_inner
|
| 179 |
+
self.activation_function = activation_function
|
| 180 |
+
self.resid_pdrop = resid_pdrop
|
| 181 |
+
self.embd_pdrop = embd_pdrop
|
| 182 |
+
self.attn_pdrop = attn_pdrop
|
| 183 |
+
self.layer_norm_epsilon = layer_norm_epsilon
|
| 184 |
+
self.initializer_range = initializer_range
|
| 185 |
+
self.summary_type = summary_type
|
| 186 |
+
self.summary_use_proj = summary_use_proj
|
| 187 |
+
self.summary_activation = summary_activation
|
| 188 |
+
self.summary_first_dropout = summary_first_dropout
|
| 189 |
+
self.summary_proj_to_labels = summary_proj_to_labels
|
| 190 |
+
self.scale_attn_weights = scale_attn_weights
|
| 191 |
+
self.use_cache = use_cache
|
| 192 |
+
self.scale_attn_by_inverse_layer_idx = scale_attn_by_inverse_layer_idx
|
| 193 |
+
self.reorder_and_upcast_attn = reorder_and_upcast_attn
|
| 194 |
+
self.attention_head_type = attention_head_type
|
| 195 |
+
# assert attention_head_type in [AttentionType.MULTI_HEAD, AttentionType.MULTI_QUERY]
|
| 196 |
+
assert attention_head_type in [MULTI_HEAD, MULTI_QUERY]
|
| 197 |
+
|
| 198 |
+
self.bos_token_id = bos_token_id
|
| 199 |
+
self.eos_token_id = eos_token_id
|
| 200 |
+
|
| 201 |
+
super().__init__(bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 49152,
|
| 4 |
+
"eos_token_id": 49152,
|
| 5 |
+
"transformers_version": "4.37.1"
|
| 6 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2dd5eb29012210f57e6646cfe88d931ee3cf621e4d652dd7a14e849be866b437
|
| 3 |
+
size 838045874
|
modeling_gpt2_mq.py
ADDED
|
@@ -0,0 +1,346 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""PyTorch OpenAI GPT-2 model modified with MultiQuery attention"""
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
import math
|
| 5 |
+
import os
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
from typing import Optional, Tuple, Union
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.utils.checkpoint
|
| 11 |
+
from torch import nn
|
| 12 |
+
from torch.cuda.amp import autocast
|
| 13 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 14 |
+
|
| 15 |
+
from transformers.activations import ACT2FN
|
| 16 |
+
from transformers.modeling_outputs import (
|
| 17 |
+
BaseModelOutputWithPastAndCrossAttentions,
|
| 18 |
+
CausalLMOutputWithCrossAttentions,
|
| 19 |
+
SequenceClassifierOutputWithPast,
|
| 20 |
+
TokenClassifierOutput,
|
| 21 |
+
)
|
| 22 |
+
from transformers.modeling_utils import PreTrainedModel, SequenceSummary
|
| 23 |
+
from transformers.pytorch_utils import Conv1D, find_pruneable_heads_and_indices, prune_conv1d_layer
|
| 24 |
+
|
| 25 |
+
from transformers.utils import (
|
| 26 |
+
ModelOutput,
|
| 27 |
+
add_code_sample_docstrings,
|
| 28 |
+
add_start_docstrings,
|
| 29 |
+
add_start_docstrings_to_model_forward,
|
| 30 |
+
logging,
|
| 31 |
+
replace_return_docstrings,
|
| 32 |
+
)
|
| 33 |
+
from transformers.utils.model_parallel_utils import assert_device_map, get_device_map
|
| 34 |
+
from transformers.models.gpt2.modeling_gpt2 import GPT2Model, GPT2Block, GPT2PreTrainedModel, GPT2LMHeadModel
|
| 35 |
+
from .configuration_gpt2_mq import GPT2CustomConfig, MULTI_QUERY, MULTI_HEAD
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class GPT2MQAttention(nn.Module):
|
| 40 |
+
def __init__(self, config, is_cross_attention=False, layer_idx=None):
|
| 41 |
+
super().__init__()
|
| 42 |
+
assert config.attention_head_type == MULTI_QUERY
|
| 43 |
+
|
| 44 |
+
max_positions = config.max_position_embeddings
|
| 45 |
+
self.register_buffer(
|
| 46 |
+
"bias",
|
| 47 |
+
torch.tril(torch.ones((max_positions, max_positions), dtype=torch.uint8)).view(
|
| 48 |
+
1, 1, max_positions, max_positions
|
| 49 |
+
),
|
| 50 |
+
)
|
| 51 |
+
self.register_buffer("masked_bias", torch.tensor(-1e4))
|
| 52 |
+
|
| 53 |
+
self.embed_dim = config.hidden_size
|
| 54 |
+
self.num_heads = config.num_attention_heads
|
| 55 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 56 |
+
self.split_size = self.embed_dim
|
| 57 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 58 |
+
raise ValueError(
|
| 59 |
+
f"`embed_dim` must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
| 60 |
+
f" {self.num_heads})."
