
Nexa Models
Collection
Tiny, multimodal on-device models
•
6 items
•
Updated
•
2
[Dec 16, 2024] Our work "OmniVLM: A Token-Compressed, Sub-Billion-Parameter Vision-Language Model for Efficient On-Device Inference" is now live on Arxiv! 🚀
[Nov 27, 2024] Model Improvements: OmniVLM v3 model's GGUF file has been updated in this Hugging Face Repo! ✨ 👉 Test these exciting changes in our Hugging Face Space
[Nov 22, 2024] Model Improvements: OmniVLM v2 model's GGUF file has been updated in this Hugging Face Repo! ✨ Key Improvements Include:
We are continuously improving OmniVLM-968M based on your valuable feedback! More exciting updates coming soon - Stay tuned! ⭐
OmniVLM is a compact, sub-billion (968M) multimodal model for processing both visual and text inputs, optimized for edge devices. Improved on LLaVA's architecture, it features:
Quick Links:
Feedback: Send questions or comments about the model in our Discord
OmniVLM is intended for Visual Question Answering (answering questions about images) and Image Captioning (describing scenes in photos), making it ideal for on-device applications.
Example Demo: Generating captions for a 1046×1568 image on M4 Pro Macbook takes < 2s processing time and requires only 988 MB RAM and 948 MB Storage.

Below we demonstrate a figure to show how OmniVLM performs against nanollava. In all the tasks, OmniVLM outperforms the previous world's smallest vision-language model.
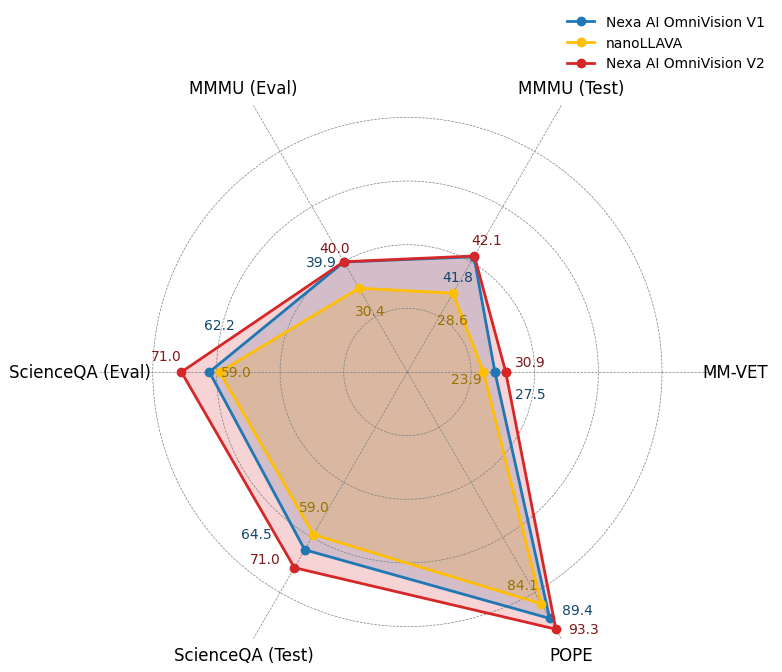
We have conducted a series of experiments on benchmark datasets, including MM-VET, ChartQA, MMMU, ScienceQA, POPE to evaluate the performance of OmniVLM.
| Benchmark | Nexa AI OmniVLM v2 | Nexa AI OmniVLM v1 | nanoLLAVA |
|---|---|---|---|
| ScienceQA (Eval) | 71.0 | 62.2 | 59.0 |
| ScienceQA (Test) | 71.0 | 64.5 | 59.0 |
| POPE | 93.3 | 89.4 | 84.1 |
| MM-VET | 30.9 | 27.5 | 23.9 |
| ChartQA (Test) | 61.9 | 59.2 | NA |
| MMMU (Test) | 42.1 | 41.8 | 28.6 |
| MMMU (Eval) | 40.0 | 39.9 | 30.4 |
In the following, we demonstrate how to run OmniVLM locally on your device.
Step 1: Install Nexa-SDK (local on-device inference framework)
Nexa-SDK is a open-sourced, local on-device inference framework, supporting text generation, image generation, vision-language models (VLM), audio-language models, speech-to-text (ASR), and text-to-speech (TTS) capabilities. Installable via Python Package or Executable Installer.
Step 2: Then run the following code in your terminal
nexa run omniVLM
OmniVLM's architecture consists of three key components:
The vision encoder first transforms input images into embeddings, which are then processed by the projection layer to match the token space of Qwen2.5-0.5B-Instruct, enabling end-to-end visual-language understanding.
We developed OmniVLM through a three-stage training pipeline:
Pretraining: The initial stage focuses on establishing basic visual-linguistic alignments using image-caption pairs, during which only the projection layer parameters are unfrozen to learn these fundamental relationships.
Supervised Fine-tuning (SFT): We enhance the model's contextual understanding using image-based question-answering datasets. This stage involves training on structured chat histories that incorporate images for the model to generate more contextually appropriate responses.
Direct Preference Optimization (DPO): The final stage implements DPO by first generating responses to images using the base model. A teacher model then produces minimally edited corrections while maintaining high semantic similarity with the original responses, focusing specifically on accuracy-critical elements. These original and corrected outputs form chosen-rejected pairs. The fine-tuning targeted at essential model output improvements without altering the model's core response characteristics
OmniVLM is in early development and we are working to address current limitations:
In the long term, we aim to develop OmniVLM as a fully optimized, production-ready solution for edge AI multimodal applications.
Blogs | Discord | X(Twitter)