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
self.scale_attn_weights = config.scale_attn_weights
|
| 64 |
+
if is_cross_attention:
|
| 65 |
+
raise NotImplementedError("Cross-attention not implemented for MQA")
|
| 66 |
+
self.is_cross_attention = is_cross_attention
|
| 67 |
+
|
| 68 |
+
# Layer-wise attention scaling, reordering, and upcasting
|
| 69 |
+
self.scale_attn_by_inverse_layer_idx = config.scale_attn_by_inverse_layer_idx
|
| 70 |
+
self.layer_idx = layer_idx
|
| 71 |
+
self.reorder_and_upcast_attn = config.reorder_and_upcast_attn
|
| 72 |
+
|
| 73 |
+
if self.is_cross_attention:
|
| 74 |
+
self.c_attn = Conv1D(2 * self.embed_dim, self.embed_dim)
|
| 75 |
+
self.q_attn = Conv1D(self.embed_dim, self.embed_dim)
|
| 76 |
+
else:
|
| 77 |
+
# self.c_attn = Conv1D(3 * self.embed_dim, self.embed_dim)
|
| 78 |
+
self.q_attn = Conv1D(self.embed_dim, self.embed_dim)
|
| 79 |
+
# Keys and values are shared across heads
|
| 80 |
+
self.kv_attn = Conv1D(2 * self.head_dim, self.embed_dim)
|
| 81 |
+
self.c_proj = Conv1D(self.embed_dim, self.embed_dim)
|
| 82 |
+
|
| 83 |
+
self.attn_dropout = nn.Dropout(config.attn_pdrop)
|
| 84 |
+
self.resid_dropout = nn.Dropout(config.resid_pdrop)
|
| 85 |
+
|
| 86 |
+
self.pruned_heads = set()
|
| 87 |
+
|
| 88 |
+
def prune_heads(self, heads):
|
| 89 |
+
if len(heads) == 0:
|
| 90 |
+
return
|
| 91 |
+
heads, index = find_pruneable_heads_and_indices(heads, self.num_heads, self.head_dim, self.pruned_heads)
|
| 92 |
+
index_attn = torch.cat([index, index + self.split_size, index + (2 * self.split_size)])
|
| 93 |
+
|
| 94 |
+
# Prune conv1d layers
|
| 95 |
+
self.c_attn = prune_conv1d_layer(self.c_attn, index_attn, dim=1)
|
| 96 |
+
self.c_proj = prune_conv1d_layer(self.c_proj, index, dim=0)
|
| 97 |
+
|
| 98 |
+
# Update hyper params
|
| 99 |
+
self.split_size = (self.split_size // self.num_heads) * (self.num_heads - len(heads))
|
| 100 |
+
self.num_heads = self.num_heads - len(heads)
|
| 101 |
+
self.pruned_heads = self.pruned_heads.union(heads)
|
| 102 |
+
|
| 103 |
+
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
|
| 104 |
+
# query: (b, num_heads * sq, head_dim)
|
| 105 |
+
# key: (b, head_dim, sk)
|
| 106 |
+
# value: (b, sk, head_dim)
|
| 107 |
+
batch_size = query.size(0)
|
| 108 |
+
query_length = query.size(1) // self.num_heads
|
| 109 |
+
key_length = key.size(2)
|
| 110 |
+
# (b, num_heads * sq, head_dim) x (b, head_dim, sk) -> (b, num_heads * sq, sk)
|
| 111 |
+
attn_weights = torch.bmm(query, key)
|
| 112 |
+
# -> (b, num_heads, sq, sk)
|
| 113 |
+
attn_weights = attn_weights.view(batch_size, self.num_heads, query_length, key_length)
|
| 114 |
+
|
| 115 |
+
if self.scale_attn_weights:
|
| 116 |
+
attn_weights = attn_weights / torch.tensor(
|
| 117 |
+
value.size(-1) ** 0.5, dtype=attn_weights.dtype, device=attn_weights.device
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
# Layer-wise attention scaling
|
| 121 |
+
if self.scale_attn_by_inverse_layer_idx:
|
| 122 |
+
attn_weights = attn_weights / float(self.layer_idx + 1)
|
| 123 |
+
|
| 124 |
+
if not self.is_cross_attention:
|
| 125 |
+
# if only "normal" attention layer implements causal mask
|
| 126 |
+
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length].to(torch.bool)
|
| 127 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 128 |
+
# Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
|
| 129 |
+
# Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
|
| 130 |
+
mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
|
| 131 |
+
attn_weights = torch.where(causal_mask, attn_weights, mask_value)
|
| 132 |
+
|
| 133 |
+
if attention_mask is not None:
|
| 134 |
+
# Apply the attention mask
|
| 135 |
+
attn_weights = attn_weights + attention_mask
|
| 136 |
+
|
| 137 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 138 |
+
|
| 139 |
+
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op otherwise
|
| 140 |
+
attn_weights = attn_weights.type(value.dtype)
|
| 141 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 142 |
+
|
| 143 |
+
# Mask heads if we want to
|
| 144 |
+
if head_mask is not None:
|
| 145 |
+
attn_weights = attn_weights * head_mask
|
| 146 |
+
|
| 147 |
+
# (b, num_heads, sq, sk) -> (b, num_heads * sq, sk)
|
| 148 |
+
_attn_weights = attn_weights.view(batch_size, self.num_heads * query_length, key_length)
|
| 149 |
+
# (b, num_heads * sq, sk) x (b, sk, head_dim) -> (b, num_heads * sq, head_dim)
|
| 150 |
+
attn_output = torch.bmm(_attn_weights, value)
|
| 151 |
+
attn_output = attn_output.view(batch_size, self.num_heads, query_length, self.head_dim)
|
| 152 |
+
|
| 153 |
+
return attn_output, attn_weights
|
| 154 |
+
|
| 155 |
+
def _upcast_and_reordered_attn(self, query, key, value, attention_mask=None, head_mask=None):
|
| 156 |
+
# Use `torch.baddbmm` (a bit more efficient w/ alpha param for scaling -- from Megatron-LM)
|
| 157 |
+
bsz, num_heads, q_seq_len, dk = query.size()
|
| 158 |
+
_, _, k_seq_len, _ = key.size()
|
| 159 |
+
|
| 160 |
+
# Preallocate attn_weights for `baddbmm`
|
| 161 |
+
attn_weights = torch.empty(bsz * num_heads, q_seq_len, k_seq_len, dtype=torch.float32, device=query.device)
|
| 162 |
+
|
| 163 |
+
# Compute Scale Factor
|
| 164 |
+
scale_factor = 1.0
|
| 165 |
+
if self.scale_attn_weights:
|
| 166 |
+
scale_factor /= float(value.size(-1)) ** 0.5
|
| 167 |
+
|
| 168 |
+
if self.scale_attn_by_inverse_layer_idx:
|
| 169 |
+
scale_factor /= float(self.layer_idx + 1)
|
| 170 |
+
|
| 171 |
+
# Upcast (turn off autocast) and reorder (Scale K by 1 / root(dk))
|
| 172 |
+
with autocast(enabled=False):
|
| 173 |
+
q, k = query.reshape(-1, q_seq_len, dk), key.transpose(-1, -2).reshape(-1, dk, k_seq_len)
|
| 174 |
+
attn_weights = torch.baddbmm(attn_weights, q.float(), k.float(), beta=0, alpha=scale_factor)
|
| 175 |
+
attn_weights = attn_weights.reshape(bsz, num_heads, q_seq_len, k_seq_len)
|
| 176 |
+
|
| 177 |
+
if not self.is_cross_attention:
|
| 178 |
+
# if only "normal" attention layer implements causal mask
|
| 179 |
+
query_length, key_length = query.size(-2), key.size(-2)
|
| 180 |
+
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length].bool()
|
| 181 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 182 |
+
# Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
|
| 183 |
+
# Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
|
| 184 |
+
mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
|
| 185 |
+
attn_weights = torch.where(causal_mask, attn_weights, mask_value)
|
| 186 |
+
|
| 187 |
+
if attention_mask is not None:
|
| 188 |
+
# Apply the attention mask
|
| 189 |
+
attn_weights = attn_weights + attention_mask
|
| 190 |
+
|
| 191 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 192 |
+
|
| 193 |
+
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op if otherwise
|
| 194 |
+
if attn_weights.dtype != torch.float32:
|
| 195 |
+
raise RuntimeError("Error with upcasting, attn_weights does not have dtype torch.float32")
|
| 196 |
+
attn_weights = attn_weights.type(value.dtype)
|
| 197 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 198 |
+
|
| 199 |
+
# Mask heads if we want to
|
| 200 |
+
if head_mask is not None:
|
| 201 |
+
attn_weights = attn_weights * head_mask
|
| 202 |
+
|
| 203 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 204 |
+
|
| 205 |
+
return attn_output, attn_weights
|
| 206 |
+
|
| 207 |
+
def _split_heads(self, tensor, num_heads, attn_head_size):
|
| 208 |
+
"""
|
| 209 |
+
Splits hidden_size dim into attn_head_size and num_heads
|
| 210 |
+
"""
|
| 211 |
+
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
|
| 212 |
+
tensor = tensor.view(new_shape)
|
| 213 |
+
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
|
| 214 |
+
|
| 215 |
+
def _merge_heads(self, tensor, num_heads, attn_head_size):
|
| 216 |
+
"""
|
| 217 |
+
Merges attn_head_size dim and num_attn_heads dim into hidden_size
|
| 218 |
+
"""
|
| 219 |
+
tensor = tensor.permute(0, 2, 1, 3).contiguous()
|
| 220 |
+
new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,)
|
| 221 |
+
return tensor.view(new_shape)
|
| 222 |
+
|
| 223 |
+
def forward(
|
| 224 |
+
self,
|
| 225 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 226 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 227 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 228 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 229 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 230 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 231 |
+
use_cache: Optional[bool] = False,
|
| 232 |
+
output_attentions: Optional[bool] = False,
|
| 233 |
+
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
|
| 234 |
+
if encoder_hidden_states is not None:
|
| 235 |
+
raise NotImplementedError("Cross-attention not implemented for MQA")
|
| 236 |
+
if not hasattr(self, "q_attn"):
|
| 237 |
+
raise ValueError(
|
| 238 |
+
"If class is used as cross attention, the weights `q_attn` have to be defined. "
|
| 239 |
+
"Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`."
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
query = self.q_attn(hidden_states)
|
| 243 |
+
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
|
| 244 |
+
attention_mask = encoder_attention_mask
|
| 245 |
+
else:
|
| 246 |
+
query = self.q_attn(hidden_states)
|
| 247 |
+
key, value = self.kv_attn(hidden_states).split(self.head_dim, dim=2)
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
batch_size, seq_length = query.shape[:2]
|
| 251 |
+
# (query_length, batch, num_heads, head_dim)
|
| 252 |
+
# (batch, num_heads * query_length, head_dim)\
|
| 253 |
+
|
| 254 |
+
# (batch, query_length, hidden_size) -> (batch, num_heads, query_length, head_dim)
|
| 255 |
+
query = query.view(batch_size, seq_length, self.num_heads, self.head_dim).permute([0, 2, 1, 3])
|
| 256 |
+
# -> (batch, num_heads * query_length, head_dim)
|
| 257 |
+
query = query.reshape(batch_size, self.num_heads * seq_length, self.head_dim)
|
| 258 |
+
|
| 259 |
+
# (batch, query_length, hidden_size) -> (batch, query_length * num_heads, head_dim)
|
| 260 |
+
# query = query.view(
|
| 261 |
+
# batch_size, seq_length, self.num_heads, self.head_dim,
|
| 262 |
+
# ).reshape(
|
| 263 |
+
# batch_size, seq_length * self.num_heads, self.head_dim
|
| 264 |
+
# )
|
| 265 |
+
key = key.permute(0, 2, 1) # (batch_size, head_dim, seq_length)
|
| 266 |
+
# value (batch_size, seq_length, head_dim)
|
| 267 |
+
|
| 268 |
+
if layer_past is not None:
|
| 269 |
+
past_key, past_value = layer_past
|
| 270 |
+
# Concatenate on sequence dimension
|
| 271 |
+
key = torch.cat((past_key, key), dim=-1)
|
| 272 |
+
value = torch.cat((past_value, value), dim=-2)
|
| 273 |
+
|
| 274 |
+
if use_cache is True:
|
| 275 |
+
present = (key, value)
|
| 276 |
+
else:
|
| 277 |
+
present = None
|
| 278 |
+
|
| 279 |
+
if self.reorder_and_upcast_attn:
|
| 280 |
+
raise NotImplementedError("Reorder and upcast attention not implemented for MQA")
|
| 281 |
+
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
|
| 282 |
+
else:
|
| 283 |
+
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
|
| 284 |
+
|
| 285 |
+
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
|
| 286 |
+
attn_output = self.c_proj(attn_output)
|
| 287 |
+
attn_output = self.resid_dropout(attn_output)
|
| 288 |
+
|
| 289 |
+
outputs = (attn_output, present)
|
| 290 |
+
if output_attentions:
|
| 291 |
+
outputs += (attn_weights,)
|
| 292 |
+
|
| 293 |
+
return outputs # a, present, (attentions)
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
# inherit from gpt_modeling.py, and override `attn` module
|
| 297 |
+
class GPT2CustomBlock(GPT2Block):
|
| 298 |
+
|
| 299 |
+
def __init__(self, config: GPT2CustomConfig, layer_idx=None):
|
| 300 |
+
super().__init__(config, layer_idx)
|
| 301 |
+
# Override attention module if using multiquery
|
| 302 |
+
if config.attention_head_type == MULTI_QUERY:
|
| 303 |
+
self.attn = GPT2MQAttention(config, layer_idx=layer_idx)
|
| 304 |
+
if config.add_cross_attention:
|
| 305 |
+
raise NotImplementedError("Cross-attention not implemented for MQA")
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
# inherit from gpt_modeling.py and override `__init__` method
|
| 309 |
+
class GPT2CustomModel(GPT2Model):
|
| 310 |
+
config_class = GPT2CustomConfig
|
| 311 |
+
|
| 312 |
+
def __init__(self, config):
|
| 313 |
+
GPT2PreTrainedModel.__init__(self, config)
|
| 314 |
+
|
| 315 |
+
self.embed_dim = config.hidden_size
|
| 316 |
+
|
| 317 |
+
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
|
| 318 |
+
self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)
|
| 319 |
+
|
| 320 |
+
self.drop = nn.Dropout(config.embd_pdrop)
|
| 321 |
+
self.h = nn.ModuleList([GPT2CustomBlock(config, layer_idx=i) for i in range(config.num_hidden_layers)])
|
| 322 |
+
self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
|
| 323 |
+
|
| 324 |
+
# Model parallel
|
| 325 |
+
self.model_parallel = False
|
| 326 |
+
self.device_map = None
|
| 327 |
+
self.gradient_checkpointing = False
|
| 328 |
+
|
| 329 |
+
# Initialize weights and apply final processing
|
| 330 |
+
self.post_init()
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
class GPT2LMHeadCustomModel(GPT2LMHeadModel):
|
| 334 |
+
config_class = GPT2CustomConfig
|
| 335 |
+
|
| 336 |
+
def __init__(self, config):
|
| 337 |
+
GPT2PreTrainedModel.__init__(self, config)
|
| 338 |
+
self.transformer = GPT2CustomModel(config)
|
| 339 |
+
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
|
| 340 |
+
|
| 341 |
+
# Model parallel
|
| 342 |
+
self.model_parallel = False
|
| 343 |
+
self.device_map = None
|
| 344 |
+
|
| 345 |
+
# Initialize weights and apply final processing
|
| 346 |
+
self.post_init()
|
plots.png
ADDED
|
smash_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"api_key": null,
|
| 3 |
+
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
+
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
+
"factorizers": "None",
|
| 7 |
+
"quantizers": "['llm-int8']",
|
| 8 |
+
"compilers": "None",
|
| 9 |
+
"task": "text_text_generation",
|
| 10 |
+
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsed4p5bm5",
|
| 12 |
+
"batch_size": 1,
|
| 13 |
+
"model_name": "bigcode/santacoder",
|
| 14 |
+
"pruning_ratio": 0.0,
|
| 15 |
+
"n_quantization_bits": 4,
|
| 16 |
+
"output_deviation": 0.005,
|
| 17 |
+
"max_batch_size": 1,
|
| 18 |
+
"qtype_weight": "torch.qint8",
|
| 19 |
+
"qtype_activation": "torch.quint8",
|
| 20 |
+
"qobserver": "<class 'torch.ao.quantization.observer.MinMaxObserver'>",
|
| 21 |
+
"qscheme": "torch.per_tensor_symmetric",
|
| 22 |
+
"qconfig": "x86",
|
| 23 |
+
"group_size": 128,
|
| 24 |
+
"damp_percent": 0.1,
|
| 25 |
+
"save_load_fn": "bitsandbytes"
|
| 26 |
+
}
|
| 27 |
+
}
|